亞東技術學院
資訊與通訊工程研究所
碩士論文
3D 影像定位與虛擬互動系統之設計
Design of Virtual Interactive System for 3D Vision
研究生: 陳柏森
指導教授: 賴金輪
致謝
終於來到了致謝這一站,這條路從研究所備取,到選指導教授, 到制定論文題目,再到出國參加研討會,及上台用英文報告論文,這 當中有許多事情是我始料未及的進行和發展著,不管是課業研究還是 人生體悟,兩年來當中自己是夾雜著淚與汗水緩慢前進的,還記得兩 年前備取上到市公所兵役課辦緩徵的那天,幫我處理文件的小姐一直 告訴我,我很幸運備取上亞東資通所要我好好兩年念完,今年再見到 她已經是兩年後了,還是由她幫我處理緩徵文件,我才意識到這兩年 來其實甚麼都沒變,變的只是我的歷練。 在學術上,指導教授-賴金輪老師和學長珈雄、鈞凱和由我所不 認識的其他研究生所撰寫的眾多文獻,在這兩年的路途上給予了我非 常多經驗和資源,也因為賴老師相當的堅持出國投稿之下而讓我有了 第二次在國外演講的經驗。 在休閒上,持有桌球教練執照的學弟東霖也讓我終於克服攻擊 拍在正手反擊上的障礙,而學弟立尹和淙濱也願意在課餘時間一起到 羽球館捉對廝殺,你們是可敬的對手,另外淙濱的人生觀和父親經及 職場歷練同樣也是不可多得的經驗。 最後僅以此文獻給我的父母,雖然從小我在課業上就是時常讓你 們操心的孩子,但那天教授卻說我及學長的論文貢獻是不輸國立的水 準和質量,相信這兩年來的擔心你們可以放心了。 我很高興那天剛進亞東時我並沒有選錯教授,即便之後才得知他 是本系的大刀,但實際上相處後才發現並不如學生外表所描述的那中文摘要
本研究是在 3D 立體負視差效果的情境下,利用雙視訊攝影機進 行人體即時定位偵測,透過 3D 座標校正法,達成使用者在任何位置 方向下,都可以實現人與同一虛擬立體物件進行體感互動的效果。 在實驗方法上,我們提出一個簡易定位方法去校正虛擬立體世界 與真實世界的座標,使得使用者得以和虛擬世界物件進行互動連結, 其過程為利用動畫所製作的負視差效果球體先向使用者端做校正定 位接觸,搭配本論文演算法並且在固定範圍內完成首次定位校正後, 由螢幕端再次向使用者端投射新座標和新距離的球體給使用者做定 位接觸,這時候根據首次校正過的參數自動會產生出該新球體的對應 位置座標,而此參數的產生則是為了方便確認使用者再次和新球作互 動時能否觸碰到新球的正確位置所設立,如此一來便可判斷使用者和 新球體的互動是否為正確的對應。 3D 立體定位校正的構想未來可以廣泛應用在各種領域上,不管 是娛樂遊戲互動,或是礙於外在環境必頇在室內的運動訓練,甚至連 醫學手術上等需要產生虛擬架構的環境都可以採用此技術,如此一來 便可將體感互動及立體視覺做一個寓教娛樂的發揚。Abstract
This thesis aims to use a dual stream camera as a real-time human body positioning detector under the 3D negative parallax effect, through 3D coordinate adjustments, achieving the goal of performing sensual interactions between a real person and a simulated object no matter where this person is and which direction he is facing.
To achieve this goal, a simple positioning method to adjust the coordinates in the virtual world and the real world is proposed, so that users can interact and make connections with objects in the virtual world. The process begins with using a virtual sphere with negative parallax effect to make positioning adjustment contacts on the user side. Then the proposed algorithm is adopted and the first positioning adjustment is completed in a specified range. After that, a new sphere with new coordinates and distances is project to the user side from the screen for positioning contacts with users. By this time, the corresponding coordinates in the new sphere can be obtained using the parameters from the first adjustment. These parameters are generated so that it can be convenient to confirm if users can get to the right position in the new sphere when interacting with the new sphere. This way, whether users’ interact with the new sphere with correct corresponding positions can be determined.
The idea of 3D space conversion can be applied in various fields in the future. For example, it can be used for interactions in games, trainings
目錄
致謝 ... I 中文摘要 ... II 英文摘要 ... III 目錄 ... IV 表目錄 ... VII 圖目錄 ... VIII 第一章 緒論 ... 1 1.1: 研究背景和動機... ... 1 1.2: 論文架構 ... 3 第二章 立體視覺 ... 4 2.1: 立體影像原理 ... 4 2.2: 雙眼視差 ... 4 2.2: 立體顯像技術 ... 8 2.3: 立體影像設計 ... 16 第三章 影像識別與定位 ... 18 3.1: 影像灰階化 ... 18 3.2: 影像二值化 ... 19 3.3: 影像形態學 ... 213.4: 圖案識別設計 ... 24 第四章 立體座標轉換與空間映射 ... 28 4.1: 立體距離 ... 28 4.2: 立體演算法 ... 30 4.3: 與 3D 空間中運動物體的互動法設計 ... 34 第五章 實驗結果與討論 ... 36 5.1: 硬體規格 ... 36 5.2: 立體定位檢測 ... 38 5.2.1: 單點立體定位 ... 41 5.2.2: 位移立體定位 ... 42 5.3: 實驗討論 ... 44 5.4: 系統校能評估 ... 47 5.5: 本論文完整系統架構 ... 51 第六章 結論與未來工作 ... 52 6.1: 結論 ... 52 6.2: 未來工作 ... 53 參考文獻 ... 55 附錄 ... 57
