以CLEC語料庫為基準來設計實作一個英語作文錯誤檢查系統
105
0
0
全文
(2) 以 CLEC 語料庫為基準來設計實作一個英語作文錯誤檢查系統 The Design and Implementation of an Error-Checking System for English Composition Based on Chinese Learner English Corpus. 研 究 生:顏佐宇. Student:Tzuo-Yu Yan. 指導教授:陳登吉. Advisor:Deng-Jyi Chen. 國 立 交 通 大 學 理學院網路學習學程 碩 士 論 文. A Thesis Submitted to Degree Program of E-Learning College of Science National Chiao Tung University in partial Fulfillment of the Requirements for the Degree of Master in Degree Program of E-Learning June 2007 Hsinchu, Taiwan, Republic of China. 中 華 民 國 九 十 六 年 六 月.
(3) 以CLEC 語料庫為基準來設計實作一個英語作文錯誤檢查系統. 學生:顏佐宇. 指導教授:陳登吉. 博士. 國立交通大學 理學院網路學習碩士在職專班 摘. 要. 隨著英語課程的進入小學,以及英語檢定的普及,學習英語已蔚為風行。因應這樣的發展, 學生們已開始在小學接受英語教學,以及相關的測驗,而在這種情形之下,在外補習或是自學的 人數也隨之增長;但是,以學習英語作文為例,當學習者在完成一篇作文的時候,只能尋求人工 的方式批改,不但耗費時間,評分標準也可能不一。不同於有著固定答案的選擇題或是非題,早 就以電腦閱卷的方式取代人工批閱,即便是有少數系統可以批改,正確率也有待提升。 因此,本研究試著去提昇實驗室中的英語作文的錯誤檢查系統之正確率,希冀以CLEC語料 庫中分類清晰,且具代表性的錯誤類型為驗證藍本,撰寫相對應的作文錯誤檢查模組。期望以一 致的角度,先將作文當中的拼字、文法錯誤,或是文不對題的情形清楚的標示出來,以提供閱卷 者在閱卷時評分的參考。 同時,由於英語對我們華人來說,畢竟屬於外來的語言,其中的文法和語態與中文也不盡相 同,導致學習上的困難。因為如此,我們希望建立起一套系統,除了可提供學習者做相關的事前 練習之外,也可作為閱卷者評分的參考;更重要的是,系統以CLEC語料庫為驗證背景,整併及 撰寫新的文法檢查模組,使錯誤類型之分類更為完整,並提高系統之錯誤檢查率。此外,也可讓 受試者在不需要他人協助的情況之下,就可以自行操作練習,並不會受到外在環境的條件限制, 也充分的運用了資訊設備,真正享受網路所帶給我們的便利性。 關鍵字:語料庫、文法檢查、英語、作文、學習者。. i.
(4) The Design and Implementation of an Error-Checking System for English Composition Based on Chinese Learner English Corpus. Student:Tzuo-Yu Yan. Advisor:Dr. Deng-Jyi Chen. Degree Program of E-Learning College of Science National Chiao Tung University. Abstract As the elementary school starts teaching English and the popularity of GEPT (General English Proficiency Test), many people consider learning English indispensable. Following this trend, many students start to receive English courses and take English tests. Therefore, the number of students who go to English institutions or appeal to self-study has increased as well. However, taking learning English composition as an example, when the learners finish their compositions, they must seek someone to check their works. This is a time-consuming process and, furthermore, the grading standard may vary. Multiple-choice and true and false questions have fixed answers that can be checked through Optical Mark Recognition, replacing the manual grading method. Even though English composition can be graded by a few systems, its accuracy may be varied due to the difference of learning background. As a result, this research intends to improve the error checking system for Chinese learner’s English composition. The explicitly categorized and the representative error types in CLEC will be the basis to write the error checking system for English composition. By using the coordinate approaches, the misspellings, grammatical errors, and the irrelevance sentences can be marked clearly and served as references for the graders. Since English is still foreign to Chinese, the differences among voice and tenses have caused difficulties in learning. Thus, we must design a system not only providing the learners to do relevant practice beforehand but also functioning as references for the graders. More importantly, our system is based upon CLEC and integrates many grammar checking modules to cover the error types as many as we can. For a learner, it can be used. ii.
(5) to his own English composition conveniently. For a grader, it can be used to uncover all possible errors before they do the final semantic checks. Thus, the grading basis for all testers’ English compositions is the same. Numeric English composition samples (list in appendix) are used to demonstrate the feasibility and applicability of the proposed system. Keywords: corpus、grammar check、English、composition、learner. iii.
(6) 誌. 謝. 對於在交大的兩年研究所生涯來說,除了在課程的學習上,帶給我不同的視 野之外;更為重要的便是在實驗室中的研究過程當中,陳登吉老師在研究上的指 導。陳老師在我兩年的研究生涯當中,不僅是傳授知識,更重要的是做學問的態 度,讓我明白研究是必須以嚴謹的態度,認真的付出時間,才會有相對應的成果, 並非是一蹴可幾的。在此特向老師致上心中最誠摯的感謝。 另外,也感謝論文口試委員劉美君老師、呂菁菁老師、洪茂盛老師、莊祚敏 主任…等,對於論文疏漏之處,給予學生指導,並提供意見。 最後,感謝洪茂盛老師在大學的教導,學弟謝豎鎧在程式技術上的協助,以 及同學陳奕錡及表妹王景宥在英語研究的幫忙,讓本研究得以順利完成。同時, 我也要感謝父母給予精神上的支持,在求學的生涯中不斷的鼓勵我。 研究所兩年的生涯是我人生的轉戾點,讓我的視野更為寬廣,感謝所有曾幫 助支持我的朋友、家人,感謝你們。. iv.
(7) 目. 錄. 中文摘要 ....................................................................................................... i 英文摘要 ...................................................................................................... ii 誌. 謝 ..................................................................................................... iv. 目. 錄 ...................................................................................................... v. 表 目 錄 .................................................................................................... vii 圖 目 錄 ....................................................................................................viii 一、. 緒論 ......................................................................................................... 1 1.1. 研究背景與動機 ................................................................................ 1. 1.2. 研究目的與範圍 ................................................................................ 2. 1.3. 研究方法與步驟 ................................................................................ 2. 1.4. 章節概要 ........................................................................................... 3. 二、. 系統技術探討 .......................................................................................... 4 2.1. GNU Aspell ....................................................................................... 4. 2.2. Apple Pie Parser ................................................................................ 6 2.2.1. Apple Pie Parser Parser ............................................................... 7. 2.3. WordNet ............................................................................................ 9. 2.4. 語料庫 ............................................................................................. 10. 三、. 2.4.1. 學習者語料庫 ...........................................................................11. 2.4.2. Chinese Learner English Corpus ................................................ 12. 2.4.3. CLEC的建立 ............................................................................ 13. 2.4.4. CLEC的統計分析 ..................................................................... 17. 2.4.5. CLEC的製作工具 ..................................................................... 18. 2.4.6. CLEC實例說明 ......................................................................... 18. 系統設計與實做 ..................................................................................... 21 3.1. 系統架構與流程 .............................................................................. 21 3.1.1. 前處理 ...................................................................................... 23. 3.2. 拼字檢查模組 ................................................................................. 23. 3.3. 文法檢查模組設計 .......................................................................... 25 3.3.1. 詞性及句構標記 ....................................................................... 26. 3.3.2. 文法檢查模組驗證方式 ............................................................ 26. v.
(8) 3.3.3. CLEC樣本統計 ......................................................................... 28. 文法檢查模組實作 .......................................................................... 30. 3.4. 3.4.1. 比較級 ...................................................................................... 31. 3.4.2. 過去分詞 .................................................................................. 35. 3.4.3. A和AN判別 .............................................................................. 39. 3.4.4. 基本動詞使用 .......................................................................... 41. 3.4.5. 時態一致 .................................................................................. 44. 3.5. 同義字檢查模組 .............................................................................. 46. 3.6. 評分模組 ......................................................................................... 47. 3.7. 軟體程式建構技術 .......................................................................... 48. 四、. 系統效能與分析 ..................................................................................... 50 4.1. 系統效能 ......................................................................................... 50. 4.2. 系統比較 ......................................................................................... 53. 五、. 系統實例展示 ........................................................................................ 56 5.1. 系統範例 ......................................................................................... 56. 5.2. 系統限制 ......................................................................................... 60. 5.3. 論文摘要之測試結果討論 ............................................................... 61. 六、. 結論與未來展望 ..................................................................................... 64 6.1. 結論 ................................................................................................ 64. 6.2. 未來展望 ......................................................................................... 65. 參考文獻 .............................................................................................................. 66 附錄. 68. vi.
(9) 表. 目. 錄. 表 2-1 英語學習者語料庫列表 .................................................................... 12 表 2-2 CLEC語料分布表 ............................................................................ 14 表 2-3 言語失誤分類表 .............................................................................. 16 表 2-4 CLEC內容範例 ............................................................................... 19 表 3-1 CLEC錯誤類型及句數統計表 ........................................................... 28 表 3-2 CLEC錯誤類型比率統計表 .............................................................. 29 表 4-1 系統錯誤檢查率統計表 .................................................................... 50 表 4-2 系統文法檢查模組列表 .................................................................... 52 表 4-3 未經CLEC分類之系統檢查率統計表 ................................................. 53 表 4-4 系統錯誤檢查率比較表 ....................................................................54 表 5-1 英文摘要測試數據 .......................................................................... 61 表 5-2 英文摘要錯誤統計表 ....................................................................... 62. vii.
