Invited Paper
Recognition
of Handwritten Chinese Characters by Self-growing
Probabilistic Decision-based Neural Networks*
Hsin-Chia Fu and Y. Y. Xu
Department of Computer Science and Information Engineering,
National Chiao Tung University,
Hsin-Chu, Taiwan, ROC.
ABSTRACT
In this paper, we present a Bayesian decision-based neural networks (BDNN) for handwritten Chinese character
recognition. The proposed Self-growing Probabilistic Decision-based Neural Networks (SPDNN) adopts a
hierarchical network structure with nonlinear basis functions and a competitive credit-assignment scheme. Our pro-totype system demonstrates a successful utilization of SPDNN to the handwriting of Chinese character recognition on the public databases, CCL/HCCR1 and in house database (NCTU/NNL). Regarding the performance, experiments on three different databases all demonstrated high recognition (86e-'94%) accuracy as well as low rejection/acceptance ( 6.7%) rates. As to the processing speed, the whole recognition process (including image preprocessing, feature ex-traction, and recognition) consumes approximately 0.27 second/character on a Pentium-100 based personal computer, without using hardware accelerator or co-processor.
Keywords : B ayesian Decision-based Neural Networks ,Self-growingProbabilistic Decision-based Neural Networks, Supervised learning, Optical Character Recognition.
1.
INTRODUCTION
In recent years ,thereis a significant increase in the electronic management of information by multimedia information systems. The handling of multimedia documents consists of the editing and display of texts, graphics, images, and handwriting. Currently, the keyboard and the mouse are still the dominant input devices for personal computer based multimedia systems. However, in preparing a first draft and concentrating on content creation, pencil aiid paper are often superior to keyboard entry. By incorporating character recognition with a text-to-speech technology, converting handwriting directly to voice will be an interesting multimedia application.
1..1. Overview of Handwriting Recognition
The machine recognition of characters has been a topic of intense research since the 1960s.14'1 11416.19 After
more than 30 years of rigorous attacks, studies in the field of handwriting recognition remain as active as ever. A comprehensive set of references to recent research and developments in handwriting recognition can be found in two special issues of the International Journal of Pattern Recognition and Artificial intelligence (Vols. 1 and 2, 1991) and Proceedings of IEEE (July 1992). These two issues describe not only the state of the art but also, in many cases, ongoing research efforts. To search for the most updated activities, achievements as well as demonstrations on handwriting recognition, the World Wide Web (WWW) seemns an excellent medium for the researcher and in fact for everyone interested.
Current Status and Related Problems
It is well known that Chinese characters (including Japanese Kanji) are unique and different from that of Western languages such as English, in that they are non-alphabetic and have quite complicated stroke structures. Such properties make Chinese character recognition by computer particularly difficult amid challenging.
Early work on machine recognition of handwritten Chinese character (HCC) research was originated in Japan —over 25 years ago.23"7 Since then, hundreds of paper have been appeared on this topic, which assumes both scientific and commercial importance.
This research was supported in part by the National Science Council under Grant NSC 86-2213-E009-099. Send correspondence to H. C. Fu: E-mail: hcfu©csie.nctu.edu.tw
Due to the large character sett in Chinese language, until 1988 Shyr et aL, built a prototype recognition system for the 5401 printed Chinese characters (FCC) and successfully demonstrated the system with a recognition rate of 95.6%.18 Fouryears later (1992), the first commercial FCC recognition machine, based on a 386 personal computer, was announced, which is capable of recognizing four types (Kai, Ming, Black, and Sung) of 5401 characters with an accuracy of 95% at a speed of 7 characters per second. Thus, machine recognition of Chinese characters is by no means a pure research topic. Nevertheless, the machine recognition of HCC is still considered to be a very difficult problem due to the following aspects:
1. large number of characters set 2. complexity of character structures 3. wide variation in personal handwriting 4. many similar characters
Recently, probabilistic decision-based neural networks (PDBNN) which has the merits of both neural network and statistical approaches was proposed to attack face and other biometrics recognition systems.13 The modular structure in the PDBNN devotes one of its subnets to the representation of a particular person's face images. In each subnets, the discriminate function of a PDBNN is in a form of fixed number of mixture of Gaussian distributions.
This yields extremely low false acceptance and rejection rates for the face recognition systems.
However, since the stroke complexity of Chinese characters varies from one stroke up to a few dozens of strokes. Hence, fixed number of mixture of Gaussian distributions is not suitable for the representation of character pixel distribution. In this paper, we propose a new PDBNN, called Self-growing Probabilistic Decision-based Neural Networks (SPDNN) to recognize Chinese characters. For different characters, the discriminate function of a SPDNN is in a form of flexible number of mixture of Gaussian distributions.
This paper is organized as follows: Section 2 presents the mathematical background, the architecture, and the learning rules of the SPDNN. Then, a multistage handwriting recognition system is presented in Section 3. The proposed system consists of three modules, which are all implemented by the SPDNN. A personal adaptive module is recommended to further improve the recognition performance. Experimental results of these modules are provided
and discussed in each section.