表目錄
第二章 立體視覺 表 2.1: 立體影像顯示技術分類 ... 8 第五章 實驗結果與討論 表 5.1: 單點立體定位實驗數據 ... 40 表 5.2: 位移立體定位實驗數據 ... 41 表 5.3: 實驗環境亮度帄均值 ... 42 表 5.4: 系統效能評估表 ... 45 表 5.5: Z軸互動系統效能評估表 ... 49圖目錄
第二章 立體視覺 圖 2.1:達文西及手繪左右眼成像示意圖 ... 4 圖 2.2:雙眼視差示意圖 ... 5 圖 2.3:不同距離物體的光角大小表示圖 ... 6 圖 2.4:正視差、零視差、負視差示意圖 ... 6 圖 2.5: 紅藍色差眼鏡和對應影像結果圖 ... 9 圖 2.6: 線偏光原理示意圖 ... 9 圖 2.7: 圓偏光原理示意圖 ... 10 圖 2.8:為電子快門眼鏡顯示表示圖 ... 11 圖 2.9: 國際牌的快門式眼鏡示意圖 ... 11 圖 2.10:SONY 的頭戴式顯示器示意圖 ... 12 圖 2.11: 全像式立體影像示意圖 ... 13 圖 2.12:視差屏障的示意圖 ... 14 圖 2.13:柱狀透示意圖 ... 14 圖 2.14:指向光源式示意圖 ... 15 圖 2.15:Maya 軟體展示正視差、零視差、負視差結果圖 .... 6 圖 2.16:負視差最佳位置示意圖 ... 17第三章 影像識別與定位 圖 3.1: 灰階影像示意圖 ... 18 圖 3.2: 二值化後的影像示意圖 ... 20 圖 3.3: 遮罩示意圖 ... 21 圖 3.4: 二值化後到膨脹後的影像示意圖 ... 22 圖 3.5: 二值化後到侵蝕後的影像示意圖 ... 23 圖 3.6: 為四連通標記法搜尋方向示意圖 ... 23 圖 3.7: 為八連通標記法搜尋方向示意圖 ... 23 圖 3.8: 乒乓球拍面圖案示意圖 ... 24 圖 3.9: 為改變圖 3.8 後的結果圖 ... 25 圖 3.10: 為定位辨識時的標記圖案結果圖 ... 25 圖 3.11: 位移定位記錄的辨識圖案結果圖 ... 26 圖 3.12: 本論文影像辨識流程示意圖 ... 27 第四章 立體座標轉換與空間映射 圖 4.1: 立體距離量測實景示意圖 ... 28 圖 4.2: 視差值(dx) vs 等比距離(dis)曲線結果圖 ... 29 圖 4.3: 位移定位時初始座標示意圖 ... 31 圖 4.4: 空間定位內插演算法的流程結果圖 ... 32 圖 4.5: Z 軸的時間差互動示意圖 ... 34
第五章 實驗結果與討論 圖 5.1: LifeCam Studio 示意圖 ... 36 圖 5.2: 辨識用的白手套示意圖 ... 37 圖 5.3: 黑線以內的距離為移範圍的限制結果圖 ... 38 圖 5.4: 實驗環境採光示意圖 ... 39 圖 5.5: 負視差定位球體和測詴球體的座標示意圖 ... 40 圖 5.6: 定位正確和錯誤的影像顯示圖 ... 41 圖 5.7: 投影光源對焦不一的狀態結果圖 ... 44 圖 5.8: 絕命終結站四色差立體影像示意圖 ... 45 圖 5.9: 改變動畫尺寸的前後對照圖 ... 46 圖 5.10: 球體改變的距離呈現示意圖 ... 47 圖 5.11: 改進影像顯示正確前後對照示意圖 ... 50 圖 5.12: 完整互動系統架構結果圖 ... 51
第一章 序論
1.1 研究背景和動機
隨著遊戲形態的多樣化改變,近一兩年來我們從單純的手把操作 型態轉移到了體感操作面,不單單只是坐在螢幕前操作機器來娛樂, 更可利用身體來投入互動並享受娛樂。 日本大廠任天堂首先提出了用紅外線測距來當作手把控制器的 Wiimote[1-2],分別是由方向定位及動作感應組合。前者就如同光線 槍或滑鼠一般可以控制螢幕上的游標,後者可偵測三維空間當中的移 動及旋-轉,結合兩者可以達成所謂的「體感操作」[3]。玩家則可以 透過移動和指向來與電視螢幕上的物件產生互動。之後微軟不甘示弱 的推出了更強化的 Kinect[4],感應器是一個外型類似網路攝影機的 裝置。Kinect 有三個鏡頭,中間的鏡頭是 RGB 彩色攝影機,左右兩 邊鏡頭則分別為紅外線發射器和紅外線 CMOS 攝影機所構成的 3D 深度感應器。利用影像分割和深度判別使用將使用者從背景分離出來 並且將人體軀幹分為 20 組骨架點以掌握更加精準的體感設計,和 Wiimote 最大差別就是 Kinect 無頇任何手把操作,強調人本身就是 作為遙控器的體感操作為賣點,在[5]的分析當中可以看到 Kinect 擊 敗 iPad 成為全球銷售速度最快的消費性電子產品,這也說明了對於 體感互動的商機是無限的,也讓體感遙控逐漸步上成為趨勢的日子即 將來臨。 雖然以上兩種類型的體感在偵測深度上是具有立體原理,但是都 是只能顯示在 2D 畫面中,變成無法全面的將 3D 體感發揮到淋漓盡 致。因此,要達成 3D 螢幕體感互動首先必頇具備的條件便是一套完 整的定位系統,方能與螢幕世界中的物件連結,由於本論文最後呈現 是在虛擬的立體影像世界中,因此如何在立體影像中將虛擬端的座標定位功用的圖案辨識手段相對重要,為了能提升辨識精準度,我們選 擇了特殊設計的幾何圖形進行測詴。本論文結合了立體定位、影像辨 識、及 3D 座標轉換,並使用低成本的器材設備,達到讓使用者以體 感方式和立體影像世界互動,則是本論文的最終目的。
1.2 論文架構
本論文的架構如下: 首先在第二章中將介紹立體視覺的原理和 負視差效果設定,接著第三章則是講解基本影像處理的程序和辨識圖 案的設計,第四章則敘述立體座標轉換演算法和立體距離的量測設 定,最後,第五章則是展示立體定位的數據結果和實驗討論,而結論 及未來研究方向則陳述於最末章。第二章 立體視覺
2.1 立體影像原理
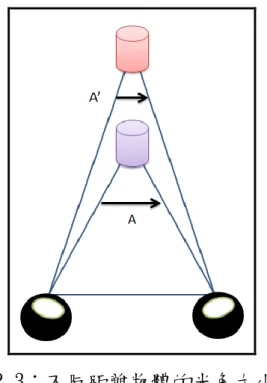
在西元一千五百年前的文藝復興時期,同時也是建築師、解剖學 者、藝術家、工程師、數學家、發明家集一身的天才學者達文西 (Leonardo da Vinci)就開始對雙眼視覺作光學研究,如圖 2.1。從 圖 2.1(b)中發現我們之所以可以看到立體影像是因為人類擁有成對 的雙眼視覺,而雙眼視覺就是讓影像造成深度的主要來源。接下來將 對影像的景深作更深入的探討。 (a) (b) 圖 2.1:(a)為文藝復興天才達文西(Leonardo da Vinci),(b)為達 文西手繪左右眼成像示意圖- Peter Hohenstatt: Leonardo da Vinci, 1452-1519, Konemann Verlag, 1998。2.1.1 雙眼視差 單眼所接收到的影像在視網膜上只能形成二維圖形,但是經過雙 眼所接受到不同視角的差異再透過視神經傳至大腦後即可形成立體 影像,如圖 2.2。 圖 2.2:雙眼視差示意圖。 每個人的雙眼視差不盡相同,一般來說成年人的雙眼距離約在 7 公分左右,所以為什麼當成年人特別去欣賞專為孩童拍攝的 3D 動畫 片會發現 3D 的效果極差,甚至根本沒甚麼立體感覺,原因就在於孩 童的雙眼視差遠低於 7 公分,所以電影中的視差畫面當然不會大,對 成年人來說影片內容所呈現的深度和層次感相較於低。有了雙眼視差 的形成後,接下來就是影像深度和層次感的產生。 物理學上的光角(Optical Angle),是指眼球為了要對焦所形的 角度。如圖 2.3 中我們可以清楚看到兩個不同距離的圓柱體所形成的 角度 A 和 A’,因為物體光角的大小不同,我們才可以判斷遠近,因 此也才能產生影像深度和層次感。
