Amazon Quantum Ledger Database (Amazon QLDB)
Developer Guide
Amazon Quantum Ledger Database (Amazon QLDB): Developer Guide
Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved.
Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon.
Table of Contents
What is Amazon QLDB? ... 1
Amazon QLDB video ... 1
Amazon QLDB pricing ... 1
Getting started with QLDB ... 1
Overview ... 2
Journal first ... 2
Immutable ... 3
Cryptographically verifiable ... 4
SQL-like and document flexible ... 4
Open source developer ecosystem ... 4
Serverless and highly available ... 5
Enterprise grade ... 5
From relational to ledger ... 5
Core concepts ... 7
QLDB data object model ... 7
Journal-first transactions ... 9
Querying your data ... 10
Data storage ... 10
QLDB API model ... 10
Next steps ... 11
Journal contents ... 11
Block example ... 11
Block contents ... 13
Sample application ... 14
See also ... 14
QLDB glossary ... 14
Accessing Amazon QLDB ... 17
Signing up for an AWS account ... 17
Creating an IAM user ... 17
Signing in as an IAM user ... 19
Getting IAM user access keys ... 19
Configuring your credentials ... 20
Using the console ... 20
Query editor quick reference ... 20
Using the AWS CLI (control plane only) ... 23
Downloading and configuring the AWS CLI ... 24
Using the AWS CLI with QLDB ... 24
Using the Amazon QLDB shell (data plane only) ... 24
Prerequisites ... 25
Installing the shell ... 25
Invoking the shell ... 26
Shell parameters ... 26
Command reference ... 27
Running individual statements ... 28
Managing transactions ... 28
Exiting the shell ... 30
Example ... 30
Using the API ... 30
Getting started with the console ... 32
Prerequisites and considerations ... 32
Setting up IAM permissions ... 33
Step 1: Create a new ledger ... 33
Step 2: Create tables, indexes, and sample data ... 35
Step 3: Query the tables ... 40
Step 4: Modify documents ... 41
Step 5: View the revision history ... 43
Step 6: Verify a document ... 45
To request a digest ... 45
To verify a document revision ... 46
Step 7: Clean up ... 47
Next steps ... 47
Getting started with the driver ... 49
Java driver ... 50
Driver resources ... 50
Prerequisites ... 50
Setting your default AWS credentials and Region ... 51
Installation ... 51
Quick start tutorial ... 53
Cookbook reference ... 58
.NET driver ... 69
Driver resources ... 70
Prerequisites ... 70
Installation ... 71
Quick start tutorial ... 71
Cookbook reference ... 87
Go driver ... 109
Driver resources ... 110
Prerequisites ... 110
Installation ... 110
Quick start tutorial ... 111
Cookbook reference ... 118
Node.js driver ... 127
Driver resources ... 127
Prerequisites ... 127
Installation ... 128
Setup recommendations ... 129
Quick start tutorial ... 131
Cookbook reference ... 142
Python driver ... 156
Driver resources ... 156
Prerequisites ... 157
Installation ... 157
Quick start tutorial ... 158
Cookbook reference ... 162
Session management with the driver ... 170
Session lifecycle ... 171
Session expiration ... 171
Session handling in the QLDB driver ... 171
Driver recommendations ... 173
Configuring the QldbDriver object ... 173
Retrying on exceptions ... 174
Optimizing performance ... 175
Running multiple statements per transaction ... 176
Driver retry policy ... 179
Types of retryable errors ... 179
Default retry policy ... 179
Common errors ... 180
Sample application tutorial ... 182
Java tutorial ... 182
Node.js tutorial ... 320
Python tutorial ... 358
Working with Amazon Ion ... 413
Prerequisites ... 414
Bool ... 414
Int ... 417
Float ... 419
Decimal ... 422
Timestamp ... 424
String ... 426
Blob ... 429
List ... 431
Struct ... 434
Null values and dynamic types ... 438
Down-converting to JSON ... 442
Working with data and history ... 443
Creating tables with indexes and inserting documents ... 444
Creating tables and indexes ... 444
Inserting documents ... 445
Querying your data ... 446
Basic queries ... 446
Projections and filters ... 448
Joins ... 448
Nested data ... 449
Querying document metadata ... 450
Committed view ... 450
Joining the committed and user views ... 452
Using the BY clause to query document ID ... 452
Joining on document ID ... 453
Updating and deleting documents ... 453
Making document revisions ... 453
Querying revision history ... 454
History function ... 454
History query example ... 455
Optimizing query performance ... 457
Transaction timeout limit ... 457
Concurrency conflicts ... 457
Optimal query patterns ... 457
Query patterns to avoid ... 459
Monitoring performance ... 459
Getting PartiQL statement statistics ... 460
I/O usage ... 460
Timing information ... 464
Querying the system catalog ... 468
Managing tables ... 469
Tagging tables on creation ... 469
Dropping tables ... 470
Querying the history of dropped tables ... 470
Undropping tables ... 470
Managing indexes ... 471
Creating indexes ... 471
Describing indexes ... 472
Dropping indexes ... 473
Common errors ... 474
Unique IDs ... 474
Properties ... 474
Usage ... 475
Examples ... 475
Concurrency model ... 476
Optimistic concurrency control ... 476
Using indexes to avoid full table scans ... 476
Insertion OCC conflicts ... 477
Making transactions idempotent ... 478
Managing concurrent sessions ... 479
Verification ... 480
What kind of data can you verify in QLDB? ... 480
What does data integrity mean? ... 481
How does verification work? ... 481
Hashing ... 481
Digest ... 482
Merkle tree ... 483
Proof ... 483
Verification example ... 483
Getting started with verification ... 484
Step 1: Requesting a digest ... 485
AWS Management Console ... 485
QLDB API ... 486
Step 2: Verifying your data ... 486
AWS Management Console ... 487
QLDB API ... 488
Verification results ... 488
Using a proof to recalculate your digest ... 489
Tutorial: Verifying data using an AWS SDK ... 490
Prerequisites ... 490
Step 1: Request a digest ... 490
Step 2: Query the document revision ... 491
Step 3: Request a proof for the revision ... 493
Step 4: Recalculate the digest from the revision ... 496
Step 5: Request a proof for the journal block ... 498
Step 6: Recalculate the digest from the block ... 501
Run the full code example ... 506
Common errors ... 522
Exporting journal data ... 524
Requesting an export ... 524
AWS Management Console ... 524
QLDB API ... 526
Export job expiration ... 527
Export output ... 527
Manifest files ... 528
Data objects ... 529
Down-converting to JSON ... 531
Export permissions ... 532
Create a permissions policy ... 532
Create an IAM role ... 534
Common errors ... 535
Streams ... 537
Common use cases ... 537
Consuming your stream ... 538
Delivery guarantee ... 538
Getting started with streams ... 538
Creating and managing streams ... 539
Stream parameters ... 539
Stream ARN ... 540
AWS Management Console ... 540
Stream states ... 541
Handling impaired streams ... 542
Developing with streams ... 543
QLDB journal stream APIs ... 543
Sample applications ... 544
Stream records ... 545
Control records ... 546
Block summary records ... 546
Revision details records ... 548
Handling duplicate and out-of-order records ... 548
Stream permissions ... 549
Create a permissions policy ... 549
Create an IAM role ... 551
Common errors ... 552
Ledger management ... 554
Basic operations for ledgers ... 554
Creating a ledger ... 554
Describing a ledger ... 557
Updating a ledger ... 559
Updating a ledger permissions mode ... 561
Deleting a ledger ... 562
Listing ledgers ... 563
AWS CloudFormation resources ... 564
