行政院國家科學委員會專題研究計畫 成果報告
多速率多載波無線傳輸之多輸入輸出訊號處理(1/3)
計畫類別: 個別型計畫
計畫編號: NSC91-2219-E-002-038-
執行期間: 91 年 08 月 01 日至 92 年 07 月 31 日
執行單位: 國立臺灣大學電信工程學研究所
計畫主持人: 李宇旼
計畫參與人員: 徐禎助、何維鴻、王柏淵、黃婉甄、陳彥倫、陳禮鈞、陳厚昕、
陳鼎堯、蔡昇甫、黃燦煌
報告類型: 精簡報告
處理方式: 本計畫可公開查詢
中 華 民 國 93 年 2 月 22 日
Abstract – In this report, we propose a reduced complexity
tree-based multi-user detection algorithm called relative threshold tree pruning (RTTP) for MC-CDMA. Two enhancements to RTTP – user ordering and user partitioning – are also investigated. Simulation results show that RTTP outperforms the conventional M-algorithm in both error performance and complexity.
I. INTRODUCTION
Multi-carrier code division multiple access (MC-CDMA) [1] is an advanced transmission technology that employs both orthogonal frequency division multiplexing (OFDM) and spread spectrum to achieve high data rate in multiple access channels. The multi-carrier component of MC-CDMA transforms an inter-symbol interference (ISI) channel into parallel one-shot channels provided that the cyclic prefix (CP) is sufficiently long, while the CDMA component provides multiple access capability. In a multi-user scenario, multiple access interference (MAI) could be severe and multi-user detection (MUD) [3] may be required to achieve useful performance.
It is possible to perform maximum-likelihood (ML) MUD for MC-CDMA by searching a perfect tree [3]. However, the complexity of perfect tree search is exponentially related to the number of active users, and can be prohibitively high even for a moderate number of users. Pre-whitening tree pruning (PWTP) [4,5] is a reduced complexity near-ML MUD based on tree search. In PWTP, a total of Mk survivors are retained at the k-th level of the tree.
It has been shown that by properly choosing Mk, significant
complexity reduction is possible without too much performance degradation. Although simple and efficient, a major drawback of PWTP is that it requires sorting the node metrics at every level of the tree, which can be costly in VLSI implementation. Furthermore, the values for Mk are chosen
empirically and are fixed. Since wireless communication channels are random in nature, it is also desirable to modify PWTP so that the number of survivors at each level of the tree somewhat adapts itself to the channel conditions.
This report presents a new pruning approach referred to as relative threshold tree pruning (RTTP) that does not require sorting the node metrics. As will be seen later, with RTTP the number of survivors at each level of the tree adapts itself to the channel conditions. We also present a user ordering algorithm that can be easily incorporated into pre-whitening. It will be seen that the algorithm can significantly enhance the performance of MUD algorithms based on searching a pruned tree, while causing only very little increase in complexity. In particular, for RTTP a performance gain of 2dB is obtainable. Finally, this report also shows that when user ordering is performed, the performance of RTTP can be further improved by operating over the real field instead of the complex field. As will be seen later, based on this principle performance gain is obtainable without increasing computational complexity.
II. ML MUD BASEDON TREE SEARCH
Consider the discrete-time baseband signal model of a multi-rate multi-user transmission system shown in Fig. 1, in which a total of K active users transmit one information symbol simultaneously. The received signal is modeled as an N × 1 vector x, where N is the spreading factor,given by
[
]
c c K K K b b b A A A n SAb n s s s x + = + = Μ Λ Μ Ο Μ Μ Λ Λ Λ 2 1 2 1 2 1 0 0 0 0 0 0 (1)where si, is the signature vector of the i-th user, Ai, and bi are,
respectively, the channel gain and information symbol of i-th user, and nc is a zero-mean circularly symmetric white
Gaussian noise vector with E[ncncH]= N0IN where IN is the
N×N identity matrix. In (1), S, A, and b are N × K, K × K, and K×1 matrices whose definitions are clear from the equation.
