基於SAO結構之中文專利文件自動摘要技術研究
67
0
0
全文
(2) 基於SAO結構之中文專利文件自動摘要技術研究 Design and Study of Automated Text Summarization for Extracting SAO Structures from Chinese Patent Documents. 研 究 生: 劉翰卿. Student : Han-Ching Liu. 指導教授: 楊維邦 博士. Advisor : Dr. Wei-Pang Yang. 蒙以亨 博士. Dr. I-Heng Meng. 國 立 交 通 大 學 電機資訊學院 資訊學程 碩 士 論 文. A Thesis Submitted to Degree Program of Electrical Engineering and Computer Science College of Electrical Engineering and Computer Science National Chiao Tung University in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science January 2005 Hsinchu, Taiwan, Republic of China. 中華民國九十四年一月.
(3) 基於SAO結構之中文專利文件自動摘要技術研究 Design and Study of Automated Text Summarization for Extracting SAO Structures from Chinese Patent Documents 研究生: 劉翰卿. 指導教授: 楊維邦博士,蒙以亨博士. 國立交通大學電機資訊學院資訊學程. 中文摘要 摘要 自動文摘的基本精神乃是將原始文件的內容經由電子計算機的演算處理後,自動萃 鍊出足資代表全文內容的精華出來,以便縮短研讀的時間,進而提升工作的效率。. 本研究試圖藉由英文的主詞、動詞與受詞(Subject-Action-Object;簡稱 SAO)結構句 型為基礎,藉由一系列的分析、運算、處理等過程,自動判讀出專利文獻的全文內容並 且取其精髓後將之匯集成為一簡明扼要的摘要內容,讓企業研發部門、專利工程師、產 業分析師或智權人員毋需詳閱艱澀難懂的專利全文,便可快速掌握到專利文獻所欲描述 之概念,以加速取得目標資訊。. 在雛型系統實驗中,我們以十六篇攸關電子商務領域的專利文獻為實驗素材,將 SAO 結構句的概念應用於中文專利文獻摘要的擷取上。經效益評估後的結果顯示,我們 所設計的概念(Concepts)及 SAO 結構句的擷取演算都有還不錯的表現。以整體平均來說 ,概念(Concepts) 擷取方面的召回率為 95.34%,準確率為 92.13%;而 SAO 結構句組擷 取方面的召回率則為 92.45 %,準確率為 93.79%。. 關鍵字:自動摘要技術、中文專利文獻、SAO 結構、經驗法則. i.
(4) Design and Study of Automated Text Summarization for Extracting SAO Structures from Chinese Patent Documents Student : Han-Ching Liu. Advisor : Dr. Wei-Pang Yang,Dr. I-Heng Meng. Program of Electrical Engineering Computer Science College of Electrical Engineering and Computer Science National Chiao Tung University. 英文摘要 ABSTRACT The basic idea of automated text summarization is that distilling the most important information from a source to produce an abridged version, in order to shorten the time to understand the original source and then improve the efficiency of the work.In this thesis, the research attempts to extract SAO Structures from a Chinese patent document based on the basic sentence patterns of English, one of which, for example, is Subject, Verb, and Object (namely, Subject-Action-Object; abbreviated as SAO). With a series of analysis, operation, complicated process,… etc., we could create a brief and concise summary for the document. In the experiment of the prototype, we use sixteen Chinese patent documents of e-commerce -related field as the experiment material, and apply the concept of one of SAO structures to the picking and fetching of the Chinese text summarization. The results which were evaluated seems to be satisfactory.. On average, it is 95.34% recalling rate of extracting the. aspects of the concepts and the rate of accuracy is 92.13%. In addition, average recalls of 92.45% and average precision of 93.79% were achieved respectively in SAOs. Keyword:Automated Text Summarization, Chinese Patent Documents, SAO, Subject-Action-Object, Heuristic Rules.. ii.
(5) 誌謝 近代極富盛名的學者王國維先生在其《人間詞話》一書中曾云:古今之成大事業、 大學問者,必經過三種之境界:『昨夜西風凋碧樹,獨上高樓,望盡天涯路』,此第一 境也。『衣帶漸寬終不悔, 為伊消得人憔悴』,此第二境也。『眾裏尋他千百度,回. 頭驀見,那人正在燈火闌珊處』,此第三境也。. 近一千個日子的步步為營,不寒不暑,不沉不淪,在交大電機資訊學院資訊學程碩 士專班修習過程當中,也深歷了這三種奇妙神境。箇中滋味,正如人飲水,冷暖自知。 工作與學業交融的辛酸血淚以及成長的歡樂喜悅,其實只有自己最能夠體會,此等刻劃 非過來人不能道矣。從資策會長官們的提攜、核准進修的那一刻起,心中就懷抱著『望 盡天涯路』那樣地雄心壯志,欲窺交大這一學術大觀園的堂奧及其點點滴滴。默默地告 訴自己要靜下心來忍住那『昨夜西風凋碧樹』的淒涼以及『獨上高樓』的孤寂,要耐得 住世間一切的誘惑,以真功夫、苦功夫、細功夫埋首通讀、努力付出、盡心鑽研;以百 折不撓的精神,在浩瀚的學術宇宙中努力不懈地“尋它千百度”,即便是“衣帶漸寬”也無 怨無悔! “為此消得人憔悴”也心甘情願!只希望在“燈火闌珊處”、不經意地“驀然回首” 的當下能夠頓悟出做學術研究的科學真諦。. “在職進修"──一個令自己深感疲累與鼻酸的代名詞,不容否認,的的確確是蠻 辛苦的一種蛻變歷程。在每週兩、三回〝台北-新竹〞兩頭往返穿流通勤的奔波中,動 轍來回一趟車程就要蹉跎我近四到六個小時的光陰歲月。在事業與課業、體力與耐力以 及親情、友情與愛情等諸多考驗不斷地矛盾衝突與相互衝擊的掙扎中,也粹鍊了我一身 的堅強與果斷,潛移默化中造就了我“凡事捨得”、“凡事盼望”、“凡事相信”、“凡事包容”、 “凡事忍耐”的堅定信仰。. 從小到大,上圖書館的次數其實是屈指可數的。儘管如此,我仍是認真向學的,只. iii.
(6) 因『交大浩然數位圖書館』的存在,總能讓我隨心所欲“Any Time、Any Where”地〝予取 予求〞。有了它,真好!感謝交大一級名師楊維邦教授的愛心與體恤,讓不才的我有個 學術研究的避風港得以依靠,並惠賜一位優越的學長蒙以亨博士來就近指導、督促我, 使我免於舟車奔波之苦,並給予我無上的啟蒙。從初探的『無所不在的運算環境(Pervasive Computing/Ubiquitous Computing Environments)』開始,以至於現今的『中文專利文獻自 動摘要技術研究』,兩位指導老師〝降龍十八掌〞的學術功力,自不在話下;清新的思 路,一絲不茍、絕對嚴謹的學術研究態度與精神,總能讓喜歡恣意遐想、迷迷糊糊、非 相關科系的我甘拜下風,耳濡目染下著實也領受了不少的啟發。同時,也非常謝謝資料 庫實驗室柯皓仁教授、葉鎮源學長友情的客串指導以及校外口試委員黃明居老師細心的 指點迷津,還有資策會電子商務研究所資源的鼎力協助。此外,也深深感謝父、母親的 劬勞與關懷,讓我在對課業與工作心灰意冷時有了向上的動力與衝勁;還有岳父、岳母 的大膽假設,願意將『我的野蠻女友』──秀卿在進修期間交託給一個一事無成的我來 加以〝馴服〞,讓她變成一個溫柔婉約又可愛的『美麗吾妻』,只可惜這段期間無法履 行對她的承諾:帶她到處遊山玩水、周遊列國而深感歉意。. 總是喜歡在上課前到交大竹湖邊坐著小憩一番,一邊聆聽著音樂、啜著一抹綠茶, 一邊欣賞著湖波盪漾、大小魚兒自由自在悠游其中、以及無憂無慮的綠頭雁鴨肆無忌憚 的追逐與嬉戲,感覺這一刻,彷如置身在愛麗絲夢遊仙境般,令人心曠神怡,忘卻了人 世間一切的紛紛擾擾,再多的煩惱與憂愁也隨著此情此景而蒸發人間!套用好友阿吉常 說的:『交大,人傑地靈,真的是一個非常不錯唸書做學問的好地方。』. 雖然這輩子註定永遠與奧運金牌絕緣,亦無法成為諾貝爾獎的得主;但,對我而言, 須感謝的人、事、物仍實實在在有許許多多,無法一語道盡,細說分明。只好謝天、謝. 地、謝謝自己。感謝有你,感謝上帝,感謝主。讓我喜歡真理,不自誇,對愛依然是永 不止息。 2005 乙酉年 自由日. iv.
