國
電信工程研究所
碩
應用於
系統下之以廣度為主做搜尋的多層
排序演算法
研究生:曾耀葦
博士
中華民國
十九
立 交 通 大 學
士 論 文
V-BLAST
Multi-level Sorted Breadth-First Signal Decoder for V-BLAST
Systems
指導教授:張文鐘
應用於
系統下之以廣度為主做搜尋的多層排序演算法
研 指導教授 文鐘 國 電信工程研究所 碩中華民國
十九
V-BLAST
Multi-level Sorted Breadth-First Signal Decoder for V-BLAST
Systems
究 生 : 曾耀葦 Student : Yao-Wei Tseng
: 張 博士 Advisor : Dr. Wen-Thong Chang
立 交 通 大 學 士 論 文
A Thesis
Submitted to Institute of Communication Engineering College of Electrical and Computer Engineering
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master
in
Computer and Information Science July 2010
Hsinchu, Taiwan, Republic of China
應用於
系統下之以廣度為主做搜尋的多層排序演算法
研究生:曾耀葦
導教授:張文鐘 博士
國
摘
在多根傳送天線及多根接收天線的系統下( ,雖然這種架構可以增加傳輸容量,但對接收端來說,如何將多根天線間 彼此互相干擾的傳輸資料進行估測與解碼是主要的議題,而學者們近年來已經提 出了數個解碼校能接近最佳估測的演算法( 稱為 。本篇論文著重於此系統中 架構( 之接收端的估測,在錯誤率與複雜度的平衡間,我們結合了 多層架構搜尋的降低複雜度特性、排序 分解的特定解碼順序與適應 性調整門檻來限制搜尋路徑個數的演算法( 以廣度為主做搜尋的多層排序演算法 演算法)。經過數學分析與電腦模擬,此演算法確實能以 很低的複雜度來逼近 估測的效能,且越高階的調變越能顯現出 多層 架構降低複雜度的特性,所以此演算法能在複雜度與解碼效能之間的取捨取得更 佳的平衡。V-BLAST
指
立 交 通 大 學 電 信 工 程 研 究 所
要
multi-input multi-output,簡稱為 MIMO) maximum-likelihood detection,簡ML detection) V-BLAST Vertical Bell Laboratories
Layered Space-Time)
N-QAM QR
breadth-first signal decoder,簡稱為 BSIDE)[12] 而衍生出一個解碼效能逼近最佳估測且複雜度低的演算法,稱為" "(multi-level sorted breadth-first signal deco- der,簡稱為 MSBSIDE
Multi-level Sorted Breadth-First Signal Decoder for V-BLAST
Systems
Student: Yao-Wei Tseng Advisor: Dr. Wen-Thong Chang
Institute of Communication Engineering
National Chiao Tung University
ABSTRACT
The use of multi-input multi-output (MIMO) architectures promises to achieve higher transmission capacity, but how to detect and decode the transmitted signals from the interference of other antennas for the receiver is the most important topic for discussion. In recent years, a number of detecting schemes have been proposed to perform maximum-likelihood (ML) detection. In this paper, we focus on the detecting algorithm design of the Vertical Bell Laboratories Layered Space-Time (V-BLAST) receiver. Consider the tradeoff between detecting error probability and detecting comp- lexity, we combine the breadth-first signal decoder (BSIDE algorithm) [12], which can limit the number of searching paths by an adaptive threshold, with multi-level search- ing structure of the N-QAM modulation constellation and specific detecting order of sorted QR decomposition to form a novel detecting algorithm, called “multi-level sorted breadth-first signal decoder (MSBSIDE algorithm) ”, and we can let the perfor- mance of this novel algorithm approach ML detector. Through analysis and computer simulation, it is shown that the MSBSIDE algorithm has the same bit-error-rate per- formance as the conventional ML detectors while allowing significantly lower compu- tational complexity. In addition, using multi-level searching structure of the N-QAM modulation constellation for higher level modulation can reduce more computational complexity, so this novel algorithm can achieve a better performance-complexity tradeoff.
誌謝
時光荏苒,兩年的時光匆匆流逝,碩士生涯至此也算圓滿結束,對於我的指 導教授張文鐘博士,心中只有滿溢的感謝,老師對於研究的專業,總是能夠在我 研究遭遇困難及瓶頸時給予我最精準又最精闢的指導,處事踏實又懂得享受生活 的人生哲學,老師給我們研究生做了一個最好的榜樣。同時也感謝口試委員王晉 良教授、林銀議教授與林大衛教授,各位口試委員都以精準的眼光和專業能力給 了研究上和論文上的建議,讓我的論文能夠更加的完備,很感謝他們。 對於能成為 實驗室的一員我滿懷感謝,實驗室的學長、學弟妹和同學們 都是我不論研究上或是生活上的好夥伴,博班學長家豪; 級學長琮壹; 級 和 級學弟妹舒評、信妤、維哲、耀駿、詩倩; 級同學怡如、明穎、雅嵐; 助理立杰。有了大家在,讓我的研究生活精彩非凡,希望大家還能時常相聚。另 外,還要謝謝家人特地從遠方寄來的綜合維他命軟膠囊素寶丁,在我趕論文的日 子都能給我很多精神上的支持。 最後也是最重要的,我最感謝我的家人,家中父母親總不吝惜長途電話費, 讓我能聽到他們聲音,了解家鄉近況,一解思鄉之愁;哥哥元駿像朋友一樣給了 我許多建議,他是我的榜樣;女朋友詩薇總是在我低潮的時候陪我度過以及加油 打氣;還有要感謝交大土地公的保佑,讓我可以在交大兩年都很平順。沒有大家 的支持,就沒有現在的我,我很感謝。 誌於 耀葦 821 96 98 99 97 2010.夏 新竹。交大目
中文摘要 英文摘要 誌謝 目錄 表目錄 圖目錄 一、 緒論 背景及動機 論文架構 二、 系統模型 系統架構 排序的 分解 三、 以廣度為主做搜尋的排序演算法 以排序 分解為基礎的 演算法 演算法 以廣度為主做搜尋的排序演算法 演算法 四、 以廣度為主做搜尋的多層排序演算法 調變訊號座標集合的多層架構 基本概念 演算法描述 演算法總結 附錄 計算錄
... i ... ii ... iii ... iv ... v ... vi ... 1 1.1 ... 1 1.2 ... 3 ... 4 2.1 V-BLAST ... 4 2.2 QR (sorted QR decomposition)... 6 ... 12 3.1 QR M (SQRD-M )... 12 3.2 (SBSIDE )... 17 ... 22 4.1 N-QAM ... 22 4.2 ... 24 4.3 ... 26 4.4 ... 33 4.5 ... 34 4.5.1 n~ 的平均值和變異數j,L 兩種計算第 以最大值為基礎 以平均值為基礎 五、 模擬結果 六、 結論 參考文獻 ... 34 4.5.2 l 層初步估計門檻 dl的方法,其中l=2…L... 35 4.5.2.1 (maximum based)計算 dl... 36 4.5.2.2 (mean based)計算 dl... 39 ... 44 ... 51 ... 52表
表 排序的 分解演算法 表 決定迴授等化估測演算法 估測演算法目 錄
2.1 QR ... 8 3.1 (DFE )... 17圖
圖 系統的傳送端架構 圖 系統的接收端架構 圖 在 的 系統、調變為 下使用原始 分 解與排序 分解於 估測演算法的錯誤率比較 圖 演算法的流程圖 圖 演算法做估測的樹狀圖示 圖 演算法與 演算法在 的 系統、調變使用 下的錯誤率比較 圖 演算法與 演算法在 的 系統、調變使用 下的錯誤率比較 圖 演算法的流程圖 圖 演算法做估測的樹狀圖示 圖 的多層架構 圖 第二象限所有訊號的樹狀關係圖 圖 演算法的流程圖 圖 演算法做估測的樹狀圖示 圖 在6 ,各 層的訊號偏差值大小及訊號值涵蓋的範圍... 38 4.6 在64-QAM 訊號座標圖下以平均值為基礎 層的 QAM 調變訊號座標圖... 42圖5.1 OSIC-ZF 演算法、OSIC-MMSE 演算法、SGA 演算法、SQRD-M 演算法與 演算法在4×4 的 ... ... 45 圖5.2 SBSIDE 演算法在 4×4 的 V-BLAST 系統、 調變使用 ... 46 5.3 演算法、SBSID 在4×4 的 ST 系統、 M 下的 錯誤率比
目 錄
2.1 V-BLAST ... 5 2.2 V-BLAST ... 5 2.3 4×4 V-BLAST 4-QAM QR QR DFE ... 10 3.1 SQRD-M ... 13 3.2 NT = 3,NR = 3,運用 SQRD-M ... 15 3.3 SQRD-M modified SQRD-M 4×4 ST 4-QAM ... 16 3.4 SQRD-M modified SQRD-M 4×4 ST 16-QAM ... 17 3.5 SBSIDE ... 18 3.6 NT = 3,NR = 3,運用 SBSIDE ... 20 4.1 64-QAM ... 22 4.2 64-QAM ... 24 4.3 MSBSIDE ... 26 4.4 NT = 3,NR = 3,運用 MSBSIDE ... 32 4.5 4-QAM 訊號座標圖下以最大值為基礎計算估計門檻時 圖 計算估計門檻時,各 假想 N-SBSIDE V-BLAST 系統、調變使用 4-QAM 下的錯誤率比較... ... SQRD-M 演算法與 4-QAM 下的錯誤率比較 圖 SQRD-M E 演算法、MSQRD-M 演算法和 MSBS-IDE 演算法 V-BLA 調變使用16-QA 較... 47圖5.4 SBSIDE 演算法、MSBSIDE-MAX 演算法和 MSBSIDE-MEAN 法在4×4 -B 、調變使用64-Q 錯誤 率比較... 5.5 SQRD-M 演算法(M=16)、SBSIDE 演算法、MSQRD-M 演算法 ( MSBSI 的V-BLA 用16-QA 的 ... ... 49 5.6 SBSID 4×4 的 變使用 的複雜 .... ... .... ... 50 演算 的V LAST 系統 AM 下的 ... 48 圖 M =16)和 DE 演算法在 4×4 ST 系統、調變使 M 下 複雜度比較 ... 圖 E 演算法、MSBSIDE-MAX 演算法和 MSBSIDE-MEAN 演算法在 V-BLAST 系統、調 64-QAM 下 度比較.. ... ... ...
