行政院國家科學委員會專題研究計畫 成果報告
區塊式流程分群法之研究 研究成果報告(精簡版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 99-2221-E-011-032-
執 行 期 間 : 99 年 08 月 01 日至 100 年 07 月 31 日 執 行 單 位 : 國立臺灣科技大學工業管理系
計 畫 主 持 人 : 歐陽超
計畫參與人員: 碩士班研究生-兼任助理人員:李又權 碩士班研究生-兼任助理人員:陳弇方 碩士班研究生-兼任助理人員:劉宜佩
處 理 方 式 : 本計畫可公開查詢
中 華 民 國 100 年 09 月 22 日
摘要
近年來作業流程自動化已廣泛的運用在企業中,因此儲存流程事件檔於流程資料庫中已是一個 非常普遍的方式。而由於商業流程的越趨複雜,流程資料庫所儲存的事件檔也就相對的非常冗 長。所以探勘出的流程模型往往過於複雜而不易了解,因此也不易分析出使用者所需的正確資 訊。因此,若能對一個包含許多案例的流程資料庫進行有效的分群,將可對不同群組的案例瞭 解其特徵,以簡化流程分析之問題。
目前所提出的流程分群演算法,對於較長的流程其運算效果也相對降低。因此, 本研究嘗 試將流程資料庫中各案例間共同的作業模型不予以考慮,僅對不同之作業進行分析及分群,以 提高運算績效。
本研究提出以區塊式的方式,對流程事件檔進行切割,將分群的區塊縮小,藉此簡化在進行 分群時的計算複雜度。並運用各案例中作業發生之頻率給予適當之權重,以增加流程相關性的 敏感度以及不同分群群組間的差異性。最後再針對每個分群結果的流程事件檔,進行流程探勘 以建構個別的流程模型,讓使用者可進而去了解不同案例族群間之特徵。
關鍵詞:流程分群,相似度比較,流程區塊,流程探勘 Abstract
Recently, workflow automation has been widely applied in industry. Log files stored the activities sequence for each case can be used to construct the process model in terms of the developed process mining algorithm. However, due to the complexity of the process, the mined model might be very complicated and hence difficult to view and to analysis. Cluster the stored cases and to mine each group of cases can simplified this issue.
Currently, the developed workflow clustering algorithm tends to compute the sequential relationship of the activities based on the whole record of the case. The computational efficiency will decrease a lot for a case with long sequence of activities.
In this research, an approach based on blocking the log into several group and clustering the activity data in each group will be proposed. This approach ignores the sections of the records having the common sequential relationship and addresses on the portions where cases have diverse string of activities. That is, based on the mined model, the sequence of activities in the log will be classified as several blocks. Then the activities in each block will be clustered and the inter‐block activities relationship also will be analyzed. By applying this approach, the computation efficiency will be increased for the log with long string of activities but contained common sequential relationship. In addition, the attributes for each group of cases can be analyzed by identifying the features of individual block of activities.
Key Words: Process Cluster, Workflow Mining, Workflow Block
1. 研究背景:
目前的流程探勘中大多為運用事件紀錄檔,以找出工作流程模型。而一個流程紀錄檔(Process Log)中含有許多案例,每個案例是由一串作業依其先後發生之順序所組成。而流程探勘便是藉由 分析各案例中,所包含之作業的相互關連性,以建構出流程模型。
而將分群的概念加到流程探勘中,其主要目的是對流程資料庫之案例進行分群,找出流程的差 異性及其特質。而在現有的流程分群演算法中,其步驟大致為:計算各案例內相關作業的距離,以判 斷兩兩案例之相似度,並進而分群。其中相似度的計算,往往是兩兩流程事件檔間進行反覆的試算,
建構出相似度分數表,然而這步驟,常會面臨到一個問題,即案例中所包含的作業過多,則計算就會 變的過於繁複,使得分群方法只能適用於較短之案例中,若要套用到較長的案例時,計算的複雜度會 呈現指數的成長,造成探勘的困難。而分群應用在流程探勘上還包含了一個缺點,即無法分析個別因 子所造成的影響。目前的分群法是將相關案例分群,並判斷每個群組之影響因子。但如要進一步判斷 個別因子會影響群組內之哪些步驟,目前則尚未有相關之分群法則進行研究。例如醫療流程可能受患 者之年齡,性別,檢查時間等數個因素影響。假設某一醫療流程運用已發展之流程分群法將將高齡,
