以語法式的屬性導向歸納演算法挖掘企業在股價上漲期間的財務資料特徵之研究-以紡織纖維業與金融業為例
67
0
0
全文
(2) 中文摘要 投資人在選擇股票時最容易接觸到有關上市企業營運狀況的公開資料為財務報 表,因此財務報表內所刊載的內容成為投資人的參考標的,然而投資人對於財務報表 內的大量資料仍需要進一步整理與歸納(Induction)來做為決策的參考,因此資料歸納 的技術仍然被重視,其中屬性導向歸納法(Attribute Oriented Induction, AOI)為該技術 中重要且具有代表性的方法。在本研究中把財務報表上的資料依照其分類轉化為一種 集合導向格式的多質屬性資料(Multi-Value Attributes),而此種多質屬性資料在 AOI 上是無法處理,因此本研究將以能夠處理多質屬性的改良屬性導向歸納法(Modified Attribute Oriented Induction, MAOI)做為基礎,藉由修改 MAOI 演算法來破突 MAOI 演算上的使用限制,達成在相同產業不同企業間財務報資料上的整理與歸納的目的, 取得同為股價上漲的企業在財務報表上的相同特徵,而此方法在本研究中稱為語法式 的屬性導向歸納法(Syntax Attribute-Oriented-Induction Algorithm, SAOI),在後續的實 驗驗證中取 2009~2010 年紡織纖維業與金融業上市上櫃公司的股價與公開財務報表 資料,經 SAOI 演算法歸納後取得了下列的結果:紡織纖維業應優先觀察觀察經營能 力上的固定資產週轉率與總資產週轉率及獲利能力上的總資產報酬率和每股盈餘,觀 察這四項財務績效指標表現和同業之間的比較結果,而金融業則是優先觀察經營能力 上的固定資產週轉率與總資產週轉率以及獲利能力上的純益率、總資產報酬率、股東 權益報酬率和每股盈餘。. 關鍵字:屬性導向歸納法、多值屬性、語法式演算法、財務績效指標、特徵. I.
(3) Abstract The financial statement is the most public financial information for the investors. However, investors still need to arrange and summarize the massive data in the financial statement in order to use it as reference for decision making, hence, data induction technique is thus highly valued, and among them, Attributed Oriented Induction (AOI) method is one of the important and representative methods. In this research, the data in the financial statement is, according to its classification, transformed into multi attributes of set oriented format, however, such multi attributes cannot be processed in AOI, hence, in this study, improved AOI induction method that can process multi attributes data is going to be used as basis, then through the modification of Modified Attribute Oriented Induction (MAOI) algorithm, the utilization limitation of MAOI algorithm is then broken through, and the summarization and induction objective of financial statement among different enterprises in the same industry can then be achieved, that is, the same f pattern in the financial statement for the enterprises with same stock price rising trend can then be obtained, and this method, in this study, it then called syntax type attribute oriented induction. In the subsequent experimental verification, we have used, in the period of 2009~2010, the stock price and announced financial statement data for enterprises with stocks listed in regular stock market and OTC (over-the-counter) stock market in the textile industry and financial industry, then through the induction of SAOI algorithm, we can obtain the following results: For the textile industry, the fixed asset turnover and total asset turnover in the business operation efficiency as well as return on total asset and earning per share in the profit ability should be observed first. In other words, the performance of these four financial performance indexes should be observed first and compared to the competitors in the same industry. However, for the financial industry, the fixed asset turnover and total asset turnover in the business operation efficiency as well as the profit margin, return on total asset, return of equity and earning per share in the profit ability should be observed first. Keyword: Attribute oriented induction, Multi-value attributes, Syntax algorithm, Financial Indicators, Pattern.. II.
(4) 誌謝 這篇論文的完成,首先要感謝父母的支持與體諒,才能在大學畢業四年後再回學 校繼續進修。感謝恩師 葉員吟教授的指導與包含,讓學生能夠選擇自己較有興趣的 領域與方法來進行,感謝老師無論是在研究或生活上的支持,讓學生能夠一步步的完 成論文,使得學生能夠在研究中明白自己的未來方向。感謝許秉瑜秘書長、黃書猛主 任、謝志明主任、鍾震耀老師以及陳岳陽教授在研究上的指點,讓學生能夠順利的突 破研究上的瓶頸,感謝審閱論文的歐陽彥晶老師與簡世文老師,感謝口試那天特地撥 空前來王信智老師,有了你們的審閱與意見才讓學生明白這篇論文不足之處。 以及感謝企電所的同學們,因為不單寫在這裡的文字才是論文,大家一起生活兩 年間的一切點點滴滴都是這篇論文的一部份,無論少了那一部份這篇論文都不再完 整。感謝徐師姐,您在我迷失時指引了方向;感謝小緋,我才能夠緊追著妳的腳步前 進;感謝傳勝學長,讓我在您那邊住了一個月才能完成研習;感謝這兩年來所有遇見 的每一個人,有了你們才有這美好的每一天,謝謝!!. 林建欣謹誌 國立屏東商業技術學院 企業電子化研究所 中華民國 100年 7月. III.
(5) 目錄 中文摘要 ...........................................................................................................................I Abstract............................................................................................................................ II 誌謝 ................................................................................................................................ III 目錄 ................................................................................................................................ IV 圖目錄 ............................................................................................................................ VI 表目錄 ...........................................................................................................................VII 1. 簡介 .......................................................................................................................... 1 1.1 研究背景與動機............................................................................................ 1 1.2 研究目的 ....................................................................................................... 4 1.3 論文架構 ....................................................................................................... 4 2. 文獻探討................................................................................................................... 5 2.1 資料探勘與演繹法、統計方法的差異 ......................................................... 5 2.2 資料探勘 ....................................................................................................... 6 2.3 AOI 演算法 ................................................................................................... 8 2.4 改良屬向導向歸納法 .................................................................................. 16 2.5 財務績效指標相關文獻探討 ...................................................................... 20 3. 語法式屬性導向歸納法.......................................................................................... 24 3.1 多值屬性資料的前置處理 .......................................................................... 24 3.1.1 計算門檻值與二進制值轉換 ........................................................... 24 3.1.2 二進制值次數累加與排序............................................................... 27 3.2 資料轉換後的化簡歸納 .............................................................................. 27 3.2.1 候選值的產生 .................................................................................. 27 3.2.2 化簡組合的支持個數定義............................................................... 27 3.2.3 化簡組合的挑選 .............................................................................. 28 3.2.4 候選值中化簡變數數量的調整 ....................................................... 28 3.2.5 SAOI 演算的停止條件 .................................................................... 29 4. 實作驗證................................................................................................................. 30 4.1 資料收集 ..................................................................................................... 30 4.2 資料前置處理.............................................................................................. 33 4.3 二進制值的加總與排序 .............................................................................. 38 4.4 資料轉換後的化簡歸納 .............................................................................. 41 5. 歸納結果與規則解讀 ............................................................................................. 45 5.1 紡織纖維業的歸納規則解讀 ...................................................................... 48 5.2 金融業的歸納規則解讀 .............................................................................. 49 6.. 結論與建議............................................................................................................. 50. IV.
(6) 研究結論 ..................................................................................................... 50 6.1.1 經營能力的特徵分析 ...................................................................... 50 6.1.2 獲利能力的特徵分析 ...................................................................... 52 6.2 研究貢獻 ..................................................................................................... 54 6.3 管理意涵 ..................................................................................................... 54 6.4 研究限制 ..................................................................................................... 55 6.5 建議 ............................................................................................................. 55 參考文獻 ........................................................................................................................ 56 中文文獻................................................................................................................. 56 英文文獻................................................................................................................. 56 參考網站................................................................................................................. 59 6.1. V.
(7) 圖目錄 圖 2-1、資料探勘演算過程 .......................................................................................... 8 圖 2-2、屬性 Status 的概念階層 ................................................................................. 10 圖 2-3、屬性 Status 的概念樹..................................................................................... 10 圖 2-4、屬性 Major 的概念階層 ................................................................................. 11 圖 2-5、屬性 Major 的概念樹..................................................................................... 11 圖 2-6、屬性 Birth Place 的概念階層 ......................................................................... 12 圖 2-7、屬性 Brith Place 的概念樹 ............................................................................. 12 圖 2-8、屬性 GPA 的概念階層 ................................................................................... 13 圖 2-9、屬性 GPA 的概念樹....................................................................................... 13 圖 2-10、卡諾圖.......................................................................................................... 17 圖 2-11、傳統卡諾圖與 MAOI 化簡方式的比較圖 ................................................... 20 圖 3-1、SAOI 演算流程 .............................................................................................. 24 圖 4-1、研究架構........................................................................................................ 30 圖 4-2、2009/1~2010/12 大盤走勢圖.......................................................................... 31 圖 4-3、紡織纖維業原始資料(部份) .......................................................................... 32 圖 4-4、金融業原始資料(部份) .................................................................................. 32 圖 4-5、紡織纖維業原始資料轉換為二進制值(部份) ............................................... 39 圖 4-6、金融業原始資料轉換為二進制值(部份) ....................................................... 39 圖 4-7、紡織纖維業以化簡後的二進制值取代原本的二進制值(部份資料)............. 44 圖 4-8、金融業以化簡後的二進制值取代原本的二進制值(部份資料) .................... 44 圖 6-1、經營能力屬性中單一指標表現較好的資料數量所占資料總量的百分比.... 51 圖 6-2、在經營能力上擁有表現較好的指標數量的資料所占資料總量的百分比.... 52 圖 6-3、獲利能力屬性中單一指標表現較好的資料數量所占資料總量的百分比.... 53 圖 6-4、在獲利能力上擁有表現較好的指標數量的資料所占資料總量的百分比.... 53. VI.
