應用模擬退火法於雙機批次流程型工廠之排程
廖麗滿
國立勤益科技大學工業工程與管理系
摘 要
以半導體產業內最終測試的預燒製程為研究主題,探討雙機流程型工廠,
且機器具批次處理之特性。批次處理是可將數個工作合併為一批同時處理,而 工作批次處理時間等於該批中工作處理時間最長者。為了提升兩部批次處理機 器之流程型工廠的使用效率,提出以模擬退火法為基的SAH 演算法,使得最 大完工時間最小化。對於10 個工作數的問題,SAH 演算結果與混合整數規畫 模式所得的最佳解比較,30 個執行例子中有 27 個為最佳解。進一步評估 SAH 在較大工作數問題的績效,與下界值比較,是以相對誤差百分比 (E
L
) 為指標;並與局部搜尋法為基的演算法比較,衡量指標為SAH 對該演算法的改善百分 比 (PI)。實驗結果顯示,SAH 演算法在效率與效果的績效上,皆有良好的表 現。
關鍵詞:批次排程,模擬退火法,雙機流程型工廠。
SA-BASED HEURISTIC FOR A TWO-MACHINE FLOWSHOP WITH BATCH PROCESSING MACHINES
Li-Man Liao
Department of Industrial Engineering and Management National Chin-Yi University of Technology
Taichung County, Taiwan 41101, R.O.C.
Key Words: batch scheduling, simulated annealing, two-machine flowshop.
ABSTRACT
The final test burn-in operation of the semiconductor industry is chosen as the topic for exploring a two-machine flowshop with batch processing machines. A batch processing machine is one that can simultaneously process several jobs in one batch. The processing time of a batch is equal to the largest processing time of any job in the batch. In order to improve efficiency of a flowshop with two batch processing machines, an effective simulated annealing based heuristic (SAH) is proposed to schedule the jobs to minimize the makespan. When used in 10-job problems, and the results of the SAH are compared with those of the mixed integer linear programming (MILP) model, in 27 out of 30 instances, the SAH results were optimum. Furthermore, in order to evaluate the performance of the SAH in larger batch problems, the results were compared with those using the lower bound and those using an existing local search based heuristic, respectively. Performance evaluation indexes used in the comparisons are the relative error percentage for the lower
bound (E
L
) and the percentage improvement (PI) for the local search based heuristic. The results show that the SAH algorithm is efficient and effective.一、緒 論
積體電路晶片製造生產系統,主要分為四個階段:晶 圓製造 (wafer fabrication)、晶圓測試 (wafer probe)、封裝 (assembly) 與最終測試 (final test)。半導體測試製程又可分 為晶圓測試和最終測試,前者為封裝前對晶圓之測試,後 者為晶粒封裝後之測試,而預燒 (burn-in) 製程是晶片製 造程序中的後段測試過程。測試記憶體產品功能後,待測 品都會上預燒爐,其目的是提供待測品於高溫、高電壓、
高電流的環境,使生命週期較短的待測品在預燒過程中,
提早顯現其特性,此製程具有批次處理之特性。Uzsoy [1]、
Chang et al. [2]、Damodaran 和 Srihari [3]與 Damodaran et al.
[4]皆為批次處理機器的研究。Uzsoy [1]與 Chang et al. [2]
研究半導體產業中的預燒製程,生產環境皆為單機批次處 理問題;而Damodaran 和 Srihari [3]研究環境為主機板裝 配下的環境壓迫篩選製程 (environmental stress screening, ESS),其製程先通過預燒,再整批進入測試室 (chamber) 進行測試。
