以詞頻、詞頻-逆向句子頻率和詞頻-句子頻率結合LDA之英語課程文字稿摘要法
286
0
0
全文
(2)
(3) 誌謝 從踏入研究所至今四年間遇到許多貴人,因為這些貴人的幫助使我的研究所 生涯得以順利地劃下完美的句點,雖然四年的研究所生涯遇到許多挫折,但也一 路走了過來,並在最後順利完成碩士論文。 首先最感謝的是我的指導教授-蕭文峰老師,從入學開始便跟著老師努力學 習,在學習的過程中蕭文峰老師很認真的教導我,雖然我的基本觀念不夠紮實, 有時會搞不清楚狀況,蕭文峰老師仍然很認真的幫助我建立觀念,使我在學業上 有所啟發,受益良多,由衷的感謝蕭文峰老師對我的教誨。 另外還要感謝張德民老師和蔡孟琳老師在論文口試時擔任我的口試委員並 於論文口試的過程中給予我相關的建議,讓我的論文內容更加完整。也感謝系上 的其他老師在課程上盡心盡力,讓我在各方面有所成長,令我獲益良多。 感謝 101 碩士班的同學,蔡政龍、黃仲杰、尤聖元、林嘉品、蕭翁一郎、林 家孙、周尙賢、吳華宗、許揚騏、王冠滕、黃盟文、朱永森、劉育辰這些同學的 陪伴與支持,因為有你們的相伴使我的研究所生涯能夠多采多姿。 感謝吳建銘學弟、陳建銘、葉智程學弟在我研究所生涯後期的陪伴與支持, 在研究所後期與你們互相學習成長的時光將會是我永遠記得的美好回憶,多虧你 們的陪伴與支持是我能順利完成研究所學業的動力。 感謝吳尚澤學長、吳宗儒學長和邱怡菁學姊在我入學時教導我許多關於研究 所的事,使我能更加順利的進入狀況適應研究所的各種事情,在此由衷的表達我 的謝意。特別是邱怡菁學姊,感謝邱怡菁學姊在我撰寫論文時給予我相關的幫助 與建議,因為有妳的幫助與指導,讓我的論文能夠步上軌道並順利完成,使我能 夠順利獲得碩士學位。 感謝許文祥學弟、莊証幃學弟和楊宗恩學弟在我口試論文時幫助我布置場地, 多虧你們的幫忙讓我的論文口試能夠順利進行,在此致上最深的謝意感謝你們的 幫忙。 I.
(4) 最後感謝我的家人一直在我背後支持我,使我能無後顧之憂順利完成學業, 不論遇到甚麼樣的困難都會幫助我走下去。 由衷的感謝所有幫助過我的人,特別再一次感謝蕭文峰老師,感謝蕭文峰老 師的教誨與指導,相信在我往後的人生對我的人生道路會有一定的幫助。. 黃喬僅致於 國立屏東大學資訊管理學系碩士班. II.
(5) 摘要 由於資訊越來越發達,現今的教育方式也逐步發展成網路線上課程,學習 者可以藉由方便的網路科技尋找自己有興趣的課程進行學習。大部分的線上課程 都會提供影片與文字稿以方便學習者下載學習,但是文字稿的字數非常龐大,如 果學習者要全部融會貫通必須花費極大的時間與心力,因此本論文決定提出適合 的方法針對文字稿進行摘要擷取。 目前已有相關研究針對文字稿進行摘要擷取,如邱怡菁提出以隱含迪利克雷 分佈(Latent Dirichlet Allocation,LDA)為基礎針對英文文字稿建立主題模型。在 邱怡菁的研究中,先將英語文字稿用 LDA 建立主題模型,再使用主題機率和關 鍵字詞在主題下發生之機率計算摘要句子權重並進行摘要擷取。本論文考量到文 字稿的內容皆為互相獨立,將所有文字稿內容視為集合計算相關權重在摘要擷取 上可能會產生誤差,因此本論文針對單一章節文字稿的計算字詞權重並計算文字 稿句子權重以提升摘要擷取效能。 在 過 去 的 研 究 中 , 字 詞 權 重 通 常 是 用 詞 頻 - 逆 向 文 件 頻 率 (Term Frequency-Inverse Document Frequency,TF-IDF)來計算,但是 TF-IDF 必須在文 件數極為龐大才能勉強有效果,同時 TF-IDF 只考慮字詞在所有文件中所佔的權 重,忽略字詞在單一文件所佔的權重,在摘要擷取中容易受到文件數的限制。本 論文決定使用其他方法計算字詞權重擷取單一文件摘要。 本 論文 分別 使用詞頻 (Term Frequency,TF) 、詞頻 -逆向句子頻率 (Term Frequency-Inverse Sentence Frequency , TF-ISF) 和 詞 頻 - 句 子 頻 率 (Term Frequency-Sentence Frequency,TF-SF)計算文字稿字詞權重,再藉由 LDA 主題 字詞在各主題下產生的機率、LDA 主題機率進行加權並依照句子權重大小擷取 摘要。TF、TF-ISF 和 TF-SF 皆能計算字詞在單一文件所佔得權重,有效改善 TF-IDF 受限於文件數的問題。本論文同時使用提示詞針對文字稿句子進行加權, III.
(6) 由於提示詞是屬於特殊的字詞,因此本論文分別使用兩種字詞權重計算方法計算 提示詞權重進行加權並進行比較。 本論文最後與邱怡菁論文所提之摘要擷取方法、曾士昌論文所提之摘要擷取 方法與線上摘要器 SweSum 進行比較。本論文使用 Precision、Recall、F1 值與雙 尾 T 檢定評估文字稿摘要擷取效能,在最後的比較結果中本論文所提的摘要方 法皆優於邱怡菁論文所提之摘要擷取方法、曾士昌論文所提之摘要擷取方法與線 上摘要器 SweSum。. 關鍵字:文字稿、LDA、詞頻、詞頻-逆向句子頻率、詞頻-句子頻率. IV.
(7) Abstract Due to information technology is getting more and more developed, the kind of education also evolve into online courses, learners can search courses to learn with network technology. Most of online courses provide videos and transcripts to learners download and learning, but transcripts have large number of words, if learners want to understand knowledge about transcripts have to spend a lot of time and working very hard, so we decide to propose suited method to retrieve summary from transcripts. At the present time there have research about summary retrieving, such as Qiu’s proposed a method about building topic model for transcripts with Latent Dirichlet Allocation (LDA). In Qiu’s research, it builded topic model for transcripts with LDA first, then used key words to calculate sentence weight in transcript and divide to topic from hight weight to low weight, at last retrieving summary from top three topics. We considered the content of transcripts are independent of each other, if take all content of transcripts as a group to calculate weight which are associate with transcripts might have error in summary retrieving, so we calculated terms weight in single section transcripts and calculated sentence weight to enhance performance of summary retrieving. During the past research, terms weight usually calculate with Term Frequency-Inverse Document Frequency (TF-IDF), but TF-IDF only consider terms weight in all documents and ignoring terms weight in single document, it will be limited by documents quality. We decide to use other method to terms weight in single document to retrieve summary. We used Term Frequency (TF), Term Frequency-Inverse Sentence Frequency (TF-ISF) and Term Frequency-Sentence Frequency (TF-SF) to calculate terms weight V.
(8) in transcript, then used LDA words probabilities under topics and LDA topics probabilities to weight sentences and retrieving summary from hight weight to low weight. TF, TF-ISF and TF-SF can calculate terms weight in single document, improving the problem that TF-IDF is limited by documents quality. We also used cue phrases to weight sentences in transcript, due to special of cue phrases, we used two methods to calculate the weight of cue phrases to weight sentences and comparing with other summary retrieving methods. We compared with Qiu’s method, Tzeng’s method and online text summarizer “SweSum”. We used Precision, recall and F1 measure to evaluate summary retrieving performance, at last comparison our summary retrieving methods is better than Qiu’s method, Tzeng’s method and online text summarizer “SweSum”. Keywords:Transcript, LDA, Terms Frequency, Term Frequency-Inverse Sentence Frequency, Term Frequency-Sentence Frequency. VI.
(9) 目錄 誌謝 ........................................................................................................................... I 摘要 ........................................................................................................................ III Abstract .....................................................................................................................V 目錄 ....................................................................................................................... VII 表目錄 .................................................................................................................... IX 圖目錄 ................................................................................................................... XV 1.. 緒論 ................................................................................................................... 1 1.1. 研究背景與動機............................................................................................ 1 1.2. 研究目的 ....................................................................................................... 3. 2.. 文獻探討 ........................................................................................................... 4 2.1. 文件摘要 ....................................................................................................... 4 2.2. 機率性潛藏語義分析(Probabilistic Latent Semantic Analysis) ..................... 5 2.3. 潛在狄利克雷分佈(Latent Dirichlet Allocation) ........................................... 5 2.3.1. LDA 參數設定 ......................................................................................... 8 2.3.2. Gibbs 抽樣方法(Gibbs Sampler) .............................................................. 9 2.4. 字詞權重 ..................................................................................................... 10. 3.. 研究方法 ......................................................................................................... 12 3.1. 資料處理階段 ............................................................................................. 12 3.2. 主題模型建立階段...................................................................................... 14 3.3. 摘要產生階段 ............................................................................................. 16 3.4. 文字稿摘要評估.......................................................................................... 19. 4.. 實驗結果 ......................................................................................................... 21 4.1. 實驗資料 ..................................................................................................... 21 4.2. 摘要結果範例 ............................................................................................. 31 4.3. 文字稿摘要結果比較 .................................................................................. 62 VII.