(10) 圖. 目. 錄. 圖 2-1 系統中呼叫Aspell檢查錯誤 ................................................................ 5 圖 2-2 Penn Treebank的詞性標記表 ............................................................ 6 圖 2-3 Apple Pie Parser執行畫面 ................................................................ 7 圖 2-4 Apple Pie Parser Parser結果輸出 ..................................................... 8 圖 2-5 Apple Pie Parser Parser結構 ............................................................ 8 圖 2-6 WordNet同義字查詢 ......................................................................... 9 圖 3-1 系統架構圖 ..................................................................................... 21 圖 3-2 系統流程圖 ..................................................................................... 22 圖 3-3 前處理流程圖 ................................................................................. 23 圖 3-4 拼字檢查模組流程圖 ....................................................................... 24 圖 3-5 文法檢查模組流程圖 ....................................................................... 25 圖 3-6 APP及APPP解析句子流程圖 ........................................................... 26 圖 3-7 文法檢查模組驗證方式設計流程圖 ................................................... 27 圖 3-8 文法檢查模組驗證方式實作流程圖 ................................................... 27 圖 3-9 CLEC錯誤類型及句數分類統計圖 .................................................... 30 圖 3-10 比較級檢查模組流程圖 .................................................................... 32 圖 3-11 比較級例句在APP中解析輸出(1) ..................................................... 33 圖 3-12 比較級例句在APP中解析輸出(2) ..................................................... 34 圖 3-13 過去分詞檢查模組流程圖 ................................................................ 35 圖 3-14 過去分詞例句在APP中解析輸出(1) .................................................. 36 圖 3-15 過去分詞例句在APP中解析輸出(2) .................................................. 37 圖 3-16 過去分詞例句在APP中解析輸出(3) .................................................. 38 圖 3-17 A和AN判別檢查模組流程圖 ............................................................. 39 圖 3-18 基本動詞使用檢查模組流程圖 ......................................................... 41 圖 3-19 基本動詞使用例句在APP中解析輸出(1) ........................................... 42 圖 3-20 基本動詞使用例句在APP中解析輸出(2) ........................................... 43 圖 3-21 時態一致檢查模組流程圖 ................................................................ 44 圖 3-22 時態一致例句在APP中解析輸出 ...................................................... 45 圖 3-23 同義字檢查模組架構圖 .................................................................... 46 圖 3-24 同義字檢查模組流程圖 .................................................................... 47 圖 3-25 評分模組流程圖 .............................................................................. 47 viii.
(11) 圖 3-26 MVC概念圖 .................................................................................... 48 圖 4-1 系統錯誤檢查率統計圖 .................................................................... 51 圖 4-2 未經CLEC分類之系統錯誤檢查率統計圖 .......................................... 53 圖 4-3. 系統錯誤檢查率比較圖 .................................................................... 54. 圖 5-1. 作文錯誤檢查系統輸入畫面 ............................................................. 56. 圖 5-2. 英語作文錯誤檢查系統錯誤輸出畫面 ............................................... 57. 圖 5-3. 評分畫面 ........................................................................................ 59. 圖 5-4. 評分送出畫面 ................................................................................. 59. 圖 5-5. 英文摘要錯誤統計圖 ....................................................................... 62. ix.
(12) 一、 緒論 1.1. 研究背景與動機. 由於國際間的貿易、經濟、社會文化等往來頻繁,英語已經日漸成為國家 之間溝通往來的溝通工具;學習英語已經成為刻不容緩的一件事情,具備基礎 的英語素養,也已成為地球村每一份子的基本能力。 因此教育部為了提升國民之英語能力,強化我國國際競爭力,便積極著手 進行相關的英語教學,更於九十四學年度宣布,英語教學提前至小學三年級開 始實施[17],財政充裕的縣市(如台北縣、市)更於低年級即開始實施英語教學, 相信不久的將來,能夠見到此政策之成效。 「全民英語能力分級檢定測驗」即是教育部推動學習英語學習的要項,教 育部核准財團法人語言訓練測驗中心辦理該測驗,自民國 89 年開辦以來,受 到社會各界的重視與採認,至 95 年總報考人數已逾 220 萬人次[20]。 在目前這樣的情形下,許多學習者為了增強自己的英語能力,平常就勤加 練習,以其中的英語作文為例,當學習者在進行相關的練習之後,通常都需要 以人工的方式來閱卷,但是人工閱卷較為耗時費力,且無法有著相同的閱卷標 準。再者,現有之電腦閱卷系統大多只能對具有標準答案的填充題、選擇題進 行批閱,少數能夠批閱作文的系統正確率也有待提升,更也有些系統是源自於 歐美語系的國家,文法檢查方式與字彙運用都不甚相同。因此我們希望能夠實 作出符合華人語言使用習慣,且正確率較高的英語作文錯誤檢查系統,能夠提 供給學習者練習使用。 所以,一個完整的學習者語料庫-Chinese Learner English Corpus[19]對 我們來說就很重要了,此語料庫中針對學習者作文當中的錯誤類型加以分類, 列出大量的使用者錯誤的句型,讓我們藉助此語料庫當中的錯誤類型作為系統 之驗證藍本,提升目前英語答題驗證系統的錯誤檢查率;同時我們希望了解目 前系統的錯誤檢查比率是多少,並且針對其文法檢查不足的向度,設計文法模 組,同時依循語料庫中分類完整且清晰的錯誤類型,整併文法模組,以達到我 們提升正確率之目的。. 1.
(13) 1.2. 研究目的與範圍. 本研究主要希望達到的目的如下: 1.. 基於 CLEC 語料庫的錯誤類型為文法模組驗證基準[19],建構一個符合華 人使用習慣的英語作文錯誤檢查系統。. 2.. 系統可以將作文之文法錯誤、拼字錯誤、文不對題的情況標示出來,以立 即回饋的方式反應給學習者。. 3.. 以 CLEC 語料庫的文法分類[19],設計系統文法模組功能,並建立標準一 致的作文錯誤檢查標準。。. 4.. 提供學習者一個可以自我學習的作文練習環境。 此研究的範圍主要是在英語測驗的作文部分,由於本實驗欲研究之作文錯. 誤檢查系統,在文法模組的設計上,需要完整而清晰的分類;同時,也需要大 量的英語作文測試樣本,以驗證文法模組,這也是 CLEC 對我們來說最重要的 目的。. 1.3. 研究方法與步驟. 我們欲先確認系統可檢查出來的錯誤數量及類型,並且運用 CLEC 語料庫 加以驗證,了解程式可找出錯誤的比率,以設計文法模組,同時提升系統可找 出錯誤的比率。我們使用的方法如下: 1.. 了解系統所能檢查出的文法、拼字錯誤類型以及文不對題的檢查方式。. 2.. 分析系統模組可檢查出 CLEC 語料庫的錯誤種類及數量。. 3.. 以 CLEC 語料庫分類方式為樣本,設計文法模組。. 4.. 以系統之文法模組,與 CLEC 語料庫相互驗證。. 5.. 統計與 CLEC 語料庫相互驗證之後的錯誤種類及數量。. 2.
(14) 1.4. 章節概要. 本研究主要分成六個章節來介紹,依序如下:. 第一章 敘明本研究的動機、目的、以及研究的方法及步驟。 第二章 系統技術及相關文獻探討 第三章 系統架構與系統模組設計 第四章 系統效能與比較。 第五章 系統畫面展示與限制說明。 第六章 說明本研究之結果與相關未來系統可以延伸開發之功能。. 3.
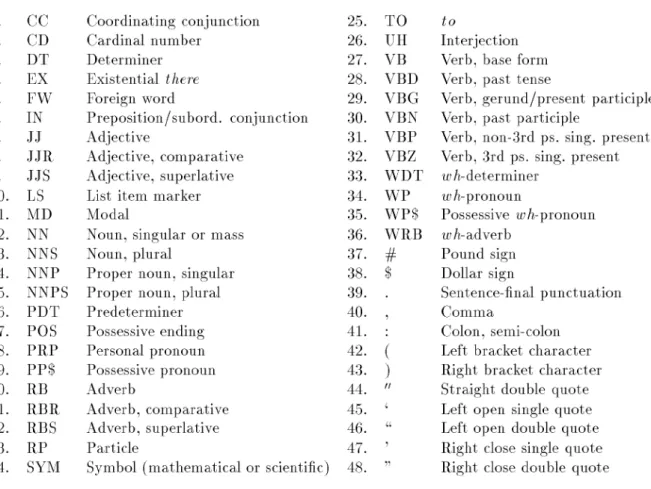
(15) 二、 系統技術探討 本研究欲研究的部份,是建構一個以 CLEC 語料庫為基準的作文錯誤檢查 系統,此系統中擁有的相關檢查功能為:拼字檢查、文法檢查、同義字檢查。 以下將逐一介紹拼字檢查、文法檢查、同義字檢查功能所使用的相關技術。. 2.1. GNU Aspell. 在作文錯誤檢查當中,拼字的正確與否,會影響到文法的判別;因此拼字 檢查雖然容易,但卻是系統中不可或缺的部份,影響的層面也可見一斑。 系統使用的軟體是 GNU Aspell[22],GNU Aspell 是一個被設計用來替換 Ispell[6]的拼字檢查程式,原本 Ispell 是一個支援很多歐洲語系的 Unix 程式。 它可以使用在 Emacs[3]編輯器下,但是大部分的人發現,在發現錯誤後的建議 字上並不十分理想,所以 Kevin Atkinson 才開始致力研究於 Aspell[4]。 Aspell 的使用方式有兩種:一種是當作函式庫,被程式呼叫使用;另一種 則是作為一個獨立的拼字檢查程式。而它主要比其他拼字檢查程式優越之處, 在於兩點[2]: 1.. 它可以建議拼錯的字該如何改正,也就是列出一些可能的建議字在旁 邊,以提供參考之用。. 2.. Aspell 優於 Ispell,的主要一點,在於 Aspell 不需要使用特定的辭典就 可以檢查用 UTF-8 編碼的文件。. 3.. 它還擁有一些 Ispell 所沒有的功能,例如:可使用多本字典和當其他 使用者在使用時,每個使用者都能擁有一部個人字典,而不會互相影 響彼此。. 很多的軟體或是系統目前都使用 Aspell 當作拼字錯誤檢查程式,如知名的 瀏覽器 Opera[14]或是作業系統 Linux 或 Unix,只要安裝至少一部 Aspell 可使 用的辭典,馬上都可以用以上的方式來操作 Aspell,把他當作單字的錯誤檢查 程式。. 4.
