國 立 交 通 大 學
運輸科技與管理學系
碩 士 論 文
分析與預測波羅的海運價指數波動之趨勢
--應用模糊時間序列法
Analyze and Forecast the Fluctuation Trend of BDI
(Baltic Dry Index) by Fuzzy Time Series Method
研 究 生:陳彥廷
指導教授:謝尚行 副教授
分析與預測波羅的海運價指數波動之趨勢
--應用模糊時間序列法
Analyze and Forecast the Fluctuation Trend of BDI
(Baltic Dry Index) by Fuzzy Time Series Method
研 究 生: 陳彥廷 Student:Yen-Ting Chen
指導教授: 謝尚行 Advisor:Shang-Hsing Hsieh
國立交通大學
運輸科技與管理學系
碩士論文
A ThesisSubmitted to Institute of Transportation Technology and Management College of Management
National Chiao Tung University In partial Fulfillment of the Requirements
for the Degree of Master
In
Transportation Technology and Management
June 2008
Hsinchu, Taiwan, Republic of China
分析與預測波羅的海運價指數波動之趨勢
--應用模糊時間序列法
學生:陳彥廷 指導教授:謝尚行
國立交通大學運輸科技與管理學系碩士班
摘 要
不定期國際散裝海運市場接近於完全競爭市場,運價波動劇烈,市場價格由 市場供給與需求間所形成之均衡狀況而決定,使得散裝海運企業面臨著極大經營 風險與不確定性;企業期望尋求避險之策略,波羅的海運價指數 BDI(Baltic Dry Index)因應而生。根據不同船型以及航線在航運市場上的重要程度和所占權重構 成的綜合性指數,可藉由 BDI 的變化,看出散裝航運市場景氣之起伏。 過往研究多使用傳統時間序列模式,如灰色理論模式以及 ARIMA 模式預測 BDI 走勢;本研究提出以模糊時間序列模式對時變性 BDI 進行預測,針對歷史 資料的模糊性和模糊相關性的問題進行探討,將誤差項視為隸屬於相同的模糊語 意變數但隸屬度不同所造成的結果,進而建構短期預測模式,希冀能提供不同以 往的預測方式。 影響模糊時間序列的預測準確度有多種屬性,論域界定、區間分隔、模糊集 合定義、資料模糊化、模糊關係建立、預測轉換、反模糊化函數之選定,都是預 測模式中須注意之處;本研究結合以及修改文獻中較合理的屬性選定,建立單變 量以及 Type-2 模式,用於預測 BDI 之走勢,進而分析本研究模式之準確度以及 模式穩定性,發現屬性修改可得到良好的結果,值得後續研究。 關鍵詞: 波羅的海運價指數 BDI;模糊邏輯關係;模糊時間序列;模糊語意變數Analyze and Forecast the Fluctuation Trend of BDI
(Baltic Dry Index) by Fuzzy Time Series Method
Student:Yen-Ting Chen Advisors:Shang-Hsing Hsieh
Institute of Transportation Technology and Management
National Chiao Tung University
Abstract
International tramp bulk marine market is a perfectly competitive market. The market price depends on the equilibrium of supply and demand of the market. It makes the enterprise to confront enormous operation risk and uncertainty. Baltic Dry Index (BDI) provides a channel for hedge, which according to the important degrees and weight of different ship size and route. It is a comprehensive index. We could see the variation of bulk marine market condition by BDI.
Past research use ARIMA model or gray theory model to forecast the tendency of BDI. We propose a fuzzy time series model to forecast the time-variant BDI. We discuss the fuzziness and the fuzzy relation of history data. Finally, we construct two short-term models. We hope it could be a different forecast method from past research.
There are many attributions could affect accuracy in fuzzy time series model: define the universe of discourse, partition interval, define fuzzy sets, fuzzify data, establish fuzzy logical relationship and defuzzify forecast data. We combine the reasonable attributions from reference and build one-variable model and Type-2 model. We find the accuracy and robustness are improved. The method is worth further study.
Keywords: Baltic Dry Index (BDI), Fuzzy Logical Relationship (FLR), Fuzzy Time
致 謝
時光飛逝,不經意的畢業季節悄悄又到來,如今真的要正式離開單純的學生 生涯,到外面社會好好的打拼一番了;求學旅途中,不論是基礎學問、專業科目 或是品德教育,對於我的一生都有著重要的意義;但是歷程中學習如何突破困 難,學習合作或是獨立自主才是我覺得學到最可貴的。 研究所期間,謝老師的教學方針讓學生非常的自由,讓我能自主的研究有興 趣的議題,並且能很享受於研究的過程之中,使我的研究能力不受侷限並且能夠 有所長進;老師亦師亦友的態度,也讓我不會深感壓力,對於生活以及學業上的 建議以及協助,亦讓我深感溫馨;另也相當感謝口試委員高凱副教授、王賢崙副 教授能撥冗參與口試審查,能讓我的論文更臻完備。 謝 lab 的成員,在老師的風格帶領下,都相當和善,金樺和大鈞不僅僅是研 究中提供意見以及互相扶持的朋友,也是壘球系隊中,重要的夥伴;學樺和善親 切的態度也不會讓人有壓力,學妹認真盡責的做事,讓我也輕鬆不少,總之,研 究所能在謝 lab 度過,讓我真的沒有遺憾。 系壘跟啦啦隊是我大學以及研究所期間投入最多的課外活動,也是我最引以 為傲的團體;不論是曾經加入過,或是跟我奮戰到最後的隊友,我都非常感謝你, 因為你帶給我的不只是曾經相處的時光,或是美好的回憶;而是對我人格上的薰 陶以及個性上的琢磨,讓我能勇於突破難關,永遠正面積極的面對挑戰。 歆璇,可愛又愛耍寶的女友,感謝你對我付出的一切,我很慶幸能及時的發 現你的好,也很努力要珍惜著你,將來請多多包含囉。 家人是我精神大最大的支柱,雖然已經在外求學很久了,也已經獨立自主, 但是遇到難關或是心情低落時,想到家人都會讓我有著安全感;爸、媽,感謝你 們多年的照顧,將來換我照顧你們了。 陳彥廷 謹致 交大 2008 夏目錄
中文摘要
………
i英文摘要
………
ii誌謝
………
iii目錄
………
iv表目錄
………
v圖目錄
………
vii第一章
緒論……… 1
1.1
研究背景與動機………
11.2
研究目的………
11.3
研究範圍………
31.4
研究重要性………
31.5
研究方法與流程………
3第二章
文獻回顧……… 6
2.1
海運運價市場分析………
62.2
模糊時間序列文獻回顧………
8第三章
研究方法與理論基礎……… 11
3.1
模糊理論概念………
113.2
模糊時間序列基礎定義………
143.3
模糊時間序列預測步驟流程………
15第四章
數值試驗……… 22
4.1
波羅的海運價指數發展過程與計算方式………
224.2