(10) 5.. 結論與未來工作 .............................................................................................. 87. 6.. 參考文獻 ......................................................................................................... 90. 7.. 附錄 ................................................................................................................. 92 7.1. 一般文字稿章節數為主題 .......................................................................... 92 7.2. 一般文字稿最低 Perplexity 值之主題數 ....................................................118 7.3. 一般文字稿 Chapter 數作為主題數 ...........................................................145 7.4. 測試資料集以章節數為主題數 .................................................................173 7.5. 測試資料集以最低 Perplexity 值之主題數為主題數 ................................202 7.6. 測試資料集以文字稿 Chapter 數為主題數................................................231 7.7. 口試委員提問 ............................................................................................261. VIII.
(11) 表目錄 表 1. LDA 參數...................................................................................................... 15 表 2. 未刪除章節課程相關資訊 ........................................................................... 21 表 3. 刪除章節課程相關資訊............................................................................... 22 表 4. 未刪章節訓練資料集課程相關資訊 ........................................................... 24 表 5. 未刪章節測試資料集相關資訊 ................................................................... 25 表 6. 刪章節訓練資料集課程相關資訊 ............................................................... 26 表 7. 刪章節測試資料集課程相關資訊 ............................................................... 27 表 8. 未刪章節時各文字稿課程最低 Perplexity 值之主題數 .............................. 28 表 9. 刪章節時各文字稿課程最低 Perplexity 值之主題數 .................................. 29 表 10. 未刪章節時訓練資料集最低 Perplexity 值之主題數 ................................ 30 表 11. 刪章節時訓練資料集最低 Perplexity 值之主題數 .................................... 30 表 12. 各摘要方法比較結果................................................................................. 56 表 13. 與一般 LDA 摘要方法和 PLSA 摘要方法雙尾 T 檢定比較結果 ............. 58 表 14. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法雙尾 T 檢定比較結果 ....... 59 表 15. 與線上摘要器 SweSum 雙尾 T 檢定比較結果 ......................................... 60 表 16. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果................................. 62 表 17. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .......................... 64 表 18. 與線上摘要器 SweSum 比較結果 ............................................................. 65 表 19. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果................................. 67 表 20. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .......................... 69 表 21. 與線上摘要器 SweSum 比較結果 ............................................................. 71 表 22. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果................................. 72 表 23. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .......................... 74 表 24. 與線上摘要器 SweSum 比較結果 ............................................................. 76 IX.
(12) 表 25. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果................................. 78 表 26. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .......................... 79 表 27. 與線上摘要器 SweSum 比較結果 ............................................................. 81 表 28. 與 PLSA 摘要方法和一般 LDA 摘要方法比較結果................................. 92 表 29. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法比較結果 .......................... 93 表 30. 與線上摘要器 SweSum 比較結果 ............................................................. 95 表 31. 與 PLSA 摘要方法和一般 LDA 摘要方法比較結果................................. 96 表 32. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法結果 .................................. 98 表 33. 與線上摘要器 SweSum 比較結果 ............................................................100 表 34. 與一般 LDA 摘要方法 PLSA 摘要方法與 PLSA 摘要方法比較結果 .....101 表 35. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .........................102 表 36. 與線上摘要器 SweSum 比較結果 ............................................................104 表 37. 與 PLSA 摘要方法和一般 LDA 摘要方法比較結果................................105 表 38. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法比較結果 .........................107 表 39. 與線上摘要器 SweSum 比較結果 ............................................................108 表 40. 與 PLSA 摘要方法和一般 LDA 摘要方法結果 ....................................... 110 表 41. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法結果 ................................. 111 表 42. 與線上摘要器 SweSum 比較結果 ............................................................ 113 表 43. 與一般 LDA 摘要方法和 PLSA 摘要方法結果 ....................................... 114 表 44. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 ......................... 116 表 45. 與線上摘要器 SweSum 比較結果 ............................................................ 117 表 46. 與 PLSA 摘要方法和一般 LDA 摘要方法比較結果................................ 118 表 47. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法比較結果 .........................120 表 48. 與線上摘要器 SweSum 比較結果 ............................................................122 表 49. 與 PLSA 摘要方法和一般 LDA 摘要方法比較結果................................123 X.
(13) 表 50. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法比較結果 .........................125 表 51. 與線上摘要器 SweSum 比較結果 ............................................................126 表 52. 與 PLSA 摘要方法和一般 LDA 摘要方法比較結果................................128 表 53. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法比較結果 .........................129 表 54. 與線上摘要器 SweSum 比較結果 ............................................................130 表 55. 與 PLSA 摘要方法和一般 LDA 摘要方法比較結果................................132 表 56. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法比較結果 .........................133 表 57. 與線上摘要器 SweSum 比較結果 ............................................................135 表 58. 與 PLSA 摘要方法和一般 LDA 摘要方法比較結果................................136 表 59. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法比較結果 .........................138 表 60. 與線上摘要器 SweSum 比較結果 ............................................................140 表 61. 與 PLSA 摘要方法和一般 LDA 摘要方法比較結果................................141 表 62. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法比較結果 .........................142 表 63. 與線上摘要器 SweSum 比較結果 ............................................................144 表 64. 與 PLSA 摘要方法和一般 LDA 摘要方法比較結果................................145 表 65. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法比較結果 .........................147 表 66. 與線上摘要器 SweSum 比較結果 ...........................................................148 表 67. 與 PLSA 摘要方法和一般摘要方法比較結果 .........................................150 表 68. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法比較結果 .........................151 表 69. 與線上摘要器 SweSum 比較結果 ............................................................153 表 70. 與 PLSA 摘要方法和一般摘要方法比較結果 .........................................155 表 71. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .........................156 表 72. 與線上摘要器 SweSum 比較結果 ............................................................157 表 73. 與 PLSA 摘要方法和一般 LDA 摘要方法比較結果................................159 表 74. 與動詞摘要方法和名詞摘要方法比較結果 .............................................161 XI.
(14) 表 75. 與線上摘要器 SweSum 比較結果 ...........................................................162 表 76. 與 PLSA 摘要方法和一般 LDA 摘要方法比較結果................................163 表 77. 與名詞 LDA 摘要方法和動詞 LDA 摘要方法比較結果 .........................165 表 78. 與線上摘要器 SweSum 比較結果 ............................................................167 表 79. 與 PLSA 摘要方法和一般摘要方法比較結果 .........................................168 表 80. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .........................170 表 81. 與線上摘要器 SweSum 比較結果 ............................................................171 表 82. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果................................173 表 83. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .........................175 表 84. 與線上摘要器 SweSum 比較結果 ............................................................176 表 85. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果................................178 表 86. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .........................179 表 87. 與線上摘要器 SweSum 比較結果 ............................................................181 表 88. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果................................183 表 89. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .........................184 表 90. 與線上摘要器 SweSum 比較結果 ............................................................186 表 91. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果................................187 表 92. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .........................189 表 93. 與線上摘要器 SweSum 比較結果 ............................................................191 表 94. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果................................192 表 95. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .........................194 表 96. 與線上摘要器 SweSum 比較結果 ............................................................195 表 97. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果................................197 表 98. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .........................199 表 99. 與線上摘要器 SweSum 比較結果 ............................................................200 XII.
(15) 表 100. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果..............................202 表 101. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .......................204 表 102. 與線上摘要器 SweSum 比較結果 ..........................................................205 表 103. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果..............................207 表 104. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法 .......................................208 表 105. 與線上摘要器 SweSum 比較結果 ..........................................................210 表 106. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果..............................212 表 107. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .......................214 表 108. 與線上摘要器 SweSum 比較結果 ..........................................................215 表 109. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果..............................217 表 110. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果........................218 表 111. 與線上摘要器 SweSum 比較結果...........................................................220 表 112. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果 ..............................222 表 113. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果........................223 表 114. 與線上摘要器 SweSum 比較結果 ..........................................................225 表 115. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果 ..............................227 表 116. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果........................228 表 117. 與線上摘要器 SweSum 比較結果 ..........................................................230 表 118. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果 ..............................231 表 119. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果........................233 表 120. 與線上摘要器 SweSum 比較結果 ..........................................................235 表 121. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果..............................236 表 122. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .......................238 表 123. 與線上摘要器 SweSum 比較結果 ..........................................................239 表 124. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果..............................241 XIII.
