應徵者與在職者在多分題人格測驗的作答差異之研究:
試題層次與試題組合層次的分析
賴姿伶
銘傳大學諮商與工商心理學系
余民寧
國立政治大學教育學系
摘要
由於大部分的人格測驗是自陳量表,因此應徵者對於人格測驗是否會有意圖地作假,一直是個 很重要的研究議題。本研究綜合運用試題反應理論(IRT)的差異試題功能(DIF)分析方法和多群 組驗證性因素分析(MCFA),從試題層次、試題組合層次、和量表層次,探討比較應徵者和在職 者在社會期許量表和人格測驗中作答反應差異,進而剖析作假的本質。研究發現:在試題層次,應 徵者的得分並非全然比在職者高,且DIF 分析結果顯示不論是人格測驗或社會期許量表中,皆有一 些題目為應徵者傾向於高估,而另有一些題目為在職者傾向於高估,此現象使得在試題組合層次, 兩組各自形成其獨特的作答反應組型;在量表層次,跨群組的因素結構恆等性檢定結果顯示不同樣 本群組的因素結構皆有差異。最後針對研究結果,提出實務應用和研究方法的建議。 關鍵詞:人格測驗、差異試題功能、多元計分試題、非參數程序、測量恆等性 DOI: 10.6147/JHRM.2015.1504.04 投稿日期:2015 年 3 月 3 日;接受日期:2015 年 11 月 26 日 通訊作者:賴姿伶(銘傳大學諮商與工商心理學系) 通訊地址:333 桃園市龜山區德明路 5 號 通訊電話:03-3507001 分機 3688 E-mail: sofi[email protected]Response Variation on Polytomous Personality Measures
between Applicants and Incumbents:
Analyses on Item-Level and Item-Composite Level
Tzu-Ling Lai
Department of Counseling and I/O Psychology, Ming Chuan University
Min-Ning Yu
Department of Education, National Chengchi University
ABSTRACT
The question of whether applicants respond to self-report personality measures differently when responding for selection purposes has been a crucial concern for decades. This study conducted an item response theory (IRT) based differential item functioning (DIF) procedure and multi-group confirmatory factor analysis (MCFA) to investigate item-level, item-composite level and scale-level response variations on polytomous Likert-type personality scales between applicants and incumbents, and thereby analyzed the essence of applicant faking. The results indicated that: (a) in the item level, applicants did not constantly score higher than incumbents; (b) several items exhibited differential item functioning, however, because DIF items did not systematically function with bias toward a particular group, therefore lead to specific response patterns for the two groups in the item-composite level; (c) results of MCFA showed that the personality factor structures are different across groups in the scale level. Implications based on the study findings are also discussed.
Keywords: personality assessment, differential item functioning, polytomous items, non-parametric procedure, measurement equivalence
DOI: 10.6147/JHRM.2015.1504.04
Received Date: March 3, 2015; Accepted Date: Novembet 26, 2015
Corresponding Author: Tzu-Ling Lai (Department of Counseling and I/O Psychology, Ming Chuan University) Address: No. 5, De Ming Rd., Gui Shan Dist., Taoyuan City 333, Taiwan, R.O.C.
Tel: +886-3-3507001 Ext. 3688 E-mail: sofi[email protected]
緒論
人格測驗是企業進行人力資源管理如:甄選、任用、績效評估等活動時經常使用的工具。大部 分的人格測驗都是自陳量表,由受試者自行評估並作答,而其在量表上的反應則被換算成人格特質 的指標(McCrae & Costa, 1983)。然而,當處在求職情境時,由於這些作答可能影響了獲得工作 的機率,求職者可能會傾向於在測驗時塑造一個「理想的員工」的形象(Leary & Kowalski, 1990; Schmit & Ryan, 1993)以有助於獲得工作。因此,當使用人格測驗來作甄選決策時,由於其目的性 明顯且具有實質效益,再加上屬於自陳式測驗且通常沒有正確的答案,因此多年以來,有個老問題 不斷被挑戰:在甄選情境時,求職者對於人格測驗,是否會有意圖地作假?(Ellingson, Sackett, & Connelly, 2007)再者,由於運用測驗在人才甄選的主要目的是比較個體間的差異,以便從眾多應徵 者當中選擇最適合的人才,因此人格測驗的計分方式以李克特式多分點量尺(Likert’s type scale)的 運用最為廣泛。然而由於測驗題項的描述模糊又難以驗證真假,此類型的量表亦經常引起「應徵者 是否會在想要獲得工作的情況之下刻意往高分的方向作答」的質疑。
主要為比較不同能力者(以實驗的操弄方式教導受試者作假或誠實作答),或不同動機者(如: 應徵者、在職者或學生)之間的作答差異(Viswesvaran & Ones, 1999);採用的測量作假工具,一 是利用測謊量表(通常採用社會期許量表[social desirability scale]),以該量表總分高低做為評 估作假的指標,二則運用人格測驗的各項統計量數為作假指標,例如通常假定作假者會刻意往高分 方向填答,故平均數較高;或者由於作假而導致了量表的建構效度產生了改變,使得不同群組之人 格因素結構在跨樣本恆等性考驗中呈現不相等的狀況(Schmit & Ryan, 1993)。近年來由於各種研 究方法、技術的發展,諸多研究者亦紛紛嘗試以新方法探討作假的原因與本質,例如Tett, Freund, Christiansen, Fox 與 Coaster(2012)以實驗操弄作假,並比較認知能力高/低者和應徵不同工作者 在人格測驗的得分;Komar, Komar, Robie 與 Taggar(2010)實驗操弄作答時間限制,並比較不同情 境下受試者在社會期許量尺的得分;van Hooft 與 Born(2012)利用眼動儀追蹤測量實驗引發的作 假者在人格測驗的反應時間和注視極端值時間長短;Wetzel, Bohnke, Carstensen, Ziegler 與 Ostendorf (2013)則是先以試題反應理論(item response theory, IRT)基礎的 Rasch 模式(Rasch model)區分 真實情境下受試者在人格測驗的作答風格(response style)之後,再運用差異試題功能(differential item functioning, DIF)的技術,探討個別試題是否對於不同性別或不同作答風格者具有相等的功用。 即使研究方法日新月異,但是基本上仍不脫離比較不同能力或不同動機者在人格測驗或社會期許量 表的得分差異。
