行政院國家科學委員會專題研究計畫 成果報告
以放射狀基函數為基礎的模糊類神經網路系統之研究
計畫類別: 個別型計畫
計畫編號: NSC92-2213-E-011-077-
執行期間: 92 年 08 月 01 日至 93 年 07 月 31 日 執行單位: 國立臺灣科技大學電機工程系
計畫主持人: 楊英魁
報告類型: 精簡報告
報告附件: 出席國際會議研究心得報告及發表論文 處理方式: 本計畫可公開查詢
中 華 民 國 93 年 12 月 23 日
行政院國家科學委員會補助專題研究計畫成果報告
※※※※※※※※※※※※※※※※※※※※※※※※※
※ ※
※ 以放射狀基函數為基礎的模糊類神經網路系統之研究 ※
※ ※
※ ※
※※※※※※※※※※※※※※※※※※※※※※※※※
計畫類別:■個別型計畫 □整合型計畫 計畫編號:NSC 92-2213-E-011-077
執行期間:92 年 08 月 01 日至 93 年 07 月 31 日
計畫主持人:楊英魁
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
■出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
執行單位:國立台灣科技大學
中 華 民 國 93 年 12 月 21 日
行政院國家科學委員會專題研究計畫成果報告
以放射狀基函數為基礎的模糊類神經網路系統之研究 計畫編號:NSC 92-2213-E-011-077
執行期限:92 年 08 月 01 日至 93 年 07 月 31 日 主持人:楊英魁 國立台灣科技大學 電機工程研究所
一、中文摘要
本計劃所提出稱為模糊推理放射狀基函 數 類 神 經 網 路 (Fuzzy-Reasoning Radial Basis Function Neural Network, F2RBF2N)的架構,是由兩個子網路組成:
動作評斷網路(Action Critic Network, ACN) 和 動 作 選 擇 網 路 (Action Selection Network, ASN),每個子網路僅需三個神經 層(neural layer)。ASN 與一個模糊推理 (fuzzy reasoning)是功能等價,擔任規則式 模糊系統的角色,用來建立目標系統的輸 入空間至輸出空間的對應,以便產生模糊 系統的輸出去控制目標系統。由於 RBFN 與規則式模糊系統之間的等價關係,可以 省略模糊推理機制的模糊化(fuzzification) 和 解 模 糊 化 (defuzzification) 介 面 , 使 得 ASN 只需要三個神經層。ACN 的功能是在 每個時間階段產生強化學習程序所需的信 賴評斷預測信號(credits critic prediction signal),以便修正 ASN 的實際輸出;另外 ACN 也參照目標系統現況所產生的外部強 化信號(external reinforcement signal),轉 換成一個啟發式的內部強化信號(heuristic internal reinforcement signal),做為 ASN 調適及學習的依據。ASN 與 ACN 共用 RBFN 的兩個神經層,使 F2RBF2N 的網 路架構比其他的 NFS 架構更為簡單,不只 可以簡化網路拓樸的複雜度,更可以因為 降低網路的計算成本,使得系統的即時處 理更高。
本計劃提出的 F2RBF2N 可擁有由經驗學 習的能力,這個系統不只可以線上地產生
規則,而且可以在環境或受控目標系統發 生變化時,能夠即時地調整模糊規則。
關鍵詞:模糊系統,類神經網路,短暫差 異強化學習,放射狀基函數類神經網路
Abstract
In this proposal, the proposed network architecture, called Fuzzy-Reasoning Radial Basis Function Neural Network (F2RBF2N), is composed of two sub-networks: Action Critic Network (ACN) and Action Selection Network (ASN). There are only three neural layers in each sub-network. The function of ASN is equivalent to that of a fuzzy reasoning system. The ASN is to serve as a rule-based fuzzy system performing the mapping function from input space to output space of a controlled target system. Due to the functional equivalence between RBFN and fuzzy system, the layers performing fuzzification and defuzzification functions can be eliminated so that there are only three neural layers in ASN. The function of ACN is to generate credit critic prediction signals at each time step for reinforcement learning procedure in order to modify the actual outputs of ASN. In addition, ACN also refers to the
external reinforcement signals generated from current status of the target system, and transforms those signals into heuristic internal reinforcement signals for the learning and tuning mechanism in ASN. The sharing of two RBFN neural layers by both ASN and ACN not only makes the F2RBF2N simpler than other NFSs on network architecture but also reduces the cost of computation because of simplified network topology.
The ability of real-time processing by our proposed system is therefore improved.
The proposed F2RBF2N in this proposal has the ability to perform well the unsupervised learning from experience. The system can not only on-line generate but also tune the rules in the system as its associated environment or controlled plant is changed.