(16) 圖 2-1 所示的是 Aspell 檢查錯誤單字後的畫面[22]。. 原句輸入. 建議字列表. 圖 2-1. 系 統中呼叫 Aspell 檢 查錯 誤. 圖 2-1 是系統利用程式呼叫 Aspell 的操作畫面,可以看到輸入的句子是 「thsi is a book」,經過檢查之後,發現錯誤的單字是「thsi」,並且將他反白 起來,表示這部份發生錯誤。另外,對於發生錯誤的單字,給予一些可能的建 議字,如:this、Thai…等,提供使用者參考。. 5.
(17) 2.2. Apple Pie Parser. 在進行文法檢查之前,我們必須要知道句子的結構與單字的詞性,但結構 與詞性必須仰賴 parser 才能將其解譯出來,解譯出來之後,提供詞性與句構给 文法模組作文法檢查,這也是本研究主要著重的部份;目前的語料庫研究中, 著重的部份首推 parser 的研究與詞性的標記(POS(part of speech) tagging), 而目前系統所使用的 Apple Pie Parser,就是基於 Pennsylvania 大學所開發的 Penn Treebank 中的詞性標記[12]。下圖即為 Penn Treebank 的詞性標記表 [11]。. 圖 2-2. Penn Treebank 的詞 性標 記表. Apple Pie Parser(APP)是一個利用 bottom-up probabilistic chart 統計方 式,以及使用 best-first search 演算法,計算最佳得分之後,產生 parse tree。 也就是說 APP 是以 Penn Treebank 中所統計的文法規則以及字典,利用演算 法所找出來的最佳解析詞性。下圖為 Apple Pie Parser 執行畫面。. 6.
(18) 圖 2-3. Apple Pie Parser 執行畫面. 圖 2-3 中輸入的句子為「Mary is a beautiful girl」 ,經過 parser 解析之後, 得到的結果是(S(NPL Mary)(VP is(NPL a beautiful girl))-PERIOD-),也就是將 輸入的句子用括號的形式輸出,每個括號中前面的字為詞性標記,如:NPL、 VP…等,括號後方的為原輸入單字。 要注意的是,無論句子中的拼字以及文法是否正確,APP 都會將句子做上 標記,再交由系統的文法檢查模組進行檢驗的。. 2.2.1 Apple Pie Parser Parser 在經過 Apple Pie Parser 對於輸入的英文句子進行標記後,接著進行的就 是 Apple Pie Parser Parser(APPP)的標記,也就是句子結構性的標記;為了系 統可以清楚的辨別各個詞性與句構,我們將剛才 APP 輸出的結果,再經過 APPP 標記一次,把我們想要的資料結構加註進去。 我們以 APP 切出 token 後,以 lex&yacc 的方式,也就是 APPP 中輸出成 具有 XML 語法標記的樹狀結構標記句型[22]: 1. LEAF:tree 的末端,格式為(tag. 單字). 例:(NN book) 2. NODE:可以是 LEAF 或(tag. NODE_LIST). 例:(NPL(DT This)(NN book)) (tag (. NODE_LIST. )). 3. NODE_LIST:NODE 或 NODE_LIST+NODE 例:(DT This)(NN book) 4. TREE:最頂端的結構。 例:(S) 7.
(19) 我們也可以藉由樹狀圖的表示方式來說明上列的結構,以及相關的標記方 式,由下兩圖可以更清楚的呈現此部分定義的結構。. 圖 2-4. 圖 2-5. Apple Pie Parser Parser 結果 輸出. Apple Pie Parser Parser 結構. 8.
(20) 上述兩圖即可清楚的呈現,句子中的每個字都是一個 LEAF,很多的 LEAF 可以合成 NODE,這些 NODE 也可再跟其餘的 LEAF 或 NODE 合成更上層的 NODE,最後所有的 NODE 合在一起而成為一顆完整的樹(TREE)。. 2.3. WordNet. 當一篇英語作文在系統的拼字檢查、文法檢查均正確的情況之下,我們就 試著檢查出其內容是否有語義上的問題;但語義檢查的範圍十分廣泛,由於目 前需檢查的部份為英語作文,因此我們僅檢查該篇作文是否文不對題。 系統在這部份運用到同義字的對照來進行檢查語義的部份,我們藉由 WordNet[15]來達成我們的要求。WordNet 是美國普林斯頓大學的認知科學實 驗室,其中 George A. Miller 所帶領研究的英語辭典,內容包含動詞、名詞、 形容詞和副詞,以上的詞類組合被組合而成所謂的同義詞組(synsets),每種詞 組都代表一個概念。這些詞組彼此之間再藉著語意的概念與詞彙的關係互相聯 繫而互相連結;如此一來,一個有意義的網絡就可以使用瀏覽器在網路上瀏覽 了。. 圖 2-6. WordNet 同義 字查詢. 9.
(21) 上圖是 WordNet 查詢關鍵字的 Web 介面,在查詢同義字時,系統就會去 查詢該字在各種詞性有哪些同義字,以查詢「display」為例,他在名詞方面的 同義字有 show、presentation…等,在動詞方面的同義字則有 expose、exhibit… 等。 WordNet 可以免費下載與公開使用,而且 WordNet 的結構讓它成為一個 研究計算機語言學和自然語言處理的好用工具。多年以來,也有著許多人投注 在 WordNet 的發展上[15]。 WordNet 在系統中運作的方式,是以模組來呼叫,也就是說,根據 APPP 所解析出來的詞性標記,再將他放進模組中檢驗。. 語料庫. 2.4. 什麼是語料庫呢?黃希敏教授提到[23][24]:其實自古以來就有「語料語言 學」(Corpus Linguistics)的存在,只是過去沒有這個名稱。單從「語料」的定 義來看,這個字翻譯自拉丁文 corpus(複數為 corpora),意思是「體」,而從 語言學的角度來看,就是「整體性的語言資料」 ,意思是指人類口語或文字紀錄 的彙編。 以上是語料庫之定義,同時黃希敏教授的論文裡也將語料庫依照內容,分 為以下四類[23][24]: 1. 單一語料庫: 為了某種特定的研究所做的語料收集,過程需要非常嚴謹,收入該語料 庫的每個字句都必須具有代表性。例如:文言文語料庫。此語料庫中所 包含的內容都必須是文言文,其中可能包含文言文的句構、詞的用法… 等等,研究者可以從語料庫中分析出一些資訊,如:文言文中不同作者 的風格,不同的朝代文風有何改變,諸如此類的資訊都可找到。 2. 複合語料庫: 此資料庫是將兩種或數種語料「集大成」,不過在收集時需要在類型之 間加以區隔,讓研究者自行選取某單一類型來做研究或某幾個跨類型語 料來做比較。例如:多語(multilingual)語料庫:包括兩種或兩種以 上語言,提供翻譯研究、語言對比研究(contrastive studies),進而可 10.
(22) 以協助電腦翻譯與語言教學法的研發。 3. 開放性語料庫: 國內中研院製作的現代漢語開放性語料庫「中央研究院平衡語料庫」 (Sinica Corpus),可不斷擴張,提供從事語言文字分析的人士使用。 4. 學習者語料庫: 廣泛蒐集學習者的語料,提供外語教學界研究。. 對於系統而言,文法錯誤的檢查模組必須以大量的錯誤樣本測試其正確性 及完備性。在這樣的情況之下,上述之語料庫就是一個最好的樣本,可以提供 給我們系統作為驗證測試之用,以便在撰寫程式碼的時候有所遵循。. 2.4.1 學習者語料庫 李珮瑛曾在文章中提到[18]:近年來,語料庫的發展已經為語言學習者提 供了寶貴的學習資源,其中學習者語料庫也是如此,而翻閱其歷史,最早的學 習者語料庫是八零年代末期所建立的朗曼學習者語料庫(Longman Learners’ Corpus)[10]。九零年代中期,比利時魯汶大學 Centre for English Corpus Linguistics[1]的 Sylvaine Granger 建立了國際學習者英語語料庫(International Corpus of Learner English, ICLE)[5],該語料庫是一廣泛國際合作的計畫,現 存有超過二百萬詞,存有十四種不同母語背景的英文學習者語料。 而 Leech[9]也曾在其論文中提到,建立學習者語料庫的目的是: 1. 比較學習者語料庫 LC(Learner Corpus)和欲學習語言為母語的語料 庫 ECNS(English Corpus of Native Speakers) ,比較其中使用過多或 過少的語詞。 2. 學習者的母語對於在使用欲學習語言時的影響程度。 3. 學習者使用新語言時,在哪些方面能夠達到所欲表達的目標,在哪些方 面無法達成。 4. 學習者在哪些方面無法達到所欲表達的目標,而需要幫助。. 11.