女性,夜間患者分成一群。但若要進一步探討高齡會影響哪些醫療行為,以目前之分群法則不易協助 做出如此判斷。因此本文延伸出區塊式的分群演算法概念,希望能藉由各區間中不同案例族群之差異 性,以協助找出各案例族群不同之特質
2. 研究目的:
目前由Jung et al.所發展之流程分群演算法[1],主要是將各模型中每個活動均納入考慮,並給 予各個活動間轉換順序的權重,其計算的複雜度為
O n m
( 2 2+n
2log )n
。因此當流程中活動越多則複雜 度越高。因此本研究擬發展一區塊式分群法將各案例中共同作業不予計算,僅計算各案例間相異之作 業,並進而分群。如圖1 所示為一現有的流程案例檔,若依據 Jung et al.所發展之流程分群演算法,則其概念圖 如下。
圖 1 流程相似度計算圖
此方法會計算流程的所有活動,對於有共同的作業而言,計算時不免出現重複的情形。若能簡 化所需計算的活動,將能降低計算的複雜度。因此本研究擬發展一區塊式分群法將各案例中共同作業
順序之區塊不予計算,僅考慮不同作業順序之區塊。其概念如圖2 所示:
圖2 分割後流程資料檔
因此以一現有的流程資料庫所探勘出的流程圖來看,我們可以依照圖2-2 的概念,找出如圖 3 的示意圖。
圖3 流程示意圖
以因果矩陣找出圖中{A,B,C}作為共同作業區塊,利用共同作業切割出兩個分群區塊{Block 1,Block2},對其進行分群,再以關聯性法則將{Block1,Block2}的分群結果產生連結,找出 整體性的分群結果,進行流程分析。可得到如圖4:
圖 4 分群概念圖
然而此概念可能會面臨到兩個問題:
A. 如何找出紀錄檔中的共同作業,進行流程原始檔的切割,因為共同作業的選擇會決定 了後續分群的結果。
B. 在進行分群的步驟中,各區塊進行完分群後,如何建立關聯法則,將分群結果做連結。
3. 文獻探討
3.1 流程的分群概念
在流程的分群概念中,可以分成兩種類型:
I. 針對現有流程的分群:
在此類型中,所儲存的流程事件均為單一的流程圖[1][2],在此兩篇文獻中所發展的 流程分群演算法,是架構在使用者可直接由圖中,了解個別流程的活動發生順序,以及活 動連結的 and、or 等資訊,因此依照每個單一事件的流程模型,給予流程發生順序的權重,
如圖 5 示:
圖5 流程權重圖
在圖中可看到,不同活動間因給予的權重,而有相互關係的產生,可將此權重圖已表 1 來加以表示:
表 1
Case (1、2) (1、3) (1、4) (2、3) (2、4) (3、4)
Case NO. 1 0.5 0.33 1 0.5 1
因此可由流程資料庫中,建立如表 1 的權重表,在以此為依據計算兩兩流程間的相似 度,接著以凝聚式的階層分群(Agglomerative Hierarchical Clustering:AHC)演算法 進行分群的探勘,AHC 的優點在於,不用預測分群的目標群數,因此可針對不同群數情況 下的流程分群,進行分析。此種類型下,進行流程資料庫的分群其目的在於,整理流程資 料庫的資料,讓使用者可選擇目標部門的流程架構進行分析,並找出不同流程分群間的相 互關係[3]。
II. 針對流程事件檔的分群:
在此類型中,流程事件檔的記錄,多半用符號來表示,每個流程事件檔只是單純的符 號組合,無從得知流程模型的概況[5][7]。因此,為了能對事件檔進行分群探勘,必需先 對Process Log檔進行屬性的定義,如活動的發生與否、活動的輸入及輸出、活動的負責 人及活動的發生時間等屬性,在定義完Process Log檔的屬性後,才能對Process Log檔進 行相似度的計算,並進行分群。亦可由Process Log檔中,找尋Feature Space(特徵空間)[4],
此方法為在資料庫中,挑選活動發生率高的建立特徵空間,並過濾發生率低的活動,因其 發生率低,在進行分群時不會有直接的影響,如此僅針對Feature Space,進行流程相似 度的計算。在分群方面,文獻中提出了三種距離計算方式:Euclidean Distance、Hamming
Distance及Jaccard Distance,以及四種分群方法:K-means Clustering、Quality Threshold Clustering、Seilf-Organizing Map及Agglomerative Hierarchical
Clustering,互相搭配找出最佳的分群結果。此種類型下,對流程資料庫進行分群的目的,
在於分析事件檔的分群歸屬,並針對各分群進行流程探勘,建構出不同族群中的流程架構,
讓使用者能快速了解流程的架構以及其差異性[6]。
3.2 分群演算法
分群是一種資料探勘或是流程探勘的手段,其可針對資料的特徵進行分類,方便使用者了解內 容,並可找出不同資料族群間的相互關係以及影響。而分群的方式大致可分為以下兩種:
I. 分割式分群演算法(Partitional Clustering):
是簡單的將資料物件集合分割成無重疊的子集合,使得每個資料物件正好會在一個子 集合中,需事先決定好分群數量的目標,才能進行分群,例如:
A. K-means 演算法[12][13]:K 是由使用者指定之參數,也就是所要分群的群數,
而在演算法中,每個點都會被分配到最近之群中心,分配到群中心的資料點構成 一個群集,而每個群集的中心點會根據所分配之資料點做更新。
B. SOM演算法[10][11]:Self-Organizing Map(SOM)類似於,是一種神經網路技術,
其包含了神經處理單元,會依照分群目標數量,對平面網格上進行分區,在以類 似K-means演算法中的概念,將資料點分配到相似度高的區域中形成群集,因此 SOM的做法是,將相類似的資料點放在同一區的方式來達成分群。
II. 階層式分群演算法(Hierarchical Clustering):
其為巢狀群集的集合,且可被組織成樹的結構,在樹中的每個節點,為其子群集的集 合,而樹的根結點則是包含所有的物件群集,在分群的過程中會逐漸合併最相似的兩個 群組,直到剩下一個分群為止,例如Agglomerative Hierarchical Clustering( AHC )演算法 [8][9],在初始階段將每個流程事件檔,視為單一群集,在依據計算相似度的結果,合併 最接近的兩個事件檔成為一個群集,在更新分數表後,合併最接近的兩個群集,因此AHC 通常以樹狀圖表示,可顯示群集與子群集的關係,以及群集被合併或是分割的順序。
4. 研究方法
本研究之方法架構將分成概念階段、設計階段、實作階段等三個部分,分別敘述研究過程。
4.1 概念階段
目前的流程探勘的研究,目的是為了從流程資料庫中萃取出有用的資訊,但過程必須花費很 多的時間進行流程探勘,找出潛藏的流程資訊,或是幫助使用者了解流程架構。因此本研究即針 對如何能快速的找出流程特性,以及建構出正確的流程圖,透過圖形化的表示方法,讓使用者能 輕易的擷取所需的流程資訊。
