“2005 Best Java Book!”
—Java Developer’s Journal
Hibernate In Action has to be considered the definitive tome on Hibernate. As the authors are intimately involved with the project, the insight on Hibernate that they provide can’t be easily duplicated.
—JavaRanch.com
“Not only gets you up to speed with Hibernate and its features…It also intro- duces you to the right way of developing and tuning an industrial-quality Hiber- nate application. …albeit very technical, it reads astonishingly
easy…unfortunately very rare nowadays…[an] excellent piece of work…”
—JavaLobby.com
“The first and only full tutorial, reference, and authoritative guide, and one of the most anticipated books of the year for Hibernate users.”
—Dr. Dobb’s Journal
“…the book was beyond my expectations…this book is the ultimate solution.”
—Javalobby.org, (second review, fall 2005)
“…from none others than the lead developer and the lead documenter, this book is a great introduction and reference documentation to using Hibernate.
It is organized in such a way that the concepts are explained in progressive order from very simple to more complex, and the authors take good care of explaining every detail with good examples. …The book not only gets you up to speed with Hibernate and its features (which the documentation does quite well). It also introduces you to the right way of developing and tuning an indus- trial-quality Hibernate application.”
—Slashdot.org
“Strongly recommended, because a contemporary and state-of-the-art topic is very well explained, and especially, because the voices come literally from the horses’ mouths.”
—C Vu, the Journal of the ACCU
tional mapping (ORM), persistence, caching, queries and describes how they are taken care with respect to Hibernate…written by the creators of Hibernate and they have made best effort to introduce and leverage Hibernate. I recom- mend this book to everyone who is interested in getting familiar with
Hibernate.”
—JavaReference.com
“Well worth the cost…While the on-line documentation is good, (Mr. Bauer, one of the authors is in charge of the on-line documentation) the book is bet- ter. It begins with a description of what you are trying to do (often left out in computer books) and leads you on in a consistent manner through the entire Hibernate system. Excellent Book!”
—Books-on-Line
“A compact (408 pages), focused, no nonsense read and an essential resource for anyone venturing into the ORM landscape. The first three chapters of this book alone are indispensable for developers that want to quickly build an application leveraging Hibernate, but more importantly really want to under- stand Hibernate concepts, framework, methodology and the reasons that shaped the framework design. The remaining chapters continue the compre- hensive overview of Hibernate that include how to map to and persist objects, inheritance, transactions, concurrency, caching, retrieving objects efficiently using HQL, configuring Hibernate for managed and unmanaged environ- ments, and the Hibernate Toolset that can be leveraged for several different development scenarios.”
—Columbia Java Users Group
“The authors show their knowledge of relational databases and the paradigm of mapping this world with the object-oriented world of Java. This is why the book is so good at explaining Hibernate in the context of solving or providing a solution to the very complex problem of object/relational mapping.”
—Denver JUG
Java Persistence with Hibernate
REVISED EDITION OF HIBERNATE IN ACTION
CHRISTIAN BAUER AND GAVIN KING
M A N N I N G
Greenwich (74° w. long.)
Special Sales Department Manning Publications Co.
Cherokee Station
PO Box 20386 Fax: (609) 877-8256
New York, NY 10021 email: [email protected]
©2007 by Manning Publications Co. All rights reserved.
No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the publisher.
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in the book, and Manning
Publications was aware of a trademark claim, the designations have been printed in initial caps or all caps.
Recognizing the importance of preserving what has been written, it is Manning’s policy to have the books we publish printed on acid-free paper, and we exert our best efforts to that end.
Manning Publications Co. Copyeditor: Tiffany Taylor 209 Bruce Park Avenue Typesetters: Dottie Marsico Greenwich, CT 06830 Cover designer: Leslie Haimes
ISBN 1-932394-88-5
Printed in the United States of America
1 2 3 4 5 6 7 8 9 10 – VHG – 10 09 08 07 06
v
P
ART1 G
ETTINGSTARTED WITHH
IBERNATE ANDEJB 3.0 ...1
1 ■ Understanding object/relational persistence 3 2 ■ Starting a project 37
3 ■ Domain models and metadata 105
P
ART2 M
APPING CONCEPTSAND STRATEGIES... 155
4 ■ Mapping persistent classes 157 5 ■ Inheritance and custom types 191
6 ■ Mapping collections and entity associations 240 7 ■ Advanced entity association mappings 277 8 ■ Legacy databases and custom SQL 322
P
ART3 C
ONVERSATIONAL OBJECT PROCESSING... 381
9 ■ Working with objects 383
10 ■ Transactions and concurrency 433 11 ■ Implementing conversations 476 12 ■ Modifying objects efficiently 517
13 ■ Optimizing fetching and caching 559 14 ■ Querying with HQL and JPA QL 614 15 ■ Advanced query options 663
16 ■ Creating and testing layered applications 697 17 ■ Introducing JBoss Seam 747
appendix A SQL fundamentals 818 appendix B Mapping quick reference 822
vii foreword to the revised edition xix foreword to the first edition xxi preface to the revised edition xxiii preface to the first edition xxv acknowledgments xxviii about this book xxix
about the cover illustration xxxiii
P ART 1 G ETTING STARTED WITH H IBERNATE
AND EJB 3.0 ...1
1 Understanding object/relational persistence 3
1.1 What is persistence? 5
Relational databases 5 ■ Understanding SQL 6 ■ Using SQL in Java 7 ■ Persistence in object-oriented applications 8 1.2 The paradigm mismatch 10