(16) 表 125. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .......................243 表 126. 與線上摘要器 SweSum 比較結果 ..........................................................245 表 127. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果..............................246 表 128. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .......................248 表 129. 線上摘要器 SweSum 比較結果 ..............................................................249 表 130. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果..............................251 表 131. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .......................253 表 132. 與線上摘要器 SweSum 比較結果 ..........................................................254 表 133. 與一般 LDA 摘要方法和 PLSA 摘要方法比較結果..............................256 表 134. 與動詞 LDA 摘要方法和名詞 LDA 摘要方法比較結果 .......................258 表 135. 與線上摘要器 SweSum 比較結果 ..........................................................259 表 136. 各摘要方法比較結果..............................................................................261 表 137. 各摘要方法比較結果..............................................................................262 表 138. 各摘要方法比較結果..............................................................................262 表 139. 各摘要方法比較結果..............................................................................263 表 140. 未刪章節各摘要方法比較結果 ..............................................................264 表 141. 刪章節各摘要方法比較結果 ..................................................................264 表 142. 未刪章節測試資料集各摘要方法比較結果 ...........................................265 表 143. 刪章節測試資料集各摘要方法比較結果 ...............................................265 表 144. 各摘要方法兩兩比較結果 ......................................................................266 表 145. 5-fold 交叉驗證摘要擷取結果。.............................................................268. XIV.
(17) 圖目錄 圖 1. LDA 主題與關鍵字範例、資料來源(Blei, Ng, & Jordan, 2003) .................... 6 圖 2. LDA 的貝氏網路結構、資料來源(Wikipedia-latent Dirichlet allocation) ...... 7 圖 3. LDA 的 Gibbs 抽樣方法流程、資料來源(概率語言模型及其變形系列 LDA 及 Gibbs Sampling) ................................................................................................... 9 圖 4. 研究流程 ...................................................................................................... 12 圖 5. 資料處理流程圖 .......................................................................................... 13 圖 6. LDA 主題模型建立流程圖 ........................................................................... 14 圖 7. 主題字詞機率 .............................................................................................. 16 圖 8. 摘要產生流程圖 .......................................................................................... 17 圖 9. TF 摘要方法、TF-ISF 摘要方法和 TF-SF 摘要方法的平均 F1 值結果...... 84 圖 10. TF 摘要方法、TF-ISF 摘要方法和 TF-SF 摘要方法的平均 F1 值結果 .... 84 圖 11. TF 摘要方法、TF-ISF 摘要方法和 TF-SF 摘要方法的平均 F1 值結果 .... 85 圖 12. TF 摘要方法、TF-ISF 摘要方法和 TF-SF 摘要方法的平均 F1 值結果 .... 86. XV.
(18) 1. 緒論 1.1. 研究背景與動機 由於網路的普及,教育者授課的環境不再侷限於教室中,取而代之的是越來 越多線上數位課程供學習者在網路上進行線上學習,如美國的麻省理工學院 (MIT) 與史丹佛大學(Stanford)便提供「大規模開放式線上課程(Massive Open Online Course, MOOC)」讓學習者只需註冊即可獲得學校課程的文字稿以及上課 影音進行學習且不受必須是該校的學生才能使用的限制。大部分的課程都有提供 與上課影音相對應的文字稿讓學習者做參考以方便理解課程內容。文字稿雖然能 幫助學習者理解課程內容,但是無法幫助學習者掌握課程重點,如果能提出一個 方法擷取文字稿的摘要內容並對應影音內容,對於學習者掌握和整理課程重點將 會有相當大的助益,學習者透過了解文字稿的核心內容再聽取演講者的講解,將 更有助於課程的學習。 現有的文件摘要方法有三種:監督式、圖形模式和主題模式 (Nenkova, Maskey & Liu, 2011)。監督式方法是以二元分類的方式進行摘要擷取,判斷文件 中的句子是否屬於摘要,但是該方法需要消耗大量的人力進行資料的標註而且可 能會有雜訊產生,不適合用在文字文件中。圖形模式方法是將文件中的句子之間 的表達視為圖形,圖形的節點(node)代表句子或是語段實體(Discourse Entities), 圖形的邊(Edge)代表句子或是語段實體之間的相似性,相似性則是用 TF-IDF 權 重進行計算。主題模式方法是找出文件中所涵蓋的主題並藉由其涵蓋的主題來分 析文件的內容以尋找重要的句子。 主題模式主要以機率性潛藏語意分析(probabilistic Latent Semantic Analysis, pLSA)(Hennig, 2009)和隱含狄利克雷分佈(Latent Dirichlet Allocation, LDA)( Blei, Ng, & Jordan, 2003)為主。PLSA 和 LDA 都是使用潛在變數來對觀察值進行解釋 (曾士昌,民 99),但是 Blei et al. (2003)指出 PLSA 沒有提供機率模型,會造成模 1.
(19) 型的參數變數因為文件的增加而成長導致「overfitting」的問題。相較之下 LDA 就比較完整,LDA 把每篇文件都當作多個主題的綜合體,在 LDA 中會假設主題 分佈是一個 Dirichlet 事前分佈,對於多文件主題的擷取有極大的幫助。 邱怡菁(民 103)所撰寫的論文「以 LDA 為基之英文課程文字稿摘要法」已經 針對文字稿提出摘要擷取方法,該論文的方法為將所有文字稿內容視為一個集合 並建立 LDA 主題模型,在使用主題機率與主題字詞機率計算文字稿中句子的權 重並擷取摘要。本論文認為文字稿內容皆為互相獨立,將所有內容視為集合併計 算相關權重在摘要擷取時可能會產生誤差,因此本論文針對單一章節文字稿計算 相關權重,將所有文字稿視為集合所建立的 LDA 主題模型產生的主題機率與主 題字詞機率則作為加權的用途。 目前最常使用的字詞權重計算方法為詞頻-逆向文件頻率(Term Frequency– Inverse Document Frequency, TF-IDF),其概念為針對字詞所存在的文件數進行權 重的計算,但是詞頻-逆向文件頻率必須在龐大的文件數才能勉強有顯著效果, 因此本論文決定使用其他方式計算關鍵字詞權重。 本論文使用詞頻(Terms-Frequency, TF)(Luhn, 1958)、詞頻-逆向句子頻率 (Terms-Frequency-Inverse Sentence Frequency, TF-ISF) (黃仁鴻、張貞瑩,民 103) 和詞頻-句子頻率(Terms-Frequency-Sentence Frequency, TF-SF)(周智勳、丁弘丞, 民 102)的概念計算 LDA 主題字詞的權重。本論文使用 TF、TF-ISF 和 TF-SF 計 算字詞權重最大原因在於 TF、TF-ISF 和 TF-SF 皆能夠針對字詞在單一文件內容 中所占有的權重且不必考慮其他文件的內容,有效解決 TF-IDF 必須在龐大的文 件數才能勉強有顯著效果與字詞權重易受文件數影響的限制。本論文將分別測試 使用 TF、TF-ISF 和 TF-SF 與 LDA 搭配並額外使用提示詞加權針對文字稿進行 摘要擷取,最後將摘要擷取結果與論文「以 LDA 為基之英文課程文字稿摘要法」 中的方法和線上摘要器 SweSum(http://SweSum.nada.kth.se/index-eng.html)進行比 較。 2.
(20) 1.2. 研究目的 本論文的具體目的如下: 1. 以詞頻、詞頻-逆向句子頻率與詞頻-句子頻率的計算 LDA 主題字詞在文 字稿中的權重並以 LDA 主題字詞的主題機率與主題-字詞機率進行加權 。 2. 探討本論文所提之文字稿摘要法與邱怡菁(民 103)所撰寫的「以 LDA 為 基之英文課程文字稿摘要法」論文所提的摘要方法、曾士昌(民 99)所撰 寫的「以句子為基礎之文件摘要」論文所提的摘要方法和線上摘要器 SweSum 的優劣。 3. 用提示詞針對句子進行加權並進行比較。 4. 運用雙尾 T 檢定分析本論文所提之摘要方法的優劣。. 3.
(21) 2. 文獻探討 2.1. 文件摘要 文件摘要的目的在於針對單一文件或多重文件擷取重要的資訊以更有效的 閱讀文件的主旨,避免浪費過多的時間與心力閱讀文件的內容。摘要擷取方式公 分為兩種,節錄式摘要和抽象式摘要。節錄式摘要為依據特定的比例從文件的內 容擷取語句作為摘要內容,抽象式摘要為在理解文件內容的前提下重新撰寫摘要 內容,通常抽象式摘要最接近日常摘要的形式,但是抽象式摘要必須使用複雜的 自然語言處理,因此目前關於文件摘要的研究仍然是以節錄式摘要為主要研究方 向。 目前摘要技術主要分為三大類,簡單詞彙與結構特徵摘要技術、監督式機器 學習摘要技術和非監督式機器學習摘要技術。簡單詞彙與結構特徵摘要技術最早 是 Luhn(1957)提出以詞頻(Term Frequency)來衡量文件中字詞的重要性與句子的 顯著性。在實作中先進行字根還原(Stemming)將字詞還原成原始字詞,同時移除 停用字(Stop Word)以避免影響字詞機率的計算,並依照計算出來的字詞權重計算 句子權重並依照權重高低進行排序,最後依照比例輸出摘要。 監督式摘要技術將摘要擷取視為二元分類問題(Binary Classification),即為 句子是否屬於摘要句子。監督式摘要技術必須準備訓練文件和相對應的標註摘要 資訊,再藉由分類器進行訓練,最後對未被分類為句子進行分類並產生摘要。監 督式摘要技術在以往的研究中其定義為: 1.. 句子長度:在一般的情況下,句子越長越重要。. 2.. 句子權重:計算句子和文件之間的相似度或句子中句子的關鍵字詞的權 重總和。. 3.. 句子在文件中位置:通常開頭的句子或特定章節的句子都是重點。. 4.. 提示詞或片語:命名實體、提示片語或是經常出現的 n-gram。. 5.. 情境屬性:句子和鄰近句子間的差異。 4.