(7) 目錄 中文摘要 ----------------------------------------------------------------------------------------------------i 英文摘要 ---------------------------------------------------------------------------------------------------ii 誌謝 -------------------------------------------------------------------------------------------------------- iii 目錄 --------------------------------------------------------------------------------------------------------- v 表目錄 ----------------------------------------------------------------------------------------------------- vi 圖目錄 ---------------------------------------------------------------------------------------------------- vii 方程式目錄 ----------------------------------------------------------------------------------------------- ix 第一章 緒論 --------------------------------------------------------------------------------------------- 1 第一節 研究背景 ---------------------------------------------------------------------------------- 1 第二節 研究動機 ---------------------------------------------------------------------------------- 2 第三節 研究目的 ---------------------------------------------------------------------------------- 3 第四節 研究範圍與限制 ------------------------------------------------------------------------- 4 第五節 研究流程及論文架構 ------------------------------------------------------------------- 5 第二章 相關研究工作 --------------------------------------------------------------------------------- 6 第一節 自動化資訊摘要概述 ------------------------------------------------------------------- 6 第二節 淺層摘要研究取向(Shallower Approaches)--------------------------------------- 12 第三節 深層摘要研究取向(Deeper Approaches) ------------------------------------------ 22 第四節 基於 SAO 結構之相關研究探討---------------------------------------------------- 26 第三章 系統架構剖析 ------------------------------------------------------------------------------- 34 第一節 系統雛型架構剖析 -------------------------------------------------------------------- 34 第二節 摘要系統之各組成元件及其運作之原理 ----------------------------------------- 37 第三節 與方法 A 之擷取技術比較 ---------------------------------------------------------- 54 第四章 系統雛型設計與實作 ---------------------------------------------------------------------- 57 第一節 中文專利摘要系統雛型之人工擷取實驗解析 ----------------------------------- 57 第二節 探索性經驗法則( Heuristic Rules)-------------------------------------------------- 69 第三節 中文專利摘要雛型系統實驗說明 -------------------------------------------------- 76 第五章 實驗結果分析與評估 ---------------------------------------------------------------------- 84 第一節 實驗結果統計 -------------------------------------------------------------------------- 84 第二節 系統評估方法描述 -------------------------------------------------------------------- 85 第三節 系統實驗結果評估與分析 ----------------------------------------------------------- 89 第六章 結論與未來研究方向 ------------------------------------------------------------------- 95 第一節 結論 -------------------------------------------------------------------------------------- 95 第二節 未來可行的研究方向 ----------------------------------------------------------------- 95 附錄 ------------------------------------------------------------------------------------------------------- 97 參考文獻 ------------------------------------------------------------------------------------------------ 103. v.
(8) 表目錄 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表. 1:文件內涵中的兩大類語意關聯性(TIES) .....................................................................22 2:英文句子的五大基本句型結構...................................................................................27 3:專利說明書(DOCUMENT PATENT)的資訊內容結構 ....................................................37 4:『下雨天留客天天留我不留』的可能斷法...............................................................40 5:假定 MAXIMUM MATCHING ALGORITHM 三個詞的可能組合 ....................................44 6:本研究與『方法 A』之概念(CONCEPTS) 擷取技術比較一覽表..............................55 7:本研究與『方法 A』之 SAO 擷取技術比較一覽表 ................................................55 8:透過人工模擬方式擷取“申請專利範圍(CLAIMS) ”中的 SAO 結構之結果 ............60 9:本研究之實驗素材一覽表...........................................................................................77 10:實驗結果【概念 (CONCEPTS)】統計一覽表(對照組:方法 A VS.本實驗) ...........84 11:實驗結果【SAO 結構句組】統計一覽表(對照組:方法 A VS.本實驗) ...............84 12:實驗結果【概念 (CONCEPTS)】統計一覽表(實驗組) .............................................85 13:實驗結果【SAO 結構句組】統計一覽表(實驗組) .................................................85 14:實驗結果【概念 (CONCEPTS)】評估一覽表(對照組:方法 A VS.本實驗) ...........90 15:實驗結果【SAO 結構句組】評估一覽表(對照組:方法 A VS.本實驗) ...............90 16:實驗結果【概念 (CONCEPTS)】評估一覽表(實驗組) .............................................91 17:實驗結果【SAO 結構句組】評估一覽表(實驗組) .................................................91 18:擷取自“申請專利範圍(CLAIMS) ”中的 SAO 結構句之應用概想 ..........................96. vi.
(9) 圖目錄 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 1:人類產生摘要的四大階段.............................................................................................2 2:本研究摘要產出之主要流程.........................................................................................4 3:研究流程示意圖.............................................................................................................5 4:自動文摘處理架構的三階段(SPÄRCK JONES(1995))....................................................6 5:自動化文件摘要處理過程的三大階段(I. MANI & M. MAYBURY (1999)) ...................6 6:自動摘要系統的架構概觀.............................................................................................7 7:文件之摘要產出流程(SUMMARIZATION PROCESSES)....................................................8 8:語言空間(THE LINGUISTIC SPACE) ................................................................................10 9:一些經典的自動文摘相關研究整理...........................................................................11 10:淺層摘要的研究取向(SHALLOWER APPROACHES)之架構 ........................................12 11:淺層摘要的研究取向(SHALLOWER APPROACHES)之執行歷程 ................................13 12:樣板摘錄(TEMPLATE EXTRACTION)法的技術架構概觀 ...........................................23 13:以 SAO 結構模式之文件摘要架構...........................................................................28 14:『方法 A』之概念(CONCEPTS) 擷取流程示意圖[31] .............................................32 15:『方法 A』之 SAO 擷取流程示意圖[31] ...............................................................33 16:本研究系統架構圖.....................................................................................................35 17:經過 CKIP 執行“自動斷詞”後的結果 .....................................................................41 18:經過 CKIP 執行“自動斷詞與標記”後的結果 .........................................................41 19:本研究之概念(CONCEPTS) 擷取流程示意圖............................................................45 20:“概念”(CONCEPTS)之下位用語擷取方法示意圖......................................................50 21:“候選關聯”(CANDIDATE RELATIONS)擷取方法示意圖 ............................................51 22:SAO 結構句擷取處理過程三部曲之第一部............................................................52 23:SAO 結構句擷取處理過程三部曲之第二部............................................................52 24:SAO 結構句擷取處理過程三部曲之第三部............................................................52 25:擷取自中華民國專利公報第 491972 號之“申請專利範圍(CLAIMS)”部份............58 26: “申請專利範圍(CLAIMS) ”部份做階層式(HIERARCHY)的剖析..............................60 27: “申請專利範圍(CLAIMS) ”內容的階層式架構樹狀圖 ...........................................65 28:以 CLAIMS 中第 1 項獨立項代表資訊量較小的摘要 ..............................................66 29:以 CLAIMS 中各獨立項代表資訊量中等的摘要 ......................................................67 30:以 CLAIMS 全體的獨立項及其所屬依附項代表資訊量較大的摘要 ......................69 31:SAO 階層式架構關聯圖 ...........................................................................................73 32:開啟專利文獻示意圖.................................................................................................78 33:概念(CONCEPTS)擷取示意圖 .....................................................................................79 34:SAO 結構句組擷取示意圖........................................................................................79 35:摘要資訊含量微量示意圖(以 SAO 結構句階層展示) ............................................80 36:摘要資訊含量微量示意圖(自然語言形式摘要全文) ..............................................80. vii.
(10) 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 37:摘要資訊含量適中示意圖(以 SAO 結構句階層展示) ............................................81 38:摘要資訊含量適中示意圖(自然語言形式摘要全文) ..............................................81 39:摘要資訊含量豐沛示意圖(以 SAO 結構句階層展示) ............................................82 40:摘要資訊含量豐沛示意圖(自然語言形式摘要全文) ..............................................82 41:上、下位用語參照示意圖.........................................................................................83 42 :自動摘要系統的三項衡量指標:召回率、準確率及其兩者之間的調和平均數87 43 :本實驗系統評估方法示意圖 ...................................................................................88 44 :概念(CONCEPTS) 之召回率(RECALL RATE) 比較圖 ...............................................92 45 :概念(CONCEPTS) 之準確率(PRECISION RATE) 比較圖 ...........................................92 46 :SAO 之召回率(RECALL RATE) 比較圖...................................................................93 47 :SAO 之準確率(PRECISION RATE) 比較圖...............................................................93 48 :SAO 關係求解示意圖 .............................................................................................96. viii.
(11) 方程式目錄 方程式 方程式 方程式 方程式 方程式 方程式 方程式 方程式. 1:TF*IDF 向量形式之定義....................................................................................15 2:EDMUNDSONIAN PARADIGM 的語句四特徵線性函式(LINEAR FUNCTION) ..........20 3:線性特徵(LINEAR FEATURE)組合公式 ................................................................20 4:MUTUAL INFORMATION MEASURE FOR STATISTICAL CO-OCCURRENCE 計算公式 .47 5:本研究概念間(CONCEPTS)的語意關聯強度計算公式 .......................................48 6:本實驗召回率(RECALL)的計算公式 ...................................................................89 7:本實驗準確率(PRECISION)的計算公式 ...............................................................89 8:本實驗準確率和召回率之間的調和平均數(F-MEASURE)計算公式 .................89. ix.
(12) 第一章. 第一節. 緒論. 研究背景. 對一個企業來說,『專利』乃是一種無形的資產,一家公司擁有的專利數愈多,意 謂著該公司的智慧財產也愈多。運用專利為籌碼,可迫使同業無法進入相同之領域與之 相抗衡。在這知識經濟與智慧財產權掛帥的今日,『專利』儼然已成為一種生存競爭的 遊戲,只要符合參賽資格且遵循遊戲規則者,即使起步較緩或是資源有限,依然有機會 可以成為最後的贏家。但申請專利過程的第一步就是得要去查證你的創意、心血結晶是 否早已是他人專屬的權利,以免誤觸了法網,侵權而不自知、徒勞而無功。. 根據世界智慧財產權組織(WIPO)的調查指出:在專利文獻中可以查考全世界每年 90-95%的發明成果;不僅如此,在研究工作中若先行查閱專利文獻不但可以縮短60% 的研發時間,還可以節省高達40%的研究經費。因此,閱讀與分析專利文獻勢必就成為 極其重要且不可或缺的一項工作!若能善加利用專利文獻,不但可以吸收滿滿具創新前 瞻性的技術資訊,也可以從中獲取不少極具商業價值的競爭情報[32]。所幸,拜由網際 網路之賜,目前已通過的專利文獻在各國相關專利管理機構皆有提供完整的網際網路檢 索功能;可惜的是,透過關鍵字詞查詢專利後的結果往往還需要以人工的方式再去過濾 這些專利文獻,以查證目前的創意點子是否與已通過的專利有所衝突。. 目前,全世界所發行的專利仍不斷地以驚人的速度持續的成長中,每個領域需要監 控的專利數量也因此而大幅增加。由於專利文獻獨特的文法結構以及特定的遣辭用語與 一般的文章大相逕庭,其晦澀拗口、難以閱讀乃是不爭的事實。因此,當找到的專利文 獻資料篇幅太過於冗長或是專利分析師不想逐字閱讀專利的全文內容時,如何透過精簡 的方式迅速且經濟的來掌握這篇專利文獻之精華,以減少專利分析師或研發工程師的閱. 1.
