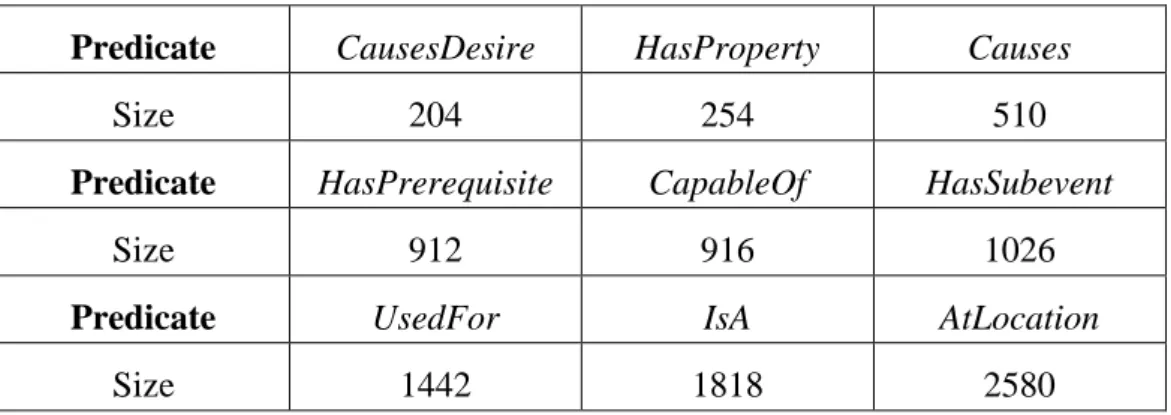
國立臺灣大電機資訊學院資訊工程研究所 博士論文
Department of Computer Science and Information Engineering College of Electrical Engineering and Computer Science
National Taiwan University Doctoral Dissertation
概念表徵及其應用
Concept Representation and Its Application
游基鑫 Chi-Hsin Yu
指導教授﹕陳信希 博士 Advisor: Hsin-Hsi Chen, Ph.D.
中華民國 102 年 8 月 August 2013
i
誌 謝
論文終於完成,要衷心感謝很多人。最要感謝的人是我的家人,在人生的這 個階段回學校念書,家人們給了我最多的體諒及支持,沒有這些,研究將無法進 行。
也要感謝指導老師陳信希教授,在這七年的時間中對我的指導、鼓勵、包容 與各種支持,有他的耐心引導及支持,這論文才能順利完成,謹在此表達深摯的 敬意與感激。另外,也要感謝眾多學弟妹們的陪伴、討論及各種幫助。
謹將這論文獻給他們。
ii
Abstract
In this dissertation, we propose a concept definition in language, derive a concept representation scheme based on this definition, and apply this framework in two applications:
commonsense knowledge classification and word sense disambiguation. In addition, we assert two important assumptions for building concept representation using knowledge extraction:
does commonsense knowledge appear in texts and is a small part of the Web sufficient for supporting important NLP tasks. Last, we introduce processed ClueWeb09 datasets. We hope the produced datasets can boost NLP research.
We give a definition of concept that meets three criteria: having native origin in computational perspective, having no undefined terms in the definition, and having build-in nature for deep analysis by human and by intelligent system itself to understand internal structures of an intelligent system. We define concept a continuation, which is a temporary state in the concept computation process. This temporary state is interpreted within the context of the evolutionary language game. Based on this definition, we define concept representation to have two parts: static and dynamic parts. We investigate some theoretical aspects using theories in machine learning literatures.
In the application of commonsense knowledge classification, we adopt vector space model to build representation and interpret this machine learning process in our framework. In WSD, we further apply our framework to develop two new concepts for solving WSD:
context appropriateness and concept fitness. We use these two new concepts to build many new algorithms to solve WSD problem.
For using knowledge extraction to build concept representation in the future, we verify two important perspectives: content of knowledge and size of knowledge sources. We find that commonsense knowledge are recorded in texts and assert that the web is a good source to
iii
extract human knowledge. We use word ordering error task to indirectly assert that a small part of the web, such as ClueWeb09 dataset, can support NLP applications to produce comparable results to that of larger datasets, such as Google Web 5-gram dataset. These two assertions give us confidence to extract knowledge from a smaller dataset to build concept representation.
Lastly, we preprocess English and Chinese web pages in ClueWeb09 and produce many resources for researchers, including (1) POS-tagged, phrase-chunked, and partly parsed English dataset, (2) segmented, POS-tagged, and discourse markers identified Chinese dataset, and (3) NTU Chinese POS-5gram dataset.
iv
摘要
在此論文中,我們為概念進行了定義,並基於此定義,提出了為系統建構概念表徵的架 構,及將此架構,套用在常識知識分類以及文字岐義消解這兩應用中。除此之外,我們 還驗證了兩個跟知識抽取有關的假設,這分別是常識知識是否出現在文字中,以及小規 模網路文件集是否足以支援重要的自然語言處理工作。最後,我們介紹了 ClueWeb09 這 一網絡規模資料集的一些前處理結果,希望能提供給其他研究者更好用的資源。
我們給出的概念定義符合三個標準:本質上具有可計算性、沒有無定義的組成、有 內建的特質可被人或機器自身進行分析。我們將概念定義成一種延續 (continuation),
這 種 延 續 可 看 成 是 一 種 概 念 運 算 過 程 的 暫 存 態 , 此 暫 存 態 則 放 在 進 化 語 言 博 弈 (evolutionary language game) 的架構下來詮釋。在此定義基礎上,我們將概念表徵 分為靜態跟動態兩方面,並使用機器學習理論來對系統的許多面向進行了理論的探討。
將概念表徵應用在常識知識分類時,我們用向量空間模型來建構表徵,並展示如何 用我們的概念定義,來詮釋一般的機器學習處理過程。而在文字岐義消解這一應用中,
我們更進一步運用了我們發展出的概念,為文字岐義消解引入了脈絡適切性 (context appropriateness) 及概念適切性 (concept fitness) 此兩面向,並用此來建構嶄新的 文字岐義消解演算法。
為了未來使用自動知識抽取的架構為機器建構概念,我們驗證了知識內容及大小這 兩基本問題。為了確認文件是好的知識內容來源,我們發現甚至連常識知識都會出現在 文件中。另外,我們利用文字語序錯誤這一問題,間接驗證了雖然 ClueWeb09 的規模 只是網路網頁的一小部份,它的規模已可產生跟 Google Web 5-gram 同樣的實驗結果,
能很好的支援重要的自然語言處理工作。
最後,我們對 ClueWeb09 這一網絡規模資料集進行了前處理,並產生了許多有用 的資源可提供給研究者,這些資源包括 (1) 完成詞性標記、詞組切分及語句剖析的英 文語料庫、(2) 完成斷詞、詞性標記及語篇標記詞標記的中文語料庫、(3) 中文詞性
v
n-gram 資料集 (NTU Chinese POS 5-gram)。
vi
Content
Chapter 1. Introduction ... 1
1.1 Motivation ... 1
1.2 Overview of this Dissertation ... 3
Chapter 2. Concept as Continuation ... 5
2.1 Concept Theory ... 5
2.2 Concept and Language ... 8
2.3 Defining Concept as a Continuation ... 11
2.4 Some Theoretical Aspects of the Definition... 15
2.5 Related Work in Concept Definition ... 21
2.6 Considerations of Implementation ... 24
Chapter 3. Concept Representation ... 26
3.1 Representation of Continuation ... 26
3.2 Related Work ... 28
3.3 Framework of Knowledge Extraction ... 31
3.4 Applications of Concept Representation ... 32
Chapter 4. Commonsense Knowledge Classification ... 34
4.1 OMCS Database ... 35
4.2 Related Work ... 35