(22) 非監督式摘要技術將摘要擷取視為排序和挑選關鍵句子的問題,其概念為藉 由計算摘要特徵供摘要句子進行排序。一般使用的特徵為:句子和文件的相關性、 語言模型生成的機率、語句之間的相關性等等。. 2.2. 機率性潛藏語義分析(Probabilistic Latent Semantic Analysis) 機率性潛藏語義分析(Probabilistic Latent Semantic Analysis, PLSA)(Hofmann, 1999)是用來改善 LSA(Deerwester, Dumais, Furnas, Landauer, & Harshman, 1990) 的不足,LSA 最大的缺陷在於沒有替文件中的字詞建立機率模型。PLSA 不但解 決了 LSA 機率模型的問題,同時使用 Multi-nomial 分佈假設取代 LSA 的高斯分 佈假設並利用各種 model selection 和 complexity control 準則來確定 topic 的維 數。 雖然 PLSA 替文件建立機率模型,但是其機率模型並不完善,同時 PLSA 機 率模型會隨著資料量的增加變得更龐大,其 EM 演算法也的計算量也隨之增加, 為了解決此問題便有學者提出潛在狄利克雷分佈。. 2.3. 潛在狄利克雷分佈(Latent Dirichlet Allocation) Latent Dirichlet Allocation(LDA)是一種非監督式學習的演算法(Blei et al, 2003),可以用來識別大型文件集合或資料庫潛在的主題。其概念為假設文件是 由不同的主題依照某個機率分佈所組成,而主題亦是由不同的字詞依照某個機率 分佈所組成,如圖 1 所示。. 5.
(23) 圖 1. LDA 主題與關鍵字範例、資料來源(Blei, Ng, & Jordan, 2003). 以圖 1 為例,圖中每個顏色表示不同的主題,每個主題下的字詞為該主題 中最能代表其主題的字詞,在 LDA 中每個主題都能找到用以對其描述的字詞。 LDA 使用了「bag of word」方法,其方法是忽略文件中字詞出現的順序, 只考慮文件中字詞出現的頻率,目前 LDA 已經廣泛運用在機器學習和資訊檢索 等領域裡。 在 LDA 中,訓練文件不會參與參數,LDA 將所有文件當作潛在主題隨機字 詞機率的混合模型以取得文件出現的機率。其中 LDA 使用的變數θ和 Z 有著相 同的維度,代表文件中主題的混合。θ對每一篇文件的狄利克雷分佈進行抽樣, θ 只需要 K 個參數便可對文件進行抽樣。LDA 模型會假設文件是從潛在的主題 進行隨機混合抽樣,藉由字詞分佈描述每一個主題的特性。在 LDA 模型中,文 件被視為字詞集合的觀察變數,即 W={𝑤1 , 𝑤2 , … , 𝑤3 },每個字詞取決於主題, 即{1,2,…,K}的可能值,而 K 必須被決定。在 LDA 模型裡存在著未觀察變數, 6.
(24) 即=(1 , 2 , … , K ),K > 0且∑K K = 1,LDA 生成模型如圖 2 所示。. φ. β. α. θ. Z. W. N M 圖 2. LDA 的貝氏網路結構、資料來源(Wikipedia-latent Dirichlet allocation). 以圖 2 來說明,為每篇文件的主題分佈的 Dirichlet 參數,為每個主題的 字詞分佈 Dirichlet 參數,i 為第 i 篇文件的主題分佈,𝑘 為第 k 個主題的字詞分 佈,𝑧𝑖𝑗 為第 i 篇文件第 j 個字詞所屬的主題,𝑤𝑖𝑗 為最終生成的字詞,M 為所有 文件的總數,N 為所有字詞的總數。建立 LDA 主題模型的流程有三: 1.. 從該文件的主題分佈中隨機抽取一個主題 Z。. 2.. 從主題 Z 所對應的字詞分佈中抽取一個字詞 W。. 3.. 重複上述過程至抽取到文件中的每一個字詞為止。. 給定生成模型,字詞和主題的聯合分佈為:. P(w, z|, ) = P(w|z)P(z|). 對於主題變數 k 其字詞的邊際分佈為:. 7.
(25) P(w|, ) = ∑ P(w|z)P(z|) 𝑧. 文件 d 和主題混合變數的聯合分佈為:. P(, d|) = P(, d|) ∏,P(w|z)P(z|)-n(d,w) w. n(d,w)為字詞 w 在文件 d 中出現的次數,P(|)為的 Dirichlet 機率密度,文 件 d 的邊際分佈為: P(d|) = ∫ P(|) ∏,∑ P(w|z)P(z|)-n(d,w) d w. z. 2.3.1. LDA 參數設定 建立 LDA 模型時需要對相關參數進行設定,其參數包含值、值、主題數 和字詞數。LDA 主題模型會因為參數設定的不同而有不同的結果,尤其值、 值對於主題分佈和字詞分佈有顯著的影響,一般來說值與值越小越能提高特 殊主題被挖掘出來的機率,通常最適當的值為 50 除以主題數,最適當的值為 0.01(Wei & Croft 2006)。主題數則可以使用 Perplexity 的概念來決定,Perplexity 是評估主題機率模型優劣常用的方法,Perplexity 值越低表示主題模型的複雜度 越低、越適當(Griffiths & Steyvers 2004)。雖然能藉由計算 Perplexity 值來決定 LDA 主題模型的主題數,但是這個方法需要花費較長的時間進行計算,同時也不能保 證 擷 取 出 來 的 主 題 關 鍵 字 能 夠 被 良 好 的 解 釋 , Chang 、 Gerrish 、 Wang 、 Boyed-Graber 與 Blei(2010)針對主題中的字詞和文件得主題相關性提供給受測者 進行評分,結果顯示最低的 Perplexity 值並不代表主題的字詞很容易解釋甚至對 主題中字詞的理解毫無幫助,因此仍然需要經由專家評估或依照使用者的需求來 決定。字詞數為 LDA 主題模型中個主題下的關鍵字詞數,目前關於字詞數仍然 沒有相關的研究,因此必須依照專家評估與使用者需求來決定。 8.
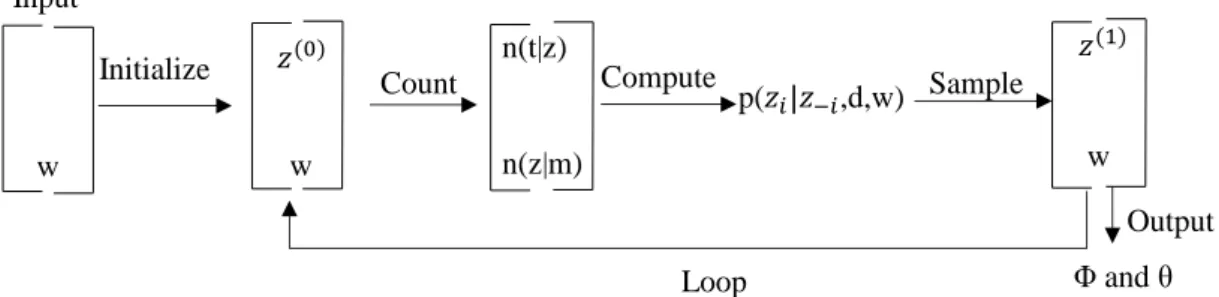
(26) 2.3.2. Gibbs 抽樣方法(Gibbs Sampler) Gibbs 抽樣方法是 Markov Chain Monte Carlo(MCMC)的一種,其概念是在聯 合分佈未知而單一變數條件機率已知的情況下進行大量抽樣和迭代計算,樣本會 逐漸收斂並接近聯合分佈(Gibbs Sampling)。Griffths 與 Steyvers (2004)提出用 Gibbs 抽樣方法執行 LDA 的理論,由於執行容易,已經廣泛運用於許多研究中, LDA 的 Gibbs 抽樣方法流程如圖 3 所示。 Input n(t|z). Initialize w. w. Compute. Count. p(. ,d,w) Sample. w. n(z|m). Output Loop. Φ and θ. 圖 3. LDA 的 Gibbs 抽樣方法流程、資料來源(概率語言模型及其變形系列 LDA 及 Gibbs Sampling). LDA 的 Gibbs 抽樣方法流程有五(概率語言模型及其變形系列 LDA 及 Gibbs Sampling): 1.. 將文件中所有字詞隨機分配至主題𝑧 (0) 。. 2.. 統計每個主題 z 的字詞 t 的數量與每個文件 m 中出現主題 z 中的字詞的 數量。. 3.. 計算排除當前字詞後的主題分配,再藉由其他字詞的主題分配估計當前 字詞分配至各主題的機率。. 4.. 根據其機率分佈為該字詞抽樣出新的主題𝑧 (1) 。. 5.. 重複以上步驟直到每個文件下的主題分佈和主題-字詞分佈收斂為 止。. 使用 Gibbs 抽樣方法執行 LDA 除了設定值、值、主題數和字詞數外,還 9.
