科技部補助專題研究計畫報告
人工智慧機器人吵雜環境多人友善對話關鍵技術之研究(第2年)
報 告 類 別 : 成果報告
計 畫 類 別 : 個別型計畫
計 畫 編 號 : MOST 107-2221-E-006-216-MY2
執 行 期 間 : 108年08月01日至109年07月31日
執 行 單 位 : 國立成功大學電機工程學系(所)
計 畫 主 持 人 : 王駿發
共 同 主 持 人 : 蔡安朝、陳璽煌、曾世邦
計畫參與人員: 碩士級-專任助理:陳美蓮
博士班研究生-兼任助理:歐陽諺
博士班研究生-兼任助理:蘇柏豪
博士班研究生-兼任助理:陳哲文
報 告 附 件 : 出席國際學術會議心得報告
本研究具有政策應用參考價值:■否 □是,建議提供機關
(勾選「是」者,請列舉建議可提供施政參考之業務主管機關)
本研究具影響公共利益之重大發現:□否 □是
中 華 民 國 109 年 10 月 29 日
中 文 摘 要 : 本報告為「人工智慧機器人吵雜環境多人友善對話關鍵技術之研究
」第二年之期末報告。本系統當麥克風陣列接收語音訊號輸入時
,利用多通道語音增強演算法去除環境干擾聲音,乾淨的語音訊號
傳送「語音辨識」將語音訊號轉成一段文字,「聊天對話系統」接
收到文字序列傳送至語句前處理,會將語句藉由Jieba斷詞,將語句
斷為詞與詞的組合,再使用已訓練完成之詞嵌入模型進行向量化之
動作,此部分完成之後會得到一組向量,此組向量包含了本輸入語
句「詞」之訊息,可稱為詞向量。端對端對話系統則是以詞向量當
作輸入,經過完成訓練之編碼器,將詞向量進行編碼,輸出一向量
給解碼器進行解碼,此向量包含了輸入語句「句」之訊息,稱為句
向量,解碼器再依據句向量產生合適的回應句。
在第一年之期中報告,測試槽填充與診斷模擬之實驗結果準確率分
別為88%與86%,成功得到正確疾病後去藥品與疾病關聯資料庫將符
合此項疾病之藥品取出。
第二年,本計畫藉由深度學習迴歸模型與麥克風陣列除噪之系統
,將其應用於對話系統。所提出的語音增強算法分為訓練階段和增
強階段兩部分。在訓練階段,使用大量數據讓DNN模型學習映射函數
,並分離估計的乾淨語音特徵與吵雜的語音特徵。此外,我們添加
卷積遞歸神經網絡以改善原始DNN模型的性能,最後利用方法重建增
強後語音。該語音增強系統用於克服現實生活中的噪音干擾,提高
語音辨識的準確性,為後端對話系統提供正確的輸入語句。在語音
增強實驗中,使用我們的模型可以提高 PESQ 分數 0.83 。這表明
我們的模型可以在不同的雜訊測試中保持一定的雜訊抑制效果。在
語音辨識實驗中,我們的模型還可以有效地將語音辨識的正確率提
高0.73%。這表明我們的模型在真實領域還具有雜訊抑制功能,提高
了語音品質。
中 文 關 鍵 詞 : 人工智慧、機器人系統、系統整合、複雜環境下的對話系統、自然
聊天對話、藥局情境中文語料庫、視聽覺整合、遞迴神經網路、長
短期記憶模型、麥克風陣列。
英 文 摘 要 : In our system, when the microphone arrays receive the input
of voice signal, the multi-channel voice enhancement
algorithm is used to remove the ambient interference sound.
"Speech recognition" receive the clean speech signal to
convert the speech signal into a text. At the same time,
Image recognition results are introduced to "multi-person
dialogue target judging" to obtain target-speaker
information, and the time tagged text sequence and the
target speaker's identity will input to back-end dialogue
system. In addition, the source localization of the speaker
will transmit the direction information to the sub-plan III
mobile system. When the dialogue system receives a sequence
of words and sends it to the sentence pre-processing, the
sentence will be separated into combinations of words using
"Jieba" system, and then the words will be vectorize by
"Word-embedding" which have been pre-trained. After words
vectorizing, a set of vectors are obtained. The set of
vectors contains the meaning of the input word, which can
be called a word vector. End-to-end dialogue system is
based on the word vector as input, through the training of
the encoder, the word vectors are encoded into "context
vector", then output the context vector to decoder. This
vector contains the information of input sentence. The
decoder then generates the appropriate response sentence to
the user based on the context vector. In the experimental
result, the accuracy of slot filling and diagnostic
reasoning simulation was 88% and 86% respectively. After
successfully obtaining the correct disease, system will
search medical product and related disease database to find
out the medical product that meets the user need. Then
system will fill all the blank in the template sentence,
synthesize sentence into a speech sentence, return to
user.In the experiments, our system achieves 0.83 score in
PESQ. This shows that our model can maintain a certain
noise suppression effect in different noise tests. In the
speech recognition experiment, our model can also
effectively improve the accuracy of speech recognition by
0.73%. This shows that our model also has a noise
suppression function in the real world, which improves the
voice quality.
英 文 關 鍵 詞 : Artificial Intelligence, Robot System, System Integration,
Spoken Dialogue Systems, Free Talk, Recurrent Neural
科技部補助專題研究計畫成果報告期末進度報告
計 畫 類 別 : 個別型計畫
計 畫 編 號 : MOST 107-2221-E-006-216-MY2
執 行 期 間 : 108年08月01日至109年07月31日
執 行 單 位 : 國立成功大學電機工程學系(所)
計畫主持人: 王駿發
共同主持人: 蔡安朝、陳璽煌、曾世邦
報 告 附 件 : 出席國際學術會議心得報告
中 華 民 國 109 年 10 月 31 日
人工智慧機器人吵雜環境多人友善對話關鍵技術之研究(第2年)
I
中 文 摘 要 :
本報告為「人工智慧機器人吵雜環境多人友善對話關鍵技術之研究」第二年之期
末報告。
本系統當麥克風陣列接收語音訊號輸入時,利用多通道語音增強演算法去除環境
干擾聲音,乾淨的語音訊號傳送「語音辨識」將語音訊號轉成一段文字,「聊天
對話系統」接收到文字序列傳送至語句前處理,會將語句藉由Jieba斷詞,將語句
斷為詞與詞的組合,再使用已訓練完成之詞嵌入模型進行向量化之動作,此部
分完成之後會得到一組向量,此組向量包含了本輸入語句「詞」之訊息,可稱
為詞向量。端對端對話系統則是以詞向量當作輸入,經過完成訓練之編碼器,
將詞向量進行編碼,輸出一向量給解碼器進行解碼,此向量包含了輸入語句「
句」之訊息,稱為句向量,解碼器再依據句向量產生合適的回應句。
在第一年之期中報告,測試槽填充與診斷模擬之實驗結果準確率分別為88%與
86%,成功得到正確疾病後去藥品與疾病關聯資料庫將符合此項疾病之藥品取
出。
第二年,本計畫藉由深度學習迴歸模型與麥克風陣列除噪之系統,將其應用於
對話系統。所提出的語音增強算法分為訓練階段和增強階段兩部分。在訓練階
段,使用大量數據讓DNN模型學習映射函數,並分離估計的乾淨語音特徵與吵
雜的語音特徵。此外,我們添加卷積遞歸神經網絡以改善原始DNN模型的性能
,最後利用方法重建增強後語音。該語音增強系統用於克服現實生活中的噪音
干擾,提高語音辨識的準確性,為後端對話系統提供正確的輸入語句。在語音
增強實驗中,使用我們的模型可以提高 PESQ 分數 0.83 。這表明我們的模型可
以在不同的雜訊測試中保持一定的雜訊抑制效果。在語音辨識實驗中,我們的
模型還可以有效地將語音辨識的正確率提高0.73%。這表明我們的模型在真實領
域還具有雜訊抑制功能,提高了語音品質。
中文關鍵詞:
人工智慧、機器人系統、系統整合、複雜環境下的對話系統、自然聊天對話、藥局情境中文語
料庫、視聽覺整合、遞迴神經網路、長短期記憶模型、麥克風陣列
II
英 文 摘 要 :
In our system, when the microphone arrays receive the input of voice signal, the
multi-channel voice enhancement algorithm is used to remove the ambient interference sound.
"Speech recognition" receive the clean speech signal to convert the speech signal into a text.