ESS 製程先通過預燒程序,再整批進入特定條件下之 測試室,不論是預燒或測試製程,其批量大小因機器容量 之故,皆有其上限,但不受工作型式的限制。另外,當某 一批工作開始處理後,該批工作未完成前,該批中的任一 工作不可被移除,也不可以在處理中加入新的工作,亦即 該批的處理時間等於該批工作中處理時間最長者。本研究 考量此生產環境,定義此環境為雙機批次流程型工廠 (two-machine batch flowshop),每一批次可處理不同型式工 作,但工作大小不可超過機器的容量。
預燒與測試製程的設備都非常昂貴,故充分使用設備 成為重要目標。為了表示機器的使用是否有效率,本研究 採用最大完工時間 (makespan) 為排程目標。
本研究首先針對批次處理機器的文獻加以探討;然 後,提出以SA 為基之啟發式演算法,稱為 SAH 演算法;
執行參數實驗,以設定較佳之參數水準;再對SAH 演算績 效加以分析;最後是結論。
二、文獻探討
Perez et al. [5]將批次處理問題分為不相容與相容工作 群兩類。第一類型問題表示相同工作群的工作才能同時處 理,Kempf et al. [6]、Uzsoy [7]、Dobson 和 Nambimadon [8]
皆發展演算法求解此類型之排程問題;第二類型問題表示 不同型式工作也能同時處理,如Lee et al. [9]認為半導體產 業的預燒製程為瓶頸作業,且不同型式的工作可同時處
理。依批次處理時間可分為三種類型,分別為常數、批次 內工作處理時間的加總與最長處理時間[10]。
Perez et al. [5]指出批次處理機器的研究,大多是單一 機器或平行機器,具批次處理機器且為流程型工廠的環 境,只有極少的研究,如Sung 和 Kim [11]、Sung et al. [12]
考慮雙機批次處理機器 (batch processing machines, BPM) 之流程型工廠,但該研究假設工作大小皆為 1。Sung 和 Min [13]將 BPM 雙機流程型工廠之兩階段機器特性分為批 次-離散機器 (batch-to-discrete machine)、離散-批次機器 (discrete-to-batch machine) 兩種型式,該研究針對離散-批 次機器型式之雙機流程型工廠,提出一虛擬多項式演算法 (pseudo-polynomial algorithm)。Sung 和 Kim [14]則針對批 次-離散機器型式之流程型工廠,提出有效之啟發式演算 法。另外,Glass et al. [15]針對雙機流程型工廠與開放工作 站的環境,建構整數規畫模式,以及提出啟發式演算法。
Damodaran 和 Srihari [3]也研究雙機批次處理機器之 流程型工廠,且每一工作大小不同,故該問題比 Sung 和 Kim [11]、Sung et al. [12]的研究環境更為複雜。Damodaran 和Srihari [3]提出了兩個混合整數規畫模式 (mixed integer linear programming, MILP),模式一為兩部機器間具有暫存 區;模式二則無暫存區。Liao 和 Liao [16]則改善 Damodaran 和Srihari [3]所提出的混合整數規畫模式,使得求解問題可 提升約為15 個工作數或 8 個批量數。Liao 和 Liao [16]更 進一步提出MILP 為基之演算法,但其演算複雜度與批量 數呈指數成長,故無法在合理的時間求解較大問題。為了 求解雙機批次流程型工廠排程的較大問題,Liao 和 Huang [17]以局部搜尋法 (local search, LS) 提出啟發式演算法,
利用工作交換與插入的機制,尋找更佳的鄰近解,但局部 搜尋過程中,可能陷入局部最佳解的窘境。
近年來,萬用式演算法 (meta-heuristic) 廣泛地應用在 最佳解搜尋策略上,具有跳脫局部最佳解之能力,強化搜 尋解的效果,故 Liao 和 Huang [18]以禁步搜尋法 (tabu search, TS) 求解雙機批次流程型工廠排程問題。本研究延 續[18]的研究,應用模擬退火法 (simulated annealing, SA) 搜尋技術,並參考Kirkpatrick et al. [19]、Eglese [20]所提 出的SA 演算架構,以及 Melouk et al. [21]應用 SA 在單一 批次機器的演算法,發展以模擬退火法為基的啟發式演算 法 (SA-based heuristic),稱之為 SAH 演算法。
本研究雙機批次處理流程型工廠的基本假設如下:
1. 每一工作的到達時間皆為 0。
2. 工作之處理時間事先已知且為固定。
3. 機器的處理容量有限制。每個工作大小可以不同,但某 一工作或是某一批工作的大小,不可超過機器的容量。
4. 某批工作一旦開始處理,該批處理的工作就不可以被中 斷,其他工作也不可以中途加入,直到整批工作皆完成 為止,故該批處理時間等於該批工作中處理時間最長 者。
5. 目標函數為最大完工時間(makespan)最小化。
為了求解雙機批次流程型工廠較大的排程問題,且能 跳脫局部最佳解的現象,本研究發展SAH 演算法改善 Liao 和Huang [17]所提出的 H 演算法。
三、SAH 演算法
SA 的基本步驟如下[22]:
步驟1: 產生起始狀態 i,其能量為 E
i
。 步驟2: 擾動產生新的狀態 j,其能量為 Ej
。 步驟3: 計算狀態 i 與 j 的能量差異值ΔE = Ej
− Ei
。 步驟4: 測試:若ΔE ≤ 0,接受新狀態 j;若ΔE > 0,此時並不完全拒絕狀態
j,而是以波茲曼 (Boltzmann)
機率函數p(ΔE, T) = exp(−ΔE/T),計算其接受機
率。步驟5: 若狀態 j 為下一個狀態,則令 i = j。
步驟6: 回到步驟 2。
以上步驟4 稱為 Metropolis 準則,是為跳脫局部最佳 解的主要步驟。SA 搜尋過程藉由溫度的逐漸降低,調整是 否接受較差新解的機率,此一機率隨著溫度的下降而降低。
