科技部補助專題研究計畫成果報告
期末報告
複合式架構下智慧家庭系統啟動與強健服務管理機制的設計與
實現
計 畫 類 別 : 個別型計畫 計 畫 編 號 : MOST 104-2221-E-004-001-執 行 期 間 : 104年08月01日至105年08月31日 執 行 單 位 : 國立政治大學資訊科學系 計 畫 主 持 人 : 廖峻鋒 計畫參與人員: 碩士班研究生-兼任助理人員:胥沛恩 碩士班研究生-兼任助理人員:王依晴 碩士班研究生-兼任助理人員:陳映如 碩士班研究生-兼任助理人員:紀宇軒 報 告 附 件 : 出席國際學術會議心得報告中 華 民 國 105 年 09 月 30 日
中 文 摘 要 : 在典型的智慧家庭中,具備許多嵌入計算裝置的各式日常生活物品 、傢俱與家電。然而,雖然過去的研究使得智慧家庭願景在技術上 已具可行性,但可惜的是目前市場接受度仍小,主要原因是缺乏在 技術整合及落實運用智慧環境技術到日常生活中的考量。尤其是強 健性(robustness)及自動錯誤處理(failsafe)的設計。也因此近年 來智慧家庭研究趨勢已從智慧環境的「原型創作」漸漸走向實際應 用的「落實維護」。本計畫擬探討的主要方向,即為針對此一趨勢 考量「佈署、啟動」及「長時間、經年累月」的智慧家庭實地佈署 應用需求,設計一個創新的混合式錯誤偵測及回復架構,並實作上 述機制初步原型,透過實驗與實作應用情境方式,驗證其功能完備 性、效能及實務上之可行性,期望此計畫所開發的技術,能使得智 慧環境服務朝向實用化、商品化的願景更進一步。 中 文 關 鍵 詞 : 智慧家庭, 服務導向架構, 服務發現, 服務管理, 錯誤偵測, 錯誤 回復
英 文 摘 要 : We can perceive the advent of the Smart Environments attributed to rapid emerging of embedded and tiny intelligent devices and sensors. However, due to the significant complexity of deployment and maintenance efforts, the degree of market acceptance is still low. Specifically, there is little research addressing the robustness and failsafe issues for Smart Home systems. Consequently, the research paradigm in this field has been migrating from prototyping smart homes to daily maintenance issues in real-world scenarios. In this project, we aim to investigate two of the most critical real-world issues of Smart Home deployment, namely, the bootstrapping and robustness of the system. We propose a bootstrapping procedure and an enhanced hybrid failure detection and recovery architecture. These schemes will be realized based on a popular service management protocol in home network, UPnP (Universal Plug and Play). Formal validations and experiments will also be performed to verify the
effectiveness of the proposed approach.
英 文 關 鍵 詞 : Smart Environments, Ambient, Service Oriented Architecture, Service Discovery, Service Management, Failure Detection, Failure Recovery
科技部專題研究計畫成果報告
計畫名稱:複合式架構下智慧家庭系統啟動與強健服務管理機制的設計與實現
計畫編號:MOST 104-2221-E-004-001
執行期限:104 年 8 月 1 日至 105 年 8 月 31 日
主持人:廖峻鋒
1
前言
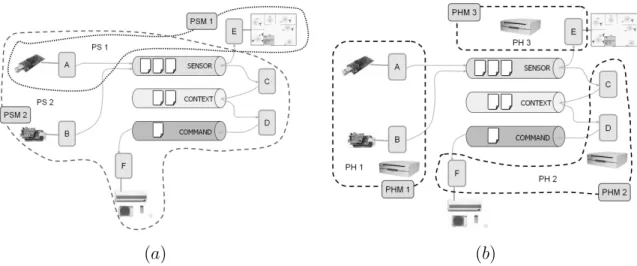
智慧家庭 (Smart Homes) 指的是將具備計算能力的裝置嵌入至各式日常生活的物品、傢 俱與家電所建構而成的生活環境。隨著近年來資訊與通訊技術的快速進展,智慧家庭的設 計與建構已成為各研究單位的研發重點。雖然此領域近年來有豐富成果產出,然到目前為 止市場接受度仍小。如同 2014 年在智慧環境領域頂尖研討會 UbiComp 中 Mennicken 等 人所指出,過去研究已經使得智慧家庭願景在技術上具可行性 (technically feasible),但 往往由於設計過於複雜或故障行為 (hazards) 太多,反而讓居住其中的使用者更加不便 利 (Mennicken et al., 2014)。值得注意的是,Hant 等人的研究團隊藉由實際佈署了超過 1,200 個感測器及自動化系統對 20 個家庭進行智慧化的經驗發現,隨著軟硬體技術發展日 益成熟,智慧家庭系統研究進行原型實作的時程相較以往已經大幅縮短,然而,花在設計 系統強健性 (robustness) 及自動錯誤處理 (failsafe) 的時間,往往佔整體開發時程的絕大部 份 (dominate the development time)(Hnat et al., 2011)。這裡的錯誤指的是系統的故障行 為 (hazards),包含網路斷線、斷電及軟硬體無預警失效等,換言之,智慧環境系統通常 不容易維護 (Eckl and MacWilliams, 2009; Cetina et al., 2009)。簡言之,近年來智慧家庭 研究趨勢已從智慧環境的「原型創作」漸漸走向實際應用的「落實維護」。因此,系統失 效的偵測與處理機制顯得格外重要。 智慧家庭之所以有「智慧」,是因為此類環境具有透過許多微型感測裝置感知環境及使 用者相關資訊,據以推測使用者意圖,進而提供適當的服務的能力,故典型的智慧家庭通 常充滿許多感測器、智慧家電等硬體元件及佈署其上的軟體元件,而這些元件藉由相互合 作提供「服務」。在此,我們將「服務 (Service)」定義為一個由分散在環境中各個位置的 基本軟硬體元件所構成的集合,而藉由這些集合中的元件的相互合作,可提供或滿足居住 者的意圖或要求 (Liao et al., 2011)。有些文獻則稱「服務」為 Application (Dey, 2000) 或 Task (Román et al., 2002)。為了讓智慧家庭從原型創作走向實際應用,需要考量到妥善使 用軟硬體資源並提升服務品質,因此,需要有「服務管理」機制來協調分散在環境中的各 式軟、硬體,並負責包含:(a) (b)
圖 1: PerSAM 的二種觀點 (a) 以 Service 為主; (b) 以 Host 為主 2. 錯誤的偵測及回復 (Failure detection and recovery)
3. 具有特定能力裝置的尋找、匹配與組合 (Service discovery and composition) 4. 使用者設置 (End user configuration/programming)
5. 服務佈署 (Deployment) 與啟動 (Bootstrapping)
等任務。然而,許多現有系統不是未具備服務管理機制,就是只實作部份服務管理功能。 如:Home OS 及 Clipoid 只著重元件佈署 (Dixon et al., 2010; Woo and Lim, 2012),不然就 是直接採用於其它領域的服務管理機制,如:Lee 等人採用 Jini(Lee et al., 2008)、Piloteur 採用檔案系統 (Feminella et al., 2014)。完全未實作或只實作部份服務管理機制的智慧環 境系統固然無法應付智慧家庭實際佈署時高度動態的特性,勉強將專為其它領域設計的服 務管理機制套用到智慧環境,也會造成水土不服的問題。
1.1
研究背景與問題
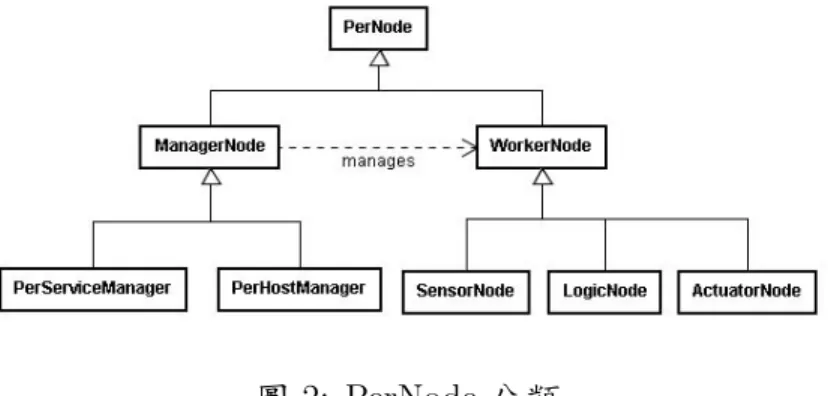
有鑑於大部份研究均未完整著墨服務管理機制,過去幾年來,敝人與研究團隊致力於 為小型智慧環境 (如智慧家庭) 設計完備的服務管理機制。尤其是我們之前所提出之 PerSAM/PSMP(Liao et al., 2011),定義了一個可支援存在性管理、自主型裝置尋找、 匹配與組合、錯誤偵測及錯誤回復之訊息導向服務模型 (Pervasive Service Application Model, PerSAM) 與其通訊協定 PSMP(Pervasive Service Management Protocol),PSMP 是基於 UPnP(Universal Plug and Play)(Jeronimo and Weast, 2003) 改良而成。採用 UPnP 最主要的理由在於其具備與特定平台無關的特色,且為專門為小型智慧環境所設計。此 外,我們也針對多人使用者設置問題提出了理論基礎與系統實作 (Liao et al., 2011),為智 慧家庭服務的落實做出了些許貢獻。為了更具體說明本計畫主要研究問題,以下將簡要說 明 PerSAM/PSMP 的基本概念。圖 2: PerNode 分類
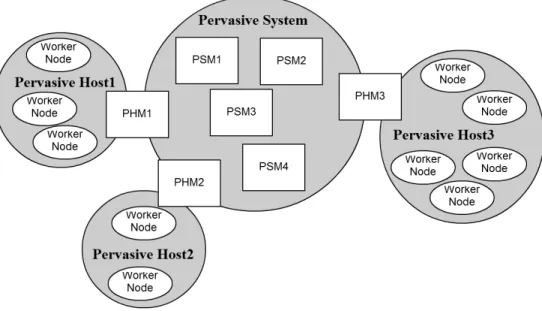
