圖書館借閱記錄探勘系統
89
0
0
全文
(2) system also utilizes “New Classification Scheme for Chinese Libraries” to mine associated categories and collections. Furthermore, this system integrates the association rules into a persobalized system, PIE@NCTU (Personalized Information Environment for National Chiao Tung University Library), to recommend associated collections to patrons.. Keywords: Association Rule Mining, Generalized Association Rule Mining, Generalized Association Rule Mining with Multiple Minimum Supports, Mining System, Borrowing History Records. II.
(3) 圖書館借閱記錄探勘系統 A Data Mining System for Mining Library Borrowing History Records 研究生:戴玉旻. 指導教授:柯皓仁博士,楊維邦博士 國立交通大學資訊科學研究所. 摘要 隨著網際網路的發展與電腦科技的日益進步,資訊數位化已成為世界的趨 勢,電子圖書館也在這股資訊潮流下日漸成熟,而如何利用電腦技術以提昇圖書 館對讀者的服務品質亦成為各圖書館努力的目標。 由於圖書館的借閱記錄有如讀者使用圖書館資源的最佳證據,因此本論文藉 由分析交通大學圖書館的借閱記錄以了解讀者借閱館藏的關聯性,再根據以往讀 者借閱的關聯性將館藏有效地推薦給其他讀者,讓交通大學圖書館在讀者探索知 識的過程中扮演著積極主動的角色。 本研究根據圖書館借閱記錄的特性,選擇適合圖書館的相關規則演算法並加 以改良應用至廣義相關規則探勘(Generalized Association Rule Mining)及多重最 小支持度廣義相關規則探勘(Generalized Association Rule Mining with Multiple Minimum Supports),實作適合圖書館的資料探勘系統「圖書館借閱記錄探勘系 統」。讓館員藉由輸入讀者借閱記錄得到最新的館藏借閱相關規則,針對不同系 所的讀者找出不同的相關規則。亦應用「中國圖書分類法」找出讀者借閱關聯類 別,且可針對不同階層的類別設定不同的最小支持度門檻值,探勘多重最小支持 度廣義相關規則,並結合交通大學個人化數位圖書資訊環境 (PIE@NCTU) 將相 關館藏推薦給讀者。 關鍵字:相關規則探勘,廣義相關規則探勘,多重最小支持度廣義相關規則探勘, 探勘系統,借閱記錄 III.
(4) 誌謝 感謝指導教授柯皓仁教授與楊維邦教授的指導。不僅在我有疑問時,指引方 向,提供解決方案,還教導我如何作研究,如何解決問題。也在我稍有怠惰時, 盡責地督促,讓我不至於因懈怠而影響研究。除了在研究上的指導外,教授也會 關心我的日常生活,關懷備至。 同時也要感謝圖書館資訊組蔡淑琴小姐熱情支援圖書館的相關資料及提供 許多寶貴的經驗與意見,使得我的論文得以順利完成。並且感謝圖書館館員們, 讓我對圖書館學及館員們的工作有更進一步的認識,以及國科會數位圖書館暨館 際合作計畫室成員們給我的意見、協助與鼓勵。 此外,還要感謝實驗室的學長姐們在研究上及生活中的啟發與指導,提供我 許多寶貴的建議及人生的經驗。謝謝實驗室的夥伴們的關懷與照顧。還有學妹莉 君在個人化數位圖書資訊環境上的支援與協助。 最後,要感謝我親愛的家人與朋友們長久以來的支持與鼓勵。在我遇到低潮 時,給我加油打氣,聽我抱怨,提供一個舒適的避風港;在我忙於研究時,替我 處理所有瑣事,成為最好的後援。讓我能專心致力於研究,並得以順利完成學業。. IV.
(5) 目錄 英文摘要.........................................................................................................................I 中文摘要...................................................................................................................... III 誌謝..............................................................................................................................IV 表目錄.........................................................................................................................VII 圖目錄....................................................................................................................... VIII 第一章 圖書館記錄探勘系統簡介..............................................................................1 第一節 研究動機及目的..........................................................................................1 第二節 研究方法及目標..........................................................................................2 第三節 論文架構......................................................................................................3 第二章 資料探勘相關研究工作..................................................................................5 第一節 資料探勘......................................................................................................5 第二節 相關規則探勘..............................................................................................8 第三節 相關規則探勘之延伸問題........................................................................19 第三章 以 H-Mine 為基礎之廣義相關規則演算法 .................................................28 第一節 廣義相關規則演算法 H-Mine(Generalized)............................................28 第二節 多重最小支持度廣義相關演算法 H-Mine(MMS) ..................................31 第四章 圖書館借閱記錄探勘系統之實作................................................................38 第一節 圖書館資料探勘系統說明........................................................................38 第二節 應用於個人化數位圖書資訊環境............................................................54 第五章 圖書館借閱記錄探勘系統評估....................................................................58 第一節 第二節 第三節 第四節. 實驗環境....................................................................................................58 探勘效益評估............................................................................................59 H-Mine(Generalized) 及 H-Mine(MMS) 效益評估 ...............................63 系統效益評估總結....................................................................................65 V.
(6) 第六章 結論與未來研究方向....................................................................................66 第一節 結論與討論................................................................................................66 第二節 未來研究方向............................................................................................67 參考文獻......................................................................................................................70 附錄一:相關規則探勘結果(部分) ...........................................................................72 附錄二:身份類別相關規則探勘結果(部分) ...........................................................75 附錄三:廣義相關規則探勘結果(部分) ...................................................................77 附錄四:多重最小支持度廣義相關規則探勘結果(部分) .......................................80. VI.
(7) 表目錄 表 2 - 2 - 1:候選項目集產生及測試法與頻繁項目集成長法之比較 ....................13 表 2 - 2 - 2:H-MINE 與 FP- GROWTH 之比較.............................................................14 表 2 - 2 - 3:相關規則探勘之交易資料庫[13]..........................................................14 表 3 - 2 - 1:多重最小支持度相關規則探勘之交易資料庫....................................33 表 4 - 1 - 1:借閱記錄檔格式....................................................................................39 表 4 - 1 - 2:借閱記錄範例........................................................................................40 表 5 - 2 - 1:相關規則借閱資料詳細資訊 ................................................................59 表 5 - 2 - 2:相關規則頻繁項目集個數 ....................................................................60 表 5 - 2 - 3:以時間間隔為一年的資料,最小支持度為 0.0005 探勘結果分析 ...60 表 5 - 2 - 4:廣義相關規則借閱資料詳細資訊 ........................................................61. VII.
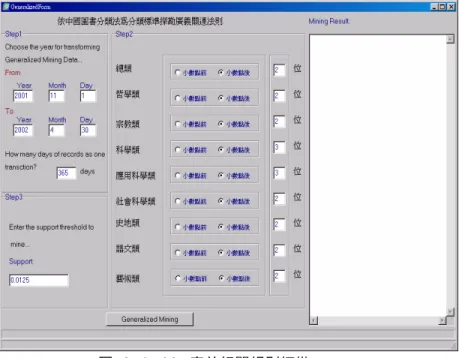
(8) 圖目錄 圖 2 - 1 - 1:資料庫之知識探索流程圖[10]................................................................6 圖 2 - 2 - 2:APRIORI 例子[3] ..................................................................................... 11 圖 2 - 2 - 3:APRIORI 演算法[3] ................................................................................. 11 圖 2 - 2 - 4:H-STRUCT[13].........................................................................................15 圖 2 - 2 - 5:標頭表格 HA 及 AC 佇列[13] .................................................................16 圖 2 - 2 - 6:標頭表格 HA 及 AD 佇列[13] .................................................................17 圖 2 - 2 - 7:調整探勘 A 投影資料庫後的連結位置[13] .........................................18 圖 2 - 3 - 8:廣義相關規則基本演算法[17]..............................................................21 圖 2 - 3 - 9:廣義相關規則累積演算法(C UMULATE) [17] ........................................23 圖 2 - 3 - 10 (A ):多重最小支持度相關規則探勘演算法[11]..................................25 圖 2 - 3 - 10 (B):產生 C2 候選項目集 LEVEL2- CANDICATE- GEN (F) 步驟[11]..........26 圖 2 - 3 - 10 (C):產生 C K (K ≠ 2)候選項目集的刪除步驟[11].................................27 圖 3 - 2 - 1:H-STRUCT(MMS)範例 ...........................................................................34 圖 3 - 2 - 2:標頭表格 HG 及 GD 佇列 .......................................................................35 圖 3 - 2 - 3:標頭表格 HGD .........................................................................................35 圖 3 - 2 - 4:調整探勘 G 投影資料庫後的連結位置 ................................................36 圖 4 - 1 - 1:圖書館資料探勘系統流程圖 ................................................................39 圖 4 - 1 - 2:系統起始畫面 ........................................................................................43 圖 4 - 1 - 3:檔案功能 ................................................................................................43 圖 4 - 1 - 4:插入資料................................................................................................44 圖 4 - 1 - 5:刪除資料 ................................................................................................44 圖 4 - 1 - 6:清理資料庫 ............................................................................................45 圖 4 - 1 - 7:轉換資料庫 ............................................................................................45 圖 4 - 1 - 8:特殊轉換 ................................................................................................46 圖 4 - 1 - 9:相關規則探勘 ........................................................................................46 VIII.
