行政院國家科學委員會專題研究計畫 成果報告
具個人化學習引導之智慧型教學代理人系統發展與研究
II(2/2)
研究成果報告(完整版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 95-2520-S-004-001-
執 行 期 間 : 95 年 08 月 01 日至 96 年 07 月 31 日
執 行 單 位 : 國立政治大學圖書資訊與檔案學研究所
計 畫 主 持 人 : 陳志銘
計畫參與人員: 碩士班研究生-兼任助理:邱偉嘉、陳佳琪、薛哲宇、彭祈叡
報 告 附 件 : 出席國際會議研究心得報告及發表論文
處 理 方 式 : 本計畫涉及專利或其他智慧財產權,1 年後可公開查詢
中 華 民 國 96 年 10 月 07 日
行政院國家科學委員會專題研究計劃成果報告
具個人化學習引導之智慧型教學代理人系統發展與研究 II (2/2)
Research on an Intelligent Tutoring Agent System with Personalized Learning Guidance
Mechanism II (2/2)
計劃編號:NSC95-2520-S-004-001 計劃執行期間:95 年 8 月 1 日至 96 年 7 月 31 日 計劃主持人:陳志銘 計劃執行單位:國立政治大學圖書資訊與檔案學研究所中文摘要
隨著電腦技術及網際網路的蓬勃發展,數位學習已 成為當今教與學的另一種趨勢。以網路為基礎的課程順 序應該因人而異,能動態安排課程順序以滿足個人化之 需求是一重要的技術。因此,近年來有許多研究者著手 於發展適性化學習系統,期許能提供個人化的學習路 徑;然而大部份的系統僅考慮學習者的興趣、喜好及瀏 覽行為,而忽略學習課程的難易度及先後備知識關係, 不適當的課程常造成學習者的負擔及學習上之迷失,且 降低學習成效。隨著人工智慧技術的快速發展,本體知 識論能夠應用來表達課程概念間的學習概念關聯,因此 可以用來協助個人化學習路徑的建構。因此本研究在同 時考量教材的難易度、先後備知識關係及學習者能力的 前提下,提出一個以本體知識概念圖(ontology-based concept map)為基礎之個人化學習路徑產生方法。透過 自動產生建構 ontology 的技術,我們能夠以圖型化的 方式呈現某一特定領域的重要知識及核心概念關係,據 此所產生的學習路徑,可以有效降低學習迷思的問題及 認知負載的發生,且可促進學習成效。本研究以國小分 數單元作為實驗教材內容,透過資料探勘的方式,將國 小分數單元彼此間的關聯利用 ontology 學習概念圖方 式來描繪,並配合基因演算法運用在個人化的學習路徑 的規劃上,以期引導個人進行符合個人需求之有效率學 習。 關鍵字:本體知識為基礎之概念圖、個人化學習路徑、 智慧型教學系統、網路學習Abstract
Developing personalized Web-based learning systems has been an important research issue in the e-learning field because no fixed learning pathway will be appropriate for all learners. However, the current most web-based learning platforms with personalized
curriculum sequencing tend to emphasize the learners’ preferences and interests for the personalized learning services, but they fail to consider difficulty levels of course materials, learning order of prior and posterior knowledge, and learners’ abilities while constructing a personalized learning path. As a result, these ignored factors easily lead to generating poor quality learning paths. Generally, learners could generate cognitive overload or fall into cognitive disorientation due to inappropriate curriculum sequencing during learning processes, thus reducing learning effect. With advancement of the artificial intelligence technologies, ontology technologies enable a linguistic infrastructure to represent concept relationships between courseware. Ontology can be served as a structured knowledge representation scheme, which can assist the construction of personalized learning path. Therefore, this study proposes a novel genetic-based curriculum sequencing scheme based on a generated ontology-based concept map, which can be automatically constructed by a large amount of learners’ pre-test results, to plan appropriate learning paths for individual learners. The experimental results indicated that the proposed approach is indeed capable of creating learning paths with high quality for individual learners to greatly reduce their cognitive overloads and to help learners learn more effectively.
Keywords: Ontology-based concept map, Personalized
learning path, Intelligent tutoring system, Web-based learning
1 Introduction
With the rapid growth of the Internet, various personalized e-learning platforms were proposed to provide adaptive curriculum sequencing services for individual learners in web-based learning environments. Although information technologies enable learners to easily access a large number of learning materials without
geographical boundaries, this phenomenon has caused several serious problems, including learner’s self-learning control, learning disorientation, and cognitive overload (Alomyan, 2004; Eppler and Mengis, 2004). In general, learner’s self-learning control implies that learners should take the initiative in their learning. However, learners would easily deviate or learn inefficiently when they are receiving unsuitable instruction and scaffold. This phenomenon will result in the great difference with the original teaching goal that the instructors expect (Rasmussen and Davidson-Shivers, 1998). Moreover, the disorientation problems derive from that most of the web-based learning systems flood with complex courseware structure due to over lots of hyperlink-based learning materials, and therefore learners easily trap into learning disorientation and are unable to construct complete and systematic domain knowledge during learning processes (Lin and Davidson-Shivers, 1996; Calvi, 1997). Regarding cognitive overload, it is also a serious problem that affects learners’ learning in hypermedia learning systems. This problem emerges from the freedom of navigation that hypermedia systems offer; moreover, it may also be compounded by the vast quantities of easily accessible information, much of which may only be peripherally relevant (Paolucci, 1998). Under the circumstances of overemphasizing the learner’s independence, the appearance of information anxiety arises easily when the learner faces cognitive overload. Furthermore, learners have to spend most efforts on deciding what to learn and where to go, which leads to cognitive overload as well.
To deal with these problems, a few researchers brought up an idea to use the learning path as a control way to guide the learning direction for individual learners (Chen et al, 2005; Chen et al, 2006; Lee, 2001). As a web-based learning system with personalized learning guidance is used to aid individual learning, it can increase much learning efficiency and help instructors succeed in achieving their educational goals. In recent years, the property of being adaptive to offer learners appropriate learning resources has been gradually regarded as an important issue in web-based learning field (Federico, 1999). More and more researches attempt to create intelligent learning systems that can arrange the curriculum sequence more flexibly in order to provide learners with more adaptive and personalized learning services (Lee, 2001; Tang and Mccalla, 2003; Papanikolaou and Grigoriadou, 2002; Chen et al, 2005; Chen et al). Among these developed intelligent learning systems with curriculum sequence mechanism, both the e-learning systems ELM-ART and CALAT indicated by Brusilovsky (1998) emphasize the function of curriculum sequencing to support the personalized learning task and provide adaptive guidance for learners. In ELM-ART system, the courseware has been organized in sequence in
advance. When learners click in the courseware beyond their ability, the system will warn learners and display the related prior course for them. However, the learning guidance is just provided while learners select the unsuitable courseware, and such a mechanism cannot help each leaner perform personalized guiding learning at any time. In CALAT system, the courseware is displayed by a tree structure and arranged previously in order according to the learning aims. When learners start to learn, the system will consider their understanding levels and the learning aims for showing the learning sequence of courseware webpage. However, these learning guidance mechanisms mentioned-above are not so adaptive to individual learners because all course materials are pre-planned by the system instead of being decided dynamically based on individual learners’ progresses and response during learning processes (Alex and Jims, 2000).
Additionally, the genetic-based personalized e-learning system, which can provide a near optimal learning path for individual learners on-line according to the difficulty levels of course materials, concept relation degree between courseware and learners’ abilities, was presented by our previous study (Chen, 2007) for personalized web-based learning. However, the concept relation degrees among courseware are served as being symmetric in the study. That is, the curriculum sequence pattern “ A → B " is identical with the curriculum sequence pattern “B→A". This outcome is inconsistent with the realistic learning situation (Hsu et al., 1998). Generally speaking, prior knowledge that refers to a range of knowledge, skills, and ability should be significantly considered in the learning process. The past researches also indicated that learners with higher level of certain domain knowledge are more competent in terms of understanding, memory, and the effect of cognitive learning (McCormick and Pressley, 1995). In this issue, quite a few researchers have discovered that the related prior knowledge affects the learning performance (Papanikolaou and Grigoriadou, 2002).