At the same time, Image recognition results are introduced to "multi-person dialogue target
judging" to obtain target-speaker information, and the time tagged text sequence and the
target speaker's identity will input to back-end dialogue system. In addition, the source
localization of the speaker will transmit the direction information to the sub-plan III mobile
system. When the dialogue system receives a sequence of words and sends it to the sentence
pre-processing, the sentence will be separated into combinations of words using "Jieba"
system, and then the words will be vectorize by "Word-embedding" which have been
pre-trained. After words vectorizing, a set of vectors are obtained. The set of vectors contains
the meaning of the input word, which can be called a word vector. End-to-end dialogue
system is based on the word vector as input, through the training of the encoder, the word
vectors are encoded into "context vector", then output the context vector to decoder. This
vector contains the information of input sentence. The decoder then generates the
appropriate response sentence to the user based on the context vector. In the experimental
result, the accuracy of slot filling and diagnostic reasoning simulation was 88% and 86%
respectively. After successfully obtaining the correct disease, system will search medical
product and related disease database to find out the medical product that meets the user
need. Then system will fill all the blank in the template sentence, synthesize sentence into
a speech sentence, return to user. In the experiments, our system achieves 0.83 score in
PESQ. This shows that our model can maintain a certain noise suppression effect in different
noise tests. In the speech recognition experiment, our model can also effectively improve
the accuracy of speech recognition by 0.73%. This shows that our model also has a noise
suppression function in the real world, which improves the voice quality.
英文關鍵詞:
Artificial Intelligence, Robot System, System Integration, Spoken Dialogue Systems, Free Talk,
Recurrent Neural Network, Long Short-Term Memory, Microphone Array.
III
目 錄
一、前言及研究目的 ... 1
1.1 探討與解決吵雜與多人環境下語音辨識的問題 ... 1
1.2 探討與解決 RNN 與 LSTM 自然聊天對話系統的問題 ... 1
二、文獻探討 ... 3
2.1 吵雜環境下語音辨識 ... 3
2.2 對話系統 ... 4
三、研究方法 ... 5
3.1 利用深度學習迴歸模型除噪系統 ... 5
3.2 噪音資料庫收集 ... 6
3.3 Deep Neural Network (DNN) ... 7
3.4 Convolutional-Recurrent Neural Networks Architecture ... 8
3.5 Long Short Term Memory Networks ... 9
3.6 Bi-directional LSTM ... 9
四、實驗結果 ... 10
4.1 語音增強演算法的評估方法 ... 10
4.2 實驗參數設定 ... 10
4.3 實驗結果 ... 11
五、結論 ... 14
六、參考文獻 ... 14
附件一 ... 15
附件二 ... 23
附件三 ... 25
1
一、前言及研究目的
本研究計畫「人工智慧機器人吵雜環境多人友善對話關鍵技術之研究」之研究目的為設計一對
話系統, 可以於吵雜環境之下順暢地與使用者對話。以下為兩項研究目的之探索及討論。
1.1 探討與解決吵雜與多人環境下語音辨識的問題
在人類社會中,語言上的溝通扮演著人們傳遞訊息的重要腳色。因此,讓語音對話系統
(Spoken Dialogue System, SDS)聽得懂使用者所說的話,語音辨識的技術快速的成長著。目前
,在日常生活中語音辨識的應用層面相當廣泛,舉凡多媒體智慧助理、語音資訊檢索、車載
導航影音系統以及居家照護機器人…等等,都和語音辨識技術息息相關。語音辨識的技術演
進,使得原本冷冰冰的機器在語音辨識的幫助下,變得更人性化,更能貼近人們的日常生
活。
2010 年以後隨著深度神經網絡(Deep Neural Networks, DNN)技術的發展,近場的語音
辨識技術越近成熟也都到達商業化階段,例如 Apple 語音助手 Siri、Google 的 Speech API
、Microsoft 的Cognitive Service 等,都在語音辨識領域有極好的表現。但當人距離麥克風較
遠處說話,變成遠場語音辨識的情況下,目前的語音識別引擎如果不做特殊的處裡,它們的準
確率會急遽下降。遇到的問題有以下四點:
(1) 迴響:如果人距離麥克風較遠的情況下,聲音會經過房間的反射、牆壁的反射、桌面
的反射… 等等,麥克風接收到的聲音包括目標說話的直達聲還包括從這些地方反射過
來的反射聲,因此麥克風接收到的訊號是這些聲音的疊加。
(2) 環境噪音:在真實情況中,當全家人正在客廳看電視或是開著電風扇、打開洗衣機的
狀態下, 都會有各式各樣的噪音,此時麥克風接收到的信噪比會急遽降低。
(3) 人聲干擾:在全家人或多人聚會的環境下,機器人同時接受到兩人以上的聲音時,容
易造成機器人答非所問或者無從得知使用者意圖。
(4) 回聲:麥克風一定會收到喇叭所發出來的聲音,所以當喇叭在撥放音樂的時候,使用
者對它下達命令,麥克風會很難收到命令詞。
一般家庭機器人在面對吵雜環境或許多人同時對機器人講話時,若直接將所收到的聲
音進行語音辨識,會因為上述四個難點造成判斷錯誤或無法辨識,使機器人發生答非所問
的情況,因此在面對上述情況下,例如家庭舉辦派對等情形時,機器人多選擇沉默不做回
答,或使用面對吵雜環境時所設定的預設回答,來避免回答錯誤的情況發生。當發生環境
聲音干擾的情況下,機器人若沒有合理的行為來面對,將導致使用者體驗不佳,減少大眾
購買及使用意願。以上所探討之吵雜環境與多人對話等問題以及如何針對這些問題提出相
應的解決辦法將為本計畫研究重點。
1.2 探討與解決 RNN 與 LSTM 自然聊天對話系統的問題
傳統的對話系統是由多個模組所組成,稱為 Modular Dialogue System 分別包含了
Automatic Speech Recognizer(ASR) 、 Natural Language Processing(NLP) 、 Dialogue
Management(DM)、Natural Language Generation(NLG) ,此種對話系統需要消耗許多人力將