(27) 必須多設定迭代次數,即為重複為字詞分配主題與重複抽樣新主題的次數,但是 目前仍然沒有相關研究說明如何決定迭代次數,因此必須依照專家評估與使用者 需求來決定。 跟 EM 方法比較起來,用 Gibbs 抽樣方法執行 LDA 更加容易且易於擴展, 同時能更快獲得極佳的近似值(Tang, 2008)。因此本研究使用 Gibbs 抽樣方法執行 LDA 替建立主題模型。. 2.4. 字詞權重 在文件摘要相關研究中,為了凸顯摘要的差異性與其效能都會對相關的字詞 進行權重的計算,目前在文件摘要領域中最常用的字詞權重方法為詞頻-逆向文 件頻率(Term Frequency-Inverse Document Frequency, TF-IDF)。 詞頻(Term Frequency, TF) (Luhn, 1957)為某一字詞在其所屬文件中出現的頻 率,若某一字詞在其所屬的文件出現的頻率越高,則該字詞在其所屬的文件的重 要性便越大,若某一字詞在其所屬的文件出現的頻率越低,則該字詞在其所屬的 文件的重要性便越低,其算法可表示為: tfi,j =. ni,j ∑k nk,j. tfi,j 為字詞 i 在文件 j 的詞頻,ni,j 為字詞 i 在文件 j 中出現的次數,𝑛k,j 為文件 j 中停用字以外的字詞數。 逆向文件頻率(Inverse Document Frequency,IDF)(Sparck, 1972)的概念為如果 某個字詞所存在的文件數越少,表示該字詞在文件集中屬於專用字詞,具有極佳 的區別能力,其字詞會賦予極高的權重。反之,如果某個字詞存在的文件數越多, 表示該字詞在文件集中屬於通用字詞,不具備區別能力,其字詞的權重極低,其 算法可表示為: idfi = log. |D| |*j: t i ∈ dj +| 10.
(28) idfi 為字詞 i 的 IDF 值,|D|為文件數,|{j:t i ∈ dj }|為包含字詞 i 的文件數,如 果該字詞為存在於文件中,會導致分母為 0,因此在此情況會用 1+|{j:t i ∈ dj }|來 表示,最後字詞的 TF-IDF 值為: tfi,j × idfi. TF-IDF 的概念雖然被廣泛運用在文件摘要領域的研究中,但是 TF-IDF 並不 能有效的反應出字詞的重要程度和關鍵字詞的分布以至於無法精確的調整字詞 的權重值,同時 IDF 必須在文件數極為龐大的文件集才能勉強有差異性,如果 文件集的文件數不夠龐大則無明顯的差異,因此開始有其他的字詞加權方法被提 出來。如黃仁鴻與張貞瑩(民 103)提出詞頻-逆向句子頻率(Term Frequency-Inverse Sentence Frequency,TF-ISF)的概念以及周智勳與丁弘丞(民 102)提出詞頻-句子頻 率(Term Frequency Sentence Frequency,TF-SF)的概念,其算法分別可表示為: 𝑇𝐹 − 𝑆𝐹 = 𝑡𝑓𝑖,𝑗 ×. 𝑑𝑓𝑖,𝑗 𝑁𝑗. TF − ISF = tfi,j × log 2 TF − SF = tfi,j ×. Nj dfi,j. dfi,j Nj. tfi,j 為字詞 i 在文件 j 的詞頻,Nj 為文件 j 中的句子總數,dfi,j 為文件 j 中包含 字詞 i 的句子數。 詞頻-逆向句子頻率和詞頻-句子頻率皆以文件中句子作為字詞權重計算的 依據,有效的避免 TF-IDF 在文件數過少時無顯著效果的問題。. 11.
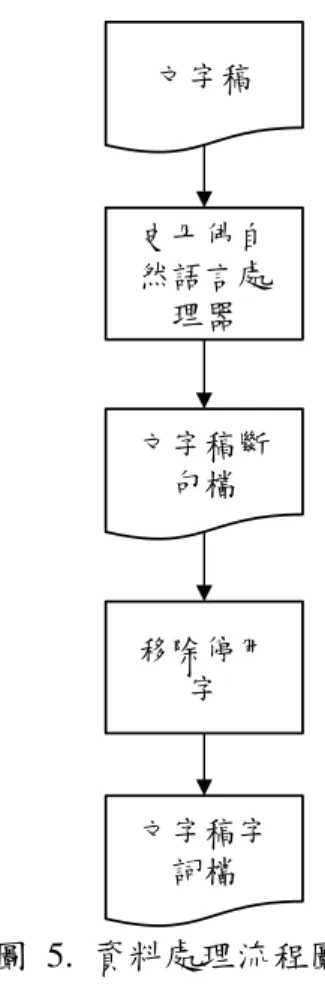
(29) 3. 研究方法 邱怡菁(民 103)的研究是將每個課程的所有章節文字稿視為集合,針對文字 稿集合建立 LDA 主題模型計算文字稿中主題機率與字詞機率,再利用主題機率 和主題字詞機率計算摘要句子權重。本論文考量到每個章節的文字稿內容皆為相 互獨立,將所有章節文字稿內容視為集合並計算相關權重在摘要擷取中可能會產 生誤差,因此本論文針對單一章節文字稿內容計算字詞權重。LDA 主題數邱怡 菁(民 103)的研究是設為文字稿章節數,本論文則是分別使用文字稿章節數、最 低 Perplexity 值之主題數與文字稿 Chapter 數作為 LDA 主題數建立主題模型並與 邱怡菁(民 103)的方法進行比較。 本論文流程共有三個階段,分別為資料處理、主題模型建立和產生摘要,其 流程如圖 4 所示。. 資料處理. 主題模型建立. 產生摘要. 圖 4. 研究流程. 資料處理階段是將文字稿處理成適當的格式以建立主題模型和擷取摘要,主 題模型建立階段是針對文字稿執行 LDA。產生摘要階段是使用 LDA 產生的結果 針對處理後的文字稿產生摘要。. 3.1. 資料處理階段 在資料處理階段,本論文使用史丹佛自然語言處理器(Stanford NLP)進行斷 句並移除停用字以獲得文字稿斷句檔和文字稿字詞檔,其流程如圖 5 所示。. 12.
(30) 文字稿. 史丹佛自 然語言處 理器. 文字稿斷 句檔. 移除停用 字. 文字稿字 詞檔. 圖 5. 資料處理流程圖. 斷句是將文字稿內的內容以句子為單位進行分割以方便選擇摘要句子,設 文字稿的一段內容如下: You’re about to embark on the study of the branch of computer science theory know as automata theory or language theory. We're going to follow fairly closely a one quarter course I gave at Stanford a few years ago. It's traditional number CS154. 經過斷句後其內容結果如下: You’re about to embark on the study of the branch of computer science theory know as automata theory or language theory. We're going to follow fairly closely a one quarter course I gave at Stanford a few 13.
(31) years ago. It's traditional number CS154. 進行斷句的好處在於進行摘要擷取時能夠在文法架構完整的情況下判斷其 內容的重要性。 移除停用字為移除文字稿內容中極為不具意義的字詞,像是 the、is、are、 at、which、on 等等。以上述的句子為例,移除停用字及標點符號,並轉換成小 寫字元的結果如下: embark study branch computer science theory automata theory language theory. follow fairly closely quarter course Stanford years ago. traditional number cs154. 移除停用字的目的在於停用字為文章中最不具意義的字詞,將其保留的話 容易對字詞權重產生影響,因此本論文將停用字移除以確保字詞權重更為精確。. 3.2. 主題模型建立階段 在主題模型建立階段,本論文使用由 Java 程式語言編寫的 LDA 工具 JGibbLDA(Phan & Nguyen 2008)讀入文字稿字詞檔分析各主題的機率和主題下 字詞的機率建立主題機率模型和主題字詞機率模型,其流程如圖 6 所示。. 文字稿字 詞檔. 執行LDA. 主題機率 與字詞機 率. 圖 6. LDA 主題模型建立流程圖. 14.