預測結果………
234.3
模型穩定性測試………
484.4
比較分析………
53第五章
結論與建議……… 56
5.1
研究成果與結論………
565.2
未來研究方向與建議………
56參考文獻
………
58附錄一
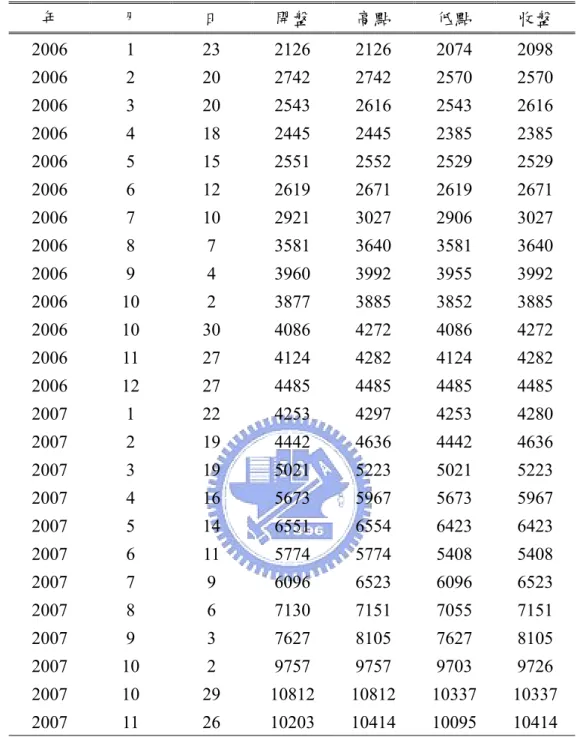
2006 年起 BDI 月資料………
60附錄二
2006 年起 BDI 周資料………
61附錄三
單變量預測 BDI 月資料………
65附錄四
單變量預測 BDI 周資料………
67附錄五
Type-2 預測 BDI 月資料………
71附錄六
Type-2 預測 BDI 周資料………
73簡歷
表目錄
表 1 Base mapping table………..……….……16
表 2 Base table………..…………...……….………17 表 3 單變量月資料之區間分隔表………..…………...………25 表 4 單變量月資料之模糊化對照表………..…………...………26 表 5 單變量月資料之模糊關係群聚表………..…………...………27 表 6 單變量月資料之門檻啟發式模糊關係群聚表…………..…………...………28 表 7 單變量月資料之預測語意變數表…………..…………...………29 表 8 單變量月資料之預測值………....…………...………..30 表 9 單變量月資料之指標數值………..…………...………....31 表 10 修正單變量月資料之區間分隔表…………...………....32 表 11 修正單變量月資料之模糊化對照表………...………....33 表 12 修正單變量月資料之模糊關係群聚表……...………....34 表 13 修正單變量月資料之門檻啟發式模糊關係群聚表………...34 表 14 修正單變量月資料之預測語意變數表…...……….…...35 表 15 修正單變量月資料之預測值…...……….…...36 表 16 修正單變量月資料之指標數值...……….…...36 表17 單變量周資料之區間分隔表...………….……….…...38 表18 單變量周資料之模糊化對照表………….……….…..39 表 19 單變量周資料之模糊關係群聚表…….…...……….…..40 表 20 單變量周資料之門檻啟發式模糊關係群聚表………...41 表 21 單變量周資料之預測語意變數表…….…...……….…..42 表 22 單變量周資料之預測值...………….……….………..43 表 23 單變量周資料之指標數值………….……….……….43 表 24 Type-2 月資料之區間分隔表….…….……….……….45 表 25 Type-2 月資料之模糊化對照表….….……….……….46 表 26 Type-2 月資料之模糊關係群聚表.….……….……….47 表 27 Type-2 月資料之門檻啟發式模糊關係群聚表……….………...48 表 28 Type-2 月資料之預測語意變數表.….……….……….49 表 29 Type-2 月資料之預測值...………….……….………...50 表 30 Type-2 月資料之指標數值………….………...51 表 31 修正 Type-2 月資料之指標數值….………..51 表 32 Type-2 周資料之指標數值………..………..51 表 33 穩定性測試調整之月資料………..……….51 表 34 穩定性測試調整之周資料………..……….52 表 35 單變數穩定性測試指標數值……..……….53 表 36 Type-2 穩定性測試指標數值……..………...53
表 37 整合兩模式預測指標數值……..………...54 表 38 整合兩模式穩定性預測指標數值………...55
圖目錄
圖 1 2006 年起 BDI 月走勢圖………2 圖 2 2006 年起 BDI 周走勢圖………2 圖 3 一般化之模糊時間序列預測流程圖………..………..………...…4 圖 4 研究流程圖………..……….…5 圖 5 Distribution based 累積分布圖.………...………16 圖 6 Ratio based 累積分布圖………...………18 圖 7 三角隸屬函數圖…..………...………19 圖 8 梯形隸屬函數圖 ………..………..………...………19 圖 9 單變量月資料之 Ratio base 累積分布圖………..………...…………...…24 圖 10 修正單變量月資料之 Ratio base 累積分布圖……..………...…………..…..31 圖 11 單變量周資料之 Ratio base 累積分布圖………..………...……….37第一章 緒論
1.1 研究背景與動機 全球經濟已無法抵擋全球化的趨勢,產業全球化分工的態勢也愈趨明顯,使 得全球貿易近年來不論是貨櫃船或散裝船的運載量皆不斷成長;再加上近年巴 西、俄羅斯、印度和中國「金磚四國」(BRICs)等新興國家成為世界經濟體系中 一股強大的力量,其因土地遼闊、腹地廣大,且具有低廉的勞力資源、富饒的礦 產資源,市場的潛力逐漸擴展,成為具有吸引力的投資地區,也激起經濟活動的 發展。 不定期國際散裝海運市場接近於完全競爭市場,運價波動劇烈,市場價格由 市場供給與需求間所形成之均衡狀況而決定;散裝船噸需求面受到全球經濟景氣 循環、季節性、長假期、天候與政治等影響;船噸供給方面則受到新船訂單數與 逾齡船解體數間增減量影響,因此,市場供給與需求平衡條件隨時發生變動,市 場價格也隨時呈現上下波動。散裝航運市場運價波動不易預測與掌控的特性,使 散裝海運企業面臨極大經營風險與不確定性,因此散裝航運企業迫切需要有一套可供避險交易平台,波羅的海乾散貨指數BDI(Baltic Dry Index)因應而生,期間
經過不斷改制跟新,根據不同船型跟路線依其在航運市場上的重要程度所占權重 構成的綜合性指數,藉由BDI 的變化,即可看出散裝航運市場景氣之變化。 自2003 年以來,波羅的海乾散貨指數因受到全球化以及金磚四國經濟起飛 的帶動,2004 年年初達到第一波高點,期間雖因海運季節性景氣循環以及中國 宏觀調控使運價下跌;2007 年年初又因澳洲塞港問題,供給不及需求,運價驟 升,4 月時已回升至前波高點水準,雖然又因為美國次級房貸等因素干擾回檔, 但2008 年的北京奧運及 2010 年的上海世博會,使得鐵礦砂需求增強,指數不如 往常的季節性下滑,船噸供給嚴重不足,使得BDI 自 2007 年 6 月回檔後,上升 幅度驚人(圖 1、圖 2)。 短期內海運市場看好,不定期散裝市場更是供不應求;BDI 能提供給船東、 租傭船人作為經營高風險之不定期船市場決策之參考,若能準確預測指數變化, 就能降低風險,達到避險之措施,為企業帶來更高利潤。 1.2 研究目的 準確的預測方法,能提供更為穩定的判斷,在高風險性及不確定性高的不定 期國際散裝海運市場,若能準確的預測 BDI 變化,完成完善的避險策略,定能 降低企業風險,並提升企業利潤。
BDI 0 2000 4000 6000 8000 10000 12000 1 3 5 7 9 11 1 3 5 7 9 11 1 3 時間 指數 圖1 2006 年起 BDI 月走勢圖 BDI 0 2000 4000 6000 8000 10000 12000 1 2 4 6 8 10 12 1 3 5 7 9 11 1 3 4 時間 指數 圖2 2006 年起 BDI 周走勢圖 過往研究預測 BDI 已有利用灰色理論模式以及 ARIMA 模式預測其走勢變 化;亦有關於季節性波動之研究。傳統時間序列建構上雖已經解決許多面向的困 難點,也證明了數學建構上的理論,但多重的限制式,無法反應現實情況,資料 的模糊性和模糊相關性的問題皆為傳統時間序列無法解決的問題,而且追求精確 數字的資料展現,其背後卻有過度解釋的重大危險;倘若結合較穩健性與符合實 際狀況的模糊統計分析,可避免隱藏這些問題。Zadeh【20】首先提出模糊集合 論,成功的解決了傳統集合0-1值邏輯無法解決的問題,也成功的將模糊概念帶 入了決策分析、人工智慧、經濟以及控制等方面的領域;直到 Q Song 與 B.S Chissom【21】建構以模糊關係預測模糊時間序列的模式,將模糊理論套入了預 測的領域,其針對歷史性的時間序列資料提出新的預測方法,定義了模糊時間序 列模型的基本架構,一般化預測模式建構的流程與方法,資料處理及模糊相關矩 陣的計算準則,證明了有較佳的預測能力。
