行政院國家科學委員會專題研究計畫 成果報告
音視訊號融合之情緒偵測系統 研究成果報告(精簡版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 99-2221-E-011-013-
執 行 期 間 : 99 年 08 月 01 日至 100 年 10 月 31 日 執 行 單 位 : 國立臺灣科技大學電子工程系
計 畫 主 持 人 : 林敬舜
計畫參與人員: 碩士班研究生-兼任助理人員:陳禕涵 博士班研究生-兼任助理人員:鄭宗超
報 告 附 件 : 出席國際會議研究心得報告及發表論文
公 開 資 訊 : 本計畫涉及專利或其他智慧財產權,2 年後可公開查詢
中 華 民 國 100 年 12 月 29 日
中 文 摘 要 : 在人機互動上,對於情緒智能的需求在近年來日益殷切。為 了適切地對使用者做出反應,電腦就需具備有使用者情緒狀 態的感知能力。就機器對人類情緒感知來說,透過影像追蹤 人臉表情可得到最多的情緒資訊。另一方面,隱含在言語中 的聲音特徵亦提供了另一個獲取情緒狀態的管道。研究發 現,同時使用聲音與影像資訊可提升對負面情緒的鑑別。目 前情緒偵測自動化碰到的困難之一就是現今並無標準資料庫 可供情緒偵測演算法的評估。人臉表情的資料庫無法自然的 反應出參與者實際的情緒狀態就是其中一個問題。有鑑於 此,在這個提案裡我們計畫完成三件任務。第一、就目前用 來做情緒偵測的語音辨識演算法逐一檢視,然後選擇計算複 雜度相對較小的模式以方便日後應用於可攜式裝備。第二、
同時對各種人臉情緒偵測的演算法做評估,使其達到即時處 理的效能。最後,對既有的 FCMAC (Fuzzy Cerebellar Model Articulation Controller)與 SVM (Support Vector Machine)等演算法做評估,針對採用的音視訊特徵做修正將 是最主要的研究方向。為了驗證系統的效能,採用的音視訊 特徵與實際情緒的一致性將會是最後情緒偵測模型的評估重 點。
中文關鍵詞: 情緒分析、情緒偵測、特徵融合、音視訊號、語音辨識、人 臉辨識
英 文 摘 要 : There is a growing demand for emotional intelligence in the human-computer interaction. To appropriately react to a user, the computer would need to have some perception of the emotional states of the user. In general, the most explicit information for machine perception of emotions is through facial expressions in video. On the other hand, emotional clues buried in speech also provide computer an alternative to recognize user‘s situation. Researchers have reported that improved recognition in negative emotions can be achieved when speech features are used along with visual features. One of the
challenges in evaluating automatic emotion detection is that there are currently no international
databases based on authentic emotions. The current existing facial expression databases contain facial expressions that are not naturally linked to the emotional states of the participant. The major tasks of this project are threefold: First, we plan to
review most of the speech recognition algorithms used in emotion detection, and then choose those with relatively low computational complexity for further implementing on portable devices. Second, we would like to revise the facial emotion detection
algorithms for a real-time processing. Evaluating and modifying the machine learning algorithms such as FCMAC (Fuzzy Cerebellar Model Articulation
Controller) and SVM (Support Vector Machine) for audiovisual feature fusion will be the most important process. To verify the performance of overall system, the proposal model is also evaluated based on the consistency between audiovisual features and real emotions.
英文關鍵詞: Affective analysis, Emotion detection, Feature fusion, Audiovisual signal, Speech recognition, and Facial expression recognition.
行政院國家科學委員會補助專題研究計畫 ■ 成 果 報 告
□期中進度報告
音視訊號融合之情緒偵測系統
Emotion Detection System Based on Audiovisual Signal Fusion
計畫類別: ■ 個別型計畫 □整合型計畫 計畫編號:NSC 99-2221-E-011-013-
執行期間: 99 年 8 月 1 日 至 100 年 10 月 31 日 執行機構及系所:國立台灣科技大學電子系
計畫主持人:林敬舜 共同主持人:無
計畫參與人員:鄭宗超、陳禕涵
成果報告類型(依經費核定清單規定繳交): ■ 精簡報告 □完整報告 本計畫除繳交成果報告外,另須繳交以下出國心得報告:
□赴國外出差或研習心得報告
□赴大陸地區出差或研習心得報告
■ 出席國際學術會議心得報告
□國際合作研究計畫國外研究報告
處理方式:除列管計畫及下列情形者外,得立即公開查詢
■ 涉及專利或其他智慧財產權,□一年 ■ 二年後可公開查詢 中 華 民 國 100 年 12 月 18 日
附件一
國科會補助專題研究計畫成果報告自評表
請就研究內容與原計畫相符程度、達成預期目標情況、研究成果之學術或應用價 值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性)、是否適 合在學術期刊發表或申請專利、主要發現或其他有關價值等,作一綜合評估。
1. 請就研究內容與原計畫相符程度、達成預期目標情況作一綜合評估
■ 達成目標
□ 未達成目標(請說明,以 100 字為限)
□ 實驗失敗
□ 因故實驗中斷
□ 其他原因 說明:
2. 研究成果在學術期刊發表或申請專利等情形:
論文:■已發表 □未發表之文稿 □撰寫中 □無 專利:□已獲得 ■申請中 □無
技轉:□已技轉 □洽談中 ■無 其他:(以 100 字為限)
與此計畫相關送審中期刊論文 2 篇,已接受研討會論文 4 篇(詳見國科會資料庫 或報告附錄),其中 2 篇正改寫成期刊論文。
附件二
3. 請依學術成就、技術創新、社會影響等方面,評估研究成果之學術或應用價 值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性)(以
500 字為限)
人類的情緒表現長久以來一直是心理學、生理學、神經學、認知科學、社會 學等學者所研究之課題,近年來由於電腦理論的快速發展,突破以往單一向度的 資訊處理框架,轉變成可以與使用者雙向互動,而原本只能靠人力判斷的情緒表 現,逐漸被電腦所取代。本研究計畫之目的,在於擷取音頻與視頻訊號中的情緒 特徵,並融合兩者以建立更精確的情緒辨識系統。
而完成之工作項目除衍生出審核中期刊論文 2 篇,研討會論文 4 篇外,亦 有 2 篇期刊論文正改寫中,並完成相關軟體實作。而參與的學生亦藉由各種不 同的實驗與模擬,配合實際測試,從圖樣辨識的角度切入相關技術的開發。透 過開發程式所達成的人機互動,將可有效做到即時的情緒偵測,幫助我們判斷 情勢的好壞、環境的安全、更有助於商業上客戶關係的管理。而其他的效益尚 有,若將情緒辨識系統結合於各類監視系統,便可從影音資訊中得知每個人的 情緒,如應用於監獄中的監視系統將可避免發生躁動,而連結於居家防護的情 緒監控系統則可透過無線設備的警報訊息來即時通知家人情緒是否有劇烈變 化。另外,由於近年來智慧型手機越見普及,情緒辨識系統將會是除了語音辨 識系統外的下一個重要功能,使用者可輕鬆得知通話對方的情緒,不用透過長 串的對話去臆測彼此的情緒狀況,以便達到更高品質的溝通交流。而此情緒偵 測系統亦有助於醫療人員從事如自閉症方面的治療,讓病人的相關資訊不但可 以透過醫生診斷得知,同時也讓這套系統提供醫病雙方更客觀的資訊。此外,
這個計畫亦可提供不同的整合思維,提升相關廠商在此服務應用平台開發的競
爭力,而這些技術也將對台灣的教育界(如 E-learning)、出版業以及多媒體產業
的發展帶來關鍵性的影響。
行政院國家科學委員會專題研究計畫成果報告
音視訊號融合之情緒偵測系統
Emotion Detection System Based on Audiovisual Signal Fusion
計畫編號:NSC 99-2221-E-011-013-
執行期限:99 年 8 月1 日 至 100 年 10 月31 日 主持人:林敬舜 國立台灣科技大學
中文摘要
在人機互動上,對於情緒智能的需求在近年來日益殷切。為了適切地對使用者做出反 應,電腦就需具備有使用者情緒狀態的感知能力。就機器對人類情緒感知來說,透過影像追 蹤人臉表情可得到最多的情緒資訊。另一方面,隱含在言語中的聲音特徵亦提供了另一個獲 取情緒狀態的管道。研究發現,同時使用聲音與影像資訊可提升對負面情緒的鑑別。目前情 緒偵測自動化碰到的困難之一就是現今並無標準資料庫可供情緒偵測演算法的評估。人臉表 情的資料庫無法自然的反應出參與者實際的情緒狀態就是其中一個問題。有鑑於此,在這個 提案裡我們計畫完成三件任務。第一、就目前用來做情緒偵測的語音辨識演算法逐一檢視,
然後選擇計算複雜度相對較小的模式以方便日後應用於可攜式裝備。第二、同時對各種人臉 情緒偵測的演算法做評估,使其達到即時處理的效能。最後,對既有的FCMAC (Fuzzy Cerebellar Model Articulation Controller)與SVM (Support Vector Machine)等演算法做評估,針 對採用的音視訊特徵做修正將是最主要的研究方向。為了驗證系統的效能,採用的音視訊特 徵與實際情緒的一致性將會是最後情緒偵測模型的評估重點。
關鍵詞:情緒分析、情緒偵測、特徵融合、音視訊號、語音辨識、人臉辨識。
Abstract
There is a growing demand for emotional intelligence in the human-computer interaction. To appropriately react to a user, the computer would need to have some perception of the emotional states of the user. In general, the most explicit information for machine perception of emotions is through facial expressions in video. On the other hand, emotional clues buried in speech also provide computer an alternative to recognize user‘s situation. Researchers have reported that improved recognition in negative emotions can be achieved when speech features are used along with visual features. One of the challenges in evaluating automatic emotion detection is that there are currently no international databases based on authentic emotions. The current existing facial expression databases contain facial expressions that are not naturally linked to the emotional states of the participant. The major tasks of this project are threefold: First, we plan to review most of the
speech recognition algorithms used in emotion detection, and then choose those with relatively low computational complexity for further implementing on portable devices. Second, we would like to revise the facial emotion detection algorithms for a real-time processing. Evaluating and modifying the machine learning algorithms such as FCMAC (Fuzzy Cerebellar Model Articulation Controller) and SVM (Support Vector Machine) for audiovisual feature fusion will be the most important process. To verify the performance of overall system, the proposal model is also evaluated based on the consistency between audiovisual features and real emotions.
