行政院國家科學委員會專題研究計劃成果報告
網際網路演化式智慧型投資代理之研究
計畫編號:NSC 89-24-16-H-004-094 執行期間:89 年 8 月 1 日起至 90 年 7 月 31 日楊 建 民 博士
國立政治大學 資訊管理學系暨研究所
中華民國九十年七月
摘 要
近年來,透過演化的觀點探討複雜的社會經濟現象的學問,正方興未艾。演 化運算(Evolutionary Computing)其發展的主要原理,係根據達爾文(Darwin)所 提出進化論的基本觀念:「物競天擇,適者生存」的演化特質為基礎,亦即在現 存有限資源的環境下,生態系中的各種物種,必須為了生存而互相競爭,失敗者 遭淘汰,而勝利者取得生存權力以及繁衍後代的機會。這一新興學門目前已經被 廣泛應用在許多複雜系統,如最佳化、設計、控制等問題的求解上,並獲致令人 驚異的成果。 由於智慧型代理(Intelligent Agent)技術的突破性進展,使得網際網路的發 展與應用,更加迅速與複雜。目前透過網路智慧型代理,已經可以進行資訊蒐集、 溝通、詢價、議價、投資理財、稅務管理等功能,是未來電子商務進一步發展極 具潛力的重要核心技術。基本上,Agent 是一具有智慧的電腦軟體,可透過感應 器 (Sensor) 認 知環 境, 學 習 並 更新 具 備的知 識 (Knowledge) , 並藉 由 作 用 器 (Effector)對環境做出適當的回應﹔以及能主動的溝通或協助其他的 Agents。 本研究將發展兼具演化與學習能力的智慧型投資代理。利用類神經網路 (Neural Net)來建構智慧型代理(Agent)內在的投資智慧與學習能力。同時建立 演化的機制,透過基因的交換與突變,演化出最佳的 Agent 族群,期能動態適應 並掌握證券市場行為的變化,並輔助投資者做出較佳決策。本研究取台灣股市從 民國 80 年 1 月到民國 88 年 12 月間 9 年的歷史資料進行模型的學習,將整個族 群分成 6 個個體同時進行。每個世代分成學習期與模擬驗證期,學習方式採用倒 傳遞類類神經網路分析。在世代的結束時評估每個個體的適應性函數,並據以決 定演化機制中複製、交配、與突變的發生。 在整個模型的設計之下,我們可以得到下列的研究結果︰ 1. 演化的結果會逐漸收斂到一種接近最優的基因組合。亦即發現在神經網路 的預測模型中可能的關鍵指標因素的所在。2. 經過演化的個體在模擬操作的績效表現上,確實能夠有優於大盤的表現。 3. 經節選後的關鍵指標因素組合,可以建立一個擁有良好預測能力的 Agent。 4. 本研究提出之模型結合遺傳演算法及類神經網路,主要貢獻在於驗證演化 式學習能有效改善類神經網路的輸出入,可作為未來相關研究之參考。 本研究之智慧型代理亦能透過網際網路線上擷取最新的資訊而進行學習與 演化,而擴展其應用。 關鍵字:人工生命、證券投資、遺傳演算法、類神經網路、智慧型代理
目 錄
論文摘要 ………I
目錄……… III
圖目錄……….IV
表目錄………..V
第一章 緒論……… 1
第一節 研究計畫之背景與動機……… 1
第二節 研究計畫目的……… 2
第三節 研究計畫方法與步驟……… 3
第四節 章節架構……… .4
第二章 文獻探討……… 5
第一節 股價分析理論……… 5
第二節 類神經網路系統在股市預測應用的相關研究探討...11
第三節 遺傳演算法……… 16
第四節 智慧型代理與人工生命……… 20
第三章 研究方法與實驗設計………24
第一節 演化式智慧型投資代理……… 24
第二節 類神經網路之架構……… 28
第三節 演化式智慧型投資代理實作……… 32
第四章 研究結果與分析………44
第一節 使用每日交易策略的演化結果……… 44
第二節 使用預測漲跌比例策略的演化結果……… 52
第三節 改變訓練時間的演化結果……… 55
第四節 演化後優良指標測試結果……… 59
第五節 小結……… 60
第五章 結論與建議……….62
第一節 結論與建議……….62
第二節 未來研究的方向……… 64
參考文獻 ………66
附錄 技術指標說明及公式………71
圖 目 錄
圖 2-1 生物神經元………11
圖 2-2 類神經網路處理單元………12
圖 3-1 倒傳遞類神經網路架構圖………28
圖 3-2 XML-Based HTML Wrapper 架構圖………33
圖 3-3 演化類神經網路的的世代交替………40
圖 3-4 演化式類神經網路股市預測模型架構圖………41
圖 4-1 每日交易策略第一循環原始績效表(實驗一)………46
圖 4-2 每日交易策略第一循環相對績效表(實驗一)………46
圖 4-3 Dummy Agent 買入持有策略績效表……… 47
圖 4-4 實驗一中各指標出現頻率統計圖………49
圖 4-5 每日交易策略第二循環原始績效表(實驗二)………50
圖 4-6 每日交易策略第二循環相對績效表(實驗二)………50
圖 4-7 實驗二中各指標出現頻率統計圖………51
圖 4-8 預測漲跌比例策略第二循環原始績效表
(實驗三)
…………52
圖 4-9 預測漲跌比例策略第二循環相對績效表
(實驗三)
…………53
圖 4-10 兩種操作策略平均操作績效比較圖………54
圖 4-11 實驗三中各指標出現頻率統計圖………55
圖 4-12 改變訓練時間後的世代交替………55
圖 4-13 改變訓練期間之第二循環原始績效表(實驗四)………56
圖 4-14 改變訓練期間之第二循環相對績效表(實驗四)………56
圖 4-15 改變訓練期間之 Dummy Agent 買入持有績效表………57
圖 4-16 演化後優良指標績效表(實驗五)………59
表 目 錄
表 2-1 技術分析方法分類表………10
表 3-1 選取指標列表………35
表 3-2 預測漲跌幅度今日操作策略表………39
表 4-1 指標代碼對照表………45
表 4-2 檢定結果綜合比較表………60
第一章 緒論
第一節
研究計畫之背景與動機
近年來,透過演化的觀點探討複雜的社會經濟現象的學問,正方興未艾。尤 其是面對複雜的經濟體系或金融市場,傳統的經濟財務理論試圖以理性與均衡分 析,來解釋所有觀察到的事實,往往是力有未逮。殊不知經濟體系係由活生生的 個體所組成的系統,個體間係透過彼此頻繁且密切的互動關係,而突現出自發性 的秩序﹔並非永遠處在趨於平衡的穩定狀態。因此,演化經濟模型這種肯定參與 者內在認知模式的重要,探討參與者內在模式與彼此互動而產生複雜經濟現象的 方式,正好彌補了傳統經濟模型只重數學與邏輯分析,雖然嚴謹卻與現實情況不 符的缺失。 由於現在正邁向知識經濟時代,在複雜與講求速度的環境中,資訊與知識扮 演著相當重要的角色。對於現代的投資人而言,擁有精確且有效的決策分析工 具,已成為其成敗的關鍵因素,目前雖有多種類型的分析工具,然而繁雜的分析 方式與運算卻也成為一種沉重的負擔。因此,如何使電腦具有像人一般的智慧, 支 援 或 取 代 投 資 者 的 決 策 , 已 成 為 一 種 可 行 的 解 決 方 案 , 所 以 人 工 智 慧 (Artificial Intelligence)的應用,如雨後春筍般的盛行,如類神經網路 (Artificial Neural Network,ANN)、模糊邏輯(Fuzzy Logic,FL)、專家系統 (Expert System,ES)、遺傳演算法(Genetic Algorithm,GA)、智慧型代理 (Intelligent Agent)等等,已經有不少的研究嘗試將這些人工智慧的技術應用 於金融投資的領域上,亦有相當不錯的成果。 除此之外,結合演化運算(Evolutionary Computing)或演化的機制,更能真 實的模擬現實世界的動態運作,所以這種以自然界生物遺傳與演化的演算法,也 廣泛的應用到金融市場與股價預測等方面。例如 Holland[1975]等提出的遺傳演 算法,具有速度快、可靠性高、具彈性等特質[Goldberg,1994],其發展原理,係根據達爾文(Darwin)所提出進化論的基本觀念:「物競天擇,適者生存」的演 化特質為基礎,亦即在現存有限資源的環境下,生態系中的各種物種,必須為了 生存而互相競爭,失敗者遭淘汰,而勝利者取得生存權力以及繁衍後代的機會。 這一新興學門目前已經被廣泛應用在許多複雜系統,如最佳化、設計、控制等問 題的求解上,並獲致令人驚異的成果。另外,近年來聖塔菲研究院(Santa Fe Institute)更以人工生命(Artificial Life)的方法,透過投資人互動關係之模 擬,來研究股市突現的行為,如投機泡沫(Speculative Bubble)等現象,或將演 化式計算應用到模擬生態系或社會經濟系統的研究,希望藉由這些模擬生態的研 究,能對複雜適應性系統的本質有更深入的了解。 近年來,網際網路爆炸性的成長,透過網網相連,迅速的將全世界無以數計 的電腦與網路串連在一起,使用人口也不斷的快速增長。由於網際網路將全球的 政府機構、企業、學校、家庭、與休閒設施等全部串連在一起,形成了一高效能 的資訊與通信網路,不僅模糊了國境界限,更衝破了各族群間的隔閡障礙,網際 網路無疑的形成了當前最龐大最複雜的適應性生態系統,也因而提供了新經濟電 子商務無窮盡的發展空間。物庸置疑的,全球的政府機構、企業、個人與家庭都 將面臨前所未有的巨大衝擊。 由於智慧型代理(Intelligent Agent)技術的突破性進展,使得網際網路的發 展與應用,更加迅速與複雜。目前透過網路智慧型代理,已經可以進行資訊蒐集、 溝通、詢價、議價、投資理財、稅務管理等功能,是未來電子商務進一步發展極 具潛力的重要核心技術。基本上,Agent 是一具有智慧的電腦軟體,可透過感應 器 (Sensor) 認知 環 境, 學 習 並 更新 具 備 的知 識 (Knowledge) , 並藉 由 作 用 器 (Effector)對環境做出適當的回應﹔以及能主動的溝通或協助其他的 Agents。因 此,智慧型代理技術可做為人工生命或模擬系統的基礎工具,