2. SELF-GROWING PROBABILISTIC DECISION-BASED NEURAL NETWORK
Self-growing Probabilistic Decision-based Neural Networks (SPDNN) is a probabilistic variant of decision-based modular neural network1° for classification. One subnet of an SPDNN is designed to represent one object class. There are two properties of the SPDNN learning rules. The first one is the decision-based learning rules. Based on the teacher information which only tells the correctness of the classification for each training pattern, an SPDNN performs a distributed and localized updating rules. The updating rule applies reinforced learning to a subnet
corresponding to the correct class and antireinforced learning to the (unduly) winning subnets.
The second property is the Iteratively Supervised Learning and Unsupervised Growing (JSL UG). There are two learning phases in this scheme: After each subnet is initialized with one cluster (see Section 2.2. 1) or is self-grown with a new cluster (Section 2.2.2), the system enters the supervised learning (SL) phase. In the SL phase, teacher information is used to reinforce or antireinforce the decision boundaries obtained during the initialization or self-growing stages. When the supervised training progress becomes very slow or is trapped in a paralysis state, yet the
classification or recognition accuracy is not at a satisfied level, the training enters the Unsupervised growing (UG) phase. In the UG phase, an SPDNN creates a new cluster in a subnet according to the proposed self-growing rule. Thereafter, the training enters the Supervised Learning phase again. The ISLUG learning procedure terminates when the training accuracy reaches a predefined satisfaction level. The detailed description of the SPDNN model is given in the following sections.
2.1. Discriminant Functions of SPDNN
One of the major differences between PDBNN'3 and SPDNN is that SPDNN extends the fixed number of clusters in PDBNN to flexible number of clusters. That is, the subnet discriminant functions of SPDNN are designed to model the log-likelihood functions of different complexed pixel distribution of handwritten characters. Thus, reinforced or antireinforced learning is applied to all the subnets of the global winner and the supposed (i.e., the correct) winner, with a weighting distribution proportional to the degree of possible involvement (measured by the likelihood) by each
subnet. Given a set of iid patterns X {x(t); t = 1, 2, .. . , N},we assume that the likelihood function p(x(t) w) for class (i.e., a character class) is a mixture of Gaussian distributions.
Define p(x(t) IWi,
er)
to be one of the Gaussian distributions which comprise p(x(t) Iwi),where êr representsthe parameter set {rj, En}fora cluster r in subnet i.
p(x(t) I
w)
=
P(er, Iw)p(x(t) IWi,whereP(Eij I
w)
denotes the prior probability of the cluster r2. By definition,P(er
wj)l, where R is
the number of clusters in w.The discriminate function of the multiclass SPDNN models the log-likelihood function
(x(t),w) = log p(x(t) I w)
= log{ P(er I
w)p(x(t) IWi,êr.i)], (1)where w2 = {i-irj ,>2rj , P(er. I
), T2}.
T, the output threshold of the subnet i.In most general formulation, the basis function of a cluster should be able to approximate the Gaussian distribution with full rank covariance matrix, i.e., Ø(x, w) = xTE;l x, where En is the covariance matrix. However, for those applications which deal with high-dimension data but finite number of training patterns, the training performance and storage space discourage such matrix modeling. A natural simplifying assumption is to assume uncorrelated features of unequal importance. That is, suppose that p(x(t) IWi,er) j5 a D-dimensional Gaussian distribution with uncorrelated features
p(x(t) Wj,êrj)
.exp[!(x(t)
—ri)T(x(t)
ri)]
(2) (2ir) 2 IEriI2where x(t) = [xi (t), x2(t), .. . , xD(t)}T
is the input pattern, ir
[1uri ,/Lr2,• • ,/LrD]T S the mean vector, and
diagonal matrix E7. = ci1 ,
. 2
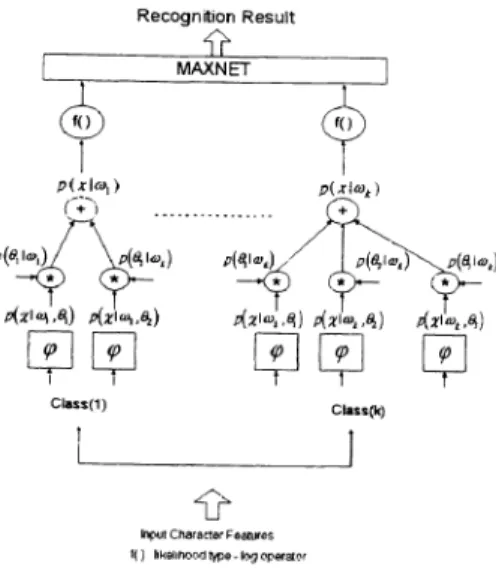
• cr D] is the covariance matrix. As shown in Figure 1 ,anSPDNN containsK subnets which are used to represent a K-category classification problem. Inside each subnet, an elliptic basis functions (EBF's) is used to serve as the basis function for each cluster r:
(x(t),wi,eri) —
rjd(Xd(t)
—rd)2
+
(3) where 6r ln 2r + lnar d . Afterpassing an exponential activation function, exp{b(x(t) ,w,er ) } can
be viewed as a Gaussian distribution, as described in (2), except a minor notational change:
2.2. Learning Rules for SPDNN
Recall that the training scheme for a multiclass SPDNN follows the ISL UG principle. The ISLUG training scherrie contains the following two phases: Supervised Learning and Unsupervised Growing.