一、緒論
在最近幾年的研究中,學者已經證明多根傳送天線與多根接收天線的系統架 構在多路徑干擾的無線通訊環境下可以提供很高的頻譜效率( 的多根傳送天線與多根接收天線架構中, 又以 系統架構( 單來達成高頻譜效率的架構,如參考文獻 系統並不包含編碼器及 解碼器,只是將原始訊號分成多個子資料串,這些子資料串經過調變後,經由不 同的傳送天線來負責傳輸不同的子資料串訊號,傳送端與接收端的架構分別如圖 與圖 在這樣的系統架構下,由不同傳送天線傳出的訊號彼此間都會互相 干擾,所以接收端如何藉由接收到的訊號並運用特定的估測演算法來區分不同根 傳送天線傳送之訊號為此系統架構主要著重的議題。 參考文獻 系統架構下有效率的估測演 算法。理論上, 估測在此架構下擁有最佳的估測效能,它的做法是將所有天 線可能的傳送訊號組合都做估測,再選取最可能發生的傳送訊號組合當成估計 解;以四根傳送天線 調變為例子,傳送訊號可能的組合就會 有 種,對越高階的調變及越多根傳送天線來說,接收端的複雜度會呈指 數遞增,而對現今越來越講究無線通訊的傳輸品質與傳輸速度來說, 估測所 需負擔的複雜度已不可行。參考文獻 或 演算法)雖然可以降低複雜度,但在估測錯誤率的表現上並不理想。在複 雜度與解碼效能間取得較好的平衡為近幾年提出的次序性高斯近似法( 稱為 演算法 、以 分解為基礎的 演算法 ( 簡稱為 演算法 及 演算法。 演算法必須算出通道矩陣的反矩陣,而反矩陣運算量較高, 且演算法過程中會讓每根天線間彼此獨立的白色高斯雜訊變成非獨立的雜訊,所 以接收端必須付出額外的複雜度來做估測。 演算法並不需要計算通道矩 陣的反矩陣,只需將通道矩陣進行 分解,其運算量也較低;因此,本篇論文1.1 背景及動機
spectral efficienc- y),如參考文獻[1]、[2]。而在這些眾多V-BLAST Vertical Bell Laboratories Layered Space-Time)是最簡
[13]。V-BLAST 2.1 2.2。 [3]、[5]-[12]提出了幾種在 V-BLAST ML NT=4,使用 QPSK 44=256 ML
[3]提出的 zero-forcing based or minimum mea- n square error based ordered successive interference cancellation(OSIC-ZF OSIC- MMSE
sequential
Gaussian approximation,簡 SGA [8]) QR M
QR decomposition based M algorithm, QRD-M [5]) sphere decod-
er(SD) SGA
QRD-M QR
( ,再結合 的多層架構 與排序 分解的特定解碼順序而來。 演算法為了解決 估測因全域搜尋所帶來的高複雜度,接收端在 估測傳送訊號前,先對通道矩陣 做 分解;由於 陣的倒三角形特性,讓解碼由一次估測全部天線的全域搜尋變成一次估測一根天 線的次序性解碼,且過程中考慮到某些部分天線之傳送訊號組合發生的機率極 低,所以不需做全域搜尋,次序性解碼過程中每次都只保留 組發生機率較高的 部分天線之傳送訊號組合。除此之外,為了提高這 組部分天線之傳送訊號組合 的正確性,將 演算法的原始 分解改成排序的 解,簡稱為 演算法,其中大寫 論文後面所提到的演算法如果使用到 排序的 分解,則演算法前都會加上大寫 來表示。 演算法並非依照 傳統 分解的解碼順序依序來估測每根天線,而是依照特定的解碼順序來做估 測,詳細的排序 分解會於第二章說明。 演算法只適合用於低階的調變,對越高階的調變來說, 值的大小 對複雜度之影響就越明顯,以調變使用 的系統為例子,在演算法過程 中, 的值如果比原來多一就意味著此次被保留下來的部分天線之傳送訊號組合 多了一組,當估測下根天線時,必須計算與比較價值函數( 式子 階的調變系統。針對 演算法的 值,進一步的降低複雜度而衍生出適 應性調整門檻來限制搜尋路徑個數的演算法,又稱為以廣度為主做搜尋的排序演 算法( 演算法),其作法與 演算法類似,都是根據特定解碼順 序依序估測出每根天線的傳送訊號,但演算法過程中並非每次都保留固定 組較 可能發生的部分天線之傳送訊號組合,而是在選取這些要保留的組合前,必須先 算出一個門檻( ,最後只保留達到此門檻要求的部分天線之傳送訊號組 合,而這些組合的總個數以 表示。因為此門檻是一個動態改變值,所以被保留 下來的訊號組合個數 為調變訊號集合大小的個數),詳細說明於第三章;所以,在兩個演算法錯誤率 都接近 估測的情況下, 演算法的複雜度會比 演算法低。
breadth-first signal decoder,簡稱為 BSIDE [12]) N-QAM
QR QRD-M ML H QR Q 矩陣的正交特性與 R 矩 M M QRD-M QR QR 分 SQRD-M S 指排序 sorted 的意思, QR S SQRD-M QR QR SQRD-M M 64-QAM M cost function,如 (13))的個數就多了六十四個,複雜度會以六十四的倍數成長,所以不適用於高 SQRD-M M SBSIDE SQRD-M M threshold) E E 也會跟著動態改變,而我們限制 E 值必須小於或等於 N(N ML SBSIDE SQRD-M
為了讓 演算法更適合用於高傳輸速度的系統,所以在高階的調變上 必須更進一步的降低複雜度;因此,本篇論文結合了 的多層架構搜尋特 性及 演算法而衍生出以廣度為主做搜尋的多層排序演算法,簡稱為 演算法。此演算法與 演算法比較,除了上述針對 值做處理外, 同時降低了 值的個數,以調變使用 的系統為例子,未使用多層架構搜 尋時,估測過程中每進一層,則必須計算與比較價值函數的個數為 個;使 用多層架構搜尋時,估測過程中每進一層,則必須計算與比較價值函數的個數只 剩 個,唯一不同的地方在於要得到一根傳送天線的估測訊號必須分成 會有詳細的說明。 瞭解了本論文的研究背景及動機之後,第二章會詳細敘述 系統架 構的傳送端及接收端之動作原理,最後說明如何由 估測的一次估測全部天線 之全域搜尋變成以 分解為基礎的一次估測一根天線之次序性解碼,並且由次 序性解碼的概念衍生出排序的 分解。第三章詳細說明如何從以排序 分解 為基礎的 演算法( 演算法)衍生出更低複雜度之以廣度為主做搜尋 的排序演算法( 演算法)。第四章先詳細定義 調變訊號在座標平 面上自然形成的多層架構,接著結合第三章的 演算法與 的多層 架構搜尋特性而衍生出以廣度為主做搜尋的多層排序演算法( 演算 法)。第五章則分別將第三章及第四章所提到的演算法應用於 系統的接 收端,並且利用 軟體來模擬並分析各個演算法的錯誤率及複雜度。第六章 為論文的總結。 SBSIDE N-QAM SBSIDE MS- BSIDE SQRD-M M N 64-QAM E×64 E×4 log464= 3 個階段來完成,如圖 4.2 的三層架構,以下章節
1.2 論文架構
V-BLAST ML QR QR QR M SQRD-M SBSIDE N-QAM SBSIDE N-QAM MSBSIDE V-BLAST Matlab二、系統模型
本論文的系統架構是建立在多根傳送天線與多根接收天線的 無線 通訊系統上,所以在 節先詳細敘述 系統架構的傳送端及接收端之動 作原理,並於 節說明當使用此系統架構時,接收端如何由 估測的一次估 測全部天線之全域搜尋變成以 分解為基礎的一次估測一根天線之次序性解 碼,並且由次序性解碼的概念衍生出排序的 分解。系統架構
在多根傳送天線與多根接收天線的系統中,傳送端可以經由多根天線的傳輸 模式來增加整體系統的分集程度( 或多工程度( 。在此系 統下增加分集程度的傳統方法為使用時空編碼( ,例如 端在錯誤率的表現,且讓接收端能 以簡單的數學運算來區分每根傳送天線的傳送訊號,但此種類型的編碼其傳送端 下一時間必須再傳送正交於上一時間的傳送訊號,所以成功傳送一筆資料必須花 費兩倍的時間,頻譜效率( 並不高。而在此系統下增加多工程 度的方法為使用分層時空編碼( ,此架構之所以被稱為 分層時空碼是因為傳送端的每根天線間之編碼器及調變器都是獨立的,每一根天 線自成一層,且傳送出去的訊號並不需要花費下一時間來傳送正交訊號,所以頻 譜效率會較高,但也因為沒有下一時間的正交訊號來幫助接收端估測與解碼傳送 訊號,所以使用分層時空編碼的架構時,如何設計接收端的估測演算法讓複雜度 與估測錯誤率間取得較好的平衡為主要著重的議題。分層時空編碼除了可以增加 系統的多工程度,各層天線的編碼器如果不是獨立的,而是幾根天線的訊號一起 進行編碼再輸出給各自獨立的調變器的話,即可增加系統的分集程度,但相對的 系統的多工程度就會降低,所以分集程度與多工程度間彼此是呈平衡關係。 本論文使用的系統為分層時空編碼架構中不加入編碼器與解碼器的系統,此 種系統因為各層天線都是獨立運作,所以可以達到最高的多工程度,學者們將此 架構特別稱為 系 統,其傳送端架構如圖 原始訊號( 先經過多路傳輸分流後( ,分成 V-BLAST 2.1 V-BLAST 2.2 ML QR QR2.1 V-BLAST