典型的智慧家庭系統由為數眾多的資訊家電、感測器與軟體服務單元所構成,在 PerSAM 中,最基本的軟體單元稱為 PerNode 或簡稱為 Node。Node 之間訊息的傳送通 常透過「虛擬」的溝通管道,稱為 Topic,以發佈、訂閱 (publish-subscribe) 機制傳送相 關訊息。如圖 1(a),與感測器相關的訊息會發佈至 SENSOR 這個 Topic,而對此一資 訊有興趣的 Node 則自行針對此一 Topic 加以訂閱; 而針對家電控制的指令則統一經由 COMMAND 來傳送。這些虛擬的溝通管道可以透過 IP Multicast 或是集中式的 Message-Oriented Middleware(MOM) 來實現。從軟體工程的角度來看,這種透過 Topic 的溝通方 式去除了 Node 和 Node 之間的相依性 (Dependency),換句話說,Node 之間是鬆散耦合 的 (loosely-coupled),因此 Node 的更換、不會影響到其它 Node 的運作,這種設計大幅 地提昇了系統的彈性。在另一方面,PerSAM 架構與 PSMP 協定主要目的即為依據居住 者的意圖,扮演協調、尋找合適的 Node,進而形成 Service。此外更需經常對各式 Service 進行維護、偵測及修復,以確保系統的強健性。為了達成上述目的,PerSAM/PSMP 中 將 Node 分為 Manager Node 與 Worker Node 兩類,Worker Node 代表實際執行服務工作 的節點,又可分為感測器 (Sensor Node)、智慧家電 (Actuator Node) 或邏輯元件 (Logic Node) 等三子類。在另一方面,Manager Node 負責服務管理機制的執行及服務維護、修 復等工作,又可分為 Pervasive Service Manager(PSM) 與 Pervasive Host Manager(PHM) 二類 (如圖 2)。
值得注意的是,在 PerSAM 中我們可以從二種觀點來看同一個系統配置。以圖 1為 例,在 (a) 中是以 Pervasive Service 的觀點來看整個系統,我們可發現此系統中配置二 個 Pervasive Services(圖中的 PS1 與 PS2),各由一個 Pervasive Service Manager (PSM) 管理 (圖中的 PSM1 與 PSM2),Worker Nodes 可以參與零到多個 Pervasive Services,例 如圖中的 A 就同時參與了 PS1 與 PS2。反之若以 Worker Nodes 所在的實體機器 (稱為 Pervasive Host, PH) 的觀點來看,這些節點在又呈現不同的分佈,佈署在同一台實體機器 上的 Worker Nodes 都受同一個 Pervasive Host Manager (PHM) 管轄。例如在 (b) 中,節 點 C, D, 與 F 是在同一個實體機器上,且同受 PHM2 管轄。
以服務導向架構角度來看,PSM 主要功能就是進行服務組合 (Service Composition), 並確保所有所需要特定功能的 Worker Nodes 都 available,並在必要時初始化節點的修復 工作。然而,以分散式系統的角度來看,PSM 永遠無法確認遠端 Worker Nodes 是「太 慢」或是已「失能」,因此,必須藉由和可能失效節點 (wf) 位於同一台 Host 的 PHM 來
及修復工作就簡化為非分散式系統問題。基於上述原則,我們已發展了一個可支援自主型 組合、錯誤偵測及錯誤回復之訊息導向服務模型與其通訊協定。其設計理由、運作細節及 流程均完整詳述於 Liao 等人 (Liao et al., 2011, 2013),在此不予贅述。
然而,要落實 PerSAM/PSMP 到真 實 環境,仍有 二個重大問題極待解決。首先, PerSAM/PSMP 並設想「佈署、啟動」的問題。例如,系統中所有元件、服務如何由無到 有一一啟動? 使用者購買所需要的服務後,會如何被安裝、分佈在機器上,並自主啟動? 啟動過程有問題時又該如何處理? 其次,在過去的研究中,為了簡化問題,我們對錯誤回 復機制亦做出了「管理節點 (含 PSM 與 PHM) 永不失效」的假設,然而此假設在「長時 間、經年累月」的真實應用場景中,幾乎不可能成立。
1.2
研究目的
本計畫主要目的即為針對上述前面提到的二個問題,基於 Manager Node 及 Worker Node 特性的不同,提出創新的混合式 (Hybrid) 錯誤偵測及回復架構。「混合式」的意思在 於混合現行常用的「Master-slave」及「Point-to-point」二種錯誤偵測及回復協定架構。 這二種架構在耗用網路頻寬、錯誤偵測延遲及強健性上各有優劣。「Master-slave」錯誤 偵測延遲短但 Master 會有單點失效問題。反之,「Point-to-point」採用 Gossip 方式偵 測 (Ranganathan et al., 2001),因此錯誤偵測延遲較長,但可避免單點失效。PerSAM/ PSMP 由於假設 Manager Nodes 不會失效,因此採用了「Master-slave」錯誤偵測及回復 架構。然如前所述,此假設在「長時間、經年累月」的真實應用場景中,此假設幾乎不可 能成立。
觀察典型智慧家庭環境,我們發現使用者對於 Worker Node 及 Manager Node 失效的 敏感度不同:Worker Node 直接對使用者提供服務,它們的失效對使用者來說,馬上會感 受到,因此應採用錯誤偵測延遲較短的「Master-slave」; 而 Manager Node 主要為維運功 能,其失效對使用者不會有立即的衝擊,又由於必須避免單點失效的限制,因此採用錯誤 偵測延遲較長但可避免單點失效的「Point-to-point」方式。當然,就工程的觀點來看,不 可能有完美、永不失效的軟體與硬體系統,但此計畫當初提出目的是在務實的前提下,用 漸近式的研究方法,設計適當的機制,將「管理節點 (含 PSM 與 PHM) 永不失效」的假設 漸次予以放寬,來完成此目的。綜合上述,本計畫提出了一個新的架構: Manager Nodes 之間採用「Point-to-point」而 Manager Node 對 Worker Node 則採用「Master-slave」。如 何設計一個結合二者特色的混合式 (Hybrid) 錯誤偵測及回復機制,讓針對 Manager Node 及 Worker Node 的不同架構協定可以無縫的運作,是本計畫成果的主要貢獻。
2
文獻探討
智慧環境由充滿了許多微小、相互通訊且具有特功定能的計算裝置及各式軟體服務, 用來整合並管理這些裝置與服務的系統稱為 Pervasive System。早期,系統大部份只是 依循軟體工程 Separation of Concerns 的原則,將底層服務與上層應用切割開來來,以 初步降低開發的難度,例如 Context Toolkits (Dey, 2000)、Gaia (Román et al., 2002) 及
Aura(Garlan et al., 2002)。當服務管理議題開始受到重視後,許多研究人員開始嘗式將 這些議題委交給底層實作平台所提供的泛用型 (General-purpose) 服務管理機制。例如 SOCAM(Gu et al., 2005) 使用 OSGi(Open Service Gateway Initiatives ) 進行服務管理, CoBra(Chen et al., 2005) 使用 JADE(Java Agent Development Framework) (Bellifemine et al., 2002) 進行服務管理。然而,此類平台只提供簡易管理機制,無法支援進階的服務 修復、服務組合等功能。 進行裝置與服務管理的首要任務就是隨時得知現在環境中有那些裝置及服務,在分散 式系統中一般稱為 View。負責記錄、更新維護最新 View 的資料儲存處稱為「目錄」。服 務目錄的實現,可分二類: 集中式與分散式。在集中式架構下,系統將所有受管節點 (軟 體服務與硬體裝置) 的狀態集中記錄到「目錄」伺服器,例如 Jini(Arnold et al.,1999)、 Context Toolkits(Dey, 2000) 與 JADE(Chen et al., 2005)。反之,分散式架構的 View 管 理並不依賴「目錄」伺服器,而是基於 IP 群播機制,將所有受管節點狀態進行群播, 再由各節點自行接並維護網內所有節點狀態,例如 UPnP(Jeronimo and Weast, 2003) 與 Bluetooth(Bluetooth, 2010)。Zhu et al. (2005) 指出,分散式服務管理協定較適合小型智 慧環境,因為在此類環境中,額外架設一目錄伺服器具有成本高及單一節點失效的問題。 就本計畫所著眼的小型智慧環境 (智慧家庭) 來說,UPnP 採用分散式管理架構是相當合 宜的設計,有關 UPnP 優劣與選定其做為智慧家庭服務管理機制的討論已詳述於 (Liao et al., 2011)。
隨著近年來新技術的提出,許多研究人員也嘗試藉由融合新的科技,來尋求智慧家庭 系統研究的突破。Xu et al. (2012b) 基於雲端技術,提出了一個雲端感測框架;Lee et al. (2008) 則應用 IMS(Instant Messaging System) 結行動技術設計了一個智慧家庭的遠端 監控機制。基於近年來興起的物聯網 (Internet of Things)、感測器技術及機器人科技, Huiyong et al. (2013) 結合了無線感測器網路及家用機器人,為智慧家庭系統提出來新的 議題: 與居家服務機器人協同整合。Xu et al. (2012a) 結合了服務導向架構 (SOA) 中的業 務流程概念,應用 BPMN(Business Process Model and Notation) 來設計並建構智慧家庭 系統。Kaldeli et al. (2013) 則基於 Web of Things 概念探討了智慧家庭中的 Web 服務組 合議題。Munir et al. (2013) 以 CPS(Cyber-Physical Systems) 概念,提出了可以自動偵測 與解讀智慧家庭服務間的衝突的系統:DepSys。
正如 Feminella et al. (2014) 及 Hnat et al. (2011) 所指出,近年來智慧家庭研究趨勢 已從智慧環境的「原型創作」漸漸走向實際應用的「落實維護」。適合智慧家庭的「佈 署」、「強健性 (robustness)」及「自動錯誤處理 (failsafe)」等技術的欠缺已成為目前此研 究領域進展的巨大挑戰。然而,即使是近年來所發表新系統,大部份現有不是未具備服務 管理機制,就是只實作部份服務管理功能。如近年來微軟的 Home OS (Dixon et al., 2010) 及韓國 KAIST 的 Clipoid(Woo and Lim, 2012) 著重元件佈署與自動整合面向,無法應 付智慧家庭實際佈署時高度動態的特性; 不然就是直接採用於其它領域的服務管理機制, 如:Lee et al. (2008) 採用 Jini、Piloteur 採用檔案系統 (Feminella et al., 2014),並未考量 智慧家庭裝置及網路環境的特殊性,造成水土不服的問題。而此一研究缺口也正是本計 畫所希望能著墨的主要方向: 智慧家庭服務的佈署與啟動及可適用於真實環境、確保系統 「強健性」服務管理機制。