(8) 表目錄 表 2-1、加拿大某大學的學生資料表中歸納前的部份原始資料................................. 9 表 2-2、爬升完成的學生資料表部份內容 ................................................................. 14 表 2-3、累加完成的學生資料表................................................................................. 14 表 2-4、合併完成的學生資料表................................................................................. 15 表 2-5、某一區域中各年齡層人口分佈 ..................................................................... 18 表 2-6、某一區域裡各類別年齡的人口集合數量...................................................... 18 表 2-7、經轉換後的年齡資料..................................................................................... 18 表 2-8、年齡的二進制值與累計次數 ......................................................................... 19 表 2-9、本研究所使用的財務績效指標名稱與定義 .................................................. 23 表 3-1、紡織業某十五家上市公司在某一季的財務績效指標資料表 ....................... 25 表 3-2、轉換成二進制值的財務績效指標資料表...................................................... 26 表 3-3、排序完成財務績效指標資料表 ..................................................................... 27 表 3-4、加入 x00x 之後的歸納資料表 ....................................................................... 28 表 3-5、移動 x00x 化簡組合之後的財務績效指標資料表 ........................................ 28 表 3-6、加入 111x 與 010x 後的歸納資料表.............................................................. 29 表 3-7、移動 111x、010x 化簡組合之後的財務績效指標資料表 ............................. 29 表 3-8、歸納資料表 .................................................................................................... 29 表 4-1、財務績效指標資料表欄位與資料來源.......................................................... 31 表 4-2、紡織纖維業財務指標相關統計敘述 ............................................................. 33 表 4-3、金融業財務指標相關統計敘述 ..................................................................... 35 表 4-4、紡織纖維業經營能力財務績效指標轉換成二進制值並排序完成 ............... 40 表 4-5、紡織纖維業獲利能力財務績效指標轉換成二進制值並排序完成 ............... 40 表 4-6、金融業經營能力財務績效指標轉換成二進制值並排序完成 ....................... 41 表 4-7、金融業獲利能力財務績效指標轉換成二進制值並排序完成 ....................... 41 表 4-8、紡織纖維業在經營能力上的歸納結果.......................................................... 42 表 4-9、紡織纖維業在獲利能力上的歸納結果.......................................................... 42 表 4-10、金融業在經營能力上的歸納結果 ............................................................... 43 表 4-11、金融業在獲利能力上的歸納結果................................................................ 43 表 5-1、紡織纖維業經化簡歸納後所得到的規則...................................................... 46 表 5-2、金融業經化簡歸納後所得到的規則 ............................................................. 47. VII.
(9) 1. 簡介 1.1 研究背景與動機 財務績效指標是投資者最容易從各個管道去收集到有關企業體質的公開資訊,投 資者在選擇其投資標的時,往往會先從企業的財務報表中去分析得到各項績效指標的 相關資訊,更可以從財務方面有關的績效指標來了解企業目前的營運狀況,過去的研 究多以時間序列(Time Series Prediction)或迴歸分析(Regression Analysis)的方式來預 測財務績效指標的走勢,然而能夠從財務報表上得到的資訊量是非常豐富的,使用者 在進行分析時往往會依照各自的專業知識來挑選應納入考量的財務績效指標(Pinches et al. ,1973;Henderson and Kaplan,2000;吳道凱,2000;Jaap et al. ,2003),而學者 Rappaport(1986)在其研究中提出企業在財務績效指標表現良好不代表股東的價值也 會跟著提升,也不能因此判定財務績效表現良好的企業就是值得投資的企業,因此使 用者在做出挑選投資標的決策時,要如何從眾多的財務績效指標中找出需要特別留意 的指標與指標的表現好壞以及如何從眾多指標裡決定觀察順序成了相當困難的問題。 這種要從大量的資訊中找出決策的參考依據的情境逐漸發生在各個領域,起因於 隨著資訊科技的發展,各式各樣的電磁資料在不同屬性的資訊系統中被快速的累積, 例如 POS 系統中的交易紀錄、CRM 系統中的消費者行為研究、ERP 系統中的企業營 運資料,系統運作過程中所產生的大量資料內容以電磁紀錄的形態進行累積與永久保 存。然而,傳統的資料分析技術能否有效率的分析數量日漸龐大的資料庫亦引起注 意。在傳統的資料分析技術無法維持以往的高效率來處理龐大資料數量的困境下,而 實務上又有分析大量資料的急迫需求,在這個情況之下帶動了資料探勘(Data Mining) 技術的興起,藉由其優異的資料過慮、演算、分析、歸納的技術,可自龐大的資料庫 中粹取出有趣且無法直接察覺的內隱知識,使得資料探勘成為資料庫領域上新的應 用,資料探勘技術更成為新興的研究領域(Koperski et al. 1996)。因此使用資料探勘的 技術與概念可以挖掘出眾多的財務績效指標中應特別關注某些財務績效指標的表現。 使用資料探勘技術所挖掘出來的結果會與使用因素分析法、時間列序或迴歸分析 技術所得到的結果產生根本上的差異,造成差異的原因在於因素分析法、時間序列或 迴歸分析技術是以演繹法為基礎,透過證明或反證假說的方式來詮譯資料中所含的意. 1.
(10) 義,而資料探勘則是透過歸納的方式從資料中挖掘出內隱知識來形成假說(Mennis and Liu, 2003)。在過去的研究中多以因素分析法、時間序列或迴歸分析搭配財務績效指 標所提供的數據來進行預測,而在資料探勘中也可依照使用不同的探勘技術把挖掘的 結果區分為預測型(Predictive)與描述型(Descriptive)兩種,預測型的內容著重在以決策 樹與非決策樹的分類法進行分類、預測(Han and Kamber,2000;Berry and Linoff,1997), 前者以決策樹為基礎的分類法有 ID3、PRISM、Gini Index,而後者以非決策樹為基礎 方分類法有屬性導向歸納法、貝氏分類法、記憶基礎推論法、類神經網路分類法。描 述型的資料探勘著重在對己發生的事實進行描述、了解、說明、內隱知識發掘 (Berry,1997),因此在本研究中將以資料探勘的技術從歷史資料中挖掘出股價呈現漲 勢的企業在財務績效指標上的特徵,然而過去的研究多以針對一個或多數的幾項財務 績效指標做為研究對象,研究結果也是以某項財務績效指標在數據變化或指標之間的 某種關係變化來做為投資決策參考的依據,缺乏從各個學者在其研究中所提出應關注 的眾多財務績效指標中去發掘出一般化的財務特徵以應用於決策的方法。 因此本研究將以如何從各個學者在其研究中所提出應關注的眾多財務績效指標 中歸納出應優先關注的指標及指標的特徵為何為做研究目的,為此本研究將採用屬性 導向歸納法(Attribute-Oriented Induction, AOI)做為主體,取其用於分類、歸納的概念 做為研究方法,AOI 是資料歸納學習領域中俱有重要代表性的方法(Cai et al., 1990; Han et al., 1992; Han et al., 1993; Chen et al., 1996; Han and Kamber, 2001),AOI 將複雜 的大量事實案例去經由概括(Summarize)、推理(Inference)的方式去尋找出資料內一般 性原則(Principles)或特徵法則(Characteristic Rule),藉此由此探勘結果來做為決策時的 參考資料的依據。在歸納演算之前必須透過領域專家(Specialist)或學者(Researcher)先 整理出具有概念階層(Concept Hierarchies)的概念樹(Concept Tree)來協助屬性資料的 歸納,此為 AOI 處理資料的特色,而此特色也成為 AOI 發展的瓶頸,造成瓶頸的主 要原因有以下兩點,分述如下,第一,在定義概念階層的過程中必須有專家學者的人 為介入,但在許多情境之下,目標屬性之間沒有一個很明顯的概念階層時,使用者只 能依照自身的背景知識來對大量的資料表格內的資料進行運算,若由多個不同背景的 使用者來對相同的資料庫進行歸納演算會使得各個不同使用者的歸納結果有所出 入。第二,概念階層在處理屬性資料時,傳統 AOI 的屬性資料格式只能容許單值屬 性(Single Value)的資料,而現實中有許多資料是以集合導向的多質屬性(Multi-Values). 2.
(11) 的格式存在,例如人口普查資料(Census Data)、地理資料(Geographic Data)或者是帶 有環境建築物的空間資料(Spatial Data),而在本研究中所使用到的財務績效指標亦可 視為一種多質屬性的資料,這類多質屬性的資料在傳統 AOI 中皆無法處理,使得 AOI 在使用上產生了限制。雖然有學者(Roy & Mumey,2010)提出了修改概念階層的方式, 使其修改後的 AOI 方法在一定的程度上能夠處理多值屬性的問題,但此種仍須要專 家學者的人為介入方式,仍然存在著不同的專家學者就有不同的歸納結論的問題。 為解決前述的兩項問題,在學者(黃書猛等人,2010;Huang et al. ,2010)研究中提 出以修改後的卡諾圖理論(Modified Karnaugh Map)為基礎的創新演算方法,稱為改良 屬性導向歸納演算法(Modified Attribute Oriented Induction, MAOI),也稱為類卡諾圖 演算法,在 MAOI 的方法中不需要定義概念階層的程序即可直接進行屬性資料歸納, 也因為不需要再借助於概念階層,使得歸納結果少了人為介入干擾的不穩定性。同時 MAOI 也具有處理多值屬性資料的功能,使得前述的多值屬性資料都能透過 MAOI 方法去歸納化簡來挖掘出資料中的廣義特徵,此外 MAOI 是以一種接近人類直接思 考的圖示(Graphic Representation)化簡方式,是屬於語意(Semantic)層次的方法,但根 據本研究整理發現到 MAOI 用圖示方式進行化簡歸納時會有存在兩個很大的缺陷, 其一,在類卡諾圖中一個多質屬性欄位最多僅能顯示並離散化(Discretization)成六個 變數,因此限制了類卡諾圖能夠處理的變數數量,如果需要化簡七個以上的變數時, 類卡諾圖便不太適用。其二,在類卡諾圖的前置處理中,有一步驟為原始的多質屬性 資料轉換為二進制值(Binary),而此種轉換方式會受到原始資料的特色來影響決定能 否轉換,當原始資料的特色不適合使用類卡諾圖的轉換方式,該屬性下所含的資料只 能直接捨棄無法納入化簡歸納;這兩個缺陷嚴重限制了 MAOI 能夠有效應用的範圍。 因此,本研究在 MAOI 化簡原理上提出一個不需要使用類卡諾圖的化簡方式,希望 能夠突破圖示上變數數量的限制缺點,且適用於任意數量變數的歸納方法,本研究稱 此種不需要借助使用類卡諾圖化簡歸納方法為語法式的屬性導向歸納演算法(Syntax Attribute Oriented Induction, SAOI)(黃書猛等人,2011),在後續將以 SAOI 演算來達到 自財務績效指標中化簡並挑選出應優先關注指標的研究目的。. 3.