It can be shown that the maximum likelihood (ML) receiver for the system in Fig. 1 consists of a bank of K filters, each matched to one active users’ signature vector weighted by the corresponding channel gain, followed by some decision logic (the multi-user detector [MUD]) for detecting the transmitted symbols of all active users [3,4]. The output of the matched filter bank (MFB) can be expressed in matrix-vector form as n Rb x SA y = = + ≡ H 1 ) ( K y y Μ (2)
where “H” denotes Hermitian transposition, R=(SA)H(SA), and n=(SA)Hnc is a zero-mean circularly symmetric complex
Gaussian noise vector with covariance matrix N0R. The
output of MUD in the ML receiver is equal to ] [ min arg ˆ H 1 Rb) (y R Rb) (y b b − − = − (3)
in which the minimization is over all mK possible choices of b, where m is the cardinality of the signal constellation1. Assuming that R is positive-definite, there exists a unique K×K lower triangular matrix L with positive diagonal elements such that
L L R= H , (4) thus 2 2 H argmin min arg ˆ (L y Lb) (r Lb) b b b − = − = −
,
(5)where r = L-Hy is the whitened received signal vector. The ML receiver obtained according to (5) is shown in Fig. 2.
1
We assume that every user has the same signal constellation.
Since L is lower-triangular, the minimization in (5) can be performed using a perfect m-ary tree shown in Fig. 3. Specifically, consider a particular (k-1)-th parent node with associated candidate subsequence bˆparent =
(
bˆ1,bˆ2,Λ ,bˆk−1)
and node metric Dparent. The parent node has m children at the
k-th level corresponding to each one of the m signal con-
x SpreadingWaveform Matched Filter Bank User 1 Decision User 2 Decision User K Decision …… … y c + + nc × × A1 s1 b1 × × AK sK bK MUD Fig. 1. General discrete-time signal model of a multi-rate multi-user transmission system.
MFB y L-H ML MUD r x User 1 Decision User 2 Decision User K Decision …… …
Fig. 2. The ML receiver structure.
root first level second level leaf nodes K-th level
Fig. 3. The tree structure for m=2.
stellation points. The associated node metric of the child node corresponding to the signal constellation point bˆ is k given by 2 ˆ k kk k parent child D z l b D = + − , (6) where ∑ − ≡ − = 1 1 ˆ k n kn n k k r l b z , (7)
in which lkn is the (k,n)-th entry of L. In addition, the
candidate subsequence associated with this child node is given by
(
parent,bˆk)
child b
b = . (8)
The algorithm is initialized by setting the metric and candidate subsequence associated with the root (0-th level) node to 0 and the null sequence, respectively. The above procedure is performed from the root to the leaf (K-th level) nodes of the tree, resulting in a total of mK candidate (sub)sequences and associated metrics . The output of the ML MUD is the candidate (sub)sequence at the K-th level with the smallest associated metric. In general, the number of additions and multiplications of the tree-search algorithm is
proportional to mK.
The model described in (1) can be used to model MC-CDMA signals. The baseband-equivalent signal model of down-link (DL) synchronous MC-CDMA system is shown in Fig. 4. The OFDM transceiver in MC-CDMA can be viewed as an equivalent multi-input multi-output (MIMO) channel characterized by the channel matrix H. The received signal x is thus given by
OFDM Modulator + s1 b1 s2 sK × A1 b2 × A2 bK × AK x OFDM Deodulator Channel c
Equivalent to MIMO channel
Fig. 4. Baseband equivalent signal model for DL MC-CDMA.
s1 b1 × A1 OFDM Modulator 1 + s2 b2 × A2 OFDM Modulator 2 sK bK × AK OFDM Modulator K
Channel DeodulatorOFDM
x c1
c2
cK
Fig. 5. Baseband equivalent signal model for ULQS MC-CDMA.
