國立臺灣大學電機資訊學院資訊網路與多媒體研究所 博士論文
Graduate Institute of Networking and Multimedia College of Electrical Engineering and Computer Science
National Taiwan University Doctoral Dissertation
設計解決複雜的創造性任務
Designing for Complex Creative Task Solving
黃怡靜 Yi-Ching Huang
指導教授:許永真博士
Advisor: Jane Yung-jen Hsu, Ph.D.
中華民國 107 年 6 月 June, 2018
誌謝
在博士研究的這段歲月,絕對是我人生中最難忘的經歷。我學會如 何在一次又一次的失敗中重新站起,拍拍身上的灰塵,繼續堅定地向 前。感謝每一次的失敗與歷練,讓我更加堅強。雖然過程中曾經迷失,
也曾經無數次地懷疑自己,但幸運的是,在孤獨的奮鬥背後總有一群 老師、朋友,以及我親愛的家人在身後支持著我,不斷的給我力量,
讓我能夠克服任何困難。這段過雖然艱辛但也喜悅,感謝我所走過的 每一條路,以及所遇到的寶貴的人、事、物,因為有你們,才有現在 的我。
在學術與人生的路上,感謝影響我最深的指導教授許永真老師。我 永遠都記得十年前大四下第一次跟妳討論研究,天花亂墜的聊天,心 中馬上就確定妳是我想要跟隨的指導老師,於是進入了人工智慧代理 人實驗室(iAgents Lab),開啟我的研究生涯。碩士畢業後,工作了三 年又回到實驗室繼續完成博士研究。從妳身上,我不只學到了專業,
還有謙卑又自信的態度,以及更多的人生道理。很高興在研究的路上,
有妳的指導與相伴。另外,我想感謝的是現在在美國UC Davis 的王浩
全老師,因為你多年的指導與提拔,讓我精進研究的思辨能力,更開
啟了我在CSCW 領域的研究,一起探索了許多有趣的想法與問題。
感謝陳玲鈴老師、梁容輝老師、徐宏民老師、余能豪老師、張俊盛 老師、古倫維老師、何建儒老師、詹力韋老師以及張永儒老師,在我 的博士論文提案以及學位考試給我許多寶貴的建議與指導。感謝泓其、
啟嘉、Joey、以及過去與現在實驗室的學長姐與學弟妹們,也很感謝
清大CSC Lab 的學弟妹們,很開心能夠跟一起學習,並分享研究的喜
悅與辛苦。
感謝OT 的好友們,讓我在追求研究的同時,也能繼續在科技藝術
上有小小的貢獻,與你們聊天真的是一種享受,很感謝讓我遇見你們 這群瘋狂的朋友們,你們的熱情總是給我滿滿的正向力量。另外,很 感謝我的冰研死黨們:芭樂、驢子、劉嚕、頭頭,等高中死黨們,總 是讓我想起小時侯那股什麼都不怕的衝勁,即使遇到任何困難,總有 你們在身旁邊吵吵鬧鬧,莫名什麼都克服了。
最後,感謝我最親愛的家人:媽咪、爸比、阿弟、哥哥,以及可愛 的小咪醬與小花花。因為你們,我才能勇敢地追尋我的夢想。當然,
還有小河童,因為有你的陪伴,我才能夠任性地做我自己。
摘要
創造性任務因沒有正確答案且缺乏標準定義,讓許多人感到非常棘 手,通常需要投入大量時間與精力去學習並精進專業知識與技能,才 能夠完成此種任務。而且,在解決問題的過程中,必須取得外部回饋,
並且透過不斷的迭代修改才能夠獲取高品質的結果。許多研究者已經 能夠利用網路系統串連提供者與使用者,取得即時的外部回饋,幫助 使用者完成任務。然而,大部分的研究只專注於回饋內容的改進,而 忽略了最重要的目的,在於如何在此過程中輔助使用者學習,並有效 的完成任務。所以,目的包含了獲得高品質的結果以及提高學習成效。
此博士論文提出了一個解決創造性任務的迭代循環回饋的框架,分別 探討產生有效且高品質回饋的生成機制以及有效整合回饋輔助編輯的 方法,來促進有效的學習行為以及創造良好的使用經驗。我們設計與 開發了一系列的智慧型回饋系統,運用群眾與機器合作的力量來幫助 使用者快速取得符合需求的高品質寫作建議,並透過結構化的設計,
引導他們有效地進行編輯,同時精進專業能力與提升作品品質。未來,
在我們提出的互動回饋框架中,機器將擔任協調者與合作者的角色,
根據使用者的偏好與行為,提供適當的回饋與引導,促進人與人以及 人與機器良好的互動,一起合作完成困難的創造性任務。
Abstract
Performing creative tasks is challenging, for such tasks are typically open- ended and ill-defined. To solve these complex problems, people need to spend much time and effort to learn professional skills and improve the in-progress work through an iterative process. Feedback is a critical component of this process for helping people discover errors and iterate toward better solutions.
To meet the demand of timely feedback, recent work has explored technolo- gies to connect problem solvers with feedback providers online. However, most research focuses on improving the content of feedback, but neglects the most important aspect of how to support problem solvers to learn and effectively facilitate the creation of high-quality outcome. In this disserta- tion, we explore several ways to support not only feedback generation but also feedback integration process, focusing on the writing tasks. We designed and developed intelligent systems that leverage the power of crowd and ma- chines to support writers for obtaining effective feedback and facilitating good revision behaviors in the process. First, we start with our crowd-powered feedback system, StructFeed, and demonstrate a crowdsourcing approach for generating useful feedback to help writers resolve high-level writing issues in their revisions. Next, we propose feedback orchestration, which guides writ- ers to resolve writing issues in a particular workflow by orchestrating feed- back presentation. In the future, we would create an iterative feedback frame- work that enables collaboration between authors and feedback providers. Au- thors and feedback providers could benefit from this framework and collab-
oratively accomplish the complex creative tasks. The system would be re- garded as a mediator for generating an ensemble of feedback from diverse feedback providers and for orchestrating feedback presentation to guide au- thors to achieve high revision performance based on individual needs.
