coding
Shen-Chuan Tai Yung-Gi Wu Ling-Shiou Huang
National Cheng Kung University Institute of Electrical Engineering University Road 1
Tainan 70101, Taiwan
E-mail: [email protected] [email protected]
Abstract. Vector quantization (VQ) has been accepted as one of the most effective image compression methods with provable rate-distortion optimality. The outputs of VQ are a collection of indices, which corre-spond to the addresses of the codevectors in the codebook. The indices are, however, not mutually independent. They are in fact very highly correlated and are thus appropriately described by a Markov system. In this paper, a Markov system for VQ indices is introduced. Statistics are gathered for various scans, such as the zig-zag, Peano, row-major and column-major scans. The proposed method, like address VQ, achieves the same image quality as conventional VQ. Simulation results show that the proposed method achieves a better bit-rate reduction than Address-VQ. Besides, both the computational complexity and memory needed for the proposed method are lower. Nevertheless, the only extra operation needed by the proposed method is a simple table retrieval operation on both the encoder side and the decoder side. We believe that it is a method worth further exploration. ©2000 Society of Photo-Optical Instrumenta-tion Engineers. [S0091-3286(00)02705-7]
Subject terms: Vector quantization; address VQ; Markov system.
Paper 990288 received July 26, 1999; revised manuscript received Oct. 26, 1999; accepted for publication Oct. 28, 1999.
1 Introduction
Vector quantization 共VQ兲 has been shown to be the best block-based compression technique for a given block size.1–3 After decades of intensive research, however, the theoretical promise of VQ has not been fully realized. The basic concept of VQ is that instead of encoding pixels sepa-rately, it encodes blocks of pixels as vectors. In a typical VQ system, an image is partitioned into nonoverlapping subblocks of size 4⫻4, each subblock being considered as a vector. Every vector is compared with codevectors of the codebook, which may be considered as representatives se-lected in some way, and replaced by the nearest neighbor-ing codevector in a least-mean-squared-error sense. The ad-dress of that codevector in the codebook is then transmitted to the channel or storage. To reconstruct the image, the receiver just retrieves the corresponding vector from the same codebook for each received address. That is, all that needs to be done by the decoder in VQ is a table lookup operation.
To reduce the bit rate, a designer may use either a larger vector dimension or a smaller codebook size. The vector dimension itself, however, must be small, considering the computational complexity and the size of storage. An intui-tive and appealing way to overcome this problem is to ex-ploit the correlation among the indices for the codevectors of neighboring vectors.
Among all previous proposals for processing VQ indi-ces, address VQ4–6 has achieved the best rate-distortion performance. However, the application of address VQ to lossy techniques, such as scalar or transform coding, has proven rather unsatisfactory because it does not allow one
to accurately control the trade-off between bit rate and dis-tortion.
Many proposals for VQ try to obtain the best possible fidelity at a given rate, or the lowest possible rate for a given fidelity. In this paper, an alternative way of approach-ing rate-distortion optimality is proposed. The Markov property is adopted to reduce the bit rate even at the same fidelity as for conventional VQ. The Markov property has been employed in many applications in the field of signal processing, including word recognition,7 speech recognition,8frequency estimation,9texture classification,10 document decoding,11 and the Markov prefetcher, which acts as an interface between on-chip and off-chip caches.12 In this paper, an application of Markov processes to VQ-based still-image compression is proposed. It achieves bet-ter bit-rate reduction, has lower computational complexity, and requires less memory space than address VQ.
2 Address VQ
To make this paper self-contained, the concept of address VQ5,6is briefly described in this section. Address VQ is a method of lossless coding on VQ indices designed for im-age compression. Let the VQ system encode 4⫻4 pixel blocks with a codebook of size k⫽128. The basic idea of address VQ is to explore the representatives of 4⫽2⫻2 neighboring VQ indices. Each of those representatives is then coded as a single symbol.
Let ri, i⫽1, 2, 3, 4, be four random variables that
冉
r1 r2r3 r4
冊
,
and P⫽兵p(r1⫽a,r2⫽b,r3⫽c,r4⫽d)兩a,b,c,d苸关0,127兴其
be the probability distribution. It is found that P differs greatly from the uniform distribution. Thus, according to information theory, further compression on the indices is possible. This encourages the designer to consider the blocks of 2⫻2 indices as another kind of vectors, and that idea is the origin of address VQ.
