FAULT TOLERANCE FOR HOME AGENTS IN MOBILE IP
6
0
0
全文
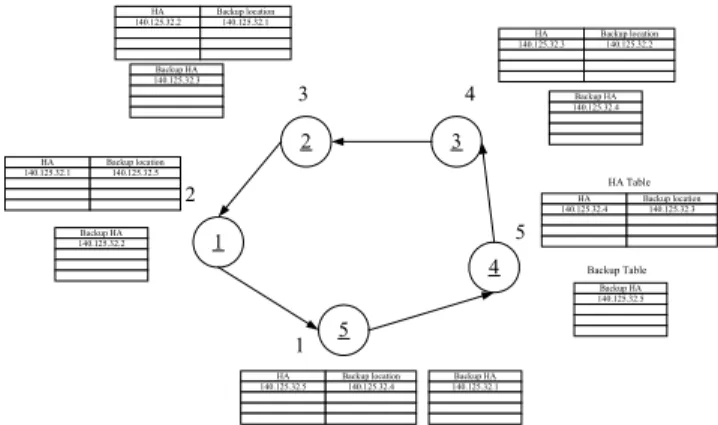
(2) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. called mobility binding, and then send a registration reply to the MN. Home Network. backs up. Initially, the logical system framework as depicted in Fig. 2 shows that only one logical HA acts on a physical HA, and it is also a supervising HA. Besides, each physical HA also backs up mobility bindings of the MNs registered with another logical HA. However, after several alternate failures and recoveries, a physical HA might take over or back up more than one logical HAs at the same time. To maintain the takeover and backup relationships between HAs, two tables called HA table and Backup table are used in each physical HA. HA table records 1) the logical HAs (including the supervising HA) being taken over by the physical HA, and 2) their backup locations. Besides, Backup table records the backup HAs, thereby enabling the physical HA to take over them when the logical HAs fail.. Mobile Node. Correspondent Node SD. Home Agent. C ONSOLE. DSU CPU S3. LP. OK. B1 B2. LO OP BRI S/ T. FDX 100 LNK. W IC 0 OK. WI C 1 OK. AUX. Cisco 1720. Internet. Tunnel. SD. Movement Data Flow. C ONSOLE. BRI S/ T. FDX 100 LNK. DSU CPU S3. LP. OK. B1 B2. LO OP. W IC 0 OK. AUX. Cisco 1720. WI C 1 OK. Foreign Agent. Mobile Node. Foreign Network. Fig. 1 Mobile IP operations. HA 140.125.32.2. Backup location 140.125.32.1 HA 140.125.32.3. 2.2 The Assumptions and Problem Definitions. Backup HA 140.125.32.3. When the number of MNs registered with the home network increases, the workload of managing and relaying packets will fall on an HA. Once the only one HA fails, all MNs managed by the HA will not receive packets normally. Therefore, multiple mobility agents (MA) can be used to deal with this problem. In our model, we have some assumptions outlined as follows: 1) not more than one MA of a home network will fail at the same time, 2) whenever an MA fails, any data in the volatile media of the MA will be gone, and can not be restored anymore, 3) the control signals used in the proposed protocol will be reliable in the network, and 4) when an MA recovers from the failed status, no MA fails during the recovery. Here for a home network with n MAs, our goal is that if the MA memory is large enough, we can still service all MNs registered with the home network, even when n-1 MAs are failed. Besides, in order to save the memory usage, we only need to maintain double mobility bindings in the whole system; i.e., only one backup for an MA. The protocol proposed here is transparent to MNs such that MNs are not aware of any MA failures, and no upgraded software should be installed within them.. 3. 4. 2 HA 140.125.32.1. Backup location 140.125.32.2. Backup HA 140.125.32.4. 3. Backup location 140.125.32.5. HA Table. 2 Backup HA 140.125.32.2. HA 140.125.32.4. Backup location 140.125.32.3. 5. 1. 4. Backup Table Backup HA 140.125.32.5. 1 HA 140.125.32.5. 5 Backup location 140.125.32.4. Backup HA 140.125.32.1. Fig. 2 Logical system framework 3.2 Failure Detection and HA Takeover During the system operation, each physical HA in the home network must monitor whether all related logical HAs are alive or not. These related logical HAs includes the supervising HAs where the logical HAs being taken over by the physical HA are backed up (i.e., “Backup location” of HA table), and the logical HAs of which bindings are backed up here (i.e., “Backup HA” of Backup table). Here agent advertisement messages sent by logical HAs are used to check whether these logical HAs are alive or not. If a physical HA receives an agent advertisement from a logical HA persistently, the logical HA can be considered alive; otherwise, it could be failed. In a physical HA, each logical HA monitored here has a timer Failure_timer. Whenever receiving an advertisement message from a logical HA, the physical HA would call procedure Adv_monitor( ) to reset the corresponding Failure_timer with value Max_failure_time. Besides, each physical HA would call procedure Failure_detect( ) periodically to decrease all the timers by one. If the timer of one logical HA expires, the HA is considered failed. If the failed HA has the backups of the logical HAs being taken over by the physical HA (i.e., “Backup location” of HA table), new backups should be found for the takeover HAs. On the other hand, if the backup of the failed HA is in the physical HA (i.e., “Backup HA” of Backup table), the physical HA will take over the. 3 FAULT-TOLERANT PROTOCOL 3.1 HA Table and Backup Table In order to still service all MNs registered with a home network even when more than one HA is failed, we must maintain double mobility bindings in the whole system; i.e., one backup for an HA. A logical system framework is illustrated as Fig. 2. A bi-directed graph is used to show the takeover and backup relationships between HAs. Each node represents a physical HA in the home network. The underlined number inside a node indicates that it is acting as a supervising HA (also a logical HA), whereas the other numbers inside the node represent logical HAs that the physical HA is taking over. Besides, the numbers labeled outside a node represent logical HAs that the physical HA. 626.