diversity) multiplexing)Space-time code) Alamouti
code,雖然增加系統的分集程度可以提升接收
spectral efficiency)
Layered space-time code)
Vertical Bell Laboratories Layered Space-Time,簡稱為 V-BLAST
NT sub-stream) NT Mod 由N 義為x = [x1 T ] T 集合A = {a1, a2, 等 NT 定義為y = [y … ]T,而y 和 個子分流訊號( ,這 ),最後 T根傳送天線傳出。這NT個傳送訊 個子分流訊號再經由各自獨立的調變器調 變後( 號定 x2 … ( T …,aN}中的 (NR必須大 x 的關係可以用 N x 於或 [] 指轉置矩陣),其中 x 的元素都是調變訊號 其中一個訊號。這些訊號經過通道H 的干擾後由NR根接收天線接收 於 ),NR個接收訊號 1 y2 下列式子表示: R N y n Hx y= + (1) 其中 是一個 的通道矩陣,且假設接收端已經知道通道狀況( , 是 矩陣的第 ,也就是從第 線到第 線間的 通道增益,這些元素都是平均值( 是一個 的雜訊向量, 且裡面的元素都是平均值等於零,變異數等於 的 後,收到的訊號 會在接收端進行傳送訊號的估測與解碼,接收端架構如圖 個接收到的訊號先經由傳送訊號估測( 個子分 流訊號,再經由解調器( 及解多路傳輸分流( 得到估計的原始訊號 ( )。 H NR×NT H) hij H i 列、第 j 行的元素 j 根傳送天 i 根接收天 mean)等於零,變異數(variance)等於一的
independent circularly symmetric complex Gaussian random variable。n NR×1
n = [n1 n2 … ]T, σ2
independent circularly symmetric complex Gaussian noise。當接收天線收到訊號
y 2.2。 NR detector)估算出原始傳送的NT Demod) P/S) R N n mˆ Mod S/P Mod m Inform. source 1 x T N x 圖 系統的傳送端架構 M 2.1 V-BLAST 1 y R N y Demod P/S Demod Detector 1 ˆx T N xˆ M mˆ
2.2 排序的 QR
分解(
sorted QR decomposition)
本篇論文著重於圖 中估測部分的演算法設計。 架構下的估測, 最簡單但複雜度最高的方法為 估測,做法為從所有可能的 訊號組合中找到 發生機率最高的組合,此組合即是最佳估測解。而在白色高斯雜訊( 系統模型下,計算機率值可以等同於計算傳送訊號組合經過通道的增益後與接收 到的訊號 之距離,最後再從這些距離中選取最小距離對應的傳送訊號組合即為 發生機率最高的最佳估測解。計算距離的方法如下式: 2.2 V-BLAST ML x AWGN)的 y distance = y−Hx2 (2) 其中, 以所有可能的訊號組合代入。這種全域搜尋方法當天線數過多或使用較 高階的調變時,計算距離的個數會呈指數遞增,對接收端來說複雜度太高。 演算法為了解決 估測因全域搜尋所帶來的高複雜度,接收端在 估測傳送訊號前,必須先對通道矩陣 做 分解,原始的 分解如下式: x QRD-M ML H QR OR R Q H= × (3) ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ × ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ = ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⇒ T T T T T R R R T T T R R R T T N N N N N N N N N N N N N N N N r r r r r r q q q q q q q q q h h h h h h h h h L M O M M L L L M O M M L L L M O M M L L 0 0 0 22 2 1 12 11 2 1 2 22 21 1 12 11 2 1 2 22 21 1 12 11 其中 是一個 的正交矩陣( ,正交矩陣的特性是它的行 向量彼此是正交關係,且每個行向量的長度都為一,因此可以用 來表 示此特性( 指共軛轉置矩陣, 上三角矩陣 ( 。而將 分解應用於解碼端是利用了 矩陣的正交特 性,讓 的共軛轉置矩陣乘上原始雜訊向量後的統計特性維持不變,依然是白色 高斯雜訊的統計特性,以利接收端估測傳送訊號,其用法如下式: Q NR×NT orthogonal matrix) QH×Q = I []H I 指單位矩陣);R 是一個 NT×NT的upper triangular matrix) QR Q
Q n x R y Q y ~ ~= H × = × + (4)
⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ + ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ × ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ = ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⇒ T T T T T T T N N N N N N N n n n x x x r r r r r r y y y ~ ~ ~ 0 0 0 ~ ~ ~ 2 1 2 1 2 22 1 12 11 2 1 M M L M O M M L L M n~= QH×n。由於 Q 是一個正交矩陣,所以 n~ 其中, 的統計特性仍然是平均值等於 零,變異數等於 的 明如
σ2 independent circularly symmetric complex Gaussian noise,證 (5)、(6)式。 ∵E{n × nH} =σ2 × I (5) ∴E{ n~ ×n~H} = E{QH × n × nH × Q} =σ2 × I × E{QH × Q} =σ2 × I (6) 由式子 分解自然的讓解碼順序由第 根天線解 回第一根天線。此原因為第 列的變數最少,所以干擾也最少,較容易進行估 測,估測的錯誤率也會較低,所以依次序從第 根天線解回第一根天線發生錯 誤延續( (4)的矩陣架構可知原始 QR NT NT NT error propagation)的機率也會較低。又因為 n~ 矩陣裡每個元素彼此都是 獨立的,所以接收端在計算價值函數時,可以分開並累積來計算,如下式: 2 1 2 ~ ~
∑
∑