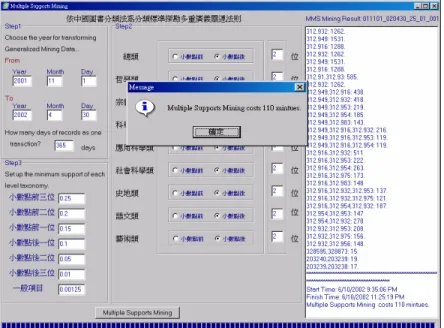
(9) 圖 4 - 1 - 10:相關規則探勘結果 ..............................................................................47 圖 4 - 1 - 11:選擇身份類別配置檔 ..........................................................................48 圖 4 - 1 - 12:選擇身份探勘資訊 ..............................................................................48 圖 4 - 1 - 13:身份探勘結果 ......................................................................................49 圖 4 - 1 - 14:廣義相關規則探勘 ..............................................................................50 圖 4 - 1 - 15:廣義相關規則探勘結果畫面 ..............................................................50 圖 4 - 1 - 16:多重最小支持度相關規則探勘..........................................................51 圖 4 - 1 - 17:多重最小支持度相關規則探勘結果 ..................................................52 圖 4 - 1 - 18:相關規則結果 ......................................................................................52 圖 4 - 1 - 19:封閉式頻繁項目集結果 ......................................................................53 圖 4 - 1 - 20:探勘資料資訊 ......................................................................................53 圖 4 - 1 - 21:系統記憶體使用量 ..............................................................................54 圖 4 - 1 - 22:離開系統 ..............................................................................................54 圖 4 - 2 - 23:個人化數位圖書資訊環境 PIE@NCTU 登入畫面............................55 圖 4 - 2 - 24:PIE@NCTU 智慧型查詢畫面.............................................................55 圖 4 - 2 - 25:PIE@NCTU 智慧型查詢結果畫面.....................................................56 圖 4 - 2 - 26:PIE@NCTU 智慧型查詢之推薦關聯館藏畫面.................................56 圖 4 - 2 - 27:PIE@NCTU 借閱歷史檔畫面.............................................................57 圖 4 - 2 - 28:PIE@NCTU 借閱歷史檔之推薦相關館藏畫面.................................57 圖 5 - 2 - 1:H-MINE 資料量與探勘時間分析 ..........................................................59 圖 5 - 2 - 2:H-MINE 資料量與記憶體耗費量分析 ..................................................61 圖 5 - 2 - 3:H-MINE(G ENERALIZED )資料量與探勘時間分析 ..................................62 圖 5 - 2 - 4:H-MINE(MMS)資料量與探勘時間分析 ...............................................62 圖 5 - 2 - 5:H-MINE(G ENERALIZED )資料量與記憶體耗費量分析 ..........................62 圖 5 - 2 - 6:H-MINE(MMS)資料量與記憶體耗費量分析 .......................................63 圖 5 - 3 - 7:H-MINE(G ENERALIZED ) VS. H-MINE(MMS) 探勘時間分析.................64 圖 5 - 3 - 8:H-MINE(G ENERALIZED ) VS. H-MINE(MMS) 記憶體耗費量分析.........64. IX.
(10) 第一章 圖書館記錄探勘系統簡介. 第一節 研究動機及目的 隨著網際網路的發展與電腦科技的日益進步,資訊數位化已成為世界的趨 勢,電子圖書館也在這股資訊潮流下日漸成熟,而如何利用電腦技術以提昇圖書 館對讀者的服務品質亦成為各圖書館努力的目標。 圖書館的目的是提供讀者良好的服務,協助讀者獲取資訊、運用資訊,從而 產生知識。然而早在 1979 年美國 Pittsburgh 大學的調查報告[7]中指出,圖書館 的館藏資源只有少數被有效利用,值此電子圖書館時代,為了讓讀者快速、有效、 完整地滿足其資訊需求,各圖書館必須善加應用資訊技術以有效幫助讀者使用館 藏資源。 當圖書館想要廣泛地運用資訊技術實施讀者服務時,首要考量即是找出讀者 迫切需求之服務及目前現行服務不足之處。在現今圖書館所提供的服務中,讀者 往往會迷失在館藏檢索系統裡,因為檢索所得資源過多,讀者難以由書名、作者、 出版社等簡要資訊抉擇要借閱的館藏;再加上館藏數量漸趨龐大,若讀者不熟悉 檢索系統的功能,常會找不到所需要的資源。要解決此一困境,圖書館可以透過 對讀者興趣的了解,幫助讀者找尋館藏資源。 卜小蝶在[24]一文中提到,圖書館借閱記錄是讀者使用圖書館資源的最佳 「證據」,也是讀者積極滿足個人資訊需求的行為結果,這類資訊能反映使用者 實際的資訊需求,因此對於掌握讀者興趣,進而作為加強圖書館資源利用的基礎 具有一定的參考價值。除此之外,由於借閱記錄蘊含大量讀者與圖書館互動的歷 史記錄,若能利用資料探勘(Data MIning)的技術從中挖掘隱藏有意義的資訊,不 僅有助於讀者資訊需求的瞭解,還可視為加強圖書館資源利用的重要指標。 1.
(11) 資料探勘(Data Mining)是知識管理的應用技術之一,其主要目的在探討如何 從大量資料中,發掘出潛藏有用的資訊或規則,以提供決策參考之用。目前這類 技術多半用於商業、醫學等資料量龐大又具有商機的領域上,如亞馬遜網路書店 (http://www.amazon.com)由銷售記錄發掘顧客消費的消費關聯性,藉此將關連性 產品推薦給有相似購買行為的顧客。運用資料探勘,經營者可更深入了解客戶需 求,甚至可提供量身訂作之個人化服務 ,亦即採用客戶關係管理 (Customer Relationship Management – CRM)的理念,以期增加客戶的滿意度與忠誠度,並確 保在激烈商業競爭的環境裡獲利[27]。 群體化(Community)乃是電子圖書館時代讀者服務的未來發展方向之一,所 謂的群體化即是社群的概念,因為知識的產生有時並非光靠單一的個體就能達成 的,而是得藉由具有相同興趣、專長的個體彼此激發靈感、分享心得與知識方能 加速知識的產出。本論文的目的即在於運用資料探勘的技術來探索讀者社群的持 性,從而達成群體化的電子圖書館讀者服務。為達此一目的,我們建置一套協助 館員瞭解讀者的興趣及需求的探勘系統,讓館員藉由分析借閱記錄找出讀者經常 一起借閱的館藏,再將關聯性館藏推薦給借閱同樣館藏的讀者。由於所找出的關 聯館藏只佔了整個館藏資源微乎其微的一小部分,並不能有效地提供讀者意見, 因此將中國圖書分類法加入分類階層探勘,並讓館員隨著分類階層設定不同的最 小支持度門檻值,挖掘出最適宜的讀者借閱類別關聯性。如此一來,藉由借閱類 別關聯性,根據讀者的借閱記錄分析興趣類別,進而推薦關聯類別的新進館藏給 讀者,讓系統有效地提供更多更實際的借閱建議。. 第二節 研究方法及目標 本論文以交通大學圖書館的借閱記錄為基礎,運用資料探勘的技術,探索讀 者借閱館藏及類別的關聯性,並運用探勘的成果來提昇圖書館的經營與服務。 本研究根據圖書館借閱記錄的特性,設計一套適合圖書館的資料探勘系統 2.
(12) 「圖書館借閱記錄探勘系統」 ,簡稱「圖書館資料探勘系統」 。藉由資料倉儲(Data Warehousing) [11] 的技術處理圖書館借閱記錄的前置作業,以及運用相關規則探 勘(Association Rule Mining)演算法 H-Mine[14] 的技術找出借閱館藏的關聯性, 除此之外,並以 H-Mine 為基礎發展廣義相關規則探勘(Generalized Association Rule Mining)演算法及多重最小支持度廣義相關規則探勘(Generalized Association Rule Mining with Multiple Minimum Supports)演算法,以便找出借閱類別的關聯 性。 在「圖書館借閱記錄探勘系統」發掘出讀者社群關係後,我們希望能運用這 些成果達到以下目標: n. 提供讀者借閱館藏的建議:透過探勘讀者借閱關聯性,將關聯性館藏推薦給 其他借閱同樣館藏的讀者。如:相關規則“5%有借閱過沉船的讀者也會借 閱盜墓及老貓這二本書”,若有讀者借閱過沉船、盜墓或是老貓中的其中一 本,則推薦另二本給該讀者。在讀者檢索沉船的同時,也可推薦其他關聯館 藏如盜墓給讀者。. n. 推薦讀者新進館藏:藉著探勘借閱類別關聯性,經由該讀者的借閱記錄或是 個人化系統中的興趣記錄,推薦讀者可能有興趣的關聯類別新書。如:經由 讀者的借閱記錄或個人興趣記錄得知讀者喜好借閱電腦科學類的書,而探勘 得知借閱類別關聯性“借閱電腦科學類書籍的讀者也同時會對語文類及企 業管理類的書籍有興趣”,因此若有電腦科學類、語文類及企業管理類的新 書時,可發出新書通報推薦該讀者借閱。. 第三節 論文架構 本論文第二章是敘述資料探勘相關研究工作,簡介產生相關規則的知名演算 法 Apriori 及我們所選擇適用於圖書館借閱記錄的相關規則演算法 H-Mine;第三. 3.
(13) 章我們提出以 H-Mine 為基礎的廣義相關規則演算法 H-Mine(Generalized)及多重 最小支持度廣義相關規則演算法 H-Mine(MMS);第四章說明實作的「圖書館借 閱記錄探勘系統」 ,簡稱「圖書館資料探勘系統」 ;第五章是圖書館資料探勘系統 效益評估;第六章則歸納結論與未來研究方向。. 4.
(14) 第二章 資料探勘相關研究工作 本論文是利用資料探勘(Data Mining)的技術,分析過去讀者借閱的歷史記 錄,了解館藏的借閱關聯性,並且將關聯館藏推薦給讀者作為借閱時的參考。本 論文運用資料探勘中的相關規則探勘(Association Rule Mining)及其延伸應用,包 括廣義相關規則探勘(Generalized Association Rule Mining)與多重最小支持度相 關規則探勘(Association Rule Mining with Multiple Minimum Supports),藉此探勘 借閱館藏的社群關係。 在本章中,第一節介紹資料探勘的技術;第二節說明相關規則探勘的二大類 方法,包括 Apriori 演算法及 H-Mine 演算法;第三節描述相關規則探勘的延伸 應用,說明廣義相關規則探勘及多重最小支持度廣義相關規則探勘的方法。. 第一節 資料探勘 所謂的資料探勘,簡單來說即是從儲存於資料庫(Database)、資料倉儲(Data Warehousing)及資訊儲存器(Information Repositio ry)的大量資料中發掘出感興趣 的知識(非瑣碎的、有隱含意義的、之前未知的、有潛力有用的)之處理過程,又 稱資料庫探勘(Database Mining)、知識萃取(Knowledge Extraction)、資料考古 (Data Dredging)及資訊收穫(Information Harvesting)等等[11]。資料探勘是資料庫 知識探索(Knowledge Discovery in Database)的步驟之一,也是其中的主要核心步 驟,因此有些學者將資料探勘與資料庫之知識探索二者視為同義詞。如圖 2 - 1 1 所示,整個知識挖掘的過程看似一個線性的過程,然而在過程中的每個步驟皆 可返回,或是加入其他步驟[1]。資料庫之知識探索的過程主要包含以下四個步 驟[11]:. 5.