QLDB and AWS CloudFormation templates ... 564
Learn more about AWS CloudFormation ... 564
Tagging resources ... 564
Supported resources in Amazon QLDB ... 565
Tag naming and usage conventions ... 565
Managing tags ... 566
Tagging resources on creation ... 566
Security ... 567
Data protection ... 567
Encryption at rest ... 568
Encryption in transit ... 579
Identity and Access Management ... 579
Audience ... 580
Authenticating with identities ... 580
Managing access using policies ... 582
How Amazon QLDB works with IAM ... 583
Getting started with the standard permissions mode ... 589
Identity-based policy examples ... 597
Cross-service confused deputy prevention ... 607
AWS managed policies ... 609
Troubleshooting ... 614
Logging and monitoring ... 616
Monitoring tools ... 616
Monitoring with Amazon CloudWatch ... 617
Automating with CloudWatch Events ... 621
Logging Amazon QLDB API calls with AWS CloudTrail ... 621
Compliance validation ... 634
Resilience ... 635
Storage durability ... 635
Data durability features ... 635
Infrastructure security ... 636
Using VPC endpoints (AWS PrivateLink) ... 636
Troubleshooting ... 639
Running transactions using the QLDB driver ... 639
Exporting journal data ... 641
Streaming journal data ... 642
Verifying journal data ... 643
PartiQL reference ... 646
What is PartiQL? ... 646
PartiQL in Amazon QLDB ... 646
PartiQL quick tips in QLDB ... 647
PartiQL reference conventions ... 647
Data types ... 648
QLDB documents ... 648
Ion document structure ... 648
PartiQL-Ion type mapping ... 649
Document ID ... 649
Querying Ion with PartiQL ... 650
Syntax and semantics ... 650
Backtick notation ... 652
Path navigation ... 653
Aliasing ... 653
PartiQL specification ... 653
PartiQL commands ... 653
DDL statements ... 654
DML statements ... 654
CREATE INDEX ... 654
CREATE TABLE ... 656
DELETE ... 658
DROP INDEX ... 659
DROP TABLE ... 660
FROM (INSERT, REMOVE, or SET) ... 660
INSERT ... 664
SELECT ... 666
UPDATE ... 670
UNDROP TABLE ... 672
PartiQL functions ... 672
Aggregate functions ... 673
Conditional functions ... 673
Date and time functions ... 673
Scalar functions ... 673
String functions ... 673
Data type formatting functions ... 673
AVG ... 674
CAST ... 674
CHAR_LENGTH ... 677
CHARACTER_LENGTH ... 677
COALESCE ... 677
COUNT ... 678
DATE_ADD ... 678
DATE_DIFF ... 679
EXISTS ... 680
EXTRACT ... 681
LOWER ... 682
MAX ... 682
MIN ... 683
NULLIF ... 683
SIZE ... 684
SUBSTRING ... 685
SUM ... 686
TO_STRING ... 686
TO_TIMESTAMP ... 687
TRIM ... 688
TXID ... 689
UPPER ... 689
UTCNOW ... 690
Timestamp format strings ... 690
PartiQL operators ... 691
Arithmetic operators ... 691
Comparison operators ... 692
Logical operators ... 692
String operators ... 692
Reserved words ... 693
Amazon Ion reference ... 697
What is Amazon Ion? ... 697
Ion specification ... 698
JSON compatible ... 698
Extensions from JSON ... 698
Ion text example ... 699
API references ... 699
Amazon Ion code examples ... 699
API reference ... 709
Actions ... 709
Amazon QLDB ... 710
Amazon QLDB Session ... 764
Data Types ... 769
Amazon QLDB ... 770
Amazon QLDB Session ... 782
Common Errors ... 800
Common Parameters ... 802
DBQMS API reference ... 804
CreateFavoriteQuery ... 804
CreateQueryHistory ... 804
CreateTab ... 804
DeleteFavoriteQueries ... 804
DeleteQueryHistory ... 804
DeleteTab ... 804
DescribeFavoriteQueries ... 805
DescribeQueryHistory ... 805
DescribeTabs ... 805
GetQueryString ... 805
UpdateFavoriteQuery ... 805
UpdateQueryHistory ... 805
UpdateTab ... 805
Quotas and limits ... 806
Default quotas ... 806
Fixed quotas ... 806
Document size ... 807
Transaction size ... 807
Naming constraints ... 808
Related information ... 809
Technical documentation ... 809
GitHub repositories ... 809
AWS blog posts and articles ... 810
Media ... 811
General AWS resources ... 812
Release history ... 813
Amazon QLDB video
What is Amazon QLDB?
Amazon Quantum Ledger Database (Amazon QLDB) is a fully managed ledger database that provides a transparent, immutable, and cryptographically verifiable transaction log owned by a central trusted authority. You can use Amazon QLDB to track all application data changes, and maintain a complete and verifiable history of changes over time.
Ledgers are typically used to record a history of economic and financial activity in an organization. Many organizations build applications with ledger-like functionality because they want to maintain an accurate history of their applications' data. For example, they might want to track the history of credits and debits in banking transactions, verify the data lineage of an insurance claim, or trace the movement of an item in a supply chain network. Ledger applications are often implemented using custom audit tables or audit trails created in relational databases.
Amazon QLDB is a new class of database that helps eliminate the need to engage in the complex development effort of building your own ledger-like applications. With QLDB, the history of changes to your data is immutable—it cannot be altered, updated, or deleted. And using cryptography, you can easily verify that there have been no unintended changes to your application's data. QLDB uses an immutable transactional log, known as a journal. The journal is append-only and is composed of a sequenced and hash-chained set of blocks that contain your committed data.
Amazon QLDB video
For an overview of Amazon QLDB and how it can benefit you, watch this QLDB overview video on YouTube.
Amazon QLDB pricing
With Amazon QLDB, you pay only for what you use with no minimum fees or mandatory service usage.
You pay only for the resources your ledger database consumes, and you do not need to provision in advance.
For more information, see Amazon QLDB pricing.
Getting started with QLDB
We recommend that you begin by reading the following topics:
• Overview of Amazon QLDB (p. 2) – To get a high-level overview of QLDB.
• Core concepts and terminology in Amazon QLDB (p. 7) – To learn fundamental QLDB concepts and terminology.
• Accessing Amazon QLDB (p. 17) – To learn how to access QLDB using the AWS Management Console, API, or AWS Command Line Interface (AWS CLI).
Overview
• How Amazon QLDB works with IAM (p. 583) – To learn how to control access to QLDB using AWS Identity and Access Management (IAM).
To get started quickly with the QLDB console, see Getting started with the Amazon QLDB console (p. 32).
To learn about developing with QLDB using an AWS-provided driver, see Getting started with the Amazon QLDB driver (p. 49).
Overview of Amazon QLDB
The following sections provide a high-level overview of Amazon QLDB service components and how they interact.
Topics
• Journal first (p. 2)
• Immutable (p. 3)
• Cryptographically verifiable (p. 4)
• SQL-like and document flexible (p. 4)
• Open source developer ecosystem (p. 4)
• Serverless and highly available (p. 5)
• Enterprise grade (p. 5)
Journal first
In traditional database architecture, you generally write data in tables as part of a transaction. A transaction log—typically an internal implementation—records all of the transactions and the database modifications that they make. The transaction log is a critical component of the database. You need the log to replay transactions in the event of a system failure, disaster recovery, or data replication. However, database transaction logs are not immutable and are not designed to provide direct and easy access to users.