(23) 對我們的研究來說,需要找到一個適當的學習者語料庫,且語料內容的範 圍限制在中國學習者之英語作文,將是最適合本研究的學習者語料庫,關於這 部份,我們在下一節將會有更詳細的說明。. 2.4.2 Chinese Learner English Corpus 在前面我們已經提到,語料庫可說是一種資料庫,運用了資訊科技,將大 量和語言相關的資料,使用具流通性的 XML 標籤語言,將之標記之後,存到 我們的電腦當中。 目前語料庫種類繁多,如果我們僅針對學習者語料庫,而且將範圍限制在 英語學習者語料庫來看,具代表性的大概有以下幾個[21]:. 表 2-1. 英 語學習 者語 料庫列 表. 語料庫名稱 ICLE ( International Corpus of Learner English)[5] JEFLL (Japanese EFL Learner) Corpus[8] 中國學習者語料庫(CLEC)[19] 大學英語學習者口語語料庫 (COLSEC)[25]. 詞數. 研究單位. 200 萬. 比利時 Louvain-La-Neuve 大學. 50 萬. 日本明海大學. 100 萬. 廣東外貿大學、上海交通大學. 5萬. 上海交通大學. 香港科技大學學習者語料庫. 2500. (HKUST Learner Corpus)[21]. 萬. 中國英語專業語料庫(CEME)[21] 148 萬 中國英語學習者口語語料庫 (SECCL)[21] 國際外語學習者英語口語語料庫 中國部分(LINSEI-China)[21] 碩士寫作語料庫(MWC)[21]. 香港科技大學 南京大學. 100 萬. 南京大學. 10 萬. 華南師大. 12 萬. 華中科技大學. 除此之外,尚有許多學習者英語語料庫,如:Longman Corpus of Learner’s English (LCLE)、美國的英語學習者語料庫―MELD、英國的商業性學習者語料. 12.
(24) 庫―CLC 和 LLC…等。 但是我們在選擇語料庫,並希望以他作為作文錯誤檢查樣本時,我們評估 的項目包括: 1. 語料庫製作背景: 希望是華人所製作的,其中語料也較具代表性。 2. 內容之關聯性: 由於我們的系統的範圍限制在英語作文錯誤檢查系統,因此語料內容也 須符合我們的需求。 3. 詞數須適中: 詞數過多或過少都會讓我們分類不易。. 綜合以上條件,上表中,Chinese Learner English Corpus 可說是最適合我 們需求的英語學習者語料庫,因為它的內容就是作文,並非其他口語、寫作或 是其他目的之語料庫,且詞數適中,較容易分析,因此我們選定 CLEC 為作文 的錯誤檢查驗證語料庫。 Chinese Learner English Corpus(簡稱 CLEC 語料庫)為上海交通大學 楊惠中、廣東外貿大學桂詩春兩位教授合力編著,內容記載著各種統計資料和 列表,而語料庫的詞數為一百萬詞,也許大家會認為以今天的技術來說,建立 個幾百、幾千萬詞並非難事,但是語料庫必須對語言失誤按照統一的語言失誤 表進行標記,而失誤標記是頗耗費人力與時間的。如果由少數人來做,則易於 統一標準,但需較多時間;如果由多數人來做則反之;因此將語料庫定在一百 萬詞是較便於操作的,又可以累積經驗,以便往後的擴充[19]。 下面我們將介紹 CLEC 的樣本內容以及建立方式,以便之後運用到文法模 組的設計與撰寫。. 2.4.3 CLEC 的建立 在介紹 CLEC 如何建立前,必須說明什麼是 LC(Learner Corpus),他和 ECNS(English Corpus of Native Speakers)有何不同。 由於英語並非我們的母語,所以英語在生活環境當中,是需要學習的一門 科目,除了課程需要,一般學生也幾乎很少在日常生活中運用。對於學習者來 說,無論是聽、說、讀、寫各方面,所用的英語詞彙大多都和學習環境與校園 13.
(25) 生活有關,從 CLEC(LC)的統計表中就可以看出端倪。 而對於英語系國家的人來說,由於英語已經是母語,需要學習的是語言的 使用技巧,以及文章體裁、結構…等方面,因而在 ECNS 中,所使用的詞彙也 與日常生活有關,是與英語學習者所使用的詞彙不同;於是我們在建立 CLEC (LC)時,樣本必須來自於不同發展階段的學習者;而制定 ECNS 則考慮文體 類型而非語言能力。學習者的寫作能力只是停留在”一般的”英語(例如我們不 能期望學習者去寫小說、社論、科技文章,而這些類型是一般 ECNS 都有的樣 本)[19]。. 1. 樣本的選定 CLEC 的語料分布,定為 5 個階段,如表 2-2 所示: 表 2-2. CLEC 語料分 布表. 類型. 詞次. ST2. 208088. ST3. 209043. ST4. 212855. ST5. 214510. ST6. 226106. 總計. 1070602. 1.. ST2:中學階段,主要是高中生。. 2.. ST3:大學英語 4 級,大學 1~2 年級非英語科系學習者。. 3.. ST4:大學英語 6 級,大學 3~4 年級非英語科系學習者。. 4.. ST5:英語專業科系 1~2 年級學習者。. 5.. ST6:英語專業科系 3~4 年級學習者。[19]. 2. 言語失誤分類表的制定 為了要以學習者語料庫作為系統文法模組的驗證依據,我們希望他是擁有 清楚而明確的錯誤類型標示的;CLEC 中的編制原則正是如此,這也是他的特 點。他的編寫原則如下[19]:. 14.
(26) 1. 簡單合理,易於系統操作。 採兩級分類,先分為十一大類(如:[vp]),每大類再細分為小類(如: [vp6]),總共六十一小類(見表 2-3)[19]。 2. 分類表的類別數量適中。 分類太粗不易看出失誤為何;分類太細,容易將同種失誤歸到不同類 別。目前六十一類屬於中等規模的分類表。 3. 提供足夠的錯誤信息。 CLEC 當中的句子提供了相當足夠的錯誤訊息標示。 例如:In the past, people are [vp6, 4-] kind to each other…,使用方 括號標示錯誤,其中的 vp6 表示是動詞第六種錯誤,也就是時態的問 題,至於 4-表示錯誤發生的範圍,-代表錯誤的位置,4 代表失誤的字 前有四個導致錯誤的字,要根據這四個字才能判斷 are 這個詞用錯了。 4. 開放性。 可定義更細分類的錯誤類型,如[vp6]可細分為[vp61]、[vp62]…等。 5. 對語體誤用或失誤原因暫不做標記。 目前只針對錯誤處進行標記,至於導致使用者使用錯誤的原因,由於牽 涉到標記者的主觀意見,因此暫不標記。. 表 2-3 為其中整理的語言失誤分類表,詳細內容請參考[19]。. 15.
(27) 表 2-3. 詞形 碼. 言 語失誤 分類 表. 動詞短語. 類型. 碼. 名詞短語. 類型. 碼. 類型. 代詞 碼. 類型. fm1 Spelling. vp1 pattern. np1 pattern. pr1 reference. fm2 word building. vp2 set phrase. np2 set phrase. pr2 anticipatory it. fm3 Capitalization vp3 agreement. np3 agreement. pr3 agreement. vp4 finite/non-finite. np4 case. pr4 case. vp5 non-finite. np5 countability. pr5 wh-. vp6 tense. np6 number. pr6 indefinite. vp7 voice. np7 article. vp8 mood. np8 quantifiers. vp9 modal/auxiliary np9 other determiners 形容詞短語 碼. 類型. 副詞 碼. 介詞短語. 類型. 碼. 類型. 連詞 碼. 類型. aj1 pattern. ad1 order. pp1 pattern. cj1. pattern. aj2 set phrase. ad2 modification. pp2 set phrase. cj2. set phrase. aj3 degree. ad3 degree. aj4 -ed/-ing confusion aj5 predicative/attributive 詞彙 碼. 類型. 搭配 碼. 句法. 類型. 碼. 類型. wd1. order. cc1. noun/noun. sn1. run-on sentence. wd2. part of speech. cc2. noun/verb. sn2. sentence fragment. wd3. substitution. cc3. verb/noun. sn3. dangling modifier. wd4. absence. cc4. adj/noun. sn4. illogical comparison. wd5. redundancy. cc5. verb/adv. sn5. topic prominence. wd6. repetition. cc6. adv/adj. sn6. coordination. wd7. ambiguity. sn7. subordination. sn8. structural deficiency. sn9. punctuation. 16.
(28) 2.4.4 CLEC 的統計分析 除此之外,先前提到的 Learner Corpus(LC)與 English Corpus of Native Speakers(ECNS) ,我們也可以從 CLEC 中的分析資訊,得到一些資料,以便 於我們可以針對這些資訊,進行我們的程式撰寫與分析。 CLEC 之中的統計表包括:詞頻排列表、拼寫失誤表、詞目表、詞頻分布 表、詞目分布表、語法標記頻數表、言語失誤表…等等,在此我們針對其中的 幾個表的分析做一些介紹。. 1. 超用詞(overused)與少用詞(underused) 在 CLEC 中提到[19],如果我們比較 FLOB Corpus(Freiburg Lancaster-Oslo/Bergen)與 CLEC 當中的詞彙,利用 Wordsmith 這個軟體分 析語料庫,他可以對某一個語料庫和一個參考語料庫作比較分析,看其中哪些 詞是超用的,哪些是少用的。 超用詞和少用詞可以呈現出語料庫的特點,學習者語料庫中可以發現,一 些漢語拼音的專有名詞都成為超用詞,但英語中的專有名詞卻是少用詞,抑或 是當題材不同時,也會有一些影響,例如:學習者語料庫中的作文都是與個人 和學校生活有關的詞彙,如:life, school, college, campus, English, friends, knowledge, teachers, students…等等,都是所謂的超用詞;相反的,British, church, European, community, Labour, minister, religious, tax…等等,這些常 出現在英語語料庫中的詞,反而成為 CLEC 的少用詞。. 2. 詞形使用錯誤 所謂詞形使用錯誤,在 CLEC 中最多的有三種[19],拼字、造詞、大小寫。 拼字及大小寫的錯誤,可能是在查詢字典的時候不小心發生錯誤的,或是並沒 有再寫完之後多檢查幾次;但有趣的是 CLEC 中 ST3 和 ST4 的學習者,他們 喜歡使用推理的方法以及造詞的規則,自行創造出不存在的詞。例如:maken, limitful, couragely, normy…等詞。. 3. 句法使用分析 由 CLEC 中的統計資料中也可以發現句型也是由超用詞與少用詞所影響. 17.