然而,上述各種方法的研究結果卻經常出現歧異。首先,實驗教導的作假使得受試者在社會期 許量表或人格量表呈現較高的分數(Komar et al., 2010),但是真實情境下的應徵者在各量表的得分 卻不一定顯著較高,學者(Smith & Ellingson, 2002; van Hooft & Born, 2012)認為不宜將實驗情境的 作假類推至真實樣本的作答,而比較Viswesvaran 與 Ones(1999)(針對實驗教導的作假和誠實作答) 和Birkeland, Manson, Kisamore, Brannick 與 Smith(2006)(針對真實情境的應徵者與其他族群)兩
篇整合研究(meta-analysis)的結果,也確實發現實驗情境和真實樣本的作答的確有所差異,例如實 驗教導的作假之得分較真實情境下的作假來得高;其次,真實情境中作假動機較高者(通常是應徵 者)和較低者(通常是在職者或學生)之人格結構亦不一定不同(Smith & Ellingson, 2002);再者, 若社會期許量表可測量到受試者作假,且作假會導致人格測驗的因素結構產生變化,則社會期許分 數應該和人格因素結構具有某種關係。然而Ellingson, Smith 與 Sackett(2001)以社會期許量表分數 高低區分高作假程度和低作假程度者,據此比較高低作假程度是否導致人格因素結構的差異。在比 較了真實情境樣本與四種人格量表的作答差異之後,結果卻顯示社會期許分數高低與人格因素結構 無關。由此可見真實情境中的應徵者是否在人格測驗作假,直到目前仍然未有定論。 本研究認為,上述各項研究結果之所以出現歧異,可能在於過去多以古典測驗理論的觀點來探 討作假。在古典測驗理論架構下,僅能就量表總分來判斷受試者的答題傾向,而本研究認為,以量 表總分可能無法真正反應出不同群體的作答差異。例如,受試者可能在某個題目刻意往高分填答, 另一題則往低分填答,其和另一個在每題都持平作答者在量表總分就無法顯現出差異。具體而言, 本研究認為具有不同動機的受試者,其作假企圖會反應在個別的題目上面,而非以一個概括的總分 高低來決斷受試者是否作假。 其次,若是單純比較測驗分數的高低,則可能忽略了受試者自身能力的影響,也許不同族群本 身的能力就有所不同,才導致他們在某個試題(或測驗)的表現不同(Lord, 1980),舉例來說, 若男生和女生在某一試題或測驗的得分有差異,可能是來自於這兩族群的能力、生活經驗、教育方 式等各種因素所造成,而這其中的影響因素才是研究者所關注的,單純比較平均數則容易忽略不同 族群原本的能力差異,進而影響對其背後的各種因素之評估。因此當我們比較不同群體受試者在題 目或整份測驗的作答差異時,必須把這些群體在該能力或特質的測量放在同一個量尺上(Drasgow, 1984, 1987),其比較才具有意義。自從 1980 年代試題反應理論(Item Response Theory, IRT)興起 之後,差異試題功能(differential item functioning, DIF)的概念與方法被大量運用在分析個別試題的 特徵,並偵測試題對於不同的受試群體,是否具有相同的意義(equivalent meaning)。此一方法學 透過等化(equating)的程序將欲比較的不同群體的能力放到同一個量尺上,進而分析個別題目對於 不同群體是否展現出不同功能,由於已經控制了受試者個別能力的影響,若分析結果呈現出差異, 則可推論出此一差異係導因於研究所關注的變項所影響。 由於作假可視為一種個體有意識地操弄作答,以造成良好的印象,因此本研究定義作假為「在 同一能力值之下,若對某些題目得分偏向高估,即視為受試者對該題有意識地往高分方向作答,即 為作假」。若在個別題項上的作假累積形成了在兩組樣本在潛在變項上的變異,則視為兩組樣本有 不同的反應組型(response pattern)。 據此,本研究之主要目的,是應用偵測DIF 的方法學來比較應徵者在多分題人格測驗的作答 是否和其他族群呈現出差異,並從多個角度(包括試題層次[item-level]、試題組合層次[item-composite level]和量表層次[scale-level])探討說明應徵者的作假反應。由於不同族群的受試者 可能因為過去經驗的影響而對個別題目的理解有所不同,造成其在個別題項的反應差異,綜合數個
測量同一個潛在能力題項的作答反應之後,形成其在潛在變項的作答型態,而集合數個潛在變項的 差異便可能形成整體量表的差異;但若受試者在的作答並未呈現系統性的偏好,則可能在個別題項 呈現作答差異,但在試題組合或量表層次未表現出不同。例如擔任主管者體認到和下屬打成一片的 重要性,因此他對於「善於融入人群」的題目較易往高分方向填答(試題層次),接著累積成為在 「社交性」這項能力呈現高分(試題組合層次),進而整體突顯了「親和性」這項人格特質(量表 層次);另一方面,擔任下屬者則可能較注重「堅忍不拔」之類的特性,而在謹慎性量表呈現高分。 因此透過這三個層次的分析,將更能瞭解不同族群在各種測量層次的差異為何。具體言之,本研究 將運用非參數的同步試題偏差檢定法(simultaneous item bias test, SIBTEST),來探討在職者和應徵 者對於社會期許量表和人格量表中的個別題目,其作答反應是否有所不同?接著,在理論架構(即 本研究各量表的二階層多向度模式)引導之下,分別將測量各子向度(潛在變項)的題項集合起來 成為一個題組,並檢測在職者和應徵者在此題組的作答是否有差異,稱為DBF(differential bundle functioning),此 DBF 的分析,能夠在試題組合層次區辨出參照組或焦點組特別在哪些特質上容易 有高估自己的程度,因而形成各組特殊的反應組型。此試題層次和試題組合層次的作答差異分析, 過去鮮少運用在多分題人格測驗作假的研究上,尤其是社會期許量表雖大量運用於偵測作假,但過 去其試題層次的分析卻付之闕如,本研究之成果當有助於增進我們對於作假本質的瞭解。另外,為 了和過去大量的量表層次研究有對話的基礎,並能比較不同層次的作答差異,本研究亦同時進行量 表層次的作答差異檢測,主要分為兩部分進行:一、為延伸DIF 檢測方法,集合各量表內的所有題 目,以測量不同群組在個別題目的作答差異是否形成了在整份量表的系統性差異,此為差異測驗功 能(differential test functioning, DTF)檢測;二、則和過去研究一致,採跨樣本驗證性因素恆等性分析, 以探究不同群組之間作答反應所形成的人格因素結構是否相等(equivalent)。
理論背景與研究假設
研究測驗作假的方法
過去在研究測驗作假的議題上,主要有2 種典範(paradigm):(1) 在人格測驗中設有一個「社 會期許量表」,專門測量受試者是否刻意在其作答中作假或撒謊(Paulhus, 1984),此方法假設受試 者在社會期許量表的作答傾向可推論到同一份測驗的其他部分,因此在社會期許量表的得分可反映 受試者蓄意作假的程度;(2) 比較作假動機較高者和較低者對人格測驗反應的差異,來檢查是否有作 假。此方法假設非求職者(例如:在職者、學生、學術研究的受試者等)較沒有理由作假,而應徵 者為了獲得工作而有較高的作假動機,因此比較兩個群體之間的差異即可反應出應徵者意圖作假的 程度(Ellingson et al., 2007)。 在上述第一個研究典範當中,是以受試者在「社會期許量表」的總得分超過某一決斷分數(cut point)即視之為有作假。然而,過去對於應徵者和在職者在社會期許量表上的作答反應卻出現了不 一致的結論,Ones, Viswesvaran 與 Reiss(1996)關於社會期許量表的整合分析發現,有些研究中應徵者和在職者在社會期許量表的分數有差異,通常是應徵者的分數較高(Rosse, Stecher, Miller, & Levin, 1998),但有另一些研究應徵者和在職者在社會期許量表的分數並無差異,還有一些甚且 發現在職者在社會期許量表的分數比應徵者來得更高。而在實驗的情境下,Ones, Viswesvaran 與 Korbin(1995)發現在有教導作假的情況下,其社會期許量表分數相差可達一個標準差;但 Dwight 與Alliger(1997)卻指出,當受測者被教導作假,其社會期許分數和誠實作答者較接近,反而是 僅提示作假者的社會期許分數較高,因此,過去研究針對社會期許量表測量作假的程度無法形成一 致定論,顯示出以社會期許量表作為測量作假的工具,其效果受到一些質疑(Burns & Christiansen, 2006; Mcfarland & Ryan, 2000)。而 Ones 等人(1996)更在整合研究報告中提出,社會期許量表之 所以無法區辨應徵者和在職者在社會期許量表分數的差異,其主要原因可能是來自於每一篇研究所 使用的題目不同,因此造成研究結果各異。