Contents
口試委員會審定書 iii
誌謝 v
摘要 vii
Abstract ix
1 Introduction 1
1.1 Background and Motivation . . . 1
1.2 Supporting Creative Task Solving . . . 2
1.3 Roadmap of Research . . . 4
1.3.1 StructFeed: Generate Effective Feedback by Crowdsourcing . . . 4
1.3.2 Feedback Orchestration: Facilitate Effective Revision . . . 5
1.3.3 Understand How Feedback Affects Revision Results . . . 6
1.3.4 Reflection Before/After Practice . . . 7
2 Related Work 9 2.1 Human Computation and Crowdsourcing . . . 9
2.1.1 Incentive, Microtasks, Quality Control . . . 9
2.1.2 Crowdsourcing for complex task . . . 11
2.2 Online Feedback Exchange . . . 11
2.3 Learning Science . . . 13
2.3.1 Self-Regulated Learning . . . 13
2.3.2 Reflection and Reflective Practice . . . 14
2.4 Writing Support Systems . . . 14
2.4.1 Automated Writing Evaluation . . . 15
2.4.2 Crowd-Powered Systems for Writing Support . . . 15
3 StructFeed: Generating Structural Feedback by Crowdsourcing 17 3.1 Introduction . . . 17
3.2 StructFeed . . . 18
3.2.1 Paragraph Unity and Topic Sentence . . . 19
3.2.2 Crowdsourcing Workflow . . . 20
3.2.3 Structural Feedback and Interface . . . 22
3.2.4 Implementation . . . 23
3.3 Unity Identification . . . 23
3.3.1 Crowd-Based Method . . . 24
3.3.2 ML-Based Methods . . . 25
3.3.3 Evaluation . . . 27
3.4 Field Deployment Study . . . 29
3.4.1 Study Design . . . 29
3.4.2 Tasks and Procedure . . . 30
3.4.3 Measure . . . 30
3.4.4 Results . . . 31
3.5 Discussion . . . 32
3.5.1 Crowd helps develop better rules for machine . . . 32
3.5.2 StructFeed not only identifies writing issues but promotes reflection 33 3.5.3 Expert feedback performed worse than crowd feedback? . . . 33
3.6 Conclusion . . . 34
4 Feedback Orchestration: Supporting Reflection and Awareness in Revision 35 4.1 Introduction . . . 35
4.2 Formative Study . . . 38
4.2.1 Task and procedure . . . 38
4.2.2 Findings . . . 39
4.3 Feedback Orchestration . . . 40
4.3.1 Expert revision practice . . . 40
4.3.2 Support reflection and awareness . . . 41
4.4 System Implementation . . . 41
4.4.1 Taxonomy of writing feedback . . . 42
4.4.2 Feedback classification . . . 44
4.4.3 Revision workflow . . . 45
4.4.4 Revision interface . . . 45
4.5 Experiment . . . 48
4.5.1 Participants . . . 48
4.5.2 Task and procedure . . . 49
4.5.3 Measures . . . 51
4.5.4 Results . . . 52
4.5.5 Insights from interviews with participants . . . 53
4.6 Discussion and Implications . . . 58
4.6.1 Feedback categorization guides learning behaviors . . . 58
4.6.2 Flexible support for varying preference . . . 59
4.6.3 Low-to-high sequence facilitates difficult problem solving . . . . 60
4.6.4 Decrease the workload of low-level, repetitive tasks . . . 61
4.6.5 Resolving editing conflicts and mental obstacles . . . 61
4.7 Limitations and Future work . . . 62
4.8 Conclusion . . . 63
5 How Feedback Affects Revision Quality? 65 5.1 Introduction . . . 65
5.2 Crowd Feedback vs Expert Feedback . . . 66
5.3 Experiment: Writing Revision Affected by Feedback of Different Types . 67 5.3.1 Participants . . . 69
5.3.2 Task and Procedure . . . 69
5.3.3 Measures . . . 70
5.3.4 Statistical Results . . . 72
5.3.5 Insights from Interview Data . . . 73
5.4 Discussion . . . 75
5.4.1 The Cost and Benefit of StructFeed . . . 75
5.4.2 The Utility of StructFeed Depends on Learners’ Level of Proficiency 75 5.4.3 Gap between Expert Reviewer and Novice Writer . . . 76
5.4.4 Macro-Task vs. Micro-Task . . . 76
6 Reflection After/Before Practice 79 6.1 Introduction . . . 79
6.2 Related Work . . . 81
6.3 Learnersourcing for Drawing Support . . . 81
6.4 ShareSketch: Draw, Review and Share . . . 82
6.4.1 Sketch Interface . . . 83
6.4.2 Timeline Interface for Sketch History . . . 83
6.5 Before/After-Practice Reflection Workflow . . . 83
6.6 Pilot Study . . . 85
6.7 Results and Findings . . . 85
6.7.1 After-practice annotation augments before-practice annotation . . 86
6.7.2 Before-practice reflection vs After-practice reflection . . . 87
6.8 Discussion . . . 87
6.8.1 Provide scaffolding for reflection and practice . . . 87
6.8.2 Learning points as feedback enhances creative task learning . . . 88
6.9 Future Work . . . 88
7 Conclusion 89 7.1 Restatement of Contributions . . . 89
7.2 Future Directions . . . 90
7.2.1 Hybrid Combination of Crowd and Machine . . . 90 7.2.2 Creative Knowledge Construction for Innovative Applications . . 91 7.3 Summary . . . 91
Bibliography 93
List of Figures
1.1 Iterative feedback framework is designed for supporting creative task solv- ing. It enables collaboration between authors and feedback providers. . . 2 1.2 The overview of this dissertation. . . 3 1.3 The concept of StructFeed. . . 4 1.4 The concept of feedback orchestration. . . 5 1.5 A series of studies to understand the relationship between revision quality
and type of feedback generation method. . . 6 1.6 Reflection-based workflow is used to support learners to reflect and ex-
tract learning points from others’ creation process. . . 7 2.1 A successful online feedback exchange framework requires five key ele-
ments: writing, feedback, revision, reflection as well as awareness. Our work incorporates reflection and awareness with a feedback framework for facilitating the effectiveness of revision. . . 13 3.1 The overview of StructFeed. The system generated writing suggestions
based on aggregated crowd annotations and writing critera. . . 19 3.2 The crowdsourcing interface contains 1) definition of topic sentence, 2)
a worked-out example, 3) working area, 4) next button, 5) check-empty button, and 6) submit button. . . 21 3.3 The feedback interface contains 1) issue summary, 2) writing hints, and
3) topic and relevance sliders. The top image shows feedback when topic weight is 2 and relevance weight is 2; the bottom image shows feedback when topic weight is 3 and relevant is 0. . . 22
3.4 Results of topic sentence prediction by aggregating topic annotations from crowd workers with different threshold. . . 24 3.5 Results of relevant sentence prediction by aggregating relevant keyword
annotations with different threshold. . . 24 3.6 Results of identifying irrelevant sentence by aggregating relevant keyword
annotations with different threshold. . . 25 3.7 Results of topic sentence identification from ML-methods and our crowd-
based method . . . 28 3.8 Results of irrelevant sentence identification from ML-methods and our
crowd-based method . . . 29 3.9 The performance of three feedback-generation process is shown at the left
three columns. The result of revision quality by three feedback-generation mechanisms is shown at the right three columns. . . 31
4.1 The overview of feedback orchestration. It guides writers to integrate feedback into revisions by a categorized structure. . . 37 4.2 The taxonomy of writing feedback follows the ESL Composition Profile.
It consists of five writing evaluation criteria including content, organi- zation, vocabulary, language use and mechanics. We grouped content and organization as high-level feedback, vocabulary and language use as medium-level, and mechanics as low-level feedback. . . 43 4.3 The two images shows the high-to-low interface that transits from the
high-level stage (left) to the medium-level one (right). (a) original article view, (b) editing area, (c) feedback rating, (d) accept and reject buttons, (e) writing tip button, (f) next button, and (g) selected annotation. . . 46 4.4 Writers can find helpful information about writing by clicking the top-
right button “writing tip.” . . . 47
4.5 One example of expert feedback collected from one expert by using Word- vice TOEFL writing feedback service. The feedback include one score, overall feedback and specific feedback containing direct editing and com- ments. . . 50 5.1 The overall comparison between an expert and an individual crowd worker. 67 5.2 The detailed comparison of feedback type between expert and crowd (in-
dividual view and overall view). . . 68 5.3 The detailed comparison of feedback form between expert and crowd (in-
dividual view and overall view). . . 68 5.4 Relation between Difference of Rating, English Proficiency Level and
Feedback condition. Points shown are results predicted by the linear mixed- model but not the raw data. Fitting lines are added to illustrate the trends. 71 6.1 The overall of learnersourcing drawing support. . . 81 6.2 ShareSketch augments web-based drawing system with an interactive time-
line. A user can create a drawing by a sketch interface (a), review the drawing process by an interactive timeline interface (b), and share the pro- cess to others (c). . . 82 6.3 A learner performs a reflection task by identifying a clip and describe what
it is, and then explain why they learned from the clip. . . 84 6.4 Learners are allowed to practice drawing based on other’s creation process
in a short practice task. . . 84 6.5 The above two images are two creative processes created by two experts.
