執 行 單 位:國立成功大學
執 行 期 間:108 年 01 月 01 日至 108 年 12 月 31 日 計畫主持人 :林冠瑋 副教授
行政院農業委員會水土保持局 編印 中華民國 108 年 12 月
(本報告書內容及建議純屬執行單位意見,僅供本局施政參考)
崩塌地動訊號自動化辨識技術精進及其應 用之研究
Improvement and application of automatic
landslide-quake identification technology
崩塌地動訊號自動化辨識技術精進及其應用之研究
摘要
大規模崩塌產生的地表振動訊號可被鄰近地震儀記錄下來,因此近年 來地動訊號分析被廣泛用於邊坡塊體滑動的研究。從連續地動記錄中判別 出崩塌訊號以往多是仰賴人工判讀,不僅過於曠日廢時,判釋結果也深受分 析人員的經驗及主觀判斷影響。將機器學習技術應用到地動訊號的自動判 釋,可更加快速且客觀的找出崩塌事件的時間點,大量減少在判釋崩塌事件 的時間及人力成本。
本計畫利用 642 個已知振動類型的地動訊號作為分類器的訓練樣本,
藉由計算時間域及頻率域上的訊號特徵值,配合機器學習演算法,建立出連 續地震記錄的自動分類器。將自動分類器運用於 2018 年及 2019 的颱風及 豪雨事件,可以成功辨識出 6 個由崩塌所產生的地表振動訊號。分析崩塌 地動訊號發現崩塌面積與包絡線面積,以及崩塌體積與平均地表速度大致 呈現正相關,表示利用崩塌地動訊號有機會進一步用於評估崩塌量體。
利用崩塌地動訊號提供的 93 個崩塌發生時間,進一步統計促崩降雨參 數,結果反映出引發大規模崩塌並不需要極端的小時降雨量,長時間的持續 降雨以及大量的累積降雨是引發大規模崩塌的主要因素。引發大規模崩塌 的土壤水分指數統計結果顯示,需要大量的水分進入深層材料中才能引發 大規模崩塌,且觸發大規模崩塌的前期降雨高於小規模崩塌。
Improvement and application of automatic landslide- quake identification technology
Abstract
The ground motions generated by large-scale landslide can be recorded by nearby seismometers. Therefore, in recent years, the analysis of ground motions has been widely used in the study of slope failure. Identifying the landslide-quake signals from the continuous seismic records used to rely on manual interpretation in the past. Not only is it too time-consuming, but the interpretation result is also deeply affected by the experience and subjective judgment of the analyst.
Applying machine learning technology to the automatic interpretation of ground motion signals can more quickly and objectively find the time point of a landslide event, and greatly reduce the time and labor cost in interpreting a collapse event.
This project uses 642 ground motion signals of known ground-motion types as training samples for the classifier. By calculating signal attribute values in the time and frequency domains, and using machine learning algorithms, an automatic classifier for continuous seismic records is established. Applying the automatic classifier to the typhoons and heavy rain events in 2018 and 2019 can successfully identify 6 ground motion signals generated by the landslide. Analysis of the landslide-quake signal found that the landslide area and the envelope area, and the landslide volume and the average ground velocity showed a roughly positive correlation, indicating that the use of the landslide-quake signal may be used to further evaluate the landslide magnitude.
Using the 93 occurrence times provided by the landslide-quakes, further statistics of the triggering rainfall parameters were obtained. The results reflect that extreme hourly rainfall is not required to initiate a large-scale landslide. Long duration and large cumulative rainfall are the main factors to cause a large-scale landslide. The statistical results of soil water index that caused large-scale landslide showed that a large amount of water was required to enter the deep material to cause a large-scale landslide, and the rainfall that triggered the large- scale landslide was higher than that of small-scale collapse.
Keywords: Large scale landslide, Seismic signal, Machine learning, Signal
features
目次
摘要 ...I
Abstract ... II
目次 ... IV 表次 ... VI 圖次 ... VIII 第一章 前言 ... 1-1 第一節 背景說明 ... 1-1 第二節 計畫目的 ... 1-2 第三節 期末檢核點 ... 1-2 第四節 文獻回顧 ... 1-3 第二章 研究方法 ... 2-1 第一節 研究資料來源 ... 2-1 第二節 分類器訓練樣本 ... 2-5 第三節 時間域特徵值 ... 2-6 第四節 頻率域特徵值 ... 2-9 第五節 建立自動分類器 ... 2-17 第六節 崩塌地動訊號定位 ... 2-25 第七節 促崩降雨條件分析 ... 2-28 第三章 研究成果 ... 3-1 第一節 演算法測試結果 ... 3-1 第二節 分類器正確度 ... 3-2 第三節 自動分類器測試結果 ... 3-3第四節 測試結果討論 ... 3-6 第五節 特徵值個別分類效果 ... 3-15 第六節 2018 年與 2019 年颱風期間連續地動訊號分類結果... 3-20 第七節 訊號分類結果應用於崩塌類型或規模評估 ... 3-28 第八節 降雨觸發大規模崩塌的降雨條件 ... 3-31 第四章 討論 ... 4-1 第一節 時間域及頻率域特徵值分類效能比較 ... 4-1 第二節 崩塌訊號傳遞距離 ... 4-4 第三節 2009 年莫拉克颱風期間崩塌定位及雨量討論 ... 4-7 第四節 前期降雨對大規模崩塌的影響 ... 4-10 第五章 結論及建議 ... 5-1 參考文獻 ... 參-1 附錄 ... 附錄-1 附錄一、建構自動分類器之崩塌事件訓練樣本 ... 附錄-1 附錄二、建構自動分類器之地震事件訓練樣本 ... 附錄-6 附錄三、驗證分類器之 2009 年莫拉克颱風訊號人工判釋結果.. 附錄-10 附錄四、期中審查意見回覆 ... 附錄-21 附錄五、期末審查意見回覆 ... 附錄-27 附錄六、公文 ... 附錄-36