Recognrtion Result
p(xke1) p(xla)
p(zl,) p(lw) p(zlw ,)p(%1w1,a2)
Class(1) Class(k)
iii
hput Character Fo5resto IkehhOocltreIegcprcr
Figure 1. Schematic diagram of a k-class SPDNN character recognizer.
2.2.1. Supervised Learning in each subnet
Since the number of cluster in a subnet of an SPDNN can be adjusted in the Unsupervisedgrowing phase, thus each subnet is initialized with one cluster. The values of the parameters (mean andcovariance) of a cluster in each subnet are initialized at the beginning of the first Supervise Learning phase. Suppose that X = {x2(1), .. . , x2(M2)}is a set of given training characters, which correspond to one of the L classes {w,
i
= 1, .• . , L},the mean ,u and covariancey_Ji of the initial cluster in subnet i can be calculated as
/tj
x(rn)
(4)m=1
Ui =
(x(m)
-
pj)(xj(rn)-(5) m=1
During the supervised learning phase, training data is then used to fine tune the decision boundariesof each
classes. The data adaptive scheme of the Supervised Learning for the multiclass SPDNNis the extension of the GS learning in.13 Each class is modeled by a subnet with discriminant functions, ç5(x(t), we), i 1, 2, .. . , L. At the beginning of each Supervised Learning phase, use the still-under-training SPDNN to classify all thetraining characters
x-
= {x(1),x(2),
.. . ,x(M)}
for i = 1, .. . ,L.x(rn)
isclassified to class w, if ç(x('m),w) > ç(xj(m),w),
'1k i, and q(xj(m), w2) T, where T2 is the output threshold for subnet i. According to the classification
results, the training characters for each class i can be divided into three subsets:
•
= {x2('rn);x2(m)E w, x2(m) is classified tow
(correctly classified set) };
•
= {x(rn);x(m)
E w, x2(m) ismisclassifiedto other class w3 (false rejection set) };•
= {x (m); x2 (m) w, x (m) is misclassified to class w (false acceptance set) }.Thefollowing reinforced and antireinforced learning rules1° are applied to thecorresponding subnets.
Reinforced Learning: w1) = w + 'qV(x(m), w)
(6)Antireinforced Learning: cm+1) = w —ijVq5(x2(m),w3)
(7) In (6) and (7), i is an user defined learning rate 0<ij 1, and the gradient vectors Vçt can be computed in a similar manner as proposed in.13
For the data set D
, reinforcedand antireinforced learning will be applied to class w and w ,respectively. Asfor the false acceptance set D,antireinforcedlearning will be applied to class w, and reinforced learning will be applied to the class w where x(m) belongs to.
Threshold Updating The threshold value T2 of a subnet iin the SPDNN recognizer can also be learned by reinforced or antireinforced learning rules.
2.2.2. Unsupervised Growing of a new cluster
The network enters the Unsupervised Growing phase when the Supervised learning reaches a saturated (learning state) but unsatisfied (classification accuracy) situation. There are three main aspects for the self-growing rules:
Ii: When should a new cluster be created?
12: Which cluster should be partitioned to create a new cluster? 13: How to initialize the center and the covariance of the new cluster?
On Issue Il, when the whole training set has been presented for a few times, the train status (especially the recognition accuracy) remains unchanged or unimproved. An extra cluster is suggested to improve the representation power of the SPDNN.
On Issue 12, when an extra cluster is needed, a new cluster is suggested to be created from the subnet which caused the most of misclassification during the recent supervised learning processes.
On Issue 13, when a new cluster is needed, its initial values of the center and covariance needs to be properly determined, otherwise poor classification situation may still exist.