本計畫以 PerSAM/PSMP 為藍本,以 UPnP 為基礎,考量「佈署、啟動」及「長時間、 經年累月」的智慧家庭實地佈署應用需求,設計一個完整的服務管理機制。較之前的研究 成果主要突破之處在於:(1)PerSAM/PSMP 並未考量「佈署、啟動」問題,且 (2)PerSAM/ PSMP 假設 Manager Node 永不失效。特別是針對第 (2) 項,過去一年來,在計畫經費的 支援下,基於對使用者對於 Worker Node 及 Manager Node 失效的敏感度不同的觀察,設 計一個創新的混合式錯誤偵測及回復架構,最後實作上述機制初步原型,透過實驗與實作 應用情境方式,驗證其功能完備性、效能及實務上之可行性,此計畫所開發的技術,能使 得智慧環境服務朝向實用化、商品化的願景更進一步。
3
系統模型與技術背景
由於本計畫所進行研究是基於 PerSAM,結合 PSMP 及 RRCP 設計與實作新的複合式機 制,因此,在深入論述改良的機制與方法前,首先在下面各節介紹相關系統模型與背景技 術。3.1
PerSAM(Pervasive Service Application Model)
本節定義問題與服務模型,以利後續服務管理機制的設計。典型的智慧生活空間由為數眾 多的資訊家電、感測器與軟體服務應用程式所構成,這些最基本的構成元素稱為 PerNode
p∈ P 或簡稱為 Node。每個 PerNode 永遠處在 3 個狀態 (state) 中的一種,其中 state ∈ {INST ALLED, DORMANT, ACT IV E}。
,我們可以用 state(p) 來取得 PerNode p 的狀態。
如 圖 2所 示,PerNode 可 分 為 Manager Node 與 Worker Node 兩 類,Worker Node
w ∈ W 代表實際執行服務工作的節點,又可分為感測器 (Sensor Node)、智慧家電
(Actuator Node) 或邏輯元件 (Logic Node) 等三子類,每個 Worker Node 會屬一個型別
τ ∈ T 。我們可用 type(w) 來取得 Worker node 的型別。另一方面,Manager Node 負
責服務管理機制的執行及服務維護、修復等工作,其又可再細分為 Pervasive Service Manager(PSM) 與 Pervasive Host Manager(PHM) 二類。
在系統中,多個 PerNodes 可形成一個 Pervasive Service ps,要定義 Pervasive Service 的成員,通常會定義 Service Template STps ∈ 2τ,用來指出所服務 ps 所需要的 Worker
Node 類型。為了要組成服務 ps,其 PSM 必須依據 STps 尋找合適類型的 Worker Node。
在服務組合過程中,很有可能還有一些類型的 Worker Node 沒找到,此時我們定義目前 還沒找到合適 Worker Node 的型別所形為的集合為 Service Vacancy V 。因此一服務 ps 的 Service Vacancy 可由 (1) 定義:
Vps ={τ|τ ∈ STps∧ ¬∃w ∈ Wps : type(w) = τ}, (1) 其中 type(w) 代表可取得 Worker Node w 型別的函式。
在一個智慧空間 P 中,PerNodes 所在的 Host 稱為 Pervasive Host ph,且
ph =⟨mph, Wph⟩。 (2) 其中 mph 是機器 ph 的 Pervasive Host Manager,且 Wph 代表了目前存在 ph 上所有
Worker Nodes 的集合。
綜合上述,在一個智慧環境中,同時存在著許多 Pervasive Services,而且各由一個 PSM 所管轄。PSM 主要責任即為在服務啟動時,透過服務發現機制 (Service Discovery), 確保 STps 中所需要的 Worker Nodes 皆能找到,在服務成功啟動並綁定的所有 Worker
Nodes 後,具必須藉由特定的 Failure Detection 程序來確保 Worker Nodes 皆存在且正常 工作。一但其中一些 Worker Nodes 不正常,將會使得 Vps ̸= ∅,此時便啟動錯誤回復程
序,透過 PHM 將發生錯誤的節點關閉並重新尋找合適的可替換節點。
在 PerSAM 中,是採用「Master-Slave」的錯誤偵測架構: Failure Detection 是由 Worker Nodes 不斷發出 heartbeat 給 PSM,然而,以分散式系統的角度來看,PSM 永遠無法確 認遠端 Worker Nodes 是「太慢」或是已「失能」,因此,在一段時間沒有收到 heartbeat 後,可藉由和可能失效節點 (wf) 位於同一台 Host 的 PHM 來進行實際偵測及錯誤修復工
作,因為 PHM 與 wf 在同一台機器,所以此時節點錯誤偵測及修復工作就簡化為非分散
式系統問題。這種做法最大的問題就是,錯誤從發生到偵測、回復,會有一段時間差,稱 為 Failure Detection Latency,而此時間差取決於 heartbeat rate 的設定。Heartbeat rate 感高,錯誤偵測的時間差愈少,但也會對網路造成重大負擔。因此,現行架構造成二個 問題:(1) 了了維持網路品質,一但節點失效,使用者勢必感受到明顯的 Failure Detection Latency (2) 如果 PSM 不執故障,則整個錯誤回復機制也就不存在。 在之前的研究中,為了簡化問題,我們對錯誤回復的機制亦做出了「管理節點 (含 PSM 與 PHM) 永不失效」的假設,然而此假設在「長時間、經年累月」的真實應用場景 中,幾乎不可能成立。本計畫設計出一個能夠在 Manager Node 可能失效的情況下,具備 低的 Failure Detection Latency 的機制。
在本計畫中,我們提出的機制為: 在 Manager Node 之間,採用 RRCP(下一節會詳加 介紹),用 Point-to-point 的方式進行錯誤偵測與回復。Gossip 方式可避免 single point of failure 問題,但一般來說 Failure Detection Latency 會較高。這樣設計的原因是因為我們 觀察到,智慧家庭的使用者對於 Manager Node 的失效是較不敏感的,因為它們不是直 接對使用者提供服務。反之,在 Worker Node 的偵錯機制我們希望能達成較低的 Failure Detection Latency,因此應該由 PSM 委交 PHM 來偵錯,主要原因是對 PHM 和佈署在 同一台 host 的 node 而言,本地的錯誤偵錯並不需要耗用網路的頻寬,如此一來,雖然 PHM 對 Worker Node 是 Master-slave,但因為我們採用混合架構,Manager Node 之間會 互相回復,因此即使擔任錯誤偵測的 PHM 不幸失效,也能透過 Gossip 方式被偵錯及回 復。而這其中主要的複雜度在於,PSM 委交給 PHM 的內容,應如何傳播,如何確保在 其中一方失效時,所委交資料仍然能回復? 此外,一但 Manager Nodes 永不失效的假設 去除之後,我們也將面臨系統啟動 (Bootstrapping) 的問題: 如何讓使用者由單一、簡單 的操作,觸發 PSM 及 PHM 及相關 Worker Nodes 的佈署? 以上這二個問題我們將後續章 節詳加討論。
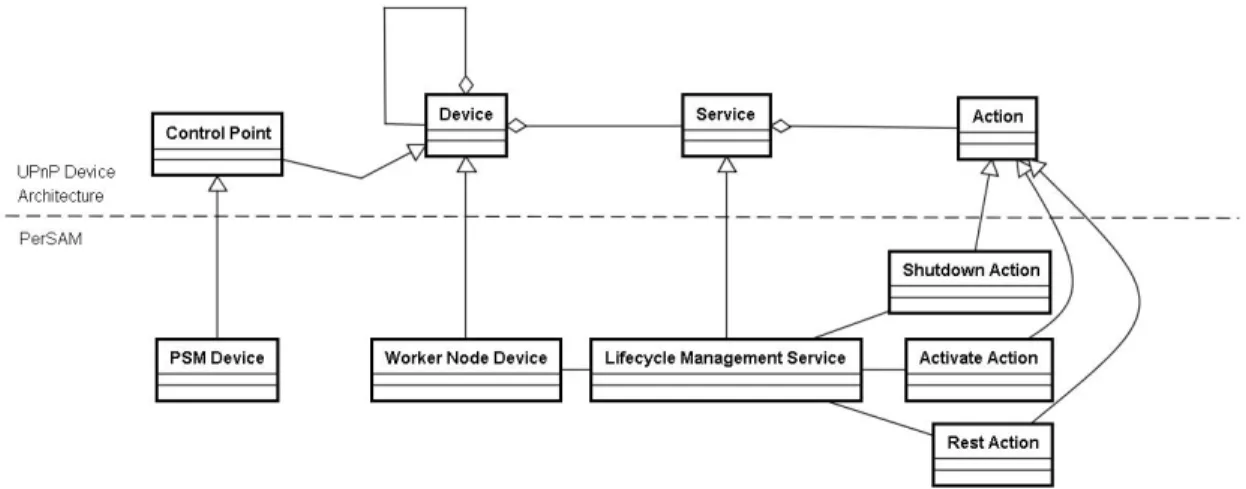
圖 3: 將 PerSAM 服務模型投射到 UPnP Device Architecture
3.2
UPnP(Universal Plug-and-Play)
由於我們在實作上以 UPnP 為設計藍本,因此在開始設計服務管理機制前,必須先對 此協定深入了解。UPnP 所有裝置的設計與實作均基於 UPnP 裝置架構 (UPnP Device Architecture) 規格,UPnP 網路服務由 Device、Service、Action 及 Control Point 所組成。 如圖 3所示,一個 Device 可能包含多組 Services,而一個 Service 會包含多組 Actions, 而 Device 本身也可以包含多個子 Devices。一個 UPnP 硬體實例通常會具有一個 Root Device,例如一個支援 UPnP 的印表機會有一個 Printer Root Device,而其下的 Service 就是它能提供的服務,也就是 Printing Service。Service 中具有一些狀態變數記錄自身 狀態,例如 Printing Service 會有狀態變數記錄列印狀態、紙張數量等。而 Service 下的 Action 的功能類似程式語言中的函式,可以透過 SOAP 協定被 Control Point 遠端呼叫, 例如 Printing Service 下會有一個稱為 print 的 Action。Control Point 是一種具有叫用 (Invoke) 及搜尋 (Search) 能力的特殊 Device,因此就物件導向的角度來說,可視為是一般 Device 的子類別。
3.3 PSMP(Pervasive Service Management Protocol)
PSMP 是以 PerSAM 為基礎,並對 UPnP 中的 SSDP(Simple Service Discovery Protocol) 做延伸的服務管理機制。SSDP 的主要功能包含尋找特定裝置以及即時得知裝置是否可 用。SSDP 的原理是透過路由器在 IP 層級所支援的群播 (Multicast) 來實現,SSDP 定義, 只要對 239.255.255.250:1900 發送訊息,就會透過群播被區域網路中的 UPnP 裝置接收到。 SSDP 是 HTTP(Hypertext Transfer Protocol) 的延伸,其在 HTTP 另行定義了 M-Search 和 Notify 封包,如圖 4a 和圖 4b 所示,若有裝置想要尋找特定類型的 M-Search;Notify 訊息包含了裝置的類型和位址等資訊,當一個裝置加入 UPnP 網路時,會發出 Notify 訊 息至群播位址,此訊息的 NTS 會被設為”ssdp:alive”,收到的裝置會比對裝置類型 (ST), 若發現有其需要的服務,則根據 Location 標頭取得描述檔,並依據需求做進一步的控制; 若有裝置離開 UPnP 網路,會發出 NTS 被設為”ssdp:bye-bye” 的 Notify 訊息,讓網路中 其他裝置知道目前無法使用離開的裝置。
