國立臺灣大學工學院土木工程學研究所 碩士論文
Graduate Institute of Civil Engineering College of Engineering
National Taiwan University Master Thesis
支援向量機於降雨逕流預報之研究
Support Vector Machines for rainfall-runoff forecasting
許峰源 Hsu, Feng-Yuan
指導教授:林國峰 教授 Major Professor: Lin, Gwo-Fong
中華民國 97 年 7 月
July 2008
誌謝
本論文承蒙指導教授林國峰老師悉心指導,方得以順利完成,在此獻上由衷 的感謝。初稿復蒙口試委員之審閱,惠賜卓見,在此一併感謝。
碩士班在學期間,受到許多師長珍貴的指導,讓學生對於知識的學習上更加 的寬闊,在此感謝學校內老師們的教誨。學長陳谷榕、王俊明、吳明璋、王宗惇、
蔡斐毓,學姐黃珮瑜對於論文與課業給予許多的幫助與寶貴意見,學弟鄭家豪、
周揚敬、張家銓的鼓勵與協助,以及小乖與小 Do 為研究生活帶來的歡樂,在此一 併感謝。
最後還要感謝在背後默默支持,無怨付出的父母,以其不斷給我打氣加油的 哥哥、姐姐,是你們給我力量,讓我能完成學業。在此將本論文獻給愛我的與我 愛的親友們。
摘要
降雨逕流的預報不論是在颱洪時期的防洪規劃上或是平時的水資源規劃上,
都是不可或缺的部分。因此,如何得到一個準確且可靠的預報結果是相當重要的 課題。在模式的準確度上已有許多人研究出許多改善的模式,而預報結果的可靠 度則是較少人探討的問題。若想得到一個可靠的預報結果,就需要一個強健性高 的預報模式。而在近幾年研究中,顯示有一種稱為「支援向量機」的類神經網路 能取代常用的倒傳遞類神經網路,主要的原因除了在準確度上有所提昇之外,在 強健性上也較佳。然而,研究中雖然有提出支援向量機具有較佳的強健性,但於 強健性方面的討論卻很少,基於此,本研究將分別以支援向量機及倒傳遞類神經 網路架構流量預報模式,並針對模式強健性的部份,分成訓練資料量、訓練場次 挑選、訓練資料內噪音及初始權重這四個可能影響模式表現的因素進行討論。結 果顯示,支援向量機的預報結果不但準確度優於倒傳遞類神經網路,且四個因素 對支援向量機的影響更遠小於對倒傳遞類神經網路的影響。這表示支援向量機的 準確度及強健性均高於倒傳遞類神經網路,亦即支援向量機的預報成果是更為有 效且可靠的。因此,本研究建議在架構降雨逕流模式時,採用支援向量機取代傳 統的倒傳遞類神經網路。
關鍵字:類神經網路、支援向量機、倒傳遞類神經網路、強健性、降雨逕流預報
Abstract
To yield reliable forecasts of stream flow, a robust flood forecasting model is required. For this purpose, effective flood forecasting models based on the support vector machine (SVM), which is a novel kind of neural networks (NNs), are proposed.
Based on statistical learning, SVMs have better generalization ability than back-propagation netwoks (BPNs), which are the most frequently used convectional NNs. In addition, the robustness of SVMs is one of the major advantages over BPNs.
However, the robustness of hydrological models has received little attention in literature.
To make comparisons between SVMs and BPNs, two kinds of NN-based (SVM-based and BPN-based) forecasting models are constructed to yield one- to five-hour ahead forecasts. Then an application is conducted to clearly demonstrate the advantages of SVMs and representative results are discussed in depth. Firstly, the results show that SVM-based models perform better than BPN-based models for one- to five-hour ahead forecasts. Thus, SVM-based models forecast stream flow more accurately. In addition, the results indicate that the performance of BPN-based models highly depend on four factors: (a) number of training events, (b) selection of training events, (c) noise included in training data and (d) initial weights. On the contrary, the influence of the four factors on the performance of SVM-based models is much less than that of BPN-based models. Hence the performance of SVM-based models is more reliable than that of BPN-based models. In conclusion, the SVM-based models are much more accurate and robust than BPN-based models. The proposed SVM-based models are recommended as an alternative to the existing models because of their accuracy and robustness.
Keyword : neural networks, support vector machines, back-propagation networks, robustness, rainfall-runoff forecasting