= = × − = × − NT T i N i j j ij i r x y x R y (7) 所以,接收端估測到第 的價值函數。而排序 分解( 的概念產生是從訊雜比 ( 及解碼錯誤延續的角度而來,以第 列為例, k 根天線的價值函數就是從第 NT根天線累積到第k 根天線 QR sorted QR decomposition) SNR) T N x = × T T T N N N r y~ T T N N n x +~ , 當 越大,訊雜比會越大,如 。 T TN N r (8)式,所以,估算出來的 T N xˆ 錯誤率也會越低 2 2 σ P r SNR T T T N N N × = (8)其中, 為每根天線傳送訊號的平均能量。除此之外,其它根天線的估測都會用 因此我們會 分解的概 排序的 分解可以藉由改變 演算法來達到。 演算法是用來找向量基底的演算法,而向量基底本身就是長度為一且彼此是正交 的向量,符合 矩陣哪一行開始分解,而判斷的方法為 矩陣行向量的長度,從最短長度的行向 量開始分解;假設從 矩陣的第 行開始分解則得到 矩陣的第 行與 矩陣 P R diagonal)從第一根解碼之天線那列的值到最後一根解碼之 QR QR 2.1。 到 的值,所以 的正確性高低也決定了解碼錯誤延續是否發生, 希望 的對角元素( 天線那列的值由大到小排列,讓整體估測的正確性更高,而有排序 念產生,詳細的排序 分解演算法如表 T N xˆ T N xˆ 初始化. order =φ 步驟一 計算 中除去 紀錄的行後其他行向量的長度,取最小長度那行 當成此次執行 分解的行(第 行),並且把k 到o ( 為 的第 . H order QR k 併 rder 裡
normi = ||hi|| hi H i 行),i=1…NT且i∉order ) ( min arg 1 N , i order i i norm k T ∉ = = L 步驟二 的第 步驟三 且 在 基底的投影量,即 裡把 在 基底的貢獻度扣掉 步驟四 如果 包含 所有數字,則結束此演算法,否則回到步驟一 表 分解演算法 . rkk = normk,並得到Q k 行,qk = hk/ rkk . j=1…NT j∉order,計算 hj qk rkj,並從hj hj qk rkj = qk‧hj(內積即投影量) hj = hj-rkj×qk . order 1…NT . 2.1 排序的 QR QR Gram-Schmidt Gram-Schmidt Q 矩陣每行的特性。在排序的 QR 分解演算法中,會先決定要從 H H H k Q k R
的第 列,並更新 行,方法與前一步驟相同,直到所有的基底 到才停止。以 一個 矩陣每一行的長度, 即 矩陣的第二行長度 最小,則把 併 入 中,即 將 矩陣的元素 設成 且計算 矩陣的 第二行 接著算出 矩陣的行 和 在 矩陣的第二行 基底上的 投影量,此投影量分別為 矩陣的元素 和 和 裡把 和 在 基底的貢獻度扣掉,也就是 中 此步驟的結果 如 由上一步驟找到 因為 更新過,所以必須再次計算 矩陣裡除了第二行之外每一行的長度,即 中 設 矩陣的第三行長度 最小,則把 併入 中, 即 將 矩陣的元素 設成 且計算 矩陣的第三行 矩陣的行 在 矩陣的第三行 基底上的投影量,此投影 量為 矩陣的元素 且從 裡把 在 基底的貢獻度扣掉,也就是 - 最後只剩下 找到,同上個步驟只需計算 矩陣第一行的長度,即 把 併入 中,即 並將 矩陣的元素 設成 計算 矩陣的第一行 此例子最 後結果如 更新 k H 矩陣未進行分解的行;接著再次決定要分解 H 矩陣的哪一 Q 矩陣與 R 矩陣都找 3×3 H order,並算出 H normi = ||hi||,其中 i = 1…3;假設 H norm2 2
order order ={2},並 R r22 norm2, Q
q2 = h2 / r22; H h1 h3 Q q2 R r21 r23,並且分別從 h1 h3 h1 h3 q2 hk = hk-r2k × q2,其 k = 1,3; (9)式: 的 矩陣為例子:令一個空矩陣
[
] [
]
⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ × = 2 21 22 23 3 2 1 h h q r r r h (9) 更新 更新 Q 矩陣的第二行與 R 矩陣的第二列後, H 矩陣裡的行已被 H normi = ||hi||,其 i = 1,3;假 H norm3 3 order order ={2,3},並 R r33 norm3, Q q3 = h3 / r33;接著算出H h1 Q q3 R r31,並 h1 h1 q3 h1 = h1 r31 × q3;此步驟的結果如(10)式:[
] [
]
⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ × = 33 31 23 22 21 3 2 3 2 1 r r r r r q q h h h (10) Q 矩陣的第一行與 R 矩陣的第一列還未H norm1 = ||h1||,且 1 order order ={2,3,1},
R r11 norm1,且 Q q1 = h1 / r11;
[
] [
]
⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ × = 33 31 23 22 21 11 3 2 1 3 2 1 r r r r r r q q q h h h (11) 為了驗證原始 分解與排序 分解在錯誤率上的差異,使用 的 系統,調變為 分解與排序 分解所找到的 式子 法( 估測演算法,如表 即 演算法將 設定成一的情況),結果如圖 行演算法前使用排序的 分解在同樣的錯誤率 下,效能比使用原始 分 解大約好 分解能讓接收端估測出來的結果更準確。 QR QR 4×4 V- BLAST 4-QAM,且分別將原始 QR QR Q 矩陣與 R 矩陣代入 (4)中,而後端的估測演算法為決定迴授等化估測演算decision feedback equalization detection,簡稱為 DFE 3.1,
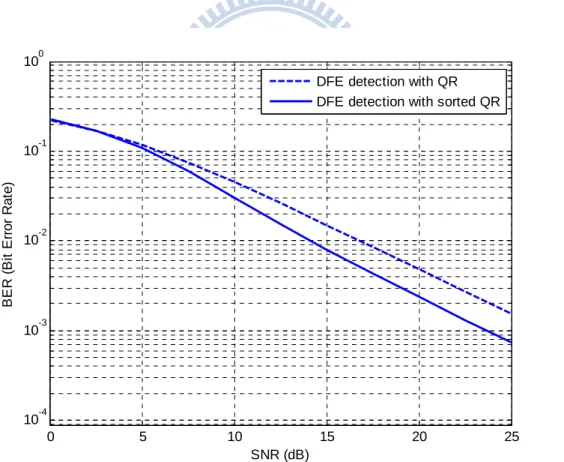
SQRD-M M 2.3。由模擬結果得知,執 QR 10-3 QR 3dB。所以,使用排序的 QR 0 5 10 15 20 25 10-4 10-3 10-2 10-1 100 SNR (dB) B E R (B it E rro r Ra te )
DFE detection with QR DFE detection with sorted QR
圖 的 系統、調變為 分解與
排序 分解於 估測演算法的錯誤率比較
2.3 在 4×4 V-BLAST 4-QAM 下使用原始 QR QR DFE
排序的 分解所得到的 矩陣並不一定是上三角矩陣,但還是符合某列元 素只有一個,某列元素只有兩個…某列元素有 個,而估測順序即是 保證 矩陣的對角元素依 的順序由大到小排列,這是因為 矩陣先天性的限制, 矩陣的元素是隨機產生的,有些情況下可以達成要求,有 些情況下則不可能,但排序的 分解提供一種方法,讓可以達成要求的情況一 定能百分之百達成,不可能的情形盡量由大到小排列(也就是說在不可能的情況 下並不一定是最佳的分解順序)。從複雜度的角度來看,排序的 分解可以在 犧牲一些複雜度的情況下得到很好的效能回報,且錯誤率接近高複雜度最佳分解 順序的 分解。 QR R NT order(i),i = NT…1,這樣就可以從干擾及變數最少的天線開始估測。排序的 QR 分解並不能 R order(i),i = NT…1 H H QR QR QR
三、以廣度為主做搜尋的排序演算法
在第二章介紹完排序 分解及它的好處後,本章著重於以廣度為主做搜尋 的排序演算法(簡稱為 演算法)如何適應性地調整門檻來限制搜尋路徑 的個數,而 演算法是結合了排序 分解與 演算法而來。 演算法是從以排序 分解為基礎的 演算法(簡稱為 演算法)衍生 而來,這兩種演算法都是以廣度為主做搜尋的演算法,它們之所以被稱為以廣度 為主做搜尋的原因是在演算法過程中,必須依照排序 分解給定的解碼順序逐 步估測每根天線,當最後一根天線的傳送訊號被估測出來後也代表演算法結束; 以深度為主做搜尋的做法是先找到一組估計解,此組估計解已經包含了每根天線 的估測訊號,再根據演算法提供的方法來更新每根天線的估測訊號,當此組估計 解的正確性已經達到預期所設的門檻也代表演算法結束。 演算法為了達 到降低複雜度的目的,不採用 演算法在過程中每次都保留固定 組較 可能發生的部分天線之傳送訊號組合,因為這固定的 組訊號組合中,某些組合 發生的機率比起那些發生機率高的組合低很多,所以並不盲從的每次都保留固定 組,而是設定一個估計門檻來篩選要保留下來的訊號組合。本章將分成兩小 節, 節詳細介紹 演算法的動作原理及其特性, 節根據 節所介 紹的 演算法來衍生出 演算法,詳細說明如下。分解為基礎的
演算法(
演算法)
