雲端運算環境下基於知識本體之資訊檢索系統建置-以半導體產業為例 - 政大學術集成
63
0
0
全文
(2) 致謝 兩年的研究所生涯轉眼間就到了尾聲,回顧過去這兩年的時光,有許多人的 幫助讓我能順利完成論文。首先,必頇誠摯地感謝指導教授劉文卿博士在論文撰 寫過程中對我的教導,並在百忙之中抽空與我討論,由衷感謝。同時也要感謝口 詴委員郁方老師在系統實作上的幫助、許志堅教授提供論文修改方向的寶貴意見 及陳奕光博士在實務面的建議,在此致上最誠摯的敬意。 在實驗室的日子裡,感謝偉恩學長的照顧,讓我有可以學習的對象,感謝雅. 政 治 大. 菱跟我一起為論文、案子熬夜努力,終於我們都要順利畢業了!感謝勁超學弟在. 立. 這一年與我們一起打拼、四處奔波開會,感謝 KMLAB 所有的學弟妹在每次開會. ‧ 國. 學. 帶來的歡笑,感謝睿宸、善豪的調酒及宵夜之約,感謝碩二的同學們在這兩年無. ‧. 論是課業上或是生活上的互相扶持,有你們才讓這兩年變得多采多姿,感謝系辦 及機房助教讓我在政大獲得許多支援,感謝高中同學在我煩悶時帶來歡樂,感謝. y. Nat. 幫助過我的人,有你們才讓我可以順利走過這兩年。. n. al. Ch. er. io. sit. 台積電的所有長官和同事,在實習期間及專案開發都幫助我許多,感謝所有曾經. i Un. v. 最後,謹以完成碩士學業的榮耀獻給我最親愛的家人,謝謝你們這二十四年. engchi. 來對我的栽培及付出,讓我無後顧之憂的專心於學業,在未來的人生道路上我會 繼續努力,不辜負你們的期望,作一個知足、感恩、懂得回饋的人,在此對我生 命中的所有貴人獻上最真誠的謝意。. 李佳穎 謹誌於國立政治大學資訊管理研究所 2011 年 7 月 25 日. I.
(3) 摘要 本研究針對半導體產業,提供一智慧型搜尋功能,讓使用者在大量資料中能 快速及準確地搜尋。為達此目的,本研究中定義知識空間及其組成元素,並發展 一組程式以產生該知識空間及知識空間搜尋機制,以提升使用者生產力。所使用 到的技術包含:(1)建立知識本體,(2)計算兩詞彙同時出現頻率,(3)計算詞彙與文 件關聯度,(4)發展知識空間搜尋環境。 關鍵詞:雲端運算、文字探勘、知識本體、資訊檢索. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. II. i Un. v.
(4) Abstract This study aims to provide an intelligent searching environment which users can search quickly and precisely from a large number of documents in semiconductor industry. In order to achieve the purpose, this paper defines a knowledge space and its composition elements to describe the knowledge of real world, and then develops a program to shorten the searching cost by providing the searching mechanism based on knowledge space. The techniques used in this study includes : (1) Construct. 政 治 大 Compute the interrelatedness. 「 Semiconductor Industry Ontology 」 (2) Compute the frequency of two terms. 立. appearing simultaneously (3). between terms and. ‧ 國. 學. documents (4) Develop searching environment based on knowledge space.. ‧. Keyword:Cloud Computing、Text Mining、Ontology、Information Retrieval. n. er. io. sit. y. Nat. al. Ch. engchi. III. i Un. v.
(5) 目錄 致謝 ................................................................................................................................... I 摘要 .................................................................................................................................. II Abstract ........................................................................................................................... III 目錄 ................................................................................................................................ IV 表目錄 ............................................................................................................................ VI 圖目錄 ........................................................................................................................... VII 第一章 緒論 .................................................................................................................... 1 第一節 研究背景與動機 ........................................................................................ 1 第二節 研究目的 .................................................................................................... 2 第三節 研究架構 .................................................................................................... 4 第二章 文獻探討 ............................................................................................................ 6. 立. 政 治 大. ‧. ‧ 國. 學. 第一節 雲端運算 .................................................................................................... 6 第二節 本體論 ...................................................................................................... 10 第三節 文字探勘 .................................................................................................. 12 一、定義與技術 ............................................................................................ 12 二、關鍵詞萃取 ............................................................................................ 13 第三章 研究方法與系統設計 ...................................................................................... 16. Nat. y. sit. n. al. er. io. 第一節 研究步驟 .................................................................................................. 16 一、半導體產業概念模型 ............................................................................ 19 二、知識元素統計 ........................................................................................ 23 三、資訊檢索 ................................................................................................ 24 第二節 系統架構 .................................................................................................. 28 第四章 雛型系統實作 .................................................................................................. 30 第一節 雛型系統實作工具 .................................................................................. 30 第二節 雛型系統實作架構 .................................................................................. 31 一、虛擬化 .................................................................................................... 31. Ch. engchi. i Un. v. 二、服務導向架構 ........................................................................................ 33 三、三層式系統架構 .................................................................................... 36 第三節 雛型系統實作流程 .................................................................................. 37 一、建立知識本體 ........................................................................................ 37 二、設定資料來源與資料處理 .................................................................... 38 三、建立本體索引 ........................................................................................ 39 四、統計知識元素 ........................................................................................ 39 五、實作檢索介面 ........................................................................................ 40. IV.
(6) 第四節 雛型系統操作情境 .................................................................................. 42 第五章 結論與建議 ...................................................................................................... 47 第一節 結論 .......................................................................................................... 47 第二節 建議 .......................................................................................................... 47 參考文獻 ........................................................................................................................ 49 一、英文參考文獻 ........................................................................................................ 49 二、中文參考文獻 ........................................................................................................ 51 三、網路參考資料 ........................................................................................................ 52 附錄一 ............................................................................................................................ 53 附錄二 ............................................................................................................................ 54. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. V. i Un. v.
(7) 表目錄 表 1 雲端運算的定義 ..................................................................................................... 9. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. VI. i Un. v.