目錄
誌謝 ... I
摘要 ... II
Abstract ... III
目錄 ... IV
圖目錄 ... VI
表目錄 ... VIII
第一章 緒論 ... 1
1-1 前言 ... 1
1-2 文獻回顧 ... 2
第二章 研究區域與水文資料 ... 5
2-1 研究區域 ... 5
2-2 水文資料概述 ... 6
第三章 理論模式與架構 ... 7
3-1 倒傳遞類神經網路 ... 7
3-2 支援向量機 ... 8
3-3 模式架構與參數設定 ... 11
3-4 評鑑指標 ... 12
第四章 結果與討論 ... 14
4-1 訓練資料量的影響 ... 14
4-2 訓練資料挑選的影響 ... 15
4-3 資料噪音的影響 ... 16
4-4 初始權重的影響 ... 17
第五章 結論 ... 18
參考文獻 ... 19
圖目錄
圖 2- 1 翡翠水庫集水區(水位站及雨量站位置) ... 53
圖 3- 1 BPN 架構圖 ... 54
圖 3- 2 SVR 架構圖 ... 54
圖 3- 3 非線性轉換函數 ... 55
圖 3- 4 Vapnik’s ε區示意圖 ... 55
圖 3- 5 支援向量迴歸... 56
圖 4- 1 訓練資料筆數與 CE 關係圖 ... 57
圖 4- 2 第一種組合 MCE 比較圖 ... 57
圖 4- 3 第二種組合 MCE 比較圖 ... 58
圖 4- 4 第三種組合 MCE 比較圖 ... 58
圖 4- 5 第四種組合 MCE 比較圖 ... 59
圖 4- 6 第五種組合 MCE 比較圖 ... 59
圖 4- 7 第六種組合 MCE 比較圖 ... 60
圖 4- 8 第七種組合 MCE 比較圖 ... 60
圖 4- 9 第八種組合 MCE 比較圖 ... 61
圖 4- 10 第二種組合 CV 比較圖 ... 61
圖 4- 11 第三種組合 CV 比較圖 ... 62
圖 4- 12 第四種組合 CV 比較圖 ... 62
圖 4- 13 第五種組合 CV 比較圖 ... 63
圖 4- 14 第六種組合 CV 比較圖 ... 63
圖 4- 15 第七種組合 CV 比較圖 ... 64
圖 4- 16 第八種組合 CV 比較圖 ... 64
圖 4- 17 BPN 加入颱風因子前後 MCE 比較圖 ... 65
圖 4- 18 SVM 加入颱風因子前後 MCE 比較圖 ... 65
圖 4- 19 SVM 與 BPN 中 60 個隨機初始權重結果 CE 比較圖 ... 66
表目錄
表 2- 1 測站資料 ... 22
表 2- 2 颱雨事件 ... 22
表 3- 1 訓練-測試資料分組之組合數 ... 23
表 4- 1 第一種組合中訓練資料 ... 24
表 4- 2 第二種組合中訓練資料 ... 24
表 4- 3 第三種組合中訓練資料 ... 25
表 4- 4 第四種組合中訓練資料 ... 26
表 4- 5 第五種組合中訓練資料 ... 29
表 4- 6 第六種組合中訓練資料 ... 32
表 4- 7 第七種組合中訓練資料 ... 35
表 4- 8 第八種組合中訓練資料 ... 36
表 4- 9 第一種組合 CE ... 37
表 4- 10 第二種組合 CE 與 MCE ... 37
表 4- 11 第三種組合 CE 與 MCE ... 38
表 4- 12 第四種組合 CE 與 MCE ... 40
表 4- 13 第五種組合 CE 與 MCE ... 43
表 4- 14 第六種組合 CE 與 MCE ... 47
表 4- 15 第七種組合 CE 與 MCE ... 50
表 4- 16 第八種組合 CE 與 MCE ... 52
表 4- 17 全組合測試結果 CV ... 52
第一章 緒論
1-1 前言
台灣地區位處西太平洋颱風路徑要衝,在每年夏季經常面臨颱風侵襲,平均 每年有三至四個颱風經過並帶來大量的豪雨,加上台灣地形狹長、山勢陡峭,往 往在一次降雨事件過後,在短時間內就會反應在下游流量的變化中,對於水庫操 作或是防汛等關乎國家人民的生命財產安全的各方面課題上,都極需要能快速且 準確的預報降雨事件所帶來的下游流量變化。如何在降雨與流量間的複雜關係 中,建立一個快速且準確的預報模式,一直以來都是許多研究的重點項目。
傳統上,要建立一個可以描述水文現象的模式,有運用物理型模式與統計型 模式。其中,物理型模式是應用物理確定定律(Law of Certainty)來探討水文歷程 中投出與產出間的關係,物理型模式雖可探究水文過程的機制,但在面對複雜、
非線性的問題時,必須經由一些假設、簡化環境後才能加以建構。而統計型模式 在處理複雜的問題時,不需要針對問題定義其物理機制,而是藉由資料的學習來 面對複雜的問題,其中又以類神經網路為近年來廣為使用的方法。
類神經網路(Artificial Neural Network, ANN)是運用模仿生物神經元特性,
接受刺激並反應,且有記憶刺激之效果,並運用數學方法加以建構。本研究在類 神經網路的許多類型中,選用最廣泛使用的倒傳遞類神經網路(Back-Propagation Network, BPN)。倒傳遞類神經網路運用在降雨與流量推估中,已被大量的應用實 例所肯定,但大部份的類神經網路由於訓練資料的挑選,會大大的影響其預報結 果。由於近年來氣候變化已不再如過去所見,極端的雨量與流量紀錄也不斷的翻 新,然而,在倒傳遞類神經網路中,訓練資料中必須要包含極端事件,這也造成 了類神經網路模式在極端事件更新後,往往需就新加入的資料來重新建構或修正
原有的模式,將花費大量的時間在此過程中。
支援向量機(Support Vector Machine, SVM),是一種基於統計學習理論的機器 學習方法,利用多元分類的方法,延伸到迴歸問題。且已運用在許多不同的領域 中,成果亦相當優異。而在許多文獻中提到,具有全域最佳解是支援向量機的重 要優點之一,只要使用的訓練資料相同,則會得到相同結果,而常被使用的倒傳 遞類神經網路則會因初始權重的不同,即使是訓練資料相同,也會造成結果差異。
相較之下,SVM 在模式本身的強健性上即較 BPN 為佳。而模式的強健性高低會影 響使用者對模式表現的信賴程度,因此,本研究中,將針對訓練資料的問題,分 成四項(1)訓練資料量;(2)訓練場次挑選;(3)資料噪音;(4)BPN 初始權重,
並將兩模式的成果加以比較。
1-2 文獻回顧
類神經網路是一種模仿生物大腦與神經網路系統所架構出來的資訊處理系 統,能對於外界輸入的資訊有儲存、學習、回想、歸納推衍等一系列動作。由於 人腦的結構複雜,因此類神經網路只能簡單的利用數學模式加以建立,因此亦可 算是一種特殊的統計模式。類神經網路中是由許多的非線性運算單元,也就是神 經元(neuron),和位於這些運算單元間的眾多連結(links)所組成,只需經由反 覆學習及可,並不需要針對該系統的轉換機制加以描述,並具有結構單純、理論 簡明、可快速運算、學習及容錯能力,對於物理模式難以敘述的非線性關係,可 發揮其特殊能力,也因此在水文領域中有許多相關的研究。