Keyword: Affective analysis, Emotion detection, Feature fusion, Audiovisual signal, Speech recognition, and Facial expression recognition.
1. 緣由與目的
情緒表達在人與人的交流上扮演著相當重要的角色,我們可以藉由得知一個人的情緒,
來了解他的身體與心理狀況。若將情緒辨識系統結合於各類監視系統,便可從影音資訊中得 知每個人的情緒,為了有效地將情緒辨識系統普及於各種層面應用上,綜合各類領域的情緒 相關研究,深入剖析各種情緒的變化特質及屬性,便成不可或缺的工作。因此,本研究的目 的在於擷取音頻與視頻訊號中的情緒特徵,並融合兩者以建立更精確的情緒辨識系統。
音頻訊號的來源主要是由麥克風收音,透過多種的語音特徵擷取方法,取得各種情緒的 特徵,以 N-best Decoder 來切割語音資料,再利用語音辨識模型,對這些特徵向量訓練並做 測試,以辨識該語音中內含的情緒種類。另一方面,視頻訊號的處理則採用 Webcam 做為輸 入,讀到的影像先做人臉偵測(Face Detection) [1, 2, 3],待完成後使用人臉特徵切割法(Face Features Segmentation) [4, 5]將五官個別分離出來,由於針對情緒辨識,只取出眉毛、眼睛和 嘴巴等特徵,接下來就是根據這些部位的動態狀況計算出特徵點,再將得到的特徵點,使用 特殊的量化方法,配合分類器做訓練測試,評估出其影像中的人物可能情緒的機率分布狀 況。Osgood 等人將情緒的概念區分為情緒激發度(Arousal) 與情緒向度(Valence)兩個標準 [6],其中 Arousal 是指情緒表現的強度,意指從極度冷靜狀態到極度激動之間變動的範圍;
而 Valence 則是用來表達情緒當中屬於正面或是屬於負面的程度。如圖 1.1 所示,情緒線索 (Emotion Curves)可由二維 Arousal-Valence 空間圖來判斷 [7],而影音內容的分析與人機介面 的設計亦可藉由情緒狀態的改變來達成[8, 9, 10],因此本研究利用音頻與視頻訊號的結合,
剖析情緒特徵融入影音介面設計時所引發的潛在效益及問題,比較各種情緒在音頻與視頻訊 號上的特性,以建立高精確度的情緒音視訊融合辨識系統。
-1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1 -1
-0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1
valence
arousal
happiness
fear
disgust sadness
boredom neutral anger
圖 1.1 Arousal-Valence 平面示意圖
2. 文獻回顧
在本計畫中,音視訊融合系統將以音頻與視頻訊號分別探討,本章舉出過去幾個重要的 特徵擷取方法,將情緒套用於這些特徵當中,並探討訊號分析辨識模型,以及回顧訊號融合 之研究。
2.1音頻訊號情緒偵測
對於音訊情緒辨識,目前大多為語言獨立(Language Independent)的研究,即不論及說話 的內容,只針對語音特徵做辨識,好處是不須建立各種語言的訓練模型,但相對的無法利用 說話的內容對情緒做進一步的分析。對於語言獨立的音訊情緒辨識,我們並未有各國語音學 或語言學的分類結構模型可参考,較可供参考的唯有二維的 Arousal-Valence 情緒平面。而
Y. H. Yang等人將音樂情緒辨識為音樂在二維情緒平面上的迴歸問題來預測音樂的 Arousal
和 Valence 值[11, 12]。在語音訊號上,亦可用類似的方法,判定每個的語句在二維情緒平面 上所屬的點,以觀測語者的情緒變化。
在音訊情緒辨識的研究中提出許多的特徵向量表示方式,如梅爾頻率倒頻譜係數 (Mel-Frequency Cepstral Coefficients, MFCC)、音高輪廓(Pitch Contour)、能量輪廓(Energy Contour)、與頻譜平坦量測(Spectral Flatness Measure) [13]等。因特徵種類繁多,進而產生了 組合爆炸的問題,不適當的特徵向量組合不僅徒增計算複雜度,更可能降低不同類別間的鑑 別度,因此,特徵選取成為首要的問題。而一些特徵選取法中的啟發式選取演算法可供我們
参考,如基本的 SFS (Sequential Forward Selection) [14],一開始只在所有的特徵群中先選一 個辨識率最好的特徵,而後遞迴在剩餘特徵群中選出一個合併後辨識率最好的加入;SFFS (Sequential Forward Floating Selection) [15]則更導入移除已選取特徵的概念。一般來說,情緒 變化需建立在一連串的互動上,適時的透過情緒事件觸發而做出反應,或是由情緒相關的字 彙來表現,但本實驗為不受這些因素影響,單純由語音特徵來判斷各種情緒,因此,我們選 擇不含情緒性字眼的中性語句作為語料內容,也建立不同性別與年齡的語者資料,以不同的 語音特徵來判定情緒種類。
因為語言獨立的音訊情緒辨識缺少語句(Sentence)、詞彙(Word)、音素(Phoneme)等結 構,較不易利用如 HMM 的狀態轉換機率(State Transition Probability)等建模[16]。因此,多 數的研究將每一種情緒語料當成一個類別,使用 GMM (Gaussian Mixture Model)、SVM
(Support Vector Machine)等方式進行訓練和分類。可想而知,若以短小音框為基礎的特徵向
量,其音訊在時間軸上的變化資訊可能會被忽略,因為許多的音訊特徵只能反映當時音框或 鄰近音框。而就人的認知來說,前後音框的情緒辨識結果,不應該有太大的不連續性,這些 不連續性可能是非語音區段(Non-speech Segment)等原因造成。通常在自動語音辨識 (Automatic Speech Recognition, ASR)中會設計一個靜音的狀態去吸收這些段落的特徵向量。
J. S. Park 等人[17]認為諸如此類的部分重疊,在不同情緒類別中的特徵向量會糊化訓練模
型,因而降低辨識的精確度,所以剔除了這些重疊的特徵向量,再進行二次模型訓練,以獲 得比原先模更好的結果。
2.2 視頻訊號情緒偵測
由於多媒體網路的快速發展,即時影像已成為通訊中不可或缺的功能,除了語音之外,
視覺動態、肢體語言等都是重要的溝通資訊,而這些非言語的訊息,便成為系統辨識情緒的 線索。人臉辨識目前廣泛應用於智慧型監視與身份辨識系統,針對人臉的情緒偵側,Paul
Ekman 列出了六種基本情緒[18],亦即生氣(Anger)、厭惡(Disgust)、恐懼(Fear)、高興
(Happiness)、悲傷(Sadness)及驚訝(Surprise),在後來的人臉情緒辨識研究中,則以這六種情 緒再新添入一中性情緒(Neutral),共七種基本情緒做辨識基準[19]。
影像的辨識中可分成即時與非即時,其運作流程大概可分為三個步驟:第一步驟為人臉 偵測;第二步驟為五官切割與特徵點擷取;最後則是根據前兩步驟所得資訊進行統計與判 斷。人臉偵測在系統中的第一個任務是判斷該空間中是否有人臉的存在,這意味著,若系統 在空間中無偵測到臉,則無須執行後面的兩個步驟,直到系統偵測到人臉的出現,才繼續下 面步驟,如此可以大幅減少系統的負擔。而第二個任務就是將人臉五官單獨分割出來,以利 下一個步驟的進行。人臉偵測可使用 Color-based [20]的方法來實現,此方法就是在空間中尋 找與人體膚色相近的區塊並加以擷取,再輔以可能的五官特徵來判斷是否為人臉,此方法雖 然簡單實用,但若因區域人種或其他因素如光影等導致膚色差異過大,可能使得偵測結果不 正確。