資料標記(Label),不同領域(Domain) 的對話也需要相關領域的專家幫忙建構規則,且不易
普遍化,一個新的領域之對話,就需要建造新的規則、模型,無法直接套用先前在其他領
域使用的模型,這使得建構對話系統之門檻過高,資源不足則很難踏入對話系統之領域。
現今研究的趨勢為使用遞迴神經網路(RNN)與長短行記憶模型(LSTM)來實現對話系統,因
為將傳統對話系統的 NLP 與 DM 合為一個模組,稱做為 End-to-End Dialogue System[1],
如圖 1 所示。兩者之間的差異可以用以下幾個特性區分:
(1) Modular Dialogue System 有兩個或以上的目標函數而 End-to-End Dialogue System 只
需要一個目標函數。
(2) Modular Dialogue System 容易訓練且所需資料庫相對於 End-to-End Dialogue System 少
許多,End-to-End Dialogue System 則需要大量資料庫。
2
(3) Modular Dialogue System 需要大量人工的特徵標記,且須事先定義 State、Action 等人工
規則,End-to-End Dialogue System 則不需要定義 State、Action 等人工規則。
(4) Modular Dialogue System 於 highly structured tasks/narrow domain 之對話系統效果出色
,但不容易普遍化(generalization),End-to-End Dialogue System 則在 general purpose 的效
果較好且相同架構可用於不同資料庫,易普遍化。
一個基於神經網路的對話系統分成兩個部分組成,分別為 Encoder 與 Decoder。
Encoder 的作用是對一句輸入語句進行編碼,編碼成一組具有輸入語句重要資訊的向量,
Decoder 再根據此向量生成一回應句,如圖 2 所示。
LSTM 為 RNN 神經元的改良版,因為 RNN 無法控制是否記憶,所以 LSTM 新增了
控制閘,來控制輸入、輸出、與記憶功能,達到可考慮上下文關係的對話系統,亦可將
Decoder 輸入視覺辨識之情緒當作資訊再產生相關回應句。此種對話模型不只有上述之優
點,亦能解決傳統對話系統無法泛化、需要大量標記(Label)資料且需要特定領域之專家幫
忙建構規則,使得建構對話系統所需資源門檻降低,加速研究之發展。
圖 1、E2E 簡化傳統對話系統模組示意圖圖 2、E2E 基本架構示意圖
1.3 探討與解決視聽覺整合之對話系統發展尚未完善的問題
世界充滿著許多事物,人類透過自己的感官能力與環境做互動,藉由感知到豐富的事物與訊息
, 藉此來學習。人們一直期待機器人可擁有像人一樣的感知行為,然而這樣的期待看似簡
單,卻實行不易。其中有很多的原因,例如運算量太大就是一個大問題,導致目前機器人
的視覺、聽覺等等領域的感知研究獨立發展,可能有個好的對話系統,但卻只能用聲音判
別周遭環境,使之準確率下降,或者回答過於單調,又或者有個很好的影像辨識系統,卻
不能透過語音與人溝通,讓他人知道它看見了什麼,這與人類的期待是相違背的。
圖 23
二、文獻探討
在此部分,本計畫針對兩個方向進行文獻探討,分別為吵雜環境下語音辨識及對話系統。
2.1 吵雜環境下語音辨識
近年來,神經網路被應用於語音增強,Tu et al.[2]在 2017 年提出「sDNN1」以及「
sDNN2」之新架構,與現有的基於 DNN 的語音增強中使用的標準前饋神經網絡不同
在於添加從網絡輸入到網絡輸出的 skip connection。實際的網路輸出是將當前幀輸入
連接到輸出,並且與最後一層的輸出相加,如圖 7 所示。通過深層神經網絡模型建立
帶噪語音和乾淨語音譜參數之間的映射關係,模型的輸入是帶噪語音的頻譜相關特徵
,模型的輸出是乾淨語音的頻譜相關特徵,通過深層神經網絡強大的非線性建模能力
重構安靜語音的頻譜相關特徵,相比於譜減法、最小均方誤差、維納濾波等傳統方法
,這類方法可以更為有效的利用上下文相關信息,對於處理非平穩噪音具有明顯的優
勢。
Pascual et al.[3]在 2017 年提出「SEGAN」之新架構,如圖 8 所示。通過語音增強 GAN
實現, 其中生成網絡用於增強。它的輸入是含噪語音訊號和潛在表徵訊號,輸出是增
強後的訊號。將生成器設計為全部是卷積層(沒有全連接層)
,這麼做可以減少訓練參
數從而縮短了訓練時間。生成網絡的一個重要特點是端到端結構,直接處理原始語音
訊號,避免了通過中間變換提取聲學特徵。在訓練過程中,鑑別器負責向生成器發送
輸入數據中真偽信息,使得生成器可以將其輸出波形朝著真實的分布微調,從而消除
干擾訊號。但是,在複雜的聲學環境下,噪音總是來自於四面八方,且其於語音訊號
在時間和頻譜上常常互相交疊,再加上回聲和迴響的影響,利用單麥克風接收相對純
淨的語音是非常困難的。而麥克風陣列融合了語音訊號空間與時間的訊息,可以同時
提取聲源並抑制噪音。以麥克風陣列進行語音增強技術則稱為多通道語音增強, 以下
介紹幾篇多通道語音增強之文獻。
圖 3、sDNN1 架構圖 圖 4、SEGAN 架構圖4
2.2 對話系統
(1) Word-Embedding
Tomas Mikolov et al.[4]在 2013 提出了 Word2Vector,運用此方法可以做
Word-level 之Embedding,於表示詞、短語、句子、段落或文章為向量時可以使用。此篇 paper
最主要的解決的問題為如何於大量數據集中,快速且精準的學習出表示詞之向量
。 本 文 提 出 的 兩 個 模 型 CBOW(Continuous Bag-of-Words Model) 和 Skip-gram
(Continuous Skip-gram Model)。CBOW 模型與 NNLM(Neural Network Language Model
)模型類似,用上下文的詞向量作為輸入,映射層在所有的詞間共享,輸出層為一個分
類器,目標是使當前詞出現的機率最大。Skip-gram 模型與CBOW 的輸入跟輸出恰好相
反,輸入層為當前詞向量,輸出層是使得上下文的預測機率最大, 如圖 11 所示。
word2vec 利用詞的上下文,讓語義信息在向量表示中更加豐富。基於 word2vec, 出現了
phrase2vec, sentence2vec 和 doc2vec。此一方法已成為深度學習在自然語言處理中最
重要的其中一個方法。
(2)
RNN
-Based Language Model
說到深度學習運用於語言模型,最有名的就是 RNN Encoder-Decoder 這方法。於
2014, Kyunghyun Cho et al.[5]所提出這種結構,如圖 12 所示。Encoder 的部分,就是一
個 RNNCell(RNN、GRU、LSTM 等)所組成。每一個 Timestep,會輸入一個字或詞 X(以
向量表示),直到輸入至最後一個輸入字或詞 XT,輸出一組語意向量 C 代表整個輸入語
句之語意。選擇使用 RNN 之原因為 RNN 會將前面每一步的輸入訊息都考慮進來,所
以 C 則能夠涵蓋整個輸入語句之訊息。在Decoder 中,根據 Encoder 所得到之語意向
量 C,一步一步將蘊含於其中的訊息分析出來。此篇論文除了提出 Encoder-Decoder
這種創新的架構之外,另一個重大之貢獻為將 RNN 之改良版 LSTM 進行修正,提出了
GRU(Gated Recurrent Unit)。 GRU 保留了 LSTM 重要的控制記憶之功能,但卻沒有
LSTM 的參數這麼龐大,減少了運算複雜度。
圖 5、CBOW 與 Skip-gram 示意圖
5
三、研究方法
3.1 利用深度學習迴歸模型除噪系統
本計畫藉由深度學習迴歸模型與麥克風陣列除噪之系統,將其應用於對話系統。所提出的語音
增強算法分為訓練階段和增強階段兩部分。在訓練階段,使用大量數據讓DNN模型學習映射函
數,並分離估計的乾淨語音特徵與吵雜的語音特徵。此外,我們添加卷積遞歸神經網絡以改善
原始DNN模型的性能。主要目的是利用卷積神經網絡來提取特徵,並使用循環神經網絡來處理
時態模型。在增強階段,利用麥克風陣列收音獲得前處理的音檔,將音檔輸入進已經訓練好的
卷積遞歸神經網絡來獲得乾淨的語音特徵,最後利用方法重建增強後語音。該語音增強系統用
於克服現實生活中的噪音干擾,提高語音辨識的準確性,為後端對話系統提供正確的輸入語句
。麥克風陣列用於收音,不僅可以幫助我們前端的除噪,還可以增長系統收音的距離。
本計畫提出的深度神經網絡在語音增強算法中的應用,主要使用深層神經模型來估計乾淨語音
頻譜的幅度,以提高語音的清晰度和清晰度。同時,它還可以提高語音識別的準確性。在訓練
階段,我們使用了噪聲和乾淨語音數據對的對數頻譜特徵來訓練基於DNN的迴歸模型。我們對
輸入信號進行短時傅立葉分析,以計算每個重疊窗口幀的離散傅立葉變換(DFT)。然後計算
對數光譜特徵。特徵縮放後,所有特徵均歸一化為零均值和單位方差。在增強階段,將嘈雜的
語音特徵輸入到由先前大量數據訓練而成的深度神經網絡中,以獲得預測的干淨語音特徵。在