Recently, ontology technologies (Gruber, 1993; Song et. al, 2007; Brewster and O’Hara, 2007) have been broadly discussed in the fields of computer science and artificial intelligence. Ontology can be employed to support a great variety of tasks in various research areas such as knowledge representation, natural language processing, information retrieval, database design, knowledge management, digital libraries, geographic information systems, multi agent systems, and e-learning, and so on (Yang et al., 2005; Yang et. al, 2004; Brewster and O’Hara, 2007). Ontology is a hierarchically structured set of terms for describing a domain knowledge that can be used as a skeletal foundation for a knowledge base system. If an ontology is implemented for a specific field well and used to describe the related knowledge such as terminology or associated notions, it can help us find out
useful or connected information when we explore under this kind of structured knowledge (Swartout, Knight and Russ, 1996).
Therefore, this research aims to improve the shortcoming of the genetic-based personalized e-learning system presented in our previous study (Chen, 2007), such that the prior and posterior knowledge of learning concept can be considered while planning personalized paths. In this work, the generated ontology-based concept map based on gathering a large number of pre-test results was applied to enhance the construction of the personalized learning path. This study is expected to establish authentic and near optimal learning paths that can help individual learners reduce the effects of cognitive overload and disorientation. Meanwhile, the proposed system can customize learning for those who have very specific needs and not much time or patience to complete topics. Experimental results show that the proposed genetic-based learning path generating scheme based on ontology-based concept map is superior to the genetic-based learning path generating scheme proposed in our previous study in terms of learning path quality because of simultaneously considering the difficulty of courseware and prior and posterior knowledge of learning concept while planning personalized paths
2. System
Design
This section is organized as follows: first, an overview of system architecture is introduced in Section 2.1. Section 2.2 aims to explain the proposed concept map generation scheme. Finally, applying the generated ontology-based concept map to personalized learning path generation is described in Section 2.3.
2.1 System Architecture
In our previous work (Chen, 2007), the personalized e-learning system including an off-line courseware and
test question construction module, six intelligent agents and four databases was presented for personalized learning path generation based on genetic algorithm. It can conduct personalized curriculum sequencing through simultaneously considering courseware difficulty level and the concept continuity of learning paths to support web-based learning. The experiment results had demonstrated that applying the proposed genetic-based personalized e-learning system with adaptive learning path guidance is superior to the freely browsing learning mode without learning guidance mechanism in terms of the promotion of learning performance.
However, the concept relation degrees among courseware are served as being symmetric in our previous study. That is, the curriculum sequence pattern “A→ B" is identical with the curriculum sequence pattern “B→A". In other words, the concept of prior and posterior knowledge had not been considered in the generated personalized learning paths. The result is inconsistent with real learning situations, thus leading to constructing unreasonable learning paths for individual learners. In this study, the previous proposed genetic-based personalized e-learning system is improved to enhance the quality of generated personalized learning paths via an automatically constructing ontology-based concept map. In the refined genetic-based personalized e-learning system, the results of the pretests are first extracted and preprocessed for the needs of constructing concept map and the concept relationships between courseware are constructed through the proposed concept relation measure and fuzzy clustering scheme. After that, the constructed ontology-based concept map is served as the constraint conditions for the employed genetic algorithm to plan an appropriate learning path for individual learner. The entire system architecture is shown as Fig. 1. The function of each component is explained below.
Learning Interface Agent Learner Account Database User Portfolio Database Learning Path Recommendation Agent Learner Teacher Account Database
Testing Items & Courseware Management Agent
Testing Items & Courseware Database Testing Items &
Courseware Modeling Process
Off-line testing items and courseware analysis 3 2 1 6 8/14/15 7 12 11 13 10 Concept Map Generation Agent Ontology -based Concept Map Database 5 Ontology-based concept map modeling process
4
9 16
Fig. 1 The system architecture of the personalized e-learning system based on ontology-based concept map
First, the courseware construction module, shown as the left rectangle frame with dotted line in Fig. 1, includes four components: the testing items and courseware modeling process, testing items and courseware management agent, teacher account database, and testing items and courseware database. These four components are detailed as follows:
Testing items and courseware modeling process: The modeling process aims to calculate each corresponding difficulty parameter for each test item according to computerized adaptive testing theory (Horward, 1990). Then, each test item will be transformed into web-based course material with the corresponding difficulty parameter. The detailed processes are explained in Section 2.2.2.
Testing items and courseware management agent: The agent helps teachers to update or maintain the course materials in the testing items and courseware database.
Teacher account database: The database records teacher’s account information for checking teacher identification to login the testing items and courseware management agent.
Testing items and courseware database: The database is designed for storing courseware and test
items developed by course experts.
The rest system components are detailed as follows: Learner account database: The database aims to
record learner’s account information for each learner.
Learning interface agent: The agent’s functions include: (1) checking learners’ accounts and monitoring learners’ learning states. (2) offering friendly learner learning interface with personalized learning path guidance to individual learners. (3) accessing the user portfolio database for personalized learning services and storing learners’ learning processes into the user portfolio database. User portfolio database: The database is in charge
of storing tracks of all the detailed learning processes for each learner.
Concept map generation agent: The agent mainly focuses on two parts. One is to handle the results of the exam and to pre-process testing responses. The right testing answers are marked as ones, and the wrong testing answers are marked as zeros. Then, a formula of computing concept correlation mentioned later is employed to calculate the relationships between courseware. Finally, this agent makes use of the fuzzy clustering method and the computing
correlation between courseware to automate the construction of the ontology-based concept map. Ontology-based concept map database: The
database stores totally 17 designed courseware and their corresponding concept correlations to each other for supporting personalized learning path generation based on genetic algorithm.
Learning path recommendation agent: The agent utilizes genetic algorithm supported by the generated ontology-based concept map to construct adaptive learning paths for individual learners and receive learners’ testing responses from the learning interface agent.
Next, the system operation procedure based on the system architecture is described as follows:
Step 1:
The course experts first design test items for each corresponding course material, and then the testing items and courseware modeling process follows to estimate the difficulty parameter of each corresponding course material according to computerized adaptive testing theory. After that, each test item is transformed into the web-based course materials according to the conveyed concept of each test item and the authorized teachers can update or maintain the courseware materials through the testing items and courseware management agent.
Step 2:
Teachers can manage test items and courseware using the user interface of the test item & courseware management agent via the legal accounts stored in the teacher account database.
Step 3:
These constructed courseware and test items are stored into the testing items and courseware database.
Step 4:
More than 600 records of elementary school examinees who participated in the exam of the unit “Fraction”, including 17 testing items covering those learning concepts, are pre-processed for constructing ontology-based concept map. In this work, the right testing answers are marked as ones and the wrong testing answers are marked as zeros. After that, the concept correlation measure mentioned later is adopted to find out the asymmetric relation among the 17 fraction-related mathematical courseware.
Step 5:
The ontology-based concept map of the “Fraction” unit is constructed by the employed fuzzy clustering method and concept correlation measure, which can group courseware with high correlation into the same cluster. After that, the generated concept map will be stored into the ontology-based concept map database for supporting personalized learning path generation
Step 6:
A learner logs in the system via a legal account for personalized learning services.
Step 7:
Once the learner logs in the system, the learner account database will offer legal account information for checking his/her identification.
Step 8-9:
The learning interface agent checks the learner’s identification to determine whether the learner is a beginner or an experienced learner. If the learner is a beginner, the testing items and courseware database will provide a pre-test for the learner to evaluate which concepts that the learner has still not learned well based on incorrect testing responses. If the learner is an experienced learner, then go to the Step 13 for unfinished learning processes; otherwise, go to the next step. Meanwhile, each learner’s learning states are also stored into the user portfolio database during learning processes.
Step 10-12:
The generated ontology-based concept map in Step 5 is used to support the learning path recommendation agent to plan a near optimal learning path based on the outcome of the learner pre-test, and then the generated learning path is transmitted to the learning interface agent to provide adaptive learning guidance for individual learner.
Step 13-14:
If the learner is identified as an experienced learner, his/her learning portfolio is first downloaded from the user portfolio database. And he/she has to learn all the unfinished courseware recorded in the download learning path before performing the post-test.
Step 15:
Once the learner finishes all courseware learning, the proposed system will provide a post-test to evaluate learner’s learning performance.
Step 16:
Complete all the learning procedures and log out the system.