表情在人臉上的定義,可以五官的變化及形狀來做判斷基準,因此如何讓系統正確地擷 取到人臉特徵成為首要關鍵,而主動外觀模型(Active Appearance Models, AAM) [21, 22]為目 前比較常見獲取人臉特徵點的演算法。AAM 是基於 ASM (Active Shape Model) [23]改進而來 的演算法,此方法是由點框出人臉及特徵的模型,使用 AAM 得出的結果雖然不錯,但仍存 在不少缺點,例如 AAM 需要謹慎完善地訓練出一個模型,才能有效的定位,且判斷物件不 能與原訓練模型差異太大,否則結果會跟預期有極大的落差,當 AAM 在進行形狀擬合時出 現誤判,就很難導向正確結果,這個缺失可歸咎於其較差的自調整性。
特徵點也有不使用類似 AAM 模型演算法來擷取,而是先做切割[24],將眉毛、眼睛和 嘴巴分隔出來,再依照五官的各自條件去做運算,例如可用 Gabor Filter [25]或 Corner
Detection [26, 27]取出特徵點,但因為眼睛與嘴巴的外觀弧線具特殊性與相似性,基於形狀
特性的擷取這兩種方法均有些類似。透過特徵點的擷取方法最大優點就是判別率與自由度 高,因為可以根據各個五官特徵以及自己的需求來完成針對性的演算法,以達成特徵點的擷 取,但其所衍伸出來的問題在於需要額外可靠的切割方法,以確保切割出來的部位能符合所 需求的格式。
影像的情緒分類,一般是根據特徵點的資訊進行分類判斷,目前較多使用的分類方法 有:AdaBoost [28, 29]、Support Vector Machine (SVM) [30]以及 Neural Network (NN) [31]。這 些演算法皆是需經過資料訓練的過程,其共通特色為,用來訓練成模組或參數調整的原始資 料,會明顯影響分類的結果,所以若是用來做訓練的資料不夠具有代表性,分類結果就會與 實際情況產生落差。其中 NN 的內部參數無法保證能調整到最佳狀況,運算速度偏慢。
AdaBoost則屬於小巧輕便的分類器,但較容易受到雜訊干擾而影響結果,且極度依賴分類器
的選擇。SVM 適用性較廣,調整性佳,在各方面表現都相當優秀,但主要缺點在於訓練時 間過長,要運用在即時系統上,需事先準備好訓練過的模組,但這也是大部分分類器的共同 缺點。
2.3 音視訊號融合
由融合的運作時機來分,訊號的融合基本上可大致分為早期融合、建模融合以及後期融
合,分述如下:
2.3.1 Early Fusion (Frame-based Signal Fusion)
融合的運作在較早的特徵處理階段,對於音訊和視訊分別抽取出的特徵向量進行融合,
融合音視訊後的特徵向量再送至辨識器進行辨識。不同時間尺度和度量程度的音視訊特徵融 合增加了特徵向量的維度並影響到辨識結果。
2.3.2 Model-based Fusion
Model-based Fusion將融合的運作整合於模型之中。一些音視訊整合語音辨識研究提供了
幾種融合音視訊的HMM模型。對於音視訊整合的情緒辨識,亦可找到類似的Multi-stream
Fused HMM (MFHMM) [32, 33]研究,其認為使用MFHMM有以下優點:每ㄧ種特徵向量可
以被建模成一個HMM元件,並以最大交互資訊和其他的資料流做聯結;且不同元件的狀態 轉移不需要同時發生,所以不同資料流的同步限制條件可以放寬,如果一個元件因某種原因 失效,其他元件仍可以工作。
2.3.3 Late Fusion (Decision Level Fusion)
先由個別的分類器基於自己的特徵資料做出決策,最後的融合中心再根據分別的決策做
出最終的結果。由於音頻和視頻訊號對於情緒的表現存在互補或相關的訊息,不適當的後級 融合可能會遺失有用的相關訊息而影響最後判斷,在本研究中我們將改善此一缺點,並充分 利用來自音視頻訊號所提供的訊息。
3. 研究方法
3.1音視訊融合系統架構
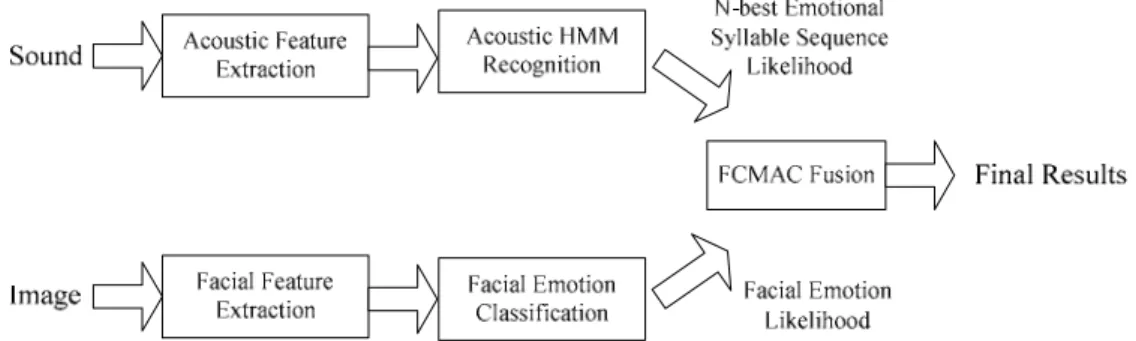
在基於 Arousal-Valence 平面與 N-best 之情緒音節序列 (Emotional Syllable Sequences)的 音視訊融合系統中,我們使用後級融合的策略,但音頻和視頻訊號在個別的辨識過程中皆適 度地被保存以供後級融合使用,其整體架構如圖 3.1 之系統方塊圖所示。在音頻辨識部份,
我們使用 EMO-DB (Berlin Emotional Speech Database)情緒聲音語料庫訓練出各種情緒語句 以及音訊中靜音片段的 HMM 模型。此外,為提供資訊給後級融合使用,在辨識過程中使用
N-best Decoder 輸出較多可能的情緒音節序列以供後級融合處理。同樣在視頻的辨識過程
中,我們擷取每張影像的情緒特徵,以 SVM 分類,將其辨識率與 Arousal-Valence 平面上相 對應的情緒分佈做比較,再取其個別相對向量,以供後級融合處理。在最後的融合過程裡,
由於情緒在時間軸上的轉折,其相對應的音視訊號將在 Arousal-Valence 平面上存在軌跡的變 動,因此我們使用具有記憶聯想特性的模糊小腦模型運算控制器(Fuzzy Cerebellar Model Articulation Controller, FCMAC)來做最後的判斷。
圖 3.1 音視訊融合情緒辨識系統方塊圖
音視訊融合系統的語音部份,選用 EMO-DB 構成訓練語料庫,此語料庫包含七種情緒,
分別為 Happiness、Fear、Neutral、Disgust、Boredom、Sadness、Anger,分別由 10 位 25-35 歲不同性別的男女生以不同情緒朗誦 10 個語句。另外我們以 Webcam 以及麥克風錄製語音 資料庫,由 10 位同學以 5 種情緒朗誦 5 個語句,用以訓練建立比對資料庫。音頻訊號的辨 識,則使用英國劍橋大學工程系(Cambridge University Engineering Department, CUED)所開發 的軟體 HTK (HMM Toolkit) [34]來訓練與測試語音資料。在視頻訊號的辨識部分,採用支援 向量機(Support Vector Machine, SVM)以 C. C. Chang 等人開發的 LIBSVM (A Library for Support Vector Machines)來進行影像資料分類 [35]。
3.2 音頻訊號情緒偵測方法
音訊的特徵擷取,使用 HTK 內建的 MFCC 函式轉換,根據人耳聽覺特性,在對數頻譜 (Log Spectra)上取出的 12 維特徵係數,加上一維的能量大小(Power Spectra),再以此 13 個係 數做一次、二次導數運算,得到 39 維的特徵向量(HTK 的表示為 MFCC_E_D_A,代表 MFCC+Energy+Delta+Acceleration)。文獻指出,音高特徵(Pitch)為情緒的重要指標,但由於 HTK 內建的特徵並未包含音高特徵,因此需使用額外的工具如 OpenEAR 來擷取音高特徵 (Pitch, Delta Pitch, and Acceleration Pitch)與加上原本由 HTK 取得的特徵構成 42 維的特徵向 量。
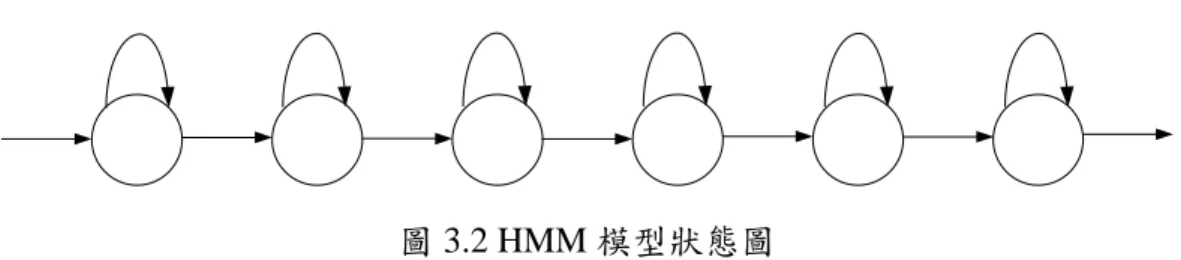
我們使用 HTK 工具,針對語料庫搭配前述的特徵向量擷取方式建立關於聲音情緒的隱 藏式馬可夫模型(Hidden Markov Model, HMM)。在模型的訓練方面,我們將每ㄧ段的聲音起 伏如 Attack(擊發)-Decay(衰減)-Sustain(延續)-Release(消逝)等當成一個情緒音節(Emotional