Keywords: fuzzy system, neural networks, reinforcement learning, temporal difference, radial basis function neural networks
二、緣由與目的
以多層類神經網路結合模糊推理機制於 一體的建模方法會有下列三項缺點:
1. 對於靜態或複雜度較低的系統,只要 取得足夠的觀測樣本,就能有效地運用類 神經網路的學習演算法進行參數的調適工 作。但是,對於動態的或互動性(interaction) 較高的複雜系統,足夠的樣本無法整批取 得,目標系統的教導知識亦無法獲得,導 致傳統的監督式學習無法勝任。
2. 多層前向類神經網路架構複雜,神經
元數量隨著神經層數量增多,需要調適的 參數也相對增加。不只前向計算的複雜度 增加,逆傳遞學習的計算複雜度亦增加。
耗費過多的計算成本,大幅降低整體效能。
3. 為了簡化 NFS 的複雜度,通常會預先 建立多層前向網路結構,當出現過度擬合 現象時,可以刪除(prune)多餘的神經元彌 補這些缺失。但是,神經元的刪減會造成 網路結構的重組,將拉長網路的學習期,
無 法 達 成 動 態 系 統 所 需 要 的 線 上 即 時 (on-line real-time)學習。
針對第一項缺點,本研究將採用增強式學 習方法(reinforcement learning method, RL) 取 代 監 督 式 學 習 (Supervised Learning, SL),RL 是一種以嘗試錯誤為主的啟發式 非監督學習策略,不必像 SL 必須依賴足夠 且精確的訓練資料對。由各種文獻可知,
已經有一些以 RL 為訓練機制的 NFS 研究 被發表,例如:ARIC、GARIC、RNN-FLCS、
FALCON-R 等。這些 NFS 的共同特點,都 是以多達五層(layer)的類神經網路去建構 模 糊 推 理 系 統 (Fuzzy Inference System, FIS),以便分別對應到輸入變數、輸入歸屬 函數、規則庫、輸出歸屬函數及輸出變數。
這種結構複雜度較高的 NFS,相對的需要 耗用較高的計算成本。
RBFNN 是最近十年逐漸被重視的一種新 的類神經網路架構,僅有輸入(input)、隱藏 (hidden) 及 輸 出 (output) 等 三 層 簡 單 的 架 構,它採用放射狀基函數當做隱藏層神經 元 (neurons of hidden layer) 的 激 發 函 數 (activation function),每個神經元僅對局部 區域有效,RBFNN 的輸出為隱藏層神經元 輸出的線性組合。這種局部性管轄的特 性,與加權平均的輸出計算方式與規則式 模 糊 系 統 的 模 糊 基 函 數 (fuzzy basis function, FBF)有相同的數學模式,並且經 過一些證明兩者是相等而可以互相替代 的。因此,針對第二項網路複雜度的缺失,
發展一種以 RBFNN 為基礎的 F2RBF2N 架
構,將模糊推理機制與強化學習機制的主 控制單元合而為一。
第三項缺失涉及類神經網路動態可變結 構的問題,固定結構的類神經網路簡單易 行,但是整體架構缺乏彈性,無法因應目 標系統的動態變化做有效的結構調整。本 研究發展一個動態建構模糊知識庫的訓練 演算法,可以量測目標系統輸入狀態的變 化,動態的增加 F2RBF2N 的神經元,促使 網路隨時維持在最佳的結構,以便提昇整 體的計算效能。
本研究致力於自動建構(self-constructing) 規則式模糊系統的方法論,研究的主要目 標是發展一個以強化學習為主的類神經- 模 糊 系 統 (Reinforcement Learning-based Neuro-fuzzy system, RL-based NFS),這個系 統除了承襲及發揚以往 NFS 的優點,也改 善 NFS 的缺點。本研究以 RBFNN 為基礎,
建立一個稱為模糊推理放射狀基函數的類 神 經 網 路 (Fuzzy Reasoning Radial Basis Function Neural Networks, F2RBF2N),將模 糊推理機制與強化學習機制的主控制單元 合而為一。對於靜態系統而言,這種新的 網路架構可以迅速地經由短暫的學習期調 適出模糊模式的相關參數;對於動態非線 性系統而言,可以隨時依據輸入的觀測資 料增加神經元,改變網路架構直到最佳的 情況為止,並且在這個過程中能夠同時調 適模糊模式的相關參數。另外,僅有三層 網路結構的 F2RBF2N 不只可以減少記憶 體的需求降低計算成本,亦可提昇網路的 學習速率(learning rate)。而且 F2RBF2N 將 擁有由經驗學習的能力,這個系統不只可 以線上地產生規則,而且可以在環境或受 控目標系統發生變化時,能夠即時地調整 模糊規則。
三、研究結果與討論
本研究在 F2RBF2N 上發展完整的學 習演算法,使其具有由經驗學習的能力,
它不只可以產生 ASN 隱藏層的接納範疇 (receptive fields),也可以在環境或受控設備 變動時,對 ASN 隱藏層神經元做增刪,以 及對接納範疇做線上調整(on-line tuning)。
換言之,F2RBF2N 可以實踐一個可變結構 的模糊推論系統,結合強化學習機制,可 以在不需要先期知識的情況下,經過線上 學習操作非常有效地建立更完美的模糊知 識庫,達成規則式模糊系統自動建模的目 標。
F2RBF2N 的特色是更少的計算時間 並且適合於即時應用,網路的隱藏層神經 元可以自動增加,使得建立一個效能令人 滿意的控制系統更為容易。對於靜態系統 而言,這種新的網路架構,可以迅速地經 由短暫的學習期,調適出模糊模式的相關 參數。對於動態非線性系統而言,可以隨 時依據系統動態觀測的樣本資料增加神經 元,改變網路架構直到最佳的情況為止,