(15) 結果呈現與評估. 資料探勘 資料轉換 資料選取 資料整合 資料倉儲 資料清理. 資料庫 圖 2 - 1 - 1:資料庫之知識探索流程圖 [11]. 一、確定目標 明確地定義出問題所在及想要得到的結果。 二、預備資料 包含資料選取與資料前置處理二部分。這是最花費時間的部分,約佔整個知 識探索過程的百分之六十,而預備資料的優劣亦會反應在知識探索的成效上。 n. 資料選取:根據探勘的目標,從所有的資料中選擇適用的資料。. n. 資料前置處理:又分為資料清理、資料整合、資料轉換、及資料簡化與量化。 u. 資料清理:資料庫中的資料可能會包含一些錯誤、遺失或是不完整的資 料,為避免影響到知識探索的正確性,必須對這些資料特別處理,例如 只保留資料中適用的部分、直接刪除有錯誤或是異常的資料、或是利用. 6.
(16) 數學統計或模糊理論方法來推論,針對不完整或前後不一致的資料作處 理。 u. 資料整合:資料整合包含以下幾種情形: l. 資料可能來自不同的資料庫、資料倉儲或其他資訊儲存器,必須將 不同來源的資料整合在統一格式的儲存器裡。. l. 整合不同來源的詮釋資料(Metadata)。. l. 將不同型態資料內容整合成一致且合理的值,如:描述日期的單位 由民國年轉換成西元年。. l. 將不同格式(Format)的資料轉換成相同格式的資料,如:轉換欄位 排列格式。. u. 資料轉換:根據採用的資料探勘演算法之需求,對原始資料進行必要的 轉換。轉換方式包含有: l. 彙整(Aggregation):將資料彙集加總。如每日營業額彙整成為每月 的營業資料。. l. 正規化(Formalization):依據特定範圍將屬性資料作刪減。. l. 歸納(Generalization) :將低階(Low Level)或是原始資料以較高階 (High Level)的觀點重新定位。. l. 建立屬性(Attribute Construction) :以屬性的方式取代原本的表示 法。如:以青少年,中年,老年屬性取代原本以年紀數字表示的資 料。. u. 資料簡化與量化:資料簡化是將資料中表示法過於複雜的部份簡化,以 較簡單明瞭,但又不會影響分析結果的方式表示。如:變換過於精確的 7.
(17) 單位為一般的單位,將錢的數量直接以千元為基本單位等。而資料量化 則是使用多次元(Dimensionality)縮減、轉換或編碼等方法減少有效的變 數或資料。 三、資料探勘 根據所定義的問題選擇適合的資料探勘演算法,在資料中找尋有用的特徵, 並決定採用探勘模式及參數是否適當。資料探勘演算法包含觀念描述(Concept Description) 、 關 連 性 (Association) 、 分 類 (Classification) 、 分 群 分 析 (Cluster Analysis)、及趨勢分析(Trend and Evolution Analysis)等等。 四、結果評估與呈現 依據一些量測的興趣度(Interestingness Measure),評估真正令人感興趣的資 料樣式,並且根據資料探勘演算法的結果,決定其適合的呈現方式,例如分類分 群的結果較適合以圖表的方式表示,而關聯性則適合以規則的方式呈現。除此之 外,尚須分析結果的適用性,期能應用到相關領域上。. 第二節 相關規則探勘 相關規則探勘是資料探勘的方法之一。相關規則探勘經常運用在商店的交易 記錄,針對使用者交易行為作關聯性分析,藉由交易商品的關聯性決定搭配促銷 商品、商品架位等行銷策略,以提高購買率,增加商店業績。例如:“20%買牙 刷的顧客也會同時買牙膏、毛巾和香皂”就是一個典型的相關規則。Agrawal 最 早提出從交易資料庫中發掘出相關規則的演算法[2],其後陸續有學者將相關規 則的概念應用到其他領域,提出適用該領域的演算法。本篇論文將相關規則探勘 應用在圖書館上,探討讀者借閱館藏及借閱類別的關聯性問題。. 8.
(18) 2.2.1 相關規則簡介 相關規則的正規敘述[1]如下: 令 I={i1 ,i2 ,… ,im} 為一個文字符號(Literal)組成的集合,每個文字符號稱為一 個項目(Item),由一個或一個以上的項目所組成的集合稱為項目集(Itemset)。令資 料庫 D 是由一群交易(Transaction) T 所組成的集合,每個 T 為一項目集,代表交 易記錄,T ⊆ I,每個交易記錄有其唯一的識別碼,稱為 TID。如果 X ⊆ I 且 X ⊆ T,則定義為 T 包含(Contain) X。以圖書館的應用來看,每一本書就是一個交易 項目,一個讀者在一段時間內來圖書館借閱館藏的集合即為一筆交易。 一個相關規則(Association Rule)表示成 X ⇒ Y,其中 X ⊆ I, Y ⊆ I, X ∩ Y = ∅ 。若 D 中包含 X 的交易裡有 c%也同時包含了 Y,我們就說規則 X⇒Y 的確 信值(Confidence)為 c%;如果 D 裡包含 X∪Y 的交易記錄有 s%,我們就說規則 X⇒Y 的支持度(Support)為 s%。相關規則探勘定義為:給定交易記錄資料庫 D, 在當中找出所有確信值和支持度大於最小支持度跟最小確信值的規則,其中最小 支持度與最小確信值的門檻值由使用者設定。 Agrawal 等學者[2] 將相關規則探勘分為二個子問題: 子問題一:找到所有支持度大於最小支持度的項目集。 為了探勘方便起見,有時把某一項目集的支持度定義為包含此項目集的交易 個數,而不是原來的交易百分率。支持度大於最小支持度的項目集稱為頻繁項目 集(Frequent Itemset)或是大項目集(Large Itemset),反之稱為罕見項目集(Infrequent Itemset)或是小項目集(Small Itemset)。 子問題二:用子問題一中所找到的頻繁項目集來產生所期望的規則。 此步驟的演算法非常直覺,即:對於任一頻繁項目集 L,找出其所有非空子. 9.
(19) 集 合 。 對 於 每 個 非 空 子 集 合 a , 如 果 規 則 a⇒(L-a) 的 確 信 值 ( 也 就 是 support(L)/support(a))大於最小確信值,則此規則即符合所求。 由於子問題二 Agrawal 已經在[3]中提出有效率的演算法,所以學者們不再 進一步探討產生規則的方法,而是針對如何有效率地找出所有的頻繁項目集作研 究,文獻上將此問題稱為探勘頻繁項目集(Mining Frequent Itemsets)。. 2.2.2 探勘頻繁項目集 探勘頻繁項目集的方法主要分為二派,一是根據 Agrawal 所提出的 Apriori [3] 演算法為研究基礎的候選項目集產生及測試法(Candidate Generation and Test Method);另一則是利用各種資料結構計算頻繁項目集的支持度,直接產生結果 的頻繁項目集成長法(Frequent Pattern Growth Method)。 以下簡介產生頻繁項目集的二大類方法: n. 候選項目集產生及測試法 這類方法是以 Agrawal 所提出的 Apriori [3]演算法為研究基礎。Apriori 演算. 法以疊代(Iteration)的方式產生頻繁項目集。每一次疊代時產生所有相同長度的頻 繁項目集,在第一次時疊代產生長度為 1 的頻繁項目集,第二次時則產生長度為 2 的頻繁項目集,依此類推。每一次產生的頻繁項目集當作下一次疊代的種子集 (Seed Set),由種子集來推論下一次疊代所有可能會出現的頻繁項目集,文獻上 稱此可能出現的頻繁項目集為候選項目集(Candidate Itemset)。每一次疊代只要將 所有交易和產生之候選項目集加以比對並計算它們的支持度,候選項目集中所有 大於最小支持度的項目集所成之集合就是這一次疊代的頻繁項目集。如此一直反 覆,直到沒有新的頻繁項目集出現為止。圖 2 - 2 - 2 是一個簡單的例子,利用 Apriori 找出所有大於最小支持度 2 的項目集。圖 2 - 2 - 3 列出 Apriori 演算法。. 10.
(20) 圖 2 - 2 - 2:Apriori 例子[3]. L1 = {large 1-itemsets};//產生長度為 1 的頻繁項目集 for (k=2;Lk-1 ≠∅;k++) do begin Ck = apriori- gen(Lk-1 );//產生 k-項目集之候選項目集 for all transactions t∈D do begin Ct = subset(C k ,t); //交易記錄中所有包含 Ck 的集合 for all candidates c∈Ct do c.count++; //計算支持度 end Lk = {c∈Ck |c.count ≥ minsup};//產生長度為 k 的頻繁項目集 end Answer =∪k (Lk );. 圖 2 - 2 - 3:Apriori 演算法[3]. 圖 2 - 2 - 3 中的 apriori_gen 函數用來產生候選項目集。由於任何頻繁項目集 的子集合也都是頻繁項目集,因此 apriori- gen 以所有頻繁 (k-1)-項目集(Lk-1 )為參 數,傳回頻繁 k-項目集的候選集(C k )。apriori-gen 分為兩個步驟來產生候選項目 集 Ck : 11.