Syllable)。這七個情緒分別使用各包含六個狀態的 HMM 建模,如圖 3.2 所示,每個狀態的
Mixture Gaussian包含十個使用 Full Covariance Variance 的 Gaussian 分佈。另外對於 Silence 和 Short-Pause 則分別建立三個狀態和一個狀態的 HMM 模型以降低音節與音節之間特徵向 量的影響。
圖 3.2 HMM 模型狀態圖
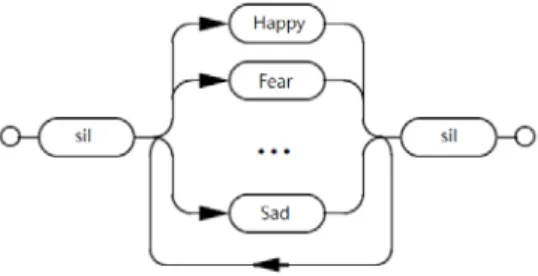
在辨識未知語句時,由於不知句中會包含多少音節,所以使用句中可能包含一個或更多個情 緒音節的簡單文法代入,形成如圖 3.3 的音訊情緒辨識網路。
圖 3.3 音訊情緒辨識網路
以一個標準的語音辨識問題來說,给定一觀測序列O={o1,o2,...,om},要找出最可能的 Word sequence W ={w1,w2,...,wn},在均勻成本(Uniform Cost)的情形下變成最大後驗機率估計如下所 示:
arg max Pr( | ) arg max Pr( ) Pr( | ) ( )
w w
W O = W O W P O (3.1) 當觀測O已確定,則Pr( )O 已固定且對各種可能的w沒有影響,上式等同於:
)
| Pr(
) Pr(
)
| Pr(
max
arg W O W O W
w = (3.2)
其 中 Pr(O|W)=Pr(o1,o2,...,om|w1,w2,...,wn) 為 語 音 模 型 所 產 生 的 機 率 , 而 )
,..., , Pr(
)
Pr(W = w1 w2 wn 為語言模型產生的機率。現階段採用情緒音節的模型,正確的音節語 言模型較難獲得,這邊先簡單地假設每一個情緒音節有相等可能出現的先驗(Prior)機率,如 圖 3.3 中,每一種音節的銜接機會視為均等。我們採用其他的方式進行音節語言模型的補償,
亦即在後級的融合策略中,利用模糊小腦模型,使用記憶中的音視訊在 Arousal-Valence 平面 上相對變化關係來提供Pr(W)的修正。在音訊階段,則採用 N-best Decoder 輸出較多可能的 情緒音節序列,以提供較多的訊息給後級融合處理。例如圖 3.4 中某個音訊經過辨識可得到 二個可能的情緒音節序列,最後這些候選情緒音節區段伴隨的似然法則(Likelihood)將被當成 後級輸入與其他訊息進行融合。
圖 3.4 音訊的情緒音節分割 3.3視頻訊號情緒偵測方法
人臉特徵擷取最常見的方法為 AAM,但在 2.2 節曾提到,AAM 需要一個強健的訓練模
型,否則會造成無法與辨識物擬合,本研究解決了這樣的問題,不建立訓練模型,而以搜尋 (Searching)的方式取得人臉五官。
首先利用連通物件標示法(Connected Components Labeling)對物件辨識與分類,以取得所 需臉部特徵之五官,一般連通法會將影像中所有獨立物件,分別標示不同的數字以做區別,
而我們在處理過程中添加了物件過濾條件,濾除掉不需要的物件,例如非五官之背景物件和 頭髮等,只擷取感興趣之物件並加以分類收集,再給予物件特定的名稱,以及儲存物件的大 小與位置參數。概述其搜尋分法,首先以雙眼作為一個重要的搜尋目標,此搜尋條件是利用 雙眼左右對稱及大小相稱的特性來做依據,接下來藉由眼睛位置來找尋代表嘴巴物件,擷取 後之物件位置參數 a~p,如圖 3.5 之標示,詳細物件位置參數定義請參考附錄 1。
經過濾後可得到眼睛、眉間與嘴巴之物件,使用邊緣偵測(Edge Detection)搜尋這些物件
的邊緣,針對這些特徵物件進行特徵點擷取。圖 3.6 為以邊緣偵測取得物件特徵之示意圖,
以嘴巴來說,我們擷取上下唇的端點與中心點,因其向量斜率可決定嘴型弧度;眼睛部份是 以特徵點計算長寬大小來決定眼睛的開合情形;眉間的紋路則可以表達眉頭的變化,根據此 三項資訊來記錄臉部的情緒。
a b
c
d
e
h f
g
(a)
i j
k l
(b)
m n
o p
(c) 圖 3.5 以連通法獨立物件 (a)左右眼(b)眉間距(c)嘴巴
Mup(1) Mup(N)
Mdown(1) Mdown(N)
Mup(1) Mup(N)
Mdown(1) Mdown(N) Mup( N/2 )
Mdown( N/2 )
(a) Eup
E down Eleft
Eright
(b)
g1
Gw
Gh
(c)
圖 3.6 物件邊緣偵測特徵點擷取 (a)嘴巴特徵(b)眼睛特徵(c)眉間特徵
影像辨識分類採用支援向量機(SVM, Support Vector Machine),由上述的特徵擷取方法,
取出每種表情的特徵向量,再以 SVM 作訓練辨識。SVM 是一種監督式學習(Supervised Learning)的分類法,其目的是在空間中找出一個邊限(Margin)最大之超平面(Hyperplane),使 不同類資料被分開。本研究之實驗選用的 SVM 核心為 Radial Basis Function(RBF),其範例 為−γ u−v2。由於 SVM 所算出的超平面並不一定是最佳超平面,又加上沒有特定的算法取 得最佳解,唯一能做的就是逐一調整下列 (3.3)式的 cost(c)與 RBF 的γ 值來微調至最佳解。
我們利用 libSVM 附的工具 grid.py 來進行測試,得到c=8.0, 0.0078125γ = 的時候為最佳解,
這也將是此後進行訓練時會使用的參數。
2
, 1
min ( , ) 1 2
n w i
i
w w c
ξ φ ξ ξ
=
= +
∑
(3.3)SVM大多是二分類的架構,但實際上在碰到的分類問題幾乎都是 N 分類,所以必須以多分 類的方法解決問題。目前大多數做法都是將多個二分類器結合在一起,此法被稱為結合法 (Combination Method),最常見的有兩種:一對一(One Against One)與一對多(One Against All)。
一對一多分類法為訓練時,以每兩種資料做一個二分類器,直至 N(N-1)/2種組合全部都 分類完成,在測試時,會將訓練模型與測試資料分別放入 N(N-1)/2個二分類器中做分類,其 最後輸出結果則以統計最高者為為預測結果;而在一對多的多分類法中,則是先挑選一種資 料給予其+1 的標籤,其他則全部給予-1 的標籤,直到 N 種組合全部分類完成為止,此方法 測試時會將測試資料放入 N 個二分類器分類,每一個分類器會給予測試資料一個相似值,最 後統計所有二分類器的相似值,以最相似的辨識作為輸出結果。
3.4音視訊融合方法
後級融合使用 FCMAC 來整合聲音影像訊號,此演算法不像一般以模糊理論為基礎的 控制器,該類神經模糊系統並不需要預先知道相關控制規則。它的學習方法乃藉由觀察系統 中輸出與輸入的關係。透過仔細地檢查小腦模型運算控制器(Cerebellar Model Articulation
Controller, CMAC)和模糊邏輯演算法的運算過程,我們將可輕易地發現這兩種方法在設計上
的明顯相似度,舉例來說,兩者在執行插值查表法時,都具有二分化與一般化的特性,此外,
CMAC的非線性映射亦可被視為模糊集合裡聚合操作中的一種子集合。
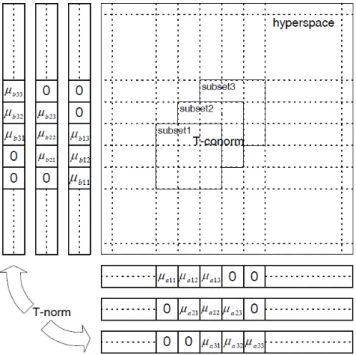
由於 CMAC 的標準單一變量基底函數是以二進制的方式來表示,以致於類神經網路的 建模只能是分段的常數。從直觀來看,以較高階的分段多項式搭配單變量基底函數可以產生 更為平滑的輸出[36, 37, 38]。也就是說,CMAC 所採用的明確集合(Crisp Set)可以被視為模糊 集合的特殊形式,因此能輕易判別任一輸入屬不屬於某個集合,這個特性就像是此狀態變數 x是否有激發 CMAC 感知層內的特定區域。將此一概念延伸,假定一歸屬函數 ( )µi x →[0,1], 將 x 代入 ( )µi x 所獲得值就是歸屬度。更廣泛的來說,在一般化參數 C=3 時,我們設計出的 三種不同歸屬函數將呈現接受域重疊的情形,相同的輸入將會被分派到相對應的 ( )µi x 空間 內以求得 x 於此區間的不同歸屬度,如圖 3.7 所示,在完成聚合操作後,在超空間(Hyperspace)