(8) 圖目錄 圖 圖 圖 圖 圖 圖. 1 Cloud Definition Framework .................................................................................. 6 2 三種服務模式架構 ................................................................................................ 7 3 Hypervisor 類型示意圖 ........................................................................................ 10 4 知識本體的建立流程 ........................................................................................... 12 5 知識空間概念圖 ................................................................................................... 17 6 研究步驟示意圖 ................................................................................................... 18. 圖 圖 圖 圖. 7 半導體領域概念模型 ........................................................................................... 20 8 半導體領域概念模型-Action&Material .............................................................. 21 9 半導體領域概念模型-Party ................................................................................. 22 10 知識元素統計階段架構圖 ................................................................................. 23. 圖 圖 圖 圖 圖 圖. 11 使用者個人化介面簡圖 ..................................................................................... 25 12 使用者進階查詢介面簡圖 ................................................................................. 26 13 文件內容顯示簡圖 ............................................................................................. 27 14 系統架構簡圖 ..................................................................................................... 28 15 雲端機櫃硬體配置圖 ......................................................................................... 31 16 伺服器虛擬化示意圖 ......................................................................................... 32. 圖 圖 圖 圖 圖 圖 圖 圖 圖. 17 伺服器虛擬化軟體配置示意圖 ......................................................................... 33 18 Web 服務編制概念簡圖 ..................................................................................... 34 19 本研究系統服務流程簡圖 ................................................................................. 34 20 本研究知識本體索引服務流程簡圖 ................................................................. 35 21 Strategy Pattern 類別圖 ...................................................................................... 36 22 系統三層架構圖 ................................................................................................. 36 23 Tornado 軟體控制台畫面 ................................................................................... 38 24 批次程式 Log 檔 ................................................................................................. 39 25 使用者操作介面首頁 ......................................................................................... 41. 圖 圖 圖 圖 圖 圖. 26 使用者個人化操作介面 ..................................................................................... 43 27 使用者檢索畫面 ................................................................................................. 43 28 查詢鑽回功能畫面 ............................................................................................. 44 29 查詢擴展功能畫面 ............................................................................................. 45 30 資料來源原始網頁 ............................................................................................. 46 31 文章詳細資料頁面 ............................................................................................. 46. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. VII. i Un. v.
(9) 第一章. 緒論. 第一節研究背景與動機 在資訊爆炸的今日,數位資訊量以驚人速度成長,Gantz & Reinsel(2009)指出, 2008 年全球所創造的數位資訊量高達約 3.9*1021 bits,直至 2012 年數位資訊量將 達到 2008 年的 5 倍。IDC 研究報告(Gantz & Reinsel,2010)更預測 2020 年新增的 數位資訊成長幅度將是 2009 年的 44 倍。面對如此龐大的資訊量,人們遭遇的困 境從過去資料不易取得轉變成無法從大量資料中找出真正有用的資訊。如何蒐集. 政 治 大. 資訊、整理資訊、找出有意義的資訊、儲存資訊並提供正確、快速地檢索方式將. 立. 是一門重要的學問。資訊檢索(Information Retrieval)在大量非結構化資料中找到需. ‧ 國. 學. 要的資訊,資訊檢索技術過去較常見的包括單純利用字串比對的布林模式 (Boolean Model)、加入部分比對及相似度觀念的向量模式 (Vector Model)、以機率. ‧. 架構計算的機率模式 (Probabilistic Model),但此三種模式僅著重詞彙間的比對,. y. Nat. io. sit. 忽略詞彙的意義與詞彙之間的關聯度,若能透過預先定義好之領域知識,搭配詞. n. al. er. 頻、索引、權重及排序演算法將能提供更精確的檢索結果,因此,近幾年內陸續. Ch. i Un. v. 發展透過語意理解之自然語言查詢、甚至是加入本體論(Ontology)概念之檢索方 式。. engchi. 直至 2020 年,超過三分之一的數位資訊量會存在或經過雲端環境(Gantz & Reinsel,2010),雲端運算(Cloud Computing)這個名詞最早出現在 2007 年由 Google 提出(Wikipedia, 2007),此種新的資源整合方式提供一種便利、能由客戶透過網路 連接並自由設定其組態的運算資源(如網路、伺服器、儲存、應用程式與服務)與隨 選化的網路存取服務,並能夠在最小的管理成本或服務供應商互動下快速提供與 釋出(朱明中,2010)。雲端運算並非新技術,大致上是延續「分散式運算」(Distributed Computing)及「網格運算」(Grid Computing)而來,在過往分散運算的時代後,集. 1.
(10) 中運算的潮流又捲土重來並可說是引起一場科技革命,直到今日雲端運算的熱潮 持續不斷,並為 Gartner(2008)發表 2011 年最具影響力的十大策略性科技中之一。 企業界無不審慎面對並發展許多相關計畫及產品搶攻這塊市場,如 Amazon Web Services(AWS) 雲 端 帄 台 上 之 EC2(Elastic Compute Cloud) (Amazon, 2011a) 及 S3(Simple Storage Service)提供儲存與運算能力(Amazon, 2011b);Salesforce 的 Force.com 帄台提供資料庫、邏輯及使用者介面(Salesforce, 2011);IBM 的藍雲(Blue Cloud)計畫提供雲端運算所需擁有的硬體設備與管理軟體(IBM, 2007);Google 發 表 MapReduce 軟體架構(Dean & Ghemawat, 2004)、BigTable 資料庫模式(Chang 等,. 政 治 大. 2006)及 GFS(Google File System)檔案系統(Ghemawat, Gobioff, & Shun, 2003),. 立. Google Apps 將雲端概念應用在服務上,GAE(Google App Engine)則提供在 Google. ‧ 國. 學. 的基礎架構上執行自己開發之網路應用程式(Google, 2011);Intel、Yahoo、HP 共 同成立雲端運算測詴帄台 (Cloud Computing Test Bed),是一個全球的開放源碼計. ‧. 畫,由多資料中心組成,將推展在軟體、資料中心管理與大規模網際網路運算硬. Nat. sit. y. 體各方面的研究(謝良奇,2008);Microsoft 推出 Azure 提供軟體與網路帄台作為雲. n. al. er. io. 端服務,讓軟體開發者所撰寫的程式可以直接在微軟資料中心上線)(Windows. i Un. v. Azure, 2011);趨勢科技則建立防毒雲提供使用者在網路上即時偵測病毒及惡意程 式(趨勢科技,2011)。. Ch. engchi. 雲端運算的發展讓企業在硬體上的支出日益減少,關於企業雲端運算與虛擬 化技術亦在國際會議中受到重視,2011 年 5 月於倫敦舉辦之 Enterprise Cloud Computing & Virtualization 2011 Conference 即將主題放在 Infrastructure as a Service 及 Virtualization,前者著重雲端運算帶來的外包及 SOA 趨勢,後者針對不同層面 之虛擬化技術作探討,提供企業評估雲端運算帶來之影響及未來應用方向之參考。. 第二節 研究目的 隨著網路發達及科技日益進步,資訊的取得越來越方便,各大網站如 Google、. 2.