The problem of granularity 12 ■ The problem of subtypes 13 The problem of identity 14 ■ Problems relating to
associations 16 ■ The problem of data navigation 18 The cost of the mismatch 19
1.3 Persistence layers and alternatives 20
Layered architecture 20 ■ Hand-coding a persistence layer with SQL/JDBC 22 ■ Using serialization 23 Object-oriented database systems 23 ■ Other options 24 1.4 Object/relational mapping 24
What is ORM? 25 ■ Generic ORM problems 27 Why ORM? 28 ■ Introducing Hibernate, EJB3, and JPA 31
1.5 Summary 35
2 Starting a project 37
2.1 Starting a Hibernate project 38
Selecting a development process 39 ■ Setting up the project 41 ■ Hibernate configuration and
startup 49 ■ Running and testing the application 60 2.2 Starting a Java Persistence project 68
Using Hibernate Annotations 68 ■ Using Hibernate EntityManager 72 ■ Introducing EJB components 79 Switching to Hibernate interfaces 86
2.3 Reverse engineering a legacy database 88 Creating a database configuration 89 ■ Customizing reverse engineering 90 ■ Generating Java source code 92 2.4 Integration with Java EE services 96
Integration with JTA 97 ■ JNDI-bound SessionFactory 101 JMX service deployment 103
2.5 Summary 104
3 Domain models and metadata 105
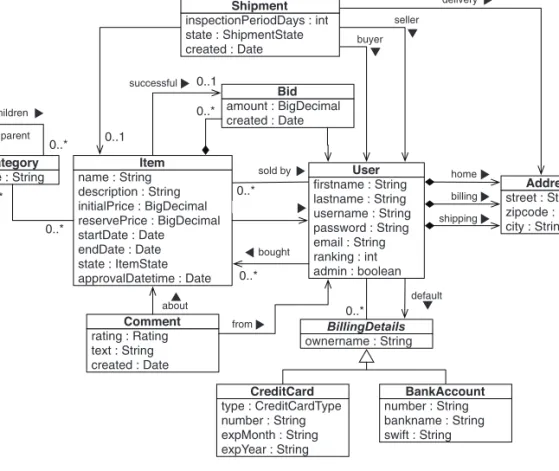
3.1 The CaveatEmptor application 106
Analyzing the business domain 107 ■ The CaveatEmptor domain model 108
3.2 Implementing the domain model 110
Addressing leakage of concerns 111 ■ Transparent and automated persistence 112 ■ Writing POJOs and persistent entity classes 113 ■ Implementing POJO associations 116 Adding logic to accessor methods 120
3.3 Object/relational mapping metadata 123
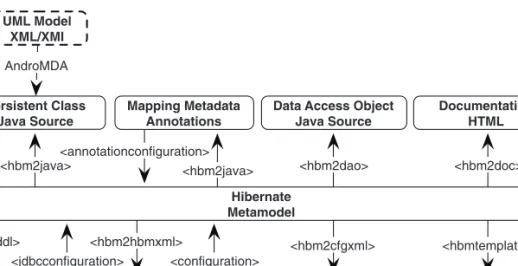
Metadata in XML 123 ■ Annotation-based metadata 125 Using XDoclet 131 ■ Handling global metadata 133 Manipulating metadata at runtime 138
3.4 Alternative entity representation 140
Creating dynamic applications 141 ■ Representing data in XML 148
3.5 Summary 152
P ART 2 M APPING CONCEPTS AND STRATEGIES ... 155
4 Mapping persistent classes 157
4.1 Understanding entities and value types 158
Fine-grained domain models 158 ■ Defining the concept 159 Identifying entities and value types 160
4.2 Mapping entities with identity 161
Understanding Java identity and equality 162 ■ Handling database identity 162 ■ Database primary keys 166 4.3 Class mapping options 171
Dynamic SQL generation 172 ■ Making an entity immutable 173 ■ Naming entities for querying 173
Declaring a package name 174 ■ Quoting SQL identifiers 175 Implementing naming conventions 175
4.4 Fine-grained models and mappings 177
Mapping basic properties 177 ■ Mapping components 184 4.5 Summary 189
5 Inheritance and custom types 191
5.1 Mapping class inheritance 192
Table per concrete class with implicit polymorphism 192 Table per concrete class with unions 195 ■ Table per class hierarchy 199 ■ Table per subclass 203 Mixing inheritance strategies 207 ■ Choosing a strategy 210
5.2 The Hibernate type system 212 Recapitulating entity and value types 212 Built-in mapping types 214 ■ Using mapping types 219
5.3 Creating custom mapping types 220 Considering custom mapping types 221 ■ The extension points 222 ■ The case for custom mapping types 223 ■ Creating a UserType 224 Creating a CompositeUserType 228 ■ Parameterizing custom types 230 ■ Mapping enumerations 233 5.4 Summary 239
6 Mapping collections and entity associations 240
6.1 Sets, bags, lists, and maps of value types 241 Selecting a collection interface 241 ■ Mapping a set 243 ■ Mapping an identifier bag 244 Mapping a list 246 ■ Mapping a map 247 Sorted and ordered collections 248
6.2 Collections of components 251
Writing the component class 252 ■ Mapping the collection 252 ■ Enabling bidirectional navigation 253 Avoiding not-null columns 254
6.3 Mapping collections with annotations 256 Basic collection mapping 256 ■ Sorted and ordered
collections 257 ■ Mapping a collection of embedded objects 258
6.4 Mapping a parent/children relationship 260 Multiplicity 261 ■ The simplest possible association 261 Making the association bidirectional 264 ■ Cascading object state 267
6.5 Summary 275
7 Advanced entity association mappings 277
7.1 Single-valued entity associations 278
Shared primary key associations 279 ■ One-to-one foreign key associations 282 ■ Mapping with a join table 285 7.2 Many-valued entity associations 290
One-to-many associations 290 ■ Many-to-many associations 297 ■ Adding columns to join tables 303 Mapping maps 310
7.3 Polymorphic associations 313
Polymorphic many-to-one associations 313 ■ Polymorphic collections 315 ■ Polymorphic associations to unions 316 Polymorphic table per concrete class 319
7.4 Summary 321
8 Legacy databases and custom SQL 322
8.1 Integrating legacy databases 323
Handling primary keys 324 ■ Arbitrary join conditions with formulas 337 ■ Joining arbitrary tables 342 ■ Working with triggers 346
8.2 Customizing SQL 350
Writing custom CRUD statements 351
Integrating stored procedures and functions 356 8.3 Improving schema DDL 364
Custom SQL names and datatypes 365 ■ Ensuring data consistency 367 ■ Adding domains and column
constraints 369 ■ Table-level constraints 370 Database constraints 373 ■ Creating indexes 375 Adding auxiliary DDL 376
8.4 Summary 378
P ART 3 C ONVERSATIONAL OBJECT PROCESSING ... 381
9 Working with objects 383
9.1 The persistence lifecycle 384
Object states 385 ■ The persistence context 388 9.2 Object identity and equality 391
Introducing conversations 391 ■ The scope of object identity 393 ■ The identity of detached objects 394 Extending a persistence context 400
9.3 The Hibernate interfaces 401
Storing and loading objects 402 ■ Working with detached objects 408 ■ Managing the persistence context 414 9.4 The Java Persistence API 417
Storing and loading objects 417 ■ Working with detached entity instances 423
9.5 Using Java Persistence in EJB components 426 Injecting an EntityManager 426 ■ Looking up an EntityManager 429 ■ Accessing an