中將只有一個最大輸出存在。這些歸屬函數於刺激區塊的中心產生單一峰值,且相對應的輸 出也會隨著輸入往刺激區塊的邊緣移動而遞減。
舉例來說,狀態變數 x 靠近刺激區域左邊界時,數列µ13 >µ12 >µ11,µ23 >µ22 >µ21,
33 32 31
µ >µ >µ 會明顯地呈現相對關係。在極端的情況下,當每一個狀態變數 x 都落在其所對 應的刺激區塊中心時,超空間中就會在每一個 Subset 彼此的交會處產生一個模糊單點µi =1。
(a)
(b)
(c)
圖 3.7 當 C=3 時不同 Subsets 的輸入歸屬函數 (a) Subset1 (b) Subset2 (c) Subset3
圖 3.8 二維 FCMAC 之非線性映射
FCMAC的非線性映射的方法,則是將 CMAC 的 AND 與 OR 邏輯運算替換成更通用的
T-norm和 T-conorm 運算,圖 3.8 為最終 FCMAC 的非線性映射結果。在此,我們選用 T-norm 的代數積(Algebraic Product)與 T-conorm 的代數和(Algebraic Sum)做為此計畫的運算核心,因 這兩種運算方法可以使輸出數值更為連續,並易於做系統性的分析。
圖 3.9 二維 FCMAC 之非線性映射結果
4. 實驗模擬與結果
本章實現情緒辨識之音視訊系統,分別以不同模型偵測音頻和視頻訊號的情緒類別,將 其結果對應到 Arousal-Valence 平面,以分析各情緒相互間的關係,並融合兩訊號於音視訊系 統中,用以改善個別訊號單獨辨識的缺失,期能提升整體系統的辨識率。
4.1音頻訊號情緒偵測結果
在語音辨識中,大多使用 HMM 模型來描述語句的狀態,本研究透過 HTK 系統來訓練
辨識語音資料,並選用德文的情緒語音資料庫 Emo-DB 作為實驗測試語料庫,以其結果當作 參考資料,來比對我們自行錄製的五種情緒中文語音資料庫。本研究的情緒語音的辨識,首 先建立語音資料庫,標示每個音檔所屬情緒,透過 HTK 的內建函式,取出 MFCC 特徵係數。
將輸入的語音資料切分成訓練組與測試組,透過 HMM 分別對兩組資料作辨識,以產出訓練 測試之辨識資料,HTK 整體工作流程如圖 4.1 所示,並分別以三種不同訊號切割方式分類辨 識,以比較其差異與優缺點。
4.1.1 GMM分類辨識
在語音和語者辨識中,高斯混合模型 GMM (Gaussian Mixture Model)為最常使用的機率 分佈模型,在不考慮語音內容的情況下,將每個語句當成一種情緒,以 GMM 來訓練分類各 種語音的情緒,統計各種情緒相互間的機率分布,表一為使用 Emo-DB 語料庫的實驗結果,
而表二則是由自行錄製的中文語音資料庫以同樣的模型所得到的實驗結果。
表一 Emo-DB 語料庫之情緒語音 GMM 辨識混淆矩陣 Confusion Matrix
Fear Disgust Happiness Boredom Neutral Sadness Anger Accuracy(%)
Fear 30 5 0 1 5 3 7 58.8
Disgust 4 38 6 1 2 0 0 74.5
Happiness 2 4 30 0 0 0 15 58.8
Boredom 3 4 1 30 3 9 1 58.8
Neutral 3 1 0 13 33 1 0 64.7
Sadness 2 4 0 3 3 39 0 76.5
Anger 0 1 4 0 0 0 46 90.2
Overall Accuracy: 68.91%
圖 4.1 HTK 語音辨識流程方塊圖
表二 中文語音資料庫之情緒語音 GMM 辨識混淆矩陣 Confusion Matrix
Neutral Happiness Sadness Anger Surprise Accuracy(%)
Neutral 17 0 11 0 2 56.7
Happiness 0 26 0 3 1 86.7
Sadness 5 0 23 0 0 82.1
Anger 0 17 0 12 1 40
Surprise 4 6 0 3 17 56.7
Overall Accuracy: 64.19%
此混淆矩陣以橫向來看,分別為所輸入的情緒語音資料被判定為各情緒之情形,而最後
一欄為各種情緒資料的辨識率,其總辨識率(Overall Accuracy)為該輸入辨識資料數的整體辨 識率。由於兩種語料庫的表情呈現不相似,資料庫的大小也不一,其辨識率有些微的差距。
觀察 Arousal-Valence 平面上各情緒的分布,並將每種情緒的位置以 A-V 兩向量表示,對映 此表格的辨識結果,當某一情緒的其中一個向量與該辨識的情緒的差值較小時,如 Anger 與
Happiness的 Arousal 向量差值小,表示其特徵在該維度的相似度較高,因此易造成誤判。這
樣的辨識方法較為粗糙,辨識率並不高,下節我們將切割情緒語句,再以 HMM 模型辨識。
4.1.2切割情緒音節辨識
一般來說,一段語句中包含多個語字,在字和字間可能存在一小段的簡短停頓
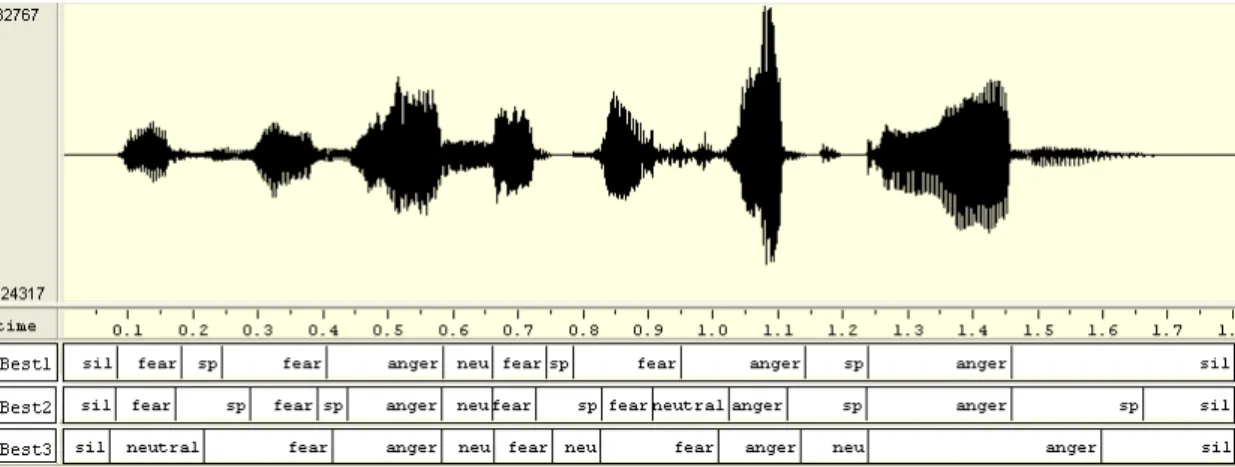
(Short-Pause, SP),為了取得更準確的情緒特徵,本節使用情緒音節(Emotion Syllable)的 HMM 模型辨識,將前一節所標示的各個情緒音節再進一步以語字標記情緒,也就是說一個音檔除 了標記前後的 Silence 之外,由音檔的波形圖上標記有聲(Voiced Sounds)的情緒,以及無聲的 簡短停頓(SP),標示如圖 4.2 所示,用此序列來擷取語音特徵,使得情緒特徵資料增廣了,
也增加了測試資料可參考辨識的資訊,最後使用 Viterbi Decoder 找出最可能的情緒音節序 列,而表三為 Emo-DB 語料庫之辨識結果,自製的中文語音資料庫辨識結果於表四所示。
由於此方法對音訊作音節的細切,辨識的結果可能產生音節刪除(Deletion) 、音節插入
(Insertion)、音節取代(Substitution) [34],故其辨識率定義為:
Accuracy N D S 100%
N
= − − × (4.1)
其中 N 為被辨識到的音節總數,D 為音節被刪除的總數,S 為音節被取代的總數。
表三 Emo-DB 語料庫經情緒標記後之分類混淆矩陣 Confusion Matrix
Fear Disgust Happiness Boredom Neutral Sadness Anger Accuracy(%)
Fear 14 0 0 0 1 1 2 77.8
Disgust 1 18 0 0 0 0 0 94.7
Happiness 0 0 15 0 0 0 3 83.3
Boredom 0 3 0 19 0 4 0 73.1
Neutral 1 1 0 1 14 0 0 82.4
Sadness 0 1 0 1 1 13 0 81.3
Anger 1 0 0 0 0 0 32 97
Overall Accuracy: 85.03%
表四 中文語音資料庫經情緒標記後之分類混淆矩陣 Confusion Matrix
Neutral Happiness Sadness Anger Surprise Accuracy(%)
Neutral 27 0 0 0 3 90
Happiness 0 21 0 1 8 70
Sadness 3 0 25 0 0 89.3