4.3 Concept Representation Scheme for Phrase ... 37
4.4 CSK Classification Algorithm ... 38
4.5 Experiment Settings ... 39
4.6 Experiment Results ... 40
4.7 Interpretation of Feature Engineering Process ... 41
Chapter 5. Word Sense Disambiguation ... 42
5.1 Introduction ... 42
5.2 Related Work ... 46
5.3 Context Appropriateness and Concept Fitness ... 50
5.4 Problem Formulations in WSD ... 54
5.4.1 Multi-class Classification (Baseline) ... 55
5.4.2 Multi-class Classification with Meaning Composition ... 55
5.4.3 Binary Classification with Meaning Composition ... 57
5.4.4 Ranking 2-Level with Meaning Composition ... 58
5.4.5 Ranking 3-Level with Meaning Composition ... 60
5.5 Feature Extraction and Experiment Settings ... 61
5.6 Experiment Results ... 64
vii
Chapter 6. Knowledge Sources ... 67
6.1 ClueWeb09 Dataset ... 68
6.2 Commonsense Knowledge in the Web ... 68
6.3 Preprocessing of English Web Pages ... 70
6.4 Preprocessing of Chinese Web Pages ... 71
6.5 A Verification of ClueWeb09 Dataset... 75
Chapter 7. Conclusion and Future Work ... 78
REFERENCE 80 APPENDIX I. The Definition of definition ... 89
APPENDIX II. The Filtering of Noise Texts ... 91
APPENDIX III. English POS Tag Distribution ... 94
viii
Illustrations
Figure 1. Diagram of Shannon's communication system for language. ... 9
Figure 2. The relations between concepts, words, and proofs. ... 12
Figure 3. Relations of signal, continuation, concept and proofs. ... 14
Figure 4. Internal structure of system for analysis. ... 17
Figure 5. The relations between frame structure, explicitization process, and system. ... 27
Figure 6. Classifiers’ accuracy on nine datasets. ... 40
Figure 7. Relationship between predicate types and explicitly stated CSK ... 69
Figure 8. Illustration of concept representation in WOE detections. ... 76
ix
Tables
Table 1. The differences of families of theories of concepts ... 7
Table 2. The relations between stability and time factor. ... 16
Table 3. Examples from OMCS database ... 35
Table 4. Datasets for CSK classification. ... 39
Table 5. WSD results of MCwoMC using different features. ... 64
Table 6. WSD results in different problem formulations. ... 65
Table 7. Statistics of English POS-tagging dataset. ... 70
Table 8. A phrase-chunking example. ... 71
Table 9. The statistics of the resulting Chinese POS-tagged dataset. ... 73
Table 10. Comparison of NTU PN-Gram corpus and Google Chinese Web N-gram corpus .. 73
Table 11. 50 unique connectives that can be both intra- and inter-sentential connectives ... 74
Table 12. Compare results using NTU PN-Gram corpus and Google Web N-gram corpus. ... 76
Table 13. English POS tag distribution. ... 94
x
Equations
Equation 1 ... 13
Equation 2 ... 51
Equation 3 ... 52
Equation 4 ... 53
Equation 5 ... 53
Equation 6 ... 54
Equation 7 ... 55
Equation 8 ... 56
Equation 9 ... 59
Equation 10 ... 59
Equation 11 ... 60
1
Chapter 1. Introduction
Concept and its representations have been studied for a long time in many disciplines.
Scholars of different fields such as philosophy, psychology, cognitive science, artificial intelligence and natural language processing try hard to define what is concept, to trace the history of a specific concept, to model concepts in human mind, to discover the subtleness between similar concepts, to organize concepts in ontology, to search words that refer to same concept, to study how to draw concept from materials and to represent concept in machine-readable resources. Different disciplines have different focuses when they study concept-related topics. In artificial intelligence and natural language processing, researchers are interest in how to define concept and how to represent concepts in machine-readable format in the hope of supporting the task in hand.
In this dissertation, we are interest in drawing a computational framework to define concept. The computational framework we used is based on continuation which is a concept used in programming language. Based on the framework, we define the concept representation scheme and apply the scheme to many applications to explore the usefulness of the computation framework and the representation scheme.
1.1 Motivation
In the pursuit of building human-like intelligent machines, defining concept and building concept representation are very important. Although concept has been studied for thousands years and scholars of different disciplines have proposed different definitions of concept for their uses, there are fewer definitions that explores computational perspective of concept. In addition, most concept definitions are always end up with some concepts that are needed to be
2
further defined. Although using undefined terms to define something is possible for human mind, these kinds of definitions introduce difficulties when we want to use these definitions to build an intelligent machine.