表次
表 1.1 自動分類器相關研究 ... 1-6 表 1.2 本計畫與吳昱杰(2018)研究內容之比較 ... 1-9 表 2.1 本計畫使用的 11 個測站及其座標 ... 2-5 表 2.2 24 項訊號特徵值 ... 2-14 表 2.3 24 項訊號特徵值及訓練樣本之平均數值 ... 2-15 表 2.4 混淆矩陣 ... 2-23 表 2.5 土壤水分指數計算所用之參數 ... 2-37 表 3.1 22 種演算法測試結果 ... 3-1 表 3.2 自動分類器的混淆矩陣 ... 3-3 表 3.3 2009 年莫拉克颱風期間人工判釋崩塌數量 ... 3-4 表 3.4 2009 年莫拉克颱風期間自動判釋結果的混淆矩陣... 3-4 表 3.5 2015 年蘇迪勒颱風期間自動判釋結果的混淆矩陣... 3-5 表 3.6 成功偵測之崩塌訊號之特徵值的平均值 ... 3-8 表 3.7 成功偵測之地震訊號之特徵值的平均值 ... 3-10 表 3.8 未偵測到之崩塌訊號之特徵值的平均值 ... 3-12 表 3.9 偵測錯誤之地震事件之特徵值的平均值 ... 3-14 表 3.10 σMA分類器的混淆矩陣 ... 3-17 表 3.11 三種類別訊號σMA平均數值 ... 3-17 表 3.12 0.02-0.1 Hz / 1-8 Hz 功率譜密度比值分類器的混淆矩陣 ... 3-19 表 3.13 三種類別訊號 0.02-0.1 Hz / 1-8 Hz 功率譜密度比值數值 ... 3-19 表 3.14 2018 年颱風期間崩塌地動訊號自動判釋結果 ... 3-21 表 4.1 時間域特徵值分類器的混淆矩陣 ... 4-1
表 4.2 頻率域特徵值分類器的混淆矩陣 ... 4-2 表 4.3 4 項時間域特徵值分類器的混淆矩陣 ... 4-2 表 4.4 4 項頻率域特徵值分類器的混淆矩陣 ... 4-3 表 4.5 4 項效果最差特徵值分類器的混淆矩陣 ... 4-4 表 4.6 三類前期土壤水分指數所對應的P98平均降雨強度、P98降雨延時 及P98累積雨量 ... 4-11
圖次
圖 1.1 雪崩事件時頻圖 ... 1-3 圖 1.2 山崩事件時頻圖 ... 1-4 圖 2.1 YULB 的小林村崩塌事件訊號 ... 2-2 圖 2.2 YHNB 的小林村崩塌事件訊號 ... 2-2 圖 2.3 RLNB 的小林村崩塌事件訊號 ... 2-3 圖 2.4 TWKB 的小林村崩塌事件訊號 ... 2-3 圖 2.5 本計畫使用之 BATS 測站分布 ... 2-4 圖 2.6 不同類型地動事件之移動平均及閃爍指數波形... 2-7 圖 2.7 不同類型地動事件平均頻譜圖 ... 2-10 圖 2.8 地動事件能量分布之劃定 ... 2-12 圖 2.9 訊號處理流程 ... 2-13 圖 2.10 時間域特徵值數值分布 ... 2-16 圖 2.11 頻率域特徵值數值分布 ... 2-16 圖 2.12 決策樹演算法架構示意圖 ... 2-18 圖 2.13 隨機森林演算法架構示意圖 ... 2-19 圖 2.14 Holdout Validation 示意圖 ... 2-20 圖 2.15 5-fold Cross Validation 示意圖 ... 2-21 圖 2.16 Leave-one-out Cross Validation 示意圖 ... 2-22 圖 2.17 地動訊號分類器建置與應用 ... 2-25 圖 2.18 崩塌定位方法示意圖 ... 2-28 圖 2.19 雨場切割與降雨參數計算示意圖 ... 2-30 圖 2.20 三種常見雙雨量參數門檻曲線 ... 2-32
圖 2.21 筒狀模型與地表逕流類比 ... 2-36 圖 2.22 筒狀雨量模式說明 ... 2-37 圖 2.23 陳有蘭溪 2018 年之觀測流深與預測流深 ... 2-38 圖 2.24 計算土壤水分指數示意圖 ... 2-38 圖 3.1 成功偵測之崩塌事件範例一 ... 3-7 圖 3.2 成功偵測之崩塌事件範例二 ... 3-7 圖 3.3 成功偵測之地震事件一 ... 3-9 圖 3.4 成功偵測之地震事件二 ... 3-9 圖 3.5 未偵測到之崩塌事件 ... 3-11 圖 3.6 判釋錯誤之地震事件一 ... 3-13 圖 3.7 判釋錯誤之地震事件二 ... 3-13 圖 3.8 24 項特徵值分類效能比較 ... 3-16 圖 3.9 三種類別訊號的移動平均波形 ... 3-18 圖 3.10 三種類別訊號的平均頻譜圖 ... 3-19 圖 3.11 (a)編號 2018-001 事件時頻圖、(b)2018 年瑪莉亞颱風期間每日累積 雨量及崩塌位置 ... 3-22 圖 3.12 編號 2018-001 事件之累積雨量及 SWI 曲線 ... 3-23 圖 3.13 (a)編號 2019-001 事件時頻圖,(b) 2019 年 6 月 23 日至 25 日豪雨 累積雨量及崩塌位置 ... 3-24 圖 3.14 編號 2019-001 事件之累積雨量及 SWI 曲線 ... 3-25 圖 3.15 2019 年白鹿颱風期間崩塌事件時頻圖:(a) 2019-002、(b) 2019-
003、(c) 2019-004、(d) 2019-005、(e) 2019 年白鹿颱風期間 8/22-8/26 累積
雨量及崩塌定位點 ... 3-26圖 3.17 濾波後波形與訊號包絡線面積、PGV、AGV ... 3-29 圖 3.18 地動訊號包絡線面積與崩塌面積之相關性 ... 3-30 圖 3.19 地動訊號平均振幅與崩塌推估體積之相關性... 3-30 圖 3.20 地動訊號最大地表速度與崩塌平均坡度之相關性 ... 3-30 圖 3.21 2001 至 2019 年大規模崩塌分布圖 ... 3-32 圖 3.22 崩塌事件之降雨延時統計 ... 3-34 圖 3.23 崩塌事件累積雨量 ... 3-35 圖 3.24 崩塌事件之降雨強度統計 ... 3-36 圖 3.25 I-D 降雨門檻 ... 3-37 圖 3.26 Re-D 降雨門檻 ... 3-39 圖 3.27 降雨型態與崩塌發生時間的關係 ... 3-39 圖 3.28 I-Re 降雨門檻 ... 3-40 圖 3.29 平均降雨強度及降雨延時與臨界水量關係圖... 3-41 圖 3.30 引發大規模崩塌之土壤水分指數及三桶水深的數量統計 ... 3-43 圖 3.31 大規模崩塌之 SWI 歷時曲線 ... 3-43 圖 3.32 (a)大規模崩塌與小規模崩塌之 SWI-D 門檻線比較、(b)大規模崩塌 與小規模崩塌發生時的 S3/SWI 百分率分布、(c)大規模崩塌與小規模崩塌 發生時的 S3/SWI 數量機率分布 ... 3-46 圖 3.33 SWI-D 門檻線驗證 ... 3-46 圖 4.1 TWGB 的隘寮南溪崩塌事件訊號 ... 4-5 圖 4.2 YHNB 的隘寮南溪崩塌事件訊號 ... 4-5 圖 4.3 WFSB 的國道三號 3.1K 崩塌事件訊號 ... 4-6 圖 4.4 ANPB 的國道三號 3.1K 崩塌事件訊號 ... 4-6 圖 4.5 2009 年莫拉克颱風期間累積雨量及累積崩塌數量... 4-7
圖 4.6 (a)累積雨量與累積崩塌數量 (b)時雨量與每小時崩塌數量 ... 4-8 圖 4.7 2009 年莫拉克颱風期間崩塌定位結果 ... 4-9 圖 4.8 前期土壤水分指數與降雨強度、延時,及累積雨量之相關性 ... 4-12
第一章 前言
第一節 背景說明
邊坡崩塌是山區最主要的地質災害之一,崩塌的發生可能會導致基礎 設施的破壞並威脅著人類的生命。大地震和暴雨被認為是觸發崩塌的重要 因素,而臺灣位於副熱帶季風氣候區,平均每年會有 4 至 5 個颱風,帶來 大量的降雨,且臺灣位於歐亞板塊與菲律賓板塊的邊界上,不僅導致臺灣的 地震相當頻繁,活躍的板塊運動也造成山多平原少的地形,同時形成臺灣丘 陵及山區破碎的地質條件。在 2009 年莫拉克颱風期間,南臺灣降下了超過 2,000 mm 的累積雨量,進而引發小林村旁獻肚山面積 2,500,000 m2、最大深 度達 80 m 的大規模崩塌,並淹沒小林村造成大量傷亡(李錫堤等人,2009)。
除了小林村事件,經前後期影像判釋發現,莫拉克颱風期間在全台各地一共 出現了超過 400 處面積大於 10 公頃的崩塌地(Wu et al., 2011)。因莫拉克颱 風而產生的崩塌事件造成的人員傷亡及財產的損失,使得邊坡崩塌災害的 潛在危機更加受到重視。
過去崩塌災害相關的研究中,不論是探討崩塌發生的機制或促崩降雨 條件,崩塌發生的時間點都是一項不易取得卻又相當重要的資訊。對此,前 人研究已經指出地震儀除了用來記錄地震產生的振動訊號,崩塌及火山活 動等事件也都會引發顯著的地表振動,而被記錄在地震波形之中,且不同類 型 的 地 動 事 件 , 在 訊 號 特 徵 上 會 有 顯 著 的 差 異 (Suriñach et al., 2005;
Dammeier et al., 2011)。對於崩塌災害發生的時間點,以往都是依據當地居 民目擊後口頭轉述得知,若能藉由分析地震訊號,從中找出屬於崩塌事件的 波形,不僅可以獲得較客觀的崩塌發生時間資訊,對於發生在較偏遠地區的