Hsu(1995)利用均方根值等準則,選取類神經網路在輸入、隱藏、輸出各層 的最佳組合個數以進行降雨逕流之日流量預測。Thirumalaiah 與 Deo(1998)採 類神經網路並以三種演算法訓練其網路。陳昶憲與陳建宏(1999)以模糊理論,
結合類神經網路,應用在河川水位預測。張斐章等人(2001)結合回饋式類神經
網路與即時學習演算法以發展一水文推估模式,並運用在大甲溪上游流量推估。
Lin 與 Chen(2004)應用全面監督式訓練法則來建立輻狀基底函數網路之網路架 構,作為洪水流量預報模式。陳信中(2006)利用類神經網路預報水位,並運用 在蘭陽溪流域中。
在類神經網路的許多類型中,又以倒傳遞類神經網路(Back-Propagation Network, BPN)為最廣泛使用的類型。Zhu 與 Fujita(1994)利用倒傳遞類神經網 路進行洪水小時流量預測,得到不錯的結果。孫建平(1996)以倒傳遞網路對短 延時降雨逕流過程做一探討並對降雨及逕流作預測。Campolo 等人(1999)使用倒 傳遞類神經網路建立降雨-逕流模式,以多個雨量站預報單一水位站。Marina 等人
(1999)、Komda 與 Markarand(2000)曾以倒傳遞類神經網路進行洪水位預測。
Chen 與 Huang(2000)則嘗試以倒傳遞與反傳遞類神經網路於洪流量預測並加以 比較。
支援向量機(Support Vector Machines, SVM)是由 Vapnik 及其共同研究者
(1995;1998),基於統計學習理論(Statistical Learning Theory),所提出的一種機 器學習方法。支援向量機基於統計學習理論中的結構風險最小化(Structural Risk Minimization)法則,來處理多維度函數的分類與迴歸問題。最初,多應用在處理 二元分類問題,後來延伸到多元分類與迴歸問題中。
在其它領域中,支援向量機被運用的相當廣泛。Joachims(1998)、Dumais
(1998)、李柏毅(2004)應用在文字分類中;Dibike(2001)應用在衛星影像分 類;Osuna 等人(1997;1998)應用在人臉辨識;郭瑞修(2004)應用特徵選擇演 算法與支援向量機於胃部組織學分類中。
而在水利領域中,支援向量機的應用仍屬剛剛起步。Sivapragasam 等人(2001)
利用支援向量機建立日雨量與日流量預報模式,進行前置一日的雨量與流量預 報。Yu 等人(2002)將 SVM 與混沌理論來預報日流量;Liong 與 Sivapragasam(2002)
利用上游日水位當作 SVM 的輸入項,來建立模式並預報下游水位;Choy 與 Chan
(2003)利用支援向量個數來決定輻狀基底函數類神經網路的架構,並用來模擬 降雨逕流;Sivapragasam 與 Liong(2004)利用支援向量機建立日水位預報模式;
Bray 與 Han(2004)著重於模式架構及參數選擇的探討,用來預報逕流量;
Sivapragasam 與 Liong(2005)將流量分三類再分別建立 SVM 模式來進行一日與 三日的流量預報;陳昶憲、游保杉與陳建宏(2005)使用 SVM 建立蘭陽大橋未來 一至六小時的水位預報模式。
前人的研究中,雖都有提及 SVM 相對於 BPN 有較佳的強健性,但卻無相關 研究來針對強健性加以討論,因此本研究將針對這兩種模式的強健性以四種問題 方向加以討論。
第二章 研究區域與水文資料
2-1 研究區域
本研究選用翡翠水庫集水區(如圖 2-1)做為研究區域,翡翠水庫位在台灣北 部新店溪支流北勢溪上,北勢溪為台北地區主要河川-淡水河的上游,共流經台 北縣雙溪鄉、坪林鄉、石碇鄉和新店市。全區約佔淡水河流域的百分之十一,集 水區面積約三百零三平方公里,平均年降雨約三千七百五十公釐。集水區內有北 勢溪主流、火燒樟溪、後坑子溪、金瓜寮溪、姑婆寮溪、逮魚溪與灣潭溪匯流。
翡翠水庫為解決大台北地區的民生用水並規劃成為台北地區公共給水長期水源之 開發,區內營運由台北市翡翠水庫管理局負責,為全台唯一的水源特定區,每日 的供水量可達三百四十五萬立方公尺,初期水庫容量約為四億六百萬立方公尺,
經翡翠電廠發電後放流於下游直潭壩、青潭堰攔引,經直潭淨水場及長興、公館 淨水廠處理利用,主要供應台北市與台北縣新店、永和、中和、三重、汐止等地,
約三百三十四平方公里面積,該區域內約三百四十六萬人口。翡翠水庫因有龐大 的蓄水量,更提供了大台北地區防洪的功能,與大漢溪上的石門水庫同為淡水河 流域內重要的防洪設施。由於翡翠水庫臨近大台北地區,距離全台重要都市之一 的台北市僅三十公里,且為台北縣市水源特定區,對於水質、水量與防洪的要求 有別於其它地區,其影響層面極為深遠,過去的許多經驗也說明,該集水區一旦 發生意外,都將影響到大台北的人民生活,造成的經濟、生活、安全等方面的損 失將難以估計。
2-2 水文資料概述
本研究中的輸入項為雨量和流量,輸出項為流量,噪音部份為颱風的位置和 颱風與測站的距離,因此針對所需要的資料,對現有水文測站收集資料,而收集 到的資料均以小時為單位。收集到的資料有坪林、碧湖、九芎根、翡翠、太平、
十三股等六個雨量站,以及翡翠一處流量站資料,如圖 2-1 及表 2-1 所示,從東至 西分別為太平、碧湖、坪林、九芎根、十三股、翡翠。
雨量所使用的資料,選用翡翠水庫集水區所發生的颱風事件中有雨量資料的 場次做為使用,從翡翠水庫管理局中挑選有連續紀錄並考量其正確性,自 1991 年 至 1996 年,六年內選取共九場的颱風事件,分別為:露絲(RUTH)、寶莉(POLLY)、 泰德(TED)、提姆(TIM)、弗雷特(FRED)、葛拉絲(GRADYS)、席斯(SETH)、
賀伯(HERB),如表 2-2 中所示。最大延時為寶莉颱風共有 137 小時,最大的雨 量資料為席斯颱風所帶來的共 85.5 mm,尖峰流量資料為席斯颱風第六十小時所測 得 1456.78m3/s。
第三章 理論模式與架構
3-1 倒傳遞類神經網路
倒傳遞類神經網路(Back-Propagation Network, BPN)為類神經網路中最為常 用的一種形式,其中包含輸入層(Input Layer)、隱藏層(Hidden Layer)、輸出層
(Output Layer),而本研究中之網路架構如圖 3-1 所示,包含一個輸入層、一個隱 藏層與一個輸出層。倒傳遞類神經網路為監督式學習網路,共可分為前饋段階段 與倒傳遞階段。在前饋時,輸入向量經輸入層,經過隱藏層至輸出層,並計算出 初始推估值;在倒傳遞階段時,將前述初始推估值與目標輸出值計算其誤差,並 依其誤差來進行神經元間連結權重的修正,也正因為此將目標誤差倒傳遞回神經 元的行為,故稱為「倒傳遞類神經網路」,並重覆此「前饋-倒傳遞」的過程來使 得輸出推估值能更符合目標輸出值。