雙機流程型工廠最大完工時間之最佳工作序列,機器 一與二的工作序列應相同[23]。應用 FF (first fit) 程序[1]
與詹森演算法 (Johnson algorithm, JA),求得起始工作批次 序列。再運用工作插入法與不同批次之兩個工作交換法,
執行搜尋機制,求得更佳的解。
為了提升搜尋績效,故先判斷批次內工作在兩部機器 上的處理時間,是否皆等於該批次處理時間最大者,若是,
該特定工作稱之為關鍵性工作。其定義如下:
關鍵性工作:假設批次
b 存在一工作 j,該工作在
兩 部 機 器 上 的 處 理 時 間 皆 為 該 批 中 最 大 者 , 即j =
arg max{ jm km, 1,2}
k b
p p m
∈ ≥ = ,則稱工作
j 為批次 b 的關鍵性
工作,表示批次b 的處理時間等於工作 j
的處理時間。工作插入法 (insert) 及兩工作交換法 (interchange) 為SAH 演算法中的兩種鄰域產生方式,詳細說明如下:
1. 工作插入法
(一) 以隨機方式選擇一批次 b,判斷此批次是否具有關鍵 性工作。
(二) 插入工作之選取:容量允許的前提下,符合以下某一 情況,選擇最佳鄰域解。
(1) 批次 b 有關鍵性工作 j,將工作 j 插入其他批次。
(2) 批次 b 沒有關鍵性工作,任選一工作插入其他批 次。
2. 兩工作交換法
(一) 以隨機方式選擇兩批次,前後批分別為批次 b 與 b', 判斷此兩批次的工作是否具有關鍵性工作。
(二) 交換工作之選取:容量允許的前提下,符合以下某一 情況,選擇最佳之鄰域解。
(1) 前批次 b 與後批次 b'分別有關鍵性工作 j 與工作
j',則選擇工作 j' 與批次 b 中的工作 k 交換,其中
工作k 不是關鍵性工作,即 k ≠ j。
(2) 只有前批次 b 有關鍵性工作 j,則選擇工作 j 與批 次
b' 中的任一工作交換。
(3) 只有後批次 b' 有關鍵性工作 j',則選擇工作 j' 與批 次
b 中的任何一工作交換。
(4) 前批次 b 與後批次 b' 皆無關鍵性工作,則擇選兩 批中的任一工作交換。
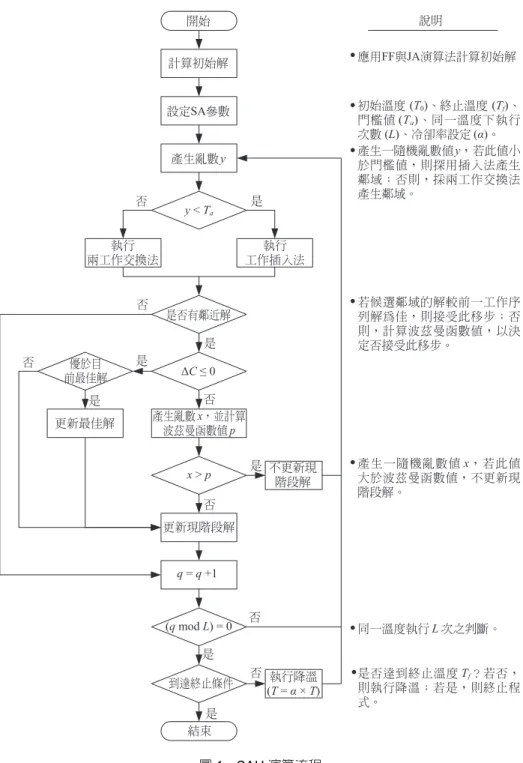
SAH 演算法流程如圖 1 所示,其主要特色為運用工作 插入法與交換法兩種鄰域搜尋機制,且以隨機方式選擇鄰 域產生方式,配合Metropolis 準則,有效地防止陷入局部 最佳解。進而利用關鍵性工作之特性,產生較佳之鄰域,
提升演算法的效率。SAH 的基本參數有:初始溫度 T
0
、終 止溫度為T f
、鄰域結構、同一溫度下執行次數L、冷卻率
α。 演算程序說明如下:步驟1: 應用 FF 與 JA 演算法求得初始解 S
0
,且令S *
= S0
、*
max max( )0
C
=C S
。步驟2: 設定門檻值 T
a
,0 ≤ Ta
≤ 1,作為判斷使用移步 方式之依據。而冷卻程式的參數包括初始溫度T 0
、終止溫度T f
、同一溫度下重複執行次數L、
冷卻率α,0 ≤ α ≤ 1。令起始搜尋次數 q = 0、目 前溫度
T = T 0
。步驟3: 隨機產生一亂數值 y,0 ≤ y ≤ 1。
步驟4: 若 y ≤ T
a
,現階段工作序列S q
執行插入法以產生鄰近解
S q + 1
;否則,執行兩工作交換法產生鄰近解。若有候選鄰近解,則選擇較佳之鄰近解,並 計算ΔC = C
max
(Sq + 1
) – Cmax
(Sq
)。若無鄰近解,則令
S q + 1
= Sq
,並至步驟7。步驟5: 若ΔC ≤ 0,至步驟 6;否則,隨機產生一亂數值
x
, 並計算p = exp(−ΔC/T)機率函數,其中 T 為目前
溫度。當x > p 時,不更新現階段解,即 S q + 1
= Sq
; 否則更新現階段解,並至步驟7。步驟6: 若 C
max
(Sq + 1
) <C
*max,則S *
= Sq + 1
。 步驟7: q = q + 1,若 (q mod L) ≠ 0,則回至步驟 3。步驟8: T = α × T,若 T > T
f
,則令q = 0,執行步驟 3;否
則,搜尋結束,輸出最佳序列S *
與最佳值C
max* 。 至於SAH 演算法的步驟 1 使用 FF 與 JA 演算法求得 起始解的詳細步驟如下:步驟1.1: 所有工作以 JA 加以排序,得到一起始工作序列 σ,此序列為σ(1), …, σ(i), …, σ(n),每一個工作 自成一批,計算此序列之最大完工時間
C max
。圖1 SAH 演算流程
設定起始批次為1,即 b = 1。
步驟1.2: ρ
b
為最新批次之工作集合。令ρb
包含序列σ中的 第一個工作,即ρb
= {σ(1)},σ(1) 由σ中移除,即σ = σ\σ(1)。σ的工作指標
i 等於 2。假如σ =
φ, 則跳至步驟1.8。步驟1.3: 假如minm=1,2
B
m−∑
j b∈ σ( )j
=0 (即批次 b 剛 好為滿批),或是 i 大於序列σ的工作數,則跳至 步驟1.7。步驟1.4: 假如σ( )
i
≤minm=1,2B
m−∑
j b∈ σ( )j
不成立,則i = i + 1 且回到步驟 1.3。
步驟1.5: ρ
b
= ρb
∪ {σ(i)},且σ = σ\{σ(i)}。使用 JA 演算 法排序批次ρ1
, …, ρb
與σ序列中的工作,得到新 的批次序列及其最大完工時間C ' max
。步驟1.6: 假如 C
' max
≥ Cmax
,則ρb
= ρb
\{σ(i)}、σ = σ ∪ {σ(i)}、i = i + 1,回到步驟 1.3。步驟1.7: 假如σ ≠ φ,則
b = b + 1 且回到步驟 1.2。
表一 範例之工作處理時間與工作大小資料
工作
j 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