第二節 計畫目的
以往在進行崩塌事件的地動訊號分析都是仰賴人工判釋,不僅曠日廢 時,分析結果也會受到個人主觀意識影響。依據前人研究,不同類型的地動 事件在訊號上會有不同的特徵,藉由蒐集訓練樣本,並將這些差異量化成特 徵值後,便可利用機器學習演算法建構出分類器,進行地動事件的自動分類,
大量減少在判釋崩塌事件的時間及人力成本。
本計畫使用臺灣寬頻地震網(Broadband Array in Taiwan for Seismology, BATS)提供之地動訊號紀錄,著重在將崩塌事件的訊號從地震及背景噪訊中 分類出來,主要研究目的包括:
一、 蒐集 3 種類型地動事件的訓練樣本,並計算訊號特徵參數,建構自動 分類器。
二、 探討各特徵參數的分類效能,將分類器應用到經人工判釋之 2009 年 莫拉克颱風期間的地動訊號紀錄進行測試。
三、 崩塌地動訊號特徵值與崩塌幾何特徵之相關性。
四、 大規模崩塌之促崩降雨條件分析。
第三節 期末檢核點
本計畫已完成所有工作項目:
一、 崩塌地動訊號自動化辨識指標計算及篩選(至少測試 20 種訊號指標) 二、 訊號分類機器學習模型測試
三、 訊號分類結果應用於崩塌類型或規模評估 四、 大規模崩塌促崩降雨門檻修正
第四節 文獻回顧
一、崩塌事件產生的地動訊號特徵
崩塌塊體在邊坡上的運動過程中會產生一連串的地動訊號,並且能夠 有效的被鄰近地震測站記錄,因此地動訊號分析已被廣泛應用於邊坡塊體 運動的研究。根據前人研究,山崩事件產生的地動訊號大多具有以下特徵:
(1)無明顯 P 波及 S 波的區分;(2)波形呈「雪茄型」(Suriñach et al., 2005;
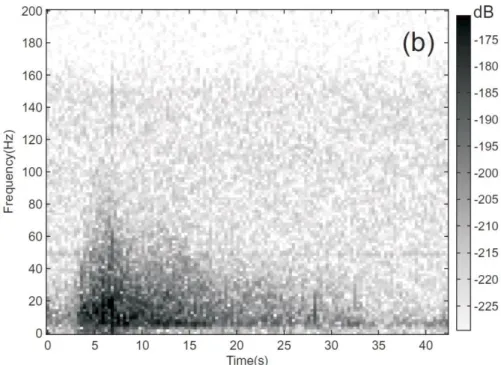
Dammeier et al., 2011)。Suriñach et al. (2005)將雪崩事件的地動訊號繪製成 時頻圖後,發現其時頻圖中可觀察到三角型的高能量區塊 (圖 1.1);而 Dammeier et al. (2011)在山崩事件的時頻圖也觀察到類似的三角型特徵(圖 1.2)。
圖 1.1 雪崩事件時頻圖(Suriñach et al., 2005)
圖 1.2 山崩事件時頻圖(Dammeier et al., 2011)
對於振源機制的解釋方面,Kanamori and Given (1982)及 Dahlen (1993) 均指出比起一般斷層地震常見的雙力偶機制 (double-couple),單力機制 (single-force)更適合用來反應山崩的運動過程。當考慮到長週期訊號時,山 崩的震源可以被描述為一隨著時間變化、有三維向量的固定點源(Brodsky et al., 2003)。對於崩塌訊號在不同頻率段的能量來源,Huang et al. (2007)及 Schneider et al. (2010)認為崩塌塊體內部顆粒的撞擊或摩擦會產生頻率數赫 茲到數十赫茲的較高頻震波;而 Kanamori and Given (1982)及 Eissler and Kanamori (1987)認為崩塌塊體在坡面上加速及減速的過程,會產生週期數十 到數百秒的長週期震波。在 2009 年莫拉克颱風過後,Lin et al. (2010)使用 全台的寬頻測站資料,以週期 20~50 秒的長週期訊號,成功判釋並定位出 52 處位於陸上的崩塌地;Kao et al. (2012)則是使用 0.5~5 Hz 做為判釋崩塌 的主要頻帶。
二、機器學習演算法在地動訊號分析上的應用
對於崩塌、火山活動及人為爆破等地動事件的監測,地震儀是一項非常 有利的工具,但由於地動事件及噪訊種類繁多,因此時常利用到機器學習技 術偵測目標事件,以減少人為判釋的工作量。
Kortström et al. (2016)使用數字化時頻圖的方式,針對芬蘭的地震及礦 場的人為爆破進行自動分類,其研究中使用支援向量機 (Support Vector Machine, SVM)在分類器上得到 94%的正確度(正確度之定義:代表所有被 正確分類的樣本佔總體樣本數量的比例)。Benítez et al. (2007)則是為了監測 南極迪塞普遜島(Deception Island)上的火山活動,使用隱藏式馬可夫模型 (Hidden Markov Model, HMM)建構自動分類器觀測島上的長週期事件、火山 構造地震、火山微震及綜合型事件等四種地動事件,並在分類器上得到 90%
的正確度。Esposito et al. (2006)用類神經網路(Neural Networks)建構義大利 斯特隆伯利火山島(Stromboli Volcano)的監測模型,使用線性預測編碼 (Linear predictive coding, LPC)作為特徵參數,對火山活動、崩塌及微震三種 事件達到 97%的分類正確度。Del Pezzo et al. (2003)及 Scarpetta et al. (2005) 皆是使用類神經網路及 LPC 建構的自動分類器對義大利拿坡里(Napoli)地 區的火山活動進行監測,前者針對火山活動及水下爆破兩種事件的區分;後 者則探討火山構造地震、水下爆破、兩種礦場爆破及閃電等五種事件,並另 外加入波型特徵做為特徵值,兩者在分類器上分別得到 91%及 94%的正確 度。Provost et al. (2017)針對法國 Super-Sauze 崩塌地持續產生的邊坡運動進 行監測,研究中使用隨機森林演算法(Random Forest, RF),並從波形、頻譜、
時頻圖、測站網路及極性五種面向計算了 71 種特徵值,分類正確度達 93%。
Parihar et al. (2018)使用日本及印度的地震資料,從時間域及頻率域計算 13 種訊號特徵值,比較了 4 種演算法對於地震事件的辨識能力,其結果顯示 SVM 演算法具有最高的正確度(99%)。Tian et al. (2002)相異於其他研究,主 要是探討兩種軍事車輛產生的地動訊號,研究中使用最近鄰居法(k-Nearest Neighbor) , 結 合 頻 譜 統 計 和 小 波 係 數 特 徵 分 類 法 (spectral statistics and
小波係數中提取了共 22 種特徵值建構分類器,並得到 90%的分類正確度,
其研究結果顯示機器學習技術可以被廣泛運用到各種類型的地動事件監測。
若要將機器學習技術應用到即時監測,有時訊號特徵的運算量過大會 使計算時間過長,因此 Cortés et al. (2015)討論了兩類將訊號特徵降維度的 方 法 : 特 徵 選 擇 (Feature Selection) 及 特 徵 空 間 轉 換 (Feature Space Transformation)。兩種處理方式的目的皆是要找出具有較佳辨識度的特徵值,
可以依不同的資料庫類型及使用上的需求選擇最適合的降維度方法,以減 少分類器的計算量。
將以上自動分類器之相關研究整理成表 1.1。
表 1.1 自動分類器相關研究(依年度排序)
作者 年份 事件類型 演算法 正確度
Tian et al. 2002 兩種軍事車輛 k-NN 90%
Pezzo et al. 2003 火山活動、
水下爆破
Neural
Networks 91%
Scarpetta et al. 2005
火山構造地震、
水下爆破、
石灰岩礦場爆破、火 山岩屑礦場爆破、
閃電
Neural
Networks 94%
Esposito et al. 2006 火山活動、崩塌、
微震
Neural
Networks 97%
Benítez et al. 2007
長週期事件、
火山構造地震、
火山微震、 HMM 90%
作者 年份 事件類型 演算法 正確度 Kortström et al. 2016 地震、礦場爆破 SVM 94%
Provost et al. 2017
邊坡內部破裂、
落石、地震、
人為噪訊
Random Forest 93%
Parihar et al. 2018 地震、噪訊
k-NN ML SVM ANN
87%
86%
99%
88%
三、與吳昱杰(2018)之比較
吳昱杰(2018)提出崩塌地動訊號偵測方法(Landslide-quake Automatic Detection, LQAD),其使用支援向量機(Support Vector Machine, SVM)演算法 做為分類器的基礎,同樣對崩塌、地震及噪訊三種類別的地動訊號進行自動 偵測。
在時間域訊號特徵值的部分,吳昱杰(2018)在移動平均及閃爍指數兩種 訊號轉換方式後,參考 Kao et al. (2007)的計算方式,只使用移動平均計算 平均值及標準差,對於閃爍指數則計算最大值與平均值比值,以及標準差與 平均值的比值。本計畫則發現移動平均及閃爍指數波形在這四種統計方式 上應該都能反映出訊號的特徵,因此便增加計算了 4 種時間域特徵值。另 外吳昱杰(2018)在時間域上還計算了似機率時間序列 (Pseudo-probability time series, PPTS)(Ross and Ben-Zion, 2014),即 STA/LTA(短時窗平均/長時 窗平均)事件偵測法的延伸,PPTS 不使用單一種短時間窗格及長時間窗格長