另一方面在分群演算法中,流程相似度的計算一直是非常繁雜的,以凝聚式的階層分群
(Agglomerative Hierarchical Clustering)演算法為例,其空間的複雜度為
O n m
( 2 2+n
2log )n
,其 中n 代表流程序列的數量,m 為流程序列的平均長度,而計算分群的總時間則需花費O m
( 2log )m ,
由公式中可以看到當流程活動越多時,流程相似度的計算,以及花費在計算上的時間,會呈現指數的成長,且目前的分群演算法,無法解析出個別因子對流程所造成的影響,因此為了能簡化流 程相似度的計算方式,以及讓使用者能了解流程中個別因子的影響,主要透過分割流程資料庫的 方式,進行流程分群,在以分群結果進行流程圖的建構。
4.2 設計階段
本研究的主要內容為:將流程資料庫中的原始檔,進行區塊切割,在各區塊中進行分群,藉 由關聯性法則將各區塊分群結果做連結,得出整體性的分群結果,進行分析,而最後利用側影係 數對此方法進行評估。圖6 為設計的架構圖,將設計階段分成七大區塊,如下圖所示。
圖6計架構圖 4.2.1 初始探勘
在流程資料探勘的初期,為了能進行流程檔的切割,必須先以Heuristic(啟發式演算法)找 出初始流程架構,Heuristic 是一種流程探勘的方法,其主要特色在於可在短時間內探勘出流程圖,
並會自動刪除流程檔中偶而發生或是異常值的流程,讓流程圖較為簡化,但相對的也可能會剔除 重要的資訊。
Heuristic 會先以定義 1 的四個規則,建構出工作流程:
1
(1)
(2)
(3) # (4) ||
Heuristic
A B if and only if there is a trace line in W in which event A is directly followed by B A B if and only if A B and not B A
A B if and only if not A B and not B A A B if
>
→ > >
> >
定義 :
and only if both A>B and B> A
其中{A、B}為事件,W為流程資料檔。其中(2)定義{A、B}事件為依賴關係,(3){A、
B}事件是非平行關係,(4){A、B}事件是代表平行關係。
接著利用定義2 建構流程關聯性/次數表:
2
(1) ( # )
(2) ( # )
(3)
Heuristic
the overall frequency of task A notation A
the frequency of task A directly preceded by another task B notation B A the frequency of A directly followed by another tas
<
定義 : 演算法
( # )
(4)
( $ ) :
$ (# - # )
L L
k B notation A B
a local metric that indicates the strength of the dependency relation between task A and another task B notation A B the local metric is as follows
A B A B B A
>
→
→ = > > / (# # 1).
(5)
( $ )
A B B A
a more global metric that indicates the strength of the dependency relation notation A B
> + > +
→
建構出流程關聯性/次數表後,在以此表計算依賴程度分數(Dependency Score:DS),利用 DS 制定
Heuristic 規則[17],如定義 3:
3
- ,
( , ) (($ )2 ($ )2) / 2.
-
( , ) max .
Suppose X and Y are events then the dependency score
D S X Y X Y X Y
M ining rule G iven a task A
Suppose X is the event for w hich D S A X M is im al Then A
= → + →
=
L
定 義 :依 賴 程 度 分 數
:
( , ) 0.95 * .
( , ) max . ( , ) 0.95 * .
Y if and only if D S A Y M
Suppose X is the event for w hich D S X A M is im al Then Y A if and only if D S Y A M
→
<
= →
<
以上述定義找出初始流程圖,因本研究方法為了切割流程資料檔,因此長串型的流程圖,會 較有利於切割,所以採用Heuristic 演算法,以較精簡的流程圖做為起始步驟。
4.2.2 因果矩陣
因果矩陣本是基因流程探勘方法中所會使用到之運算格式,在本研究的發展方法中,將因果 矩陣應用在找尋共同作業的一種輸入資料格式,發展出因果矩陣表示法,如定義4 所示。
其中A 代表活動之集合,C 代表活動與活動之間的關聯,I 代表活動 A 的輸入活動集合的集 合,O 代表活動 A 的輸出活動集合的集合。因此 C 包含活動 a1以及以a1為輸入活動時,所有a1
之輸出活動集合的集合,或是活動a2,以及以a2為輸出活動時,所有a2之輸入活動集合的集合。
4.2.3 區塊切割。
共同作業又可稱為Sequence Pattern,其定義為直接相連的單一活動,活動的進入以及輸出只 能包含一個邊,不能包含分支或結合,以此定義為依據找出Sequence Pattern。
再找出共同作業後,以此做為切割依據,進行流程資料檔的切割,找出分群區塊。因此可產 定義 4:因果矩陣
).
I(a )
I(a
A.
P(A)
h.
ected grap ongly conn
} is a str a
A|a A ) ,a {(a C
)}, I(a A|a
A ) ,a {(a C
)}, I(a A|a
A ) ,a {(a C such that
, n function t conditio
the outpu P(P(A)) is
A O
function, condition
the input P(P(A)) is
A I
elation, ausality r
A is the c A
C
es, f activiti nite set o
