第 3 章 自動摘要模型
如何才能從文件中自動擷取出重要的字句,以之做為整篇文件的摘要,這是自動 摘要所要探討的問題,本論文提出嵌入式潛藏語意分析模型、隱藏式馬可夫模 型、主題混合模型等自動摘要模型,茲將其分別說明如下各小節。
3.1 嵌入式潛藏語意分析(Embedded LSA)模型
基於對潛藏語意分析與向量空間模型的探討,本論文提出嵌入式潛藏語意分析模 型,其將每一字句與整篇文件共同投影到潛藏語意空間,最後藉由向量空間模 型,估測各字句與整篇文件的相關性,演算法如下:
1. 將文件 D 斷句,D ={S1, , S2 ..Si.., SN}
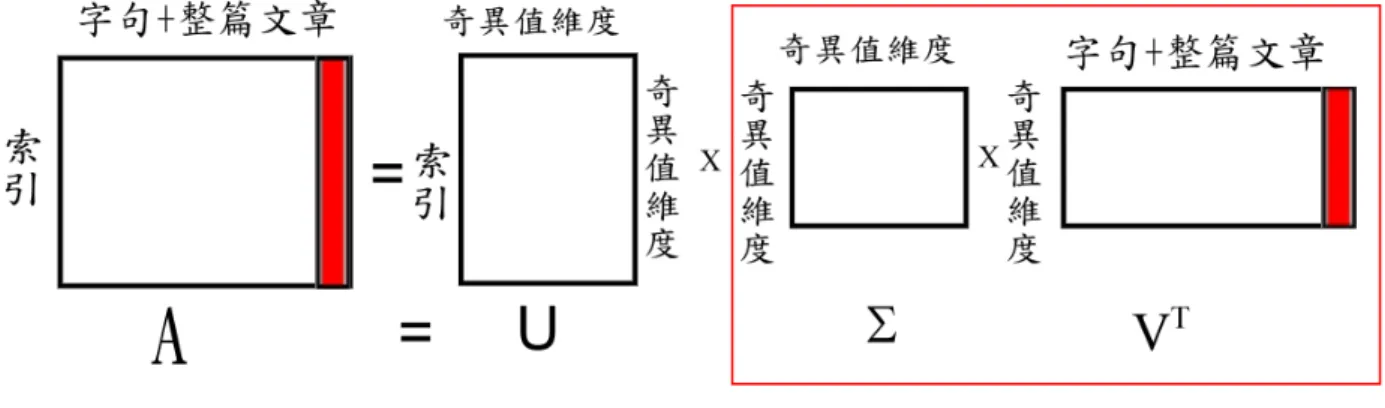
2. 由文件 D 建立 索引 字句矩陣 A,並將整篇文件嵌入到矩陣的最後一行 × 3. 對 A 進行奇異值分解,得到左奇異向量矩陣 U、奇異值矩陣∑ 與右奇異
向量矩陣 V t
4. 在右奇異向量矩陣 V t中,最後一行向量即為整篇文件在語意空間的表示 法,其餘行向量即為原始文件中各字句在語意空間的表示法,將∑ 與 V t 相乘得到各字句與整篇文件在潛藏語意空間的投影(B= ∑×VT) 5. 將 B 的最後一行(即整篇文件的投影)與 B 中的其他行向量(各字句),
以向量空間模型表示,並進行餘弦相關度估測,得到一句排名 6. 依摘要比例,將句排名所對應的字句,摘錄形成摘要
如圖 3. 1 所示,紅色部份即為所嵌入的整篇文件,矩陣B 最後一行向量即為 整篇文件的投影,將其與其他行向量(字句)做餘弦相關度估測後,得到一句排 名,用以依摘要比例摘錄形成摘要。
圖 3. 1 嵌入式潛藏語意分析模型示意圖
3.2 隱藏式馬可夫模型-型一(HMM-Type1)
近年來有學者提出 HMM/N-gram based Model 用於中文語音文件檢索上 [Chen et al. 2004a]。延伸其應用,視文件為一機率生成模型(Probabilistic Generative Model),對於每個索引都有一對應的機率分佈,文件與文件中每一字句的相關 性,是藉由每一字句的所有索引在文件發生的相似值(Likelihood)來決定,也 就是說當字句的索引在文件的機率分佈值連乘積越高,則字句與文件的相關性就 越高,如圖 3. 2 所示,數學式如下:
( )
( | )( )
(1 )( )
i i
i w S w S
p S D p w D λp w D λ p w Corpus
∈ ∈
⎡ ⎤
= ∏ ≈
∏
⎣ + − ⎦ (3. 1)其中 ( | )p w D 為文件 D 產生索引 w 的機率值,並與一更大語料庫做平滑化
(Smooth), ( |p w Corpus 。 ) 演算法如下:
1. 將文件 D 斷句,D ={S1, , S2 ..Si.., SN} 2. 計算文件 D 的單連語言模型
3. 對文件 D 中各字句S 估測i
( ) ( )
(1 )( )
i
i
w S
p S D λp w D λ p w Corpus
∈
⎡ ⎤
≈
∏
⎣ + − ⎦機率值,並依此做排序形成一句排名
4. 依摘要比例,將句排名所對應的字句,輸出形成摘要
假設在一篇文件中的索引,其重要性皆相同,愈長的字句其分數愈低,是以 B= ∑×VT
圖 3. 2 隱藏式馬可夫模型-型一示意圖
在估測文件產生每一字句的機率 ( | )p S D 時,以每一字句長度分之 1 為次方對分i 數開根號(正規化),Si p S D ,以避免句長影響到選取摘要字句的正確性。
(
i)
此外,對於每一個文件,將文件 D 視為與自已相關,則參數λ 與文件 D 產 生各索引 w 的機率值可藉由期望值最大化演算法 [Dempster et al. 1977],自動調 整參數與訓練模型,數學式如下所示:
( , )
ˆ w D
E w D λ = ∑∈ D
(3. 2)
l ( )
(, )
( | )
,
w D
E w D p w D
E w D
∈
= ∑ (3. 3)
( ) ( ) ( )
( ) ( ) ( )
, ,
1 p w D E w D n w D
p w D p w C orpus λ
λ λ
= + − (3. 4)
其中 D 是文件 D 的長度,n w D( , )是索引 w 出現在文件 D 的次數。
更進一步來說,文件 D 中每一字句S 可利用與其相關的字句 li S (可由字句i Si 與一斷句後的文件語料庫,經由餘弦估測其相關度,最後再選取最相關的字句組 成 lS )i ,做字句擴充(Sentence Expansion),如下所示:
( )
l l( )
(1 )( )
i
i
w S
p S D λp w D λ p w Corpus
∈
⎡ ⎤
=
∏
⎣ + − ⎦ (3. 5)(1−λ)
∑
1 2.. i.. N D = S S S S
( )
p w D
( )
p w Corpus λ
3.3 隱藏式馬可夫模型-型二(HMM-Type2)
圖 3. 3 隱藏式馬可夫模型-型二示意圖
同隱藏式馬可夫模型-型一的概念,當一篇文件進來時,視文件中每一字句為一 機率生成模型,對於每個索引都有一個對應的機率分佈,文件中每一字句與文件 的相關性,是藉由文件的所有索引在每一字句發生的相似值來決定,如圖 3. 3 所 示,數學式如下:
( ) ( )
( | i) ( | i) i (1 )
w D w D
p D S p w S λp w S λ p w Corpus
∈ ∈ ⎡ ⎤
= ∏ ≈ ∏ ⎣ + − ⎦ (3. 6) 其中 ( | )p w S 為文件中字句i S 產生索引 w 的機率值,並與一更大語料庫做平滑i
化, ( |p w Corpus 。 ) 演算法如下:
1. 將文件 D 斷句,D ={S1, , S2 ..Si.., SN}
2. 對文件 D 中每一字句S ,計算其單連語言模型 i
3. 對文件 D 中各字句S 估測i
(
i) (
i)
(1 )( )
w D
p D S λp w S λ p w Corpus
∈
⎡ ⎤
≈∏⎣ + − ⎦
機率值,並依此做排序形成一句排名
4. 依摘要比例,將句排名所對應的字句,輸出形成摘要
此外,對於每一個文件,將文件中每一字句S 視為與文件 D 相關,則參數i λ 與每一字句S 產生各索引 w 的機率值可藉由期望值最大化演算法 [Dempster et i al. 1977],自動調整參數與訓練模型,數學式如下所示:
(1−λ) ∑
1 2.. i.. N D = S S S S
λ
( i )
p w S
( )
p w Corpus
( , )
ˆ w D i
E w S λ = ∑∈ D
(3. 7)
l ( )
( )
i
( | S ) ,
,
i
i
w D
E w S
p w E w S
∈
= ∑ (3. 8)
( ) ( ) ( )
( ) ( ) ( )
, ,
1
i
i i
i
p w S E w S n w S
p w S p w C orpus λ
λ λ
= ⋅
+ − (3. 9)
其中 D 是文件 D 的長度,n w S( , i)是索引 w 出現在字句S 的次數。 i
更進一步來說,因每個觀測(Observation)文件 D 中,皆含有模型S 的資訊,i 是以可去除文件 D 中模型S 的字詞,做字句移除(Sentence Removal)i ,如下所 示:
( )
( )
( | ) ( | ) (1 )