(13) 讀時間,在這個分秒必爭的時代,便成為一個不容忽視的重要課題。. 第二節. 研究動機. 『科技始終來自於人性』。科技的研發,相關機制的創新與設計,都不能自外於人 類的基本需求,尤其是在這資訊急速爆炸的時代更是如此。在分秒必爭繁忙的工商業社 會中,若能藉由簡明扼要的摘要內容來縮短研讀的時間,免於閱讀篇幅很長的文章內 容,讓讀者不費吹灰之力即可知曉全文之意涵,快速而又有效率地吸取原始文件內容之 菁華,不曉得該有多麼地好呀?想法很好,但問題是:該要如何透過電腦機器來幫我們 自動判讀相關知識庫中的原始文件內容,以去蕪存菁的方式來產生摘要呢?而產出的摘 要內容又當如何確知已涵蓋原始文件所要表達的意涵而不至南轅北轍呢?. 學者 Pinto Molina(1995)認為人類產生摘要的歷程可以分為四大階段(如圖 1所示) ,分別是:解譯(Interpretation)、挑選(Selection)、再詮譯(Re-interpretation)以及綜合 (Synthesis)等 [13]。 n 解 譯. o 挑 選. p 再詮譯. 包括閱讀及瞭. 依使用者需求. 將上述訊息之. 解文件之內容. 選取相關訊息. 內容重新解釋. q 綜 合 將重新詮釋後 的訊息綜合後 產生摘要輸出. 圖 1:人類產生摘要的四大階段. 也就是說,對一般人而言,我們在撰寫摘要的過程當中,通常必須先對原始文件的內容 進行所謂全文式的閱讀、分析並且在瞭解文章的語意內容後,才能夠對原文的內容重新 給予詮釋進而產生所謂的摘要(Abstract)結果輸出。換言之,撰寫摘要的過程就是要想辦 法透過一套邏輯的思維去除較為瑣碎、不重要的訊息,而保留比較重要的訊息內容,以 提供相關使用者來閱讀,以快速吸收原文之意涵,見微知著。而這種人為產生摘要的方 式,如無太大之意外,通常都是採取重新編寫(Re-writing)的方式來進行,也就是由摘要. 2.
(14) 撰寫者依據其個人主觀的價值經驗以及判斷,將理解過後的文件內容重新予以詮釋並加 以組織後,以不同於原始文章內容的方式來加以改寫。在自動化摘要方法的研究當中, 依據摘要產出的形式不同,通常我們可以將自動化摘要的方法概分為兩大類:第一種方 法稱為重新詮釋法﹕從瞭解文章內容開始,依照個人本身的背景、經驗以及主、客觀的 價值判斷來進行詮釋,進而重新編寫摘要,最後將原文的內容以較精簡的模式來產出, 此種方法所產生的摘要我們謂之為『摘述(Abstraction)』;而另一種較為簡易的方法則 稱之為複製剪貼法,其概念乃是基於某一種演算法來衡量不同段落、語句或是關鍵詞彙 所映射出來的重要性差異並據此來決定其順序,然後再依序抽取一定比例的句子作為摘 要,這種摘要我們謂之為『節錄(Extraction)』[4][5][10][11][12][18][19][23]。. 有鑑於此,我們在此提出一個自動摘要的方法,讓簡短的摘要內容可以用來代表某 一篇專利文獻的內容,甚而取代原來的專利全文。透過這種見微知著的方式,以減少專 利分析師瀏覽以及閱讀的時間。本研究企圖透過前人研究的智慧結晶,嘗試以英文語言 SAO(Subject-Action-Object)結構的特性,應用於中文專利文獻的摘要擷取上,最後並將 之運用於本實驗的雛型系統中。. 第三節. 研究目的. 文件自動化摘要的基本精神乃是將原始文件的內容透過電腦計算機的運算處理後, 自動萃鍊出足資代表全文內容的精華出來。因此,本研究乃從解讀專利說明書中最重要 的權利宣告部份(即“申請專利範圍";Claims)開始,分解其構成要件,並釐清各要件 之間的組合關係,將晦澀拗口、難以閱讀的專利文獻,轉換成簡明易讀的摘要內容,以 提供企業研發部門、專利工程師、產業分析師或智權人員一目了然的專利資訊,縮短研 讀的時間,進而提升其工作效率。. 然而,無庸置疑的,一個言簡意賅的自動文件摘要技術應該是要能夠在理解原始文. 3.
(15) 件的內容後,建構出足以代表該原始文件所要表達的知識意涵模型,以便透過該知識模 型來生成最後的摘要結果才是 [27]。因此,本研究為了要迅速且正確地萃取出中文專利 文獻當中的精華內容,我們需要藉助外在工具以便於在短時間內可以理解該專利所隱含 的意義。首先,先擷取出申請專利範圍(Claims) 的資料,然後透過概念(Concepts) 擷取 技術去萃取出此申請專利範圍(Claims) 中重要的概念(Concepts),然後利用SAO(SubjectAction-Object) 的句型結構設法將概念(Concept)、以及概念與概念之間的關聯(Relation) 串接起來。之後,利用概念(Concepts)與概念(Concepts)之間的統計共現矩陣來判斷概念 (Concepts)間的語意關聯強度。此後,我們再根據一些組合規則(Rules) 將之合成,便可 以完成代表此篇專利文獻的摘要內容(Summarization)出來 (如圖 2所示)。. 擷取申請專利範圍. 計算Concepts 間共現矩陣. 概念(Concepts)擷取. 依Rules將SAO結構合成. SAO 結構句組擷取. 產生此專利文獻的摘要內容. 圖 2:本研究摘要產出之主要流程. 第四節. 研究範圍與限制. 本研究係與資策會共同合作之創新前瞻技術之研究,所有據以實驗用之專利文獻之 取得,皆係由資策會統籌提供,以作為本研究實驗素材之來源。因不同領域的專利文獻, 其技術語句、專業文法及語意剖析可能會有所差異;故本研究之實驗範圍乃是以電子商 務(e-Commerce) 相關領域(包含軟體)之專利文獻為主要實驗對象。. 而關於中文斷詞切字方面,將直接採用中央研究院中文詞庫小組所研發的『CKIP. 4.
(16) 中文自動斷詞系統1.0版』來處理。該工具除了具有中文自動斷詞的功能外,更可以標示 每個字或詞的中文詞類;同時,CKIP 也允許使用者根據自己的需求選擇不同的詞典, 作為斷詞與及詞性標記的參考。. 第五節. 研究流程及論文架構. 本論文的研究架構如圖 3所示,共分為六章。首先在第一章透過簡介形式來概略描 述本研究之背景、動機、目的以及研究的範圍與限制,隨後在第二章深入探討自動文件 摘要的相關研究及文獻資料(包括自動化資訊摘要、淺層摘要研究取向、深層摘要研究 取向等),並將相關論述加以歸納並整合之。第三章及第四章則詳細描述了本研究的系 統架構,經由相關工具及方法的使用,構建模式,並實作一雛型系統;之後在第五章處, 進行實驗結果的解釋、剖析與評估,探討此模式在實務上應用的機會與限制,並藉自動 化資訊摘要評估模式的探討來驗證本研究方法的可行性。最後,第六章針對研究的過程 與實驗的結果做一總結及心得分享,並進一步描述未來可行的研究方向。 Ⅰ.研究背景、動機與目的. Ⅱ.相關研究工作 自動資訊摘要簡介. 淺層摘要研究取向. 深層摘要研究取向. Ⅲ.& Ⅳ.系統架構與雛型系統實作. Ⅴ.實驗結果分析與評估. Ⅵ.結論與未來研究方向 圖 3:研究流程示意圖. 5.
(17) 第二章. 第一節. 相關研究工作. 自動化資訊摘要概述. 自動化資訊摘要的研究已將近有50年的歷史了,是一種融合了自然語言處理、資訊 檢索、圖書資訊學、統計學、認知心理學和人工智慧等多學門的綜合應用 [12]。近年來 隨著計算語言學(Computational Linguistics)理論的興起,自動摘要又再度成為眾所矚目 的熱門研究焦點。. 英國劍橋大學的K. Spärck Jones (Jones 1995)率先把自動文摘的處理架構歸納成為 三個階段( The framework for summarization in terms of the three-phase architecture ),分別 是:解譯(Interpretation)、轉換(Transformation)、產生(Generation) (如圖 4所示)。 n 解 譯 (I:interpretation). o 轉 換 (T:transformation). p 產 生 (G:generation). 圖 4:自動文摘處理架構的三階段(Spärck Jones(1995)). 也就是說,將原始文字的內容透過某一種演算法先把它解譯成為某一種形式的表達 ,再將此原始的表達透過另一種演算法轉換成摘要形式的表達,最後再將此摘要形式的 表達透過某一種演算法產生出恰當的文字摘要 [21]。而 I. Mani 及 M. Maybury (1999) 等人則依據上述Spärck Jones(1995)的摘要架構重新將自動摘要系統予以詮釋,將自動化 文件摘要的處理過程概分為三大階段,依序為:分析(Analysis)、轉換(Transformation)、 合成(Synthesis)等(如圖 5所示) [12][18]。 n 分 析 (Analysis). o 轉 換 (Transformation). p 合 成 (Synthesis). 圖 5:自動化文件摘要處理過程的三大階段(I. Mani & M. Maybury (1999)). 6.