(a) (b)
圖 4: (a)SSDP Notify 訊息範例; (b)SSDP M-Search 訊息範例
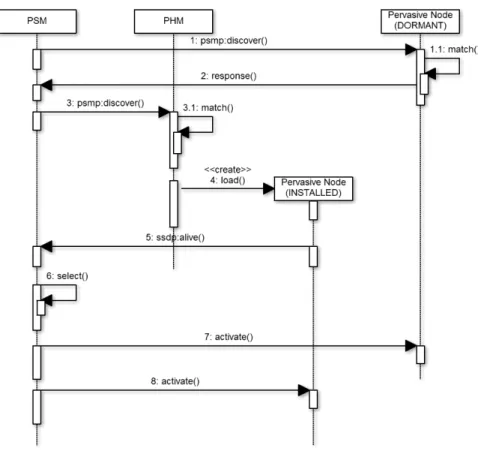
當 PSM 要啟動一個服務時,須先送出”psmp:discover” 訊息以尋找符合資格的 Node(圖 5之步驟 1),”psmp:discover” 為延伸 SSDP 定義出的方法,相較於 SSDP,定義了新的 標頭:CRITERIA,CRITERIA 標頭包含許多 key-value pair,這些 key-value pair 可以 描述額外的資訊,例如時間和地點,在 Service Discovery 的過程中,Node 需要完全符 合 CRITERIA 標頭才算符合資格,”psmp:discover” 封包內容如圖所示。當符合資格的 Node 收到此訊息後,必須發送回應訊息 (Response message) 給該 PSM(圖 5之步驟 2), 此外,PHM 收到”psmp:discover” 訊息時,會尋找位在同一機器是否有符合資格且狀態為 INSTALLED 的 Node,如果有的話,會將該 Node 載入至記憶體,使之從 INSTALLED 狀態轉變為 DORMANT 狀態 (圖 5之步驟 4),如此一來,PSM 便可將該 Node 加入服務 成員中 (圖 5之步驟 6),最後,PSM 將會啟動所有的 Node,讓服務開始運行 (圖 5之步驟 7、8)。
PSMP 的錯誤偵測與回復機制是建立在 PSM 與 PHM 永遠不會失效的假設下,如圖 6所示,在 ACTIVE 狀態下的 Node 必須每隔一小段時間就送出”psmp:heartbeat” 訊息 給 PSM(圖 6之步驟 1、2),讓 PSM 知道自己正常運作中,若 PSM 一段時間沒有收到某 個 Node 的 heartbeat 訊息,PSM 會將”psmp:suspect” 訊息送給與該 Node 同一台機器的 PHM(圖 6之步驟 3),一般來說,Node 沒有如期送出 heartbeat 訊息,可能是 Node 停止 運作或者是 Node 速度太慢,不管是哪一種情況,PHM 都會將該 Node 關閉 (圖 6之步驟 4),並代替該 Node 向群播位址發出”ssdp:bye-bye” 訊息 (圖 6之步驟 5)。PSM 收到 Node 的 Leave announcement 後,進入錯誤回復階段,在此階段,PSM 會先試著檢查是否有符 合資格且在 DORMANT 狀態的 Node,如果有,PSM 會啟動該 Node 來回復這個服務; 如果沒有,PSM 會發出”ssdp:discover” 訊息,重新開始服務組成及啟動程序。
3.4
RRCP
RRCP(Jong et al., 2009) 是點對點式的錯誤偵測與錯誤回復機制,當 RRCP 啟動時, Node 間必須透過 Leader Eleciton 選出 Leader,以進行錯誤偵測流程,Leader 會發送 Check message(CHK 訊息) 給其他 Node(圖 7之步驟 1、3、5),當 Node 收到 CHK 訊息 時,必須在一定時間內回傳確認訊息 (Acknowledgement, ACK) 給 Leader,如果 Leader
圖 5: PSMP 服務組成與啟動流程
圖 7: RRCP 錯誤偵測與回復流程
等待一段時間後沒有收到回應,則 Leader 會標記該 Node 為懷疑 (Suspect),每個 Node 皆會擁有一份懷疑清單 (Suspect list),而這份懷疑清單會在 Leader 交接時一併更新,當 Leader 完成檢查程序後,必須確認懷疑名單上是否有 Node 被標記超過 n/2 次,n 為系 統中正常運作的 Node 總數,如果有,Leader 會宣布此 Node 失效,並將此失效資訊透過 FAIL(Failure) 訊息通知系統中其他的 Node(圖 7之步驟 6、7),收到 FAIL 訊息的 Node 必須回傳 FACK(Failure Acknowledgement) 訊息給 Leader。Leader 完成檢查程序後,會 隨機選擇一個 Node 做為下一輪的 Leader,並繼續進行錯誤偵測流程。偵測到 Node 失效 的 Leader 必須負責回復該 Node 的運作,當 PSM 從失效中回復後,必須重新檢查自己原 本管理的服務;而 PHM 從失效回復後,須重新檢查在同一台機器正在運作的 Node。
4
研究方法
PSMP 完整的定義了一個智慧家庭服務管理機制,然而,PSMP 最大的問題在於 PSMP 假設 Manager Node(PSM 和 PHM) 永遠不會失效,這在真實環境中不可能發生;而 RRCP 雖透過 Gossip 機制,解決了單點失效的問題,但 RRCP 僅針對 Manager Node 的 錯誤偵測,並沒有敘述如何整合 Manager Node 和 Worker Node 之間的偵錯、回復機制, 也沒有對於 Node 的回復細節加以說明。例如,若有一個 PHM 失效,位在不同機器的 Leader 要如何將該 PHM 從錯誤中回復,又或者,在 PHM 失效的狀況下,系統是否無法 回復。最後,PSMP 及 RRCP 皆未考量到在真實環境中,MOM 也有可能會失效。本計畫 為了解決上述問題,以 PerSAM 為基礎設計出複合式 HSM(Hybrid Service Management)
圖 8: psm-config 範例
架構,在 Manager Node 的部分,使用點對點架構的錯誤偵測與回復;在 Worker Node 則 是用主從式架構,透過 Manager Node 進行管理。此外,HSM 架構亦考量到 MOM 失效 的問題。以下分成三個小節詳細說明相關機制。
4.1
HSM 啟動架構與程序
本節主要目的,是說明在服務管理系統剛啟動,以及因為嚴重錯誤導致系統必須重新啟 動時,使用者該如何操作或設定系統。在 HSM 中,每一台機器 (device) 都有一個 PHM, PHM 會在所處 device 的電源開啟後自動被載入,如果無法被載入,則此 device 無法加入 網路,視為失效 (failed)。所有的服務都會透過各自的 PSM 管理,使用者可以指定家中 一支手機做為 Bootstrapping Node,以下簡稱 BN,BN 中有個目錄是/init/,目錄底下的 psm-config.ini 會在使用者分配 PSM 時,記錄所有 PSM 所在 device 的 IP 及目錄路徑, 如圖 8。當使用者欲啟動服務管理系統時,使用者透過 BN 選擇要啟動的服務,BN 會發 送訊息要求其他 device 上的 PHM 開啟這些服務的 PSM,在這同時,BN 也會將此設定 檔的內容傳送給所有的 PHM,PHM 在開啟 device 上的 PSM 時也會將此設定檔傳送給 這些 PSM,以便後續的錯誤偵測流程進行。此外,當系統需要重新啟動時,BN 會主動發 出訊息,提醒使用者手動重啟系統。4.2
複合式架構 (HSM) 下的錯誤偵測
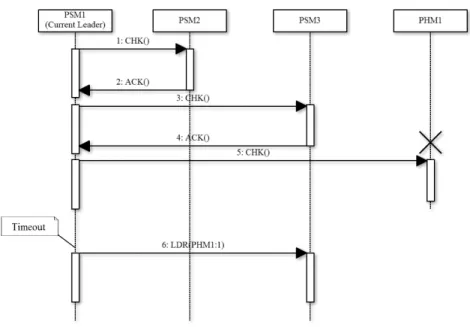
如圖 9,HSM 的錯誤偵測分兩層進行。首先,在 Pervasive System 的部分,最初,使用 Leader Election 選擇一個 PSM 當 Leader,Leader 會發送 CHK 封包給網路中的 Manager Node,封包中必須包含當 Leader 的 PSM 所管理的 Worker Node 資訊,此舉是為了在回 復 PSM 時,讓 PSM 繼續管理原本的 Worker Node。收到 CHK 封包的 Manager Node 必 須在一定時間內回傳 ACK 封包給 Leader,如果是 PHM 收到 CHK 封包中附上自己管理 的 Worker Node 存在與否資訊 (Available information),這裡指的存在與否指的是 Node 是否正常運作;如果是 PSM 收到 CHK 封包,則封包內不需要額外附上其他資訊。若 Leader 在一定時間內沒有收到該 Node 發出的 ACK 封包,則 Leader 會將此 Node 標記為 懷疑 (Suspect),並將此 Node 放入懷疑名單 (Suspect List) 中。當 Leader 對所有 Manager Node 都發送過一次 CHK 封包後,Leader 須將 Leader 的權限以及 Suspect List 透過 LDR 封包交接給下一個 PSM,新的 Leader 依照上述的流程繼續進行錯誤偵測,如圖 10。Leader 沒有收到 ACK 封包並不代表 node 失效,有時候是因為網路延遲或者 device 速度較慢,因此,為了提升可靠度,假設系統中有 n 個運作中的 PSM,當上述過程中 Leader 發現 suspect list 內有 Node 被標記次數在 n/2 以上,Leader 才會宣告此 Node 失
圖 9: HSM 錯誤偵測與回復架構圖
效,並將此 Node 移出 suspect list,而後,Leader 替此 Node 發送”ssdp:bye-bye”訊息至 群播位址,接著啟動錯誤回復機制。此外,當 Leader 與未回傳 ACK 封包的 Node 在同一 台 device 上時,由於不會因為網路延遲而沒有回應,此時,Leader 可以直接宣告該 Node 失效,而不用將它放到 suspect list 中。
在 Worker Node(Pervasive Host) 的錯誤偵測部分,Worker Node 必須定期發送 heart-beat 訊息給 PHM,當 PHM 一段時間沒有收到某個 Worker Node 的 heartheart-beat 訊息時, 代表此 Worker Node 失效,PHM 會在回復 Leader 的 ACK 封包中附上 Worker Node 失 效資訊。此舉和 Worker Node 向 PSM 發送 heartbeat 不同的地方在於,Worker Node 和 PHM 在同一台機器上,因此不會耗費網路頻寬,亦不需要太多的傳輸時間。