For example, philosophers usually define concept in terms of the roles that concept plays in their problems of interests or the world they believe. If they believe the world has a pre -existing structure, they may prefer to define concept in terms of ontology or may believe that concept has a predefined structure which reflects the world's inherent properties and most fundamental structures. Plato’s theory of Forms holds this belief of relation between concept and the world in two thousand years ago. In this approach, philosophers give different structures for different concepts in terms of different terminologies, such as attributes, roles, categories, mental representations, abstract objects, and abilities. These terminologies are usually regarded as well-known or self-defined objects. When computer scientists adopt these definitions in their tasks such as machine reading, information extraction, and word sense disambiguation, these undefined objects are simply translated to features of a feature matrix in machine learning fields. For example, the features maybe the co-occurrence words in distributional representation approach (Harris, 1954). These words are undefined. More precisely, researchers interpret these words by themselves. In such cases, the whole system is a mathematical model and this model a black box for researchers. Researchers may manipulate different mathematical models or different model parameters to see how the models response to the operations, but researchers have little chance and face great difficulty to analyze the internal structures of these words. They do not know how the internal structures response to a specific model in a specific configuration of model parameters. If researchers use engineering perspectives to deal with the task, this is not a big problem because they have a workable system to solve their tasks in hand. If researchers want to build a real intelligent system, the system must interpret these words by itself and it must has knowledge on what it
3
is doing. This problem highlight the need to eliminate the use of undefined terms and the use of human-interpret concepts.
We will explain these issues in length in later chapters. In summary, when concept definition ends up in undefined terms or human interpreted terms, it restricts the ability for researchers to conduct a deep analysis on the behaviors and internal structures of intelligent systems. It also restricts the ability for an intelligent system to interpret its behaviors by itself.
Therefore, in this dissertation, we want to give a definition of concept that meets the criteria below:
(1) has native origin in computational perspective, (2) has no undefined terms in the definitions,
(3) and has the build-in nature in deep analysis for human and for intelligent system itself to understand internal structures of an intelligent system.
We hope that with this concept definition, we can shed light on building real intelligent systems and boost the understanding of model building on solving a specific research task in engineering perspectives.
1.2 Overview of this Dissertation
In this dissertation, we define concept as continuation, define a representation scheme based on this definition, and adopt the concept representation in architecture of automatic knowledge extraction.
In chapter 2, we describe the concept definition and investigate some computational aspects of this definition. We elaborate advantages of new definition by comparing it with some well-known definitions.
In chapter 3, we draw a concept representation scheme from our definition of concept.
The concept representation scheme is a simple instantiation of our definition for the
4
implementation purpose. When using a simple instantiation, we can focus our attention on the definition and avoid describing a complicated system.
In chapter 4, we use the concept representation scheme to interpret a classical machine learning procedure. We explain that our representation scheme is capable of subsuming machine learning process and the is more general and useful for human to understand system.
We use commonsense knowledge classification to demonstrate our claim.
In chapter 5, we use the concept representation scheme to consider the relation between concept and its context. We identify concept fitness and context appropriateness for word sense disambiguation (WSD) problems. Using these two perspectives, we develop a novel ranking algorithm for WSD. We conduct experiments and report results in this chapter.
In chapter 6, we describe resources processing procedures and results.
In the last chapter, we summarize our dissertation and picture some future work.
5
Chapter 2. Concept as Continuation
Our concept definition is originated from the context of language study. We propose a computational architecture, and define concept as continuation in this architecture. After that, we investigate some important issues related to this definition. We organize materials in the order below.
(1) We introduce concept theory (Hjørland, 2009) first, which concisely describes how scholars study the theories of concepts.
(2) We introduce Shannon’s communication system, evolutionary language game (Trapa
& Nowak, 2000) and the Chinese Room problem, which inspire us to derive our concept definition.
(3) We describe our concept definition, which defines concept as continuation.
(4) We investigate the implication of this definition in theoretical perspectives.
(5) We compare our concept definition with other definitions.
(6) We describe some considerations and variations on implementing the proposed definition.
2.1 Concept Theory
Although concepts have been studied thousand years, people still do not have a generally accepted agreement on what concepts are. Researchers often credit Plato (424 – 348 BC) and Aristotle (384 – 322 BC) being the earliest scholars to study concept formally. However, their ideas of concepts provide an important reference on the study of concepts but not a generally accepted consensus. Scholars propose many theories of concepts and discuss many views of concepts, and that does not result in consensus but in enlarging the border of our understanding of concepts. Hjørland (2009) systematically survey the theories of concepts and
6
classify these theories into four families. His classification is based on epistemological viewpoint, and he uses theories of knowledge to classify theories of concepts.
We describe these four families here because it can give us a reference framework when we want to understand our proposed concept definition. These four families of theories of concepts are empiricism, rationalism, historicism, and pragmatism.
Empiricism argues that knowledge is draw from observations. These observations are given by settings and are not contextual or theory-dependent. When applying empiricism to semantic, empiricism argues that meanings are defined based on observable features. When applying empiricism to concepts, empiricism argues that human’s sensations derive the concept. In computer science, empiricism argues that neural networks can be seen as modeling concept in empiricism.
Rationalism argues that knowledge is based on predefined structures or rules, which can be logics, principles, or ontology. Plato’s theory of Forms is in this family. When applying rationalism to concepts, rationalism argues that concepts are prior to human’s sensations.
Hjørland (2009) regard Formal Concept Analysis (FCA) (Priss, 2004, 2006) as a prominent mathematical formation of rationalist concept theory. The FCA uses features to define concept, and these features are regarded as simple and well-defined for the human.
Historicism argues that knowledge has its social context and is time-variant. It argues that observations are theory-dependent and always be influenced by cultures, environments, or contexts. When applying historicism to concepts, historicism argues that concepts are always evolving. The concepts will change when the cognitive mechanisms are functioning.
To understand a concept, historicism concerns about discovering the effective assumptions behind the concept and tracing the changes of these assumptions.
Pragmatism argues that knowledge is based on “the analysis of goals, purposes, values, and consequences“. That is to say, knowledge is always based on some specific aspects of
7
reality. Pragmatism also argues that observations are theory-dependent, but it argues that knowledge cannot be neutral because it is derived for some purposes. When applying pragmatism to concepts, pragmatism argues that concepts are faceted. A concept describes reality in some aspects and ignores other aspects of the reality for their purposes.
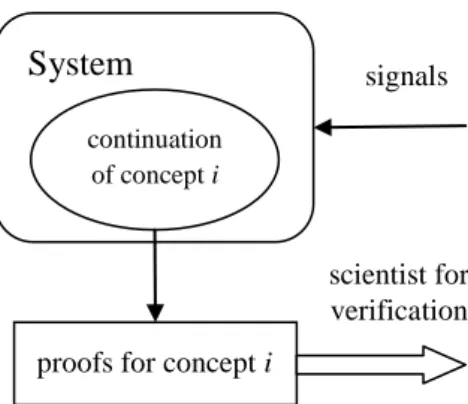
Hjørland (2009) gives three examples to illustrate the difference of concept theories, but we summarize three factors to make a more concise distinctions of these concept theories. The factors are structure-depend, time-variant, and faceted. We show the summary in Table 1.