Anger 0 0 0 29 1 96
Surprise 2 6 0 1 21 70
Overall Accuracy: 83.11%
此結果中雖還有些誤判的情形,但其情況已大幅改善,由於語句區段被切割辨識,所以
特徵資料較明確,其辨識率也較粗糙的 GMM 模型高。同樣的,由於語料庫的資料量不同,
因此兩種資料庫的辨識情況略有落差。
圖 4.2 以 Emotion Syllable 切割的音檔
4.1.3 N-best Stack Decoder辨識
由上述有誤判的情形來看,可推測在每筆資料中,除了本身所標記的情緒特性之外,可
能還含有其他相似的情緒特徵,因此本節進一步改進前一節的方法,在辨識時使用 N-best
Stack Decoder,依照情緒特性,於音訊波形上手動標記每段有聲語句所屬的情緒,找出 N 個
最可能的情緒音節序列如圖 4.3,並將這些情緒音節對應 Arousal-Valence 平面,分別取出 A-V 二維向量,圖 4.4 為圖 4.3 中部分區段轉換為 A-V 向量之示意圖,而這些轉換後的向量則可 供後級的音視訊融合。
圖 4.3 N-best Stack Decoder 音訊切割示意圖
圖 4.4 N-best 音訊區段對應 Arousal-Valence 向量示意圖
4.2視頻訊號情緒偵測結果
本研究的情緒影像的辨識,首先以 Webcam 錄取五種情緒的影像資料,分別由 10 位同 學以 5 種情緒朗讀的影片當中擷取 10 張照片,用以訓練建立比對資料庫,圖 4.5 為資料庫中 10人的部分影像範例。情緒部分分別可得到 Neutral、Happiness、Anger、Sadness、Surprise 五種表情,透過連通法選取特徵物件後,再以邊緣偵測取出其相關特徵係數資料,並手動標 示出每個影像所屬情緒,接著透過 SVM 系統對影像資料來訓練辨識,以建立辨識資料庫,
待 SVM 訓練完畢後,藉由得到的模型對測試檔進行分類與預測,並計算出其識別率以作為 情緒影像偵測結果的判別,整體工作流程如圖 4.6 所示。
圖 4.5 資料庫影像範例
由圖 1.1 的情緒線索(Emotion Curves)二維 Arousal- Valence 空間平面圖中,得知中性情 緒 Neutral 落於平面之中心點,為突顯各情緒之特徵,我們以 Neutral 為基準參考情緒,在錄 得的影像資訊中,除了 Neutral 之外的另外四個情緒,取其各特徵的特徵值平均,分別與 Neutral之特徵做比較,如圖 4.7 所示,其中橫軸的α( ) ,i i=1, 2,..., 7代表嘴型特徵,由於人臉 的情緒表現大多以嘴型的變化來判定,可參照圖 2.1 之影像,在 4.7 圖中前段表示嘴型特徵 值相較於 Neutral 有較大的變化,而α( ) ,i i=8, 9,...,12表示眼睛部分特徵,因眼睛的變化幅度 較不明顯,以至於 Neutral 特徵與其他情緒特徵之相吻性相對較高。由此結果可推測,以這 些特徵點作為表情辨識的依據,極有可能帶來誤判的情形,本研究利用 SVM 學習機器對這 些向量作訓練分析,以取得影像資料對於各情緒的辨識率,統計各情緒相互判定的辨識情 形,將其結果及整體辨識率列於表五中。
圖 4.6 SVM 影像辨識流程方塊圖
表五 SVM 對視訊情緒特徵訓練分類混淆矩陣 Confusion Matrix
Accuracy(%) Neutral Happiness Sadness Anger Surprise
Neutral 73 4 23 0 0
Happiness 0 90 0 3 7
Sadness 11 2 84 3 0
Anger 0 4 2 89 5
Surprise 0 2 0 6 92 Overall Accuracy: 85.60%
圖 4.7 特徵值平均變化圖
表五分別表示輸入的情緒影像資料被判定為各情緒之情形,由於 Surprise 及 Anger 的情 緒表現較為誇張,此兩種情緒被判定為自身情緒的機率相對較高。將表五與圖 4.7 相對應,
圖 4.8(b) Neutral 與 Sadness 兩情緒特徵向量最相近,因此其誤判情形較其他情緒高,其餘特 徵向量差異較多的,誤判情形相對較少。由此實驗結果得知,以 SVM 對視頻訊號做辨識,
其準確率較佳。
4.3音視訊號融合分析
經過前段的聲音和影像的情緒判斷可分別得到兩組情緒分數,接著我們需要將兩組情緒
分數適當融合並產生更合理之系統最終情緒分數。由於 FCMAC (Fuzzy Cerebellar Model
Articulation Controller)具有快速的聯想記憶學習功能,在此我們使用其來學習音視訊在 A-V 平面上的相對規則,以此作為融合聲音和影像的核心。
我們自行錄製的影音檔,共有五種情緒,分別為 Neutral、Happiness、Anger、Sadness、
Surprise,由前兩小節的偵測結果,可得到聲音(Sound)與影像(Image)資訊,並各自計算取其
情緒 Arousal 與 Valence 量值,分別表示為 ( )A t , S A t , I( ) V t , S( ) V tI( ),並且取其時間軸上的 變化dA t , S( ) dA t , I( ) dV t , S( ) dV tI( ),將這 8 項資料輸入到 FCMAC 取得 5 項輸出Eneu( )t ,
hap( )
E t , Eang( )t , Esad( )t , Esur( )t ,其系統方塊如圖 4.8 所示。由於從影像取得的結果 ( )A tI I ,
I( )I
V t 與聲音取得的結果 ( )A tS S , V tS( )S ,其時間取樣間隔不同,若要融合兩種訊號,則需把 時間單位統一,而影像部分的取樣時間為 1/10 秒,聲音部分則為 1/100 秒,因此最直接的方 法為取每 10 筆聲音資料的平均,如圖 4.9 所示,將聲音的取樣時間調整成 1/10 秒。
圖 4.8 FCMAC 音視訊融合系統方塊圖
(a) (b)
圖 4.9 音視訊號時間單位同步 (a)聲音原始向量(b)資料平均
取得聲音與影像同步資料後,為了使其有時間軸上連續性關聯,各自計算出這些數值與
前一時間之差異,其計算如下:
( ) ( )
( ) S S
S
V t t V t
dV t t
+ ∆ −
= ∆ (4.2a)
( ) ( )
( ) S S
S
A t t A t
dA t t
+ ∆ −
= ∆ (4.2b)
( ) ( )
( ) I I
I
V t t V t
dV t t
+ ∆ −
= ∆ (4.2c)
( ) ( )
( ) I I
I
A t t A t
dA t t
+ ∆ −
= ∆ (4.2d)
產生 8 組輸入訊號之後,將資料輸入至 FCMAC 模組去做訓練,如圖 4.8 所示,此八維度輸 入訊號的每一維度都使用如圖 4.10 模型之歸屬函數,再利用 T-norm 運算得到 3 組於超平面 上的 Subset,將這三個 Subset 通過 T-conorm 運算後得到八維非線性函數 G。
1 -1 0
µ1
(a)
1 -1 0
µ2
(b)
1 -1 0
µ3
(c) 圖 4.10 歸屬函數模型 (a)左偏態(b)無偏態(c)右偏態
由於八維度不易表示,在此以二維結果表現其函數 G,相較於 CMAC,如圖 4.11 所示,
FCMAC將有較精細的變化。
0 10 20 30 40 50
0 10 20 30 40 50
0 0.2 0.4 0.6 0.8 1
Dimension 1 Dimension 2
Gij
圖 4.11 FCMAC 之單次觸發非線性函數
由於我們需要得到五種情緒輸出以產生情緒向量,因此需採用五種不同的權重函數Wneu, Whap, Wang, Wsad, Wsup,其輸出則為函數 G 與權重函數運算後之結果:
8 7 1
1, 2,..., 8 ( 1, 2,..., 8),
8 7 1
... , 1, 2,..., 5
m m m
j i i i i i i j
i i i
E =
∑∑ ∑
G ⊗W j = (4.3)其中 j=1,2,...,5 分別表示 5 種不同情緒 Neutral、Happiness、Anger、Sadness、Surprise,而⊗ 運算元代表每個元素於相對應的位置逐項相乘,m 為每一維度的劃分區間數。而權重函數Wj
的學習方程式為:
( 1, 2,..., 8), ( 1, 2,..., 8), i i i j( 1) i i i j( ) (Dj Ej) , 1, 2,..., 5
W t W t j
ρ N−
+ = + = (4.4)
其中ρ為學習率,其值介於 0 到 1 之間、N 為觸發區塊數,Dj為所預期之輸出結果。
( )t I( )t
S dV
A µ
µ ,..., Ti=µAS( )t,...,µdVI( )t
3 , 2 ,
=1
i G=
(
T1+T2−T1T2)
+T3−T3(
T1+T2−T1T2)
8 ,..., 2 ,
1i i
Gi
(i i i )j
W 1,2,...,8, Dj
5 ,..., 2 ,
=1 j
圖 4.12 八維 FCAMC 模型訓練方塊圖
最後我們以輸出誤差來觀察訓練成效,由圖 4.13 可觀察出 FCMAC 整體結果誤差趨於收斂,
訓練資料量越多則越準確。
0 1 2 3 4 5 6 7
-25 -20 -15 -10 -5 0 5 10 15 20 25
Training cycle
Error
圖 4.13 FCAMC 之訓練誤差
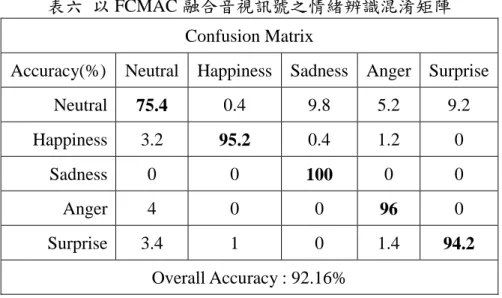
將每種情緒相對的 Arousal 與 Valence 量值輸入於 FCMAC 模組訓練測試,其辨識結果 於表六所示。此結果為訊號融合後每種情緒之辨識混淆矩陣,對映圖 1.1 之情緒二維
Arousal-Valence空間平面,所取的情緒種類多分布於上平面,而下平面只取 Sadness 一種情
緒,因此其誤判為其他情緒機會較小,另一方面,由於 Neutral 位於平面中心,會是每種情 緒均有機會被誤判的情況,故其辨識率較其他情緒來得小。
表六 以 FCMAC 融合音視訊號之情緒辨識混淆矩陣 Confusion Matrix
Accuracy(%) Neutral Happiness Sadness Anger Surprise
Neutral 75.4 0.4 9.8 5.2 9.2
Happiness 3.2 95.2 0.4 1.2 0
Sadness 0 0 100 0 0
Anger 4 0 0 96 0
Surprise 3.4 1 0 1.4 94.2
Overall Accuracy: 92.16%
圖 4.14 為音視訊號與兩種訊號融合系統的各種情緒辨識率統計圖,由此結果可見,音視訊號 經過融合,情緒特徵被參考的資訊增加了,其整體辨識率明顯提升。
5. 結論與未來展望
本研究利用音頻和視頻訊號的各種特徵擷取方法,剖析情緒在訊號上的特性,並以訓練 學習機在系統上建立各種情緒的特徵模型,以辨識訊號的情緒種類,並對應情緒線索二維平 面上的 Arousal 與 Valence 兩向度情緒空間,分析各種情緒相互間的關係。根據 4.3 節的實驗 結果,得知將音頻和視頻訊號融合於同一系統中,加上特徵參考變數的增加,將更準確地描 述各情緒的 Arousal 與 Valence 向度,降低了各情緒在兩向度上的模糊關係,以提升了系統 對於訊號的辨識度。而得到的訊號特徵皆以最通用簡潔的方式來取得,事實上,在過去的研 究中,不論是音頻或視頻訊號皆有相當多的特徵擷取方式,因此,應以更多種的方式來取得 更多元的情緒特徵,並對其加以訓練辨識,再比較分析現有的各情緒辨識結果,使整體系統 達到最佳化。
Accuracy
0%
20%
40%
60%
80%
100%
Neutral Happiness Sadness Anger Surprise
Sound Image Fusion
圖 4.14 音視訊號與融合訊號之辨識統計圖
雖然以目前結果來看,音視訊號融合系統的情緒辨識率較單一訊號高,但由於融合系統 需取音頻和視頻訊號個別的特徵來做分析運算,以至於 FCMAC 需以八維度的函數來計算,
對於融合系統來說,這樣的資料量相當龐大,於訓練階段需要長時間的計算,因此,未來的 研究可透過心理學或生理學的文獻探討,引入更精確的情緒模型來簡化這樣的運算模式,以 利更多資料帶入此系統時,能更有效率的得到最佳的結果。
6. 參考文獻
[1] J. Ruiz-del-Solar and P. Navarrete, "Eigenspace-based face recognition: a comparative study of different approaches," IEEE Systems, Man, and Cybernetics Society, vol. 35, no. 3, pp. 315-325, Aug. 2005.
[2] S. L. Phung, A. Bouzerdoum, and D. Chai, "A novel skin color model in YCbCr color space and its application to human face detection," International Conference on Image Processing, vol. 1, pp. I-289 - I-292, Oct 2002.
[3] H. Wu, Q. Chen, and M. Yachida, "Face detection from color images using a fuzzy pattern matching method," IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 21, no. 6, pp.
557-563, June 1999.
[4] Z. Hammal and A. Caplier, "Eyes and eyebrows parametric models for automatic segmentation," 6th IEEE Southwest Symposium on Image Analysis and Interpretation, pp.
138-141, Mar. 2004.
[5] J. B. Gómez-Mendoza, F. Prieto, and T. Redarce, "Automatic lip-contour extraction and mouth-structure segmentation in images," Computing in Science and Engineering, vol. 13, pp.
22-30, May-Jun. 2011.
[6] C. E. Osgood, J.G. Suci, and P. H. Tannenbaum, The Measurement of Meaning, The University of Illinois Press, Urbana, 1957.
[7] J. Pittermann, A. Pittermann, and W. Minker, Handling Emotions in Human-Computer Dialogues, Springer, Germany, Jan. 2010.