獲得估計的干淨語音對數頻譜特徵後,我們使用傅立葉逆變換切換回時域信號。最後,通過重
疊相加法重構相應的語音信號,本系統架構圖如下。
圖 7、系統架構圖6
3.2 噪音資料庫收集
我們在多人吵雜的公共區域(包括超市、餐館和百貨公司)收集音訊,並在每個欄位中選擇一個
固定點,使用麥克風陣列進行錄製。我們在總共收集了5小時的錄音,並手動分段並記錄了不同的
噪音。下表顯示了每個欄位中的不同雜訊類型。
表格 1. The information of the database collection
在資料前處理階段,需計算原始語音和雜訊檔案的SNR,資料及中的語音信號不是靜止的,而是從
短時間的角度來看的。此外,離散的 Fourier 變換 (DFT) 需要資料在塊 [26]中。幀的長度會影響語音
資訊。如果幀持續時間太大,則無法捕獲音訊信號的時變特性。
另一方面,如果幀持續時間太小,則網路參數將增加 [27]。如果我們想要減少相鄰幀之間的差值,我們
可以允許它們之間的重疊,重疊區域包含 50% 的幀點。由視窗函數增加其相鄰幀的連續性,在本計
畫中使用 512 點的Hamming Window。
由於時域中語音信號的振幅變化通常難以觀察到雜訊和語音的特徵,因此通常通過更改頻域來觀察每
個不同區域的能量的大小和分佈。頻率點。快速 Fourier 變換 (FFT) 是離散 Fourier 變換 (DFT) 的快
速演演演算法。FFT 是用於在時域和頻域之間轉換信號的數學轉換。 因此,我們執行 FFT 以取得每
個幀的幅度頻率回應。使 DNN 輸入在感知上更相關的另一個技巧是,採取量級譜的對數,以模擬
我們對體積變化呈指數級敏感這一事實。
要素縮放是將所選要素的值縮放到大致相似的範圍。這樣做的目的是加快收斂速度,減少使用梯度下
降演算法的反覆運算次數。要素縮放使數據中每個要素的值具有零平均值(減去分子中的平均值時)
和單位方差。一般計算方法是確定每個要素的分佈均值和標準差。接下來,我們減去每個要素的均
值。
Devices for Collecting
Audio
Microphone array and notebook
Way to Collect Audio
Fixed position recording
Field
1. Supermarket
2. Restaurant
3. Department store
Number of Audio Files
100 audio files per field, a total of 300 files
Total Duration of Audio
Files
5 hours per field for a total of 15 hours
7
3.3 Deep Neural Network (DNN)
在計算輸出和學習目標之間的損耗后,使用反傳播演算法來調整網路中每個權重和偏差。
最後,我們希望將輸出和目標之間的損失降至最低。在訓練階段
,
回歸DNN模型根據立體聲
數據的集合進行訓練。在預處理後
,
立體聲資料將轉換為日誌光譜功能
,
用於嘈雜語音和乾
淨語音。我們將雜訊語音的 7 幀對光譜要素進行堆疊
,
以獲得輸入向量
,
模型將輸出光譜要
素的中心幀
,
以生成估計的乾淨語音。然後採用基於平均絕對誤差(MAE)的基於物件函數的
回傳播演算法,在估計的規範化光譜特徵與參考乾淨語音之間進行訓練。
圖 8、deep network architecture diagram
此處採用的體系結構是具有許多非線性級別的前饋神經網路,允許它們表示一個高度非
線性回歸函數,該函數映射嘈雜的語音特徵以清除語音特徵。它有三個隱藏層,每個層都有
2048 個節點和 ReLU 啟動功能。使用學習速率的Adam最佳化器對隱藏圖層進行 20% optimizer
的Dropout訓練10
−4,輸出層的激活函數是線性的。
該演演演算法的體系結構是,在學習過程中,使用DNN來學習映射函數。嘈雜的言語和乾
淨語的關係是沒有假設的。給定足夠的訓練樣本,它會自動瞭解將語音與嘈雜信號分離的複雜
關係。此外,DNN可以通過將聲學上下文資訊串聯到長輸入特徵向量中,以用於DNN學習,
同時在高斯混合模型中,不同維度之間的獨立假設是高斯混合模型中降低計算複雜性的常見做
法,從而沿時間軸(使用多幀雜訊語音作為輸入)和沿頻率軸(使用全頻頻譜資訊)。
8
3.4 Convolutional-Recurrent Neural Networks Architecture
卷積循環神經網路是兩個神經網路的組合,即卷積網路和循環網路。主要目的是利用特
徵提取中的卷積網路,並利用循環網路來處理時間模型。建議的系統結構如下所示。對嘈雜言
語與乾淨言語之間的關係也沒有假設。給定足夠的訓練樣本,它會自動瞭解將語音與嘈雜信號
分離的複雜關係。
圖 9、Convolutional-Recurrent neural network architecture diagram
首先,將預處理的日誌光譜特徵輸入網路前端,即卷積層。每個輸入都是一個二維()陣列,
包含一系列連續光譜特徵向量,每個大小我們認為卷積層為特徵提取器,並使用b × w size 大小
捲積內核從輸入中有效捕獲光譜時態特徵。這個過程可視為使用卷積內核捲積輸入要素矩陣,
並產生一個矩陣,稱為啟動映射或𝑓
′× t 要素映射。
網路的第二個結構是雙向迴圈層,在將要素映射饋入 BRNN 之前,d 要素映射沿頻率軸堆疊,
以便對於每個時間步長,我們現在都有大小要素向量(參見圖d × 𝑓
′錯誤! 找不到參照來源。)。此
操作保留 t 幀的時間連續性,以及來自上一個卷積要素圖的所有資訊。在這篇論文中,我們使用
長期短期記憶單位在循環層。要建譯深度雙向 LSTM,我們可以將其他 LSTM 圖層堆疊在一起。
9
3.5 Long Short Term Memory Networks
在深度神經網路中,只考慮輸出和輸入之間的關係,不考慮數據之間的關係。循環神經
網路 (RNN) 用於對序列資料進行建模,即網路輸出與最後一個時間點的輸入相關。
簡單地說,RNN 實際上是在向 DNN 體系結構添加記憶體。它存儲前一個時刻的隱藏圖
層資訊,然後輸入到當前時刻的隱藏層中。該函數不僅具有輸入和輸出之間的連接,而且具有
前一時刻的資訊。它有助於功能更好地保持乾淨的語音和去除噪音成分。
雖然 RNN 可以利用任意長的歷史,但在實踐中,RNN 的有效上下文長度非常有限。提出
了長期短期記憶(LSTM)神經網路,以彌補這一限制[33]]。 LSTM 塊還克服了 RNN 訓練中的消失
梯度問題。這些記憶體塊類似於計算機的記憶體,可以在其中讀取、寫入和存儲或重置資訊。
LSTM 模組由一個自連接的單元和三個門組成,分別決定何時使用輸入門、輸出門和忘記門執行
寫入、讀取和重置操作,如下所示。 。
圖 11、Schematic of LSTM unit.3.6 Bi-directional LSTM
LSTM只能依據之前時刻的順序信息來預測下一時刻的輸出,但在某些問題中,當前時刻的輸出替
換和之前的狀態有關,還可能和未來的狀態有關係。 Bi-LSTM有兩個LSTM上下重疊在一起的組成,
輸出由這兩個LSTM的狀態共同決定,雙向LSTM架構如下所示。
圖 12 、Schematic of LSTM unit.10
四、實驗結果
本研究計畫「人工智慧機器人吵雜環境多人友善對話關鍵技術之研究」為兩年期計畫,第
二年本計畫主要以完成吵雜環境下的語音辨識模組。本計畫在第二年完成了降噪語音辨識模組的
設計, 並且實際測試了系統的可靠度及高辨識率。
4.1 語音增強演算法的評估方法
作為語音增強系統,一個可用於評價績效的客觀評價指標是必不可少的。平均意見評分
(MOS) 是可用於客觀評估的指標。MOS是由IEEE提出,用於測量通信系統的語音品質,也可用於
評估語音增強領域的語音增強性能。在 MOS 方法中,0 分代表最差品質,5 分代表最高分。
有兩種常見的MOS評分方法:主觀MOS和客觀MOS。主觀MOS由不同的人對原始語料庫和
輸入系統失真語料庫進行比較和評分。目標方法主要是使用語音品質感知評估(PESQ)對設備或軟
體進行測試。對於語音增強,我們可以與嘈雜的語音和降噪語音進行比較。
通常MOS分為幾個不同的級別來表示不同的語音品質。本計畫將採用基於PESQ的客觀
MOS評價方法。評估需要同時輸入兩個音訊信號,ref 表示引用語音,deg 表示降級的聲音。
系統構建後,首先輸入乾淨語音作為參考,雜訊語音作為 deg 來評估 MOS_MIXED。此外,
輸入乾淨語音作為參考,輸出語音后降噪通過神經網路作為deg MOS_NET。根據系統MOS_NET
MOS_MIXED判斷系統後語音退化的程度小於嘈雜語音的退化程度。
4.2 實驗參數設定
我們在收集的雜訊資料庫中從每個領域選擇了40種雜訊,共120種雜訊。雜訊記錄文件大約需
要 3-5 秒。乾淨的語音資料來自TIMIT資料庫,所有訓練數據集加起來大約 40 小時。
TIMIT 測試集中另外 168 個隨機選擇的話語用於為雜訊類型和 SNR 級別的每個組合構造測
試集。由於我們只評估了本文中看不見的雜訊類型,我們選擇了 4 每個場要測試哪種噪聲,總共有
12種噪聲。下表顯示了實驗數據集。
表格 2 The experimental dataset.