在這個過程中也能夠同時調適出模糊模式 的相關參數。另外,僅有三層網路結構的 F2RBF2N 不只可以減少記憶體的需求降低 計 算 成 本 , 亦 可 提 昇 網 路 的 學 習 速 率 (learning rate)。F2RBF2N 的另一個特色是 網路架構簡單,ACN 與 ASN 共同使用網 路的輸入及隱藏層,只有輸出層產生各別 的結果。這種共用結構的網路,使 F2RBF2N 的空間複雜度(space complexity)降低,進而 提昇整體的計算效能,非常有利於即時動 態系統的學習。
F2RBF2N 的另一重要特色,就是利用 NFRL 模式的精髓,發展出一個與以往的 AHC 模式不同的 F2RBF2N 架構,並設計 各種有效率的即時學習演算法。F2RBF2N 是改良的 NFRL 模式,基本架構是以等效 於單值規則式模糊系統的 RBFNN,經由非 監督式的強化學習階段,可以對無法提供
完整觀測樣本或無法定義的動態系統,透 過動態線上學習的手段,自動地建立模糊 系統的模式。綜合言之,本研究的預期成 果可以歸納為下列數點:
1. F2RBF2N 是以 NFRL 模式為基 礎,主要的特徵是把 RL 與類神經模糊推論 機制合而為一的適應性模糊推論系統。這 個系統有非常精簡的網路架構與自動建構 模糊規則的能力,使其學習階段可以改善 以往 NFSL 模式學習階段過長的限制,以 便處理動態的或互動性較高的複雜系統。
2. 基於模糊推論系統與 RBFNN 之 間存在函數等價的關係,以 RBFNN 為核 心的 F2RBF2N 已經將模糊化與解模糊化 功能,包含在三個類神經網路層的架構 中。這個特點大量地降低模糊推論網路的 空間複雜度,並且明顯地減少網路的計算 成 本 。 F2RBF2N 的 功 能 與 ANFIS 、 FALCON-R 類似,都是把學習網路與模糊 推論系統合為一體。但是,F2RBF2N 網路 的架構比較簡單。F2RBF2N 的兩個主要網 路 ASN 與 ACN 共用 RBFNN 的輸入及隱 藏層,簡化了 F2RBF2N 結構的複雜度。但 是,ANFIS 則需以五個類神經層分別實踐 TSK 模 糊 規 則 的 前 件 部 與 結 論 部 , FALCON-R 用了兩個獨立的五層結構的 FALCON-ART 網路。
3. F2RBF2N 的學習機制,是由網路 結構學習與網路參數學習組成。網路結構 的學習機制可將目前擷取的輸入狀態與已 存在的規則節點做比對,以便動態地增加 F2RBF2N 的規則節點。網路參數的學習機 制是以短暫差異強化學習為基礎發展出來 的,除了可以調適規則節點核心函數的相 關參數之外,亦可調適模糊規則的單值後 件部。亦即,F2RBF2N 是一種可以動態地 改變網路結構的調適的模糊推論系統。這 項優點,較 ANFIS、FALCON-R 有更佳學 習表現。因為 ANFIS 以監督式學習為主,
必須先對輸入空間做適當的分割,以便建
立網路的結構,才能分別對 TSK 模糊模式 的前件部及結論部以不同的學習演算法調 適相關的參數。FALCON-R 必須先對輸入 及輸出空間做模糊超盒聚類,組合輸出入 關係為模糊規則,以便建立網路的雛形。
4. F2RBF2N 網路的隱藏層規則節點 採用多維的高斯形核函數,對於多輸入變 數的系統而言,每個規則節點的核函數就 是輸入變數的多維歸屬函數,可以完整地 表 現 一 個 模 糊 規 則 的 前 件 部 。 亦 即 , F2RBF2N 不必像 ANFIS 或 FLCON-R 單獨 建立每個輸入變數的一維歸屬函數。這個 優點,使得 F2RBF2N 不但簡化了網路的拓 樸,也簡化了規則節點的學習演算法,而 使網路的學習效能得以提昇。
5. F2RBF2N 中 網 路 參 數 是 透 過 ASN 及 ACN 的調適參數演算法獲得調 適,這些調適演算法都是以包含合格紀錄 (eligibility trace)能力的 TD(λ)強化學習法 發展出來的,其特色是能快速學習。
我們希望這個研究計劃的成果,能夠
對快速模糊系統自動建模的系統性方法,提
出改善的方向,改善以往方法的缺點。本計
畫研究的成果,是一種新的模糊系統快速 自動建模方法。對於一個模糊系統的應用 者而言,利用這種方法,可以不必經過以 往的試誤階段(trial and error),就可以順利 地依據系統數據將模糊系統建立出來。基 本上,這種方法只需要以系統的輸入輸出 資料為建模的依據即可,對於沒有太多先 期知識(priori knowledge)的灰箱系統(grey box system)或黑箱系統(black box system) 都可以利用本研究的成果,把雜亂無章的 資料背後隱藏的知識萃取出來。因此,希 望本研究的成果在下列個領域皆會有的貢 獻:
1. 應用在資料挖掘(data mining)及 知識發掘(knowledge discovery),目前這兩 種技術被產業界廣泛使用,由各種資料庫
(data base)把需要的企業情報分析與知識 萃取出來。
2. 可以充分發揮在研發智慧型應用
系統,可以降低開發期間的成本,使產品 能夠順利完成。
3. 對學術研究而言,提出一種系統 性、更有效率的模糊系統快速自動建模方 法。
四、重要參考文獻
1. H. R. Berenji and P. Khedkar, “Learning and Tuning Logic Controllers Through Reinforcements”, IEEE Trans. on Neural Networks, vol.3, no.5, Sept. 1992.