本研究據此進而推論,社會期許量表無法區分應徵者和 在職者的作假程度,可能是來自於當中的某些題目對應徵者而言,更容易使他們往高分的方向作答, 而另外一些題目,則使得在職者往高分的方向作答,因而應徵者與在職者在同一社會期許量表上的 作答,由於高分與低分的相互抵銷,使得採用量表總分來比較應徵者與在職者的差異,會變得沒有 顯著效果出來,因此,除了在量表層次以總分或平均數來評估受試者作假程度之外,亦應回歸到社 會期許量表的個別試題層次來思考。 第二個典範則是比較作假動機高和低者對在人格測驗作答的差異,來檢查是否有作假,例如以 獨立樣本t 考驗來評估應徵者的測驗分數是否比較高,或者進行跨群組因素結構恆等性檢測,若不 同群體所表現出來的統計量不同,因其背後所代表的是不同的作假動機,因而比較不同群體的作答 差異,即可推論至有無作假。例如,同一個測驗若應徵者作答結果呈現六個向度、而在職者為五個 向度,則推論由於應徵者作假而導致了人格因素結構的差異。在此一典範中,所測量和比較的都是 人格測驗本身,並非社會期許量表或其他測謊量表。其方法主要有: (1) 在實驗的操弄下,要求受試者誠實作答或作假,接著比較在接受不同的操弄之下,受試者的人格 測驗分數是否不同,或者運用多群組驗證性因素分析(multiple-group confirmatory factor analysis, MCFA)來比較不同組受試者之人格結構是否呈現差異。例如:Griffith(1997)和 Frei, Griffith, McDaniel, Snell 與 Douglas(1997) 比較實驗室操弄的作假組和誠實組之間的人格結構差異,兩 個研究結果皆顯示當受試者被教導作假時,會改變人格因素結構。然而,另外有一些研究,如 Zickar 與 Robie(1999)、Ellingson, Smith 與 Sackett(2001)則發現實驗引發的作假組和誠實作 答組之間有相同的人格因素結構模式。
(2) 比較真實情境下作假動機高低的不同群體在人格測驗的作答是否有所不同?例如 Schmit 與 Ryan (1993)採五大人格因素量表,學生和應徵者樣本呈現出不同的因素結構,應徵者比學生多出一 個因素,稱之為理想的員工因素(ideal-employee factor),但是 Smith 與 Ellingson(2002)同樣 以應徵者和學生為樣本,研究結果卻顯示兩族群人格因素結構一致,且應徵者只有在某些分量表 的平均數高於學生組,並非所有分量表都一致較高。另外,Ellingson 等人(2007),以及 Hogan, Barrett 與 Hogan(2007)採取重複測量的人格測驗資料,分析結果顯示不論測驗目的是甄選還是
發展,真實情境下受試者在人格測驗的作假意圖效果有限,不論是量表分數或量表結構(各測量 指標與人格五大因素之間的因素負荷量)都沒有差異。然而,卻也有另外一些研究(Birkeland et al., 2006; Rosse et al., 1998; Zicker, Gibby, & Robie, 2004)顯示應徵者在人格向度的分數一般都比 在職者要來得高。因此,過去研究關於作假對測驗分數或人格測驗的建構效度之影響並無一致之 定論。 上述研究不論比較的群體是實驗樣本或真實樣本,其比較標的主要為人格測驗的統計量如:描 述統計量(平均數、標準差等),或者是人格因素結構(因素個數、因素負荷量、測量誤差等), 皆以試題組合層次或量表層次為研究重點,Zickar 與 Robie(1999)認為,不論是針對人格測驗或是 社會期許量表,量表層次的分析對於受試者作答歷程的瞭解所能提供的訊息有限──作假本質上是 試題層次的現象,受試者針對個別試題作答或作假,而非量表。當研究者把個別題目的分數集合成 總分之後,即失去了原本個別題目之特殊變異性了。也許作假者運用了不同的行為或策略去展現出 作假(Zicker et al., 2004),當然,也有可能是有些題目本身即相當容易作假,有些則否。而無論原 因為何,要回答上述問題,都必須從題目的層次來加以測量、估計,然後才能賦予有意義的解釋, 不論是針對社會期許量表的題目或是人格量表的題目皆是如此。Schmit 與 Ryan(1993)也認為,不 同的受試者可能對不同的題目有不同的反應方式,其反應取決於受試者對題目和工作相關度之間的 判斷。近來以眼動儀追蹤受試者在人格測驗的作答歷程(van Hooft & Born, 2012),結果亦發現受 試者在被要求作假或誠實作答時,基於自己本身的認知能力或參考架構,在每個題項的反應時間或 針對選項的注視時間是不同的。因此本研究認為,從試題的層次來探討受試者在人格測驗上的作假, 以及其是否會影響人格測驗的建構,實有其必要性。
試題反應理論與測驗作假的研究
在此觀點下,透過試題反應理論(IRT)則能分析每一個試題的特徵,在個別題目的層次上探 討上述問題。IRT 的方法中,差異試題功能(DIF)的概念是本研究用來區辨不同群組受試的作答 反應之主要基礎,DIF 指的是兩組能力或表現相同的受試群體之答題表現有顯著的差異(Dorans & Holland, 1993)其分析一般是用來偵測試題對於相同能力的不同的受試群體,是否具有相同的意義。 目前能被大多數學者所接受的DIF 定義方式為:「來自不同的族群或團體但能力相同的個人,在作 答某試題的機率卻有所不同,則該試題便具有DIF 現象」(余民寧,2009)。 若測驗題目展現DIF 現象,則表示同一試題於不同群體當中展現出不同的功能。因此,本研究 採用DIF 的分析技術,來評估不同群體對於個別題項是否有相同的作答反應。例如:若應徵者和相 同能力的在職者在某一試題選擇某個選項的機率不同,則稱該試題為不同群組間具有DIF,因此未 來運用該試題時,將有助於區辨來自於不同群體受試者的作假動機。而由於試題層次的測量特徵差異不一定導致量表層次的差異(Robie, Zickar, & Schmit, 2001), 若受試者有意識地在某個潛在能力上刻意作假,則集合多個有DIF 的試題即能檢測出不同族群在量
表的特殊作答組型(Stark, Chernyshenko, Chan, Lee, & Drasgow, 2001),此一程序稱為差異題組功能 (differential bundle functioning, DBF),能用來檢測試題組合層次或量表層次的作答差異。
IRT發展多年以來,學者已經相繼提出許多DIF的檢測方法,主要可分為參數估計取向(parametric procedure)和非參數估計取向(non-parametric procedure)兩大類。前者係比較兩個族群在某特定 IRT 模式的參數,若參數呈現不同則代表各族群的作答有差異。例如Zickar 與 Robie(1999)運用等級反 應模式(graded response model, GRM; Samejima, 1969)檢驗實驗操弄的作假和誠實作答之間的作答差 異;後續Robie 等人(2001)也運用 GRM 檢測應徵者和在職者在人格測驗的測量特性差異;但這兩 個研究的結論卻有極大歧異,前者檢測出有22% 的題目有 DIF,且各量表皆呈現 DTF,而後者則僅 發現六個量表中只有一個含有DIF 題目,且沒有量表呈現 DTF。由於使用參數估計法僅能比較不同 族群的作答「是否有差異」,上述兩個研究是以「應徵者作假動機較高」這個前提假設進行並賦予解 釋,即若應徵者的作答和在職者相較之下有DIF 或 DTF,則表示應徵者作假。 然而,近期的研究如O’Brien 與 LaHuis(2011)比較應徵者和在職者的試題反應函數(item response function, IRFs),發現有過半的題目有 DIF,但其中只有 24% 試題呈現預期的方向(亦即, 應徵者作答偏向高估,表示有作假),卻另有16% 的題目呈現完全相反的方向(顯示應徵者往低分 的方向填答)。他們認為這是由於不同族群對個別題目的知覺不同而產生了不同的函數型態。因此, 該研究結果打破了過去普遍認同的「應徵者作假且在職者誠實作答」的假設前提。Zickar 等人(2004) 也指出受試者在作答多分題人格測驗時的策略相當多元,應徵者中某些人傾向誠實作答,在職者中 亦有一部份人往極端方向填答,作答型態非僅以其所隸屬的族群而定;近年Wetzel 等人(2013)亦 提出受試者在多分題人格測驗具有不同的作答風格,有些人傾向選擇極端值,有些則否。Stark 等人 (2001)綜合參數估計法(Lord’s 1980 chi-square method)和非參數估計法(Mantel-Haenszel method 和 SIBTEST method)的分析結果,更證實了受試者會評估「情境因素」(是否處在求職的情況下) 而決定作答方向。