所有乾淨語音和雜訊波形的採樣速率設置為 16 KHz, 幀長度為 32 ms(512 個樣本),幀移位為
16 ms(256 個採樣),日誌光譜特徵向量的尺寸為 257。DNN設有三個隱藏層,每個層有 2048 個節
點和 ReLU,使用Adam最佳化器對隱藏圖層進行 20% optimizer 的 Dropout 訓練
。輸出層的激
活函式是線性的,批次處理大小設定為 500 。均值和方差規範化應用於DNN的輸入和目標特徵向
量,因此可以壓縮日誌光譜特徵的動態範圍,使其適用於反傳播訓練。
Type
Number
of
sentences
Number
of
synthetic
recordings
total
time
Train
4365
34920
40
hours
Test
168
2016
2.24
hours
11
4.3 實驗結果
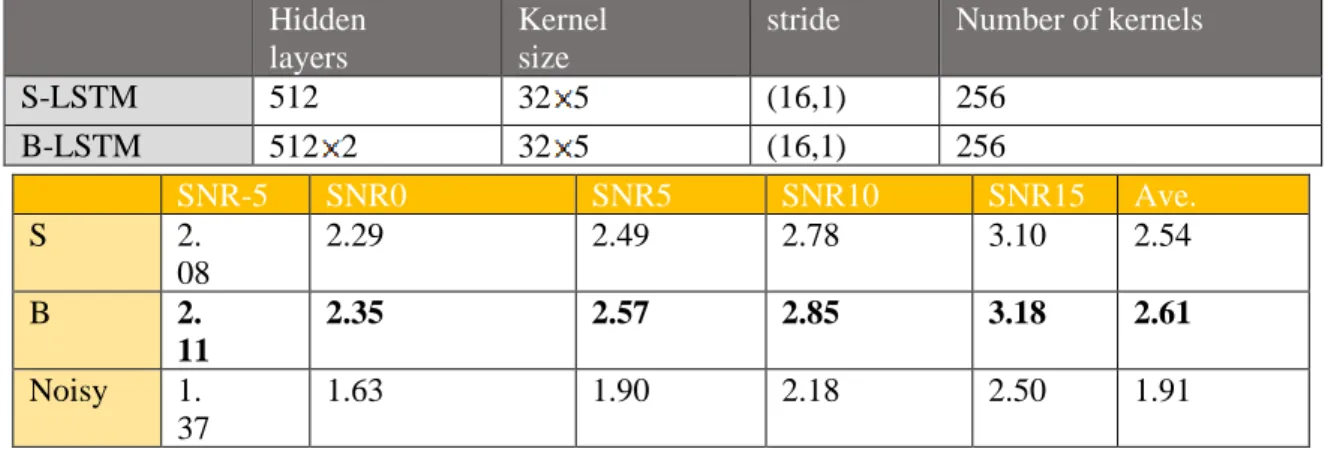
表格 3 、Experiment of Single LSTM vs. Bidirectional LSTM
Hidden
layers
Kernel
size
stride
Number of kernels
S-LSTM
512
32 5
(16,1)
256
B-LSTM
512 2
32 5
(16,1)
256
我們為CRNN做了以下實驗,以選擇最好的模型。首先,對單LSTM和雙向LSTM進行了實
驗。從上表中發現,雙向LSTM具有較高的PESQ。我們認為,雙向 LSTM 的結構為輸出序列中每
個點提供完整的過去和未來上下文資訊,因此性能良好。
Table 4 Experiment of different kernel size
Hidden
layers
Kernel
size
stride
Number of kernels
1-conv
512 2
32 1
(16,1)
256
3-conv
512 2
32 3
(16,1)
256
5-conv
512 2
32 5
(16,1)
256
接下來,對於不同的內核大小實驗,我們發現內核大小為5 x 32,PESQ 分數較高。如上表所示。
我們還試驗了不同的內核數位。在確定卷積分量的參數後,我們還對分量進行了多次實驗,以確
定最佳參數。
Table 5 Experiment of different number of kernels
Hidden
layers
Kernel
size
stride
Number of kernels
128
512 2
32 5
(16,1)
128
256
512 2
32 5
(16,1)
256
512
512 2
32 5
(16,1)
512
對於雙向迴圈元件,我們試驗了不同層的隱藏層。從下表中,我們可以發現這三個層具有較
高的 PESQ 分數,但兩個層之間沒有太大的區別。 因此,考慮到PESQ分數和訓練時間,我們選擇了
SNR-5
SNR0
SNR5
SNR10
SNR15
Ave.
S
2.
08
2.29
2.49
2.78
3.10
2.54
B
2.
11
2.35
2.57
2.85
3.18
2.61
Noisy
1.
37
1.63
1.90
2.18
2.50
1.91
SNR-5
SNR0
SNR5
SNR10
SNR15
Ave.
1-conv
2.09
2.30
2.49
2.80
3.10
2.556
3-conv
2.09
2.33
2.54
2.84
3.16
2.592
5-conv
2.11
2.35
2.57
2.85
3.18
2.612
Noisy
1.37
1.63
1.90
2.18
2.50
1.916
SNR-5
SNR0
SNR5
SNR10
SNR15
Ave.
128
2.09
2.31
2.54
2.82
3.15
2.582
256
2.11
2.35
2.57
2.85
3.18
2.612
512
2.11
2.36
2.55
2.85
3.16
2.606
Noisy
1.37
1.63
1.90
2.18
2.50
1.916
12
兩層架構。
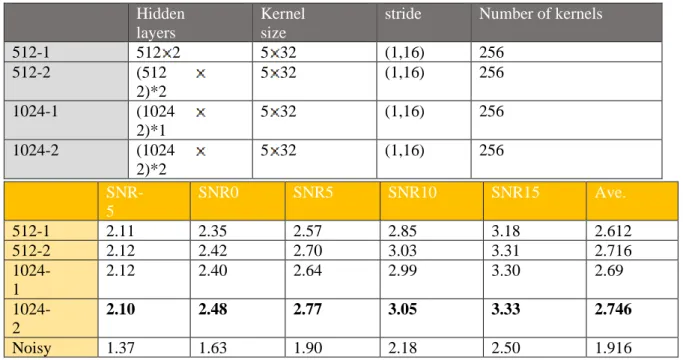
Table 0-1 Experiment of different number of hidden layers
Hidden
layers
Kernel
size
stride
Number of kernels
1L
512 2
32 5
(16,1)
256
2L
(512 2)*2
32 5
(16,1)
256
3L
(512 2)*3
32 5
(16,1)
256
最後,我們還試驗了不同單元的隱藏層。從下面的錯誤! 書籤的自我參照不正確。中,我們可
以發現 1024 個單位的 PESQ 分數較高。RCNN 的體系結構如下:卷積元件包含 256 個內核的大小,
分別沿頻率和時間維度前進。在卷積元件之後,我們使用兩層雙向 LSTM,每個層都有 1024 個隱藏
單元。
Table 0-2 Experiment of different units of hidden layers
Hidden
layers
Kernel
size
stride
Number of kernels
512-1
512 2
5 32
(1,16)
256
512-2
(512
2)*2
5 32
(1,16)
256
1024-1
(1024
2)*1
5 32
(1,16)
256
1024-2
(1024
2)*2
5 32
(1,16)
256
RCNN 能夠將感知品質 (PESQ 度量) 提高 0.83。 與其他方法相比,RCNN的PESQ改進率最高。
Table 0-3 Speech enhancement system PESQ experimental result
SNR-5
SNR0
SNR5
SNR10
SNR15
Ave.
SS
[15]
1.60
1.99
2.36
2.38
2.45
2.156
DNN
1.74
2.12
2.45
2.76
3.08
2.43
RNN
[38]
2.01
2.32
2.59
2.84
3.16
2.584
CRNN
2.10
2.48
2.77
3.05
3.33
2.746
Noisy
1.37
1.63
1.90
2.18
2.50
1.916
SNR-5
SNR0
SNR5
SNR10
SNR15
Ave.
1L
2.11
2.35
2.57
2.85
3.18
2.612
2L
2.12
2.42
2.70
3.03
3.31
2.716
3L
2.12
2.45
2.71
3.02
3.29
2.718
Noisy
1.37
1.63
1.90
2.18
2.50
1.916
SNR-5
SNR0
SNR5
SNR10
SNR15
Ave.
512-1
2.11
2.35
2.57
2.85
3.18
2.612
512-2
2.12
2.42
2.70
3.03
3.31
2.716
1024-1
2.12
2.40
2.64
2.99
3.30
2.69
1024-2
2.10
2.48
2.77
3.05
3.33
2.746
Noisy
1.37
1.63
1.90
2.18
2.50
1.916
13
為了瞭解我們系統的實用性和實用性,我們到實田對系統進行了測試。我們讓5名參與者在
每個真實領域測試20個句子,以計算語音增強系統後語音辨識的結果。用語音辨識的單字錯誤率
來評價。
調查報告的結果表式,該系統可以提高語音辨識的準確性。具體來說,RCNN 能夠將感知
品質 (PESQ 度量) 提高 0.83,而不會降低識別精度。這是非常令人驚訝的,因為我們使用的SSR系
統是谷歌SSR,我們不能在實驗中微調。為了進行比較,雖然所有其他方法都可以提高 PESQ,但它
們通常會降低辨識精度。
Table 0-4 Speech enhancement system WER experimental result
Wrong
words/
Total
words
(A)
Wrong
words/
Total
words
(B)
Wrong
words/
Total
words
(C)
WER
SS
[15]
153/775
170/775
225/775
23.57%
DNN
156/775
177/775
196/775
22.75%
RNN
[38]
145/775
153/775
174/775
20.3%
CRNN
102/775
130/775
136/775
15.83%
Noisy
116/775
125/775
144/775
16.56%
以下表4Table 0-5表Table 0-64。.