p j, 1
26 45 54 25 8 32 85 64 80 70 49 85 11 85 65p j, 2
28 67 27 26 99 57 82 47 27 30 91 84 52 63 44s j
4 3 2 2 4 1 3 4 1 2 1 3 4 1 2表二 使用JA 演算法產生之工作批次序列
批次
b 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
工作
j 5 13 4 1 6 2 11 12 7 14 8 15 10 9 3
P b, 1
8 11 25 26 32 45 49 85 85 85 64 65 70 80 54P b, 2
99 52 26 28 57 67 91 84 82 63 47 44 30 27 27B b
4 4 2 4 1 3 1 3 3 1 4 2 2 1 2C b, 1
8 19 44 70 102 147 196 281 366 451 515 580 650 730 784C b, 2
107 159 185 213 270 337 428 512 594 657 704 748 778 805832
表三 完成第一批次工作的合併 (a)
批次
b 1 2 3 4 5 6 7 8 9 10 11 12 13 14
工作
j 5,
13 4 1 6 2 11 12 7 14 8 15 10 9 3P b, 1
11 25 26 32 45 49 85 85 85 64 65 70 80 54P b, 2
99 26 28 57 67 91 84 82 63 47 44 30 27 27B b
8 2 4 1 3 1 3 3 1 4 2 2 1 2C b, 1
11 36 62 94 139 188 273 358 443 507 572 642 722 776C b, 2
110 136 164 221 288 379 463 545 608 655 699 729 756803
(b)批次
b 1 2 3 4 5 6 7 8 9 10 11 12 13
工作
j 5,
13, 4 1 6 2 11 12 7 14 8 15 10 9 3P b, 1
25 26 32 45 49 85 85 85 64 65 70 80 54P b, 2
99 28 57 67 91 84 82 63 47 44 30 27 27B b
10 4 1 3 1 3 3 1 4 2 2 1 2C b, 1
25 51 83 128 177 262 347 432 496 561 631 711 765C b, 2
124 152 209 276 367 451 533 596 643 687 717 744792
步驟1.8: 使用 JA 排序工作批次,得到起始批次序列 S
0
。 本研究以工作數為15 實驗問題中的例子 1 為範例。首先,說明SAH 之初始解的演算程序,然後,以 SA 之搜 尋機制,求得更佳的解。
範例:已知有15 個工作,工作 j 在機器一、二的處理 時間分別為
p j, 1
、pj, 2
,其工作大小為s j
,如表一所示。假 設兩部機器的容量限制皆為10 單位。SAH 求解範例之初 始解的演算程序如下:步驟1.1: 以 JA 演算法將工作加以排序,得到一初始序列 σ = {5, 13, 4, 1, 6, 2, 11, 12, 7, 14, 8, 15, 10, 9,
3},其 C
max
= 832,如表二。設定起始批次 b 為 1。步驟1.2: ρ
1
= {5}、σ = {5, 13, 4, 1, 6, 2, 11, 12, 7, 14, 8, 15, 10, 9, 3}。序列σ的工作指標i = 2。
σ ≠ φ,故執 行步驟1.3。步驟1.3: minm=1,2
B
m−∑
j b∈ σ( )j
= 10 – 4 = 6 > 0,且 i = 2 < 15,故執行步驟 1.4。步驟1.4: σ(2)= 3 ≤ 6,故執行步驟 1.5。
步驟1.5: ρ
1
= {5, 13},且σ = {4, 1, 6, 2, 11, 12, 7, 14, 8, 15, 10, 9, 3},使用 JA 執行批次排序,求得 C' max
= 803。步驟1.6: 因為 C
' max
< Cmax
,更新C max
= 803,新的批次序 列請詳見表三(a),回到步驟 1.3。步驟1.3: mini=1,2
B
m−∑
j b∈ σ( )j
= 10 – 7 = 3 > 0,且 i = 3 < 10,故執行步驟 1.4。步驟1.4: σ(2)= 3 ≤ 3,故執行步驟 1.5。
步驟1.5: ρ
1
= {5, 13, 4},且σ = {1, 6, 2, 11, 12, 7, 14, 8, 15, 10, 9, 3}。使用 JA 執行批次排序,求得 C' max
= 792。步驟1.6: 因為 C
' max
< Cmax
,更新C max
= 792,新的批次序 列請詳見表三(b),回到步驟 1.3。步驟1.3: mini=1,2
B
m−∑
j b∈ σ( )j
= 10 – 10 = 0,表示第一 批剛好為滿批,故執行步驟1.7。步驟1.7: σ = {1, 6, 2, 11, 12, 7, 14, 8, 15, 10, 9, 3},b = 2,
回到步驟1.2。
由步驟1.7 回到步驟 1.2,表示新批的開始,以此反覆 運算至所有的工作都排入特定批次為止,再執行步驟1.8。
本範例執行反覆運算共4 次,工作批次為 4。
步驟1.8: 使用 JA 排序工作批次ρ
1
, …, ρ4
,得到初始批次 序列S 0
= {(5, 13, 4), (1, 6, 2, 11, 14), (12, 7, 8), (15, 10, 9, 3)},其 Cmax
(S0
) = 343,請詳見表四。求得