過去聚焦試題層次以分析應徵者和在職者在人格測驗的作答差異的研究並不多,其中從非參數 估計方法切入者更少,Stark 等人(2001)是本研究所知僅有的一篇,但可惜的是,只針對二分試 題進行分析。由於參數估計法在DIF 檢測上有其諸多限制,例如首先必須符合觀察資料和參數模式 的適配性(Stark et al., 2001);再者,雖然可比較各族群的選項反應函數(option response function, ORF)差異即可瞭解其作答差異,但若一個題目有四個選項,則必須比較四組選項函數的差異,這 對於多分題人格測驗而言,若選項較多則其比較相當複雜且難以解釋,這也是過去試題層次的研究 較少探討多元計分試題的原因之一。相對的,非參數估計法通常把作答反應與能力之間視為單調的 對應關係(monotonicity),使得多分題 DIF 的檢測結果較容易解釋(Stark et al., 2001),估計時通 常以測驗總分做為焦點組與對照組的配對變項(類似參數估計法的等化程序),且從估計值的正或 負即可得知偏利的族群,除此之外,非 參數DIF 的運算較為簡便,例如不需選擇適配的 IRT 模式並 轉換成參數,僅以測驗原始分數進行等化和作答差異分析,計算簡單,理論易懂,且可運用市售的 統計套裝軟體(如:SPSS、SAS)進行 DIF 分析(余民寧,2009)等應用上的便利性。尤其是許多
實務上運用廣泛的人格測驗多以李克特式多點量尺計分,且有許多學者認為非參數估計法較為適配 李克特式多點量尺的資料,據此,本研究擬採取非參數估計法中的SIBTEST 法進行分析,在試題層 次和試題組合層次探討高/低作假動機者在多元計分的社會期許量表和人格測驗的作答反應,期望 能促進我們對於應徵者和在職者在多分題人格測驗作答差異的瞭解。
關於作假在題目層次的模式,主要有兩種解釋(Zickar & Robie, 1999):
(1) 試題知覺改變觀點(changing items paradigm):認為作假的過程會改變試題的參數或影響受試者 作答──既然試題本身的敘述等物理結構並未改變,所以可解釋為誠實作答者和作假者之間對同 一試題的知覺(perception)不同。這種不同的知覺可能和選擇某個選項或/和不同的參考架構 (frames of reference)的期望值改變有關。此觀點假設受試者的潛在能力並未因作假而改變。 (2) 潛在能力改變觀點(changing persons paradigm):認為作假受到受試者潛在能力(latent trait)改
變的影響。雖然大多數IRT 理論認為潛在能力是相對穩定的,且和測量工具或目的無關,但此典 範假設作假者的真實能力暫時性且有意識地改變,以增進測驗分數。此假設受試者有能力在作答 題目時好似他們有比真實能力更高的能力。例如原本θ = -1.5 者,當有作假出現時,其作答反應 類似θ = 1 者。採取此一觀點的研究,目的在測量 θ 值改變量(θ 代表能力)。 本研究認為,潛在能力(在本研究中係指人格特質)基本上是穩定的,不會因測驗的情境或目 的而改變,反而是受試者在不同的測驗情境或目的之下,會對題目的知覺與解釋不同,因而產生了 不同的作答反應。因此本研究朝向受試者對試題的知覺改變的方向解釋。當受試者作假時,會因為 受試的情境或目的,而影響了其對題目敘述的認知,從而改變了他們的作答反應,以符合測驗目的 所需。而由於本研究關心的是甄選員工的過程中,應徵者是否會為了獲得工作而產生特殊的作答反 應,因此將研究焦點放在比較不同受試情境(即應徵者和在職者)下的作答差異。
SIBTEST 檢測方法
由Shealy 與 Stout(1993)所提出,後由 Chang, Mazzeo 與 Roussos(1996)擴展至多分題模式。 其主要程序為:將欲比較的兩組樣本以相同的量表總分進行配對,此總分即代表相同的潛在能力值 (θ)。若
ER[Y|t] ≠ EF[Y|t]
則該題呈現DIF,其中 Y 代表欲檢測題目的觀察分數,而 t 代表比對基準題組(matching subtest)總 分,足標R 或 F 分別代表參照組(reference group)或焦點組(focal group)。
用SIBTEST 進行 DIF 分析時,主要設定在某一量表的原始總分之下,分析兩群樣本之間答題的 差異,不需經過等化的程序,因為同一總分,即代表兩組的潛在能力相同,若在同一能力值之下, A 樣本比 B 樣本在某一題得分顯著較高,即代表 A 樣本在這一題有高估的傾向,反之則有低估傾向, 如此,我們可以得知不同群組在個別題目的反應方向。
若欲進行某個試題組合S 的 DBF 檢測時,若 S 並無 DBF,則 ER (hs(U)|θ) – EF (hs(U)|θ) ≈ 0 其中hs(U→) 代表由原始試題組合得分 (U1, U2, ..., UN ) 所轉換而成的函數。 由於作假可視為一種有意識地操弄作答,以造成良好的印象,因此,在此方法學之下,本研究 定義「作假」為「在同一能力值之下,若對某題目得分偏向高估,視為受試者對該題有意識地往高 分方向作答,即為作假」。而若在題目上作假在形成了兩組樣本在潛在變項上的變異,則反應出參 照組或焦點組特別在哪些特質上容易高估的程度,因而形成各組特殊的反應組型。在本研究中,是 以組成潛在變項的數個試題所反映的 DBF,亦即在試題組合層次來探討不同群組之間是否具有不同 的反應組型。接著,集合各量表內的所有題目,以測量不同群組在個別題目的作答差異是否形成了 在整份量表的系統性差異,為量表層次的DTF 檢測。 除了上述IRT 取向的 DIF、DBF、DTF 分析之外,有可能作假會導致潛在特質結構發生變化 (Zickar & Robie, 1999)。為了與過去作假是否影響人格因素結構的研究進行討論,並與 DTF 的 結果進行比較,因此,本研究亦另再運用結構方程式模型(structural equation modeling, SEM)方 法學中的多群組比較驗證性因素(MCFA)分析,來探究比較不同族群之間作答反應結構的恆等性 (equivalence)。透過試題層次、試題組合層次和量表層次之多元分析,相信能對於應徵者在人格 測驗的作答情況有更深入的認識。 根據上述的文獻分析與推論,為達研究目的,本研究提出以下假設: 假設一:應徵者與在職者在「社會期許量表」和「人格測驗」的作答分數有差異,應徵者在社會期 許量表中個別題項和總平均數皆較在職者來得高,且應徵者在人格測驗各量表的總平均數 皆較在職者來得高。 假設二:應徵者與在職者在「社會期許量表」的單項題目上的反應有差異(即:「社會期許量表」 的某些題目具有DIF),因此所組成的社會期許作答反應,會形成不同的反應組型。 假設三:應徵者與在職者在「人格測驗」的單項題目上的反應有差異(即:「人格測驗」的某些題 目具有DIF),因此所組成的人格測驗作答反應,會形成不同的反應組型。 假設四:應徵者和在職者分別在「社會期許量表」展現不同的因素結構。 假設五:應徵者和在職者分別在「人格測驗」展現不同的因素結構。
研究方法
研究樣本
本研究的資料乃自某大型顧問公司資料庫取得,共有分別來自於應徵者和在職者的樣本,皆填 答「員工甄選人格量表」和「社會期許量表」,所有受試者填答時,皆是透過網路介面完成。其中: (1) 應徵者:作答資料來源為受試者應徵職缺時,要求該應徵者作答一份人格測驗,並告知其測驗結 果亦作為評定能否錄取的參考資料之一。 (2) 在職者:作答資料來源為受試者於任職的公司要求之下填答該人格測驗,其目的可能是作為公司 內部員工職能調查或者是作為員工發展的評估資料,員工在進行填答之前,已被告知該測驗資料 將僅做為員工個人生涯發展與規劃的參考,和績效考核無關,且受試者全部皆為自行透過網路介 面連結至顧問公司的施測網頁,非其任職公司的內部系統。 由於研究工具軟體的限制,以及遵守該顧問公司資料保護政策、個資法的限制,本研究透過該 公司資料庫管理員的協助,自其中隨機抽取出應徵者、在職者各7,000 名樣本。所從事或應徵的職 業類別含括行政、財務、業務、工程、藝文等各大類型的工作,且兩組樣本的性別、學歷、年資、 職級等背景變項分佈情形相當一致,可視為等組。研究工具
社會期許量表
本量表是為偵測受試者有無朝向社會所期望的方向作答而設計,共包含6 個題目,皆以李克特 式六點量表呈現,且都是測量「印象整飾」(impression management),此乃植基於文獻上指出作 假主要是來自於印象整飾的效果(Komar et al., 2010)。 Cronbach’s α 內部一致性信度在 .80 以上, 雖只有6 題,但其內部一致性信度相當良好。員工甄選人格量表
由於諸多研究已證實五大人格特質能夠準確預測未來工作表現,因此本量表的編製係搜集過去 文獻中曾經用於人格(特質)測量的向度,尤其是曾經用於工作情境中者,排除掉臨床或心理疾病 診斷的向度,並參酌(但不限於)五大人格因素理論架構,整理出42 個人格特質向度及其行為指標, 以作為量表題目編製的基礎,歷經兩次大型預試及修改,最終完成包含124 題目,可測量 27 個人格 向度和五大人格因素,所有題目皆以李克特式六點量表(1 代表「非常不符合」、6 代表「非常符合」) 呈現。總量表α 係數為 .948,各分量表之 α 值則介於 .76 ~ .92 之間(參見表 1),顯示 Cronbach’s α 內部一致性信度良好。另外根據探索性因素分析和驗證性因素分析所得結果顯示,其階層性的建 構效度良好(賴姿伶、余民寧、徐崇文,2009),可符合本研究之主要研究目的,且五大人格因素結構和國外作假研究中所使用的研究工具一致。因此,本研究以該量表所預設之二階層測量模式, 依研究目的,切分為開放性、謹慎性、外向性、親和性、及情緒穩定性等五個量表,進行研究議題 探討。此區分為五個量表為和過去諸多作假的研究(Birkeland et al., 2006; Viswesvaran & Ones, 1999; Wetzel et al., 2013)採取一致的作法,以便後續進行討論。