Table 0-5 The example of improved speech recognition results-1
Table 0-6 The example of improved speech recognition results-2
Sentence type
Recognition result
clean sentence
今天的特餐是什麼?
noisy sentence
今天的特產是什麼?
enhanced sentence
今天的特餐是什麼?
Sentence type
Recognition result
clean sentence
飲料續杯需要收費嗎?
noisy sentence
你要去杯需要收費嗎?
14
五、結論
在計畫第一年中,我們提出了診斷推理模塊,我們採用TF-IDF算法來訓練我們的醫療
產品和相關疾病語料庫中的疾病和症狀的重量。訓練體重後,我們可以了解每種症狀和疾
病的重要性。我們提出了一個公式來計算疾病的分數,該分數可以知道用戶可能患有哪種
疾病。最後,我們可以得到最可能的疾病。在醫療產品選擇模塊中,我們可以根據從前模
塊收集的信息搜索我們的醫療產品數據庫,並為用戶選擇最合適的產品。在實驗結果中,
診斷推理模擬的準確率為86%。並且也完成了吵雜環境下的語音辨識模組。第二年,本計
畫進行深度學習模型應用於語音增強演演演算法。增加了對循環神經網路的體系結構,以
提高模型提取特徵和處理時間模型的能力。在語音增強實驗中
附件一
使用我們的模型可
以提高 PESQ 分數 0.83 。這表明,我們的模型可以在不同的雜訊測試中保持一定的雜訊抑
制效果。在語音辨識實驗中
附件一
我們的模型還可以有效地將語音辨識的正確率提高
0.73%。這表明我們的模型在真實領域還具有雜訊抑制功能,提高了語音品質。
六、參考文獻
[1] S. J. Young, "Probabilistic methods in spoken–dialogue systems," Philosophical
Transactions of the Royal Society of London A: Mathematical, Physical and Engineering
Sciences, vol. 358, no.
1769, pp. 1389-1402, 2000.
[2] M. Tu and X. Zhang, "Speech enhancement based on Deep Neural Networks with skip
connections," in 2017 IEEE International Conference on Acoustics, Speech and Signal
Processing (ICASSP), 2017, pp. 5565-5569: IEEE.
[3] S. Pascual, A. Bonafonte, and J. Serrà, "SEGAN: Speech Enhancement Generative
Adversarial Network," arXiv preprint arXiv:1703.09452, 2017.
[4] T. Mikolov, K. Chen, G. Corrado, and J. Dean, "Efficient estimation of word
representations in vector space," arXiv preprint arXiv:1301.3781, 2013.
[5] D. Bahdanau, K. Cho, and Y. Bengio, "Neural machine translation by jointly learning
to align and translate," arXiv preprint arXiv:1409.0473, 2014.
15
附件一
科技部補助專題研究計畫出席國際學術會議心得報告
日期:108 年 12 月 10 日
計畫編號
MOST 107-2221-E-006 -216 -MY2
計畫名稱
人工智慧機器人吵雜環境多人友善對話關鍵技術之研究(2/2)
出國人員
姓名
王駿發
服務機構
及職稱
成功大學電機系教授
會議時間
108 年 11 月 14 日至
108 年 11 月 17 日
會議地點
CHANGZHOU JIANGSU, CHINA
中國江蘇省常州市
會議名稱
(中文) 2019 橘色科技國際會議
(英文)
The 2019 IEEE International Conference on Orange Technologies (ICOT 2019)
發表論文
題目
(中文) 基於美食部落格文本之混合階層中文閱讀理解
(英文)
Hybrid Layers of Chinese Machine Reading Comprehension for Delicacy Food Blog
一、參加會議經過
108.11.12 (二)從台南至桃園國際機場搭機至無錫。
108.11.14 ( 四 )-17( 日 ) 參加 The 2019 IEEE International Conference on Orange
Technologies (ICOT 2019) 國 際 研 討 會 , 發 表論文” Hybrid Layers of Chinese
Machine Reading Comprehension for Delicacy Food Blog”,並與會中各國專家學
者討論及交流研究計畫相關技術及研發趨勢並搜集研究計畫相關資料。
108.11.19 (二)早上從上海搭機抵達台灣高雄國際機場。
16
本會議包含以下主題:
➢
Health Technology
--Artificial Intelligence on Healthcare
--Biomedical Informatics
--Information Technology in Biomedicine
--Medical Imaging Processing
--Affordable and Adaptive Healthcare IOT
--Intelligent Health Instrumentation and Robotics
--Networking and Security for Health/Medical Care
--Intelligent Health Multimedia Information Processing
➢
Happiness Technology and Index
--Affective Computing for Happiness Detection
--Internet of Things for Smart Living
--Smart Manufacturing for GNH
--Healthcare Service Oriented Computing
--Industry IOT for GNH
--Natural Language Processing for Happiness
--Happiness Detection from Psychological/Physiological Bio-Signals
--System Design for Happiness Promotion
➢
Warming Care Technology
--Human-Machine Interface for Senior and Children Care
--Cloud Health and Mental Care Services
--Assistive Technology and Senior Companion Robot
--Multimedia Information Processing for Healthcare
--Big Data application on Health/Medical Care
--Care Service Oriented Computing
17
二、與會心得
1.
與澳洲Victoria University Prof. Yanchun Zhang,討論老人睡眠品質偵
測技術與建置系統。
2.
與大陸西安Northwestern Polytechnical University 謝磊教授, 討論電
腦語音最新發展趨勢包括客製化TTS、多人語音對話系統、多模式影
像及語音整合對話系統。
3.
與印尼Bina Nusantara University Dr. Emil Kaburuan 洽談橘色科技垃
圾生態處理及管理系統。
4.
與香港理工大學Dr. Jiannong Cao曹建農教授洽談大數據及區塊鏈之
最新發展及應用趨勢。
三、發表論文全文或摘要如
附件一
四、建議
無
五、攜回資料名稱及內容
ICOT 2019 會議資料
六、其他
18
Hybrid Layers of Chinese Machine Reading
Comprehension for Delicacy Food Blog
Ta-Wen, Kuan 3*, Bo-Hao Su1, Yuan-Ta Hsu1, Jhing-Fa Wang1,2, Tzong-Song Wang41 Department of
Electrical Engineering, National Cheng Kung University
2 Department of Information Engineering, Tajen University 3 School of AI,Guangdong & Taiwan, Foshan University, Guangdong 4 Graduate Institute of Culture and Creative Industries E-mail: [email protected] †
Abstract— In this paper, a Strong Attention Architecture
with Hybrid Vectors framework for Machine Reading
Comprehension (MRC) system is proposed, to effectively
solve the MRC problem in Chinese. The system is
consisted of five layers, including 1) Hybrid embedding
layer. 2) Encoding layer. 3) Stronger attention layer. 4)
Output layer and 5) Generate layer, in which the hybrid
embedded layer and the stronger attention layer are
inspected, where the character-embedding and the
word-embedding models are utilized, respectively, to convert the
words of the article and the question into a character vector
and a word vector, whereas the words in article being
highly relevant to the problem are then weighted by
stronger attentional architecture. In dataset, the Delta
Reading Comprehension Dataset (DRCD) and a Tainan
Delicacy corpus are applied for a series of experiments. In
experimental results, the criteria on Exact Match (EM) can
be achieved 70.43%, and F1-score is also reached 72.61%.
Overall, the proposed work gives the superior performance
compared to other two related works, yet worse than the
human performance.
Index Terms — Word embedding model; Character
embedding model; pointer network model; long short-term
memory model; stronger attention architecture; Chinese
machine reading comprehension system
I. INTRODUCTION
Reading comprehension is a human fundamental skill through systematically learning since elementary school by reading and questioning from an article content. To answer these questions, summarization, assertion, inference, refinement of those evidences then finally answering by words. However, to infer the writer’s intention from article is a challenge work, this motivates us to proposed this work to investigate the reading comprehension question for answering questions from a given document.
Dataset for benchmark is a critical factor for usability in MRC, broadly divided into four categories: 1) Multiple choices such as McTest [1], 2) Cloze as CNN / Daily News [2], 3) Extraction in SQUAD [3], and 4) Abstraction e.g. MS MARCO [4]. MRC investigation in English, Wang et. al [5] utilized semantics through match-LSTM and Pointer Net to predict the position of the answer in the article. Seo et al. [6] examined interaction
Fig. 1. System architecture
information between questions and paragraphs through a bidirectional attention mechanism. Xiong et al. [7] built a network model with dynamically co-attentional flow to iteratively predict the range of answers.