本研究冀望能運用模糊時間序列模型的優點,建構完整且符合現實的模式供 預測之用,進而探討 BDI 走勢變化,對其未來走勢作出預測,希冀對船東、租 傭船人提供營運上之參考。 1.3 研究範圍 國際海運運價大體可分為不定期船運價和定期船運價,前者的費率水準隨航 運市場的供需關係而波動,在市場繁榮時期,不定期船運費率就會上漲;在市場 不景氣時,就會隨之下跌。後者由貨櫃公會和經營人確定,多與經營成本密切相 關,在一定時期內保持相對穩定。本研究針對不定期國際散裝海運市場運價進行 分析,蒐集2006 年後 BDI 最新改制過的週、月之開、收盤資料以及周期間最高 點以及最低點,以供預測之用。 1.4 研究重要性 海運業因期初沉沒成本極高、回收期長,導致進入此行業之門檻很高;而且 對已經在營運的不定期散裝海運企業,又面對著相當競爭的跨國性市場,無運價 表,完全由市場供需決定運價及租金,且又具備運輸的不可儲存性,以及再加上 海運產業經濟直接受到整個世界經濟景氣週期興衰起伏的影響,具有高風險及不 確定性。 傳統上不定期船航商所採用之避險方式多為買賣船舶或是合約簽訂,但其缺 乏彈性又不完全可靠;自1985 年設立了波羅的海國際運費期貨交易所,運費期 貨成為了不定期航運的新避險工具。經過期間不斷的改制跟新,BDI 根據不同船 型與路線依其在航運市場上的重要程度與所占權重構成的綜合性指數,藉由BDI 的變化,即可看出散裝航運市場景氣之變化。 準確的預測 BDI 走勢變化是不定期船海運業者營運中重要的決策依據;過 往預測 BDI 指數都無法反應現實情況,資料的模糊性和模糊相關性的問題皆無 法解決。本研究使用模糊時間序列模式預測短期 BDI 走勢,將誤差項視為歸屬 於相同的模糊語意變數但隸屬度不同所造成的結果,運用 BDI 歷史資料進行模 擬預測,希冀能提供船東、租傭船人營運之參考。 1.5 研究方法與流程 本研究採用以下研究方法 1.文獻研析法:
藉由分析國內外有關模糊時間序列的相關文獻,經由回顧評析,藉以比較分 析其內容合理性與優缺點,並找出其對模糊時間序列預測步驟內重要屬性的貢 獻,以作為本研究的參考。 2.模式分析法: 本研究將建構BDI短期預測模式,藉此預測未來BDI趨勢變化,除了進行單 變量模式預測外,亦加入Type-2模式進行預測比較;將以In sample資料組準確度 評量模式配適度,Out sample資料組準確度判定模式優劣,並以隨機數值調整測 試模式穩定性。 3.模糊時間序列分析法:
本研究採用模糊時間序列來預測BDI,自Q Song 與B.S Chissom【21】定義 了模糊時間序列模式的基本架構,並且一般化預測模式建構的流程與方法後,後 續研究者皆以此架構進行各屬性研究,預測流程如下圖3: 圖3 一般化之模糊時間序列預測流程圖 決定模糊關係 模式預測 模糊化歷史資料 定義模糊語意變數 區間分隔 定義論域 反模糊化 A. 根據歷史資料定義論域:將歷史資料中之最大值以及最小值各加減一適 當之正數,界定成模式所討論的論域U。 B. 區間分隔:將論域合理的分割為數個區間。
C. 定義模糊語意變數:將各區間定義為一語意變數。 D. 模糊化歷史資料:將歷史數值經由隸屬函數模糊化後,隸屬到所屬之語 意變數。 E. 決定模糊關係:將各期之歷史數值模糊化後之語意變數間,建立模糊關 係。 F. 預測:利用轉換後之語意變數與模糊關係預測未來之語意變數。 G. 反模糊化資料:將所預測之語意變數反模糊化成確定性數值。 本研究將結合文獻中各步驟屬性優良的部分進行修改,進而建構一完整的模 式進行預測。 本研究之研究流程如下: A. 研究範圍界定:本研究針對不定期國際散裝海運市場進行分析,以模糊時間 序列對BDI 進行分析預測。 B. 資料蒐集:針對研究範圍,蒐集 BDI 週、月之開、收盤資料以及周期間最 高點以及最低點,以供預測之用。 C. 針對模糊理論以及模糊時間序列文獻進行研讀,並對其使用基礎,理論架構 以及定義進行研究。 D. 模式建立:將歷史精確數值資料轉換為模糊時間序列進而建構時變性模型。 E. 實證預測分析:檢驗模式準確度以及穩定性,比較本研究兩模式之優劣。 F. 結論與建議:總結本研究之成果以及貢獻,並提出後續研究走向建議。 模糊時間序列 文獻回顧 模糊理論 資料蒐集 研究範圍界定 模式建立 實證預測分析 結論與建議 圖 4 研究流程圖
第二章 文獻回顧
影響航運經營管理之關鍵因素,除海上風險之外,最主要有(1)海運市場風 險(Freight market risk)、(2)燃料價格風險(Bunker price risk)、(3)利率風險(Interest rate risk)與(4)幣值風險(Currency risk)等四項。成功的船東須了解收益之不確定性 較成本之不確定性重要,能掌握不確定因素者即是贏家,然而航運市場風險是風 險最重要的部分。運費與租金深受航運市場船貨供需之影響,極度不易掌握,若 可預先安排與估算,並有效分析航運市場與運價之變化,當可增加航次利潤。 傳統時間序列模式太強調精確數字的預測資料展現,並有太多不合實際的假 設;而模糊時間序列模式針對歷史資料多種屬性進行探討,證明了有較佳的預測 能力,能提供更為穩定的判斷。 2.1 海運運價市場分析
Bendall and Stent【13】指出,航運公司須面對高度競爭的環境,通常是在 不確定情況下進行策略性決策。同時航運是服務性產業,會隨全球貿易需求與型 態而變動。由於市場之不確定性,航運間或取決於不可預知的變動因素,對其航 運收益必有重大影響。當景氣繁榮時,運價連帶上升;反之,當景氣蕭條時,船 東須面對運價下挫局面。因此,航運事業之經營,有必要作好策略性規劃,管理 的意義即是在不確定性下作決策。 溫珮伶【4】先探討海運市場運價決定機制及影響因素,其後以 GARCH(1,1) 模型結合自我迴歸項,進行海運價格間的交互影響效果實證分析,以及分析海運 價格與其他影響海運價格的重要經濟變數之間的交互影響。研究結果發現,油 價、煤價及鋼價等原物料價格皆會影響到海運市場BPI、BCI 的價格,原物料價 格上漲時,運價也會隨之上揚,此意謂原物料的需求會推動海運需求量。從研究 實證中得知,海運價格BPI、BCI 的不確定性高,且運價的變動率均會受自身前 期影響,此說明了儘管影響海運市場價格之因素雖無法正確預測,然前期運價在 經營者制定決策時亦為一重要的經濟因素。 陳永順【2】提出散裝乾貨船無固定航線或限定區域,且營運大多形成單向 有貨、回程無貨的現象,貨載流向長期易受新興工業化國家發展、新礦區開發及 主要原料供需國家政策改變等產生結構變動。影響因素可能有重疊出現或甚至交 互效應影響,導致引發投資人心理作用,過度反應。由於船噸供給與需求量不易 以模型量化來估計預測,故迄今仍無法找到合適的計量模型供市場預測價格,市 場投資者大多以簡單相對程度判定市場可能走勢與上漲或下跌程度來協助擬定 投資決策。雖然依貨載型態需求將市場區分為三種大小型態船舶,包括海岬型船
市場、巴拿馬極限型船市場與超極限型船市場,此三型船市場價格行情變動相差 某一定程度時,彼此會產生替代效果,因此價格變動受到牽制或拉引作用。 海運市場依船舶營運型態分類可分為:定期船運輸與不定期船運輸。定期船 運輸是指船舶運輸有固定航線、固定靠泊港口、固定費率表,以提供眾多託運人 服務,運輸服務業者扮演公共運送人角色,目前多半是指貨櫃船運輸型態。不定 期船運輸是指在船東以追求市場最高利潤為導向下,不限定航線或貨載而選擇出 最佳營運操作與最佳船舶配置,ㄧ般將船舶當作商品化並視現在及未來市場的條 件,在船舶租傭船市場訂定私人合約,在此情況下,不定期船運輸型態具有多元 化且高度彈性,營運管理與經營策略與定期船運輸截然不同,也因市場價格差異 的特性,而導致業務行銷與交易型態不同。 散裝船是以租約為主要經營模式,方式有空船租賃、論時傭船、論程傭船及 長期合約四種為主。空船租賃是租船人擁有絕對的控制權,須負擔所有費用,但 基於風險考量,船東一般不願意,因此現在較少看到。論時傭船是指船東在一定 期間內,將船舶出租,報價方式是依船舶大小以每日若干美元計算。論程傭船是 船東將船舶的全部或部分空間出租,來運送承租人所託運的貨物,報價方式是依 貨物種類,以每噸若干美元計價。長期合約是船東與租船人雙方事先簽訂長期合 約,期間為1 年或1 年以上,甚至可長達3年,依不同的租約方式而有所不同, 簡易分為現貨價及合約價。 陳澄隆【3】曾彙整歸納定期海運及散裝海運業有以下相同的經營特性: 1.資本密集性:龐大的沉沒成本,固定成本高且回收期長,故進入障礙高,公司 負債比率高,利率之波動亦會影響航商之獲利。 2.全球性產業:為跨國性產業,國際性色彩濃厚,各海運公司競爭激烈,全球經 濟景氣興衰、原物料價格之高低、天候、匯率及船噸供需等因素均與航商之營 運息息相關。 3.完全競爭:國際性的物流服務業,相同航線上有多家同業競爭,且面臨空運、 陸運業者的競爭,使得海運業者均為價格接受者,無單一訂價能力。且在散 裝海運市場中,所運送之貨物多為低價的初級產品,託運人對運價的負擔能力 低。 4.景氣循環:海運產業通常會循不景氣、衰退、持平、向榮、過熱之軌跡反覆 演變,大致二至三年為一小週期,五至七年為一大週期。其週期常受天候、 戰爭、政治及經濟等影響。 5.季節性:散裝海運貨物以煤、鐵礦砂以及穀物等原物料為主。由於北半球主要 穀物出口國收割季節在春、秋兩季,而南美洲與澳洲的穀物、煤集中於3 月出 口,因此傳統海運旺季為每年10 月至次年4 月。定期海運貨物以半成品、成 品為主,其運量的季節性變化亦相當大,貨源的不穩定性影響了海運業者的經
營狀況。 6.產品不可儲存性:提供的運送服務具有艙位不可儲存性,啟航後若有多餘之艙 位則立即失去價值,故航商無不希望其船隊艙位能充分的利用。 7.去回貨載不平衡:貨櫃運輸因貨物本身種類及貨物質量輕重不同,且各國國際 分工方式不一,使遠洋洲際航線上,貨櫃供需數量不平衡,如在越太平洋航線上, 東向貨物大多為勞力密集產品,以紡織品及鞋類為大宗,其貨櫃量往往較大,西 向貨物常為高價商品,其貨櫃量較小,造成兩端貨櫃數量不易調配使用。 而目前海運產業發展的有以下趨勢