2.2 The Proposed Concept Map Generation Scheme
2.2.1 The designed course materials in the course unit “fraction” for exploring ontology-based concept map
Currently, under the course category, “Mathematics of elementary school”, the proposed system contains one course unit “Fraction” and includes 17 course materials designed by several mathematical teachers. Moreover, each course material has a corresponding difficulty parameter, initially determined by statistics analysis, and each courseware corresponds to several testing questions
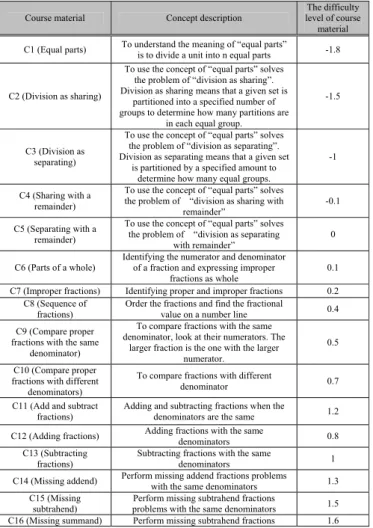
which can be employed to exanimate whether the learned courseware can be understood. In this study, there is a learning portfolio database storing testing records of more than 600 elementary school students who participated in the exam in the “Fraction” unit. In the exam, the learned courseware with wrong answer will be served as “focused concept” to evaluate the correlation with the other courseware with wrong answer as well for the proposed ontology-based generation scheme. All designed course materials for the learning process and their corresponding difficulty parameters are listed in Table 1.
Table 1. The contents of the designed course materials and the difficulty levels of the corresponding course materials in the course unit “Fraction”
Course material Concept description level of course The difficulty material C1 (Equal parts) To understand the meaning of “equal parts” is to divide a unit into n equal parts -1.8
C2 (Division as sharing)
To use the concept of “equal parts” solves the problem of “division as sharing”. Division as sharing means that a given set is
partitioned into a specified number of groups to determine how many partitions are
in each equal group.
-1.5
C3 (Division as separating)
To use the concept of “equal parts” solves the problem of “division as separating”. Division as separating means that a given set
is partitioned by a specified amount to determine how many equal groups.
-1
C4 (Sharing with a remainder)
To use the concept of “equal parts” solves the problem of “division as sharing with
remainder”
-0.1 C5 (Separating with a
remainder)
To use the concept of “equal parts” solves the problem of “division as separating
with remainder”
0
C6 (Parts of a whole)
Identifying the numerator and denominator of a fraction and expressing improper
fractions as whole
0.1 C7 (Improper fractions) Identifying proper and improper fractions 0.2
C8 (Sequence of fractions)
Order the fractions and find the fractional
value on a number line 0.4 C9 (Compare proper
fractions with the same denominator)
To compare fractions with the same denominator, look at their numerators. The
larger fraction is the one with the larger numerator.
0.5 C10 (Compare proper
fractions with different denominators)
To compare fractions with different
denominator 0.7
C11 (Add and subtract fractions)
Adding and subtracting fractions when the
denominators are the same 1.2 C12 (Adding fractions) Adding fractions with the same denominators 0.8
C13 (Subtracting fractions)
Subtracting fractions with the same
denominators 1
C14 (Missing addend) Perform missing addend fractions problems with the same denominators 1.3 C15 (Missing
subtrahend)
Perform missing subtrahend fractions
problems with the same denominators 1.5 C16 (Missing summand) Perform missing subtrahend fractions 1.6
problems with the same denominators
C17 (Missing minuend) problems with the same denominators Perform missing minuend fractions 1.8
2.2.2 The computing method of concept correlation for exploring ontology-based concept map
According to the result of the testing question exam, the right answers would be marked with ones, and the wrong answers would be marked with zeros. Next, this study proposes a computing formula of correlation to calculate the concept relationships between courseware. And the adopted formula is formulated as follows,
) N(C ) C N(C R i j i C Ci j I = , (1) where j iC C
R , represents the concept relation between the
th
i learning concept and the jth learning concept,
) (Ci
N is the number of the learners who gave wrong
answer for the corresponding testing question that conveys the th
i learning concept, and N(Ci ICj)
stands for the number of the learners who gave wrong answer for the corresponding testing question that conveys the th
j learning concept as well under learners
had given wrong answer for the corresponding testing question that conveys the th
i learning concept.
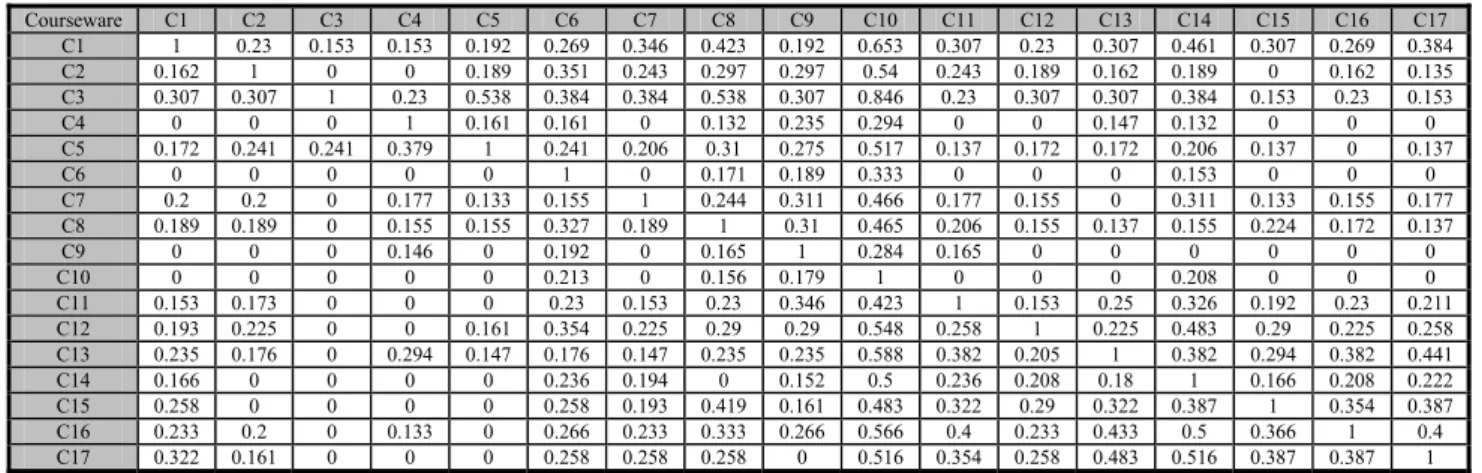
In Eq. (1), we can figure out the concept relationships between courseware obtained via calculating correlations based on learners’ responses in the testing question exam. All correlations among the 17 designed course materials in the unit “Fraction” can be represented as a concept correlation table, listed in Table 2. Moreover, to simplify the generated ontology-based concept map mentioned later, the concept correlations with weak correlation value will be first filtered out, and these concept entries with weak correlation are set to zeros. These weak concept correlations mean that their correlation values are less than a given threshold. Table 3 illustrates the revised concept correlation table of the 17 designed course materials after filtering out the weak concept correlations.