EntityManagerFactory 429 9.6 Summary 431
10 Transactions and concurrency 433
10.1 Transaction essentials 434
Database and system transactions 435 ■ Transactions in a Hibernate application 437 ■ Transactions with Java Persistence 449
10.2 Controlling concurrent access 453
Understanding database-level concurrency 453 ■ Optimistic concurrency control 458 ■ Obtaining additional isolation guarantees 465
10.3 Nontransactional data access 469
Debunking autocommit myths 470 ■ Working nontransactionally with Hibernate 471 ■ Optional transactions with JTA 473
10.4 Summary 474
11 Implementing conversations 476
11.1 Propagating the Hibernate Session 477
The use case for Session propagation 478 ■ Propagation through thread-local 480 ■ Propagation with
JTA 482 ■ Propagation with EJBs 483 11.2 Conversations with Hibernate 485
Providing conversational guarantees 485 ■ Conversations with detached objects 486 ■ Extending a Session for a conversation 489
11.3 Conversations with JPA 497
Persistence context propagation in Java SE 498 Merging detached objects in conversations 499 Extending the persistence context in Java SE 501 11.4 Conversations with EJB 3.0 506
Context propagation with EJBs 506 Extended persistence contexts with EJBs 510 11.5 Summary 515
12 Modifying objects efficiently 517
12.1 Transitive persistence 518
Persistence by reachability 519 ■ Applying cascading to associations 520 ■ Working with transitive state 524 Transitive associations with JPA 531
12.2 Bulk and batch operations 532
Bulk statements with HQL and JPA QL 533 ■ Processing with batches 537 ■ Using a stateless Session 539 12.3 Data filtering and interception 540
Dynamic data filters 541 ■ Intercepting Hibernate events 546 The core event system 553 ■ Entity listeners and callbacks 556 12.4 Summary 558
13 Optimizing fetching and caching 559
13.1 Defining the global fetch plan 560
The object-retrieval options 560 ■ The lazy default fetch plan 564 ■ Understanding proxies 564 ■ Disabling proxy generation 567 ■ Eager loading of associations and
collections 568 ■ Lazy loading with interception 571 13.2 Selecting a fetch strategy 573
Prefetching data in batches 574 ■ Prefetching collections with subselects 577 ■ Eager fetching with joins 578 ■ Optimizing fetching for secondary tables 581 ■ Optimization
guidelines 584
13.3 Caching fundamentals 592
Caching strategies and scopes 593 ■ The Hibernate cache architecture 597
13.4 Caching in practice 602
Selecting a concurrency control strategy 602 ■ Understanding cache regions 604 ■ Setting up a local cache provider 605 Setting up a replicated cache 606 ■ Controlling the second-level cache 611
13.5 Summary 612
14 Querying with HQL and JPA QL 614
14.1 Creating and running queries 615
Preparing a query 616 ■ Executing a query 625 Using named queries 629
14.2 Basic HQL and JPA QL queries 633
Selection 633 ■ Restriction 635 ■ Projection 641 14.3 Joins, reporting queries, and subselects 643
Joining relations and associations 643 ■ Reporting queries 655 ■ Using subselects 659
14.4 Summary 662
15 Advanced query options 663
15.1 Querying with criteria and example 664 Basic criteria queries 665 ■ Joins and dynamic fetching 670 ■ Projection and report queries 676 Query by example 680
15.2 Using native SQL queries 683
Automatic resultset handling 683 ■ Retrieving scalar values 684 ■ Native SQL in Java Persistence 686
15.3 Filtering collections 688 15.4 Caching query results 691
Enabling the query result cache 691 ■ Understanding the query cache 692 ■ When to use the query cache 693 Natural identifier cache lookups 693
15.5 Summary 695
16 Creating and testing layered applications 697
16.1 Hibernate in a web application 698
Introducing the use case 698 ■ Writing a controller 699 The Open Session in View pattern 701 ■ Designing smart domain models 705
16.2 Creating a persistence layer 708
A generic data-access object pattern 709 ■ Implementing the generic CRUD interface 711 ■ Implementing entity DAOs 713 Using data-access objects 715
16.3 Introducing the Command pattern 718
The basic interfaces 719 ■ Executing command objects 721 Variations of the Command pattern 723
16.4 Designing applications with EJB 3.0 725
Implementing a conversation with stateful beans 725 ■ Writing DAOs with EJBs 727 ■ Utilizing dependency injection 728 16.5 Testing 730
Understanding different kinds of tests 731 ■ Introducing TestNG 732 ■ Testing the persistence layer 736 Considering performance benchmarks 744 16.6 Summary 746
17 Introducing JBoss Seam 747
17.1 The Java EE 5.0 programming model 748
Considering JavaServer Faces 749 ■ Considering EJB 3.0 751 Writing a web application with JSF and EJB 3.0 752
Analyzing the application 762
17.2 Improving the application with Seam 765
Configuring Seam 766 ■ Binding pages to stateful Seam components 767 ■ Analyzing the Seam application 773 17.3 Understanding contextual components 779
Writing the login page 779 ■ Creating the components 781 Aliasing contextual variables 784 ■ Completing the login/logout feature 786
17.4 Validating user input 789
Introducing Hibernate Validator 790 ■ Creating the registration page 791 ■ Internationalization with Seam 799
17.5 Simplifying persistence with Seam 803
Implementing a conversation 804 ■ Letting Seam manage the persistence context 811
17.6 Summary 816
appendix A SQL fundamentals 818 appendix B Mapping quick reference 822
references 824
index 825
xix
When Hibernate in Action was published two years ago, it was immediately recog- nized not only as the definitive book on Hibernate, but also as the definitive work on object/relational mapping.
In the intervening time, the persistence landscape has changed with the release of the Java Persistence API, the new standard for object/relational map- ping for Java EE and Java SE which was developed under the Java Community Pro- cess as part of the Enterprise JavaBeans 3.0 Specification.