(21) 1.. 連結(Join):用 Lk-1 來連結 Lk-1 insert into Ck select p.item1 ,p.item2 ,… ,p.itemk-1 , q.itemk-1 from Lk-1 p, Lk-1 q where p.item1 =q.item1,… , p.itemk-2 =q.itemk-2, p.itemk-1 <q.itemk-1. 2.. 刪除(Prune):對於所有的 c∈Ck ,只要任何一個子集合不在 Lk-1 中就刪除它. for all itemsets c∈Ck do for all (k-1)-subsets s of c do If (s∉Lk-1 )then delete c from Ck ;. n. 頻繁項目集成長法 頻繁項目集成長法的最大特色就是利用各種資料結構計算頻繁項目的支持. 度,直接產生結果。如 FP-growth [10]及 Tree-projection [4]均是利用樹狀結構儲 存頻繁項目,並運用樹狀結構計算各頻繁項目的支持度,而 H-Mine [14]則是運 用 Pei 等學者所提出的 H-Struct,利用動態調整 H-Struct 的連結計算各頻繁項目 的支持度,以求出最後的頻繁項目集。 由於 Apriori 在項目重疊性高、交易項目長的項目集或是在支持度相當小的 情況下,效能並不夠好,因此,Han 等學者[4][10][14]分析可能造成效能不彰的 因素,並針對缺失提出新演算法。Han 等學者[10]分析 Apriori 效能不彰的原因為 二,一是在上述情況下,Apriori 必須處理龐大數目的候選項目集,所以拖垮整 體效能,另一則在產生在長項目集時,必須耗費大量時間來掃瞄資料庫並檢查比 對候選項目集。表 2 - 2 - 1 是二類頻繁項目集產生方法的比較。. 12.
(22) 方法 優點. 缺點. 候選項目集產生及測試法. 頻繁項目集成長法. 1.. 不 需 再 另 建 資 料 結 構 儲 1. 存交易項目. 有效減少重複讀取資料 庫的次數. 2.. 演算法較簡單直覺. 2.. 不需要額外產生候選項 目集. 1.. 花 費 時 間 產 生 可 能 不 是 1. 結果的候選項目集. 2.. 一再重複地掃瞄資料庫. 需額外花費時間空間建 立資料結構儲存交易項 目資料. 2.. 演算法較複雜. 表 2 - 2 - 1:候選項目集產生及測試法 與頻繁項目集成長法之比較. 由於圖書館的資料量龐大,若是使用候選項目集產生及測試法勢必會因為重 複掃描資料庫而拖垮探勘的效能,且由 Han [10]得知,在支持度小、交易量大時, FP-growth 的效能都比 Apriori 佳。圖書館交易記錄的資料量大且讀者借閱的館藏 重疊性不高,在設定高支持度時,不易找到頻繁項目集,因此,我們得設定較低 的支持度,但如此一來,頻繁項目成長法就較候選項目集產生及測試法適用於圖 書館的資料探勘。 現有的頻繁項目成長法主要有三種演算法,分別為 FP-growth [10]、Tree Projection [4] 及 H-Mine [14],由 Han [10]得知,FP- growth 的效能不管在支持度 或是資料量的擴充性上都略勝於 Tree Projection 一籌,但是,將 FP- growth 用在 交易項目分散、稀疏、重複性很低的資料集上時,表現又不如 H-Mine 出色。 由於圖書館讀者借閱的期限大多為一個月,若館藏無複本,平均一年只會被 借出 12 次,且館藏有複本的數量很少,館藏被借出後其他讀者便無法借閱相同 書籍,故圖書館的館藏流通率較一般商店商品流通率低,讀者借閱同一館藏的重 疊性亦較顧客購買相同商品重疊性低。 總結以上分析,圖書館資料的特性是資料量大、借閱重疊性低,故在支持度 小時才會有比較好的結果,所以,我們採用 H-Mine 為圖書館借閱記錄資料探勘 系統的核心演算法。表 2 - 2 - 2 是 H-Mine 與 FP- growth 的優劣比較。 13.
(23) 頻繁項目集成長法 優點. 缺點. 最適合資料集. H-Mine. FP-growth. 重 新 調 整 資 料 結 構 在不同交易中若有共同前 H-Struct 的連結即可,不會 幾個項目即可共用相同項 一直重複產生小的投影資 目的節點,不需再重複產 料庫(Projected Database)。 生相同的樹狀節點。 不同交易中即使項目十分 重複產生小的投 影資料庫 相 似 仍 無 法 共 用 資 料 結 (Projected Database)及附帶 構。 的 頻 繁 項 目 樹 (FP- Tree: Frequent Pattern Tree)。 交易項目分散、稀疏、重 交易項目多且重複性、壓 複性很低的資料集,可共 縮性很高的資料集。 用項目少的資料集。 表 2 - 2 - 2:H-Mine 與 FP-growth 之比較. 由於 H-Mine 較適用於探勘圖書館的借閱資料,故本論文乃以 H-Mine 為基 礎發展圖書館資料探勘系統。以下進一步介紹 H-Mine 的運作方式。 H-Mine[14]是由 Jian Pei 等學者所提出的頻繁項目集成長法,H-Mine 運用一 資料結構 H-Struct 儲存交易中的頻繁項目集,並透過 H-Struct 動態調整連結,進 行資料探勘。這個方法的最大特點就是在 H-Struct 中調整連結以達到如在投影資 料庫(Projected Database)中探勘的效果,這個方法的記憶體空間複雜度是可預期 的,而 Apriori、FP-growth 在記憶體的使用上則無法預期。 H-Mine 演算法針對資料量大小設計不同的演算法。當所有交易均可置入主 要記憶體時,使用 H-Mine(Mem) 演算法;當交易量龐大以致於無法置入主要記 憶體時,則是使用 H-Mine 演算法。 直接舉例說明 H-Mine(Mem)。表 2 - 2 - 3 前二欄是假設的交易資料庫,最 小支持度設定為 2。 交易編號 100 200 300 400. 項目集 c, d, e, f, g, i a, c, d, e, m a, b, d, e, g, a, c, d, h. 頻繁投影 c, d, e, g a, c, d, e a, d, e, g a, c, d. 表 2 - 2 - 3:相關規則探勘之交易資料庫[14] 14.
(24) H-Mine 演算法的關鍵步驟就是建立資料結構 H-Struct。首先,掃瞄整個資料 庫找出符合最小支持度且長度為 1 的單一項目頻繁項目集,得到{a:3, c:3, d:4, e:3, g:2},a:3 表示交易資料庫中有 3 筆資料包括項目 a。將單一頻繁項目集以標頭表 格(Header Table) H 表示,每個頻繁項目包含三個欄位:項目編號、項目支持度 及連結位置,其中頻繁項目集的順序為任意順序,而本例是依字母順序排列。再 將資料庫中每筆交易項目只保留頻繁項目,並按照頻繁項目集順序排列,得到每 筆交易的頻繁投影(Frequent Projection),而頻繁投影的集合則稱為投影資料庫 (Projected Database)。每一個存在 H-Struct 中的頻繁項目包含二個欄位:項目編 號及連結位置。H-Struct 的資料結構如圖 2 - 2 - 4。 當交易中所有頻繁投影均可置入主要記憶體時,在每筆投影中的第一個頻繁 項目都會以佇列的方式經由連結位置連結起來,而標頭表格 H 中的連結位置則 是儲存每一個佇列第一個項目的位置。如圖 2 - 2 - 4,標頭表格 H 的項目 a 即是 存放 a 佇列第一個項目的指標 (指向交易投影 200 中第一個項目 a 的指標),a 佇 列則連結 200,300 及 400 三筆交易的投影。 標頭表格 H. 頻繁投影. a. c. d. e. g. 3. 3. 4. 3. 2. 100. c. d. e. g. 200. a. c. d. e. 300. a. d. e. g. 400. a. c. d. 圖 2 - 2 - 4:H-Struct[14]. 顯然地,要建立這個 H-Struct 只要掃瞄整個資料庫二次,一次是計算所有的 頻繁項目集,另一次則是在每筆交易中保留頻繁項目,建立投影資料庫。之後整 15.
(25) 個探勘過程全都在 H-Struct 上進行,不會再使用到原本的交易資料庫。 如圖 2 - 2 - 4 探勘由標頭表格 H 表示的五個項目,分為五個子集,亦可視 為五個虛擬投影資料庫,在各自的子集中探勘,找出屬於個別的頻繁項目集。先 從第一個子集 a 投影資料庫(屬於 a 佇列的頻繁投影)開始,所有屬於 a 投影資料 庫的交易已被連結成 a 佇列,所以,掃瞄 a 投影資料庫時,只要利用 a 佇列的連 結即可瀏覽整個 a 投影資料庫。 探勘 a 投影資料庫中的頻繁項目時,必須先建立屬於 a 投影資料庫的標頭表 格 Ha,如下圖 2 - 2 - 5。標頭表格 Ha 的欄位就如同標頭表格 H 的欄位。但是, 項目支持度是記錄頻繁項目在 a 投影資料庫中出現的次數,如項目 c 在 a 投影資 料庫出現 2 次,故在 Ha 中項目 c 的項目支持度為 2。 標頭表格 H. 標頭表格 Ha. a. c. d. e. g. c. d. e. 3. 3. 4. 3. 2. 2. 3. 2. 100. c. d. e. g. 200. a. c. d. e. 300. a. d. e. g. 400. a. c. d. 頻繁投影. 圖 2 - 2 - 5:標頭表格 Ha 及 ac 佇列[14]. 掃瞄整個 a 投影資料庫,找出除了項目 a 以外的頻繁項目集,得到{c:3, d:3, e:2},建立標頭表格 Ha,即可輸出部分結果頻繁項目集{ac:3, ad:3, ae:2},並建立 Ha 與頻繁投影的連結。如圖 2 - 2 - 5,對 a 投影資料庫而言,交易投影 200 及 400 的第一個項目均為 c,故使標頭表格 Ha 中項目 c 的連結位置指向 200,200 項目 c 的連結位置指向 400,成為 ac 佇列。 16.