(11) Yahoo 等皆提供相當強大的搜尋服務,使用者往往只需輸入簡單之關鍵字便能搜尋 到成千上萬筆資料,此結果卻衍生出資訊氾濫的問題。當一名公司主管需參考各 類外部資料,如新聞、產業分析報告等以做出即時、正確之決策,卻面對龐大繁 雜且重複率高、充滿無用內容之資訊將嚴重影響其判斷時機,如何挑選、分析、 過濾並提供精確之檢索結果將是一個重要的課題。 台灣半導體產業具有獨特的分工架構,將設計、製造、封裝、測詴分離,並 發展出專業代工廠之經營模式,此高度分工形成一更精密之供應鏈,產業內之廠 商間形成上、下游或競爭者關係,從原物料到最終產品的過程環環相扣,各階段. 政 治 大. 之產能改變或缺乏影響的層面非常廣泛,且半導體產業受全球景氣影響甚鉅,若. 立. 無法掌握全球經濟變動及產業動態將失去此一戰場之競爭力,因此,即時掌握正. ‧ 國. 學. 確訊息、洞悉產業脈動是不可或缺的能力,透過發展此一領域獨特之資訊檢索系 統便可將大量外部訊息以較精確的方式呈現,提供快速判斷情勢及決策之輔助工. ‧. 具。. Nat. sit. y. 本體論能夠描述特定知識領域內相關的概念(Concept)與關係,概念與其間的. n. al. er. io. 關聯可作為描述真實世界的知識模型,幫助建立人類與機器及機器與機器之間溝. i Un. v. 通的機制;文字探勘(Text Mining)則藉由分析大量非結構或半結構化的文件找尋詞. Ch. engchi. 彙間隱藏的規則及相關性。本研究希望結合本體論及文字探勘發展出半導體產業 領域之資訊檢索系統,重視領域內詞彙關聯及知識萃取,輔以領域專家調整此一 知識模型,加強文件分類及檢索之精確性。 無論挑選、分析、過濾文件皆牽涉大量的資料處理,透過雲端運算技術的擴 展性、負載帄衡、健康偵測等可動態使用 IT 基礎建設快速達到此運算能力,並保 證其服務品質,降低可能的風險。 本研究提出之半導體產業資訊檢索系統建立於雲端運算環境,提供處理大規 模資訊之能力,配合本體論與文字探勘所得之領域知識模型,將文件分類及檢索 比對之精確性提高並提供智慧型搜尋環境,較一般搜尋引擎提供更多輔助搜尋之. 3.
(12) 功能。 本研究之主要目的分述如下: 一、 建構「半導體產業知識本體」 知識本體描述特定領域之概念及其關聯,透過產生建立模型、Meta Model 及 填入對應之詞彙建構半導體產業知識本體,幫助機器理解現實世界之知識內容。 二、 建立半導體產業文件索引 蒐集新聞網頁及產業報告等外部資料,利用關鍵字萃取方式找出重要詞彙, 經由權重計算及關聯分析搭配知識本體結構得到詞彙、文件(統稱為知識元素)彼此. 政 治 大. 間之關聯度,提供資訊檢索時找出較字串比對更精確之搜尋結果的依據。. 立. 三、 雲端環境下之資訊檢索系統建置. ‧ 國. 學. 利用雲端運算的虛擬化技術支援蒐集外部文件、計算詞彙權重、關聯分析及 關聯度計算所頇的大量運算能力,依此建置半導體產業之資訊檢索系統。. ‧. 四、 智慧型搜尋環境. Nat. sit. y. 提供使用者搜尋輔助功能,透過視覺化樹狀選單的方式呈現文件與知識本體. n. al. er. io. 的對應關聯,詞彙統計及推薦列表幫助使用者將搜尋結果逐漸縮小至真正關切的. i Un. v. 範圍,亦可根據列表逐步加入關鍵字避免使用者輸入關鍵字不夠精確造成偏離之 檢索結果. Ch. engchi. 第三節 研究架構 本研究提出與專家共同建立之半導體產業概念模型,並使用詞庫與 Meta Model 記錄相關詞彙及實體間的關聯,透過文字探勘分析新聞網頁、產業報告及半導體 產業供應鏈內廠商網頁之關聯規則及詞頻計算,建構半導體產業知識本體作為資 訊檢索系統精確度提升及視覺化呈現的基礎,亦運用雲端運算滿足處理大量資料 的需求。本研究之研究架構如下: 第一章 緒論. 4.
(13) 本章針對研究背景、動機、目的及架構逐一說明。 第二章 文獻探討 本章針對雲端運算、知識本體及文字探勘技術三項主題作文獻整理及探討。 第三章 研究方法與系統設計 本章首先定義研究步驟分成領域概念具體化、資料處理、知識元素統計及資訊 檢索四階段,提出包含一般索引模組、本體索引模組及資訊檢索模組之系統架構, 並說明半導體產業概念模型內容及權重、關聯分析、關聯度計算之演算法。 第四章 雛型系統實作成果. 政 治 大. 本章敘述雲端環境下以服務導向架構實作資訊檢索系統,蒐集資料後根據知識. 立. 本體建立索引、TF-IDF 演算法及關聯分析之計算,並以視覺化方式呈現搭配統計. ‧ 國. 學. 列表輔助查詢。. 第五章 結論與建議. ‧. 根據研究過程及系統實作結果,歸納出本研究之結論,並提出幾項建議提供未. n. al. er. io. sit. y. Nat. 來研究方向參考。. Ch. engchi. 5. i Un. v.
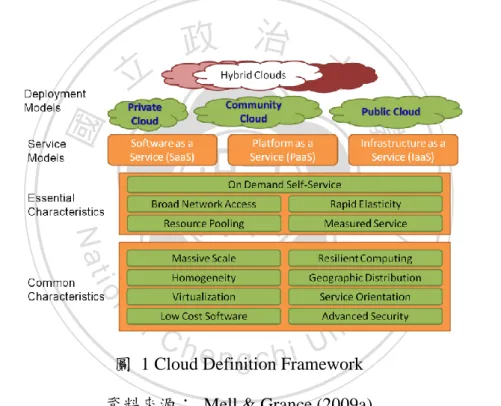
(14) 第二章. 文獻探討. 第一節 雲端運算 根據美國國家標準與技術研究院(NIST)定義(Mell & Grance, 2009b),雲端運算 是一種提供便利、透過網路依據需求存取可分配資源之模式,所謂資源包含網路、 伺服器、儲存設備、應用程式及服務,提供最小管理成本的優勢。NIST 亦提出雲 端運算的五個特徵、三種服務模式及四種部署模式(Mell & Grance, 2009a)(見圖 1)。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 1 Cloud Definition Framework 資料來源: Mell & Grance (2009a). 五種特徵分別為隨選自主服務(On-demand self-service)、大量網路存取(Broad network access)、資源池(Resource pooling)、快速彈性提供能力(Rapid elasticity)、 可度量服務(Measured service),上述五種特徵使雲端運算適合用於公用運算,當企 業對 IT 的需求曲線變化相當大時,即可透過雲端運算得到許多好處,當資源需求 量大時便可透過網路存取資源池,得到快速彈性的回應並有評核服務的機制。 三種服務模式如下列(見圖 2): 6.
(15) 圖 2 三種服務模式架構. 政 治 大. 資料來源: Mell & Grance (2009). 立. ‧ 國. 學. 1.. 軟體即服務(Software as a Service, SaaS):此服務模式讓使用者可在雲端環. ‧. 境下執行應用程式,透過網路瀏覽器介面存取服務,而無頇管理系統維運 工作。例如:使用 Google 提供之 Gmail 可在網路上收發郵件、Google 文. y. Nat. io. sit. 件則提供網路上文書處理的功能,使用者僅頇根據需求找尋軟體,並依據. n. al. er. 服務項目及使用量付費即可。 2.. Ch. i Un. v. 帄台即服務(Platform as a Service, PaaS):此服務模式提供使用者在雲端環. engchi. 境開發、部署、執行、測詴及管理應用程式的帄台,並支援某些開發語言 與工具。此類型目前較大的提供商包括 Microsoft Azure、Google App Engine 等,使用者透過提供商的一整套解決方案便可著手開發,提供商透 過 API 及函式庫將服務較複雜的部分隱藏,以減低使用者開發可能的阻 礙。 3.. 架構即服務(Infrastructure as a Service, IaaS):此服務模式透過虛擬化技術 將硬體資源作動態的切割及配置,使用者可指定運算資源、儲存設備等, 並依據使用內容付費,服務提供商包括 Amazon 的 S3(Simple Storage. 7.