Family Factor Structure-depend Time-variant Faceted
Empiricism No No No
Rationalism Yes No No
Historicism Yes Yes No
Pragmatism Yes Yes Yes
Table 1. The differences of families of theories of concepts
In Table 1, we replace theory-dependent with structure-depend because the theory sometimes refers to ontology or reflects a specific world structure. In those cases, structure is more precise for describing the idea. In historicism and pragmatism, the structure is from the context or the purpose, which are different from rationalism. The time-variant factor in historicism and pragmatism contains the cases that the perceived concepts may affect the process of following concept perception. In terminology of machine learning, system feeds outputs to its inputs, which may result in recurrent neural network architecture. We do not put any implication between time-variant factor and self-feed architecture here.
With the theories of concepts in mind, we can use it to explain our concept definition.
Before defining concept, we put some words on the distinctions between concept definition
8
and theories of concepts.
When we use the term definition, it means we refer one term to something. For example, a concept definition is to refer concept to something. Abstractly speaking, a definition connects object to other objects and use criteria to rate the goodness of this connection. In the philosophy of science, this means we use something to explain concept in order to reach a good understanding of concept. The criteria of judging the goodness of explanation is not easy to formulate. According to Friedman (1974), the judgment is the problem of scientific explanation:
In Friedman’s article, he describes three views of scientific explanations. One of viewpoints of explanation is that “scientific explanations give us understanding of the world by relating (or reducing) unfamiliar phenomena to familiar ones.” We adopt this viewpoint when we construct our concept definition1.
In our concept definition, we relate concept to a computational architecture, which is unambiguous and well-defined mathematical computation model. In this way, we avoid the use of human interpreted terms in defining concept. Next section, we will ground our concept definition to existing computation models.
2.2 Concept and Language
When we want to define concept in context of language, we must consider the relations between concepts and languages first. The relations between concepts and languages are
1 Actually, the explanation of definition covers three views in Friedman’s article. We give a more detail analysis in Appendix A.
“The central problem for the theory of scientific explanation comes down to this: what is the relation between phenomena in virtue of which one phenomenon can constitute an explanation of another, and what is it about this relation that gives understanding of the explained phenomenon?” (Friedman, 1974)
9
complicated. When studying the relations, different disciplines have different focus and different assumptions. For example, psychologist may focus on concept development, and hence the language is just tokens to denote concepts in human mind. For some theorists, language is just tokens. They ignore concepts and may focus on topics such as the learnability of language, language identification (Gold, 1967). For Noam Chomsky, language has its structures and is generated by deep structures in the human mind, and concept is a general term to refer idea in mind. For some linguists, concepts denote components in real languages such as phoneme, words, phrases, and sentences. In this case, concepts are denoted by tokens.
However, some scholars assert that concept has its own internal structure. For example, Margolis and Laurence (2011) investigate many proposals about the structure of lexical concepts2. We adopt this viewpoint and use continuation as an instantiation of concept’s internal structure. Moreover, we embed the continuation in communication model to let our concept definition have a solid computational ground.
Now, we consider computational models about language. In Shannon’s communication system (Shannon, 1948), the language is signals from sender to receiver, and the signal may be corrupted by noises when signals are transmitted (see Figure 1). In this communication system, concepts are conveyed by words and are transmitted to receiver with possibility of
2 In their definition, lexical concept is a word-sized concept, and it can be used to compose complex concepts.
Sender’s
concepts Noisy channel
Receiver’s concepts
Encoder Decoder
Words (information)
Figure 1. Diagram of Shannon's communication system for language.
10
misunderstanding. In this case, concepts are transparently encoded in words and jump into head when receiver decodes the received words. Although the concept definition is not necessary here, the communication system do capture an important aspect of language. Not like Shannon who concerns the communication process, we are interested in the words’
ability to trigger receiver to do computation. Because words carry concepts, the concepts trigger computations in both sides.
Nowak’s evolutionary language game (Komarova, Niyogi, & Nowak, 2002; Nowak, Plotkin, & Krakauer, 1999; Plotkin & Nowak, 2000; Trapa & Nowak, 2000) further extends the communication system in a game setting. The meanings of signals are explicitly modeled in the evolutionary language game. In his settings, sender and receiver have a matrix P and Q, respectively. The matrix P encodes the sender’s knowledge of signals associated with meanings3, and the matrix Q encodes the receiver’s knowledge of signals associated with meanings. In this way, a concept can be denoted by many signals and vice versa. He then defines language for an individual. For two individuals, they may have different knowledge about language, and hence they have different language and respectively. Trapa and Nowak (2000) defines payoff function and proves that a group of individuals with random knowledge of language can communicate to each other in the evolutionary language game setting. In summary, Nowak proves that it is possible to communicate concepts using signals even the initial knowledge of signals and concepts are different between individuals. But Nowak’s model consider language of an individual as a whole, it is difficult to apply his results in various applications.
Although Nowak asserts that the communication between different individuals with different language knowledge is possible no matter the individual being a human or a machine, some philosophers concern the ability for a machine to understand the communicated
3 In Nowak’s paper, signals are associated with objects, which are anything that can be referred to, including concepts and meanings in human mind.
11
information. This is the core problem questioned in the famous Chinese Room problem (Searle, 1980).
The Chinese Room problem is a thought experiment. It assumes that a computer system already passes the Turing test in Chinese language. If a man who has no knowledge about Chinese replaces the computer, the conversation in the Turing test can continue theoretically.
The man runs the program, but this man doesn't understand Chinese. Searle concludes that the machines cannot understand human languages even thought machines conduct successful conversations with human. It means successful communication does not entail successful understanding. Although Searle’s argument is controversial, it highlights an important point that communication model cannot completely model all aspects of language. Language understanding is an important aspect of language and concept modeling. It inspires us to give a concept definition.
2.3 Defining Concept as a Continuation
Now, we have mentioned that Nowak’s evolutionary language game asserts communication between machine and human is possible. On the other hand, the Chinese Room problem argues that communication does not entail understanding. How do we build machines with abilities of language communication and understanding?
In logical positivism, all meaningful statements must be verifiable. This follows that if we want to assert the statement “a machine understands language”, we must have a proof for verification. The empirical proofs for language understanding can be anything that been used to test a human for his/her understanding of language. We denote these empirical proofs as a verification set V and proof .