4.3
複合式架構 (HSM) 下的回復程序
由於 HSM 架構有三種不同的成員,此外,我們亦須考量到 MOM 之失效問題,以下將分 四部份討論不同情況下的錯誤發生與回復。
4.3.1 Worker Node 的回復
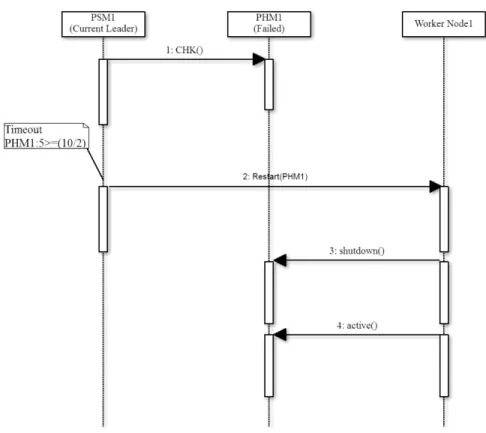
當 Leader 收到 PHM 傳來的 Available information 時,若有 unavailable worker node,則 Leader 會比較這些 Node 是否在自己管理的服務成員中,如果是,Leader 會先要求 PHM 重新啟動這些 Worker Node 以回復服務的運作,若無法重新啟動失效的 Node,則 Leader 會重新進行服務組成的程序。如圖 11,Leader(PSM1) 從 PHM1 給的資訊得知 Worker Node1 unavailable(圖 11之步驟 2),由於 PSM1 中需要 Worker Node1 才能組成完整的
圖 10: HSM 錯誤偵測機制
服務,因此 Leader 要求 PHM1 重新啟動 Worker Node1(圖 11之步驟 3),PHM1 會先將 Worker Node1 關閉後再重新啟動它 (圖 11之步驟 4、5)。
4.3.2 PHM 的回復
雖然 PHM 失效時不會影響 Worker Node 的功能,但若沒有 PHM 回傳 available infor-mation,有可能會發生 PSM 管理的服務中斷卻沒辦法回復。當 Leader 宣告 PHM 失效 時,Leader 會要求與該 PHM 位於同一台機器上的 Worker Node 重新啟動此 PHM。如圖 12,在一包含 10 個 PSM 的智慧家庭系統中,由於 PHM1 已經被標記了 9 次,目前的 Leader(PSM1) 標記第 10 次後,宣告 PHM1 失效,Leader 通知與 PHM1 位在同一台機器 上的 Worker Node1,要求 Worker Node1 重新啟動 PHM1(圖 12之步驟 3),由於 Worker Node1 與 PHM1 在同一台機器上,因此,Worker Node1 可以將 PHM1 關閉後 (圖 12之 步驟 4),重新啟動 PHM1(圖 12之步驟 5)。
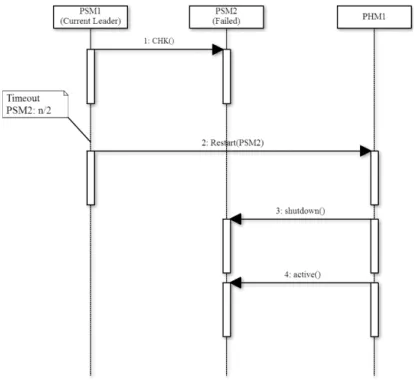
4.3.3 PSM 的回復
PSM 的失效代表無人管理該服務,一旦此服務的 Worker Node 失效而導致服務中斷,則 系統及使用者皆不會發現。當 PSM 被視為失效時,Leader 必須根據設定檔內容找到此 PSM 位在哪一台機器上,並要求此機器的 PHM 關閉失效的 PSM,接著重新啟動它,如 圖 13,Leader(PSM1) 由 suspect list 的資訊將 PSM2 視為失效,Leader 根據設定檔找到 PSM2 與 PHM1 在同一台機器上,因此要求 PHM1 回復 PSM2(圖 13之步驟 2、3、4)。 此外,若所有的 PSM 都失效,表示沒有人當 Leader,系統必須重新啟動。
圖 11: HSM 架構下 Worker Node 錯誤回復機制
圖 13: HSM 架構下 PHM 錯誤回復機制 4.3.4 MOM 的回復
當 MOM 失效時,所有有訂閱 MOM 的 Node 皆會收到例外通知,收到例外通知的 PSM 會主動通知 Leader,Leader 會要求與 MOM 在同一台機器的 PHM 重新啟動 MOM。
5
結果與討論
本章將詳述在計畫進行過程中,對我們所提出機制的分析、評估與討論,首先我們針對所 提出方法是否能處理所有可能發生錯誤情況進行分析討論,其次,我們進行了強健性與效 能關連的實驗與探討,接下來我們比較本計畫成果與傳統 PSMP 所獲得的強健性改善, 與硬體錯誤對軟體錯誤率造成的影響,最後我們也呈現了回復效過的評估與討論。5.1
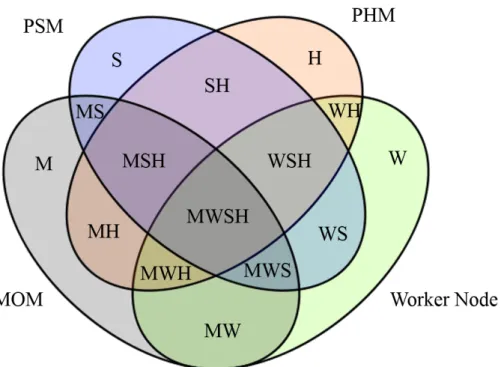
錯誤場景分析驗證
在 PerSAM 中有 PSM、PHM、MOM 與 WorkerNode 等角色。為了要驗證我們所提出 的方法是否能完整應對所有可能發生的錯誤情況,我們首先將這四個可能情況進行冪 集合的列舉,排出所有可能的情況。結果如圖 14所示,共有 15 個錯誤類型,本研究以 縮寫命名,如 M-Type、MH-Type 等等。在這 15 類中,根據失效的節點是否在同一台 機器或服務,有 9 類可以再細分數種子類別。傳統的 PSMP 主要是解決 W-Type 錯誤 的問題,本計畫在透過複合式架構改良錯誤偵測與回復流程後,可以偵測並回復前段所 述之 15 種類型錯誤,為了驗證 HSM 可以解決這些類型的錯誤,本節將透過圖 4.9 中
圖 14: PerSAM 架構下所有可能發生錯誤情況之分析 圖 15: 一個以 HSM 建構之智慧家庭服務管理系統範例 的系統進行討論與分析。如圖 15,假設在一個以 HSM 建構的智慧家庭服務管理系統 中,有三部機器 (Device1、Device2、Device3)、四個服務 (Service1、Service2、Service3、 Service4) 以及一個 MOM,Device1、Device2、Device3 分別由 PHM1、PHM2、PHM3 管 理,Service1、Service2、Service3、Service4 分別由 PSM1、PSM2、PSM3、PSM4 管理, Service1 中有三個 Worker Node:A、B、C,Service2 中有兩個 Worker Node:D、E, Service3 則是由一個 Worker Node:F 構成,Service4 中有兩個 Worker Node:G、H。A、 B、C、D、PSM1 及 MOM 位在 Device1 上,E、F、PSM2、PSM3 位在 Device2 上,G、 H、I、PSM4 位在 Device3 上。以下我們逐一分析如何基於我們所提出的架構錯誤偵測與 回復這 15 種類型。
S-Type 錯誤 : 此類錯誤代表系統中僅有 PSM 失效,Leader 在發現失效的 PSM 在 Suspect List 中被標記過多次時,便會啟動錯誤回復流程,要求與失效 PSM 位在同一台
機器的 PHM 將之回復。舉例來說,若 PSM1 失效,Leader 會在 PSM1 被加到 Suspect List 兩次後,要求 PHM1 回復 PSM1。
H-Type 錯誤 : 此類錯誤代表系統中僅有 PHM 失效,Leader 在發現失效的 PSM 在 Suspect List 中被標記過多次時,便會啟動錯誤回復流程,要求與失效 PHM 位在同一台 機器的其中一個 Worker Node 將之回復。舉例來說,若 PHM1 失效,Leader 會在 PHM1 被加入到 Suspect List 兩次後,要求 A、B、C 或 D 其中之一回復 PHM1。
W-Type 錯誤 : 此類錯誤代表系統中僅有 Worker Node 失效,Worker Node 失效時,位 在同一台機器的 PHM 會將其資訊記錄在 Available Information 中,並在回復 Leader 的 ACK 訊息中附上此 Available Information,當 Leader 發現 Available Information 中有正 在管理的 Worker Node,則會啟動錯誤回復流程,要求該 PHM 進行回復失效的 Worker Node。舉例來說,若 Worker Node A 失效,當 PSM1 擔任 Leader 並發送 CHK 給 PHM1 時,會在 PHM1 回復的 ACK 訊息中發現 A 失效,此時,PSM1 便會要求 PHM1 回復 Worker Node A。
M-Type 錯誤 : 此類錯誤代表系統中僅有 MOM 失效,MOM 失效時,所有有訂閱 MOM 的節點皆會收到例外通知,收到例外通知的節點會主動通知 Leader,Leader 收到 通知後會啟動錯誤回復流程,要求與失效 MOM 位在同一台機器的 PHM 將之回復。舉 例來說,若 MOM 失效,A I 等九個節點皆會收到例外通知並告知目前的 Leader,接著 Leader 便會要求 PHM1 重新啟動 MOM,並在 MOM 被重新啟動後,發送 MRC 訊息給 系統中所有節點,讓這些節點重新訂閱 MOM。 SH-Type 錯誤 : 此類錯誤代表系統中有 PSM 和 PHM 同時失效,根據失效的 PSM 與 PHM 是否位在同一台機器,可再細分為兩種子類別。 • 有失效的 PSM 與 PHM 位在同一台機器:Leader 在發現失效的 PSM 及 PHM 在 Suspect List 中被標記過多次時,便會啟動錯誤回復流程,然而,由於 PSM 的回復 仰賴位在同一台機器的 PHM,因此,在 PHM 回復後,便會轉變為 S-Type 錯誤之 處理策略。舉例來說,若 PSM1 和 PHM1 同時失效,在 PHM1 被 A、B、C 或 D 其中之一回復後,Leader 才會要求 PHM1 回復 PSM1。 • 失效的 PSM 與 PHM 皆不在同一台機器:Leader 在發現失效的 PSM 及 PHM 在 Suspect List 中被標記過多次時,便會啟動錯誤回復流程,由於失效的 PSM 和 PHM 皆不在同一台機器,因此,錯誤回復的順序即為 Leader 以 Gossip-like 機制點 名的先後次序,先被點到超過一定次數的節點會優先被回復,並依照先被回復的節 點類型,轉變為 S-Type 或 H-Type 處理。舉例來說,若 PSM2 及 PHM1 同時失效, 則先被 Leader 點到超過兩次的節點會先被回復。
WS-Type 錯誤 : 此類錯誤代表系統中有 Worker Node 和 PSM 同時失效,根據失效的 Worker Node 是否正在被失效的 PSM 管理,會再細分為兩種子類別。
• 有失效的 Worker Node 正在被失效的 PSM 管理: 失效的 Worker Node 會在其 PSM 擔任 Leader 時被發現,若其 PSM 也失效,則失效的 Worker Node 並不會被要求 回復,因此必須先在 Leader 發現失效的 PSM 在 Suspect List 中被標記過多次,並 啟動錯誤回復流程使 PSM 繼續運作後,轉變為 W-Type 錯誤之處理策略。舉例來 說,若 Worker Node A 及 PSM1 同時失效,會在 Leader 發現 PSM1 被加入 Suspect List 兩次後,要求 PHM1 重新啟動 PSM1,接著在 PSM1 擔任 Leader 時,才會藉 由 PHM1 的通知發現 A 失效,並要求 PHM1 回復 A。�
• 失效的 Worker Node 皆未被失效的 PSM 管理: 失效的 Worker Node 會在其 PSM 擔 任 Leader 時被發現,在 Leader 發現失效的 PSM 在 Suspect List 中被標記過多次 時,會啟動 PSM 的錯誤回復流程,一般來說,Worker Node 失效會先被偵測到,回 復 Worker Node 後,轉變為 S-Type 處理策略。當系統中 PSM 數量較少時,則有 可能在輪到管理失效 Worker Node 的 PSM 擔任 Leader 之前,就先偵測到 PSM 失 效,這時會變成 W-Type 錯誤。舉例來說,若 Worker Node E 和 PSM1 同時失效, 在 PSM2 擔任 Leader 時,假設 PSM2 先發送 CHK 給 PHM2,則 PSM2 會偵測到 E 失效;如果 PSM2 先發送 CHK 給 PSM1,在經過一段時間沒收到 ACK 後,會將 PSM1 加到 Suspect List 中,由於正在運作的 PSM 僅有三個,PSM1 僅需被加入兩 次就達到失效的標準,因此,會先啟動回復 PSM1 的程序。
MS-Type 錯誤 : 此類錯誤代表系統中有 MOM 和 PSM 同時失效,由於 MOM 的失 效代表系統中所有服務皆會無法正常運作,因此必須優先回復 MOM。MOM 失效時, 所有有訂閱 MOM 的節點皆會收到例外通知,收到例外通知的節點會主動通知 Leader, Leader 收到通知後會啟動錯誤回復流程,要求與失效 MOM 位在同一台機器的 PHM 將 之回復,並轉變為 S-Type 錯誤處理。舉例來說,若 MOM 及 PSM1 同時失效,A I 等九 個節點皆會收到例外通知並告知目前的 Leader,接著 Leader 便會要求 PHM1 重新啟動 MOM,在 MOM 被重新啟動後,當 PSM1 被加入 Suspect List 兩次,則 Leader 會要求 PHM1 將 PSM1 回復。
WH-Type 錯誤 : 此類錯誤代表系統中有 Worker Node 和 PHM 同時失效,根據失效的 Worker Node 是否正在被失效的 PHM 管理,會再細分為兩種子類別。
• 有失效的 Worker Node 正在被失效的 PHM 管理:Worker Node 的回復仰賴位在同一 台機器的 PHM,若其 PHM 亦失效,則 Worker Node 無法被回復,因此,在失效的 Worker Node 被加入至 Suspect List 達一定次數後,Leader 會要求與失效 PHM 位在 同一台機器的 Worker Node 將 PHM 回復,使 WH-Type 錯誤轉變為 W-Type 錯誤 處理。舉例來說,若 Worker Node A 及 PHM1 同時失效,當 PHM1 被加入 Suspect List 兩次後,Leader 會根據 B、C 和 D 傳送 RTW 訊息的先後順序,要求三者之一
將 PHM1 回復,接著,當 PSM1 擔任 Leader 並發送 CHK 給 PHM1,且 PHM1 回 復 ACK 時,PSM1 才會發現 A 失效,並要求 PHM1 將 A 回復。
• 失效的 Worker Node 皆不被失效的 PHM 管理: 失效的 Worker Node 會在其 PSM 擔任 Leader 時被發現,在 Leader 發現失效的 PHM 在 Suspect List 中被標記過多 次時,會啟動 PHM 的錯誤回復流程,一般來說,Worker Node 失效會先被偵測到, 回復 Worker Node 後,轉變為 H-Type 錯誤之處理策略。當系統中 PSM 數量較少 時,則有可能在輪到管理失效 Worker Node 的 PSM 擔任 Leader 之前,就先偵測到 PHM 失效,這時會變成 W-Type 錯誤。舉例來說,若 Worker Node E 及 PHM1 同 時失效,在 PSM2 擔任 Leader 時,假設 PSM2 先發送 CHK 給 PHM2,則 PSM2 會偵測到 E 失效;如果 PHM1 先被加到 Suspect List 兩次,則會先依照啟動回復 PHM1 的程序。
MH-Type 錯誤 : 此類錯誤代表系統中有 MOM 和 PHM 同時失效,根據失效的 MOM 是否與失效的 PHM 位在同一台機器,會再細分為兩種子類別。
• 失效的 MOM 與失效的 PHM 位在同一台機器: 由於 MOM 的失效代表系統中所有 服務皆會無法正常運作,策略上必須優先回復 MOM,然而,MOM 的回復仰賴位 在同一台機器的 PHM,因此,須先在 Leader 發現失效的 PSM 在 Suspect List 中 被標記過多次時,啟動 PHM 的錯誤回復流程使 PHM 恢復運作,而後變成 M-Type 錯誤處理。舉例來說,若 MOM 及 PHM1 同時失效,當 PHM1 被加到 Suspect List 兩次後,Leader 會要求 A、B、C 和 D 其中之一將 PHM1 重新啟動,接著,A I 等 九個節點通知 Leader 後,Leader 便會要求 PHM1 回復失效的 MOM。
• 失效的 MOM 與失效的 PHM 不在同一台機器: 由於失效的 MOM 與失效的 PHM 並 不在同一台機器上,因此,MOM 的回復不會被阻礙,在有訂閱 MOM 的節點通知 Leader 後,Leader 會要求與失效 MOM 在同一台機器上的 PHM 重新啟動 MOM, 使其轉變為 H-Type 錯誤處理。舉例來說,若 MOM 與 PHM2 同時失效,A I 等 九個節點會先收到例外通知,接著通知 Leader 此失效資訊,Leader 收到後便會要 求 PHM1 重新啟動 MOM,在 MOM 被恢復且 Leader 發送完 MRC 訊息後,一旦 PHM2 被加入至 Suspect List 兩次,則 Leader 會要求 E 或 F 回復 PHM2。
�
MW-Type 錯誤 : 此類錯誤代表系統中有 MOM 和 Worker Node 同時失效,由於 MOM 失效代表系統中所有服務皆會無法正常運作,因此,策略上必須先回復 MOM,當 MOM 失效,所有有訂閱 MOM 的節點會通知 Leader,Leader 收到此通知後,會要求與 MOM 位在同一台機器上的 PHM 將 MOM 回復,變成 W-Type 錯誤處理。舉例來說,若 MOM 與 Worker Node A 同時失效,B I 等八個節點會通知 Leader,Leader 要求 PHM1 重新 啟動 MOM 後,在 PSM1 擔任 Leader 並發送 CHK 訊息給 PHM1 且 PHM1 回復 ACK 時,PSM1 會發現其管理名單中的 Worker Node A 失效,從而要求 PHM1 回復 A,使 Service1 可以繼續運作。
WSH-Type 錯誤 : 此類錯誤代表系統中有 Worker Node、PSM 和 PHM 同時失效,根 據失效的節點是否在同一個服務或機器,會再細分為八種子類別。
• Worker Node 同時被 PSM 和 PHM 管理,且 PSM 與 PHM 在同一台機器上:Worker Node 的回復仰賴管理自己的 PSM 及 PHM,然而,管理該節點的 PHM 也失效,因 此,必須透過同一台機器的 Worker Node 先將其 PHM 回復,而後便能以 WS-Type 錯誤處理。舉例來說,若 Worker Node A、PSM1 及 PHM1 同時失效,由於 A 的回 復仰賴 PSM1 及 PHM1,又 PSM1 的回復仰賴 PHM1,因此,在 PHM1 被加入至 Suspect List 兩次後,Leader 會要求 B、C 或 D 其中之一將 PHM1 回復,在 PHM1 恢復運作後,一旦 PSM1 被加入至 Suspect List 兩次,則 Leader 會要求 PHM1 回復 PSM1,最後,當 PSM1 擔任 Leader 並傳送 CHK 給 PHM1 時,PSM1 會在 PHM1 回傳的 ACK 中發現 A 失效,並要求 PHM1 重新啟動 A。
• Worker Node 同 時 被 PSM 和 PHM 管 理, 且 PSM 與 PHM 不 在 同 一 台 機 器 上:Worker Node 的回復仰賴管理自己的 PSM 及 PHM,又失效的 PSM 與 PHM 並不在同一台機器上,因此,PSM 與 PHM 的回復順序取決於誰先被加入至 Sus-pect List 達到一定次數,進而轉變成 WH-Type 或 WS-Type 處理。舉例來說,若 Worker Node D、PSM2 及 PHM1 同時失效,假如 PSM2 先被加到 Suspect List 兩 次,則 PSM2 會被 PHM2 回復,接著當 PHM1 被加到 Suspect List 兩次時,PHM1 會被 A、B 或 C 回復,最後,當 PSM2 擔任 Leader 並發送 CHK 訊息給 PHM1 時, PHM1 會在 ACK 訊息中附上 D 失效的資訊,PSM2 便會要求 PHM1 將 D 回復; 反之,回復順序則會是 PHM1、PSM2 及 D。
• Worker Node 僅被 PSM 管理,且 PSM 與 PHM 在同一台機器上:Worker Node 的 回復仰賴管理自己的 PSM 及 PHM,由於管理自己的 PHM 並未失效,因此,只要 PSM 恢復運作,則失效的 Worker Node 便可被回復,然而,PSM 的回復仰賴位在 同一台機器的 PHM,因此,仍須等待該 PHM 被回復,才能轉變成 WS-Type 錯誤 處理。舉例來說,若 Worker Node D、PSM2 及 PHM2 同時失效,由於 PSM2 必 須由 PHM2 重開,因此,在 PHM2 被加入 Suspect List 兩次後,Leader 會要求 E 或 F 重新啟動 PHM2,接著在 PSM2 被加入 Suspect List 兩次後,PHM2 會回復 PSM2,最後,當 PSM2 擔任 Leader 時,會回復 Worker Node D。