(26) 同樣地,探勘 ac 投影資料庫中的頻繁項目時,利用 ac 佇列的連結瀏覽 ac 投影資料庫,並建立屬於 ac 投影資料庫的標頭表格 Hac。標頭表格 Hac 中只有項 目 d 是頻繁項目,因此只有 acd:2 是結果頻繁項目集。搜尋 ac 為首的頻繁項目集 就此結束。 結束以 ac 為首頻繁項目集的搜尋後,回到標頭表格 Ha,下一步尋找包含 ad 但不包含 c 的頻繁項目集。因為在探勘 ac 投影資料庫時就已經找出所有跟 c 有 關的項目集,所以在接下來的探勘就不需要再考慮那些已經探勘過的項目。 ad 佇列從標頭表格 Ha 項目的連結位置開始,除了在標頭表格 Ha 一建立就連 結好的交易投影 300 外,還必須加入屬於 ac 投影資料庫但是包含有項目 d 的交 易。如圖 2 - 2 - 6,交易投影 300 的連結位置指向 200,200 的連結位置指向 400。 在調整連結位置之後,ad 佇列收齊所有頻繁投影中含有項目 ad 的完整集 合。經由追蹤 ad 佇列的連結,找到唯一的頻繁項目 e,因此只有 ade:2 是結果頻 繁項目集。同樣地,搜尋包含 ad 的頻繁項目集也就此結束。 搜尋包含 ae 的頻繁項目集時,由於項目 e 並無連結,表示並無以 ae 為首的 結果頻繁項目集。搜尋 ae 亦就此結束。 標頭表格 H. 標頭表格 Ha. a. c. d. e. g. c. d. e. 3. 3. 4. 3. 2. 2. 3. 2. 100. c. d. e. g. 200. a. c. d. e. 300. a. d. e. g. 400. a. c. d. 頻繁投影. 圖 2 - 2 - 6:標頭表格 Ha 及 ad 佇列[14] 17.
(27) 結束所有以 a 為首頻繁項目集的搜尋後,回到標頭表格 H,追蹤 c 頻繁項目 集的搜尋,此時 c 佇列包含了所有第一個項目為 c 的頻繁投影,但是 a 佇列中仍 有同時包含項目 a 及 c 的頻繁投影,即那些在 a 佇列中的投影亦有可能會有以 c 為首的頻繁項目。因此,必須再追蹤 a 佇列的連結,將屬於 a 佇列頻繁投影在項 目 a 之後的項目,即第二個頻繁項目(第一個項目均為 a), 與各自歸屬的佇列 連結起來。如圖 2 - 2 - 7 所示,頻繁投影 acde、acd 插入 c 佇列,而頻繁投影 adeg 插入 d 佇列。 標頭表格 H. a. c. d. e. g. 3. 3. 4. 3. 2. 100. c. d. e. g. 200. a. c. d. e. 300. a. d. e. g. 400. a. c. d. 頻繁投影. 圖 2 - 2 - 7:調整探勘 a 投影資料庫後的連結位置[14]. 依照探勘 a 投影資料庫的模式,探勘 c 投影資料庫。先找出頻繁項目中含有 項目 c,但是不含有項目 a,因為與 a 項目有關的頻繁項目集已在 a 投影資料庫 探勘完畢。建立標頭表格 Hc,並仿照上面遞迴的方式探勘出以 c 為首的頻繁項 目集。接下來,依序探勘 d、e 投影資料庫,即可找出所有的結果頻繁項目集。 當交易中所有頻繁投影均可置入主要記憶體時,依照上述方法即可找出所有 的結果頻繁項目集。但是,若是資料量龐大到無法置入主要記憶體時,就得將整 個資料庫分為幾個子資料庫,分別利用 H-Mine(Mem) 探勘子資料庫,最後再整 18.
(28) 合(Merge)結果,即 Jian Pei等學者所提出適合探勘大資料庫的 H-Mine[14]演算法。 H-Mine 演算法分為以下四個步驟。步驟一:先掃瞄過整個資料庫找出所有 單一項目的頻繁項目集。步驟二:將整個交易資料庫的頻繁投影分成幾個子資料 庫,讓每一個子資料庫所有交易的頻繁投影都可以置入主記憶體中。步驟三:將 每個子資料庫的頻繁投影利用 H-Mine(Mem) 演算法找出符合各自最小支持度的 頻繁項目集,各自最小支持度的算法為使用者設定整個資料庫的最小支持度乘以 該子資料庫占整個資料庫的比例。步驟四:將每個子資料庫中的頻繁項目集(為 區域頻繁項目集(Local Frequent Itemsets))及各項目集的支持度收集起來,掃瞄最 後一次資料庫,確定區域頻繁項目集滿足整體最小支持度,得到整體頻繁項目集 (Global Frequent Itemsets)。 H-Mine 與其他分割關聯演算法如 Partitioned Apriori [15]最大的不同在於 H-Mine 所需要的空間是可預測的,所需要的空間只有交易頻繁項目投影及標頭 表格,空間負擔比 Apriori 所耗費的空間小許多。且 H-Mine 一開始就直接考慮 整體頻繁項目,並不會耗費時間去運算那些不屬於整體頻繁項目但屬於區域頻繁 項目的項目集,相反地,Partitioned Apriori 在分配不均的子資料庫中,會耗費許 多時間計算及產生無用的候選項目集。. 第三節 相關規則探勘之延伸問題 相關規則探勘延伸出各式各樣的問題,包括將項目分類加入探勘項目的廣義 相關規則探勘[18][19]、依照項目特性設定不同支持度的多重最小支持度相關規 則探勘[12][20]、相關規則更新[6][15] 及考慮交易項目序列順序的循序探勘[17] 等等問題,其解決方法和基本問題息息相關,且可以應用在更多不同的領域。 以下簡介本論文會應用到的二種延伸問題:廣義相關規則探勘及多重最小支 持度相關規則探勘。. 19.
(29) 2.3.1 廣義相關規則探勘(Generalized Association Rule Mining) 廣義相關規則是將項目分類 (Taxonomy) 的資訊加入相關規則探勘,一方面 可將與分類有關的資訊反映在相關規則探勘上,不會只侷限在項目相關規則,使 相關規則更有意義,另一方面還可得知不同階層間項目的關聯性。 廣義相關規則的正規敘述[18][19]如下: 令 I={i1 ,i2 ,… ,im} 為一個文字符號組成的集合,每個文字符號稱為一個項 目,由一個或一個以上的項目所組成的集合稱為項目集。令 J={j1 ,j2 ,… ,jp }為由 I 延伸之廣義項目(Generalized Items)的集合。令 Γ 為由文字符號 I 及其廣義項目 J 所組成的非環狀有向圖, Γ 上的邊線(Edge)代表著 is-a 的關係,而 Γ 代表分類 (Taxonomy) 的集合。如果在 Γ 上有一邊線從 p 指向 c,我們則稱 p 為 c 的母體 (Parent),稱 c 為 p 的子體(Child) ,也表示 p 為 c 的廣義延伸(Generalization)。如 果在有遞移封閉性(Transitive Closure) 的 Γ 上,有一邊線從 xˆ 指向 x,我們則稱 xˆ 為 x 的祖先(Ancestor),稱 x 為 xˆ 的後裔(Descendant)。令資料庫 D 是由一群交易 T 所組成的集合,每個 T 為一項目集,代表交易記錄,T ⊆ I,每個交易記錄有其 唯一的識別碼,稱為 TID。 一個廣義相關規則(Generalized Association Rule)表示成 X ⇒ Y,其中 X ,Y ⊆ I∪J, X ∩ Y = ∅ ,而且 Y 中項目並無包含 X 中任何項目的祖先。若 D 中包含 X 的交易裡有 c%也同時包含了 Y,我們就說規則 X⇒Y 的確信值(Confidence)為 c%;如果 D 裡包含 X∪Y的交易記錄有 s%,我們就說規則 X⇒Y的支持度(Support) 為 s%。條件限制 Y 中並無包含 X 中任何項目祖先的原因是規則 ”x=>ancestor(x)” 是保證 100%正確的,但是這樣的規則卻是已知且累贅的。廣義相關規則探勘定 義為:給定交易記錄資料庫 D 及分類Γ ,在當中找出所有支持度和確信值大於 最小支持度跟最小確信值的廣義相關規則,其中最小支持度與最小確信值的門檻 值由使用者給定。 20.
(30) 廣義相關規則探勘,直覺地來說,將交易中的項目加上分類項目,再利用探 勘相關規則演算法探勘即可。如圖 2 - 3 - 8,Srikant 等學者所提出的基本演算法 [18],將交易中每個項目的廣義項目加入交易,並移除同筆交易中重複出現的廣 義項目,而加入廣義項目的交易稱為延伸交易(Extended Transactions) 。最直覺 的探勘方法即是直接將延伸交易利用相關法則演算法找出廣義相關法則。 L1 := {frequent 1-itemsets}; k:=2; //k represents the pass number while(Lk ≠ φ ) do begi. Ck := New candidate of size k generated from Lk-1 . for all transactions t ∈ D do begin Add all ancestors of each item in t to t, removing any duplicates. Increment the count of all candidates in Ck that are contained in t. End. Lk := All candidates in Ck with minimum support. k := k+1; End while Result = ∪k Lk; 圖 2 - 3 - 8:廣義相關規則基本演算法 [18]. 廣義相關規則基本演算法的第一步驟,先找出長度為 1 的頻繁項目集。其中 包括分類中的葉節點(Leaf Node,即一般項目)及內部節點(Internal Node,即廣義 項目)。只要一般項目及廣義項目的支持度大於使用者定義的最小支持度都是屬 於頻繁項目集。之後,就如同 Apriori [3]的步驟,每次疊代利用前次頻繁項目集 找出候選項目集,並且掃瞄每筆交易及其對應的廣義項目(即延伸交易),找出各 個項目的支持度。 然而,廣義相關規則基本演算法並不夠有效率,可再利用廣義關聯法則及分 類的特性進一步地改善廣義關聯演算法,因此 Srikant 等學者還提出三個可以使 基本演算法最佳化的規則,發展出累積演算法(Cumulate)[18]。. 21.