In Nowak’s evolutionary language game, concept encoding matrix , in which n is the number of objects (concepts) and m is the number of signals (words). The concept
12
decoding matrix is defined in the same way. Now, because we must have proofs for asserting statement “system understands a concept i”, we let concept encoding matrix P be a product of two matrices and (see Figure 2). The concept decoding matrix can be defined in the same way, in which and .
We denote matrix as a concept-proof matrix, and matrix as a proof-word information matrix. For example, for a concept , , we may have multiple proofs , , to assert that system understand concept . With this formation, the machine has verifiable nature of its internal structure for human understanding.
In Trapa and Nowak (2000), they define different types of languages based on constraints for matrices P, Q, and payoff function . For example, a language is a Nash language if for all language , in which has same dimension with P, has same dimension with Q, ,
, and . On the other hand, if and , we do not have the necessary to impose constraints for matrices G, H, R, and S. Matrices G and S are for verification by the third individuals. We can let and which means if proof k is used to verify concept i, , else, . In this case, a proof can be used to verify multiple concepts and vice-versa.
Now, we have grounded the understanding of a concept on Nowak’s evolutionary
=
proofs 1..|V|
words 1..m concepts
1..n P G H
words 1..m
Figure 2. The relations between concepts, words, and proofs.
13
language game, which is a solid computation model. In this model, concept , , in which and . In other word, concepts are represented by words and proofs.
We can define an operational measure for language understanding. We have the Equation 1, which states that if the difference between matrices G and S of human and machine is smaller than a threshold , we assert the statement “the machine understands the language like human” is true.
Equation 1
Although the definition of concept understanding on Nowak’s evolutionary language game is clear, it is not a good choice to use this as a concept definition. Nowak’s evolutionary language game describes stationary status of a group of communicating individuals, but we want a concept definition that can be used to design a system to communicate with members of group with stationary language knowledge.
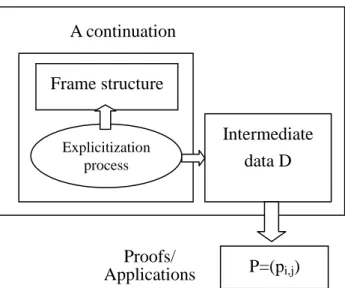
Now, consider the situation that two systems communicate with each other, and a scientist studies the change of concept understanding of the two systems in the communication. This situation is much like that developmental psychologists study human language development except the scientist has access to internal structures of systems. When a system receives a signal (word), it may triggers many concepts, and hence a concept may triggers proofs to be verified by the scientist. When this process continues, in a snapshot, how does the scientist define what is concept in a system?
This scientist will notice that there are words, concepts, computation, and computed proofs of concepts. For a concept, there is pre-existing structure in the last communication, and system uses the information to compute related proofs (see Figure 3). We can say that a concept is represented by this pre-existing structure, and this structure is actually an
14
un-finished computation in the communication process. In other words, concept is a continuation in a computation process. We propose concept as continuation to be the definition of concept.
This definition is well-defined because this is based on evolutionary language game setting. This definition also gives us a computational viewpoint of concept, which gives great advantages when we want to design real systems. In this concept definition, we have a uniform view of system’s concepts. In this definition, we can unambiguously define concept, concept computation, and language understanding. We can have a single viewpoint to integrate NLP tasks, which usually have their own definitions of concepts and understanding.
This uniform viewpoint of concept is very important when we are interesting in designing a real intelligent system and when we are integrating multiple NLP tasks into a single intelligent system.
Notice that although we define concept as continuation, we do not specify the structure of a continuation, what does a concept refers to, and what a proof is. We think these as the flexibility of our concept definition and will explain these issues in detail later. We consider some theoretical aspects of our concept definition first.
System
continuation of concept i
signals
proofs for concept i
scientist for verification
Figure 3. Relations of signal, continuation, concept and proofs.
15
2.4 Some Theoretical Aspects of the Definition
We are concerned with some theoretical aspects of concept definition. The central problem is stability of a system. The stability problem has three different aspects, which are called dogma stability, input stability, and test stability. We describe them below.
1. A system of dogma stability means the system has ability to strictly obeying some specific rules embedded by human. Human may want machine to obey the rules in any situation that the system may encounter. We can also use controllability to denote dogma stability of a machine.
2. A system of input stability means its language understanding ability will not change significantly when the system has small changes inside the system.
3. A system of test stability means the system has a general knowledge of language, and its language understanding ability will not change significantly when we use different verification sets, which may also change when the language is in evolution. Because a system is also a learning algorithm, the test stability is just the generalization of a learning algorithm.
Using our concept definition, we can study these aspects of stability from machine learning viewpoint. When studying these stabilities, the theories of concepts and time orders of magnitude are two very important factors. The theories of concepts define how signals are sampled from reality. This sampling of signals reflects data distribution, and then affects the standard of judging system’s understanding ability. The time order of magnitude defines the scope of validity of stability analysis. There are three time orders of magnitude to be concerned: static world, short-term period, and long-term period. We describe them below.
1. Static world: the time factor is not considered in the analysis. In this case, the distribution that generates signals is unknown but fixed for all time. Most analyses of
16
machine learning algorithms are in this situation.
2. Short-term period: the system has small changes which may be due to system’s shift in its learning process or small environmental shift. For example, when a man changes his taste of food, a machine must adopt to this change to serve this man.
3. Long-term period refer to system’s lifetime. Although we have full control in the birth of a system, we want to understand how it will behave in a long time without human’s interference.
When the period is longer than system’s lifetime, test stability can be modeled by Nowak’s evolutionary language game. This implies that human language will co-evolve with concepts in machines because signals are exchanged between human and machines just like the setting in evolutionary language game. Input stability and dogma stability is meaningless when time period is larger than system’s lifetime. In Table 2, we sketch the theorems that are adopted in analyzing relations between stability and time period. In the table, blank cell means relations are not covered in this dissertation, and ML denotes machine learning.
Input stability Test stability Dogma stability Static world Sensitivity analysis
(stability in ML)
Generalization in
ML Rice’s Theorem
Short-term period Stability in ML
Long-term period Stability in ML The No Free Lunch Theorem
Table 2. The relations between stability and time factor.
We will use existing theorems in machine learning literatures to analyze system’s stability. We define some mathematical terminologies first.