S 0
= {(5, 13, 4), (1, 6, 2, 11, 14), (12, 7, 8), (15, 10, 9, 3)}初始解,Cmax
(S0
) = 343。令C
*max= Cmax
(S0
) = 343 至步驟 2。步驟2: 此範例的門檻值 T
a
設為 0.2,初始溫度 T0
設為 500,終止溫度 Tf
設為1,同一溫度下重複執行次 數L 設為
40,冷卻率α設為0.95。且令起始搜尋 次數q = 0,當時溫度為初始溫度,即 T = T 0
= 500。步驟3: 隨機產生一亂數值 y = 0.1234247。
步驟4: y ≤ 0.2,故 S
0
採用插入法以產生鄰近解,得到序 列S 1
= {(5, 13, 4), (1, 6, 2, 11, 14), (12, 7, 8), (15, 10, 9, 3)},Cmax
(S1
) = 381,如表五。ΔC = 381 – 343 = 38。步驟5: ΔC = 38 > 0,p = exp(−ΔC/T) = 0.9268,產生一亂 數
x = 0.7358562。因 p > x,接受此較差的鄰域解,
即
S 1
= {(5, 13, 4), (1, 6, 2, 11, 14), (12, 7, 8), (15, 10, 9, 3)},至步驟 7。步驟7: q = q + 1 = 2,因 (q mod L) ≠ 0,回至步驟 3。
步驟3: 隨機產生一亂數值 y = 0.3132114。
步驟4: y > T
a
,S1
採用兩工作交換法產生鄰近解,得到序 列S 2
= {(5, 13, 4), (1, 6, 7, 11, 14), (12, 8), (2, 15, 10, 9, 3)},其 Cmax
(S2
) = 366,如表六。ΔC = 366 – 381 = −16。步驟5: ΔC ≤ 0,至步驟 6。
步驟6: C
max
(S2
) >C
*max,至步驟7。步驟7: q = q + 1 = 3,因 (q mod L) ≠ 0,回至步驟 3。
步驟3: 隨機產生一亂數值 y = 0.2647181。
步驟4: y > T
a
,S2
採用兩工作交換法產生鄰近解,得到序 列S 3
= {(5, 12, 4), (12, 6, 7, 11, 14), (1, 8), (2, 15,表四 初始序列
S 0
與C max
(S0
)批次
b
1 2 3 4工作
j
5, 13, 4 1, 6, 2, 11, 14 12, 7, 8 15, 10, 9, 3P b, 1
25 85 85 80P b, 2
99 91 84 44B b
10 10 10 7C b, 1
25 110 195 275C b, 2
124 215 299343
表五 序列
S 1
與C max
(S1
)批次
b
1 2 3 4工作
j
5, 13, 4 1, 6, 2, 11, 14 12, 8 7,15, 10, 9, 3P b, 1
25 85 85 85P b, 2
99 84 84 82B b
10 10 7 10C b, 1
25 110 195 280C b, 2
124 215 299381
表六 序列
S 2
與C max
(S2
)批次
b
1 2 3 4工作
j
5, 13, 4 1, 6, 7, 11, 14 12, 8 2, 15, 10, 9, 3P b, 1
25 85 85 80P b, 2
99 91 84 67B b
10 10 7 10C b, 1
25 110 195 275C b, 2
124 215 299 366表七 序列
S 3
與C max
(S3
)批次
b
1 2 3 4工作
j
5, 13, 4 12, 6, 7, 11, 14 1, 8 2, 15, 10, 9, 3P b, 1
25 85 64 80P b, 2
99 91 47 67B b
10 9 8 10C b, 1
25 110 174 254C b, 2
124 215 262 32910, 9, 3)},其 C
max
(S3
) = 329,如表七,故ΔC = 329 – 366 = −37。步驟5: ΔC ≤ 0,至步驟 6。
步驟6: C
max
(S3
) <C
max* ,故S *
= S3
,至步驟7。步驟7: q = q + 1 = 4,因 (q mod L) ≠ 0,回至步驟 3。
依步驟3 至 7 的反覆步驟,執行某一溫度下之序列搜 尋,共40 次。再至步驟 8 執行降溫,然後回到步驟 3~7 之反覆步驟,直到溫度降至符合終止溫度為止。本範例的
表八 最佳序列
S *
與C * max
批次b 1 2 3 4
工作j 5, 13 2, 11, 7, 12 4, 14, 3, 1 10, 15, 9, 8, 6
P b, 1
11 85 85 80P b, 2
99 91 63 28B b
8 10 8 9C b, 1
11 96 181 261C b, 2
110 201 264292
表九 工作大小之三種問題型式 問題型式 (a
min
, amax
) 說明I (1, 5) 工作大小相對較小 II (4, 10) 工作大小相對較大 III (1, 10) 工作大小之分散程度較寬
最佳序列為S
*
= {(5, 13), (2, 11, 7, 12), (4, 14, 3, 1), (10, 15, 9, 8, 6)},最佳目標值C
*max= 292,如表八所示。四、參數設定
SAH 演算法的鄰域搜尋策略有工作插入法與兩工作 交換法,故以門檻值
T a
判斷使用何種策略,加上SA 的四 項基本參數:T0
、Tf
、L、α,共有五項參數。本研究以 Visual Basic 撰寫演算法之程式,並使用 Pentium(R) D 2.80 GHz 的電腦進行實驗。實驗例子的工作 數有10、15、20,例子產生與 Damodaran 和 Srihari [3]相 同。工作處理時間為 U (1,100);兩部機器容量皆設定為 10;工作大小為 a