(
)
, 2 1 c c K c n Ab S' n Ab s , , s , s H n Hc x + = + = + = Λ Λ (9)where c=SAb. It can be seen that (9) can be obtained by replacing S with S′ in (1). On the other hand, the baseband equivalent signal model of up-link quasi-synchronous (ULQS) MC-CDMA system is shown in Fig. 5, where “quasi-synchronous” means that the maximum differential delay between users is less than the CP. Viewing the OFDM modulators as equivalent MIMO channels characterized by channel matrices H1, H2, …, HK, we can express the received
signal x as
(
)
, " 2 2 1 1 1 c c K K c K i i i n Ab S n Ab s H , , s H , s H n c H x + = + = + ∑ = = Λ Λ (10)where ci =si×(bi×Ai). It is then clear that (10) can also be obtained from (1). Since both DL MC-CDMA and ULQS MC-CDMA signals fit the general model in (1), all techniques discussed in this report apply equally well to each one of them.
III. RELATIVE THRESHOLD TREE PRUNING
Although the performance of the ML detector is very appealing [4], it is too complex to be practical. The
prohibitively high complexity arises from keeping track of all possible paths from the root to the mK leaf nodes. Therefore, one method for complexity reduction is by tree-pruning, i.e., discarding some nodes at every level according to certain criterion as we proceed from the root of the tree to the leaves. In [6], conventional tree-pruning algorithms such as the M-, T-, and MT-algorithms are applied to synchronous CDMA. In the M-algorithm, for example, only M survivors with lowest metrics are retained at each level. A generalization to the M-algorithm, referred to as pre-whitened tree-pruning (PWTP), has also been proposed in [4] in which the number of survivors is made different from level to level. Let Mk be
the number of survivors retained at level k, the sequence {Mk}
controls the trade-off between computational complexity and symbol error rate (SER) of PWTP and must be chosen carefully. If Mk = M for all k, PWTP degenerates to the
conventional M-algorithm. In [4], {Mk} was chosen
empirically by computer simulation.
Although both PWTP and M-algorithm achieve very good performance as reported in [4,5], their main drawback is that partial sorting is required at each level k to pick the best Mk nodes from mMk-1 candidates. To overcome this
drawback, we propose a new tree-pruning algorithm referred to as relative threshold tree pruning (RTTP). In RTTP, instead of retaining Mk nodes with smallest metrics as
survivors, at level k a node is retained if and only if its metric is no greater than T plus the minimum node metric in this level, where T is a pre-determined threshold value. In other words, at each level k we first scan all candidate nodes to determine the minimum node metric Dmin(k). Nodes at this
level with metrics exceeding Dmin(k) by T are discarded.
This concept is depicted in Fig. 6.
RTTP has several advantages over PWTP and the conventional M-algorithm. First, as previously mentioned, RTTP avoids the costly partial sorting operations that are required at every level in the conventional M-algorithmand
Fig. 6 The concept of RTTP.
PWTP. Secondly, as will be shown by simulation, with a suitable T, on average the computational complexity of RTTP, characterized by the expected maximum number of survivors,
reduces at both high and low signal-to-noise ratio (SNR). This is because for both high and low SNR, paths through the tree are well separated, thus the average maximum number of retained survivors automatically decreases. This is clearly an advantage over PWTP and the M-algorithm which have fixed complexity.