第二節
研究計畫目的
本研究計畫即在網際網路上發展兼具演化與學習能力的智慧型投資代理。利用類神經網路來建構 Agent 內在的投資理財智慧與學習能力。同時建立演化的機 制,透過基因的交換與突變,演化出最佳的 Agent 族群,期能動態適應並掌握證 券市場行為的變化。 綜上所述,本研究主要目的可以分為以下數端: 一、 以演化觀點探討股市行為。 二、 利用類神經網路學習建構智慧型投資代理,並建立其演化機制。 三、 以台灣上市公司股市資訊,實際測試並驗證所發展完成之演化式智慧型投 資代理。並運用 WRAPER 透過網際網路線上擷取最新的資訊進行學習與演化。
第三節
研究計畫方法與步驟
綜合之前所述之研究目的,本研究計畫主要是希望建立一個演化式的類神經 網路智慧型投資代理模型,其進行步驟將包含下列幾個階段: 一、文獻探討 回顧各種股價理論的歷史性文獻,及探討類神經網路、遺傳演算法與智 慧型代理之理論基礎與應用。 二、類神經網路智慧型投資代理模型之建立 包括類神經網路的架構、指標的選取、輸出入變數的轉換、以及參數說 明。 三、演化機制的加入 說明 Agents 族群如何產生、族群進行基因演化的詳細過程與方式。 四、整合與實作 包括如何從網際網路取得資料與模型運作,含智慧型投資代理的學習與模擬驗證兩部分,實例驗證本研究之可行性。
第四節
章節架構
本研究計畫共分為五章,茲分別摘要說明各章主要內容如下: 第一章為緒論。主要在於說明研究計畫的背景、動機、目的以及整體的研究 架構摘要,最後並說明本研究計畫的章節安排。 第二章為文獻探討。本章主要有四個部分,首先是探討股價分析的相關理 論,包含效率市場假說以及不同學派的分析模式。第二部分是類神經網路應用於 財務以及股市的相關研究討論。第三部份為遺傳演算法的理論與發展。最後則是 智慧型代理的理論與應用探討。 第三章為研究設計。本章將詳細說明本研究計畫的研究方法與系統建構及運 作的流程。首先,在第一節對於研究設計中所引用的資料來源與時間,還有採用 的各類股市指標作討論與說明。第二節敘述類神經網路,智慧型投資代理模式之 建構方法與參數的設定。第三節則引用遺傳演算法的概念,說明整個演化學習系 統進行的詳細過程與方式。 第四章為研究結果與分析。將以實際資料來作驗證,說明學習系統演化的結 果,對於整體狀況作相關的研究討論。並將最後演化得出之類神經網路模型套用 於現行資料來作模擬操作,並對其預測能力做評估與說明。 第五章為結論與建議。主要在提出本文的研究結論與建議,並對未來可能的 後續研究方向作簡單的描述與說明。第二章 文獻探討
本章主要分為四個部分,首先是探討股價分析的相關理論,包含效率市場假 說以及不同學派的分析模式。其次將對類神經網路應用於股市分析的相關文獻做 回顧。第三部份則引進本研究將採用的遺傳演算法的概念。最後探討智慧型代理 隻理論與應用。第一節
股價分析理論
一、效率市場假說
效率市場假說(Efficient Market Hypothesis,EMH)是由 Fama[1965]所提 出,其中提到的「效率」一詞,指的是資訊流通的效率。整個假說包含下面幾個 重點,在一個有效率的市場中︰ 1. 所有的資訊均可以無償的方式取得。 2. 投資者是理性而自我激勵的,他能根據所有可獲得的資訊來作投資的決 策。 3. 因此市場將能立即且充分地反映新的資訊,並調整至新的價位。 4. 故價格的變化主要取決於新資訊的產生,而由於新資訊進入市場的不可 預測性,股價行為可能將依隨機漫步(Random Walk)的方式來波動。 依照上述的定義,Fama[1970]接著依效率性的強弱不同,而將資本市場分成 下面三種型態︰
1. 弱式效率市場(Weak Form Efficient Market)
資者無法透過之前的股價資料來作分析預測,亦即無法使用技術分析來 獲取超額報酬。
2. 半強式效率市場(Semi-Strong Form Efficient Market)
目前的股票價格已經充分的反映了所有已公開之資訊。因此投資者無法 透過現有的財務報表等資料來作分析預測,亦即無法使用基本分析來獲 取超額報酬。
3. 強式效率市場(Strong Form Efficient Market)
目前的股票價格已經充分的反映了所有已公開與未公開之資訊。所有的 投資者都已經取得了完全的資訊,因此即使是內線交易者也無法獲取任 何超額報酬。 對此三個市場的分類,林煜宗[1988]指出弱式效率市場應為其他兩種效率市 場檢定的根本。因為三種市場類型擁有效率性程度上的關聯︰當半強式效率市場 成立時,弱式效率市場亦會成立;而當強式效率市場成立時,半強式以及弱式效 率市場也都會成立。 然而,自 1980 年之後,序列相關、變異數比例法、迴歸係數法等新的研究 檢定方法流行之後,部分的研究開始發現弱勢效率市場其實並不一定成立。Fama 自己也在 1991 建議將弱式、半強式、以及強式效率市場的檢定分別更名為報酬 的可預測性研究(Return Predictable)、事件研究(Event Studies)、和私有 資訊的研究(Private Information)。他認為之前得出隨機波動的假設是限於研 究方法的緣故,效率市場是否成立應視價格能否被預測而定,而且檢定方法也應 該擴大到更多層面的資訊才合理。 至於台灣的股票市場型態,杜金龍[1993]曾針對國內股市,從民國五十一年 起的三十年間資料,以技術指標分析的方式作實證研究。結果發現,因為國內股 市有漲跌停板的限制,且投資資訊的管道不足,加上一般投資人的知識以及經驗 都稍嫌欠缺,所以使得國內的股票市場並不具備有弱式效率市場的條件。亦即在
國內的股市使用技術分析的方法,仍然有可能獲得超額報酬。而其在 1996 年的 另一份實證研究則顯示,總體經濟面的好壞對於股市多空轉折具有關鍵性的影 響,而台灣經濟係以外交為導向,受到國際經濟景氣影響更大。所以基本分析對 於台灣股市也能夠發揮其功能。此外國內亦有一些相關的研究例如︰葉日武 [1987]以技術分析研判股市進出時機、蔡宜龍[1990]分析國內技術指標衡量的有 效性、劉寶桂[1990]對台灣股市股價行為和漲跌限幅關聯性之研究、羅國宏[1995] 使用 R/S 分析法研究發現國內股價並非隨機、吳康祺[1995]使用 R/S 分析法研究 顯示國內股價走勢可能含有週期性的結構…這些文獻均顯示國內股票市場可能 並不符合弱式效率市場的條件,而能夠以技術或基本分析來預測股價的走勢。
二、基本分析
一家公司的股票價格,往往能夠反映出其營運績效的好壞-這就是傳統的股 價理論所持的觀點。當公司的營運狀況良好時,盈餘增加,自然能夠帶動公司的 股價上漲;反之,當公司營運狀況不佳,盈餘降低甚至虧損,則公司的股價也會 跟著跌落。基本分析假設依目前公司的整體營運情形會對應出一個目前該股票所 應有的真實股價(Intrinsic Value),而目前股價可能等於或不等於真實的股價。 當兩者不同時,目前股價將會向真實股價作調整。所以當目前股價低於真實股價 時,投資者預期未來股價會向上調整,故買進該股票;而當目前股價高於真實股 價時,投資者則預期未來股價會向下調整,故賣出該股票。依此預測進行操作策 略將能夠獲得超額報酬,這就是基本分析的主要觀點。 由上面敘述可知,股價的變動與股票的交易,實際上乃是投資者基於對該公 司盈餘變化的好壞之預期,所採取的投資策略反映出來的結果。而為了能夠正確 的預期,投資者必須蒐集所有可能影響公司營運狀況的資訊,來計算出股票的真 實價值,以作為投資決策的參考。這些資訊包括了各種的基本因素如︰總體經濟 情勢、產業展望、市場競爭狀況、公司盈餘與股利政策、資本結構、管理哲學、 以及成長潛力等等[Grahm & Dodd,1962]。但是基本分析的理論仍遭受到一些批評與質疑,例如據以研判的資訊不符時 效或難以取得。根據 Levy[1967]的分析指出,必須要有相當的人力與財力支持, 股價才會向真值移動,否則即使能正確預測,資金也會因股價移動的緩慢而被凍 結。其次,許多公司的財務報表中所包含的資訊並不夠詳盡,就算資料足夠豐富, 也可能因為使用的會計原則不同而使其代表的意義有所偏差。再者,真正有能力 作完整而深入的分析的投資人實際上並不多見,即使克服了此問題而作出了盈餘 預測,如何決定適當的價盈比顯然又是一個新的問題。