In developing the Java Persistence API, the EJB 3.0 Expert Group benefitted heavily from the experience of the O/R mapping frameworks already in use in the Java community. As one of the leaders among these, Hibernate has had a very significant influence on the technical direction of Java Persistence. This was due not only to the participation of Gavin King and other members of the Hibernate team in the EJB 3.0 standardization effort, but was also due in large part to the direct and pragmatic approach that Hibernate has taken towards O/R mapping and to the simplicity, clarity, and power of its APIs--and their resulting appeal to the Java community.
In addition to their contributions to Java Persistence, the Hibernate develop- ers also have taken major steps forward for Hibernate with the Hibernate 3 release described in this book. Among these are support for operations over large datasets; additional and more sophisticated mapping options, especially for han- dling legacy databases; data filters; strategies for managing conversations; and
integration with Seam, the new framework for web application development with JSF and EJB 3.0.
Java Persistence with Hibernate is therefore considerably more than simply a sec- ond edition to Hibernate in Action. It provides a comprehensive overview of all the capabilities of the Java Persistence API in addition to those of Hibernate 3, as well as a detailed comparative analysis of the two. It describes how Hibernate has been used to implement the Java Persistence standard, and how to leverage the Hiber- nate extensions to Java Persistence.
More important, throughout the presentation of Hibernate and Java Persis- tence, Christian Bauer and Gavin King illustrate and explain the fundamental principles and decisions that need to be taken into account in both the design and use of an object/relational mapping framework. The insights they provide into the underlying issues of ORM give the reader a deep understanding into the effective application of ORM as an enterprise technology.
Java Persistence with Hibernate thus reaches out to a wide range of developers—
from newcomers to object/relational mapping to experienced developers—seek- ing to learn more about cutting-edge technological innovations in the Java com- munity that have occurred and are continuing to emerge as a result of this work.
LINDA DEMICHIEL
Specification Lead Enterprise JavaBeans 3.0 and Java Persistence Sun Microsystems
xxi
Relational databases are indisputably at the core of the modern enterprise.
While modern programming languages, including JavaTM, provide an intuitive, object-oriented view of application-level business entities, the enterprise data underlying these entities is heavily relational in nature. Further, the main strength of the relational model—over earlier navigational models as well as over later OODB models—is that by design it is intrinsically agnostic to the programmatic manipulation and application-level view of the data that it serves up.
Many attempts have been made to bridge relational and object-oriented tech- nologies, or to replace one with the other, but the gap between the two is one of the hard facts of enterprise computing today. It is this challenge—to provide a bridge between relational data and JavaTM objects—that Hibernate takes on through its object/relational mapping (ORM) approach. Hibernate meets this challenge in a very pragmatic, direct, and realistic way.
As Christian Bauer and Gavin King demonstrate in this book, the effective use of ORM technology in all but the simplest of enterprise environments requires understanding and configuring how the mediation between relational data and objects is performed. This demands that the developer be aware and knowledge- able both of the application and its data requirements, and of the SQL query lan- guage, relational storage structures, and the potential for optimization that relational technology offers.
Not only does Hibernate provide a full-function solution that meets these requirements head on, it is also a flexible and configurable architecture. Hiber- nate’s developers designed it with modularity, pluggability, extensibility, and user customization in mind. As a result, in the few years since its initial release, Hibernate has rapidly become one of the leading ORM technologies for enter- prise developers—and deservedly so.
This book provides a comprehensive overview of Hibernate. It covers how to use its type mapping capabilities and facilities for modeling associations and inheritance; how to retrieve objects efficiently using the Hibernate query lan- guage; how to configure Hibernate for use in both managed and unmanaged environments; and how to use its tools. In addition, throughout the book the authors provide insight into the underlying issues of ORM and into the design choices behind Hibernate. These insights give the reader a deep understanding of the effective use of ORM as an enterprise technology.
Hibernate in Action is the definitive guide to using Hibernate and to object/rela- tional mapping in enterprise computing today.
LINDA DEMICHIEL Lead Architect, Enterprise JavaBeans Sun Microsystems
xxiii
The predecessor of this book, Hibernate in Action, started with a quote from Anthony Berglas: “Just because it is possible to push twigs along the ground with one’s nose does not necessarily mean that that is the best way to collect firewood.”
Since then, the Hibernate project and the strategies and concepts software devel- opers rely on to manage information have evolved. However, the fundamental issues are still the same—every company we work with every day still uses SQL data- bases, and Java is entrenched in the industry as the first choice for enterprise application development.
The tabular representation of data in a relational system is still fundamentally different than the networks of objects used in object-oriented Java applications.
We still see the object/relational impedance mismatch, and we frequently see that the importance and cost of this mismatch is underestimated.
On the other hand, we now have a range of tools and solutions available to deal with this problem. We’re done collecting firewood, and the pocket lighter has been replaced with a flame thrower.
Hibernate is now available in its third major release; Hibernate 3.2 is the ver- sion we describe in this book. Compared to older Hibernate versions, this new major release has twice as many features—and this book is almost double the size of Hibernate in Action. Most of these features are ones that you, the developers working with Hibernate every day, have asked for. We’ve sometimes said that Hibernate is a 90 percent solution for all the problems a Java application devel-
oper has to deal with when creating a database application. With the latest Hiber- nate version, this number is more likely 99 percent.
As Hibernate matured and its user base and community kept growing, the Java standards for data management and database application development were found lacking by many developers. We even told you not to use EJB 2.x entity beans in Hibernate in Action.
Enter EJB 3.0 and the new Java Persistence standard. This new industry stan- dard is a major step forward for the Java developer community. It defines a light- weight and simplified programming model and powerful object/relational persistence. Many of the key concepts of the new standard were modeled after Hibernate and other successful object/relational persistence solutions. The latest Hibernate version implements the Java Persistence standard.
So, in addition to the new all-in-one Hibernate for every purpose, you can now use Hibernate like any Java Persistence provider, with or without other EJB 3.0 components and Java EE 5.0 services. This deep integration of Hibernate with such a rich programming model enables you to design and implement applica- tion functionality that was difficult to create by hand before.
We wrote this book to give you a complete and accurate guide to both Hiber- nate and Java Persistence (and also all relevant EJB 3.0 concepts). We hope that you’ll enjoy learning Hibernate and that you'll keep this reference bible on your desk for your daily work.
xxv
Just because it is possible to push twigs along the ground with one’s nose does not necessarily mean that that is the best way to collect firewood.
—Anthony Berglas
Today, many software developers work with Enterprise Information Systems (EIS).
This kind of application creates, manages, and stores structured information and shares this information between many users in multiple physical locations.