其中網路神經元的連結權重,為了將其誤差函數(如 3-1 式)最小化,一般上 是使用最陡坡降法(Gradient Steppest Descent Method)。
( )
⎥⎦
⎢ ⎤
⎣
⎡ −
=
∑∑
= =
M
i N
j
ij
ij y
d F
1 1
2
2
1 (3-1)
3-1 式中d 為輸出值;ij y 為實際值;M 為訓練資料個數;ij N 為輸出層神經元個數。
於整個網路中,第k層中第 j 個神經元的輸出值為:
⎟⎠
⎜ ⎞
⎝
= ⎛
∑
=
− m −
i
k j k k ij k
j f w u
u
1
1 ,
1 (3-2)
其中,wijk−1,k為連結第k−1層中第 i 個神經元與第k層中第 j 個神經元之權重;m為 傳遞至第k−1層中的神經元個數;uik−1為第k−1層中第 i 個神經元之輸出。而在倒 傳遞類神經網路中,會將結果誤差倒傳遞到隱藏層中,再經由下式修改其連結權
重:
( )
nw u
n
wijk−1,k( +1)= kj ik−1 + Δ ijk−1,k
Δ ηδ α (3-3)
其中,Δwijk−1,k(n+1)為連結權重的修改量;n為迭代次數;η為學習速度參數;α為
慣性項(momentum term);δkj 為第k層中第 j 個神經元之差距量,其計算方式可 由下式推求:
⎪⎪
⎩
⎪⎪
⎨
⎧
=
∑
+=
+
+ ,for node in hidden layer )
(
layer output in node for , ) (
1
1
1 ,
1w j k
du u df
l du j
u e df
mk
r
k k jr k k r
j k j l j l j j k j
δ
δ (3-4)
其中mk+1為傳遞到k+1中第 r 個神經元之輸入單元數目;e 為第 j 個神經元之誤j 差; f
( )
為神經元之非線性轉換函數,而最常被使用的非線性轉換函數為雙彎曲 函數(sigmoid function):( )
ukj( )
ukjf = + − exp 1
1 (3-5)
其中ukj範圍在± ,也因此∞ f
( )
ukj 的範圍落在 0 跟 1 之間,而使得類神經網路具有 學習與回想的功能,故可進行定率的預測。3-2 支援向量機
支援向量機是由 Vapnik 及其共同研究者(1995;1998),基於統計學習理論,
所提出的一個機器學習方法。支援向量機基於統計學習理論中的結構風險最小化 法則,來處理多維度函數的分類與迴歸問題。本研究中,使用支援向量迴歸的部 份來建立降雨逕流預報模式。
支 援 向 量 迴 歸 ( Support Vector Regression, SVR ), 假 定 一 組 訓 練 資 料
( ) ( ) ( )
{
x1,y1 , x2,y2 L xl,yl}
,其中x項為輸入向量; y 項為輸出向量。加上其容許的誤差範圍(b),可建立一個符合輸入與輸出資料特性的迴歸函數。如果是線性系 統,可令其迴歸函數為:
( ) ( )
x x bf = ω⋅ + (3-8)
其架構圖如圖 3-2。在式(3-8)中,ω 表示 f
( )
x 的複雜程度(complexity),越小 表示模式越單純。但在一般使用時,處理的問題多為非線性系統,故在式(3-8)中加入一轉換函數φ
( )
x ,將問題映射到高維度空間(feature space)中,使其轉變 為線性問題,如圖 3-3 所示。( )
x( )
x bf =ω⋅φ + (3-9)
故依照結構風險最小化的法則,可將 SVR 問題轉變為:
Minimize
( )
⎥⎦⎢ ⎤
⎣
⎡ +
+
∑
= l
i
i i
C
1 2 *
2
1 ω ξ ξ
S.T. yi −
[
ω⋅φ( )
xi +b]
≤ε+ξi[
ω⋅φ( )
xi +b]
−yi ≤ε+ξi* 0, i* ≥
i ξ
ξ for i=1,L,l (3-10)
其中ε 即為訂定的容許誤差範圍,ξi與ξi*為沉滯係數(slack variables),分別代表 資料點落在容忍誤差區外的誤差值;C為懲罰係數,將誤差值累加後乘上一懲罰 係數C,C越大時表示誤差對於目標函數的影響也越大。
基於 Vapnik’s ε-insensitive loss function,如圖 3-4:
( )
=⎩⎨⎧ −( )
−− f x ε y f x ε
y 0
( )
otherwise x f y
if − ≤ε (3-11)
也就是說如果實際值落在此容許的區間中,其損失函數(loss function)為零;反 之當實際值在容許區間外時,則不為零。當資料點落在容許誤差範圍外時,將給 予一個懲罰,這時的損失函數即為實際值與估計值之誤差,也就是所需要的支援 向量,表示如圖 3-5 所示。
傳統上的迴歸方法,需要全部的資料才能建立其迴歸式;而支援向量機有其誤差
容許範圍(ε-tube),若資料點落在容許誤差範圍內,將其視為無益的資料,僅考 慮在容許誤差範圍外,也就是式(3-11)中所說明的部份。因此即可利用少數且有 用的資料點來建立函數。如以數理規劃模式表示,即為式(3-10)中的最佳化問題,
可利用 Lagrange multipliers 並將限制式賦予一參數α1,α1*,η1,η1*,可得:
( ) ( )
⎥⎦⎢ ⎤
⎣
⎡ +
+
=
∑
= l
i
C b
L
1
* 1 1
* 2
*
*
2 , 1 , ,
; , ,
, ξ ξ α α ηη ω ξ ξ ω
( )
[ ]
∑
=+
⋅ +
− +
− l
1 i
b x yi i
i
i ε ξ ω
α
( )
[ ]
∑
=−
⋅
− + +
− l
1 i
*
* i yi xi b
i ε ξ ω
α
( )
∑
=+
− l
i
i i i i 1
*
*ξ η ξ
η (3-12)
此問題的解即為式(3-12)的鞍點,也就是 max, *, , * min, , , *
(
ω, ,ξ,ξ*;α,α*,η,η*)
ξ ξ ω η η α
α L b
b
,可 得:
=0
∂
∂ ω
L →
( )
01
* =
−
−
∑
= l
i
i i
i α x
α ω
=0
∂
∂ b
L →
∑ ( )
=
=
l −
i
i i 1
* 0
α α
=0
∂
∂
i
L
ξ → C−αi−ηi =0
* =0
∂
∂
i
L
ξ → 0
*
* − =
− i i
C α η
l
i i
i i
i,α*,η ,η* ≥0, =1,K,
α (3-13)
將式(3-13)代入式(3-10)式中,並轉為對偶問題(Dual Problem):
Maximize
∑ ( )( ) [ ( ) ( ) ] ∑ ( ) ∑ ( )
=
= =
+ +
+
−
⋅
−
−
− l
i
i i i l
j i
l
i
i i j
i j j i
i x x y
1
*
1
. 1
*
*
*
2
1 α α α α φ φ ε α α α α
S.T.