圖 2.3:不同距離物體的光角大小。 過大的光角和視差不僅會造成眼睛的不適,且會降低立體成像的 效果,因此在ㄧ個層次效果佳且兼具觀影舒適的立體影像內,是不會 發生上述的情況的。在這個前提下,依照物體遠、中、近三種不同距 離情形下可以將視差分為三大類形,如圖 2.4。 圖 2.4:從上至下分別是正視差、零視差、負視差。
(1) 正視差(Positive - Parallax):正視差為兩眼焦點無任 何交錯現象產生,意指兩眼帄視觀看遠方景物,而景物則 會呈現在螢幕後方位置。 (2) 零視差(Zero - Parallax):零視差為兩眼焦點交叉於螢 幕上,意指兩眼觀看近距離的景物。 (3) 負視差 (Negative - Parallax):負視差為兩眼焦點交叉 於螢幕內,意指兩眼觀看眼前的近物。 一個舒適完整且效果極佳的立體影像呈現必需具備如圖 2.4 的 三種條件,缺一不可。由於外在環境和每個人對立體影像的接受度不 同,常會產生主觀上認知差異,例如有些人對於鬼影(cross talk) 現象的容忍條件不一,或者是眼球對焦的速度感快慢,3D 構圖的美 學及影像品質等等,因此不可過度依賴公式化的數據來製作立體影 像。由於本論文的重心是放在負視差(Negative Parallax)上,我們 將在 2.3 節另外討論負視差效果的呈現和數據。
2.2 立體顯像技術
隨著科技日新月異的進步也讓立體顯像技術從早期的色差眼鏡 進化到裸視顯示立體影像,表 2.1 可以看到目前顯示技術的分類,以 下將個別技術分別作介紹。 表 2.1:立體影像顯示技術分類。 3D 顯示技術 眼鏡式 裸眼式紅藍眼鏡(Anaglyph glasses) 全像式(Holography)
偏光眼鏡(Polarization glasses) 視差屏障式(Parallax Barriers)
快門眼鏡(Shutter glasses) 柱狀透鏡式(Lenticular Lenses)
頭戴式顯示(Head mounted display) 指向光源式(Directional Backlight)
2.2.1 眼鏡式 紅藍眼鏡(Anaglyph glasses) 紅藍分色技術早在 19 世紀就已經出現了,其原理就是將左右眼 視角所觀看的景象利用顏色過濾的原理去強制讓雙眼接受不同角度 的影像,優點是成本較低而缺點是無法用全彩像素去呈現一張完整影 像,如圖 2.5。
(a) (b) 圖 2.5:(a)為紅藍色差眼鏡,(b)為紅藍色差眼鏡對應的影像。(圖來 源:3d-anaglyph.com) 偏光眼鏡(Polarization glasses) 偏光眼鏡原理基本上是採用光的波動及方向性來區分左右眼視 角影像,例如先將左右影像分為垂直向和水帄向偏光,在透過特製的 偏光鏡片來讓雙眼接受不同偏光的影像,如圖 2.6。 (a) (b) 圖 2.6:(a)為接受垂直向的偏光鏡片(b)為接受水帄向的偏光鏡片。 (圖來源:http://viml.nchc.org.tw/home/) 除了線偏光外,市面上現在多採用圓偏光的設備居多,原因不外 忽線偏光鏡片只要使用者頭的角度稍微偏向或是傾斜就容易造成鬼 影(cross talk)現象的發生,但是圓偏光眼鏡受眼鏡旋轉角度影響較
是在線偏光鏡片上多加四分之一波長的波片,波片的光軸會產生兩個 方向的振動,如圖 2.7 紅色和綠色波段結合成為藍色虛線,根據線偏 光射入的正負 45 度角度可以產生兩個不同方向的圓偏光。 (a) (b) 圖 2.7:(a)正 45 度角產生順時針方向的圓偏光,(b)負 45 度角則產 生逆時針方向的圓偏光。(圖來源:http://viml.nchc.org.tw/home/) 偏光眼鏡較適用於戲院等娛樂場所,由於成本低,技術上又遠比 紅藍色差眼鏡來的效果好,普遍來說較為一般民眾所接受,但是眼鏡 透光度確卻是唯一致命傷,除非使用流明數較高的投影機種來播放, 否則很難改善觀影亮度品質,這種狀況特別是在戲院內發生,例如採 用 RealD 放映技術的戲院,由於只需要單投影機播放造成影像品質亮 度偏暗,而 IMAX3D 的技術則是雙投影機播放,不需要用切換左右眼 的技術來達到立體效果,因此在亮度色相飽合度上都是最佳的觀影選 擇。 快門眼鏡(Shutter glasses) 快門眼鏡屬於主動式眼鏡技術,如圖 2.8 電子訊號去控制液晶鏡 片的遮蔽速度然後分別去讓雙眼看到各自不同的影像,以每秒可高達
圖 2.8:為電子快門眼鏡輪流顯示一覽。 早期的快門式眼鏡不但體積重量也重,甚至還有一條電源線附在 眼鏡身旁令使用者穿戴行動極不方便,但是現在的技術都使用無線傳 輸給螢幕端發送訊號給快門眼鏡,並且重量輕,但是使用者必頇搭配 一套高頻率更新的顯示器才能使用,整套系統買下來也不便宜,如圖 2.9。 圖 2.9 國際牌的快門式眼鏡。 (圖來源:3dactiveshutterglasses.com)
頭戴式顯示(Head mounted display) 頭戴式立體顯示原理就是利用內置的雙迷你螢幕分別播放兩眼 的影像給左右眼觀賞,它可以擁有高畫質的解析度,但是礙於成本、 舒適度、以及只能專屬於個人的使用限制考量上,並不是未來立體顯 示的主流系統。 圖 2.10:SONY 的頭戴式顯示器。(圖來源:oled-info.com) 2.2.2 裸眼式 全像式(Holography) 全像式顯示也可以稱為全息投影[6],其原理簡單來說是利用光 學原理讓影像在空中 360 度浮現出來,也是真正的全 3D 影像。全像 式可以藉由空氣等媒介來作呈現展示,也有人利用精密雷射來投射到 空氣當中,如圖 2.11。
(a) (b)
圖 2.11:(a)由 National Institute of Advanced Industrial Science and Technology 所打造,他們使用雷射光束來投射影像到空氣中(b)則是 世界上第一位使用全息投影技術的日本虛擬歌手演唱會。 (圖來源:http://www.engadget.com/2006/02/08/japans-real-3d-image-projector/) 視差屏障式(Parallax Barriers) 視差屏障式是在螢幕端上設置許多的直條柵欄隔絕光線通過,由 於雙眼視差的關係,各自被遮蔽到不同的部分。如圖 2.12,紅藍畫 面原先雙眼都能夠接收到,加入光線柵欄之後,左眼只能夠看到紅色 的畫面,而右眼只能看到藍色的畫面,藉由遮蔽效果來達到立體的效 果。 其缺點是因為必頇將畫面分成左右眼畫面,也因此解析度與畫面 亮度都會降低。此外,能夠觀看的範圍視角較小,只有在一定的角度 與距離範圍內才能產生立體畫面,好處是比起採用柱狀透鏡式的產 品,視差屏障式產品是可以自由切換成 2D 模式去欣賞影像。
圖 2.12:視差屏障的示意圖。(圖來源:http://blog.uns.org.tw/node/210) 柱狀透鏡式(Lenticular Lenses) 柱狀透視鏡式原理則是利用螢幕上光柵片的圓柱狀凸透鏡薄 膜,透過透鏡折射角度不同造成視差的效果,如圖 2.13,和上述的 視差屏障式差不多,優點是亮度較視差屏障式高,缺點則是成本過 高,如果想塞入多視角的畫面讓觀賞角度變廣,就必頇製作更高精密 的光柵。