Assume that a training character x corresponding to class w is presented to an SPDNN classifier: the cluster
e,
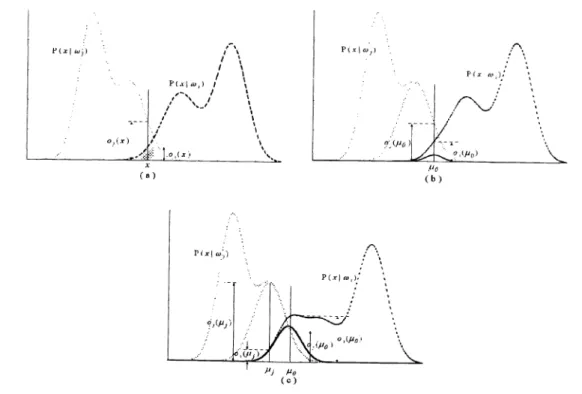
isin class w, and the cluster (say e3)is in the class w which corresponds to the largest response among the classes other than w . Leto and o be the output of x from class w and class w ,respectively. According to the retrieving scheme of the proposed SPDNN, if o is larger than or equal to o ,theretrieving result for the training character x must be wrong. As shown in Figure 2(a), clearly the best position for the center of the new clustershould be located at x, i.e., p = x,so that the class with new cluster ê will generate the maximal output o for
the training character x. To determine the covariance matrix E, first let E =aoland a be a positive constant
(to be determined). As shown in Figure 2(b), if the o of the new cluster eis not properly determined, the class with the new cluster will have its largest possible output o2(x) to be smaller than the output o3(x) of class w . In other word, the cluster E is overwhelmed by cluster EJ ,where, and E3 are the center and covariance of cluster
e
. Toprevent the overwhelming problem, Figure 2(c) presents a properly initiated new cluster E . Thefollowing two constraints are suggested for a proper initial value of a.P(e I
w)
1 (x —,)T(x
P(eoIo3(x)
=
I
exp—
+ €3 < o(x) =
+
ci (8)(2rr) EJ2 L (2ira)2
P(e0
)
1(x —)T(x
jt)
,P(e
w)
o() =
exp+
€2<
o() =
, +
(9)(2ica) 2 '-ii (2rr) 2
where
P(e0 I
w)
and P(e3 w) are the prior probability of cluster eande3, respectively. e2 and e3 represent thepartial output of classes w and w from the clusters other than e,ande3 at
x. c and e are the partial output
at j of the clusters other than 9 and e3
. Theprior probability P(e0 w) of cluster e
canbe initialized as (/o)P(e
I), where
=
(1/R)E1
a,.1, in which o'r 5 the covariance of cluster r in class w. Since q,€, e,and e ,arevery small at x and jz ,theyare ignored in the following a estimation.
These two constraints imply that cluster eandcluster e3 willnot overwhelm each other. To satisfy (8), a is
. . . . P(eIw) _.-_ .
initializedto be lesser than ((2)D/2O(X))D-2 Then, a can be iteratively decreased by a small value 'rj (0 < rj 1) until (9) is satisfied, and the final value of a can be a proper initial value of a0 for the new cluster E.
k(xI wp
. . I '
. . / \
Figure 2. Example of creating a new cluster in a mixture of Gaussian distributions. (a) Forx(t) E
w
the x(t) is
not correctly classified, since o(x(t)) is smaller than o3(x(t)). A new cluster eisneeded in w2. (b) The new clustere overwhelmed by the cluster ®, i.e., Oj(j)
isstill smaller than Oj(jiØ). (c)By having initialized with proper /o, OO andP(e0 wi), the new cluster e
can contribute enough to support class w2. Forexample, o(o) is larger than o(,ao), and Oj(jj)issmaller than
3. MULTISTAGE HANDWRITTEN CHARACTER RECOGNITION
SYSTEM
An SPDNN-based Handwritten character Recognition system is being developed in the Neural Networks Laboratory of National Chiao Tung University. The system configuration is depicted in Figure 3. All the three main modules, including preprocessing and feature extraction module, coarse classifier, characterrecognizer and its personal adaptive module are implemented on a Pentium-lOU based personal computer.
The system built upon the proposed SPDNN has been demonstrated to beapplicable under reasonable variations of character orientation, size, and stroke width. This system also has been shown to be very robust in recognizing characters written by various tools; such as pencils, ink pens, mark pens as well as the Chinese calligraphy brushes. The prototype system takes 270 ms in average to identify a characterimage out of a commonly used Chinese character set (e.g., the 5401 sect21) on a Pentium-lOU based personal computer. For alphanumericalcharacter recognition, the recognition is about three times faster.
3.1. Image preprocessing and Feature Extraction
Image preprocessing of a Chinese character recognition is by no means ofany different from the monolanguage character recognition. Character segmentation on free format handwritten character is a very difficult task, thus it is usually an interactive task between segmentation and recognition. Since the Chinese character recognition is already a complicated recognition problems, and the interactive segmentation methods would slow down the processing speed, we must restrict our handwritten character domain to be free format on Chinese characters and handprinted characters on alphanumerics. Thus, an Interactive Rule-Based CharacterSegmentation5 is applied to slice and separate the whole page image into a sequence of characterimage. Basically, this method is based on some heuristic rules to combine several isolated connected-components intoa separated character.