(18) 首先是依據某種重要的特徵(Salient Features)來『分析原始文件』(Analysis:Analyze the input and build an internal representation of it.);接著將分析的結果轉換為系統內部的 摘要表示法(Transformation 有時也稱之為 Refinement: Transform the internal representation into a representation of the summary.);最後是透過相關的演算法權衡內部摘 要表示法的相對重要性,挑選重要性較高的表示法來合成摘要的格式後輸出 (Synthesis:The summary representation is rendered back into natural language.) (如圖 6所示) [12][18]。. 壓縮 閱聽人. 功 能. 連貫性. 文件庫. ~一般性 ~指示性 使用者導向 資訊性 評論性. 斷斷續續 ~連續性 文字 文件摘要. 分析. 轉換. 合成. 原始文件 特性:. 產生的形式:. 來源、跨越、類型、媒體、語言等. ) 節錄(Extract) ) 摘述(Abstract). 圖 6:自動摘要系統的架構概觀. 在上圖 6中,我們可以看出有幾好個不同的重要參數會來影響到自動摘要系統的設 計,如文件摘要的壓縮率(Compression rate)、原始資料的媒體(Media)性質、讀者(Audience) 的角色、所欲達成之功能(Function)、語言(Language)、原始文件數量的多寡(Span)、摘. 7.
(19) 要產生的形式(Genre)或者是構成摘要的參考來源(Relation to source)等,Mani & Maybury (1999);Sparck-Jones(1999);Hovy(2001)等人都曾深入討論過。. Mani & Maybury(1999)曾替文件摘要(Text Summarization)作了如下之定義: The process of distilling the most important information from a source (or sources) to produce an abridged version for a particular user (or users) and task (or tasks). 所謂的『文摘』就是從來源文件當中萃取出最重要資訊的一種過程,並依照特定 使用者的特殊需求或者是應用系統所欲達成之功能要求來產生一個忠於原始文件 內容的精緻版本。. 根據上述之定義,我們可將摘要產出的歷程圖解如下(如圖 7 所示) [20]:. 文件摘要 Intermediary Representation. q Presentation. pCondensation Abstraction Aggregation. o Selection. n Analysis. Planning Realization Layout. Word Count Clue Phrases Statistical Structural. Word Frequencies Clue Phrases Layout Syntax Semantics Discourse Pragmatics. Source(s) 圖 7:文件之摘要產出流程(Summarization Processes). 8.
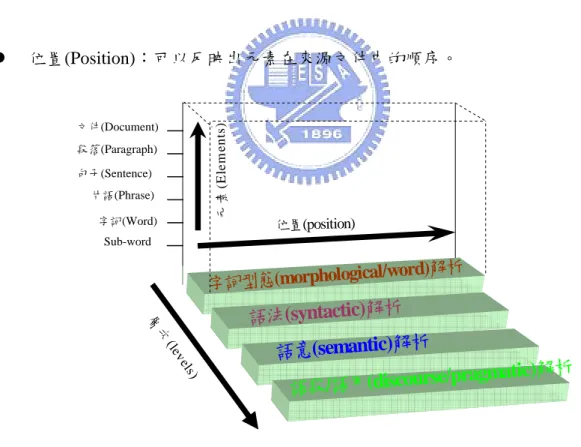
(20) 也就是說,在自動文摘的處理過程中,我們可以透過Selection、Aggregation、 Generalization等三大基本的操作處理(Condensation operations) 來使之實現(Mani & Maybury(1999);Paice(1981)等人) [12]。其中,. z. 揀選(Selection:filtering of elements): 依據某種顯著性的重要特徵來加以演算,權衡單位元素(例如:字、詞、句子、段 落等)之間的相對重要性,選取重要性較高且未重複的資訊出來。. z. 聚合(Aggregation:merging of elements): 將不同語言描述或者是來源文件當中的不同部份之資訊加以融合、組織起來。. z. 泛化(Generalization:substitution of elements with more general/abstract ones): 用更一般化或是更抽象化的概念來替換單位元素;也就是說,以抽象、廣泛的上位 概念來含括較為具體的下位概念。比如說:火車、轎車、摩托車、腳踏車等皆以“交 通工具”來替代。. 2.1.2 兩大類摘要研究取向(Summarization Approaches) 自動摘要方法的研究從1950年代迄今已將近有半個世紀的歷史了,無論是使用的方 法、應用的領域、評估的方式等等皆有一定的研究水準與成果發表。藉著前人研究的智 慧結晶,也促進了各式各樣、匠心獨具的精湛方法源源不斷地傾流而出。. 我們可以把某一種語言文字想像成是一種由多維度構建而成的空間,稱之為『語言 空間』(Linguistic Space)。透過元素(Elements)、層次(Levels)及位置(Position)等三個面向 可以形塑這語言或文字的三維空間,如圖 8所示[12]。其中,. z. 元素(Elements):乃是以字詞(Word)、片語(Phrase)、子句(Clause)、句子(Sentence)、. 9.
(21) 段落(Paragraph)、文件(Document)等作為運算操作處理的基本單位。. z. 層次(Levels):可將上述之元素依照深淺程度不同之層次進行語言的分析。一般而 言,依層次由淺到深的程度可將之區分為四種,分別是: n 構詞(Morphological/Word)解析 o 句法(Syntactic)解析 p 語意(Semantic)解析 q 話語(Discourse/Pragmatic)解析 等不同深度的層次。而在上述自動文摘處理過程的三大階段中,其中分析(Analysis) 階段可以視作是一種由淺到深的處理過程(亦即,朝向更多的語意及語段分析);而 合成(Synthesis)階段則與分析階段的方向恰好相反。. z. 位置(Position):可以反映出元素在來源文件中的順序。. 元 素 (Eleme nts). 文件(Document) 段落(Paragraph) 句子(Sentence) 片語(Phrase) 字詞(Word). 位置(position). Sub-word. ical/word)解析 字詞型態(morpholog 層 次 ( le ve. 語法(syntactic)解析 語意(semantic)解析. ls ). 析 rse/pragmatic)解 u co is (d 用 /語 段 語. 圖 8:語言空間(The linguistic space). 同一種語言現象,研究的出發點不同,往往會得出不同的結果。『語法學』研究句 法結構關係,著重於描寫語法之特徵;『修辭學』研究表達之效果,著重分析倒裝等之. 10.
(22) 效用;而『語用學』研究的則是制約語言使用的各種現象。因此,我們可以透過這種『語 言空間』(The linguistic space) 的層次(Level) 概念,把摘要研究的取向(Summarization Approaches)區分為兩大類:一為淺層的研究取向(Shallower Approaches),另一則為深層 的研究取向(Deeper Approaches) [12][19]。但此種劃分方式絕不是一種決然的楚河漢界, 隨著技術不斷地推陳出新,現在已有愈來愈多的研究融合了這兩大取向所述的方法 (Hybrid Approaches)以及原則運用於自動摘要的系統上。以下,我們依照年份的先後對 於上述兩大類研究取向做了一些經典相關研究工作的整理(如圖 9所示) [1][2][4][5][6] [8][9][11][18][19][20]。. 2003 2002. Adaikkalavan 03 Jing 02. Kan&McKeown 02. 2001 2000 Myaeng 99. 1999. Hahn&Mani 2000. Chan 2000 Jing & McKeown 99. Mani 99. Opitz 99 Okumura 99 Teufel 99 Hahn 99. 1998. Endres-Nigemey 98. Mani&BloedornMarcu 99 Hovy 98 1998 Hovy 97 Barzilay 97 Strzalkowski 98 Aone 97 Boguraev 97 Salton 97. Cremmins 96. Knott&Dale 96. 1997 1996. 研究取向. Human Expert Summarizers. Surface- Entitylevel level. Discourse-. level. Shallower Approaches. Template filling. Deeper Approaches. 1995 Endres-Nigemey 95. 年份. Liddy 91. van Dijk 79. 1950. K.P.C. 95. Maybury 95. Brandow 95 Harman 92 Black 90 Paice 81 Pollock 75 Spärck-Jones 72 Edmundson 69. Mann 87. Paice&Jones 93. McKeown 95 Lin 95 Alterman 92 Reimer 88. Hobbs 85. Lehnert 82. Skorochod'ko 71. van Dijk 79. Baxendale 58 Luhn 58. 圖 9:一些經典的自動文摘相關研究整理. 11. Concept Abstraction.