• Worker Node 僅被 PSM 管理,且 PSM 與 PHM 不在同一台機器上:Worker Node 的 回復仰賴管理自己的 PSM 及 PHM,由於管理自己的 PHM 並未失效,因此,只要 PSM 恢復運作,則失效的 Worker Node 便可被回復,又失效的 PSM 與 PHM 並不 在同一台機器上,因此,PSM 與 PHM 的回復順序取決於誰先被加入至 Suspect List 達一定次數,進而轉變成 WH-Type 或 WS-Type 處理。舉例來說,Worker Node A、 PSM1 及 PHM2 同時失效,假如 PSM1 先被加到 Suspect List 兩次,則 PSM1 會被 PHM1 回復,並轉變為 WH-Type 錯誤;反之,PHM2 會在被 E 或 F 回復後,轉變 為 WS-Type 錯誤。
• Worker Node 僅被 PHM 管理,且 PSM 與 PHM 在同一台機器上:Worker Node 的 回復仰賴管理自己的 PSM 及 PHM,儘管管理自己的 PSM 並未失效,但 Worker Node 仍須等待管理自己的 PHM 正常運作才能被回復,又失效的 PSM 與 PHM 位 在同一台機器上,PSM 也需等待 PHM 恢復運作才能被回復,因此,在 PHM 被加 入至 Suspect List 達一定次數後,Leader 會要求位在同一台機器的 Worker Node 重 新啟動失效的 PHM,進而使錯誤類型轉變成 WS-Type 處理。舉例來說,若 Worker Node F、PSM2 及 PHM2 同時失效,在 PHM2 被加到 Suspect List 兩次後,Leader 會要求 E 重新啟動 PHM2,使錯誤類型轉為 WS-Type 處理。
• Worker Node 僅被 PHM 管理,且 PSM 與 PHM 不在同一台機器上:Worker Node 的 回復仰賴管理自己的 PSM 及 PHM,儘管管理自己的 PSM 並未失效,但 Worker Node 仍須等待管理自己的 PHM 正常運作才能被回復,又失效的 PSM 與 PHM 不 在同一台機器上,因此,PSM 與 PHM 的回復順序取決於誰先被加入至 Suspect List 達一定次數,進而轉變成 WH-Type 或 WS-Type 處理。舉例來說,若 Worker Node A、PSM2 及 PHM1 同時失效,假如 PSM2 先被加到 Suspect List 兩次,則 PSM2 會被 PHM2 回復,並轉變為 WH-Type 錯誤;反之,PHM1 會在被 B、C 或 D 回復後,轉變為 WS-Type 錯誤。
• Worker Node 不被 PSM 及 PHM 管理,且 PSM 與 PHM 在同一台機器上:Worker Node 的回復仰賴管理自己的 PSM 及 PHM,由於失效的 PSM 與 PHM 與 Worker Node 無關,又 PSM 與 PHM 在同一台機器上,PSM 必須等待 PHM 回復後才可 以被回復,因此,回復順序將取決於管理失效 Worker Node 的 PSM 先擔任 Leader 並點到管理失效 Worker Node 的 PHM,或者失效的 PHM 先被加入至 Suspect List 達一定次數,進而轉變為 SH-Type 或 WS-Type 錯誤處理。舉例來說,若 Worker Node A、PSM2 及 PHM2 同時失效,假如在 PHM2 被加入到 Suspect List 兩次之 前,PSM1 就先擔任 Leader 並點到 PHM1,則 PSM1 會先將 A 回復,並轉變為 SH-Type 錯誤;反之,假如在 PSM1 還沒擔任 Leader 並點到 PHM1 時,PHM2 就 被加入到 Suspect List 兩次,則 PHM2 回復後,便會轉變為 WS-Type 錯誤,再卷 WS-Type 錯誤來處理。
• Worker Node 不被 PSM 及 PHM 管理,且 PSM 與 PHM 不在同一台機器上:Worker Node 的回復仰賴管理自己的 PSM 及 PHM,由於失效的 PSM 與 PHM 與 Worker Node 無關,且 PSM 與 PHM 並不在同一台機器上,因此,這三種節點之回復順序 將取決於管理失效 Worker Node 之 PSM 擔任 Leader 且點到管理失效 Worker Node 之 PHM、失效 PSM 被加入至 Suspect List 達一定次數以及失效 PHM 被加入至 Suspect List 達一定次數之次序,進而轉變為 SH-Type、WH-Type 以及 WS-Type 錯誤。舉例來說,若 Worker Node A、PSM2 及 PHM3 同時失效,假如 PSM1 擔 任 Leader,且在 PSM2 及 PHM3 被加入 Suspect List 兩次之前就點到 PHM1,錯 誤類型為轉變為 SH-Type;假如 PSM2 先被加入至 Suspect List 兩次,會轉變為 WH-Type;假如 PHM3 先被加入至 Suspect List 兩次,則會轉變為 WS-Type 錯誤。
�
MSH-Type 錯誤 : 此類錯誤代表系統中有 MOM、PSM 和 PHM 同時失效,根據失效 的 MOM 是否與失效的 PHM 在同一台機器,會再細分為兩種子類別。
• MOM 與 PHM 在同一台機器: 由於 MOM 的失效代表系統中所有服務皆會無法正 常運作,策略上必須優先回復 MOM,然而,MOM 的回復仰賴位在同一台機器的 PHM,因此,須先在 Leader 發現失效的 PHM 在 Suspect List 中被標記過多次時, 啟動 PHM 的錯誤回復流程使 PHM 恢復運作,而後變成 MS-Type 錯誤處理。舉例 來說,若 MOM、PHM1 與任一 PSM 失效,Leader 會先在 PHM1 被加入至 Suspect List 兩次後,要求 A、B、C 或 D 將 PHM1 重新啟動,接著便可以以 MS-Type 錯 誤進行處理。
• MOM 與 PHM 不在同一台機器: 由於 MOM 的失效代表系統中所有服務皆會無法正 常運作,策略上必須優先回復 MOM,又與 MOM 位在同一台機器的 PHM 並沒有 失效,因此,MOM 可以先被回復,進而將錯誤類型轉變為 SH-Type 處理。舉例來 說,若 MOM、PHM2 與任一 PSM 失效,Leader 會先接收到 A I 等九個節點所發 出的 MOM 失效通知,接著 Leader 便會要求 PHM1 重新啟動 MOM,使錯誤類型 轉變為 SH-Type。
�
MWS-Type 錯誤 : 此類錯誤代表系統中有 MOM、Worker Node 和 PSM 同時失效,在 此,我們並不依照失效的 Worker Node 是否與失效的 PSM 在同一個服務將之細分為兩種 子類別,原因是不論是哪種狀況,MOM 皆會優先被回復,因此,在 MOM 被回復後,即 轉變為 WS-Type 錯誤。舉例來說,若 MOM、任一 Worker Node 及任一 PSM 同時失效, Leader 接收到除了失效 Worker Node 以外八個節點的 MOM 失效通知後,會要求 PHM1 重新啟動 MOM,進而轉變成 WS-Type 錯誤處理。
MWH-Type 錯誤 : 此類錯誤代表系統中有 MOM、Worker Node 和 PHM 同時失效, 根據失效的 MOM 是否與失效的 PHM 在同一台機器,會再細分為兩種子類別。
• MOM 與 PHM 在同一台機器: 由於 MOM 的失效代表系統中所有服務皆會無法正 常運作,策略上必須優先回復 MOM,然而,MOM 的回復仰賴位在同一台機器的 PHM,因此,須先在 Leader 發現失效的 PHM 在 Suspect List 中被標記過多次時, 啟動 PHM 的錯誤回復流程使 PHM 恢復運作,而後變成 MW-Type 錯誤處理。舉 例來說,若 MOM、任一 Worker Node 與 PHM1 失效,Leader 會先在 PHM1 被加 入至 Suspect List 兩次後,要求未失效的 A、B、C 或 D 將 PHM1 重新啟動,轉變 為 MW-Type 錯誤進行處理。
• MOM 與 PHM 不在同一台機器: 由於 MOM 的失效代表系統中所有服務皆會無法正 常運作,策略上必須優先回復 MOM,又與 MOM 位在同一台機器的 PHM 並沒有
失效,因此,MOM 可以先被回復,進而將錯誤類型轉變為 WH-Type 處理。舉例來 說,若 MOM、任一 Worker Node 與 PHM2 失效,Leader 接收到除了失效 Worker Node 以外八個節點的 MOM 失效通知後,會要求 PHM1 重新啟動 MOM,進而轉 變成 WH-Type 錯誤處理。
MWSH-Type 錯誤 : 此類錯誤代表系統中有 MOM、Worker Node、PSM 和 PHM 同 時失效,根據失效的 MOM 是否與失效的 PHM 在同一台機器,會再細分為兩種子類別。 • MOM 與 PHM 在同一台機器: 由於 MOM 的失效代表系統中所有服務皆會無法正 常運作,策略上必須優先回復 MOM,然而,MOM 的回復仰賴位在同一台機器的 PHM,因此,須先在 Leader 發現失效的 PHM 在 Suspect List 中被標記過多次時, 啟動 PHM 的錯誤回復流程使 PHM 恢復運作,而後變成 MWS-Type 錯誤處理。舉 例來說,若 MOM、任一 Worker Node、任一 PSM 與 PHM1 失效,Leader 會先在 PHM1 被加入至 Suspect List 兩次後,要求未失效的 A、B、C 或 D 將 PHM1 重新 啟動,接著便可以以 MWS-Type 錯誤進行處理。
• MOM 與 PHM 不在同一台機器: 由於 MOM 的失效代表系統中所有服務皆會無法正 常運作,策略上必須優先回復 MOM,又與 MOM 位在同一台機器的 PHM 並沒有 失效,因此,MOM 可以先被回復,進而將錯誤類型轉變為 WSH-Type 處理。舉例 來說,若 MOM、任一 Worker Node、任一 PSM 與 PHM2 失效,Leader 接收到除 了失效 Worker Node 以外八個節點的 MOM 失效通知後,會要求 PHM1 重新啟動 MOM,進而轉變成 WSH-Type 錯誤處理。
由上述各種狀況可以觀察到,為了能讓服務盡快繼續運作,總體來說,最優先要被 回復的是 MOM,第二的是 Worker Node,接著才是 PHM 與 PSM,然而,當失效的 MOM、Worker Node 與失效的 PHM 位在同一台機器時,則必須先回復 PHM,才能讓 PHM 重新啟動失效的 MOM 與 Worker Node;而當正在管理失效 Worker Node 的 PSM 失效時,則要先回復 PSM,才有辦法回復失效的 Worker Node。依照上述策略再觀察圖 14,可以發現,錯誤類型的簡化是由下往上,由左往右,原因是 MOM 與 Worker Node 直接影響服務的運作,回復優先度會是 MOM、Worker Node 較 PSM、PHM 前面,導致 簡化是由下往上;而 MOM 之優先度又大於 Worker Node,因此 MOM 的回復順序又比 Worker Node 前面,導致簡化是由左往右。本節的討論證明了 HSM 確實涵蓋了所有錯誤 狀況,並盡可能以讓服務恢復運作為目標進行回復。