(32) JGibbLDA 使用 Gibbs 抽樣方法(Griffiths & Steyvers 2004)來建立 LDA 主題 模型。用 JGibbLDA 建立主題模型時首先必須設定其參數,在 JGibbLDA 中提供 九個參數進行設定,如表 1 所示。. 表 1. LDA 參數 參數 -est -estc -inf -alpha -beta -ntopic -niters -savestep -twords. 參數說明 從頭開始估計 LDA 參數。 從先前的模型繼續估計。 從先前的估計模型中未被察覺或新的資料來做推論。 LDA 的值,本研究使用預設值 50 除以主題數。 LDA 的值,本研究使用預設值 0.01。 主題數。 每幾次抽樣數次,迭代幾次,本論文使用邱怡菁的論文使用的次數 300 次。 迭代幾次後儲存資料供使用者參考,本論文使用邱怡菁的論文使用的次 數 300 次。 每個主題關鍵字詞數,本論文設為 20 個。. 本論文使用的的值為 50 除以主題數,值為 0.01(Wei & Croft 2006)。在主 題數的部分,本論文分為三個部分進行探討,文字稿章節數、Perplexity 值與文 字稿 Chapter 數。Perplexity 值是由(Griffiths & Steyvers 2004)所提出的主題模型計 算方式,當 Perplexity 值越低時,表示其主題數的主題模型複雜度越低越適當。 本論文使用由史丹佛大學所開發的 Stanford Topic Model Toolbox 計算各文字稿的 Perplexity 值。文字稿章節數則是根據邱怡菁(民 103)之論文所提之主題數量設定, 直接以文字稿的章節數量作為主題數量,本論文將在第四章探討兩者在文字稿摘 要擷取上的差異。 在關鍵字詞數的部分,在以往的 LDA 研究中都是處理大量文件,其字詞數 最多設為 100 個,但是本論文所處理的文件並沒有那麼龐大,因此將關鍵字詞數 設為 20 個。在迭代次數和迭代次數間隔次數的部分目前並沒有相關研究對其進 行討論與研究,因此本論文使用預設值 300 次。 本論文的 LDA 會產生兩種結果,主題機率和主題字詞機率。主題機率為每 15.
(33) 個主題在文件中所發生的機率,結果如下: topic 1:0.056877 topic 2:0.029078 topic 3:0.052235 topic 4:0.041534 topic 5:0.039496 topic 6:0.028342 topic 7:0.039269 topic 8:0.043063 topic 9:0.028852. 主題字詞機率為每個主題的字詞在其所屬的主題下所發生的機率,如圖 7 所示:. 圖 7. 主題字詞機率. 3.3. 摘要產生階段 在摘要產生階段,本論文使用文字稿斷句檔、主題機率模型、主題字詞與其 16.
(34) 機率計算文字稿內句子的權重,同時藉由提示詞進行加權形成摘要,其流程如圖 8 所示。. 主題機 率模型. 主題字詞 機率模型. 文字稿 斷句檔. 計算句子權重. 主題機率和主 題字詞機率加 權. 提示詞加權. 文字稿摘 要. 圖 8. 摘要產生流程圖. 本論文會先計算主題字詞在文字稿的 TF 值(Luhn, 1957)、TF-ISF 值(黃仁鵬、 張貞瑩,民 103)與 TF-SF 值(周智勳、丁鴻誠,民 102)作為主題字詞在文字稿的 權重,計算方式可表示為: TFi =. ni N. TF − ISFi = TFi × log 2 TF − SFi = TFi ×. S si. si S. 其中 i 為文字稿中的主題字詞,ni 為文字稿中主題字詞 i 的總數,N 為文字 稿中所有字詞總數,S 為文字稿中的句子總數,si 為文字稿中包含主題字詞 i 的 17.
(35) 的句子數。 接著藉由主題字詞在文字稿的 TF 值、TF-ISF 值與 TF-SF 值計算文字稿中各 句子的權重並依照權重值進行排序。句子權重計算方式可表示為:. w(sent i ) = ∑. j=1. twordi,j. w(sent i )為文字稿中句子 i 的權重,twordi,j 為句子 i 中第 j 個主題字詞的權 重。 獲得句子權重後,本論文使用洪崇洋(民 100)提出的主題加權方法對文字稿 的句子進行加權以調整句子的權重值, LDA 主題加權方式可表示為:. topicwj = topicj + ∑ tfk × twordj,k k=1. 其中topicwj 為主題 j 加權後的主題機率,topicj 為主題 j 加權前的主題機率, 𝑡𝑓𝑘 為主題字詞 k 在文字稿中的 TF 值,twordj,k為主題字詞 k 在主題 j 的機率。 獲得加權後的主題便可對摘要句子進行加權,摘要句子加權方式可表示為:. w(𝑠𝑒𝑛𝑡𝑖 ) + ∑ 𝑡𝑓𝑘 × 𝑡𝑜𝑝𝑖𝑐𝑤𝑗 × 𝑡𝑤𝑜𝑟𝑑𝑗,𝑘 𝑗=1. 本論文額外使用提示詞針對文字稿句子進行加權,本論文分別使用兩種加權 方式探討文字稿句子進行提示詞加權後的結果與差異,加權的方法分別為提示詞 TF 權重正規化與陳若涵、許肇凌、張智星與羅鳳珠(民 95)所提出的加權方法, 兩個加權方法分別可表示為:. 18.
(36) 提示詞 TF 權重正規化 = 𝑖. 提示詞. 𝑖. ∑𝑗𝑗=1 提示詞. 𝑗. 提示詞 出現次數 × 提示詞 TF 權重 𝑖. 𝑖. 本論文使用課程投影片字數做為摘要字數,主因在於課程投影片為課程內容 的重點部分,因此以投影片字數作為摘要字數可以有效的評估其摘要擷取的效能 。. 3.4. 文字稿摘要評估 為了評估本論文所提之文字稿摘要擷取方法是否有更好的效能,本論文使用 精確率(Precision)、召回率(Recall)和 F1-Measure 作為文字稿摘要的評估準則。精 確率(Precision)、召回率(Recall)和 F1-Measure 計算方式可表示為:. min(abw , ppt w ) ab min(abw , ppt w ) Recall = ppt. Precision =. F1 − Measure =. 2 × Precision × Recall Precision + Recall. ab 為文字稿摘要字詞數,ppt 為投影片內容字詞數,w 為文字稿摘要和投影 片內容都包含的字詞,abw 為文字稿摘要和投影片內容都包含的字詞文字稿摘要 的字數,ppt w 為文字稿摘要和投影片內容都包含的字詞在投影片內容的字數。 本論文所提之方法的摘要擷取結果將與曾士昌(民 99)所提之 PLSA 方法、邱 怡菁(民 103)的論文所提之摘要方法與線上摘要器 SweSum 進行比較。在曾士昌 (民 99)的論文中使用 PLSA 針對電子論文擷取摘要,本論文使用 PLSA 針對文字 稿擷取摘要並稱為 PLSA 摘要方法。在邱怡菁(民 103)的論文中分別針對文字稿 19.
(37) 的所有字詞、所有動詞和所有名詞建立 LDA 主題模型並計算相關權重針對文字 稿進行摘要擷取,本論文將邱怡菁(民 103)的論文中用所有字詞建立 LDA 主題模 型計算相關權重針對文字稿進行摘要擷取的方法稱為一般 LDA 摘要方法,用所 有動詞建立 LDA 主題模型計算相關權重針對文字稿進行摘要擷取的方法稱為動 詞 LDA 摘要方法,用所有名詞建立 LDA 主題模型計算相關權重針對文字稿進 行摘要擷取的方法稱為名詞 LDA 摘要方法,實驗結果將於第四章進行說明。. 20.
(38) 4. 實驗結果 4.1. 實驗資料 本論文實驗目的為測試本論文的摘要擷取方法是否有更好的效能,本論文將 實驗果與邱怡菁(民 103)之論文所提到的摘要方法、曾士昌(民 99)之論文所提到 的摘要方法和線上摘要器 SweSum 進行比較以探討摘要擷取效能。為了探討本論 文所提出的文字稿摘要方法之效能,本論文從線上課程網站 Coursera 與 Edx 收 集三十篇課程文字稿與投影片,由於有些線上課程的某些章節的文字稿字詞數比 該章節的投影片字詞數還要來的少,因此本論文將實驗資料分為未刪除章節和刪 除章節兩部分。本論文除了用所有文字稿建立主題模型並擷取摘要外,本論文同 時使用文字稿將百分之八十的課程文字稿做為訓練資料集建立主題模型與百分 之二十的課程文字稿做為測試資料集擷取摘要進行比較。未刪除章節課程資訊如 表 2 所示,刪除章節課程資訊如表 3 所示,未刪除章節課程訓練資料集資訊如 表 4 所示,未刪除章節課程測試資料集資訊如表 5 所示,刪除章節課程訓練資 料集資訊如表 6 所示,刪除章節課程測試資料集資訊如表 7 所示,未刪除章節 課程的最低 Perplexity 值之主題數如表 8 所示,刪除章節課程的最低 Perplexity 值之主題數如表 9 所示,未刪除章節課程訓練資料集的最低 Perplexity 值之主題 數如表 10 所示,刪除章節課程訓練資料集的最低 Perplexity 值之主題數如表 11 所示。. 表 2. 未刪除章節課程相關資訊 課程來源. 課程名稱. coursera coursera coursera coursera. The Hardware/Software Interface Social Network Analysis Web Application Architectures Audio Signal Processing for Music Applications Malicious Software and its Underground Economy Two Sides to. coursera. 21. 章節 數 62 26 34 22. Chapter 數 12 8 5 9. 句子 數 6004 2875 2238 2248. 投影片 張數 621 532 194 291. 39. 6. 3332. 383.