The storage of EIS data involves massive usage of SQL-based database manage- ment systems. Every company we’ve met during our careers uses at least one SQL database; most are completely dependent on relational database technology at the core of their business.
In the past five years, broad adoption of the Java programming language has brought about the ascendancy of the object-oriented paradigm for software devel- opment. Developers are now sold on the benefits of object orientation. However, the vast majority of businesses are also tied to long-term investments in expensive relational database systems. Not only are particular vendor products entrenched, but existing legacy data must be made available to (and via) the shiny new object- oriented web applications.
However, the tabular representation of data in a relational system is fundamen- tally different than the networks of objects used in object-oriented Java applica- tions. This difference has led to the so-called object/relational paradigm mismatch.
Traditionally, the importance and cost of this mismatch have been underesti- mated, and tools for solving the mismatch have been insufficient. Meanwhile, Java developers blame relational technology for the mismatch; data professionals blame object technology.
Object/relational mapping (ORM) is the name given to automated solutions to the mismatch problem. For developers weary of tedious data access code, the good news is that ORM has come of age. Applications built with ORM middleware can be expected to be cheaper, more performant, less vendor-specific, and more able to cope with changes to the internal object or underlying SQL schema. The astonish- ing thing is that these benefits are now available to Java developers for free.
Gavin King began developing Hibernate in late 2001 when he found that the popular persistence solution at the time—CMP Entity Beans—didn’t scale to non- trivial applications with complex data models. Hibernate began life as an inde- pendent, noncommercial open source project.
The Hibernate team (including the authors) has learned ORM the hard way—
that is, by listening to user requests and implementing what was needed to satisfy those requests. The result, Hibernate, is a practical solution, emphasizing devel- oper productivity and technical leadership. Hibernate has been used by tens of thousands of users and in many thousands of production applications.
When the demands on their time became overwhelming, the Hibernate team concluded that the future success of the project (and Gavin’s continued sanity) demanded professional developers dedicated full-time to Hibernate. Hibernate joined jboss.org in late 2003 and now has a commercial aspect; you can purchase commercial support and training from JBoss Inc. But commercial training shouldn’t be the only way to learn about Hibernate.
It’s obvious that many, perhaps even most, Java projects benefit from the use of an ORM solution like Hibernate—although this wasn’t obvious a couple of years ago! As ORM technology becomes increasingly mainstream, product documenta- tion such as Hibernate’s free user manual is no longer sufficient. We realized that the Hibernate community and new Hibernate users needed a full-length book, not only to learn about developing software with Hibernate, but also to under- stand and appreciate the object/relational mismatch and the motivations behind Hibernate’s design.
The book you’re holding was an enormous effort that occupied most of our spare time for more than a year. It was also the source of many heated disputes and learning experiences. We hope this book is an excellent guide to Hibernate (or, “the Hibernate bible,” as one of our reviewers put it) and also the first com- prehensive documentation of the object/relational mismatch and ORM in gen- eral. We hope you find it helpful and enjoy working with Hibernate.
xxviii
This book grew from a small second edition of Hibernate in Action into a volume of considerable size. We couldn’t have created it without the help of many people.
Emmanuel Bernard did an excellent job as the technical reviewer of this book;
thank you for the many hours you spent editing our broken code examples. We’d also like to thank our other reviewers: Patrick Dennis, Jon Skeet, Awais Bajwa, Dan Dobrin, Deiveehan Nallazhagappan, Ryan Daigle, Stuart Caborn, Patrick Peak, TVS Murthy, Bill Fly, David Walend, Dave Dribin, Anjan Bacchu, Gary Udstrand, and Srinivas Nallapati. Special thanks to Linda DiMichiel for agreeing to write the foreword to our book, as she did to the first edition
Marjan Bace again assembled a great production team at Manning: Sydney Jones edited our crude manuscript and turned it into a real book. Tiffany Taylor, Elizabeth Martin, and Andy Carroll found all our typos and made the book read- able. Dottie Marsico was responsible for typesetting and gave this book its great look. Mary Piergies coordinated and organized the production process. We’d like to thank you all for working with us.
xxix
We had three goals when writing this book, so you can read it as
■ A tutorial for Hibernate, Java Persistence, and EJB 3.0 that guides you through your first steps with these solutions
■ A guide for learning all basic and advanced Hibernate features for object/
relational mapping, object processing, querying, performance optimiza- tion, and application design
■ A reference for whenever you need a complete and technically accurate def- inition of Hibernate and Java Persistence functionality
Usually, books are either tutorials or reference guides, so this stretch comes at a price. If you’re new to Hibernate, we suggest that you start reading the book from the start, with the tutorials in chapters 1 and 2. If you have used an older version of Hibernate, you should read the first two chapters quickly to get an overview and then jump into the middle with chapter 3.
We will, whenever appropriate, tell you if a particular section or subject is optional or reference material that you can safely skip during your first read.
Roadmap
This book is divided into three major parts.
In part 1, we introduce the object/relational paradigm mismatch and explain the fundamentals behind object/relational mapping. We walk through a hands-
on tutorial to get you started with your first Hibernate, Java Persistence, or EJB 3.0 project. We look at Java application design for domain models and at the options for creating object/relational mapping metadata.
Mapping Java classes and properties to SQL tables and columns is the focus of part 2. We explore all basic and advanced mapping options in Hibernate and Java Persistence, with XML mapping files and Java annotations. We show you how to deal with inheritance, collections, and complex class associations. Finally, we dis- cuss integration with legacy database schemas and some mapping strategies that are especially tricky.
Part 3 is all about the processing of objects and how you can load and store data with Hibernate and Java Persistence. We introduce the programming inter- faces, how to write transactional and conversation-aware applications, and how to write queries. Later, we focus on the correct design and implementation of lay- ered Java applications. We discuss the most common design patterns that are used with Hibernate, such as the Data Access Object (DAO) and EJB Command pat- terns. You’ll see how you can test your Hibernate application easily and what other best practices are relevant if you work an object/relational mapping software.
Finally, we introduce the JBoss Seam framework, which takes many Hibernate concepts to the next level and enables you to create conversational web applica- tions with ease. We promise you’ll find this chapter interesting, even if you don’t plan to use Seam.
Who should read this book?
Readers of this book should have basic knowledge of object-oriented software development and should have used this knowledge in practice. To understand the application examples, you should be familiar with the Java programming lan- guage and the Unified Modeling Language.