i
i i
w D w S
p D S λp w S λ p w Corpus
∈ ∧ ∉
=
∏
+ − (3. 10)3.4 主題混合模型(Topical Mixture Model, TMM)
根 據 2.7 節 關 於 主 題 混 合 模 型 的 討 論 , 給 定 一 使 用 者 查 詢 Query
1 2.. n.. N
Q = q q q q ,一文件D 可根據其相關程度做排名, (i p D Q ,經由推導後i| ) 可由式(2.17)表示:
1 1
( | ) ( | ) ( | )
N K
i n k k i
k n
p Q D p q T p T D
=
=
=
∏ ∑
延伸其應用於自動摘要模型上,將使用者查詢 Q 視查詢為一文件 D,一標題Hi
(標題可視為某一字句)可根據其相關程度做排名, (p Hi|D ,類同於 2.7 節的) 推導,最後可仿照式(2.17)表示成:
1 1
( | ) ( | ) ( | )
N K
i n k k i
k n
p D H p q T p T H
=
=
=
∏ ∑
(3. 11)也就是說,將原先以文件為模型,轉為以標題為模型。
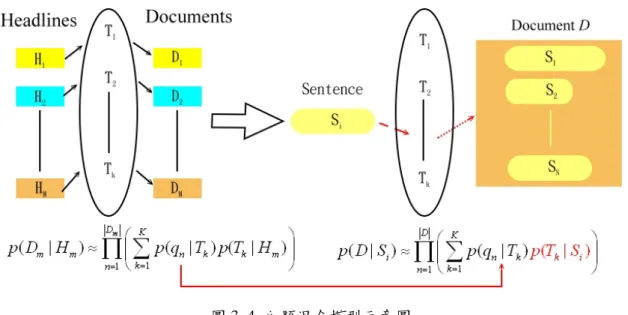
於 此 以 標 題 為 模 型 主 題 混 合 模 型 中 , 可 得 到 主 題 單 連 語 言 模 型 , 如 ( n| k)
p q T ,與其在各標題的權重,如 (p Tk|H 。 i)
在訓練時,如果文件集已含有文件與標題相對應的資訊,如在一般新聞網站
圖 3. 4 主題混合模型示意圖
的新聞文件通常皆含有標題,則可藉由每一篇新聞的文件與其所相對應的標題來 訓練。相對應的標題可使用當篇新聞的標題(本研究使用),也可由相關的新聞 構成標題集,接著藉由式(2.20)-(2.22) 將 Q 轉為 D、D 轉成i H 做監督式訓練,i 以優化主題單連語言模型與其在各標題的權重。透過此訓練過程來學習標題(可 視為字句)產生文件的流程。
在訓練時,如果文件集並無文件與標題相對應的資訊,則可將每一標題視為 與自已相關,也就是將文件以標題取代,並藉由式(2.23)-(2.24) 將 Q 轉為 D、Di 轉成H 來進行非監督式訓練。 i
經由訓練過後,使用主題單連語言模型來代表主題的資訊。考慮如下情況,
給定一使用者查詢文件D =q q1 2..qn..qN,文件中每一字句S 可根據其相關程度做i 排名, ( | )p S D ,類同於 2.7 節的推導,最後可仿照式(2.17)表示成: i
1 1
( | ) ( | ) ( | )
N K
i n k k i
k n
p D S p q T p T S
=
=
=
∏ ∑
(3. 12)此機率, ( | )p D S ,即為主題混合模型在自動摘要的模型,其中主題單連語言模i 型由式(3.11)以標題為模型的主題混合模型訓練得之,如 (p q T ,是以目前尚n| k) 不知 (p Tk|S 的機率值,於此可利用原以標題為模型的主題混合模型,所得到的i) 主題資訊,在摘要時即時迭代更新 (p Tk |S ,來估測每一字句i) S 產生整篇文件 Di 的機率,如圖 3. 4 所示。
進一步來說, (p Tk|S 的初始值,可用下式估計: i)
1
( , ) ( | )
( , )
i k
k i k
i r r
R S T p T S
R S T
=
=
∑
JJK JK
JJK JK (3. 13)
其中主題T 是由原以標題為模型的主題混合模型而來,k R T(JK JJKk,Si)
代表利用餘弦估 測字句S 與主題i T 的距離,如下所示: k
( k, i) k i
k i
T S R T S