而 Edwards & Magee[1966]則提出下列的批評︰在某一特定的時間裡,給定 某一股票一個真實的價值是毫無意義的,股票價值僅由限定的、冷酷的市場供需 所決定。所以只要有正確的交易紀錄和足夠的資料來了解該股票的背景與習性, 投資人就可以僅靠知道一些記號來做買賣並且獲利,而不用花時間去徹底了解該 公司的運作情形。其次,基本分析僅只是市場供需方程式中的部分而非全部,實 際上還包括希望、恐懼、猜測等理性與非理性的其他複雜因素。最後,他更批評 基本分析者,使用大量的過去資料來作統計分析預測其實是不合時宜且少有用處 的,股市應該是反映、衡量並平衡所有投資人的投資策略所獲致的綜合結果。 所以儘管基本分析理論認為市場的股價應逐漸向其內在價值調整,我們卻仍 然經常可以發現許多反面的實例。例如 U.S. Steel 的市場股價從 1929 年到 1946 年間歷經上下波動,最高達$261,最低時只有$22。而在同一時期內其帳面價值 波動幅度卻遠小於市場價值,僅從$204 變化到$117 而已[Edwards & Magee, 1966]。這個現象更顯示出市場價格的決定除了基本面的因素之外,還必須參考 其他因素才合理。
三、技術分析
技術分析為股價分析理論的另一個學派,又稱為行情分析或內部分析。主要 是使用圖表型態解析(Chart Analysis)或計量的技術指標(Technical Index) 所產生的買賣訊號,配合統計科學的方法,藉由股票市場過去的軌跡來探索未來
股價的變動趨勢。依照 Levy[1967]與 Edwards & Magee[1966]的研究,將技術分 析先行之基本假設要點歸納如下︰ 1. 股價是由供給與需求之相互作用而決定。 2. 影響供給與需求的因素極其複雜,兩者均受到包括基本分析學派重視的 理性因素,以及觀點、心理、猜測等非理性的因素所影響,而市場本身 持續且自發的權衡這些因素。 3. 忽略市場上的微小波動後,股票價格的動向將會呈現持續相當時間的趨 勢。 4. 股價趨勢的改變是由於供需關係改變所致,因此不論原因為何,遲早可 由市場本身的動向中察覺其改變。 5. 股價所反映的包括未來的外在因素與市場心理。而這些只會在市場中反 映出來,是基本分析所無法辦到的。 6. 歷史不斷的重演,投資者也不斷的重蹈覆轍,因此歷史性的資料、圖形 與型態將會反覆的出現。 技術分析的理論龐雜、流派眾多,但基本上均認為證券市場上的股價與報酬 之間有系統性的關聯存在,因此只要下工夫找出兩者間背後所隱含的關係,應可 以獲得超額報酬。因為歷史會重演,股價有特定的型態可尋,且在市場機能的運 作下,市場本身會反映基本分析者所關心的各項資訊。因此投資者只要研究市場 本身所包含的各項資訊,即可找到能獲取利潤的交易策略。 然而技術分析的理論仍然未趨完善,而在理論與實務上遭到許多的質疑與批 評,尤其在 60 年代更是因為當時興起「隨機漫步」(Random Walk Hypothesis) 的假說-認為股價是由出現在市場上的資訊所左右,而市場上的資訊乃是隨機出 現,因此股價應該是呈隨機波動,歷史也不容易重演-而使得技術分析理論的可 行性受到不小的打擊。
另外,Levy 的研究也提出了幾個問題︰第一、過去的股市行為可能不會在 未來重新發生。第二、根據技術分析來作投資決策的結果,可能會因此創造出符
合技術分析者所預期的趨勢與型態。亦即市場動向反映了技術分析者的活動,而 不是技術分析者預測到股市的動態。第三、若技術分析持續有效,則加入技術分 析陣營的人日漸增加,結果將會降低了採用技術分析所能獲取的利潤。第四、許 多技術分析方法必須靠分析者主觀的判斷,而一個有系統的科學應該要以理性客 觀為基礎。 實務上,Reilly[1985]指出許多技術性指標本身並沒有價值,必須和過去的 數字相比較之後才可供研判之用。但隨著時間與環境的變化,某些過去的標準值 可能有所變動,因此必須要常常修正判斷的準則。此外,只使用單一技術指標的 情況下很可能會有誤判的情形發生,因此大多是同時使用多種技術指標來研判市 場狀況[Granville,1976],但若不同的指標間顯示出不同的市場狀況,則如何 整合或取捨分析的資訊又將是一個問題。 雖然技術分析的可行性與理論架構一直受到反對者的質疑,但是技術分析多 年來在不斷的批評中仍然是屹立不搖。現在許多學者所作相關技術分析的研究, 對於技術分析的做法是否能在證券市場上獲得超額報酬,看法也還是相當的分 歧。然而,在包括華爾街在內的各地證券交易中心,都仍然充斥著許多技術分析 的專家,其中亦不乏藉技術分析而獲得巨額報酬的專業投資人。因此,技術分析 的股市理論仍然佔有舉足輕重的地位,並且有許多學者紛紛以技術指標來研究台 灣的證券市場。目前各類研究常用的技術指標依其特性可分成四大類,大致上如 表 2-1 所示。 表 2-1 技術分析方法分類表 技術分析種類 技術分析方法 價格型態 K 線圖、條型圖、型態、缺口、OX 圖等 市場特性 RSI、KD、OBV、DMI、TAPI、VR、AR、升降線(ADL)、乖離率、 心理線、MACD、平均量值、新高、新低、賣空比率、反向操作 理論、逆時鐘曲線等 遵循趨勢 移動平均線、趨勢線、支撐線、阻力線、股票箱理論等 結構理論 艾略特波浪理論、市場季節變動、價格循環、黃金分割率、三 角方式等 資料來源︰[賴勝章,1980]
基本分析和技術分析兩派學者經過多年爭辯,至今仍然互相指摘對方的缺 失。然一般皆認為,基本分析較適於決定投資對象,而技術分析則較適於決定投 資的時機。因此若兩者並用,應當可以得出更具參考性的分析結果[Wyckoff, 1970]。此外,也有越來越多的學者開始使用新的分析工具,配合原有的基本面 與技術面指標來應用於股市上,其中尤以人工智慧最為流行。例如範例學習法、 遺傳演算法、和本研究將採用的類神經網路等,關於這一部分將於後面的章節中 介紹。
第二節
類神經網路在證券投資應用的相關研究探討
過去類神經網路在國內外各領域已經被證明是一種有用的分析工具,而且也 得到不少成功的應用,例如製程、商業、工程、娛樂、醫療、軍事等領域。其中 在財務金融方面的研究更是豐富,包括信用風險預測、股票評價、投資選股,股 價預測、投資策略支援等等。而本研究類神經網路相關部分的重心乃在於台灣股 市未來股價的預測,故以下將針對國內外關於類神經網路於股市應用的各類研究 作概要的回顧,並將著重於國內文獻的探討:一、國外相關文獻
Schoneburg [1990] 將類神經網路的技術應用於預測短期股票價格的可能 性。其做法為隨機選取三支股票,並分別以 Perceptron,Adline,Madaline 配 合倒傳遞神經網路架構來對隔日股價漲跌進行預測分析。結果發現,在短期預測 方面,最好的情況下曾達到 90%的準確度。另外,若是直接以倒傳遞神經網路架 構預測明日的股價,並以前 10 日的股價做為輸入量。結果顯示遞傳遞神經網路 可以發展出自己的試探法則(Heuristic),且其表現出來的行為類似指數平滑演算法(Exponential Smoothing Algorithm),因此 Schoneburg 相信類神經網路有 能力 做到對股市或半混亂時間序列的預測。
日本的 Fujitsu Laboratories Ltd. 與 Nikko Securities Co., Ltd.合作, 由日本學者 Kimoto et al.在 1990 年運用倒傳遞神經網路預測 TOPIX(Tokyo Stock Exchange Prices Indexs)之買賣時機。網路的輸入變數為技術指標與經濟指標, 輸出則是最佳買賣時機指標,網路採三層架構,並以 Sigmoid Function 作為轉 換函數。其貢獻在於建立了模組化的神經網路,以四個獨立的神經網路個別學習 某一輸入變數,再經後續處理予以整合。這樣做的好處在於可以解釋各變數與股 市變化之間的相關,使得類神經網路內部處理不再是一個黑盒子。而經由買賣模 擬的結果顯示,此系統與買入持有的策略相比,的確可獲得較高的報酬。 此外,Jang et al.[1991]也架構了一個雙模組(Dual-Module)的類神經網 路,但其模組與 Kimoto 之定義不同。並非單獨學習一輸入變數,而是由兩個模 組群分別針對台灣股市短期(六日)與長期(一季)之現象作學習,並以技術指 標為主要輸入變數,而未來六天的漲跌趨勢作為輸出。兩個模組的目的在於判斷 目前是否處於股市的有效反轉點(Effective Reversal Pattern),並由預設的 交易法則給於投資人買賣的建議。結果顯示,無論長期或短期,類神經網路的績 效均優於多重線性迴歸分析。而神經網路的獲利程度雖不及買進持有的策略,但 也降低了交易的風險。