(23) 接下來,我們將針對兩大研究取向中的重要概念做選擇性的說明:首先,將在第二 節處先來介紹淺層研究取向(Shallower Approaches)之方法及其運用,隨後在第三節的地 方再來簡介一下深層研究取向(Deeper Approaches)的概念及其運用。. 第二節. 淺層摘要研究取向(Shallower Approaches). 淺層摘要的研究取向(Shallower Approaches)乃是依據某種淺顯易懂的實體特徵作為 分析之依據。所謂的淺顯易懂的實體特徵(Shallow Physical Features) 可以是線索字(Cue Words)、關鍵詞(Keyword)、主題特徵(Thematic Features)、背景特徵(Background Features)、語句位於文件中的位置(Location)或是提示片語(Cue Phrases)等等。之後,藉由某 種有效的演算法來權衡語句之相對重要性,以選出具關鍵性的語句(Sentence Extraction) ,然後再利用剪貼(Cut-And-Paste)的技巧,將語句重新予以排列,進而組成摘錄(Extracts) 後輸出(如圖 10所示) [6][8][12][14][15][18][19]。. 分 析 重要特徵 擷取處理 1 重要特徵 擷取處理 2. 轉 換 (選 取). 合 成 (使其流暢). 重要特徵 加權演算. 語句挑選 及重組處理. (權重值公式) αF1+βF2+γF3. 原始文件 重要特徵 擷取處理N. 語句校訂 處理. 圖 10:淺層摘要的研究取向(Shallower Approaches)之架構. 茲將此類作法的執行機制圖解如下(如圖 11所示): [19][27]. 12. 文件摘要.
(24) n 分析原始文件中 語句的實體特徵. o 利用這些淺顯易 懂的實體特徵作 為語句的表示法. p 依據特徵相對重 要性賦予每個語 句不同之權重值. s摘錄成原始文件 的摘要. r 依壓縮需求挑選 出權重值較高的 數個語句. q將所有候選語句 依照權重值大小 做排序. 圖 11:淺層摘要的研究取向(Shallower Approaches)之執行歷程. 通常這類的研究方法與所應用之領域較無關聯(Domain-Independent),意即這是一種 所謂的〝Knowledge-Poor〞(Very General-Purpose:通用性)的方法。語句(Sentences)通常 至多也只解析至語法層(Syntactic Level)而已。由於透過這種節錄式節錄出的語句在銜接 組合後極有可能會與原文的本意發生了脫節,產生了風馬牛不相及的文摘內容出來,所 以我們依據 I. Mani 及 M. Maybury (1999)等人三階段的自動文摘處理架構來審視,可 能需做一些適度的修正與調整:其中,在轉換(Transformation)階段需包含選取顯著而重 要的單元(Salient Units)出來;而在合成(Synthesis)階段則需考量內容的流暢度(Smoothing ),修正不連貫的敘述,藉由語句的重新排列,使文摘更加地簡潔、易懂 [12][19]。. 總而言之,此類取向之研究方法乃是採用與人類專業文摘作者極其類似的淺顯特徵 (Shallow Features)作為編輯摘要的線索,是一種花費較為低廉的自動摘要解決方案,系 統程式易於建構,所建構出的摘要系統也比較穩健,並且還可以使用語料庫(Corpus)等 來加以訓練。只是這些方法所產生出的摘要內容較為貧乏,因它僅僅是透過某些特定 且層次較低的特徵(Shallow Features)來加以分析、處理,進而建構出統計之模型來進行 決策。然而,正因為未實際考慮到較高層次的語意分析,如知識概念(Knowledge Concepts) 等課題,因此,節錄可能無法真實反映到文件內容的基本精髓[12][19][27]。在附錄二中, 我們將淺層摘要研究取向(Shallower Approaches)依照實體參考特徵的深淺程度不同而區 分為表層(Surface-Level)取向、個體元素層(Entity-Level)取向、以及語段層(Discourse-. 13.
(25) Level) 取向等三種方法[18]。. 2.2.1 重要的參考實體特徵(Shallow Heuristics)舉隅 目前關於華語文的研究其實都脫離不了對中文字詞方面的探索。其中攸關於字詞方 面的相關性研究──“字與字間"、“字與詞間"以及“詞與詞間"等等之間的相關性 可以歸結為現代華語文的Markov特徵,是揭示現代中文內在規律的重要途徑之一。語言 本身可以說是一種習慣性的系統,也是一種少數服從多數的統計學原則。其中有許許多 多是有章法可循的規律或是道理,比如說:詞語創造的原則及其構成方式等都是約定俗 成的;然而這當中卻也充斥著不少既沒道理、亦無跡可循的例外──一些強制性的積非 成是的習慣或是語言事實,例如:唾手可得 vs. 垂手可得。可是,如果我們從數理的角 度運用統計學的方法出發,就會發現在這些語言事實中,不管是“規律"還是“例外 ",都可能會符合一種統計學上的規律──藉由“字詞相關性"的統計,找出字與字、 字與詞、詞與詞之間是否經常在一起出現的通則。若再將其推而廣之,就可以發現中文 文件中的“詞法"、“句法"甚至“章法"的結構與組織規律了[8][25]。底下,我們依 據圖 9所列的參考文獻以及 [8][23][26][27][30],嘗試歸納出這近五十年來學者們對於 自動摘要研究此課題中攸關語句重要性判斷的關鍵特徵,分別闡述如下:. . 主題特徵(Thematic features):[4][9][18][19]. 所謂的『主題特徵』乃是在文件當中具有重要作用的專業詞彙,可用以表達某種明 確概念的關鍵字詞(或稱主題詞)。所以,主題詞乃是在組成一篇文章的單字當中,最能 夠用來表達該文章意義的重要詞語。而在文件當中若包含了相對多數主題詞的語句,我 們就稱該語句為主題句──可用以代表一個段落或是文章的最重要句子之一。一般來說 ,計算句子權重的方法大部分皆採用了詞頻統計(Term-frequency Statistics)的方法來做分 析,若在一篇文件當中某個關鍵字或詞重複(Repetition)出現許多次,超過了某一閾限值. 14.
(26) 或門檻值(Threshold),達到了統計上顯著的差異水準,那麼這個關鍵字、詞極可能就是 這篇文件的主題。因此,若某個語句擁有愈多的主題特徵,那麼此語句越有可能入選 而成為摘要內容之一。. 一個極具代表性、最常用於計算字彙頻率與文件重要性的演算法為 TF*IDF演算法 ,將關鍵詞彙與文件相關程度作內積相乘,以此來評判相關程度之高低。TF*IDF的公式 後來也有了許許多多的變種,其基本量測演算想法如下(如方程式 1 所示),每個向量分 量TF*IDF(i)對應到某一個關鍵詞 Wi:. TF * IDF(i) = TF(W i, D j) * IDF(W i) = TF(W i, D j) * log(D / DF(W i)) 方程式 1:TF*IDF 向量形式之定義. 其中,TF(Wi,Dj)表示詞 Wi 在文檔 Dj 中的出現頻率;D 為總文件數;DF(Wi)表示包 含詞Wi 的文件數。. 所謂的TF (Term Frequency;關鍵詞頻率/詞頻)乃為關鍵詞彙位於文件中所出現的頻 率,意謂著該詞彙於個別文件中的重要性,TF 值愈高代表該詞彙是文件主題詞的可能 性愈高;而 IDF(Inverse Document Frequency:文件頻率倒數)則是表示詞彙於同一個領 域(Domain)文件集合中的重要性,若在一文件集中如果一個關鍵詞彙出現次數很高的 話,那麼表示該關鍵詞彙的字義很廣,不應給予太高的加權;反之,如果一個關鍵詞彙 出現在文件集的次數很低,那麼就代表該關鍵詞彙很重要。因此,IDF 愈高代表該詞彙 用來鑑別主題的能力愈高。 TF 與 IDF 乃是計算文件符合程度的重要指標,由於 TF 指標對文件長度不一的情形誤差較大,所以必須藉由兩者來“共同決定"哪些文件與關 鍵詞彙的相關度最高。其中 TF 關係到召回率(Recall Rate),而 IDF 則關係到精確度 (Precision Rate)。. 15.
(27) . 位置特徵(Location Features):[1][4][9][13][18]. 一份文件當中重要的語句通常都會出現在某幾個特定的位置上而有跡可循。因此, 位置的資訊(Positional Information:Position in text, position in paragraph, section depth, particular sections)依據經驗法則通常也可以成為一種判斷語句重要性的線索之一。舉例 來說:以整篇文章為例,若我們將之區分為數個段落,那麼通常在第一段可能會說明全 篇的主旨、最後一段會總結出摘要而與主題有高度的相關。而以每一個段落(Paragraph) 為例,通常在第一句和最後一句這兩個語句,往往會帶有較高的可能性包含與主題高度 相關或是總結主題的資訊而成為候選的摘要內容,所以,落於這兩個部份的語句相對地 來說就具有較高的重要性。因此,依據語句位置的不同應該要賦予其不同的重要性。換 言之,我們可以透過每個語句不同的期望權重值來計算該語句所具有的相對位置特徵值 ,以此來權衡語句之相對重要性。. . 背景特徵(Background Features/Add Term):[4][18][19]. 從文章的標題(The title or headings in the text)、簡介(Introduction) 或前言(The initial part of the text)等部分,甚至是使用者的查詢(A user's query)等線索詞彙(Lexical cues),通 常都可以用來代表文件中所要描述的主題。因此,假如文件中語句的詞彙出現在上述背 景當中越多,則代表該語句與文件主題的相關程度也越高。但是,這種方法的最大缺點 在於必須依賴特定的寫作格式以及使用特定的字詞才能有效篩選出有用的資訊;一旦寫 作的模式改變,透過這種文章背景結構分析技術所選取出來的摘要品質也會大受影響。. . 語句長度(Sentence Length):[4][9]. 語句的長度往往會左右語句所涵蓋資訊量的多寡。也就是說,較長的語句所包含的 資訊量通常會比較短的語句所含的資訊量來得更加豐富,語意也會更加地完整,也比較 能夠用來代表原始文件所欲表達的意涵。因此,我們可以依據實際的經驗法則來定義一. 16.