The binary images of a handwritten character are then passed through a series of image processing stages, such as
P(XICO,)
P(x
P (x
Iii Ajo
Original
Figure 3. System configuration of the multistage character recognition system. Character recognition system
acquires images from a scanner. The coarse classifier determines an input character image tobe one of the predefined subclass. The character recognizer matches the input character with a reference character. The personal adaptive module learns the user's own written style to enhance the recognition accuracy.
boundary smoothing, noise removing, space normalization, and stroke thinning operations. Figure4 depicts a series of preprocessing results of some Chinese and English characters.
lI
___
SmoothedI(1 [JktJ
NdftJ
___
ThuinedEi IJ r:j
Figure 4. Image preprocessing on handwritten characters: (from top) original text image, smoothed text,linear
normalized text, nonlinear normalized text and thinned text.
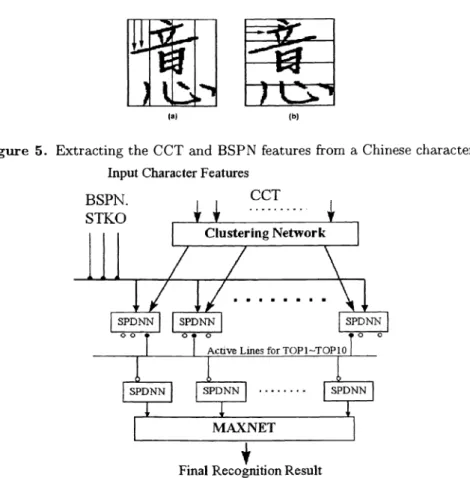
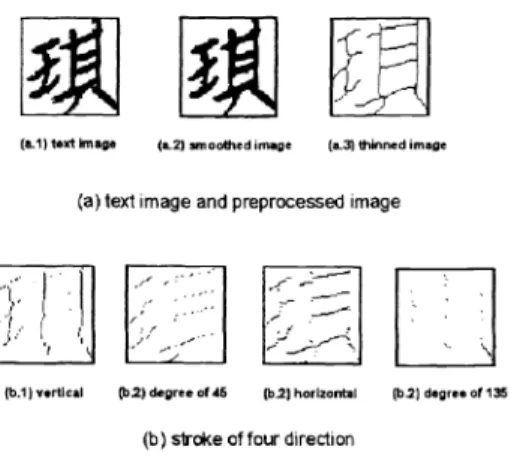
Feature extraction Using statistical features in pattern recognition has been very successful for a long time. A character can be well represented by a 2-D image pattern, thus many statistical pattern recognition techniques have been applied in this type of character recognition. Among various statistical features,6 we selected the crossing count (CCT), belt shape pixel number (BSPN), and stroke orientation feature (STKO) as candidatefeatures for the proposed character recognition system. As shown in Figure 5, features such as CCT and BSPN represent the stroke complexity and the pixel density of a character image. In,9 Kimura et al. proposedthe directional code histogram, and used this feature for Chinese character recognition successfully. As shown in Figure 7, the STKO is a simplified version of Kimura's directional code histogram.
I)c:
(a) (b)
Figure 5. Extracting the CCT and BSPN features from a Chinese character. Input Character Features
Figure 6. The architecture of the three-stage recognition system.
3.2. Multistage character recognition
Since there are as many as 5401 commonly used characters, and 62 alphanumerics and symbols in a Chinese document, it is desirable to perform a coarse classification (or clustering) to reduce the number of candidate characters for the
character recognition. With a smaller candidate set, not only the overall recognition speed and recognition accuracy can be greatly improved, but also the training on the SPDNN character recognizer can be much easier and faster. The architecture of a multistage SPDNN character recognizer is depicted in Figure 6.
3.2.1. Coarse classification
In order to achieve a balanced recognition performance in a multistage recognition system, the coarse classifier needs to maintain a very high accuracy, (e.g., 99.9%). Although this is a difficult task, we proposed to use the OCT feature and the SPDNN with overlapped boundaries to implement the coarse classifier. This design is to achieve low sensitivity in personal writing style and high classification rate among characters. By applying the two public databases suggested in Section 3.2.3 and the ISL UG principle, we have trained the proposed coarse classifier to achieve this goal. The training and testing results are listed in Table 1. At the end of the retrieving phase of the coarse classifier, the number of candidate characters with respect to the input character is reduced to 516 characters in average.
3.2.2. Character recognition
The design of the character recognizer is also based on the SPDNN model. For a K-character recognition problem, an SPDNN character recognizer consists of K subnets. A subnet i in the SPDNN recognizer estimates the distribution
on the patterns of character i only, and treats those patterns which do not belong to character i as the "non i'
patterns. The combined features such as CCT, BSPN, and STKO are used in the SPDNN character recognizer. The training of the character SPDNN was conducted with the ISL UG principle. During the retrieving phase, each of the
Table 1. THE TRAINING AND TESTING RESULTS OF COARSE CLASSIFICATION ON THE CCL/HCCR1 AND THE CEDAR DATABASES. HALF OF THE RANDOMLY SELECTED CHARACTERS IN EACH OF DATABASES ARE USED FOR TRAINING AND THE OTHER HALF ARE USED FOR TESTING.