In this study, a Strong Attention Architecture with Hybrid Vectors for Chinese MRC with corresponding proposed system framework shown in Fig 1, to deal with the challenges of MRC in Chinese in three aspects. Firstly, Chinese is differentiated from English in words discrimination by space. Secondly, related works on MRC in Chinese generally used word vectors for sentences, yet problems met on the out of vector (OOV) in terms of training efficiency issues. Thirdly, extracting the words relating questions in the article would meet problems if article is too long, led to hardly find the appropriate answer.
The remaining parts in this work is as follows. Section II introduces the proposed system. Section III shows the experimental results, and Section IV concludes the proposed work.
19
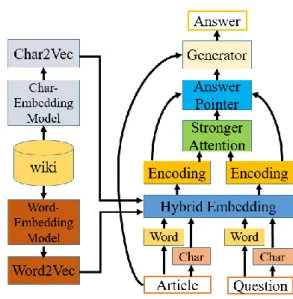
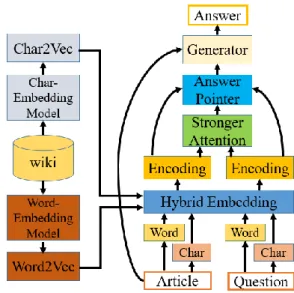
II. PROPOSED SYSTEM
Framework Overview
Figure 1 is shown the proposed framework wherein five layers are composited, including 1) hybrid embedding layer, 2) encoding layer, 3) stronger attention layer, 4) output layer, and 5) generation layer, whereas the corresponding characters and words are featured as vectors, respectively. Hybrid embedding layer maps each character and word to a vector space using a pre-trained hybrid character and word embedding model. After that, encoding layer utilizes surrounding word and character vectors to yield the contextual information. Previous two layers are then applied to the question and article. Next, stronger attention layer merged the question and article vectors to generate question-awareness featured vectors for each word in article, and employs a Long Short-Term Memory (LSTM) [8] to scan the article. Thereafter, output layer provides an answer index to the question. Eventually, generation layer generates an answer from the article through the answer index.
Hybrid Embedding Layer
1) Layer Overview
The flow diagram of Hybrid Embedding Layer is shown in Fig. 2, including for parts, that is, 1) input question and article,
2) Jieba for segmentation, 3) word-embedding and char-
embedding, 4) word vectorization and character vectorization and 5) concatenation. Question and article firstly are segmented separately, then using Jieba for input text processing and customizing nouns for related domains by User_dict, example shown in Table I. The result is thereafter segmented into the words and the characters by the word-embedding and char- embedding models to create language vector space for trained models through wiki dataset. Word vectorization and character vectorization are then used to map words and characters into the language vector space, where each converted word and character can be operated by machine. Finally, the concatenation part merges the word and character vectors of article into a hybrid vector, the steps for the question is the same as the article step.
2) Embedding and Vectorization
Word Embedding [9] is a method to map words into a vector space, having a denser representation compared to one-hot encode method, by using a variety of language models for learning shown in Table II. Word embedding hints that many hidden relationships between words can be obtained, for example, vector ("Spain") - vector ("Madrid") are similar to vector ("Italy") - vector ("Rome"), given the relationship between country and capital. For word-embedding treats a word as a non-binary numeric vector, such that a lower and denser dimension is then obtained. Intuitively, suitable word embedding gives the better similarity between similar words or hidden semantic relationships, where word contexts can be learned and understood by contextual information, for similar words often appeared in similar contexts.
In word2vec, Chinese version of Wikipedia files are downloaded for training contained about 3.7 million articles for transformation into text format, herein the genism word2vec model from Google is used to train these data, and defined the dimension size 300 as a word space, additionally, Continous Bag of Words Model (CBOW) is chosen here as the model for its lower computational complexity O(V), whereas Skip-gram
is O(5V) and 5 is a window size. Then feeding sentence contained 5 words into the model, after that the vector of each word is then acquired. The example is shown in table II. In the case of char2vec, as previously downloaded files from Wikipedia used for training data. Herein the genism char2vec model from Google, used to train these data, size in 200 treated as the dimension of the character space and CBOW is also used
Fig. 2. The flow diagram of Hybrid Embedding Layer
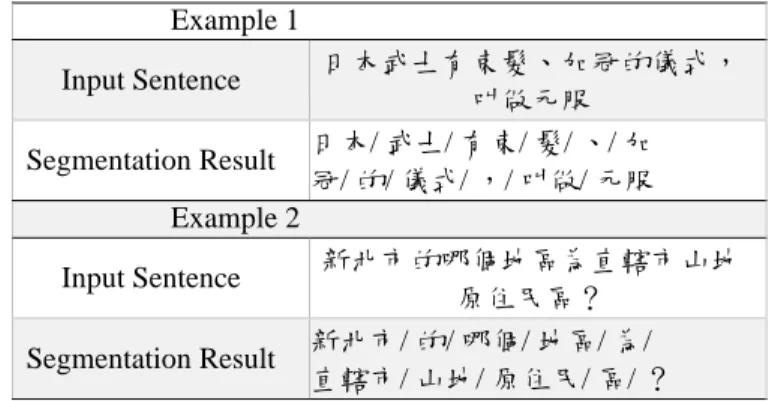
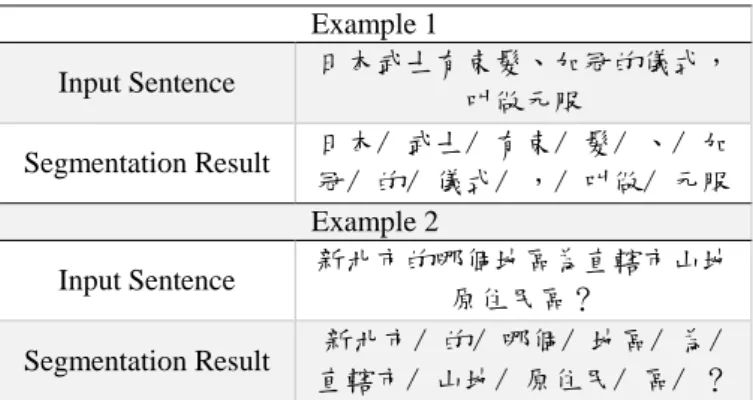
TABLE I. SEGMENTATION WITH JIEBA
Example 1 Input Sentence 日本武士有束髮、加冠的儀式, 叫做元服 Segmentation Result 日本/ 武士/ 有束/ 髮/ 、/ 加 冠/ 的/ 儀式/ ,/ 叫做/ 元服 Example 2 Input Sentence 新北市的哪個地區為直轄市山地 原住民區? Segmentation Result 新北市/ 的/ 哪個/ 地區/ 為/ 直轄市/ 山地/ 原住民/ 區/ ?
TABLE ⅠⅠ THE RESULT Of WORD EMBEDDING AND VECTORIZATION
Word Vector representation of word Size of dimension=300 台灣大雞排 [-0.19855534,…,-0.0057442924]
很 [-0.02085873,…, -0.50289285] 好吃 [-0.1597478,…,-0.22335216]
TABLE ⅠⅠⅠ THE RESULT OF CHARACTER EMBEDDING AND VECTORIZATION
Character Vector representation of character Size of dimension=200 台 [0.028282,…, 0.009892] 灣 [-0.334899,…,0.060722] … 好 [0.443514,…, 0.201379] 吃 [0.402922,…, 0.354191]
as word2sec case. Then feeding sentence formatted as 5 characters to get the vector of each character after training. Example of the trained character vector is shown in table III.
20
A. Stronger Attention
Layer
e
ij(s
i 1,h
j)
(5) 1) Framework OverviewFramework of stronger attention layer is mainly divided into two parts including, question-article attention and self-attention, as shown Fig. 3. Firstly, use the question-article attention to capture words relating the problem in the article. Secondly, weight of the words is emphasized by the Self-Attention Architecture according to the relevance, such that greatly differentiates between the related and the unrelated words, and benefits to the subsequent decoder to get a more appropriate answer.
2) Question-Article Attention
The question-article attention scores the relevance degree between the article and the question, for not all words are beneficial for the answer, therefore, by weighting skill to score the relevance degree between problem and article, that is, the higher relevance implied the higher weight between article words and question.