(31) 累積演算法的三個最佳化規則: 1.. 過濾掉要加到交易中的廣義項目。沒有必要把分類中所有交易項目的廣 義項目加入交易裡。相反地,我們只需要將在疊代的某一輪(Pass) 有用 到的候選項目的廣義項目加入交易中即可。事實上,如果原本的項目並 不在任何頻繁項目集中出現,該項目亦可直接從交易中刪除。舉個例子 說明,假設”外套” 的母體是”外衣”, 而”外衣”的母體是”衣服”。令{衣 服, 鞋子}為唯一滿足最小支持度的項目集。之後,若任何交易中有包 含”外套”,以”衣服”取代”外套”。我們不需要在交易中保留”外套”這個 項目,也不需要在交易中加入”外衣”這個項目。. 2.. 預先計算廣義項目。與其在每次追蹤每一個項目時就瀏覽整個分類階 層,可以預先計算每一個項目的廣義項目集合。同時,我們也可以從分 類階層中丟棄那些從未出現在候選項目集的廣義項目。. 3.. 刪除項目集中同時包含一個項目及由該項目延伸而來的廣義項目。. 利用以上的三個最佳化規則,再配合原本的廣義相關規則基本演算法,即是 廣義相關規則累積演算法。演算法如圖 2 - 3 - 9。粗體字是與基本演算法相異的 部分,即是應用最佳化規則改善演算法的部分。. 22.
(32) Compute Γ * , the set of ancestors of each item, from Γ . //Optimization 2 L1 := {frequent 1-itemsets}; k:=2; //k represents the pass number while(Lk ≠ φ ) do begin Ck := New candidate of size k generated from Lk-1 . If (k=2) then Delete any candidate in C2 that consists of an item and its ancestor. // Optimization 3 Delete any ancestors in Γ * that are not present in any of the candidate in Ck ; // Optimization 1 for all transactions t ∈ D do begin Add all ancestors of each item in t to t, removing any duplicates. Increment the count of all candidates in Ck that are contained in t. End. Lk := All candidates in Ck with minimum support. k := k+1; End while Result = ∪k Lk; 圖 2 - 3 - 9:廣義相關規則累積演算法 (Cumulate) [18]. 2.3.2 多 重 最小支持度 相關規則 探 勘 (Association Rule Mining with Multiple Minimum Supports) 決定相關法則實用與否的關鍵在於最小支持度設定的適當與否。一般的相關 規則探勘都是在單一支持度下產生規則,然而只用一個最小支持度並無法表示所 有不同特性項目的支持度。因此,Liu [12]等學者提出為不同特性的項目訂定不 同支持度的想法,並設計一個架構在 Apriori 上的多重最小支持度相關規則探勘 演算法,以符合現實情況之需求。 例如在超級市場的交易資料中,有些項目集雖然支持度較低(亦即較不常被 購買) ,但是可以產生相當高的利潤,若要把此類相關規則找尋出來,則必須將 最小支持度設定得比較低,以利產生有用的規則,如: 食物處理器 ⇒ 烹調平底鍋 (支持度 = 0.5%,確信值 = 60%) 23.
(33) 但是假如所有項目都訂定同一的最小支持度,則下列沒有意義的規則也會產 生: 麵包,起司 ⇒ 牛奶 (支持度 = 5%,確信值 = 68%) 知道 5%顧客一起買此三種食品是沒有用的,因為這些食品在超級市場同時 被買的機率是十分頻繁,這樣的規則太繁瑣,並非是使用者會想要知道的。若要 使這類的規則變得非常有用,則需要將最小支持度定得比較高才有意義,但是相 對地會無法產生“食物處理器 ⇒ 烹調平底鍋”此類相關規則。由此例可以發 現,必須針對項目的特性設定不同的支持度,才能產生有意義且適用的相關規則。 多重最小支持度相關規則的定義和相關規則的差別在於前者修改了最小支 持度的定義。在多重最小支持度相關規則中,一個規則的最小支持度為出現在該 規則內所有項目的最小支持度之最小值。每一項目的最小支持度稱為最小項目支 持度(Minimum Item Supports),簡寫為 MIS。將經常出現的項目設定高的最小支 持度,將罕見但價值高的規則設定低的最小支持度,可以使規則更符合現實需求。 多重最小支持度相關規則探勘演算法的精神在於 Liu [12]等學者歸納出多重 最小支持度規則的特性:排序封閉的特性(Sorted Closure Property),此一特性是 從 Apriori 向下封閉的特性(Downward Closure Property) 延伸而來。Apriori 向下 封閉的特性是指若一個項目集滿足最小支持度,那麼它所有的子集也都會滿足最 小支持度。但是向下封閉的特性並不能適用於多重最小支持度相關規則探勘。例 如資料庫中有四個項目:1, 2, 3, 4;各自的最小支持度分別為 MIS(1)=10%, MIS(2)=20%, MIS(3)=5%, MIS(4)=6%。如果我們找出{1,2}的支持度為 9%,由於 並不滿足 1 或 2 的最小支持度,因此{1,2}不屬於頻繁項目集,對 Apriori 而言, 項目集{1,2,3}及{1,2,4}也會跟著不可能成為頻繁項目集,但是事實上項目集 {1,2,3}及{1,2,4}的最小支持度分別為 5%及 6%,是符合頻繁項目集的。因此, Liu 提出了排序封閉的特性應用在刪除候選項目集上。. 24.
(34) 多重最小支持度相關規則演算法的關鍵在於探勘規則時必須將所有項目依 項目最小支持度遞增排列。如上例,四個項目的最小支持度分別為 MIS(1)=10%, MIS(2)=20%, MIS(3)=5%, MIS(4)=6%,就得排列成 3, 4, 1, 2。這樣的排列有助於 解決不符合 Apriori 向下封閉的特性。 令 Lk 表示頻繁 k 項目集的集合。每一個項目集 c 的表示法為,<c[1], c[2], … ,c[k]> ,且 MIS(c[1]) ≤ MIS(c[2]) ≤ …. ≤ MIS(c[k])。Liu[12] 提出多重最. 小支持度相關規則演算法 MSappriori 如圖 2 - 3 - 10(a)。 M=sort(I, MS); //according to MIS(i)’s stored in MS F=init-pass(M, T); //make first pass over database T, only keep frequent 1- itemsets L1 := {<f>|f∈ F, f.count ≥ MIS(f)}; for(k=2;Lk ≠ φ ;k++) do // k represents the pass number if(k=2) then C2 =level2-candidate-gen(F) else Ck=candidate-gen(Lk-1 ) end for each transaction t ∈ T do begin Ct=subset(Ct,t); for each candidate c ∈ Ct do c.count++; End. Lk := {c ∈ Ck |c.count ≥ MIS(c[1])}; //itemset must larger than the minimum MIS end for Result = ∪k Lk;. 圖 2 - 3 - 10 (a):多重最小支持度相關規則探勘演算法[12]. 首先,將所有項目依最小項目支持度遞增排列,存成 MS。掃瞄一次資料庫, 找出長度為 1 的候選項目集 F 及頻繁項目集 L1 ,其中候選項目集 F 的每個項目 都必須符合最小項目支持度之最小值 minMIS (以 minMIS 表示所有最小項目支 持度之最小值),而頻繁項目集 L1 的每個項目都必須符合各自的最小項目支持 度。類似 Apriori 的步驟,產生候選項目集。當欲產生長度為 2 候選項目集時, 必須利用長度為 1 的候選項目集,即還沒經過各自最小項目支持度測試的項目集 25.
(35) F,來找出長度為 2 候選項目集,以避免錯失一些項目集。 例如第一次掃瞄 100 筆的資料庫得到 3.count=6, 4.count=3, 1.count=9 及 2.count=25 。 而. MIS(1)=10%,. MIS(2)=20%,. MIS(3)=5%,. MIS(4)=6%,. minMIS=5%。因此,依序排列,F={<3>, <1>, <2>},而 L1 ={<3>,<2>}。因為 4.count 小於 minMIS,所以不在 F 中。而 1 不在 L1 中是因為 1.count 小於項目 1 的最小 支持度 10%。而經由候選項目集 F,得到 C2 ={<3,1>,<3,2>}。(其中<1,2>不屬於 C2 是因為<1,2>支持度只有 9,而項目集的最小支持度為 10%。) 若是經由 L1 產 生 C2,則會因不適用 Apriori 的向下封閉特性,而失去<3,1>這個亦符合候選資格 的項目集。 產生 C2 候選項目集 level2-candicate-gen(F) 步驟如圖 2 - 3 - 11(b)。 for each item f in F in the same order do if f.count ≥ MIS(f) then for each item h in F that is after f do if h.count ≥ MIS(f) then insert <f, h> into C2 圖 2 - 3 - 12 (b):產生 C2 候選項目集 level2-candicate-gen(F) 步驟[12]. 至於產生其他候選項目集 candicate- gen(Lk-1 )的方式,則是類似 Apriori 的 apriori- gen 方式分為二步驟,連結(Join)與刪除(Prune)。連結步驟與 Apriori 的連 結 步 驟 完 全 相 同 , 至 於 刪 除 步 驟 , 則 是 利 用 排 序 封 閉 特 性 (Sorted Closure Property)。刪除步驟的目的在於刪除一些已知不可能符合最小支持度的項目集, 因此,依據向下封閉特性,必須刪除項目集中其子集不屬於候選項目集的項目 集。但是,為了符合多重最小支持度的特性,有個情形是例外不能刪除的,就是 當該子集內不含有項目集的第一個項目時,是不需要刪除的。這是因為第一個項 目代表著項目集的最小支持度,而當其子集不在候選項目集時,除了最小的二個 項目最小支持度相等(MIS(c[1])=MIS(c[2])),我們無法確定它是否會不滿足最小. 26.