Address-VQ achieves the best rate-distortion perfor-mance among all VQ variants, but it is a rather complex scheme. It needs heavy computation and a large amount of memory. Clearly, as it stands now, address VQ is not a viable engineering solution to image coding.
In Ref. 6, the index compression scheme uses three codebooks. The first codebook is used to quantize the mean removed residual image. The size of this codebook is 128. The indices obtained are then processed by a lossless VQ scheme, which uses the second codebook 共first address codebook兲. Every index block—which, as just described, contains 4⫽2⫻2 neighboring indices—is compared with a big codebook of index patterns; the number of patterns is 16,384. If there is a match, it will then be considered as a candidate for another test; otherwise the four indices in it are transmitted directly共the second codebook is used here兲. Consider the case that there is a match. Since it matches some index pattern, it can be expressed as an index, the same as in VQ. We call it a superindex, since it is an index of indices. Four neighboring superindices, if they exist, can be processed similarly. For that purpose the third codebook, which is of size 1024, is used. If there is a match, then instead of the 16 indices, one superindex is sufficient, which corresponds to four superindices, and in turn each superindex corresponds to four indices. A map is used to record the matching results. Now it is clear why address VQ takes heavy computation and a large amount of memory space.
One cause of the high computational complexity of ad-dress VQ is that it uses blocks of indices as its source symbols. In this paper, in contrast, the proposed method uses the Markov model to reduce the computational cost; in the proposed system, the source symbol is just a single VQ index. Although coding blocks of VQ indices can be help-ful in capturing high-order pixel dependences, this ap-proach may not outperform conditional entropy coding of individual VQ indices, as will become clear later.
3 Markov Property
Consider a stochastic process兵X(t)其 taking values from a discrete state space S⫽兵0,1,2, . . .其. For any two points in time, say t and t
⬘
, and for any two states, say m and n, define the transition probability aspm,nt,t⬘⫽P关X共t
⬘
兲⫽n兩X共t兲⫽m兴, 共1兲which is the conditional probability that the process is in state n at time t
⬘
, given that it is in state m at time t. In general, given a sequence of time points t1⬍t2⬍¯ ⬍tk⫺1⬍tk, the conditional probability that the process isin state mk at time tk, given that it has been in states m1
through mk⫺1 at times t1 through tk⫺1, respectively,
de-pends on the values of the process at times t1,t2, . . . ,tk⫺1.
The Markov property can be defined as P关X共tk兲
⫽mk兩X共tk⫺1兲⫽mk⫺1, . . . , X共t2兲⫽m2, X共t1兲⫽m1兴
⫽P关X共tk兲⫽mk兩X共tk⫺1兲⫽mk⫺1兴⫽Pmk⫺1,mk tk⫺1,tk
. 共2兲
However, in some cases the conditional probability de-pends strongly on the most recent values prior to tk⫺1. In
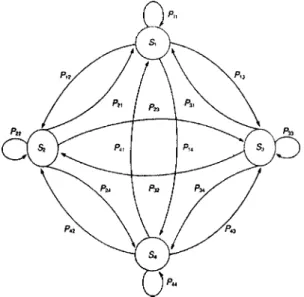
such a case, the analysis of the process is greatly simplified. Refer to Fig. 1, which shows a simplified version of a Mar-kov process with four states, depicted as a directed graph. State si, i.e., node siof the directed graph, represents index
i. A directed edge ei j from state sito sjmeans a transition
from state si to state sj. Corresponding to each ei j in the Markov process, there is a probability Pi, j, which is the conditional probability P(sj兩si). If an entropy coding
tech-nique is used to encode the directed edges ejected from si,
then the code length Li j for edge ei j is given by
Li, j⫽log2
1
Pi, j. 共3兲
This can achieve a smaller average code length.
In the proposed system, every VQ index is regarded as a state. The Markov system just exploits the relationship be-tween the present state and the next one. The basic idea is straightforward: Since in natural images spatially close blocks are strongly correlated, the indices associated with them also exhibit statistical dependence, as can be seen from Fig. 2, which shows the VQ indices expressed as 128 ⫻128 images where the codebook size is 256 and the code-vectors, which are of dimension 4⫻4, are sorted according to their mean values. Therefore, it is quite natural and will be effective to encode the VQ indices by extensively ex-ploring this kind of dependence. The reader may refer to Ref. 13 for a detailed description of the Markov property.