(39) coursera. coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera edx edx esx edx. edx. Every Story Big Data Science with the BD2K-LINCS Data Coordination and Integration Center Experimental Methods in Systems Biology Dynamical Modeling Methods for Systems Biology The Brain and Space Network Analysis in Systems Biology automata Natural Language Processing 2013 Beginning Game Programming with C# Climate Change Journalism Skills for Engaged Citizens Algorithms Design and Analysis Part 1 Algorithms Design and Analysis Part 2 Introduction to Chemistry Reactions and Ratios Genomic and Precision Medicine Epigenetic Control of Gene Expression Take the Lead on Healthcare Quality Improvement Surviving Disruptive Technologies Caries Management by Risk Assessment CAMBRA Computational Neuroscience Introduction to Data Science Discrete Optimization Foundations of Virtual Instruction Virology I How Viruses Work Introduction to Computer Science Big Data in Education Cellular mechanisms of brain function Introduction to Programming with Java Part 1 Starting to Code with Java Programming Basics. 28. 12. 1931. 384. 23. 6. 3244. 286. 30. 8. 5737. 342. 51 33. 6 7. 2635 2440. 669 395. 23 116 49. 7 20 8. 5085 6433 4589. 689 410 360. 22 18. 4 6. 2781 1457. 106 115. 74. 10. 10873. 475. 103. 20. 9991. 572. 42. 6. 5250. 446. 31 57. 7 7. 3395 5166. 431 281. 18. 10. 1885. 446. 42 51. 14 6. 2997 5133. 425 617. 28 93 43 24 60 60 43 35. 8 10 7 5 11 11 8 7. 4137 7608 8540 1569 7246 15177 3970 3936. 439 832 546 133 605 2004 1281 471. 46. 5. 1846. 265. 72. 11. 6287. 1377. Chapter 數 12. 句子 數 5922. 投影片 張數 607. 表 3. 刪除章節課程相關資訊 課程來源 coursera. 課程名稱 The Hardware/Software Interface 22. 章節 數 61.
(40) coursera coursera coursera coursera. coursera. coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera edx edx esx edx. edx. Social Network Analysis Web Application Architectures Audio Signal Processing for Music Applications Malicious Software and its Underground Economy Two Sides to Every Story Big Data Science with the BD2K-LINCS Data Coordination and Integration Center Experimental Methods in Systems Biology Dynamical Modeling Methods for Systems Biology The Brain and Space Network Analysis in Systems Biology automata Natural Language Processing 2013 Beginning Game Programming with C# Climate Change Journalism Skills for Engaged Citizens Algorithms Design and Analysis Part 1 Algorithms Design and Analysis Part 2 Introduction to Chemistry Reactions and Ratios Genomic and Precision Medicine Epigenetic Control of Gene Expression Take the Lead on Healthcare Quality Improvement Surviving Disruptive Technologies Caries Management by Risk Assessment CAMBRA Computational Neuroscience Introduction to Data Science Discrete Optimization Foundations of Virtual Instruction Virology I How Viruses Work Introduction to Computer Science Big Data in Education Cellular mechanisms of brain function Introduction to Programming with Java Part 1 Starting to Code with Java Programming Basics 23. 24 33 22. 7 5 9. 2670 2199 2248. 462 190 291. 37. 6. 3148. 334. 20. 8. 1580. 268. 23. 6. 3244. 286. 29. 8. 5533. 308. 51 27. 6 6. 2635 2114. 669 322. 23 115 49. 7 20 8. 5085 6412 4589. 689 406 360. 22 12. 4 5. 2781 1037. 106 73. 74. 10. 10873. 475. 103. 20. 9991. 572. 41. 6. 5134. 433. 20 57. 7 7. 2295 5166. 232 281. 17. 10. 1838. 417. 40 51. 14 6. 2908 5133. 403 617. 28 86 43 24 59 52 24 35. 8 10 7 5 11 11 8 7. 4137 7153 8540 1569 7052 14671 2167 3936. 439 672 546 133 591 1798 615 471. 39. 5. 1599. 222. 31. 11. 2506. 421.
(41) 表 4. 未刪章節訓練資料集課程相關資訊 課程來源. 課程名稱. coursera coursera coursera coursera. The Hardware/Software Interface Social Network Analysis Web Application Architectures Audio Signal Processing for Music Applications Malicious Software and its Underground Economy Two Sides to Every Story Big Data Science with the BD2K-LINCS Data Coordination and Integration Center Experimental Methods in Systems Biology Dynamical Modeling Methods for Systems Biology The Brain and Space Network Analysis in Systems Biology automata Natural Language Processing 2013 Beginning Game Programming with C# Climate Change Journalism Skills for Engaged Citizens Algorithms Design and Analysis Part 1 Algorithms Design and Analysis Part 2 Introduction to Chemistry Reactions and Ratios Genomic and Precision Medicine Epigenetic Control of Gene Expression Take the Lead on Healthcare Quality Improvement Surviving Disruptive Technologies Caries Management by Risk Assessment CAMBRA Computational Neuroscience Introduction to Data Science Discrete Optimization Foundations of Virtual Instruction Virology I How Viruses Work Introduction to Computer Science Big Data in Education Cellular mechanisms of brain function. coursera. coursera. coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera edx edx esx. 24. 章節 數 50 21 27 18. Chapter 數 10 6 5 8. 句子 數 4654 2477 1810 1789. 投影片 張數 487 452 149 250. 31. 5. 2590. 294. 22. 10. 1393. 318. 19. 5. 2673. 249. 24. 6. 4784. 264. 41 27. 5 6. 2192 2059. 528 315. 19 93 40. 5 16 6. 4166 5382 3927. 565 341 303. 18 15. 3 4. 2281 1219. 84 96. 60. 10. 8599. 379. 83. 17. 8105. 448. 34. 5. 4361. 357. 25 46. 6 6. 2637 4007. 331 230. 15. 8. 1575. 381. 34 41. 12 5. 2508 4035. 350 492. 23 75 35 20 48 48 35 28. 7 8 5 4 10 8 7 6. 3423 6510 6724 1452 5980 11291 3279 3057. 405 697 442 119 509 1577 1102 382.
(42) edx. edx. Introduction to Programming with Java Part 1 Starting to Code with Java Programming Basics. 37. 4. 1495. 207. 58. 7. 5104. 1110. 表 5. 未刪章節測試資料集相關資訊 課程來源. 課程名稱. coursera coursera coursera coursera. The Hardware/Software Interface Social Network Analysis Web Application Architectures Audio Signal Processing for Music Applications Malicious Software and its Underground Economy Two Sides to Every Story Big Data Science with the BD2K-LINCS Data Coordination and Integration Center Experimental Methods in Systems Biology Dynamical Modeling Methods for Systems Biology The Brain and Space Network Analysis in Systems Biology automata Natural Language Processing 2013 Beginning Game Programming with C# Climate Change Journalism Skills for Engaged Citizens Algorithms Design and Analysis Part 1 Algorithms Design and Analysis Part 2 Introduction to Chemistry Reactions and Ratios Genomic and Precision Medicine Epigenetic Control of Gene Expression Take the Lead on Healthcare Quality Improvement Surviving Disruptive Technologies Caries Management by Risk Assessment CAMBRA Computational Neuroscience Introduction to Data Science Discrete Optimization. coursera. coursera. coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera. 25. 章節 數 12 5 7 4. Chapter 數 3 3 1 2. 句子 數 1350 398 428 459. 投影片 張數 134 80 45 41. 8. 2. 742. 89. 6. 2. 538. 66. 4. 2. 571. 37. 6. 3. 953. 78. 10 6. 2 2. 443 381. 141 80. 4 23 9. 2 4 3. 919 1051 662. 124 69 57. 4 3. 1 3. 500 238. 22 19. 14. 4. 2274. 96. 20. 4. 1886. 124. 8. 2. 889. 89. 6 11. 2 1. 758 1159. 100 51. 3. 3. 310. 65. 8 10. 3 1. 489 1098. 75 125. 5 18 8. 2 3 3. 714 1098 1816. 34 135 104.
(43) coursera coursera edx edx esx edx. edx. Foundations of Virtual Instruction Virology I How Viruses Work Introduction to Computer Science Big Data in Education Cellular mechanisms of brain function Introduction to Programming with Java Part 1 Starting to Code with Java Programming Basics. 4 12 12 8 7. 1 2 3 2 2. 117 1266 3886 691 879. 14 96 427 179 89. 9. 2. 351. 58. 14. 3. 1183. 267. 表 6. 刪章節訓練資料集課程相關資訊 課程來源. 課程名稱. coursera coursera coursera coursera. The Hardware/Software Interface Social Network Analysis Web Application Architectures Audio Signal Processing for Music Applications Malicious Software and its Underground Economy Two Sides to Every Story Big Data Science with the BD2K-LINCS Data Coordination and Integration Center Experimental Methods in Systems Biology Dynamical Modeling Methods for Systems Biology The Brain and Space Network Analysis in Systems Biology automata Natural Language Processing 2013 Beginning Game Programming with C# Climate Change Journalism Skills for Engaged Citizens Algorithms Design and Analysis Part 1 Algorithms Design and Analysis Part 2 Introduction to Chemistry Reactions and Ratios Genomic and Precision Medicine Epigenetic Control of Gene Expression Take the Lead on Healthcare Quality Improvement Surviving Disruptive Technologies. coursera. coursera. coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera. 26. 章節 數 49 20 27 18. Chapter 數 10 6 5 8. 句子 數 4572 2346 1737 1789. 投影片 張數 473 415 157 250. 30. 5. 2494. 274. 16. 7. 1327. 231. 19. 5. 2673. 249. 24. 6. 4866. 256. 41 22. 5 4. 2192 1759. 528 259. 19 93 40. 5 17 6. 4166 5366 3927. 565 338 303. 18 10. 3 4. 2281 836. 84 59. 60. 10. 8599. 379. 83. 17. 8105. 448. 33. 5. 4245. 344. 16 46. 6 6. 1797 4007. 174 230. 14. 8. 1528. 352. 32. 12. 2419. 328.