資料分析方法與步驟
本研究綜合運用SPSS 15.0 for Windows、LISREL 8.72、以及 Poly-SIBTEST 等軟體進行資料分 析:使用SPSS 針對不同群組進行題目和量表得分之平均數差異性考驗;運用 Poly-SIBTEST 分析軟 體,在題目的層次上探討「社會期許量表」和「人格測驗」之個別題目對應徵者/在職者是否具有 DIF ?以及在試題組合的層次上探討「社會期許量表」和「人格測驗」之潛在特質對應徵者/在職 者是否具有 DBF 或 DTF ?另外,以 SEM 多群組 CFA 分析方法,在量表層次上探討應徵者/在職 者分別在「社會期許量表」和「人格測驗」,是否呈現不同的因素結構。
研究結果與討論
首先進行原始資料的歸類和計分,並將反向題做反向計分轉換,讓所有分數的呈現,愈高分代 表正向特質愈強烈。而由於本研究所使用的人格量表,其多向度、階層性的建構效度良好,由124 個題項組成27 個一階潛在變項,再組合成五大人格因素結構,可符合本研究之主要研究目的,因此 以該量表所預設之二階層測量模式,依研究目的,切分為開放性、謹慎性、外向性、親和性、及情 緒穩定性等五個量表,進行研究議題探討。平均數差異分析
茲將各群組在各分量表的平均數、標準差及Cronbach’s α 內部一致性信度等基本統計量列於表 1。 由表1 可知,各量表的標準差在不同樣本之間差異不大,表示各樣本在同一量表的作答變異性 表1 樣本在各量表之平均數、標準差及 Cronbach’s α 信度 量表 題數 在職者 應徵者 平均數差異 顯著性檢定 Mean SD α Mean SD α 社會期許量表 6 2.92 0.87 .81 2.95 0.91 .82 開放性 32 4.28 0.55 .92 4.41 0.53 .92 * 謹慎性 23 4.37 0.48 .85 4.49 0.47 .85 * 外向性 27 4.03 0.58 .91 4.06 0.54 .90 親和性 24 3.63 0.42 .76 3.82 0.41 .77 * 情緒穩定性 18 3.77 0.60 .85 3.93 0.58 .86 * *p < .001不大。各量表的平均數差異方面,社會期許量表中應徵者較在職者平均每一題的得分僅高約0.03 分, 並無顯著差異。人格測驗部份,開放性量表中應徵者較在職者平均每一題的得分高約0.13 分,已達 顯著差異。謹慎性量表中應徵者較在職者平均每一題的得分高約0.11 分,達顯著差異。外向性量表 中應徵者較在職者平均每一題的得分僅高約0.03 分,未達顯著差異。親和性量表中應徵者較在職者 平均每一題的得分高約0.19 分,達顯著差異。情緒穩定性量表中應徵者較在職者平均每一題的得分 高約0.17 分,已達顯著差異。整體而言,應徵者和在職者在社會期許量表和外向性量表的得分並無 差異。 至於個別題項的平均數差異方面,雖然整體來說應徵者得分顯著較在職者高的題項占較多比例, 但卻也有些題項應徵者和在職者得分幾乎相同,另外也有些題項甚至是在職者得分顯著較高。例如 社會期許量表中應徵者的得分顯著高於在職者只有2 題,另外 4 題則沒有差異;而在人格量表中亦 有些題項在職者得分顯著較應徵者來得高,例如開放性量表中有2 題、外向性量表中有 5 題(參見 表2)。此結果顯示應徵者和在職者都有往高分填答的作答行為,只是二者傾向於高估的題項不同。 故假設一僅獲得部分支持。
DIF / DBF / DTF 分析
由於本研究用來檢測DIF 的 SIBTEST 法在運算時會先將觀察分數轉成潛在變項分數,並將欲 比較的兩組樣本分數限定在相同的潛在能力值以進行DIF 檢測,因此需符合單向度假設。根據 Raju, Laffitte 與 Byrne(2002)的建議,在進行 DIF 檢測之前,可先以 CFA 檢查量表題目是否都測到一個 共同的潛在變項,因此本研究首先分別針對六個量表的測量模式進行驗證性因素分析,以確認每個 量表對二組樣本而言,都能測到單一的潛在變項。接著,再以Poly-SIBTEST 程式軟體,進行 DIF、 DBF 和 DTF 分析。單向度假設檢定
驗證性因素分析結果顯示,六個量表之RMSEA 值介於 0.052 ~ 0.078 之間,CFI 和 IFI 值皆 表2 六個量表中呈現平均數顯著差異的題數(比例)統計表 量表 題數 在職者平均數較高的題數(比例) 應徵者平均數較高的題數(比例) 社會期許量表 6 0 (0%) 2 (33%) 開放性量表 32 2 (6%) 29 (91%) 謹慎性量表 23 0 (0%) 16 (70%) 外向性量表 27 5 (19%) 12 (44%) 親和性量表 24 0 (0%) 22 (92%) 情緒穩定性量表 18 0 (0%) 16 (89%) 人格量表 124 7 (6%) 95 (77%) 註:表中所列平均數差異檢定皆以p < .001 為顯著基準。
在0.9 以 上。 根 據 Browne 與 Cudeck(1993),RMSEA 值 介 於 0.05 ~ 0.08 為 合 理 適 配(adequate fit);分析結果顯示模式適配良好,因此,六個量表皆符合單向度假設檢定,各量表之題目所測到 的都是相同的潛在構念,即以此個別之測量模式作為後續分析之基礎。
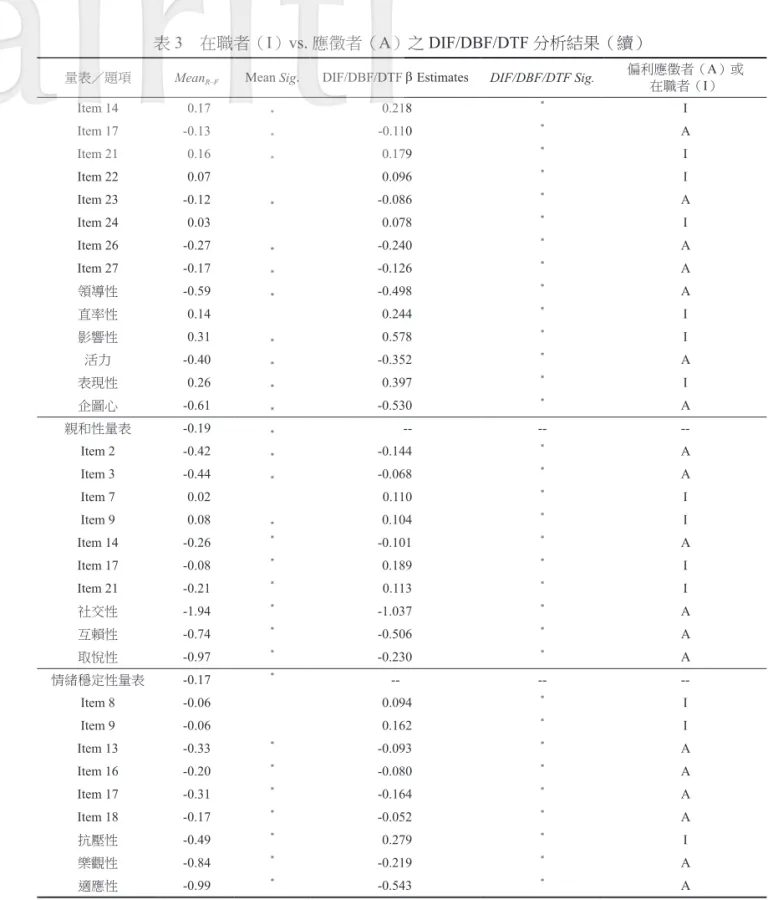
DIF/DBF/DTF 分析結果
本節分別 (1) 針對所有個別題目進行 DIF 分析;(2) 對六個量表中的子向度進行試題組合所呈現 的反應組型做DBF 分析;以及 (3) 針對六個分量表分別進行 DTF 分析。茲將 DIF/DBF/DTF 進行程 序和意義說明如下:DIF 檢測採用一次估計一題(one item at a time)的方式,並以全部其餘非估計題項作為比對的 基準題組(matching subtest)。由於此比對需在相同潛在特質之下進行才有意義,因此 DIF 的檢測 是分別限定在六個分量表內進行。例如,當估計社會期許量表的第3 題是否有 DIF 時,則以社會期 許量表中的第1、2、4、5、6 題合併做為比對的基準題組。
Zickar 與 Ribbie(1999)認為,若題目在不同群組間呈現 DIF,則代表該題的「可作假度」 (fakability)不同,而在本研究中,則代表不同群組對該題目的知覺(perception)和解讀程度不同, 因而影響受試者在該題作答時,傾向於往高分或低分的方向作答;且若DIF 分析的 β 估計值呈現負 值,則代表焦點組(在本研究中為「應徵者」)傾向於對該題高估,即焦點組在該題有作假。
至於DIF 顯著性考驗的 p-value,依據 Shealy 與 Stout(1993)的建議,為一般的 p-value 除以題數, 由於本研究樣本龐大,因此採取較嚴格的p < .001,且本研究中各分量表的題數為 6 ~ 32 題不等,因 此各量表DIF 是否顯著的判斷標準分別為 p < .001/ 該量表題數。
當個別題項有DIF,則需接著進行 DTF 檢定,以測試整份量表的測量特性是否會因為 DIF 而產 生扭曲的現象(Raju, van der Linden, & Fleer, 1995)。在本研究中,則是運用 DTF 的概念和作法, 但主要目的是為了找出在個別題項上的作答差異所形成的作答反應組型,其作法為:先進行個別題 項的DIF 檢定,接著,在理論架構(即本研究各量表的二階層多向度模式)引導之下,分別將測量 各子向度(潛在變項)的題項集合起來成為一個題組,並檢測參照組和焦點組在此題組的作答是否 有差異,稱為DBF,此 DBF 的分析,能夠找出參照組或焦點組特別在哪些特質上容易高估自己的程 度,因而形成各組特殊的反應組型。最後,再將各量表之所有題目集合起來進行DTF 檢定,以測試 整份量表的測量特性是否會因為DIF 而扭曲。各層次分析結果呈現於表 3,並說明如下。
DIF/DBF 檢測
由表3 整理可知,社會期許量表中,第 1、3、5、6 題在應徵者和在職者之間有 DIF 的情況;再 就其β 估計值來看,可發現其中第 1、3 題是應徵者傾向於高估,而第 5、6 題則是在職者傾向於高估。 兩個族群傾向於高估的題項比例相同,皆為33%。故假設二獲得支持。 在人格測驗部分,開放性量表中共有10 題在應徵者和在職者之間有 DIF 的情況,其中 7 題為應 徵者有高估的傾向,比例達22%,而另外 3 題則是在職者有高估的傾向,其比例較低,只有 9 %。表3 在職者(I)vs. 應徵者(A)之 DIF/DBF/DTF 分析結果
量表/題項 MeanR–F Mean Sig. DIF/DBF/DTF β Estimates DIF/DBF/DTF Sig.