Table 2. The concept correlations between the 17 designed courseware
Courseware C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 C15 C16 C17 C1 1 0.23 0.153 0.153 0.192 0.269 0.346 0.423 0.192 0.653 0.307 0.23 0.307 0.461 0.307 0.269 0.384 C2 0.162 1 0.108 0.108 0.189 0.351 0.243 0.297 0.297 0.54 0.243 0.189 0.162 0.189 0.108 0.162 0.135 C3 0.307 0.307 1 0.23 0.538 0.384 0.384 0.538 0.307 0.846 0.23 0.307 0.307 0.384 0.153 0.23 0.153 C4 0.058 0.058 0.044 1 0.161 0.161 0.117 0.132 0.235 0.294 0.058 0.058 0.147 0.132 0.058 0.058 0.058 C5 0.172 0.241 0.241 0.379 1 0.241 0.206 0.31 0.275 0.517 0.137 0.172 0.172 0.206 0.137 0.103 0.137 C6 0.063 0.117 0.045 0.099 0.063 1 0.063 0.171 0.189 0.333 0.108 0.099 0.054 0.153 0.072 0.072 0.072 C7 0.2 0.2 0.111 0.177 0.133 0.155 1 0.244 0.311 0.466 0.177 0.155 0.111 0.311 0.133 0.155 0.177 C8 0.189 0.189 0.112 0.155 0.155 0.327 0.189 1 0.31 0.465 0.206 0.155 0.137 0.155 0.224 0.172 0.137 C9 0.045 0.1 0.036 0.146 0.073 0.192 0.128 0.165 1 0.284 0.165 0.082 0.073 0.1 0.045 0.073 0.036 C10 0.098 0.115 0.063 0.115 0.086 0.213 0.121 0.156 0.179 1 0.127 0.098 0.115 0.208 0.086 0.098 0.092 C11 0.153 0.173 0.057 0.076 0.076 0.23 0.153 0.23 0.346 0.423 1 0.153 0.25 0.326 0.192 0.23 0.211 C12 0.193 0.225 0.129 0.129 0.161 0.354 0.225 0.29 0.29 0.548 0.258 1 0.225 0.483 0.29 0.225 0.258 C13 0.235 0.176 0.117 0.294 0.147 0.176 0.147 0.235 0.235 0.588 0.382 0.205 1 0.382 0.294 0.382 0.441
C14 0.166 0.097 0.069 0.125 0.083 0.236 0.194 0.125 0.152 0.5 0.236 0.208 0.18 1 0.166 0.208 0.222
C15 0.258 0.129 0.064 0.129 0.129 0.258 0.193 0.419 0.161 0.483 0.322 0.29 0.322 0.387 1 0.354 0.387
C16 0.233 0.2 0.1 0.133 0.1 0.266 0.233 0.333 0.266 0.566 0.4 0.233 0.433 0.5 0.366 1 0.4
C17 0.322 0.161 0.064 0.129 0.129 0.258 0.258 0.258 0.129 0.516 0.354 0.258 0.483 0.516 0.387 0.387 1
Table 3. The revised concept correlations between the 17 designed courseware after setting the weak concept correlations as zeros Courseware C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 C15 C16 C17 C1 1 0.23 0.153 0.153 0.192 0.269 0.346 0.423 0.192 0.653 0.307 0.23 0.307 0.461 0.307 0.269 0.384 C2 0.162 1 0 0 0.189 0.351 0.243 0.297 0.297 0.54 0.243 0.189 0.162 0.189 0 0.162 0.135 C3 0.307 0.307 1 0.23 0.538 0.384 0.384 0.538 0.307 0.846 0.23 0.307 0.307 0.384 0.153 0.23 0.153 C4 0 0 0 1 0.161 0.161 0 0.132 0.235 0.294 0 0 0.147 0.132 0 0 0 C5 0.172 0.241 0.241 0.379 1 0.241 0.206 0.31 0.275 0.517 0.137 0.172 0.172 0.206 0.137 0 0.137 C6 0 0 0 0 0 1 0 0.171 0.189 0.333 0 0 0 0.153 0 0 0 C7 0.2 0.2 0 0.177 0.133 0.155 1 0.244 0.311 0.466 0.177 0.155 0 0.311 0.133 0.155 0.177 C8 0.189 0.189 0 0.155 0.155 0.327 0.189 1 0.31 0.465 0.206 0.155 0.137 0.155 0.224 0.172 0.137 C9 0 0 0 0.146 0 0.192 0 0.165 1 0.284 0.165 0 0 0 0 0 0 C10 0 0 0 0 0 0.213 0 0.156 0.179 1 0 0 0 0.208 0 0 0 C11 0.153 0.173 0 0 0 0.23 0.153 0.23 0.346 0.423 1 0.153 0.25 0.326 0.192 0.23 0.211 C12 0.193 0.225 0 0 0.161 0.354 0.225 0.29 0.29 0.548 0.258 1 0.225 0.483 0.29 0.225 0.258 C13 0.235 0.176 0 0.294 0.147 0.176 0.147 0.235 0.235 0.588 0.382 0.205 1 0.382 0.294 0.382 0.441 C14 0.166 0 0 0 0 0.236 0.194 0 0.152 0.5 0.236 0.208 0.18 1 0.166 0.208 0.222 C15 0.258 0 0 0 0 0.258 0.193 0.419 0.161 0.483 0.322 0.29 0.322 0.387 1 0.354 0.387 C16 0.233 0.2 0 0.133 0 0.266 0.233 0.333 0.266 0.566 0.4 0.233 0.433 0.5 0.366 1 0.4 C17 0.322 0.161 0 0 0 0.258 0.258 0.258 0 0.516 0.354 0.258 0.483 0.516 0.387 0.387 1
2.2.3 The proposed concept map generation scheme based on the computing concept correlations and fuzzy clustering scheme
2.2.3.1 Concept map generation based on fuzzy clustering scheme
In this section, how to use the clustering algorithm to group courseware with high correlation into the same clusters will be introduced. The adopted method in this study is the fuzzy clustering analysis scheme (Zimmermann, 1991). For the purpose of getting more meaningful clusters, as the above-mentioned consideration, the weak concept correlations are first filtered out, and these concept entries are set to zeros. In the employed fuzzy clustering analysis scheme, the clustering result will be affected by different α -cuts (Zimmermann, 1991). To optimize the clustering result, the concept correlations within the same cluster are expected as high as possible, but the ones between different clusters are expected as low as possible. Thus, the cost function, which integrates maximizing the concept correlations in the same cluster and minimizing the concept correlations among different clusters, was employed to determine best appropriate number of clusters under considering differentα-cuts in the employed fuzzy clustering analysis scheme. In other words, the used cost function aims to consider that the courseware within the same cluster should be as similar as possible, but the courseware of different clusters should be as dissimilar as possible. The final clustering outcome under considering optimal number of clusters is listed in Table 4.
Table 4. The result of concept clustering by the fuzzy clustering scheme The clustering results based on concept correlations among courseware
The clustered set of courseware
Cluster 1
C4 (Sharing with a remainder)、C5 (Separating with a remainder) 、 C9 (Compare proper fractions with the same denominator)、C1 (Equal parts)、 C17 (Missing minuend)、C12 (Adding fractions)
Cluster 2 C6 (Parts of a whole) Cluster 3 C3 (Division as separating) Cluster 4 C8 (Sequence of fractions) Cluster 5 C2 (Division as sharing) Cluster 6 C7 (Improper fractions)
Cluster 7 C10 (Compare proper fractions with different denominators)
Cluster 8
C11 (Add and subtract fractions)、C15 (Missing subtrahend)、C13 (Subtracting fractions)
Cluster 9 C16 (Missing summand) Cluster 10 C14 (Missing addend)
The ontology-based concept map can be depicted according to the clustered courseware by the fuzzy clustering algorithm and the asymmetric concept correlation table listed in Table 3. The following descriptions will detail how to construct a concept map:
Step 1: Constructing the inner correlations
Here we only need to consider the clusters that contain more than one courseware, such as Cluster 1 and Cluster 8.
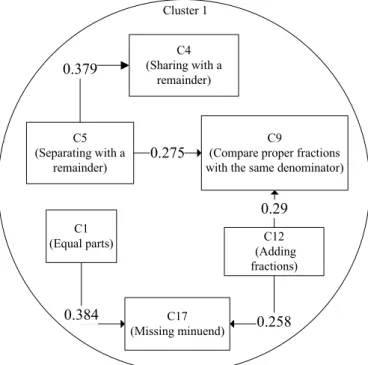
Taking Cluster 1 as example, we can first find out all correlations between the 6 courses and draw connections where their weights can be indicated based on the asymmetric concept table listed in Table 3. To simplify the generated ontology concept map, this study only considers connecting the concepts with top five high correlation values. Thus, the drawing ontology concept map of the Cluster 1 can be shown as Fig. 2. The same method can be applied to construct the ontology concept map of the Cluster 8. C4 (Sharing with a remainder) C5 (Separating with a remainder) C1 (Equal parts) C17 (Missing minuend) C9
(Compare proper fractions with the same denominator)
C12 (Adding fractions) Cluster 1 0.379 0.275 0.29 0.384 0.258
Fig. 2 The generated ontology concept map of the Cluster 1
Step 2: Constructing the outer correlations
In this step, the main idea of constructing ontology concept map is similar to Step 1. Based on the clustering results of Table 4, the total needed number of connections to link each cluster is 9 since 10 concept clusters are
grouped by the employed fuzzy clustering scheme. However, how to denote the weight of correlations between any two clusters is a needed consideration issue. Step 3: Calculating the weights of correlations
between any two clusters.
This study employed a similarity measure to estimate the weights of correlations between two clusters, and formulated as follows: n j i weight where n n A A rel weight ij j i n p n q jq p i i j j i = × ≤ ≤ ≤ ≤
∑∑
= = , 1 , 1 0 , ) , ( , 1 1 , (2)where weighti,j is the correlation between the i th
cluster and the th
j cluster, ni , is the number of
courseware in the th
i cluster, nj is the number of courseware in the th j cluster, Ai,p is the th p courseware in the th i cluster, Aj,q is the th q courseware in the th
j cluster, and rel
(
Aip,Ajq)
is thecorrelation between the th
p courseware in the ith
cluster and the th
q courseware in the jth cluster.