II Nuniber Ave. No. of Traiiiiiig Testing
II of characters Accuracy Accuracy
II cluster iii a cluster
U- 61 516 99.9 % 99.8%
subnets corresponding to candidate characters from coarse classifier produces a score according to its discriminate function q5(x(t), w2). The subnet which produces the highest score is the winner and its corresponding reference character is considered as the result of the character recognizer.
aj
(a.1) toxt niage (a2)smoothedimage (&3) thinned image
(a)text imageand preprocessed image
,: , L 1
(b.1) vertical (b.2) degree o145 (b2) horizontal (b.2) degree or 35
(b)strokeoffourdirection
Figure 7. Preprocessing and STKO feature extraction of a Chinese character.
3.2.3. Experimental Results
In this section, experimental results for handwriting recognition will be discussed. We will use the 21
handwritten characters database, which have been used by several handwritten character recognition research groups.5'6'12
Handwritten Chinese Recognition: We have conducted experiments on the CCL/HCCR1 database, which contains more than 200 samples of 5401 frequently used Chinese characters. The samples were collected from 2600 people including junior high school and college students as well as employees of ERSO/ITRI. According to the most recent survey on handwriting recognition,4"4'20 most of the handwritten Chinese OCR were done on small database, i.e., training and testing on very small size of character set, e.g., a few hundred characters. As far as studies conducted on the recognition on a complete set of commonly used Chinese characters, Xia22 developed an experimental system on the 3755 character set and achieved a 80% recognition rate. Recently, Li and Y&2 reported a 93.43% recognition accuracy on the CCL/HCCR1 database. Our SPDNN-based system achieved a slightly lower accuracy performance (90.11%). Table 2 summarizes the performance comparison of these two systems based on CCL/HCCR1 database. We would like to comment on why the SPDNN has inferior performance. First, compared to the huge number of character feature sets (4OO'5OO) used by,12 the features used by SPDNN only consists of 96 sets. A mnore relevant comparison could be made if comparable number of training and testing features for these two systems were available. In fact, the SPDNN character recognizer is designed to use no more than 100 sets of features, since more feature set means more memory storage and longer recognition time. Two reasons explain why SPDNN can live with lesser features and yet achieve a comparable performance. (1) The mixture of Gaussian-based discriminant function permits the SPDNN to learn the precise decision boundaries. (2) The self-growing rules allow for just enough number of Gaussian clusters to represent the character image distribution. Therefore, the proposed SPDNN system is very suitable to implemented on a personal computer system. Li and Yu's system was implemented on a Sparc-2 workstation.
Table 2. PERFORMANCE OF DIFFERENT HANDWRITTEN CHARACTER RECOGNIZERS ON TilE CCL/H('CRI DATABASE. [HE Li-ojuI SYSTEM WAS IMPLEMENTED BY THEIR MAIN FEATURES. AND Li-gu2 SYSTEM WAS
IM-IIJ:MENFED BY 1 HEIR FULL SET OF FEATURES12.
I1SysteI1ks Accuracy Feature sets Train/Test ratio
SPDNNI flLi-yu1 Li-yu2 90.12 88.65% 96 400 50-50 50-1 93.43N 500 50-1
SPDNN2 114.O2eX 194 50-50with 6N rej.
3.3. SPDNN for Personal Adaptive Recognition
lit order to further enhance the recognition accuracy, we proposed personal adaptation on the SPDNN character
recognizer.
L nconstrazned freehand-written character recognition
Most of rite recently announced handwritten character recognition systeoris claimed their beiicliinarking recognition perforniaiice to he higher than 90%. However, when they were tested on unconstrained freehand-writing, most of their recognition accuracy fell between 40% and 5Q%•7 Hence, we suggested an unconstrained freehand-writing rtcogiution module to adaptively fine tune the parameters of the SPDNN character recognizer in order to learn the users own writing style. When input characters were misclassified, the erroneous recognition results will he manually
corrected by a user. In the mean time, the parameters or the decision boundaries of the corresponding character
8P1)NN are modified and improved by performing the reinforced and antireinforced learning processes. In addition,
when it is necessary, clusters iii a character SPDNN may be created (self-growing rules) to better approximate the partition boundaries. In order to prevent the excessive learning of the designated character boundary, the
adaptive learning process usually include a verification process. Naturally, the reinforced arid aritireinforced learning processes are applied to the SPDNNs associated with the mismatched character and its similar characters (the 101' 1(1 candidates). When more and more unconstrained freehand-written characters are presented to the system. each (:hiaracter SPDNN will gradually learn the user's personal writing style.
- to
- 1i
iit $itti 4+
t'tF ileip
CJJ
itF12T4Z
•J.:::::::.:::::::L
I8t5gl
it' 3J:
Cr0IE
0.24 2 — .Figure 8. The user interface and a recognition snapshot of the proposed three-stage recognizer.