The below eight images are the results of participants’ practices. . . 86
List of Tables
4.1 Survey items for perceived helpfulness of overall system and feedback categorization. . . 52 4.2 The means (and standard errors) of perceived usefulness and helpfulness,
as well as objective measures in each condition. There is no significant relationship between three conditions. . . 52 4.3 Non-novice writers preferred a workflow that is consisted to their previous
revision strategies; novice writers changed their revision strategies after experiencing three types of workflows. The star symbol (*) indicates a novice writer who got low-level score and had less than one year of writing course experience. . . 56
Chapter 1 Introduction
1.1 Background and Motivation
Solving creative problems like writing or design is challenging, for such problems are open-ended and usually may not have well-defined answers. The answer is not true or false, but how good the answer is. Therefore, evaluating the answer is also a difficult prob- lem. The quality of answer usually can be evaluated by multiple criteria, yet the criteria may be change under distinct situations. For example, writing an essay or creating a re- sume requires very different criteria to evaluate the achievement. To achieve high-quality results, people have to acquire domain-specific knowledge and develop professional skills by learning and practicing repeatedly. As problem gets large and complicate, people often need external support to accomplish such complex creative tasks.
Feedback is a critical component in the creative process for supporting people iterate toward better results. It helps people acquire conceptual knowledge, discover weakness, and fix errors. However, obtaining high-quality feedback is difficult due to a limited pool of experts. To meet the demand of obtaining timely feedback, recent work has explored online feedback exchange platforms to connect problem solvers with feedback providers from diverse sources [72, 50, 27].
Crowdsourcing has been applied and proven to be useful for helping designers im- prove their design by diverse feedback obtained from the crowd [72, 51, 50]. Most studies focus on how to generate multiple types of useful feedback including high-level impres-
Creative Work
Author
Practice Review
Feedback Utilization
Collaboration
Feedback Generation
Feedback
Provider Learner
Reflection Feedback
Learning by Reflection
Reflection
Collaboration
Creative Work
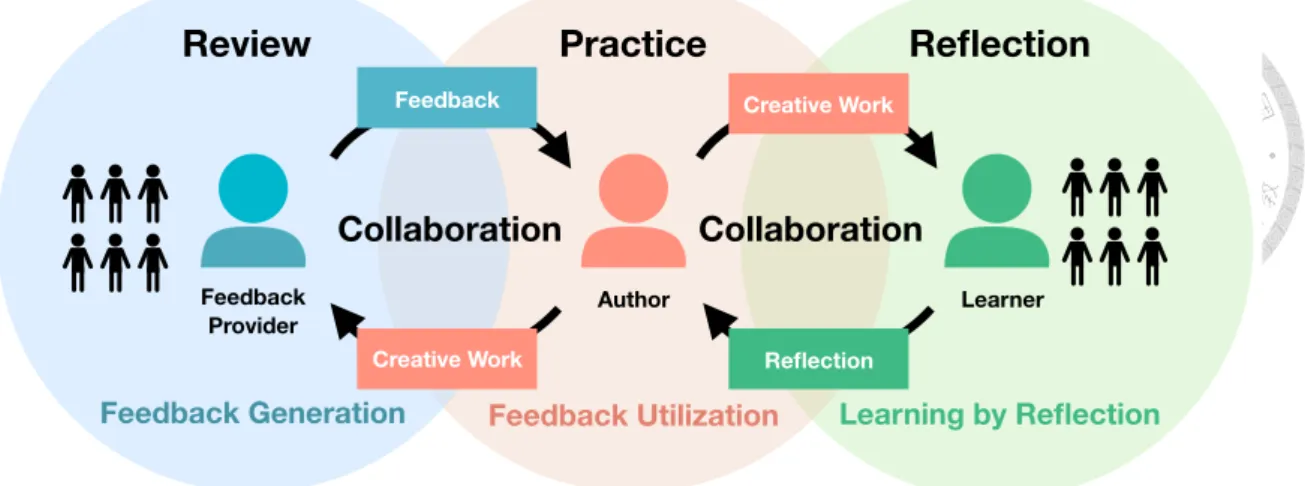
Figure 1.1: Iterative feedback framework is designed for supporting creative task solving.
It enables collaboration between authors and feedback providers.
sions and concrete suggestions regarding design principles. In addition, crowdsourcing workflows and structural interfaces were proposed for guiding crowd workers to gener- ate high-quality results. These studies have demonstrated that designers have benefited from diverse feedback generated by the crowd in the design process. However, diverse feedback not always leads to good results. Most recent studies focus on feedback genera- tion process, but ignore feedback integration process. Therefore, we attempts to provide a complete understanding of online feedback exchange and explore possibilities of crowd- powered feedback systems to from both aspects.
In my dissertation, I build on studies of learning science and develops intelligent sys- tems that generate effective feedback and facilitate good revision behaviors, focusing on the writing domain. The goal is to leverage the power of crowd and machine to sup- port people to solve the complex creative tasks from diverse aspects and improve the task quality effectively; more importantly, the work aims to provide people better learning experiences in the iterative problem-solving process.
1.2 Supporting Creative Task Solving
To solve creative tasks, we propose an iterative feedback framework that enables collab- orations between authors and feedback providers. In this framework, authors can learn to
Feedback Provider
Crowd Machine
Crowdsourcing Workflow Data Annotations
Expert Crowd
Part I: Feedback Generation
Feedback
Author
Revision Workflow
Part II: Feedback Utilization
Rhetorical Structure High-Level
Medium-Level Low-Level Feedback
High Medium Low Feedback
Collaboration
Learner Creative Work
Extract Reflective Annotations
Learn & Reflect
Learning
Part III: Learning through Reflection
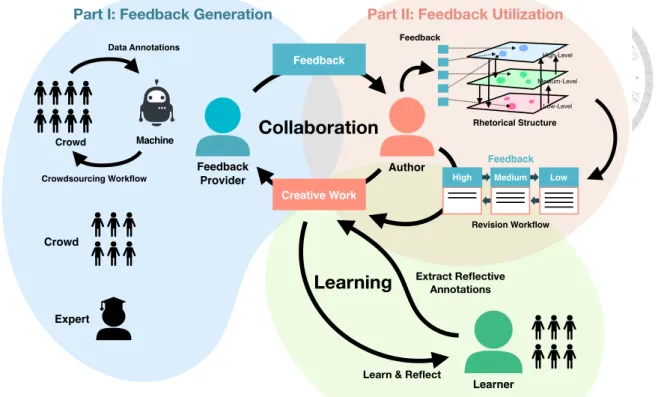
Figure 1.2: The overview of this dissertation.
improve the quality results by feedback obtained from the feedback providers; feedback providers can also learn to evaluate the quality of outcome and provide helpful feedback to authors. The overview of the framework is depicted in Figure 1.1. Both roles of people can learn from each other and collaborate to achieve the best performance in the iterative process.
In my dissertation, I structure this problem into four aspects: 1) understand how to generate effective feedback for supporting creative tasks solving, and 2) investigate how to effective integrate feedback and facilitate high-quality results, 3) understand how different types of feedback affects the revision quality in the iterative process, and 4) explore how to promote reflection to enhance learning process.
Author Feedback
Writing
Crowd Machine
Revision
Crowdsourcing Workflow Data Annotations
Supporting Writing Revision by Crowdsourced Structural Feedback
StructFeed
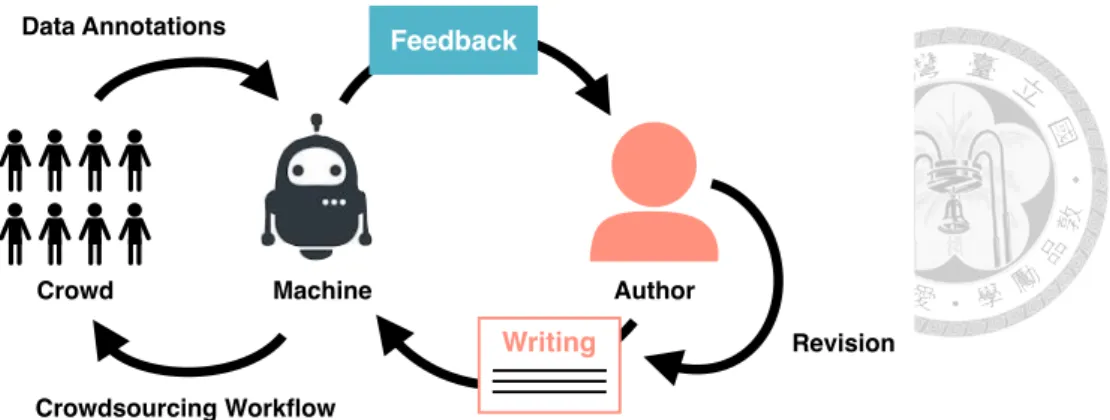
Figure 1.3: The concept of StructFeed.