動訊號進行事件的偵測,並生成一個事件機率序列,將 10 組結果之機率相 乘即得到該地動訊號的似機率序列,當似機率大於門檻值時便會被判定為 一個地動事件。PPTS 避免了單一種窗格長度無法概括偵測所有事件的情況,
使用 10 種不同的窗格長度組合可以更穩定的得到可能的事件時間點,因為 在同一時間點,若有其中幾組窗格的偵測結果認為該時間點有較低的事件 機率,即使有另外幾組窗格計算出非常高的事件機率,經相乘後,整體的似 機率依然會被顯著地拉低,避免誤判的情形發生。
在頻率域特徵值的部分,吳昱杰(2018)將地動訊號的能量分為低頻段及 高頻段,低頻段範圍為 1-5 Hz,高頻段範圍為 5-10 Hz,再使用這兩個頻段 的功率譜密度(PSD)計算比值。而本計畫考慮了小於 1 Hz 的頻段,進一步計 算了 7 個不同頻帶的功率譜密度,及 5 組不同頻帶的功率譜密度比值。
在崩塌與地震的區隔上,吳昱杰(2018)也計算了事件的芮氏規模(local magnitude, ML)及延時規模(duration magnitude, MD)比值,其中 ML及 MD的 計算方式如下:
𝑀𝐿 = log10𝐴 + 1.11 log10𝑅 + 0.00189𝑅 + 3.591 式(1.1) 𝑀𝐷 = 2 log10𝜏 + 0.082𝑅 − 0.87 式(1.2) 其中𝐴為經轉換過後的芮氏地震儀振幅值;𝑅為測站與震央的距離;𝜏為 訊號持續時間。根據 Manconi et al. (2016)的研究,地震事件有相對較大的規 模及較短的延時,因此 ML / MD數值會大於 1。崩塌事件則有相對較小的地 震規模及較長的延時,因此 ML / MD數值會小於 1,藉此來對崩塌及地震做 進一步的區隔。
崩塌地動訊號偵測方法採用階段式的事件篩選,先使用時間域特徵值 將噪訊去除,再使用頻率域特徵值及 ML / MD區分地震及崩塌,而本計畫則
是同時使用全部的時間域及頻率域特徵值對事件進行分類,整體的差異如 表 1.2 所示。
在分類器訓練樣本的選擇上,吳昱杰(2018)使用了 34 個崩塌訊號及 446 個非崩塌訊號,共 480 筆訓練樣本,其中崩塌訊號內包含了地震訊號及環 境噪訊,而本計畫為了更有效的反應分類器的正確度,因此在三種類別地震 訊號上選用了相同的數量。
表 1.2 本計畫與吳昱杰(2018)研究內容之比較
本計畫 吳昱杰(2018)
訓練樣本種類 崩塌、地震及噪訊
訓練樣本數
崩塌:214 地震:214 噪訊:214
崩塌:34 非崩塌:446
偵測時間窗格 5 分鐘 3 分鐘
演算法 Random Forest SVM
特 徵 值
時間域
移動平均、閃爍指數及振 幅平均值等共 9 種
移動平均、閃爍指數及 PPTS 等
共 5 種
頻率域
各頻段之功率譜密度、功 率譜密度比值及能量集 中頻率等共 15 種
1-5 Hz / 5-10 Hz 功率譜 密度比值
其它 無 ML / MD
分類器正確度 91.3% 98.1%
第二章 研究方法
第一節 研究資料來源
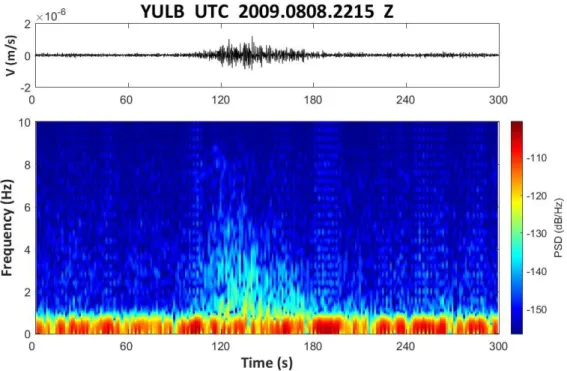
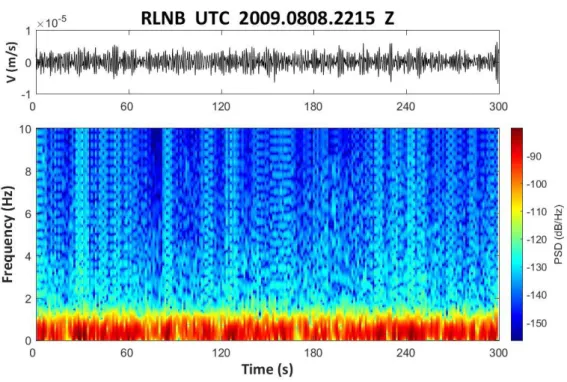
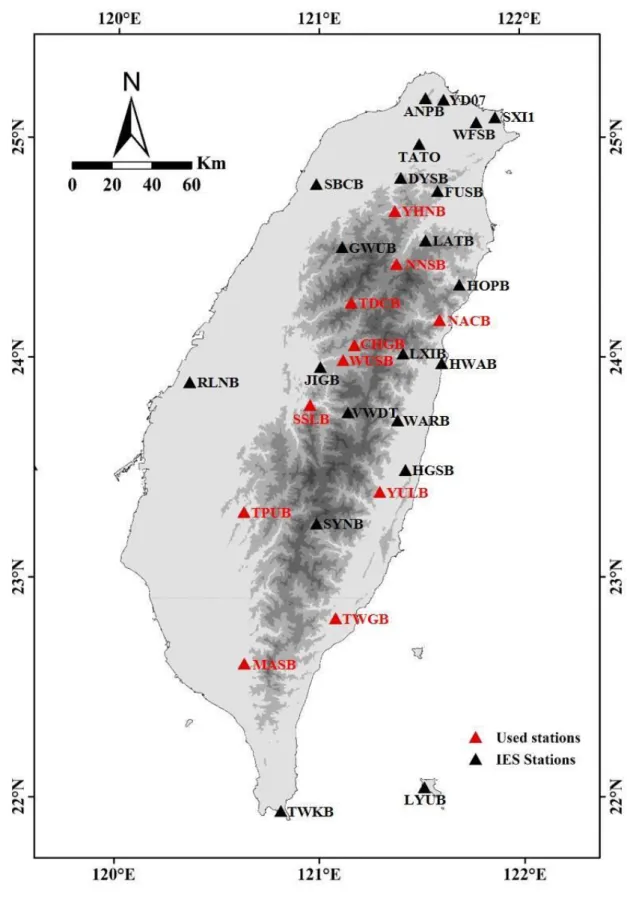
本 計 畫 使 用 中 研 院 及 中 央 氣 象 局 共 同 設 立 的 臺 灣 寬 頻 地 震 網 (Broadband Array in Taiwan for Seismology, BATS)提供之地動訊號紀錄(IES, 1996)。BATS 地震測站的分布密度大約是 30 公里,其地震儀紀錄了連續且 高精度的地震訊號,訊號頻段也有效記錄了崩塌造成的地表振動,本計畫所 採用之記錄取樣率為 20 Hz。截至 2018 年,BATS 共架設 39 個運作中的地 震測站,但本計畫著重在發生於臺灣本島的大規模崩塌事件,因此並非每個 測站都適合用於崩塌訊號的分析,故在本計畫中先排除了離島測站,再分析 島內各個測站之記錄品質。圖 2.1 至圖 2.4 為 2009 年莫拉克颱風期間 UTC 時間 8 月 8 日 22 時 16 分小林村崩塌發生時,各測站接收到的訊號波形及 時頻圖。距離崩塌 70 公里的 YULB 測站為最近之地震站,其紀錄中可以清 晰發現由小林崩塌所引致的地表振動,地震訊號可觀察到明顯的雪茄型波 型,而時頻圖中三角形的高能量區塊被認為是崩塌塊體中,土石互相撞擊產 生的訊號,三角形的頂點代表崩塌塊體撞擊河谷的時間點,隨著崩塌塊體的 運動停止,高頻能量也逐漸消散(Lin, 2015)。距離最遠的 YHNB 測站(185 公 里)依然可以觀察到清晰的崩塌訊號,而相對較近的 RLNB 測站(85 公里)及 TWKB 測站(135 公里)卻完全無法觀察到小林村崩塌的地動訊號。由於水平 向之地動訊號振幅會受到崩塌坡向之影響,因此本研究皆使用垂直向地動 訊號進行分析。本計畫以小林崩塌之地動訊號在不同地震站中的紀錄狀況,
最終篩選出 11 個用來研究崩塌事件的地震測站。表 2.1 及圖 2.5 展示了本 計畫所使用的測站及 BATS 地震測站的分布位置。
圖 2.1 YULB 的小林村崩塌事件訊號
圖 2.3 RLNB 的小林村崩塌事件訊號
圖 2.5 本計畫使用之 BATS 測站分布
表 2.1 本計畫使用的 11 個測站及其座標
測站名稱 經度 緯度
CHGB 121.1740 24.0602
MASB 120.6326 22.6109
NACB 121.5947 24.1738
NNSB 121.3828 24.4284
SSLB 120.9540 23.7876
TDCB 121.1583 24.2527
TPUB 120.6296 23.3005
TWGB 121.0799 22.8177
WUSB 121.1175 23.9919
YHNB 121.3757 24.6695
YULB 121.2971 23.3925
第二節 分類器訓練樣本
建構自動分類器必須要有足夠代表性的事件來做為訓練樣本,因此本 計畫從前人文獻(Chen et al., 2013; Chao et al., 2016)及 RLMS reports (Chao et al., 2017)蒐集崩塌事件發生的時間點,再依崩塌發生時間對 11 個地震測站 的訊號紀錄進行人工判釋,最終挑選出 214 筆振動紀錄做為崩塌的訓練樣 本(附錄一)。由於分類器內不同類型的訓練樣本數保持相近的數量能較公平 地反應分類效果,因此依照崩塌樣本數,亦從中央氣象局公布的區域地震時 間點,在 11 個地震測站同樣挑出 214 筆地震事件訓練樣本(附錄二)。另外,
人為活動、降雨等皆為可能的來源,本計畫在收集噪訊樣本時並無選用特定 之噪訊種類,而是廣泛收集不同的噪訊,增加分類器的辨識度。最終使用 3 種事件類型共 642 筆訓練樣本來製作分類器,每筆訓練樣本的時間窗格皆 為 5 分鐘。在計算訓練樣本的特徵值前,所有地動訊號皆會先進行移除平 均、移除線性趨勢及去除儀器響應的處理,再依事件發生時間切出完整包含 事件的 5 分鐘長度訊號段,計算時間域及頻率域的特徵值。
第三節 時間域特徵值
Kao et al. (2007)對週期性微震及滑坡事件(episodic tremor and slip, ETS) 進行了自動監測,其中使用了時間域的移動平均(Moving Average, MA)及閃 爍指數(Scintillation Index, SI)兩種特徵值來量化波形隨時間的變化。在訊號 前處理後,本計畫先使用四階巴特沃斯帶通濾波器進行濾波後才做時間域 特徵值的計算,濾波頻段為 1~5 Hz,因為此頻段最可以清晰的觀察出崩塌 事件的地動訊號(Kao et al., 2006)。
一、移動平均(MA)
移動平均即是對地動訊號進行平滑化,可以反映整體訊號隨時間的變 化趨勢。在計算移動平均前,先將 5 分鐘訊號之振幅取絕對值,再除以每 5 分鐘訊號的前 8 個最大值的平均值做標準化,然後再放大 10 倍。取 8 個數 值最大值的平均值做標準化的目的是為了避免異常值造成的影響。本計畫 計算每一時間窗格內訊號振幅絕對值的平均值,做為計算窗格中央時間點 之數值。移動平均的計算方式如下:
𝑖 |𝑦|𝜇 = ( ∑ |𝑦(𝑗)|
𝑗=𝑖+(𝑡−1)/2
𝑗=𝑖−(𝑡−1)/2
) 𝑁⁄ 式(2.1)
其中 𝜇𝑖 |𝑦|表示為第 i 個計算窗格的移動平均值;y 為窗格內振幅值;|𝑦(𝑗)|
代表第𝑗個數據點的振幅絕對值;𝑁代表以𝑖為中心點的時間窗格內的資料點 總數;t 為計算窗格的時間長度。一般來說,時間窗格的長度必須能夠完整 反映出波形的變化趨勢,因此本計畫使用的計算窗格長度為 100 秒,而訊 號採樣率為 20Hz,即每個計算窗格內有 2000 個資料點。
從圖 2.6 可看出,將訊號進行標準化過後,由於噪訊本身訊號的起伏就 不大,因此整段訊號的移動平均數值皆偏大;相反的在地震及崩塌訊號的部 份,由於有明顯的事件訊號段,因此除了事件本身的波段,其餘的噪訊段的 移動平均數值皆被壓低。
圖 2.6 不同類型地動事件之移動平均及閃爍指數波形
將濾波後的訊號波形轉化成移動平均波形後,Kao et al. (2007)認為有 4 項統計指標可以有效反映出整體的變化趨勢,分別為平均值(𝜇𝑀𝐴)、標準差