( )
01
*− =
∑
= li
i
i α
α
l i
C C
i i
, , 1 , 0
, 0
* ≤ = K
≤
≤
≤ α
α (3-14)
上式中,每一組的
(
αi*−αi)
向量中,非零的則表示該向量可供目標函數所用,也就 是「支援向量」(support vector)。也就是說,(
αi*−αi)
=0時的資料點視為無用的資 料,只使用(
αi*−αi)
≠0向量中的資料點。而在(3-14)式中,真正會影響結果的是φ
( )
xi ⋅φ( )
xj ,為此引入核函數(Kernal Function),表示為:(
xi xj) ( )
xi( )
xjK , =φ ⋅φ (3-15)
此核函數並要滿足 Mercer’s condition:
( ) ( ) ( )
∫
K xi,xj z xi z xj dxidxj (3-16)最後則可將支援向量迴歸式表示成:
( )
x( ) ( )
K x x bf
l
j i
j i i
i − +
=
∑
=1 ,
* α ,
α (3-17)
其中b可由 Karush-Kuhn-Tucker condition(Fletcher, 1987)求得。
3-3 模式架構與參數設定
首先,因 BPN 在過去使用上,會將資料分為訓練、驗證、測試三類,在本研 究中為探求訓練資料對於 BPN 與 SVM 兩模式的影響,故將九場颱風事件排列出 所有訓練資料分別求其可能的各種組合,又因在 BPN 中,需將極端事件列入在訓 練資料中,因此第一種組合為九場颱風中挑取一場為訓練資料,該場次為賀伯颱 風,另八場為測試資料,即C ,故只有一種訓練資料;第二種組合為九場颱風中08 挑取兩場為訓練資料,另七場為測試資料,即C ,故共有八種訓練資料;第三種18 組合為九場颱風中挑取三場為訓練資料,另六場為測試資料,即C ,故共有二十28 八種訓練資料;以此類推,第八種組合為九場颱風中挑取八場為訓練資料,剩餘
的一場為測試資料,即C ,故共有八種訓練資料。最後若挑取九場全為訓練資料,78 將無測試資料,因此在全組合中並無此組合。詳細各組合中的訓練資料個數如表 3-1 所示。
由於在許多文獻中提到 SVM 具有全域最佳解的效能,是故本研究將針對不同 組合下 SVM 與 BPN 之模擬,來對於其結果做比較,分別使用如表 3-1 中的訓練 資料,並就其結果加以討論。
模式輸入項中,因兩模式需有相同的輸入值,以便於比較其結果。首先只放 當期流量與當期雨量為輸入值,再加入前一期雨量、前一期流量、前二期雨量、
前二期流量,而加入到前三期資料時,對模式並無改善,反而有降低效果的現象,
故此輸入值定為當期與前兩期流量與雨量(R 、t Rt−1、Rt−2、Q 、t Qt−1、Qt−2),
來預測後五期之流量(Qt+1、Qt+2、Qt+3、Qt+4、Qt+5)。
[
t j t j]
i
t R
Q+ =SVMQ+ , + (3-18)
[
t j t j]
i
t R
Q+ =BPNQ+ , + (3-19)
其中, i 為推估的領前時間,共計 1 至 5 小時; j 輸入項中的前期資料,共計為 0 至 2 小時。而在 BPN 中,訓練次數定為 10000 次,權重修正步幅為 1.0。SVM 中 採試誤法找其容許誤差ε與懲罰係數C。
3-4 評鑑指標
本研究中,為對結果之好壞加以判斷,採用「效率係數」(Coefficient of Efficiency, CE)對模式進行分析,其公式如:
CE
( )
( )
∑
∑
=
=
−
−
−
= n
i i n
i
i i
Q Q
Q Q
1
2 1
ˆ 2
1 (3-20)
其中Q 表在 i 時間的觀測值;i Qˆi表 i 時間時推估流量; Q 表觀測值的平均值;n為 資料筆數。由於每一場颱風事件之平均流量皆不同,所以效率係數是每場分開來 計算的,如果效率係數等於一,則表示結果預測的非常完美,因此 CE 值越趨近 1 結果越理想。
在各組合中,由於訓練資料數量相當多,為對全組合進行探討,在此再採用 平均效率係數(Mean Coefficient of Efficiency, MCE)作為組合間的評鑑指標,平 均效率係數公式如下:
∑
== N
i
N 1 i
1 CE
MCE (3-21)
N 為組合內的訓練資料數:CE 為第 i 個訓練資料下,測試結果的 CE 值。 i
另外為確認在不同訓練資料下,去比較 SVM 與 BPN 的強健性,採用變異係 數(Coefficient of Variation, CV)對各組合的結果加以分析:
% 100 CV= ×
μ
σ (3-22)
其中,σ 為標準差;μ為平均值。CV 值越大,表示模式的變異性越大,也就越不 穩定,因此在評斷模式的強健性上,採 CV 值越小越好。
第四章 結果與討論
針對模式的強健性評估,本研究考慮可能造成結果變異的情況,分別為訓練 資料量不同、訓練資料挑選不同、資料噪音大小以及模式初始權重不同。於此章 節分析這四種不同情況對 BPN 模式以及 SVM 模式造成的影響,並進行討論。
4-1 訓練資料量的影響
本研究中針對九場資料分別挑選一至九場,以全組合方式建立訓練與測試資 料,而其中 Herb 因有極端的事件資料,故必須在模式訓練資料中,其餘八場為 Polly、Gradys、Tim、Fred、Ted、Ruth、Seth、Doug。各組合內數目如表 3-1 中 所示。
資料的取得在研究過程中,一直以來是相當重要的一個環節,但有時由於測 站故障等天然或人為的因素下,資料並無法順利取得,而在資料量短少的情況下,
模式是否依然可以推估出需要的結果,對於模式的強健性將是一大考驗。在此,
本研究針對不同訓練資料量進行測試,最先加入的是擁有極端資料的 Herb 颱風,
但對於接下來要加入何場資料,目前並無定論說明究竟該如何挑選,故此針對第 一類組合到第九類組合中所有訓練資料進行測試,一共有 255 種不同的訓練資料,
如表 4-1 至表 4-8 所示。測試的結果大致上趨勢相同,故在此使用其中一例來說 明,此例為推估未來五小時流量的結果,如圖 4-1 所示。在圖中可看出,BPN 在 訓練資料量少時,表現的並不良好。在此例中,訓練資料量 200 筆以下時 CE 值更 低於 0,但在逐漸增加訓練資料量後,將提升測試結果的 CE 值,慢慢的增加到接 近 SVM 的水準。反觀,SVM 在不同訓練資料量時,對其測試結果的影響並不大,
能一直維持在一定水平內。這說明了 BPN 受到資料量的影響大過 SVM,BPN 在
訓練資料充足時,方可呈現良好的測試結果。而 SVM 對於訓練資料量的依賴度低 過 BPN,不需要大量的訓練資料即可建構出良好的模式,也就是說,在訓練資料 數的影響下,SVM 的強健性高過於 BPN。