(44) coursera coursera coursera coursera coursera coursera edx edx esx edx. edx. Caries Management by Risk Assessment CAMBRA Computational Neuroscience Introduction to Data Science Discrete Optimization Foundations of Virtual Instruction Virology I How Viruses Work Introduction to Computer Science Big Data in Education Cellular mechanisms of brain function Introduction to Programming with Java Part 1 Starting to Code with Java Programming Basics. 41. 5. 4035. 492. 23 69 35 20 48 42 20 28. 7 8 5 4 10 9 7 6. 3423 6051 6724 1452 5932 11674 1907 3057. 405 543 442 119 506 1426 554 382. 32. 4. 1302. 174. 25. 8. 2039. 333. 表 7. 刪章節測試資料集課程相關資訊 課程來源. 課程名稱. coursera coursera coursera coursera. The Hardware/Software Interface Social Network Analysis Web Application Architectures Audio Signal Processing for Music Applications Malicious Software and its Underground Economy Two Sides to Every Story Big Data Science with the BD2K-LINCS Data Coordination and Integration Center Experimental Methods in Systems Biology Dynamical Modeling Methods for Systems Biology The Brain and Space Network Analysis in Systems Biology automata Natural Language Processing 2013 Beginning Game Programming with C# Climate Change Journalism Skills for Engaged Citizens Algorithms Design and Analysis Part 1 Algorithms Design and Analysis Part 2 Introduction to Chemistry Reactions and Ratios. coursera. coursera. coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera. 27. 章節 數 12 4 6 4. Chapter 數 3 2 1 2. 句子 數 1350 324 462 459. 投影片 張數 134 47 33 41. 7. 2. 654. 60. 4. 2. 253. 37. 4. 2. 571. 37. 5. 2. 667. 52. 10 5. 2 2. 443 355. 141 63. 4 22 9. 2 4 3. 919 1046 662. 124 68 57. 4 2. 1 1. 500 201. 22 14. 14. 4. 2274. 96. 20. 4. 1886. 124. 8. 2. 889. 89.
(45) coursera coursera coursera coursera coursera coursera coursera coursera coursera coursera edx edx edx edx. edx. Genomic and Precision Medicine Epigenetic Control of Gene Expression Take the Lead on Healthcare Quality Improvement Surviving Disruptive Technologies Caries Management by Risk Assessment CAMBRA Computational Neuroscience Introduction to Data Science Discrete Optimization Foundations of Virtual Instruction Virology I How Viruses Work Introduction to Computer Science Big Data in Education Cellular mechanisms of brain function Introduction to Programming with Java Part 1 Starting to Code with Java Programming Basics. 4 11. 1 1. 498 1159. 58 51. 3. 3. 310. 65. 8 10. 3 1. 489 1098. 75 125. 5 17 8 4 11 10 4 7. 2 3 3 1 2 3 1 2. 714 1102 1816 117 1120 2997 260 879. 34 129 104 14 85 372 61 89. 7. 2. 297. 48. 6. 3. 467. 88. 表 8. 未刪章節時各文字稿課程最低 Perplexity 值之主題數 課程名稱 The Hardware/Software Interface Social Network Analysis Web Application Architectures Audio Signal Processing for Music Applications Malicious Software and its Underground Economy Two Sides to Every Story Big Data Science with the BD2K-LINCS Data Coordination and Integration Center Experimental Methods in Systems Biology Dynamical Modeling Methods for Systems Biology The Brain and Space Network Analysis in Systems Biology automata Natural Language Processing 2013 Beginning Game Programming with C# Climate Change Journalism Skills for Engaged Citizens Algorithms Design and Analysis Part 1 Algorithms Design and Analysis Part 2 Introduction to Chemistry Reactions and Ratios Genomic and Precision Medicine Epigenetic Control of Gene Expression Take the Lead on Healthcare Quality Improvement Surviving Disruptive Technologies Caries Management by Risk Assessment CAMBRA 28. 最低 Perplexity 值 之主題數 89 51 51 49 71 47 70 73 85 66 40 37 13 51 40 43 48 19 59 92 42 1 10.
(46) Computational Neuroscience Introduction to Data Science Discrete Optimization Foundations of Virtual Instruction Virology I How Viruses Work Edx Introduction to Computer Science Edx Big Data in Education Edx Cellular mechanisms of brain function Edx Introduction to Programming with Java Part 1 Starting to Code with Java Edx Programming Basics. 59 12 25 16 29 36 165 10 44 91. 表 9. 刪章節時各文字稿課程最低 Perplexity 值之主題數 課程名稱 The Hardware/Software Interface Social Network Analysis Web Application Architectures Audio Signal Processing for Music Applications Malicious Software and its Underground Economy Two Sides to Every Story Big Data Science with the BD2K-LINCS Data Coordination and Integration Center Experimental Methods in Systems Biology Dynamical Modeling Methods for Systems Biology The Brain and Space Network Analysis in Systems Biology automata Natural Language Processing 2013 Beginning Game Programming with C# Climate Change Journalism Skills for Engaged Citizens Algorithms Design and Analysis Part 1 Algorithms Design and Analysis Part 2 Introduction to Chemistry Reactions and Ratios Genomic and Precision Medicine Epigenetic Control of Gene Expression Take the Lead on Healthcare Quality Improvement Surviving Disruptive Technologies Caries Management by Risk Assessment CAMBRA Computational Neuroscience Introduction to Data Science Discrete Optimization Foundations of Virtual Instruction Virology I How Viruses Work Edx Introduction to Computer Science Edx Big Data in Education Edx Cellular mechanisms of brain function Edx Introduction to Programming with Java Part 1 Starting to Code with Java 29. 最低 Perplexity 值 之主題數 99 55 62 49 84 36 70 73 85 55 40 32 13 51 40 43 48 18 50 92 39 71 10 59 122 25 16 94 23 187 10 10.
(47) Edx Programming Basics. 55. 表 10. 未刪章節時訓練資料集最低 Perplexity 值之主題數 課程名稱 The Hardware/Software Interface Social Network Analysis Web Application Architectures Audio Signal Processing for Music Applications Malicious Software and its Underground Economy Two Sides to Every Story Big Data Science with the BD2K-LINCS Data Coordination and Integration Center Experimental Methods in Systems Biology Dynamical Modeling Methods for Systems Biology The Brain and Space Network Analysis in Systems Biology automata Natural Language Processing 2013 Beginning Game Programming with C# Climate Change Journalism Skills for Engaged Citizens Algorithms Design and Analysis Part 1 Algorithms Design and Analysis Part 2 Introduction to Chemistry Reactions and Ratios Genomic and Precision Medicine Epigenetic Control of Gene Expression Take the Lead on Healthcare Quality Improvement Surviving Disruptive Technologies Caries Management by Risk Assessment CAMBRA Computational Neuroscience Introduction to Data Science Discrete Optimization Foundations of Virtual Instruction Virology I How Viruses Work Edx Introduction to Computer Science Edx Big Data in Education Edx Cellular mechanisms of brain function Edx Introduction to Programming with Java Part 1 Starting to Code with Java Edx Programming Basics. 最低 Perplexity 值 之主題數 38 145 76 139 35 38 144 54 79 12 52 37 26 42 1 32 9 58 18 19 1 71 14 156 125 17 53 1 34 70 68 91 39. 表 11. 刪章節時訓練資料集最低 Perplexity 值之主題數. 課程名稱. 最低 Perplexity 值 之主題數 1 121 17. The Hardware/Software Interface Social Network Analysis Web Application Architectures 30.
數據


+7



相關文件
「世俗化」( secularization)一詞是當下宗教社會學研究中使用
共集放大器 MATLAB 分析. CC
語文運用 留意錯別字 辨識近義詞及詞語 的感情色彩 認識成語
語文素養重視積累、感悟和薰陶,基本內涵 和要素包括:字詞句篇的積累,語感、讀寫 聽說能力、語文學習方法和習慣的培養,以
z 香港政府對 RFID 的發展亦大力支持,創新科技署 06 年資助 1400 萬元 予香港貨品編碼協會推出「蹤橫網」,這系統利用 RFID
Does your daughter like to drink apple juice.. She eats breakfast
Overview of a variety of business software, graphics and multimedia software, and home/personal/educational software Web applications and application software for
「節日起源」的 篇章;音樂科 聆聽及演奏/演唱 以節日為題材的 樂曲,並創作 節奏頻現句