(3) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. failed HA. Then, it also needs to find a new backup for the failed HA. Procedure Adv_monitor( ) and Failure_detect( ) are given as follows:. the one requiring less memory, since the former has less chances to find a new backup than the latter. Procedure Select_backup( ) is described as follows:. Procedure Adv_monitor(i){ Failure_timer[i]ÅMax_failure_time; }// Adv_monitor end. Procedure Select_backup(j){ /* Each logical HA has a Tbk and a Backup_ACK_count */ TbkÅ0; Backup_ACK_countÅ0; Send Backup messages to all physical HAs in the home network; Wait Backup_ACK messages for a period of time Tbk; TbkÅ1; If (Backup_ACK_count=0) Fill “fail” into “Backup location” of HA table; Keep on waiting for other Backup_ACK messages; /* Receiving multiple Backup_ACK messages during Tbk */ Else Compare the information from these Backup_ACK messages and choose one physical HAk with the lightest loading; Send Confirm message to the physical HAk; Send Release messages to the other physical HAs; Occupied_flagÅ1; Fill HAk into “Backup location” of HA table; Transmit bindings of the MNs registered with HAj to the physical HAk; Occupied_flagÅ0; }// Select_backup end. Procedure Failure_detect( ){ For all monitored HAi Failure_timer[i]ÅFailure_timer[i]-1; For all monitored HAj with timer=0 If (HAj exists in “Backup location” of HA table) /* Find new backups for all corresponding “HA”s of HA table */ For all HAk in “HA” of HA table Select_backup(k); Else Takeover(j); /* Find a new backup for “Backup HA” of Backup table */ Select_backup(j); }// Failure_detect end If a physical HA takes over a failed HA, it must perform Gratuitous ARP mapping the IP address of the failed HA to its physical address [7], and then fills the IP address into its HA table. Afterward, the failed HA can be operational on the physical HA, including sending agent advertisements for the failed HA and forwarding packets to the MNs registered with the failed HA. Procedure Takeover( ) is given as follows:. In order to avoid that more than one logical HA selects the same physical HA as the backup at the same time, a semaphore is used to synchronize their backup actions. A physical HA can reply to a Backup message only when it can satisfy the memory requirement of the Backup message and is not being “occupied” by other Backup message. The synchronization among the physical HAs is accomplished with message passing. Whenever a physical HA receives a message, it would call procedure Message_handler( ) to execute the corresponding action using multi-thread techniques. As mentioned, since a physical HA can process only one Backup message at a time, a semaphore is used to synchronize these message-trigger threads. Procedure Message_handler( ) is given as follows:. Procedure Takeover(j){ Perform Gratuitous ARP for HAj; Add HAj into ‘HA’ of HA table; Send agent advertisements for HAj; Forward packets to the MNs registered with HAj; }// Takeover end 3.3 Selecting the Backup HA After the failure of a physical HA, new backups should be found for the takeover HAs or for the failed HA, as mentioned in Section 3.2. Each backup action must be performed individually. All physical HAs alive could be the backup candidates as long as their remaining memory is large enough to back up the HA. The physical HA selected here should be the one with the lightest loading in the home network. What we call the loading is based on the following factors ordered by their priorities, such as 1) the numbers of logical HAs backed up at the physical HA, 2) the number of logical HAs acting on the physical HA, 3) the number of the MNs which from other home networks, now are being served by the physical HA, and 4) the remaining memory size at the physical HA. If more than one new backup should be found on a physical HA, the “Backup” message for the takeover HA requiring more memory is issued before. Procedure Message_handler(msg){ /* Occupied_flag: global flag for a physical HA, S: semaphore initialized to 1 */ Switch(msg){ Case Backup wait(S); Occupied_flagÅ1; /* Back_ACK contains loading information */ Reply Backup_ACK message; break; Case Backup_ACK If (Tbk=0) /* Receiving ACK before timeout */. 627.