[8] A. Hanjalic and L. Q. Xu, "User-oriented affective video content analysis," IEEE Workshop on Content-Based Access of Image and Video Libraries, pp. 50-57, Dec. 2001.
[9] R. W. Picard, Affective Computing, Cambridge, MIT Press, 1997.
[10] M. Pantic and L. J. M. Rothkrantz, "Toward an affect-sensitive multimodal human-computer interaction," IEEE Proc., vol. 9, no. 9, pp. 1370-1390, Sep. 2003.
[11] Y. H. Yang, Y. C. Lin, Y. F. Su, and H. H. Chen, "A regression approach to music emotion recognition," IEEE Trans. on Audio, Speech and Language Processing, pp. 448-457, 2008.
[12] Y. H. Yang and H. H. Chen, "Ranking-based emotion recognition for music organization and retrieval," Trans. on Audio, Speech and Language Processing, vol. 19, no. 4, May 2011.
[13] E. H. Kim, K. H. Hyun, S. H. Kim, and Y. K. Kwak, "Improved emotion recognition with a novel speaker-independent feature," IEEE/ASME Trans. on Mechatronics, vol. 14, pp.
1083-4435, 2009
[14] A. W. Whitney, "A direct method of nonparametric measurement selection," IEEE Trans.
on Computers, vol. 20, no. 9, pp. 1100-1103, 1971.
[15] P. Pudil, F. J. Ferri, and J. Kittler, "Floating search methods for feature selection with nonmonotonic criterion functions," IEEE Trans. on Computer Vision and Image Processing, vol. 2, pp. 279-283, Oct. 1994.
[16] L. R. Rabiner, "A tutorial on hidden Markov models and selected applications in speech recognition," Proc. of the IEEE, vol. 77, pp. 257-286, Feb. 1989.
[17] J. S. Park, J. H. Kim, and Y. H. Oh, "Feature vector classification based speech emotion recognition for service robots," IEEE Trans. on Consumer Electronics, vol. 55, no. 3, pp.
1590-1596, Oct. 2009.
[18] P. Ekman, "Facial expression and emotion," American Psychologist, vol. 48, no. 4, pp.
384-392, Apr. 1993.
[19] M. Lyons and S. Akamatsu, "Coding facial expressions with Gabor wavelets," The Third IEEE International Conference on Automatic Face and Gesture Recognition, pp. 200-205, Apr. 1998.
[20] M. Soriano, S. Huovinen, B. Martinkauppi, and M. Laaksonen, "Using the skin locus to cope with changing illumination conditions in color-based face tracking," Proc. of IEEE Nordic Signal Processing Symposium, pp. 383-386, 2000.
[21] T. F. Cootes, G. J. Edwards, and C. J. Taylor, "Active appearance models," IEEE Trans.
Pattern Analysis and Machine Intelligence, vol. 23, no. 6, pp. 681-685, Jun. 2001.
[22] G. J. Edwards, C. J. Taylor, and T. F. Cootes, "Interpreting face images using active appearance models," Third IEEE International Conference on Automatic Face and Gesture Recognition, pp. 300-305, Apr. 1998.
[23] P. Ekman, "Facial expression and emotion," American Psychologist, vol. 48, no. 4, pp.
384-392, Apr. 1993.
[24] S. L. Zhang, Q. Tian, S. Q. Jiang, Q. M. Huang, and W. Gao, "Affective MTV analysis based on arousal and valence features," IEEE International Conference on Multimedia and Expo, pp. 1369-1372, Apr. 2008.
[25] J. Ou, X. B. Bai, Y. Pei, L. Ma, and W. Liu, "Automatic facial expression recognition using Gabor filter and expression analysis," Second International Conference on Computer Modeling and Simulation, pp. 215-218, Jan. 2010.
[26] C. Harris and M. Stephens, "A combined corner and edge detector," Alvey Vision Conference, vol. 15, pp. 147-151, 1988.
[27] E. Rosten and T. Drummond, "Machine learning for high-speed corner detection,"
European Conference on Computer Vision, vol. 1, pp. 430-443, May 2006.
[28] G. Eibl and K. P. Pfeiffer, "How to make adaboost.m1 work for weak base classifiers by changing only one line of the code," Europe Conference on Machine Learning, vol. 2430, pp.
72-83, 2002.
[29] G. Eibl and K. P. Pfeiffer, "Multiclass boosting for weak classifiers," The Journal of Machine Learning Research, vol. 6, pp. 189-210, Dec. 2005.
[30] C. J. C. Burges, "A tutorial on support vector machine for pattern recognition," Data Mining and Knowledge Discovery, vol. 2, no. 2, pp. 121-167, Jun. 1998.
[31] J. J. Hopfield, "Neural networks and physical systems with emergent collective computational abilities," Proc. of the National Academy of Sciences of the United States of America, vol. 79, pp. 2554-2558, Apr. 1982.
[32] Z. Zhihong, T. Jilin, B. M. Pianfetti, and T. S. Huang, "Audio-Visual affective expression recognition through multistream fused HMM," IEEE Trans. on Multimedia, vol. 10, no. 4, pp.
570-577, Jun. 2008.
[33] T. S. Huang, M. A. Hasegawa-Johnson, S. M. Chu, Z. Zhihong, and T. Hao, "Sensitive talking heads," IEEE Signal Processing Magazine, vol. 26, no. 4, pp. 67-72, Jul. 2009.
[34] M. Gales, T. Hain, D. Kershaw, X. Liu, G. Moore, J. Odell, D. Ollason, D. Povey, V.
Valtchev, and P. Wooland, The HTK Book, Cambridge University Engineering Department, Mar. 2009.
[35] C. C. Chang, C. W. Hsu, and C. J. Lin, "The analysis of decomposition methods for support vector machines," IEEE Trans. on Neural Networks, vol. 11, no. 4, pp. 1003-1008, Jul. 2000.
[36] C. C. Jou, "A fuzzy cerebellar model articulation controller," IEEE Int. Conf. on Fuzzy Systems, pp. 1171-1178, Mar. 1992.
[37] S. H. Lane, D. A. Handelman, and J. J. Gelfand, "Theory and development of higher-order CMAC Neural Networks," IEEE Control System, pp. 23-30, Apr. 1992.
[38] M. Brown and C. J. Harris, "A Perspective and critique of adaptive neurofuzzy systems used for modelling and control applications," Int. J. of Neural Systems, vol. 6, no. 2, pp.
197-220, 1995.
附錄 1. 物件位置參數定義
附錄 2. 已發表期刊論文與研討會論文
已投稿期刊論文 2 篇:
[1] C. S. Lin, "Adaptive spectrogram morphing for synthesizing multichannel recordings,"
submitted to Journal of the Acoustical Society of America.
[2] C. S. Lin and J. S. Wang, "Fast ensemble empirical mode decomposition for speech-like signal based on non-white noise addition," submitted to IEEE Signal Processing Letters.
研討會論文 4 篇:
[1] C. S. Lin, S. J. Hong, D. L. Shih, and Z. C. Cheng, "Instantaneously warping interval computation using low level intrinsic mode functions," IEEE International Conference on Granular Computing, pp. 393-398, Kaohsiung, Taiwan, Nov. 2011. (EI)
[3] C. S. Lin, J. S. Wang, and Z. C. Cheng, "Fast ensemble empirical mode decomposition for speech-like signal analysis using shaped noise addition," 4th International Conference on Interaction Sciences: IT, Human and Digital Content, pp. 112-117, Busan, Korea, Aug. 2011.
(EI)
[4] Z. C. Cheng, C. S. Lin, and Y. H. Chen, "PAT-tree based DTW for fast music retrieval," 23rd Symposium of Acoustical Society of the Republic of China, pp. 105-115, Taichung, Taiwan, Nov. 2010.
[5] C. S. Lin and Y. C. Chao, "Spatial audio analysis based on perceptually empirical mode decomposition," 40th AES Conference on Spatial Audio: Sense the Sound of Space, Tokyo, Japan, Oct. 2010.
左眼Y軸座標位置 左眼X軸大小(寬度) 左眼Y軸座標位置
左眼Y軸大小(高度) a
c b
d
左眼X軸座標位置 左眼X軸大小(寬度) 左眼Y軸座標位置
左眼Y軸大小(高度) e
h f g
嘴巴的X軸座大小 (寬度) 嘴巴的Y軸座標 嘴巴的X軸座標
嘴巴的Y軸座標大小(高度) m
o n
p 相對於雙眼,眉間的寬度
相對於雙眼,眉間的Y軸座標 相對於雙眼,眉間的X軸座標
相對於雙眼,眉間的高度 i
k j
l