Experimental results and Performance evaluation
ln order to evaluate the performance of the unconstrained freehand-writing recognition module for its adaptation arid recognition capabilities, we prepared our in house database (NCTU/NNL) in the following manlier. We first. selected the most commonly used 300 characters from the Chinese textbooks for the elementary schools in Taiwan. And then, these 300 Chinese characters and the alphanumerics were written! without any restriction on the writing style by several students in our university for 10 times in several days. We intended to simulate a natural and general
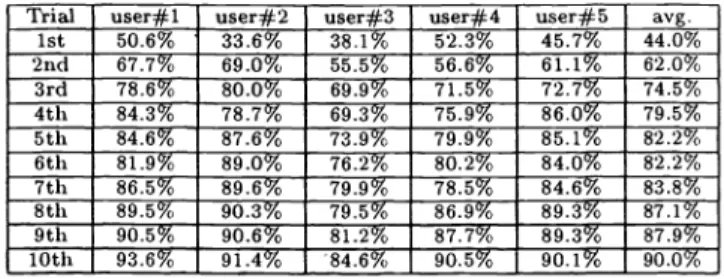
unconstrained freehand-written database in this manner. The testing results for 5 user's adaptation processes are illustrated in Table 3. The recognition rates was raised from 44.09% to 82.2% during the 5 learning cycles. Arid
Table 3. B APPLYING 300 COMMONLY USED CHARACTERS WRITTEN WITHOUT ANY CONSTRAINTS BY FIVE STU-DENTS, THE PROPOSED ADAPTIVE SYSTEM SHOWS SIGNIFICANT IMPROVEMENT ON THE RECOGNITION ACCURACY DURING THE 10 LEARNING CYCLES.
—ri:i-- user#1 user#2 user#3 user#4 user#5 avg.
1st
i
50.6% 33.6% 38.1% 52.3% 45.7% 44.0% 67.7% 69.0% 55.5% 56.6% 61.1% 62.0% 78.6% 84.3% 80.0% 78.7% 69.9% 69.3% 71.5% 75.9% 72.7% 86.0% 74.5% 79.5% .__.&_ 84.6% 81.9% 87.6% 89.0% 73.9% 76.2% 79.9% 80.2% 85.1% 84.0% 82.2% 82.2% 7th 86.5% 89.6% 79.9% 78.5% 84.6% 83.8%••tli
89.5% 90.3% 79.5% 86.9% 89.3% 87.1% 90.5% 90.6% 81.2% 87.7% 89.3% 87.9%:i:
93.6% 91.4% 84.6% 90.5% 90.1% 90.0%4. PROTOTYPING AND USER INTERFACE DESIGN
The proposed multi-stage recognition system has been implemented on a Pentium-100 based personal computer. The hardware equipment and software environment are:
S hardware: a Pentium-lOU personal computer with 8-16 M bytes RAM, and an optical scanner; . software: TWAIN scanner interface, and Chinese Windows 3.1, or 95.
User interface design Since this system may require an user to correct recognition errors, thus a friendly user interface becomes necessary. Figure 8 depicts the user interface and a snapshot of recognition results of the prototype system.
The user interactive window contains three partitions: the left partition displays the binary image of an A4 sized handwritten document, the upper-right partition displays the recognition results and the lower-right partition contains an interactive error correcting interface. When a user intends to correct some errors from the primary recognition results, one can move the cursor to point the misclassified word first, then the top 10 recognition results will be displayed at the buttons. If a correct word is displayed in one of the button, then the user can point and click the cursor to make the correction. If the correct character is not in the top 10 list, then the user can manually type in a character to correct the misclassified character.
5. CONCLUDING REMARKS
In this paper, a neural network handwritten Chinese character recognition system is proposed and implemented on a Pentium-100 based personal computer. This system performs classification, character recognition, and unconstrained freehand-writing recognition. The SPDNN, a Bayesian Decision-based Neural network, was applied to implement the major modules of this system. This modular neural network deploys one subnet to take care one object (character) and therefore it is able to approximate the decision region of each class locally and precisely. This locality property is attractive especially for personal freehand-writing or signature identification applications. A personal adaptation for the character recognition module is proposed and implemented to improve the recognition performance on the unconstrained freehand-writing. On the other hand, due to the enormous number of variations involved, handwriting recognition applications still require more work before they can reach comparable performance by a human. There-fore, document analysis and recognition become an interesting and fascinating research topic in the field of intelligent information processing.
Acknowledgments
The authors acknowledge Prof. S. -Y. Kung, Dr. S. -H. Lin for their helpful suggestions regarding the probabilistic DBNN and statistical pattern recognition methods.
REFERENCES
1. H.S. Baird, "Feature identification for hybrid structural/statistical pattern classification," Computer Vision, Graphics, and Image Processing, vol. 42, pp. 318-333, 1988.
2. R.M. Bozinovic and S.N. Srihari, "Off-line cursive word recognition," IEEE Trans. Pattern Anal. Machine Intell., vol. 11, pp. 68-83, Jan 1989.