偏利應徵者(A)或 在職者(I) 社會期許量表 -0.03 -- -- --Item 1 -0.08 * -0.062 * A Item 3 -0.11 * -0.087 * A Item 5 0.02 0.068 * I Item 6 0.01 0.063 * I 開放性量表 -0.13 * -- -- --Item 1 -0.19 * -0.114 * A Item 2 -0.17 * -0.094 * A Item 6 0.11 * 0.236 * I Item 9 -0.04 0.105 * I Item 17 -0.15 * -0.049 * A Item 24 -0.22 * -0.122 * A Item 25 -0.20 * -0.081 * A Item 27 -0.19 * -0.050 * A Item 28 -0.24 * -0.103 * A Item 32 0.09 * 0.198 * I 求變性 -0.38 * 0.333 * I 同理心 -1.01 * -0.511 * A 冒險性 -0.37 * 0.223 * I 謹慎性量表 -0.11 * -- -- --Item 1 -0.03 0.089 * I Item 5 -0.17 * -0.078 * A Item 6 -0.17 * -0.092 * A Item 7 0.04 0.118 * I Item 8 -0.19 * -0.114 * A Item 10 -0.32 * -0.179 * A Item 12 -0.21 * -0.067 * A Item 13 -0.06 * 0.092 * I Item 14 -0.03 0.098 * I Item 15 -0.03 0.090 * I Item 17 -0.19 * -0.076 * A Item 23 -0.03 0.069 * I 堅毅性 -0.63 * -0.289 * A 外向性量表 -0.03 -- -- --Item 2 -0.18 * -0.138 * A Item 3 -0.15 * -0.125 * A Item 5 -0.15 * -0.108 * A Item 7 0.09 * 0.110 * I Item 8 0.09 * 0.113 * I Item 11 0.04 0.077 * I Item 13 0.10 * 0.151 * I
量表/題項 MeanR–F Mean Sig. DIF/DBF/DTF β Estimates DIF/DBF/DTF Sig. 偏利應徵者(A)或 在職者(I) Item 14 0.17 * 0.218 * I Item 17 -0.13 * -0.110 * A Item 21 0.16 * 0.179 * I Item 22 0.07 0.096 * I Item 23 -0.12 * -0.086 * A Item 24 0.03 0.078 * I Item 26 -0.27 * -0.240 * A Item 27 -0.17 * -0.126 * A 領導性 -0.59 * -0.498 * A 直率性 0.14 0.244 * I 影響性 0.31 * 0.578 * I 活力 -0.40 * -0.352 * A 表現性 0.26 * 0.397 * I 企圖心 -0.61 * -0.530 * A 親和性量表 -0.19 * -- -- --Item 2 -0.42 * -0.144 * A Item 3 -0.44 * -0.068 * A Item 7 0.02 0.110 * I Item 9 0.08 * 0.104 * I Item 14 -0.26 * -0.101 * A Item 17 -0.08 * 0.189 * I Item 21 -0.21 * 0.113 * I 社交性 -1.94 * -1.037 * A 互賴性 -0.74 * -0.506 * A 取悅性 -0.97 * -0.230 * A 情緒穩定性量表 -0.17 * -- -- --Item 8 -0.06 0.094 * I Item 9 -0.06 0.162 * I Item 13 -0.33 * -0.093 * A Item 16 -0.20 * -0.080 * A Item 17 -0.31 * -0.164 * A Item 18 -0.17 * -0.052 * A 抗壓性 -0.49 * 0.279 * I 樂觀性 -0.84 * -0.219 * A 適應性 -0.99 * -0.543 * A 註:1. MeanR–F:代表在職者(參照組R)與應徵者(焦點組 F)之平均數差異,正值代表在職者平均數顯著較應徵者高;顯 著性考驗。 2. DIF/DBF/DTF β Estimates:DIF/DBF/DTF 估計值,正值代表該題對在職者有利(即在職者傾向於高估),負值代表該 題對應徵者有利(即應徵者傾向於高估);顯著性考驗採 p < .001/ 該量表題數。 3. I 表示在職者,A 表示應徵者。 *p < .001
進一步從兩個族群的DBF 檢測所反映的作答組型來看,應徵者在「同理心」這項潛在特質傾向於高 估,而在職者則在「求變性」和「冒險性」這兩項特質傾向於高估。 謹慎性量表中共有12 題在應徵者和在職者之間有 DIF 的情況;再就其 β 估計值來看,可發現其 中6 題是應徵者有高估的傾向,而另有 6 題則是在職者有高估的傾向。兩個族群傾向於高估的比例 皆各自有26%。進一步從兩個族群的 DBF 檢測所反映的作答組型來看,應徵者整體反應出在「堅毅 性」這項潛在特質傾向於高估,而在職者則無特定的高估組型。 外向性量表中共有15 題在應徵者和在職者之間有 DIF 的情況;其中 7 題是應徵者呈現高估的傾 向,比例達26%;而另有 8 題則是在職者有高估的傾向,且比例較高,達 30 %。進一步從兩個族群 的DBF 檢測所反映的作答組型來看,應徵者在「領導性」、「活力」、「企圖心」這三項潛在特質 傾向於高估,而在職者則在「直率性」、「影響性」和「表現性」這三項特質傾向於高估。 親和性量表中共有7 題在應徵者和在職者之間有 DIF 的情況;再就其 β 估計值來看,可發現其 中3 題為應徵者有高估的傾向,比例有 13%,而另有 4 題則是在職者有高估的傾向,比例稍高,有 17 % 。進一步從兩個族群的 DBF 檢測所反映的作答組型來看,應徵者在「社交性」、「互賴性」、 和「取悅性」這三項潛在特質傾向於高估,而在職者則無表現出特別的高估傾向。 情緒穩定性量表中共有6 題在應徵者和在職者之間有 DIF 的情況;其中 4 題是應徵者呈現高估 的傾向,比例達22%,而另有 2 題則是在職者有高估的傾向,在職者傾向於高估的比例較低,只有 11%。進一步從兩個族群的 DBF 檢測所反映的作答組型來看,應徵者在「樂觀性」和「適應性」這 兩項潛在特質傾向於高估,而在職者則在「抗壓性」這項特質傾向於高估。 上述結果顯示,在試題的層次,應徵者或在職者都有傾向於往高分方向填答以造成良好印象的 行為,只是二者關注的良好印象不甚相同,因而高估的傾向展現在不同題項上面。這些往某特質一 致性的高估傾向進而呈現出兩個族群的不同反應組型,例如在開放性量表,應徵者傾向於呈現出自 己是富有同理心的,而在職者則較傾向於表現出求新求變的特質;或是在情緒穩定性量表,應徵者 傾向於呈現出自己能從正面角度看待人或事物以及能因環境而調整既定行為模式的特質,而在職者 則較傾向於表現出能夠面對並調適壓力的特質。故假設三獲得支持。
DTF 檢測
在上述題目層次的分析顯示,有些題目存在DIF 的現象,且方向並不一致,有些題項偏利於在 職者,另有些題項則偏利於應徵者,因此需再進一步做量表層次的DTF 分析,以檢驗對於所關心的 群體而言,是否有累積的高估或低估效果(Stark, Chernyshenko, & Drasgow, 2004)。經過檢測之後,社會期許量表的DTF 分析結果,β 估計值為 0,p = 1,顯示並無 DTF 的情況存在。 同樣的,五個人格量表DTF 分析結果,β 估計值皆為 0,p = 1,顯示皆無 DTF 的情況存在。這是因 為整份量表中的各題目偏利方向不盡相同,有些偏向於對應徵者有利,有些則偏向於對在職者有利, 因此互相抵銷之後,呈現無DTF 的狀態。
平均數差異與
DIF/DBF/DTF 檢定結果之比較
表3 中同時列出 DIF 題項之原始分數平均數差異檢定情形。對照 DIF/DBF/DTF 檢定和平均數差 異檢定結果可發現,在試題層次,呈現DIF 的題項不一定有平均數差異(例如社會期許量表第 5 題), 亦有些題項應徵者平均數顯著較高,但DIF 分析卻顯示偏利於在職者(例如謹慎性量表第 13 題); 在試題組合層次,某些潛在能力為應徵者得分顯著較高,但DBF 結果卻顯示偏利於在職者(例如開 放性量表中的求變性向度);在量表層次,平均數差異顯著卻不一定呈現DTF(例如謹慎性量表)。 可見DIF/DBF/DTF 檢定和平均數差異檢定的結果非完全相同,亦即,雖然應徵者可能在大多數的情 況下較在職者更往高分的方向填答,但若採取DIF 分析,則能呈現出不同題目對於兩個族群具有不 同功能,此係導因於兩個族群對個別試題的解讀不同。此乃由於DIF/DBF/DTF 檢定已將不同群組受 試者的能力列入考量,使得分析結果呈現出相同能力的應徵者和在職者在哪些題項或潛在特質上呈 現出差異,不僅如此,透過β 估計值的正負值也能同時判斷該題項或特質容易引起哪個族群的高估。跨群組量表因素結構恆等性分析
本節以驗證性因素分析的方法,運用LISREL 8.72 進行的多群組樣本測量模式比較,以檢查社 會期許量表和五個人格量表在應徵者與在職者之間的結構是否相等。依據Raju 等人(2002)之建議, 此方法包含兩個步驟:(1) 分別估計各組樣本的潛在因素結構和因素負荷量,再由適配度指標判斷各 組樣本是否分別符合基準模式(baseline model);(2) 在多群組比較中,限定各群組之因素負荷量一 致(model 1),並比較此模式與另一允許各群組因素負荷量可分別自由估計的模式(model 2)之間 的差異,若model 1 與 model 2 之間的卡方值差異達顯著,則表示各群組的結構並不相等。 因此,本研究先以六個量表編製時之預設的模式為基礎,分別檢查二個樣本群組在其預設模式的 適配度,以建立各量表跨群組比較的基準模式。各樣本群組與六個量表預設模式的適配度如表4所示。 表4 二組樣本在六個量表之基準模式適配度指標一覽表χ2 df RMSEA NFI NNFI CFI RFI