(12) 1.2 研究目的 1.. 使用化簡歸納的方式從選定的產業中找特定企業在財務績效指標上的共通特徵 做為決策的參考。. 2.. 修改 MAOI 演算法的化簡方式使其突破限有的最大六個變數的限制,讓使用者能 夠依照需求去離散化成更多的變數。. 3.. 針對多質屬性資料的特色設計新的轉換方法,讓目前己知不適合使用 MAOI 演算 法進行二進制值轉換的多質屬性資料亦能轉換成二進制值。. 1.3 論文架構 本論文內容共分為五個章節:第一章為緒論,包含研究背景與動機、研究目的、 研究限制以及論文的架構,第二章為文獻探討,分別是資料探勘、屬性導向歸納法、 改良屬性導向歸納法,第三章為語法式屬性導向歸納,包含演算流程、多質屬性資料 前置處理、資料轉換後的化簡歸納,第四章為實作驗證,透過真實的 281 筆上市公司 屬於財務績效指標的資料來進行演算,第五章為研究結果,用以解讀化簡歸納後的特 徵。第六章則是結論。. 4.
(13) 2. 文獻探討 2.1 資料探勘與演繹法、統計方法的差異 資料探勘的起源是來自於對大量資料分析的需求,特別是傳統的紙張作業被硬 碟、鍵盤與滑鼠所取代之後,以往的人工作業亦被大量的資訊系統所取代,而資訊系 統上線運作對於資料的收集更加容易,任何經由資訊系統處理的資料都可以數位化的 格式收集到資料庫之內,資訊系統就成了自動化的收集工具,所收集到的資料數量只 能以爆炸性成長來形容。資料探勘與傳統的演繹法(Deductive)、統計方法(Statistics) 不同的地方在於資料探勘是「從資料中挖掘出資料之間關係不明確但有意義且前所未 知的資訊」(Frawley et al., 1991),當資料庫內的資料數量與種類大幅增加時,相較於 專為處理大量資料而生的資料探勘技術,演繹法與統計方法在資料分析的效率上都面 臨了挑戰(盧洲城,2002)。 演繹法是以亞里斯多德(Aristotle)三段論為基礎,「可從已知的事實作為大、小 前提,去推理出”必然的”結論」,而後經由笛卡爾(Descartes)依據唯物論(Materialism) 加以修整定義,認為演繹法的前提是一般性知識和結論的個別性知識之間必然有種聯 繫存在,結論就隱藏在前提之中,結論是否正確則是取決作為前提的一般性知識能否 正確客觀的反映事物的本質,而前提與結論之間能否正確的反映出某種聯繫,若以上 的假設皆為正確,則能產生正確可靠的結論。由此可以知演繹法的推理過程與資料探 勘的探勘過程有著本質上的差異,演繹法是由證明或反證明的方式來判斷資料之間的 關係假設是否成立(Mennis and Liu, 2003),而資料探勘是透過整理、歸納的方式從資 料中找出隱藏的關聯來產生假設進而提升成為知識。 同時也有學者認為資料探勘是從己存在的事實中去挖掘出專家未知的新事實 (Grupe & Owrang,1995),此種由已知的資料去推理出未知事實的過程與統計方法的先 建立假設再由資料去驗證假設是否成立的過程正好相反。統計方法的前提亦是假設在 某種已知的統計分佈與資料之間是彼此分開、獨立的,必須透過驗證的方式才能證明 假設的關係是真的存在,若目前所假設的關係在驗證下並不成立,則需要重新建立一 個新的假設來重新驗證,而此種前提便是建立在忽略了資料之間會有某種難以想像的 關聯或是依存性存在,以 Wal-Mart 超市從銷售資料中挖掘出來的隱含知識為例,每. 5.
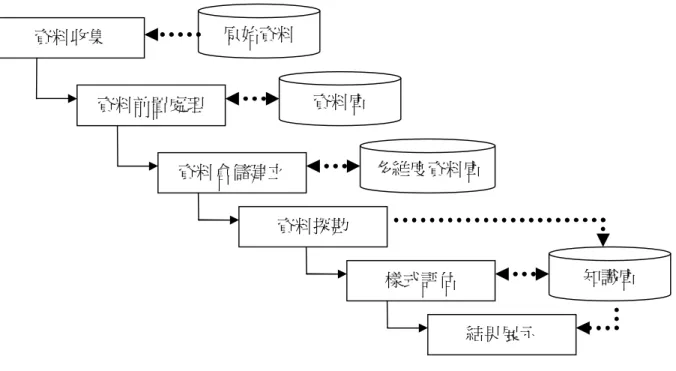
(14) 到星期四尿布與啤酒經常一起被購買,但尿布與啤酒之間的關聯在此知識被發掘之前 則是較難聯想在一起,也因此依賴專家知識所提出的假設並不會去考慮到此種表面上 沒有任何直接關聯的關係。. 2.2 資料探勘 依據學者 Berry & Linoff(1997)的定義,資料探勘技術應依照使用者的需求將資料 進行分析與應用,會因不同的需求而挖掘出不同的特徵(Pattern)與模式(Model),因此 可依照欲解決的問題將資料勘技術分為六大類,分別如下 一、分類 (Classification) : 挖掘出已知的規則和屬性來將現有的資料進行分類 (Class),歸納出較能解釋資料的一個模式,當有新的資料加入能便能利用這個 模式來進行預測新的資料應指派到那一個分類。 二、推估(Estimation):利用現有的連續性數值資料及其相關屬性資料,來推估出連 續性的變數或是屬性資料。 三、預測(Prediction):根據特定目標在過去的行為或歷史資料變化的情形,來建立 一個新的特徵或模式,使得新輸入的資料便可依照特徵或模式來預測未來的數 值變化或行為趨勢。 四、關聯法則(Association Rule):主要的挖掘目標是龐大的資料庫中,項目(Item) 與項目之間的關聯,即是會同時發生的狀況,但此種關聯通常不會是一般知識 所能夠推理出來的關係,而是一種被隱藏在項目的特徵或屬性之下的關係。 五、分群(Clustering):依照項目之間的相似性與差異性,將項目分成一定數量的群 體,使其逹成群體之間的差異最大化、群體內的項目差異最小化。 六、時間序列(Time Sequential):目的在於了解時間與和各個事件發生的關聯性, 可分為順序型與週期型兩種,順序型旨在了解事件發生在時間上的先後狀況, 週期型旨在了解時間區段內所發生的事件,在其他相同的時間區段上仍否會發 生或有何差異。 學者 Fayyad 等人(1996)認為資料探勘是「使用某些電腦演算的技術,在可接受的 演算效率下,發掘出隱藏在資料中的特定知識」,因此資料探勘的應在有限的步驟中 去完成知識挖掘,學者(Fayyad et al., 1996;曾憲雄等人,2008)將知識挖掘的過程分為 六個步驟:. 6.
(15) 一、資料收集:資料的來源可以是資訊系統的資料庫、Excel 的表格、文字檔案等 等,將所有要使用在資料探勘上的原始資料統一納入資料庫中。 二、資料前置處理:此階段的主要工作為資料的淨化、補缺與格式轉換。淨化的目 的在於原始資料收集過程中可能會納入許多異常的數據,例如人口資料中關於 人的年齡錯誤輸入到 150 歲,此類被稱為雜訊(Noise)應設法去除;補缺的目的 為資料收集過程中,某些欄位會因疏失而沒有呈現空值(Null)的狀態,此種狀 況發生時應依照資料的性質與專家的意見進行補缺;格式轉換則是相同類型的 資料從不同來源的資料庫中取得時,會有不同格式的狀況發生,此時便要進行 異質資料的整合,其他格式統一。 三、資料倉儲建立:將前置處理完成的資料建立成資料倉儲。依照 Fayyad 的定義, 建立資料倉儲並非知識挖掘過程中必要的環節,使用者只需要把資料根據欲分 析的問題和使用的演算方法,由原始形態轉換成可分析的形式即可,但也有學 者認為資料倉儲本身所提供的統計及分析的功能對使用者來說可以很方便的 找到有用的統計資訊,而資料倉儲所提供的資料萃取能力更可以簡化資料探勘 的過程。 四、資料探勘:使用能夠挖掘出隱含知識的資料探勘演算法去挖掘出資料中所隱 藏、未知的知識。 五、樣式評估:資料探勘所挖掘出的知識不一定都符合使用者的需求,需要再經過 一個樣式評估的動作,用以評斷挖掘出來的知識是否真的有用,特別是這個知 識是否是未知的。 六、結果展示:通常挖掘出來的結果是相當複雜的,需要透過知識工作者與適當的 呈現介面來幫助使用者迅速了解到他所發掘出來的知識有何意涵,讓使用者可 以把知識加以運用到決策。. 7.