1.船隊規模擴大:Clarkson Research Studies 市場研究部預測市場上的散裝船船噸 將快速增加。雖然交付船噸增加,短期仍然供不應求,以致新船、二手船價格 節節高升,高齡船舶可暫時紓緩供需緊張,因此船東拆解船舶之意願不高。全 球對船噸需求的增加,航商為了降低海運成本及考量船舶航次之規模經濟,船 舶大型化趨勢日益明顯。大型船舶因運載能力增加,人事成本減少,且每單位 (噸)分擔的港埠費用相對降低,對航商而言較具成本競爭優勢。 2.港口擁擠問題日益嚴重:造船技術進步加上貨運量增加迅速,海運市場在規模 經濟的驅動下,紛紛採用大型化的船舶以增加船噸供給,然而全球港埠碼頭基 礎設施卻因場地狹小而無法配合大量貨物的裝卸,以致於全球港口擁擠問題日 益嚴重,造成船期延誤,船噸供應更顯不足,進ㄧ步使得運價高漲。為解決港 埠擁擠的關鍵是重視港埠碼頭硬體設施的建設,但港埠硬體設施建設成本高昂 且需要長時間建造,在短期內港口擁擠問題對海運業者仍是一大隱憂。 BDI是衡量國際不定期海運之乾散貨船運的權威性指數,指數值計算由目前 市場上海峽型、巴拿馬極限型、輕便極限型,三種散裝貨船型主要航行路線所洽 定之運價,作權重運算所得之數值,在乾散貨船運市場上供其他同業在洽約定價 之參考定價,為呈現市場景氣重要指標之一。 2.2 模糊時間序列文獻回顧 自Zadeh【20】提出模糊集合論作為測試不明確隸屬度的工具以來,許多的 模糊領域的研究都以此方法當為理論架構,成功的解決了傳統集合0-1值邏輯無 法解決的問題(式 1),亦成功的將模糊概念帶入了決策分析、人工智慧、經濟、 心理學以及控制等方面的領域;直到Q Song, B.S Chissom【21】建構以模糊關係 預測模糊時間序列的模式,將模糊理論套入了預測的領域。 A 1, X ( ) 0, x A x x A ∈ ⎧ = ⎨ ∉ ⎩ ………(1)
的時間序列資料提出新的預測方法,定義了模糊時間序列模型的基本架構,並以
美國 Alabama 大學註冊資料為例,說明預測模式建構的流程與方法;並提出針
對非時變性【22】以及時變性【23】資料的模糊相關性矩陣的建立步驟,並提出 了高階次影響因素觀念和反模糊化的運算方式。
S.M Chen【24】簡化 Q Song, B.S Chissom【21】【22】【23】所提出的模糊相
關性矩陣的建立步驟,改以簡單的數學計算式代替複雜的Max-Min 組成運算式,
並提出模糊邏輯關係群聚(fuzzy logical relationship group)的觀念,證實模式準確
度優於Q Song, B.S Chissom【23】所建立的模式。
J.R Hwang, S.M Chen, C.H Lee【14】提出先以差分方式使歷史資料穩定的方 法,先預測未來變動量而非直接預測值,再將預測之變動量與前期值相加後得預
測值;建構之模糊相關性矩陣區分為window basis 以及 operation matrix,使模糊
相關性矩陣更為合理化,且運算時間更有效率,預測準確度也優於文獻模式【23】 【24】。 K Huarng【15】提出兩種啟發式模式改良 S.M Chen【24】的模式,由歷史 資料的上升以及下降關係建立啟發式的模糊邏輯關係群聚;一為單純由上升以及 下降的關係建立兩個前後期模糊邏輯關係群聚;令一加入了門檻值設定,上升以 及下降的程度必須要超過門檻值才認定顯著,進而建立三個前後期模糊邏輯關係 群聚。並針對過往文獻對於區間分隔過於武斷而提出兩種有效的分區方式【16】: Distribution based 和 Average based,說明區間分隔太大會造成無波動趨勢性的模 糊時間序列,無法得知歷史資料的變動趨勢,使預測準確度下降;而區間分隔太 小會導致與模糊時間序列的本意有牴觸,且預測結果說明,區間分隔越小,預測 準確度會越趨準確的說法並不成立。 H.K Yu【12】認為歷史資料中重複出現的模糊邏輯關係應進行加權的處理, 並根據模糊邏輯關係出現的頻次以及順序給於適當的權重,讓在反模糊化資料時 能充分表現出歷史資料所提供的資訊,並使用 K Huarng【16】所提出的兩種區 間分隔方法建構模式。
C.H Cheng, J.R Chang, C.A Yeh【6】認為文獻中對於區間分隔等長的設定無 法有說服力,且使用模糊時間序列文獻中從未使用的梯形隸屬函數去模糊化歷史
資料;提出Minimize entropy principle approach(MEPA)用於找出適當的區間分隔
中點,形成不等長的區間分隔;Trapezoid fuzzification approach(TFA)為不同於以
往文獻皆使用三角隸屬函數的方式,使各區間分隔內不僅僅一值的隸屬度為1;
K Huarng, Tiffany H.K Yu【19】亦提出一種使區間分隔不等長的方式,將區間長 度隨一比例逐漸增大,認定同一變動值在不同區間範圍內的效力不相等。
K Huarng, Tiffany H.K Yu【18】引入纇神經網路到模糊時間序列的預測模式 中,使用纇神經網路非線性的結構,運用回朔繁殖的方式進行預測,資料模糊關 係皆為一對一,中間的隱藏層僅僅分兩點。
S.T Li, Y.C Cheng【26】認為 S.M Chen【24】所提出的模糊邏輯關係群聚是 造成預測的不確定性因素,因而提出使用回朔追蹤系統去建立唯一且確定的模糊 邏輯關係,證明了歷史資料如要架構確定性模糊時間序列模式的最大階次以及最
小階次;且異於 K Huarng【16】的結論,此模式之區間分隔越小,預測準確度
會越趨準確。
C.H Cheng, T.L Chen, H.J Teoh, C.H Chiang【7】導入修正模式的概念以修正
模糊時間序列的缺點。延續了C.H Wang, L.C Hsu【8】以及 H.K Yu【12】的概
念,對區間分隔後分區進行再分區處理以及對模糊邏輯關係出現的頻次給於適當 的權重;重點是結合了非線性以及線性概念,在非線性的模糊邏輯關係推倒後, 反模糊化後再進行線性的修正,將預測值與上期實際值的差給於適當的權重,再 重新計算新預測值。
S.M Chen, J.R Hwang【25】首次將模糊時間序列的預測引入雙變數,結合 J.R Hwang, S.M Chen, C.H Lee【14】模糊相關性矩陣概念,進行矩陣運算時,加 入第二變數經模糊化後的模糊集合,藉由其他變數輔助預測主要變數;另一方面 K Huarng, H.K Yu【17】認為 type-1 模式中,經由隸屬函數決定的隸屬度為一明 確的值有缺陷,所以提出隸屬度有一模糊區間的概念;將此概念運用於同一變數
因時間等因素有不同面向值時,將其他面向值視為type-2,輔助預測。
F.M Tseng, G.H Tzeng, H.C Yu, Benjamin J.C. Yuan【9】和 F.M Tseng, G.H Tzeng 【10】使用不同於模糊時間序列的預測方式,而使用模糊 ARIMA 以及模糊迴歸 的方式進行季節性預測,先建立傳統ARIMA 或迴歸方程式,再進行參數的隸屬 度模糊化,而後求解各區間最小化模糊,各參數將得到一區間的數值,而預測值 也將是一區間的預測值。 模糊時間序列已經應用於許多領域的預測,新生註冊人數、股市、旅遊、交 通事故量、IT 產業成本、貨櫃量、機械工業產值以及財務方面,本研究將運用 於預測BDI 的走勢。
第三章 研究方法與理論基礎
3.1 模糊理論概念
模糊理論是由加州柏克萊分校 Zadeh 教授於 1965 年在 Information and
Control 期刊中發表了”Fuzzy Sets”【20】一文而誕生。現實生活中原本就存在著 許多模糊不清的事物,然而一般傳統數學是無法解釋模糊性和模糊相關性;模糊 理論就是把人類語言中的不確定性加以量化處理的一門學問,如此即可將模糊的 事物利用明確嚴謹的數學加以描述出來,彌補傳統集合(式 1)中二元值(0-1)的缺 點。
傳統古典數學以明確集合來表示集合的概念,只考慮所要討論的要素是否屬
於此集合。設U 為討論之論域,稱為宇集合,A 是U 的子集合,由隸屬函數X ( )A x
來表示元素x 是否屬於明確集合 A,表示式為X (x)A ∈
{ }
0,1 。 明確集合即是明確地分辨元素屬於哪一個集合,可在“是”與“否”之間做出清 楚的判斷,通常以0 與 1 兩數值作表示;但實務語意表達上通常難以做明確的區 分辨別,即是含有模糊、不明確的敘述。模糊集合,如同人類的思維模式,將二 值邏輯擴展成多值邏輯,除了以 0 和 1 來表示所隸屬程度外,並延展至介於 0 與1 之間的數值來表示。 隸屬函數將明確值0 與 1 二值的特徵函數擴展成[0,1]區間的連續值函數, A µ∼ 為模糊集合A的隸屬函數,隸屬函數的值 ∼ ( ) A x µ∼ 為表示元素x 隸屬於集合 的程 度, A ∼ 0 A 1 µ ≤ ∼ ≤ 。模糊集合的表示方式如下。[ ]
( ) 0,1
Ax
µ
∼∈
1 2 1 2 ( ) ( ) ( )...