4-2 訓練資料挑選的影響
在收集資料後,該將那些場次挑選為訓練資料,在模式的建立上一直以來尚 未有一定論,通常在架構模式時,會花費大量的時間在於挑選訓練資料上,而挑 選不同的訓練資料對模式表現會有所影響,甚至不確定是否有可能因訓練資料挑 選的不同而造成結果上的差異,因此,模式表現是否會因訓練資料挑選的不同而 不同,這也關乎模式的強健性高低。因此,本研究將表 4-1 至表 4-8 中全部組合 進行測試並計算 CE,結果如表 4-9 至表 4-16,並將每一類組合中 BPN 與 SVM 結果的 MCE 比較如圖 4-2 至圖 4-9 所示。再針對每一類組合中不同訓練資料計算 其 CV,結果如表 4-17 與圖 4-10 至圖 4-16,由於第一類組合只有一個訓練資料,
故無 CV,在此不討論。從圖 4-2 至圖 4-9 中可看出,SVM 的 MCE 略高於 BPN 的 MCE,且差距隨推估時刻的增加而增加,在預報未來五小時流量時最高差達 0.035,而在圖 4-10 至圖 4-16 中卻可發現,BPN 的 CV 隨著預報延時的增加,變 異性也隨著增加。這說明了 BPN 會隨著訓練資料的不同而影響其結果的變化,同 一組合中 BPN 預報結果的 CE 值差可達近 0.3,雖然在 MCE 結果差不多,但卻有 相當大的變異性,也就是說,BPN 受訓練資料影響大過 SVM,而 SVM 並不會因 為訓練資料挑選而有太大的變異。所以,在訓練資料挑選上,SVM 不會像 BPN 受 到相當大的影響,也就是 SVM 並不需要特別去測試訓練資料的組合,其強健性在 建立模式是優於 BPN。
4-3 資料噪音的影響
對於 data-based 的模式而言,用來架構模式的資料是決定模式表現的重要關 鍵,除了資料量以及場次不同的選取方式會對結果產生影響之外,資料中包含噪 音量的多寡,也可能對模式的表現造成影響,而輸入因子與輸出項之間會由於關 連性的強弱造成資料噪音的大小,假設 A 因子與輸出項之間的關連性高於 B 因子,
相對來說,即表示 B 因子對於輸出項而言,資料中所含的噪音會高於 A 因子。若 能藉由改變輸入項來改變噪音量,分析模式表現,便能對模式的容噪音能力有所 認知。若模式容噪音的能力高,則表示模式較不受無用的資料或是有誤差的資料 影響,也就表示模式的強健性較高。
從前人研究得知,颱風因子具有描述降雨趨勢的能力,而降雨資料對流量而 言是相當重要的影響因子,由此猜測颱風資料可能能夠提供較長延時的流量預測 一些資訊。但由於颱風因子在量測上不是非常精密,加上從颱風侵台到產生流量 的過程複雜,颱風因子與流量的關係並不直接,因此對流量而言,颱風因子是具 有相當大噪音量的因子。因此,本研究藉由在 BPN 及 SVM 模式中加入颱風因子 來觀察噪音對模式的影響。
在 BPN 模式中,加入颱風因子使得模式的表現明顯變差,尤其預測時間越長,
模式準確度降低越多,如圖 4-17。預測時間越長代表輸入項與輸出項的相關性越 低,也就表示輸入項對輸出項而言噪音越多。此結果呈現出 BPN 模式對於颱風因 子內包含的噪音無法容忍,且當噪音量越大,對模式影響程度就越大。反觀 SVM 的結果,如圖 4-18。其受影響的程度不明顯,而隨著預測時間拉長,颱風因子對 流量的影響有逐漸顯現的趨勢,在預測 5 小時流量時,有加入颱風因子的 SVM 模 式甚至有略為的增進模式準確度。此現象說明 SVM 容忍噪音的能力優於 BPN,且 SVM 萃取有效資訊的能力也優於 BPN。即從容噪音能力來看,SVM 的強健性亦 優於 BPN。
4-4 初始權重的影響
BPN 因其特性,隱藏層的權重需訂定一初始值,在反覆訓練下修正其權重,
以達到良好的測試結果,但在初始權重不同下,有可能落入區域最佳解的問題,
而初始權重該如何決定也尚未有一定論,一般 BPN 避免權重影響的作法是訓練多 次之後取最佳結果,且需訓練多少次也是因事件而異,這樣的過程相當耗時費力。
而 SVM 是一最佳化問題,解空間為凸面圖形,因此有全域最佳解的特性,在決定 懲罰係數與容許誤差後,將有唯一解。為評估 BPN 受初始權重影響的程度,因此 假定一案例,選用 4-1 節中所使用預報未來五小時流量的結果,並讓 BPN 隨機產 生 60 組初始權重,並將 60 組不同權重產生的結果與 SVM 的結果比較,結果如圖 4-19。從結果可看出,BPN 的測試結果受到初始權重相當大的影響,而 SVM 不論 測試幾次,結果都是相同的,也就是說 SVM 並無初始權重的問題,在建立模式時 無須懷疑每回可能產生不同結果,這表示 SVM 在模式本身的強健性優於 BPN,並 於模式架構過程能節省相當多的時間。
第五章 結論
1. 本研究分別應用 SVM 及 BPN 架構降雨逕流預報模式,並針對兩種類神經網 路模式的預報結果進行比較,根據 1-5 小時流量的預報結果顯示支援向量機的 準確度均優於倒傳遞類神經網路。
2. SVM 對於訓練資料量的依賴度低過 BPN,不需要大量的訓練資料即可建構出 良好的模式,也就是說,在訓練資料數的影響下,SVM 的強健性高過於 BPN。
3. BPN 受訓練資料影響大過 SVM,BPN 會隨著訓練資料的不同而影響預報結 果,預報結果的變異性相當大,而 SVM 並不會因為訓練資料挑選而有太大的 變異。換言之,在訓練資料挑選上,SVM 不會像 BPN 受到相當大的影響,也 就是 SVM 並不需要特別去測試訓練資料的組合。
4. SVM 容忍噪音的能力優於 BPN,且 SVM 萃取有效資訊的能力也優於 BPN。
即從容噪音能力來看,SVM 的強健性亦優於 BPN。
5. BPN 的測試結果受到初始權重相當大的影響,而 SVM 不論測試幾次,結果都 是相同的,也就是說 SVM 並無初始權重的問題,在建立模式時無須懷疑每回 可能產生不同結果,這表示 SVM 在模式本身的強健性優於 BPN,並於模式架 構過程能節省相當多的時間。
6. 支援向量機的準確度及強健性均高於倒傳遞類神經網路,亦即支援向量機的 預報成果更為有效且可靠。因此,本研究建議在架構降雨逕流模式時,採用 支援向量機取代傳統的倒傳遞類神經網路。
參考文獻
Bae, D.H., Jeong D.M., Kim, G, 2007, “Monthly Dam Inflow Forecasts Using Weather Forecasting Information and Neuro-Fuzzy Technique,” Hydrological Sciences Journal 52 (1), 99-113.