Our primary target audience consists of Java developers who work with SQL- based database systems. We’ll show you how to substantially increase your produc- tivity by leveraging ORM.
If you’re a database developer, the book can be part of your introduction to object-oriented software development.
If you’re a database administrator, you’ll be interested in how ORM affects per- formance and how you can tune the performance of the SQL database-manage- ment system and persistence layer to achieve performance targets. Because data
access is the bottleneck in most Java applications, this book pays close attention to performance issues. Many DBAs are understandably nervous about entrusting per- formance to tool-generated SQL code; we seek to allay those fears and also to highlight cases where applications shouldn’t use tool-managed data access. You may be relieved to discover that we don’t claim that ORM is the best solution to every problem.
Code conventions
This book provides copious examples, which include all the Hibernate applica- tion artifacts: Java code, Hibernate configuration files, and XML mapping meta- data files. Source code in listings or in text is in a fixed-widthfontlikethis to separate it from ordinary text. Additionally, Java method names, component parameters, object properties, and XML elements and attributes in text are also presented using fixed-width font.
Java, HTML, and XML can all be verbose. In many cases, the original source code (available online) has been reformatted; we’ve added line breaks and reworked indentation to accommodate the available page space in the book. In rare cases, even this was not enough, and listings include line-continuation mark- ers. Additionally, comments in the source code have often been removed from the listings when the code is described in the text.
Code annotations accompany some of the source code listings, highlighting important concepts. In some cases, numbered bullets link to explanations that fol- low the listing.
Source code downloads
Hibernate is an open source project released under the Lesser GNU Public License. Directions for downloading Hibernate packages, in source or binary form, are available from the Hibernate web site: www.hibernate.org/.
The source code for all Hello World and CaveatEmptor examples in this book is available from http://caveatemptor.hibernate.org/ under a free (BSD-like) license. The CaveatEmptor example application code is available on this web site in different flavors—for example, with a focus on native Hibernate, on Java Persis- tence, and on JBoss Seam. You can also download the code for the examples in this book from the publisher’s website, www.manning.com/bauer2.
About the authors
Christian Bauer is a member of the Hibernate developer team. He works as a trainer, consultant, and product manager for Hibernate, EJB 3.0, and JBoss Seam at JBoss, a division of Red Hat. With Gavin King, Christian wrote Hibernate in Action.
Gavin King is the founder of the Hibernate and JBoss Seam projects, and a member of the EJB 3.0 (JSR 220) expert group. He also leads the Web Beans JSR 299, a standardization effort involving Hibernate concepts, JBoss Seam, JSF, and EJB 3.0. Gavin works as a lead developer at JBoss, a division of Red Hat.
Author Online
Your purchase of Java Persistence with Hibernate includes free access to a private web forum run by Manning Publications, where you can make comments about the book, ask technical questions, and receive help from the authors and from other users. To access the forum and subscribe to it, point your web browser to www.manning.com/bauer2. This page provides information on how to get onto the forum once you are registered, what kind of help is available, and the rules of con- duct on the forum.
Manning’s commitment to our readers is to provide a venue where a meaning- ful dialogue among individual readers and between readers and the authors can take place. It is not a commitment to any specific amount of participation on the part of the author, whose contribution to the AO remains voluntary (and unpaid).
We suggest you try asking the authors some challenging questions, lest their inter- est stray!
The Author Online forum and the archives of previous discussions will be accessible from the publisher’s website as long as the book is in print.
xxxiii
The illustration on the cover of Java Persistence with Hibernate is taken from a col- lection of costumes of the Ottoman Empire published on January 1, 1802, by Wil- liam Miller of Old Bond Street, London. The title page is missing from the collection and we have been unable to track it down to date. The book’s table of contents identifies the figures in both English and French, and each illustration bears the names of two artists who worked on it, both of whom would no doubt be surprised to find their art gracing the front cover of a computer programming book…two hundred years later.
The collection was purchased by a Manning editor at an antiquarian flea mar- ket in the “Garage” on West 26th Street in Manhattan. The seller was an American based in Ankara, Turkey, and the transaction took place just as he was packing up his stand for the day. The Manning editor did not have on his person the substan- tial amount of cash that was required for the purchase and a credit card and check were both politely turned down. With the seller flying back to Ankara that evening the situation was getting hopeless. What was the solution? It turned out to be nothing more than an old-fashioned verbal agreement sealed with a hand- shake. The seller simply proposed that the money be transferred to him by wire and the editor walked out with the bank information on a piece of paper and the portfolio of images under his arm. Needless to say, we transferred the funds the next day, and we remain grateful and impressed by this unknown person’s trust in one of us. It recalls something that might have happened a long time ago.
The pictures from the Ottoman collection, like the other illustrations that appear on our covers, bring to life the richness and variety of dress customs of two centuries ago. They recall the sense of isolation and distance of that period—and of every other historic period except our own hyperkinetic present.
Dress codes have changed since then and the diversity by region, so rich at the time, has faded away. It is now often hard to tell the inhabitant of one continent from another. Perhaps, trying to view it optimistically, we have traded a cultural and visual diversity for a more varied personal life. Or a more varied and interest- ing intellectual and technical life.
We at Manning celebrate the inventiveness, the initiative, and, yes, the fun of the computer business with book covers based on the rich diversity of regional life of two centuries ago‚ brought back to life by the pictures from this collection.
Getting started with Hibernate and EJB 3.0
I
n part 1, we show you why object persistence is such a complex topic and what solutions you can apply in practice. Chapter 1 introduces the object/relational paradigm mismatch and several strategies to deal with it, foremost object/rela- tional mapping (ORM). In chapter 2, we guide you step by step through a tutorial with Hibernate, Java Persistence, and EJB 3.0—you’ll implement and test a “Hello World” example in all variations. Thus prepared, in chapter 3 you’re ready to learn how to design and implement complex business domain models in Java, and which mapping metadata options you have available.After reading this part of the book, you’ll understand why you need object/
relational mapping, and how Hibernate, Java Persistence, and EJB 3.0 work in practice. You’ll have written your first small project, and you’ll be ready to take on more complex problems. You’ll also understand how real-world business entities can be implemented as a Java domain model, and in what format you prefer to work with object/relational mapping metadata.