A is a fi
, where (A,C,I,O)
tuple CM atrix is a
A Causal M
2 2
2 1
i o
i o
1 2
2 1
2 2 1
2 1
1
C C
set in sets the of union the is
set some of powerset the
denotes ________
∪
∪
∪
φ φ
∧• =•=
×
∈
∪
−
∈
×
∈
=
−
∈
×
∈
=
−
→
∈
−
→
∈
−
×
⊆
−
−
=
生如圖7 的分群區塊示意圖。
圖7 分群區塊示意圖 4.2.4 分群
本研究方法利用凝聚式的階層分群(Agglomerative Hierarchical Clustering:AHC)演算法[1][9]
進行分群。AHC 方法的特色為,初始將資料點當成個別群集,在每一步驟合併相似度最高的為 一組群集,直到剩下一個群集為止。其定義5 如下:
5 :
1 : _ ( );
2 : _ ( ) 3 : ( )
4 : ( , ) _ _ ( ) 5 : ( , )
6 : _ ( , , , ) 7 : _
A H C
P extra ct stru ctu re W C P S co m p u te sim ila rity C
w h ile n C k d o
u v fin d n ea rest p a ir C w m erg e u v
u p d a te clu ster C u v w u p d a te sim ila
= =
=
<
=
=
定 義 演 算 法
( , )
8 :
rity S w en d w h ile
第一步為將每個流程視為單一分群,第二步開始計算每個流程間的相似度,
k
表示分群數量,第四及第五則是尋找兩個相似度最大的流程( , )u v ,並將其分為同一群,重複上述的步驟,更新 分群數量,直到達到目標的
k
群數量。其中相似度的計算,代表了計算兩兩流程間的距離,依照參數的屬性,相似度的計算可以有 許多的變化,舉例如下:
(1) Transition:以流程活動間轉換的邊為屬性,計算流程間的相似度。
(2) Activity Attributes:依活動是否有發生為屬性,計算流程間相似度。
(3) Originator Attributes:依負責或直行的人員為屬性,計算相似度。
(4) Performance:依執行的時間為屬性,計算流程間相似度。
在本研究中為了能了解流程間,活動發生的相關性,以及流程活動順序的資料,因此選擇 Transition 為屬性,計算兩兩流程間的相似度[1][2]。其定義 6 如下:
,
,
,
, ,
( , ) 2 , ( , )
6 : ( ) ,
1 , 1,...,
( , ) ( ) , ( )
( , )
x ij x
ij x
ij x
ij x ij y
x y i j
tran x y
x y ij x
i j
t t transition vector of process x
t i j n
d
where i j T x T x set of transitions in process x t t
sim P P t t
t t t t
=
= =
∈ =
⋅ ⋅
= =
∑
∑
∑
定義 相似度計算
2 , ( , )
, ( , ) ( ) ( )
ij y i j
where i j ∈ T x ∪ T y
∑
其中 ,
,
1
ij x
ij x
t
=d
∑
,此定義代表了,流程活動間距離的權重,越遠的活動所給予的權重越少,主要強調活動順序的相關性,如下圖8 所示:
圖4-2-4 : 流程權重圖 接著可由圖4-2-3 所示,建構如表 2 的順序權重表:
表2 順序權重表
Case {A,B} {A,C} {A,D} {B,C} {B,D} {C,D}
Case 1 1 1/2 1/3 1 1/2 1
因此本研究利用區塊切割步驟中,所找出的分群區塊,對於個別區塊的流程資料檔,建構順 序權重表,並以此表計算相似度分數,進行AHC 分群,直到達到目標的
k
群數量。而在AHC 分群演算法中,依點的選擇,可分為以下三種:
(1) MIN(單一鏈結):定義不同群集中,兩個最接近的點之間的鄰近值。
(2) MAX(完全鏈結):定義不同群集中,兩個最遠的點之間的鄰近值。
(3) 群平均:定義不同群集中,所有成對資料點之平均成對鄰近值。
因本研究中每個點代表流程,因此將距離的遠近視為相似度的大小,並採取群平均的方式找尋分 群結果。針對群平均,群集(
C C )的群集鄰近值以下列公式表示[8],其中
i, jm ,
im 代表群集大小:
j( , ) ( , )
*
i j
x c y c
i j
i j
x y
C C m m
∈∈
=
∑
鄰近值鄰近值 。
4.2.5 群組連結
在得出各區塊的分群結果後,可分析出各區塊中的個別因子影響,也可藉由定義7 的關聯 性法則,進行分群連結,找尋整體性的分群結果。
7 :
(( ) ( )) (( ) ( ))
( ) ( )
Re
i i i j j i j j
i j
x y x y x y x y
x x
lationship
n
σ σ
σ σ
∩ ∪ ∩ ∩ ∪ ∩
+
=
∑
定義 關聯性法則
以定義7,可由下圖 9 加以說明:
圖 4-2-7 關聯性法則示意圖
其中
n
代表x 及
ix 分群項目集的總頻率,
jx 為前區塊分群中的序列項目集,
ix 為同一分群
j中的第二項目集,計算當
x 及
ix 的情況下發生
jy 及
iy 序列項目集的頻率,而將發生的頻率做加
j 總平均,即代表兩分群間的關聯性強度。對於個別區塊分群做出關聯性分數的計算後,藉由分數 高低的判定,將其合併為同一分群,再將這一分群視為同一群集,往後延伸直到得出整體的分群 結果。若在進行關聯性計算時,遇到分數相同的情況下,則將後方序列項目集,合併到前一區塊 的個別分群中,在往後計算直到找出不同分群為止。4.2.6 流程探勘
在得出整體的分群結果後,將此結果在以Heuristic 進行流程探勘,找出個別分群的流程架 構圖,並加以分析。
4.2.7 結果評估
在分群結果的評估方面,本研究使用了側影系數,進行評估。側影系數(silhouette coefficient) 的方法是結合了,分群評估中的內聚力(cohesion)以及分散力(separation)進行評估,其中內聚力定 義為鄰近分群中所有鏈結的權重,而分散力為兩個群集之間的鏈結的權重,其計算步驟如下[23]:
(1) 對第i個流程,計算它至群集中所有流程的平均相似度,稱此值為
a 。
i(2) 對第i個流程,和任何沒有包含這個流程的群集,計算它至特定群集內所有流程之平均相 似度,找到所有群集的最小值
b 。