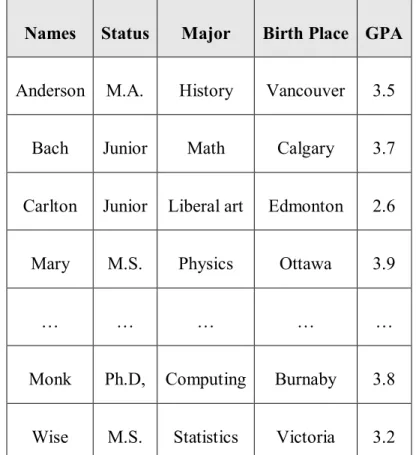
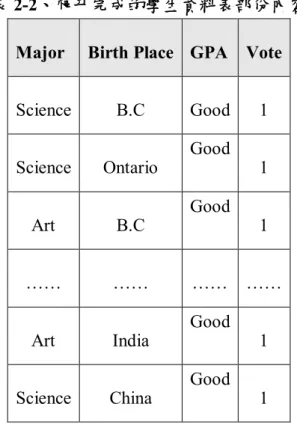
(16) 原始資料. 資料收集. 資料庫. 資料前置處理. 多維度資料庫. 資料倉儲建立 資料探勘. 知識庫. 樣式評估 結果展示 圖 2-1、資料探勘演算過程 資料來源:曾憲雄等(2005),資料探勘 Data Mining. 2.3 AOI 演算法 屬性導向歸納法(AOI)在 1990 年由 Cai, Cercone & Han 所提出,化簡的過程分成 兩個主要的環節「概念樹的建立」以及「概念階層的爬升」,其核心的精神為「屬性 移除(Attribute Removal)」和「屬性抽象化」(Han, 2001)。 屬性移除的主要目的為將 資料之間相異過大、無法以更高概念層級取代的資料欄位進行移除,例如學生資料中 的姓名,同時將意義重覆的欄位進行移除,例如學生資料中同時存在著出生年月日及 年紀兩個欄位,而年紀可由出生年月日來推算,故年紀欄位便可移除。而接下來將使 用加拿大某大學的學生資料為例,如表 2-1 所示,來說明資料表與概念樹、概念階層 之間的關係,並以此資料表來示範屬性導向歸納法的演算七個步驟中,各個步驟所應 完成的內容。. 8.
(17) 表 2-1、加拿大某大學的學生資料表中歸納前的部份原始資料 Names. Status. Major. Birth Place GPA. Anderson. M.A.. History. Vancouver. 3.5. Bach. Junior. Math. Calgary. 3.7. Carlton. Junior. Liberal art. Edmonton. 2.6. Mary. M.S.. Physics. Ottawa. 3.9. …. …. …. …. …. Monk. Ph.D,. Computing. Burnaby. 3.8. Wise. M.S.. Statistics. Victoria. 3.2. 資料來源:Attribute-Oriented Induction in Relational Database, Y. Cai, N. Cercone, and J. Han, 1991, Knowledge Discovery in Databases ,Ch 12, AAAI/MIT Press. 一、屬性移除:在檢視過資料表的內容後,便可確定屬性 Names 的屬性值有太多 不同的內容,同時也沒有較高的概念階層可以表示它,因此在歸納過程中屬性 Names 是需要被移除,餘下的屬性 Status、Major、Birth Place、GPA 便可依照 專家的意見與建議來建立概念層級,並依照概念層級來畫出概念樹以方便理解 層級與層級之間的關係。 在屬性 Status 的概念階層(圖 2-2)裡,概念階層的最頂端為 ANY,意指底 下包含所有的屬性階層與屬性值,第二層為 Graduate 與 Undergraduate 兩個屬 性值,代表將學生資料依照其特徵分為 Graduate 與 Undergraduate 兩類,第三 層則是說明第二層底的各個屬性值分別是由第三層的哪些屬性值所集合構 成。第二層的 Graduate 底下包含了第三層的 M.S.、M.A.、Ph.D.等三個屬性值, 而同為第二層的 Undergraduate 底下包含第三層的 freshman、sophomore、 junior、senior 等四個屬性值,若將屬性 Status 的概念階層以樹狀圖來表示則可. 9.
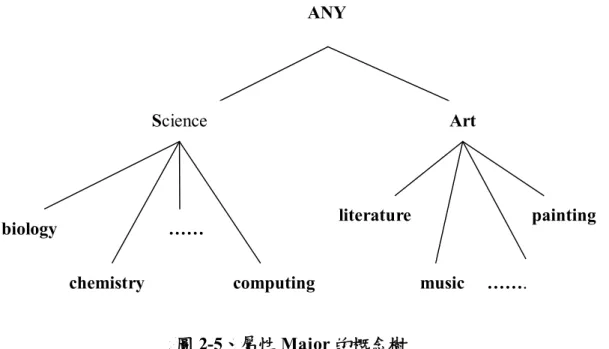
(18) 得到如圖 2-3 的概念樹。 {freshman, sophomore, junior, senior} Undergraduate {M.S., M.A., Ph.D.} Graduate {undergraduate, graduate} ANY 圖 2-2、屬性 Status 的概念階層 資料來源:Attribute-Oriented Induction in Relational Database, Y. Cai, N. Cercone, and J. Han, 1991, Knowledge Discovery in Databases ,Ch 12, AAAI/MIT Press ANY. Undergraduate. freshman sophomore. Graduate. senior. M.S.. M.A.. Ph.D. junior 圖 2-3、屬性 Status 的概念樹. 資料來源:Attribute-Oriented Induction in Relational Database, Y. Cai, N. Cercone, and J. Han, 1991, Knowledge Discovery in Databases ,Ch 12, AAAI/MIT Press 在屬性 Major 的概念階層(圖 2-4)裡,概念階層的最頂端 ANY 則是包含第 二階層 Science 與 Art 兩個屬性值,此處依照科目的內容分為 Science 與 Art 兩大類, 第二階層 Science 底下包含了第三階層的 biology、 chemistry、 computing、physics…等多個屬性值,而第二階層 Art 底下亦包含第三階層 literature、music、painting…等多個屬性值,將屬性 Major 的概念階層以樹狀 圖來表示則可得到如圖 2-5 的概念樹。. 10.
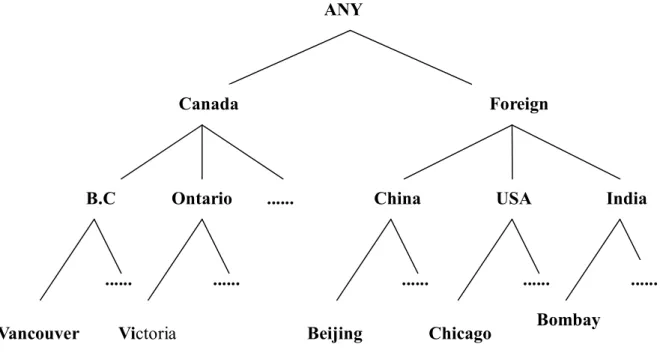
(19) {biology, chemistry, computing,…..,physics} Science {literature, music,…..,painting} Art {Science, Art } ANY 圖 2-4、屬性 Major 的概念階層 資料來源:Attribute-Oriented Induction in Relational Database, Y. Cai, N. Cercone, and J. Han, 1991, Knowledge Discovery in Databases ,Ch 12, AAAI/MIT Press ANY. Science. biology. Art. literature. …… chemistry. computing. painting. music. …….. 圖 2-5、屬性 Major 的概念樹 資料來源:Attribute-Oriented Induction in Relational Database, Y. Cai, N. Cercone, and J. Han, 1991, Knowledge Discovery in Databases ,Ch 12, AAAI/MIT Press 在屬性 Birth Place 的概念階層(圖 2-6)裡,在最頂端的階層 ANY 之下依照 出生地的所在位置進行分類,第二階層分為 Canada 與 foreign 兩大類,第二階 層 Canada 底下的第三層階包含了不同的省份 British Columbia、Alberta、Ontario 等多個屬性值,而同為第二階層的 foreign,其底下的第三階層則是依照不同 的國家劃分為 India 與 China 兩個屬性值。較特別的是在 Canada 這一個屬性 值再往下的第三階層所代表的是省份,不同的省份再對應到第四階層中不同的 城市,而在 foreign 這屬性值再往下的第三階層所代表的是 Canada 以外的國 家,但再往下對應到第四階層時並不像 Canada 一樣建立一個省份的階層,而 是直接跳過省份、對應到城市,因此 Major 的概念階層並不像其他的屬性一樣 在相同的階層對應到的是同一類型的屬性值,而是一種不對稱的屬性階層概. 11.
(20) 念,若將屬性 Birth Place 的概念階層以樹狀圖來表示則可得到如圖 2-7 的概念 樹。 {Bumaby, ….., Vancouver, Victoria} British Columbia {Calgary, ….., Edmonton, Lethbridge} Alberta {Hamilton, Toronto, Waterloo} Ontario {Bombay, …..,New Delhi} India {Beijing, Nanjing, …..,Shanghai} China {India, China} foreign { British Columbia, Alberta,…..,Ontario} Canada {foreign, Canada} ANY 圖 2-6、屬性 Birth Place 的概念階層 資料來源:Attribute-Oriented Induction in Relational Database, Y. Cai, N. Cercone, and J. Han, 1991, Knowledge Discovery in Databases ,Ch 12, AAAI/MIT Press ANY. Canada. B.C. Ontario. ...... Vancouver. Foreign. ....... China. ....... Victoria. USA. ...... Beijing. Chicago. India. ...... Bombay. 圖 2-7、屬性 Brith Place 的概念樹 資料來源:Attribute-Oriented Induction in Relational Database, Y. Cai, N. Cercone, and J. Han, 1991, Knowledge Discovery in Databases ,Ch 12, AAAI/MIT Press. 在屬性 GPA 的概念階層(圖 2-8)裡,概念階層的最頂端 ANY 的底下包含. 12. .......
(21) 第二階層 Poor、Average、Good 與 Excellent 等四個屬性值,此處依照分數的 高低分為四大類不同的評語,第二階層的不同評語分別對應到第三階層不同的 分數範圍,0.00-1.99 對應到 Poor,2.0-2.99 對應到 Average,3.0-3.99 對應到 Good,4.0-4.99 對應到 Excellent,將屬性 GPA 的概念階層以樹狀圖來表示則 可得到如圖 2-9 的概念樹。 {0.0-1.99} Poor {2.0-2.99} Average {3.0-3.99} Good {4.0-4.99} Excellent {Poor, Average, Good, Excellent} ANY 圖 2-8、屬性 GPA 的概念階層 資料來源:Attribute-Oriented Induction in Relational Database, Y. Cai, N. Cercone, and J. Han, 1991, Knowledge Discovery in Databases ,Ch 12, AAAI/MIT Press ANY. Poor. 0.00. ....... Average. 1.99 2.00. ....... Good. 2.99. 3.00. ....... Excellent. 3.99 4.00. ....... 圖 2-9、屬性 GPA 的概念樹 資料來源:Attribute-Oriented Induction in Relational Database, Y. Cai, N. Cercone, and J. Han, 1991, Knowledge Discovery in Databases ,Ch 12, AAAI/MIT Press. 所有的屬性與其相對應的概念階層、概念樹都建立好之後就可以準備進行下一 個步驟,此時為了避免最後挖掘出來的結果太過分散,也為了讓挖掘出來的結 果有一定的解釋範圍,因此鎖定屬性 Status 為 Graduate 的資料做為挖掘廣義知 識的目標,最後則是在資料表中加上名為 Vote 的屬性欄位用以紀錄目前的資 料筆數。. 13. 4.99.