T S
= ⋅
⋅ JK JJK JK JJK
JK JJK (3. 14)
得到 (p Tk|S 的初始值之後, (i) p Tk |S 可藉由非監督式訓練,視每一字句i) Si 與自已相關,即時迭代更新得之,如下所示:
l ( , ) ( | , )
( | ) s i
s i k s i
q S
k i
i
n q S p T q S P T S
S
= ∑∈
(3. 15)
1
( | ) ( | ) ( | , )
( | ) ( | )
k i s k
k s i K
l i s l
l
p T S p q T p T q S
p T S p q T
=
=
∑
(3. 16)Si 是字句S 的長度, ( ,i n q S 是查詢項s i) q 出現在字句s S 的次數, (i p Tk |q S 是s, i) 在查詢項q 與字句s S 出現的條件下潛藏主題i T 發生的機率。 k
在實作上,額外考慮每一查詢項在各字句中的重要性,是以式(3.12)可進一 步延伸為:
1 1
( | ) ( | ) (1 ) ( | ) ( | )
N K
i n i n k k i
k n
p D S λp q S λ p q T p T S
=
=
⎛ ⎞
= ⎜ + − ⎟
⎝
∑
⎠∏
(3. 17)( n| i)
p q S 為字句S 產生查詢項i q 的機率, (n p q Tn| k)可由以標題為模型的主題混 合模型訓練得之, (p Tk|S 可經由非監督式訓練即時迭代更新得之。 i)
演算法如下:
1. 訓練以標題為模型的主題混合模型
1 1
( | ) ( | ) ( | )
N K
i n k k i
k n
p D H p q T p T H
=
=
=
∏ ∑
,得到主題單連語言模型用以代表潛藏主題的資訊 2. 將文件 D 斷句,D ={S1, , S2 ..Si.., SN}
3. 由式(3.17) 估測 D 在每一字句S 的機率值, (i p D S :計算各字句| i) S 的 i 單連語言模型,如 (p qn |S ,與查詢項i) q 發生在潛藏主題及字句產生各n 別主題的機率值,
1
( | ) ( | )
K
n k k i
k
p q T p T S
∑
= 。並依此機率值做排序,形成一句 排名4. 依摘要比例,將句排名所對應的字句,輸出形成摘要
此外,對於每一個文件,將文件中每一字句S 視為與文件 D 相關,則參數i λ 與每一字句S 產生各索引 w 的機率值可藉由期望值最大化演算法 [Dempster et i al. 1977],自動調整參數與訓練模型,數學式如下所示:
( , )
ˆ w D i
E w S λ = ∑∈ D
(3. 18)
l ( )
( )
i
( | S ) ,
,
i
i
w D
E w S
p w E w S
∈
= ∑ (3. 19)
( ) ( ) ( )
( ) ( )
1
, ,
1 ( | ) ( | )
i
i i K
i k k i
k
p w S E w S n w S
p w S p w T p T S
λ
λ λ
=
= ⋅
+ − ∑
(3. 20)
其中 D 是文件 D 的長度,n w S( , i)是索引 w 出現在字句S 的次數。 i
更進一步來說,因每個觀測(Observation)文件 D 中,皆含有模型S 的資訊,i 是以可去除文件 D 中模型S 的字詞,做字句移除(Sentence Removal)i ,如下所 示:
( | ) ( | ) (1 ) ( | ) ( | )
i
i i k k i
k w D w S
p D S λp w S λ p w T p T S
∈ ∧ ∉
⎛ ⎞
= ⎜ + − ⎟
⎝