𝜇𝑀𝐴 = (∑ 𝜇𝑖 |𝑦|
𝐾
𝑖=1
) 𝐾⁄ 式(2.2)
𝜎𝑀𝐴 = √∑(|𝑦(𝑖)| − 𝜇𝑀𝐴)2
𝐾
𝑖=1
𝐾
⁄ 式(2.3)
𝑀𝐴𝑅 = 𝑀𝐴𝑚𝑎𝑥⁄𝜇𝑀𝐴 式(2.4) 其中|𝑦(𝑖)|代表第𝑖個數據點的振幅絕對值;𝐾代表訊號段內的資料總數。
二、閃爍指數(SI)
閃爍指數是 Yeh and Liu (1982)提出用來計算電離層無線電波強度變化 的指標,而 Kao et al. (2007)將其應用於地動訊號分析,同樣能反映地動訊 號強度的變化。閃爍指數值即是訊號強度標準化變異數的平方根,也就是說,
當時間窗格內偵測到訊號強度改變(振動事件發生)時,閃爍指數值便會驟然 上升。其計算方式如下:
𝑆𝐼𝑖 = √[( 𝜇𝑖 |𝑦|2 − 𝜇𝑖 |𝑦|2 )⁄ 𝑖 |𝑦|𝜇2 ] 式(2.5)
其中 𝜇𝑖 |𝑦|2代表以𝑖為中心點的時間窗格內的振幅絕對值平方的移動平均值;
𝑖 |𝑦|𝜇2 代表以𝑖為中心點的時間窗格內的振幅絕對值的移動平均值的平方。
將濾波後的訊號波形轉化成閃爍指數波形後,同樣計算 4 種指標:平 均值(𝜇𝑆𝐼)、標準差(𝜎𝑆𝐼)、閃爍指數比(Scintillation Index Ration, 𝑆𝐼𝑅)及標準 差平均值比值(𝜎𝑆𝐼 𝜇𝑆𝐼⁄ )。其計算方式參考移動平均所延伸的 4 種指標。
從圖 2.6 可以發現,相較於地震及崩塌,背景噪訊由於本身在訊號上就 沒有太大的起伏,因此其移動平均及閃爍指數的數值隨著時間幾乎沒有產
生顯著的變動,導致移動平均及閃爍指數的標準差及𝑀𝐴𝑅(及𝑆𝐼𝑅)數值也都 偏低;而平均值的部份,上述提到由於進行標準化的關係,𝜇𝑀𝐴的數值會呈 現𝜇𝑀𝐴噪訊 > 𝜇𝑀𝐴崩塌 > 𝜇𝑀𝐴地震的趨勢,但在𝜇𝑆𝐼的數值上,由於閃爍指數 反應的是訊號強度的變化,因此會呈現𝜇𝑆𝐼地震 > 𝜇𝑆𝐼崩塌 > 𝜇𝑆𝐼噪訊。 三、平均振幅
除了移動平均及閃爍指數,地動訊號本身的平均振幅也反映了不同事 件之間的差異,因此也納入作為時間域特徵值。
第四節 頻率域特徵值
除了時間域上的差異,前人研究已經指出不同類型的地動事件,其訊號 能量在不同頻段的分布也有差異(Kao et al., 2006)。
圖 2.7 顯示 10 個區域地震、10 個崩塌及 10 個背景噪訊的平均頻譜,
並對最大值做標準化後的頻譜圖。在高頻段(>1 Hz),地震的能量明顯大於 崩塌能量;但相反的在低頻段(<0.1 Hz),崩塌事件的能量高於地震事件。因 此,我們可以計算單一事件在不同頻段的能量,來反映該事件之能量在不同 頻率的分布,作為頻率域上的特徵值。圖 2.7 中崩塌及背景噪訊之尖峰頻率 約為 0.2-0.3Hz,而 0.1~0.6 Hz 為海浪噪訊之頻率,由於颱風期間風浪較大,
地動訊號在該頻段皆會包含高能量的訊號,因此計算各項特徵值時也大多 會避開該頻率段。本計畫所使用之寬頻地震測站的有效低通截止頻率為 8 Hz,而高通截止頻率為 0.00833 Hz。所以,雖然測站本身的採樣率為 20 Hz,
但在 8~10 Hz 頻段的訊號無法有效被記錄,若採計此頻段之訊號會有失真
圖 2.7 不同類型地動事件平均頻譜圖
一、功率譜密度(PSD)
功率譜密度為 Welch (1967)所提出,將快速傅立葉轉換用於功率譜 (power spectra)的計算,得到一段時間序列紀錄在頻率上的能量分布。藉由 不同類型地動事件在頻率分布上的差異,便可以計算在不同頻段之功率譜 密度,用來區分不同類型之地動事件。計算功率譜密度時,本計畫使用的頻 率解析度為 0.01 Hz,時間窗格為 5 秒鐘、窗格間有 50%的重疊率。為了避 免因事件大小或與測站間的距離直接反應到各個頻段功率譜密度的絕對數 值,在計算功率譜密度後會以最大值做標準化,因此最終得到之功率譜密度 數值實為各頻段所佔總能量的比例。
在本計畫中共計算了 7 個頻段的功率譜密度,分別為:
2. 0.05-0.1 Hz 3. 0.02-0.1 Hz 4. 0.1-1 Hz 5. 1-5 Hz 6. 5-8 Hz 7. 1-8 Hz
二、功率譜密度比值(RPSD)
在計算完各個頻段之功率譜密度後,並計算各個頻段間功率譜密度的 比值,同樣作為頻率域的特徵值。
其中共計算了 5 組功率譜密度的比值,分別為:
1. 0.02-0.1 Hz / 1-8 Hz 2. 0.02-0.05 Hz / 1-5 Hz 3. 0.05-0.1 Hz / 1-5 Hz 4. 0.02-0.05 Hz / 5-8 Hz 5. 0.05-0.1 Hz / 5-8 Hz 三、能量集中範圍
在 Provost et al. (2018)對於地動事件類型的研究中,將事件能量集中的 頻率範圍做為判斷事件類型的參考依據,包括最高能頻率(𝐹_𝑚𝑎𝑥)、最高頻 率(𝐹_ℎ𝑖𝑔ℎ)及最低頻率(𝐹_𝑙𝑜𝑤)。將一段事件訊號進行快速傅立葉轉換繪製 頻譜圖後(圖 2.8),振幅最大值對應到的位置即是該事件能量最高的頻率,
再由該振幅值取 0.2 倍做為門檻值(紅線),該門檻值與頻譜圖相交的 2 點即 為該事件能量集中的最高頻率及最低頻率。其計算方式如下:
𝐹_𝑙𝑜𝑤 = min
𝐹 (𝑃𝑆𝐷(𝐹) < 0.2 × max(𝑃𝑆𝐷)) 式(2.7) 其中𝑃𝑆𝐷(𝐹)代表對應到𝐹頻率的功率譜密度值。
圖 2.8 地動事件能量分布之劃定
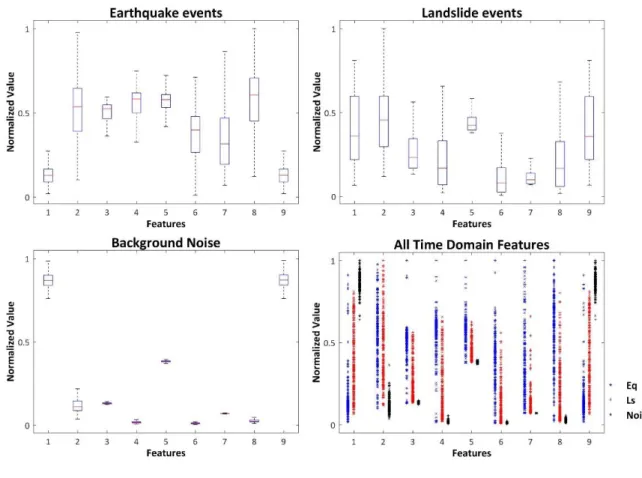
最終在時間域及頻率域共計算了 24 項特徵值來反映出每一個地動事件 的訊號特徵(表 2.2),整體訊號處理過程如圖 2.9 所示。在計算 642 筆訓練 樣本的 24 項特徵值後,本計畫統計了三種類型之地動事件在各項特徵值的 平均值(表 2.3),並且也將三種類型之地動事件的各個特徵值數值分別對其 最大值做標準化,用於觀察各個特徵值數值的分布情形(圖 2.10、圖 2.11)。
其結果顯示並沒有任何一個特徵值可以完美的區分出三種事件,但 3 類事 件的特徵值箱型圖顯示,不同類型之事件的各個特徵值還是具有一定程度 的分布差異,因此需透過結合多個特徵值來建構自動分類器,以達到更好的 分類效果。
圖 2.9 訊號處理流程
表 2.2 24 項訊號特徵值
時間域 頻率域
1. μMA 2. σMA 3. MAR
4. σMA/μMA 5. μSI
6. σSI 7. SIR 8. σSI/μSI 9. 平均振幅
10. 0.02-0.05 Hz PSD 11. 0.05-0.1 Hz PSD 12. 0.02-0.1 Hz PSD 13. 0.1-1 Hz PSD 14. 1-5 Hz PSD 15. 5-8 Hz PSD 16. 1-8 Hz PSD
17. 0.02-0.1 Hz / 1-8 Hz RPSD 18. 0.02-0.05 Hz / 1-5 Hz RPSD 19. 0.05-0.1 Hz / 1-5 Hz RPSD 20. 0.02-0.05 Hz / 5-8 Hz RPSD 21. 0.05-0.1 Hz / 5-8 Hz RPSD 22. F_max
23. F_high 24. F_low
表 2.3 24 項訊號特徵值及訓練樣本之平均數值
編號 特徵值 崩塌訓練樣本
特徵值平均值
地震訓練樣本 特徵值平均值
噪訊訓練樣本 特徵值平均值
1 μMA 1.066 0.423 2.291
2 σMA 0.382 0.436 0.100
3 MAR 2.255 4.103 1.097
4 σMA/μMA 0.543 1.322 0.044
5 μSI 0.875 1.132 0.756
6 σSI 0.196 0.626 0.018
7 SIR 1.870 5.387 1.058
8 σSI/μSI 0.203 0.531 0.024
9 平均振幅 0.107 0.042 0.229
10 0.02-0.05 Hz PSD 0.092 0.033 0.030 11 0.05-0.1 Hz PSD 0.146 0.080 0.147 12 0.02-0.1 Hz PSD 0.127 0.063 0.106 13 0.1-1 Hz PSD 0.240 0.258 0.190 14 1-5 Hz PSD 0.021 0.177 0.00016 15 5-8 Hz PSD 0.010 0.052 0.00030 16 1-8 Hz PSD 0.017 0.123 0.00022 17 0.02-0.1 Hz / 1-8 Hz RPSD 828.867 73.914 5508.433 18 0.02-0.05 Hz / 1-5 Hz RPSD 200.426 17.856 1070.261 19 0.05-0.1 Hz / 1-5 Hz RPSD 794.365 64.146 5255.047 20 0.02-0.05 Hz / 5-8 Hz RPSD 1985.425 149.191 6567.327 21 0.05-0.1 Hz / 5-8 Hz RPSD 5585.904 580.960 32874.808
22 F_max 0.348 1.404 0.207
23 F_high 0.844 3.428 0.343
圖 2.10 時間域特徵值數值分布
圖 2.11 頻率域特徵值數值分布
第五節 建立自動分類器