(29) 的,例如:被動語態(been、by),從屬句(where、which、who…),是學習 者所少用的句型;英語中關於時態的句型,也是在此之中所少見的類型,因為 這也是學習者最常見的動詞失誤,可能因為怕用錯,所以出現頻率不高。 另外,句法失誤在 CLEC 中分成九種,其中四種佔的比例最大[19],分別 是:結構缺陷、不斷句、不完全句和標點符號。根據分析,結構缺陷和標點符 號有密切關係,而不斷句和不完全句有密切關係。其他的句型失誤則自成一類, 和不斷句與不完全句有關係,可見不斷句是學習者語料庫中常見的失誤,這種 失誤和中文的表達方式很有關係。例如 It is used not only in studying English but also in many ways, dancing is a good exercise, when I begin to learn, I feel it difficult to do, but I do every day, little by little…,這就是很明顯的例子, 屬於不斷句(run-on sentences) ,我們除了應該注意使用者該寫完整的句子之 外,還應該注意標點符號的用法,避免由標點符號所組成的不斷句。. 2.4.5 CLEC 的製作工具 語料庫是將語言資料輸入資料庫,且加上分類及相關資訊的資料庫;應用 在輸入上面的軟體有[19]:WordCruncher, MicroConcord, Longman’s Concordancer, Concordance, Concordancer, Lexa, TACT, Wordsmith…等 等,經過實驗和比較功能,也因為他們是免費或共享軟體,於是選用 TACT 和 Wordsmith。除此之外,CLEC 的研究人員也撰寫了相關的專門軟體;這些所 建立的資料都是純文字檔,方便讀取與加工,而統計方面的資料,則交由 Microsoft Office Excel 來製作,如果是較為複雜的統計,則使用了 SPSS、 Statistica 和 Havard Chart。. 2.4.6 CLEC 實例說明 表 2-4 的作文是 CLEC 樣本中的 ST2 類型,我們可以很清楚的看到,所有 CLEC 中的句子都是使用 XML 語法來標記,XML 它是一九八六年國際標準組 織(International Standards Organization, ISO)公佈的一個名為「標準通用標示 語言」(Standard Generalized Markup Language, SGML)的精簡版/子集合。 XML 掌握了 SGML 其延展性、文件自我描述特性、以及其強大的文件結構化 功能,但 XML 卻摒除了 SGML 過於龐大複雜以及不易普及化的缺點。字面上 18.
(30) 來看 XML 是一種標示語言,但嚴格來說它和 SGML 一樣是一種「元語言」 (meta-language)。換言之,XML 是一種用來定義其它語言的語法系統。這正 是 XML 功能強大的主因。它可促進各專業機構、不同產業界、學術界和特定 應用領域發展各自標準的文件和訊息,以利資訊的交換、處理和相關衍生性資 料加值服務[16]。XML 語法讓我們在研究 CLEC 的時候,能夠了解一些與文章 有關的資訊。 以表 2-4 來看,01、02 列分別標示出此篇作文作者的資訊,如:<ST 2>, 前面的 ST 表示是學生,後方的 2 則代表該考生是第二類型;接著是<SEX ?> 性別不詳,<SCH GDWYWMDXFSWYXX >就讀學校使用代號,<TITLE A Shop>代表本篇的作文題目是 A Shop,其餘部份 03~11 列就是考生主要的作 文內容了。標示問號的部分代表沒有作者的該項資訊;另外由於 ST2 類型的學 生文章並非考試,因此未標示出分數是多少。. 表 2-4. CLEC 內容範 例. 01 <ST 2> <SEX ?><Y ?> <SCH GDWYWMDXFSWYXX> <AGE ?> 02 <WAY ?><DIC ?> <TYP 2> <TITLE A Shop> 03 There is a fruit shop near my home. its [fm3, 1-] name is Many [fm1,-] 04 fruit shop. It's not very big, but it's clean and bright. There is [vp3,-2] two 05 women working in it. The women are very friendly [wd2, 1-] and busy. 06 Every buyer comes to the shop, they both give them smiles and say. 07 [sn9, s] Hello. Can I help you? So every buyer comes to here are very 08 satisfy. [sn8,s]The shop has many different kinds of fruit. There are 09 apples [sn9, s]oranges bananes [fm1,-]pears bananas many [wd6]. 10 [sn8,s] So it aways [fm1,-] give [vp3, 1-] the buyers a good time. I like 11 the shop very much.. 以下是 CLEC 中錯誤標記的方式,分為錯誤位置、錯誤類型與錯誤範圍標 記。錯誤位置是在句子當中使用方括號標記在錯誤單字的後方,括號中左邊標 示錯誤類型,右邊則標示出錯誤範圍,如 03 列後方:its [fm3, 1-] name is Many [fm1,-] fruit shop.,即表示此句中 its、Many 兩個字是錯誤位置,而錯誤類型 分別是 fm3(大小寫錯誤)、fm1(拼字錯誤)。 至於針對錯誤範圍標示部分,有以下幾種分類,分別說明如下(詳細請參閱 19.
(31) [19]): 1. 錯誤字前方導致錯誤: 05 列:The women are very friendly [wd2, 1-] and busy. 括號中錯誤範圍標示的 1 在-號前,表示是 friendly 是錯誤,是因為往前 數一個字的位置的字導致該字發生錯誤,也就是因為 very 也是副詞,而導 致錯誤。 2. 錯誤字後方導致錯誤: 04 列:There is [vp3,-2] two women working in it. 括號中錯誤範圍標示的 2 在-號後,仍表示是 is 發生錯誤,但原因是後方 的兩個字 two women 所導致的。 3. 本身錯誤: 03 列:its [fm3, 1-] name is Many [fm1,-] fruit shop. 此句所示的第二個括號,在-號前後並沒有任何數字標示,此即表示並沒 有其他的字導致 Many 發生錯誤,是這個字本身就拼錯,並非原本作者所 要使用的字。 4. 句中結構或標點錯誤: 08 列:There are apples [sn9,s] oranges bananes [fm1,-] pears… 此句的第一個錯誤標示範圍僅用一個 s 表示,此代表是句中的結構或標點 發生錯誤,因此這裡發生錯誤的原因,在於表示多個名詞的時候,需要用 逗點分開。. 了解錯誤的標記方式與相關資訊之後,在下一章將會詳細的介紹如何利用 這些分類資訊,以設計實作系統。. 20.
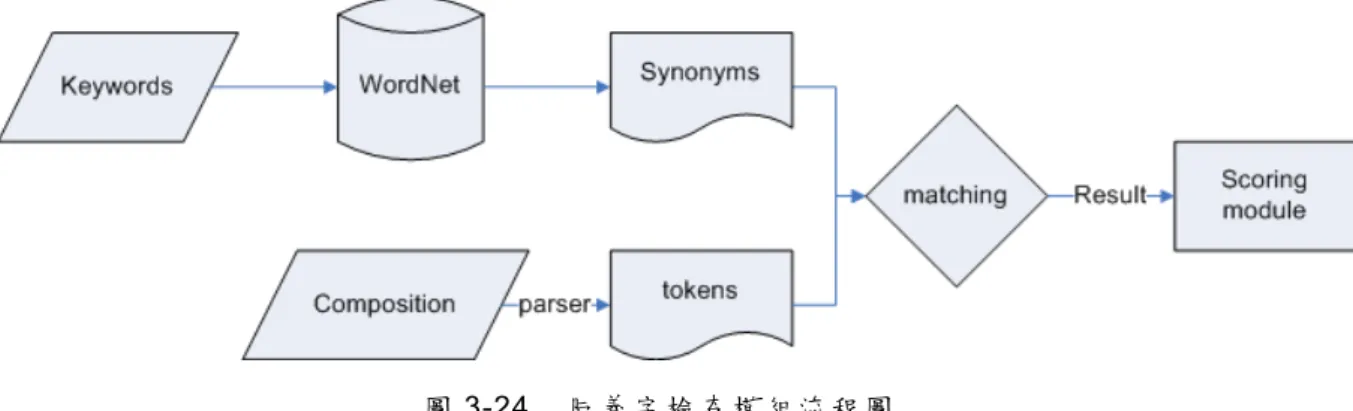
(32) 三、 系統設計與實做 3.1. 系統架構與流程. 下圖是系統設計架構圖,學習者首先在系統當中輸入英文作文,接著依序 經過三個部份的檢查,分別是拼字檢查、文法檢查、同義字檢查,最後將前述 三種類型的錯誤檢查結果標示出來,再交給評分系統,由人工進行最後的判別 評分,同時把結果輸出到網頁上面。. 圖 3-1. 系 統架構 圖. 基於以上的系統架構,我們繼續詳述系統的程式流程,以便清楚系統是如 何處理一篇英語作文,從其中挑出錯誤並且標示出來。. 21.
(33) 圖 3-2. 系 統流程 圖. 從流程圖當中[22],我們可以看到系統中運作的情形。首先作文會經過前 處理,進行斷句、斷詞的程序,接著進入拼字檢查,如果不通過就直接評分, 通過的話則繼續以 APP 進行詞性標記,完畢之後便開始以文法模組檢驗,如果 上述的拼字、文法的檢查均正確,我們最後送到同義字檢查模組,檢查文章是 否文不對題。所有以上的結果,將送至評分系統,可讓閱卷者針對系統檢查的 情形加以評分及建議,最後以網頁輸出。. 22.