For example, the procedure of calculating the cluster correlation weight between the 7th cluster and the 8th cluster is detailed as follows:
498 . 0 1 3 ) 10 , 13 ( ) 10 , 15 ( ) 10 , 11 ( 7 , 8 × = + +
=relC C relC C relC C
weight (3)
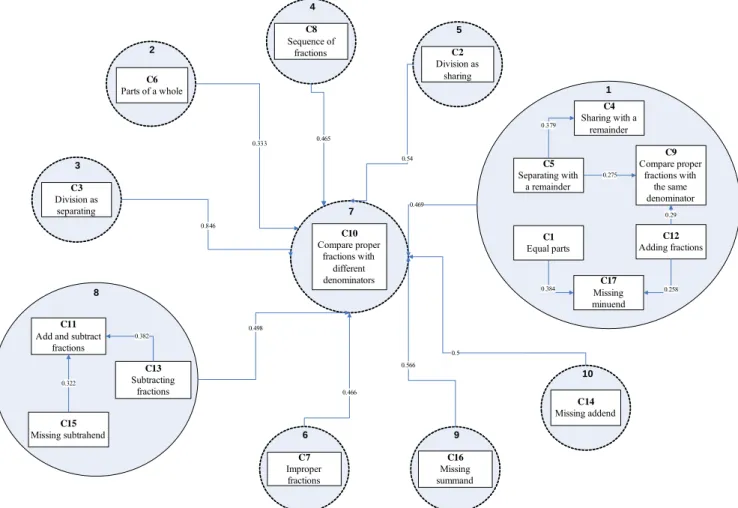
The final complete ontology-based concept map is displayed as Fig. 3.
4 C8 Sequence of fractions 5 C2 Division as sharing 6 C7 Improper fractions 7 C10 Compare proper fractions with different denominators 9 C16 Missing summand 10 C14 Missing addend C4 Sharing with a remainder 1 C5 Separating with a remainder C1 Equal parts C12 Adding fractions C17 Missing minuend 0.379 0.275 0.384 0.29 0.258 8 C11
Add and subtract fractions C15 Missing subtrahend C13 Subtracting fractions 0.322 0.382 0.333 0.846 0.465 0.54 0.466 0.566 0.5 0.498 0.469 3 C3 Division as separating C6 Parts of a whole 2 C9 Compare proper fractions with the same denominator
Fig. 3 The generated ontology-based concept map for the 17 designed courseware
2.2.3.2 Courseware teaching sequence pattern derived from the ontology-based concept map
Based on the generated ontology-based concept map shown as Fig. 3, 23 courseware teaching sequence patterns are summarized and listed in Table 5. In each courseware teaching sequence pattern, premise part can be viewed as prior knowledge of conclusion part. This property is beneficial to planning a logical learning path while providing curriculum sequencing for personalized learning services.
Table 5. The courseware teaching sequence pattern derived from ontology-based concept map
No. Courseware teaching sequence pattern No.
Courseware teaching sequence pattern 1
C1(Equal parts) → C10 (Compare proper fractions with different denominators)
13
C11 (Add and subtract fractions) → C10 (Compare proper fractions with different denominators)
2 C1 (Equal parts) → C17 (Missing minuend) 14
C12 (Adding fractions) → C9 (Compare proper fractions with the same denominator)
3
C2 (Division as sharing) → C10 (Compare proper fractions with different denominators)
15
C12 (Adding fractions) → C10 (Compare proper fractions with different denominators)
4
C3 (Division as separating) → C10 (Compare proper fractions with different denominators)
16 C12 (Adding fractions) → C17 (Missing minuend) 5
C4 (Sharing with a remainder) → C10 (Compare proper fractions with different denominators)
17
C13 (Subtracting fractions) → C10 (Compare proper fractions with different denominators)
6 C5 (Separating with a remainder) → C4 (Sharing with a remainder) 18 C13 (Subtracting fractions) → C11 (Add and subtract fractions) 7
C5 (Separating with a remainder) → C9 (Compare proper fractions with the same denominator)
19
C14 (Missing addend) → C10 (Compare proper fractions with different denominators)
8
C5 (Separating with a remainder) → C10 (Compare proper fractions with different denominators)
20
C15 (Missing subtrahend) → C10 (Compare proper fractions with different denominators)
9
C6 (Parts of a whole) → C10 (Compare proper fractions with different denominators)
21 C15 (Missing subtrahend) → C11 (Add and subtract fractions) 10
C7 (Improper fractions) → C10 (Compare proper fractions with different denominators)
22
C16 (Missing summand) → C10 (Compare proper fractions with different denominators)
11
C8 (Sequence of fractions) → C10 (Compare proper fractions with different denominators)
23
C17 (Missing minuend) → C10 (Compare proper fractions with different denominators)
12
C9 (Compare proper fractions with the same denominator) → C10 (Compare proper fractions with different denominators)
2.3 Applying Ontology-based Concept Map to Personalized Learning Path Generation
To plan more appropriate learning path than our previous study (Chen, 2007), the curriculum structure contained in the generated ontology-based concept map is
used as the constraint conditions of the employed genetic algorithm to plan personalized learning paths for individual learners. In other words, a planning learning path by the genetic algorithm must be evaluated whether it satisfies the curriculum sequence implied in the generated ontology-based concept map. If a planning learning path by the genetic algorithm conflicts with the order of prior knowledge between courseware, it will be treated as an inappropriate learning path. To measure the qualities of planning learning paths, this study proposes a penalty term α to calculate the violated value by comparing the rules of prior and posterior knowledge derived from ontology-based concept map with the generated learning path, so that those learning paths which conflict with the order of prior knowledge decline the corresponding fitness function value. Thus, a high quality learning path should get a penalty value as less as possible. The proposed penalty term is defines as the following formula:
)
0
(
2, 1 1 k n k kP
P
MAX
−
=
∑
=α
(4)
where
α
is the proposed penalty term,n
is the total number of prior and posterior knowledge rules,P
k1 and2 k
P
are the corresponding position index values in a planning learning path which violates with the antecedent and consequent parts of the thk rule of prior and
posterior knowledge derived from ontology-based concept map, respectively.
Next, an example is illustrated to explain how to calculate theαvalue. Suppose that “1→2→15→13→3 →12→9→16→7→17→6→11→4→5→8→14→10" is a generated learning path by the employed genetic-algorithm. To compare the teaching sequence of the planning learning path with the 23 rules of prior and posterior knowledge listed in Table 5, only the rule “5→ 9" violates with the teaching sequence listed in Table 5. The corresponding position index value of the antecedent and consequent parts of the violated rule in the generated learning path are 14 and 7, respectively. Thus, the values of and in the penalty function are 14 and 7, respectively. The calculated penalty value of α is equal to 7 in this case.
In order to combine the penalty term with the difficulty parameter into the fitness function, the penalty function value and difficulty parameter are normalized between 0 to 1. To do so, the planning learning path will simultaneously satisfy the difficult levels of courseware, and the curriculum sequence based on the order of prior knowledge as possible. Finally, the proposed fitness function for planning personalized learning path is formulated as follows: ) 1 ( ) 1 ( ) 1 ( 2
∑
= − × + − × − = n i i b w w fα
(5)
where
f
is the proposed fitness function,α
is a penalty term for evaluating the violated value of a generated learning path with the rules of prior and posterior knowledge derived from ontology-based concept map,b
i stands for the difficulty level of the ith courseware, andw
is an adjustable weight.3. Experiments
The study aims to revise the personalized learning path generation scheme proposed by our previous work (Chen, 2007) to construct a near-optimal learning path based on ontology concept map and the results of the pre-test in hopes of aiding learners to learn efficiently. Therefore, the experimental analysis mainly focuses on the performance comparison of the genetic-based learning path generation scheme with the proposed genetic-based learning path generation scheme supported by ontology concept map.
3.1 Parameter Setting of Fitness Function
The research adopted the genetic algorithm assisted by a generated ontology-based concept map to construct personalized learning paths according to the pre-test results for personalized learning of individual learners. In the process, the parameter setting for the proposed revised fitness function will affect the qualities of the generated learning paths. Particularly, the adjustable weight in Eq. (7) is an important parameter affecting the quality of the generated learning path. To determine an appropriate weight for planning personalized learning path, several parameter combinations were evaluated by setting different ratio combinations of the difficulty level of courseware to the penalty level of measuring violated degree of the teaching sequence with the sequence of prior and posterior knowledge obtained from the constructed ontology-based concept map. That is, the adjustable weight determines the importance degree of the difficulty level to the penalty level when evaluating the quality of a generated learning path. In our experiments, the termination condition for the genetic algorithm is set to 150 generations, the population size is set to 50, the mutation rate is set to 0.1, and the duplication rate is set to 1. Moreover, the research adopted the ratio of 3:7 to construct the personalized learning paths for individual learners because this ratio can obtain the best quality learning path as well as fast convergence speed.