一、隨機森林演算法(Random Forest)
決策樹(Decision Trees)為一種樹狀結構的監督式(supervised)機器學習 演算法,適用於各種分類問題(Quinlan, 1986)。決策樹會列出一系列的決策 問題,將資料庫內的樣本依次分群,通過將大量資料有目的地分類,從中找 到在各類樣本間最具有鑑別性的資訊。依照給定的訓練樣本的各項特徵值,
決策樹會遞迴地對訓練樣本進行劃分,選擇最佳的特徵值及分類門檻,使該 節點延伸出的子節點內的資料類別有最高的同質性。通常在決策樹架構內,
位在最上層的特徵值具有最高的鑑別度,如圖 2.12 的 Feature B。通常在以 下三種情況下,決策樹便不再進行分支:(1)子節點內的每筆資料都屬於同 一類別、(2)子節點內只包含 1 筆資料、(3)繼續進行分支對於資料庫內同質 性的改善有限,即雖然節點內有不同類別的樣本,但在各項特徵值的數據上 無太大的差異。在一層一層的將訓練資料庫內的樣本做分類之後,最終目的 是讓每個子集的資料全屬於同一類別或某一類占壓倒性的多數。決策樹的 優點是決策階段明確且易於視覺化(圖 2.12),缺點則是若沒有對分支層數做 限制或進行後續的剪枝(pruning),很容易產生過度擬合(overfitting)的情況 (Quinlan, 1987)。一個分類器只要夠複雜,即使資料品質不佳也能達到百分 之百的分類正確度,但卻無法應用到未來資料的預測,如此便是所謂的過度 擬合。
圖 2.12 決策樹演算法架構示意圖
隨機森林演算法的概念便是將多棵決策樹結合(圖 2.13),以達到更穩定 的分類效果(Breiman, 2001)。在訓練過程中,會先將訓練樣本隨機取樣,產 生 k 個訓練子集,每個子集再各自訓練,產生 k 棵決策樹。建構子集的過 程為依次隨機抽選,每一次抽到的樣本都會放回,因此有機會在一個子集內 抽選到重複的樣本,同時某些樣本是沒有被抽到的。若原始資料庫內含有 N 筆資料,則每個訓練子集也會重複抽選放回直到含有 N 筆訓練樣本,這種 方法稱為 Bagging (Breiman, 1996),不僅使每個子集內的樣本具有差異性,
也確保每一棵決策樹使用的都不是全部的訓練樣本。除了訓練樣本,每棵決 策樹使用的特徵值也是隨機取樣,從 M 個特徵值中,選擇 m 個(m < M)做 為分類依據。透過對訓練樣本及特徵值的隨機取樣,每棵決策樹皆是使用不 同的訓練樣本及訊號特徵值建構分類器,因此訓練出來的決策樹皆是互相 獨立的。實際運算時,每棵決策樹都會得出各自的分類結果,而最終分類結
果則是由這 k 棵決策樹進行投票(voting)決定,以所有決策樹中相對多數的 初步判釋結果為最終結果。隨機森林演算法在訓練分類器時,會根據各項特 徵值的分類效果優劣進行權重分配,本研究讓演算法自動調整各特徵值的 權重,因人為調整權重易產生主觀判定,便喪失了使用機器學習演算法時的 客觀性。
而透過隨機森林產生的決策樹也沒有必要進行剪枝,因為在訓練樣本 及特徵值取樣的過程中已經確保了隨機性,雖然單棵樹的架構可能是複雜 且有過度擬合的情況,但在多棵決策樹的運作下,只要一開始的抽樣具有足 夠的隨機性,便能避免整體演算法過度擬合的情形發生(Breiman, 2001)。若 隨機森林演算法產生過度擬合的情況,除了可能是抽樣時的隨機性不夠高,
另一個原因便是演算法內所包含的決策樹棵數不夠多,無法有效反映大數 法則(Law of Large Numbers) (Bernoulli, 1713; Breiman, 2001)。本計畫最終使 用之隨機森林演算法內包含了 100 棵決策樹。
二、分類器建構
在建立分類器時,常用來評估訓練樣本分類效果的方式有以下三種:
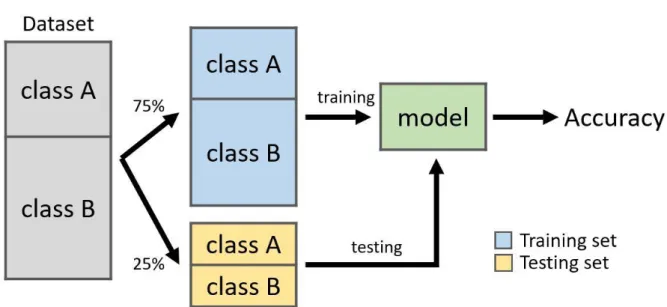
(一) Holdout Validation
Holdout 是指從資料庫中隨機挑選 n%的資料做為訓練集(Training set),
對演算法進行訓練,挑選的過程會從每種類型的資料都挑選 n%;剩下的 (100-n)%資料則是做為測試集(Testing set),進行分類器的測試(Schneider, 1997)。訓練的分類效果則是用測試集的測試結果與真實答案進行比對(圖 2.14)。
圖 2.14 Holdout Validation 示意圖
(二) K-fold Cross Validation
K-fold 是先將資料庫平均分成 K 個子集,每個子集中各種類的資料會 有相近的比例,然後每次使用其中 1 個子集做為測試集,剩下(K-1)個子集
則做為訓練集,反覆執行 K 次,每一次的測試都會得到 1 個分類正確度,
再將 K 次的結果平均後得到最終的分類效果(圖 2.15) (Schneider, 1997)。
圖 2.15 5-fold Cross Validation 示意圖
(三) Leave-one-out Cross Validation
Leave-one-out 為假設在有 N 筆資料的資料庫中,在每次的訓練過程都 只挑出 1 筆資料做為測試集,剩下的(N-1)筆資料則做為訓練集,反覆執行 N 次,因此每筆資料都會被用做訓練及測試,分類效果則是把全部資料的測 試結果與真實答案進行比對(圖 2.16) (Schneider, 1997)。Leave-one-out Cross Validation 也可以視為 K 等於資料數量的 K-fold Cross Validation。
圖 2.16 Leave-one-out Cross Validation 示意圖
經過測試後,由於 Holdout Validation 並非交叉驗證,本計畫使用的訓 練資料庫也不算特別大(<1000 筆),因此每一次訓練的分類正確度會嚴重受 到該次挑選的訓練集與測試集資料差異的影響,造成分類結果間有較大的 標準差。Leave-one-out Cross Validation 雖然可以有效反映整體資料庫的分 類效果,但計算量將過於龐大,因此本計畫折衷採用 K-fold Cross Validation 方法,其中 K 為 5。
三、混淆矩陣
混淆矩陣是最常被用來呈現監督式機器學習演算法效能的工具,它能 夠有效且清楚的表示分類器的正確度及對於各種類事件的敏感度(Kohavi and Provost, 1998)。在混淆矩陣中(表 2.4),True Positive (TP)代表實際屬於 A 類的樣本,演算法也判定為 A 類的數量;False Negative (FN)代表實際屬 於 A 類的樣本,卻被演算法判定為 B 類的數量;False Positive (FP)代表實 際屬於 B 類的樣本,卻被演算法判定為 A 類的數量;True Negative (TN)代
表實際不屬於 A 類的樣本,演算法也判定不為 A 類的數量。橫列代表的是 實際屬於該類別的樣本,即 TP 和 FN 的數量合即為 A 類事件實際數量;直 欄代表的是被演算法判釋為該類事件的樣本,即 TP 和 FP 的數量合即為被 判釋為 A 的樣本數。
表 2.4 混淆矩陣
Predicted
A B
Actual A
True Positive
False Negative
B
False Positive
True Negative
在混淆矩陣中,True Positive (真陽性)表示為預測為正,實際也為正;
False Positive (假陽性)表示為預測為正,實際為負;False Negative (假陰性) 表示為預測為負、實際為正;True Negative (真陰性)表示為預測為負、實際 也為負。而混淆矩陣中時常使用以下三項指標評估演算法效能:
(一) 正確度(Accuracy):
代表所有被正確分類的樣本佔總體樣本數量的比例。其計算方式如下:
𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝑇𝑃 + 𝑇𝑁
𝑇𝑃 + 𝑇𝑁 + 𝐹𝑃 + 𝐹𝑁 式(2.8)
(二) 敏感度(Sensitivity)
代表某一類別的樣本中,被正確分類的樣本的比例,又稱為召回率 (Recall)。其計算方式如下:
𝑆𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑦 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑁 式(2.9)
(三) 陽性預測值(Positive Predictive Value, PPV)
代表所有被分類為某一類的樣本中,實際屬於該類別的樣本的比例,又 稱為準確率(Precision)。其計算方式如下:
𝑃𝑃𝑉 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑃 式(2.10)
(四) 協調分數(F1-score)
為敏感度和陽性預測值的調和平均數,用以衡量分類器精確度的一種指 標,最大值是 1,最小值是 0。計算方式如下:
F1 = 2
1
𝑃𝑃𝑉+ 1 𝑆𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑦
式(2.11)
四、分類器運作過程
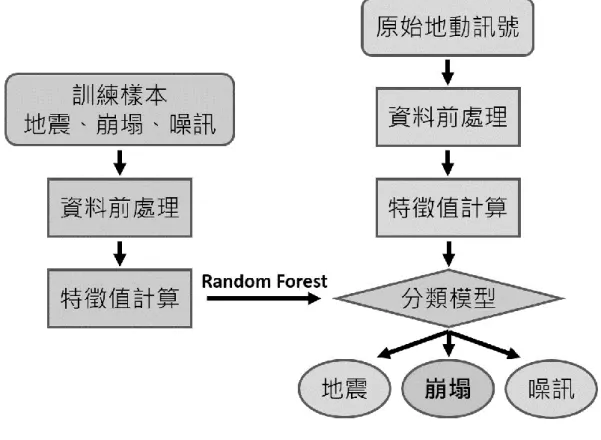