i(3) 對於第i個流程,其側影系數為 ( )
max( , )
i i
i
i i
a b
S a b
= − 。
側影系數的值可能會在-1 與 1 之間變化,當側影系數為負值時,代表群集內點的平均相似
度
a ,是小於其他群集內點的平均相似度
ib ,這表示此分群結果是不好的。因此為了要讓側影系
i數的分數為正必須(
a
i > ),且b
ib 盡可能的接近0,因為當
ib =0時側影系數的最大值為1,表
i 示此分群結果是好的。
4.3 實作階段
本步驟為最後實作階段,其內包含了實作以及驗證的部分。在實作方面把設計階段所設計之 方法,用在實際的流程資料庫上,其詳細的步驟如下圖10 所示:
圖 10 實作階段圖 4.3.1 實作部分
依據圖4-3-1 的步驟,進行實作,在初始流程探勘的階段,本研究資料的來源使用了國內某 教學醫院的中風醫療流程資料庫,希望能藉由本研究之分群法找出,不同族群病患治療時可能有 之不同途徑。表3 為醫療流程的活動資料檔:
表3 活動資料檔
編號 病 歷 Case Case1 Case2 Case3 Case4 Case5
1 就診事件項目/發生日期、時間 89.06.21 88.12.21 89.01.17 89.03.12 88.12.21
2 家人或病人發覺症狀 15:30 - 16:00 13:45 23:10
3 打119 等 ambulance 前往醫院/自行前往醫院急診/掛號門診 15:30 - 16:00 13:45 23:10
4 於急診處掛號 15:30 ? 17:00 14:10 23:46
5 急診內科醫師看診,發現疑似腦中風 15:30 ? 17:00 14:10 23:46
6 抽血時間 15:32 ? 17:20 14:15 00:00
7 血液檢驗報告時間(CBC/DC.PT/APTT;生化) 16:44 13:30 17:05 15:24 00:26
8 F/U EKG 15:32 8:30 17:10 14:37 00:39
9 安排Brain CT(查 PACE) 15:32;22:10 00:15 17:20 14:30 00:20
10 安排CXR - - 17:20 14:30 00:00
11 致電神內CR 照會 21:10 00:15 19:00 15:00 00:20 12 神內CR 診視,問病史並評估 NIHSS,診斷為急性血性中風 21:15 00:15 19:10 15:00 00:35 13 若為三小時內發生,評估是否符合打rtPA 21:15 00:20 19:10 15:00 00:35 14 若符合,家屬閱讀打rtPA 同意書及簽署 21:15 00:20 19:10 15:00 01:20
15 量體重 21:15 00:20 19:10 15:00 01:20
16 量血壓 22:55 00:15 19:30 16:00 01:20
17 安排ICU 床 23:30 02:00 20:55 16:20 01:20 18 施打rtPA 22:39 02:00 20:30 16:10 01:20
19 轉床至ICU 23:45 03:10 21:10 16:35 02:00
20 前一小時每15 分鐘量血壓,控制血壓小於 180/105mmHg 23:45 03:10 21:10 16:35 02:00
21 24 小時再 F/U Brain CT 隔日9:00 - 15:45 -
22 給予口服Aspirin - - 4 日後服用 ? 09:00
23 F/U Duplex 隔日F/U ? 3 日後 F/U ? ?
24 F/U MRI - ? 當日20:15 ? 11:40
25 病情穩定後轉一般病房 - - 隔日4PM 13:00 17:00
26 開始安排復健;復健科醫師會診 - - - - -
27 至復健科進行復健 - - - - -
28 病情穩定後出院 ? ? ? ? ?
根據表3 的活動資料檔,將流程資料庫中的活動依照時間做排序,整理成如表 4 的資料檔。
表4
Case Process Case1 1 2 3 4 15 5 9 7 8 6 10 11 12 13 14 16 17 18 22 19 23 21 24 20 25 26 27
Case2 1 2 3 4 5 7 8 6 10 11 12 13 14 17 15 16 18 19 20 22 27 Case3 3 4 5 6 7 8 10 11 15 12 13 14 16 17 18 19 20 22 23 27 Case4 1 2 3 4 6 7 5 8 9 10 14 11 12 13 23 15 17 16 18 19 24 22 21 27 Case5 1 2 3 4 5 8 9 7 10 11 12 13 14 6 15 17 16 18 19 20 21 22 24 23 27
以表4-3-2 為基礎,將流程資料檔轉為 XML 文件,在以 ProM 軟體中的 Heuristic 流程探勘 演算法,進行初始的流程探勘,得到如圖11 的初始流程圖。
而初始流程探勘中所得到的初始流程圖,以定義4-2-4 因果矩陣為準則,進行因果矩陣的轉 換,並可得到如表4-3-3 的因果矩陣表。
表 5
Activity Input Output S {} {1}
1 {S} {2}
2 {1} {{3},{7}}
3 {2} {4}
以因果矩陣表為基礎,找出共同作業活動集:Sequence Pattern,其定義為直接相連的單一活 動,活動的進入以及輸出只能包含一個邊,不能包含分支或結合,建構出共同作業清單,以表5 為例,{S、1、2}即為一個共同作業活動集。
在建立出共同作業清單後,進行流程資料檔的切割,建立流程區塊圖。以圖11 為例,可切 割成如圖12。
接著以圖11 為基準,給予各區塊內流程活動的 Transition 權重,計算活動的 Transition Similarity,並建構出流程相似度分數表。
在AHC 分群方面,依據所建構出的相似度分數表,使用 Clementine 進行 AHC 的階層式分 群,找出每個區塊中的分群結果。而此分群結果,依據定義7 的關聯性法則,進行分群連結,找 出整體性的分群結果。再將此分群結果,轉成XML 文件,在以 ProM 軟體中的 Heuristic,進行 流程探勘。
在結果評估方面,將對同一流程資料庫,使用傳統的分群演算法,進行分群以及流程探勘,
並利用側影系數對兩個分群結果進行評估。
圖11 中風資料庫初始與中風醫療流程區塊切割圖 II. 分群
以圖11 基礎,將表 4 的活動資料表進行分組切割,可得到完整流程活動切割表,並透過 MATLAB 撰寫,給予各Block 內流程活動的 Transition 權重以及計算活動的 Transition Similarity 並建構出流程 相似度分數表。