The encoded article and question are denoted as A and Q, respectively. The similarity between article and question is calculated through a trainable scalar function as (1), where the
where the score is based on the RNN hidden state Si-1 and the j- th
annotation hj of the input sentence, and
β
is the learning function.Fig. 3. The flow of Stronger Attention Layer
similarity matrix S I×Jis given by
S
i, j(A
i,Q
j)
(1)
where α is the trainable scalar function, Ai is i-th word of the
article and Qj is j-th word of the question. To indicate that the
degree of words in the article are critical or relevant to the question. Next normalizing each column of S by the softmax function. The question-article attention is calculated as:
C
A
soft max(S
T
) A
T
(2)
Fig. 4. The original architecture of auto-encoder
3) Self-Attention Layer
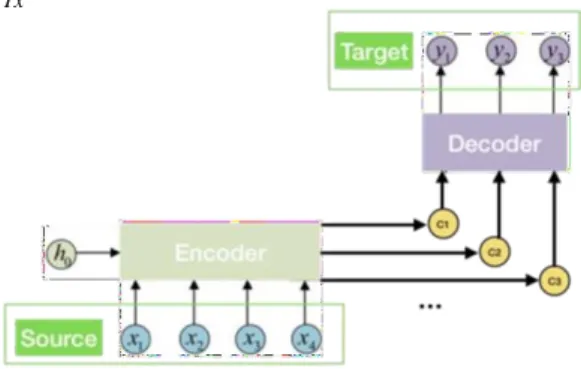
The attention model is used to solve the problem of weak translation on MRC when met the long sentence, by creating a context vector for each word of input, rather than just creating a context vector from the hidden state for the input. For example, if a N-words sentence input, then N-context vectors are generated to benefit the decoding efficiency. Noted that above is different from the standard encoder-decoder method as Fig.
4. The probability is conditioned on the different context vector
ci of each target word yi shown Fig. 5.
The context vector ci relied on a sequence of annotations
(h1…hTx), of which an encoder maps the input sentence. Each
annotation hi contains information for the whole input sequence
with a strong focus on the parts surrounding the i-th word of the input sequence. The context vector ci is, then, computed as a
weighted sum of these annotations hi in (3):
Tx
Fig. 5. The architecture of self-attention
TABLE ⅠV EXAMPLE OF DRCD DATASET
c
i ijh
j j 1 (3)The weight αij of each annotation hj is computed as (4), and
(5) is an attention model to score how well the inputs surrounding
Type Content Article 新北市總人口中客家人口約占 14.1%, 雖非全臺灣最高,但總人口數為全臺灣 第二多,僅次於桃園市……永和區的中 興街則為早期韓國華僑的聚集所在,又 有『韓國街』之稱。 Question 臺灣哪一行政區所擁有的客家人 口比例是最高的?
21
1) Dataset
III.
EXPERIMENTAL RESULTS
TABLE V THE EVALUATION RESULTS OF DIFFERENT MODEL ON DRCDTwo datasets including, Delta Reading Comprehension Dataset (DRCD) [10] and Tainan delicacy corpus, are mainly used to evaluate the proposed work, wherein DRCD used to train the proposed model for accuracy inspection. The observation is shown that by training Tainan delicacy food dataset, the proposed work is able to reach the higher accurate MRC performance in the domain of Tainan cuisine compared to ORCD. For DRCD is a machine comprehension dataset based on a set of Wikipedia articles in Chinese, having more than 30,000 questions and 10,000 paragraphs. The answer to each question is always a span in the context, where the model given a credit if the answer is matched one of the human written answers. The example is shown in Table IV.
2) Model Evaluation
Two criterions, that is, Exact Match (EM) and F1 score, based on statistical analysis and measurement of classification herein used to examine the preformation of proposed model. Both criterions ignore the punctuations and the definite articles
i.e. a, an, the. EM measures the percentage of predictions to match any one of the ground truth answers exactly as (6).
and a stronger attention architecture, wherein the approaches of a semantic understanding and question answering in Chinese are applied. Due to the complexity on Chinese language led to dataset incompleteness, such that would be influencing the semantic understanding. Accordingly, the hybrid vector is used to solve the problem in terms of three aspects. Firstly, most of the known words are converted into vectors through the word- embedding model, and the character vector generated by the character-embedding model used to represent vectors for the unknown word, thereby alleviating the common problem of out of vector in Chinese. Secondly, the stronger attention architecture is proposed to understand articles and questions, in order to find words that are highly relevant to the questions in the article. Thirdly, the pointer network model is used to predict the answer relating the question in the article. In corpus, the DRCD dataset used for training and Tainan delicacy food corpus
is then used to predict the appropriate answer regarding the questions. In experimental results, the criteria EM can be achieved 70.43%, and F1-score is also reached 72.61%, overall the proposed work gives the superior performance compared to
Accuracy correct 100%
test
(6)
other two related works, yet being worse than the human performance.
F1-Score (F1) inspects the character-level fuzzy matching between the prediction and the ground truth. That is, measuring the overlap between the prediction and the answer. Herein we used the maximum F1 throughout the ground truth answers for a given question as (7): Note that, non-Chinese words will not be segmented.
2×𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛×𝑅𝑒𝑐𝑎𝑙𝑙
REFERENCES
[1] M.Richardson, C.J.Burges, and E.Renshaw, " Mctest: Achallenge dataset for the open-domain machine comprehension of text," in Proc.
Conf. Empirical Methods Natural Lang. Process., 2013, pp. 193–203.
K. M. Hermann et al., " Teaching machines to read and comprehend, n Proc. Adv.
Neural Inf. Process. Syst., 2015, pp. 1693–1701. iP. Rajpurkar, J. Zhang, K. Lopyrev,
and P. Liang. (2016). " Squad: 100000+questions for machine comprehension of text." [Online].
[2] "
𝐹1 =
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛+𝑅𝑒𝑐𝑎𝑙𝑙 (7)3) Experimental Results
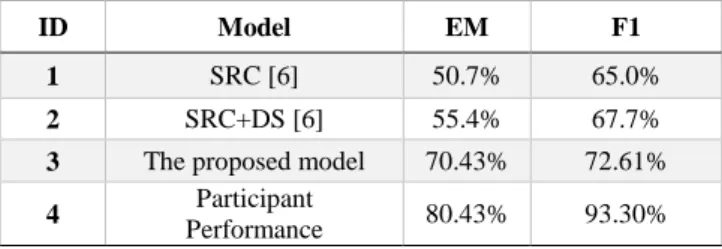
Totally 3,485 questions and 1,000 articles are collected into the dataset for evaluation through EM and F1 score criterions. Table V illustrates the experimental results of two related works’ models (ID1 and ID2) on DRCD having comparison with the proposed model (ID3) as well as the real human participant (ID4). The model marked “SRC” [11] indicated fine tuning with DRCD data only matching the BERTserini condition proposed by Yang et al. [11], where the model marked “SRC + DS” [11] released the fine tune BERT with all data grouped together. Although model SRC+DS outperformed the original SRC model in both EM and F1 score, yet the proposed model significantly achieved the superior performance among three models, however being worse than human performance, luckily, the EM and F1 scores are improved about 15.03% and 4.91% of accuracies compared to SRC and SRC + DS models, respectively.
CONCLUSION
This paper proposed a framework of machine reading
comprehension for Tainan gastronomy, based on a hybrid vector
Available: https://arxiv.org /abs/1606.05250.
[3] T. Nguyen, M. Rosenberg, S. Xia, J. Gao, and D. Li. (2016). " Ms marco: A human generated machine reading comprehension dataset. " [Online]. Available: https://arxiv.org/abs/1611.09268. [4] S. Wang and J. Jiang. (2016). ‘‘Machine comprehension using match- LSTM and answer pointer.’’ [Online]. Available: https://arxiv. org/abs/1608.07905.
[5] M. Seo, A. Kembhavi, A. Farhadi, and H. Hajishirzi. (2016). ‘‘Bidirectional attention flow for machine comprehension.’’ [Online]. Available: https://arxiv.org/abs/1611.01603. [6] C. Xiong, V. Zhong, and R. Socher. (2014). ‘‘Dynamic coattention networks for question answering.’’ [Online]. Available: https://arxiv. org/abs/1611.01604.
[7] Sepp Hochreiter and Jürgen Schmidhuber. Long Short-Term memory.
Neural computation, 9(8):1735–1780, 1997.
[8] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, "Distributed representations of words and phrases and their compositionality," in Advances in neural information processing
systems, 2013, pp. 3111-3119.
ID Model EM F1
1 SRC [6] 50.7% 65.0%
2 SRC+DS [6] 55.4% 67.7% 3 The proposed model 70.43% 72.61% 4 Participant Performance 80.43% 93.30%
![Table 0-4 Speech enhancement system WER experimental result Wrong words/ Total words (A) Wrong words/ Total words (B) Wrong words/ Total words (C) WER SS [15] 153/775 170/775 225/775 23.57% DNN 156/775 177/775 196/775 22.75% RNN [38]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8998937.284795/20.893.159.758.314.563/table-speech-enhancement-experimental-wrong-total-wrong-total.webp)