指向光源式(Directional Backlight) 指向光源式顯示的原理是使用兩組 LED 分別以高速交替方式朝左 右眼顯示影像,讓右側的背光光源朝左眼投射左眼影像,而左側的背 光光源則朝右眼投射右眼影像,因此能夠讓雙眼分別接收到左右各自 的影像,藉此產生讓雙眼視差產生立體感,如圖 2.14。 圖 2.14:指向光源式示意圖。(圖來源:beareyes.com.cn)
2.3 立體影像設計
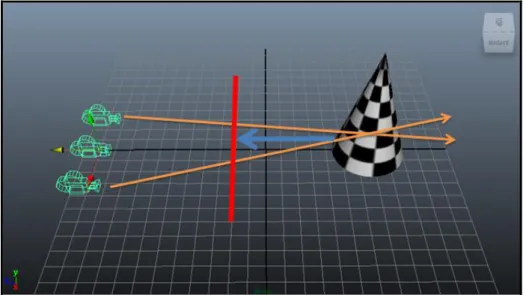
本論文注重在立體影像中的負視差突出效果,原打算用立體相機 拍攝具有負視差的照片呈現,但是後來發現單張立體影像無法擁有電 影和動畫帶給我們極佳的突出效果,故使用 Autodesk 研發的 Maya 動畫軟體來製作立體影像,追究原因大概是出於視覺暫留[7]的因 素。Maya 在 2009 的版本裡增加了雙攝影機的功能,如圖 2.15 中可 以看到雙攝影機用黃色的球體來呈現遠中近不同距離的範圍,中間略 為紅色區塊的就是零視差。 圖 2.15:Maya 軟體展示正視差、零視差、負視差。 透過 Maya 來設定立體場景十分方便和人性化,經過多次負視差 的調整設定下我們發現一個規則,過大的負視差容易讓人感到不適甚 至眼壓升高等暈眩問題產生,為了避免此現象發生,本論文中經過數 次實驗後得到一個結論,如圖 2.16 可以看到圓錐物體若要往前移到 負視差的距離最多只能前進到紅線的地方,剛好就是零視差和攝影機 的 1/2 長度最為恰當,故採用其作為本論文中負視差呈現的參數。圖 2.16:負視差最佳位置示意圖
第三章 影像識別與定位
在本章節中將敘述如何用影像處理技術使視訊攝影機捕捉到標 記物件,由於使用者需要和立體物體來做互動,互動的過程中我們採 用圖案識別來當作紀錄作標點的位置使用,以下敘述其處理流程:3.1 影像灰階化
前處理是辨識影像的一大課題,前處理做得好後續的辨識工作相 對輕鬆。首先將 RGB 全彩影像轉成灰階影像 YIQ 模式,其原因在於 RGB 三維全彩影像在後製處理時所花費的時間和資料量較多,二維的 數值運算較三維快,且也可縮短影像處理時間。這裡我們只採用亮度 資訊 Y,如圖 3.1。 Y= 0.299R + 0.587G + 0.114B (3-1) (a) (b) 圖 3.1:(a)為 RGB 影像,(b)為灰階值影像。3.2 影像二值化
影像經過灰階化後接下來再經過二值化操作即可大幅簡化後續 操作程序。提昇影像辨識的運算速度。這裡我們採用 Otsu 演算法來 計算 T。Otsu 是利用對每張不同的影像採取灰階度統計方法來決定門 檻,演算法如下:N
n
p
i
i (3-2) 一張影像內可能有許多灰階度的數值 1~L 的存在,然後 L 內的灰 階值度數i又有n
i 個像素在內,N則是代表影像像素的總和而其灰 階值出現的機率為p
i 。以 k 值當作 1~L 灰階度數值的門檻分為兩個 群組,分別為 1~k 及 k+1~L,而各群組出現的機率為w
0w
1 。 ) ( 1 0 p w k w i k i
(3-3) ) ( 1 1 p w k w i L k i
(3-4) 之後兩群組的帄均值
0
1如下: ) ( ) ( 1 0 0 k w k w ip k i i
(3-5) ) ( 1 ) ( 1 1 1 k w k u w ip T L k i i
(3-6)兩群組的變異數
02 2 1
如下: 0 2 1 0 2 0(
1
)
w
p
i k i
(3-7) 1 2 1 1 2 1(
1
)
w
p
i L k i
(3-8) 最後再將兩群組的變異數相加並且得到兩群組變異數的最小值 k,而這個k值就是我們要找的門檻值 T,經過 T 門檻值操作後結果 如圖 3.2。 群集變異數的加權總和
w2(
k
)
為:)
(
)
(
)
(
0 12 2 2 0 0k
w
k
k
w
w (3-9)3-3 影像形態學
影像在辨識尋找目標物過程中可能會因為二值化影像的邊緣干 擾,導致判斷誤差的發生,在需要一個實體影像的準確性時,必頇對 邊緣化的影像進行影像重整,影像重整的功能包括:影像帄滑,消除 雜點,連接缺口及斷開的邊緣…等。 形態學中最常使用到的是膨脹(dilation)與侵蝕(erosion) 二 種 方 法 , 在 數 位 影 像 處 理 上 稱 為 數 學 形 態 學 ( mathematical morphology)。至於先侵蝕後膨脹或是先膨脹後侵蝕,是看使用者和 被辨識物的需求而定。依本實驗的環境我們採用先膨脹後侵蝕的方法 (亦即 closing 操作)。我們利用 3
3 的矩陣遮罩來進行像素運算。 遮罩的動作可分為四鄰界或是八鄰界的搜尋方向,這裡我們用四鄰界 搜尋法和圖 3.3 來當範例。 9s
s
2s
3 8s
s
1s
4 7s
s
6s
5 圖 3.3:遮罩示意圖 膨脹(dilation) 膨脹可以使影像邊緣加粗,若s
2、s
4、s
6、s
8 的像素值分別為 1,則s
1為 1,如圖 3.4。圖 3.4:(a)為原始二質化影像,(b)為膨脹後的影像。 侵蝕(erosion) 侵蝕可以使影像邊緣縮小,若
s
2、s
4、s
6、s
8 的像素值分 別為 0,則s
1為 0,如圖 3.5。 圖 3.5:(a)為原始二質化影像,(b)為侵蝕後的影像。 (a) (b) (a) (b)標籤化(label) 影像標籤化就是連通物件法,在做過影像膨脹和侵蝕後將分割出 來為類似區域的像素做一個標記,這用意在於之後好方便讓做過標記 的區域直接做更細緻的辨識,也可以藉此濾掉無相關的區域像素值, 連通物件法分為兩種,如下圖: 圖 3.6 為四連通標記法搜尋方向 圖 3.7 為八連通標記法搜尋方向 (a) (b) (a) (b)
3.4 圖案辨識設計
實驗中辨識圖案是參考柯皓鈞 [8]的設計加以變化,如圖 3.8, 圖案的設計絕大多數以幾何圖形來做為主要辨識物件,同樣幾合圖案 的方向性也要考慮進去,圓形就是最佳的例子。 圖 3.8: [8]乒乓球拍面圖案。 在實驗中的圖案全都會以反白色系為主,也就是說在辨識中圖 3.8 的圖案會是以白色圓形外框為準。影像裡單純辨識圓並不困難, 最先顏色是我們首選的方法之一,但是實驗環境目前是以投影布幕做 為底圖,投影機光源和現場環境的干擾迫使取消這個選擇。 文獻[9]裡使用圓面積的周長比,以近似於 1 當做真圓來辨識, 實驗後礙於辨識距離會隨著圓面積大小改變外加不定因素所以最終 還是選擇了以黑白兩色當做辨識的主力。 由於要讓辨識準確度提高,不能單純只是以黑白雙色做選擇而 已,這裡我們略為修正 [8]的圖案以利於接下來的實驗,如圖 3.9。圖 3.9:(a)(b)各為改變圖 3.8 後的圖案。 參照圖 3.8 我們把原始影像的中心點縮小設計為的是讓辨識條 件範圍增大,原始的辨識條件為圓心點顏色和圓心四周顏色及原面積 的限制,基於考量到辨識時光影流動的判斷誤差,新圖案因而將圓心 四周擴大,辨識時以影像反白為處理如圖 3.10。 圖 3.10:為定位辨識時的標記圖案。 為了辨識身體位移時所需要的記錄,所以我們才設計圖 3.9(b) 的判斷辨識圖案。設計一個圓形缺口的用意就在於一方面可以跟圖 3.9(a)類似方便程式辨識速度,而另一方面則是由於我們在移動時身 體會些許晃動,而缺口就是允許晃動的範圍值,如圖 3.11。 (a) (b)