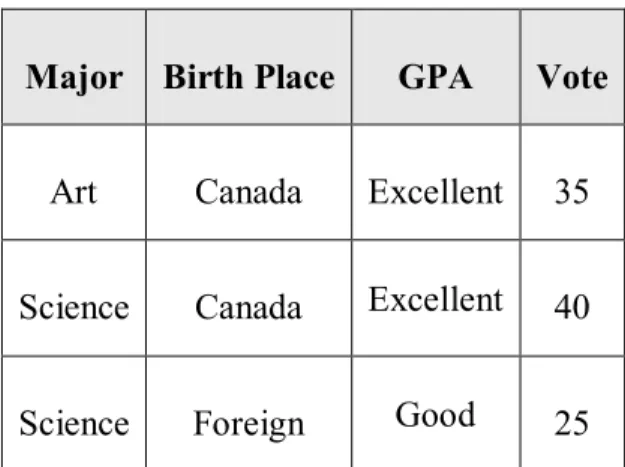
(22) 二、概念樹爬升:若某一個屬性值在概念層級之中有著更高層級的概念存在,就要 以更高層級的屬性值來取代原本的屬性值。以 Birth Place 為例,Bumaby、 Vancouver、Victoria 等爬升為 B.C(British Columbia),Hamilton,、Toronto、 Waterloo 爬升為 Ontario。其他的屬性也依照同樣的概念進行爬升,爬升完成 後的資料表內容如表 2-2 所示。 表 2-2、爬升完成的學生資料表部份內容 Major. Birth Place GPA. Science. B.C. Science. Ontario. Art. B.C. ……. ……. Art. India. Science. China. Good. Vote 1. Good 1 Good 1 ……. ……. Good 1 Good 1. 資料來源:Attribute-Oriented Induction in Relational Database, Y. Cai, N. Cercone, and J. Han, 1991, Knowledge Discovery in Databases ,Ch 12, AAAI/MIT Press. 資料數的累加:爬升結束後,在資料表中開始出現各屬性欄位內容皆相同的資 料,此時就要將內容相同的資料進行合併歸納,並將 Vote 的值進行累加到歸納後的 資料中,累加完成後的資料表內容如表 2-3 所示。. 表 2-3、累加完成的學生資料表. 14.
(23) Major. Birth Place. GPA. Vote. Art. Canada. Excellent. 35. Science. Canada. Excellent. 40. Science. Foreign. Good. 25. 資料來源:Attribute-Oriented Induction in Relational Database, Y. Cai, N. Cercone, and J. Han, 1991, Knowledge Discovery in Databases ,Ch 12, AAAI/MIT Press. 三、門檻設定:在此階段需要對所有屬性或單一的屬性設下門檻值,該屬性的屬性 值個數超過此門檻值,則此門檻值就需要被移除或與專家討論如何修改概念階 層的設計以減少屬性值的個數。而在此範例中,專家認為表 2-3 裡前兩筆資料 的內容除了 Major 之外,Birth Place 及 GPA 的內容皆相同,為了簡化歸納後 的規則數量,可以將前兩把資料進行合併,合併後得到如表 2-4 的內容。 表 2-4、合併完成的學生資料表 Major. Birth Place. GPA. Vote. {Art, Science }. Canada. Excellent. 75. Science. Foreign. Good. 25. 資料來源:Attribute-Oriented Induction in Relational Database, Y. Cai, N. Cercone, and J. Han, 1991, Knowledge Discovery in Databases ,Ch 12, AAAI/MIT Press. 四、規則轉換:歸納完成後的結果需要轉換成較容易解讀的規則,方便使用者了解 此次挖掘的結果為何,而此範例中所得到的規納結果為:在屬性 Status 中,屬 性值為 Graduate 的學生裡,會有 75%的機率是在 GPA 屬性得到 Excellent 的 Canada 人或 25%的機率是在 GPA 屬性得到 Good 的 Foreign 人。. 15.
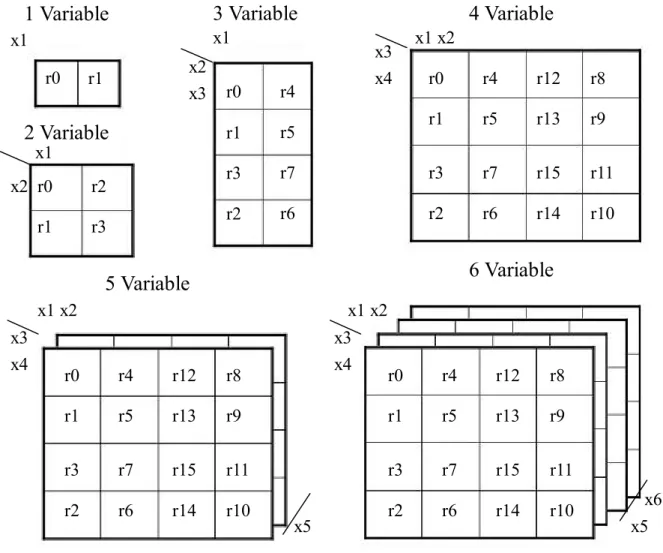
(24) 2.4 改良屬向導向歸納法 改良屬性導向歸納法(Modified Attribute-Oriented-Induction, MAOI),亦稱為類卡 諾圖演算法,是由黃書猛等人在 2010 年所提出,以貝爾實驗室(Bell Laboratories)的 電信工程師莫里斯(Maurice Karnaugh)發明用來化簡二進制(Binary)布林值的卡諾圖 (Karnaugh Map)為基礎(Karnaugh, Maurice, 1953),經修改歸納規則後而成。卡諾圖是 以一種接近人類思考的圖示來呈現資料化簡的方法,卡諾圖會依照布林值每一個變數 (Variable)是 0 或 1 在圖示上給予一個相對應的方格,一個變數的卡諾圖有 2(=21)個方 格,二個變數會有 4(=22)個方格,三個變數會有 8(=23)個方格,四個變數會有 16(=24) 個方格,五個變數會有 32(=25)個方格,六個變數會有 64(=26)個方格,如圖 2-10 的方 式來呈現。. 16.
(25) 3 Variable. 1 Variable. 4 Variable. x1. x1 r0. x2 x3. r1. 2 Variable. x3 x4. x1 x2 r0. r4. r12. r8. r1. r5. r13. r9. r7. r3. r7. r15. r11. r6. r2. r6. r14. r10. r0. r4. r1. r5. r3 r2. x1 x2 r0. r2. r1. r3. 6 Variable. 5 Variable x1 x2 x3 x4. x1 x2. r0. r4. r12. r8. r1. r5. r13. r3. r7. r2. r6. x3 x4. r0. r4. r12. r8. r9. r1. r5. r13. r9. r15. r11. r3. r7. r15. r11. r14. r10. r2. r6. r14. r10. x5. x6 x5. 圖 2-10、卡諾圖 資料來源:本研究整理 MAOI 演算過程分為三個階段,第一階段為”二進制值轉換”,第二階段為”二進 制值化簡”,第三階段為”規則解讀”,接下來將以一個真實的治安死角普查資料中的 年齡資料來呈現 MAOI 演算法化簡過程,在普查資料中,每一筆資料即代表某一個 區域中構成人口的年齡資料。 第一階段的”二進制值轉換”主要目的是把集合導向的多值儲存格式的資料轉換 成 MAOI 演算法可以處理的格式,其轉換的標準是採用門檻值(Thresholds)判斷的方 式,把每一筆多值屬性的資料轉換成有意義的二進位值。以普查資料中某一區域為 例,區域當中各年齡層的人口分佈如下表 2-5 所示。. 17.
(26) 表 2-5、某一區域中各年齡層人口分佈 年齡範圍 0-10 10-20 20-30 30-40 40-50 50-60 60-70 70-80 80-90 90-100 人口數. 707. 730. 823. 946. 990. 437. 318. 183. 59. 7. 資料來源:改良屬性導向歸納法(AOI)挖掘多值(Multi-Values)屬性資料演算法之研 究, 黃書猛等,2010, 電子商務學報,12 卷 2 期,P.251-266 在年齡資料中為了突顯出某一區域的人口資料中組成為了取得門檻值,因此需要 先將年齡子集合切割成更小子集合來組成多值屬性中的一個特定類別,在此處將子集 合切割成四個類別,以 a1 代表 0~20 歲的年輕人、a2 代表 21~40 歲的成年人、a3 代 表 41~60 歲的中年人,a4 代表年齡在 60 歲以上的老年人,依照各個類別將相對應的 人口數相加後得到表 2-6 的結果。 表 2-6、某一區域裡各類別年齡的人口集合數量 年齡(Age) <a1,1437><a2,1769><a3,1427><a4,567> 資料來源:改良屬性導向歸納法(AOI)挖掘多值(Multi-Values)屬性資料演算法之研 究, 黃書猛等,2010, 電子商務學報,12 卷 2 期,P.251-266 該地區的人數總數是 5200,因此子集合的平均人數是 1300,此平均人數即為轉 換的門檻值,接著將各個類別的人口數與門檻值進行比較,若高於門檻值則將該類別 的資料內容轉換為 1,表示該類別所代表的年齡層在某一區域中較多,反之,低於門 檻值則轉換為 0,表示該類別所代表的年齡層在某一區域中較少,而某一區域的各類 別年齡資料經轉換過後得到如表 2-7 的內容,在表 2-7 中可以看到原始資料己經被轉 換成二進制值,接著使用同樣的方法,把剩下的年齡資料全部進行轉換成二進制值, 並將相同的二進制值進行出現次數的累計會得到如表 2-8 的結果。 表 2-7、經轉換後的年齡資料 年齡(Age) 1110 資料來源:改良屬性導向歸納法(AOI)挖掘多值(Multi-Values)屬性資料演算法之研 究, 黃書猛等,2010, 電子商務學報,12 卷 2 期,P.251-266. 18.