Suppose a system has n concepts, proofs, and their continuations , in which denotes continuation of concept i. Concept i has proofs
, and is concept-proof matrix which is given by human. We define
17
empirical loss to measure language understanding of system, in which is the input of function f, is system learned knowledge to judge the relation between a concept and a proof, and is a loss function for function , , and . Because continuation is an un-finished computation and may changes, it is difficult to analyze system in this form. Therefore, we let the system has a specific internal structure for the convenience of analysis. We suppose that the system uses its knowledge to generate intermediate data and uses intermediate data to learn a function for P (see Figure 4). In this setting, we can analyze system in two stages: the feature generating stage and machine learning stage. System generates features using continuations of concepts, and adopts standard machine learning approaches to learn a good function to show its understanding of language.
The input stability of system considers the problem that the language understanding ability will not change significantly when the system has small changes. The small changes may be caused by external signals or by system’s internal operations, and the changes may be in continuations or in intermediate data D. This stability problem concerns if a system can act like a stable average person and won’t go crazy for changes from noises, inputs or internal operations.
C: continuation
intermediate data D
System
P= (pi,j)
Figure 4. Internal structure of system for analysis.
18
If the small changes is in intermediate data D, according bipartite stability of ranking algorithms (Agarwal & Niyogi, 2005), there are learning algorithms that can result in a stable system. Because it is helpful to understand definition of system stability, we state stability of ranking functions in information retrieval in detail. In information retrieval, a query has a set of relevant documents, and system learns a ranking function to rank relevant documents and non-relevant documents of a set of queries. In our system, the concept acts like query, proof acts like relevant document, and non-proof of a concept acts like non-relevant document.
Bousquet and Elisseeff (2002) gives many stability definitions for learning algorithms, and Agarwal and Niyogi (2005) uses similar definitions to prove that some ranking algorithms are stable. For example, ranking algorithm RankingSVM (Joachims, 2002), which uses reproducing kernel Hilbert space (RKHS) with kernel, has uniform leave-one-instance-out stability4 (Geng et al., 2008).
Definition 1. Uniform leave-one-instance-out stability
Let , in which , , ,5 D is the input space, and p is the label. Let denotes a training set that is drawn i.i.d. (Independent and identically distributed6) from an unknown distribution, and denotes a training set with one instance out. The denotes the resulting model of a learning algorithm L using training set S. This model minimizes loss function , where . The cost function . Now, we say L has uniform leave-one-instance-out stability , , if
, .
4 Uniform leave-one-instance-out stability is defined in Geng et al. (2008) and is similar to uniform score stability defined in Agarwal and Niyogi (2005).
5 In Agarwal and Niyogi (2005), can be the set of real number.
6 In our definition of intermediate data D, it must be drawn i.i.d. in order to adopt this stability definition. This can be done by many methods. For example, we can draw a i.i.d. signal set, and feed this signal set to generate an i.i.d. intermediate set.
19
This definition states that if learning algorithms have uniform leave-one-instance-out stability, the resulting model will not change significantly when the training set has a small change (leaving one instance out). In Agarwal and Niyogi (2005), they proves that
, where is a regularization parameter, , and is the kernel of RKHS. Geng et al. (2008) show that for two training sets and , ,
, where is the size of set S.
In static world, the whole system still has good input stability, because the role of continuations is just like a component of algorithm, and it will generate same distribution of intermediate data D if the distribution to generate signals is the same. In this case, the generalization (test stability) of system can be analyzed by using generalization theorems in ML. The generalization ability depends on the learning algorithms we adopted in intermediate data D.
According to the No Free Lunch Theorem (Wolpert & Macready, 1997), if a system is built based on static world assumption, which is a viewpoint that holds by empiricism and rationalism on the theories of concepts, theoretically, the system cannot guarantee to have a good language understanding in long-term period for test stability. The No Free Lunch Theorem states that if a learning algorithm performs well in some tasks, it must perform badly in other tasks. The system is a learning algorithm, and it understands language well in the very beginning. Theoretically, we cannot guarantee how the world will change. Therefore, it is possible that this already built machine will perform badly in some cases in future. This theorem prompts that we can only have results in probability for system’s understanding ability in long-term period.
We turn our attention to dogma stability in static world. A system with dogma stability
20
means it will strictly obey some specific rules without exception in any cases. The most famous example is The Three Laws of Robotics, which is coined by the science fiction author Isaac Asimov (1920 – 1992). Briefly speaking, scientists do not want a designed machine to hurt people. The possibility to design such machine is the issue of dogma stability. Dogma stability is different from input stability because system maybe misunderstands some concepts but is still have a good understanding of language. According to Rice's Theorem, which states that it is un-decidable for any non-trivial property of Turing machines, we can say that dogma stability can't be guaranteed if we do not put some assumptions on the human world. On the other hand, because scientists can always conclude a probability of violating dogma stability for a system, dogma stability may not a major concern for some real systems.
In the long-term period, the input stability is the same as short-term period because system can continuously make a small changes like in short-term period. Therefore, we discuss the input stability in short-term period. In the short-term period, the system may modify their concepts to adopt the environmental changes, which also means the distribution to generate signals may not be stationary. For input stability in short-term, the input stability of whole system and intermediate data D depends on how we design the system. If all concepts are interrelated, the system with continuations is much like a recurrent neural networks (RNNs), and the output of RNNs is usually non-linear and is hard to be predicted (Barabanov & Prokhorov, 2002). Therefore, if we design system to have independent concepts or independent group of concepts, we can analyze system theoretically. We can analyze this issue in different cases such as same signal distribution but different concepts, different signal distribution but same concepts, and different signal distribution and different concepts. In other words, the proposed concept definition can be analyzed mathematically.
This is very important when we want to design a real intelligent system.
21
2.5 Related Work in Concept Definition
Scholars of different disciplines have their concept definitions to apply in their work. For philosophers, concept has intension and extension that represent knowledge of concept in human mind. For logicians (Jurafsky & Martin, 2009a, 2009b), a concept can be a symbol to denote an object in a logic model, can be a category to denote a group of objects, and can be a first order logic sentence(s) which specifies its relations with other concepts. In Formal Concept Analysis (Priss, 2006), concepts are objects that have attributes. The objects and attributes are defined by human’s commonsense, in which its meaning is interpreted by human in the context. For linguists, concept may be represented by words. Therefore, they use words to denote a lexicalized concept. The distinguished WordNet (Fellbaum, 1998) database adopt this viewpoint, and no formal definition of concept is given. In WordNet, concept is represented by a synset which contains words for a concept. For ontology builders and users, concept may play different roles in ontology. It may be an object, predicate, quantifier, function, and relation. These terminologies gain their meaning in the ontology. Its connection to real world is also interpreted by human. For researchers in artificial intelligence, concept may be represented by words or an object in a logic model.