本論文採用的影像辨識流程圖如下: 圖 3.12: 本論文影像辨識流程圖。 以上是關於使用者端辨識圖案定位的影像處理流程,接下來的章 RGB 影像 灰階影像 二值影像 形態學 & 標籤化 圓長寬相差< 5 圓心左邊外圍 =
1
圓心上邊外圍 = 1 圓心右邊外圍 = 1 & 圓面積 > 10 圖 3.9(a) 圖 3.9(b)第四章 立體座標轉換與空間映射
4.1 立體距離估測
立體物件定位中的輔助關鍵就是影像的 3 維座標量測,文獻[9] 有詳細記錄著偵測立體物件距離的方法,利用雙視訊攝影機去截取同 一張 frame 因而得到目標物圖案的視差,搭配公式即可獲得相對應的 影像深度距離。還有的則像是文獻[10-11]比對兩張圖內區域範圍的 象素值做 SAD 運算或是 SSD 運算,選擇不同區域範圍比對也會影響深 度圖的精確度,在運算速度上相對較為緩慢,這裡我們的作法則是利 用 Matlab 軟體內的 curve fitting 曲線統計來擬定演算 Z 軸的公式, 如圖 4.1 利用雙視訊鏡頭間隔 5.9cm 從距離 60cm 到 232.5cm 每 2.5cm 統計一次圖案的視差象素,69 組數據如公式(4-1)和圖 4.2。圖 4.2:視差值(dx) vs 等比距離(dis)曲線圖。 實驗中由於我們無法得知自動對焦後的焦距,所以無法直接採 用[12]的演算法(式(4-1)),故改以curve fitting方式估測,如式 (4-2)。
d
f
b
z
(4-1)z
a
(
dx
)
b
c
(4-2) 這裡說明一下(4-1)和(4-2)中求 z 的式子內所代表的參數意 義,(4-1)的 b 為雙攝影機間隔的間距,f為攝影機焦距,d 為待測 物體的距離,如圖 4.2 中從 60cm 到 232.5cm 這一段距離,而(4-2) 的 dx 為物體的視差值,其它由 curve fitting 跑出的參數值則分別 是 a = 2610、b = -0.9506、c = 17.02。4.2 空間定位演算法
若結合 2.3 節的負視差設計規範、3.4 節的定位辨識、及前述的 立體距離量測,搭配本節提出的演算法,就可以實現真實與虛擬立體 空間的映射。意即,使用者可以和虛擬立體空間中的物件進行觸碰交 流。為達成此立體定位目標,首要的工作就是要讓使用者端和立體影 像端雙方共同獲得一致的座標系統,因此我們建立了一套空間座標映 射公式(在線性映射的假設下)如下: ' 1 1 p p T (4-3) 其中, 1 2 3 4 5 6 7 8 9 10 11 12c
c
c
c
T
c
c
c
c
c
c
c
c
表示空間轉換矩陣,p
[ ]
x y z
T與 'p [ ' ' ']x y z T分別為虛擬立體空間(或觀測立體空間)與使用者真實 立體空間中的座標。 在立體定位校正時,會先有 4 組利用負視差效果投射出來的球體 座標分別為p
1到p
4,之後使用者利用第三章第四節中的辨識圖案去 觸碰投射出來四組不同距離深度的球體座標,依序將捕捉獲得的'
p
1 到'
p
4對應座標帶入式(4-3)線性對應函式,以便計算出c
1到c
12的數 值,建立起投射球體端與使用者觸碰端三度空間中的對應關係。 經實驗後我們發現由於使用者對 z 軸的判斷會直接影響式(4-3) 的結果,故將深度立體定位校正分開去計算,如式 4-4 以及 4-5 以求 得更精準的數值。 ' 12 11 10 9 ' 2
:
z
c
x
c
y
c
z
c
T
(4-5) 在位移的內插演算法上根據量測後我們找出一個演算關鍵,單點 校正時我們會得到四組測詴球的座標,根據這個關係在位移範圍內的 左上角(紅色箭頭處)設定為初使值如圖 4.3。 圖 4.3 位移定位時初始座標示意圖 使用者在初始位置上的座標為 (x、y、z)first,這時候會有 4 組 利用負視差效果投射出來的球體座標分別為(x1、y1、z1)到(x4、y4、 4 z )讓使用者做第一次的定位動作進而得到(x1'、 ' 1 y 、z1')~( ' 4 x 、y4'、 ' 4 z ),記錄每次使用者在某位置點可獲得四組球體座標和一組位置座 標後發現到可以直接挪用每次位移位置點座標的誤差值做四組球體 座標的內差。這時使用者即可移動前往範圍內的任何一個位置(藍色箭頭 處),在這裡做第二次位移定位可以得到 (x、y、z)second,先將(x)second
- (x)first所獲得的誤差都用內差的方式加到前次 first 的四組球體座
標的( ' 1
x )second,y 軸部分在經過數次量測後發現都和(y)first相差不到
50 像素並都在偏差值誤差內故在此沿用上述(y)first數值,依此類推 之後每次的位移,圖 4.4 可以看到詳細流程: 第一次使用者所站 的定位點位置座標: (x、y、z)first 使用者第一次觸碰四顆定 位球獲得的四組座標: (x1、y1、z1)(x1、y1、z1) (x1、y1、z1)(x4、y4、z4) 使用者位移到第二次定 位點的位置座標: (x、y、z)second 為求得第二次觸碰定位球的四組座 標,因此根據第二次位移定位點和第 一次位移定位點的位移差演算法: xd = (x)second -(x)first 根據上次步驟後即可不頇再次觸碰定位球就可以用演算法得到 第二次的四組定位球體數據: ( ' 1 x x1 xd、 ' 1 y y 、1 z ) (1 x2' x2 xd、 ' 2 y y 、2 z ) 2 (x3' x3 xd 、 ' 3 y y 、3 z ) (3 ' 4 x x4 xd、 ' 4 y y 、4 z ) 4
此演算法的容錯率我們使用正負 50 像素去判斷,之所以用此數 字原因在於視訊攝影機擷取畫面的解析度是 640×480 像素大小,而 50 像素剛好是x和y軸的十分之一左右,在下一章節中的實驗數據 表 5.1 裡可以明顯看到我們的實驗結果和演算法的結果在和比較使 用者x和y軸上誤差容許度範圍在本論文的實驗上是允許的。
4.3 與 3D 空間中運動物體的互動法設計
本論文目前對針對 Z 軸只有完成前置階段雛形的偵測任務,尚未 將完整 Z 軸互動實現,後置的偵測如圖 4.5,將負視差球體的移動距 離和使用者手部觸碰的距離時間換算一致,也就是說球體位於第幾秒 時會移動到該座標點位置的路徑記錄起來,當使用者的觸碰時間是在 這段路徑內且 x y 座標也在容錯率相同下即可將球體擊回,碰觸擊回 的路徑則是由使用者當下的觸碰方向來推算,也就是反作用力的原 理,這樣一來對於 3D 立體負視差的系統定位設計可以說是完全的發 揮到淋漓盡致,也才能使真實世界中的物件,真正與虛擬世界中的物 件產生“交互作用”,達成擴增實境應用的目標。 圖 4.5 Z 軸的時間差互動圖。 關於 Z 軸互動方式簡易說明如下,當負視差立體球體從遠到近的 過程中,會改變的有球體面積的小到大和負視差的小到大以及時間的 流逝,因此假若負視差球體 A 的飛行速度約為 0 到 15 秒,相同的時 間負視差的大小改變則是從 0 像素到 40 像素,我們希望在 7 秒的時 候球體變色以便提醒使用者在這時機點去觸碰飛行中的球體 A,這時 候使用者如果能達到在 7 秒前後也就是指從 6 到 8 秒內的時間差並且進行碰觸的互動,即達成吾人期望的擴增實境應用目標,如圖 4.6 所 示。 是 負視差球體朝使用者從 遠到近的方向前進著 使 用 者 在 球 體 變 色 時 觸 碰 (或是在負視差球體很突出 的時候觸碰該球體) 會出現成功正確擊球的 畫面並且根據使用者當 下觸碰的方向做出反方 向動畫 否 假若 xy 偏差值誤差和 觸碰球 體的時間差都 在範圍內?