i A A A i x x x x x x iA
µ µ µ=
∼+
∼+
=
∑
∼ ∼ 模糊集合的運算也有別明確集合:設 、A ∼ B ∼ 為兩個模糊集合,其歸屬函數為 A µ∼ 及 B µ∼ 。1.聯集: ( ) ( ) ( ) max( ( ), ( )) A B A B A B A B µ x µ x µ x µ x µ ∪ ∪ → ∼ ∼ = ∼ ∨ ∼ = ∼ ∼ ∼ ∼ x 2.交集: ( ) ( ) ( ) min( ( ), ( )) A B A B A B A B µ x µ x µ x µ x µ x ∩ ∩ → ∼ ∼ = ∼ ∧ ∼ = ∼ ∼ ∼ ∼ 3.補集: ( ) 1 ( ) A A A→
µ
x = −µ
∼ x常用的隸屬函數有四種,及Ζ-type、 Λ -type、Π -type 和S-type;而正規化
函數,表示此函數的隸屬度最大值為1,最小值為 0,定義如下: Ζ-type: ( ) x b, r b A x r x b µ − − ≤ ⎧ ⎪ < ≤ ⎨ ⎪ ⎩ ∼ 1, 若x r 若 0, 其他 Λ -type: , ( ) , x a r a x b A r b a x r x r x b µ − − − − ≤ < ⎧ ⎪ ⎪ ⎨ < ≤ ⎪ ⎪⎩ ∼ 若 1, 若x=r 若 0, 其他 Π -type: 1 2 1 1 2 2 , ( ) , x a r a x b A r b a x r r r x r x µ − − − − ≤ < ⎧ ⎪ ≤ ≤ ⎪ ⎨ b < ≤ ⎪ ⎪ ⎩ ∼ 若 1, 若 x 若 0, 其他 S-type: , ( ) x a r a A a x r x r µ − − ≤ < ⎧ ⎪ ≥ ⎨ ⎪ ⎩ ∼ 若 1, 若x 0, 其他 Π-type S-type Ζ-type Λ-type 這些隸屬函數優點為屬於簡單的函數,並且能滿足大部分的邏輯系統設計, 且容易理解,所以在實際應用上,可使計算效率提高很多。 模糊關係為假設R 為 X->Y 之模糊關係,其表示法為X→ ,S 為 Y->Z 的R Y 模糊關係,其表示法為Y→s Z,R 與 S 的合成為 T(T=R。S),T 則成為 X->Z 的
模糊關係其合成運算有多為下列兩種常用型式。 1. Max-min composition
( , ) ( ( , ) ( , ))
T x z y Y R x y s y z
X
= ∨∈X
∧X
2. Max-product (or max-dot) composition
( , ) ( ( , ) ( , )) T x z y Y R x y s y z
X
= ∨∈X
•X
反模糊化就是將模糊集合轉成一明確值,其方法有很多種,一般常用的方法 有下列幾種: 1.Max-membership principleÎ 以模糊數中最大的隸屬值作為反模糊化之值,先決條件是模糊數一定要是尖 峰形。 * ( )z
( )z
µ
∼ ≥µ
∼ c c for all z∈Z 2.Centroid methodÎ 將模糊數所形成的面積,以積分的方式求出所有面積和,再計算此面積的重 心,作為反模糊化值。 * ( ) ( ) zdz z dzz
z
µ
µ
• =∫
∫
∼ ∼ c c3.Weighted average methodÎ
利用所有的隸屬值當作權重,再以所有隸屬值的加總取平均值。 * ( ) ( ) z z z z
µ
µ
• =∑
∑
∼ ∼ c c 4,Mean-max membershipÎ 針對最大面積的模糊數,挑出最大的兩個隸屬值取平均,即為反模糊化值。 * 2 a b z = + 5.Center of sumsÎ 將各塊面積與面積中點值之隸屬值相乘並積分後,除以個別面積和之積分值,即為反模糊化值。 6.Center of largest areaÎ
類似Centroid method,差別在於只計算最大面積的重心,即為反模糊化值。
7.First (or last) of maximaÎ
找出最大面積的模糊數,以形成此面積的第一個最大值(最後一個最大值), 作為反模糊化的值。 3.2 模糊時間序列基礎定義 模糊集合的理論架構被Zadeh【20】提出後,它在理論和應用上均有顯著的 成就。人們開始利用這個理論架構創造新的研究方法,希望藉此理論的特性來處 理一些較無法量化的資料。 將模糊理論的概念應用到時間序列分析上,即為模糊時間序列,其將傳統時 間序列中以明確值表示的方式,改為以模糊集合表示的運算數值。定義如下: 定義1: 令
{
Y t( )∈R t, =1, 2,...n}
為一個時間數列,U 為其論域,給定U 的一個次序分割 集合,{
f ii, =1, 2,...r}
, 1 r i i f U = =∪
,其相對於語意變數為{
A ii, = 1, 2,...r}
,若在{
A ii, =1, 2,...r}
上 相 對 於 Y t( ) 的 模 糊 集 合 F t( ) 有 隸 屬 函 數 為{
µ1( ( )),Y t µ2( ( )),... ( ( ))Y t µr Y t}
,0≤µi( ( )) 1,Y t ≤ i=1, 2...r,則稱{
F t( )}
。 的集 合為佈於 上的一個模糊時間數列, ( ) F t ( ) Y t 1 1 1 2 ( ) ( ) ( ) ( ) t t ... r r Y Y A A A F t = µ + µ + + µ Yt 。 定義2: 如果模糊時間序列前後期F t 、( ) F t( 1)− 存在著一模糊邏輯關係R t( 1, )− t ,則存在 一關係式F t( )=F t( 1)− ×R t( 1, )− t ;表示F t( 1)− Î ( )F t 。 定義3: 令F t( 1)− = ,Ai F t( )= ,則此兩期的模糊邏輯關係可以表示為 Î , 稱為 LHS, 稱為RHS。 j A Ai Aj Ai j A定義4: 將所有的歷史資料模糊化後所隸屬的語意變數分群聚集,將相同的 LHS 和不同 的RHS 整理成一個群聚,而形成模糊邏輯關係群聚; ÎAi Aj,Ak。 定義5: 如果F t( )只受F t( 1)− 影響,且R t( 1, )− t 和時間t 是獨立的,則表示F t( )是非時變 性模糊時間序列,否則皆為時變性模糊時間序列。 定義6: 如果F t( )受到F t( 1)− andF t( − )2 ……F t( −n)的影響,則模糊邏輯關係表示為 , …… ( 1) F t− F t( − )2 F t( −n)ÎF t( ),稱之為n 階模糊時間序列模式。 3.3 模糊時間序列預測步驟流程
Q Song, B.S Chissom【21】以 Zadeh【20】之模糊理論為基礎,針對歷史性 的時間序列資料提出新的預測方法,定義了模糊時間序列模型的基本架構,並以 美國 Alabama 大學註冊資料為例,一般化預測模式建構的流程與方法,後續研 究者皆以此架構進行各屬性研究,預測流程如圖三,以下將詳述本研究整理文獻 中較為合理的。 1.定義論域:. (DMin−D D1, Max +D2) 其中D 、Min DMax為歷史資料中或是經差分後穩定序列數值的最小值以及最大 值; 、 為主觀認定的適當正整數,可使論域較容易分隔區間;亦或可以根 據步驟2 區間分隔所選取的方式,再根據其方法規定決定 和 。 1 D D2 1 D D2 例1:有一排序過之序列,{1,2,3,3,4,4,5,6,8,9},DMin=1、DMax=9,現設定 、 皆為1,則論域可定義為(1-1,9+1)Î(0,10)。 1 D 2 D 2.區間分隔: 根據文獻得知區間分割的求得方式整理為下列四種。 (1).主觀認定 由研究者主觀認定將其論域分隔為適當之等長區間。如例1,可將論域等分 為五個區間,{(0,2),(2,4),(4,6),(6,8),(8,10)} (2). Distribution based
表1 Base mapping table Range Base 0.1-1.0 0.1 1.1-10 1 11-100 10 101-1000 100 Distribution based 演算法 1.計算所有歷史資料一階差分的絕對值,並計算其平均值。 2.根據平均值,從 Base mapping table 決定 base for length。
3.根據步驟 2 的 base for length,畫出一階差分的絕對值的累積分布圖。 4.找出分布圖中最大的長度,此長度的累積數剛好大於資料筆數的一半。
例2:有一經差分過且取絕對值後排序之序列,{1,2,3,4,5,6,7},平均值為4,
從Base mapping table 決定以”1”當作 base 往上累加,由圖 5 之累積分布圖可得長
度”3”剛好是超過筆數一半的最大值,所以用長度”3”作為此例題的區間分隔長 度。 累積分佈圖 0 2 4 6 8 1 2 3 4 5 6 7 base length 筆數 圖5 Distribution based 累積分布圖 (3). Average based
根據K Huarng【16】所建立的 Base mapping table 進行演算法決定區間分割。
Distribution based 演算法
1.計算所有歷史資料一階差分的絕對值,並計算其平均值。 2.根據平均值,將其值取一半。
3.根據步驟 2 的值,從 Base mapping table 決定 base for length。
4.將根據步驟 2 的值 round down 到最適當的 base length 當作最終決定區間分 隔長度。
作base,所以 2 以”1”去 round down 還是 2,所以用長度”2”作為此例題的區間分 隔長度。
(4) Ratio based
根據K Huarng, Tiffany H.K Yu【19】提出之區間分隔方式,不同於(1)(2)(3)