In summary, concept definition in these disciplines is an object to be operated, while in our concept definition, a concept itself is a computational process that uses a continuation to represent it. Moreover, the continuation exists in the environment it lives like a continuation in programming language. This viewpoint adopts pragmatism concept theories. Its connection to real world is defined by its ability of understanding language and is modeled inside the definition. A continuation do not contain all information because some information is stored in its environment. A continuation is similar to a device that stores links to its environment and links to machine's internal states. Therefore, a continuation may has its internal structures
22
to store different types of information. We discuss this issue in next chapter.
In the viewpoint of continuation, human do not interpret a concept in machine. Human just provides proofs to test the comprehension of concept in language understanding of a machine.
Computer scientist John Sowa (Sowa, 1984) gives a concept definition in pragmatism viewpoint, and we quote it below.
The core insight of his definition is similar to our definition which captures the computational aspect of concept, but we further formulate concept definition in evolutionary language game and add mechanism for verifying language understanding. Marvin Minsky proposes a similar viewpoint of concept definition but uses different terminologies. In his book The society of Mind (Minsky, 1986), mind is a society which is composed of a group of agents. These agents represent various processes in human’s brain, and these processes can be any concepts interested by researchers such as free well, the sense of self, belief, memory, and consciousness. In our definition, we denote all processes in human mind as concepts and do not put any assumption on the structure and implementation of concept in order to gain the ability to analyze system theoretically in modern machine learning perspectives. Our concept definition is also similar to intelligent agent (Russell & Norvig, 2003) in artificial intelligence literatures, but we connect agent’s output to language understanding.
Barker (2004) emphasizes the similarities between formal languages and natural languages and uses continuation to analyze linguistic phenomena in natural language. He
“Concepts are inventions of the human mind used to construct a model of the world. They package reality into discrete units for further processing, they support powerful mechanisms for doing logic, and they are indispensable for precise, extended chains of reasoning. But concepts and percepts cannot form a perfect model of the world,—they are abstractions that select features that are important for one purpose, but they ignore details and complexities that may be just as important for some other purpose.” (Sowa, 1984, p.p. 344)
23
treats quantification words like everyone, no one, and someone as a continuation, and defines these words in formal language context. He uses control operators like control, prompt, shift, and reset in delimited continuation (Felleisen, 1988) to demonstrates computation of quantification words in syntax tree. Barker also studies a phenomenon called focus, which is denoted by focus particles such as only. His approach use first order logic to represent the semantic of sentences like the approaches in computational semantics (Jurafsky & Martin, 2009a). Because continuation is a flexible mechanism to handle execution flow of formal language, he uses continuation as a mechanism to handle complex relations and phenomena in natural language, such as coordination, ambiguity, and quantification. In Baker’s formulation, a concept actually is a predefined continuation that has specific effects in parse tree. Although this definition is similar to our definition, the meaning of a concept is interpreted in FOL context, and hence, is interpreted by human.
When considering the relations between concept and language, researchers usually regard concepts as states of mind and study the procedure of translating mind states to languages. For Noam Chomsky (1986), the translation procedure is the knowledge of languages, and languages are internalized language (I-language) that translating the structure of concepts (mind states) to externalized language (E-language), which is independent of mind. In this viewpoint, language understanding is the problem to understand the correspondences between I-language grammars and E-language grammars. In our concept definition, the grammars are one type of concepts, and the E-language is just one type of proofs that can be adopted to measure system’s understanding level.
When considering a concept to be a program that has the ability to do something in an environment, researchers usually regard concepts as a computer program. They follow the approaches of reductionism, which reduces complex thing to many simpler and smaller things and combines these smaller results to solve the complex thing. For example, when studying
24
machine understanding, researchers in natural language frame the understanding problem to many smaller problems such as named entity recognition (NER), co-reference resolution, template element, template relation, and scenario template in the Message Understanding Conference. In this case, a program that archives good results in sub-problem is regarded as understanding language well. This approach is similar to our concept definition, which define concept to be a program represented by continuation, and we further link this approach to evolutionary language game to form a more general framework to integrate sub-problems. In other words, we provide a general framework to integrate many sub-systems, and this integration is still within language understanding framework.
In the next section, we will mention some considerations of the proposed definition in implementation.
2.6 Considerations of Implementation
We have sketched a framework in our concept definition, and we give detail descriptions of continuation and proofs here.
In our concept definition, we equally treat all types of concepts, but in literatures, researchers may manually gives definitions for concepts like beliefs, goals, plans, commonsense, knowledge, and intentions (Mueller, 2010). It is straightforward to build continuations for these concepts. Therefore, when we implement our concept definition, the implementation of continuation and the source of proofs are the keys to build intelligent systems. In this dissertation, we use a concept representation scheme to represent continuation and use automatically extracted knowledge as proofs. We will explain concept representation scheme in chapter 3 and knowledge extraction in chapter 4.
We put some words on the proofs. We already have a continuation to represent a concept.
Now, we explain how to test concepts with proofs here. In Figure 3, we use a set of proofs to
25
verify that a concept is studied by system. When the concept is settled in the concept-proof matrix, we use one row to represent it. For example, we want to know the concept <car> is well acquired by system, we can test it with proof <a car is a vehicle> or <a car is a human>.
When we have a set of similar proofs such as <a car is a machine> and <a car has four wheels>, we can change the concept-proof matrix in other equivalent formats. One of the equivalent formats is to assign relations to concept. For example, the <car> has human-readable relations such as <is_a>, <has>, and <type_of>. Using this way, we connect system implementations to a general case and easy to be understand.
26
Chapter 3. Concept Representation
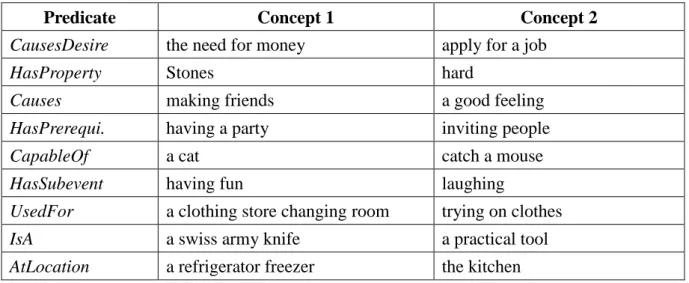
We use a concept representation scheme to represent continuation in this chapter. The proposed concept representation scheme is similar to continuation in programming language but has greater flexibility to adopt complex world. Just like a continuation in programming language store state of current program, we use structured format to represent the state of a continuation. In order to connect state to its environment, we use an explicitization process to do this job. In summary, we define our concept representation “a scheme that employs an explicitization process in a specific perspective to elicit a mathematical object for a concept.” The mathematical object is the intermediate data D in Figure 4, and this object usually is adopted as feature matrix for machine learning algorithms.