1.3 Roadmap of Research
The section presents a brief overview of this dissertation (see Figure 1.2). First, we focus on feedback generation process and introduce StructFeed, a crowd-powered system that generates effective feedback for writing support. Second, we explore feedback integra- tion process and propose feedback orchestration to facilitate good revision and learning behaviors. In the end, we will explore a series of studies to understand the significant factors that impact the creative task performance in the iterative process. This disserta- tion will contribute rich insights of designing a successful intelligent feedback systems for supporting creative tasks.
1.3.1 StructFeed: Generate Effective Feedback by Crowdsourcing
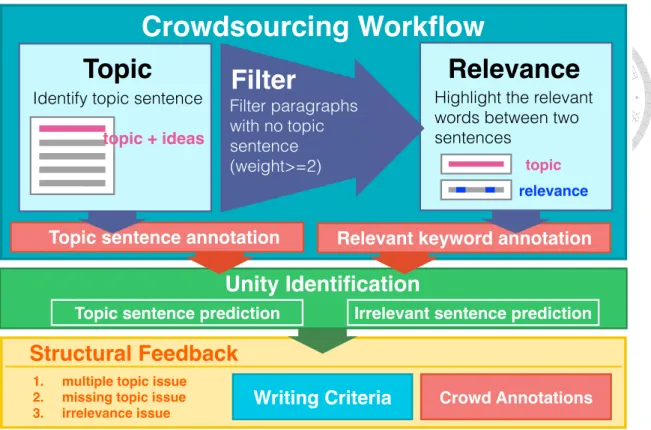
StructFeed is a crowd-powered system that supports non-native writers to create a uni- fied articles by providing useful suggestions including writing hints and crowd annota- tions. In this project, we consulted with English writing teachers and textbooks to find the key principles of writing evaluation criteria. Based on the understandings, we designed a crowdsourcing workflow with a goal of evaluating unity of writing, which is the most important criterion of good writing. The workflow decomposed the evaluation tasks into micro-tasks and allowed multiple crowd workers to annotate topic sentence and relevant keywords. Next, the system identified topic and irrelevant sentences based on aggregated results. Last, it generated suggestions based on writing criteria. The concept of StructFeed
Author Feedback
Provider Feedback
Revision Workflow Writing
High Medium Low Feedback Rhetorical Structure
High-Level Medium-Level Low-Level content
organization
vocabulary grammar
mechanics Feedback
2018.04.19 for CSCW 2018
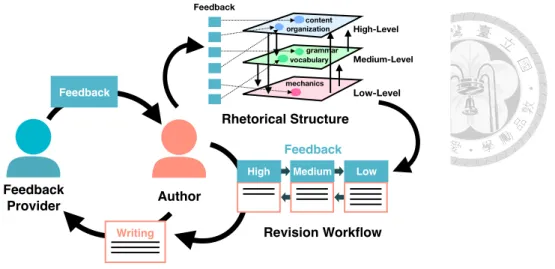
Figure 1.4: The concept of feedback orchestration.
is shown in Figure 1.3.
In a field experiment, we recruited 18 self-motivated non-native speakers to write an independent essay and revise the essay by feedback obtained from experts, crowds, and StructFeed. We compared the quality of the original and revised article in three groups.
The results showed that non-native writers who received feedback from StructFeed got the best performance, compared with feedback from a single expert or crowd worker. Two interesting findings are as follows:
• Feedback provided by experts did not lead to the best revision results, despite the fact that it got the highest scores of perceived usefulness.
• Providing indirect feedback containing writing hints about subgoal and aggregated crowd annotations, which is generated by StructFeed, promotes people to reflect their deficiency, resulting in better revision results.
1.3.2 Feedback Orchestration: Facilitate Effective Revision
Diverse feedback provides useful information that helps people improve task performance.
However, good feedback may not lead to high-quality outcome. In this work, we attempt to understand people’s behaviors in the feedback integration process and explore ways to facilitate effective revision behaviors by adjusting feedback presentation. We proposed
Crowd Machine Crowdsourcing Workflow
Data Annotations
Expert Crowd
Author Feedback
Writing Feedback
Feedback Revision
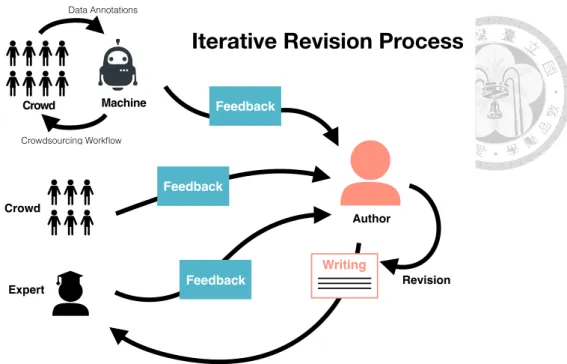
Iterative Revision Process
Figure 1.5: A series of studies to understand the relationship between revision quality and type of feedback generation method.
feedback orchestration that uses a categorized structure to guide writers to learn and inte- grate feedback in a revision workflow (see Figure 1.4). To evaluate the idea, we implement ReviseO, a web-based writing support system that use a standard writing rubric to classify feedback and enable sequential and concurrent revision workflows.
In a within-subjects experiment, we explored how three types of feedback presentation (high-to-low, low-to-high, and all) affect revision behaviors and task performance. The results showed that our system guided people to improve their writings and helped people discover their weaknesses of writing. Furthermore, The findings suggested that people receiving feedback separately spent more time but fewer edits on their revision, compared with people receiving all types of feedback together. In addition, people receiving feed- back in the low-to-high process developed momentum to solve the harder problems like content and organization.
1.3.3 Understand How Feedback Affects Revision Results
According to our previous research, we observed that expert feedback performed worse than crowd feedback when all participants had high satisfaction about obtaining it. In this
Leaner Creative Work
Author
Before/After-Practice Reflection Workflow
Generate Learning Points
learning points
Identify Self-Explain Reflection Workflows
Practice Identify Self-Explain Practice
Identify Self-Explain
Learn & Reflect Create
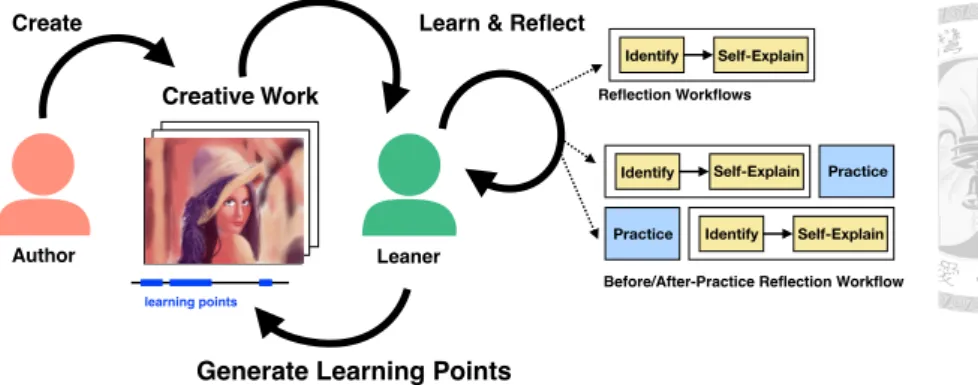
Figure 1.6: Reflection-based workflow is used to support learners to reflect and extract learning points from others’ creation process.
project, we are interested in how difference of expert feedback and crowd feedback, and which one can benefit the writers in what ways. which factors significantly influence the quality of results.