之處,此分隔法將形成不等長的區間長度,會依循一比例逐漸將區間長度增大。 Ratio based 演算法
1.計算所有歷史資料一階差分的絕對值。 2.計算前後期變動率 r。
3.根據步驟 2 中最小值,從 Base table 決定 base of ratio。 4.畫出變動率的累積分布圖。 5.找出分布圖中最小的 ratio,此 ratio 的累積數剛好小於資料筆數的一半。 6.將歷史資料中最小值保留前兩位數,後面值全部無條件捨去,區間長度以 所選取的ratio 逐漸增大,到最大值能被內包含為止。 表2 Base table Range Base r<0.05% 0.01% 0.05%<r<0.5% 0.1% 0.5%<r<5.0% 1% 5.0%<r<50% 10% 例3:有一排序過之變動率,{0.21,0.25,0.32,0.5,0.78,0.8,0.9},r 的最小值為
0.21%,從 Base table 決定以 0.1%為 base of ratio 往上累加,畫出變動率的累積分
布圖圖6;可得 ratio”0.41%”剛好是小於筆數一半的最小值,所以用 ratio”0.41%” 作為此例題的ratio 增長基準;若此例題歷史值最小為 2378,將保留 2300,無條 件 捨 去 78 , 第 一 區 間 將 為 (2300,2300*1.041) , 第 二 區 間 將 為 (2300*1.041,2300*1.041^2),以此類推,到歷史最大值能在最後一區間內即可 3.定義模糊語意變數: 模糊語意值主要是表示區間值的程度,例如:變化很多,變化不多,或是沒 有 變 化… 等 , 如 此 即 可 依 照 資 料 值 的 程 度 , 定 義 其 隸 屬 的 模 糊 集 合 , 即
{
A
i,i=1, 2...,r}
為不同語意變數的模糊集合。模糊語意變數的定義如下:累積分布圖 0 2 4 6 8 0.21 0.31 0.41 0.51 0.61 0.71 0.81 0.91 Ratio 筆數 圖6 Ratio based 累積分布圖 1 1 2 ( ) / ( ) / ... ( ) / i i i r i u u u u u u A A A
f
f
f
A
= + 2+ + r………..(2)[ ]
( ) / 0,1 i l l u u Af
∈ 1 1 1.0 /u 0.5 /u 0 / ... 0 /u urA
= + 2+ 3 + 1 2 0.5 /u 1.0 /u 0.5 /u 0 / ... 0 /u urA
= + 2+ 3+ 4 + 1 5 3 0 /u 0.5 /u 1.0 /u 0.5 /u 0 / ... 0 /u urA
= + 2+ 3+ 4+ + ………. 1 0 / 0 / ... 0.5 / 1.0 / r r u u u uA
= + 2 + r-1+ 可根據研究議題,自行定義語意變數之意涵 4.模糊化歷史資料: 將歷史數值模糊化後,隸屬到所屬之語意變數;實際值若隸屬值最大在 範 圍之內,則屬於 之模糊集合;資料模糊化後,即可獲得每個模糊時間序列( ( ) 隸屬的模糊集合,再利用模糊集合代入模糊預測模式。 k u k A F t)) 根據文獻得知模糊化歷史資料的求得方式整理為下列兩種:三角隸屬函數=>使用三角形決定值的隸屬度 1 0 圖7 三角隸屬函數圖 梯形隸屬函數=>使用梯形決定值的隸屬度 1 0 圖8 梯形隸屬函數圖 5.決定模糊關係: 將各期之歷史數值模糊化後之語意變數間,建立模糊關係,文獻中求得模糊 關係的求得方式整理為下列兩種。 (1)模糊邏輯關係群聚 將相同的 LHS 模糊邏輯群聚,得到一關係式Ai →A A Ai, j, k..(i,j,k=1,2…..r), 視F t( 1)− 隸屬哪一個語意變數,選取所屬之關係式。
(2)高階次 window based and operator matrix
利用最相關的w階設定其模糊邏輯關係,而 值必須設定在2 階以上,才能 符合模糊邏輯關係之合成運算;以 代表模糊時間數列 w (t) C F t( 1− 的基準矩陣,) 代表 階的運算矩陣,兩者再作合成運算,即可求得模糊關係 w O ( )t w R t 之值。 ( )
[
1 2]
(t)= ( 1) . ... r C F t− = C C C 11 12 1 21 22 2 w ( 1)1 ( 1)2 ( 1) .. .. .. ( 2) .. .. .. ( 3) O ( ) .. .. .. ( ) r r w w w r O O O F t O O O F t t M M M M M O O O F t w − − − ∧ ⎡ ⎤ − ⎡ ⎤ ⎢ ⎥ ⎢ − ⎥ ∧ ⎢ ⎥ ⎢ ⎥ = =⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ − ⎥ ∧ ⎢ ⎥ ⎣ ⎦ ⎣ ⎦w ( ) O ( ) (t) R t = t ⊗C = 1 11 1 11 1 21 1 2 21 2 ( 1)1 1 ( 1)1 ( 1)1 ( 1) n r r n r r w w r w O C O C R R O C O C R R O − C O − C R − R × × ⎛ ⎞ ⎛ ⎞ ⎜ × × ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜= ⎟ ⎜ ⎟ ⎜ ⎟ × × ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ ⎝ ⎠ … … w− r 由上述公式即可得到的模糊邏輯關係式R t ( ) 6.預測: 利用轉換後之語意變數與模糊關係預測未來之語意變數,根據文獻得知模糊 關係的求得方式整理為下列兩種。 (1)模糊邏輯關係群聚預測 根據模糊邏輯群聚,從關係式Ai →A A Ai, j, k..以前期的語言變數預測出下期 的語言變數集。 如果是啟發式求解,求解前必須先決定 LHS 在哪些條件下會造成哪些 RHS,將規則訂好後,亦可加入些門檻值讓變化更多元。
(2)高階次 window based and operator matrix 預測
將R t( ) O ( )= w t ⊗C(t)每 column 的最大值求出,即可得到一模糊間時數列
,則隸屬度最大的為預測之語言變數。 ( )
F t
11, 21,..., ( 1)1 12, 22,..., ( 1)2 1 , 2 ,..., ( 1)
( ) max( w ), max( w )..., max( r r )
F t = ⎣⎡ R R R − R R R − R R Rw− r ⎤⎦ 7.反模糊化資料: 將所預測之語意變數反模糊化成確定性數值,根據文獻得知模糊關係的求得 方式整理為下列兩種。 (1)基礎法則 1.若預測出之語言變數為 none,則以前一期的語言變數當作預測語言變數, 預測值為該語言變數之中點值。 2.若預測出之語言變數 only one,則以此一語言變數當作預測語言變數,預 測值為該語言變數之中點值。
3.若預測出之語言變數 more than one,則以該些語言變數當作預測語言變 數,預測值為該些語言變數之中點值平均。
通式:在 中,若有 k 個最大值落在區間 ,且 區間中點值 分別為 ,則預測值如下。 ( ) F t u u1, ,...2 uk u u1, ,...2 uk 1, 2,... k m m m 1 2 ( ... ) ( ) m m mk Y t k + + + = ………(3) (2)權重修正 1.語言變數加權重:可依據出現的頻次以及順序於反模糊化時加上權重,反 應出重要性 1 1 2 2 ( ... ) ( ) f m f m f mk k Y t k + + + = 2.適應修正:可於初反模糊化後,進行修正動作,將預測值與上期實際值的 差值乘上一參數,再和上期實際值相加,參數由歷史資料中模擬學習得出 1 ( ) ( 1) *( ( ) ( 1)) F t =P t− +h F t −P t− ( ) F t 為最後預測值;P t( 1)− 為上期實際值; 為參數;h F t( )1 為初預測值。 以上為一般化模糊時間序列之預測流程,研究者可依循研究議題之特性,整 合及修改屬性。
第四章 數值試驗
4.1 波羅的海運價指數發展過程與計算方式
散裝航運市場運價波動不易預測與掌控,使散裝海運企業面臨極大經營風險 與不確定性,因此英國波羅的海海運交易所(Baltic Freight Exchange Ltd)仿美國芝
加哥商品期貨交易制度,於 1985 年創立波羅的海海運現貨指數(Baltic Freight
Index;BFI),於 1999 年被波羅的海乾散貨指數(Baltic Dry Index;以下簡稱 BDI) 所取代。該指數是由若干條傳統乾散貨船航線的運價,按照各自在航運市場上的 重要程度和所占比重構成的綜合性指數,納入三項乾散貨船指數:波羅的海海岬 型指數(Baltic Capesize Index,以下簡稱 BCI)、波羅的海巴拿馬極限型指數(Baltic Panamax Index,以下簡稱 BPI)與波羅的海超極限型指數(Baltic Supramax Index,
以下簡稱 BSI)加權計算而來。各指數分別代表不同船型,所包含不同路線於簽
訂運送契約時市場之參考運價,故藉由 BDI 的變化,即可看出散裝航運市場景
氣之變化。
波羅的海交易中心於1985 年 1 月 4 日開始發佈每日運費指數,稱為波羅的