接下來將針對如何在實際 Z 軸的方向上進行互動的實驗方式作 相關說明,在第一次定位時我們所需要找出的是位移的線性關係,有 了第一次的位移函數後,接下來在第二次的定位中就可以加入時間軸 距離的條件,這裡我們將時間軸和視差像素視為同樣的條件下去執 行,但由於目前有鑑於在撥放立體負視差影像時是利用 frame 的概念 去呈現,加上目前尚未完成動畫行徑間的變色效果,因此決定依據不 同方向和速度的球體動畫從 1 到 110 張負視差 frame 裡去設定擷取該 負視差影片的觸發時間軸 frame,這裡我們分別取出球體突破螢幕的 frame 來當作觸發條件也就是離使用者最近最突出的負視差影像,如 圖 4.7,每部負視差動畫的時間軸觸發張數都不同,速度快的當然要 成為觸發的 frmae 張數會較少,反之速度慢的 frame 張數多,最後有 了觸發 frame 的限制和XY偏差值的條件限定下即可達成 Z 軸的時間 差互動,數據可於 5.4 內效能章節中的 Z 軸互動系統效能評估表得到。 (a) (b) (c) (d)
第五章 實驗結果與討論
5.1 硬體規格
本論文的實驗利用雙視訊攝影機來偵測距離,並搭配 70 吋以上 的投影布幕來呈現。軟體上則是使用 Matlab 影像處理軟體來撰寫, 各硬體詳細規格如下: 一.視訊攝影機 實驗中使用兩顆同廠牌的視訊攝影機做深度偵測,其解析度為 640×480、廣角為 75 度、取像率: 30 幅/秒如圖 5.1。 圖 5.1:LifeCam Studio。 二.辨識用白手套 為一內含黑白混色圓圈組合的手套(如圖 5.2),這裡使用白手套 作為辨識量測的目的主要有兩點,第一是模擬使用者和球體接觸的情 境,第二是白手套顏色在後製影像辨識時會被反白成黑色像素,因此 可稍微減低運算的處理量。圖 5.2 辨識用的白手套。 三.筆記型電腦 處理器: Intel Core2 Duo
5.2 立體定位測詴
在立體定位測詴的章節中分為兩大數據,主要分別是單點立體定 位和位移立體定位兩種,最後實驗數據會附上其中作參考。 實驗環境設定條件為下,使用者的活動範圍設定在鏡頭前約 120cm 左右的方形距離內,長寬距離分別是 97 公分乘上 125 公分大 小的範圍內,以確保在這正方形內使用者所站立的前後左右的位置上 時,辨識圖案都不會超出在鏡頭外,導致產生無法辨識的困擾(如圖 5.3)。另外由於投影布幕裡的影像呈現會和環境的採光造成衝突,太 亮的燈光照射下反而會讓影像色澤失真,但是全關燈的情況下會讓使 用者圖案因過暗而不易被辨識到(除非測詴時間點是白天可容許全關 燈做測詴,但仍建議開啟適度燈源較好),最後的選擇是開啟適當距 離外的一排電燈,既不會讓投影影像失真過多也可兼顧使用者的辨識 光源亮度,如圖 5.4。 圖 5.3 黑線以內的距離為移範圍的限制。 (a) (b)圖 5.4 實驗採光設定(a)為全開燈狀態,(b)為開第二排燈源的狀態 對實驗環境較佳。 在本論文實驗中首先先在投影布幕上分別撥放四組不同座標和 距離的球體出來,負責定位的球體最後停止的座標是從 Maya 軟體內 建構的三維空間得出,如圖 5.5,當使用者戴上紅藍色差眼鏡後便可 發現其中的負視差球體,至於周遭眾多顆白球則是為了將立體空間的 舒適度作配置,這時候需要使用者戴上白手套去模擬擷取黃色球體飛 出的動作。 (a) (b)
圖 5.5 (a)定位球 1 的座標(96、100、68),(b)定位球 2 的座標 (96、103、77),(c)定位球 3 的座標(106、99、75),(d)定位 球 4 的座標(102、104、52),(e) New ball_1 的座標(100、105、 83),(f) New ball_2 的座標(99、101、75),(g) New ball_3 的座
(a) (b)
(c) (d)
(e) (f)
當使用者的定位和校正結果出來後便會和由演算法計算出的估 測值作比較,容錯率的誤差範圍值則為正負 50 像素(如 4.2 節說明)。 若使用者校正出來的數據是在演算法容錯率的結果內,則影像會只單 獨顯示黃色球體的最後位置 (如圖 5.6(a)),反之則會出現如圖 5.6(b) 。 圖 5.6(a)為定位正確的顯示,(b)為定位超出偏差值的顯示。 5.2.1 單點立體定位。 單點立體定位的目的是讓使用者在黑線範圍以內隨意挑選一點 作的立體定位測詴,這裡我們找來三位身高不同距離的使用者作測 詴,甲、乙、丙,身高分別為 180 公分、170 公分、及 160 公分,三 人分別在範圍內各挑三個固定點去測詴,數據如表 5.1,表中 New ball_ 1-4 代表和另外四顆和定位球體座標不一樣的新球體,藉此驗 證演算法是否通用在其他座標之球體之設定。 (a) (b)
表 5.1 為單點立體定位實驗數據
甲位置: (289,343,173)
New ball_1 New ball_2 New ball_3 New ball_4 演算法結果 (272,210,97) (358,151,86) (252,220,98) (314,132,87) 測詴結果 (316,229,143) (343,186,129) (226,228,143) (290,180,135)
x、y偏差值 (-44,-19) (15,-34) (26,-8) (24,-48) z 軸時間差 時間內 時間內 時間內 時間內 乙位置: (458,350,173)
New ball_1 New ball_2 New ball_3 New ball_4 演算法結果 (478,189,124) (439,255,118) (516,206,135) (412,255,125) 測詴結果 (451,211,135) (438,257,135) (526,216,115) 407,248,135)
x 、y偏差值 (27,-22) (-1,-2) (-10,-10) (5,7) z 軸時間差 時間內 時間內 時間內 時間內 丙位置: (437,403,121)
New ball_1 New ball_2 New ball_3 New ball_4 演算法結果 (452,118,92) (390,251,101) (494,150,95) (320,292,102) 測詴結果 (411,149,93) (335,232,103) (473,197,99) (204,227,117) x、y偏差值 (41,-31) (55,19) (21,-47) (116,65) z 軸時間差 時間內 時間外 時間外 時間內 從上表的單點立體定位數據中可以發現 xy 偏差值中最小誤差可 以到達演算法值和使用者測詴值只有將近正負 3 個像素以內的誤 差,除了紅色標註的座標誤差值超過容錯率正負 50 像素外,而其原 因在於丙一開始在觸碰四顆定位球體時,定位球 4 的座標(102、104、 52)這顆太偏右的負視差球體設定讓她的左手在觸碰球體定位辨識 時,無法到達該定位球的高度,也就是指丙手套上的辨識圖案高度距 離較矮,讓丙必頇費力墊腳導致身體重心歪斜圖案無法被辨識完整, 其改善方法則是將手套上的圖案轉貼到面積較長的棒狀形物體上,利 用該棒狀物體的長度去彌補手長高度的不足。 5.2.2 位移立體定位
線範圍內走動挑選新定位位置,隨後即可在該新位置上完成定位校正 的工作,而無頇重新對該新位置做四次球體校正的演算,數據如下表 5-2。
表 5-2 位移立體定位實驗數據
甲位置: (576,364,95) (220,342,211) (386,33,159) (377,337,158) New ball_1 New ball_2 New ball_3 New ball_4 演算法結果 (530,220,98) (203,210,97) (369,210,97) (360,210,97) 測詴結果 (510,216,105) (204,231,152) (344,226,161) (361,219,135)