In Amazon QLDB, the journal is the core of the database. Structurally similar to a transaction log, the journal is an immutable, append-only data structure that stores your application data along with the associated metadata. All write transactions, including updates and deletes, are committed to the journal first.
QLDB uses the journal to determine the current state of your ledger data by materializing it into queryable, user-defined tables. These tables also provide an accessible history of all transaction data, including document revisions and metadata. In addition, the journal handles concurrency, sequencing, cryptographic verification, and availability of the ledger data.
The following diagram illustrates the QLDB journal architecture.
Immutable
• In this example, an application connects to a ledger and runs transactions that insert, update, and delete a document into a table named cars.
• The data is first written to the journal in sequenced order.
• Then the data is materialized into the table with built-in views. These views let you query both the current state and the complete history of the car, with each revision assigned a version number.
• You can also export or stream data directly from the journal.
Immutable
Because the QLDB journal is append-only, it keeps a full record of all changes to your data that cannot be deleted, modified, or overwritten. There are no APIs or other methods to alter any committed data in place. This enables you to access and query the full history of your ledger.
QLDB writes one or more blocks to the journal in a transaction. Each block contains entry objects that represent the documents that you insert, update, and delete, along with the statements that you ran to commit them. These blocks are sequenced and hash-chained to guarantee data integrity.
The following diagram illustrates this journal structure.
The diagram shows that transactions are committed to the journal as blocks that are hash-chained for verification. Each block has a sequence number to specify its address.
Cryptographically verifiable
Cryptographically verifiable
Journal blocks are sequenced and chained together with cryptographic hashing techniques, similar to blockchains. This feature enables the journal to provide transactional data integrity using a
cryptographic verification method. Using a digest (a hash value that represents a journal's full hash chain as of a point in time) and a Merkle audit proof (a mechanism that proves the validity of any node within a binary hash tree), you can verify that there have been no unintended changes to your data at any time.
The following diagram shows a digest that covers a journal's full hash chain at a point in time.
In this diagram, the journal blocks are hashed using the SHA-256 cryptographic hash function and are sequentially chained to subsequent blocks. Each block contains entries that include your data documents, metadata, and the PartiQL statements that ran in the transaction.
For more information, see Data verification in Amazon QLDB (p. 480).
SQL-like and document flexible
QLDB uses PartiQL as its query language and Amazon Ion as its document-oriented data model. PartiQL is an open source, SQL-compatible query language that has been extended to work with Ion. With PartiQL, you can insert, query, and manage your data with familiar SQL operators. When you're querying flat documents, the syntax is the same as using SQL to query relational tables. To learn more about the QLDB implementation of PartiQL, see the Amazon QLDB PartiQL reference (p. 646).
Amazon Ion is a superset of JSON. Ion is an open source, document-based data format that gives you the flexibility of storing and processing structured, semistructured, and nested data. To learn more about Ion in QLDB, see the Amazon Ion data format reference in Amazon QLDB (p. 697).
For a high-level comparison of the core components and features in traditional relational databases versus QLDB, see From relational to ledger (p. 5).
Open source developer ecosystem
To simplify application development, QLDB provides open source drivers in various programming languages. You can use these drivers to interact with the transactional data API by running PartiQL
Serverless and highly available
statements on a ledger and processing the results of those statements. For information and tutorials about the driver languages that are currently supported, see Getting started with the Amazon QLDB driver (p. 49).
Amazon Ion also provides client libraries that process Ion data for you. For developer guides and code examples of processing Ion data, see the Amazon Ion documentation on GitHub.
Serverless and highly available
QLDB is fully managed, serverless, and highly available. The service automatically scales to support the demands of your application, and you don't need to provision instances or capacity. Multiple copies of your data are replicated within an Availability Zone and across Availability Zones in an AWS Region.
Enterprise grade
QLDB transactions are fully compliant with ACID (atomicity, consistency, isolation, and durability) properties. QLDB uses optimistic concurrency control (OCC), and transactions operate with full serializability—the highest level of isolation. This means that there's no risk of seeing phantom reads, dirty reads, write skew, or other similar concurrency issues. For more information, see Amazon QLDB concurrency model (p. 476).
From relational to ledger
If you are an application developer, you might have some experience using a relational database management system (RDBMS) and Structured Query Language (SQL). As you begin working with Amazon QLDB, you will encounter many similarities. As you progress to more advanced topics, you will also encounter powerful new features that QLDB has built on the RDBMS foundation. This section describes common database components and operations, comparing and contrasting them with their equivalents in QLDB.
The following diagram shows the mapping constructs of the core components between a traditional RDBMS and Amazon QLDB.
From relational to ledger
The following table shows the primary high-level similarities and differences of built-in operational features between a traditional RDBMS and QLDB.
Operation RDBMS QLDB
Creating tables CREATE TABLE statement that
defines all column names and data types
CREATE TABLE statement that doesn't define any table attributes or data types to allow schemaless and open content
Creating indexes CREATE INDEX statement CREATE INDEX statement for
any top-level fields on a table Inserting data INSERT statement that specifies
values within a new row or tuple that adheres to the schema as defined by the table
INSERT statement that specifies values within a new document in any valid Amazon Ion format regardless of the existing documents in the table
Querying data SELECT-FROM-WHERE
statement SELECT-FROM-WHERE
statement in the same syntax as SQL when querying flat documents
Updating data UPDATE-SET-WHERE statement UPDATE-SET-WHERE statement
in the same syntax as SQL when updating flat documents
Core concepts
Operation RDBMS QLDB
Deleting data DELETE-FROM-WHERE
statement DELETE-FROM-WHERE
statement in the same syntax as SQL when deleting flat documents
Nested and semistructured data Flat rows or tuples only Documents that can have any structured, semistructured, or nested data as supported by the Amazon Ion data format and the PartiQL query language
Querying metadata No built-in metadata SELECT statement that queries from the built-in committed view of a table
Querying revision history No built-in data history SELECT statement that queries from the built-in history function
Cryptographic verification No built-in cryptography or
immutability APIs that return a digest of a journal and a proof that verifies the integrity of any document revision relative to that digest
For an overview of the core concepts and terminology in QLDB, see Core concepts (p. 7).
For detailed information about the process of creating, querying, and managing your data in a ledger, see Working with data and history (p. 443).
Core concepts and terminology in Amazon QLDB
This section provides an overview of the core concepts and terminology in Amazon QLDB, including ledger structure and how a ledger manages data. As a ledger database, QLDB differs from other document-based databases when it comes to the following key concepts.
Topics
• QLDB data object model (p. 7)
• Journal-first transactions (p. 9)
• Querying your data (p. 10)
• Data storage (p. 10)
• QLDB API model (p. 10)
• Next steps (p. 11)
QLDB data object model
The fundamental data object model in Amazon QLDB is described as follows:
1.Ledger
QLDB data object model
Your first step is to create a ledger, which is the primary AWS resource type in QLDB. To learn how to create a ledger, see Step 1: Create a new ledger (p. 33) in Getting started with the console, or Basic operations for Amazon QLDB ledgers (p. 554).
For both the ALLOW_ALL and STANDARD permissions modes of a ledger, you create AWS Identity and Access Management (IAM) policies that grant permissions to run API operations on this ledger resource.
Ledger ARN format:
arn:aws:qldb:${region}:${account-id}:ledger/${ledger-name}
2.Journal and tables
To start writing data in a QLDB ledger, you first create a table with a basic CREATE TABLE (p. 656) statement. Ledger data consists of revisions of documents that are committed to the ledger's journal.