5.2
強健性與效能關連探討
為了使 Manager Node 可以被回復,提高系統強健性,HSM 以非集中式架構進行 Manager Node 的錯誤偵測流程,理論上,HSM 在錯誤偵測與回復的效能表現上會比集中式架構 的 PSMP 還差,為了驗證上述推論,此實驗在以 PSMP 及 HSM 實作的服務管理系統 中,分別佈署了 1 個 MOM、3 個 PHM、10 個服務 (PSM) 以及 50 個 Worker Node,並 以 0% 100% 的軟體錯誤率,在特定時間同時隨機使所有 Worker Node 失效,兩個系統
圖 16: PSMP 與 HSM 在不同軟體錯誤率下,錯誤回復所需時間之比較
皆以 10% 軟體錯誤率為分界,每個軟體錯誤率進行 100 次實驗,此處的軟體錯誤率代表 Worker Node 失效的機率,也就是說,本實驗並不考慮硬體、Manager Node 以及 MOM 錯誤。在隨機使所有 Worker Node 失效後,將會等待一段時間,讓系統透過 HSM 回復失 效的 Worker Node,當系統無法再回復任何失效 Worker Node 時,將服務中斷到服務被 回復所經過的時間記錄下來,取平均後繪製折線圖。
實驗結果如圖 16,X 軸為軟體錯誤率 (%),Y 軸為錯誤回復時間 (毫秒),藍色虛線為 PSMP,綠色實線為 HSM。可以觀察到,在任何的軟體錯誤率下,PSMP 所需的錯誤回 復時間皆較 HSM 還短,原因是在 PSMP 的錯誤偵測機制下,一旦有 Worker Node 失效, 管理該 Worker Node 的 PSM 會因為沒有收到 heartbeat 而較快發現,並啟動錯誤回復機 制;而 HSM 則是要在管理該 Worker Node 的 PSM 當上 Leader,並在該 Worker Node 的 PHM 回復 ACK 訊息時,才會發現 Worker Node 失效。這證明了本節一開始所述,HSM 犧牲了些許效能,以此提高了系統強健性。
5.3
HSM 與 PSMP 之強健性比較
由於 HSM 延伸自 PSMP,為了驗證 HSM 在強健性的改良,本實驗在以 PSMP 及 HSM 實作的服務管理系統中,分別佈署了 1 個 MOM、3 個 PHM、10 個服務 (PSM) 以及 50 個 Worker Node,並以 0% 100% 的錯誤率,在特定時間同時隨機使所有 Node 失效,兩 個系統皆以 10% 錯誤率為分界,每個錯誤率進行 100 次實驗,此處的錯誤率是指 Node 失效 (fail) 的機率。其中,由於通常在系統剛開始啟動以及將要關閉系統時,硬體發生錯 誤的機率會比系統穩定運作時高,因此,本實驗將分別針對上述狀況做討論,本實驗假 設系統剛開始啟動以及將要關閉系統時,若一個 Node 失效,會有 40% 的機率發生硬體 錯誤;而系統穩定運作時,有 10% 的機率在 Node 失效時發生硬體錯誤。此處的硬體錯 誤是指 Node 無法透過 PSMP 和 HSM 等軟體回復方法被修復。在隨機使所有 Node 失效 後,將會等待一段時間,讓系統透過 PSMP 或 HSM 回復系統中失效的 Node,當系統無
圖 17: 系統穩定運作下,PSMP 與 HSM 在不同錯誤率的錯誤回復能力比較 法再回復任何失效 Node 時,記錄系統中正常運作的服務數量,取 100 次實驗結果之平均 後繪製折線圖。 實驗結果如圖 17和圖 18,藍色虛線為 PSMP,綠色實線為 HSM,X 軸為錯誤率 (%), Y 軸為正常運作的服務數量。首先,圖 17為在 10% 硬體錯誤率,也就是系統穩定運作 下的實驗結果,可以發現就算在 90% 的錯誤率下,HSM 仍有約 70% 的服務正常運作, PSMP 則是從接近 30% 的錯誤率開始,系統中正常運作的服務比例就低於一半,原因是 PSMP 並沒有針對 Manager Node 的錯誤做處理,一旦 Manager Node 發生錯誤,若再有 Worker Node 失效,則失效的 Worker Node 便無法回復運作,服務也會隨之中斷。此外, 一旦 MOM 失效,PSMP 亦無法將之回復;而在 HSM 架構下,只有在系統中所有 PSM 皆失效以及一台機器中所有 PHM 及 Worker Node 皆失效時,會有服務無法被回復,因 此,錯誤回復的能力較佳。圖 18則是在 40% 硬體錯誤率,也就是系統非穩定運作時的實 驗結果,與圖 17相比,可以看出 PSMP 和 HSM 成功回復服務的比例皆下降,值得注意 的是,HSM 的下降幅度較 PSMP 明顯許多,原因是在 40% 硬體錯誤率的條件下,MOM 發生硬體錯誤而無法被回復的機率變高了,在 PerSAM 架構下,一旦 MOM 失效,系統 中所有服務皆會無法運作,因此,HSM 的錯誤回復能力受到大幅影響;而 PSMP 並未處 理 MOM 失效問題,不論 MOM 是軟體或硬體失效,系統中所有服務皆會無法運作,因 此對於 PSMP 來說影響相對較小。 此實驗的目的是比較 PSMP 和 HSM 在真實環境中的錯誤回復能力,在真實環境中, Manager Node 和 MOM 皆有可能會失效,因此,PSMP 在此條件下,如圖 17和圖 18, 錯誤回復能力並不是太理想;而 HSM 在系統穩定運作的狀況下,就算錯誤率高達 90%, 依然可以有接近 70% 的服務可以正常運作。此外,由於真實環境較不會像實驗一樣,所 有 Node 在同一時間點一起失效,因此,HSM 實際可以回復的服務比例會更高。
圖 18: 系統剛啟動及將關閉時,PSMP 與 HSM 在不同錯誤率之錯誤回復能力比較
5.4
硬體錯誤對軟體錯誤的影響評估
在 HSM 中,節點的錯誤回復仰賴 PHM 才得以進行,而當 PHM 發生錯誤時,則需要透 過位在同一台機器的 Worker Node 修復,因此,若一台機器中的 PHM 以及所有 Worker Node 皆失效時,該機器中的節點便無法再被回復,我們將此種狀況定義為系統錯誤 (System Failure)。本實驗之目的即為分析在以 HSM 實作的服務管理系統中,發生系統錯 誤的機率,此外,為了了解備用 Worker Node 數量對於系統錯誤機率之影響,本實驗亦 針對 0 2 個備用 Worker Node 進行量測。實驗佈署了 1 個 MOM、3 個 PHM、10 個服務 (PSM) 以及 50 150 個 Worker Node,以 0% 100% 的軟體錯誤率,在特定時間同時隨機使 所有 Node 失效,並以 10% 軟體錯誤率為分界,對每個軟體錯誤率進行 100 次實驗,此 處的軟體錯誤率為 Node 發生軟體錯誤的機率,換句話說,本實驗中,並不考慮 Node 的 硬體錯誤。在隨機使所有 Node 失效後,將會等待一段時間,讓系統透過 HSM 回復失效 的 Node,當系統無法再回復任何失效 Node 時,將系統錯誤的次數記錄下來,取 100 次 實驗結果後計算系統錯誤率並繪製折線圖。 實驗結果如圖 19,X 軸為軟體錯誤率 (%),Y 軸為系統錯誤率 (%),藍色點狀虛線、 綠色線狀虛線以及黃色實線分別為 0、1 和 2 個備用 Worker Node 的結果。從圖中可觀察 到,隨著軟體錯誤率的上升,發生系統錯誤的機率也同時增加,原因是當系統中發生錯誤 的節點越多,越容易出現一台機器中的 PHM 與所有 Worker Node 皆失效的狀況;此外, 當備用 Worker Node 數提升,發生系統錯誤的機率也會隨之下降,原因是在機器中有備 用節點的狀況下,較不容易使所有節點都失效。此實驗目的為分析 HSM 的強健性,從結 果可以看到,在沒有備用 Worker Node 的狀況下,軟體錯誤率從 70% 開始才發生有服務 無法被回復的狀況,在軟體錯誤率 90% 時,系統錯誤率約為 40%;而當系統中有兩個備 用 Worker Node 時,儘管軟體錯誤率高達 90%,系統錯誤率仍只有 1.5% 左右;在軟體錯 誤率 80% 時,不論備用 Worker Node 的個數是多少,系統錯誤率僅約 5%。此外,與 5.2 節的實驗相同,真實環境較不會像實驗一樣,所有 Node 在同一時間點一起失效,因此,
圖 19: HSM 在不同備用 Worker Node 數量下,軟體錯誤率與系統錯誤率之關係 實際發生系統錯誤的機率會更低。證明以 HSM 實作的服務管理系統,在絕大多數的情況 下都可以將失效的服務回復。
5.5
回復效果評估
為了測量 HSM 在錯誤偵測與回復的效能,也為了了解系統中不同服務個數對於回復效能 的影響,此實驗在以 HSM 實作的服務管理系統中,佈署了 1 個 MOM、3 個 PHM 以及 50 個 Worker Node,此外,為了觀察軟體錯誤率對回復效能的影響,實驗以 10%、40% 及 80% 的軟體錯誤率,在特定時間同時隨機使所有 Node 失效,並對系統中 1 10 的服務 數量分別進行 100 次實驗,與 5.2 的實驗相同,本實驗亦不考慮 Node 的硬體錯誤。在隨 機使所有 Node 失效後,將會等待一段時間,讓系統透過 HSM 回復失效的 Node,當系 統無法再回復任何失效 Node 時,將服務中斷到服務被回復所經過的時間記錄下來,取平 均後繪製折線圖。 實驗結果如圖 5.5,X 軸為服務數量,Y 軸為平均錯誤回復時間 (毫秒),藍色點狀虛 線、綠色線狀虛線及黃色實線分別為 10%、40% 及 80% 軟體錯誤率 (%)。從圖中可觀察 到,隨著軟體錯誤率上升,所需的錯誤回復時間也隨之提高,這是因為當一個服務內發 生錯誤的 Node 越多,該服務要回復的時間也會越長,因此,整體平均的回復時間也隨 之上升。而當系統中服務個數越多,服務平均所需的回復時間也較長,原因是 HSM 在 Manager Node 的錯誤偵測是採用非集中式架構,需要等待 PSM 輪流擔任 Leader,當系 統中的 PSM 數量越多,則每個 PSM 成為 Leader 的所需時間也越長,因此,錯誤偵測與 回復耗時會越久。從實驗結果可以發現,在系統中有 10 個服務的狀況下,在軟體錯誤率 40% 時,平均所需的錯誤回復時間約 2.25 秒,當軟體錯誤率達到 80% 時,亦能在 3 秒內 完成錯誤回復。圖 20: HSM 在不同軟體錯誤率下,服務個數與錯誤回復時間之關係