min
至a max
的均勻分配,如表九所示。SAH 演算法參數組合之設定分為兩階段,說明如下。
1. 初始溫度 T
0
與T f
之設定SA 的初始溫度之設定,是為了在搜尋的開始,較差 的解也可以被接受,故本研究以工作數為 10、15、20,
各執行10 個例子,每一個例子以局部搜尋法 (local search, LS) 方式產生較佳的解(
C
maxLS ),與應用FF [1]與 JA 求得 之 起 始 解(C
maxFFJA)比 較 , 分 別 計 算 各 例 子 的 差 值δ(i) =maxFFJA( ) maxLS ( )
C i
−C i
,並選出δ = maxi
δ(i) 值,使得 eδ /T
0 ≈ 1,所得到較適合之
T 0
值約為500。另外,當 Tf
為1 時,搜尋 解的過程近似LS,較差的解已不容易執行移步。2. T
a
、L 與 α 之設定T 0
值為500、Tf
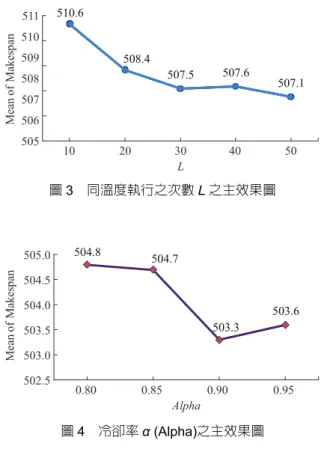
為1 的設定下,其他三項參數設定如 表十。經變異數分析 (analysis of variance, ANOVA) 後發 現,Ta
、L 與α之P 值均近似於 0,表示此三項參數皆明顯 影響演算結果,如表十一所示。表十 SAH 實驗階段二的參數水準
參數 水準
門檻值
T a
0, 0.1, 0.2, 0.3, 0.4, 0.5 同溫度執行之次數L
10, 20, 30, 40, 50 冷卻率α 0.8, 0.85, 0.9, 0.95表十一 ANOVA 分析之主變異來源 變異來源 自由度 平方和 F 比例 P 值 門檻值
T a
5 257250 1099.74 0.00 冷卻率α 3 5525 39.36 0.00 次數L 4
8405 44.91 0.00圖2 門檻值 T
a
之主效果圖至於
T a
、L 與α之水準選擇過程說明如下:(一) 因 T
a
參數的差異最大,如圖2 所示,故以逐步刪除較 差的水準,再做檢定之,結果顯示:當門檻值刪除了 0 與 0.1 後,其差異不再顯著,故 0.2、0.3、0.4、0.5 皆為可行之門檻值。(二) 當 L 為 10 與 20 時,效果明顯較差,如圖 3 所示,故 逐步刪除較差的水準檢定之。在執行時間與執行結果 的權衡下,工作數為10 時,較適 L 值為 30;工作數 為15 時,較適 L 值為 40;工作數為 20 時,較適 L 值 為50。表示工作數越大,工作序列的組合越多,故搜 尋次數
L 值也要增加,以尋找更佳的解。
(三) 當α為0.8 與 0.85 時,效果明顯較差,如圖 4 所示,
逐步刪除較差水準檢定之。當工作數為10 時,較適α 值為0.90;而工作數為 15 與 20 時,較適α值為0.95。
五、實驗結果
以軟體Lingo 撰寫 MILP 模式,再以 Visual Basic 撰 寫SAH 演算法。求解工作數為 10、15、20 的問題,加上 三種不同的工作大小型式 (I、II、III),各產生 10 個例子,
故工作數10、15、20 的問題,皆分別執行 30 個例子。
圖3 同溫度執行之次數 L 之主效果圖
圖4 冷卻率 α (Alpha)之主效果圖
首先,實驗工作數為10 的問題,以 MILP 模式求出最 佳 解 。 使 用 績 效 指 標 為 與 最 佳 解 之 相 對 誤 差 百 分 比 (relative error percentage, E),公式如下。
*
max max
* max
100%
C
SAHC
E C
= − × (1)
從表十二可看出SAH 在工作數為 10 問題的演算績 效,工作大小型式I、II 的問題,10 個例子皆為最佳解,
而工作大小型式為 III 的 10 個例子中,有 7 個為最佳 解,與最佳解的平均相對誤差百分比為1.18%,整體而 言,最佳解百分比達 90%,而平均相對誤差百分比為 0.39%。
SAH 演算結果若與其下界值比較,其 LB/
C
max* 值在三 種型式中,分別為0.89, 0.99 與 0.94。從以上比值推論:在 工作大小相對較大的問題中,工作不容易合併,故下界值 相當接近最佳解,比值達0.99;另一方面,在工作大小相 對較小的問題中,因多個工作可合併為同一批次的彈性較 大,故下界值與最佳解的差異值較大。其次,分別執行工作數為15 與 20 的問題。因工作 數較大,極少的例子能在24 小時內運用 MILP 模式求得 最佳解,因此,SAH 的執行結果與其下界值 (LB) 比較。
衡量指標為與下界值之相對誤差百分比 (E
L
),公式如下:maxSAH 100%
L
C LB
E LB
= − × (2)
表十二 工作數10 之計算結果
問題型式 最佳解個數 最佳解比例 (%)
E (%)
I 10 100 0 II 10 100 0 III 7 70 1.18
平均 27 90 0.39
因為推導下界值過程中,先考慮了工作的可合併性,
再假設工作具有可分割性,故三種工大小的型式中,接近 最佳解的程度有所不同。故為了進一步衡量SAH 演算法的 績效,故與局部搜尋法建構的H 演算法[14]比較,以對 H 演算法的改善百分比 (percentage improvement, PI) 衡量 之,公式如下:
max max
max
100%
H SAH
H
C C
PI C
= − × (3)
從表十三與表十四可看出SAH 在工作數為 15、20 問 題的演算績效。在型式II 的問題,E
L
平均值分別為5.37%與3.04%,很明顯地,型式 II 的問題比在型式 I 和 III 的情 況下的
E L