You commit document revisions to the ledger in the context of user-defined tables. In QLDB, a table represents a materialized view of a collection of document revisions from the journal.
In the STANDARD permissions mode of a ledger, you must create IAM policies that grant permissions to run PartiQL statements on this table resource. With permissions on a table resource, you can run statements that access the current state of the table. You can also query the revision history of the table by using the built-in history() function.
Table ARN format:
arn:aws:qldb:${region}:${account-id}:ledger/${ledger-name}/table/${table-id}
For more information about granting permissions on a ledger and its associated resources, see How Amazon QLDB works with IAM (p. 583).
3.Documents
Tables consist of revisions of QLDB documents (p. 648), which are datasets in Amazon Ion (p. 697) struct format. A document revision represents a single version of a sequence of documents that are identified by a unique document ID.
QLDB stores the complete change history of your committed documents. A table lets you query the current state of its documents, while the history() function lets you query the entire revision history of a table's documents. For details on querying and writing revisions, see Working with data and history (p. 443).
4.System catalog
Each ledger also provides a system-defined catalog resource that you can query to list all of the tables and indexes in a ledger. In the STANDARD permissions mode of a ledger, you need the qldb:PartiQLSelect permission on this catalog resource to do the following:
• Run SELECT statements on the system catalog table information_schema.user_tables (p. 468).
• View table and index information on the ledger details page on the QLDB console (p. 20).
• View the list of tables and indexes in the Query editor on the QLDB console.
Catalog ARN format:
arn:aws:qldb:${region}:${account-id}:ledger/${ledger-name}/information_schema/user_tables
Journal-first transactions
Journal-first transactions
When an application reads or writes data in a QLDB ledger, it does so in a database transaction. All transactions are subject to limits as defined in Quotas and limits in Amazon QLDB (p. 806). Within a transaction, QLDB does the following steps:
1. Read the current state of the data from the ledger.
2. Perform the statements provided in the transaction, and then check for any conflicts using optimistic concurrency control (OCC) (p. 476) to ensure fully serializable isolation.
3. If no OCC conflicts are found, return the transaction results as follows:
• For reads, return the result set and commit the SELECT statements to the journal in an append-only manner.
• For writes, commit any updates, deletes, or newly inserted data to the journal in an append-only manner.
The journal represents a complete and immutable history of all the changes to your data. QLDB writes one or more chained blocks to the journal in a transaction. Each block contains entry objects that represent the document revisions that you insert, update, and delete, along with the PartiQL (p. 646) statements that committed them.
The following diagram illustrates this journal structure.
The diagram shows that transactions are committed to the journal as blocks that contain document revision entries. Each block is hashed and chained to subsequent blocks for verification (p. 480). Each block has a sequence number to specify its address within the strand.
Note
In Amazon QLDB, a strand is a partition of your ledger's journal. QLDB currently supports journals with a single strand only.
For information about the data contents in a block, see Journal contents in Amazon QLDB (p. 11).
Querying your data
Querying your data
QLDB is intended to address the needs of high-performance online transaction processing (OLTP) workloads. A ledger provides queryable table views of your data based on the transaction information that is committed to the journal. A table view in QLDB is a subset of the data in a table. Views are maintained in real time, so that they're always available for applications to query.
You can query the following system-defined views using PartiQL SELECT statements:
• User – The latest active revision of only the data that you wrote in the table (that is, the current state of your user data). This is the default view in QLDB.
• Committed – The latest active revision of both your user data and the system-generated metadata.
This is the full system-defined table that corresponds directly to your user table.
In addition to these queryable views, you can query the revision history of your data by using the built-in History function (p. 454). The history function returns both your user data and the associated metadata in the same schema as the committed view.
Data storage
There are two types of data storage in QLDB:
• Journal storage – The disk space that is used by a ledger's journal. The journal is append-only and contains the complete, immutable, and verifiable history of all the changes to your data.
• Indexed storage – The disk space that is used by a ledger's tables, indexes, and indexed history. Indexed storage consists of ledger data that is optimized for high-performance queries.
After your data is committed to the journal, it is materialized into the tables that you defined. These tables enable faster and more efficient queries. When an application uses the transactional data API to read data, it accesses the tables and indexes that are stored in your indexed storage.
QLDB API model
QLDB provides two types of APIs that your application code can interact with:
• Amazon QLDB – The QLDB control plane. These API actions are used only for managing ledgers and for non-transactional data operations. You can use these actions to create, delete, describe, list, and update ledgers. You can also verify data cryptographically, and export or stream journal blocks.
• Amazon QLDB Session – The QLDB transactional data plane. You can use this API to run data transactions on a ledger with PartiQL (p. 646) statements.
Important
Instead of interacting directly with the QLDB Session API, we recommend using the QLDB driver or the QLDB shell to run data transactions on a ledger.
• If you are working with an AWS SDK, use the QLDB driver. The driver provides a high-level abstraction layer above the QLDB Session data plane and manages SendCommand API calls for you. For information and a list of supported programming languages, see Getting started with the driver (p. 49).
• If you are working with the AWS CLI, use the QLDB shell. The shell is a command line interface that uses the QLDB driver to interact with a ledger. For information, see Using the Amazon QLDB shell (data plane only) (p. 24).
For more information about these API operations, see the Amazon QLDB API reference (p. 709).
Next steps
Next steps
To learn how to use a ledger with your data, see Working with data and history in Amazon
QLDB (p. 443) and follow the examples that describe the process of creating tables, inserting data, and running basic queries. This guide explains how these concepts work in depth, using sample data and query examples for context.
To get started quickly with a sample application tutorial using the QLDB console, see Getting started with the Amazon QLDB console (p. 32).
For a list of the key terms and definitions described in this section, see the Amazon QLDB glossary (p. 14).
Journal contents in Amazon QLDB
In Amazon QLDB, the journal is the immutable transactional log that stores the complete and verifiable history of all the changes to your data. The journal is append-only and is composed of a sequenced and hash-chained set of blocks that contain your committed data and other system metadata. QLDB writes one or more chained blocks to the journal in a transaction.
This section provides an example of a journal block with sample data and describes the contents of a block.
Topics
• Block example (p. 11)
• Block contents (p. 13)
• Sample application (p. 14)
• See also (p. 14)
Block example
A journal block contains transaction metadata along with entries that represent the document revisions that were committed in the transaction and the PartiQL (p. 646) statements that committed them.
The following is an example of a block with sample data.
NoteThis block example is for informational purposes only. The hashes shown are not real calculated hash values.