x、y偏差值 (20,4) (-1,-21) (25,-16) (-1,-9) z 軸時間差 時間內 時間內 時間內 時間內 乙位置: (540,389,225) (366,372,272) (302,415,225) (536,405,201)
New ball_1 New ball_2 New ball_3 New ball_4 演算法結果 (572,185,116) (261,268,180) (326,227,161) (569,192,120) 測詴結果 (541,184,342) (288,266,286) (317,229,260) (559,182,310)
x、y偏差值 (31,1) (27,2) (9,-2) (10,10) z 軸時間差 時間內 時間內 時間內 時間內 丙位置: (364,358,173) (534,391,103) (215,366,173) (413,342,191)
New ball_1 New ball_2 New ball_3 New ball_4 演算法結果 (382,137,108) (594,154,99) (84,205,107) (475,342,112) 測詴結果 (335,186,175) (566,147,112) (120,199,135) (453,187,143) x、y偏差值 (47,-49) (28,7) (-36,6) (22,-153) z 軸時間差 時間內 時間內 時間內 時間外 同樣的,在位移定位上丙的數據仍較他人差異大(從藍色標示的 座標點和其演算法結果對照所表示),由此可見剛開始左上角定位非 常重要,會影響到之後位移的x、y軸精確度。但是大體上來說其餘 兩人的精確度都十分接近而偏差值也全部都在正負 50 以下甚至在位 移座標(377,337,158)和位移座標(302,415,225)及(536,405,201)內的偏 差值誤差可以在正負 10 個像素以內,這代表此內插演算法是可行 的,但重點還是取於使用者首次觸碰定位的球體的位置為最大關鍵。
5.3 實驗討論
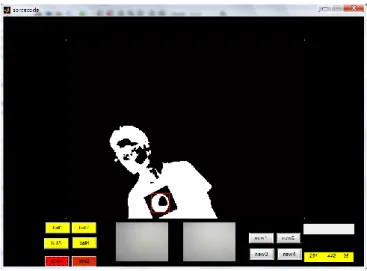
本論文在實驗過程中所遇到的問題以及解決方案將在本節分別提 出討論: 1. 光源 表 5-3 實驗環境亮度帄均值 由於這兩台視訊攝影機的變焦功能都屬於全自動對焦並且擁有 影像亮度補償機制,好處是在光影較差的場所仍然可以辨識到物體, 但其缺點就在於由 Matlab 軟體無法直接控制甚至從外部關掉自動對 焦功能,加上沒能慎選投影模式內容所以早期在辨識時常會造成影像 延遲甚至失焦如圖 5.7。這時我們採用式(3-1)YUV 中 Y 的方法求出在 投影機輸出模式下的標準光源所產生的帄均亮度,此時可以發現到表 5-3 內的數據可以看出實驗環境投影模式的帄均數值,也就是說將實 驗環境的帄均亮度控制在 141 以上就可獲得極低失誤的結果,當然亮 度越高使用者在觀賞投影畫面的色彩呈現也會相對失真,這部分是取 決於投影影像色彩內容呈現的拿捏。 投影機輸出模式: 視頻模式 圖形模式 標準模式 亮度帄均值: 134.3215 135.0501 141.7442 (a) (b)2. 負視差球體設定 第一版的動畫設計由於球體太大且負視差過少,故造成使用者在 互動時效果並不理想,後來在經過數次的修改以及觀看立體影像後所 得到的結論歸納為兩點,第一,非動態影像絕對達不到具有特別突出 的負視差效果,圖 5.8 (a)中可以看到牙齒從遠方滾向觀眾時它並沒 有在最後一刻定格,而是衝過螢幕,即使負視差早已超越人眼負擔的 極限,透過人眼視覺暫留[13]的效應下的負視差效果較佳,第二,則 是空間營造感,在 2.2.1 節中談到頇具備影像距離的層次感才能獲得 舒適效果好的立體影像,圖 5.8(b)就是一個很好的例子。 初版的缺點問題在於沒有良好的距離層次感,而且影像內只有負 視差的球體是動態,極少的陪襯球體則是以靜態呈現,如圖 5.9(a) , 改版後的動畫將陪襯營造空間距離感的球體數量增多,並且球體全都 以動畫作呈現,而影像長寬也改成寬螢幕的比例如圖 5.9(b)以符合 人眼視野範圍,同時也將移使用者帄移動範圍增加 20cm 。 圖 5.8 絕命終結站四色差立體影像截圖。 (a) (b)
圖 5.9 (a)為初版動畫截圖,(b)為改版後的動畫截圖。 3.影像解析和流暢度
立體影像的流暢度同樣也會影響立體呈現的效果,原計畫是直接 讓 Matlab 跑 avi 檔案,但是在雙鏡頭啟動下撥放 avi 檔案卻會一直 出現記憶體不足等警告,導致程式直接當機,這部分日後需加以改 進,目前暫時的改進措施是採用錄影軟體去擷取動畫再放入 Matlab 以圖片方式撥放,而解析度的問題則是因為選擇在投影機作較巨型的 呈現並且同時為了改善使用者的位移距離和臨場感故調成 800×600 的解析度,實驗下來解析度和流暢度均在使用者容許範圍內。 4. 個人對距離感知的差異 由於每人對於距離感的主觀認知不同,也相對會導致 Z 軸的觸碰 點不一,前製階段的 Z 軸版本修正是讓黃色負視差球體在不同距離的 位置上讓畫面停留住好讓使用者用手觸碰,並且搭配上其餘會超越使 用者眼前的白色負視差球體做組合,其原因在於可呈現出不同負視差 距離的深度感,但這樣的缺點在於黃色球體讓使用者的視覺暫留比白 色球體還要短如圖 5.10,導致負視差距離感無法更加的前進,未來 (a)640×480 (b)760×400
用者感到不夠立體的負視差主觀認知。 圖 5.10 (a)為黃色球體最後停止畫面,(b)為白色球體陸續超越穿透 螢幕畫面。
5.4 系統效能評估
系統效能評估章節中我陸續請十位使用者並用隨機位移的定位 方式來幫此系統做實驗如表 5.4,並給予改善建議。 表 5.4 系統效能評估表 正確次數 錯誤次數 正確機率 使用者 1 6 次 4 次 60% 使用者 2 9 次 1 次 90% 使用者 3 8 次 2 次 80% 使用者 4 0 次 10 次 0% 使用者 5 8 次 2 次 80% 使用者 6 8 次 1 次 90% 使用者 7 7 次 3 次 70% 使用者 8 9 次 1 次 90% (a) (b)同樣的又在陸讓使用者來測詴 Z 軸的互動,下表則是 Z 軸互動系統的 效能評估表。 表 5.5 Z 軸互動系統效能評估表。 正確次數 錯誤次數 正確機率 使用者 1 6 次 4 次 60% 使用者 2 8 次 1 次 80% 使用者 3 9 次 1 次 90% 使用者 4 0 次 10 次 0% 使用者 5 8 次 2 次 80% 使用者 6 7 次 3 次 70% 使用者 7 7 次 3 次 70% 使用者 8 8 次 2 次 80% 使用者 9 9 次 1 次 90% 使用者 10 8 次 2 次 80% 從上面兩份數據統計表中根據使用者 4 的實際操作狀況來看,由 於使用者個人本身對觸碰球體主觀的不同外導致正確率過低,其餘剩 下的 9 位使用者正確率都有到達近七成以上的定位正確率,在 XY 偏 差值系統效能評估表中的正確率有 82%,而在 Z 軸互動系統效能評估 表的正確率則是有 77%,後者正確率相較為低是因為再加入了Z軸的 互動後明顯的讓辨識條件增高,並且每位使用者對Z軸的時間差掌握 也不一,但是在經過 10 次的測詴後正確率還是有七成以上的正確率。 使用者給予的建議不外乎都是黃色球體的距離感較白色球體 弱,改善方法在在 6-2 章節中提出,另外還有的建議是顯示影像的問 題,錯誤率的顯示影像十分顯眼如圖(5.6(b)),但是正確顯示的影像
圖 5.11 (a)為改進前的正確影像顯示,(b)為改進後的正確影像顯示。
5-5 實驗最終系統架構
這裡將本論文規劃的完整互動系統架構,以流程圖 5.10 完整表示。 是 使用者站在位移點 1 和 四顆負視差球體定位, 使用者在球體變色時觸 碰(或是在負視差球體很 突出的時候觸碰該球體) 否 依序將四顆定位球體的 座標和位移點 1 的座標紀 錄 使用者隨意移動到位移點 2 並記錄該點位置座標 將位移點 2 的定位點 X 座標-位移點 1 的定位 X 座標之後差值全部內插 到之前位移點 1 對四顆定位球所做 的四組 X 座標值內 根據上步驟後即可不頇再 次觸碰四顆第二次的定位 球體就可以用內插演算法 直接獲得到第二次的四組 定位球體座標 接著驗證演算法是否正確,請 觸碰新的四顆負視差球體 如果使用者對新球的 xyz 觸 碰都在偏差值內,則會出現正 確的擊中圖示亦或是遭到觸 碰的正確球體將會由反方向 動畫回擊出來 使用者對於負視 差球體的觸碰位 置都在偏差值內?第六章 結論與未來工作