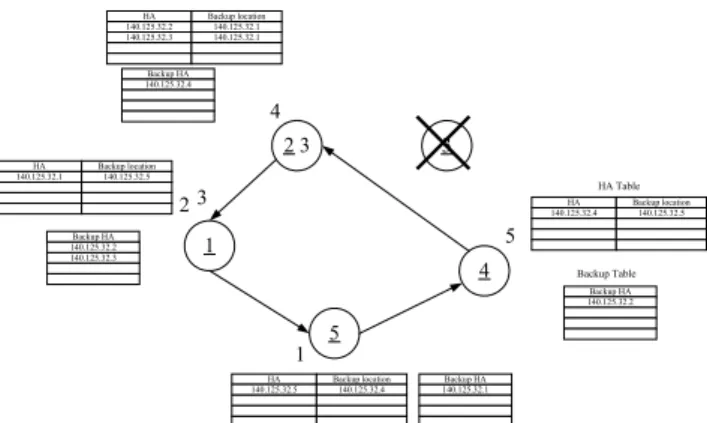
(4) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. Record the loading information in the message; Backup_ACK_countÅBackup_ACK_count+1; Else /* Receiving ACK after timeout */ If (the corresponding “Backup location” of HA table=“fail”) /* Choose the first sender as the backup */ Reply Confirm message; Occupied_flagÅ1; Fill the sender into “Backup location” of HA table; Transmit bindings of the MNs registered with the takeover HA to the sender; Occupied_flagÅ0; Else Reply Release message; break;. HA 140.125.32.2 140.125.32.3. Backup location 140.125.32.1 140.125.32.1. Backup HA 140.125.32.4. 4 23 HA 140.125.32.1. 3. Backup location 140.125.32.5. HA Table. 23 Backup HA 140.125.32.2 140.125.32.3. HA 140.125.32.4. Backup location 140.125.32.5. 5. 1. 4. Backup Table Backup HA 140.125.32.2. 1 HA 140.125.32.5. 5 Backup location 140.125.32.4. Backup HA 140.125.32.1. Fig. 3 After the physical HA3 fails 4 HA RECOVERY. Case Confirm Occupied_flagÅ0; signal(S); Fill the sender into “Backup HA” of Backup table; Receive bindings of the MNs registered with the sender; break;. When a physical HA comes up from the failed state, it immediately listens to whether any agent advertisement on the link contains its IP address. If none (i.e., the physical HA starts up for the first time), it performs Gratuitous ARP mapping the IP address to its physical address, and start functioning with no mobility bindings. On the contrary, in addition to perform Gratuitous ARP, it must restore the mobility bindings accumulated by the physical HA that took over it when it failed. Procedure Recovery( ) is given as follows:. Case Release Occupied_flagÅ0; signal(S); break;. Procedure Recovery(j){ If (no agent advertisement on the link, sent by HAk, contains the IP address of HAj) Perform Gratuitous ARP for HAj; Add HAj into ‘HA’ of HA table; Send agent advertisements for HAj; Choose the precedent physical HAi as the backup of HAj; Fill HAi into “Backup location” of HA table; Transmit bindings of the MNs registered with HAj to the physical HAi; Else Perform Gratuitous ARP for HAj; Add HAj into ‘HA’ of HA table; Send agent advertisements for HAj; Get backup location and mobility bindings of HAj from HAk; Fill the backup location into “Backup location” of HA table; Forward packets to the MNs registered with HAj; Balance( ); }// Recovery end. Case Balance Occupied_flagÅ1; /* Balance_ACK contains loading information */ Reply Balance_ACK message; break; Case Balance_ACK Record the loading information in the message; break; }// Switch end }// Message_handler end Here the example as shown in Fig. 2 is used to explain the HA takeover and backup. When the physical HA3 fails, the physical HA2 will take over HA3 and also need to find a new backup for HA3. Besides, since the physical HA3 backs up HA4, the physical HA4 must find a new backup for HA4. After the physical HA2 selects the physical HA1 as a new backup for HA3 and the physical HA4 selects the physical HA2 as a new backup for HA4, the statuses become as shown in Fig. 3.. After a physical HA recovers from crash, the HA loading in the home network, such as the number of takeover HAs and backup HAs, will be balanced. The recovered physical HA is responsible for issuing balance signals to all physical HAs in the home network. After gathering the loading information from other physical HAs, the recovered HA can start the deducing process to reassign the takeover HAs and backup HAs in the home network.. 628.