Yoon and Swales[1991]建立一個四層的倒傳遞類神經網路,以區分一家公 司的股票價格績效表現為好或壞。其中神經網路的輸入部分,採取九個非線性的 環境變數。並將 ANN 的分析結果和 MDA(Multiple Discriminant Analysis)分 析做比較。結果顯示,無論是在訓練資料或是預測資料的分類上,類神經網路都 優於 MDA 法。且即使將隱藏層降低到三層,正確率都仍然比 MDA 要高。 Margarita [1991]運用類神經網路來分析股票市場的動態性。並且希望藉此 找出一個較佳的投資策略。作者建構了一個三層前向式的類神經網路,並以最近 5 日的股票價格、30 日移動平均價格與前一期的輸出策略做為輸入,而以買入、 賣出、持有三種投資策略做為網路的輸出值。此外,為了找出網路的最佳結構, 他同時也引進遺傳演算法來尋找。而實驗結果發現,在該實驗的情況下,當隱藏 層的個數為 10 個時,網路結構會達到最好的績效。提供了未來一個建立網路結
構的方法。 McCluskey [1993]運用遺傳基因演算法結合類神經網路來預測 S&P500 的股 價指數。並且將單獨使用類神經網路、回饋式類神經網路、遺傳演算法與整合式 演算法之間的準確程度做比較。另外,他也發現慎選輸入的變數與智慧型的前置 處理,將會比使用回饋法得到更為顯著的效果。
二、國內相關文獻
吳振坤[1992]提出一套學習台灣股價的類神經網路模型。在輸入變數部分整 合了包括 WMS%R、RSI、MACD、OBV 等在內的 15 種技術指標,並經過其「資訊價 值衰減模式」的前置處理;而在訓練方法部分則採用了 Wasserman 的倒傳遞演算 法與快速模擬退火演算法組合之改進方式。但可能因為此研究訓練範例之期間正 好是台灣股市股價波動最劇烈的時期,所以研究結果出現測試期的表現(誤差 1.8%)反而比學習期間(誤差 2.3%)更佳之現象。 岑英勤 [1993]結合類神經網路及模糊邏輯推論等方法,建構智慧型決策系 統以做次日股價預測與未來走勢之研判。其研究主要包含三個系統模組:K 線預 測之類神經網路、型態辨識之類神經網路和模糊邏輯決策。以技術指標為輸入變 數,分別針對這三個模組進行測試。結果發現無論在預測能力或是辨識型態方 面,都有令人滿意的結果,而且可以綜合各類股價分析的資訊,以對股票趨勢做 總合研判。最後再將這三個模組整合發展成為一個智慧型決策系統,以提供投資 顧問的服務。 張 家 澍 [1993] 提 出 一 個 以 可 調 結 構 雙 模 組 類 神 經 網 路 ( Dual Adaptive-Structure Neural Networks)為基礎的股票交易決策支援系統。針對 台灣上市股票,以隨機指標、震盪指標、相對強弱指標、乖離率等技術指標為輸 入,擷取前 24 日與前 72 日為訓練範例,組成雙模組神經網路,並調整兩網路之輸出權數以預測未來六日的股價走勢。在輸出變數上,使用 FK 指標來研判股價 頭底部訊號。經過測試,在 1990 年的空頭走勢和 1991 年的多頭走勢,其績效均 優於買入持有的策略,也高於各封閉式基金之年報酬率。 曾淑青 [1994]以價量關係配合技術分析為出發點,應用倒傳遞神經網路學 習掌握價與量的行為模式,並做預測分析。其做法為取台灣股市的歷史性日資料 與週資料,依股價與成交量的漲跌幅度,將資料分成價漲量增、價漲量縮、價跌 量縮、價跌量增四種群組。然後針對每個資料群組,分別以不同的資料輸入型態 應用於兩種類神經網路模式,並進行網路的學習與測試。實驗結果發現,將資料 依照價量關係分組後的預測準確率,大多優於未經分組的預測結果,且對於未來 價量趨勢預測可達到 70%以上的準確率。 陳啟煌 [1995]嘗試整合類神經網路,專家法則(Rule-Based)及遺傳演算 法則。系統之一部分為修正後的倒傳遞類神經網路模組,並嘗試從訓練之後的神 經網路模式中萃取出專家法則,此模組融合了類神經網路和專家系統的優點來預 測股價。另一部分則為遺傳演算法模組,能產生一些有用之交易準則,來為 Rule-Based 類神經網路做鍵節(weight)的初始化設定,使整個系統之效率更加 提昇。 賴宏仁 [1995]仍使用倒傳遞類神經網路為基礎,但輸入變數的部分有別於 以往的多數研究,不採用直接以技術指標值為輸入的方式,而改變成各種技術指 標的轉折點與交叉點訊號(如 MA 交叉、DI 交叉、RSI 交叉等)。而輸出變數則為 買、賣、持有三種決策。其研究結果證明,在整合模式下的投資報酬率能優於買 入持有以及使用單一技術指標做判斷的分析策略。 朱 佩 亭 [1996] 使 用 雙 模 組 化 的 多 層 回 饋 式 類 神 經 網 路 ( Multilayer Recurrent Neural Network )為架構對股市做兩類不同的預測,一為整體型態 辨認系統,另一為短期趨勢預測系統。並將兩系統的輸出做綜合研判後,再做買 賣點的確認。而研究結果顯示,回饋式神經網路的短期預測績效比前向式網路要 好。此外,對於類神經網路的訓練,有別於傳統的研究多使用相同的訓練期間,
其分別使用不同的訓練天數作測試,結果發現使用不同的訓練期間對於系統報酬 率亦有明顯的影響。 邱亦德[1996]使用蔡瑞煌[1995]所發展之理解神經網路(Reasoning Neural Networks,RN)以解決網路學習階段所可能遇到的過度配適(Over-Fitting)問 題。並分別以量、價、經濟指標三個模組來預測台灣股價指數。經研究結果顯示, 價模組表現最佳,而量模組表現最差,並推論以技術分析為主的價模組適用於一 個月內的短期投資預測。
三、結語
由以上的研究文獻,我們可以發現,類神經網路於證券市場的應用研究,其 實是朝向發展一種更準確的預測方法在進行。包括改變神經網路的架構(例如模 組化設計、回饋式網路、理解式網路等)、改變輸出入變數(價量關係、不同指 標訊號)或系統參數、結合類神經網路與其他人工智慧(例如模糊演算法、範例 學習法、遺傳演算法等)、使用統計性的分析來篩選網路的輸入變數等等。然而 在諸多研究中,如何決定類神經網路的輸出入變數,對研究結果都仍然具有舉足 輕重的影響。 而在國內的眾多研究中,對於輸入變數的選擇,除了少數使用統計方法(逐 步迴歸、因素分析法)篩選之外,其餘大多均由經驗、直覺或過去的研究直接選 定。亦即,研究重點多在於架構與方法的改善,而非關鍵因素的找尋。也因此發 展一個具有自我演化能力以篩選輸入變數的類神經網路股價預測模型,是重要且 可行的一項工作。下一節我們將引進遺傳演算法的概念,並簡述其內容。第三節
遺傳演算法
本節將簡單介紹遺傳演算法,及其相關的文獻,以及對本研究所引用的演化 機制能有基本的說明。
遺傳演算法(Genetic Algorithms,GA)當初發展時,主要是根據達爾文的 「物競天擇,適者生存」的想法而來,以類似自然生物界中優勝劣敗的演化法則 所建立的一種適應性的搜尋法則(Adaptive Search Procedure)。其最早的起源 要追溯到 50 年代的一群生物學家,以電腦來模擬生物系統。但是一直到 1975 年, 由密西根(Michigan)大學的 Holland 出版了「自然與人工智慧系統的適應演化」 [Holland,1975],並且完成著名的「概型定理」(Schema Theorem)之後,遺傳 演算法才逐漸的廣為人知,並開始大量的應用到各個領域。 近年來遺傳演算法已經成為許多學者經常引用來做最佳化求解的工具,尤其 適合用來處理複雜的非線性問題,且能夠求出所謂的全域最佳解(Global Optimization)或近似最佳解。在進行整個遺傳演算法的搜尋過程前,首先需要 下列的幾個準備步驟︰ 1. 先針對問題的型態定義可能發生的解集合,確定解集合參數的搜尋範 圍,並建立編碼(Encoding)與解碼(Decoding)的方式。將這些解集合 編碼成為一種方便演化發生與進行的形式(例如二進位碼、數字、文字 等等)。 2. 編碼完成之後,就可以將之組成一組位元字串(Bit String),這些不同 解集合構成的一個個字串位元可以視為是每個個體本身所擁有的獨特遺 傳基因,而由不同基因所組合而成的每一個個體我們則可視之為一條染 色體(Chromosome)。不同的個體群集則合稱之為族群(Population)。 3. 將原先要解決的問題轉化成對應的函數,這也就是所謂的適應度函數