(36) 項 目 的 支 持 度 MIS(c[1]) , 只 能 確 定 該 子 集 不 滿 足 MIS(c[2]) (MIS(c[1])< MIS(c[2]))。 例如令 L3 為{<1,2,3>, <1,2,5>, <1,3,4>, <1,3,5>, <1,4,5>, <1,4,6>, <2,3,5>}, 項 目 在 項 目 集 內已 排 序過。經過連結步驟,得到 C4 ={<1,2,3,5>, <1,3,4,5>, <1,4,5,6>}。項目集<1,4,5,6>會在刪除步驟裡被刪除,因為<1,5,6>不屬於候選項 目集,且<1,5,6>包含該項目集的最小項目 1。而<1,3,4,5>卻不會被刪除,雖然 <3,4,5>不屬於候選項目集,但是其最小支持度為 MIS(3),最小支持度可能會大 於整個項目集<1,3,4,5>的最小項目支持度 MIS(1),而我們無法確定<3,4,5>是否 會大於 MIS(1) ,所以除非我們知道項目 1 與 3 的項目最小支持度相等,否則我 們就不刪除候選項目集<1,3,4,5>。 產生 Ck (k ≠ 2)候選項目集的刪除步驟如圖 2 - 3 - 13(c): for each itemset c ∈ Ck do for each (k-1)-subset s of c do if(c[1] ∈ s) or (MIS(c[2])= MIS(c[1])) then if(s ∉Ck-1 ) then delete c from Ck; 圖 2 - 3 - 13 (c):產生 C k (k ≠ 2)候選項目集的刪除步驟[12]. 27.
(37) 第三章 以 H-Mine 為基礎之廣義相關規則演算法 本論文針對圖書館借閱記錄的特性,選擇適合的演算法 H-Mine 來探勘圖書 館借閱記錄,期望能夠找出借閱館藏的關聯性,並且讓館員能夠針對不同身份不 同系所的讀者,找出不同的相關規則。此外,本論文亦將廣義相關規則探勘及多 重 最 小 支 持 度 相 關 規 則 探 勘 的 觀 念 與 H-Mine 演 算 法 結 合 , 提 出 H-Mine(Generalized) 及 H-Mine(MMS) 演算法,以探勘借閱類別的關聯性。 在本章中,第一節介紹我們所提出的廣義相關規則演算法 H-Mine(Generalized);第二節說明如何加入多重最小支持度的概念探勘廣義相關 規則,進而提出多重最小支持度廣義相關規則演算法 H-Mine(MMS)。. 第一節 廣義相關規則演算法 H-Mine(Generalized) H-Mine(Generalized) 演算法是根據 H-Mine 演算法結合廣義相關演算法的 概念而提出的延伸演算法。主要動機是因為在探勘圖書館借閱記錄時,由於探勘 所得的讀者借閱關聯館藏只佔了微乎其微的一小部分,對館藏龐大的圖書館而言 效益不大,因此本論文進一步地找出讀者借閱類別的關聯性,藉由推薦讀者有興 趣關聯類別的新書,更有效地提供讀者借閱建議。 H-Mine(Generalized) 演算法是將交易資料中的所有項目根據其隸屬分類階 層將分類項目(即廣義項目)加入每筆交易資料,成為延伸交易,再將延伸交易利 用改進 H-Mine 演算法找出廣義相關法則。詳述步驟如下: 步驟一:根據項目隸屬分類階層加上其廣義項目,得到延伸交易。例如以圖 書館中文館藏為例,若採用「中國圖書分類法」做為分類階層,若有本書的分類 號為 448.82,則將含有該本書的交易加上分類廣義項目 4XX、44X、448、448.8 及 448.82。. 28.
(38) 步驟二:將交易的每一項目,包括原本交易項目及廣義項目,都當成一般項 目,找出長度為 1 的單一頻繁項目集,並據以建立 H-Struct 資料結構的標頭表格 H,H 中每個項目包含三個欄位:項目編號、項目支持度及連結位置,其中頻繁 項目集的順序為任意順序。 步驟三:刪除多餘項目,重新調整頻繁項目集,找出新標頭表格 H’。因為 本方法將廣義項目當成一般項目運作,這樣一來分類項目的子體(Child)與母體 (Parent)或是後裔(Descendant)與祖先(Ancestor)就可能會同時存在標頭表格內,若 是子體(後裔)與母體(祖先)的支持度又是相同,母體(祖先)所代表的意義就已經隱 含在子體(後裔)中,則母體(祖先)則成了多餘的頻繁項目,沒有必要再保留。重 新調整頻繁項目集的方法是掃瞄 H 中的所有頻繁項目,若是有二個頻繁廣義項 目皆屬於同一大類分類項目,則判斷是否有一項目為另一項目的母體(祖先)。若 是,又二者支持度相同,則刪除母體(祖先)項目,表示母體(祖先)資訊已經隱含 在子體(後裔)中,則沒有必要再保留母體(祖先)。 步驟四:將資料庫中每筆交易項目只保留經過調整的所有頻繁項目,包含原 本交易項目及廣義項目,即新標頭表格 H’內的頻繁項目集,並依照頻繁項目集 順序排列,得到每筆交易的頻繁投影。如同 H-Mine,每一個存在 H-Struct 中的 頻繁項目亦包含二個欄位:項目編號及連結位置。H-Struct 即是包含標頭表格及 頻繁投影的資料結構。 步驟五:將新標題表格 H’ 的每一項目,找出每個頻繁投影的第一個項目與 之對應連結,得到完整 H-Mine 的 H-Struct 資料結構。 步驟六:由於標頭表格內仍有母體(祖先)與子體(後裔)同時存在,但二者支 持度卻不相同的情形,為確保在同一個結果頻繁項目集內不會有母體(祖先)及子 體(後裔)同時出現的情形,本步驟將要輸出的結果頻繁項目集進行最後測試。利 用之前步驟三調整頻繁項目集的方法,判斷每一個頻繁項目集中的所有廣義項目. 29.
(39) 是否有其他廣義項目為其子體(後裔)的情形,確認每一結果頻繁項目集皆是最精 簡的。最後則輸出所有精簡後的頻繁項目集。 步驟七:類似 H-Mine 方法,標頭表格 H’ 的每個項目可各自組成一個投影 資料庫。在每個投影資料庫中重複執行二、三、五及六的步驟:找出頻繁項目集, 得到各自的標頭表格 H、經由分類測試後調整成為 H’標頭表格、根據標頭表格 重新與頻繁投影連結、測試結果頻繁項目集並輸出精簡後的頻繁項目集、再遞迴 一層層深入探勘,直到所有標頭表格的頻繁項目集完全找完。 本論文中我們所提出的 H-Mine(Generalized)演算法,是利用 H-Mine 演算 法,再加上二個最佳化的條件,一是調整標頭表格中母體(祖先)與子體(後裔)同 時出現,且支持度又相同的項目,刪除母體(祖先)的項目,只保留子體(後裔)的 項目;另一則是,在印出結果頻繁項目集時,必須測試同一結果頻繁項目集內的 所有廣義項目是否有子體(後裔)包含母體(祖先)的情形,確定頻繁項目集是最精 簡的。H-Mine(Generalized)演算法如下,其中粗體字則是改變原本演算法的部分。. 30.
(40) Add generalized items to transactions. //Step1 H := {frequent 1-itemsets}; //Step2: get Header Table H H’ := re-adjust H; //Step3: delete redundant itemsets in H Construct frequent projections according to H’. //Step4 Link frequent projections and H’. //Step5 Mine(H’); Function Mine(itemset H) { For each itemset i∈ H do begin //Step6 Delete any item in itemset i that consists of a taxonomy item and its ancestor. Print out final frequent itemset i. End. Traverse_projected_db(H); //Step7 } Function Traverse_projected_db(itemset I) { For each itemset i∈ I do begin Traverse i as i-projected database Generate new Header Table Hi. Re-adjust Header Table, get H i ’. //Delete any item in Hi that which next item is the descendant of this item Link frequent projections and Hi ’. Mine(Hi ’); End. }. 第二節 多重最小支持度廣義相關演算法 H-Mine(MMS) H-Mine(MMS)演算法是根據 H-Mine 演算法結合廣義相關規則演算法與多重 最小支持度演算法的概念,提出的延伸演算法。由於我們想要找出讀者借閱館藏 與類別的關聯性,但是因為在所有分類階層設定相同的支持度,不足以展現出分 類的效果,因此,提出 H-Mine(MMS) 演算法,將分類法的分類階層作進一步設 定,針對不同階層的類別給予不同最小支持度,探勘最適宜的相關規則。. 31.
(41) H-Mine(MMS)演算法是利用 H-Mine 演算法的 H-Struct 資料結構,增加一個 儲存該項目最小支持度的欄位,再設定各標頭表格探勘時的最小支持度,改進成 為適用於多重最小支持度的廣義相關規則演算法。詳述步驟如下: 步驟一:根據項目隸屬分類加上各階層分類廣義項目,得到延伸交易。 步驟二:掃瞄整個交易資料庫,找出長度為 1 的頻繁項目候選集,即項目支 持度必須大於所有項目的最小項目支持度之最小值(minMIS)。此頻繁項目集即為 H-Struct(MMS)的標頭表格 H。H-Struct(MMS)標頭表格的項目包含四個欄位:項 目編號、項目支持度、最小項目支持度(MIS: Minimum Item Support)及連結位置。 步驟三:刪除多餘廣義項目,重新調整頻繁項目集,找出新標頭表格 Hre。 步驟四:將標頭表格 Hre 中的每一個頻繁項目之最小項目支持度值存入欄 位,並將標頭表格依照各項目的最小項目支持度遞增排列,得標頭表格 H’。 步驟五:將資料庫中每筆交易只保留經過調整的頻繁項目,即標頭表格 H’ 內的頻繁項目集,並按頻繁項目集順序排列,得到每筆交易的頻繁投影。每一個 存 在 H-Struct(MMS) 中 的 頻 繁 項 目 包 含 二 個 欄 位: 項 目 編 號 及 連 結 位 置 。 H-Struct(MMS)即是包含標頭表格及頻繁投影的資料結構。 步驟六:將標頭表格 H’,找出每個頻繁投影的第一個項目與之對應連結, 則得到完整 H-Mine(MMS)的 H-Struct(MMS)資料結構。 步驟七:由於標頭表格 H’內仍有母體(祖先)與子體(後裔)同時存在,但二者 支持度卻不相同的情形,為確保在同一個結果頻繁項目集內不會有母體(祖先)及 子體(後裔)同時出現的情形,本步驟將要輸出的結果頻繁項目集進行刪減,確定 頻繁項目集是最精簡的。最後則測試是否符合各自的最小項目支持度,輸出標頭 表格中所有符合的頻繁項目集。 步驟八:類似 H-Mine(Generalized)方法,標頭表格 H’ 的每個項目可各自組 32.