圖 為 演算法的流程圖。 演算法在進行訊號估測前必須 先執行排序的 分解,並將計算出的 基礎來做次序性的訊號估測。為了方便說明,將排序的 分解所找到之解碼順 序設成從第 根天線估測到第一根天線,即 是一個標準 倒三角形矩陣。執行演算法會遇到兩種情況,第一種情況是估計第 根天線的 傳送訊號。而篩選是比較機率值的大小,也就是直接將傳送訊號集合 所有的訊 號代入 求出這 中保留前 及所對應的部分天線之傳送訊號組合 中 便 演算法執行下一步驟。 演算法的 QR SBSIDESBSIDE QR BSIDE SBSIDE
QR M SQRD-M QR SBSIDE SQRD-M M M M 3.1 SQRD-M 3.2 3.1 SQRD-M SBSIDE
3.1 以排序 QR
M
SQRD-M
3.1 SQRD-M SQRD-M QR Q 矩陣及 R 矩陣代入(4)式,並以(4)式為 QR NT order ={1,2,3… NT},R NT A (12)式中的 N 個延伸路徑的價值函數。接著從這 N 個價值函數 M 個最小的價值函數,其餘則刪除,並記錄這 M 個價值函數 = [ ]T,其 m =1…M,以 SQRD-M M 值是事先給定的且為固定值,M 值 T N x ) (xNT ψ ( T N m x ψ ) (m) NT θ (m) NT x越大被保留下來的價值函數會越多,對估測下根天線的運算量影響很大 的也會影響估測的準確度。 ,但相對 2 2 2 2 2 ~ ) ( ) ( log ~ 1 ) ~ | ( log ) ( ) ~ 1 exp( ) ( ) | ~ ( ) ~ | ( T T T T T T T T T T T T T T T T T T T T T T N N N N N N N N N N N N N N N N N N N N N N x r y x ψ x P x r y σ y x P x P x r y σ x P x y P y x P − ≡ ⇒ − − ≈ − ⇒ × − − ≈ × ∝ (12) 將通道矩陣 進行排序 的 分解 H QR 在接收訊號 矩陣 y 前乘上 QH k=NT 於第 線延伸所有可能的 傳送訊號,並計算 其對應的價值函數 order(k)根天 保留前 組最小 的價值函數所對 應的部分天線之 傳送訊號組合 M k=k-1 根據此 組被保留下 來的組合,分別於它 們的第 根天 線延伸所有可能之傳 送訊號,並計算其對 應的價值函數 M order(k) 保留前 組最小 的價值函數所對 應的部分天線之 傳送訊號組合 M 否 k=0 是 輸出最小價值函數 對應的訊號組合
第二種情況是開始要估計第 根天線估計出來的 組部分天線之傳送訊號組合 及對 應的價值函數 ,其中 據這 的訊號代入 求出這 價值函數 函數 及對應的部分天線之傳送訊號組合 j 根天線的傳送訊號,假設此時已經有第 j+1… NT M =[ … ]T m =1…M。估計第 j 根天線的傳 M N 條路徑,也就是將傳送訊號集合 A 所有 (13)式中的 M×N 個延伸路徑的價值函數。接著從這 M×N 個 M 個最小的價值函數,其餘則刪除,並記錄這 M 個價值 =[ … ]T,其中 m = 1…M,以便演算法執行下一步驟。 ) ( 1 m j+ θ ) (m j x x ) ( 1 m j x + 送 ) 1 m + ) ( 2 m j x + 訊號 ) (m NT x ) (m NT x 要根 ) ( j+1 m x ψ 組部分天線之傳送訊號組合各別去延伸 ) j 中保留前 j x (x ψ ) j x ( m ψ (m) j θ ( j M m x r x r y x ψ x ψ x P x r x r y σ y y x x P y y y x x x P x P x r x r y σ x P x x y y P x P x x x y P x P x x x y y P x P x P x x x y y y P y y y x x x P T T T T T T T T T T T T T T T T T T T N j k j jj m k jk j j m j j N j k j jj m k jk j N j m N m j N j j m N m j j j N j k j jj m k jk j N j k m k m N m j N j j m N m j j j N j k m k m N m j j N j N j k m k j m N m j j N j j N j j m N m j j L L L L L L L L L L L L L L 1 , ~ ) ( ) ( ) ( log ~ 1 ) ~ , , ~ | , , ( log ) ~ , , ~ , ~ | , , , ( log ) ( ) ~ 1 exp( ) ( ) , , | ~ , , ~ ( ) ( ) , , , | ~ ( ) ( ) , , , | ~ , , ~ ( ) ( ) ( ) , , , | ~ , , ~ , ~ ( ) ~ , , ~ , ~ | , , , ( 2 1 ) ( 1 2 1 ) ( 2 1 ) ( ) ( 1 1 ) ( ) ( 1 2 1 ) ( 2 1 ) ( ) ( ) ( 1 1 ) ( ) ( 1 1 ) ( ) ( ) ( 1 1 1 ) ( ) ( ) ( 1 1 1 ) ( ) ( 1 = − − + ≡ ⇒ − − − + − ≈ − ⇒ − − − × ≈ × = ∝
∑
∑
∑
∏
∏
∏
+ = + + = + + + + + = + = + + + + = + + + = + + + + (13) 此演算法會一直執行到部分天線之傳送訊號組合 包含所有天線的估計訊號 才停止,而此時最小價值函數對應的訊號組合 即為使用此演算法得到的最佳 估計解 。以下用一個簡單的例子來說明演算法步驟:系統為三根傳送天線及三 根接收天線的 系統,調變使用 , 演算法的 值設為 θ ) 1 ( θ xˆ V-BLAST 4-QAM SQRD-M M二,且假設排序的 分解所找到之解碼順序是從第三根天線估測回第一根天 線。如圖 對應之路徑,圓形點是可能的傳送訊號,節點旁的數字為路徑延伸到此節點所累 積的價值函數。估計第三根天線的傳送訊號時,直接將 代入 例子被保留下來的節點所對應之價值函數分別為 及 送訊號時,必須根據上一步驟保留下來的兩條路徑,分別去延伸四個可能的傳送 訊號,即將 的四個調變訊號代入 ,求出八個價值函數, 個最小的價值函數所對應之節點,此例子被保留下來的節點所對應之價值函數分 QR 3.2,虛線是延伸的路徑,實線是被保留下來的前兩個最小價值函數 4-QAM (12)式求出四個價值函數,並且保留兩個最小的價值函數所對應之節點,此 2.3 3.0; 4-QAM (13)式 2.4 3.4; 2.5 2.7; SQRD-M 所 的四個調變訊號 估計第二根天線的傳 並且保留兩 別為 及 估計第一根天線的傳送訊號也是一樣的做法,必須根據上一步驟 保留下來的兩條路徑,分別去延伸四個可能的傳送訊號,並且保留兩個最小的價 值函數所對應之節點,此例子被保留下來的節點所對應之價值函數分別為 及 最後再從這兩個被保留下來的路徑中選取最小價值函數所對應的路徑即為使 用 演算法得到的最佳估計解。 從模擬結果可以得知 演算法的 徑,且讓錯誤率趨近於 估計曲線,其中 演算法是一次估測一根天線的次序 圖3.2 NT = 3,NR = 3,運用 SQRD-M 演算法做估測的樹狀圖示 SQRD-M M 值最大只需到 N 即可包含最佳路 ML N 為傳送訊號集合 A 裡元素的總個數; M 值再大只會增加複雜度,效能改善的程度並不明顯,所以我們限制 M≦N。而 M 值最大只需等於 N 的原因如下:SQRD-M 天線1 2.7 2.5 3.1 2.9 4.4 4.2 3.4 5.1 5.8 2.3 3.9 3.0 3.6 2.4 5.3 3.7 天線3 天線2 3.7 3.5 5.1 4.4
性解碼,所以第一根天線的估測訊號之正確性會影響其它根天線的估測訊號之正 確性,即錯誤延續,所以如果被保留下來的部分天線之傳送訊號組合個數 等於 調變訊號集合大小 表示估測第一根天線時,此根天線所有可能的傳送訊號都被 保留下來,才不會發生正確的傳送訊號在估測第一根天線時就被刪除。圖 和 圖 分別為調變使用 於 的 系統下, 演算法與 演算法的錯誤率比較圖。由圖可知, 演算 法在 很明顯的錯誤率落差;而 演 算法在 錯誤率差距較不明顯,尤其在更高階的調變 下差距更小,其原因是因為 演算法在估測第一根天線時,強迫 讓此根天線所有可能的傳送訊號都保留下來,參數 的限制只存在其它根天線的 估測,所以在相同的 值下,經過兩種演算法的錯誤率比較後得到結論如下:第 一根天線的估測訊號之正確性是影響 演算法的效能最主要之因素,尤 其在越高階調變下影響越明顯。所以,通常我們限制 演算法的 值最 大只需到 即可。 M N 3.3