海運費指數(BFI),是由全球主要十三條論程傭船路線(Voyage Charter routes)所組 成,並未包含論時傭船路線(Time Charter routes)。BFI 即迅速獲得全球航運業界 之接受,作為乾散貨運費市場最為可靠之總體指標。 發展階段: 一.第一階段(1985 年 1 月 4 日至 1988 年 11 月 3 日): BFI 包含三條海岬型船航線(15%)、五條巴拿馬極限型船航線(65%)與五條輕 便型船航線(20%),合計十三條運費航線所組成。 二.第二階段(1988 年 11 月 4 日至 1991 年 2 月 5 日): 在 1988 年 11 月 4 日將 BFI 組合航線中剔除一條輕便型船航線,之後 BFI 由十二條運費航線所組成。接著在1990 年 8 月 6 日將三條租金航線納入 BFI 組 合航線中,使BFI 組合航線達十五條。最後在 1991 年 2 月 5 日又將其中巴拿馬 極限型航線由新的海岬型船航線取代,以及再引入一條新的巴拿馬極限型租金航 線。 三.第三階段(1993 年 2 月 5 日至 1993 年 11 月 4 日): 1993 年 2 月 5 日再引入一條海岬型船租金航線,又於 1993 年 11 月 4 日將 輕便型船航線全部從 BFI 組合中剔除,自此之後 BFI 僅由海岬型船與巴拿馬極 限型船計十一條運費及租金航線組合而成。
四.第四階段(1998 年 12 月至 1999 年 11 月): 1998 年 12 月將 BFI 組合中的巴拿馬極限型與海岬型船航線各自分立,巴拿 馬極限型計七條運費及租金航線組成為 BPI,之後在 1999 年 4 月推出海岬型船 計九條運費及租金航線(在 2004 年 4 月增加一條航線,成為現在十條航線的組 合),同時也在 1999 年 11 月推出輕便極限型船六條租金航線組成 BHMI,自此 綜合指數BDI 即告建立,BFI 也於 1999 年 11 月終止使用。
BDI 為 BCI、BPI 及 BHMI 三船型指數各占 1/3 比例組成,波羅的海交易所
確保1999 年將 BFI 轉換為 BDI 後之連續性,建構乘數 α 作為 BDI 之調整(α=
0.99800799) , 建 構 乘 數 β 作 為 BHMI 納 入 BDI 計 算 時 之 數 值 調 整 (β = 0.112183226),以作為全球乾散貨市場的運價指標。 2005 年前 BDI 之計算公式為: BDI=[(BCI+BPI+BHMI×β)/3]×α 五.第五階段(2006 年~~) 波羅的海交易所公布,2006 年將以超輕便極限型指數(Baltic Supramax Index,以下簡稱 BSI)取代 BHMI 納入 BDI 作計算。在波羅的海交易所決定將 BSI 取代 BHMI 納入 BDI 之計算的同時,BSI 與 BHMI 兩指數並行半年,且
建構一乘數使得BHMI 在被替代的同時,不至於改變 BDI 計算的基礎,以確保 指數的延續性。 至2006 年後,BDI 之計算公式改為: BDI=[(BSI+BPI+BCI)/3]×0.99800799 BDI 是衡量國際不定期海運之乾散貨船運的權威性指數,指數值計算由目 前市場上海峽型、巴拿馬極限型、輕便極限型,三種散裝貨船型主要航行路線所 洽定之運價,作權重運算所得之數值,在乾散貨船運市場上供其他同業在洽約定 價之參考定價,為呈現市場景氣重要指標之一。 4.2 預測結果 本研究蒐集2006 年後 BDI 最新改制的週、月之開、收盤資料以及周期間最 高點以及最低點(附錄一、二),再結合文獻【12】、【15】、【17】、【19】、【24】進 行修改,進而建構一完整的模式進行預測,模式都將針對收盤指數進行預測。 預測資料分為樣本內(2006/01-2007/12)及樣本外(2008/01-2008/05/02),用以 將檢驗準確度以及穩定性;並以RMSE 以及 MAPE 做為指標。公式如下:
RMSE= 2 1 ( ( ) ( ) n t actual t forecast t n = −
∑
) MAPE= 1 ( ) ( ) 100% ( ) n t actual t forecast t actual t n = − ×∑
(一) 單變量模式 (1) 月資料測試 A.定義論域:根據樣本內資料,DMin=2081 andDMax=10886,但本研究所採用Ratio base
的區間分隔有決定論域最低點的規則,所以最低點為DMin保留前兩位數,後
面值全部無條件捨去,值為”2000”,而最高點必須視採Ratio base所形成的最 後一個區間上值而定,所以論域先定為{2000,10886+}。
B.區間分隔:
本模式採用Ratio base決定區間長度,首先根據樣本內資料的變動率最 小值為1.6%,再由Base table決定以1%為base of ratio,以1.6%累加1%做累積 分布圖如下: 累積分布圖 0 5 10 15 1.6 2.6 3.6 4.6 5.6 6.6 7.6 8.6 Ratio% 次數 圖9 單變量月資料之Ratio base累積分布圖 因為樣本內資料的變動率筆數共23筆,所以根據圖9,可得ratio”6.6%” 對應9筆,剛好是小於筆數一半的最小值,將以6.6%當作此模式的增長基準。 因此區間分隔第一區間定義為{2000,2000*1.066}={2000,2132};第二區 間區域定義為{2132,2000*(1.066^2)}={2132,2273},以此類推,因為 BDI 為 一整數,所以運算後之數值會經過四捨五入以符合實際情況;經運算共須 27 個區間,最後一區間有包含樣本內資料最大值,分群如下表:
表3 單變量月資料之區間分隔表 區間 下值 上值 1 2000 2132 2 2132 2273 3 2273 2423 4 2423 2583 5 2583 2753 6 2753 2935 7 2935 3128 8 3128 3335 9 3335 3555 10 3555 3790 11 3790 4040 12 4040 4306 13 4306 4591 14 4591 4894 15 4894 5217 16 5217 5561 17 5561 5928 18 5928 6319 19 6319 6736 20 6736 7181 21 7181 7655 22 7655 8160 23 8160 8699 24 8699 9273 25 9273 9885 26 9885 10537 27 10537 11232 此時可將論域確實定為{2000,11232},可發現區間長度越漸增長。 C.定義模糊語意變數: 根 據 式 2 , 將 步 驟 2 的 所 有 區 間 都 定 義 為 一 個 語 意 變 數
{
A
i,i=1, 2..., 27}
。D.模糊化歷史資料: 將樣本內、外資料模糊化後,隸屬到所屬之語意變數;本研究使用三角 隸屬度作為模糊化的函數,理論應將數值對所有三角隸屬函數進行運算,求 得模糊集合後,以最大度隸屬的區間作為所隸屬之語意變數;其實等同於數 值落於哪個區間內,即可直接將當期數值歸屬到所對應之語意變數,模糊後 之對照表如下: 表4 單變量月資料之模糊化對照表 年份 月份 指數 隸屬語意A 2006 1 2081 A1 2006 2 2680 A5 2006 3 2496 A4 2006 4 2368 A3 2006 5 2416 A3 2006 6 2935 A7 2006 7 3260 A8 2006 8 3795 A11 2006 9 3944 A11 2006 10 4006 A11 2006 11 4298 A12 2006 12 4397 A13 2007 1 4225 A12 2007 2 4609 A14 2007 3 5388 A16 2007 4 6230 A18 2007 5 6123 A18 2007 6 6278 A18 2007 7 6720 A19 2007 8 7702 A22 2007 9 9370 A25 2007 10 10886 A27 2007 11 10210 A26 2007 12 9392 A25 2008 1 5900 A17 2008 2 7613 A21 2008 3 8069 A22 2008 4 9273 A25
舉一例:2006/01之指數為2081,落於區間1={2000,2132}內,所以當期 模糊化後隻語意變數歸屬為”A1”,以此類推而得表4。 E.決定模糊關係: 將表4樣本內前後期語意變數間,建構一階模糊關係,如2006/01-2006/02 為A1ÎA5,2006/02-2006/03為A5ÎA4,以此類推;可將樣本內之所有一階 模糊關係的相同LHS群聚,RHS則完全展示出,可得表5。 表5 單變量月資料之模糊關係群聚表 LHS RHS A1 A5 A3 A3, A7 A4 A3 A5 A4 A7 A8 A8 A11
A11 A11, A11, A12
A12 A13, A14
A13 A12
A14 A16
A16 A18
A18 A18, A18, A19
A19 A22 A22 A25 A25 A27 A26 A25 A27 A26 本研究另結合門檻啟發式法,所以還須考慮一門檻值來代表前後期變動 是否顯著,決定以步驟2之ratio=6.6%值作為門檻值,若前後期變動率在正、 負6.6%內表示模糊關係群聚無改變,若變動率之絕對值大於6.6%,則模糊 關係群聚RHS將改變;當下期之語意變數為比原語意變數大時,則模糊關係 群聚RHS將改成對應比當期語意變數大的語意變數(包含原語意變數);反 之當下期之語意變數為比原語意變數小時,則模糊關係群聚RHS將改成對應 比當期語意變數小的語意變數(包含原語意變數),舉A12和A18為例
ÎA13,A14 if |r|>6.6%,and 下期之語意變數為比A12大 A12 ÎA13,A14 if |r|<6.6%
ÎA12 if |r|>6.6%,and 下期之語意變數為比A12小
Î A18,A18,A19 if |r|>6.6%,and 下期之語意變數為比A18大 A18 Î A18 A18,A19 if |r|<6.6%