(28) 個閾限值或門檻值(Threshold),比如說:7 個中文字,也就是說一個語句的長度必須至 少要具有7 個中文字才有可能候選而成為摘要的一部分。. . 線索字詞/提示片語(Cue words and phrases/Fixed phrases):[1][4][9][13][18]. 在文件當中往往會使用一些提示片語或轉折語來介紹或總結主題之敘述,如:『首 先』、『總之』、『總而言之』(“In summary") 等等,或是與特定領域相關的特定詞 彙(“bonus” or “stigma” term),例如:在專利文獻申請專利範圍(Claims)當中常用『如申 請專利範圍第2項所述之系統,......』(A system as set forth in claim 2,...)、『其中,......』 (wherein said)、『更包括......』(further comprising...)等。因此,文件中的語句如果包含這 些常用的提示性片語或轉折語,那麼該語句便有極高的可能性是屬於摘要。. . 相似度(Similarity):[18]. 所謂的『相似度』乃是指語句間語彙的重複性(Vocabulary Overlap),亦即兩個詞語 在不同的上下文當中可以互相替換使用而不會影響到文本中的句法語意結構。如果兩個 語彙在不同的上下文之間可以相互的替換而不會影響到原文之句法語意結構的可能性 愈大的話,那麼此二者的相似度就愈高;反之,相似度就越低。詞語相似度是一個主觀 性相當強的概念,迄今尚無明確的標準可以用來客觀地衡量。目前常用的方法主要有兩 種:一種是利用句子的表層資訊(如:組成句子的詞之語法、語意資訊等),但不包含任 何結構上的分析,也未考慮到句子整體結構的相似性;另一種方法則是對語句進行完全 的句法分析,並將分析的結果以結構樹(Parse Tree)的形式來加以呈現,依此基礎來進行 相似度的計算。. . 鄰近度(Proximity):[18]. 所謂的『鄰近度』乃是指文字單元(如關鍵詞、概念等)在文件當中的距離,是一種. 17.
(29) 位置運算子--布林邏輯運算子 “AND” 的延伸。它描繪了語意空間中語彙基本要素(Text Units)之間的出現順序和相對距離,是語意空間分析的一個重要方法,可以經由距離或 位置向量的關係來加以度量。. . 同時並列出現(Co-occurrence):[18]. 詞語同時並列出現(Co-occurrence)是指相關的詞彙在文件中常常一起出現且在統計 上具有顯著意義的線索,通常存有類似、相關和同義等等關係。這種關係是一種存在於 所有人類語言的普遍現象,表示詞語與詞語之間的語意和語法的關係,但卻又是一種隨 意性的語言現象,鮮有規律可尋。自動化的方法,大抵都倚賴此種共現型態,來建構索 引典。以關鍵詞與關鍵詞關聯的假設為基礎,透過詞頻等屬性來計算出詞彙與詞彙之間 的相關性,並以其相關性的值來分類詞彙,此種方式將關鍵詞分成為數個類別,且將同 一類別中的成員視之為是擁有相同概念的。因此,利用這種同步出現之分析技術可用以 描述概念之空間(Concept Space)。. . 同指涉/共同參照關係(Coreference):[1][2][18][27]. 同指涉(Coreference) 是達到自然語言 “理解” 中幾個特殊而困難的問題之一,其較 廣義地來說乃是指重複語法中前向對映詞的解析 (Anaphora Resolution) ──亦即,設法 找出文件當中指向同一真實世界裡的共同事物(Entity) 之語詞。 例如:『好巧喔!早上 搭你的車來,現在回去也是搭你的。』其中,第二個“你的"所指的乃是前一子句中的 “你的車"之意。再舉一例:『侯佩岑是當今年代新聞台超人氣主播,她笑容可掬,擁 有迷人的甜美臉蛋與明眸皓齒,即使在播報新聞時不小心吃了個螺絲,這也常讓喜歡她 的粉絲為之瘋狂,她永遠是最可愛的甜姐兒主播。』在這個範例中,三個 “她” 所指稱 的都是 “侯佩岑” 。其中三個代名詞 “她” 為 Anaphor(s),而被參照的對象 “侯佩岑” 則 為Antecedent。一般的代名詞(包括反身代名詞) 都可當成 Anaphor;而找出文件中所有 的 Anaphor 參照到的 Antecedent 這些詞的過程,就稱為 Anaphora Resolution (指示解. 18.
(30) 析/前向對映詞的解析) 或是 Coreference Resolution (同指涉的解析)。同指涉(Coreference) 的現象亦可用來協助解決文摘(Text Summarization) 的問題,是達到自然語言 “理解” 的 一個重要步驟。. . 句法關聯(Syntactic relations):[1][18]. 句子是由詞和片語按照語法規則構築而成的,是表示一個完整意思的語言單位。而 一個句子的表意主要是透過詞義、句法結構、語義、層次、語氣等五大因素的交叉作用 而來。當代形式句法理論已將句法關係歸納為有限的幾種,分別由特定的結構關係來表 達。所謂的『句法關聯』指的是經由一定的語法形式將詞和詞組合後所表現出來的各種 語法關係,通常可以分為陳述、修飾、支配、平行、補充等關係以及主謂、偏正、動賓、 聯合、後補等五種結構模式。所有的關聯,可藉由結構樹(Parse Trees)中的附加語來表 示句法的問題,實質上就是語法的邏輯問題,利用固定的詞序來表現各種句法關係── 亦即,一個相同的字詞在語句中擺放的位置不同,那麼它的句法角色也會因此而跟著不 同,例如:“我愛紅娘”和“紅娘愛我”,又如: Ⅰ. Ⅱ. Ⅲ. Ⅳ.. 他已經破解了這個密碼。 這個密碼他已經破解了。 他已經把這個密碼破解了。 這個密碼已經被他破解了。. 利用文法剖析器與辭典來解析本文句法,可將每個詞彙皆產生一個自身的關聯詞彙串 列,透過這些串列就可以用來計算詞彙間之相關性。. 2.2.2 Edmundsonian 典範 絕大多數以語料為基礎(Corpus-based)的自動摘要研究其實都是濫觴於Edmundson (1969),後續類似這種節錄式摘要(Extraction)的研究可以說都是以他的研究為主要的典. 19.
(31) 範,我們稱之為『Edmundsonian paradigm』[14]。. Edmundson(1969) 在其研究中所認為的特徵主要有四,分別是:Cue words (線索字 詞)、Title words(標題字)、Key words(關鍵字)以及Sentence Location(語句位置),其中前 三者屬於字詞(Word-Level)特徵。而為了權衡語句的重要性,我們可以透過一個線性函 式(如方程式 2所示)來對這四個特徵分別評分而後再予以加權之 [4][14]。 W (s) = α C (s) + β K (s) + γ L(s) + δ T (s). 方程式 2:Edmundsonian paradigm的語句四特徵線性函式(Linear function). 其中,C=Cue word,K=Key word,L=Sentence Location,T=Title word,C(s)代表某語句 s在Cue word特徵上的權重值,其餘依此類推。而α、β、γ、δ則是依訓練回饋結果比 較後動態調整的參數。. 然而,此類的研究未必是以語句(Sentence)為基本單位,所以我們可以將上述方程式 2 所述的幾個特徵更進一步地重新予以詮釋,得到如下之線性特徵(Linear Feature)組合 公式(如方程式 3所示) [19]: Weight (U ) = α * FixedPhras e(U ) + β * ThematicTe rm (U ) + γ * Location (U ) + δ * AddTerm (U ). 方程式 3:線性特徵(Linear Feature)組合公式. 其中,U 所代表的是文字單元(Text Unit , 例如:字、詞、片語、子句、句子、節、段)、 FixedPhrase 代表指標性片語(Indicator Phrases or Cue Phrases , 例如:“總而言之"、 “In summary” )、ThematicTerm 代表主題詞(Thematic terms , 例如: tf.idf 相對權重值較 高者)、Location 代表該文字單元的位置(Position , 例如:整篇文章中的首段、中段、末 段;段落中的首句、末句等;或是科技論文中的簡介(Introduction)或是結論(Conclusion). 20.
(32) 部份等等。)、AddTerm 則代表了文字單元中的關鍵語彙亦出現在“書目"、“題目"、 “文章標題"、“第一段"、“使用者偏好" 、“使用者查詢"等背景資訊者,而α、. β、γ、δ等希臘字則是依實際研究情境動態調整的參數(Tuning Parameters) [14][19]。. 2.2.3 以全文整體結構特徵(Discourse Features)來剖析之自動文摘 根據文件的起、承、轉、合,文件依其所使用的功能、所欲達成的目標而有各式各 樣、形形色色之格式產生(Layout in terms of sections, chapters, etc.)。比如說:『歷史』 書寫時常是以某一種特定的形式、類型與詮釋策略來編撰雜亂無章的各種原始資料。而 一則『新聞』可能就是由『人』(Persons)、『事』(Events)、『時』(Time)、『地』(Places)、 『物』(Things)、『觀念』(Concepts)等基本要素所構築而成的。也就是說,不同類型、 目的的文件,可能因著寫作方式以及用字遣詞等等特性的不同,造成了文件格式亦有所 不同(Narrative structure)。由於文件格式的不同,最後所產生的摘要形式也可能會因此 而有所差異。以科技論文為例,科技論文的摘要可以著重於緒論(Introduction)以及結論 (Conclusion)這兩部分;而以專利文獻為例,我們則可以把重心擺在描述較為抽象的『申 請專利範圍』(Claims)部份,再輔以陳述較為具體的『發明說明』(Detailed Description of the Invention)來加以闡釋,即可完成代表此篇專利文獻的摘要內容(Summarization)。而 新聞文件的摘要在本質上可能須著重於給讀者一個全面而概觀的描述──講重點、說明 白。然而,無庸置疑的,若文件之間的格式類型相同或是相似的話,其所產生的文件摘 要就有可能具有某些共通的特性。從認知心理學的角度來看,一份文件的誕生,乃是由 作者本身依其所認知的概念空間來進行詮釋並加以組織後所得之結果。所以,我們可以 將一份完整的文件予以解構,用一些共通的特性將字詞共聚為某一集合,用以代表某一 種概念或認知。因此,語段層的方法(Discourse-level Approaches)主要是傾向於剖析出全 文內容的整體結構原型及其各組成要件或稱為「命題」(Proposition) (例如:關聯詞彙) 之間的關聯性(Cohesive ties),以這些命題之間的語意關係,來明白作者的思路,進而建 構出自動文摘出來。此類的語意鏈結關係,一般來說可以分成兩大類,如表 1所示 [19]。. 21.