3
object/relational persistence
This chapter covers
■ Object persistence with SQL databases
■ The object/relational paradigm mismatch
■ Persistence layers in object-oriented applications
■ Object/relational mapping background
The approach to managing persistent data has been a key design decision in every software project we’ve worked on. Given that persistent data isn’t a new or unusual requirement for Java applications, you’d expect to be able to make a simple choice among similar, well-established persistence solutions. Think of web application frameworks (Struts versus WebWork), GUI component frame- works (Swing versus SWT), or template engines (JSP versus Velocity). Each of the competing solutions has various advantages and disadvantages, but they all share the same scope and overall approach. Unfortunately, this isn’t yet the case with persistence technologies, where we see some wildly differing solutions to the same problem.
For several years, persistence has been a hot topic of debate in the Java commu- nity. Many developers don’t even agree on the scope of the problem. Is persistence a problem that is already solved by relational technology and extensions such as stored procedures, or is it a more pervasive problem that must be addressed by spe- cial Java component models, such as EJB entity beans? Should we hand-code even the most primitive CRUD (create, read, update, delete) operations in SQL and JDBC, or should this work be automated? How do we achieve portability if every database management system has its own SQL dialect? Should we abandon SQL completely and adopt a different database technology, such as object database sys- tems? Debate continues, but a solution called object/relational mapping (ORM) now has wide acceptance. Hibernate is an open source ORM service implementation.
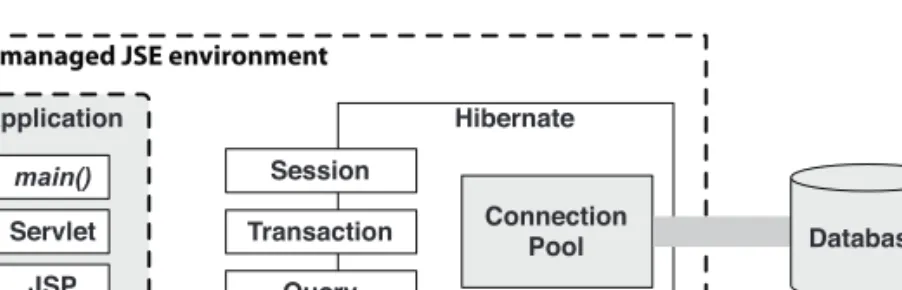
Hibernate is an ambitious project that aims to be a complete solution to the problem of managing persistent data in Java. It mediates the application’s interac- tion with a relational database, leaving the developer free to concentrate on the business problem at hand. Hibernate is a nonintrusive solution. You aren’t required to follow many Hibernate-specific rules and design patterns when writing your business logic and persistent classes; thus, Hibernate integrates smoothly with most new and existing applications and doesn’t require disruptive changes to the rest of the application.
This book is about Hibernate. We’ll cover basic and advanced features and describe some ways to develop new applications using Hibernate. Often, these recommendations won’t even be specific to Hibernate. Sometimes they will be our ideas about the best ways to do things when working with persistent data, explained in the context of Hibernate. This book is also about Java Persistence, a new standard for persistence that is part of the also updated EJB 3.0 specification.
Hibernate implements Java Persistence and supports all the standardized map- pings, queries, and APIs. Before we can get started with Hibernate, however, you need to understand the core problems of object persistence and object/relational
mapping. This chapter explains why tools like Hibernate and specifications such as Java Persistence and EJB 3.0 are needed.
First, we define persistent data management in the context of object-oriented applications and discuss the relationship of SQL, JDBC, and Java, the underlying technologies and standards that Hibernate is built on. We then discuss the so- called object/relational paradigm mismatch and the generic problems we encounter in object-oriented software development with relational databases. These prob- lems make it clear that we need tools and patterns to minimize the time we have to spend on the persistence-related code of our applications. After we look at alternative tools and persistence mechanisms, you’ll see that ORM is the best avail- able solution for many scenarios. Our discussion of the advantages and drawbacks of ORM will give you the full background to make the best decision when picking a persistence solution for your own project.
We also take a look at the various Hibernate software modules, and how you can combine them to either work with Hibernate only, or with Java Persistence and EJB3.0-compliant features.
The best way to learn Hibernate isn’t necessarily linear. We understand that you may want to try Hibernate right away. If this is how you’d like to proceed, skip to the second chapter of this book and have a look at the “Hello World” example and set up a project. We recommend that you return here at some point as you circle through the book. That way, you’ll be prepared and have all the back- ground concepts you need for the rest of the material.
1.1 What is persistence?
Almost all applications require persistent data. Persistence is one of the funda- mental concepts in application development. If an information system didn’t preserve data when it was powered off, the system would be of little practical use.
When we talk about persistence in Java, we’re normally talking about storing data in a relational database using SQL. We’ll start by taking a brief look at the technology and how we use it with Java. Armed with that information, we’ll then continue our discussion of persistence and how it’s implemented in object-ori- ented applications.
1.1.1 Relational databases
You, like most other developers, have probably worked with a relational database.
Most of us use a relational database every day. Relational technology is a known quantity, and this alone is sufficient reason for many organizations to choose it.
But to say only this is to pay less respect than is due. Relational databases are entrenched because they’re an incredibly flexible and robust approach to data management. Due to the complete and consistent theoretical foundation of the relational data model, relational databases can effectively guarantee and protect the integrity of the data, among other desirable characteristics. Some people would even say that the last big invention in computing has been the relational concept for data management as first introduced by E.F. Codd (Codd, 1970) more than three decades ago.
Relational database management systems aren’t specific to Java, nor is a rela- tional database specific to a particular application. This important principle is known as data independence. In other words, and we can’t stress this important fact enough, data lives longer than any application does. Relational technology provides a way of sharing data among different applications, or among different technolo- gies that form parts of the same application (the transactional engine and the reporting engine, for example). Relational technology is a common denominator of many disparate systems and technology platforms. Hence, the relational data model is often the common enterprise-wide representation of business entities.
Relational database management systems have SQL-based application program- ming interfaces; hence, we call today’s relational database products SQL database management systems or, when we’re talking about particular systems, SQL databases.
Before we go into more detail about the practical aspects of SQL databases, we have to mention an important issue: Although marketed as relational, a database system providing only an SQL data language interface isn’t really relational and in many ways isn’t even close to the original concept. Naturally, this has led to confu- sion. SQL practitioners blame the relational data model for shortcomings in the SQL language, and relational data management experts blame the SQL standard for being a weak implementation of the relational model and ideals. Application developers are stuck somewhere in the middle, with the burden to deliver some- thing that works. We’ll highlight some important and significant aspects of this issue throughout the book, but generally we’ll focus on the practical aspects. If you’re interested in more background material, we highly recommend Practical Issues in Database Management: A Reference for the Thinking Practitioner by Fabian Pas- cal (Pascal, 2000).