本計畫整體進行地動訊號分類器建置與應用流程如圖 2.17 所示,先蒐 集欲自動分類之地動事件訓練樣本,將訊號做基本前處理後計算訊號特徵
值,再使用隨機森林演算法建構自動分類器,之後便可將連續地動記錄輸入 分類器內,快速得到各測站記錄到的崩塌事件發生時間,再做進一步的驗證。
圖 2.17 地動訊號分類器建置與應用
第六節 崩塌地動訊號定位
Hibert et al. (2011)及 Kao et al. (2007)均認為山崩所造成的地表振動訊 號並不會產生明顯的 P 波及 S 波。因此,無法將傳統的地震定位機制方法 運用於山崩訊號的定位。故本計畫採用 Wech and Creager (2008) 監測微震
(tremor)所發展出來的定位方法針對山崩訊源做定位。其山崩定位程序如 下所述:
一、將判釋出的地動訊號資料重新裁切時間。
二、計算水平方向上的方均根振幅值(E-W 及 N-S 方向),並將水平分量 的波形計算出一包絡線函數。
三、將所有包絡線函數分別進行交叉相關分析(cross-correlation)。
四、運用網格搜尋方式找出最佳解。為了提高運算效率,分為兩階段進 行:
第一階段將訊噪比(Signal-to-Noise Ratio, SNR)最大值的測站設為中心,
建立一個長寬各 2˚的方格,方格中每個網格長寬各為 0.2˚,在方格中搜尋擁 有最大相關係數的網格。
第二階段將前一步驟搜尋到的網格重新設為中心,建立一個長寬各 0.4˚
的方格,方格中每個網格長寬各為 0.01˚,搜尋相關係數最大的網格。
在前人研究中,認為山崩訊號主要是由雷利波(Rayleigh wave)及剪力波 所組成(Lin et al., 2010; Suwa et al., 2010; Dammeier et al., 2011; Feng, 2011;
Hibert et al., 2011),而且在波形中最大振幅值出現的時間,極有可能是最大 塊體撞擊到地表的時間(Dammeier et al., 2011)。而 Favreau et al. (2010)的研 究顯示,振幅內連續出現的高峰值是因為塊體在滑落時,不斷地跳動或滾動 的運動過程對地表造成的撞擊而產生。Hibert et al. (2011)的研究推論出,不 同的山崩行為所產生的振幅值和波形都會不同。例如,當塊體滑落的是緩坡 時,所產生的峰值較為平緩。
在進行交叉相關分析的計算時,以兩個接收到訊號的測站 f、g 為例,
由水平包絡線函數 uf、ug,計算它們之間的交叉相關,可得到最大相關係數 (Cfg),再由測站各自的最大自相關係數(Cff、Cgg)進行常態化,其計算公式如 下:
C(𝑡) = ∫ 𝑢𝑓(𝑡+𝜏)𝑢𝑔(𝜏)𝑑𝜏
𝑇
−𝑇
√CffCgg 式(2.12)
C𝑚𝑎𝑥 = Cfg
√CffCgg 式(2.13) 其中,t 為兩個目標波形的時間長度。uf和 ug為相關分析之兩測站包絡線函 數。本計畫在資料的選擇上,設定山崩訊號必須至少被三個以上的測站所記 錄,且波形的最大相關係數須大於 0.7,以及訊噪比必須大於 2.5,三項條件 皆符合者才繼續定位程序。在圖 2.18 中,顯示了 NANB 和 SGSB 兩個測站 計算交叉相關後得到的交叉相關圖,以及兩測站間的最大交相關係數(Cfg)。
另外,也定義了最大交相關係數的權重比,以優化不同係數的比重(Cmax)。
在一個假設的訊源處(ξ),其交叉相關振幅值的殘差值定義為 Am,其公式 如下:
𝐴𝑚(ξ) = 1
𝑁𝑝∑𝑖=1𝑁𝑝 ∑𝑁𝑗=𝑖+1𝑝 [𝐶𝑖𝑗𝑚𝑎𝑥 − 𝐶𝑖𝑗(∆𝑇𝑖𝑗𝑆(ξ))]× 𝑤𝑖𝑗 式(2.14) 其中,ΔT 是震波到兩目標測站之間的走時差,Np 是所取用的測站個 數,w 為權重係數。一般來說,Cmax的最佳解出現在調整兩目標測站最大振 幅值時間達到波形最吻合的地方,而這調整的延滯時間,就代表了震波的走 時差。在山崩定位的程序中,最佳震源解出現於 Am達到最小值的位置,可 將其視為該山崩的形狀中心。
山崩定位流程完成之後,將定位出來的山崩位置解和由衛星影像判釋 出的大規模崩塌地位置比對。兩者若比對成功,則可以確定該次訊號為該崩 塌地所觸發。
圖 2.18 崩塌定位方法示意圖(Chen et al., 2013)
第七節 促崩降雨條件分析
一、雨量資料來源
本計畫採用中央氣象局及經濟部水利署所架設的地面雨量站,除了統 計颱風豪雨事件期間的全島雨量分布狀況外,也作為崩塌降雨資訊的資料 來源。崩塌警戒雨量分析所用之雨量資料以直線距離崩塌地 3 公里內的雨
量測站紀錄為原則,並且和崩塌地坐落於同一集水區,若崩塌地 3 公里內 無可用雨量站,則利用距離反比權重內插法來獲得崩塌地之雨量資料。
二、雨量統計方法
由於山崩產生的地動訊號完整了記錄大規模崩塌的發生時間,藉由成 功的判釋與配對,可以運用所得到的時間記錄準確計算出山崩發生時的雨 量條件。本計畫中所指的雨場是一次豪雨事件的開始與結束的時間。由前期 計畫的崩塌雨場條件計算,可以歸納出,長降雨延時是引發大規模崩塌的重 要降雨條件之一。在前期計畫中,本團隊參考前人研究將雨場開始的標準設 定為當每小時降雨大於 4 mm 時;而當連續 6 小時時雨量開始小於 4 mm 時,
視為降雨事件結束(圖 2.19)。然而,因本計畫研究的對象多為颱風造成的豪 雨,由颱風引致的同一個降雨事件常可能在這樣的標準下被切割為 2 個以 上的不同雨場,導致在統計降雨延時很有可能低估的狀況。因此,本計畫修 改雨場切割修改方法,改為以日當作切割單位,當小時降雨量超過 4 mm,
即視為雨場開始時間;單日降雨量低於 4 mm 時,當日 24 時作為雨場結束 時間。採用修改後的雨場切割標準將使得完整降雨事件不易被雨勢趨緩或 是降雨中止而切斷,而崩塌事件發生時的降雨延時則是統計至崩塌發生的 時刻,並不會有高估雨場的狀況存在。運用此方法為基準,統計引發各崩塌 的降雨強度、累積雨量、降雨延時等參數,做為降雨門檻值分析之因子。其 中,降雨延時(D),單位為小時;累積雨量(Rc),單位為 mm;平均降雨強度 (I),單位為 mm/h。除了上述的三個因子之外,本計畫根據前期經驗,同時 將前期的降雨量 Ra納入計算。前人研究對於前期降雨的定義因為針對的邊
(1990)在雲南蔣家溝的土石流觀測研究之中,以 10 分鐘降雨量以及前期降 雨量為參數,建立雲南蔣家溝土石流發生判別式及受災判別式。本計畫採用 詹錢登(2002)提出的有效累積雨量模式:
𝑅𝑒 = 𝑅𝑎 + 𝑅𝐶 式(2.15) 上式中 Re為有效累積雨量,Rc 為統計至崩塌發生時的累積降雨量。此 處的前期降雨選擇範圍為雨場開始前七日,每日累積雨量以 0.7 指數衰減 (Ra = ∑7𝑖=10.7𝑖𝑅𝑖,i 為雨場開始前的日數)。
圖 2.19 雨場切割與降雨參數計算示意圖
大規模崩塌門檻值降雨因子統計將依據不同的降雨參數選擇,會產生 不同的雨量關係式。本計畫分別分析了以下三種雨量關係式:
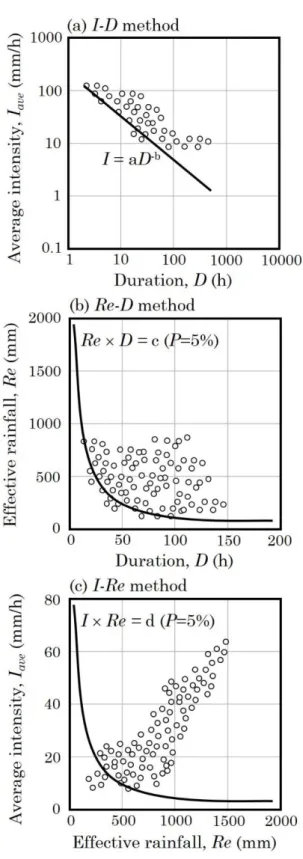
(一) I-D 法:此方法以降雨強度 I 及降雨延時 D 作為雨量指標(Caine, 1980;
Cannon & Ellen, 1985; Wieczorek, 1987; Keefer et al., 1987; Arattano &
Marchi, 2000),I-D 法目前是最為廣泛被討論及應用之促崩降雨門檻計 算方法。此方法主要利用引發該次災害的降雨事件,並未將前期降雨所 造成的影響納入考慮。將各山崩事件的 I 及 D 以對數座標作圖後,所 有資料點的下緣切線即為雨量門檻值曲線(圖 2.20a),該曲線一般常用 的公式形式為:I=aD-b。為了有一致的 I-D 門檻值計算方式,本計畫採 用涵蓋資料數 5%之曲線做為門檻曲線。採用之累積機率模型為高斯機 率函數,以乘冪回歸分析所得之曲線斜率為門檻曲線斜率,藉此獲得資 料累積機率為 5%時之曲線公式,作為整體資料點之下緣曲線公式。
(二) I-R 法:此方法使用降雨強度 I 及累積雨量 R 為雨量指標(圖 2.20c),藉 此界定出山崩發生的臨界降雨線(譚萬沛,1991;謝正倫,2001;詹錢 登,2004)。I-R 法將崩塌發生的平均降雨強度 I 和累積雨量 R 作圖,以 韋伯法取累積雨量機率為 5 %的值記為 R-I5。相對於 I-D 法取累積機 率 5 %時之曲線公式為臨界門檻,I-R 法同樣也以 R-I5 作為 I-R 法之門 檻值。
(三) R-D 法:此方法使用累積雨量 R 和降雨延時 D 作為雨量指標(圖 2.20b) (青木佑久,1980;范正成等人,1999,2002)。R-D 關係式的分析方法 和 I-R 法雷同,而且在考慮 R-D 關係式時,也會分別將前期降雨以及 年平均雨量納入考慮。在報告中將代表累積機率 5 %之 D 與 Rt 乘積值 表示為 RTD5。參考 I-D 法之門檻值計算方法,以 R-D5 作為 R-D 法之 門檻值。
本研究希望能夠完整反映出促崩雨量對於大規模崩塌的影響,因此除了
並且遵循前述的降雨門檻值計算方法,以累積機率 5 %之 Re-D5 及 Re-I5 作 為雨量門檻值的參考。
圖 2.20 三種常見雙雨量參數門檻曲線
三、崩塌破壞臨界水量模式