{ blockAddress:{
strandId:"JdxjkR9bSYB5jMHWcI464T", sequenceNo:1234
},
transactionId:"D35qctdJRU1L1N2VhxbwSn", blockTimestamp:2019-10-25T17:20:21.009Z,
blockHash:{{WYLOfZClk0lYWT3lUsSr0ONXh+Pw8MxxB+9zvTgSvlQ=}}, entriesHash:{{xN9X96atkMvhvF3nEy6jMSVQzKjHJfz1H3bsNeg8GMA=}}, previousBlockHash:{{IAfZ0h22ZjvcuHPSBCDy/6XNQTsqEmeY3GW0gBae8mg=}}, entriesHashList:[
{{F7rQIKCNn0vXVWPexilGfJn5+MCrtsSQqqVdlQxXpS4=}}, {{C+L8gRhkzVcxt3qRJpw8w6hVEqA5A6ImGne+E7iHizo=}}
], transactionInfo:{
statements:[
{
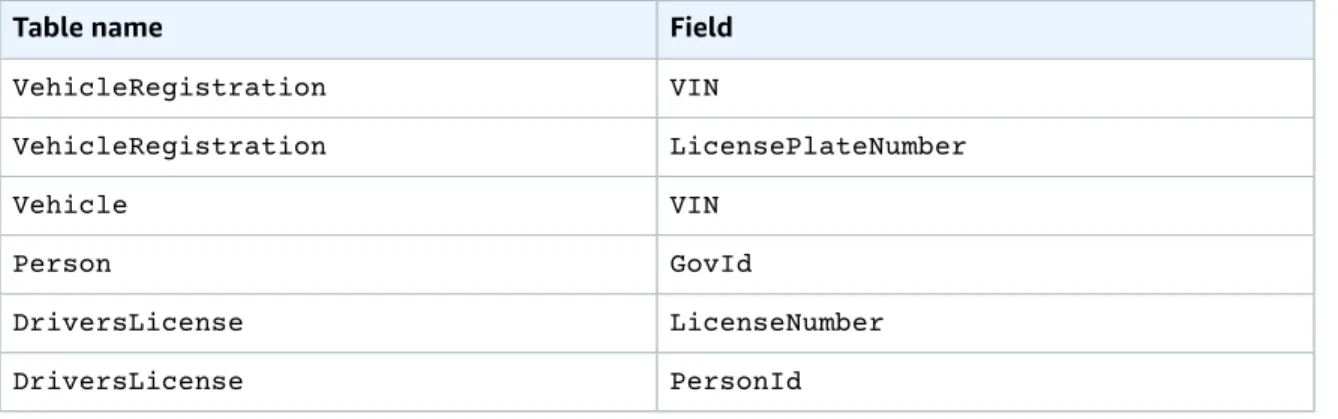
Block example statement:"CREATE TABLE VehicleRegistration", startTime:2019-10-25T17:20:20.496Z,
statementDigest:{{3jeSdejOgp6spJ8huZxDRUtp2fRXRqpOMtG43V0nXg8=}}
}, {
statement:"CREATE INDEX ON VehicleRegistration (VIN)", startTime:2019-10-25T17:20:20.549Z,
statementDigest:{{099D+5ZWDgA7r+aWeNUrWhc8ebBTXjgscq+mZ2dVibI=}}
}, {
statement:"CREATE INDEX ON VehicleRegistration (LicensePlateNumber)", startTime:2019-10-25T17:20:20.560Z,
statementDigest:{{B73tVJzVyVXicnH4n96NzU2L2JFY8e9Tjg895suWMew=}}
}, {
statement:"INSERT INTO VehicleRegistration ?", startTime:2019-10-25T17:20:20.595Z,
statementDigest:{{ggpon5qCXLo95K578YVhAD8ix0A0M5CcBx/W40Ey/Tk=}}
} ],
documents:{
'8F0TPCmdNQ6JTRpiLj2TmW':{
tableName:"VehicleRegistration", tableId:"BPxNiDQXCIB5l5F68KZoOz", statements:[3]
} }
}, revisions:[
{
hash:{{FR1IWcWew0yw1TnRklo2YMF/qtwb7ohsu5FD8A4DSVg=}}
}, {
blockAddress:{
strandId:"JdxjkR9bSYB5jMHWcI464T", sequenceNo:1234
},
hash:{{t8Hj6/VC4SBitxnvBqJbOmrGytF2XAA/1c0AoSq2NQY=}}, data:{
VIN:"1N4AL11D75C109151",
LicensePlateNumber:"LEWISR261LL", State:"WA",
City:"Seattle",
PendingPenaltyTicketAmount:90.25, ValidFromDate:2017-08-21,
ValidToDate:2020-05-11, Owners:{
PrimaryOwner:{
PersonId:"GddsXfIYfDlKCEprOLOwYt"
},
SecondaryOwners:[]
} },
metadata:{
id:"8F0TPCmdNQ6JTRpiLj2TmW", version:0,
txTime:2019-10-25T17:20:20.618Z, txId:"D35qctdJRU1L1N2VhxbwSn"
} } ] }
Block contents
In the revisions field, some revision objects might only contain a hash value and no other attributes.
These are internal-only system revisions that don't contain user data. The hashes of these revisions are part of the journal's full hash chain, which is required for cryptographic verification.
Block contents
A journal block has the following fields:
blockAddress
The location of the block in the journal. An address is an Amazon Ion (p. 697) structure that has two fields: strandId and sequenceNo.
For example: {strandId:"BlFTjlSXze9BIh1KOszcE3",sequenceNo:14}
transactionId
The unique ID of the transaction that committed the block.
blockTimestamp
The timestamp when the block was committed to the journal.
blockHash
The 256-bit hash value that uniquely represents the block. This is the hash of the concatenation of entriesHash and previousBlockHash.
entriesHash
The hash that represents all of the entries within the block, including internal-only system entries.
This is the root hash of the Merkle tree (p. 483) in which the leaf nodes consist of all the hashes in entriesHashList.
previousBlockHash
The hash of the previous chained block in the journal.
entriesHashList
The list of hashes that represent each entry within the block. This list includes the following entry hashes:
• The Ion hash that represents transactionInfo. This value is calculated by hashing the entire transactionInfo Ion structure.
• The root hash of the Merkle tree in which the leaf nodes consist of all the hashes in revisions.
• Hashes that represent internal-only system metadata. These hashes might not exist in all blocks.
transactionInfo
An Amazon Ion structure that contains information about the statements in the transaction that committed the block. This structure has the following fields:
• statements – The list of PartiQL statements and the startTime when they started running.
Each statement has a statementDigest hash, which is required to calculate the hash of the transactionInfo structure.
• documents – The document IDs that were updated by the statements. Each document includes the tableName and tableId that it belongs to, and the index of the statement that updated it.
revisions
The list of document revisions that were committed in the block. Each revision structure contains all of the fields from the committed view (p. 450) of the revision.
This can also include hashes that represent internal-only system revisions that are part of the full hash chain of a journal.
Sample application
Sample application
For a Java code example that validates a journal's hash chain using exported data, see the GitHub repository aws-samples/amazon-qldb-dmv-sample-java. This sample application includes the following class files:
• ValidateQldbHashChain.java – Contains tutorial code that exports journal blocks from a ledger and uses the exported data to validate the hash chain between blocks.
• JournalBlock.java – Contains a method named verifyBlockHash() that demonstrates how to calculate each individual hash component within a block. This method is called by the tutorial code in ValidateQldbHashChain.java.
For instructions on how to download and install this complete sample application, see Installing the Amazon QLDB Java sample application (p. 183). Before you run the tutorial code, make sure that you follow Steps 1–3 in the Java tutorial (p. 182) to set up a sample ledger and load it with sample data.
See also
For more information about journals in QLDB, see the following topics:
• Exporting journal data from Amazon QLDB (p. 524) – To learn how to export journal data to Amazon Simple Storage Service (Amazon S3).
• Streaming journal data from Amazon QLDB (p. 537) – To learn how to stream journal data to Amazon Kinesis Data Streams.
• Data verification in Amazon QLDB (p. 480) – To learn about cryptographic verification of journal data.