(Fitness Function),代表族群對其所生存的環境適應能力之績效指 標,不同的個體因各自的基因相異而會有不同的表現,遺傳演算法的目 的就是要找出適應度函數表現最好的基因組合。 4. 產生初始族群,先以隨機或其他方式產生第零代的染色體,稱之為原始 族群,其數量大小視問題的複雜度而決定。 在適應度函數和編碼方式決定以後,遺傳演化的部分則是靠三種類型的運算 子來進行演算法的部分︰複製、交換、突變,依此反覆的運作來達到演化及篩選 的目的,詳細說明如下。 1.複製(Reproduction) 複製類似生物的無性生殖,意即新的子代(Offspring)其基因直接由其 上一代複製,至於應該從親代(Parent)保留多少數目的基因,則是根據 每個個體所得到的適應度函數高低來決定。若某一個體其適應度函數越 高,代表他所擁有的基因組合比較能夠達成我們想要解決的問題,因此其 子代理所當然的應複製多一點與其相同的遺傳基因(即 Bit String 個 數),反之若某個體的適應度函數表現不佳,則我們應限制其基因在族群 中存留下來的個數,甚至將之完全淘汰,這樣才能類似自然界的物競天 擇,並達到整個族群逐漸進化的結果。 2.交配(Crossover) 交配運算子提供了一種新的訊息交換機制,使得族群中的不同個體可以藉 由隨機交配,互換基因並產生新的子代。交配的過程,簡單的說,便是隨 機地或適當地選擇一對交配親代,並彼此交換染色體中的部份基因(Bit String 中的部分 Bits),以其能夠產生比上一代更具適應性的子代。而交 配的演算法一般常用的有下列三種︰ (1)單點交配(One-Point Crossover) 在選出的兩條染色體中,隨機在其中選擇一個切點,然後將兩親代成
對的基因從切點開始的位置全部彼此交換。 (2)雙點交配(Two-Points Crossover) 雖然單點交配的原理是依據生物演化過程而來,但是在邏輯上卻有一 些缺點,例如有時候無法有效的組合染色體中的一些編碼特性。為了 克服這個缺點,因此產生了雙點交配運算法。基本上雙點交配和單點 交配的原理以及操作方式均相同,只是以兩個切點來代替原來的一個 切點。 (3)均勻交配(Uniform Crossover) 均勻交配的運作方式為選擇兩個親代染色體做交配之前,先隨機產生 一和染色體相同長度的位元遮罩(Mask)K,當作交配選擇的指標。當 產生新的子代時,端視 K 中相同位置的位元為 0 或 1,若為 0 則該位置 基因由親代一提供,若為 1 位則由親代二提供。 均勻交配與單、雙點交配運算大致上有下列兩點差異︰一、均勻交配 的作用與染色體在編碼特性上的位置無關。二、單點與雙點交配比均 勻交配具有區域性,產生的子代會比較一致性的保留親代的部分特性。 3.突變(Mutation) 經由複製和交配的運算作用之後,已經可以達到個體演進最佳化的目的, 然而為了防止染色體在複製與交配的過程中,可能遺漏了重要的訊息而落 入區域最佳解(Local Optimal),並避免物種演進的僵化,因此突變的發 生成為了新染色體來源的另一種途徑。然而,突變雖有上述的功能,但也 破壞了正常的繁殖程序,因此突變率通常並不高,但有時候在實際應用 上,為了能較快速地產生適應性強的個體,則有可能將突變率加以提高。 突變的演算法在實作上都是針對個別的基因所發生的,通常是先設定好突 變機率的高低,然後在演化的進行中針對每個基因,隨機選取一個介於 0 與 1 之間的突變指標。若此指標小於預設的突變率,則發生突變;若指標 大於預設突變率,則維持基因型態之原狀。
遺傳演算法具有下列幾個特性[Goldberg,1989]︰ 1. 遺傳演算法直接針對變數的基因型態去做運算,意即複製、交配、突變 等運算都是直接作用於編碼過的 Bit String,而不是在原始的變數本身 上操作。 2. 一次搜尋整個群組的變數,為多點搜尋而不是單點搜尋法,其他的搜尋 方法大多一次只搜尋一個解。 3. 遺傳演算法所需要的資訊只有適應性函數的值,不需要其他輔助資訊。 所以可以使用各種型態的適應性函數,例如多目標或非線性函數。 4. 具備盲目搜尋(Blind Search)的特色,因此即使不具備該領域的專業知 識(Domain Knowledge),仍然可以使用遺傳演算法找出效果不錯的可行 解。 5. 遺傳演算法使用機率規則來引導求解,而非使用明確的規格,因此可以 較有效率的得到最佳解。 因遺傳演算法具有迥異於其他演算法的特性,因此當我們應用遺傳演算法作 最佳化設計時,對於如何決定(1)編碼範圍(2)位元長度(3)族群大小(4) 交配機率(5)突變機率(6)適應度函數等部分,都應該要做仔細的考量與取捨, 才能獲得較好的結果。 近幾年來,遺傳演算法這一新興學科已經被應用在許多問題上,例如最佳化 問題、設計、控制和機器學習上。且由於其具有速度快、可靠性高、具彈性等特 性,所以也廣泛地被應用在金融證券市場等複雜系統的模擬方面。Arthur 與 Holland 等人在 1996 年所提出的研究報告中,更是利用聖塔菲研究院(Santa Fe Institute)的 SWARM[Stefansson,1997]模型,以人工生命(Artificial Life) 的 Agent 方式來模擬投資人之間的互動行為,以及據以建構出來的複雜證券市 場。希望藉由這種模擬生態的研究,能對複雜適應性系統的行為模式有更深入的 了解。以下,則探討智慧型代理與人工生命。
第四節
智慧型代理與人工生命
一、智慧型軟體代理
(一)智慧型代理(Intelligent Agents)
智慧型代理或稱為智慧型代理人,其並無一個精確的定義,會因不同 領域而有所差異。一般可將智慧型代理分為三大類:1.人類的代理(Human Agents),如旅行社代理(Travel Agent)﹔2.硬體代理(Hardware Agents), 如機器人﹔3.軟體代理(Software Agents),此類的代理人,又依一般工作 領域可再分為(1)資訊代理(Information Agents),主要支援使用者在分散 式系統或網路搜尋資訊,即確定資訊資源所在地、萃取資訊、依據使用的 興 趣 篩 選 相 關 資 訊 、 用 適 當 的 形 式 展 示 結 果 ﹔ (2)協 同 代 理 (Cooperation Agents),主要的工作是藉由與其他個體(如代理人、人類或外部資源)的溝 通與合作的機制,解決複雜的問題,其所需要的智慧,要比資訊代理人高﹔ (3)交易代理(Transaction Agents),主要的工作是在電子商務、網路應用 環境及傳統的資料庫環境中,處理和監視交易的過程,安全性、資料的保 護 、 健 全 、 可 信 賴 性 等 為 其 主 要 的 重 點 [Brenner, Zarnekow & Wittig 1998] 。 其 他 , 如 Nwana(1996) 將 代 理 分 為 合 作 (Collaborative) 、 介 面 (Interface)、 行 動 (Mobile)、 資 訊 /網 際 網 路 (Information/Internet)、 反應(Reactive)、混合(Hybrid)和聰明(Smart)等各種不 同的軟 體代理人 。 Sycara 等 人 [1996] , 則 分 為 介 面 (Interface) 、 工 作 (Task) 和 資 訊 (Information)等代理。
另外,何謂智慧型代理人?不同領域有不同的解釋,如人工智慧的研 究人員可能認為代理人是「一種藉由執行某些工作,模擬人類關係的電腦 程式」[Selker 1994];若以軟體工程的角度,則認為代理人是「軟體的一 部份,能用一組語言相互溝通、交換訊息」[Genesereth & Ketchpel 1994]; 在分散式系統的看法,代理人代表著「一種可以克服異質性電腦網路中,
程式介面、資料格式與通信協定之間不相容的方法」[Ousterhout 1995]。
就 一 般 的 代 理 而 言 , 有 以 下 幾 個 基 本 特 性 : 1. 自 主 性 (Autonomy) (Castelfranchi 1995)。2.反應性(Reactivity) [Wooldridge & Jennings 1995]。3.積極性(Proactiveness) [Wooldridge & Jennings 1995]。4.社 會 能 力 (Social ability) [Genesereth & Ketchpel 1994] 。 5. 誠 實 性 (Veracity): [Genesereth & Ketchpel 1994]。而智慧型代理人除了必須 有以上 基本 特性 外, 還必須 具有 6.推理/學習(Reasoning/Learning)。7.