2. A. G. Barto and R.S. Sutton and C.W.
Aderson, “Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problems”, IEEE Trans. on Systems, Man, and Cybernetics, vol.
SMC-13 No. 5, pp834-847, 1983.
3. S. Chen, S. A. Billings, C.F.N. Cowan and P. M. Grant, “Non-Linear Systems Identification Using Radial Basis Functions”, Int. J. Sys. Sci. vol.21, no.12, pp2513-2539 1990.
4. K. B. Cho and B. H. Wang, “Radial Basis Function Based Adaptive Fuzzy Systems and Their Applications to System Identification and Prediction”, Fuzzy Sets and Systems 83, pp325-339, 1996.
5. J. A. Franklin, ”Input Space Representation for Refinement Learning Control”, Proc. IEEE Int. Symp. Intell.
Control, p115-122 1989.
6. B. Fritzke, “Transforming Hard Problems into Linearly Separable Ones with Incremental Radial Basis Function Networks”, International Workshop on Neural Networks, Proceeding. Volume
I/II (1994/1995), VU University Press, 1996.
7. M. E. Harmon and S. S. Harmon,
“Reinforcement Learning: A Tutorial”,
Available on http://www-anw.cs.umass.edu.
8. K. J. Hunt, R. Haas and R. M. Smith,
“Extending the Functional Equivalence of Radial Basis Function Networks and Fuzzy Inference Systems”, IEEE Trans.
On Neural Networks, vol.7, no.3, May 1996.
9. J. -S. Jang, “Self-Learning Fuzzy Controllers Based on Temporal Back Propagation”, IEEE Trans. on Neural Networks, 3(6), pp741-723, 1992.
10. J. -S. Jang and C. T. Sun, “Function Equivalence Between Radial Basis Function Networks and Fuzzy Inference Systems”, IEEE Trans. on Neural Networks, vol. 4 no. 1, Jan 1993.
11. J. –S. Roger Jang, ”ANFIS:
Adaptive-Network-based Fuzzy Inference Systems,” IEEE Trans. SMC, 23(03):665-685, May , 1993.
12. J. –S. Jang, C. –T. Sun, ”Neuro-fuzzy Modeling and Control,” Proceedings of the IEEE, 83(3), 378-406, March, 1995.
13. L. P. Kaelbling, M. L. Littman and A. W.
Moore, “Reinforcement Learning: A Survey”, Journal of Artificial Intelligence Research 4, pp237-285 1996.
14. B. Kosko, ”Fuzzy Systems are Universal Approximators,” IEEE Trans. Computers, 43, 1329-1333, 1994.
15. C. C. Lee, “Fuzzy logic in control systems: fuzzy logic controller, part I”, IEEE Trans. On Syst., Man, and Cybern., SMC-20, no. 2, 404-418, 1990.
16. C. C. Lee, “Fuzzy logic in control
systems: fuzzy logic controller, part II”, IEEE Trans. On Syst., Man, and Cybern., SMC-20, no. 2, 419-435, 1990.
17. C. C. Lee, “A Self-Learning Rule-Based Controller Employing Approximate Reasoning and Neural Net Concepts”, Int.
Journal of Int. Systems, vol.6, pp71-93, 1991.
18. C. J. Lin, “A Fuzzy Adaptive Learning Control Network with On-Line Structure and Parameter Learning”, Neural Network, 1996.
19. C. T. Lin and C. S. Lee, “Reinforcement Structure/Parameter Learning for Neural Network-Based Fuzzy Logic Control Systems” IEEE Trans. on Fuzzy Systems, vol.2 no.1, Feb. 1994.
20. C. T. Lin and C.S. Lee, “Neural Fuzzy Systems: a Neuro-Fuzzy Synergism to Intelligent Systems”, Prentice Hall , 1996.
21. E. H. Mamdani, and S. Assilian, “An experiment in linguistic synthesis with a fuzzy logic controller”, Int. J. Man mach.
Studies, 7, 1, pp. 1-13, 1975.
22. E. H. Mamdani, “Application of fuzzy logic to approximate reasoning using linguistic systems”, Fuzzy Sets and Systems, 26, 1182-1191, 1977.