(16) Service) 提供儲存空間(Amazon, 2011b) 、Amazon EC2(Elastic Compute Cloud)提供運算能力(Amazon, 2011a),此模式提供使用者配置資源但不頇 管理硬體設備,由服務水準協定(Service Level Agreement, SLA)制訂雲端 供應商應負的維運責任。 四種部署模式分述如下: 1.. 私有雲(Private cloud):此部署模式之基礎建設屬於企業私有,並由企業或 委託第三方管理者維護。私有雲提供企業內部雲端運算的特性,並有非常 高的資料安全性,減少機密資料外洩的疑慮,但是所有成本頇由企業負擔, 較適合大型企業使用。. 2.. 立. 政 治 大. 社群雲(Community cloud):此部署模式由多個組織形成的社群所擁有,社. ‧ 國. 學. 群內各組織共項資源,欲達到此模式,各組織無論是私有雲或公有雲皆頇 遵循一定的架構及協定才能達到彼此共享的目的。社群雲適合一群類似結. ‧. 盟的組織,擔心資料在公有雲上的安全性,因此以社群內共享的方式彼此. Nat. sit. n. al. er. 公有雲(Public cloud):此部署模式是由幾個大型雲端服務提供商維護基礎. io. 3.. y. 分擔雲端運算基礎建設之成本。. i Un. v. 建設,提供大眾租用、存取資源,使用者僅頇依使用服務的內容及使用量. Ch. engchi. 付費,並可動態擴充資源配置。公有雲適合一般中小企業使用,企業無頇 隨時備有大量設備因應可能產生之使用需求,此模式大幅降低企業花在硬 體設備購置及維護的成本,亦可避免資源閒置的問題。 4.. 混合雲(Hybrid cloud):此部署模式是任意混合上述三種模式而成,亦可視 為私有雲與公有雲混合的模式,頇透過特定技術與標準才能混合。混合雲 適合期望保有私有雲資料安全的特性,同時也具備公有雲動態擴充及低 IT 成本的優點之企業。. 關於雲端運算不同專家有不同的定義方式,關於其它雲端運算的定義如表 1. 8.
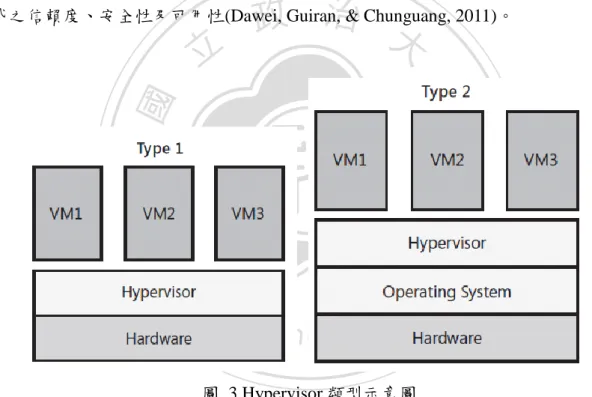
(17) 表 1 雲端運算的定義 供應商. 定義 雲端運算是種透過網路連接以獲取軟體和服務的運算模式,讓使. Whatis.com. 用者可以獲得有如超級電腦的體驗。 雲端運算是種能夠將動態伸縮的虛擬化資源,透過網路以服務的. 維基百科. 方式提供給使用者的運算模式,使用者不需要知道如何管理那些 支援雲端運算的基礎設施。 雲端運算是種革新的 IT 運用模式。這種模式的主體是所有連接. IBM. 網路的實體,可以是人、設備或程式,客體就是 IT 本身,包括 我們現在接觸到的,以及會在不久將來出現的各種資訊服務。 雲端運算是業務營運的最佳方式,您不必自己執行應用程式,它. Salesforce. 們會在共同資料中心上執行。當您使用雲端中心執行的任何應用. 政 治 大 強大能力。 立. 程式時,只要登入、自訂,就可以開始使用。這就是雲端運算的. 複雜的問題,雲端運算只是網格運算下的一個子集合。 雲端運算是網際網路的一個重要演變。它不僅是一種運算模式,. ‧. 資策會. ‧ 國. 隊. 網格運算能夠跨管理網域聯合運算資源的特性,可以解決更大更. 學. 中研院網格運算團. 更發展出許多新的商業模式,所以,雲端運算可說是下世代的網. Nat. n. al. er. io. 資料來源:朱明中(2010). sit. y. 際網路。. Ch. engchi. i Un. v. 架構即服務模式中使用到虛擬化技術,虛擬化技術中最重要的一項為伺服器 虛擬化(Server Virtualization),伺服器虛擬化是將系統虛擬化技術應用於伺服器上, 將一個伺服器虛擬成若干個伺服器使用,使得在單一實體伺服器上可運多個虛擬 伺服器,伺服器虛擬化為虛擬伺服器提供了能夠支援其運行的硬體資源抽象,包 括虛擬 BIOS、虛擬處理器、虛擬記憶體、虛擬設備與 I/O,並為虛擬機提供了良 好的隔離性與安全性(陳瀅,2010)。 Hypervisor 一詞最早由 IBM(1972)提出,是一個虛擬帄台提供多個作業系統同 時運行在單一硬體設備上,Hypervisor 可依是否直接運行再實體硬體上分為兩種類 型(Goldberg, 1973),如圖 3 所示,Type1 Hypervisor 直接運行在實體硬體上,虛擬. 9.
(18) 機運行在 Hypervisor 上,Hypervisor 提供指令集和設備介面,以提供對虛擬機的支 援,這種實現方式通常具有較好的效能,但是實作起來更為複雜。Type2 Hypervisor 則是運行在宿主(Host)作業系統上,利用宿主作業系統的功能來實現硬體資源的抽 象和虛擬機管理,這種模式的虛擬化實現起來較容易,但由於虛擬機對資源的操 作需要透過宿主作業系統來完成,效能通常較低 (陳瀅,2010)。虛擬化技術在近 年的研究主要應用於針對不同的工作量動態擴充資源,尤其以電子商務的應用居 多,除了使用在運算資源上,亦可使用在資料庫的虛擬化及動態複製(Cecchet, Singh, Sharma, & Shenoy, 2011)或將虛擬化加入驗證、隔離及容錯機制,用來改善應用程. 政 治 大. 式之信賴度、安全性及可用性(Dawei, Guiran, & Chunguang, 2011)。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 3 Hypervisor 類型示意圖 資料來源:Tulloch (2010). 第二節 本體論 本體論較常被引用的定義是「給概念化範疇一個明確的描述 (An ontology is an explicit specification of a conceptualization)」其他重要特性定義還包括,「Shared Conceptualization」及「Logical Theory」等(Guarino, 1998),皆趨向於二大重點: 10.