依據Jung 所提出的相似度計算定義計算兩兩流程間的相似度,如圖 12 似度分數圖所示:
圖12 似度分數圖
在獲得流程相似度分數表後,將其另存為.txt 格式,使用 Cluster 3.0 軟體進行分群,將所建構出 的相似度分數表匯入Cluster3.0 中,選擇 Cluster3.0 內的 AHC 階層式分群演算法進行分群,找出每個 Block 中的分群結果。接著利用 Java Treeview 將 Cluster3.0 所計算的結果以樹狀圖加以表示,若以 Cluster Block A 所包含的流程活動進行分群,可得到如圖 13 分群樹狀圖。
圖13Java Treeview 分群樹狀圖
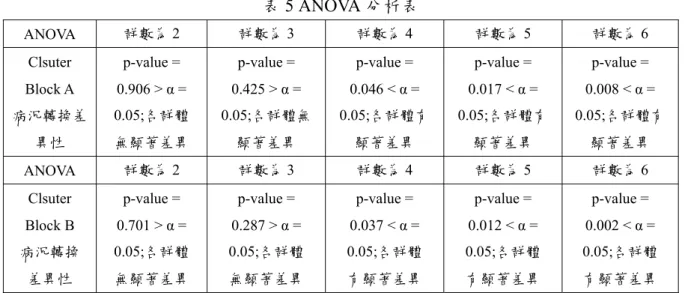
由於AHC 分群演算法之特性為不預設分群數量,因此本研究利用 ANOVA 統計分析,針對病況
轉換的欄位屬性進行組內變異的分析,尋找群體可產生顯著差異的最低分群數量,以此決定所需切割 之分群數量。
由群數二為起始分群數量,對各Cluster Block 中的分群結果進行 ANOVA 分析並搜尋最低分群數 量,其結果如表5 所示:
表5 ANOVA 分析表
ANOVA 群數為2 群數為3 群數為4 群數為5 群數為6
Clsuter Block A 病況轉換差
異性
p-value = 0.906 > α = 0.05;各群體 無顯著差異
p-value = 0.425 > α = 0.05;各群體無
顯著差異
p-value = 0.046 < α = 0.05;各群體有
顯著差異
p-value = 0.017 < α = 0.05;各群體有
顯著差異
p-value = 0.008 < α = 0.05;各群體有
顯著差異
ANOVA 群數為2 群數為3 群數為4 群數為5 群數為6
Clsuter Block B 病況轉換
差異性
p-value = 0.701 > α = 0.05;各群體 無顯著差異
p-value = 0.287 > α = 0.05;各群體 無顯著差異
p-value = 0.037 < α = 0.05;各群體 有顯著差異
p-value = 0.012 < α = 0.05;各群體 有顯著差異
p-value = 0.002 < α = 0.05;各群體 有顯著差異
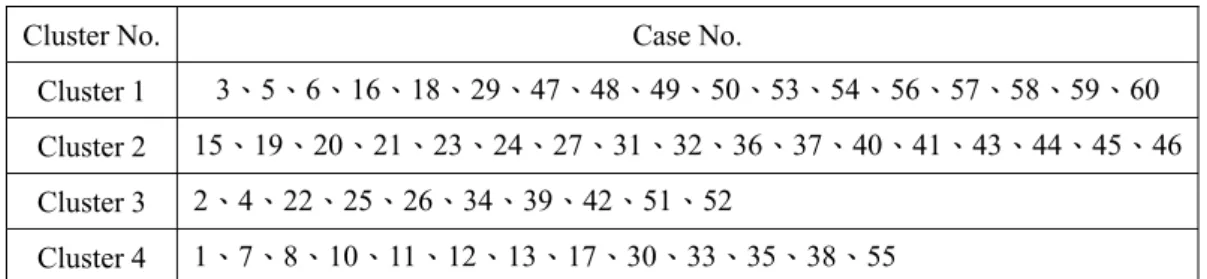
由表6 中可以發現 Cluster Block A 可檢定出有顯著差異性的最低分群數量為 4,而 Cluster Block B 可檢定出有顯著差異性的最低分群數量為4,因此藉由 Java Treeview 匯出分群資料取群數為四,可得 到如表4-22 的各 Block 分群結果表:
表 6 各分區分群結果表
Block No. Cluster No. Case No.
Block A
Cluster 1 3、10、11、12、15、21、23、24、27、32、37、40、41、45、47 Cluster 2 2、4、7、16、20、22、25、26、31、33、34、35、43、44、46 Cluster 3 1、8、13、18、19、30、36、38、39、48、52、53、54 Cluster 4 5、6、17、29、42、49、50、51、55、56、57、58、59、60
Block B
Cluster 1 7、8、11、12、13、17、27、30、35、38、40、41、44、47、55、57、58、59、60 Cluster 2 1、2、4、10、19、24、25、39、45、50、51、56
Cluster 3 15、18、21、22、29、31、32、34、36、37、42、43、46、54 Cluster 4 3、5、6、16、20、23、26、30、33、48、49、52、53
接著利用3-2-5 的關聯性法則演算法,以分群數目為目標群數,搜尋標竿流程,以表 6 為基礎,
定義標竿流程如表7 所示:
表7 標竿流程表
Cluster No. Case No.
Cluster 1 {5、6、49}
Cluster 2 {15、21、32、37}
Cluster 3 {2、4、25}
Cluster 4 {8、13、30、38}
以表7 為分群目標,依關聯性法則將流程分群重新組合成一整體分群,其結果如表 8 所示:
表8 整體分群結果
Cluster No. Case No.
Cluster 1 3、5、6、16、18、29、47、48、49、50、53、54、56、57、58、59、60 Cluster 2 15、19、20、21、23、24、27、31、32、36、37、40、41、43、44、45、46 Cluster 3 2、4、22、25、26、34、39、42、51、52
Cluster 4 1、7、8、10、11、12、13、17、30、33、35、38、55
III. 結果評估
依此分群結果與中風醫療流程資料庫中的病況轉換欄位,以組合方式結合各群集,並統計病況轉 換欄位。接著利用卡方檢定將各組合的病況改善與嚴重度之相關性進行檢定。
獨立性檢定:
在獨立性檢定中,為了配合檢定流程分群與病況轉換間的相關性,因此獨立性列聯表如表9 所 示:
表9 獨立性列聯表
C1 C2 C3 C4 ∑
中 輕 7 0 4 0 11
重 輕 2 4 1 1 8
重 中 0 0 0 1 1
∑ 9 4 5 2 20
設定虛無假設與對立假設:
:群體與病況改善相互獨立。
:群體與病況改善有相關性。
本研究在以組合方式combine 各群集,運用統計檢定可得到結果如表 10 所示,檢定在群數為四 的組合群集情況下,存在群體與病況改善間有顯著關係。
表10 統計結果表
統計檢定 群數為四
Cluster 1 & Cluster 3 組合 Cluster 2 & Cluster 4 組合
獨立性
p-value=0.005864<α=0.05 所以不同的群體與病況改善存在差異性。
病患病況轉好的機率:60.87% 病患病況轉好的機率:21.42%
持平機率:39.13% 持平機率:78.5%
齊一性檢定
在齊一性檢定中,為了配合檢定流程分群與活動17(施打 rtPA)是否有效的情況中,其在流程資料 庫中所佔比率上是否有差異性,因此本研究利用ANOVA 統計分析,針對施打 rtPA 是否有效的欄位 屬性進行組內變異的分析,尋找群體可產生顯著差異的最低分群數量,以此決定所需切割之分群數 量。
由群數二為起始分群數量,對各Cluster Block 中的分群結果進行 ANOVA 分析並搜尋最低分群數 11 所示:
病況轉換 Cluster No.