Î A18,A18 if |r|>6.6%,and 下期之語意變數為比A18小 根據以上做法可將表5修改成下表6:
表6 單變量月資料之門檻啟發式模糊關係群聚表
LHS RHS LHS RHS LHS RHS
A5 A11, A11, A12 A22
A1 A5 -- A11 A11, A11, A12 A19 A22
A1 A11A11 A19
A3, A7 A13, A14 A25
A3 A3, A7 A12 A13, A14 A22 A25
A3 A12 A22
A4 A13 A27
A4 A3 A13 A12 A25 A27
A3 A12 A25
A5 A16 A26
A5 A4 A14 A16 A26 A25
A4 A14 A25
A8 A18 A27
A7 A8 A16 A18 A27 A26
A7 A16 A26
A11 A18, A18, A19
A8 A11 A18 A18, A18, A19
F.預測: 利用表4之當期語意變數以及表6之模糊關係群聚表加上前後期變動 率,可得表7之預測語意變數 表7 單變量月資料之預測語意變數表 年份 月份 隸屬語意 年份 月份 預測語意 2006 1 A1 2006 2 A5 2006 2 A5 2006 3 A4 2006 3 A4 2006 4 A3 2006 4 A3 2006 5 A3, A7 2006 5 A3 2006 6 A3, A7 2006 6 A7 2006 7 A8 2006 7 A8 2006 8 A11
2006 8 A11 2006 9 A11, A11, A12
2006 9 A11 2006 10 A11, A11, A12
2006 10 A11 2006 11 A11, A11, A12
2006 11 A12 2006 12 A13, A14
2006 12 A13 2007 1 A12
2007 1 A12 2007 2 A13, A14
2007 2 A14 2007 3 A16
2007 3 A16 2007 4 A18
2007 4 A18 2007 5 A18, A18, A19
2007 5 A18 2007 6 A18, A18, A19
2007 6 A18 2007 7 A18, A18, A19
2007 7 A19 2007 8 A22 2007 8 A22 2007 9 A25 2007 9 A25 2007 10 A27 2007 10 A27 2007 11 A26 2007 11 A26 2007 12 A25 2007 12 A25 2008 1 A25 2008 1 A17 2008 2 A17 2008 2 A21 2008 3 A21 2008 3 A22 2008 4 A25 舉2006/01、2006/04以及2008/01為例,2006/01所對應之語意變數為A1, 對照表6以及2006/01和2006/02兩期間的變動率絕對值為28.74%大於門檻值 6.6%,且下期之語意變數A5大於A1,所以預測2006/02之語意變數為{A5};
2006/04所對應之語意變數亦為A3,對照表6以及2006/04和2006/05兩期間的 變動率絕對值為2.03%小於門檻值6.6%,所以預測2006/05之語意變數為{A3, A7};2008/01所對應之語意變數為A17,但從表6中無法對應出A17的下期預 測語意變數,所以以{A17}當作2008/02之預測語意變數,根據以上邏輯即可 完成表7推算。 G. 反模糊化資料: 本研究使用基礎法則即可,因為在模糊關係群聚處理時,已經將重複出 現過的模糊關係重複表現出;根據式3,可將預測之語意變數反模糊化為表8。 表8 單變量月資料之預測值 年份 月份 收盤 預測值 2006 2 2680 2668 2006 3 2496 2503 2006 4 2368 2348 2006 5 2416 2690 2006 6 2935 2690 2006 7 3260 3232 2006 8 3795 3915 2006 9 3944 4001 2006 10 4006 4001 2006 11 4298 4001 2006 12 4397 4595 2007 1 4225 4173 2007 2 4609 4595 2007 3 5388 5389 2007 4 6230 6124 2007 5 6123 6258 2007 6 6278 6258 2007 7 6720 6258 2007 8 7702 7907 2007 9 9370 9579 2007 10 10886 10885 2007 11 10210 10211 2007 12 9392 9579 2008 1 5900 9579 2008 2 7613 5744 2008 3 8069 7418 2008 4 9273 9579
舉2006/02、2006/05 以及 2008/02 為例;因其所對應之預測語意變數為 {A5} 、 {A3, A7} 、 {A17} 。 所 以 計 算 各 區 間 中 點 分 別 為 2668 ; (2348+3032)/2=2690 以及第 17 區中點為 5744,以上述做法可得表 8(注:資料 呈現皆為整數,但實際運算過程中可能有小數情況,最後才以四捨五入法以 符合實際狀況。 H. 分析:模式結果測試如下表9 表9 單變量月資料之指標數值 MAPE RMSE 最小誤差 最大誤差 樣本內 2.51% 167.9 0.01% 11.33% 樣本外 24.57% 2094.12 3.30% 62.35% 結果顯示樣本內模式配適良好,但樣本外卻準確度差,發現是因為有離 群值之故,以修正數值將2007/9,10,11,12離群值刪去,對上述步驟重新求解 一次。 a定義論域:
根據修正樣本內資料,DMin=2081 andDMax=7702,所以論域先定為
{2000,7702+}。 b區間分隔: 修正樣本內資料的變動率最小值為1.6%,由Base table決定以1%為base of ratio,以1.6%累加1%做累積分布圖如下: 累積分布圖 0 2 4 6 8 10 12 1.6 2.6 3.6 4.6 5.6 6.6 7.6 8.6 Ratio% 次數 圖10 修正單變量月資料之Ratio base累積分布圖 因為修正樣本內資料的變動率筆數共19筆,所以根據圖10,可得 ratio ”6.6%”對應9筆,剛好是小於筆數一半的最小值,將以6.6%當作此模式
的增長基準。 區間分隔分群如下表10,可將論域確實定為{2000,8160}。 表10 修正單變量月資料之區間分隔表 區間 下值 上值 1 2000 2132 2 2132 2273 3 2273 2423 4 2423 2583 5 2583 2753 6 2753 2935 7 2935 3128 8 3128 3335 9 3335 3555 10 3555 3790 11 3790 4040 12 4040 4306 13 4306 4591 14 4591 4894 15 4894 5217 16 5217 5561 17 5561 5928 18 5928 6319 19 6319 6736 20 6736 7181 21 7181 7655 22 7655 8160 c定義模糊語意變數: 根 據 式 2 , 將 步 驟 2 的 所 有 區 間 都 定 義 為 一 個 語 意 變 數
{
A
i,i=1, 2..., 22}
。 d模糊化歷史資料: 將修正樣本內、外資料模糊化,隸屬到所屬之語意變數;數值落於哪個 區間內,即可直接將當期數值歸屬到所對應之語意變數,模糊後之對照表如下: 值得注意的一點是,2008/03,04的指數已經超過論域的範圍,所以以論 域的最大語意變數當成當其語意變數。 表11 修正單變量月資料之模糊化對照表 年份 月份 指數 隸屬語意A 2006 1 2081 A1 2006 2 2680 A5 2006 3 2496 A4 2006 4 2368 A3 2006 5 2416 A3 2006 6 2935 A7 2006 7 3260 A8 2006 8 3795 A11 2006 9 3944 A11 2006 10 4006 A11 2006 11 4298 A12 2006 12 4397 A13 2007 1 4225 A12 2007 2 4609 A14 2007 3 5388 A16 2007 4 6230 A18 2007 5 6123 A18 2007 6 6278 A18 2007 7 6720 A19 2007 8 7702 A22 2008 1 5900 A17 2008 2 7613 A21 2008 3 8069 A22 2008 4 9273 A22 e決定模糊關係: 將表11樣本內前後期語意變數間,建構一階模糊關係,可得表12。 再結合門檻啟發式法,以步驟2之ratio=8.2%值作為門檻值,將表12轉換 成表13。
表12 修正單變量月資料之模糊關係群聚表 LHS RHS A1 A5 A3 A3, A7 A4 A3 A5 A4 A7 A8 A8 A11
A11 A11, A11, A12
A12 A13, A14
A13 A12
A14 A16
A16 A18
A18 A18, A18, A19
A19 A22
表13 修正單變量月資料之門檻啟發式模糊關係群聚表
LHS RHS LHS RHS LHS RHS
A5 A11, A11, A12 A22
A1 A5 -- A11 A11, A11, A12 A19 A22
A1 A11A11 A19
A3, A7 A13, A14
A3 A3, A7 A12 A13, A14
A3 A12 A4 A13 A4 A3 A13 A12 A3 A12 A5 A16 A5 A4 A14 A16 A4 A14 A8 A18 A7 A8 A16 A18 A7 A16