4 Proposed Markov System for VQ Coding Consider a finite sequence of VQ indices y1,y2, . . . yn
ob-tained by some kind of scan of the image subblock, and let k denote the size of the codebook that is generated by the LBG algorithm. So there are k states in the Markov system. According to information theory, the minimum code length
of the VQ index sequence in bits is given by
⫺log2⌸i⫽1 n
P(yi兩yi⫺1). This is the minimum possible rate.
The key issue in Markov systems is the estimation of P( yi兩yi⫺1). Note that depending on the scan pattern, the
previous state yi⫺1may differ from yi. Typical scans that are considered in this paper include the zig-zag, Peano, row-major, and column-major scans as shown in Fig. 3. That figure shows the four scans applied to 4⫻4 indices, to simplify the presentation. However, four scans are applied to 128⫻128 关共512/4兲⫻共512/4兲兴 indices in the case where the image size is 512⫻512 and the codeword is 4⫻4.
To estimate P( yi兩yi⫺1), yi,yi⫺1苸兵1,2, . . . ,k其, a large
training set is used. The estimated conditional probabilities P(yi兩yi⫺1), yi, yi⫺1苸兵1,2, . . . ,k其, are then stored and
used to drive an entropy coder for compressing VQ index sequences. In order to achieve the most efficient and effec-tive compression of VQ indices, all the scan patterns in Fig. 3 are explored.
For the statistics of state transitions, a two-dimensional array (k⫻k) that accumulates the frequencies of transi-tions between two state pairs is used. Initially, we set every element of (k⫻k) to 1. To avoid the zero-frequency problem, we have to make sure that every state can transit to all the other states, i.e., Pi j⫽0, i, j苸兵1,2, . . . ,k其. The
algorithm is as follows:
• Input: A well-trained codebook generated by LBG. Training images that are used to generate the state-transition matrix.
• Output: A code table for every state transition. • Step 1: Initially, for each i and j, set关i兴关 j兴 to 1.
• Step 2: Find out the best match codevectors yt from
the codebook for the incoming unencoded vector utat
time t.
• Step 3: Increase关yt⫺1兴关yt兴 by 1.
• Step 4: If all vectors in the training images have been processed, go to step 5, else go to step 2.
• Step 5: Calculate the transition probability Pi, j from
state i to j as follows: for 共i⫽0; i⬍k; i⫹⫹兲
for 共 j⫽0; j⬍k; j⫹⫹兲 Pi, j⫽ 关i兴关 j兴 兺j⫽0 k⫺1 关i兴关 j兴. 共4兲
• Step 6: Calculate the minimum code-length table as follows:
for 共i⫽0; i⬍k; i⫹⫹兲 for 共 j⫽0; j⬍k; j⫹⫹兲
Li, j⫽
d
log2冉
1 Pi, j
冊
e
. 共5兲
If the model is properly selected, the Pi, j’s for each i
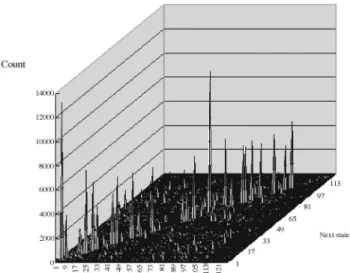
will differ greatly from the uniform distribution, and thus, according to information theory, one can build a Huffman code tree for each state and the average code length for each state will be small. To make the proposed system simple and effective, the models used simply correspond to different scans. Figure 4 illustrates the count distribution of our Markov transition matrixi, jthat was attained by
train-ing 22 images with column-major scan. As can be seen from Fig. 4, for any present state si, the distribution兵Pi, j其
does differ greatly from the uniform distribution; in fact, all values except Pi,iare small. Therefore, it is quite natural to
adopt the Markov system to describe VQ indices. In that case, the codes to be transmitted or stored are not the VQ indices themselves. It is the state transitions that are trans-mitted or stored. For example, let the code sequence be Fig. 2 VQ indices show the same image (codebook size⫽256).