表 11 ANOVA 分析表
ANOVA 群數為2 群數為3 群數為4 群數為5 群數為6
Clsuter Block A 施打rtPA
差異性
p-value = 0.312 > α = 0.05;各群體 無顯著差異
p-value = 0.140 > α = 0.05;各群體無
顯著差異
p-value = 0.045 < α = 0.05;各群體有
顯著差異
p-value = 0.014 < α = 0.05;各群體有
顯著差異
p-value = 0.010 < α = 0.05;各群體有
顯著差異
ANOVA 群數為2 群數為3 群數為4 群數為5 群數為6
Clsuter Block B 施打rtPA
差異性
p-value = 0.108 > α = 0.05;各群體 無顯著差異
p-value = 0.033 < α = 0.05;各群體 有顯著差異
p-value = 0.014 < α = 0.05;各群體 有顯著差異
p-value = 0.010 < α = 0.05;各群體 有顯著差異
p-value = 0.006 < α = 0.05;各群體 有顯著差異
由表11 中可以發現 Cluster Block A 可檢定出有顯著差異性的最低分群數量為 4,而 Cluster Block B 可檢定出有顯著差異性的最低分群數量為 3,由於關聯性法則的定義需以最大的分群數量為主,因 此將Cluster Block B 以群數為四進行分群,因此藉由 Java Treeview 匯出分群資料取群數為四,進行 齊一性檢定。
齊一性列聯表如表12 所示:
表 12 齊一性列聯表
C1 C2 C3 C4 ∑
施打rtPA:有效 11 6 5 2 24
施打rtPA:無效 6 11 5 11 33
∑ 17 17 10 13 57
設定虛無假設與對立假設:
:群體在施打rtPA 有效的情況上,有相同比率。
:群體在施打rtPA 有效的情況上,有相異性。
本研究在以組合方式combine 各群集,運用統計檢定可得到結果如表 13 所示,檢定在群數為四 的組合群集情況下,存在群體與施打rtPA 的有效比率上有明顯差異。
表13 統計結果表
統計檢定 群數為四
Cluster 1 & Cluster 3 組合 Cluster 2 & Cluster 4 組合
齊一性
p-value=0.0128<α=0.05 所以不同的群體在施打 rtPA 是否有效的情況中,存在比率上的差異性。 。
施打rtPA 的有發生效果的機率:59.25% 施打rtPA 的有發生效果的機率:26.66%
無效的機率:40.74% 無效的機率:73.33%
5. 結論與建議
流程探勘演算法,為一種可以幫助使用者了解流程架構之方法。透過此方法的應用,可以從流程 資料庫中架構出企業的流程模型,而透過分群的方式,對流程資料庫之案例進行分群,藉此找出流程 資料庫內流程間的差異性及潛藏的影響因子。這整個過程包括了,分群演算法在流程探勘上的應用,
以及企業流程資料庫的分析,並將此結果做為決策時的分析之用。
Cluster No.
病況嚴重度
在現實企業流程中,透過資料庫紀錄事件發生的流程紀錄檔有增加的趨勢,企業可藉由此資料庫 進行流程管理或企業模型之建構。而將分群概念加到流程探勘中,主要目的在於透過分群的方法簡化 流程探勘結果。然而日趨龐大的企業流程資料庫,因大量資訊的儲存,在透過分群的方式進行流程探 勘時,對於某部分相對少數之流程活動,常會因筆數較少或活動的順序差異不大,而無法輕易與其他 群體進行切割,變成隱性的流程差異。因此本研究提出一切割流程探勘結果之方式,消除重複性活動 對於分群結果的影響,以期找出潛藏的差異性流程。本研究使用Petri Net 塑模初始企業流程模型,並 透過對初始模型的資料檔切割,將原始流程資料庫進行精簡的處理,在將此精簡後結果進行分群,透 過分區式的分群方式,放大各區塊中的流程差異性,在透過關聯性法則將各區塊進行連結,建構整體 分群結果,並以此進行流程探勘。
本研究具體成果如下所述:
¾ 提出一流程區塊切割之方法,藉此消除計算重複性活動相似度的分數,造成流程差異性被稀釋的 問題點。
¾ 提供一套關聯性法則,將各區塊中之分群進行關聯性連結,建構整體性分群,此結果可放大各區 塊中流程的差異性。
¾ 將統計檢定應用在流程分析中,透過此方式評估分群結果的優劣。
¾ 透過本研究之流程分群演算法,找出某國內中風急診流程資料庫中,造成病人病況轉換的可能潛 藏因素,提高病人的病況改善率。
Reference
[1] J. Jung and J. Bae,(2006) "Workflow Clustering Model Based on Process Similarity" In Proc. of
Int’l Conf. Computer Science and Applications, LNCS, Springer-Verlag , Berlin, pp. 379-389.