臨界水量模式 QC是由 Keefer et al. (1987) 針對美國加州地區,在豪雨 期間提出且成功發布崩塌警戒的一個方法,Keefer et al. (1987)採用的雨量參 數為降雨延時(D)以及降雨強度(I)。獲得 I-D 圖中的警戒曲線方法則使用一 簡單的地質材料模型進行計算。首先假設邊坡材料任一點中,材料所受的剪 力強度 s 可表示為:
𝑠 = 𝑐′ + (𝑝 − 𝑢𝑤)𝑡𝑎𝑛𝜙′ (式 2.16) 其中𝑐′為邊坡地質材料的有效凝聚力,p 為垂直於潛在滑動面的總應力,
𝑢𝑤為孔隙水壓,𝜙′則為邊坡材料的有效摩擦角。由於降雨引起邊坡災害的 主要原因為雨水入滲至邊坡內,並於不透水層上方飽和帶聚集,進而導致邊 坡材料之孔隙水壓上升。當孔隙水壓不斷上升,而使得剪力強度降低,最終 便導致邊坡發生破壞。Keefer et al. (1987) 所建立之崩塌雨量警戒系統便是 假設在每一個邊坡上都存在一個臨界孔隙水壓𝑢𝑤𝑐,並且臨界孔隙水壓與地 層厚度 Z、邊坡地質材料單位重𝛾𝑡、邊坡傾角θ,以及地質材料有效摩擦角 𝜙′有關,可以下列公式計算:
𝑢𝑤𝑐 = 𝑍 ∙ 𝛾𝑡(1 − 𝑡𝑎𝑛𝜃
𝑡𝑎𝑛𝜙′) (式 2.17) 而孔隙水壓上升至臨界孔隙水壓則需要一個臨界水量 Qc,這個臨界水 量可以下列式子計算:
𝑄𝑐 = (𝑢𝑤𝑐/𝛾𝑤) ∙ 𝑛𝑒𝑓 (式 2.18) 其中𝑢𝑤𝑐為臨界孔隙水壓,𝛾𝑤為水的單位重,𝑛𝑒𝑓 為有效孔隙率,即邊 坡材料在自由重力排水下,尚存的孔隙率。同時再假設降雨開始後,所有的
為代表,其單位為 mm/hr。則在一個豪雨事件中,引發邊坡災害的臨界水量 為:
(I − Io) ∙ 𝐷 = 𝑄𝑐 (式2.19) 其中 I 為小時降雨強度,D 為降雨延時。在式 2.19 中的 Io與 Qc,可以 藉由詳細地質調查(小區域尺度)或是大量數據資料計算而得(大區域尺度),
如 Caine (1980)所用之降雨資料可計算出 Io為 4.49 mm/hr,而 Qc為 13.65 mm。
此雨量警戒值運用於崩塌警報曾有相當成功之經驗,且該警戒方法同 時涵蓋了降雨強度 I、延時 D,以及累積雨量 R(在此處取代 Qc)等 3 種最廣 為採用的降雨因子,能同時考量不同降雨型態之事件。本計畫將參考舊金山 灣區的雨量警戒曲線建立方法,運用於臺灣地區的大規模崩塌雨量警戒值 預測,作為警戒系統設計之基礎,並且也將土壤水分指數和深層水量當作因 子進行統計,希望可以找到最適合臺灣大規模崩塌降雨警戒的模式,或運用 不同的方法,進行雞尾酒式的混合使用,達到最有效率的警戒方式。
四、土壤水分指數
土壤水分指數(Soil Water Index, SWI)或者是稱為筒狀雨量模式,此方法 利用三個筒內降流入水流出的變化順序來模擬雨水由地表逕流、進入淺層 土壤再入滲至深層土壤的過程,透過計算可以得到最後入滲至地層的總水 量(圖 2.21)。其計算過程為假設此事件總降雨量為 I (mm),每個筒內的水深 為 S (mm),筒內出流的水深為 L (mm),出流量為 Q (mm),F (mm)為雨水 的入滲量,雨水出流比為 a,雨水入滲比為 b,以上所有參數中,L、a、b 三 者為固定參數。
每筒水中的流出量 Qi即為筒內水深 Si扣除出流水深 L,乘上出流比 ai ,i
在三筒水中,只有第一筒水含有兩個出流量 Q1、Q2,分別為第一流出量和 第二流出量,第一流出水量可視為無法進入土壤層的地表逕流,第二流出水 量則是未進入地面的水例如冰川或是其他遮蔽物,F1 則是由第一筒水流入 第二筒水的總量;Q3是第二筒水的出水量,可視為表層滲出水流;Q4是第 三筒水的出水量,可視為地下水流(圖 2.22)。經計算之後可以得到各筒水深,
加總之後便為土壤水分指數 SWI (mm) = S1 + S2 + S3,(岡田憲治,2002;陳 樹群等人,2013)。
有鑑於過去計算土壤水分指數多採用日本氣象廳公告之日本參數,難 以評估是否確實適用於臺灣山區。本計畫利用 2010 年至 2018 年的河川流 量、雨量,以及蒸發散量的觀測資料,擬合出臺灣參數進行土壤水分指數的 分析(表 2.5)。其中蒸發散量的計算使用 Penman-Monteith 法,計算資料採用 中央氣象局三等及四等氣象站的觀測資料,並以徐昇法求得每一氣象站在 計算流域內的代表面積,再求得計算流域的代表蒸發散量。河川流量採用經 濟部水利署流量站紀錄,並且除以流域面積求得單位流深。雨量則採用中央 氣象局雨量站紀錄,並以徐昇法求得計算流域內的代表雨量。土壤水分指數 計算參數的擬合則利用 Matlab 內建 Simulink 功能,編寫單位流深及土壤水 分指數計算程式,並進行參數擬合,待觀測流深與預測流深間有最小方差時,
獲得最佳參數組合解(圖 2.23)。在本計畫中,針對陳有蘭溪、清水溪、大甲 溪、大漢溪及花蓮溪進行土壤水分指數計算參數的擬合,並以平均值作為最 後土壤水分指數的計算參數。
在採用土壤水分指數分析時,本計畫也將降雨事件發生前的土壤水分 指數納入考量,本次計畫採用的前期土壤水分指數為降雨事件發生前 30 日
豪雨事件,而在颱風季節時常在短期內颱風連續侵襲,這些事件帶來的降水 也很有可能是觸發大規模崩塌的因子之一。因為在進行土壤水分指數的計 算時,會考慮土壤層中的水體入滲與排出,經由這樣的計算,相較於單純的 考慮前期的降雨量,更有可能反映出前期降雨在土壤層中造成的影響。
而在 SWI 的計算中,除了總土壤水分指數之外,還會有不同層的含水 量,由前期計畫的經驗得知,深層水的含水量變化的關係和引發大規模崩塌 的降雨條件較為密切,因此本計畫也會採用第三桶深層水深 S3 當作統計降 雨條件的一個因子。
圖 2.21 筒狀模型與地表逕流類比(岡田憲治,2002)
圖 2.22 筒狀雨量模式說明(修改自陳樹群等人,2013)
表 2.5 土壤水分指數計算所用之參數
參數 數值
a1 0.018 a2 0.117 a3 0.033 a4 0.009 b1 0.087 b2 0.084 b3 0.013 L1 31 L2 110 L3 16 L4 16
圖 2.23 陳有蘭溪 2018 年之觀測流深與預測流深
圖 2.24 計算土壤水分指數示意圖
第三章 研究成果
第一節 演算法測試結果
本研究使用相同的訓練樣本測試了 22 種機器學習演算法(表 3.1),其中 隨機森林(Random Forest)演算法得到最高之分類正確度(91.3%)及崩塌事件 敏感度(86.9%),而其崩塌事件 PPV 雖不是最高,但也高達 89%,因此最終 選用隨機森林演算法製作自動分類器。
表 3.1 22 種演算法測試結果
編號 演算法 正確度(%) 崩塌敏感度(%) 崩塌 PPV(%) 1 Complex Tree 87.2 79.6 81.6 2 Medium Tree 87.6 76.3 84.2 3 Simple Tree 86.6 78.9 80.5 4 Linear Discriminant 86.3 69.4 85.4 5 Quadratic
Discriminant 86.2 61.7 92.7 6 Linear SVM 88.2 72.5 88.6 7 Quadratic SVM 88.0 76.8 85.0 8 Cubic SVM 88.7 82.7 82.7 9 Fine Gaussian SVM 87.5 68.9 92.1 10 Medium Gaussian
SVM 87.2 69.8 87.8
11 Coarse Gaussian
SVM 84.9 65.0 84.6
12 Fine KNN 87.3 80.8 80.8
14 Coarse KNN 82.7 58.7 83.1 15 Cosine KNN 87.4 70.7 88.0 16 Cubic KNN 88.2 73.6 87.8 17 Weighted KNN 88.9 76.8 87.2 18 Boosted Trees 88.8 78.4 86.0 19 Random Forest 91.3 86.9 89.0 20 Subspace
Discriminant 84.8 64.7 84.2 21 Subspace KNN 79.2 65.7 69.3 22 RUSBoosted Trees 86.8 74.8 82.8
第二節 分類器正確度
本計畫以混淆矩陣呈現自動分類器之分類效果(表 3.2),結果顯示,在 214 筆崩塌訊號中,有 186 筆被正確分類、25 筆被判釋為地震、3 筆被判釋 為噪訊,對於崩塌訊號的敏感度為 86.9%;214 筆地震訊號中,有 190 筆被 正確分類、19 筆被判釋為崩塌、5 筆被判釋為噪訊,對於地震訊號的敏感 度為 88.8%;214 筆噪訊中,有 210 筆被正確分類、4 筆被判釋為崩塌,對 於噪訊的敏感度為 98.1%。
而 209 筆被歸類為崩塌的訊號中,有 186 筆確實屬於崩塌,另外有 19 筆實際上是地震訊號、4 筆是噪訊,對於崩塌訊號的 PPV 為 89.0%,協調 分數為 0.88。215 筆被歸類為地震的訊號中,有 190 筆確實屬於地震,另外 25 筆實際上是崩塌訊號,對於地震訊號的 PPV 為 88.4%,協調分數為 0.97。
218 筆被歸類為噪訊的訊號中,有 210 筆確實屬於噪訊,另外有 3 筆實際 上是崩塌訊號、5 筆是地震訊號,對於噪訊的 PPV 為 96.3%。