To better understand how feedback generated from different sources affects revision quality (see Figure 1.5). First. we conducted a content analysis on two groups of feedback collect from experts and crowd workers. We observed that although a single expert can generate more types of feedback than a single crowd workers, both of them tend to less high-level feedback about content and organization. Next, we will design a within-subject experiment to examine the relationship between type of feedback, order of feedback type, and writers’English abilities.
1.3.4 Reflection Before/After Practice
To support the acquisition of drawing skills, this research explores a learnersourcing ap- proach to generating personalized learning points. These are annotations containing a clip of a drawing process, a description, and an explanation. This paper presents ShareSketch, a web-based drawing system that enables learners to practice drawing, review the draw- ing process, and share their works with others. In particular, we propose the before/after- practice reflection workflow that allows learners to generate learning points before or af- ter each short practice. We evaluated our reflection workflow with eight self-motivated drawing learners. The results showed that our reflection workflow can guide learners to
generate high-level subgoal or concept labels, low-level steps, and personalized coping strategies.
Chapter 2
Related Work
This dissertation builds upon four main research areas: human computation and crowd- sourcing to incorporate human intelligence to solve the complex creative tasks in a dis- tributed way; online feedback exchange to solicit feedback for improving the quality of creative tasks; learning science to make feedback and revision effective for support- ing novices to learn domain knowledge, develop specific skills, and generate high-quality content; writing support applications to better understand the challenge of designing intelligent systems for supporting creative tasks.
2.1 Human Computation and Crowdsourcing
Over the last decades, human computation has established a popular research area that har- nesses human intelligence to solve difficult problems that are beyond the scope of existing Artificial Intelligence (AI) approaches. Many researchers have successfully leveraged hu- man abilities to tackle the problems that computers cannot solve, from image labeling [70], to protein folding [11], to text digitization, and to word processing [1].
2.1.1 Incentive, Microtasks, Quality Control
Most human computation systems solicit human inputs for a part of computation in a dis- tributed way. They treat humans as processors, but unlike machine, humans require an incentive to make contributions to a computation goal. As a result, one of challenges for
designing human computation systems is incentive design. The incentive can be various forms including monetary or social rewards, enjoyment of task, a sense of duty or a desire of learning. For example, Game with a Purpose (GWAP) attracts online players to per- form some specific tasks (e.g., tagging object from an image [70] or protein folding [11]) for entertainment as playing a game. In addition, many human computation systems may recruit paid workers through an online labor market such as Amazon Mechanical Turk or CrowdFlower, in which workers earn small amount of money by accomplishing “micro- task” in a short time. Another systems allows friends or followers on social media sites such as Facebook or Twitter to make contributions based on social relationship [2]. Fur- thermore, volunteering-based systems motivate non-paid crowds to make contributions for the goal that is serving the public good. For example, Zooniverse1 engages volunteers to help professional reserchers to perform various science tasks including classifying galax- ies from photos, identifying crater entries, and so on. Learnersourcing engages a large group of leaners to contribute their efforts for improving video contents and interfaces in the context of learning [71].
Instead of incentive, human attention and task complexity are another important design considerations. Attracting a large number of crowd workers to perform an arbitrary task may lead to noise data, because of limited attention and a lack of expertise. To handle noise data, human computation systems aim to apply “divide and conquer” strategy to break large problems into smaller subtasks, called microtask, and devise various quality control mechanisms for improving the quality of outcome from large amounts of crowd workers.
While human computation systems focus on leveraging human intelligence to solve the task that machine cannot solve, crowdsourcing systems addresses this issues in a scalable way by recruiting a group of crowd workers. This work is inspired by previous research about crowdsourcing and aims to design crowd-powered systems that support novices to solve complex creative tasks and develop their professional skills.
1https://www.zooniverse.org
2.1.2 Crowdsourcing for complex task
To allow online crowd workers to solve complex task, existing crowd-powered systems break complex into subtasks and guide workers to perform the subtasks in a workflow.
For example, Soylent [1] has demonstrated that dividing complex tasks into various small tasks in a multi-stage process improves the quality of document editing. CrowdForge [41] uses a MapReduce framework to guide workers to write encyclopedia articles. Other workflows are used to retrieve nutrition information from food photographs [56], taxon- omy generation [10], and travel planning [76]. These workflows can even be created by workers themselves [44]. However, some tasks cannot be divided into independent tasks and may lose global context or information while applying such decomposition strategies.
To addresses these issues, many researchers explored ways to enable crowd collabora- tion to solve complex tasks requiring global context [38, 69, 29], such as travel planning, short story [38] or wikipedia article writing [29], etc. Ensemble [38] used a team leader to coordinate a group of crowd workers to write short stories. The Knowledge Accelerator [29] developed several crowdsourcing techniques like “vote-then-edit” and “task of least resistance” to guide crowd workers to enhance global consistency of writing. Flash teams [61] or Turkomatic [44] have relied on a invested contributor such as a moderator or an experienced contributor to maintain the big picture.
This thesis contributes crowdsourced workflow design for allowing crowd workers to examine quality of creative work and generate annotations for effective writing feedback.
2.2 Online Feedback Exchange
Feedback is critical to the success of creative work, from essay writing to design [63, 45].
The CSCW community have explored Online Feedback Exchange (OFE) systems for re- questing and receiving information from distributed feedback providers to help designers improve the quality of creative work [24]. However, the feedback collected from different sources, including online communities, crowds and peers, can be general and ambiguous because those providers may have different motivations, expertise and perspectives [73].
To collect timely, specific and useful feedback, prior work used multiple-stage workflows [72] or a structured interface [50] to guide novice workers to accomplish the task. Rubrics [50, 27, 75] and comparative examples [43] have been proven to be effective in structuring feedback generation process because they encourage novice providers to generate specific suggestions based on diverse criteria.
Furthermore, many researchers have investigated the characteristics of feedback that can affect feedback reception and work performance [54, 43, 32, 30]. In addition to speci- ficity, feedback framed with positive language from an anonymous source improves per- ceived helpfulness of design critique [54, 32]. The motivation of providers also affects the quantity, quality, and content of feedback. For example, a paid task market provides longer and more positive suggestions and a web forum provides more process-oriented feedback [73]. Moreover, researchers have developed a natural language model based on these characteristics (e.g., specificity, sentiment, etc.) to provide guidance with feedback examples to help providers self-assess and improve their critique [43].
Although these studies have improved the perceived helpfulness of feedback, some designers still failed to improve their design work [72, 50]. Researchers found that novice designers tended to focus on solving minor, easily-identified issues rather than important ones [50]. Therefore, recent work have started to investigate the relationship between feedback provided and the actual performance, especially focusing on understanding the effectiveness of different approaches to interpreting feedback [25, 74]. Foong et al. have found that expert and novice designers make sense of feedback in different ways and suggest different forms of support for them to successfully integrate feedback into revision [25]. In addition, Yen et al. have shown that combining feedback review with a reflective activity can support deeper interpretation of feedback [74].
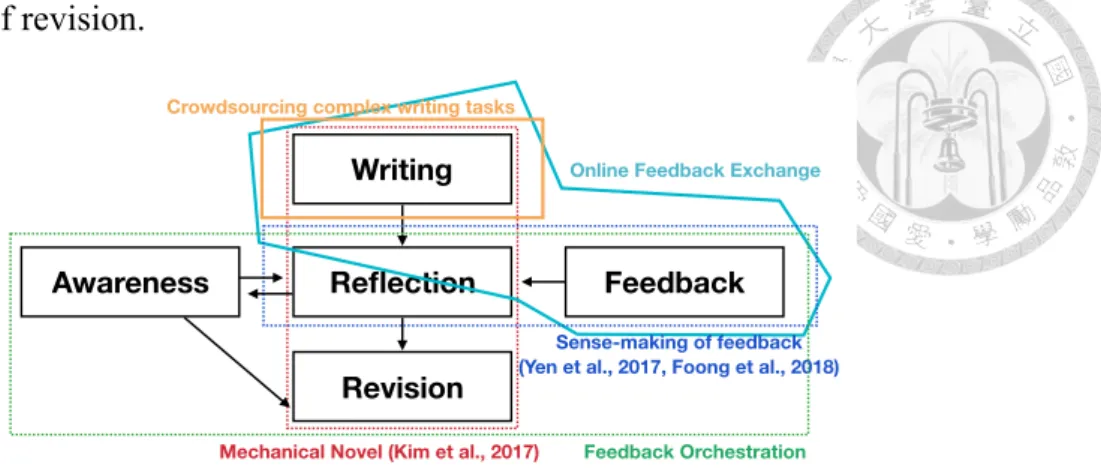
Our research also investigates how feedback receivers interpret and integrate feedback in revision; however, we focus on understanding writers’ revision behaviors and develop- ing approaches to facilitating reflection and awareness, leading writers to take advantage of feedback and revise effectively. Figure 2.1 describes how our work relate to prior work.