Fig. 3 Four scan patterns.
兵y1, y2, y3, y4其. Then the codes to be transmitted or stored
for 兵y2, y3, y4其 will be Code共transition (y1→y2)兲⫹Code
共transition (y2→y3)兲⫹Code共transition (y3→y1)).
In conventional VQ, the coding order does not influence the results at all. In the proposed system, however, the or-ders, which correspond to the models, do affect the simu-lation results, as will be clear in the next section.
5 Simulation Results
To assess the performance of the Markov system, simula-tions have been carried out on a set of gray-scale images widely used in the research community. All images are of 512⫻512 pixels with 8-bit pixel gray intensity. The code-vector dimension is 4⫻4. A problem that must be consid-ered in the proposed method that does not happen in con-ventional VQ is the error propagation problem. Once a single code in the sequence is corrupted, all the following codes will be wrong. To prevent the propagation of errors caused by channel noise, the codes are transmitted in seg-ments. A special symbol is inserted into the sequences after every t transitions to indicate the start of a segment. Refer to Fig. 5. In this example, t is set to 4. In practical experi-ments, t is set to 128 so that the error propagation will be limited below 128. Extra bits for this special symbol are of course added to all the experimental results on bit rates in this paper.
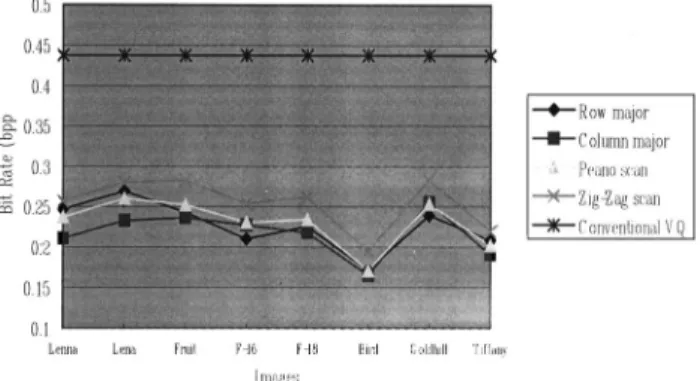
Twenty-two images are used to generate the Markov state transition table. After that, the corresponding Huffman trees for every state are generated. Codebooks of size 128 and 256 are generated and tested. Due to the heavy com-putation required to determine the codebooks and Markov transition tables, the programs are run on a DEC 8400. However, since that is done offline in advance, it does not increase the burden on the coding procedures. Figures 6 and 7 illustrate the simulation results with codebooks of size 128 and 256, respectively. As can be seen from the two
figures, adopting the column-major scanning pattern gives the best correlation reduction in most cases. Detailed nu-merical data are shown in Table 1.
In Table 1, the bit rates and PSNR obtained by the pro-posed system with the four different scanning orders are shown. The bit rates and PSNR of the proposed method are 0.233 bits/pixel and 29.72 dB for ‘‘Lena,’’ versus 0.256 bits/pixel and 30.6 dB with address VQ.6 The PSNR de-pends on the way the codebooks are generated. Since the authors of Ref. 6 did not describe the way they generated the codebook, the PSNRs by the proposed method may be a little different from theirs. However, the extent of bit-rate reduction is obviously higher than with address VQ. In all tests, the test images are excluded from the training sets. Even so, their bit rates decrease significantly. As to the computational complexity and memory requirement of the proposed method, the computation burden for codebook searching is the same as in conventional VQ. Processing the Markov transition matrix is simply table retrieval. The memory requirement for the Markov transition matrix is given in Table 2. Four memory sizes required by the Mar-kov transition matrixes for the four scan patterns are shown. For the case of codebook size 128, the total memory needed is about 25 kbyte. It is about 95 kbyte for codebook size 256. Address VQ6 needs three codebook-searching operations, and the sizes of the three codebooks are 128, 16,384, and 1024 respectively. The total memory size needed is about 260 kbyte. It is clear that the proposed system needs less memory. Therefore, the proposed method outperforms that of Ref. 6 in computational complexity, memory requirement, and bit-rate reduction.