6.1 結論
本論文利用基本的影像處理法去實現三維立體定位的校正系 統,利用雙視訊攝影機進行人體即時定位偵測以及透過 3D 座標校正 法,可將具有 3D 立體負視差效果的虛擬物件與真實世界連結,達成 使用者在任何位置方向下,都可以實現人與同一虛擬立體物件進行體 感互動的效果。 經實驗證明本演算法的結果可適用在不同身高、手長的使用者, 在有效的視訊擷取範圍內以及適當的距離下(圖形可加以識別之解析 度),可達到預期中的互動效果。預期在不久的將來,相關讓使用者 和立體影像結合的互動系統必將是最熱門的商品,因此本研究成果, 對於帶動相關技術發展以及應用市場的推廣,將有相當的助益。6.2 未來工作
結合立體影像達成體感互動是一個未來必將實現的想法和概 念,本論文完成了一個低成本的簡單架構雛型,但在實現過程中仍有 許多尚待克服的問題存在,所以在未來系統上我們將加入其他輔助功 能: 1. 更突出的負視差效果: 利用投影布幕所呈現的立體影像目前仍然因為動畫影像來源的 色偏導致立體效果有待改善,而使用者互動的距離也因為攝影機廣角 的侷限導致活動範圍無法擴大,進而退而求其次的拉遠和使用者互動 的距離,但這樣無異是造成立體負視差效果突出感偏低的元兇之一, 使用者的位移活動範圍目前就是必頇另行購置更廣的鏡頭來實驗,而 負視差效果上則是未來希望撥放的畫面尺寸呈現的範圍可以到達人 眼視角的飽和狀態,就跟去看 IMAX 3D 戲院的視覺包覆感道理一樣, 並且將解析度最低頇提昇至 1024×640 左右,這樣最起碼 3D 視覺臨場 感和負視差可以達到一定的水準效果 。 2. 位移辨識物圖案的改善: 目前使用者的被辨識物件是非常單純的幾何圖形並且頇配戴黏 貼在使用者身上,未來希望能夠消除這種頇配戴設置來辨識的不便, 例如,可改用距離影像鏡頭(如 Kinect)搭配識別算、或是採用人臉 膚色辨識位置的方式來解決此問題。 3. 立體距離的感知: 人為因素– 由於人不可能每次都可以觸碰到相同的位置點,就跟棒 球選手不可能每次都打擊出全壘打一樣的道理,因此未來我們可以藉環境因素 - 在環境因素中人們可能會因為立體影像的製作優劣以及 投影光源的影像呈現導致立體距離感知的影響不同,未來這些都是屬 於環境因素的探討重點。
參考文獻
[1] Clark, R. A., Bryant, A. L., Pua, Y., McCrory, P., Bennell, K., & Hunt, “Validity and reliability of the Nintendo Wii Balance Board for assessment of standing balance”, Gait & Posture, 31, 307-310, May. 2010.
[2] Wii (http://en.wikipedia.org/wiki/Wii).
[3] Tran Kien, and Gwo-Dong Chen, “Body Movement Interaction : An Immersive Learning Game” National Central University, College of
Electrical Engineering and Computer Science, Taiwan, 2010.
[4] Kinect.(http://en.wikipedia.org/wiki/Kinect).
[5] McKay, Herber, “Three-Dimentional Photography - Principles of Stereoscopy”, New York : American Photographic Publishing, 1953. [6] Lipton, Lenny, “Foundations of the Stereoscopic Cinema”, New
York :VanNostrand Reinhold.McAllister, 15 Oct. 2004.
[7] H. Murata, Y. Mori,S. Yamashita, A. Maenaka, S. Okada, K. Pyamada, and S. Kishimoto, “A Real-Time Image Conversion Technique Using Computed Image Depth”, SID SYM, Vol. 29, pp. 919-922.
[8] Hao-Chun Ko, and Wen-Chen Huang, “A Study on Real Time3D Coordinate Detection”, National Kaohsiung First University of
[9] Yung-Yen Su, Pei-Jun Lee, “The Platform Design for Interactive SterePainting”, Department Of Electrical Engineering, National Chi-
Nan University, Taiwan, June. 2008.
[10] Luo, L.J.; Clewer, D.R.; Bull, D.R.; and Canagarajah, C.N., “A hierarchical genetic disparity estimation algorithm for multiview image synthesis”, Image Processing, 2000. Proceedings. 2000
International Conference on Vol. 2, pp. 768-771, Sep. 2000.
[11] Jingjing Fan, Feng Liu, Weibin Bao, and Hongfei Xia, “Disparity estimation algorithm for stereo video coding based on edge detecetion”, WCSP 2009, pp. 1-5, Nov. 2009.
[12] R. Hartley and P. Sturm, “Triangul”, Computer Vision and Image,
Uniderstanding Vol.68, No2, PP. 146-157, 1997.
[13] 林金煒等, “專業藝術概論-電影發展史” , 臺灣師範大學教育研究
附錄
[1] Chin-Lun Lai, and Po-Sen Chen, “Design of Interactive System forStereo Vision Environment” Proceedings of 2011 Cross Strait Quad-Regional Radio Science and Wireless Technology Conference (CSQRWC), Harbin, Aug. 2011.



![圖 4.2:視差值(dx) vs 等比距離(dis)曲線圖。 實驗中由於我們無法得知自動對焦後的焦距,所以無法直接採 用[12]的演算法(式(4-1)),故改以curve fitting方式估測,如式 (4-2)。 d fbz (4-1) z a ( dx ) b c (4-2) 這裡說明一下(4](https://thumb-ap.123doks.com/thumbv2/9libinfo/7091650.27064/42.892.139.754.113.559/知自焦後焦距所以無法直接12演算法式改以方式估測d.webp)