In this chapter, we organize materials in the order below.
(1) We describe a proposed structured format used in a scheme.
(2) We describe related work of concept/word representation in natural language processing.
(3) We describe the connection to feature engineering of machine learning.
3.1 Representation of Continuation
We use traditional frame structure to store the static knowledge of a concept, and we use the explicitization process to represent the dynamic part of a concept. We show the relations between frame structure, explicitization process, and system in Figure 5. In Figure 5, system can access the internal frame structure, and this ability completes our third claim that the concept definition (concept as continuation) has the build-in nature in deep analysis for human and for intelligent system itself to understand internal structures of an intelligent system. In summary, our concept definition originates from the evolutionary language game
27
and has native origin in computational perspective. We use continuation to eliminate the need of undefined terms in the definition, and use frame structure to let the system having build-in nature in deep analysis about system’s behaviors. The whole concept representation scheme is similar a feature engineering process except the scheme is grounded in a language understanding context.
The frame structure contains static knowledge of a concept, and explicitization process represents dynamic connection between static knowledge and intermediate data D. Now, we face a cold start problem, which means we do not have the static knowledge but we must use the knowledge to let explicitization process to generate intermediate data D. Therefore, we extract knowledge from web pages to solve cold start problem.
The frame structure may contains many kinds of knowledge. We classify frequently used knowledge in frame structure below.
(1) Knowledge of language:
This category contains knowledge about language, including lexical knowledge and syntactical knowledge.
A continuation
System
Intermediate data D Frame structure
Explicitization process
P=(pi,j) Proofs/
Applications
Figure 5. The relations between frame structure, explicitization process, and system.
28
(2) World knowledge:
This category contains world knowledge and knowledge that connects world knowledge to language knowledge. We further classify the knowledge into three types, including relation knowledge, pattern knowledge, and grounded knowledge.
Relation knowledge connects two phrases by using relation such as type_of relation in knowledge <bank, type_of, company>. Pattern knowledge is a knowledge extraction pattern and connects concept to language usages. For example, pattern
<is_a, STRING> extracts knowledge <bank, is_a, company>. Grounded knowledge contains source sentences like the sentences we remembered and frequently used as prototype examples. For example, <The bank is a company incorporated …> is a prototype sentence used in pattern <is_a, STRING>. We use these three types of knowledge to extraction world knowledge.
(3) Explicitization knowledge:
This is the knowledge that been learned in explicitization process. Its detail information of the knowledge is subject to adopted learning algorithms.
3.2 Related Work
In literature, many representation schemes have been proposed. Some schemes are used to represent words while some schemes are used to represent concepts. We classify these representation schemes (static knowledge) in two categories (from human and from texts) according the source of the representation. We describe these representations below.
The first type of knowledge source is human. Researchers directly derive static knowledge from human. These static knowledge include commonly used resources in NLP such as linguistic database (WordNet, FrameNet, VerbNet), ontology (Suggested Upper Merged Ontology, SUMO), commonsense knowledge (CYC, ConceptNet), and collaborative
29
knowledge base (Freebase). Experts or general users manually enter the knowledge, and the size of the knowledge is limited.
The second type of knowledge source is texts. Researchers can design systems to extract knowledge from texts or design mathematical models to represent knowledge in texts. We ignore knowledge extraction here and describe the mathematical representations.
Researchers use mathematical objects to derive representations from texts for words and concepts. These derived representations may be adopted in machine learning algorithms, but some representations store representations in internal network. These mathematical objects can be classified into three categories.
(1) Frequency-based: This category counts the frequency of features in texts and uses approaches to select features. For example, distributional representation approach (Harris, 1954) collects co-occurrence words in texts to represent a target word or concept. Turney and Pantel (2010) gives a good review on using different kinds of lexical patterns to derive meaning for words.
(2) Model-based: This category relies on mathematical models to build representations and capture static meaning of a word. For example, Latent Semantic Indexing adopts singular value decomposition (SVD) to derive latent concepts for word representation. Brown clustering (Brown et. al., 1992) uses clustering algorithms to cluster similar words and assigns bit strings to represent words in a cluster. Word embedding (Bengio, 2008) encodes word knowledge in a real-valued vector and uses neural language model to learn the representation. Turian et. al. (2010) adopts many semi-supervised learning algorithms including word embedding to represent words and conducts experiments on many NLP tasks to compare the usefulness of different approaches.
(3) Operation-based: This category also relies on mathematical models to build
30
representations, but the algorithms in this category focus on capturing dynamic aspects of words, which are different from the model-based approaches. For example, holographic lexicon (Jones & Mewhort, 2007; Plate, 1995, 2003) uses neural network framework to learn representations that encode word order information and word composition information in distributed representations. Thater et. al. (2010) uses vector model to integrate compositionality knowledge of concepts and context information of a word.
In addition to above approaches, some researchers adopt logic to represents word meaning. These approaches usually need human to encode domain knowledge manually.
Therefore, it is similar the approaches that derive knowledge from human.
When researchers want to measure the usefulness of a concept/word representation scheme, they proposed many criteria for this purpose. Commonly used intrinsic criteria to evaluate a representation include (a) encoded knowledge/information, (b) computational properties, such as accessibility, efficiency, affordance of generalization, robustness and graceful degradation (Plate, 2003), (c) supported operations, such as composition, decomposition, and manipulations, (d) expression power of the representation, (e) transparency, which means the results is easy to be understand by human, and (f) flexibility, which means the representation can be used in different situations. Researchers also adopt extrinsic applications to assert the usefulness of a representation. These applications can be any NLP applications such as chunking, WSD, word similarity, and GRE word test.
In our representation, we emphasize on transparency and flexibility because we are want the representation can easily integrate different kinds of knowledge and has internal structure that is readable for human. Therefore, we put the readable part in the frame structure and put the un-readable and somewhat mysterious part in explicitization process. In this way, we can easily adopt our representation in existing machine learning approaches, and we still have