為佳。SAH 的演算結果,明顯地改善了 H 演算法,特別是在 型式I 和 III 的情況下,在工作數為 15 的問題,其改善程 度分別為6.18%、8.65%;在工作數為 20 的問題,其改善 程度分別為9.03%、10.36%,改善幅度大表示本研究改善 了LS 陷入局部最佳解的狀況。
六、結 論
SAH 演算法是以 SA 為基之啟發式演算法,本研究使 用變異數分析法 (ANOVA) 選定 SAH 之參數。在工作數 為10 的批量時,SAH 演算法求得最佳解的比例達 90%,
特別是型式I 與 II 的問題,100%可求出最佳解。而工作數 為15 與 20 的批量問題,由於整數規劃法無法在 12 小時內 求得最佳解,故其結果與下界值比較,其相對誤差有八成 的例子落在10%之內,且平均相對誤差約為 6.47%。另外,
SAH 也改善了 H 的演算結果,平均約為 6.21%,最大改善 率更達21.44%,且求解較大問題皆可在 3 秒內完成,顯示 SAH 為效率高且效果佳之演算法。
符號索引
B b
批次b 的 工 作 大 小 B
m 機器m 的 容 量 上 限
C b, m
批次b 在 機器 m 的 完 成 時 間 C max
最大完工時間*
C
max 最大完工時間的最佳值表十三 工作數為15 之計算結果
型式 例子
C
maxSAHE L
(%)C
maxHPI(%)
I 1 292 9.36 336 13.10 2 356 8.87 369 3.52 3 297 8.39 333 10.81 4 316 7.48 337 6.23 5 313 7.93 346 9.54 6 361 4.94 371 2.70 7 379 14.85 389 2.57 8 420 9.66 451 6.87 9 389 14.75 398 2.26 10 341 10.71 356 4.21平均 9.70 6.18
II 1 717 4.67 737 2.71 2 788 0.90 788 0.00 3 636 6.18 650 2.15 4 588 0.34 596 1.34 5 725 9.19 756 4.10 6 802 0.38 815 1.60 7 742 9.60 742 0.00 8 905 0.00 905 0.00 9 755 9.90 786 3.94 10 688 12.60 717 4.04
平均 5.37 1.99
III 1 594 3.30 643 7.62 2 664 5.23 685 3.07 3 490 4.93 509 3.73 4 418 10.58 461 9.33 5 478 3.46 564 15.25 6 646 8.21 708 8.76 7 504 1.00 542 7.01 8 634 3.93 807 21.44 9 615 16.04 615 0.00 10 470 3.52 524 10.31
平均 6.02 8.65
L
同一溫度下執行次數p j, m
工作j 在機器 m 的處理時間 P b, m
批次b 在 機器 m 的 處 理 時 間 s j
工作j 的工作大小
S q
第q 次搜尋的工作批次序列 T 0
初始溫度T a
鄰域策略選擇門檻值T f
終止溫度為α 冷卻率
σ 工作序列
ρ
b
批次b 之工作集合
參考文獻
1. Uzsoy, R., “Scheduling a Single Batch Processing Machine
表十四 工作數為20 之計算結果
型式 例子
C
maxSAHE L
(%)C
maxHPI(%)
I 1 407 10.24 429 5.132 404 12.61 444 9.01 3 375 12.61 392 4.34 4 476 2.20 524 9.16 5 427 8.48 453 5.74 6 431 17.76 494 12.75 7 420 6.27 439 4.33 8 372 13.29 401 7.23 9 340 18.25 432 21.30 10 333 3.74 372 11.29
平均 10.17 9.03
II 1 881 8.90 892 1.23 2 878 6.17 893 1.68 3 881 2.92 933 5.57 4 914 0.99 916 0.22 5 786 0.00 786 0.00 6 902 2.97 972 7.20 7 1208 1.77 1253 3.59 8 900 3.81 922 2.39 9 773 0.00 773 0.00 10 676 2.89 676 0.00
平均 3.04 2.19
III 1 548 1.29 647 15.30 2 720 3.15 832 13.46
3 602 10.46 685 12.12 4 770 5.91 924 16.67 5 754 1.75 804 6.22 6 774 5.16 811 4.56 7 895 0.00 910 1.65 8 659 0.61 735 10.34 9 633 8.02 762 16.93 10 626 0.16 643 2.64
平均 3.25 10.36
with Non-Identical Job Sizes,” International Journal of
Production Research, Vol. 32, No. 7, pp. 1615-1635
(1994).2. Chang, P. C., Chen, Y. S., and Wang, H. M., “Dynamic Scheduling Problem of Batch Processing Machine in Semi- conductor Burn-in Operations,” Computational Science
and its Applications, Vol. 3483, No. 4, pp. 172-181 (2005).