行 動 性 (Mobility) 。 8. 溝 通 / 合 作 / 協 調
(Communication/Cooperation/Coor-dination) 。 9. 人 類 特 徵 [Brenner, Zarnekow & Wittig, 1998]。
然而,代理與物件(Object)有何差別呢?Luck 等人提出一個 Entity 的階層架構;認為世界全部是由 Entity 所組成,而每個 Entity 由其屬性 (Attribute)加以描述,在 Entity 中有一些則是屬於物件(Object),每個 物件有其特定的能力 (Capability)或行動(Action),在物件中有一些則 為代理人(Agent),因其有特定的目標(Goal),而在代理人中有一部份屬於 自 主 性 代 理 人 (Autonomous Agent), 其 具有 自 主 性 的 動 機 (Motivation)。 由此可知,Agent 是物件的一種,但其具有目標及自主性[Luck & d’Inverno 1995]。至於代理人的內部結構為何?Rao 與 Georgeff 等人提出一種 BDI 代 理 結 構 , 其 主 要 由信 念 (Beliefs)、 願望 (Desires)及 意 圖 (Intentions) 所構成而得名。 因此, 本研究對智慧型代理的定義,則是結合人工智慧與軟體工程的 觀點,定義為「是一種軟體,透過彼此相互溝通、交換訊息,動態地執行 某些工作,並有自我調適與學習的能力,以模擬人類社會關係」,屬於智 慧型軟體代理的一種。 (二)智慧型軟體代理系統及其應用
近年來,以代理人為基礎的系統(Agent-Based Systems)廣受討論與應 用,因其不受應用領域的限制,無論是自然科學、人文社會科學、生 態學、 政治學、心理學及管理學等均可採用。如 Fulkerson 利用代理人技術來探 討 在 商 業 市 場 上 對 於 動 態 改 變 (Dynamic Change) 的 回 應 (Response)[Fulkerson 1997]。 Axelrod 則 利 用 代 理 人 基 礎 的 適 應 性 模 式 (Agent-based Adaptive Model)來 顯示 個 人與 群組 之 間不 同的 信念 、屬 性 與 行 為 , 其 互 相 影 響 的 過 程 , 以 此 探 討 社 會 性 的 影 響 機 制 (Social Influence Mechanism)[Axelrod 1997]。 另 外 , 還 有 以 此 模 式 來 研 究 市 場 與經濟活動,進而探討複雜系統(Complex System)[Langton etc. 1996]。 智慧型代理系統之應用雖相當廣泛,大致上可分兩為兩類,一是智慧型代 理就像真的人一樣在系統上或網路內遊走,有其特定的行為與目標,可代 替人們處理特定的工作,例如在網路上搜尋資訊的智慧型代理人﹔二是此 代理系統,本身為一個「模擬」系統,用來模擬真實世界上的運作狀況, 例如由美國 Santafe 所開發的 Swarm 工具,所發展出來的各種模擬系統, 可模擬真實世界的運作過程,藉此解釋真實世界的運作方式,甚至可以調 控及預測真實世界。例如以下所介紹的人工生命。
二、人工生命
人工生命最早之概念可以追溯至 Von Neumann[1966]的自我複製自動 機(Self Replicating Automata)。但一直到晚近複雜科學興起後,才正式 成為一個獨立的學門。人工生命與傳統生物學在立場上是一致的,也就是 基於探索生命現象而進行的科學研究﹔不同的是,人工生命並非以分析法 (Analytic)來了解生命,而是經由綜合法(Synthetic)檢視如何透過組合簡 單的元件以創造出近似生命的行為。 人工生命的信念乃在於運用電腦或機械人等新媒介,探索生物學的其 他發展可能,而且實務上更希望能將研究回饋予電腦科學、醫藥、自動化技術等領域。所以,人工生命發起人之一的 Christopher Langton 開宗明 義地將其定義為「一門致力於瞭解生命現象的學門,而探討方向則著重在 基 本 的 動 態 原 則 (Dynamic Principles) , 並 且 希 望 將 其 重 現 於 電 腦 實 驗 中,以便於作進一步的測試與研究,只有我們能夠從『生命的可能形態』 來看『生命的目前形態』,我們才得以真正瞭解其本質所在」。相較於傳統 人工智慧的做法,人工生命較為突出的概念有三點,分別是: (一) 由下而上(Bottom-up):意即拒絕將複雜系統由上而下地依照功能漸 次拆解的作法:相反地,強調由下而上的產生方式。 (二) 突現(Emergence):乃由系統內部各元件按照簡單法則彼此互動而產 生之現象,無法由外界直接影響或掌控。 (三) 無 目 的 性 (Goalessness): 強 調 系 統 隨 著 時 間 推 移 而 發 生 的 結 構 演 變,而不是朝著既定的路徑。 因此,本研究希望能以類似 Arthur 的做法,建構出能夠自我學習的類神經 網路 Agent 族群,並以遺傳演化的形式,正如生命般的進行基因(輸入變數)的 篩選,並從事證券投資的行為。整個系統的架構將於下一章中介紹。
第三章 研究方法與實驗設計
本章主要的重點在於研究方法的說明以及模式的建構。首先,第一節將著重 於演化式智慧型投資代理模型之建立和其操作型定義。而在第二節裡,將描述此 演化模式中類神經網路運作的詳細架構與生成。第三節則說明如何在網際網路的 平台上,採用實際的股市歷史資料與各種操作指標來實作此架構的學習、驗證與 演化等各個子系統,並對整個演化的機制與相關步驟作深入的探討。第一節
演化式智慧型投資代理
就過去應用於證券投資股市預測的各種類神經網路研究來說,其據以學習的 輸入變數大多是由過去經驗或直覺所決定。這種做法雖然方便,但卻難免因直接 捨棄部分變數而有所缺憾。所以本研究將透過遺傳演算法的融入,使得學習與演 化並存。以自然界的優勝劣敗競爭原則,和染色體內基因演化的各種機制,應用 於神經網路輸入變數的建構與篩選,並由眾多的股市指標輸入中找出適合的關鍵 因素。一、演化式智慧型投資代理的定義
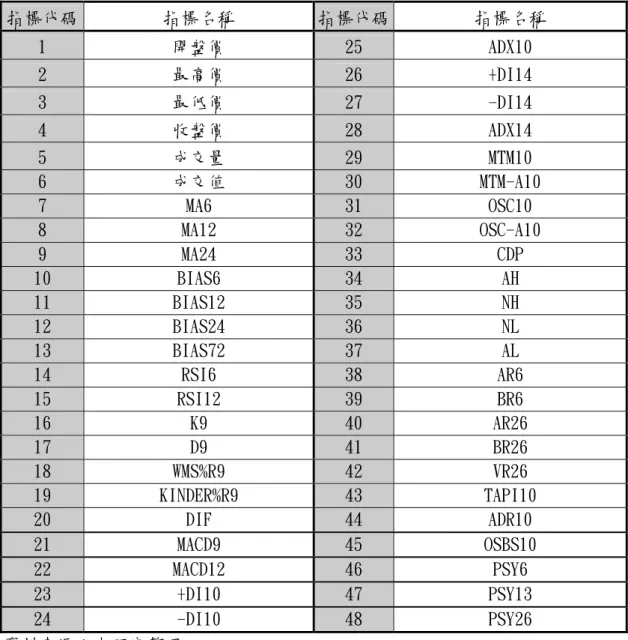
本研究乃是根據 Arthur、Holland[1996]等所提出演化式證券市場模型中的 人工生命(Artificial Life)為基礎,建立多個擁有不同輸入變數的類神經網 路系統(本研究將其稱之為智慧型代理,即 Agent),用以學習並模擬股市的操 作。再加上演化的機制,最後觀察其中表現績效較佳的的 Agent 所使用的投資策 略為何。稱之為「演化式智慧型投資代理模型」,並針對國內的證券市場做研究。本研究採用的倒傳遞類神經網路系統乃是藉由給予輸出入變數的範例,來學 習各個節點之間的關係。因此當使用不同的變數作為網路輸入值時,系統輸出的 結果也將會有所差異。而在本研究建構的演化系統中,我們可以將一個獨特的神 經網路系統視為一個個體(即 Agent),經過一定時間的學習後,擁有不同輸入 變數的 Agent 也將輸出不同的預測結果,亦即使用不同的投資策略來模擬操作。 而再透過遺傳演化的概念,將使得 Agent 的預測能力逐漸的提昇,以下就將本模 型中提到的遺傳演算法相關名詞,對應到神經網路系統,並做其操作型定義︰ (1) 個體︰在遺傳演算法中,能夠表現出獨特性質的物種稱之為一個個體,亦 即所謂的智慧型投資代理。個體可以擁有一個或多個染色體,而染色體則 是由若干的基因所組合而成。