(34) 3.1.1. 前處理. 在文章在進入各模組進行檢查之前,系統進行文章的前處理 (preprocess),所謂前處理是將學習者的英文作文切分成單詞,以便進行拼字 檢查的動作。. 圖 3-3. 前 處理流 程圖. 當學習者將英語作文輸入之後,首先便進行前處理的動作,在這裡分成兩 個部份[22]: 1. 切成句子: 首先先將文章依據句點切分成許多句子,這部分系統忽略某些縮寫的部 份,如:Mr.、Dr.…等。 2. 切成單字: 作文經過以上的切分,已成為單一的句子,此時系統再依據單字之間所出 現的空白切成單字,這邊將縮寫 don’t 以及句中出現逗點時,是緊連單字 的情況考慮進去。 經過前處理之後,我們就會將這些處理好的文字,送到 Aspell 裡面去檢查, 以便進行之後步驟。. 3.2. 拼字檢查模組. 系統將學習者的文章切成多個單字(token)之後,接著進行的就是將已經切 好的單字送入拼字檢查模組,進行錯誤檢查。我們所使用 Aspell 的版本是. 23.
(35) 0.60.3,並且在模組中以函式庫的方式呼叫使用。. 圖 3-4. 拼 字檢查 模組 流程圖. 進行檢查時,程式會將剛才的 token 放入字典中進行比對,如果拼字檢查 正確,就繼續進行下個模組;因為如果拼字錯誤,則可能導致在文法檢查模組 中,標記詞性的時候無法辨識該字而導致文法判別錯誤。因此如果未通過拼字 檢查的句子,我們便不送到文法檢查模組,而直接送往評分模組。 而經過統計之後,發現關於拼字的錯誤大致有下列三種: 1. 拼字錯誤(spelling): 例:saidÆsiad、importantÆimporten、luckyÆluckly 此類型的錯誤可直接由 Aspell 找出來,但是比率並非達到 90%的原因,是因為 存在某些特例無法解決。如:every thing。這兩個字都沒有錯誤,文法也沒有 錯誤,但是大家都知道在英文文法中並非以此種方式使用,因而 CLEC 標記為 錯誤。 想要解決此一類型的問題,我們可以用例外(exception)的方式記錄在程式模組 當中,直接將錯誤挑出。 2. 人工造詞(word building): 例:usingÆuseing、uselessÆuseness、happilyÆhappyly 造成這些錯誤的原因,多半是對於詞性的變化不甚熟悉,而產生這種張冠李戴 的情形。此類型同 1 也可由 Aspell 找出。 24.
(36) 有些例外的情形,如:I be live that learning English…,很明顯出錯是用法加 上拼字錯誤的問題,應該是 I believe that learning English…,這類無法由 Aspell 找出來的問題,我們就會利用文法模組加以解決,因為 be、live 都是動 詞,我們知道一個句子裡面如果有兩個動詞,是需要用連接詞將其分開的。 3. 大小寫錯誤(capitalization): 例: 「we [fm3,-] will make it better.」 、 「I am sure that china[fm3,-] will…」 、 「For example, In [fm3,1-] 1960 the life」 上述三種情形,分別是句子開頭沒有大寫、專有名詞沒有大寫、逗點後面應該 是小寫。開頭或句中需要大小寫的辨別,這可以由程式解決;但專有名詞的部 份,則需要在程式當中撰寫所遇到的例外才可以辨別。. 以上錯誤除了可以用軟體(如:Aspell)來檢查之外,關於例外的情形是需要 文法檢查模組來輔助的,從以上針對詞形的分析範例中,說明了系統分析的過 程及相關的內容。除此之外,其餘的錯誤部份,我們也是針對分析的結果,再 加以撰寫相關的文法檢查模組來檢查錯誤,這也是在下一節中主要的研究重點。. 3.3. 文法檢查模組設計. 文法檢查模組包含以下幾個部份,依序如後:詞性標記(APP)、結構標記 (APPP)、文法檢查(modules)、CLEC 驗證。. 圖 3-5. 文 法檢查 模組 流程圖. 25.
(37) 從此圖即可以清楚的看出,剛才經過 Aspell 檢查無誤的句子,經過詞性以 及句子結構的標記,便依照這些標記進行文法檢查,句子經過每一個文法檢查 的模組檢查過後,如果全部都正確無誤,就將資訊送到同義字檢查模組;如果 發生錯誤,便一一記錄下來錯誤的模組有幾個,並且送到評分模組。. 3.3.1 詞性及句構標記 我們採用的 parser 是 Apple Pie Parser(APP)。我們將通過拼字檢查的句 子,送進 APP,APP 會對句中的單字作出詞性標記以及句子的結構;之後,再 將句子送進 Apple Pie Parser Parser(APPP)進行樹狀標記,標記完之後,再交 由文法模組做錯誤檢查。. 圖 3-6. APP 及 APPP 解 析句 子流 程圖. 3.3.2 文法檢查模組驗證方式 系統將文章做過以上的處理之後,就會送到文法檢查模組中做檢查,但是 這些文法模組的設計分類方式,以及相關的驗證,需要大量的樣本來做測試。 因此,我們將依照文法模組在 CLEC 各類型句子中的驗證結果,去設計及撰寫 文法模組,如下圖所示:. 26.
(38) 圖 3-7. 文 法檢查 模組 驗證方 式設 計流程 圖. 我們每設計一個文法模組,便以 CLEC 中的錯誤句子做測試,測試完畢後, 便統計尚有多少數量及類型錯誤還未能找出,針對模組不足之處再加以補強, 並且重複這樣的步驟,以新增各類型文法檢查模組。 實做的方式則如下圖所示:. 圖 3-8. 文 法檢查 模組 驗證方 式實 作流程 圖. 圖中 CLEC 的資料送進我們的文法檢查模組中檢驗,檢驗後主要分成兩個 部份: 1.. 後端錯誤統計: 利用 perl 去呼叫檢驗程式,將 CLEC 中有錯但尚未檢查出錯誤的句子 經過主程式檢驗之後做成列表,由於 perl 對於字串的處理能力很強, 所以在這個部份能很快的計算出句子數目,以利後續在撰寫程式時, 確認哪類型的文法錯誤數量較多,需要先行解決。. 27.
(39) 2.. 前端網頁測試: 後端撰寫完畢的文法檢查模組,可以由前端網頁呼叫,測試目前文法 檢查模組可以偵測的狀況有哪些。並將檢查出的拼字錯誤、文法錯誤、 語義錯誤的訊息呈現在網頁上。. 3.3.3 CLEC 樣本統計 系統藉由以上檢驗方式,首先統計出兩項資料: 1.. CLEC 原本樣本句數:. 我們將 CLEC 中的 ST2~ST6 樣本輸入 perl 中,雖然已知在 CLEC 中的詞 數為一百萬詞,但並非所有文章中的句子都有發生錯誤,因此我們僅統計 有發生錯誤的句數有多少,同時將它分類。 2.. CLEC 句數錯誤類型比率:. 表 3-1 是 CLEC 語料庫經過 perl 程式檢驗後,而得到的各類型錯誤數量。 表 3-1. CLEC 錯誤類 型及句 數統 計表. 錯誤類型. 句數. 錯誤類型. 句數. 錯誤類型. 句數. [ad1]. 151. [np2]. 56. [sn5]. 25. [ad2]. 72. [np3]. 678. [sn6]. 131. [ad3]. 17. [np4]. 109. [sn7]. 125. [aj1]. 30. [np5]. 209. [sn8]. 2523. [aj2]. 29. [np6]. 1251. [sn9]. 1888. [aj3]. 156. [np7]. 436. [vp1]. 776. [aj4]. 37. [np8]. 99. [vp2]. 321. [aj5]. 10. [np9]. 45. [vp3]. 1499. [cc1]. 154. [pp1]. 309. [vp4]. 285. [cc2]. 167. [pp2]. 380. [vp5]. 300. [cc3]. 673. [pr1]. 340. [vp6]. 1548. [cc4]. 228. [pr2]. 94. [vp7]. 318. 28.
(40) [cc5]. 48. [pr3]. 203. [vp8]. 57. [cc6]. 24. [pr4]. 116. [vp9]. 484. [cj1]. 60. [pr5]. 69. [wd1]. 210. [cj2]. 21. [pr6]. 12. [wd2]. 1375. [fm1]. 6586. [sn1]. 1116. [wd3]. 3405. [fm2]. 1119. [sn2]. 1232. [wd4]. 1613. [fm3]. 2402. [sn3]. 42. [wd5]. 1185. [np1]. 74. [sn4]. 43. [wd6]. 119. [wd7]. 811. 統計之後,在 CLEC 裡面的錯誤句數總共有 37895 句,但由於上表並不容 易看出來各類型錯誤比率是多少,因此我們再針對 CLEC 中的言語失誤分類表 上面的 11 大類做出分類和百分比。 表 3-2 是以 CLEC 中 11 大類的錯誤類型,分別統計數量而得到的,並且 計算各大類所佔的比率。. 表 3-2. CLEC 錯誤類 型比率 統計 表. 詞形[fm]. 10107. 26.7%. 動詞短語[vp]. 5588. 14.7%. 名詞短語[np]. 2957. 7.8%. 代詞[pr]. 834. 2.2%. 形容詞短語[aj]. 262. 0.7%. 副詞[ad]. 240. 0.6%. 介詞短語[pp]. 689. 1.8%. 連詞[cj]. 81. 0.2%. 詞彙[wd]. 8718. 23.0%. 搭配[cc]. 1294. 3.4%. 句法[sn]. 7125. 18.8%. 總計. 37895. 100.00%. 29.