社會期許量表 在職者 178.97 9 0.052 0.99 0.99 0.99 0.98 應徵者 222.51 9 0.058 0.99 0.98 0.99 0.98 開放性量表 在職者 9,998.56 443 0.056 0.97 0.97 0.97 0.96 應徵者 9,786.51 443 0.055 0.97 0.97 0.97 0.96 謹慎性量表 在職者 9,445.12 220 0.077 0.92 0.91 0.92 0.91 應徵者 10,246.06 220 0.081 0.92 0.91 0.92 0.91 外向性量表 在職者 8,535.58 309 0.062 0.97 0.96 0.97 0.96 應徵者 8,438.00 309 0.061 0.96 0.96 0.96 0.96 親和性量表 在職者 8,941.18 239 0.072 0.89 0.88 0.90 0.88 應徵者 9,008.08 239 0.072 0.90 0.89 0.90 0.88 情緒穩定性量表 在職者 4,833.79 125 0.073 0.95 0.94 0.95 0.94 應徵者 5,013.36 125 0.075 0.95 0.94 0.95 0.94
其中,社會期許量表、開放性量表和外向性量表以原始預設的模式,即已產生合理適配:其 各組RMSEA 值都在 Browne 與 Cudeck(1993)所界定的合理適配值 0.08 以內,且 NFI、NNFI、 AGFI、CFI、RFI 等指標,皆 > 0.9 以上,因此可視為具備良好適配,顯示各樣本群組分別在三個量 表所測量的構念型態相同;而在謹慎性量表部份,應徵者的RMSEA 值雖超過合理適配值 0.08,但 只超出一些,且NFI、NNFI、CFI、RFI 等指標,皆能 > 0.9 以上,因此可視為具備適配性,顯示各 樣本群組所測量的謹慎性量表構念型態相同。綜合所有適配度指標的分析結果,本研究不擬針對社 會期許量表、開放性量表、謹慎性量表和外向性量表的模式做任何修正,即以此做為後續群組間測 量恆等性比較的基準模式。 另外在親和性量表和情緒穩定性量表部份,由於若以原始預設的模式,則RMSEA 值會超過 0.08 以上,但在經過允許各子向度內的題項彼此之間的誤差變異數可以相關之後,此二個量表之 RMSEA 值都有效降低至 0.08 以內,且 NFI、NNFI、CFI、RFI 等指標,除了在親和性量表有小部份 稍低於0.9 之外,其餘皆能 > 0.9 以上,可視為具備適配性,顯示各樣本群組分別在此二個量表分別 所測得之構念型態相同,且符合原始預設的測量模式。因此,在這兩個分量表,即以原始測量模式 並放寬誤差變異數的相關,做為基準模式。
接著,在基準模式之下,進行因素負荷量恆等性(factor loading invariance)(Marsh, 1994) 或稱量尺恆等性(metric invariance)(Horn & McArdle, 1992)之檢定,此檢定能說明在潛在構念 上每單位的改變,所對應在測量指標上期望觀察分數的改變是跨群組間均等的(余民寧、謝進昌, 2009)。
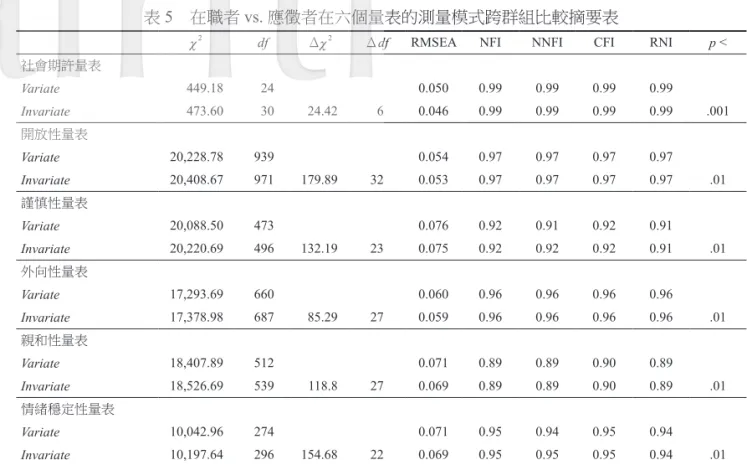
研究者先完全開放參數估計(即沒有設限參數均等),再進行參數的設限,以判斷跨群組間因 素結構是否一致。其中Variate 允許欲比較的兩個群組因素負荷量可個別估計,而 Invariate 則為限定 因素負荷量一致。檢查Invariate 和 Variate 之間的卡方值變化(當大樣本時,從 Variate 到 Invariate 之間卡方值的改變量接近於自由度改變量之下的卡方分配),若卡方值變化達顯著,則表示Variate 模式較適配,則不同群組的因素結構不同。資料分析結果如表5 所示。
其中,社會期許量表的跨群組比較,不論是Invariate 模式或 Variate 模式,RMSEA 值皆達到合 理適配,且NFI、NNFI、CFI、RFI 等指標,皆能在 0.9 以上,顯示因素負荷量相等或分別估計的模式, 基本上都與觀察資料適配;接著判斷跨群組的結構因素負荷量是否相等,從Variate 到 Invariate 之間 卡方值的改變量大於12.592,已達 .05 顯著水準,因此,可視為在職者 vs. 應徵者的跨群組結構並不 相等,代表這兩個族群的作答反應有差異。由此可推論是可能是因各群組背後之作假動機高低所影 響,而使得他們展現在的社會期許量表因素結構不一致。故假設四獲得支持。
而五個人格量表的跨群組比較,不論是Invariate 模式或 Variate 模式,RMSEA 值皆在 0.08 以內, 達到合理適配,且NFI、NNFI、CFI、RFI 等指標,大部分皆能在 0.9 以上,其中僅親和性量表有少 數幾個指標略小於0.9,但因 RMSEA 在合理範圍之內,此結果顯示各量表因素負荷量相等或分別估 計的模式,基本上都與觀察資料適配。接著判斷跨群組的結構因素負荷量是否相等。人格的五個分 量表,如表5 所示,從 Variate 到 Invariate 之間卡方值改變量皆達 .01 顯著水準,因此,不論是開放
性量表、謹慎性量表、外向性量表、親和性量表、或情緒穩定性量表,在兩個族群的跨群組因素結 構並不相等。此可以推論是由於在職者和應徵者背後之作假動機高低不同而影響了作答反應,因而 使得他們展現在人格量表的量表因素結構不一致。故假設五獲得支持。
綜合討論
本研究運用一筆實證資料檢驗應徵者和在職者在人格測驗的作答差異,並且運用非參數多分題 DIF 的檢測方法和多群組 CFA 分析,綜合說明在試題層次、試題組合層次、以及測驗層次的作答差 異。茲綜合各項研究結果,提出討論如下。社會期許量表
過去使用社會期許量表來偵測作假,有個很重要的前提假設,即「作假動機高者會反映在社會 期許的「印象整飾」部份;當印象整飾的分數高時,則代表有受試者作假」。然而本研究比較了作 假動機分別為高、低的兩個族群(應徵者vs. 在職者),且使用了全部用來測量「印象整飾」構念的 社會期許量表,檢視應徵者的社會期許分數是否會較高。結果顯示應徵者和在職者在社會期許量表 的總分沒有差異,且個別題項方面,應徵者只有在33% 的題項得分比在職者高。此結果和過去以實 驗操弄的作假(Komar et al., 2010)卻是相互抵觸的,Komar 等人相信,受試者在被要求作假時傾向表5 在職者 vs. 應徵者在六個量表的測量模式跨群組比較摘要表
χ2 df Δχ2 Δdf RMSEA NFI NNFI CFI RNI p <
社會期許量表 Variate 449.18 24 0.050 0.99 0.99 0.99 0.99 Invariate 473.60 30 24.42 6 0.046 0.99 0.99 0.99 0.99 .001 開放性量表 Variate 20,228.78 939 0.054 0.97 0.97 0.97 0.97 Invariate 20,408.67 971 179.89 32 0.053 0.97 0.97 0.97 0.97 .01 謹慎性量表 Variate 20,088.50 473 0.076 0.92 0.91 0.92 0.91 Invariate 20,220.69 496 132.19 23 0.075 0.92 0.92 0.92 0.91 .01 外向性量表 Variate 17,293.69 660 0.060 0.96 0.96 0.96 0.96 Invariate 17,378.98 687 85.29 27 0.059 0.96 0.96 0.96 0.96 .01 親和性量表 Variate 18,407.89 512 0.071 0.89 0.89 0.90 0.89 Invariate 18,526.69 539 118.8 27 0.069 0.89 0.89 0.90 0.89 .01 情緒穩定性量表 Variate 10,042.96 274 0.071 0.95 0.94 0.95 0.94 Invariate 10,197.64 296 154.68 22 0.069 0.95 0.95 0.95 0.94 .01
於在社會期許量表選擇最極端的選項,但是他們同時也認為,該情況係受試者在不清楚測驗目的時 才會發生。此現象令本研究不得不質疑以社會期許量表得分作為鑑定受試者是否有作假的效果,尤 其是應用於真實情境下。對照過去亦有學者對社會期許量表偵測作假的效果提出質疑,例如Dwight 與Alliger(1997)發現,當受測者接受教導作假,其社會期許量表的分數和誠實作答者較接近,反 而是僅提示作假者的社會期許分數較高,因此他認為雖然社會期許量表被設計來偵測作假,該量表 本身卻容易受到作假與否的影響,而Ellingson 等人(2001)比較社會期許分數高者與低者之間,其 人格結構都沒有差異,對照本研究的結果相當一致,本研究認為,這應該是社會期許量表本身無法 發揮其偵測並區分作假程度的功能所致。因此,以社會期許量表總分高低作為「判斷是否作假的工 具」是否恰當?值得進一步思考。此外,社會期許量表之所以無法發揮其偵測並區分作假程度的功 能,其真正的原因,可能是因為在真實的測驗情境中,應徵者會評估測驗之目地,而使得其作答並 非全然的「刻意作假」,因而在社會期許類與工作無關之題項的反應分數接近在職者的分數。另外 一項證據來自社會期許量表的總平均數,不論是應徵者或在職者,平均數皆未達3,以 6 點量表而言, 這樣的得分是偏低的,再以該量表第二題「我從來沒有討厭過任何人」為例,不同群組的平均數差 異未顯著,推測原因,可能是由於受試者認為此敘述和正常情況極不相符,若填答高分則顯得太過 矯情。凡此皆足以說明真實情境下,應徵者還是會視情況評估在哪些題項上作假以及作假的程度, 而不會完全以獲得高分為考量。 再對照DIF 檢測結果來看,第 1 題和第 3 題是明顯的應徵者會比在職者傾向高估的題目,且研 究結果亦同時顯示,在職者在第5 題和第 6 題卻會傾向於高估,依據本研究的定義,此即表示在職 者在第5 題和第 6 題作假。此結果說明了在職者和應徵者都會作假,只是呈現在不同的題目。因此, 本研究認為社會期許量表雖可解釋某一部份的作假效果,但不是在總分,而是在量表的某些題目上。 尤其,當應徵者或在職者很一致地在某些題目上有高估的現象時,即表現出兩族群特殊的反應組型, 此現象值得測驗使用者多加注意。 上述DIF 結果亦支持「應徵者和在職者之間對於社會期許量表當中的個別題目所知覺到的意義 是不一致的」看法,其結果使得某些題目對應徵者而言,更容易使他們往高分的方向作答,而另外 一些題目,則使在職者往高分的方向作答。或許這正是本研究中,以及Ellingson 等人(2001)、 Dwight 與 Alliger(1997)、甚或是 Ones 等人(1996)整合分析等研究中,應徵者與在職者的社會 期許總得分沒有差異的潛在原因。因此,在真實的情境中,社會期許量表對於偵測應徵者作假的效 果並不顯著。