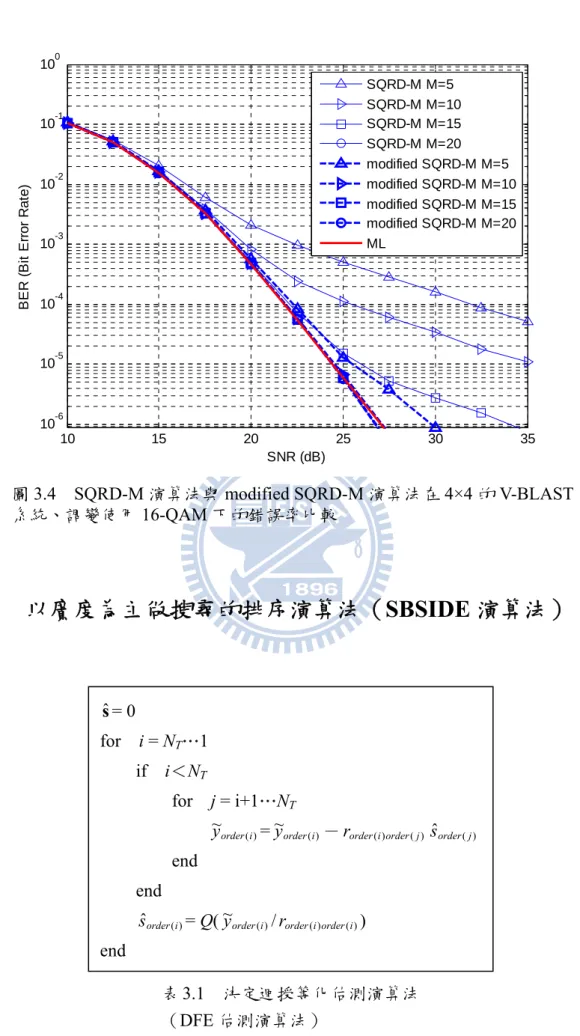
3.4 4-QAM 及 16-QAM 4×4 V-BLAST SQRD-M
modified SQRD-M SQRD-M M 小於 N 與 M 等於 N 之間有 modified SQRD-M M 小於 N 與 M 等於 N 之間的 modified SQRD-M M M SQRD-M SQRD-M M N 0 5 10 15 20 25 10-6 10-5 10-4 10-3 10-2 10-1 100 SNR (dB) BE R ( B it Er ro r R a te ) SQRD-M M=1 SQRD-M M=2 SQRD-M M=3 SQRD-M M=4 modified SQRD-M M=1 modified SQRD-M M=2 modified SQRD-M M=3 modified SQRD-M M=4 ML 圖 演算法與 演算法在 的 系統、調變使用 下的錯誤率比較 3.3 SQRD-M modified SQRD-M 4×4 V-BLAST 4-QAM
10 15 20 25 30 35 10-6 10-5 10-4 10-3 10-2 10-1 100 SNR (dB) B E R (B it E rro r Ra te ) SQRD-M M=5 SQRD-M M=10 SQRD-M M=15 SQRD-M M=20 modified SQRD-M M=5 modified SQRD-M M=10 modified SQRD-M M=15 modified SQRD-M M=20 ML 圖 演算法與 演算法在 的 系統、調變使用 下的錯誤率比較
演算法)
3.4 SQRD-M modified SQRD-M 4×4 V-BLAST 16-QAM3.2 以廣度為主做搜尋的排序演算法(SBSIDE
sˆ = 0 for i = NT…1 if i<NT for j = i+1…NT ) ( ~ i order y =~yorder(i)- end end = Q ) ( ) (iorder j order r sˆorder(j) ) ( ˆorderis (~yorder(i)/rorder(i)order(i))
end
表3.1 決定迴授等化估測演算法 (DFE 估測演算法)
圖 為 演算法的流程圖。 演算法與 演算法相同 在進行訊號估測前必須先執行排序的 分解,為了方便說明,將排序 所找到之解碼順序設成從第 根天線估測到第一根天線,即 是一個標準倒三角形矩陣。而執行演算法前,必須先根據排序的 之解碼順序加上決定迴授等化估測演算法( 估測演算法)估算出一個初步估 計解sˆ ˆs1 ˆs2 sˆNT 表 中 ,並且算出初步估計門檻 - ˆ 而使用排序的Q 解可以讓初步估計解sˆ 更準確,sˆ 越準確也會讓初步 估計門檻d 越小,此時篩選的依據就更嚴苛,被保留下來的部分天線之傳送訊號 組合就越少,反應在複雜度上也會較低。 演算法相同 在進行訊號估測前必須先執行排序的 分解,為了方便說明,將排序 所找到之解碼順序設成從第 根天線估測到第一根天線,即 是一個標準倒三角形矩陣。而執行演算法前,必須先根據排序的 之解碼順序加上決定迴授等化估測演算法( 估測演算法)估算出一個初步估 計解 表 中 ,並且算出初步估計門檻 - Q 解可以讓初步估計解 更準確, 越準確也會讓初步 估計門檻d ,此時篩選的依據就更嚴苛,被保留下來的部分天線之傳送訊號 組合就越少,反應在複雜度上也會較低。 3.5 SBSIDE SBSIDE SQRD-M QR QR NT order={1,2,3… NT}, R QR DFE = [ … ]T,如 3.1,其 Q( )指量化 d= || Rs ||2。 R 分 QR QR NT order={1,2,3… NT}, R QR DFE = [ … ]T,如 3.1,其 Q( )指量化 d= || Rs ||2。 R 分 越小 , 分解 分解找到 圖3.5 SBSIDE 演算法的流程圖 , 分解 分解找到 圖3.5 SBSIDE 演算法的流程圖 y~y~ sˆ ˆ 1 ˆs ˆs2 sˆNT 而使用排序的 sˆ sˆ k=NT 將通道矩陣H 進 行排序的QR 分解 在接收訊號y 前 乘上QH矩陣 於第order(k)根天 線延伸所有可能的 傳送訊號,並計算 其對應的價值函數 更新sˆ 及 d,並保 留小於或等於d 的價值函數所對 應的部分天線之 傳送訊號組合 由決定迴授等化估測 演算法算出初步估計 解sˆ 及初步估計門檻 d k=k-1 根據這些被保留下來 的組合,分別於它們 的第order(k) 根天線 延伸所有可能之傳送 訊號,並計算其對應 的價值函數 k=0 更新sˆ 及 d,並保 留小於或等於d 的價值函數所對 應的部分天線之 傳送訊號組合 否 是 輸出最小價值函數 對應的訊號組合 k=1 否 是
執行演算法會遇到兩種情況,第一種情況是估計第 根天線的傳送訊號。而 篩選是比較機率值的大小,與 演算法計算價值函數的方法相同,不同 的地方在於保留價值函數的機制,所以同樣直接將傳送訊號集合 所有的訊號代 入 ,求出這 中取出最小的價值函數(以 表示)所對應之部分天線的傳送訊號組 果 ,則令一個向量 中 到 位置的值為初步估計解 中 位置的值,而 中 位置的值為 求 NT SQRD-M A (12)式中的 N 個延伸路徑的價值函數。接著從這 N 個價值函數 =[ ]T,如 g,其 1 NT-1 1 NT-1 g NT g = [ … ]T,並 = || T N x 1 ˆs ) ( T N x ψ 合 (1) T N θ ) 1 ( T N θ ,即 ) ( 1 xNT ψ 不等於初步估計解中的 到 得dˆ y ) 1 ( T N x (1) T N θ 1 − θ(N1 T N sˆ sˆ ˆ T N s ) T ~ - 如果 小於初步估計門檻 個價值函數 中保留 其中 第二種情況是開始要估計第 根天線估計出來的 組部分天線之傳送訊號組合 及對應的 價值函數 ,其中 計解 路徑 所有的訊號代入 (以 表示) 矩陣裡的值不等於 到 為 個價值函數 設保留了 法執行下一步驟。 此演算法會一直執行到部分天線之傳送訊號組合 包含所有天線的估計訊號 才停止,而此時最小價值函數對應的訊號組合 演算法得到 Rg||2; d, d = g。最後從這N d 的價值函數,假設保留了 E 個,其餘則刪除,並記錄 E = [ ]T, m =1…E,以便演算法執行下一步驟。 dˆ 則讓 這 等於 個價值函數 dˆ 小於或等於初步估計門檻 ψ ,且更新初步估計解 ) T N x sˆ ( ) T N x ψ ) (m NT x ( m 及所對應的部分天線之傳送訊號組合 ) (m NT θ j 根天線的傳送訊號,假設此時已經有第 j+1…NT E =[ … ]T m =1…E,且已知更新過後的初步估計門檻 d 及初步估 j 根天線的傳送訊號要根據這 E 組傳送訊號組合各別去延伸 N 條 A (13)式中的 (13)式中的m
=1…E,來求出這 E×N 個延伸路徑的價值函數。接著從這 E×N 個價值函數 )
= [ … ]T,如果 j 到 NT g,其中 1 j-1 1 j-1 g j 到 NT位置 g = [ … ]T, = || Rg||2;如果 d,則讓 d 等於d ,且更新初步 = g。最後從這 E×N d E 個,其餘則刪除,並記錄這 E 個價值函數 j)及對 = [ … ]T,其中m =1…E,以便演算 ) ( 1 m j+ θ ) :NT 矩陣對應的值,即 ) (m NT x ) ( 1 m j x + 所對應之部分天線的傳送訊號組合 位置的值為初步估計解 ) ( 2 m j x + j x ,且 ,即初步估計解中 中保留小於或等於初步估計門檻 ) (m NT x 讓 sˆ 中 1 ˆs ˆ ψ ) ( j+1 m x ψ 。估計第 也就是將傳送訊號集合 中取出最小的價值函數 ) 1 ( T N x 位置的值,則令一個向量 中 y~ - ,假 應的部分天線之傳送訊號組合 sˆ , 1 ( j x 的價值函數 (xj ψ ) 1 ( j θ 到 ) 1 ( j ) ( 1 xj ψ 的值 dˆ ) (m j θ ) 1 ( j x 並求得 估計解 ) 1 + 位置的值,而 dˆ sˆ ) 1 ( j θ sˆ j( ) j ) 1 ( j θ 小於初步估計門檻 ) (m j x 1 ˆj− s ( m x θ (x ψ ) ( 1 m j x + θ 即為使用 ) 1 ( θ SBSIDE