(33) 表 1:文件內涵中的兩大類語意關聯性(ties). 文法關聯性(Grammatical cohesion). 語彙關聯性(Lexical cohesion). n代名詞前向指涉名詞關係(anaphora). n同義詞(synonymy). o省略(ellipsis)與取代(Substitution). o上位語(hypernymy). p連接關係(conjunction). p重複語(repetition). 第三節. 深層摘要研究取向(Deeper Approaches). 深層摘要的研究取向(Deeper Approaches)乃是將原始文件透過語意層或語段層的內 部解構來表達其原文意涵的知識體系,然後再利用自然語言的經驗法則來加以組織後產 生文摘(Abstracts)輸出。因此,透過這種方法所產生的文摘內容有可能不是直接取自於 原始文件當中的內容。. 一般而言,這類的研究方法通常與所應用之領域是息息相關的(Domain-dependent / Background knowledge-dependent),意即這是一種所謂的〝Knowledge-rich〞(Knowledgeintensive)的方法。語句(Sentences)通常至少要被解析至語意層(Semantic Level)。由於透 過這種重述法可能事先需建構出與應用領域知識高度相關的資源(如:知識本體(Ontologies))來產生摘要(Abstracts),因此,隨著應用領域的不同,往往需要額外之編碼(Coding)。 除此之外,可能還需借助語言學的專門知識來分析語句之意涵或是用以協助產生文本。 所以我們依據 I. Mani 及 M. Maybury (1999)等人三階段的自動文摘處理架構(如圖 5所 示) 來審視,可能需做一些適度的修正與調整:尤其是在合成(Synthesis)階段通常需從 語意層或語段層的表達當中透過自然語言的處理(NLP)以及一些探索性的經驗法則 (Heuristic Rules)方式來加以試探,以產生出具連貫性的文摘輸出 [12][16][19]。. 總而言之,此類取向之研究方法乃是以文件全文內容意義為根基來做簡化並且可以 產生出具語意連貫性、資訊更為豐富的摘要內容出來,所產生的摘要也比較符合人類的 閱讀習慣。不但如此,它還允許非常高的壓縮(極低的壓縮率),以提供更為一般化的文. 22.
(34) 摘內容。可惜,此類系統建構成本昂貴、代價亦高,且實作較為不易。稍有不慎,可能 會由於摘要生成過程的瑕疵而導致文摘的內容有誤,間接誤導了讀者們的判斷。. 以下,分別簡介此類研究取向常用的兩種方法:樣板摘錄(Template Extraction)法以 及概念擷取(Concept Abstraction)法 [16]。. 2.3.1 樣板摘錄(Template Extraction)法 所謂樣板(Template)擷取文章摘要的方法,簡單來說乃是利用語意的架構(例如:語 篇中的人物關係、時間關係、空間關係或情節發展所用之關聯詞等)來進行重要資訊的 選取。由於同一類型的文章(例如:政治新聞)其表達資訊的型式較為固定,因此若有某 些句型雷同且不斷地重複出現,則此類句型便極有可能是用來記載重要資訊的句型。所 以,我們可以透過事先已定義好的語意標籤來分析文章中的內容,將內容轉換成各式語 意標籤的組合,然後再利用標籤組合的重複性找出此文中較為重要的句型出來,以這些 重要句型作為摘要的範本(如圖 12所示) [16][19][20][23]。. 樣 板(Templates). 轉. <TEMPLATE-News98> := Persons: 馬英九 Events: 扮大廚打牙祭站台 Time: 2004/07/23(星期五) Places: 台北 Things: 快餐、煎餃、麵食 Concepts: 給猪吃不如先餵馬. Source. Transformation. 分 析. 合 成. Analysis. Synthesis. 文件摘要 圖 12:樣板摘錄(Template Extraction)法的技術架構概觀. 23. 換.
(35) 其演算步驟概述如下:. n 首先,透過自然語言處理的系統(Natural Language Processing)分析文章中的內容, 利用人工建立的語料資料庫(e.g. Ontology)由機器標上語意標籤。此標籤的目的在 於將此文中有意義的詞彙轉變成具有語意訊息的處理模式。. o 利用這些已標記好的語意標籤找出在文章中出現頻率較高的標籤組合,作為摘要 樣板(Template)的句型。. p 將原文(Source)中句子的句型與摘要樣板(Template)中的句型進行逐一比對,若發現 摘要樣板(Template)的標籤組合為文章句子標籤組合的子集(Subset)且順序相同的 話,就選取該語句成為候選摘要內容之一。. q 將候選出的摘要內容依照原文內容的順序加以排序。 r 將選出的每一個語句去除未標上語意標籤的字彙,只將含有語意標籤的詞彙留 下,最後所餘之結果便是『摘要』──樣板法所產生的摘錄(Template Extraction)。. 使用此法的最大優點是可從大型語料庫(Large Corpora) 中透過機器學習並以穩定 漸進的方式來擷取出部分具語意內容的最重要資訊;而其缺點則是以有限的語意標籤作 為摘要的輸出方式,可能會因刪除了原語句中部分的字詞而使得新語句之閱讀變得更令 人難以理解。此外,透過語意標籤組合所形塑出的新語句,可能會因某個原始語句比較 長及其語意標籤與語意標籤之間的間隔字、詞稍多,致使語意標籤的順序恰好吻合了摘 要樣板(Template)中的句型而已,但卻間接造成了選出的語句是較無意義、不具代表性 的摘要內容結果輸出[16]。. 2.3.2 概念擷取(Concept Abstraction)法 所謂的『概念』(Concepts)乃是一種概念性的術語,簡單來說就是指一些字彙或是 詞彙等相關名詞(Term),而透過這些字或詞可以用來描述相同領域中普遍存在的共通基. 24.
(36) 本知識或是實體。. 我們可以將某一領域中的知識拆解成好幾個樹狀結構的方式來加以呈現,其中所呈 現的每一樹節點(Node)就代表了某一種獨立之概念。藉由這一棵棵的樹,就可以明白得 知該領域內有哪些重要的觀念,所定義的名詞之間又是以怎樣子的關係連結而成的;也 是藉由這樣的分享機制,使得每一個人都可以更清楚地知道屬於這個領域中的關鍵字、 詞的組織脈絡而有跡可循。不同的樹狀結構所呈現的概念(Concepts)也意謂著各式各樣 不同的文章主題;透過特定領域下一致性之概念(Concepts),不但可用以描述對於特定 文件中的知識,有效釐清因觀念或是用詞所產生的認知上的混淆;更能夠提昇語意關聯 搜尋的準確性,達到有效的名詞分享。我們透過這種階層式的架構即可將文章內容整合 成為各種主題資訊,以利摘要的抽取及分析。. 目前,階層式(Hierarchy)的架構仍是建構『概念』與『概念』之間最常見的關聯。 概念階層(Concept Hierarchy)定義了從下位概念(即較具體、特殊化之概念)集合到上位概 念(即較抽象、一般化之概念) 之間一連串的對應關係,用以描述概念之間的種種語意關 係。而對於不同概念之間的語意關係,主要可將之區分為三種:. n 一般化關係(Generalization Relationship):一般化關係主要用以描述概念與概念之間 的上、下位關係,亦即子概念必須無條件地繼承父概念之屬性與關連性,並可衍生 出新的屬性和關連性。比如說:動物(上位) vs. 老虎(下位)。. o 屬性關係(Attribute Relationship):屬性關係主要用以描述概念與概念或屬性值間基於 某個特徵之關連性。. p 包含關係(Inclusion Relationship):包含關係主要用以描述概念之間的整體-部份關係 ,代表特定概念與一般概念之間的對應(Mapping),而利用概念階層方式來加以呈現, 舉例來說:台北市包含了大安區、信義區、士林區等更特定之概念;反過來說,大. 25.