(41) 圖 3-9 是將表 3-2 以統計圖的方式呈現,讓我們可以更清楚的看出各類型 錯誤在整體錯誤類型中所佔的比率。. 名詞短語 8% 動詞短語 15%. 其他 9%. 詞形 26%. 詞彙 23%. 句法 19%. 詞形. 詞彙 圖 3-9. 句法. 動詞短語. 名詞短語. 其他. CLEC 錯誤類 型及句 數分 類統計 圖. 經過我們的 perl 程式統計,可以看到上圖是使用不同的圖表來表示目前 CLEC 中的錯誤樣本句數,其中代詞、形容詞短語、副詞、介詞短語、連詞、 詞彙、搭配在統計圖中表示「其他」 ,而前五名數量的錯誤數量多寡依序分別是 「詞形」、「詞彙」、「句法」、「動詞短語」、「名詞短語」…等。. 文法檢查模組實作. 3.4. 在文法檢查模組當中,我們是用以下幾種方式來進行分析: 1.. 詞性:. 語言當中所包含的詞彙範圍很廣,詞數可達成千上萬,因此我們需要詞性 來做為這些單字的分類,APP 依照這些單字在句中的結構位置,分析出最 恰當的詞性,讓我們可以得到分析的詞性之後,以詞性做為文法檢查的依 據。 例如:被動語態Æbe 動詞+過去分詞,就可以表示「is broken」、「was opened」、「were selected」…等句型,而不需一一列舉。 30.
(42) 2.. 單字:. 當 APP 不能夠解析出正確的詞性時,或者有時屬於同詞性的單字,但是用 法不同時,我們就無法由詞性來做文法檢查。 例如:A 或 AN 的用法。這兩者都是被 APP 解析成[DT],我們如果使用詞 性,就無法判別兩者的不同,因此需要以單字本身作判斷。 3.. 句構:. 除了一般的詞性、單字的文法判斷之外,另外還有屬於需要句子結構的分 析部份,才能幫助我們做上述 1、2 的文法判別。 例如:時態一致性的判斷。由於在這個模組裡面,我們需要找到主要子句 和從屬子句中的動詞,進行一致性的判別,首先需要先找出”子句”的位置, 而在 APP 的解析中,單字經由各種的組合,而成為某些句子結構,例如: 從屬子句就被解析為[SBAR]。我們便可以經由此來做接下來的文法判別。. 分析完畢後,使用 C++語言撰寫相關程式模組,並針對以上三者加以分析 探討,看是否可檢查出文章的錯誤之處,如果通過這部份的檢驗,或是發生不 足以影響文法的警告(warning),那麼將繼續進行同義字檢查模組,進行其餘的 錯誤檢查部份;但如文法已是錯誤(error),程式就直接進入評分模組。 以下將詳細說明五個文法模組,以了解模組是如何在系統中運作,以達到 文法檢查的目的。. 3.4.1 比較級 這個模組主要是解決下列幾種類型的文法錯誤,並且附上程式流程圖,以 便清楚地知道程式是如何依照 APP 所解析出來的詞性,進行錯誤檢查。 我們首先觀察大量 CLEC 中此類型錯誤的句子,如: The footprint was more larger for him. I am taller and more heavy than last year. It is more stronger and lively than before. New computer is more smaller than the first one. English becomes more important and more important. 31.
(43) 以上五句都有錯誤,我們把以上的句子都經過 APP 解析,並且觀察解析後 的詞性,便可以歸類出來下列三種錯誤類型: 1. 副詞比較級[RBR]+單音節形容詞[JJ] 2. 形容詞比較級[JJR]+形容詞比較級[JJR] 3. 副詞比較級[RBR]+多音節形容詞[JJ]+and+副詞比較級[RBR]+多音節 形容詞[JJ]. 圖 3-10. 比 較級檢 查模 組流程 圖. 32.
(44) 1. 副詞比較級[RBR]+單音節形容詞[JJ] 例句:John is more tall than Tom. APP 的解析結果如下: <Tree> <CNode tag="S" > <CNode tag="NPL" > <CLeaf tag="NNP" word="John" index="0" /> </CNode> <CNode tag="VP" > <CLeaf tag="VBZ" word="is" index="1" /> <CNode tag="SBAR" > <CNode tag="SS" > <CNode tag="ADJP" > <CLeaf tag="RBR" word="more" index="2" /> <CLeaf tag="JJ" word="tall" index="3" /> </CNode> <CNode tag="PP" > <CLeaf tag="IN" word="than" index="4" /> <CNode tag="NPL" > <CLeaf tag="NNP" word="Tom" index="5" /> <CLeaf tag="-PERIOD-" word="." index="6" /> </CNode> </CNode> </CNode> </CNode> </CNode> </CNode> </Tree> 圖 3-11. 比 較級例 句在 APP 中 解析 輸出 (1). 由圖 3-11 中 APP 的解析結果可以發現,當句子裡面出現「比較級」加上「形 容詞」的時候,APP 會將比較級單字解析成「副詞比較級(RBR)」加上「形容 詞(JJ)」。 就此句而言,由於 more 是形容後面的 tall,因此程式將它當成[RBR],而含有 單音節的形容詞此時的詞性變化,應該直接將 tall 寫成形容詞比較級 taller,並 且刪除前方的 more 才對;這也呼應了 CLEC 的介紹,由於學習者常常不清楚 某些詞性變化的規則,因而製造了錯誤的用法。正確的寫法是,如果此句的 tall 改成多音節的單字時,才可以用 more 來修飾。例如:John is more handsome than Tom.. 33.
(45) 2. 形容詞比較級[JJR]+形容詞比較級[JJR] 例句:John is more taller than Tom. 形容詞比較級相連時,APP 會把比較級的單字解析成[JJR]加上[JJR]。 此句中 more 後面接著 taller,也就是有「形容詞比較級」相連接的時候,從流 程圖的判斷中可以看出,程式會找出這個錯誤;但是在剛才的規則之下其實還 有些例外情形,如:The days are getting longer and longer.。此句雖然也出 現形容詞比較級相連接的情形,但仍然是正確的用法,因此我們多將句子經過 一次是否為[JJR]+and+[JJR]的檢查,以確保檢查結果正確。 <Tree> <CNode tag="S" > <CNode tag="NPL" > <CLeaf tag="NNP" word="John" index="0" /> </CNode> <CNode tag="VP" > <CLeaf tag="VBZ" word="is" index="1" /> <CNode tag="ADVP" > <CNode tag="NPL" > <CLeaf tag="JJR" word="more" index="2" /> </CNode> <CLeaf tag="JJR" word="taller" index="3" /> </CNode> <CNode tag="PP" > <CLeaf tag="IN" word="than" index="4" /> <CNode tag="NPL" > <CLeaf tag="NNP" word="Tom" index="5" /> <CLeaf tag="-PERIOD-" word="." index="6" /> </CNode> </CNode> </CNode> </CNode> </Tree> 圖 3-12. 比 較級例 句在 APP 中 解析 輸出 (2). 以上的例子目的是要找出在句子當中這幾種類型的錯誤用法。而在流程當中 需要用到單音節與多音節的判斷,因此我們另外加入此類判斷的副程式。 另外,我們也在程式當中加入一些例外情形。 例如:英國著名作家 George Orwell 喬治奧威爾的一部作品《動物農莊》 (Animal Farm),裡面提到「All animals are equal, but some animals are. 34.
(46) more equal than others.」,這算是反諷用法,在一般的文法當中,是不會 有所謂”更”平等(more equal)的詞出現的。. 3.4.2 過去分詞 學習者通常在學習動詞的時候,常搞不清楚時態的變化而導致錯誤,尤其 是在過去分詞的使用上,因為時態對於華人來說,並不是原本母語中所擁有的 東西,我們只會在句子當中加入表示時間的詞,例如:我已經「吃」過蘋果了, 並不會因為時間的不同而改變「吃」這個字;但在英語當中的「吃」卻因為時 間不同而有所謂的時態變化,這邊就要用「I have eaten the apple.」。 例如 go 在動詞三態中的變化是「go, went, gone」,屬於不規則的動詞三 態變化。在 CLEC 的錯誤類型當中,我們也發現過去分詞使用錯誤的比例相當 高,常常會有「have(has、had)+過去式動詞」的情形出現;另外,被動語態 的用法也是學習者容易忽略的部份,會有「be 動詞+過去式動詞」或「主詞+ 過去分詞」的情形發生。因此本模組將針對這三種情形進行檢查。 1. have(has、had)+過去式動詞[VBD] 2. be 動詞+過去式動詞[VBD] 3. 主詞+過去分詞[VBN]. 圖 3-13. 過 去分詞 檢查 模組流 程圖. 35.
(47) 1. have(has、had)+過去式動詞[VBD] 例句:The plane has took off. 此句經過 APP 解析輸出如下: <Tree> <CNode tag="S" > <CNode tag="S" > <CNode tag="NPL" > <CLeaf tag="DT" word="The" index="0" /> <CLeaf tag="NN" word="plane" index="1" /> </CNode> <CNode tag="VP" > <CLeaf tag="VBZ" word="has" index="2" /> <CNode tag="SBAR" > <CNode tag="SS" > <CNode tag="VP" > <CLeaf tag="VBD" word="took" index="3" /> <CNode tag="ADVP" > <CLeaf tag="RB" word="off" index="4" /> </CNode> </CNode> </CNode> </CNode> </CNode> </CNode> <CLeaf tag="-PERIOD-" word="." index="5" /> </CNode> </Tree> 圖 3-14. 過 去分詞 例句在 APP 中 解 析輸出 (1). 一般來說,如果有「be 動詞+動作」的句子,其中的動作必須使用「be 動詞+ 過去分詞」 ,也就是被動語態來表示,而不是過去式動詞。所以當程式中遇到過 去式動詞[VBD]之後,就開始尋找前面的詞是否有 has,當找到的時候程式就輸 出錯誤訊息,因為他並不符合過去式動詞的用法,換句話說,其實兩個動詞根 本是不能相連接的,所以如果沒有找到[VBN]的情況下,則繼續尋找有無 [VBN],繼續進行其他的判斷。 這句正確的寫法應為「The plane has taken off.」。. 36.