(27) 表 2-8、年齡的二進制值與累計次數 年齡(Age) 0001 出現次數. 1. 0100. 0110. 1000. 1100. 1110. 7. 28. 1. 31. 49. 資料來源:改良屬性導向歸納法(AOI)挖掘多值(Multi-Values)屬性資料演算法之研 究, 黃書猛等,2010, 電子商務學報,12 卷 2 期,P.251-266 由於卡諾圖是用來化簡二進制值的最好方式,以卡諾圖為基礎的 MAOI 演算法 也繼承了這個優點,在第二階段的”二進制值化簡”就透過 MAOI 特有的化簡規則來消 去各個多值屬性資料之間的差異。其中 MAOI 與傳統的卡諾圖最大的差異在於歸納 規則的改變,傳統的卡諾圖歸納規則為: 一、以一次包含 2n(n=0,1,2,3,…)個相鄰項目為原則,畫可能把最多的相鄰項目包進 去。 二、卡諾圖中值不為 0 的項目都要被圈過,除非該項目集相鄰的值皆為 0。 三、每一個圈至少要有一個不同的項目,而這個不同的項目,其值必須不為 0。 四、項目可以重覆圈選,但圈的數量要盡量最少。 在 MAOI 的定義中,認為重覆圈選造成某些項目的值被重覆計算,使得最後的 化簡結果產生偏頗,因此 MAOI 提出以”併大不併小,不重覆圈選”的化簡概念來修改 卡諾圖的化簡方式,所得到的歸納原則為下列三點: 一、依照一次包含 2n(n=0,1,2,3,…)個相鄰項的原則,盡量圈出項目內的值加總最大 的組合,但值為 0 的項目不得被包入。 二、若有兩個圈選的組合中有項目被重覆圈選到,就組合中的加總值最大的組合為 優先,加總值較小的組合在此次化簡將被放棄,留待下次化簡的機會。若兩個 加總值剛好一樣,則隨機保留其中一個組合,另一個組合放棄此次的化簡機 會,留待下次處理。 三、若最後有不為 0 的項目沒有被包進組合裡,則表示該項目無法與其他的項目進 行合併化簡。 使用兩種不同的歸納原則化簡出來的結果會產生根本上的差異,如圖 2-11 所示, 左圖為使用傳統卡諾圖規則進行化簡的圖示,右圖為使用 MAOI 規則化簡的圖示. 19.
(28) a1 a2. a1 a2. a3 00 a4 00 0. 01. 11. 10. 01. 11. 10. 1. a3 00 a4 00 0. 7. 31. 7. 31. 1. 01. 1. 0. 0. 0. 01. 1. 0. 0. 0. 11. 0. 0. 0. 0. 11. 0. 0. 0. 0. 10. 0. 28. 49. 0. 10. 0. 28. 49. 0. 圖 2-11、傳統卡諾圖與 MAOI 化簡方式的比較圖 資料來源:改良屬性導向歸納法(AOI)挖掘多值(Multi-Values)屬性資料演算法之研 究, 黃書猛等,2010, 電子商務學報,12 卷 2 期,P.251-266 在圖 2-11 中可以看到以 r4、r6、r12、r14 的加總次數 115 最大,而傳統的卡諾 圖化簡規則會因為 r8 的次數不為 0,就需要再與相鄰的 r12 做圈選,此時 r12 的次數 就會被重覆計算導致歸納結果的失敗。而在 MAOI 演算中會選擇 r4 的 0100、r6 的 0110、r12 的 1100、r14 的 1110 做為化簡組合,合併的原則為化簡組合中在同一個變 數位置若有相異的布林值,則表示該化簡組合的二進制值之間在特定的變數上有著相 當的差異,而此差異對化簡的結果來說是可以被忽視的,因此便以 x 取代原本相異的 變數來表示該變數為 don’t care,即是將 0100、0110、1110 與 1100 轉換為 x1x0,化 簡之後四組二進制值所剩下的變數內容完全相等便可進行合併歸納,而 r1 與 r8 的次 數雖不為 0,但己經沒有同樣與其相鄰且不為 0 的二進制值可供化簡,這表示在此次 的化簡中 r1 與 r8 將不與其他的值合併。 在化簡完成後則進入了第三階段的”規則解讀”,化簡完成所得到的規則為 x1x0 98.29%,而以二進制值表示的規則不易解讀,故將規則依據先前的定義轉換為較容易 解讀的規則,0 表示低於門檻值,所以採用 L 來表示;1 表示高於門檻值,採用 H 來 表示,經轉換後得到的規則為{<a2,H><a4,L>} 98.29%,規則所代表的意義為「有 98.29%的治安事件是發生在人口構成以成年人較多、老年人較少的地區」。. 2.5 財務績效指標相關文獻探討 自學者提出使用單變量分析方法針對公司的財務比率特性來分析企業經營績效 的優劣後(Ramser & Forster,1931),學界開始使用單變量分析、區別分析、多重迴歸分 析與時間序列對企業財務績效進行研究,其中在研究企業的財務結構時多以應用因素. 20.
(29) 分析法來進行,因素分析法早期是應用在心理學之上,基本原理為將數個具有高度相 關的變數轉換簡化為幾個因素,並取因素的特徵來解釋研究對象的某些現像,或將其 特徵做進一步的分析研究之用,結合敘述統計、線性分析、迴歸分析來建立預測模型, 有關運用因素分析針對使用財務績效指標在評估企業的經營狀況與股票選擇的相關 研究文獻如下: Pinches 等學者(1973)在其研究中利用因素分析方法從 221 家企業、不同年度的 財務報表中,探討產業財務型態之穩定性來發展出適合產業間一般基本因素,根據實 務上對財務比率的分類方式,找出使用投資報酬率、財務槓桿度、總資產週轉率、短 期流動比率、現金流量分析、存貨週轉率及應收帳款週轉率等七項因素來解釋企業的 經營狀況是最有效的。 陳杏如(1999)在研究造紙業上市公司財務比率與獲利率關聯性探討時,得到造紙 業的獲利能力與經營效能、資產運用能力有顯著性關聯的結論。 吳道凱(2000)在研究銀行業績效評估時,設計了 25 項經營績效指標,配合因素 分析法進行經營績效分析,發現純益率、總資產週轉率、放款及貼現成長、利息支出 /利息收入等幾項經營指標和本益比、市價淨值可以用來作為選股指標參考,同時也 發現在選股時使用越多的指標或設定更多的條件並不一定可以提昇更多的投資績效。 學者 Jaap van der Hart, Erica Slagter,Dick van Dijk(2003)在其研究中提出選股時應 使用益本比、淨值市價比、股票殖利率、預測益本比、慣性、規模、股票週轉率等變 數來做為選股時的參考指標。 陳俊銘(2003)在其研究中,使用 Panel Data 模型研究全球銀行業的風險管理與財 務危機,而 Panel Data 模型即是使用時間序列的研究方法,其研究結果顯示風險管理 與總資產報酬率、稅前純益有關,而危機方面則與稅前純益、本益比有關。 蔡源泰(2009)以紡織業為對象進行研究企業財務風險與效率時,提出應從上市公 司公開的資訊中選擇負債比率、速動比率、營業費用率、每股稅前淨利、資產週轉率、 應收帳款週轉率、營收成長率、每人營業額等財務比率來反應企業過去的經營成效及 預測產業未來的獲利效率。. 21.
(30) 國立中央大學管理學院 ERP 中心(2010)認為應將財務績效指標視為一種關鍵績 效指標(Key Performance Indicators, KPI),因此企業的利害關係皆應重視企業在 KPI 上的表現,在進行經營能力分析時應從存貨週轉率、平均銷貨日數、應收款項週轉率、 平均收現日數、營業循環日數、應付款項週轉率、平均付款日數、現金變現日數、固 定資產週轉率、股東權益週轉率和總資產週轉率去了解企業運轉的速度快慢,而進行 獲利能力分析時應從純益率、稅前利益率、營業利益率、毛利率、銷貨成本率、邊際 貢獻率、間接費用率、營業利益占實收資本比率、稅前利益占資本率、總資產報酬率、 股東權益報酬率、每股盈餘、每股淨值、本益比、價格與股利比、股利分配率、殖利 率、每位員工之營收、每位員工之營業利益、每位員工之經濟附加價值、各主要訂單 之利潤率、IT 費用占管理費用比率、研發費用占理費用比率來了解企業的獲利能力。 由上述的文獻可以得知過去的研究是先選定產業類別、再選定企業、最後則是選 擇用財務績效指標上的表現來做績效評比,由於本研究中所選用的產業為傳統產業的 紡織纖維業與金融業,所以在財務績效指標的選擇上將參考前述文獻中的研究結果, 在經營能力相關的財務績效指標選擇了下面的三個指標:固定資產週轉率、股東權益 週轉率和總資產週轉率來做為評比的標準,在獲利能力方面則是選擇下面的七個指 標:純益率、營業利益率、總資產報酬率、股東權益報酬率、每股盈餘、每股淨值、 本益比來進行評比,相關指標的定義與計算方式如下:. 22.
(31) 表 2-9、本研究所使用的財務績效指標名稱與定義 指標名稱 經 營 能 力. 指標定義. 固 定 資 產 週 轉 銷貨淨額 / 平均固定資產淨額 率 股 東 權 益 週 轉 銷貨淨額 / 平均股東權益淨額 率. 獲. 總資產週轉率. 銷貨淨額 / 平均資產總額. 純益率. 稅後純益 / 銷貨淨額. 營業利益率. 營業利益 / 銷貨淨額. 總資產報酬率. 純益率 * 總資產週轉率. 利. 股 東 權 益 報 酬 (稅後純益 – 特別股股利) / 平均普通股股東權益 率 能. 每股盈餘. (稅後純益 – 特別股股利) / 加權平均流通在外普通股股 數. 力. 每股淨值. (稅後純益 – 特別股權益) / 平均普通股股東權益. 本益比. 每股市價 / 每股盈餘. 資料來源:國立中央大學管理學院 ERP 中心,商業智慧 Business Intelligence,2010. 23.