Amazon QLDB glossary
The following are definitions for key terms that you might encounter as you work with Amazon QLDB.
block (p. 14) | digest (p. 14) | document (p. 15) | document ID (p. 15) | document revision (p. 15) | entry (p. 15) | field (p. 15) | index (p. 15) | indexed storage (p. 15) |
journal (p. 15) | journal block (p. 15) | journal storage (p. 15) | journal strand (p. 15) | journal tip (p. 15) | ledger (p. 15) | proof (p. 16) | revision (p. 16) | session (p. 16) | strand (p. 16)
| table (p. 16) | table view (p. 16) | view (p. 16) block
An object that is committed to the journal in a transaction. A single transaction writes one or more blocks in the journal, but a block can only be associated with one transaction. A block contains entries that represent the document revisions that were committed in the transaction, along with the PartiQL (p. 646) statements that committed them.
Each block also has a hash value for verification. A block hash is calculated from the entry hashes within that block combined with the hash of the previous chained block.
digest
A 256-bit hash value that uniquely represents your ledger's entire history of document revisions as of a point in time. A digest hash is calculated from your journal's full hash chain as of the latest committed block in the journal at that time.
QLDB lets you generate a digest as a secure output file. Then, you can use that output file to verify the integrity of your document revisions relative to that hash.
QLDB glossary document
A set of data in Amazon Ion (p. 697) struct format that can be inserted, updated, and deleted in a table. A QLDB document can have structured, semistructured, nested, and schema-less data.
document ID
The universally unique identifier (UUID) that QLDB assigns to each document that you insert into a table. This ID is a 128-bit number that is represented in a Base62-encoded alphanumeric string with a fixed length of 22 characters.
document revision
An Ion structure that represents a single version of a sequence of documents that are identified by a unique document ID. A revision includes both your user data (that is, the data that you wrote in the table) and QLDB-generated metadata. Each revision is associated with a table, and is uniquely identified by a combination of the document ID and a zero-based version number.
entry
An object that is contained in a block. Entries represent document revisions that are inserted, updated, and deleted in a transaction, along with the PartiQL statements that committed them.
Each entry also has a hash value for verification. An entry hash is calculated from the revision hashes or the statement hashes within that entry.
field
A name-value pair that makes up each attribute of a QLDB document. The name is a symbol token, and the value is unrestricted.
index
A data structure that you can create on a table to optimize the performance of data retrieval operations. For information about indexes in QLDB, see CREATE INDEX (p. 654) in the Amazon QLDB PartiQL reference.
indexed storage
The disk space that is used by a ledger's tables, indexes, and indexed history. Indexed storage consists of ledger data that is optimized for high-performance queries.
journal
The hash-chained set of all blocks that are committed in your ledger. The journal is append-only and represents a complete and immutable history of all the changes to your ledger data.
journal block See block (p. 14).
journal storage
The disk space that is used by a ledger's journal.
journal strand See strand (p. 16).
journal tip
The latest committed block in a journal at a point in time.
ledger
An instance of an Amazon QLDB ledger database resource. This is the primary AWS resource type in QLDB. A ledger consists of both journal storage and indexed storage. After ledger data is committed to the journal, it is available to query in tables of Amazon Ion document revisions.
QLDB glossary proof
The ordered list of 256-bit hash values that QLDB returns for a given digest and document revision.
It consists of the hashes that are required by a Merkle tree model to chain the given revision hash to the digest hash. A proof enables you to verify the integrity of your revisions relative to the digest.
For more information, see Data verification in Amazon QLDB (p. 480).
revision
See document revision (p. 15).
session
An object that manages information about your data transaction requests and responses to and from a ledger. An active session (one that is actively running a transaction) represents a single connection to a ledger. QLDB supports one actively running transaction per session.
strand
A partition of a journal. QLDB currently supports journals with a single strand only.
table
A materialized view of an unordered collection of document revisions that are committed in the ledger's journal.
table view
A queryable subset of the data in a table, based on transactions committed to the journal. In a PartiQL statement, a view is denoted by a prefix qualifier (starting with _ql_) for a table name.
You can query the following system-defined views using SELECT statements:
• User – The latest active revision of only the data that you wrote in the table (that is, the current state of your user data). This is the default view in QLDB.
• Committed – The latest active revision of both your user data and the system-generated metadata.
This is the full system-defined table that corresponds directly to your user table. For example:
_ql_committed_TableName. view
See table view (p. 16).
Signing up for an AWS account
Accessing Amazon QLDB
You can access Amazon QLDB using the AWS Management Console, the AWS Command Line Interface (AWS CLI), or the QLDB API. Before accessing QLDB, you must do the following:
1.Sign up for an AWS account. (p. 17)
2.Create an AWS Identity and Access Management (IAM) user. (p. 17) 3.Get an IAM access key (p. 19) (to access QLDB programmatically).
Note
If you plan to interact with QLDB only through the console, you don't need an IAM access key, and you can skip ahead to Accessing Amazon QLDB using the console (p. 20).
4.Configure your credentials (p. 20) (to access QLDB programmatically).
After completing these steps, see the following topics to learn more about how to access QLDB:
• Using the console (p. 20)
• Using the AWS CLI (control plane only) (p. 23)
• Using the Amazon QLDB shell (data plane only) (p. 24)
• Using the API (p. 30)
Signing up for an AWS account
To use the QLDB service, you must have an AWS account. If you don't already have an account, you are prompted to create one when you sign up. You're not charged for any AWS services that you sign up for unless you use them.
To sign up for AWS
1. Open https://portal.aws.amazon.com/billing/signup.
2. Follow the online instructions.
Part of the sign-up procedure involves receiving a phone call and entering a verification code on the phone keypad.
AWS sends you a confirmation email after the sign-up process is complete. At any time, you can view your current account activity and manage your account by going to https://aws.amazon.com/ and choosing My Account.
Creating an IAM user
If your account already includes an AWS Identity and Access Management (IAM) user with full AWS administrative permissions, you can skip this section.
When you first create an Amazon Web Services (AWS) account, you begin with a single sign-in identity.
That identity has complete access to all AWS services and resources in the account. This identity is called
Creating an IAM user
the AWS account root user. When you sign in, enter the email address and password that you used to create the account.
Important
We strongly recommend that you do not use the root user for your everyday tasks, even the administrative ones. Instead, adhere to the best practice of using the root user only to create your first IAM user. Then securely lock away the root user credentials and use them to perform only a few account and service management tasks. To view the tasks that require you to sign in as the root user, see Tasks that require root user credentials.
To create an administrator user for yourself and add the user to an administrators group (console)
1. Sign in to the IAM console as the account owner by choosing Root user and entering your AWS account email address. On the next page, enter your password.
Note
We strongly recommend that you adhere to the best practice of using the Administrator IAM user that follows and securely lock away the root user credentials. Sign in as the root user only to perform a few account and service management tasks.
2. In the navigation pane, choose Users and then choose Add user.
3. For User name, enter Administrator.
4. Select the check box next to AWS Management Console access. Then select Custom password, and then enter your new password in the text box.
5. (Optional) By default, AWS requires the new user to create a new password when first signing in. You can clear the check box next to User must create a new password at next sign-in to allow the new user to reset their password after they sign in.
6. Choose Next: Permissions.
7. Under Set permissions, choose Add user to group.
8. Choose Create group.
9. In the Create group dialog box, for Group name enter Administrators.
10. Choose Filter policies, and then select AWS managed - job function to filter the table contents.
11. In the policy list, select the check box for AdministratorAccess. Then choose Create group.
NoteYou must activate IAM user and role access to Billing before you can use the
AdministratorAccess permissions to access the AWS Billing and Cost Management console. To do this, follow the instructions in step 1 of the tutorial about delegating access to the billing console.