(37) 安區、信義區、士林區亦可對應至較為整體之概念『台北市』。. 運用這種概念階層(Concept Hierarchy)的方法,其最大的好處是可以將真實世界當中 的資源知識內容及可能的資訊架構描述方式予以統一並加以簡化,同時也清楚地定義出 概念之間的關係和推理的邏輯規則,以期建構出一個共通的知識背景平台,進而提高了 機器對資訊處理之能力以及語意之理解,大幅降低了機器交換訊息的困難度。然而其最 大的缺點就是概念階層(Concept Hierarchy) 的建構是一項極為艱鉅之工作,尤其是需要 建立一個龐大架構的領域知識的時候,不管是採用人工的方式抑或是透過機器學習的完 全自動化處理技術,將會耗費非常大量的時間以及金錢的投入。因此,儘管在一個概念 階層(Concept Hierarchy)中可以包含許許多多的應用領域,但其所含括的領域知識愈廣, 則其複雜度也將會隨之而增加[16]。. 第四節. 基於 SAO 結構之相關研究探討. 以下簡單說明使用SAO的理由及其相關之作法:. 2.4.1 從英文句型剖析為何要 SAO: 一個合理完整的句子必須文法、句型結構和語意三者兼顧,才能使之言之成理、言 之有物。對於英文語句來說,我們可以將其常用的句型結構歸納整理成為所謂的『五大 基本句型』(Five Basic Sentence Patterns)(如表 2 所示)。. 也就是說,不管英文句子再怎麼樣地千變萬化與複雜多變,它的基本結構和句型卻 可以建立在亙古不變的──〝主詞(Subject)與動詞(Verb)〞的架構上,而句子的基 本結構就由動詞來開始啟動,並由此向外擴張,進而衍生出五大基本的動詞句型,形成 簡單句的『內在主要基本結構』。透過這五大基本句型結構之脈絡,任何外在擴張、複. 26.
(38) 雜橫生的句子,皆可信手拈來、藉收立竿見影之效而有跡可循。. 表 2:英文句子的五大基本句型結構 [整理自 http://cc.vit.edu.tw/~cfs/9301/CD.htm]. 英文的五大基本句型(FIVE BASIC SENTENCE PATTERNS) Ⅰ.. S. + Vi.. 主詞 + 完全不及物動詞.. Ⅱ.. S. + Vi. + S.C.. 主詞 + 不完全不及物動詞 + 主詞補語.. Ⅲ.. S. + Vt. + O.. 主詞 + 完全及物動詞 + 受詞.. Ⅳ.. S. + Vt. + O. + O.C.. 主詞 + 不完全及物動詞 + 受詞補語.. Ⅴ.. S. + Vt. + I.O. + D.O.. 主詞 + 授與動詞 + 間接受詞 + 直接受詞.. 其中, S. = Subject (主詞)、 O. = Object (受詞)、 C. = Complement (補語)、 Vi. = Intransitive Verb (不及物動詞)、 Vt. = Transitive Verb (及物動詞)、 I.O. = Indirect Object(間接受詞)、 D.O. = Direct Object(直接受詞) 一篇文章乃是由許許多多的『命題』(Proposition) 所組織而成的,而一個命題之意 義以傳統簡單的語言邏輯來說就是透過了〝主詞(Subject Term)〞與〝述詞(Predicate Term) 〞此類的基本結構所構築而成的主賓式陳述句,其中的『述詞』乃是用以描述主詞之狀 態,作為主詞的性質或是屬性,但屬性本身是無法獨立存在的,它必須附屬在某些事物 如 Subject 或是 Object 之下。因此,透過此一觀點,我們可將上述英文的『五大基本句 型』(Five Basic Sentence Patterns) 約化成為『主詞(S)-動詞(V)-受詞(O)』或是『Subject(S)Action(A)-Object(O)』的結構形式,其中 Subject(S)與 Object(O)依被動式或主動式的呈現 方式的不同未必要同時存在。亦即,對於每個語句來說,可單由『Subject-Action-Object』 (簡稱 SAO)、『Action-Object』(簡稱-AO)、『Subject(S)-Action(A)』(簡稱 SA-)三種形 式之一來加以呈現。所以,由此觀之,『主詞-動詞-受詞』(Subject-Action-Object,簡稱 SAO』的語句結構最能保證較好的理解效果。. 儘管中文的語言結構和英文的情形並無法相提並論、完全等同,但我們仍舊可以仿 照這種 SAO 的結構句型作為參考,透過“名詞"和“動詞"的關係來嘗試理解其語 意。[32]. 27.
(39) User Request. 2.4.2 透過 SAO 結構模式的文件摘要(美國專利第 6,167,370 號文件探討). Local DB. Web. DB of Original Documents. SAO Analyzer of Text Pre-formatter. (Natural Language Texts). Tagging Verb/Noue Group. Semantic Processor System. Parsing. DB of Summaries of. SAO Extraction. Original Documents. SAO Normalizer. Processor. (Natural Language Texts). DB of New Concepts. Semantic. SAO Processor Comparison. (Natural Language Texts). Re-organization. To Local DB. To Web. Filtering. DB of. DB of Accurate Key Words/Phrases Representations of. SAO-Structure SAO Synthesizer of Natural Language Text. Original Texts SAO Synthesizer of. Key Words/Phrases Representations. 圖 13:以SAO結構模式之文件摘要架構(取自:Valery M. Tsourikov等,美國專利第6,167,370號). 經由上述之探究,我們可以得知對於一個完整的英文語句來說,可能需要同時包含 主詞(Subject)、動詞(Verb) 與受詞(Object)。以美國專利第 6,167,370 號文件 (專利名稱 :Document Semantic Analysis / Selection with Knowledge Creativity Capability Utilizing Subject-Action-Object (SAO) Structures)為例,該篇專利主要描述透過某一種電腦系統可 將各種文件先行轉換成一組一組的SAO(Subject-Action-Object) 結構句,並且將這些SAO. 28.
(40) 的結構句儲存至資料庫中,用以代表該篇文件之語意內容。之後,當使用者輸入了自然 語言的查詢需求(Request)後,此時,系統亦會將該查詢需求轉換為SAO的結構句,接著 再將代表此使用者需求(Request)的SAO 結構作為一種關鍵詞彙(Key Words/Phrases),拿 來跟代表各文件語意內容片段之SAO 結構作匹配(Match) 的處理,以協助使用者找出所 需求之文件出來,並下載之。最後,將這些相關文件的SAO 結構句加以分析其關係, 以此創造出新的SAO 結構句以及新的知識概念,並根據這些相關文件的SAO 結構依照 一些規則將之串連後,表達出自然語言的摘要(Summaries)出來(如圖 13所示)。. 上述專利所述之系統乃是一種自然語言文件分析及揀選的電腦化系統,其中,由圖 13來看,此系統之核心──語意處理部份,主要是由關鍵性的四大模組來運作達成的。. ¾. SAO分析器(SAO Text Analyzer): 包含了許許多多的規則在裡頭,如:文字格式規則、編碼規則、字詞標記規則(例 如:Markov chain theory code)、SAO 動詞(Verb)及名詞(Noun)辨識規則(註:透過 建立動詞(Verb)、名詞(Noun)群組)、解析規則、SAO 擷取規則、SAO 正規原則 等等,以便將候選文件的資料以及使用者自然語言的查詢需求轉換為 SAO 結構句 組的表達。其中,在這個系統語意處理的過程當中,會將此查詢需求之 SAO 結構 句組的表達予以合成,以作為查詢用之關鍵詞彙,然後再透過 WEB 或是本機資料 庫的文件搜尋引擎下載候選文件的資料至系統的 CPU 裡,以便做後續之處理。. ¾. SAO處理器(SAO Processor): 主要是將上述使用者自然語言查詢需求之 SAO 結構句組的表達拿來跟候選文件之 SAO 結構句組的表達做匹配處理,以比較是否至少有一 SAO 結構句相符合,以便 做過濾篩選,將完全無法匹配的候選文件及其相對映已儲存之 SAO 結構句組逕予 淘汰、刪除。. ¾. 自然語言之SAO合成器(SAO Synthesizer of Natural Language Text):. 29.
數據



+7
![表 2:英文句子的五大基本句型結構 [整理自 http://cc.vit.edu.tw/~cfs/9301/CD.htm]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8388536.178591/38.892.124.815.227.519/表2英文句子的五大基本句型結構整理自httpccvitedutw~cfs931CDhtm.webp)

![圖 14:『方法 A』之概念(Concepts) 擷取流程示意圖[31] 『方法 A』之 SAO 擷取技術:[31] 如圖 15 之流程圖所示[31]。根據從 Claims 的句子擷取出來的 Concepts(概念) 及 Relations(關聯),再進一步擷取出 SAO 的物件。其主要的擷取方法為判斷句子的主動式 及被動式,包括句子中的主詞、動詞及受詞之架構。 首先,針對每個 Claim 中的每一子句來進行判斷,先行判斷是否有 S-A-O 之順序 的物件存在於此子句中。若沒有的話,則](https://thumb-ap.123doks.com/thumbv2/9libinfo/8388536.178591/43.892.273.698.107.737/斷句子主動及被動式包括句子中的主詞及受每一子句來於此子話則.webp)


相關文件
• (語文)術語學習 無助學生掌握有關概念,如 果教師只灌輸術語的定義,例如何謂「動
and Dagtekin, I., “Mixed convection in two-sided lid-driven differentially heated square cavity,” International Journal of Heat and Mass Transfer, Vol.47, 2004, pp. M.,
Lessons-learned file (LLF) is commonly adopted to retain previous knowledge and experiences for future use in many construction organizations.. Current practice in capturing LLF
In recent years, many of researches have already put forward various methods to detect R wave, for example, filter banks, artificial intelligence algorithms, Hidden Markov
The experimental results show that the developed light-on test methodology can effectively detect point defects (bright point, dark point, weak point), line defects (bright line,
近年來,國內積極發展彩色影像顯示器之產業,已有非常不錯的成果,其中 TFT-LCD 之生產研發已在國際間佔有舉足輕重的地位,以下針對 TFT-LCD 之生
There are Socket Dimensions Measurement, Actuation Force Measurement, Durability Test, Temperature Life Test, Solder Ball Deformation, Cycle Test, Contact Inductance &
This is why both enterprises and job-finding people need a more efficient human resource allocation channels, and human resources websites are becoming a new media between the