23. W. T. Miller, III, R. S. Sutton, and P. J.
Werbos. “Neural Control Application”, Cambridge, Mass. MIT Press, 1990.
24. J. Moody and C. J. Darken, “Fast Learning in Networks of Locally-Tuned Processing Units”, Neural Computation 1, pp281-294, 1989.
25. M. T. Musavi, W. Ahmed , K. H. Chan, K. B. Faris and D. M. Hummels, “On the Training of Radial Basis Function Classifies”, Neural Networks, Vol.5, pp595-603, 1992.
26. J. Nie and D. A. Linkens, “Learning Control Using Fuzzified Self-Organizing Radial Basis Function Network”, IEEE Trans. on Fuzzy Systems”, vol.1, no.4, Nov. 1993.
27. M. J. L. Orr, “Regularization in the Selection of Radial Basis Function Centers”, Neural Computation, vol.7, pp606-623, 1995.
28. T. Poggio and F. Giros, “Networks for Approximation and Learning”, IEEE Proc.
vol. 78, no. 9, pp1481-1497, Sept. 1990.
29. W. Z. Qiao, W. P. Zhuang and T. H.
Heng, “A Rule Self-Regulating Fuzzy Controller”, Fuzzy Sets and Systems, 47, pp13-21, 1992.
30. S. P. Singh and R. S. Sutton,
“Reinforcement Learning with Replacing Eligibility Traces”, Machine Learning, 22, 123-158, 1996.
31. R. S. Sutton, “Temporal Credit Assignment in Reinforcement Learning”, Doctoral Dissertation, Department of Computer and Information Science, University of Massachusetts, Amherst, 1984.
32. R. S. Sutton, “Learning to Predict by the Method of Temporal Differences”, Machine Learning 3:9-44, 1988.
33. R. S. Sutton, “On Step-Size and Bias in
Temporal-Difference Learning”, Proceedings of the Eighth Yale Workshop
on Adaptive and Learning Systems, pp91-96. 1994.
34. R. S. Sutton, “Generalization in Reinforcement Learning: Successful Examples Using Sparse Coarse Coding”, Advances in Neural Information Processing Systems 8, pp.1038-1044,MIT Press, 1996.
35. S. H. G. ten Hagen and B. J. A. Krose,
“Generalizing in TD(λ) Learning”, Proc.
of Third Joint Conf. on Information Sciences, Vol. 2, pp319-322, 1997.
36. T. Takagi and M. Sugeno, “Fuzzy Identification of Systems and its Application to Modeling and Control,” IEEE Trans.
SMC., 15(1), 116-132, 1985.
37. L. X. Wang, “Fuzzy systems are universal approximators”, Proc. IEEE International Conf. On Fuzzy Systems, San Diego, pp. 1163-1170, 1992.
38. L. X. Wang, and J. M. Mendel, “Fuzzy basis functions, universal approximation, and orthogonal least squares learning”, IEEE Trans. On Neural Networks, 3, no.
5, pp. 807-814, 1992.
39. L. X. Wang, “A Course in Fuzzy Systems and Control”, Prentice-Hall, Inc. 1997.
40. B. Wang and K. B. Cho, “Radial Basis Function Network with Short Term Memory for Temporal Sequence Processing”, IEEE Conf. on Neural Networks, pp2683-2688, 1995.
41. A. R. Webb and S. Shannon,
“Shape-Adaptive Radial Basis Functions”, IEEE Trans. on Neural Networks, vol.9 no.6, Nov. 1998.
42. H. Ying, ”General SISO Takagi-Sugeno Fuzzy Systems with Linear Rule Consequent are Universal Approximators,” IEEE Trans. Fuzzy Set
Syst., 6(04): 582-587, 1998.
43. L. A. Zadeh, “Fuzzy sets”, Informat.
Control, 8, pp. 338-353, 1965.
44. L. A. Zadeh, “Outline of a new approach to the analysis of complex systems and decision processes”, IEEE Trans. On Systems, man, and Cybern., 3, 1, pp.
28-44, 1973.
45. L. A. Zadeh, “The concept of a linguistic variable and its application to approximate reasoning I, II, III”, Information Sciences, 8, pp. 199-251, pp.
301-357; 9, pp. 43-80, 1975.