Our work regards reflection and awareness as key elements for designing a successful on-
line feedback exchange system because reflection and awareness can help enhance the effectiveness of revision.
Writing
Revision
Reflection Feedback
Mechanical Novel (Kim et al., 2017)
Sense-making of feedback (Yen et al., 2017, Foong et al., 2018)
Feedback Orchestration
Awareness
Online Feedback Exchange Crowdsourcing complex writing tasks
Figure 2.1: A successful online feedback exchange framework requires five key elements:
writing, feedback, revision, reflection as well as awareness. Our work incorporates re- flection and awareness with a feedback framework for facilitating the effectiveness of revision.
2.3 Learning Science
2.3.1 Self-Regulated Learning
To support successful learning on creative tasks, self-regulation should be considered in the process. This work draws on the idea of self-regulated learning. There is considerable research evidence suggesting that effective feedback leads to learning gains. In particular, Sadler identified three conditions for effective feedback. He argued that good feedback must help a student to 1) possess a concept of the standard being aimed for, 2) compare the actual level of performance with the standard, and 3) engage in appropriate action that closes the gap [63].
Self-regulated learning has been regarded as an important component for successful learning in school and beyond [4, 77]. Pintrich defined self-regulated learning as “an active, constructive process whereby learners set goals for their learning and then attempt to monitor, regulate, and control their cognitions, motivation, and behavior, guided and constrained by their goals and the contextual features in the environment” (p.453) [5]. To support learners to take control of their own learning, Nicol [55] identified seven principles of good feedback practice that support self-regulation: 1) clarify what good performance
is (goal/criteria/standards); 2) facilitate self-assessment; 3) deliver high-quality feedback;
4) encourage dialogue between teachers and peers; 5) encourage positive motivation and self-esteem; 6) provide opportunities to close the gap; and 7) use feedback to improve teaching.
2.3.2 Reflection and Reflective Practice
Reflection is defined as a purposeful thinking toward a goal [13]. John Dewey argued that reflecting on experience facilitates learning from experience. It is regarded as a mental activity of internal problem-solving. Furthermore, Donald A. Schön introduced reflective practice and explained the relationship between reflection and practice. He theorized that reflective practice represents an important factor to improve professional activity and dis- tinguished two types of reflection: reflection-in-action and reflection-on-action [64, 65].
Reflection-in-action indicates that students monitor and modify actions during the learn- ing process. For example, students are encouraged to think about their current learning performance and figure out achievable steps to accomplish the goal. On the other hand, reflection-on-action indicates that students evaluate the past action and make a plan to improve future actions after the learning process. For example, students are encouraged to think back to their previous learning process and identify what was done well and what could have been done better.
To facilitate effective revision, our systems apply a rhetorical structure, provide meta- feedback and structural feedback to help people be aware of their weaknesses, and reflect in or on actions to develop their strategies. In addition, this work incorporates reflection into the system design and presents a reflection workflow and a reflection-before/after- practice workflow to solicit annotations for supporting learning behaviors.
2.4 Writing Support Systems
Writing is considered as a series of cognitive processes, including planning, translating, reviewing and monitoring [22]. These processes were distinctive and hierarchically orga-
nized; however, any process can be embedded within any other, leading writers to create highly personal and complex workflows. Breaking down the complex writing process into smaller, more manageable subtasks is a commonly used writing strategy. This strategy has been shown to reduce cognitive load and improve writing quality [52, 28].
2.4.1 Automated Writing Evaluation
State-of-the-art automated writing evaluation systems (AWE) for supporting second lan- guage writing utilize supervised learning on large training datasets to predict the holistic score and to generate diagnostic feedback of an essay [14]. As an example, ETS Criterion [8] uses a discourse structure trained on 1,462 labeled essays, and builds a specific scoring model for each topic trained on a sample of 200–250 labeled essays. Consequently, it only supports limited topics for writing practices due to the cost of training data collection, an- notation, and processing. The proposed crowd-based writing framework is scalable, which supports any topic by collecting annotations on key elements of an essay (e.g., topic sen- tences, keywords) and providing structural feedback in alignment with the principles of writing.
2.4.2 Crowd-Powered Systems for Writing Support
Many researchers have applied such strategies to divide writing into a series of micro- tasks and have allowed crowd workers to accomplish them using a workflow [48, 1, 41, 38, 39, 67, 53]. For example, Soylent [1] split writing into stages and guided crowd work- ers to shorten texts, proofread and provide writing suggestions. CrowdForge [41] used MapReduce-like framework to generate encyclopedia articles by guiding multiple inde- pendent workers to perform simple tasks such as creating an outline, collecting facts and writing paragraphs. Storia [39] used a narrative structure to guide novice crowd workers to write a short story based on social media content. In addition, WearWrite [53] demon- strated the feasibility of writing a paper using a smartwatch by using microtasks and online crowd workers. Nevertheless, creating coherent and comprehensive writing can be chal- lenging by microtask design because crowd workers lack a global view.
To address this issue, researchers have explored several approaches that promote col- laborative work and allow crowd workers to perform microtasks while achieving high- level goals [38, 69, 29, 40]. Ensemble [38] used a team leader to guide crowd workers to write short stories. The leader was used to direct the overall collaborative process by establishing creative goals. MicroWriter [67] focused on coordinating a group of collo- cated people to write a single report with a shared goal via microtasks. In addition, some crowdsourcing techniques were also introduced to enhance global consistency of writing.
Voting activities can be used to help workers think about work from a global viewpoint and organize ideas to achieve high-level goals [29]. Guiding crowd workers to reflect on a high-level goal and revising the work by splitting it into low-level, actionable tasks can lead to high-quality results [40].
Those studies focus mainly on the challenges of breaking down the complex writing process into smaller, easier subtasks and aim for enabling collaboration between writers to accomplish the tasks. Although some researchers have noticed the effectiveness of incorporating reflection and revision in the writing process, novice writers still cannot fully benefit from these activities without any intervention [23]. Our research addresses the difficulties of revision and scaffolds novice writers to self-assess their work based on a rhetorical structure and structured feedback and support them to think and revise effectively.
Chapter 3
StructFeed: Generating Structural Feedback by Crowdsourcing
3.1 Introduction
Writing is a difficult task, especially for non-native speakers. To construct a well-structured essay, ESL writers usually take much efforts and time to write and rewrite iteratively. Dur- ing the iterative process, many written compositions which have many writing issues like lack of clarity or focus, or incomplete topic development are generated by ESL learners.
They need a pair of outside eyes to identify their weak spots and to suggest ways of fixing them. However, collecting high-quality feedback is challenging due to the limited pool of experts available. To support on-demand help, we require an approach that supports ESL writers to identify writing issues and suggest ways for improving their writing.
Previous studies have explored automated writing evaluation systems (AWE) for sup- porting second language writing. Almost all studies utilize supervised learning on large training datasets to predict the holistic score and to generate diagnostic feedback of an essay [14]. However, those automated methods only support limited topics for writing practices due to the cost of training data collection, annotation, and processing. To enable diverse writing support, we leverage the power of native speaker to make small contribu- tions for identifying basic writing elements like topic sentences and supporting data in the
texts.