Results of the proposed method are also compared with those by JPEG. Three images—‘‘Lenna,’’ ‘‘Lena,’’ and ‘‘Bird’’—are compressed at the same bit rates and code-book size 128. The PSNR values of the three reconstructed images are 30.71, 29.80, and 35.27 dB, respectively. The proposed Markov system achieves a little worse results
Fig. 5 Example of sequences.
Fig. 6 Bit-rate curves with different scan patterns (codebook size
⫽128).
Fig. 7 Bit-rate curves with different scan patterns (codebook size
than JPEG in terms of PNSR, but it should be noted that the computation burden for inverse DCT is much heavier than for simple index retrieval.
References 14 and 15 also describe a VQ index com-pression technique. They achieved bit rates of 0.254 and 0.2185 bits/pixel, respectively. The proposed system does better.
6 Conclusion and Future Work
In this paper, a bit-rate reduction technique for still-image coding, referred to as the Markov system for VQ, is pro-posed. Like address VQ, it adopts statistical coding of the addresses obtained by VQ searching. However, it requires considerably less computation time and memory space than address VQ. On both the encoder and decoder sides, the extra operations needed are simply table retrievals, which add negligible complexity. Nevertheless, the bit rate is sig-nificantly reduced.
The proposed method provides the same reconstruction fidelity as conventional VQ does. However, the number of codes to be transmitted or stored decreases by 40% to 60%, which is a significant improvement. As compared with other bit-rate reduction technique such as address VQ, the performance of the proposed Markov system is better in reduction degree, computational complexity, and memory requirement. Furthermore, the simulation results will get better if better codebooks are used. In this paper, no special technique is used to generate optimal or near-optimal code-books. The results will be better if a more sophisticated algorithm is used to generate the codebooks. Besides, the proposed Markov system is general in the sense that it can be used with other VQ systems, such as classified VQ and finite-state VQ, and with other optimal codebook genera-tion strategies to raise the performance.
We are now studying the possibility of utilizing the pro-posed coding scheme to transform images. In particular, we Table 1 Simulation results. Boldface values correspond to test images, excluded from the training
sets. Image PSNR (dB) Correlation reduction Row-major scan Column-major scan Peano scan Zig-zag scan Bit saving for best scan (%) Codebook size 128; bit rate 0.4375 bits/pixel
Lenna 30.51 0.2469 0.2110 0.2373 0.2570 51.76 Lena 29.72 0.2692 0.2332 0.2604 0.2801 46.68 Fruit 29.53 0.2428 0.2363 0.2521 0.2829 45.97 F-16 29.38 0.2104 0.2274 0.2307 0.2539 51.89 F-18 24.13 0.2256 0.2181 0.2341 0.2618 48.41 Bird 35.74 0.1714 0.1650 0.1706 0.1949 62.27 Goldhill 29.96 0.2391 0.2555 0.2531 0.2831 45.34 Tiffany 28.67 0.2083 0.1907 0.2019 0.2192 56.40
Codebook size 256; bit rate 0.5000 bits/pixel
Lenna 31.39 0.2891 0.2548 0.2828 0.3375 49.03 Lena 30.62 0.3197 0.2807 0.3132 0.3375 43.84 Fruit 30.25 0.2817 0.2776 0.2952 0.3247 44.47 F-16 30.26 0.2451 0.2691 0.2684 0.2975 50.97 F-18 24.48 0.2724 0.2770 0.2798 0.3191 45.50 Bird 36.51 0.1992 0.1934 0.2000 0.2267 61.30 Goldhill 30.74 0.2903 0.3111 0.3108 0.3473 41.93 Tiffany 29.83 0.2495 0.2337 0.2433 0.2674 53.25
Table 2 Memory requirement for Markov transition matrix and LBG codebook.
Scan
Codebook size 128 Codebook size 256 Markov transition matrix (bytes) Codebook (bytes) Total (bytes) Markov transition matrix (bytes) Codebook (bytes) Total (bytes) Row major 22,838 2048 24,886 92,694 4096 96,790 Column major 26,815 2048 28,863 92,932 4096 97,028 Peano 21,679 2048 23,727 90,573 4096 94,669 Zig-zag 20,735 2048 22,783 88,624 4096 92,720
are interested in wavelet-transformed images where the horizontally, vertically, and diagonally oriented details are separated after wavelet decomposition. Applying different scanning orders to different band signals should raise the performance significantly.