的最佳估計解 。同樣以一個簡單的例子來說明演算法步驟:系統為三根傳送天 線及三根接收天線的 系統,調變使用 並限制 演算法 估測回第一 被 的四個調變 之值為 此例子被保 ,必 ,即將 的四個調變訊號代入 ,假設此時更新過後的初步估 計門檻 之值為 的價值函數所對應之 節點,此例子被保留下來的節點所對應之價值函數為 傳 送訊號也是一樣的做法,必須根據上一步驟保留下來的一條路徑,去延伸四個可 能的傳送訊號 即將 的四個調變訊號代入 ,最後 再從這四個價值函數選取最小價值函數所對應的路徑即為使用 演算法得 到的最佳估計解。 圖3.6 NT = 3,NR = 3,運用 SBSIDE 演算法做估測的樹狀圖示 xˆ ,
V-BLAST 4-QAM, SBSIDE
E 為 1≦E≦4,且假設排序的 QR 分解所找到之解碼 3.6,虛線是延伸的路徑,實線是經過初步估計門檻的篩選後而 4-QAM (12)式求出四個價值函數,假設此時更 d 3.8, d 2.3 3.0; 4- QAM (13)式求出八個價值函數 d 3.3,則保留小於或等於此初步估計門檻 d 2.4;估計第一根天線的 4-QAM (13)式求出四個價值函數 SBSIDE 過程中經過初步估計門檻篩選後被保留下來的部分天線之傳送訊號組合個數 順序是從第三根天線 根天線。如圖 保留下來之路徑,圓形點是可能的傳送訊號,節點旁的數字為路徑延伸到此節點 所累積的價值函數。估計第三根天線的傳送訊號時,直接將 訊號代入 新過後的初步估計門檻 則保留小於或等於此初步估計門檻 的價值函數所對應之節點, 留下來的節點所對應之價值函數為 及 估計第二根天線的傳送訊號時 須根據上一步驟保留下來的兩條路徑,分別去延伸四個可能的傳送訊號 天線 2.7 2.5 3.1 2.9 1 4.4 4.2 3.4 5.1 5.8 2.3 3.9 3.0 3.6 2.4 5.3 3.7 天線 d=3.8 3 天線 d=3.3 2
執行演算法過程中,初步估計解 會不斷的更新,且越來越準確,也代表初 步估計門檻 越來越小,但由第 估測完一根天線後價值函數都會增加;由以上結果得知,當接收端使用 演算法估測越後面順序之天線的傳送訊號時,其所算出的價值函數經過初步估計 門檻 的篩選後被保留下來之個數會越來越少,反應在複雜度上也會越低。 由上述演算法的推導過程可知被保留下來的部分天線之傳送訊號組合個數 並非定值,此論文中,我們限制 兩個極端值 和 得到的方式如下: 演算法在篩選 或等於此門檻的價值函數,而這些被保留下來的價值函數之個數就是解下一根天 線時必須延伸路徑的節點個數 節 的 演算法中得到一個結果, 徑,且 讓錯誤率趨近於 估測的曲線, 值再大只會增加複雜度,效能改善的程度並 不明顯,所以我們限制 不會讓接收端在某些情況下複雜度變很高。另 外,在高訊雜比時 值有很高的機率會等於一,也就是解下一根天線時需要延伸 路徑的節點只有最小價值函數的節點,所以我們也限制 sˆ d (13)式可知價值函數是不斷累加而得到,所以每 SBSIDE d E 1≦E≦N,這 1 N SBSIDE E×N 個價值函數時,會根據一個初步估計門檻 d 保留小於 E。有些情況下 E 值會比 N 還要大,但是從 3.1 SQRD-M M 值最大只需到 N 即可包含最佳路 ML M E≦N,才 E 1≦E。
四、以廣度為主做搜尋的多層排序
在第三章介紹完 演算法後,本章結合了 整門檻來限制搜尋路徑個數特性與 的多層架構搜尋特性而衍生出以廣度 為主做搜尋的多層排序演算法,簡稱為 演算法。 先天性的多層架構,並在此架構下定義傳送訊號的機率模型; 演算法的基本概念及動作原理; 節則詳細說明 數學推導,並將較複雜的數學運算列於 節附錄中;最後於調變訊號座標集合的多層架構
演算法
演算法的適應性調 節先介紹 節說明 演算法的執行過程與 節將此演算法 做總結。 在介紹 演算法之前必須先定義 的多層架構。圖 描述了 所有訊號在座標平面自然形成的多層架構。原始六十四個調變訊號的集 SBSIDE SBSIDE N-QAM MSBSIDE 4.1 N-QAM 4.2 MSBSIDE 4.3 MSBSIDE 4.5 4.44.1 N-QAM
MSBSIDE N-QAM 4.1 64-QAM 圖4.1 64-QAM 的多層架構 1 a 2 a 3 a 4 a 7 a 8 a 9 a 10 a 11 a 12 a 15 a 16 a 17 a 18 a 19 a 20 a 23 a 24 a 25 a 26 a 27 a 28 a 31 a 32 a 33 a 34 a 35 a 36 a 39 a 40 a 37 38 41 a 42 a 43 a 44 a 47 a 48 a 49 a 50 a 51 a 52 a 55 a 56 a 57 a 58 a 59 a 60 a 63 a 64 a 1 , 2 a 2 , 2 a 4 , 2 a 5 , 2 a 6 , 2 a 8 , 2 a 9 , 2 a 10 , 2 a 12 , 2 a 13 , 2 a 14 , 2 a 16 , 2 a 1 , 3 a a3,3 5 a 6 a 13 a 14 a 21 a 22 a 29 a 30 a a a 45 a 46 a 53 a 54 a 61 a 62 a 3 , 2 a a2,7 a2,15 a2,11 2 , 3 a a3,4合(圓形點)為第一層訊號, 訊 號點,這十六個正方形點都是在其周圍四個第一層訊號的平均值,並且把這十六 個訊號點歸類為第二層訊號, 訊號點, 這四個星形點都是在其周圍四個第二層假想訊號的平均值,並且把這四個訊號點 歸類為第三層訊號, 從圖 中,我們可以把這些點依照象限位置來做分類, 例如位於第二象限的所有原始訊號與假想訊號都可以定義出一個樹狀圖,如圖 子代的概念,後面會詳加說明。 更明確的定義這些假想訊號如下,第 層的假想訊號集合可以用下面式子表 示: 而 總共會有幾個階層的訊號; 第 想訊號 這裡稱為親代 是 集合 裡其中四個元素的平均值(這裡稱這四個元素為子代 ,且將這四個元素 集合稱為 ,所以 是 的子集合,這些元素的關係可以用下列式子表示: l=1;十六個正方形點可以視為假想的 16-QAM l=2;四個星形點可以視為假想的 4-QAM l=3。 4.1 4.2,而有了樹狀圖就會衍生出親代與 l Al ≣{al,1,al,2,L,al,Nl } (14) l=1…L,其中 L≣log4 N,指 N-QAM Nl≣N41-l,指 l 層訊號集合的元素個數。其中必須特別注意的是當 l=1,A1即是A,且 a1,k=ak, k=1…N。每一個在 Al集合裡的假 al,s( parent)都 Al-1 children) Al-1 s l A−1 s l A−1
∑
− − ∈ − × = s l k l A a k l s l a a 1 , 1 , 1 , 0.25 (15) 其中l=2…L,s=1…Nl。Als除了是Al的子集合外,還具有∪k =Al及 ∩ = k l A k l A n l A φ 的特性,其中 且 定義完假想訊號和原始訊號的樹狀架構及它們的集合特性後,我們知道一個 原始訊號 義機率模型如下: k, n=1…Nl+1 k≠n。 ak∈A 在樹狀圖的每層都有屬於它自己的唯一祖先 al, s,所以我們可以定 × ≡ ( ) ) , (ak al,s P ak P Ⅱ(ak是al, s的子代) (16)其中 的敘述是正確的,則 敘述是錯的 以 以下式子得到: Ⅱ( )是指示方程式(如果( )裡 Ⅱ( )等於一;如果( )裡的 Ⅱ( )等於零) k = 1…N,l = 2…L,s = 1…Nl;所 P(al, s)可以由 ,則 ,
∑
∈ × = A a k s l k a P a P( , ) ( ) Ⅱ(ak是al, s的子代) (17) 也就是各層假想訊號的機率是它在第一層的所有子代訊號的機率和。4.2 基本概念