(48) 2. be 動詞+過去式動詞[VBD] 例句:He was knew to people. 此句經過 APP 解析輸出如下: <Tree> <CNode tag="S" > <CNode tag="NPL" > <CLeaf tag="PRP" word="He" index="0" /> </CNode> <CNode tag="VP" > <CLeaf tag="VBD" word="was" index="1" /> <CNode tag="SBAR" > <CNode tag="SS" > <CNode tag="VP" > <CLeaf tag="VBD" word="knew" index="2" /> <CNode tag="PP" > <CLeaf tag="TO" word="to" index="3" /> <CNode tag="NPL" > <CLeaf tag="NNS" word="people" index="4" /> <CLeaf tag="-PERIOD-" word="." index="5" /> </CNode> </CNode> </CNode> </CNode> </CNode> </CNode> </CNode> </Tree> 圖 3-15. 過 去分詞 例句在 APP 中 解 析輸出 (2). 我們根據解析之後的詞性進行文法判斷,首先找到句中的過去式動詞 knew[VBD],結果在他的前面發現有 be 動詞 was 存在,根據流程圖所示,程 式可以在這邊找到錯誤,需要更正為「be 動詞+過去分詞」。 同(1),這句也可由另外的角度來看,在一個句子中,動詞是不可以相連的,除 非有連接詞分開。. 37.
(49) 3. 主詞+過去分詞[VBN] 例句:The hamburger eaten by my brother. 此句經過 APP 解析輸出如下: <Tree> <CNode tag="S" > <CNode tag="NPL" > <CLeaf tag="DT" word="The" index="0" /> <CLeaf tag="NN" word="hamburger" index="1" /> </CNode> <CNode tag="VP" > <CLeaf tag="VBN" word="eaten" index="2" /> <CNode tag="PP" > <CLeaf tag="IN" word="by" index="3" /> <CNode tag="NP" > <CLeaf tag="PRP$" word="my" index="4" /> <CNode tag="NPL" > <CLeaf tag="NN" word="brother" index="5" /> <CLeaf tag="-PERIOD-" word="." index="6" /> </CNode> </CNode> </CNode> </CNode> </CNode> </Tree> 圖 3-16. 過 去分詞 例句在 APP 中 解 析輸出 (3). 同上,我們找到句中的[VBN],接著在他的前面找到 A hamburger[NPL], 這邊所謂的主詞,是含有名詞的最小名詞子句[NPL],因此在缺少 be 動詞的情 況之下,程式找到錯誤,應該將此句更正為「A hamburger was eaten by my brother.」才對。. 38.
(50) 3.4.3 A 和 AN 判別 在文法當中,不定冠詞 A 和 AN 的用法,也是常被提到的,在 CLEC 中, 也佔了一定的比例。這部份不需要使用 APP 解析出來的詞性,只需要檢驗單字 之間的關係即可。. 我們歸類下列四種情形,都是錯誤的狀況,提供程式作為檢查之用。. 1. A+母音開頭單字 2. A+子音開頭單字(例外) 3. AN+子音開頭單字 4. AN+母音開頭單字(例外). 圖 3-17. A 和 AN 判別 檢查模 組流 程圖. 一般來說,大部分 A 和 AN 的用法,都可以用單字開頭的字母作為判別的 標準,只要開頭是母音的單字就用 AN,是子音的就用 A;但是,嚴格說來, 其實是要根據單字的發音為準,發音的開頭是母音就用 AN,是子音才用 A,. 39.
(51) 但是程式中不容易做到,因此我們使用特例的方式,直接寫入一些例外的字, 讓程式的判別能夠正確。 這個模組中並不需要用到詞性的解析,只需要運用到單字,也就是說不需 要經過 APP,就可以直接以文法檢查模組判斷正確與否。以下分別說明能夠判 斷的四種類型。 1. A+母音開頭單字 例句:This is a apple. Apple 的開頭不能使用 A 作為不定冠詞。 2. A+子音開頭單字(例外) 例句:I only spent a hour to study. 這是 A or AN 的例外用法,由於 hour 的 h 是不發音的,因此這時候仍然需要使 用 an 來當作不定冠詞。 3. AN+子音開頭單字 例句:An train has just arrived the station. Train 的開頭是子音,因此不能使用 an 作為不定冠詞。 4. AN+母音開頭單字(例外) 例句:He studied in an university. 固然 university 的開頭字母是母音 u,但是在發音來說,開頭的發音是[ju],並 非母音,因此這邊的不定冠詞應該使用 a 才對。. 40.
(52) 3.4.4 基本動詞使用 在動詞的使用上,我們提出幾個需要注意的地方,主要是屬於動詞出現的 次數;通常句子中只會有一個動詞,如果出現兩個動詞的話,動詞之間就必須 以連接詞分開。另外,也檢查多個動詞的狀況。 因此這個模組在檢查下列兩種情形: 1. 句中沒有任何動詞。 2. 句中有兩個以上的動詞,但是動詞之間並沒有出現連接詞、不定詞、關 係代名詞、助動詞…等。. 圖 3-18. 基 本動詞 使用 檢查模 組流 程圖. 41.
(53) 1. 句中沒有任何動詞: 例句:In China, during the last year and just before the armistice. 任何句子中都需要出現動詞,我們列出所有動詞的列表,只要是經過 APP 之 後,沒有被解析成原形動詞[VB]、現在式動詞[VBP]、現在式或過去式動詞 [VBX]、過去式動詞[VBD]、第三人稱單數動詞[VBZ]其中之一的,就算是在句 中沒有找到任何的動詞,我們就在程式當中送出錯誤訊息。 當我們將例句送進 APP 解析,出來的結果是: <Tree> <CNode tag="S" > <CNode tag="PP" > <CLeaf tag="IN" word="In" index="0" /> <CNode tag="NPL" > <CLeaf tag="NNP" word="China" index="1" /> </CNode> </CNode> <CLeaf tag="-COMMA-" word="," index="2" /> <CNode tag="SS" > <CNode tag="PP" > <CLeaf tag="IN" word="during" index="3" /> <CNode tag="NPL" > <CLeaf tag="DT" word="the" index="4" /> <CLeaf tag="JJ" word="last" index="5" /> <CLeaf tag="NN" word="year" index="6" /> </CNode> </CNode> </CNode> <CLeaf tag="CC" word="and" index="7" /> <CNode tag="SS" > <CNode tag="NP" > <CNode tag="NPL" > <CLeaf tag="RB" word="just" index="8" /> </CNode> <CNode tag="PP" > <CLeaf tag="IN" word="before" index="9" /> <CNode tag="NPL" > <CLeaf tag="DT" word="the" index="10" /> </CNode> </CNode> </CNode> <CNode tag="NPL" > <CLeaf tag="NN" word="armistice" index="11" /> <CLeaf tag="-PERIOD-" word="." index="12" /> </CNode> </CNode> </CNode> </Tree> 圖 3-19. 基 本動詞 使用 例句在 APP 中 解析 輸出 (1). 42.
數據
![圖 2-1 所示的是 Aspell 檢查錯誤單字後的畫面[22]。 原句輸入 建議字列表 圖 2-1 系 統中呼叫 Aspell 檢查錯誤 圖 2-1 是系統利用程式呼叫 Aspell 的操作畫面,可以看到輸入的句子是 「thsi is a book」,經過檢查之後,發現錯誤的單字是「thsi」,並且將他反白 起來,表示這部份發生錯誤。另外,對於發生錯誤的單字,給予一些可能的建 議字,如:this、Thai…等,提供使用者參考。](https://thumb-ap.123doks.com/thumbv2/9libinfo/8102249.165234/16.892.121.781.90.859/統中可以看到句子經過檢查之後發現錯誤單字並且將他表示參考.webp)


+7
![圖 3-2 系 統流程 圖 從流程圖當中 [22],我們可以看到系統中運作的情形。首先作文會經過前 處理,進行斷句、斷詞的程序,接著進入拼字檢查,如果不通過就直接評分, 通過的話則繼續以 APP 進行詞性標記,完畢之後便開始以文法模組檢驗,如果 上述的拼字、文法的檢查均正確,我們最後送到同義字檢查模組,檢查文章是 否文不對題。所有以上的結果,將送至評分系統,可讓閱卷者針對系統檢查的 情形加以評分及建議,最後以網頁輸出。](https://thumb-ap.123doks.com/thumbv2/9libinfo/8102249.165234/33.892.133.818.118.849/統流程檢查均正確我們最後送到同義字檢查有以上系統檢查輸出.webp)




相關文件
Now, nearly all of the current flows through wire S since it has a much lower resistance than the light bulb. The light bulb does not glow because the current flowing through it
The MNE subject, characterised by its (i) curriculum structure; (ii) curriculum aims; (iii) learning and teaching strategies; and (iv) curriculum contents, can enhance the
• to develop a culture of learning to learn through self-evaluation and self-improvement, and to develop a research culture for improving the quality of learning and teaching
In view of the large quantity of information that can be obtained on the Internet and from the social media, while teachers need to develop skills in selecting suitable
Information technology learning targets: A guideline for schools to organize teaching and learning activities to develop our students' capability in using IT. Hong
Internal assessment refers to the assessment practices that teachers and schools employ as part of the ongoing learning and teaching process during the three years
to introduce how teachers may enhance learning and teaching effectiveness by adopting virtual reality (VR) technology and relevant strategies in the classroom as well as
(2) Buddha used teaching of dharma, teaching of meaning, and teaching of practice to make disciples gain the profit of dharma, the profit of meaning, and the profit of pure