IV. PERFORMANCE ENHANCEMENTBY USER ORDERING
It is well known that the detection order of the active users is critical to the performance of sequential detectors. In general, tree-search-based MUD algorithms are sequential in nature because of the triangular property of L. However, if all paths through the tree are retained until the leaf nodes as in the ML detector, e.g., when T = ∞ in RTTP, then the detection order is of no importance. On the other hand, in the M-algorithm, PWTP, and the proposed RTTP, some paths are discarded in order to lower the complexity. The SER of these algorithms is therefore dominated by the premature elimination of the correct path. It has been observed in [5] that premature elimination of the correct path can be avoided by rearranging the users to make the values of lkk larger for
small k’s. Since
( )
R det 1 2 =∏
= K k kk l (11)is a constant as can be seen from (4), we can alternatively rearrange the users to make the values of lkk smaller for large
k’s. We thus propose a new algorithm referred to as reverse minimum orthogonal power sorting (RMOPS) for determining the user detection order. The procedure of RMOPS is as follows:
Step 1: Let R(K) = R;
Step 2: For j = 0, 1, …, K–1 repeat:
A. The (K – j)-th user to detected is given by
{
( )}
1 min arg iiK j j K i j K R i − − ≤ ≤ − = (12)where Rii(K-j) is the i-th diagonal entry of R(K- j);
B. Interchange the iK-j-th and (K-j)-th rows of R (K-j)
. C. Interchange the iK-j-th and (K-j)-th columns of R
(K-j) . D. Compute ) ( ) )( ( ) ( ) ( ) ( ) 1 ( j K j K j K H j K j K j K j K j K j K R −− − − − − − − − − =R −r r R ,(13)
where rK(K−−jj) is the (K – j)-th column of R(K- j). Note that first, (13) is needed [7] when computing L regardless of whether user ordering is done, therefore RMOPS can be incorporated into the factorization in (4) without additional computational burden. Second, it can be shown that for 1≤i≤(K–j), Rii(K-j) is the energy (square-norm)
of the orthogonal projection of the signature vector of the i-th remaining user onto the orthogonal complement of the span of j users whose detection orders have already been decided. In other words, suppose that the K-th to (K-j+1)-th users to
1 2 0 3 Retained N ode m etr ic Discarded T k
detect have already been chosen, RMOPS chooses as the (K–j)-th user to detect the remaining user with the least energy in the orthogonal complement of the subspace spanned by the signature vectors of the last j users to detect. Finally, it can be shown that (l(K-j) (K-j))2 is the energy of the (K–j)-th
user in the orthogonal complement of the subspace spanned by the signature vectors of the K-th to the (K-j+1)-th users. Thus RMOPS indeed results in smaller values of lkk for large
k’s.
V. PERFORMANCE ENHANCEMENT BY USER PARTITIONING
When complex quadrature amplitude modulation (QAM) constellations are used, the performance of pruned-tree-search-based MUD algorithms can possibly be further enhanced by partitioning a complex user into two real users and operating over the real field instead of the complex field. In other words, for a system with K active users, instead of viewing the vector of transmitted symbols as the K-dimensional complex vector b in (1), we view them as a 2K-dimensional real vector bUP given by
( )
( )
( )
( )
[
]
T K K b b b b Im Re Im Re 1 1 UP = Λ b (14) Similarly, instead of viewing the received signal as theN-dimensional complex vector x in Fig. 1, we view it as a 2N-dimensional real vector xUP given by
( )
( )
( )
( )
[
]
T N N x x x x Im Re Im Re 1 1 UP = Λ x (15)where xi is the i-th component of x. The vectors xUP and bUP
are related by UP UP UP UP S b n x = + , (16)
where nUP is the user-partitioned real white Gaussian noise
vector obtained similarly from nc, and SUP is a 2N×2K real
matrix given by = K N N K , 1 , , 1 1 , 1 UP Q Q Q Q S Λ Μ Ο Μ Λ (17) in which
{ }
{ }
{ }
{ }
− = j ij j ij j ij j ij j i A S A S A S A S Re Im Im Re , Q , (18)where Sij is the (i,j)-entry of S. It is then straightforward to
formulate the ML MUD as a search problem over a real tree with height 2K. We will refer to this technique as user partitioning (UP). Since no tree pruning is performed, this ML MUD is mathematically equivalent to the complex-valued ML MUD discussed in Section II. It can also be verified that, without pruning, tree search over the real tree with height 2K and complex tree with height K have roughly the same complexities.