(32) 3. 語法式屬性導向歸納法 在 MAOI 演算法中,發現了兩個使用上的限制,使其無法應用在更廣泛的領域, 其一為直觀式的類卡諾圖化簡方法無法化簡六個以上的變數,其二為門檻值的計算會 受到資料本身屬性的影響,使得原本的轉換機制無法發揮作用,因此本研究將針對這 兩個限制提出改良的方法來突破使用上的限制。SAOI 方法的演算流程共分為兩階 段,演算流程如圖 3-1 所示。第一階段的主要工作為原始資料的前置處理,第二階的 主要工作為資料轉換後的化簡歸納階段。. 第一階段. 第二階段. 開始 SAOI 演算. 決定啟始值. 彙整原始多值屬性資料. 產生候選值. 計算屬性轉換門檻值. 化簡、組合、篩選. 二進制值轉換. 挑選組合. 計算二進制值群組個數. 完成化簡. 依群組個數進行排序. 結束 SAOI 演算. 圖 3-1、SAOI 演算流程 資料來源:本研究整理. 3.1 多值屬性資料的前置處理 3.1.1 計算門檻值與二進制值轉換 在 MAOI 演算法中提出的將屬性集中的子類別個數加總後再除以子類別的個數. 24.
(33) 以取得平均值做為門檻值,再將子類別的個數與門檻值進行比較,若子類別的個數大 於等於門檻值則用 1 表示在集合中該屬性較為突出,如果子類別的個數小於門檻值則 用 0 表示在集合中該屬性較不突出。在 MAOI 研究中所舉出的實做範例是以”人口” 做為各個屬性資料中的共通單位,因此在每一筆治安死角的地區資料中進行各屬性的 二進制值轉換時,可以用地區內的”人口平均值”來做為門檻值,但在本研究中所使用 的財務績效指標資料即無法使用相同的方法取得門檻值,如下表 3-1 以紡織業某十五 家上市公司在某一季所公佈的經營能力資料為例,在獲利能力屬性裡包含純益率、營 業利益率、總資產報酬率及股東權益報酬率四個指標。若以 MAOI 所定義的計算門 檻值方式來處理編號 1 的資料,則會變成(6.44% + 2.11% + 1.45% + 2.96%) / 4 = 3.45%,雖然三個不同的財務績效指標都跟 MAOI 範例中一樣,都有著共通的單 位”%”,但是將四個財務績效指標的值加總再取平均值是沒有意義的,因此依照 MAOI 轉換機制轉換出來的二進制值也無法提供任何有意義的資訊,此類型的資料便無法使 用 MAOI 來進行化簡。 表 3-1、紡織業某十五家上市公司在某一季的財務績效指標資料表 獲利能力 編號 純益率 營業利益率 資產報酬率 股東權益報酬率 1 6.44% 2.11% 1.45% 2.96% 2. -1.96%. 4.36%. 0.32%. 1.71%. 3. 3.53%. 2.50%. 0.19%. 1.49%. 4. 4.07%. 7.57%. 1.89%. 8.59%. 5. 3.87%. -6.55%. 0.48%. -21.02%. 6. 8.90%. 7.65%. 1.89%. 5.45%. 7. 3.40%. 3.12%. 1.28%. -1.65%. 8. 3.05%. -6.28%. 1.24%. 0.76%. 9. -6.88%. 2.24%. -2.98%. -2.56%. 10. 5.81%. 8.70%. 6.21%. -7.99%. 11. 6.42%. 1.84%. 0.90%. 0.20%. 12. 3.53%. 1.01%. 0.74%. 0.50%. 13. 5.81%. 8.70%. 6.21%. -7.99%. 14. 5.42%. 1.87%. 0.88%. 0.30%. 15. 3.31%. 0.01%. 1.03%. 0.60%. 資料來源:本研究整理 為解決前述的問題,必須先了解到財務績效指標的定義為何,Gasbarro and. 25.
(34) Zumwalt(2002)定義「財務績效指標是以財務比率做為評估企業營運表現的工具」, 透過財務比率即能了解到企業運營運的表現,基於以上的定義,本研究提出針對財務 績效指標一種新的轉換方式,捨棄了 MAOI 原先所定義的以同一筆資料內、屬性內 不同類別值之間的比較,要了解到企業的經營績效是否良好,是需要以同業平均值做 為比較的基礎,因為與同業相比較才能知道自身的表現是好或壞(黃德舜,1998),改以 在同一時段內、不同資料之間,針對屬性內的同一類別值進行比較,以表 3-1 內的資 料的純益率為例,表內的 15 筆資料皆屬同一季的財務比率,因此便可將純益率的數 值進行相加取得純益率的平均值為 3.65%((6.44% - 1.96% + 3.53% + 4.07% + 3.87% + 8.90% + 3.40% + 3.05% - 6.88% + 5.81% +6.42% + 3.53% + 5.81% +5.42% + 3.31% )/15) 做為門檻值,接著將各筆資料的純益率與門檻值進行比較,若是大於等於門檻值則給 1,表示該企業在純益率上的表現與相同時段內的同業相較是屬於較優的,反之,若 是低於門檻值給 0,表示該企業在純益率上的表現與相同時段內的同業相較是屬於較 差的。接著依照同樣的轉換標準把另外兩個指標也進行轉換並將結果進行群組,便得 到如表 3-2 的結果,第一個變數代表純益率、第二個變數代表營業利益率、第三個變 數代表總資產報酬率、第四個變數代表股東權益報酬率。 表 3-2、轉換成二進制值的財務績效指標資料表 編號 獲利能力 1 1011 2. 0101. 3. 0001. 4. 1111. 5. 1000. 6. 1111. 7. 0100. 8. 0001. 9. 0000. 10. 1110. 11. 1001. 12. 0001. 13. 1110. 14. 1001. 15. 0001. 資料來源:本研究整理. 26.
(35) 3.1.2 二進制值次數累加與排序 資料轉換成二進制後,便將相同的二進制值以群組的方式進行個數加總(Count), 並依照加總個數大小進行排序,表 3-3 即為加總後並完成排序的結果。 表 3-3、排序完成財務績效指標資料表 獲利能力. 0001. 1001. 1111. 1110. 1000. 0100. 0000. 0101. 1011. 加總個數. 4. 2. 2. 2. 1. 1. 1. 1. 1. 資料來源:本研究整理. 3.2 資料轉換後的化簡歸納 3.2.1 候選值的產生 在表 3-3 中,以 0001 的加總個數 4 為最大值,因此選定 0001 做為產生化簡組合 的啟始值,為了保持化簡後的資料仍保有多質屬性的特徵,假設 0001 的四個變數在 化簡歸納之後最多有兩個變數可以被化簡掉,表示 0001 之中會有兩個變數被保留下 來,因此便可以 0001 中拆解出化簡後的可能值,就以”x”(don’t care 的意思)來代表被 化簡的變數來拆解組合出下列的六組候選值:00xx、0x0x、0xx1、x00x、x0x1、xx01, 接著用候選值做為條件與表 3-3 中、啟始值之後的二進制值做比較。以候選值 00xx 為例,因為第三、第四變數是 don’t care 的”x”,所以只以候選值的前兩個變數,即是 被保留下來的變數做為比對的標的,比對表 3-3 的獲利能力資料中有多少筆資料的第 一、第二變數是與候選值相符。. 3.2.2 化簡組合的支持個數定義 在整理 MAOI 與卡諾圖資料時,本研究有發現到下面的重要規則:要化簡掉 N 個變數,就需要有 2N 筆資料。會形成此一規則的原因在於 MAOI 中任意兩個相鄰的 二進值會有一個變數的差異,在兩個不同的二進制值要進行合併時即是化簡掉這個相 異的變數,因此將此一規則運用到本研究中做為挑選與候選值比對相符的二進制值支 持個數是否有達到可以列入化簡合併考慮的標準,而候選值是由啟始值所產生的,因 此將候選值與啟始值進行比對一定會符合,所以在進行比對時可以從啟始值之後的資 料開始比對,而要達到化簡門檻所需要的支持個數則由原本的 2N 筆資料扣去啟始值 改為 2N-1 筆資料。. 27.
(36) 3.2.3 化簡組合的挑選 在比對完成後,與候選值 00xx 相符的二進制值有 1 筆,與 0x0x 相符的 3 筆,與 0xx1 相符的 0 筆,與 x00x 相符的有 3 筆,與 x0x1 相符的有 1 筆,與 xx01 相符的有 2 筆,而要化簡掉兩個變數所需要達到的支持個數的門檻值 22-1 共 3 筆,前述的化簡 組合中只有 0x0x 與 x00x 有達到標準。在 MAOI 的化簡原則中有著不得重覆使用二 進值制的規則存在,在本研究中中也採用相同的觀點,0x0x 與 x00x 兩個化簡組合只 能挑選一組做為化簡後的結果。在擁有複數的化簡組合時,為了使化簡的結果能夠包 含到最多的資料數量,在本研究中是以化簡組合下所包含的二進制值其加總個數總合 的最大值做為挑選的對像,在本例中 0x0x 的加總個數總合為 7,而 x00x 的加總個數 總合為 8,因此以 x00x 做為啟始值 0001 的化簡結果。在決定好化簡結果之後便依序 將候選值 x00x、啟始值、化簡組合及加總個數總合移動到化簡完成的表 3-4、歸納資 料表中,原先表 3-3 排序完成財務績效指標資料內容將更新為表 3-5 的內容。 表 3-4、加入 x00x 之後的歸納資料表 歸納值. 組合. 加總筆數. x00x 0001、0000、1001、1000. 8. 資料來源:本研究整理 表 3-5、移動 x00x 化簡組合之後的財務績效指標資料表 獲利能力. 1111. 1110. 0100. 0101. 1011. 加總個數. 2. 2. 1. 1. 1. 資料來源:本研究整理. 3.2.4 候選值中化簡變數數量的調整 經過一次的化簡歸納之後,表 3-5 的財務績效指標資料表中加總個數最大值為 2 的二進值制 1111 與同樣是 2 的二進制值 1110,當有複數的二進制值的加總個數相同 時,只需隨機選取其中一個做為啟始值即可,在這邊挑選了 1111 做為啟始值來產生 以化簡兩個變數為目標的六組候選值 11xx、1x1x、1xx1、x11x、x1x1、xx11,與表 十三中的二進制值相比對得到分別得到支持個數為 1 筆、2 筆、1 筆、1 筆、0 筆、1 筆,所有的支持個數皆未達到 22-1 的 3 筆,在這個狀況下就需要減少化簡的變數數 量,由化簡兩個變數改為化簡一個變數來產生新的候選值 x111、1x11、11x1 及 111x 與表 3-5 的資料進行比對,比對結果分別為 0 筆、1 筆、0 筆、1 筆,此時的支持個數 亦由 22-1 的 3 筆減少為 21-1 的 1 筆,1x11 與 111x 皆有達到門檻值,其中 111x 的加. 28.