Acknowledgment
This research was partially supported by the National Sci-ence Council of the Republic of China under contract no. NSC 89-2213-E-006-112. The authors appreciate the com-ments of the reviewers.
References
1. J. Makhoul, S. Roucos, and H. Gish, ‘‘Vector quantization in speech coding,’’ Proc. IEEE 73, 1551–1588共1985兲.
2. A. Gersho and R. M. Gray, Vector Quantization and Signal Compres-sion. Kluwer, Boston共1992兲.
3. Y. Linde, A. Buzo, and R. M. Gray, ‘‘An algorithm for vector quan-tizer design,’’ IEEE Trans. Commun. 28, 84–95共1980兲.
4. K. Zeger, J. Vaisey, and A. Gersho, ‘‘Globally optimal vector quan-tizer design by stochastic relaxation,’’ IEEE Trans. Signal Process.
40, 310–322共1992兲.
5. ‘‘Vector Quantization,’’ special issue, IEEE Trans. Signal Process.
共1995兲.
6. N. M. Nasrabadi and Y. Feng, ‘‘A multilayer address vector quanti-zation technique,’’ IEEE Trans. Circuits Syst. 38共7兲, 912–921 共1990兲. 7. J. Dai, ‘‘Isolated word recognition using Markov chain models,’’
IEEE Trans. Speech Audio Process. 3共6兲, 458–463 共1995兲. 8. J. Dai, J. E. Tyler, and I. G. Mackezie, ‘‘Application of Markov
chains to speech recognition,’’ Electron. Lett. 27共25兲, 2360–2361
共1991兲.
9. P. Handel, ‘‘Markov-based single-tone frequency estimation,’’ IEEE Trans. Circuits Syst. 45共2兲, 230–232 共1998兲.
10. B. R. Povlow and S. M. Dunn, ‘‘Texture classification using non-causal hidden Markov models,’’ IEEE Trans. Pattern Anal. Mach. Intell. 17共10兲, 1010–1014 共1995兲.
11. G. E. Kopec and P. A. Chou, ‘‘Document image decoding using Mar-kov source models,’’ IEEE Trans. Pattern Anal. Mach. Intell. 16共6兲, 602–617共1994兲.
12. D. Joseph and D. Grunwald, ‘‘Perfecting using Markov predictors,’’ IEEE Trans. Comput. 48共2兲, 121–133 共1999兲.
13. R. W. Hamming, Coding and Information Theory, Prentice-Hall, Englewood Cliffs, NJ共1986兲.
14. J. Shanbehzadeh and P. O. Ogunbona, ‘‘Index compressed tree-structured vector quantization,’’ Signal Process. Image Commun. 14, 229–243共1999兲.
15. Y. G. Wu and S. C. Tai, ‘‘A bit rate reduction technique for vector quantization image data compression,’’ IEICE Trans. Fundam. Elec-tron. Commun. Comput. Sci. 10, 2147–2153共1999兲.
Shen-Chuan Tai received BS and MS de-grees in electrical engineering from the Na-tional Taiwan University, Taipei, in 1982 and 1986, respectively, and a PhD degree in computer science from the National Tsing Hua University, Hsinchu, Taiwan, in 1989. From 1989 to 1997, he was an asso-ciate professor of electrical engineering at the National Cheng Kung University, Tainan, Taiwan. He is now a professor at the same institute. Prof. Tai has published more than 90 papers. His teaching and research interests include data compression, DSP VSLI array processor, computerized elec-trocardiogram processing, multimedia system, and algorithms.
Yung-Gi Wu received his BS in informa-tion and computer engineering from Chung Yuan Christian University, Chung-Li, Tai-wan, in 1992 and his MS in electrical engi-neering from National Cheng Kung Univer-sity, Tainan, Taiwan, in 1994. From 1994 to 1996, he was an officer in the army. He is currently working toward his PhD at the In-stitute of Electrical Engineering, National Cheng Kung University. His research inter-ests include image processing, data com-pression, and biomedical signal processing.
Ling-Shiou Huang graduated from Na-tional Taipei Institute of Technology in 1995. Now she is a graduate student in the Institute of Electrical Engineering, National Cheng Kung University. Her primary re-search interests are in image processing and data compression.