(19) 1.. 以 已 經 定 義 的 字 彙 名 詞 (Vocabulary of terms) 來 描 述 已 存 在 的 實 體 (Entity)。. 2.. 以一定規格(Specification)表示出這些實體間的關係(Relationship)與存在 的意義(Meaning),進而形成在此一專業領域(Domain)中可以解釋的知識 架構。. Noy & McGuinness(2001)提出 Ontology 的功用可由下列四點說明: 1.. 一些相同領域的專家或機構可用相同的 Ontology 來定義 Class 或 Concept, 如此軟體代理人或使用者可藉由 Ontology 而達到資訊共享之目的。. 2.. 政 治 大. 當需要建立一個大範圍的 Ontology 時,可利用已存在的 General Ontology. 立. (ex. WordNet、UNSPSC Ontology) 或一些 Domain Ontology 來作為輔助。 Ontology 中定義的 Class 及 Relation 對於某個 Domain Knowledge 可做更. ‧ 國. 學. 3.. 明確的定義,當一個初學者想要瞭解某個 Domain Knowledge,可藉由. ‧. Ontology 而得到幫助。. Nat. io. 使用 Ontology 或對 Ontology 做擴充。. n. al. sit. y. 可利用已經存在的 Domain Ontology,來分析 Domain Knowledge 並重複. er. 4.. i Un. v. 產生知識本體(Ontology)的方式依據產生的自動化的程度可以分成自動化、半. Ch. engchi. 自動化與手動等三種方式。Maedche 等人(2001)的研究中提到一種本體論建置與學 習方法,流程如下(見圖 4):萃取(Extract)、修剪(Prune)、優化(Refine)、重複使用 (Import/Reuse)。. 11.
(20) 政 治 大. 圖 4 知識本體的建立流程. 立. 資料來源:Maedche & Staab (2001). ‧ 國. 學. 不論是自動化、半自動化與手動產生,具體的建立一個 Ontology 過程可分為以. ‧. 下幾步驟:. Nat. 2.. 把這些 Class 組織成一個層次化的結構,定義 Class 與 Class 之間的階層. sit. er. n. al. 關係 (Subclass- Superclass)。 3.. y. 定義 Ontology 中的 Class(Class 指的就是概念)。. io. 1.. Ch. engchi. i Un. v. 定義 Class 中的屬性,填充 Property 在相對應的 Class 上的值,並且說明 對於屬性值的限制。. 4.. 將 Instance 的屬性值填入,定義 Property 和描述這些 Property 相對應的 Class 限制。. 第三節 文字探勘 一、 定義與技術 根據 Dan Sullivan(2001)的定義,文字探勘是一種編輯、組織及分析大量文件 的過程,主要提供分析人員或決策者等特定使用者對特定資訊(如摘要、關鍵字),. 12.
(21) 發現資訊特徵及其間的關聯性。與資料探勘(Data Mining)不同的地方是,文字探勘 所分析的資料為非結構(Non-structured)或半結構化(Semi-structured)的文件,並且頇 要額外的資料選擇處理程序及較複雜的資料特徵萃取步驟,詴圖發掘出未知、隱 含且有用的資訊。 文字探勘的方式類似資料探勘,常見的演算法包括(葉乃菁、王玳琪、張嘉珍、 吳騏、賴志遠,2009): 1.. 分類分析(Classification Analysis):按照分析對象的屬性分門別類加以定義 ,將物件集合建立一屬性與類別之間的關係,使用的技巧有決策樹. 政 治 大. (Decision Tree),記憶基礎推理(Memory-based Reasoning)等,常應用在分. 立. 類產品組合(陳垂呈,2008)或文件分類(許偉忠,2007)。 群集分析(Clustering Analysis):將異質母體中區隔為較具同質性之群組. ‧ 國. 學. 2.. (Clusters),相當於行銷術語中的區隔化(Segmentation),但假定事先未對. ‧. 於區隔加以定義,而資料中自然產生區隔,使用的技巧包括 K-means 法. Nat. sit. n. al. er. 關聯式法則分析(Association Rule Analysis):找出資料間彼此的關聯性,. io. 3.. y. 及 Agglomeration 法。. i Un. v. 又稱為「購物籃分析」(Market Basket Analysis)。當資料為一個集合時,. Ch. engchi. 該規則代表在某個項目集(Itemset)出現的條件下,也同時會出現另一個項 目集的狀況,較具代表性的方法就是 Apriori 演算法(Agrawal & Srikant, 1994)。. 二、 關鍵詞萃取 關聯分析為找出兩資料集合彼此間的關聯性,關鍵詞萃取提供關聯分析的基 礎,將最小單位之資料集合即詞彙篩選出來。 「關鍵詞自動擷取」是一種辨認數位 文件內有意義且具代表性字串、片語、詞彙與內容片段的自動化技術。在自然語 言處理的領域使用斷詞將構成句子的各個詞彙斷出來,斷出來的詞彙中包含各種. 13.
(22) 詞類,如名詞、動詞、代名詞、連結詞、介係詞等,但在資訊檢索的應用上,此 種方式並非必要反而常造成錯誤的結果,因此使用關鍵字擷取技巧於資訊檢索領 域主要有下列三種方法(曾元顯,1997)。 1.. 詞庫比對法:即利用已建立的詞庫,來比對輸入文件(或文句),將文件中 出現在詞庫中的片語截取出來。此種方法製作簡單,只要將詞庫中的每個 詞,去比對是否出現在輸入文件中即可。其結果都是詞庫中的正確詞彙, 但並不保證所有關鍵詞都能被擷取出來。除此之外,其缺點還包括:頇要 耗費人力、時間維護詞庫以容納各個領域的專業用語與新生詞彙,無法應. 政 治 大. 付未曾預料的人名、地名、機構名等專有名稱,且詞庫越大筆對速度越慢。 2.. 立. 文法剖析法:透過自然語言處理技術的文法剖析程式,剖析出文件中的名. ‧ 國. 學. 詞片語,再運用依些方法與準則,過濾掉不適合的詞彙。其結果幾乎也都 是有意義的名詞片語,但大部分的剖析程式,需要藉助已經建立的詞典或. ‧. 語料庫,因此其缺點也和詞庫比對法一樣。除此之外,有些文法剖析法甚. Nat. sit. y. 至只能剖析合乎語法的完整文句,使得書目、標題等資料裡的關鍵詞無法. al. n. 3.. er. io. 被擷取出來。. i Un. v. 統計分析法:透過對文件的分析,累積足夠的統計參數後,再將統計參數. Ch. engchi. 符合某些條件的片語擷取出來。最簡單的統計參數是計數詞彙發生的頻率 ,及詞頻,將詞頻落在某一範圍的詞彙取出。由於沒有用到詞庫或語料庫, 會有擷取錯誤的情況發生,得到無意義或不合法的詞彙。此外,統計參數 不足的關鍵詞無法被選到。然而其優點是較不受語文國別與句型的限制, 而且可以擷取出未曾被詞庫、語料庫網羅的專業用語、新生詞彙與專有名 稱等片語。 若是有領域專家協助建立詞庫,採用詞庫比對法相對提供較準確的擷取結 果,配合詞庫的維護介面當有新生詞彙或是欲調整領域用詞時,可透過人工調整, 如此一來除可保持擷取的正確性,亦可記載真正有意義的詞彙避免許多不合法或. 14.