參加 CIMCA2004 研討會心得報告
報告人: 楊英魁 2004.7.26
時間: 2004 年 7 月 12 日 ~ 2004 年 7 月 14 日 地點: 澳大利亞 黃金海岸 (Gold Coast, Australia) 報告內容:
這次在澳大利亞為期三天所舉行的研討會 CIMCA2004 (International Conference on Computational Intelligence for Modeling, Control & Automation),是學術界在人工智慧 與控制領域上重要的一次會議。由於它的重要性,所以另一個與人工智慧領域有關的 研討會 International Conference on Intelligent Agents, Web Technologies, and Internet Commerce 一起舉行。總共有來自全球不同領域的 435 個專家學者參與,氣氛熱絡,
尤其兩位榮譽大會主席都是在人工智慧領域裡大師級的人物。
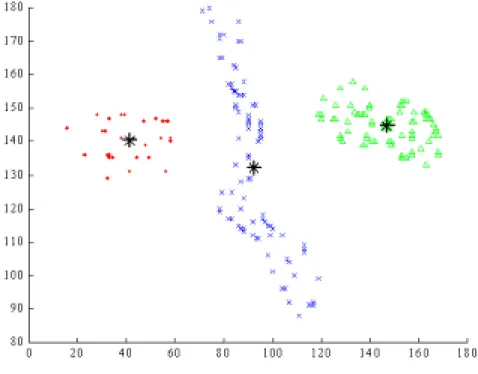
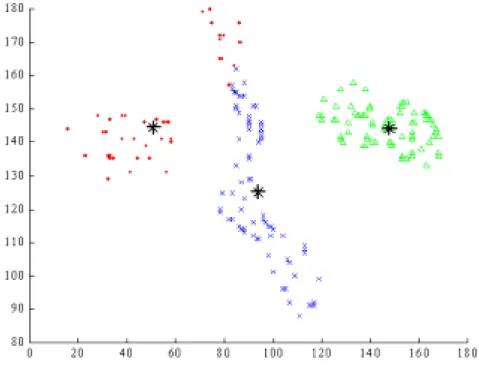
參加這次 CIMCA2004 主要是去發表二篇由國科會所支持研究的成果論文。第一篇 為 Constructing a Fuzzy Clustering Model Based on its Data Distribution,此論文提出一個 簡單又快速的 algorithm,能精確的從樣本資料 (sample data) 中描述系統的
Takagi-Sugeno 模糊模式,方法簡單,但效果很好,與會者對這方法都極為肯定。另一 篇論文為 A Weight- and Data-Distribution-Featured Approach for Fuzzy Pattern
Classification,此論文由觀察樣品資料間彼此距離的特性,消除掉目前所用方法中不合 理及不需要的運算過程,進而快速的自動建成效果良好的模糊聚集 (clusters),進而建 立一個精確又有效的模糊系統模式 (fuzzy system model),對於圖樣識別 (pattern recognition) 的應用,無論識別的正確性及執行速度都有很好的 performance.
這三天期間,與各地學者專家深入討論各個不同的領域,受益良多,也能正確的 掌握目前人工智慧的領域,尤其是每天第一場的 keynote speech 更是精采。主講者不但 學術豐富,有幽默感,而且明確指出今後在此領域上可以進行的幾個方向,足以當作 最好的參考。參加此研討會,不但有機會與來自世界各地的學者專家廣泛討論,相互 切磋,也因此更確定目前所進行的研究方向是正確的。
A Weight- and Data-Distribution-featured Approach for Fuzzy Pattern Classification
Ying-Kuei Yang, Chien-Nan Lee, and Horng-Lin Shieh Dept. of Electrical Engineering
National Taiwan University of Science & Technology No 43, Sec 4, Keelung Road
Taipei, TAIWAN
e-mail: [email protected] Phone: 886-2-27376681 Fax: 886-2-273736699
Abstract
This paper proposes an approach that can appropriately cluster a given data set automatically based on data distribution of a given data set without the need of specifying the number of resultant clusters and setting up subjective parameters. Some special data distributions, such as stripe-shaped or belt-shaped distributions, can therefore be nicely clustered for better pattern classification.
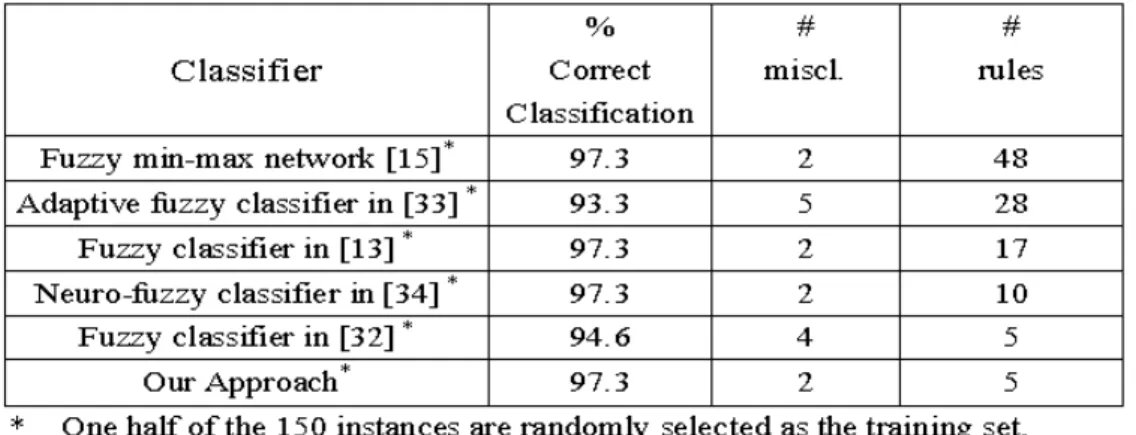
Statistical concept is also applied to define weights of pattern features so that the weight of a pattern feature is proportional to the contribution the feature can provide to the task of pattern classification. The proposed weight definition not only reduces the dimensionality of feature space so as to speed up the classification process but also increases the accuracy rate of classification result. The experiments in this paper demonstrate the proposed method has fewer fuzzy rules and better classification accuracy than other related methods.