與 演算法相同, 演算法為了達到降低複雜度的目的,不採 用 演算法過程中每次都保留固定 組發生機率較高的部分天線之傳送 訊號組合,因為這固定的 組訊號組合中,某些組合發生的機率比起那些發生機 率高的組合低很多,所以並不盲從的每次都保留固定 組,而是設定一個估計門 檻來篩選要保留下來的訊號組合;這些被保留下來的部分天線之傳送訊號組合個 數 值與 演算法得到的結論相同,我們一樣限制 此限制內, 被保留下來的訊號組合即可包含最佳的估測解,讓錯誤率逼近 估測且複雜度 不會太高。 SBSIDE MSBSIDE SQRD-M M M M E SBSIDE 1≦E≦N,在 ML 5 a 6 a 13 a 14 a 8 a 7 a 16 a 15 a 29 a 30 a 21 a 22 a 32 a 31 a 24 a 23 a 8 , 2 a 3 , 2 a a2,4 a2,7 2 , 3 a 2 2 A 3 1 A 4 1 A 7 1 A 8 1 A 圖4.2 64-QAM第二象限所有訊號的樹狀關係圖MSBSIDE SBSIDE MS- BSIDE N-QAM L L≣log4 N。而每個階段(如第 l 階段,其中 l=1…L)都是用 4.1 節中 l l 階段的估計門檻 dl來表示之,其中l=1…L。 l=1 d1 SBSIDE d 的定義及更新方法相同,而第 l 階段之估計門檻 dl的定義及更新方法會 4.5 l=2…L。 演算法與 演算法同為以廣度為主做搜尋的演算法,但 演算法為了進一步降低計算與比較價值函數的個數而利用 本身多 層架構搜尋的特性,將每層在估測一根天線的傳送訊號又分成 個階段來完成, 其中 對應的 第 層訊號集合來估測傳送訊號,所以過程中每個階段用來篩選價值函數的估計 門檻都是不同的,以第 需特別注意 的是當 時,第一階段之估計門檻 的定義及更新方法與 演算法中估 計門檻 於 節中詳細說明,其中 演算法降低複雜度的基本概念如下:假設接收端開始要估測第 ,且已經有前幾次估計出來之天線(第 組可能的部分天線之傳送訊號組合及其對應的價值函數。對高 階的調變來說,例如在一個使用 的系統中, 演算法在解此根天 線時必須計算與比較 個價值函數,如果此時 值很大,對接收端來說複雜 度還是太高。而 演算法將估測此根天線的傳送訊號分成三個階段,且 順序是從第三階段進行到第一階段。第三階段是以第三層假想訊號來估測, 而第三層的假想訊號只有四個(星形),所以只需計算 個價值函數即可, 並且檢查是否需要更新第三階段的估計門檻 再從這些價值函數中比較並保留 小於或等於此估計門檻的價值函數,假設保留了 ;接著進行第二階段的訊號 估測,此階段是以第二層假想訊號來估測, 值 函數所對應的部分天線之傳送訊號組合中的第三層假想訊號,分別去找到它在第 二層假想訊號集合中的子代( ,而這些子代只會有四個(方形),所以只 需計算 個價值函數即可,並且檢查是否需要更新第二階段的估計門檻 再從這些價值函數中比較並保留小於或等於此估計門檻的價值函數,假設保留了 行第一階段的訊號估測, 線的估測。由上述過程可知,每成功估測出一根天線的傳送訊號, 演 算法總共計算與比較這些價值函數的個數為 是 演算法 的 MSBSIDE order(j)根天線的傳送訊號 order(i)根天線, i = NT…j+1)的 E 64-QAM SBSIDE E×64 E MSBSIDE l=L= 3, E×4 d3, E’個 l=2,根據這 E’個被保留下來的價 children) E’×4 d2, E’’個;最後重覆上一步驟的作法進 l=1,即完成此根天 MSBSIDE E×4+E’×4+E’’×4, SBSIDE
在使用 演算法估算傳送訊號的過程中,必須包含計算與更新各個 階段的估計門檻、計算這些假想訊號集合及由親代訊號找到對應之子代訊號的複 雜度,以下會有詳細的演算法說明。 MSBSIDE
4.3 演算法描述
圖4.3 MSBSIDE演算法的流程圖 k=NT 將通道矩陣 進 行排序的 H QR 分解 在接收訊號 前 乘上 矩陣 y QH 於第 線延伸所有第一層 原始訊號,並計算 其對應的價值函數 order(k)根天 更新sˆ 及 d 並保 留小於或等於d1 價值函數所對 應的部分天線之 傳送訊號組合 1, 的 k=k-1 由決定迴授等化估測 演算法算出初步估計 解sˆ 及第一層初步估 計門檻d1 根據這些被保留下來 的組合,分別於它們 的第 根天線 延伸所有第 層假想 訊號,並計算其對應 的價值函數 order(k) L k=0 如果此時 則必須更新sˆ;計 算或更新dL 保留小於或等於 dL 值函數所 對應的訊號組合 L=1, ,並 的價 否 是 輸出最小價值函數 對應的訊號組合 否 是 l=L l=l-1 l=0 k=1 是 如果此時l 則 必須更新sˆ;計算 或更新dl,並保 留小於或等於dl 的價值函數所對 應的訊號組合 =1, 根據這些被保留下來 的組合,分別於它們 的第 根天線 延伸其 層訊號的 子代訊號,並計算其 對應的價值函數 order(k) l+1 否圖 為 演算法的流程圖。 演算法與 演算法相 同,在進行訊號估測前必須先執行排序的 分解,為了方便說明,將排序的 分解所找到之解碼順序設成從第 根天線估測到第一根天線,即 是一個標準倒三角形矩陣。而執行演算法前,必須先根據排序的 分解 找到之解碼順序加上決定迴授等化估測演算法估算出一個初步估計解 表 並且算出第一層的初步估計門檻 - 分解可以讓初步估計解 更準確, 越準確也會讓第一層的初步估計門檻 越小,此時篩選的依據就更嚴苛,被保留下來的部分天線之傳送訊號組合就越 少,反應在複雜度上也會較低。 執行演算法會遇到四種情況,第一種情況是估計第 根天線的傳送訊號。與 演算法得到的結論相同,我們限制被保留下來的部分天線之傳送訊號組 合個數 為 由 演算法的結論得到第一根天線的估測訊號 之正確性是影響演算法效能最主要的因素,因此在估測此根天線時, 的值落在 附近的機率會很高。在此限制下,未使用 的多層架構特性做搜尋時, 估計此根天線的傳送訊號所計算的 個價值函數最多會全部被保留下來;而使用 的多層架構特性做搜尋時,最多也會將這 個價值函數保留下來,所以 未使用 多層架構特性來估測此根天線之傳送訊號的複雜度是最低的,只 需計算與比較 階段來估測此根天線的傳送訊號。而篩選過程是比較機率值的大小,所以直接將 第一層原始傳送訊號集合 所有的訊號代入 求出這 個延伸路徑 的價值函數,與 來表示,目的是為 了要區分使用不同層訊號集合來做估測,例 來做估測,就以 表示。接著從這 個價值函數 中取出最小的價值函 數(以 所對應之部分天線的傳送訊號組合 如果 ,則令一個向量 位置的值為初步估 計解 ,而 中 位置的值為 並求得
4.3 MSBSIDE MSBSIDE SBSIDE
QR QR NT order={1,2,3… NT},R QR =[ … ]T,如 3.1, d1= || R ||2。 QR d1 sˆ ˆs1 而使用排序的 2 ˆs T N sˆ y~ sˆ sˆ sˆ NT SBSIDE E 1≦E≦N,且 SQRD-M E N N-QAM N N-QAM N N-QAM N 個價值函數,複雜度並未開始成長,因此並不需要額外利用 L 個 A1 (18)式中的 N (12)式不同的地方在於這裡不用 A1 N = [ ]T, g, 1 NT-1 1 NT-1 g NT g =[ … ]T, = || 1 , T N x 而改以xN ) 1 , T N x ) 1 ( 1 , T N θ 1 ,,即 T N x 其中 1 , T 如這裡以第一層原始傳送訊號集合 1 , T N x 表示) ( ψ 到 ) 1 ( T N θ ) ( ,1 1 xNT ψ 不等於初步估計解中的 中 到 dˆ y ) 1 ( 1 , T N x 1 ˆs ) 1 ( 1 , T N θ ) 1 1 , T T N sˆ 位置的值 sˆ ˆ −1 T N s ( N θ ~ - 更新初步估計解 初步估計門檻 ( N ,1 m x ψ Rg||2;如 d1,則 d1 = g。最後從這 N d1 E 個,其餘則刪除,並記錄這 E 個價 = [ ]T, m =1… 果dˆ 的價值函數,假設保留了 小於第一層的初步估計門檻 個價值函數 值函數 及所對應的部分天線之傳送訊號組合 讓 中保留小於或等於第一層 ) 1 , m 等於 其中 dˆ ,且 sˆ ,1) T θ (xN ψ ) ( ) 1 , m N ( N x