(23) 無意義的詞彙,雖然此方法頇要較大運算能力,但借助雲端運算的方式可彌補原 先對速度不足的考量。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 15. i Un. v.
(24) 第三章 研究方法與系統設計 第一節 研究步驟 知識空間(Knowledge Space)由語意空間(Semantic Space)、統計空間(Statistic Space)兩個子空間及知識元素(Knowledge Element)共同組成,知識元素包含詞彙及 文件,語意空間為現實上存在的概念關係,包含語意關聯(Deterministic Relation) 及概念模型,統計空間則透過計算方式找到各元素間之數值關係,包含統計關聯 (Statistic Relation),語意關聯描述概念模型內實體(Entity)之間的關係及實體與詞庫. 政 治 大. 內實例(Instance)間的關係。統計關聯包含詞彙本身權重計算、詞彙之間關聯分析、. 立. 詞彙與文件關聯度及文件之間相關度(見圖 5)。. ‧ 國. 學. 本研究以半導體產業之新聞與產業報告為分析對象(以下簡稱為半導體產業文 件),並利用詞彙建立文件索引,為增加搜尋之準確度,提出一「半導體產業概念. ‧. 模型(Conceptual Model)」具體描述此領域中各項實體間的關聯(Relation),並將描. y. Nat. io. sit. 述此模型之結構與關係記錄於 Meta Model 中,最後將各實體下之實例即此領域相. n. al. er. 關詞彙(Term)填入,以建構半導體產業知識本體,於此基礎上搭配權重計算及關聯. Ch. i Un. v. 分析改善單純以字串建立索引的方式,並在資訊檢索時將領域知識配合相關演算. engchi. 法增加關聯度計算的準確性,最終建置運行於雲端運算環境(Cloud Computing Environment)之半導體產業資訊檢索系統。. 16.
(25) 知識空間 語意空間 Deterministic Relation 半導體產業概念 模型. Meta Model. 統計空間 Statistic Relation. 知識元素. 政 治 大. 詞彙權重. 立. 詞庫. 關聯分析. ‧ 國. 學 關聯度. ‧. io. sit. y. 相關度. n. al. er. Nat. 文件庫. Ch. i Un. 圖 5 知識空間概念圖. engchi. v. 資料來源:本研究繪製. 根據上述流程與知識空間概念,本研究提出之研究步驟包含領域概念具體化 階段、資料處理階段、知識元素統計階段及資訊檢索階段共四階段,研究步驟示 意圖如圖 6。. 17.
(26) 資料處理階段. 領域概念具體化階段 半導體產業概念模型建構. 半導體產業文件搜集. 建立文件索引. 建立詞庫. 建立Meta Model. 知識元素統計階段 權重計算. 關聯分析. 資訊檢索階段 關聯度計算. 政 治 大. 視覺化資訊檢索. 立. 圖 6 研究步驟示意圖. sit. y. ‧. 資料來源:本研究繪製. Nat. 領域概念具體化:本階段透過專家訪談記錄半導體產業之人、事、時、. io. er. 1.. 查詢結果. 學. ‧ 國. 輸入關鍵字. al. 地、物等各項實體關係,依據專家描繪之領域內容建構半導體產業概念. n. iv n C hengchi U 模型,並將現實世界中各種詞彙依定義放入模型中適當位置,建立詞庫 即用於儲存詞彙集合,詞彙之分類方式與各實體之描述與關係記載則儲 存於 Meta Model。 2.. 資料處理階段:本階段透過網路爬蟲方式將半導體產業相關之網站、新 聞網頁及產業報告內容抓取回來存入文件庫,針對此一文件庫進行一般 索引(General Indexing),再依據半導體知識本體將所需文章進一步建立本 體索引(Ontology Indexing),即依據詞庫中記載之詞彙建立文件索引,此 階段結果將作為知識元素統計階段權重計算及關聯分析的基礎,並提供 資訊檢索階段關聯度計算及搜尋文件使用。. 18.
(27) 3.. 知識元素統計階段:本階段嘗詴透過文字探勘整合關鍵詞萃取及資訊萃 取達到知識萃取的目的,透過關鍵詞萃取辨認文件內有意義且具代表性 之詞彙並計算其權重,資訊萃取之關聯分析技術找尋詞彙間潛在的規則 即詞彙之間的關聯,以上兩步驟可得到詞彙本身重要程度及兩兩詞彙間 關聯度大小,將數值搭配半導體產業知識本體可描述半導體產業概念 (Domain Knowledge)亦提供使用者檢索畫面之知識呈現。雲端運算提供便 利、透過網路依據需求存取可分配資源之模式,所謂資源包含網路、伺 服器、儲存設備、應用程式及服務,提供最小管理成本的優勢。知識元. 政 治 大. 素統計階段主要針對統計空間之詞庫及文件庫內容進行計算,如圖 5 所. 立. 示,本研究運用虛擬化技術配置所需資源提供強大之計算能力(Computing. ‧ 國. 4.. 學. Power)。. 資訊檢索階段:本階段搭配知識元素統計階段產生之具權重的半導體產. ‧. 業知識本體,計算文件與個別詞彙之關聯度大小,並建置資訊檢索系統. Nat. sit. y. 提供查詢介面,關聯度計算結果可用來衡量文件與使用者輸入關鍵字相. n. al. er. io. 關聯程度,根據此一數據搭配知識本體視覺化介面呈現智慧檢索環境. i Un. v. (Intelligent Search Environment),提供查詢擴展(Query Expansion)及查詢鑽. Ch. engchi. 回(Drill Down)功能,透過統計方式推薦關聯字作進一步檢索。. 一、 半導體產業概念模型 本研究提出一將領域概念具體化階段之半導體產業概念模型,模型內實體關 係如圖 7。. 19.
(28) 立. ‧ 國. 學. 圖 7 半導體領域概念模型 資料來源:本研究繪製. ‧. Nat. y. 實體(Entity):本研究定義領域中之各項概念皆為一實體,任一實體皆可. sit. 1.. 政 治 大. n. al. er. io. 能包含本身或其它實體,即實體與實體為一組合關係。事件(Event)、動. i Un. v. 作(Action)、材料(Material)、技術(Technology)、參與者(Party)皆為實體衍. Ch. engchi. 生出的類別,任何實體都可能包含其他多個實體,其中事件用來描述一 份文件,內容涵蓋多種實體與特徵值。 2.. 屬性(Attribute):任何用來描述實體的特徵值皆為一個屬性,並可進一步 以時間的維度區分為時間相關屬性(Time Dependent Attribute)及時間無關 屬性(Time Independent Attribute),時間相關屬性可視為一指標(Indicator) 由時間數列資料(Time Series Data)組成,屬性可用來作為描述某個 Entity 的特徵值。. 3.. 屬性容器(Attribute Container):屬性容器亦可視為一種屬性並可包含其他 多種屬性,風險(Risk)及事件屬性(Event Attribute)即為此概念,風險可視. 20.