3.2 Quality Evaluation of the Personalized Learning Path Generated by the Proposed
Scheme
To measure the quality of the generated learning path planned by the proposed ontology-based learning path generation scheme, two methods were used to measure the quality of learning path under the ratio of the difficulty level to penalty level is set to 3:7. First, the teaching sequence of the learning path generated by the proposed novel scheme in the “Fraction” course unit is compared with the teaching sequence of four version textbooks used in Taiwan elementary schools. Additionally, the teaching sequence of generated learning path is also compared with the teaching sequence suggested by 3 experienced mathematical teachers to examine the validity of the planned learning path.
How to obtain the teaching sequence of four version textbooks for evaluating the quality of the personalized learning path generated by the proposed scheme is
detailed as the following steps: Step 1:
Finding out the teaching sequence of 17 courseware designed for the “Fraction” unit in the selected four textbooks used in Taiwan elementary schools.
Step 2:
The 17 courseware related to the “Fraction” unit are ranked as a sequencing learning path according to teaching order in the four textbooks.
Step 3:
An integrated learning path is obtained based on ranking the average teaching order in the selected four textbooks, and listed as Table 6.
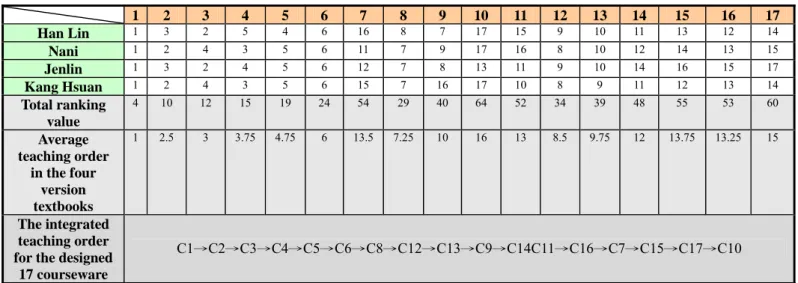
Table 6. Summarization of teaching orders of the designed 17 courseware in the “Fraction” unit in the selected four textbooks for obtaining the integrated learning path
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Han Lin 1 3 2 5 4 6 16 8 7 17 15 9 10 11 13 12 14 Nani 1 2 4 3 5 6 11 7 9 17 16 8 10 12 14 13 15 Jenlin 1 3 2 4 5 6 12 7 8 13 11 9 10 14 16 15 17 Kang Hsuan 1 2 4 3 5 6 15 7 16 17 10 8 9 11 12 13 14 Total ranking value 4 10 12 15 19 24 54 29 40 64 52 34 39 48 55 53 60 Average teaching order in the four version textbooks 1 2.5 3 3.75 4.75 6 13.5 7.25 10 16 13 8.5 9.75 12 13.75 13.25 15 The integrated teaching order for the designed
17 courseware
C1→C2→C3→C4→C5→C6→C8→C12→C13→C9→C14C11→C16→C7→C15→C17→C10
Next, the integrated learning path sequence was extracted from the four version textbooks are served as target learning path and compared with the planned learning paths generated by the proposed scheme in our previous study and the proposed novel genetic-based learning path generation scheme supported by the ontology-based concept map. To evaluate the quality of the generated learning path, the total violated distance of teaching sequence is defined and formulated as follows:
∑ ∑
− = = +−
=
1 1 ( 1) ,)
0
(
n i j n i j iP
P
MAX
γ
(6)
where
γ
is the total value of violated distance for a planned learning path,n
is the total number of course materials in the course unit “Fraction”,P
i is the corresponding position index value in a planning learning path which violates with the antecedent part of the thi
rule of prior and posterior knowledge derived from ontology-based concept map,
P
j is the corresponding position index value in a planning learning path which violates with the consequent part of the thj rule of prior
and posterior knowledge derived from ontology-based concept map.
Table 7 shows an example to illustrate how to compute the total violated distance of the learning path generated by the proposed genetic-based learning path generation scheme supported by ontology-based concept map with the teaching sequence of Han Lin version textbook. In Table 7, the courseware ID is marked with parentheses when the planned learning path violates the teaching sequence of the compared textbook. Finally, the total violated distance in the generated learning path can be obtained by calculating the summation of all violated distance values.
Table 7. An example for computing the total violated distance of the learning path generated by the proposed genetic-based learning path generation scheme supported by ontology-based concept map with the teaching sequence of Han Lin version textbook
The teaching sequence of the
generated learning path in Han Lin version
textbook
The violated status of the generated learning path with the teaching sequence of the Han Lin version
textbook
Computing violated distance by comparing
the learning path sequence of the Han-Lin
version with the sequence of the generated learning path
[3]→[2] (2)→(3)→17→9→16→8→14→4→10 2-1=1 [4]→[8] 2→3→17→9→16→(8)→14→(4)→10 8-6=2 [4]→[9] 2→3→17→(9)→16→8→14→(4)→10 8-4=4 [4]→[14] 2→3→17→9→16→8→(14)→(4)→10 8-7=1 [4]→[16] 2→3→17→9→(16)→8→14→(4)→10 8-5=3 [4]→[17] 2→3→(17)→9→16→8→14→(4)→10 8-3=5 [8]→[16] 2→3→17→9→(16)→(8)→14→4→10 6-5=1 [8]→[17] 2→3→(17)→9→16→(8)→14→4→10 6-3=3 [9]→[17] 2→3→(17)→(9)→16→8→14→4→10 4-3=1 [14]→[16] 2→3→17→9→(16)→8→(14)→4→10 7-5=2 [14]→[17] 2→3→(17)→9→16→8→(14)→4→10 7-3=4 [16]→[17] 2→3→(17)→9→(16)→8→14→4→10 5-3=2
The total of violated distance in the generated learning path 29
Next, two main experiments for evaluating the quality of the generated learning path are introduced as follows.
I. Comparing the generated learning path with the teaching sequences of four version textbooks to examine the quality of the planned learning path
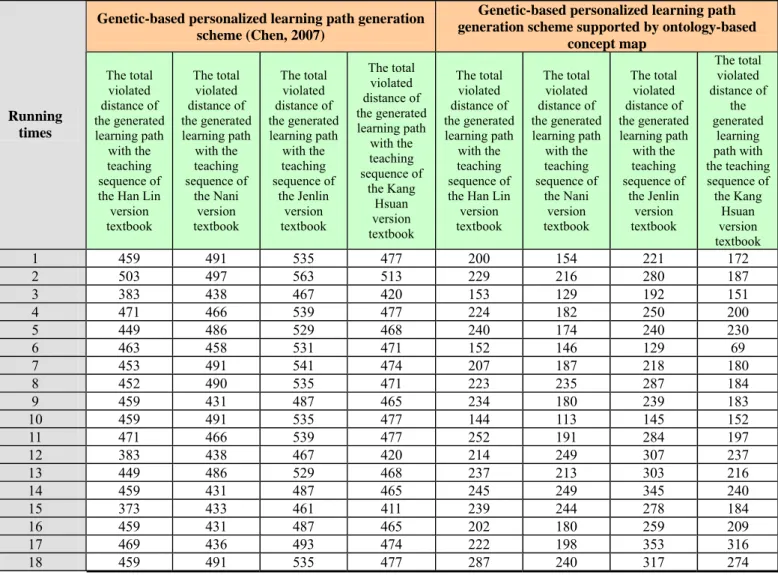
In this work, 20 learning paths randomly generated by the genetic algorithm based learning path generation scheme supported by the ontology-based concept map, and then are compared with the teaching sequence of four version textbooks. Table 8 displays the comparison results of the total violated distance between both the personalized learning path generation schemes with the teaching sequence of four version textbooks under the adjustable weight is set to 3:7. In addition, a further experiment was designed to compare the qualities of the learning paths generated by both the personalized learning path generation schemes with the integrated learning path from four version textbooks. Table 9 shows the comparison results.