Key words: fuzzy clustering, fuzzy inference system, pattern classification, rule extraction, data distribution, self-organization
1. Introduction
Nowadays, much and wide research has been done on these areas due to the reality that most object patterns that are often used do not have crisp boundaries [1][2][3][4][5][6].
Clustering analysis plays a very important role in pattern classification field. Given a finite data set X, the clustering problem of X is to find out some cluster centers that can represent the characteristics of X properly and naturally. A good fuzzy clustering approach should be able to appropriately partition a pattern space based on the data distribution of a given data set [7][8][9][10][11].
The task of pattern classification can be well done only when there are good standard class patterns to be based on. Therefore, this paper first proposes a fuzzy clustering algorithm
that automatically generates standard class patterns based on the data distribution of a given training data set without the need of specifying the number of resultant clusters and setting up subjective parameters. Secondly, the definition of discrimination function is proposed for pattern classification based on the fuzzy rules extracted from the clustering result in the first stage and the weights of pattern features defined by the application of statistical concept. In this approach, statistical concept is applied to calculate the weight of each pattern feature (i.e., every dimension) to indicate the level of importance for the feature on pattern classification.
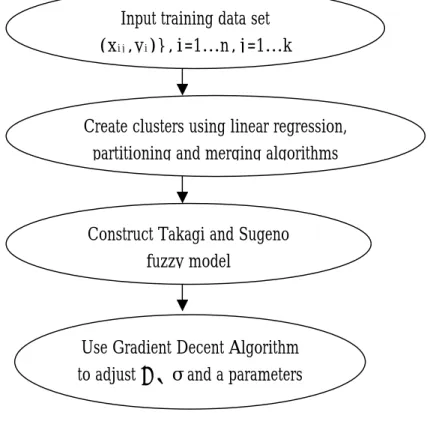
The weights of features are used on a discrimination function not only to reduce the dimensionality of feature space so as to speed up the classification process but also to increase the accuracy rate of classification result. The proposed approach is shown in Figure 1.
Figure 1: Architecture of proposed approach 2. Proposed Approach of Fuzzy Pattern Classification
As indicated in Figure 1, three phases are performed in the approach proposed in this paper to perform the task of pattern fuzzy classification
2.2 Fuzzy Clustering Inference System
The inputs to FCIS are the distances between data points and their associated cluster centers, and the outputs of FCIS are integration coefficients indicating the degrees to which data points and their associated clusters should be integrated.
2.2.1 Database
2.2.1.1 Distance and Linguistic Terms
Given a data set, think of how human being does clustering by eyes: based on the data distribution of the whole data domain. That is, the status of data distribution plays an important role on deciding how clusters are formed or partitioned for a given data set. The
sense of how close or how far a data point is to or from another point is not an absolute value solely based on Euclidean distance, but is a relative value based on the data distribution of the whole data domain.
Let P={P1 , P2 ,…, Pn} be a given data set of multi-dimensional patterns, Ω={ω1,ω2 ,…,ω
q} be a set of class labels, Ω’={1, 2 ,…, q} be a set of class labels represented in numeric form, Pi =(Xi;Yi ) be a pair of data point Xi and class Yi where Pi ∈ P, 1≦i≦n, Xi
=[xi1,xi2,...,xiM ]∈RM is a M-dimensional feature vector and Yi ∈Ω’is the class Xi belongs to. Furthermore, let X={X1 , X2 ,…, Xn} be a set of input data, V={V1 ,V2 ,…, Vc} be the set of resultant cluster centers after X is completely clustered, in which each cluster center Vj=[vj1,vj2,...,vjM] is a M-dimensional feature vector, Vj∈RM, 1≦j≦c. Let dsjλ be the distance between vjsand xλs that are the components of cluster center Vj and data point Xλ on s dimension respectively, and dKL*s be the distance between xKsand xLsthat are the components of a data point XK and another data point XL on s-dimension respectively. Then
M s n c
j x
v
dsjλ = js − λs 1≤ ≤ ,2≤λ≤ ,1≤ ≤ (1) L
K M s n L n
K x
x
dKL*s = Ks − Ls 1≤ ≤ −1,2 ≤ ≤ ,1≤ ≤ , ≠ (2) where ||.|| stands for Euclidean distance. . Then
{ }
L K M s n L n
K
d d d d MAX
dmaxs s s KLs ns n
≠
≤
≤
≤
≤
−
≤
≤
= −
, 1
, 2
, 1 1
, , , ,
, 13* * *1,
*
12 Λ Λ (3)
{ }
L K M s n L n K
d d d d MIN
dmins s s KLs ns n
≠
≤
≤
≤
≤
≤
≤
= −
, 1
, 1
, 1
, , , ,
, 13* * *1,
*
12 Λ Λ (4)
2 ) ( maxs mins
s
mean d d
d = + (5) The domain of distance dsjλ can be defined as [dmins ,dmaxs ] . The linguistic terms are defined by the following membership functions:
≤
<
>
≤
− ≤
−
≤
=
s max s near s min
s near s j
s near s j s s min
min s near
s j s near
s min s j
s j near
d d d where
d d
d d d d
d d d
d d
d
λ λ λ
λ
λ
if , 0
if ,
if , 1
)
µ (
(6)
≤
− ≤
−
≤
− ≤
−
=
if ,
if , )
(
s max s j s s mean mean s max
s j s max
s mean s j s s min
min s mean
s min s j s j medium
d d d d
d d d
d d d d
d d d d
λ λ
λ λ
µ λ (7)
≥
≤
− ≤
−
<
=
s max s j
s max s j s s mean mean s max
s mean s j
s mean s j s
j far
d d
d d d d
d d d
d d d
λ λ λ
λ λ
if , 1
if ,
if , 0 )
µ ( (8)
2.2.1.2 Integration Coefficient and Linguistic Terms
The fuzzy clustering is performed by self-organizing approach on a given data set in this paper. The proposed approach generates an integration coefficient through fuzzy reasoning based on both the distance between a data point and a cluster center and the fuzzy production rules in the knowledge base. The generated integration coefficient indicates not only how well the integration will be but also how much influence the data point has when cluster center is being adjusted.