On the other hand, when tree pruning is employed the relative performance of these two algorithms is somewhat trickier to characterize. In the following, we first assume that without UP, the complex tree is pruned at every level, while when UP is used, the real tree is pruned at every other
level. This assumption is made to ensure that the complexity with and without UP are exactly the same if the same M-algorithm is used for both cases. Under this assumption, it can be proved that UP does not bring any performance gain regardless of the specific tree pruning method if user sorting is not used. However, if user sorting is done after UP, “softer” user ordering is obtainable because the complex users are first partitioned into independent real users. In other words, with complex users partitioned into independent real users, the in-phase and quadrature-phase components of a complex user could be assigned different detection orders, whereas each user must have the same detection order for its in-phase and quadrature-phase components if UP is not used. Therefore improved performance is achievable when user ordering is performed after UP, as will be shown by simulations.
VI. SIMULATION RESULTS
The algorithms proposed in this report are simulated for ULQS MC-CDMA with N = K = 32. Channel gains of all sub-carriers are uncorrelated in the simulations. The noise vector n is a zero-mean, circularly symmetric, complex white Gaussian random vector with covariance matrix N0IN. The
Hadamard-Walsh codes are used to spread user symbols in frequency domain.
The SER of RTTP is shown in Fig. 7 as functions of Eb/N0, where Eb is the average transmitted energy per bit for
each subsymbol 8-level phase shift keying (8-PSK) is used by all users. The SER of the M-algorithm with M = 64 is also shown as a baseline for comparison. For RTTP the threshold T must be chosen carefully. If T is too large then RTTP would not be selective enough when pruning the tree, resulting in very high computational complexity. If T is too small then too many paths will be eliminated at each level, causing poor SER performance. In Fig. 7, T is chosen so that the SER of RTTP at Eb/N0 = 14 dB is roughly the same as
that for the M-algorithm with M = 64. It can be seen that both T = 3.6 and T = 3.7 are possible, with the performance of T = 3.7 being slightly better at high SNR as expected. It can also be seen that RTTP outperforms the M-algorithm for Eb/N0 > 14 dB, while the reverse is true for Eb/N0 < 14 dB.
This suggests that at high SNR, RTTP is more efficient in pruning the unlikely paths.
Fig. 8 shows the corresponding complexity of Fig. 7 as functions of Eb/N0, where complexity is evaluated in terms of
E[max{M1 … MK}], where Mk is the number of retained
nodes at the k-th level of the tree. Note that for the M-algorithm, the complexity is fixed at m. For both RTTP with T = 3.6 and T = 3.7, the complexity is lower than the M-algorithm for both low and high SNR, and higher than the M-algorithm at Eb/N0 around 12 dB. The complexity of T =
3.7 is higher than T = 3.6 because a larger value of T eliminates fewer paths through the tree. It also achieves a lower SER as sown in Fig. 7. It is, however, interesting to note that at high SNR, RTTP outperforms the M-algorithm in
both SER and complexity. This is because RTTP decides 4 6 8 10 12 14 16 10-6 10-5 10-4 10 -3 10-2 10-1 100 Eb/N0(dB) SE R M-algorithm, M=64 RTTP, T=3.6 RTTP, T=3.7
Fig. 7. SER of RTTP and the M-algorithm for ULQS MC-CDMA with
K=N=32 using 8PSK. 4 6 8 10 12 14 16 35 40 45 50 55 60 65 70 75 Eb/N0(dB) E[ m a x (M k )] RTTP, T=3.7 RTTP, T=3.6 M-algorithm, M=64
Fig. 8. Complexity of RTTP and the M-algorithm for ULQS MC-CDMA system using 8PSK with K=N=32.