Table 8. Comparison of the qualities of the learning paths generated by both the personalized learning path generation schemes with the individual teaching sequences of four version textbooks
Genetic-based personalized learning path generation scheme (Chen, 2007)
Genetic-based personalized learning path generation scheme supported by ontology-based
concept map Running times The total violated distance of the generated learning path with the teaching sequence of the Han Lin version textbook The total violated distance of the generated learning path with the teaching sequence of the Nani version textbook The total violated distance of the generated learning path with the teaching sequence of the Jenlin version textbook The total violated distance of the generated learning path with the teaching sequence of the Kang Hsuan version textbook The total violated distance of the generated learning path with the teaching sequence of the Han Lin version textbook The total violated distance of the generated learning path with the teaching sequence of the Nani version textbook The total violated distance of the generated learning path with the teaching sequence of the Jenlin version textbook The total violated distance of the generated learning path with the teaching sequence of the Kang Hsuan version textbook 1 459 491 535 477 200 154 221 172 2 503 497 563 513 229 216 280 187 3 383 438 467 420 153 129 192 151 4 471 466 539 477 224 182 250 200 5 449 486 529 468 240 174 240 230 6 463 458 531 471 152 146 129 69 7 453 491 541 474 207 187 218 180 8 452 490 535 471 223 235 287 184 9 459 431 487 465 234 180 239 183 10 459 491 535 477 144 113 145 152 11 471 466 539 477 252 191 284 197 12 383 438 467 420 214 249 307 237 13 449 486 529 468 237 213 303 216 14 459 431 487 465 245 249 345 240 15 373 433 461 411 239 244 278 184 16 459 431 487 465 202 180 259 209 17 469 436 493 474 222 198 353 316 18 459 491 535 477 287 240 317 274
19 373 433 461 411 216 200 260 234 20 449 486 529 468 231 198 249 175 Total violated distance 8895 9270 10250 9249 4351 3878 5156 3990 Average violated distance 470 217
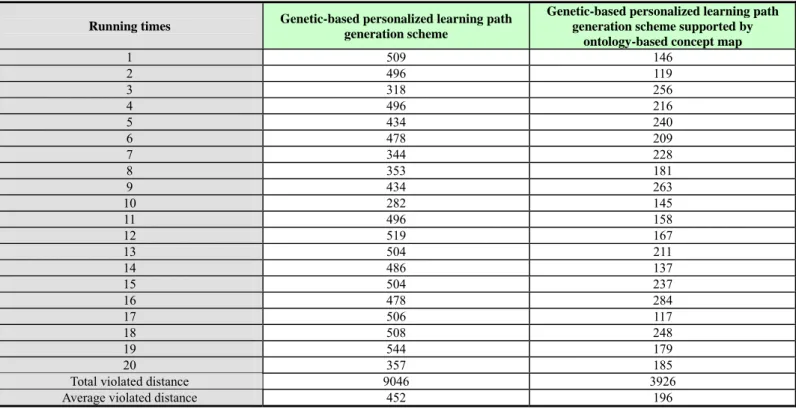
Table 9. Comparison of the qualities of the learning paths generated by both the personalized learning path generation schemes with the integrated learning path from four version textbooks
Running times Genetic-based personalized learning path
generation scheme
Genetic-based personalized learning path generation scheme supported by
ontology-based concept map
1 509 146 2 496 119 3 318 256 4 496 216 5 434 240 6 478 209 7 344 228 8 353 181 9 434 263 10 282 145 11 496 158 12 519 167 13 504 211 14 486 137 15 504 237 16 478 284 17 506 117 18 508 248 19 544 179 20 357 185
Total violated distance 9046 3926
Average violated distance 452 196
Based on the experimental results mentioned-above, we can find that the quality of the learning path planned by proposed genetic-based personalized learning path generation scheme supported by ontology-based concept map is superior to the genetic-based personalized learning path generation scheme presented by our previous work (Chen, 2007). Therefore, this study logically inferred that the learning paths generated by the proposed novel scheme match the learning sequence of the textbooks much more than the scheme proposed by our previous work. It means that the proposed novel scheme can plan a more accurate learning path for individual learner. And those generated learning paths can also be adopted as a valuable reference for planning teaching sequence of the textbooks.
II. Comparing the generated learning path with the teaching sequences from course expert’s suggestion to examine the validity of the planned learning path
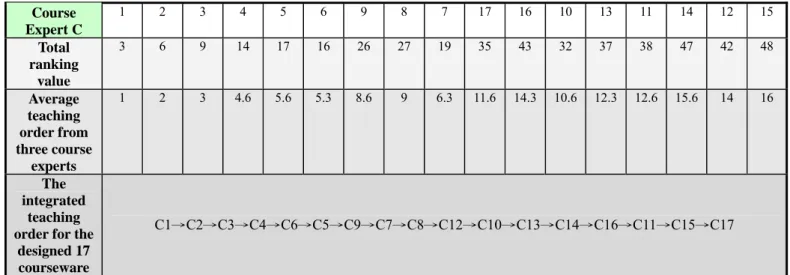
In order to further evaluate the quality of the learning path generated by the proposed novel scheme, this study invited three experienced mathematical teachers who came from Kuan-Hua elementary school in Hualien of Taiwan to ask for their suggestions on the learning sequence of the 17 designed courseware related to the “Fraction” unit. Table 10 reveals the learning sequence of the 17 designed courseware in the “Fraction” unit suggested by 3 experienced mathematical teachers of Kuan-Hua elementary school and the integrated learning path sequence from the three mathematical teachers.
Table 10. The integrated learning path sequence suggested by 3 experienced mathematical teachers of Kuan-Hua elementary school for the 17 designed courseware in the “Fraction” unit
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Course Expert A 1 2 3 4 5 6 9 10 7 8 13 11 12 14 16 15 17 Course Expert B 1 2 3 6 7 4 8 9 5 10 14 11 12 13 17 15 16
Course Expert C 1 2 3 4 5 6 9 8 7 17 16 10 13 11 14 12 15 Total ranking value 3 6 9 14 17 16 26 27 19 35 43 32 37 38 47 42 48 Average teaching order from three course experts 1 2 3 4.6 5.6 5.3 8.6 9 6.3 11.6 14.3 10.6 12.3 12.6 15.6 14 16 The integrated teaching order for the
designed 17 courseware
C1→C2→C3→C4→C6→C5→C9→C7→C8→C12→C10→C13→C14→C16→C11→C15→C17
Next, 20 learning paths randomly generated by both the learning path generation schemes are compared with the learning paths suggested by 3 experienced mathematical teachers of Kuan-Hua elementary school for the 17 designed courseware in the “Fraction”. Tables 11
and 12 respectively show the comparison results of the quality of the learning path generated by both the personalized learning path generation schemes with the individual learning path and the integrated learning path suggested from three experienced mathematical teachers.
Table 11. Comparison of the qualities of the learning paths generated by both the personalized learning path generation schemes with the individual learning paths from three experienced mathematical teachers
Genetic-based personalized learning path generation scheme
Genetic-based personalized learning path generation scheme supported by ontology-based concept map Running
times
Course Expert A Course Expert B Course Expert C Course Expert A Course Expert B Course Expert C
1 542 562 501 300 308 217 2 219 207 279 310 277 204 3 538 556 508 300 294 224 4 484 505 437 288 298 228 5 539 558 498 469 449 350 6 458 436 426 212 187 173 7 212 205 270 227 240 181 8 415 393 377 359 331 252 9 511 508 467 348 350 278 10 216 203 276 258 265 183 11 535 552 505 228 222 148 12 483 503 447 289 281 204 13 480 499 444 279 294 210 14 461 440 429 197 189 118 15 535 552 505 252 233 153 16 247 212 299 203 219 190 17 506 502 449 288 267 210 18 514 512 470 307 297 228 19 535 552 505 249 240 167 20 516 520 485 309 298 231 Total violated distance 8946 8977 8577 5672 5539 4149 Average violated distance 441 256 Table 12. Comparison of the qualities of the learning paths generated by both the personalized learning path
generation schemes with the integrated learning paths from three experienced mathematical teachers
Running times Genetic-based personalized learning
path generation scheme
Genetic-based personalized learning path generation scheme supported by
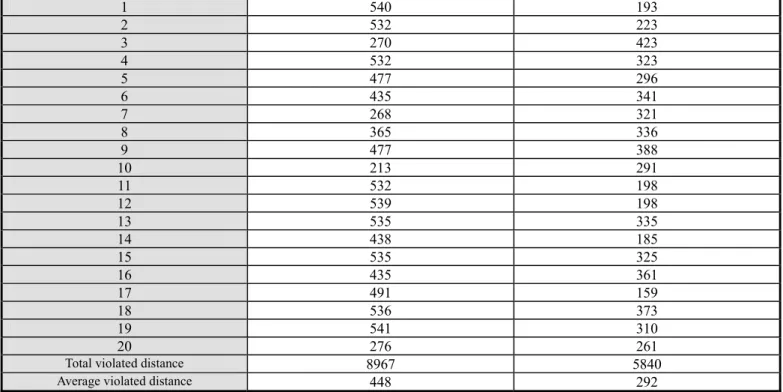
1 540 193 2 532 223 3 270 423 4 532 323 5 477 296 6 435 341 7 268 321 8 365 336 9 477 388 10 213 291 11 532 198 12 539 198 13 535 335 14 438 185 15 535 325 16 435 361 17 491 159 18 536 373 19 541 310 20 276 261
Total violated distance 8967 5840
Average violated distance 448 292
Based on the experimental results mentioned-above, we can also find that the quality of the learning path planned by proposed genetic-based personalized learning path generation scheme supported by ontology-based concept map is superior to the genetic-based personalized learning path generation scheme presented by our previous work. The results can also confirm that the learning paths generated by the proposed novel scheme match the learning sequence suggested by course experts much more than the scheme proposed by our previous work.