Let βsjλ∈[0,1] be the integration coefficient indicating how well the integration will be betweenvjs and xλs that are the component of cluster center Vj and the component of data point X
λ on s-dimension respectively. The linguistic terms are defined by the following membership functions:
>
≤
− ≤
=
=
5 . 0 if
, 0
5 . 0 0
if 5 , . 0 5 . 0
0 if , 1 ) (
s j
s j s
j
s j
s
weak j
λ λ λ
λ
λ
β β β
β β
µ
(9)
≤
≤
− ≤
−
≥
≤
− ≤
=
and 1 0.5
if , 5 . 0 1 1
and 0.5 0
if , 5 . 0
0 )
(
s mean s j s
j s
j
s mean s j s
j s
j s j medium
d d
d d
λ λ
λ
λ λ
λ λ
β β β β β
µ
(10)
=
≤
− ≤
−
<
=
1 if , 1
1 0.5
if , 5 . 0 1
5 . 0
5 . 0 if
, 0 )
(
s j
s j s
j
s j
s j strong
λ λ λ
λ
λ
β β β
β β
µ
(11)
2.2.2 Fuzzy Production Rule Base
2.2.2.1 Preprocessing Rules
The spreading situation of a given data point set has a big variety, but when all data points actually belong to the same cluster, what should we do to find out and present this characteristic for the data set faithfully? Let e be a threshold value and X={X1,X2,...,Xn} be a given finite data set. It is obvious that all data points form one cluster when the maximum distancedmaxs of all dimensions is less than or equal to the threshold that should be a small value relative to the range of the data set domain. Let
} ,..., ,...,
,
{ max1 max2 maxs maxM
A
max MAX d d d d
d = , then the preprocessing rule R1 is as follows.
R1 : IF dmaxA ≤e
THEN the whole data set X belongs to the same cluster
AND the cluster center is ∑
= n
k Xk
n 1
1 (12)
AND escape from FCIS ELSE continue FCIS
2.2.2.2 Rules of Reasoning Integration Coefficients
The integration coefficient should indicate not only the integrating degree between a data point and a cluster but also the level of influence on location of cluster center from the data point when the data point is to be integrated with the cluster. Integration coefficient
sjλ
β for a cluster center Vj and a data point Xl is derived by fuzzy reasoning according to the membership grade of the distance between these two points on the s-dimension. There are three fuzzy rules for inferring such relationships.
R2 : IF dsjλ is near THEN βsjλ is strong (13) R3 : IF dsjλ is medium THEN βsjλ is medium (14) R4 : IF dsjλ is far THEN βsjλ is weak
(15) Obviously, these rules naturally reflect the relationships between distance and integration coefficient.
2.2.2.3. Rules of Integrating Data Points Into Existing Clusters
Let (Xλ;Yλ) be a data pair of data point Xλ and class Yλ that Xλ belongs to, and (Vj;Yj) be a data pair of cluster center Vj and class Yj that Vj belongs to, where 1≤ λ≤n, 1≤ j≤c, Xλ
=[xλ1,xλ2,...,xλM]∈RM is a M-dimensional feature vector and Yλ ∈Ω’.
Strong α-cut set [13] is used to construct this rule in this paper. LetA be a strong α-cut set of α' fuzzy set A, thenA will be a crisp set. α'
{ µ α}
α' = x| (x)>
A A (16)
Similarly, the definition of the strong α-cut set for fuzzy set near is
{
µ α}
α' = dsj | near(dsj )>
Near λ λ (17)
Assume CVj represents the cluster centered at Vj, then the rule for data point Xλ to be integrated into cluster CVj is below.
R5 : IF Yλ= Yj AND d1jλ∈Nearα' AND d2jλ∈Nearα' AND… AND dsjλ∈Nearα' AND…AND dMjλ∈Nearα'
THEN Xλ∈ CVj, add Xλ to the cluster CVj