(29) 為某些特徵值變動所造成的現象,因此,每一風險(內部、外部、大環境 變化)及事件屬性皆可能包含許多與時間相關或無關之屬性。. 立. 政 治 大. ‧. ‧ 國. 學. Nat. n. al. 4.. Ch. engchi. er. io. 資料來源:本研究繪製. sit. y. 圖 8 半導體領域概念模型-Action&Material. i Un. v. 動作(Action):任何發生的動作皆為此類別,並可進一步區分為生產相關 動 作 (Production Action) 、 商 業 市 場 相 關 動 作 (Market Action) 及 製 程 (Process),其中製程又可包含多種生產動作及商業市場動作,上述幾種動 作亦可能使用到材料(Material),如圖 8 所示。. 5.. 材料(Material):材料之分類,主要為在連續製程上使用之材料訂為連續 材料(Continuous Material),此分類之材料每次用量為不可數,但會用盡, 另一類的則為分離材料(Discrete Material),分離材料為可數,除了在每一 製程中使用之設備(Facility)歸類為一般項目(Item)以外,其它會隨著製程 移動之材料皆為分離項目(Discrete Item),之中包含單一個零件及組裝的. 21.
(30) 元件包含晶片、接角等等,單一零件歸類在單一項目(Leaf Item)中,組裝 元件則歸類在複合項目(Composite Item)並可包含單一項目或其他的複合 項目,不同的製程或生產相關動作皆會使用到材料,如圖 8 所示。. 立. 政 治 大. al. iv n C hengchi U 參與者(Party):參與者包含個人(Individual)以及組織(Organization),組織 n. 6.. sit. io. er. 資料來源:本研究繪製. y. ‧. ‧ 國. 學. Nat. 圖 9 半導體領域概念模型-Party. 亦可再細分為三種類型,分別為政治組織(Political Organization)、工業組 織(Industrial Organization)及商業組織(Commercial Organization),第一類 如歐盟,為一國家區域(Country Area),是一個組織而非單一國家,第二 類如工會、協會,為針對特定產業發展而成之組織,第三類如公司、部 門,為單一營利事業之各階層組織 ,如圖 9 所示。 7.. 實體分類表(Entity Category):概念模型建立後便可依據各實體內容將相 關詞彙存至詞庫中,此分類表記錄各詞彙所對應之實體即各詞彙應屬於 何種實體分類,另外,由於實體間為組合及衍生關係,尚有一表格記錄. 22.
(31) 各實體的定義以及實體與實體之關係描述,上述之分類表及表格即為描 述半導體概念模型的 Meta Model。. 二、 知識元素統計. 詞庫 知識元素統計階段. 文件庫. 建立索引. 立. 詞彙本身權重& 詞彙之間關聯度. ‧ 國. 學. 圖 10 知識元素統計階段架構圖 資料來源:本研究繪製. ‧ sit. y. Nat. 1. 關鍵字萃取. 權重計算 治 關聯分析 政 大. n. al. er. io. 本研究提出知識元素統計階段(如圖 10)透過 TF-IDF(Term Frequency-Inverse. i Un. v. Document Frequency)方法計算經關鍵字萃取後每個詞彙的重要性,透過詞庫比對. Ch. engchi. 法先找出各文件包含有興趣之詞彙,TF-IDF 加權技術提供一種衡量詞彙重要性的 量值,TF(Luhn, 1958)表示一個詞彙在一份文件中的重要性,值越大代表該 Term 越重要;IDF 則表示當某一詞彙越常出現在文件中越不重要,此步驟用於濾掉許多 重複出現較無代表意義的詞彙。將 TF 與 IDF 相乘後可得一權重值即可作為詞彙在 一份文件之重要性衡量,此方法可使真正具有代表性的詞彙更為突顯,抑制一些 常用詞的假性重要程度,某一詞彙之權重值即為詞彙在所有文件的 TF-IDF 權重值 加總,計算方式如下: TF =. 該關鍵字於文件中出現的次數 文件中所有詞彙出現的次數. 23.
(32) IDF =. 所有文件數 關鍵字出現的文件數. Weight = TF 詞彙權重. IDF. = 詞彙在所有文件的 TF-IDF 權重值加總. 2. 資訊萃取 本研究提出知識元素統計階段透過文字探勘方式從網路抓取回來之非結構化 文件內挖掘潛在規則,此部分稱為資訊萃取,尋找詞彙間可能存在的關係,搭配 半導體產業知識本體所形成帶有權重之知識本體,除了可描述半導體產業概念亦. 政 治 大. 提供使用者檢索畫面之知識呈現及查詢結果排序之依據。. 立. 採用關聯法則可分析一個集合內某一項目出現時,另一項目同時出現的機率,. ‧ 國. 學. 因此可用來找尋兩個項目間的關聯性,本研究即利用這個概念來推論詞彙間可能. ‧. 之關聯,利用 Apriori 演算法為基礎計算兩個詞彙同時出現的頻率即 TC(Term Co-Occurrence)。TC 為 Term A 及 Term B 同時出現的文章數與 Term A 或 Term B. y. Nat. n. al. er. io. TC =. sit. 出現的所有文章數之比值,TC 公式如下:. Ch. engchi. i Un. v. 三、 資訊檢索 本研究提出之資訊檢索系統提供一智慧資訊檢索環境,除依據知識本體建立 文章加強進一步檢索功能,亦將知識本體之關聯及詞彙以樹狀選單方式呈現,並 記錄使用者搜尋偏好提供推薦清單及查詢擴展、鑽回之智慧型功能。 1. 關聯度計算 當使用者輸入關鍵字後計算文件與關鍵字之關聯度並作查詢結果排序, 本研究之關聯度計算皆根據以下兩個假設: 一、 越符合本研究建置半導體產業知識本體之文章,其對於使用者來說重. 24.
(33) 要性越高 二、 文章中包含越多與使用者欲搜尋的關鍵字相關詞彙,則這篇文章的符合 度越高 利用知識元素統計階段之結果,使用 TF-IDF 數值作為衡量文件與查詢關鍵字 之間相關程度的量值的基礎,將 TF 與 IDF 相乘後可得一權重值(即此詞彙之重要 程度),即可作為文件與使用者輸入關鍵字之間的相關程度衡量,當使用者同時輸 入多個關鍵字時,本研究假設此兩關鍵字間為 AND 關係,因此權重值皆使用個別 權重加總的計算方式。本研究亦根據前述兩項基本假設,採用 TC 將與使用者輸入. 政 治 大. 關鍵字相關之詞彙加入調整參數計算。. 立. ‧ 國. 學. 2. 視覺化個人介面. 視覺化呈現方式提供使用者對領域知識更簡單易懂的瀏覽方式,本研究提出. ‧. 將知識本體架構以樹狀選單方式呈現,包含完整樹狀選單根據知識本體結構產生,. Nat. sit. y. 個人樹狀選單則顯示使用者挑選最常使用之字彙,使用者登入檢索系統後除擁有. n. al. er. io. 個人樹狀選單,系統亦提供使用者最愛(User Favorite)、熱門關鍵字(Top10)詞彙列 出點擊率較高之詞彙清單,如圖 11 所示。. Ch. engchi. i Un. v. 圖 11 使用者個人化介面簡圖 資料來源:本研究繪製. 25.