In order to compare the entire quality of the learning path generated by the proposed novel personalized learning path generation scheme with our previous proposed scheme, the experimental results mentioned-above are summarized in Table 13. Based on the results, this study confirms that the proposed learning path generation scheme satisfies the criterion of course experts and various versions of textbooks much more than the learning path generation scheme proposed by our previous study. Thus, the learning paths planned by the proposed genetic algorithm based personalized learning path generation scheme supported by the ontology-based concept map are more accurate and reliable than those constructed learning paths by our previous proposed scheme.
Table 13. The entire quality evaluation of the learning path generated by both the personalized learning path generation schemes
Learning mode
Comparison items
Genetic-based personalized learning path generation scheme
Genetic-based personalized learning path generation scheme
supported by ontology-based concept
map The average violated distance of
the generated learning path with the individual teaching sequences of the four version
textbooks
470 217
The average violated distance of the generated learning path with the integrated teaching sequence of the four version textbooks
452 196 The average violated distance of
the generated learning path with the individual teaching sequences of the three course
experts
441 256
The average violated distance of the generated learning path with the integrated teaching sequence of the three course experts
448 292
3.3 The Implemented System for Personalized Learning Service
In this section, the implemented system is introduced in detail. Fig. 4 shows the entire layout of the user’s learning interface. As a learner logins this system, he/she must conduct a pre-test if he/she is a beginner; otherwise, the system will guide the learner to learn the courseware according to the previous unfinished learning procedures.
Figure 4. The logon user interface
Fig. 5 shows the interface of performing a pre-test for a beginner. After performing the pre-test, the system will plan a near optimal learning path based on those learning materials that the learner fails to give correct answer responses in the pre-test to support the adaptive learning guidance for the learner. Fig. 6 displays the user interface of courseware recommendation learning mode. In the left frame of Fig. 6, those course materials will be ordered according to the learning sequence of the planned learning path. Next, when learners click in the courseware with first learning priority in the left frame of Fig. 6, the proposed learning system will bring out the corresponding learning content for individual learner learning. Fig. 6 shows the courseware with first learning priority in the generated learning path. Moreover, one randomly selecting testing item related to the current learning courseware is arranged in the bottom-right window to help system get the learner’s comprehension percentage for the learning courseware. When a learner can pass a test question of the current learning courseware, he/she is served as has acquired the learned courseware. If a learner cannot pass two randomly selected testing questions for the current learning courseware, the proposed system will guide the learner to conduct the remedy learning. In this work, the courseware database contains course materials with easier difficulty level than the current learning courseware for supporting remedy learning. The remedial course materials convey similar learning concepts with the current learning courseware, but they contain different learning content. The remedy learning mechanism aims at improving the learning performances of individual learners for the courseware that they cannot acquire well through the standard courseware. Once learners complete all of the course materials, the system will provide the post-test for learners to assess their entire learning effects.
Figure 5. The user interface of pre-test
Figure 6. The user interface of courseware recommendation learning mode
Figure 7. The courseware with first learning priority in the generated learning path
4. Conclusions
This study presents a novel genetic-based personalized learning path generation scheme supported by an automatically generated ontology-based concept map to improve the shortcoming of planning a personalized learning path proposed by our previous study that concept relations of prior and posterior knowledge between courseware has not been considered. The proposed personalized learning path generation scheme, which can simultaneously consider courseware difficulty level and the concept relations of prior and posterior knowledge between courseware according to the incorrect
testing responses in a pre-test, thus it is capable of creating higher quality learning paths than the previous proposed genetic-based personalized learning path generation scheme for individual learners. Compared to the freely browsing learning mode used in most web-based learning systems, our previous study had indicated that the proposed learning mode of curriculum sequencing recommendation based on planning personalized learning path can promote learner’s learning effectiveness during learning processes. Meanwhile, the proposed personalized learning path generation scheme can effectively reduce learner cognitive overload or disorientation during learning processes, thus promoting learning performance. Particularly, the learning mode of curriculum sequencing recommendation customizes learning for those who have very specific needs and not much time or patience to complete topics they have learned.
Although the proposed ontology-based personalized learning path generation scheme can provide high quality curriculum sequencing for individual learners in a web-based learning environment, there are several critical issues that need to be further investigated in the future. First of all, to record the ontology-based concept map more flexible, the database design for storing ontology-based concept map can be replaced by RDF with XML syntax in the future. The improvement is not only to easily extend the number of courseware, but also make the ontology-based concept map conveniently applied to other web-based educational systems in hopes of supporting adaptive learning materials. Secondly, to integrate the proposed personalized learning path with SCORM (Sharable Content Object Reference Model) curriculum sequencing standard for developing an e-learning system with adaptive learning guidance is also a valuable research issue.
References
Alex C. W. Fung & Jims C. F. Yeung (2000). An object model for a web-based adaptive educational system.
Proceedings of ICEUT, 420-426.
Alomyan, H. (2004). Individual differences: implications for web-based learning design. International Education
Journal, 4(4), 188-196.
AppServ Open Project. (2007), Available at http://www.appservnetwork.com/.
Brewster, C., O’Hara, K. (2007). Knowledge representation with ontologies: Present challenges—Future possibilities. International Journal of
Human - Computer Studies, 65(7), 563-568.
Brusilovsky, P. (1998). Adaptive educational systems on the world-wide-web: a review of available technologies.
In Proceeding of Workshop WWW-Based Tutoring at 4th International Conference in Intelligent Tutoring Systems.
Calvi, C. (1997). Navigation and disorientation: a case study. Journal of Educational Multimedia and
hypermedia, 6(3/4), 305-320.
Chen, C. M. (2007). Intelligent web-based learning system with personalized learning path guidance.
Computers & Education (Article in press).
Chen, C. M., Lee, H. M. and Chen Y. H. (2005). Personalized E-Learning System Using Item Response Theory. Computers & Education, 44(3), 237-255.
Chen, C. M., Liu, C. Y. and Chang, M. H. (2006). Personalized Curriculum Sequencing Using Modified Item Response Theory for Web-based Instruction. Expert
Systems with Applications, 30(2), 378-396.
Eppler, M. J., and Mengis J. (2004). Concept of information overload: a review of literature from organization science, accounting, marketing, MIS, and related disciplines. The Information Society, 20, 325–344. Federico, Pat-Anthony (1999). Hypermedia environments and adaptive instruction. Computers in Human Behavior, 15, 653-692.
Gruber, T. R. (1993). A translation approach to portable ontology. Knowledge Acquisition, 5(2), 199-220.
Hsu, Chin-Shen, Tu, Shu-Fen, Hwang, Gwo-Jen (1998). A concept inheritance method for learning diagnosis of a network-based testing and evaluation System. The 7th
International Conference on Computer-Assisted Instructions, 602-609.
Horward W. (1990). Computerized adaptive testing: a
primer, Hillsdale, New Jersey: Lawerence Erwrence
Erlbaum Associates.
Lee, Myung-Geun (2001). Profiling students’ adaptation styles in web-based learning. Computers & Education, 36, 121-132.
Lin, C. H., and Davidson-Shivers, G. V. (1996). Effects of linking structure and cognitive style on students' performance and attitude in a computer based hypertext environment. Journal of Educational Computing Research, 15(4), 317-329.
McCormick, C.B. and Pressley, M. (1995). Educational
psychology: learning, instruction, assessment, New York:
Longman.
Paolucci, R. (1998). The effect of cognitive style and knowledge structure on performance using a hypermedia learning system. Journal of Educational Multimedia and
Hypermedia, 7(2/3), 123-150.