(37) 總個數總合為 4 最大,便選擇 111x 做為此次化簡歸納的結果。需要特別注意的是, 若啟始值在減少化簡變數量到僅化簡一個變數都無法產生支持個數能夠達到門檻值 的化簡組合時,即表示該啟始值無法其他的二進制值進行化簡歸納,此時就要將該啟 始值直接移動到歸納資料表中。在將候選值 111x、啟始值、化簡組合及加總個數總 合移動到歸納資料表後,財務績效指標資料表中所剩餘的加總個數皆為 1,便取出 0100 做為啟始值來產生候選值,經過與上述相同的減少化簡變數數量過程後,得到 了 010x 這個化簡歸納結果,在將相關的資料進行移動歸納資料表並更新財務績效指 標資料表,更新過後的歸納資料表與財務績效指標資料表內容如下表 3-6、3-7 所示。 表 3-6、加入 111x 與 010x 後的歸納資料表 歸納值. 組合. 加總筆數. x00x 0001、0000、1001、1000. 8. 111x. 1111、1110. 4. 010x. 0100、0101. 2. 資料來源:本研究整理 表 3-7、移動 111x、010x 化簡組合之後的財務績效指標資料表 獲利能力. 1011. 加總個數. 1. 資料來源:本研究整理. 3.2.5 SAOI 演算的停止條件 目前財務績效指標資料表中僅剩 1011 一組二進制值,由於已無其他的二進制值 可與其進行化簡歸納,因此當財務績效指標資料表除了啟始值之外己經沒有其他的二 進制值存在或資料表己經完全清空時,即表示 SAOI 演算法停止演算。最後得到的歸 納資料內容與結果如表 3-8 所示。 表 3-8、歸納資料表 歸納值. 組合. 百分比 加總筆數. x00x 0001、0000、1001、1000 53.33%. 8. 111x. 1111、1110. 26.67%. 4. 010x. 0100、0101. 13.33%. 2. 1011. 1011. 6.67%. 1. 資料來源:本研究整理. 29.
(38) 4. 實作驗證 本研究是以 SAOI 演算法針對企業股價的變化來整理歸納出不同的企業在財務績 效指標表現上的共同特徵,進而探討不同產業間在相同的條件下,經歸納所得的財務 績效指標特徵上的差異與原因分析,由資料來源中選取特定的產業基本資料,再由參 考文獻中選取經研究後較常用或較具有代表性的財務績效指標做為化簡標的,經 SAOI 演算後得到該產業在財務績效指標上的共通特徵,研究架構如下圖 4-1 所示。 本研究所使用的相關工具為用於整理資料的 Microsoft Excel 2003、資料庫管理的 Microsoft Access 2003 以及基於 Tomcat、JSP 平台上自行開發的 SAOI 系統。 收集特定產業內企業的基本資料. 自考參文獻中選擇財務績效指標. 財務績效指標資料收集. 資料前置處理. 設定適用資料條件. SAOI 演算. 結果分析 圖 4-1、研究架構 資料來源:本研究整理. 4.1 資料收集 本研究使用的資料為台灣股市 04 類的紡織纖維業與 92 類金融業上市上櫃公司的 財務績效指標資料,選取範圍為民國 98 年第一季到民國 99 年第四季共八季的資料內 容,在這段期間內台灣股市的大盤走勢為多頭市場的牛市(Bull Market),段期間內的 大盤月線如圖 4-2 所示,而這段期間內在紡織纖維業共有 54 家企業、432 筆資料(如 圖 4-3),在金融業共有 32 家企業、272 筆資料(如圖 4-4),資料來源為台灣證券交易. 30.
(39) 所、公開資訊觀測站、證券櫃檯買賣中心、台灣經濟新報(TEJ)、E-STOCK 發財網, 資料欄位與細部資料來源如表 4-1 所示,其中部份資料是直接引用資料來源中所提供 計算完成的數據,而部份資料則是依據資料來源中所提供的原始資料計算而得。 10000 8000 6000 收盤指數. 4000 2000 2010/9. 2010/5. 2010/1. 2009/9. 2009/5. 2009/1. 0. 期間. 圖 4-2、2009/1~2010/12 大盤走勢圖 資料來源:本研究整理 表 4-1、財務績效指標資料表欄位與資料來源 分類 欄位名稱. 基本資料 資料 編號. 資料來源. 公司代碼. 季末收盤 固定資產 股東權益週 總資產週 報表期間 價 週轉率 轉率 轉率. 台灣證券交易所. 分類 欄位名稱 資料來源. 經營能力. 計算而得. 公開資訊觀 公開資訊 測站 觀測站. 獲利能力 純益 率. 營業利益率. 總資產報 股東權益 每股盈餘 每股淨值 酬率 報酬率. 計算而 E-STOCK 發 計算而得 得. TEJ. 財網. 台灣證券 證券櫃檯買 計算而得 交易所 賣中心. 資料來源:本研究整理. 31. 純益率.
(40) 圖 4-3、紡織纖維業原始資料(部份) 資料來源:本研究整理. 圖 4-4、金融業原始資料(部份) 資料來源:本研究整理. 32.
(41) 4.2 資料前置處理 由於部份企業所公佈的資料內容在前述的資料來源中並不完整,為了避免因納入 不完整的資料導致歸納結果失真,對於任何內容不完整的資料將以一筆資料為單位, 對該筆資料採取排除的做法,經處理過後,紡織纖維業有 352 筆資料,金融業有 232 筆資料。二進制值的轉換規則為對同一季內的資料採取縱向分析(Vertical analysis), 即是在特定時間內對不同企業選擇相同的財務績效指標項目進行比較,因此就以這些 經過篩選的指標資料依照”計算門檻值與二進制值轉換”的定義進行二進制值的轉 換,轉換標準的門檻值為”同一季內同業間在該指標表現的平均值”,將經過篩選的 資料進行二進制值的轉換。同時為了使歸納化簡的結果有特定的解釋範圍,因此選定 與上一季相比較,股價呈現漲勢的資料做為化簡對象,選擇的條件為”上一季季末收 盤價與本季季末收盤價做比較,在同一季內依照漲幅進行排序,取同業間排名前 50% 的財務績效指標資料,若前 50%內的資料己出現跌勢,則取到漲勢資料的最後一 筆”,經篩檢後紡織纖維業有 173 筆資料,金融業有 108 筆資料,資料內容的相關統 計敘述呈現在表 4-2、表 4-3。 表 4-2、紡織纖維業財務指標相關統計敘述 財務指標. 期間. 平均值 中位數 標準差. 最小值. 最大值. 2009 Q1 122.66% 40.42% 409.47% 0.82% 2695.87% 2009 Q2 254.98% 93.60% 840.23% 1.61% 5538.22% 2009 Q3 405.57% 145.93% 1395.10% 2.97% 9224.46% 固定資產週轉率. 2009 Q4 554.37% 198.11% 1909.43% 3.46% 12626.64% 2010 Q1 147.05% 49.92% 478.06% 1.11% 3159.06% 2010 Q2 292.16% 113.44% 891.21% 2.32% 5888.52% 2010 Q3 472.87% 173.74% 1500.47% 4.14% 9929.69% 2010 Q4 642.47% 239.82% 1995.30% 5.09% 13208.85%. 股東權益週轉率. 總資產週轉率. 2009 Q1 30.66% 19.44% 28.54%. 0.58%. 139.91%. 2009 Q2 64.53% 39.97% 58.30%. 1.14%. 282.52%. 2009 Q3 99.17% 63.36% 90.69%. 2.04%. 440.39%. 2009 Q4 134.20% 85.44% 121.79% 2.39%. 533.49%. 2010 Q1 38.23% 25.83% 36.13%. 0.75%. 177.98%. 2010 Q2 80.83% 57.16% 72.46%. 1.53%. 344.28%. 2010 Q3 116.86% 77.66% 106.91% 2.55%. 502.63%. 2010 Q4 158.33% 103.08% 142.12% 3.19%. 573.72%. 2009 Q1 16.83% 12.93% 15.27%. 82.56%. 33. 0.48%.
數據

+7


Outline
相關文件
青年經公立就業服務機構媒合就業,並依 法參加就業保險,受僱期間 連續滿30日 之日起90日內 ,可以向
RMI,及 DCOM 這些以專屬 binary 格式傳送資料所不及之處,那 就是對程式語言、作業平台的獨立性--由於是純文字 XML 格 式,
Financial Reporting),及英國研究企業管治財務範 疇的委員會(Committee on the Financial Aspects of Corporate Governance),又稱「坎特伯里委員
The proof is suitable for R n if the statement is that every closed set in R n is the intersection of a countable collection of open sets.. All we need is to change intervals
1900年, Bachelier以數學方法分析巴黎股票交易的價格變化,自
本論文之目的,便是以 The Up-to-date Patterns Mining 演算法為基礎以及導 入 WDPA 演算法的平行分散技術,藉由 WDPA
資料探勘 ( Data Mining )
“ Consumer choice behavior in online and traditional supermarkets: the effects of brand name, price, and other search attributes”, International Journal of Research in Marketing,