whether to retain a particular node based on the difference between its metric and the minimum node metric. At high SNR, the node metric of the correct path is statistically close to the minimum node metric at each level. Therefore, it can be argued that RTTP retains a node only when its metric is not much greater than the node metric of the correct path. Thus, RTTP is a more efficient tree pruning algorithm because it dynamically adjusts the number of survivors so that the correct path is retained without preserving excessively many survivors. On the other hand, it is also interesting to note that at low SNR the complexity of RTTP is also lower than the M-algorithm. This is because at low SNR the node metrics are, in general, more separated. Since RTTP only retains nodes whose metrics are no greater than the minimum node metric by T, few nodes are retained at each level when the SNR is low. Unfortunately, at low SNR, the candidate subsequence corresponding to the minimum node metric is different from the transmitted sequence with high probability, therefore RTTP misses the correct path with higher probability than the M-algorithm. In other words, the complexity curves of RTTP in Fig. 8 are shaped like an inverted “U” with peak complexity at Eb/N0 ≅ 12 dB. The
region where Eb/N0 >> 12 dB can be regarded as the “reliable
operating region” of RTTP because with Eb/N0 >> 12 dB,
RTTP retains fewer survivors than the M-algorithm without prematurely eliminating the correct path. On the other hand, Eb/N0 << 12 dB is the “unreliable operating region” for RTTP
because at low SNR, RTTP retains fewer nodes than the M-algorithm but has a higher probability of premature elimination of the correct path.
The effect of user ordering is next investigated in Figs. 9 and 10. In Fig. 9, the
4 6 8 10 12 14 16 10-7 10-6 10-5 10 -4 10 -3 10-2 10-1 100 Eb/N0(dB) SER M-algorithm, NO SORT, M=8 RTTP, NO SORT, T=3.9 M-algorithm, RMOPS, M=8 RTTP, RMOPS, T=7.5
Fig. 9. SER of RTTP and M-algorithm with and without user ordering for ULQS MC-CDMA with K=N=32 using 4-QAM.
4 6 8 10 12 14 16 5.5 6 6.5 7 7.5 8 8.5 Eb/N0(dB) E[ m a x( Mk )] M-algorithm, NO SORT, M=8 M-algorithm, RMOPS, M=8 RTTP, NO SORT, T=3.9 RTTP, RMOPS, T=7.5
Fig. 10. Complexity of RTTP and M-algorithm with and without user ordering for ULQS MC-CDMA with K=N=32 using 4-QAM.
SER for RTTP and the M-algorithm with M=8 are shown as functions of Eb/N0 for both with and without user ordering,
whereas in Fig. 10, the corresponding complexities are shown as functions of Eb/N0. Four-level QAM (4-QAM)
constellations are used in these figures. The value of T is chosen so that the SER curves of RTTP and the corresponding M-algorithm roughly intersect at an SER of10-3. It can be seen from Fig. 9 that user ordering has a significant effect on SER performance. In particular, a performance gain of roughly 2 dB is achievable for both RTTP and the M-algorithm. Secondly, RTTP outperforms the M-algorithm at high SNR, while the reverse is true at low SNR, regardless of whether user ordering is used. Finally, the complexity curves for RTTP are also shaped like an inverted “U” as in Fig.
8, therefore RTTP has lower complexity than the M-algorithm at both high and low SNR as before. It can be seen that user ordering shifts the peak of the complexity curve to the left, thus increasing its reliable operating region. This is because RMOPS proposed in this report has the effect of making the candidate paths more separated while at the same time reducing the difference between the metric of the correct path and the minimum metric.