[2] Jae-Yoon Jung, J. Bae, and Ling Liu, (2008) "Hierarchical Business Process Clustering" IEEE
International Conference on Services Computing, pp.613-616
[3] C. Li, M. Reichert, and A. Wombacher. (2008) "Discovering Process Reference Models from Process Variants Using Clustering Techniques.”Technical Report TR-CTIT-08-30 Centre for Telematics and
Information Technology, University of Twente, Enschede
[4] Valerie Guralnik, George Karypis(2000) " A Scalable Algorithm for Clustering Sequential"
DataDepartment of Computer Science and Engineering/Army HPC Research Center University of Minnesota pp. 1–13
[5] Greco, G., Guzzo, A., Pontieri, L., Sacca, D. (2006) "Discovering expressive process models by clustering log traces". IEEE Transactions on Knowledge and Data Engineering 18(8), 1010-1027 [6] Ana Karla Alves de Medeiros, Antonella Guzzo, Gianluigi Greco, Wil M.P. van der Aalst, A.J.M.M.
Weijters, Boudewijn F. van Dongen, and Domenico Sacc`a(2008)"Process Mining Based on
Clustering: A Quest for Precision" pringer-Verlag Berlin Heidelberg, BPM Workshops, LNCS 4928, pp. 17–29
[7] M. Song, C.W. G unther, and W.M.P. van der Aalst (2008) "Trace Clustering in Process Mining"
Eindhoven University of Technology pp.1-12.
[8] Hisashi Koga, Tetsuo Ishibashi, Toshinori Watanabe (2007) " Fast agglomerative hierarchical clustering algorithm using Locality-Sensitive Hashing" Knowl INF Syst 12(1): pp. 25–53
[9] Aristomenis S. Lampropoulos and George A. Tsihrintzis (2003)"Agglomerative Hierarchical
Clustering For Musical Database Visualization and Browsing" Department of Informatics University
of Piraeus
[10] K. Lagus, T. Honkela, S. Kaski and T. Kohonen,(1996) "Self-Organizing Maps of Document Collections: A New Approach to Interactive Exploration", in: KDD-96: Proceedings Second
International Conference on Knowledge Discovery & Data Mining, E. Simoudis and J. Han, eds,
AAAI Press/MIT Press , pp. 238–243.[11] A. Ultsch, (1993) "Self-organizing Neural Networks for Visualization and Classification", in:
Information and Classification, O. Opitz et al., eds, Springer, Berlin, pp. 307–313.
國科會補助計畫衍生研發成果推廣資料表
日期:2011/09/21
國科會補助計畫
計畫名稱: 區塊式流程分群法之研究 計畫主持人: 歐陽超
計畫編號: 99-2221-E-011-032- 學門領域: 資訊系統
無研發成果推廣資料
99 年度專題研究計畫研究成果彙整表
計畫主持人:歐陽超 計畫編號:99-2221-E-011-032- 計畫名稱:區塊式流程分群法之研究
量化
成果項目 實際已達成
數(被接受 或已發表)
預期總達成 數(含實際已
達成數)
本計畫實 際貢獻百
分比
單位
備 註 ( 質 化 說 明:如 數 個 計 畫 共 同 成 果、成 果 列 為 該 期 刊 之 封 面 故 事 ...
等)
期刊論文 0 0 100%
研究報告/技術報告 0 0 100%
研討會論文 0 0 100%
論文著作 篇
專書 0 0 100%
申請中件數 0 0 100%
專利 已獲得件數 0 0 100% 件
件數 0 0 100% 件
技術移轉
權利金 0 0 100% 千元
碩士生 3 3 100%
博士生 0 0 100%
博士後研究員 0 0 100%
國內
參與計畫人力
(本國籍)
專任助理 0 0 100%
人次
期刊論文 0 0 100%
研究報告/技術報告 0 0 100%
研討會論文 0 0 100%
論文著作 篇
專書 0 0 100% 章/本
申請中件數 0 0 100%
專利 已獲得件數 0 0 100% 件
件數 0 0 100% 件
技術移轉
權利金 0 0 100% 千元
碩士生 0 0 100%
博士生 0 0 100%
博士後研究員 0 0 100%
國外
參與計畫人力
(外國籍)
專任助理 0 0 100%
人次
其他成果 (無法以量化表達之成 果如辦理學術活動、獲 得獎項、重要國際合 作、研究成果國際影響 力及其他協助產業技 術發展之具體效益事 項等,請以文字敘述填 列。)
透過本研究之流程分群演算法,找出某國內中風急診流程資料庫中,造成病人 病況轉換的可能潛藏因素,提高病人的病況改善率。
成果項目 量化 名稱或內容性質簡述
測驗工具(含質性與量性) 0
課程/模組 0
電腦及網路系統或工具 0
教材 0
舉辦之活動/競賽 0
研討會/工作坊 0
電子報、網站 0
科 教 處 計 畫 加 填 項
目 計畫成果推廣之參與(閱聽)人數 0
國科會補助專題研究計畫成果報告自評表
請就研究內容與原計畫相符程度、達成預期目標情況、研究成果之學術或應用價 值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性)、是否適 合在學術期刊發表或申請專利、主要發現或其他有關價值等,作一綜合評估。
1. 請就研究內容與原計畫相符程度、達成預期目標情況作一綜合評估
■達成目標
□未達成目標(請說明,以 100 字為限)
□實驗失敗
□因故實驗中斷
□其他原因 說明:
2. 研究成果在學術期刊發表或申請專利等情形:
論文:□已發表 □未發表之文稿 ■撰寫中 □無 專利:□已獲得 □申請中 ■無
技轉:□已技轉 □洽談中 ■無 其他:(以 100 字為限)
3. 請依學術成就、技術創新、社會影響等方面,評估研究成果之學術或應用價 值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性)(以 500 字為限)
本研究提出一區怪事流程分群演算法,主要成果如下:
1.本研究提出一流程區塊切割之方法,藉此消除計算重複性活動相似度的分數,造成流程 差異性被稀釋的問題點。
2.本研究提供一套關聯性法則,將各區塊中之分群進行關聯性連結,建構整體性分群,此 結果可放大各區塊中流程的差異性。
3.本研究將統計檢定應用在流程分析中,透過此方式評估分群結果的優劣。
4.透過本研究之流程分群演算法,找出某國內中風急診流程資料庫中,造成病人病況轉換 的可能潛藏因素,提高病人的病況改善率。