本模型將一個類神經網路學習系統稱之為一 個個體,即一個智慧型投資代理,而在整個模型中,同時存在著多個個體 進行各自的學習行為。 (2) 染色體︰在神經網路的系統中,只有輸入與輸出層的節點具有代表性的意 義,隱藏層的節點則具有變數轉換的功能,但不具實質性的意義。因此, 本模型將輸入的節點組合視為一個個體所擁有的染色體,不同的染色體也 意味著個體將表現出不同的行為。 (3) 基因︰基因是組成染色體的主要成分,在本模型中可視每個神經網路系統 所擁有的輸入節點為其組成基因。由於每個神經網路系統皆是經由其輸入 變數來學習行為的策略,因此透過輸入變數節點的改變與重組,就可以使 個體達到演化的目的,並逐漸篩選出優良的基因組合。這種基因層面的演 化方式也是本研究的核心所在。 (4) 基因庫︰所有可能使用於證券投資的股價預測的基本、技術、以及其他種 類的指標在定義上應該都屬於可行的神經網路輸入變數,也就是基因。然 而指標的種類極其繁多,限於資料取得的限制,本研究乃參考金必煌[1994] 的指標定義原則和杜金龍[1996]之台灣股市重要指標而選取了各具不同代 表性的 48 種技術指標,這些指標的集合也將成為本演化模型中所將引用的
基因來源,稱之為基因庫。而基因的選取以及汰換機制將在後面說明。
二、 智慧型投資代理的演化機制
智慧型投資代理的演化機制,主要是以物競天擇的原則為基礎,並經由世代 的交替,而發生在基因的層次。亦即不同的神經網路學習系統,可以藉由指標(基 因)的交換以及突變等機制,使整個模型中的個體,逐漸朝向最優的方向進化。 以下為本模型所建立的遺傳演化機制︰ (1) 適合度函數(Fitness Function)︰適合度函數在遺傳演算法中是最為重 要的一個環節,因為這是所有的個體據以評估表現績效的原則,也就是天 擇的法則之所在。經由適合度函數的評估,可以對每個個體的表現做排序, 以分辨出適於生存者和需要淘汰者。在本模型中,是以個體在學習過後模 擬操作的績效來當作適合度函數。 (2) 世代交替︰世代的交替是遺傳演算法中演化所發生的期間。在本模型中, 經過一定時間的學習之後,個體將再進行一段時間的模擬操作。當操作結 束後,我們就可以依適合度函數來決定每個個體的表現績效,這也是一個 世代的結束。而在新的世代開始之前,系統將會依事先訂定的演化機制來 對舊一代的個體進行交配、突變等過程,並產生新一代的個體,來進行新 的世代。 (3) 演化機制︰如之前文獻探討所提出,常用的演化機制有三種︰複製、交配 與突變。複製就是單純的從親代複製其遺傳基因予子代,在本研究中,表 現較佳的個體將可以完全複製其基因到一個新的子代。 至於交配則提供了一種基因交換的機制,使得優良的基因能夠交互傳承, 以嘗試演化出更好的子代。交配不能保證可以得到較佳的子代,但經由基 因組合的改變,可能可以找出適合度更高的下一代。在本研究的模型中, 交配的進行是經由表現績效較高的個體,隨機選取其部分基因來取代績效較差的個體之部分基因。採取這種做法的原因在於神經網路的預測能力是 由所有的輸入指標組合所決定,故表現佳的個體很可能擁有較重要的關鍵 指標,但表現差的個體也可能是因為組合不佳造成績效低落,因此採用隨 機替換的方式,希望能在多個世代的演化後逐漸發現關鍵的指標。 第三種機制則是突變。在自然界中,突變是創造新物種的一種捷徑。突變 不需要子代的基因一定是從親代所繼承而來,而可以透過部分的完全改 變,來演化成一種新的個體。在本模型中,突變的發生僅限於表現最差的 個體,原因如上交配部分所述,藉由突變的發生來產生新的個體。此外, 突變發生時的基因改變,將在基因庫的範圍內隨機選取。 (4) 終止條件︰遺傳演算法會朝向較適合度高的方向不斷的演進,但演化到達 一個程度之後,亦即找到最佳解或近似最佳解以後,若再繼續演化下去就 失去其意義了。故必須給定一個演化系統終止的驗證條件。一般常用的方 式有三種︰第一種為給定執行世代,當演化發生一定的世代之後便使之停 止。這種方式最為簡單直接,但時間長短的決定則要視問題的複雜度與資 料的收斂度而定。第二種為目標值的給定,僅能用於已知最佳解範圍的情 況下,當演化到成可接受的範圍即使知停止,但條件的範圍設定必須注意, 若設定值過於簡單則演化將會太快到達目標,若過於困難則可能永遠無法 達到目標而陷入無窮的迴圈。第三種為個體一致性的達成,當系統中所有 個體的同質性都已約略相同時,代表演化已經到達一個穩定的狀態,有可 能已經是全域最佳解(Global Optimal)。但缺點是也可能陷入區域最佳解 (Local Optimal),因此,在演化達到穩定時給予一些大型的突變來測試 是否可能有更佳的解是一種可行的方法。本研究因資料收集的限制,演化 會在一定的世代後停止。但是經由觀察模型演化的結果,我們可以判定演 化是否達到某種收斂的的程度;亦可以透過將多次執行的結果相比較來了 解演化進行的趨勢。
第二節
類神經網路之架構
傳傳遞網路(Back-Propagation Network,BPN)為目前最廣為被使用的類 神經網路之一,而其應用於財務金融上也常獲得不錯的成果。故本研究之進行亦 將採用倒傳遞神經網路之架構與學習型態,作為股價預測的基礎。本節將說明倒 傳遞網路的相關架構。一、倒傳遞類神經網路基本架構
倒傳遞類神經網路為目前的各種神經網路學習模式中最具有代表性,且應用 最為廣泛的一種。倒傳遞網路屬於監督式的網路,雖然在 1974 年 Werbos 和 1982 年 Parker 就曾經提出過類似的觀念,但是直到 Rumelhart、Hinton、Williams[1986] 發表關於 Parallel Distributed Processing 的論文才將倒傳遞網路的的理論與 詳細的演算法定義出來。倒傳遞網路與早期的 Delta-Rule(或稱 Widrow-Hoff 法則)相當類似,Delta-Rule 的構想在於透過連續性的修正,來降低期望輸出 值和實際輸出值的差距,由其數學公式可證明當網路學習到最後將能夠收斂到一 個穩定的狀態。倒傳遞理論相當於其延伸,處理過程可分為兩個階段︰Forward Phase 和 Backward Phase。在多層的網路架構中,透過此兩階段,可以使網路的 誤差減小,而達成期望的學習效果。 倒傳遞網路的基本架構如圖 3-1 所示,包含幾個重要的部分︰ 輸出層 (Output Layer) 隱藏層 (Hidden Layer) 輸入層 (Input Layer) 圖3-1 倒傳遞類神經網路架構圖倒傳遞網路的架構除了輸入與輸出節點外,還有可處理複雜分類問題的若干 隱藏層存在,再加上採用平滑可微分的非遞減型連續函數作為節點的轉換函數, 使其在運作上能充分的學習到輸入樣本特徵資訊與輸出結果之間的非線性相對 應關係,並能夠經由學習而具備對樣本以外的輸入訊息做出正確輸出的反應能 力。底下就三層節點所扮演的角色做簡要的說明︰ 輸入層︰即網路的輸入變數,其處理單元的數目應視問題的結構而定。 隱藏層︰倒傳遞神經網路的重點之一,隱藏層主要是在處理輸入單元間的交互影 響。隱藏層的層數並無限制,但一般只要一或兩層即已足夠。又每個隱 藏層處理單元的數目亦無一定的標準。當處理複雜問題時,使用非線性 轉換函數作為轉換函數會有較好的效果。 輸出層︰表現網路模式的輸出變數,其處理單元的數目也同樣視問題結構而定。 隱藏層的層數與節點的數目一直是一個難以定論的問題,Bybento[1989]認 為只要有一個隱藏層的神經網路就可以獲得所要求的精確度,而 Yoon & Swales [1993]等人則以實驗的方式,認為擁有兩層隱藏層的網路能更準確的預測。但實 際上視問題結構與輸入變數的不同,多個隱藏層數雖然涵蓋的複雜度較高,但相 對的計算也更加的繁雜,有無其實際價值值得商榷。因此本研究將採用一層隱藏 層來達成計算上與精確度的平衡。至於隱藏層的節點數目,許多研究均作過此方 面的探討,例如葉怡成[1993]曾提出建議,以輸入節點和輸出節點之算數平均數 為其數目。而根據數學家 Kolmogorov [1957]提出的定理,證明了任何一個從 m 維空間映射到實數向量的連續函數 ,都可以用一個「輸入 m 個節 點、隱藏 2m+1 個節點」的三層層狀前饋網路系統來實行。經過多次的學習試驗 結果,在可以兼顧良好學習效果與學習速率的平衡下,本研究決定採用輸入層 8 層和隱藏層 17 層的網路架構來實作。 q m R f :[0,1] ® 至於倒傳遞神經網路的學習演算法,在許多的類神經網路相關書籍中均有詳 細說明[蔡瑞煌,1995],在此即不再贅述。