3. Damodaran, P. and Srihari K., “Mixed Integer Formula- tion to Minimize Makespan in a Flow Shop with Batch Processing Machines,” Mathematical and Computer Model-
ing, Vol. 40, No. 13, pp. 1465-1472 (2004).
4. Damodaran, P., Srihari, K., and Lam, S. S., “Scheduling a Capacitated Batch-Processing Machine to Minimize Makespan,” Robotics and Computer-Integrated Manufac-
turing, Vol. 23, No. 2, pp. 208-216 (2007).
5. Perez, I. C., Fowler, J. W., and Carlyle, W. M., “Minimiz- ing Total Weighted Tardiness on a Single Batch Process Machine with Incompatible Job Families,” Computers
and Operations Research, Vol. 32, No. 2, pp. 327-341
(2005).6. Kempf, K. G., Uzsoy, R., and Wang, C. S., “Scheduling a Single Batch Processing Machine with Secondary Re- source Constraints,” Journal of Manufacturing Systems, Vol. 17, No. 1, pp. 37-51 (1998).
7. Uzsoy, R., “Scheduling Batch Processing Machines with Incompatible Job Families,” International Journal of Pro-
duction Research, Vol. 33, No. 10, pp. 2685-2708 (1995).
8. Dobson, G. and Nambimadon, R. S., “The Batch Loading and Scheduling Problem,” Operations Research, Vol. 49, No. 1, pp. 52-65 (2001).
9. Lee, C. Y., Uzsoy, R., and Martin-Vega, L. A., “Efficient Algorithms for Scheduling Semiconductor Burn-In Opera- tions,” Operations Research, Vol. 40, No. 4, pp. 764-775 (1992).
10. Domodaran, P., Melouk, S., and Chang, P. Y., “Minimiz- ing Makespan for Single Machine Batch Process with Non-Identical Job Sizes Using Simulated Annealing,”
International Journal of Production Economics, Vol. 87,
No. 2, pp. 141-147 (2004).11. Sung, C. S. and Kim, Y. H., “Minimizing Due Date Related Performance Measures on Two Batch Processing Machine,” European Journal of Operational Research, Vol. 147, No. 3, pp. 644-656 (2003).
12. Sung, C. S., Kim, Y. H., and Yoon, S. H., “Problem Reduction and Decomposition Approach for Scheduling for a Flowshop of Batch Processing Machines,” European
Journal Operational Research, Vol. 121, No. 1, pp. 179-
192 (2000).13. Sung, C. S. and Min, J. I., “Scheduling in a Two-Machine Flowshop with Batch Processing Machines for Earliness/
Tardiness Measure Under a Common Due Date,” Euro-
pean Journal of Operational Research, Vol. 131, No. 1,
pp. 95-106 (2001).14. Sung, C. S. and Kim, Y. H., “Minimizing Makespan in a Two-Machine Flowshop with Dynamic Arrivals Allowed,”
Computers and Operations Research, Vol. 29, No. 3, pp.
275-294 (2002).
15. Glass, C. A., Potts, C. N., and Strusevich, V. A., “Sched- uling Batches with Sequential Job Processing for Two- Machine Flow and Open Shops,” INFORMS Journal on
Computing, Vol. 13, No. 2, pp. 120-137 (2001).
16. Liao, C. J. and Liao, L. M., “Improved MILP Models for Two-Machine Flowshop with Batch Processing Time,”
Mathematical and Computer Modelling, Vol. 48, No. 7-8,
pp. 1254-1264 (2008).17. Liao, L. M. and Huang, C. J., “An effective heuristic for two-machine flowshop with batch processing machines,”
The 38th conference on Computers and Industrial Engi- neering (ICCIE2008), Beijing, China (2008).
18. Liao, L. M. and Huang, C. J., “Tabu Search Heuristic for Two-Machine Flowshop with Batch Processing Machines,”
Computers and Industrial Engineering, Vol. 60, No. 3, pp.
426-432 (2011).
19. Kirkpatrick, S., Gelatt, C. D., and Vecchi, M. P., “Opti- mization by Simulated Annealing,” Science, Vol. 220, No.
4598, pp. 671-680 (1983).
20. Eglese, R. W., “Simulated Annealing: A Tool for Opera- tional Research,” European Journal Operation Research, Vol. 46, No. 3, pp. 271-281 (1990).
21. Melouk, S., Damodaran, P., and Chang, P. Y., “Minimiz- ing Makespan for Single Machine Batch Processing with Non-Identical Job Sizes Using Simulated Annealing,”
International Journal Production Economics, Vol. 87, No.
2, pp. 141-147 (2004).
22. Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., and Teller, E., “Equation of State Calcula- tions by Fast Computing Machines,” The Journal of
Chemical Physics, Vol. 21, No. 6, pp. 1087-1092 (1953).
23. Pinedo, M., Scheduling: Theory, Algorithms, and Sys-