Choy, K.Y., Chan, C.W., 2003, “Modeling of River Discharges and Rainfall Using Radial Basis Function Networks Based on Support Vector Regression,” International Journal of Systems Science, 34(14-15), 763-773.
Chang, F.J., Chang, Y.T., 2006, “Adaptive Neuro-Fuzzy Inference System for Prediction of Water Level In Reservoir,” Advances in Water Resources. 29(1), 1-10.
Chen S.T., Yu P.S., 2007, “Pruning of Support Vector Networks on Flood Forecasting,”
Journal of Hydrology, 347(1-2), 67-78.
Lin, G.F., Chen, L.H., 2005, “Application of An Artificial Neural Network to Typhoon Rainfall Forecasting,” Hydrological Processes,” 19(9), 1825-1837.
Liong, S. Y., Sivapragasam, C., 2002, “Flood Stage Forecasting With Support Vector Machines,” Journal of the American Water Resources Association. 38(1), 173-186.
Liong, S. Y., Sivapragasam, C., 2005, “Flow Categorization Model for Improving Forecasting,” Nordic Hydrology. 36(1), 37-48.
Ioannis N. D., Paulin C., Ioannis K.T., 2005, “Groundwater Level Forecasting Using Artificial Neural Networks,” Journal of Hydrology, 309, 229-240.
Mahesh Pal, Arun Goel,2006, “Estimation of Discharge and End Depth in Trapezoidal Channel by Support Vector Machines,” Water Resource Management, 21, pp.1762-1780。
Shivam Tripathi, V.V. Srinivas, Ravi S. Nanjundiah, Downscaling of precipitation for climate change scenarios:A support vector machine approach, Journal of Hydrology, 330, pp.621-640.
Vapnik, V., 1995, “The Nature of Statistical Learning Theory,” Sprinter, New York.
Vapnik, V., 1998, “Statistical Learing Theory.” John Wiley, New York.
Xu, Z.X., Li, J.Y., 2002, “Short-Term Inflow Forecasting Using An Artificial Neural Network Model,” Hydrological Processes, 16, 2423-2439.
Yu, P.S., Chen, S.T., 2005, “Updating Real-Time Flood Forecasting Using a Fuzzy Rule-Based Model,” Hydrological Sciences Journal, 50(2), 265-278.
Yu, X.Y., Liong, S. Y., 2007, “Forecasting of Hydrologic Time Series with Ridge Regression in Feature Space,” Journal of Hydrology. 332, 290-302.
Yu, X.Y., Liong, S.Y., Babovic, V., 2004, “EC-SVM Approach for Real-Time Hydrologic 487 forecasting,” Journal of Hydroinformatics 6(3), 209-223.
陳憲忠,2006,「支援向量機及模糊推理模式應用於洪水水位之即時預報」,國立 成功大學水利及海洋工程學系博士論文。
陳信中,2006,「蘭陽溪洪水預報模式之研究」,國立台灣大學生物環境系統工程 學研究所碩士論文。
陳憲忠、游保杉,2007,「洪水位之即時機率預報-結合支援向量機與模糊理論」,
農業工程學報,第五十三卷,第四期,第 1-20 頁。