1.1.2 Understanding SQL
To use Hibernate effectively, a solid understanding of the relational model and SQL is a prerequisite. You need to understand the relational model and topics such as normalization to guarantee the integrity of your data, and you’ll need to
use your knowledge of SQL to tune the performance of your Hibernate applica- tion. Hibernate automates many repetitive coding tasks, but your knowledge of persistence technology must extend beyond Hibernate itself if you want to take advantage of the full power of modern SQL databases. Remember that the under- lying goal is robust, efficient management of persistent data.
Let’s review some of the SQL terms used in this book. You use SQL as a data def- inition language (DDL) to create a database schema with CREATE and ALTER state- ments. After creating tables (and indexes, sequences, and so on), you use SQL as a data manipulation language (DML) to manipulate and retrieve data. The manipula- tion operations include insertions, updates, and deletions. You retrieve data by exe- cuting queries with restrictions, projections, and join operations (including the Cartesian product). For efficient reporting, you use SQL to group, order, and aggregate data as necessary. You can even nest SQL statements inside each other; this tech- nique uses subselects.
You’ve probably used SQL for many years and are familiar with the basic opera- tions and statements written in this language. Still, we know from our own experi- ence that SQL is sometimes hard to remember, and some terms vary in usage. To understand this book, we must use the same terms and concepts, so we advise you to read appendix A if any of the terms we’ve mentioned are new or unclear.
If you need more details, especially about any performance aspects and how SQL is executed, get a copy of the excellent book SQL Tuning by Dan Tow (Tow, 2003). Also read An Introduction to Database Systems by Chris Date (Date, 2003) for the theory, concepts, and ideals of (relational) database systems. The latter book is an excellent reference (it’s big) for all questions you may possibly have about databases and data management.
Although the relational database is one part of ORM, the other part, of course, consists of the objects in your Java application that need to be persisted to and loaded from the database using SQL.
1.1.3 Using SQL in Java
When you work with an SQL database in a Java application, the Java code issues SQL statements to the database via the Java Database Connectivity (JDBC) API. Whether the SQL was written by hand and embedded in the Java code, or gener- ated on the fly by Java code, you use the JDBCAPI to bind arguments to prepare query parameters, execute the query, scroll through the query result table, retrieve values from the result set, and so on. These are low-level data access tasks;
as application developers, we’re more interested in the business problem that requires this data access. What we’d really like to write is code that saves and
retrieves objects—the instances of our classes—to and from the database, reliev- ing us of this low-level drudgery.
Because the data access tasks are often so tedious, we have to ask: Are the rela- tional data model and (especially) SQL the right choices for persistence in object- oriented applications? We answer this question immediately: Yes! There are many reasons why SQL databases dominate the computing industry—relational data- base management systems are the only proven data management technology, and they’re almost always a requirement in any Java project.
However, for the last 15 years, developers have spoken of a paradigm mismatch.
This mismatch explains why so much effort is expended on persistence-related concerns in every enterprise project. The paradigms referred to are object model- ing and relational modeling, or perhaps object-oriented programming and SQL.
Let’s begin our exploration of the mismatch problem by asking what persistence means in the context of object-oriented application development. First we’ll widen the simplistic definition of persistence stated at the beginning of this sec- tion to a broader, more mature understanding of what is involved in maintaining and using persistent data.
1.1.4 Persistence in object-oriented applications
In an object-oriented application, persistence allows an object to outlive the pro- cess that created it. The state of the object can be stored to disk, and an object with the same state can be re-created at some point in the future.
This isn’t limited to single objects—entire networks of interconnected objects can be made persistent and later re-created in a new process. Most objects aren’t persistent; a transient object has a limited lifetime that is bounded by the life of the process that instantiated it. Almost all Java applications contain a mix of per- sistent and transient objects; hence, we need a subsystem that manages our per- sistent data.
Modern relational databases provide a structured representation of persistent data, enabling the manipulating, sorting, searching, and aggregating of data.
Database management systems are responsible for managing concurrency and data integrity; they’re responsible for sharing data between multiple users and multiple applications. They guarantee the integrity of the data through integrity rules that have been implemented with constraints. A database management sys- tem provides data-level security. When we discuss persistence in this book, we’re thinking of all these things:
■ Storage, organization, and retrieval of structured data
■ Concurrency and data integrity
■ Data sharing
And, in particular, we’re thinking of these problems in the context of an object- oriented application that uses a domain model.
An application with a domain model doesn’t work directly with the tabular rep- resentation of the business entities; the application has its own object-oriented model of the business entities. If the database of an online auction system has ITEM and BID tables, for example, the Java application defines Item and Bid classes.
Then, instead of directly working with the rows and columns of an SQL result set, the business logic interacts with this object-oriented domain model and its runtime realization as a network of interconnected objects. Each instance of a Bid has a reference to an auction Item, and each Item may have a collection of refer- ences to Bid instances. The business logic isn’t executed in the database (as an SQL stored procedure); it’s implemented in Java in the application tier. This allows business logic to make use of sophisticated object-oriented concepts such as inheritance and polymorphism. For example, we could use well-known design patterns such as Strategy, Mediator, and Composite (Gamma and others, 1995), all of which depend on polymorphic method calls.
Now a caveat: Not all Java applications are designed this way, nor should they be. Simple applications may be much better off without a domain model. Com- plex applications may have to reuse existing stored procedures. SQL and the JDBC API are perfectly serviceable for dealing with pure tabular data, and the JDBC RowSet makes CRUD operations even easier. Working with a tabular representation of persistent data is straightforward and well understood.
However, in the case of applications with nontrivial business logic, the domain model approach helps to improve code reuse and maintainability significantly. In practice, both strategies are common and needed. Many applications need to exe- cute procedures that modify large sets of data, close to the data. At the same time, other application modules could benefit from an object-oriented domain model that executes regular online transaction processing logic in the application tier.
An efficient way to bring persistent data closer to the application code is required.
If we consider SQL and relational databases again, we finally observe the mis- match between the two paradigms. SQL operations such as projection and join always result in a tabular representation of the resulting data. (This is known as