(42) 成一個投影資料庫。在每個投影資料庫中重複執行二、三、四、六及七的步驟: 找出頻繁項目集,其中各標頭表格探勘時的最小支持度為隸屬於各投影資料庫項 目的最小項目支持度(如:探勘 a 投影資料庫時,最小支持度為 a 的最小項目支 持度;探勘 bc 投影資料庫時,最小支持度為 b 的最小項目支持度),得到各自的 標頭表格 H、經由分類測試調整及重新排序成為 H’標頭表格、根據標頭表格重 新與頻繁投影連結、測試頻繁項目集找出精簡且符合各自最小項目支持度的結果 頻繁項目集、再遞迴一層層深入探勘,直到所有標頭表格的頻繁項目集完全找完。 以下舉例說明 H-Mine(MMS),為求精簡起見,本例中不將分類廣義項目加 入探勘,直接說明如何應用多重最小支持度的概念。下表前二欄是假設的交易 資料庫 TDB,項目 a, b, c, d, e, f, g, h, i, k, m的項目最小支持度分別為 3, 2, 3, 4, 4, 2, 2, 2, 2, 2, 2。 交易編號. 項目集. 100 200 300 400. c, d, e, f, g, i a, c, d, e, m a, b, d, e, g, a, c, e, h. 頻繁投影 c, d, e, g a, c, d, e a, d, e, g a, c, e. 依最小項目支持度排序之頻繁投影 g, c, d, e a, c, d, e g, a, d, e a, c, e. 表 3 - 2 - 1:多重最小支持度相關規則探勘之交易資料庫. 首先,步驟一,掃瞄資料庫找出符合最小項目支持度之最小值 2 的單一項目 頻繁項目集,得到{a:3, c:3, d:3, e:4, g:2}。步驟二:將標頭表格所有項目依各最 小項目支持度遞增排列,則得到{g:2, a:3, c:3, d:3, e:4},即是 H-Struct(MMS) 的 標頭表格 H。步驟三:經由項目最小支持度測試,由於項目 d 不符合所要求的最 小項目支持度,故單一結果頻繁項目集為{g:2, a:3, c:3, e:4}。步驟四:找出頻繁 投影並將標頭表格與之連結,如圖 3 - 2 - 1,標頭表格 H 的項目 g 即是存放 g 佇 列第一個項目的指標(指向交易投影 100 中第一個項目 g 的指標) ,g 佇列則連結 100 及 300 二筆交易的投影。. 33.
(43) 標頭表格 H. g. a. c. d. e. 項目支持度. 2. 3. 3. 3. 4. 最小項目支持度. 2. 3. 3. 4. 4. 100. g. c. d. e. 200. a. c. d. e. 300. g. a. d. e. 400. a. c. e. 頻繁投影. 圖 3 - 2 - 1:H-Struct(MMS)範例. 如圖 3 - 2 - 1,由於 d 不滿足項目最小支持度,d 投影資料庫的其他項目集 亦不可能滿足項目最小支持度,因此探勘經由標頭表格 H 的除 d 外的四個項目, 分為四個子集,可視為四個虛擬投影資料庫,在各自的子集中探勘,找出屬於個 別子集的頻繁項目集。 先從第一個子集 g 投影資料庫(屬於 g 佇列的頻繁投影)開始,首先掃瞄整 個 g 投影資料庫,建立屬於 g 投影資料庫的標頭表格 Hg。標頭表格 Hg 的欄位就 如同標頭表格 H 的四個欄位。但是,項目支持度是存放頻繁項目在 g 投影資料 庫中出現的次數,且標頭表格 Hg 的最小支持度為 g 項目最小支持度 MIS(g)。建 立 g 投影資料庫的標頭表格 Hg {d:2, e:2},輸出部分結果頻繁項目集{gd:2, ge:2}, 並建立 Hg 與頻繁投影的連結,如圖 3 - 2 - 2。對 g 投影資料庫而言,交易投影 100 及 300 的第一個項目均為 d,因為 a 與 c 在 g 投影資料庫中並非頻繁項目。 標頭表格 Hg 中項目 d 的連結位置指向 100,100 項目 d 的連結位置指向 300,成 為 gd 佇列。 34.
(44) 標頭表格 H. 標頭表格 Hg. g a. c. d. e. d e. 2 3. 3 3. 4. 2 2. 2 3. 3 4. 4. 4 4. 100. g. c. d. e. 200. a. c. d. e. 300. g. a. d. e. 400. a. c. e. 圖 3 - 2 - 2:標頭表格 Hg 及 gd 佇列. 同樣地,探勘 gd 投影資料庫中的頻繁項目時,利用 gd 佇列的連結瀏覽 gd 投影資料庫,並建立屬於 gd 投影資料庫的標頭表格 Hgd,最小支持度亦是 g 項 目最小支持度 MIS(g),如圖 3 - 2 - 3。標頭表格 Hgd 中只有項目 e 是頻繁項目, 因此只有 gde:2 是結果頻繁項目集。搜尋 gd 為首的頻繁項目集就此結束。 標頭表格 H. 標頭表格 Hg. 標頭表格 Hgd. g a. c. d. e. d e. e. 2 3. 3 3. 4. 2 2. 2. 2 3. 3 4. 4. 4 4. 4. 100. g. c. d. 200. a. c. d. e. 300. g. a. d. e. 400. a. c. e. 圖 3 - 2 - 3:標頭表格 Hgd 35. e.
(45) 結束以 gd 為首頻繁項目集的搜尋後,回到標頭表格 Hg,因為 e 為 Hg 的最 後一個項目,並不會有以 e 為首的項目集,搜尋 Hg 亦就此結束。 結束所有以 g 為首頻繁項目集的搜尋後,回到標頭表格 H,追蹤 a 頻繁項目 集的搜尋,此時 a 佇列只包含了所有第一個項目為 a 的頻繁投影,但是 g 佇列中 仍有同時包含項目 g 及 a 的頻繁投影,那些在 g 佇列中的投影亦有可能會有以 a 為首的頻繁項目。因此,必須再追蹤 g 佇列的連結,將屬於 g 佇列的每個頻繁投 影中項目 g 之後的項目,即第二個頻繁項目(第一個項目均為 g),與各自歸屬的 佇列連結起來。如圖 3 - 2 - 4,頻繁投影 gcde 插入 c 佇列,而頻繁投影 gade 插 入 a 佇列。. 標頭表格 H 項目支持度 最小項目支持度. 100. g. a. c. d. e. 2. 3. 3. 3. 4. 2. 3. 3. 4. 4. g. c. d. e. 200. a. c. d. e. 300. g. a. d. e. 400. a. c. e. 頻繁投影. 圖 3 - 2 - 4:調整探勘 g 投影資料庫後的連結位置. 依照探勘 g 投影資料庫的模式,探勘 a 投影資料庫。先找出頻繁項目中含有 項目 a,但是不含有項目 g,因為與 g 項目有關的頻繁項目集已在 g 投影資料庫 探勘完畢。建立標頭表格 Ha,並仿照上面遞迴的方式探勘出以 a 為首的頻繁項 目集。接下來,依序探勘 c 投影資料庫(不需探勘 d 投影資料庫是因為 d 並不滿 36.
數據
![圖 2 - 2 - 2:Apriori 例子[3] 圖 2 - 2 - 3:Apriori 演算法[3] 圖 2 - 2 - 3 中的 apriori_gen 函數用來產生候選項目集。由於任何頻繁項目集 的子集合也都是頻繁項目集,因此 apriori- gen 以所有頻繁 (k-1)-項目集(L k-1 )為參 數,傳回頻繁 k-項目集的候選集(C k )。apriori-gen 分為兩個步驟來產生候選項目 集 C k : L1 = {large 1-itemsets};//產生長度為 1 的頻](https://thumb-ap.123doks.com/thumbv2/9libinfo/8376031.177933/20.894.163.739.136.641/的子也都是頻繁項目集因此以所目集L為參數傳回頻項目集的的頻.webp)
![圖 2 - 3 - 9:廣義相關規則累積演算法 (Cumulate) [18]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8376031.177933/32.894.136.757.113.619/圖239廣義相關規則累積演算法Cumulate18.webp)
+2
相關文件
110年 測量金手獎第二名 109年 測量金手獎第二名 108年建築製圖優 勝第六名 測量金手獎第二名 107年建築製圖金手獎第三名 測量金手獎第一名
第一名 第二名 第三名 第五名 第七名 臺北市太平國小 .. 段劭謀
72 國服 第三名 鄭伊珊 勞動部勞動力發展署雲嘉南分署 45 機器人 第一名. 45
第一名 第二名 第三名 第五名 第一名 第二名 第三名 第五名..
(六) 法務部廉政署受理檢舉電話:0800-286-586;檢舉信箱:「10099 國史館郵局第 153
第三節 研究方法 第四節 研究範圍 第五節 電影院簡介 第二章 文獻探討 第一節 電影片映演業 第二節 服務品質 第三節 服務行銷組合 第四節 顧客滿意度 第五節 顧客忠誠度
另一位傳教師 (泌kanava Pra- 或托跡僧,見 學家書記官, ( Vachhi- Dárd晶bllÌsara的 bhásalla '舍利 桑奇銘文第 33 見桑奇銘文第 Suvijayata 習. 問修,舍利發 發現於桑奇與 號。)
這部紀錄片遭到中共中央宣傳部下令封殺,三月七日在中國各大主流影音網站