12. Back in the list of groups, select the check box for your new group. Choose Refresh if necessary to see the group in the list.
13. Choose Next: Tags.
14. (Optional) Add metadata to the user by attaching tags as key-value pairs. For more information about using tags in IAM, see Tagging IAM entities in the IAM User Guide.
15. Choose Next: Review to see the list of group memberships to be added to the new user. When you are ready to proceed, choose Create user.
You can use this same process to create more groups and users and to give your users access to your AWS account resources. To learn about using policies that restrict user permissions to specific AWS resources, see Access management and Example policies.
For information about using IAM to manage access to QLDB, see How Amazon QLDB works with IAM (p. 583).
Signing in as an IAM user
Signing in as an IAM user
Sign in to the IAM console by choosing IAM user and entering your AWS account ID or account alias. On the next page, enter your IAM user name and your password.
NoteFor your convenience, the AWS sign-in page uses a browser cookie to remember your IAM user name and account information. If you previously signed in as a different user, choose the sign-in link beneath the button to return to the main sign-in page. From there, you can enter your AWS account ID or account alias to be redirected to the IAM user sign-in page for your account.
Getting IAM user access keys
Before you can access Amazon QLDB programmatically or through the AWS CLI, you must have an IAM access key. You don't need an access key if you plan to use the QLDB console only.
Access keys consist of an access key ID and secret access key, which are used to sign programmatic requests that you make to AWS. If you don't have access keys, you can create them from the AWS Management Console. As a best practice, do not use the AWS account root user access keys for any task where it's not required. Instead, create a new administrator IAM user with access keys for yourself.
The only time that you can view or download the secret access key is when you create the keys. You cannot recover them later. However, you can create new access keys at any time. You must also have permissions to perform the required IAM actions. For more information, see Permissions required to access IAM resources in the IAM User Guide.
To create access keys for an IAM user
1. Sign in to the AWS Management Console and open the IAM console at https://
console.aws.amazon.com/iam/.
2. In the navigation pane, choose Users.
3. Choose the name of the user whose access keys you want to create, and then choose the Security credentials tab.
4. In the Access keys section, choose Create access key.
5. To view the new access key pair, choose Show. You will not have access to the secret access key again after this dialog box closes. Your credentials will look something like this:
• Access key ID: AKIAIOSFODNN7EXAMPLE
• Secret access key: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
6. To download the key pair, choose Download .csv file. Store the keys in a secure location. You will not have access to the secret access key again after this dialog box closes.
Keep the keys confidential in order to protect your AWS account and never email them. Do not share them outside your organization, even if an inquiry appears to come from AWS or Amazon.com. No one who legitimately represents Amazon will ever ask you for your secret key.
7. After you download the .csv file, choose Close. When you create an access key, the key pair is active by default, and you can use the pair right away.
Related topics
• What is IAM? in the IAM User Guide
• AWS security credentials in AWS General Reference
Configuring your credentials
Configuring your credentials
Before you can access Amazon QLDB programmatically or through the AWS CLI, you must configure your credentials to enable authorization for your applications.
There are several ways to do this, including the following methods:
• Manually create a credentials file to store your IAM access key ID and secret access key.
• Use the aws configure command of the AWS CLI to automatically create the file.
To install and configure the AWS CLI, see Accessing Amazon QLDB using the AWS CLI (control plane only) (p. 23).
• Use environment variables.
For instructions on configuring your credentials, see Getting started with the Amazon QLDB
driver (p. 49). Each programming language has specific prerequisites with links to instructions in their respective AWS SDK developer guide.
Accessing Amazon QLDB using the console
You can access the AWS Management Console for Amazon QLDB here: https://console.aws.amazon.com/
qldb
You can use the console to do the following in QLDB:
• Create, delete, describe, and list ledgers.
• Run PartiQL (p. 646) statements by using the Query editor.
• Manage tags for QLDB resources.
• Verify journal data cryptographically.
• Export or stream journal blocks.
To learn how to create an Amazon QLDB ledger and set it up with sample application data, see Getting started with the Amazon QLDB console (p. 32).
Query editor quick reference
Amazon QLDB supports a subset of PartiQL as its query language and Amazon Ion as its document- oriented data format. For a complete guide about the QLDB implementation of PartiQL, see the Amazon QLDB PartiQL reference (p. 646).
The following topics provide a quick reference overview of how to use PartiQL in QLDB.
Topics
• PartiQL quick tips in QLDB (p. 21)
• Commands (p. 21)
• System-defined views (p. 22)
• Basic syntax rules (p. 23)
• Query editor keyboard shortcuts (p. 23)
Query editor quick reference
PartiQL quick tips in QLDB
The following is a short summary of tips and best practices for working with PartiQL in QLDB:
• Concurrency and transaction limits – All statements, including SELECT queries, are subject to optimistic concurrency control (OCC) (p. 476) conflicts and transaction limits (p. 806), including a 30-second transaction timeout.
• Use indexes – Use high-cardinality indexes and run targeted queries to optimize your statements and avoid full table scans. To learn more, see Optimizing query performance (p. 457).
• Use equality predicates – Indexed lookups require an equality operator (= or IN). Inequality operators (<, >, LIKE, BETWEEN) don't qualify for indexed lookups and result in full table scans.
• Inner joins only – QLDB currently supports inner joins only. As a best practice, join on fields that are indexed for each table that you're joining. Choose high-cardinality indexes for both the join criteria and the equality predicates.
Commands
QLDB supports the following PartiQL commands.
Data definition language (DDL)
Command Description
CREATE INDEX (p. 654) Creates an index for a top-level document field on a table
CREATE TABLE (p. 656) Creates a table
DROP INDEX (p. 659) Deletes an index from a table
DROP TABLE (p. 660) Inactivates an existing table
UNDROP TABLE (p. 672) Reactivates an inactive table
Data manipulation language (DML)
Command Description
DELETE (p. 658) Marks an active document as deleted by creating a new, final revision of the document
FROM (INSERT, REMOVE, or SET) (p. 660) Inserts, removes, or updates specific elements within a document
INSERT (p. 664) Adds one or more documents (p. 648) to a table
SELECT (p. 666) Retrieves data from one or more tables
UPDATE (p. 670) Modifies the value of one or more existing
elements within a document
DML statement examples
INSERT
INSERT INTO VehicleRegistration VALUE
Query editor quick reference {
'VIN' : 'KM8SRDHF6EU074761', --string 'RegNum' : 1722, --integer
'PendingPenaltyTicketAmount' : 130.75, --decimal 'Owners' : { --nested struct
'PrimaryOwner' : { 'PersonId': '294jJ3YUoH1IEEm8GSabOs' }, 'SecondaryOwners' : [ --list of structs
{ 'PersonId' : '1nmeDdLo3AhGswBtyM1eYh' }, { 'PersonId': 'IN7MvYtUjkp1GMZu0F6CG9' } ]
},
'ValidToDate' : `2020-06-25T` --Ion timestamp literal with day precision }
FROM-INSERT
FROM Vehicle AS v
WHERE v.VIN = '1N4AL11D75C109151' INSERT INTO v VALUE 26500 AT 'Mileage'
FROM-REMOVE
FROM Person AS p
WHERE p.GovId = '111-22-3333' REMOVE p.Address
SELECT – Correlated subquery
SELECT r.VIN, o.SecondaryOwners
FROM VehicleRegistration AS r, @r.Owners AS o
WHERE r.VIN IN ('1N4AL11D75C109151', 'KM8SRDHF6EU074761')
SELECT – Inner join
SELECT v.Make, v.Model, r.Owners
FROM VehicleRegistration AS r INNER JOIN Vehicle AS v ON r.VIN = v.VIN
WHERE r.VIN IN ('1N4AL11D75C109151', 'KM8SRDHF6EU074761')
SELECT – Get document ID using BY clause
SELECT r_id FROM VehicleRegistration AS r BY r_id WHERE r.VIN = '1HVBBAANXWH544237'
System-defined views
QLDB supports the following system-defined views of a table.