3. D.J. Burr, "Designing a handwriting reader," IEEE Trans. Pattern Anal. Machine Intell., vol.PAMT-5, pp554-559, 1983.
4. F.H. Cheng and W.H. Hsu, "Researchon Chinese OCR in Taiwan," mt. J. of Pattern Recognition and Artificial Intelligence, Vol. 5, No. 1 & 2 (1991), pp. 139-164.
5. Cheng-Chin Chiang, Tze Cheng, Shiaw-Shien Yu, "An Iterative Rule-Based Character Segmentation Method for Chinese Documents," in Proc. of mt. Conf. on Chinese Computing'96, June 4-7, 1996 Singapore.
6. H.C. Fu and K.P. Chiang, "Recognition of Handwritten Chinese characters by Multi-stage Neural network classifiers," in Proc. of 1995 IEEE mt. Conf. Neural Networks, Perth, Australia.
7. H.C. Fi, S.C. Chuang, Y.Y. Xu, W.H. Su, and K.T. Sun, "A Personal Adaptive Module for Unconstrained Handwritten Chinese Characters Recognition, "in Proc. of the International Symposium on Multi-technology Information Processing, Hsinchu, Taiwan, ROC, Dec., 1996.
8. Jonathan J. Hull, "A Database for Handwritten Text Recognition Research," in IEEE Trans. Pattern Analysis Mach. Intell., Vol. 16, No. 6, pp. 550-554, 1994.
9. F. Kimura, K.Takashina, S. Tsuruoka and Y. Miyake, "Modified quadratic discrirnininant functions and Ap-plication to Chinese character recognition," in IEEE Trans. Pattern Analysis Mach. Intell., Vol. 9, No. 1, pp.
149-153, 1987.
10. S.Y. Kung, and J.S. Taur, "Decision-based Hierarchical Neural Networks with Signal/Image Classification Ap-plications," in IEEE Transactions on Neural Networks, Vol. 6, No. 1, pp. 170-181, Jan 1995.
11. Y. Le Cun, B. Boser, J.S. Denker, D. Henderson, R.R. Howard, W. Hubbard, and L.D. Jackel, "Handwritten zip code recognition with multi-layer networks," in Proc. 10th Int. Conf. Pattern Recognition, 1990, pp.35-40. 12. Tze-Fen Li, and Shiaw-Shian Yu, "Hand-printed Chinese Character Recognition Using the Probability
Distri-bution Feature," mt. J. of Pattern Recognition and Artificial Intelligence, Vol. 8, No. 5, (1994), pp. 1241-1258. 13. Shang-Hung Lin, S.Y. Kung, and L.J. Lin, "Face Recognition/Detection by Probabilistic Decision-based Neural Networks," in IEEE Transactions on Neural Networks, special issue on Artificial Neural Network and Pattern Recoqnition, Vol. 8, No. 1, pp. 114-132, 1997.
14. 5. Mori, C.Y. Suen, and K. Yamamoto, "Historical Review of OCR Research and Development," Proceedings of IEEE, vol. 80, no. 7, pp. 1029-1058, July, 1992.
15. G. Nagy, "Optical character recognition," Handbook of Statistics, P. R. Krishnaiah, L. N. Kanal, Eds., pp. 621-649, North Holland, 1982.
16. G. Nagy, "Chinese character recognition: A twenty-five year retrospective," in Proc. 12th mt. Conf. Pattern Recognition, ppl63-l67, 1988.
17. H. Ogawa and Y. Tezuka, "Recognition of handwritten Chinese characters by means of hierarchical representa-tion,' in Proc. mt. Comput. Symp., Taipei, 1975, Vol. 1, pp. 411-420.
18. 1.-S. Shyu, L.-T. Tu, M.-Y. Chen, K.-H. Chou, and W.-W. Lin, "Design of a decision tree and its application to large-set printed Chinese character recognition," in Proc. Int. Conf. Comp. Processing of Chinese & Oriental Lang., Toronto, Canada, 1988, pp. 126-130.
19. C.Y. Suen, M. Berthod, and S. Mori, "Automatic recognition of hand-printed character -thestate of the art," IEEE Proceedings, vol. 68, pp. 469-487, April 1980.
20. Ju-Wei Tai "Some Research Achievements on Chinese Character Recognition in China," Int. J. of Pattern Recognition and Artificial Intelligence, Vol. 5, No. 1 & 2 (1991), pp. 199-206.
21. L.T. Tu, Y.S. Lin, C.P. Yeh, I.S. Shyu, J.L. Wang, K.H. Joe, and W.-W. Lin, "Recognition of hand-printed Chinese characters by feature matching," in Proc. of 1991 First National Workshop on Character Recognition, Taipei, ROC, 1991, pp. 166-175.
22. Yin Xia, "Research Report on interactive self-learning system of handwritten Chinese characters," Department of Computer Science, QingHua University, Nov. 1989.
23. M. Yoshida and M. Eden, "Handwritten Chinese character recognition by A-b-s method," in Proc. 1st mt. Joint Conf Pattern Recognition, Nov. 1973, pp. 197-204.