According to our observations, many ESL students with more than 10-year English learning experience still struggled with identifying topic sentence for a basic five-paragraph essay and usually failed to develop a unified essay in our pilot study. That is why the ESL writing pedagogy always starts with teaching topic sentence writing, and move on the development of paragraph and essay later [57]. Therefore, we propose StructFeed, a crowd-powered system that generates structural feedback for helping ESL writers recog- nize high-level writing issues and produce a unified article. A crowdsourcing workflow is used for allowing native-speakers to identify topic sentence and relevant keywords in an article. Next, the system will predict the location of topic sentences and irrelevant sen- tence by aggregating crowd annotations and then generate writing suggestions. The goal is to guide people to revise the paragraph to achieve the paragraph unity based on writing criteria.
We compare our crowd-based method with three naïve machine learning (ML) meth- ods. The results suggest that the crowd-based method outperforms all ML methods. In addition, the new rule derived from crowd annotations outperformed all initial methods.
Furthermore, we evaluate StructFeed with 18 ESL writers recruited through online post- ings in the community sites. A between-subject experiment was conducted to investigate how and whether people can improve their writing after receiving feedback generated by one crowd worker, one expert, or StructFeed. The results showed that people who received writing suggestions from StructFeed achieved the best performance than other people who received writing suggestions from one crowd worker or one expert.
3.2 StructFeed
StructFeed is a crowd-based system that allows a user to request, receive, and review writing feedback for recognizing and fixing structural issues of writing. Instead of pro- viding feedback on local issues like grammatical or spelling errors, StructFeed attempts to address global issues like irrelevant ideas or missing main topic.
In this section, we introduce the design of StructFeed, and the overview of the system
Topic
Identify topic sentence
topic + ideas
Crowdsourcing Workflow
Relevance
Highlight the relevant words between two sentences
relevance topic
Filter
Filter paragraphs with no topic sentence (weight>=2)
Topic sentence annotation Relevant keyword annotation
Structural Feedback
Unity Identification
Writing Criteria
1. multiple topic issue 2. missing topic issue 3. irrelevance issue
Topic sentence prediction Irrelevant sentence prediction
Crowd Annotations
Figure 3.1: The overview of StructFeed. The system generated writing suggestions based on aggregated crowd annotations and writing critera.
is depicted in Figure 3.1. First, we describe the essential principle of writing – paragraph unity. Next, we introduce our crowdsourcing workflow that allows crowd workers who are native speakers to examine the paragraph unity through two types of micro-tasks. Finally, we present the structural feedback with a visualization interface.
3.2.1 Paragraph Unity and Topic Sentence
A good essay should have a clear structure in which all elements are well organized and linked. An essay consists of introduction, body, and conclusion and each part is composed of paragraphs. A paragraph is the basic component of writing, and it is a group of related sentences that are organized to develop a single idea. It contains a topic sentence, several supporting sentences, and a concluding sentence. The topic sentence is the most important one because it indicates the main idea of a paragraph. The supporting sentences are used to provide evidence to support the main idea. The concluding sentence is used to summarize the main idea presented in the topic sentence and emphasize the impression on the readers.
A good paragraph should follow an important principle called unity. Unity is used to evaluate the quality of oneness in a paragraph or an essay. It can be achieved by the following two steps.
• All sub-points are related to one main idea.
• No irrelevant sentence exists in the paragraph.
3.2.2 Crowdsourcing Workflow
The designed workflow breaks down the process of unity identification into two stages:
Topic and Relevance stage.
The system dispatches micro-tasks to online crowdsourcing marketplace in both Topic and Relevance stages. There is a filter between the two stages. It aggregates results from Topic stage and passes qualified results to Relevance stage.
Topic Stage
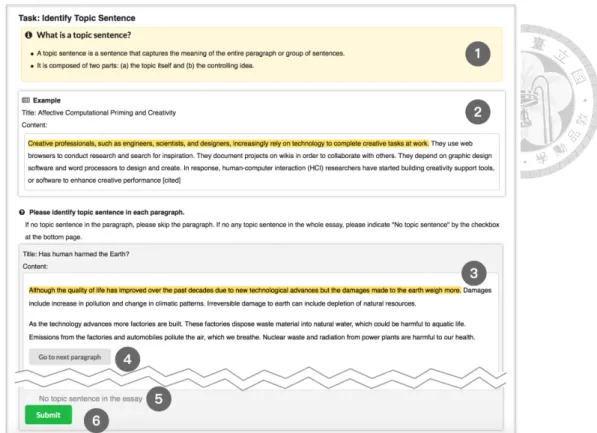
The goal of Topic stage is to examine whether all paragraphs have a topic sentence. In this stage, the system creates a task with five assignments and distribute it to distinct crowd workers. The task asks workers to mark every topic sentence in an essay. Our tool lets workers make sentence-level annotation by clicking on any part of a candidate sentence.
The selected sentence will be highlighted with yellow background. The annotation can be cancelled by re-clicking.
The crowdsourcing interface in Figure 3.2 is designed to guide workers to accomplish the task with good quality. The interface contains a brief description of topic sentence (1), a worked-out example (2) for teaching workers how to identify topic sentence, and a working area (3). In the working area, a crowd worker can annotate a sentence with a sim- ple click. A next button (4) is used to make workers focus one paragraph at a time; when it is clicked, the next paragraph will appear in the working area. When all the paragraphs appears, the check-empty (5) and submit button (6) will show up. In the end, a worker can submit the answer and finish the task.
Figure 3.2: The crowdsourcing interface contains 1) definition of topic sentence, 2) a worked-out example, 3) working area, 4) next button, 5) check-empty button, and 6) sub- mit button.
Relevance Stage
The goal of Relevance stage is to determine whether every other sentence is related to the topic sentence in a paragraph.
In this stage, the system creates a task with three assignments and dispatch it to dif- ferent workers. The task contains one paragraph with topic sentence labeled. The given topic sentence is determined by majority voting from the previous stage and is highlighted in yellow color. The task asks workers to locate the word which is related to the given topic sentence. Similar to the design of the previous stage, workers can make word-level annotation by clicking on any part of a candidate word. The selected sentence will be highlighted with a green background. The annotation can be canceled by re-clicking.
Filter
Filter is a bridge component which aggregates all annotations generated from the Topic stage and determines which one is a topic sentence by at least two annotations labeled from
Figure 3.3: The feedback interface contains 1) issue summary, 2) writing hints, and 3) topic and relevance sliders. The top image shows feedback when topic weight is 2 and relevance weight is 2; the bottom image shows feedback when topic weight is 3 and relevant is 0.
different workers. Next, the Filter would choose paragraphs existing a topic sentence to pass them to the Relevance stage.
3.2.3 Structural Feedback and Interface
Structural feedback is designed for helping writers identify their writing issues and fa- cilitate rewriting behaviors by prompting writing hints. The feedback consists of two elements: issue summary (1) and writing hints (2). The issue summary indicates the type of writing issue including multiple topics issue, irrelevance issue, and missing topic is- sue, and a suggested editing action (see Figure 3.3); the writing hints show the detailed of writing issues by a number of low-level annotations. The annotations include topic sentences, irrelevant sentences, and relevant keywords. The design of writing feedback follows Sadler’s requirements for high-quality feedback [63].
We not only show the location but also the weight for the annotations of topic sentences and relevant keywords. The weight of annotation presents the number of agreements made from different people. The blue highlighted sentence is topic sentence. The brightness of background color indicates the number of agreement from different people. When
more people annotate the same sentence as topic sentence, the background color of this sentence is much deeper than the other. In addition, the annotation of a relevant keyword is indicated by green highlighting. The brightness of background color is also determined by the number of annotations generated by workers. The red dotted underline indicates the location of an irrelevant sentence.
The two sliders (3) at the top left corner of the page are used to filter two types of annotation by different weight. By moving the slider back and forth, the writer can see the annotations with different weight appears in sequential order (see Figure 3.3).