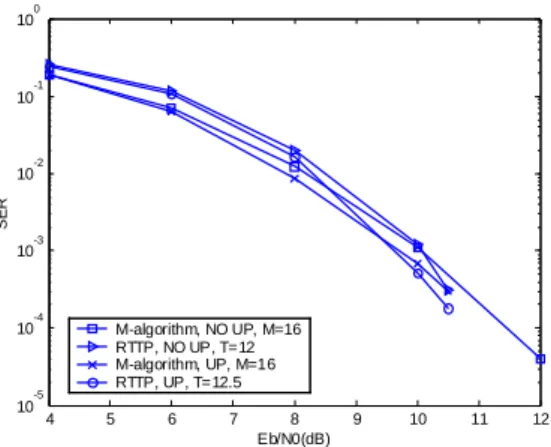
Finally, the effect of UP is shown in Figs. 11 and 12. 4-QAM constellations are used in these figures. The value of T is chosen so that the SER curves of RTTP and the M-algorithm with M=16 in Fig. 11 roughly intersect at an SER of 10-3. It can be seen that with user ordering, UP indeed brings further performance gain for both RTTP and the M-algorithm. Furthermore, UP also slightly shifts the complexity curves of RTTP to the left, thus increasing its reliable operating region.
VII. CONCLUSIONS
In this report, we propose a new reduced complexity tree-based MUD for MC-CDMA referred to as RTTP. Unlike the previously proposed M-algorithm and PWTP, RTTP does not require sorting at every level of the tree. Furthermore, RTTP also dynamically adjusts the number of survivors according to channel conditions, and is therefore more suitable for wireless communications. The performance of RTTP is further enhanced by user ordering and user partitioning. Simulation results show that at high SNR, RTTP can in fact outperform the M-algorithm at lower complexity. 4 5 6 7 8 9 10 11 12 10-5 10-4 10-3 10-2 10 -1 100 Eb/N0(dB) SE R M-algorithm, NO UP, M=16 RTTP, NO UP, T=12 M-algorithm, UP, M=16 RTTP, UP, T=12.5
Fig. 11. SER of RTTP and the M-algorithm with user ordering and with or without UP for ULQS MC-CDMA with K=N=32 using 4-QAM.
4 5 6 7 8 9 10 11 12 10 11 12 13 14 15 16 17 18 19 20 Eb/N0(dB) E[ m a x( Mk )] M-algorithm, NO UP, M=16 M-algorithm, UP, M=16 RTTP, NO UP, T=12 RTTP, UP, T=12.5
Fig. 12. Complexity of RTTP and the M-algorithm with user ordering and with or without UP for ULQS MC-CDMA with K=N=32 using 4-QAM.
REFERENCES
[1] Shinsuke Hara and Ramjee Prasad, “Overview of Multicarrier CDMA”,
IEEE Communication Magzine, pp. 126-133, Dec. 1997.
[2] R. van Nee and R. Prasad, OFDM for Wireless Multimedia Communications, Artech Hous, 2000.
[3] S. Verdu, Multiuser Detection, Cambridge university press, 1998. [4] Yi-Lin Li and Yumin Lee, “A novel low-complexity near-ML multiuser
detector for DS-CDMA and MC-CDMA systems”, Proceeding in IEEE Globecom 2002, pp. 493-498.
[5] Yi-Lin Li, “Tree-Pruning and Sorting Algorithms and Signal Dimensionality Issues for Multi-User Detection in DS-CDMA and MC-CDMA”, M.S. thesis, National Taiwan University, June 2002. [6] Lei Wei, Lars K. Rasmussen, Richard Wyrwas, “Near Optimum
Tree-Search Detection Schemes for Bit-Synchronous Multiuser CDMA Systems over Gaussian and Two-Path Rayleigh-Fading Channels,”
IEEE Trans. on Communications, Vol. 45, No. 6, June 1997.
[7] Golub, G. and Van Loan, C. F., Matrix Computations, 3rd Ed., Johns


![Fig. 7. SER of RTTP and the M-algorithm for ULQS MC-CDMA with K=N=32 using 8PSK. 4 6 8 10 12 14 16354045505560657075 Eb/N0(dB)E[max(Mk)] RTTP, T=3.7RTTP, T=3.6 M-algorithm, M=64](https://thumb-ap.123doks.com/thumbv2/9libinfo/8827690.234449/6.892.56.341.125.348/rttp-algorithm-ulqs-cdma-using-rttp-rttp-algorithm.webp)