View Description
table_name The default user view (p. 446) of a table that includes the current state of your user data only
_ql_committed_table_nameThe full system-defined committed view (p. 450) of a table that includes the current state of both your user data and system-generated metadata, such as a document ID
Using the AWS CLI (control plane only)
View Description
history(table_name)The built-in history function (p. 454) that returns the complete revision history of a table
Basic syntax rules
QLDB supports the following basic syntax rules for PartiQL.
Character Description
' Single quotes denote string values, or field names in Amazon Ion structures
" Double quotes denote quoted identifiers, such as a reserved word (p. 693) that is used as a table name
` Backticks denote Ion literal values
. Dot notation accesses field names of a parent structure
[ ] Square brackets define an Ion list, or denote a zero-based ordinal number for an existing list
{ } Curly braces define an Ion struct
<< >> Double angle brackets define a PartiQL bag, which you use to insert multiple documents into a table
Case sensitivity All QLDB system object names—including field names and table names—are case sensitive
Query editor keyboard shortcuts
The Query editor on the QLDB console supports the following keyboard shortcuts.
Action macOS Windows
Run Cmd+Return Ctrl+Enter
Save Cmd+S Ctrl+S
Clear Cmd+Shift+Delete Ctrl+Shift+Backspace
Accessing Amazon QLDB using the AWS CLI (control plane only)
You can use the AWS Command Line Interface (AWS CLI) to control multiple AWS services from the command line and automate them through scripts. You can use the AWS CLI for ad hoc operations. You can also use it to embed Amazon QLDB operations within utility scripts.
Before you can use the AWS CLI with QLDB, you must get an access key ID and secret access key. For more information, see Getting IAM user access keys (p. 19).
Downloading and configuring the AWS CLI
For a complete listing of all the commands available for QLDB in the AWS CLI, see the AWS CLI Command Reference.
NoteThe AWS CLI only supports the qldb control plane API operations that are listed in the Amazon QLDB API reference (p. 709). These actions are used only for managing ledgers and for non- transactional data operations.
To run data transactions with the qldb-session API using a command line interface, see Accessing Amazon QLDB using the QLDB shell (data plane only) (p. 24).
Topics
• Downloading and configuring the AWS CLI (p. 24)
• Using the AWS CLI with QLDB (p. 24)
Downloading and configuring the AWS CLI
The AWS CLI runs on Windows, macOS, or Linux. To download, install, and configure it, follow these steps:
1. Download the AWS CLI at http://aws.amazon.com/cli.
2. Follow the instructions for Installing the AWS CLI and Configuring the AWS CLI in the AWS Command Line Interface User Guide.
Using the AWS CLI with QLDB
The command line format consists of an Amazon QLDB operation name, followed by the parameters for that operation. The AWS CLI supports a shorthand syntax for the parameter values, in addition to JSON.
Use help to list all available commands in QLDB:
aws qldb help
You can also use help to describe a specific command and learn more about its usage:
aws qldb create-ledger help
For example, to create a ledger:
aws qldb create-ledger --name my-example-ledger --permissions-mode STANDARD
Accessing Amazon QLDB using the QLDB shell (data plane only)
Amazon QLDB provides a command line shell for interaction with the transactional data API. With the QLDB shell, you can run PartiQL (p. 646) statements on ledger data.
The latest version of this shell is written in Rust and is open-sourced in the GitHub repository awslabs/
amazon-qldb-shell on the default main branch. The Python version (v1) is also still available for use in the same repository on the master branch.
Prerequisites
NoteThe Amazon QLDB shell only supports the qldb-session transactional data API. This API is used only for running PartiQL statements on a QLDB ledger.
To interact with the qldb control plane API operations using a command line interface, see Accessing Amazon QLDB using the AWS CLI (control plane only) (p. 23).
This tool is not intended to be incorporated into an application or adopted for production purposes. The objective of this tool is to let you rapidly experiment with QLDB and PartiQL.
The following sections describe how to get started with the QLDB shell.
Topics
• Prerequisites (p. 25)
• Installing the shell (p. 25)
• Invoking the shell (p. 26)
• Shell parameters (p. 26)
• Command reference (p. 27)
• Running individual statements (p. 28)
• Managing transactions (p. 28)
• Exiting the shell (p. 30)
• Example (p. 30)
Prerequisites
Before you get started with the QLDB shell, you must do the following:
1. Follow the AWS setup instructions in Accessing Amazon QLDB (p. 17). This includes the following:
1. Sign up for AWS.
2. Create an AWS Identity and Access Management (IAM) user with the appropriate QLDB permissions.
3. Get an IAM access key for development.
2. Set up your AWS credentials and your default AWS Region. For instructions, see Configuration basics in the AWS Command Line Interface User Guide.
For a complete list of available Regions, see Amazon QLDB endpoints and quotas in the AWS General Reference.
3. For any ledgers in the STANDARD permissions mode, create IAM policies that grant you permissions to run PartiQL statements on the appropriate tables. To learn how to create these policies, see Getting started with the standard permissions mode in Amazon QLDB (p. 589).
Installing the shell
To install the latest version of the QLDB shell, see the README.md file on GitHub. QLDB provides pre- built binary files for Linux, macOS, and Windows in the Releases section of the GitHub repository.
For macOS, the shell integrates with the aws/tap Homebrew tap. To install the shell on macOS using Homebrew, run the following commands.
$ xcode-select --install # Required to use Homebrew
$ brew tap aws/tap # Add AWS as a Homebrew tap
$ brew install qldbshell
Invoking the shell
Configuration
After installation, the shell loads the default configuration file that is located at $XDG_CONFIG_HOME/
qldbshell/config.ion during initialization. On Linux and macOS, this file is typically at ~/.config/
qldbshell/config.ion. If such a file doesn't exist, the shell runs with default settings.
You can create a config.ion file manually after installation. This configuration file uses the Amazon Ion (p. 697) data format. The following is an example of a minimal config.ion file.
{
default_ledger: "my-example-ledger"
}
If default_ledger is not set in your configuration file, the --ledger parameter is required when you invoke the shell. For a full list of configuration options, see the README.md file on GitHub.
Invoking the shell
To invoke the QLDB shell on your command line terminal for a specific ledger, run the following command. Replace my-example-ledger with your ledger name.
$ qldb --ledger my-example-ledger
This command connects to your default AWS Region. To explicitly specify the Region, you can run the command with the --region or --qldb-session-endpoint parameter, as described in the following section.
After invoking a qldb shell session, you can enter the following types of input:
• Shell commands (p. 27)
• Single PartiQL statements in separate transactions (p. 28)
• Multiple PartiQL statements within a transaction (p. 28)
Shell parameters
For a full list of available flags and options for invoking a shell, run the qldb command with the --help flag, as follows.
$ qldb --help
The following are some key flags and options for the qldb command. You can add these optional parameters to override the AWS Region, credentials profile, endpoint, results format, and other configuration options.
Usage
$ qldb [FLAGS] [OPTIONS]
FLAGS -h, --help
Prints help information.