3.2.4 Implementation
StructFeed is a Web application built in Python, Javascript, and Postgres, which has been deployed on Heroku. The two types of micro-tasks in the workflow generated as two external HITs are submitted to Amazon.com’s Mechanical Turk, a popular online crowd- sourcing platform. Workers who have at least 80% task approval rate are considered to perform our tasks. Each task costs $0.05 and one worker can perform 2.5-3 tasks in a minute. The worker can get at least $7.5-$9 per hour (higher than $7.25).
3.3 Unity Identification
To support writing on any topic, StructFeed needs to work in the absence of enough data, i.e. the “cold-start problem” in the context of computer-assisted writing. Therefore, we compare our crowdsourcing approach of unity identification with three naïve machine learning (ML) methods. These ML methods are commonly used for solving problems without large amounts of labeled training data.
In this section, we evaluate all methods by calculating average precision, recall, and F1-score (combined precision and recall) of identifying topic sentence, and irrelevant sen- tence.
Figure 3.4: Results of topic sentence prediction by aggregating topic annotations from crowd workers with different threshold.
Figure 3.5: Results of relevant sentence prediction by aggregating relevant keyword an- notations with different threshold.
3.3.1 Crowd-Based Method
Topic/irrelevant sentence prediction
A topic sentence is directly determined by at least two distinct crowd workers. Relevant sentence is determined by at least three distinct crowd workers who clicked the same sentence including relevant keywords. The threshold of a topic or relevant sentence is determined by empirical data discussed in the following paragraph. An irrelevant sentence is a sentence which is neither a topic sentence nor a relevant sentence.
Crowd Agreement and Performance
To obtain the aggregated answers, we set 2 agreements as a threshold for identifying topic sentence and 3 agreements as a threshold for identifying (ir)relevant sentence, respectively.
The detail performance of topic sentence, relevant sentence, and irrelevant sentence are described in Figure 3.4, 3.5, and 3.6, respectively.
Figure 3.6: Results of identifying irrelevant sentence by aggregating relevant keyword annotations with different threshold.
3.3.2 ML-Based Methods
To solve the problem lacking labeled data, we propose three naïve methods to predict topic sentence, relevant and irrelevance sentence.
Word Similarity
In our work, we choose two well-known methods for obtaining word similarity, Word2vec1 and Wordnet2. Word2vec is a group of related models that are used to produce word em- beddings. It is trained by skip-grams and CBOW (continuous bag-of-words) and turns words into a vector; its pairwise similarity is got by cosine distance. Wordnet is a corpus built by experts; its pairwise similarity is got by path similarity. We use these two methods to define the distance of two words and the synonym between two words.
Topic Sentence Prediction
This section we purposed three kinds of method to predict topic sentence: rule-based method, TF-IDF (term frequency-inverse document frequency) and average sentence sim- ilarity. The notation s in below means a sentence, which is also a set of word w, and the set of sentences in a paragraph is noted as P . A represents the set of P , which means the whole article. The length(s) represents the total word count in sentence s. The total relation between these sets is w ∈ s ∈ P ∈ A.
1http://deeplearning4j.org/word2vec
2https://wordnet.princeton.edu
• Rule-based method: A paragraph usually begins with a topic sentence [37]. We adopted the first sentence rule in the rule-based method.
• TF-IDF: A topic sentence is a sentence that identifies the main idea in a paragraph.
Each paragraph should have a different main idea in the standard essay writing. In other words, a topic sentence can be regarded as a sentence that contains the most number of keywords in the paragraph. Therefore, we adopted the concept of TF-IDF to extract keywords in the paragraph. Term frequency is calculated by sentence and inverse document frequency is calculated by paragraph. For term calculation, we aggregated the results of words with a high similarity. This method is used because with too few articles, and the same term may appear too few to find it second times.
Sentence with highest average TF-IDF would be chosen to be the topic sentence in a paragraph.
maxs∈P
!
w∈s
tf idfw,P
"
length(s)
tf idfw,P = nw,s
#
s∈P
#
w′∈snw′,s × log |P |
|{P ∈ A : w ∈ P }|
• Average sentence similarity (ASS): If there exists a topic sentence, it should have smallest average distance to other sentences in the paragraph. This method based on the corpus and calculate a pairwise distance of words between sentences in a para- graph, and then average the sum by the word aggregation. Sentence with smallest average distance sum would be chosen to be the topic sentence of a paragraph.
mins∈P
!
wi∈s
!
wj∈P \s
distance(wi, wj)
"
length(s)
Irrelevant Sentence Prediction
Based on the outcome of topic sentence prediction, we predicted irrelevant sentences by calculating the similarity of a sentence with a given topic sentence based on two kinds of corpus mentioned above. For Word2vec, we used “cosine similarity”; for Wordnet, we used “path similarity.” Then, we used leave-one-out validation to train PLA (perceptron
learning algorithm) for (ir)relevant sentence identification. The ground truths are anno- tated by two experts (as described in the following paragraphs).
3.3.3 Evaluation
To evaluate these methods, we recruited 15 participants who are all non-native speakers to write an essay in 30 minutes and crowdsourced those essays to obtain annotations from crowd workers. We compared precision, recall, and F1-score for evaluating the perfor- mance of prediction of topic sentences and irrelevant sentence.
The precision is the number of correct annotations divided by the number of all col- lected annotations. The recall is the percent of all correct annotations that are collected from an essay. The F-score that combines precision and recall is also used to evaluate the effectiveness of retrieved sentence.
Ground-Truth Data
We recruited two experts with 5+ ESL teaching and training experience to construct the gold standard annotations for 15 essays. Both experts have Ph.D. degree, and one’s major is Applied Linguistics, and the other’s is English Education. They were asked to annotate topic sentence, relevant keywords, and irrelevant sentence independently. The topic anno- tation (Kappa k = 0.98, p < .0001) and relevant keyword annotations (Kappa k = 0.92, p < .0001) created by two experts had high consistency. The gold standard annotations are the union of two experts’ results.
According to our observations, the two experts followed consistent principles to an- notate relevant keywords.
• identify supporting data with high relevance to the topic sentence
• identify the synonym appearing in the sentence with an argument but ignore simply repeating keywords
• identify chunks with a specific relation like cause-and-effect, etc.
Results of Topic Sentence Prediction
Precision Recall F1-score
TF-IDF
(Wordnet) 0.284 0.253 0.268
TF-IDF
(Word2vec) 0.269 0.240 0.253
ASS
(Wordnet) 0.403 0.360 0.380
ASS
(Word2vec) 0.343 0.307 0.324
Rule-based 0.658 0.587 0.620
Crowd-based 0.607 0.720 0.659
0 0.2 0.4 0.6 0.8
TF-IDF
(Wordnet) TF-IDF
(Word2vec) ASS
(Wordnet) ASS
(Word2vec) Rule Crowd
0.62 0.66
0.32 0.38
0.27 0.25
0.72 0.59
0.36 0.31 0.25 0.24
0.66 0.61
0.34 0.40
0.28 0.27
Precision Recall F1-score
Results of Topic Sentence Prediction
1
Figure 3.7: Results of topic sentence identification from ML-methods and our crowd- based method
Crowd Annotations
We crowdsourced 15 essays using our workflow in Amazon Mechanical Turk. 106 distinct workers were recruited for identifying topic sentence and relevant keywords. 55 workers completed 75 topic tasks (15 HITs with 5 assignments) and 51 workers completed 445 relevance tasks (89 HITs with 5 assignments). In total, there were 336 topic annotations and 1923 relevance annotations created in the workflow. The total cost is $26.
Topic Sentence Prediction
Figure 3.7 shows the results of topic sentence prediction for three ML-based methods and the crowd-based method. The best performance is the crowd-based method (agree- ment=2). Its precision, recall and F1-score 0.61, 0.72, and 0.66, respectively. The worst result comes from TF-IDF with Wordnet, its precision, recall, and F1-score is 0.28, 0.25, and 0.27, respectively. The rule-based method (all-first) is slightly worse than the crowd- based method. In detail, it has higher precision but lower recall than the crowd-based method.