人格測驗
平均數差異
結果顯示,整體而言應徵者明顯比在職者得分較高者,約有77.4%(124 題中的 96 題),但卻 也另有5.6% 的題目(124 題中的 7 題),在職者明顯比應徵者得分較高;其餘約有 16.9%(124 題中的21 題),應徵者和在職者得分並無差異。某些量表的總分,在應徵者和在職者之間的差異並 不明顯,個別題項中亦有一些題目並非所有應徵者得分都比在職者高。此結果對應Ellingson 等人 (2001)、Ellingson 等人(2007)、和 Hogan 等人(2007)等以應徵者和在職者樣本所做的研究結 果甚為一致,這些研究亦發現真實的應徵者在人格測驗的作答,不會必然比在職者來得高分。然而 相對於如Hough(1998)、Zickar 與 Ribie(1999)以實驗操弄的方式比較作假者與誠實者之間的平 均數差異,卻發現作假者的分數皆一致地高於誠實作答者。本研究認為,實驗室的操弄和真實作答 資料之間還是存在著落差,實驗室中極端的作假和現實世界中「給人好印象」的作假,基本上是相 當不同的。因此,若是單純以得分差異來說明受試者是否有作假,則恐怕是過於簡化對「作假」本 質的理解了。
DIF/DBF 檢測結果
研究結果符合原始假設,題目層次的分析顯示,有許多題目存在DIF 的現象,且不一定偏利於 應徵者,比例的分配亦不見得應徵者作假的程度較高;這表示不同群組的受試者的確會往其所希望 造成良好印象的方向去作答,主要原因是來自於不同群組對每個題目的知覺和解讀程度不同(如: 題目描述和工作的相關程度),因而影響受試者在該題作答時,傾向於往高分或低分的方向作答。 若對應過去僅有的少數幾篇運用DIF 的方法探討人格測驗作假的研究,由於本研究和過去的方 法、觀點、問題的角度等等,皆有極大差異,尤其是, 過去研究大多是在作假使得潛在能力改變的 基礎下測量不同作假組的試題參數改變量,因此較難有可以對話的空間,但是卻可呼應一個共同的 觀點:作假不全然是動機高低所引發,而是受試者根據測驗情境和目的而決定的作答方向(Stark et al., 2001)。另外,本研究結果亦間接呼應 Tett 等人(2012)和 van Hooft 與 Born(2012)等研究之 看法,受試者的作假行為需要運用到極高的認知能力,據以理解和評估題目與工作(績效)之間的 關係,進而決定該如何「恰當地」作假。 然而類似上述這種難以和過去研究對話的情況,也反映出對於人格測驗,從試題層次的觀點來 切入的研究實在太少,且基礎和方法迥異,然而,誠如Zickar 與 Ribie(1999)所言,作假本質上就 是試題層次的現象,受試者針對個別試題作答或作假,而非量表。因此,將作假的研究聚焦在試題 層次是相當重要的。對於促進作假本質的瞭解,從試題的層次,還有待進一步的努力。各量表因素結構差異與
DIF 檢測的關係
本研究亦檢查了DIF 的檢測效果和跨群組因素結構恆等性之間是否有對應的關係存在,結果發 現,各量表的檢測,如果該比較組中含有數個DIF 題項,則該量表在跨群組的因素負荷量恆等性檢 定中則會有差異,顯示兩個群組的結構並不相等。而Zickar 與 Ribie(1999)用 IRT 二參數 GRM 模 式下,用實驗的方式操弄作假程度,檢測出不同作假程度下存在有數量不等的DIF 題,然後再以和 本研究相類似的多群組驗證性因素分析,檢驗不同作假程度下其呈現的人格結構是否相等,MCFA 的結果顯示不同作假程度下,其人格因素結構大致是相等的。對應本研究和Zickar 與 Ribie(1999)的研究,可以發現 DIF 對測量恆等性的檢測效果和 MCFA 的檢測效果可能存在著落差。這也許是來自於各個研究者所使用的DIF 檢測工具或 MCFA 檢測程序 的不同,本研究使用的是SIBTEST 來檢測 DIF(屬於非參數估計法),而 Zickar 與 Ribie(1999) 則是使用MULTILOG 6.0(屬於參數估計法);本研究對於跨群組結構恆等性的檢測採取 Raju 等人 (2002)建議的程序,只放寬或限制因素負荷量來比較差異,而 Zickar 與 Ribie (1999) 則除了因素負 荷量之外還加入誤差變異量。另外,也可能是來自於方法學本身的差異,依據Raju 等人(2002), CFA 的方法主要優勢是在同時處理與比較多重潛在構念(latent constructs)與多重群體(multiple populations)之間的差異;而大多數的基於 IRT 的 DIF 方法學,則主要在處理單向度量表中,個別 題目的差異。 另外,若跨群組因素負荷量恆等性檢定結果大致上和DIF 檢定結果一致,亦即,當量表中含有 DIF 題目時,即會使得該量表因素結構不相等,那麼,是否可以推測,當量表中 DIF 題目愈多,則 因素負荷量恆等性檢定中的卡方值改變量(Δχ2)會愈大?研究者嘗試探究各個量表的DIF 題數與 卡方值改變量之間的關係,但無法找到一個共同的趨勢。但上述推論在社會期許量表中卻是成立的。 究其原因,研究者認為應該是方法學本身的運算基礎不同所致。社會期許量表題數只有6 題,且為 單一潛在構念結構,但人格各量表的結構較為複雜,為二階的單一潛在構念結構,且題數較多,最 少有18 題以上。當此情況之下時,跨群組因素負荷量恆等性檢定的結果,可能無法和 DIF 檢定的結 果完全一致。
其他議題
在DIF 的檢測結果和平均數差異檢測結果的方面,本研究發現一個有趣的現象,即若該題 DIF 是應徵者高估,則平均數差異部份,必然都是應徵者顯著高於在職者,但若該題DIF 顯示在職者高 估,則平均數差異部份,不必然都是在職者得分顯著高於應徵者,此時有更多可能是應徵者和在職 者的得分差異並不顯著,或者是應徵者得分僅小幅高於在職者(參見表3)。推測造成這種現象的 原因,可能是由於應徵者的得分通常較高,而DIF 分析是在限定同一能力值之下所進行,因此在總 分一樣的情況下,當某一題在職者與應徵者的得分相當接近時,很容易就凸顯在職者在該題傾向於 高估。但此一推論還需進一步的驗證。 此外,本研究發現應徵者和在職者在五大人格向度的分數僅外向性量表平均數沒有差異,對照 Birkeland 等人(2006)的整合研究指出外向性人格差異的效果量最小,這一點和本研究是吻合的, 且由DIF 分析可進一步提供證據,因外向性量表中 DIF 試題是最多的,且其中應徵者傾向高估和在 職者傾向高估的比例相當接近,說明應徵者或在職者在外向性量表的作答皆未表現出系統性的偏差。 準此,本研究最終認為,應徵者的確呈現出其特殊的作答反應組型,塑造出他的特殊良好形象。 然而,該反應組型並非全然性的「刻意的作假」,因為應徵者的目的並非表現出他是一個「聖人」 的形象,而是有目的的根據他對測驗情境的理解以對測驗題目的知覺而調整作答策略!結論與建議
過去,人格測驗從DIF 角度研究者,焦點大多集中在分析測驗題目本身的作假敏感度,若檢測 結果呈現DIF,則視為容易作假的題目(為 Changing persons paradigm 的角度,認為作假的過程是受 試者潛在能力暫時且有意識地改變的改變);然而本研究卻認為受試者的能力是相對穩定的,不會 受到測量工具或目的所影響,因此嘗試以changing items paradigm 的角度,傾向將作假解釋為誠實者 和作假者之間對同一試題的知覺不同。因此在本研究中的DIF,是指受試者在具有相同特質或能力 的條件下,因為個人經驗、知覺等差異而使其對題目的解讀方向不同,因而產生作答差異的情形。 期望能藉由題目層次的分析,進而找出不同群組個別的作假反應組型,探討應徵者在人格測驗上作 假反應的真正本質,以俾利未來實務上使用人格測驗作為甄選工具的參考。 本研究最主要的突破在於從IRT DIF 的方法學從題目層次探討人格測驗的作假議題,並且綜合 探討社會期許量表和人格測驗的作假效果,此一突破是植基於本研究所欲探討的人格測驗並無標準 答案之特點,因而運用DIF 檢測方法來評估是否不同的受試群體(應徵者/在職者)在個別題項上, 選擇某個選項的機率不同(即使他們的能力相同),而據以判斷不同群體受試者是否具有不同的反 應組型。 根據分析結果,整理主要的研究結論為:(1) 在個別試題層次,應徵者在社會期許量表或人格測 驗的得分並非全然比在職者高;(2) 在個別試題層次和試題組合層次,社會期許量表和人格五個量表 當中都檢測出DIF 題目,且當中有些是應徵者傾向高估,亦有些是在職者傾向高估自己的分數,因 此形成每一樣本在試題組合層次呈現出獨特的作答反應組型;(3) 在量表層次,跨群組的因素結構恆 等性檢定結果顯示,社會期許量表和五個人格量表在不同群組的因素結構皆有所差異。 本研究乃屬初探性質,研究方法突破過去傳統DIF 的觀點和運用,且研究結果具有實務上的參 考價值,但研究過程中遭遇許多現階段尚無法克服的困難、限制與疏忽之處,茲提出來以供進一步 研究的參考。