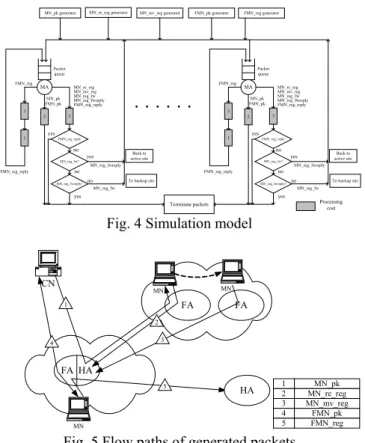
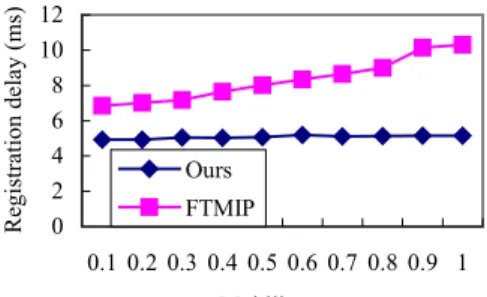
(5) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. Procedure Balance( ) is omitted here.. FTMIP, each HA maintains all bindings of MNs registered with other peers, and thus an HA must wait all other peers to complete binding synchronization when it receives a registration request from its MN. The situation would be worse especially when there are more MNs registered in the network. Besides, we also plot the binding numbers maintained per HA in both methods, as shown in Fig. 6(c). 140 120 100 80 60 40 20 0. Ours. MN_pk generator. MN_re_reg generator. MN_mv_reg generator. FMN_pk generator. 50 0. 40 0. FTMIP. 10 0. Registration delay (sec.). The simulation model is illustrated in Fig. 4. Five packet generators are used to generate MN_pk, MN_re_reg, MN_mv_reg, FMN_pk, and FMN_reg packets, respectively. These packets are submitted to waiting queues of MAs in the home network, and their flow paths are described in Fig. 5. Each MA would process different packet types with different processing costs and flows. The simulation was done using GPSS World developed by Minuteman Software, Inc.. 30 0. 5.1 Simulation Model. 20 0. 5 PERFORMANCE EVALUATIONS. FMN_reg generator. MN number. yes. no. no MN_reg_fwreply. no. FMN_reg_reply. no. Back to active site. yes MN_reg_fw?. MN_reg_fwreply. no MN_reg_fwreply?. FMN_reg_reply. Back to active site. yes MN_reg_fw?. yes. 1. FMN_reg_reply. FMN_reg_reply. 3. 2. To backup site. MN_reg_fwreply?. no. MN_reg_fw. To backup site MN_reg_fw. yes. yes Terminate packets. Processing cost. 3000 2500 2000 1500 1000 500 0. Ours FTMIP. Fig. 4 Simulation model. 50 0. 3. 3. 40 0. 1. MN_re_reg MN_mv_reg MN_reg_fw MN_reg_fwreply FMN_reg_reply. 30 0. 3. MA MN_pk FMN_pk. ••••••. 10 0. MN_re_reg MN_mv_reg MN_reg_fw MN_reg_fwreply FMN_reg_reply. MN_pk FMN_pk. 20 0. FMN_reg. Extra registration messages (thousand). MA. 2. Fig. 6(a) Registration delay of different MN numbers. Packet queue. Packet queue. FMN_reg. MN number CN. FA. 1. Fig. 6(b) Extra registration messages of different MN numbers. MN. MN. FA. 2. Bindings per HA. 3. 4. FA HA 5. MN. HA. 1 2 3 4 5. MN_pk MN_re_reg MN_mv_reg FMN_pk FMN_reg. Fig. 5 Flow paths of generated packets. 600 500 400 300 200 100 0. Ours FTMIP. 100 150 200 250 300 350 400 450 500 MN number. 5.2 Experimental Results. Fig. 6(c) Bindings per HA of different MN numbers. Experiment 1: overheads of different MN numbers. Experiment 2: overheads of different mobility rates. In the experiment, we observe the overheads of our method and FTMIP [4]. Those include registration delay, extra registration messages (i.e., registration forwarding and registration forwarding reply), and average numbers of bindings maintained per HA. The registration delay is the interval between the time an HA receives a registration request and the time it finishes processing the corresponding reply from its backup site. As shown in Fig. 6(a) and Fig. 6(b), our method has less registration delay and less extra registration messages than FTMIP. The reason is that, in. In the experiment, we observe the registration delay and registration forwarding number for total 300 MNs with different mobility rates. As shown in Fig. 7(a) and Fig. 7(b), we found that our method has smoother overheads than FTMIP, regardless of the registration delay and registration forwarding number, when considering different mobility rates.. 629.