張逸凡,2005,「支援向量機在即時河川水位預報之應用」,國立成功大學水利及 海洋工程學系碩士論文。
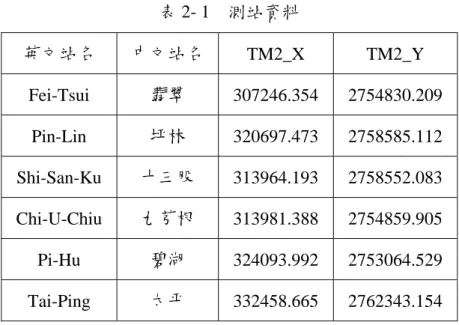
表 2- 1 測站資料
英文站名 中文站名 TM2_X TM2_Y
Fei-Tsui 翡翠 307246.354 2754830.209 Pin-Lin 坪林 320697.473 2758585.112 Shi-San-Ku 十三股 313964.193 2758552.083 Chi-U-Chiu 九芎根 313981.388 2754859.905 Pi-Hu 碧湖 324093.992 2753064.529 Tai-Ping 太平 332458.665 2762343.154
表 2- 2 颱雨事件
事件編號 颱風名稱 發生時間 延時(hr) 尖峰流量(cms)
1 賀伯(HERB) 1996/7/30 97 2586.39 2 寶莉(POLLY) 1992/8/26 137 970.43 3 葛拉絲(GRADYS) 1994/8/31 65 1449.33
4 提姆(TIM) 1994/7/9 61 673.61
5 弗雷特(FRED) 1994/8/19 96 718.30
6 泰德(TED) 1992/9/20 97 922.00
7 露絲(RUTH) 1991/10/27 130 828.36 8 席斯(SETH) 1994/10/8 96 1456.78
9 道格(DOUG) 1994/8/6 97 535.83
表 3- 1 訓練-測試資料分組之組合數 組合(訓練場數-測試場數) 組合數
第一種組合(1-8) 1 第二種組合(2-7) 8 第三種組合(3-6) 28 第四種組合(4-5) 56 第五種組合(5-4) 70 第六種組合(6-3) 56 第七種組合(7-2) 28 第八種組合(8-1) 8
表 4- 1 第一種組合中訓練資料
Herb Polly Gradys Tim Fred Ted Ruth Seth Doug 01 ●
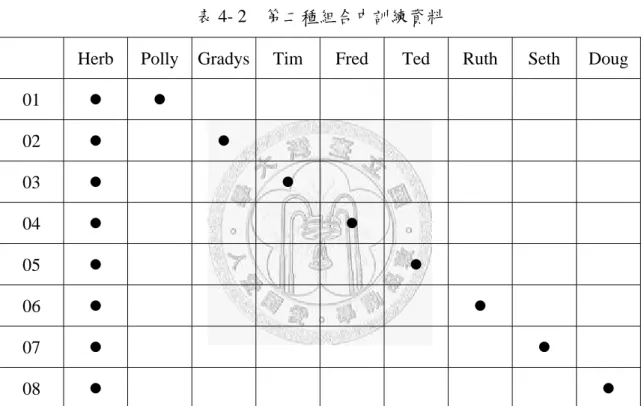
表 4- 2 第二種組合中訓練資料
Herb Polly Gradys Tim Fred Ted Ruth Seth Doug 01 ● ●
02 ● ●
03 ● ●
04 ● ●
05 ● ●
06 ● ●
07 ● ●
08 ● ●
表 4- 3 第三種組合中訓練資料
Herb Polly Gradys Tim Fred Ted Ruth Seth Doug 01 ● ● ●
02 ● ● ●
03 ● ● ●
04 ● ● ●
05 ● ● ●
06 ● ● ●
07 ● ● ●
08 ● ● ●
09 ● ● ●
10 ● ● ●
11 ● ● ●
12 ● ● ●
13 ● ● ●
14 ● ● ●
15 ● ● ●
16 ● ● ●
17 ● ● ●
18 ● ● ●
19 ● ● ●
20 ● ● ●
21 ● ● ●
22 ● ● ●
表 4- 3 第三種組合中訓練資料(續)
Herb Polly Gradys Tim Fred Ted Ruth Seth Doug
23 ● ● ●
24 ● ● ●
25 ● ● ●
26 ● ● ●
27 ● ● ●
28 ● ● ●
表 4- 4 第四種組合中訓練資料
Herb Polly Gradys Tim Fred Ted Ruth Seth Doug 01 ● ● ● ●
02 ● ● ● ●
03 ● ● ● ●
04 ● ● ● ●
05 ● ● ● ●
06 ● ● ● ●
07 ● ● ● ●
08 ● ● ● ●
09 ● ● ● ●
10 ● ● ● ●
11 ● ● ● ●
12 ● ● ● ●
13 ● ● ● ●
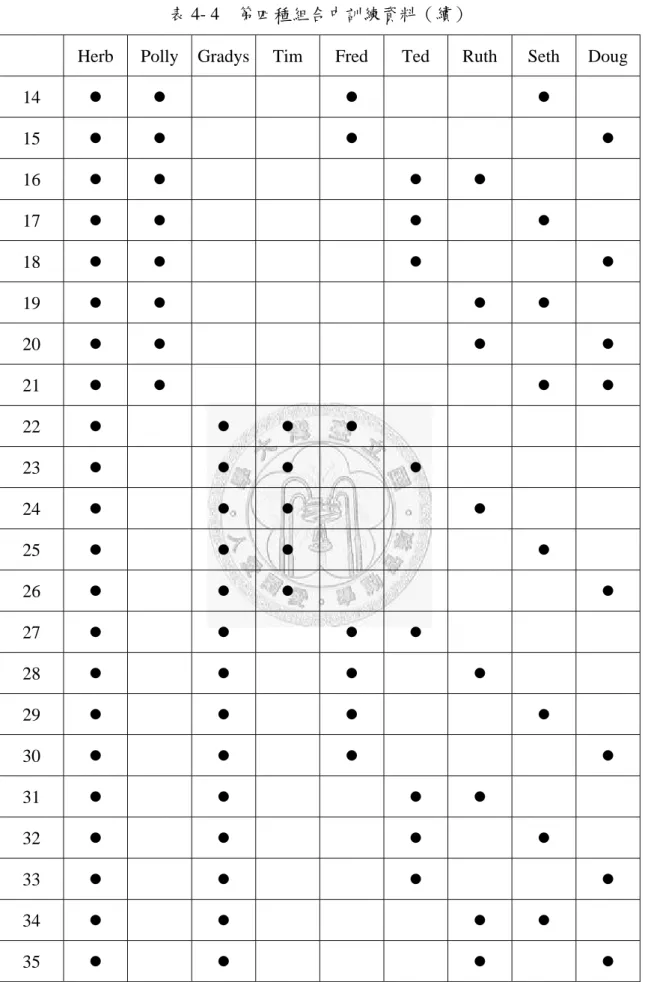
表 4- 4 第四種組合中訓練資料(續)
Herb Polly Gradys Tim Fred Ted Ruth Seth Doug
14 ● ● ● ●
15 ● ● ● ●
16 ● ● ● ●
17 ● ● ● ●
18 ● ● ● ●
19 ● ● ● ●
20 ● ● ● ●
21 ● ● ● ●
22 ● ● ● ●
23 ● ● ● ●
24 ● ● ● ●
25 ● ● ● ●
26 ● ● ● ●
27 ● ● ● ●
28 ● ● ● ●
29 ● ● ● ●
30 ● ● ● ●
31 ● ● ● ●
32 ● ● ● ●
33 ● ● ● ●
34 ● ● ● ●
35 ● ● ● ●
表 4- 4 第四種組合中訓練資料(續)
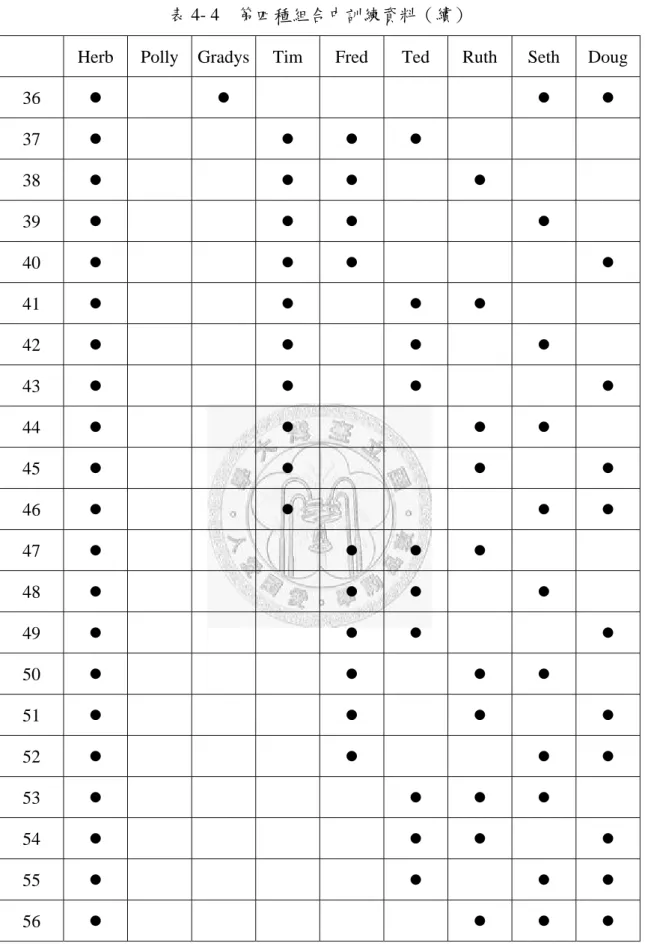
Herb Polly Gradys Tim Fred Ted Ruth Seth Doug
36 ● ● ● ●
37 ● ● ● ●
38 ● ● ● ●
39 ● ● ● ●
40 ● ● ● ●
41 ● ● ● ●
42 ● ● ● ●
43 ● ● ● ●
44 ● ● ● ●
45 ● ● ● ●
46 ● ● ● ●
47 ● ● ● ●
48 ● ● ● ●
49 ● ● ● ●
50 ● ● ● ●
51 ● ● ● ●
52 ● ● ● ●
53 ● ● ● ●
54 ● ● ● ●
55 ● ● ● ●
56 ● ● ● ●