二、倒傳遞神經網路輸出入變數的選取
本研究的預測模式係採用倒傳遞網路架構模式來進行,因此網路輸入變數的 選取,將會決定輸入節點的個數,相對的會影響隱藏層的數目,也同時會造成不 同的輸出結果。由於本研究的神經網路系統是演化模型中的個體,因此不同的個 體將擁有不同的輸入變數,但是就學習的公平性來說,除了不同的輸入變數之 外,每個個體的其他條件應該是相同的,因此我們將給予每個神經網路系統相同 的輸入節點個數、相同的輸出目標、以及一樣數目的隱藏層與隱藏節點數目。 在輸入變數個數的選擇上,由於我們在基因庫中擁有 48 個不同的指標(詳 述於後),因此由歷史文獻中歸納再加上運算的方便性起見,本研究將給予每個 個體 8 個不同的輸入變數,同時在系統中以 6 個不同的 Agent 來進行學習與演化。 而在輸出變數的決定上,因本模型所要預測的標的為整體股市的漲跌情形, 因此將以次日股市的大盤加權指數漲跌幅作為所有網路的輸出值。同時也因具有 相同的輸出變數,才得以藉操作績效來做個體的適合度評量。三、演化式智慧型投資代理模式
本研究將使用各式的股市指標作為神經網路系統的輸入變數,而不同的輸入 變數將產生出不同的個體,並依輸入的歷史資料學習不同的操作策略,以下將就 整個模型中,智慧型投資代理的生成與演化做說明︰ 1) 基因的選取與汰換︰基因的選取將決定一個個體的獨特行為。在本模型中, 乃採取從基因庫的 48 個指標(基因)中隨機選取的方式,在演化的初始化過 程(Initialization)中依亂數選取分配成各自擁有不同基因的數個神經網 路系統個體,並將完全使用所有的基因。這樣做的原因是希望能從系統開始進行就將大部分的指標納入系統的學習過程中,以避免有些指標在演化過程 中將無法使用到的缺點。而在經過世代交替的演化後,表現較差的個體將被 隨機的抽取出數個輸入變數淘汰至基因庫中,而被淘汰的基因在之後的突變 機制中,仍有可能被選出而重新進入個體並展開新的學習過程。如此則可避 免優良的基因由於機率問題而意外遭到淘汰。 2) 輸入資料︰每個世代的學習過程都分成兩個階段,第一階段為學習。在同一 個世代的每個個體,雖然擁有不同的輸入變數,但都採用相同的歷史資料來 學習,這些輸入的歷史資料即為訓練資料集(Training Data)。第二個階段 則為驗證,個體分別依其學習的結果來預測並模擬操作,此時的輸入資料即 為測試資料集(Testing Data)。 3) 適合度的評估︰每個神經網路個體,在經過了訓練資料集的學習過程之後, 發展出各自的預測能力。此時我們將使其進行模擬操作,以其預測的大盤指 數漲跌幅輸出為標的進行買賣策略。在這裡我們使用了三種方式來作為每個 世代的評量方法: a) 每日交易策略:此為預設的操作策略,當輸出為正值則買進,輸出為負值 則賣出。每日都依預測的漲跌來進行交易,並於隔日馬上進行損益計算。 b) 預測漲跌比例策略:當輸出為正值時且預測上漲的幅度超過一定比例,代 表出現買進訊號,因此進行買進或贖回策略;而當輸出為負值時且預測下跌 的幅度超過一定比例,則代表出現賣出訊號,因此進行賣出或放空策略。 c) 買入持有策略:此即為標準大盤的績效值,為以上兩種策略的基本對照 組。若績效能超過買入持有策略則代表該操作超越大盤表現。 當學習階段結束時,即依不同的操作策略結算每個個體的總合績效,並以之 作為適合度函數的輸出,買入持有策略則設定為 Dummy Agent,可作為後續 分析績效評估時的對照組。 4) 交配與突變︰個體的演化除了單純的複製以外,是透過交配與突變的過程來 達成。然而類神經演算法中的基因為個別的股價指標,和傳統遺傳演算法中 的基因有所差異,而無法以字串值(Bit String)的改變來進行交配與突變。
因此本模型乃是取遺傳演算法中交配與突變的涵義,並以自行訂定的機制達 成相同的目的。以交配為例,原始的目的在於達成優良基因的保留與交換, 然而在神經網路的學習過程中,我們並沒有辦法得知個體中較為關鍵的基因 為何,只知道在這樣的基因組合下會有較佳的輸出結果。但這卻隱含了表現 較佳的個體中很可能含有較為關鍵的輸入變數。在關鍵基因未知的情況下, 我們採取了以隨機的方式來淘汰表現差的個體基因,並以表現佳的個體基因 取代之。這樣的做法,雖然不能保證經過替代的基因組合一定會有較佳的表 現,但卻能確保在不斷的演化中,只有表現更佳的基因組合才有存活下來的 可能,相對的將使整個模型逐漸往最優的方向演進。而突變的機制也是相同 的道理,但是擁有另一項功能,就是使遭淘汰的基因仍有重新進入個體進行 演化的機會,避免優良的基因由於機率問題而遭到意外淘汰。 5) 世代交替︰本研究在經過考量後所使用的資料為台灣股市民國 80~88 年之間 9 年的歷史資料,取半年為學習階段,再加上一季的模擬操作驗證,每個世 代的經歷期間為 3 季。在此我們依不同的移動學習方法,可以分成兩種不同 的學習世代。以 9 年的歷史資料而言,模型分別能夠進行 17 或 34 個世代的 演化過程。在所有世代都結束時,我們將對於現存的個體進行檢視,並計算 其收斂的程度與演化後的 Agent 之績效表現。
第三節
演化式智慧型投資代理實作
本節將採用台灣的股市歷史資料與各種操作指標來實作此模型的學習、驗證 與演化等子系統,並對整個演化的機制與相關步驟作深入的探討。在第一小節 中,我們主要探討研究樣本的選取及其處理轉換的過程。第二小節則是說明實作 系統的平台與環境。第三小節說明本研究的研究範圍與限制。最後在第四、五兩 個小節裡詳細說明系統的核心部分-操作策略與演化流程。一、研究樣本的選取與轉換
本研究主要的實驗設計在於預測股市大盤的指數漲跌,而由於預測標的為大 盤指數,故將以廣泛的蒐集各種常用的技術面指標為主。模型所採用的原始股市 交易資料,主要來源係自台灣經濟新報社(Taiwan Economic Journal,TEJ)等 資料庫。該資料庫包含證交所所公佈之台灣各上市公司以及每日大盤之收盤價、 成交量等交易資料。本研究主要取用其中每個交易日大盤的加權股價指數開盤 價、最高價、最低價、收盤價與成交量等資料,並據以換算出其他指標,以作為 類神經網路系統的輸出入變數。 上述樣本亦可透過網際網路取得即時的資料,在此採用 XML-Base HTML Wrapper 的技術[楊建民,2001],彙整各異質性資訊來源,可立即轉換最新的資 料做為本研究模型中智慧型投資代理的輸入資料,其架構圖如圖 3-2 所示[張子 文,2001]。 圖 3-2 XML-Based HTML Wrapper 架構圖[張子文,2001]