(6) Registration delay (ms). Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. 12 10 8 6 4 2 0. longer registration delay, maintaining all bindings of MNs in each HA, and a single point failure or even a performance bottleneck based on centralized managements. Here we propose a novel distributed protocol only maintaining double mobility bindings in the whole system. Our method issues less extra registration messages in order to prevent long registration delay. Besides, we also consider the load balancing during HA takeover and recovery to make the system performance more efficient. Through the experiments, we found that our method has less registration overheads, better MN-scalability, and less sensitivity on MN mobility than others.. Ours FTMIP 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Mobility rate. REFERENCES. 2000. Ours. 1500. [1]. FTMIP. 1000 500 0 0. 9. 0. 7. 0. 3. 0. 5. [2]. 0. 1. Extra registration messages (thousand). Fig. 7(a) Registration delay of different mobility rates. [3]. Mobility rate. [4]. Fig. 7(b) Extra registration messages of different mobility rates. [5]. Experiment 3: effects with/without doing balance during HA recovery. [6]. Registration delay (sec.). In the experiment, after eight HAs are failed, we make the HAs recover from failure one by one in order to observe the effect on the system performance with/without doing balance during HA recovery. As shown in Fig. 8, we found that the registration delay without doing balance are obviously much longer than that with doing balance unless the number of alive HAs is more than half of the total HA number.. [7]. [8] [9] [10]. 120 100 80 60 40 20 0. Balance No balance. 1. 2. 3. 4. 5. 6. [11]. 7. Recovered HA numbers. Fig. 8 Registration delay of different recovered HA numbers 6 CONCLUSIONS In this paper, we point out some drawbacks of previous fault tolerant protocols for Mobile IP, such as. 630. JinHo Ahn and ChongSun Hwang, “Efficient fault-tolerant protocol for mobility agents in mobile IP,” Proc. 15th International Conference on Parallel and Distributed Processing Symposium, 2001, pp. 1273-1280. B. Chambless and J. Binkley, “HARP – home agent redundancy protocol,” IETF Draft, 1997. R. Droms, “Dynamic host configuration protocol,” IETF RFC 1541, 1993. R. Ghosh and G. Varghese, “Fault-tolerant mobile IP,” Technical Report WUCS-98-11, Washington University, 1998. C. E. Perkins, “IP mobility support,” IETF RFC 2002, 1996. C. E. Perkins, Mobile IP: Design Principles and Practices, Addison-Wesley Longman, Reading, Mass., 1998. D. C. Plummer, “An Ethernet address resolution protocol-or-converting Network protocol address to 48 bit Ethernet address for transmission on Ethernet hardware,” IETF RFC 826, 1982. J. Postel, “Internet protocol,” IETF RFC 791, 1981. J. Postel, “Transmission control protocol,” IETF RFC 793, 1981. J. D. Solomon, Mobile IP: The Internet Unplugged, Prentice-Hall, Upper Saddle River, NJ, 1998. A. Vasilache, Jie Li, and H. Kameda, “Load balancing policies for multiple home agents mobile IP networks,” Proc. 2nd International Conference on Web Information Systems Engineering, 2001, pp. 178 –185..
(7)
數據
相關文件
Over there, there is a celebration of Christmas and the little kid, Tiny Tim, is very ill and the family has no money to send him to a doctor.. Cratchit asks the family
The inverted page table is sorted by physical addresses, whereas a page reference is in a logical address. The use of Hash Table
(A) The PC has the TCP/IP protocol stack correctly installed (B) The PC has connectivity with a local host (C) The Pc has a default gateway correctly configured (D) The Pc
• The solution to Schrödinger’s equation for the hydrogen atom yields a set of wave functions called orbitals.. Each orbital has a characteristic shape
One way to select a procedure to accelerate convergence is to choose a method whose associated matrix has minimal spectral radius....
experiences in choral speaking, and to see a short segment of their performance at the School Speech Day... Drama Festival and In-school Drama Shows HPCCSS has a tradition
• If students/ children develop fever and symptoms of respiratory tract infection, advise them to stay at home for rest until fever has subsided for at least 2 days. • Staff
One way to select a procedure to accelerate convergence is to choose a method whose associated matrix has minimal spectral