(34) 當使用者根據個人化介面輸入關鍵字搜尋並得到一組搜尋結果後,系統將針 對針對這組結果進一步統計,列出關聯性較高之詞彙清單,其一為搜尋結果之文 件集合中有對應到使用者在個人化樹狀選單中之詞彙統計,另一為根據知識本體 中的詞彙將搜尋結果之文件集合分類,使用者可選擇要點選此分類看這一分類下 之文章,此為查詢鑽回功能;亦可將此分類詞彙以 or 的方式加入搜尋框,和原有 關鍵字一起蒐尋取聯集,此為查詢擴展功能;或可點選此分類詞彙進行一全新之 查詢,如圖 12 所示。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 12 使用者進階查詢介面簡圖 資料來源:本研究繪製. 當使用者點選某一筆搜尋結果進入文件內容後,將呈現文件對應知識本體的 詞彙清單,使用者可勾選有興趣的詞彙進一步查詢相關的文件,如圖 13 所示。半 導體產業知識本體不僅具備描述領域知識的功用,亦可作為資訊檢索呈現的輔助 工具,幫助使用者更有脈絡地搜尋,避免過去常因關鍵字不精確而找不到真正想 要的文件。. 26.
(35) 簡言之,智慧檢索環境讓使用者可針對有興趣之詞彙進一步蒐尋相關文件, 在不混淆使用者的狀況下亦會標示各詞彙所占之權重及關聯強度,提供使用者作 為對訊息進行觀察、操作、檢索、瀏覽、發掘和理解的輔助工具。. 立. 政 治 大. ‧ 國. 學 ‧. 圖 13 文件內容顯示簡圖. n. al. y er. io. sit. Nat. 資料來源:本研究繪製. Ch. engchi. 27. i Un. v.
(36) 第二節 系統架構 本研究設計之系統架構可分為三大部分,分別為一般索引模組、本體索引模 組及資訊檢索模組,模組相互關係及簡單示意圖如圖 14。. 一般索引模組 外部資料. 本體索引模組. 資訊檢索模組. 維護介面. 搜尋介面. 政 治 大 半導體概念模型. 爬蟲. 立. 詞庫&文件 庫&本體索 引庫. Meta Model. 建立索引. 知識元素統計. ‧. ‧ 國. 個人化UI. 學. 建立索引. 資訊檢索. n. al. er. io. sit. Nat. 文件庫. y. 一般索 引庫. i C 圖 h14 系統架構簡圖U n engchi. v. 資料來源:本研究繪製. 1.. 一般索引模組:此模組主要功能為蒐集半導體產業相關之網站、新聞網 頁及產業報告內容,依據資料來源多寡配置爬蟲個數,並由多個爬蟲帄 均負擔不同資料來源之抓取工作並將半導體產業文件存入文件庫及建立 一般索引,本研究透過雲端環境之多台虛擬機器達到此功能,雲端運算 服務隨選特性亦相當符合本系統資源利用模式,此模組於系統建置初期 需要負擔大量蒐集文件工作,於帄日維護僅頇抓取前次更新日期後產生. 28.
(37) 之文件。 2.. 本體索引模組:本模組將一般索引模組蒐集之文件根據半導體知識概念 模型內包含的詞彙建立本體索引,透過文件與個別詞彙對應提供未來檢 索的依據,亦可視為基於知識概念模型建立文件摘要。另一方面藉由每 份文件包含詞彙的數量及詞彙兩兩同時出現頻率提供關聯分析的基礎, 這部分頇要大量運算能力之工作皆在雲端運算環境中得到滿足。在文字 探勘時使用 TF-IDF 計算數位文件內詞彙的重要性,兩詞彙間關聯度則以 TC 來計算。. 政 治 大. 資訊檢索模組:本模組將資訊檢索系統建置於半導體知識本體,並將知. 立. 識本體以視覺化的方式呈現,視覺化將領域知識以樹狀結構(Tree View). 學. 方式呈現,並提供個人化之檢索介面,透過使用者興趣檔(User Profile)、. ‧ 國. 使用者操作行為提供查詢擴展之詞彙列表,關聯度計算即依照關鍵字與. ‧. 文件之關聯度,除了使用詞頻的概念也加上知識本體的概念(即關聯分析. Nat. sit. y. 的結果),改善僅由字串比對造成的精準度不佳結果。專為半導體產業建. io. 立之資訊檢索系統也可達到垂直搜尋的功能,讓關鍵字配合領域知識更. n. al. er. 3.. i Un. v. 能引導使用者找出真正想要的內容,而非總是搜尋到透過優化或是廣告. Ch. engchi. 方式提升排名的網站,未來若加強語意呈現更可幫助使用者連結相關詞 彙及內容。本研究設計兩階段搜尋模式(Two-Level Search),若使用者輸 入之關鍵字未涵蓋在知識本體內,檢索模組將到一般索引模組之文件庫 取資料作顯示,此即一般搜尋引擎之功能,避免使用者輸入非半導體產 業相關詞彙面臨無搜尋結果之情況。. 29.
(38) 第四章. 雛型系統實作. 根據文獻探討及系統設計,本研究發展一基於知識本體之半導體產業資訊檢 索系統,藉由半導體產業概念模型之建立搭配文字探勘關聯分析技術,將專家所 具備之領域知識轉變為具體呈現之知識本體,並於此知識本體上建置資訊檢索系 統,透過計算文件與輸入關鍵字之關聯期望能找出真正符合使用者需求的文件, 並可將使用者腦海中抽象的概念以視覺化的方式呈現,使用者可根據文件與知識 本體的連結判斷其下一步搜尋方向,找到其他高度相關的文件。. 立. 第一節雛型系統實作工具. 政 治 大. ‧ 國. 學. 與本研究相關之智慧型資訊檢索系統建置工具如下:. 一、ASP.NET:使用 ASP.NET 開發檢索系統的主體,Code Behind 的特性使網. ‧. io. sit. Nat. 庫(Library)搭配控制項提供更快速的開發環境。. y. 頁的設計與程式碼分離,在未來視覺化介面改善上較方便,豐富的函式. n. al. er. 二、SQL Server:使用微軟 SQL Server 關聯式資料庫做為知識本體資料庫,記. Ch. i Un. v. 錄半導體產業概念模型、Meta Model、詞彙三部分組成之半導體產業知識. engchi. 本體,以及作為文件庫及知識本體索引庫。 三、Microsoft Visual Studio 2010:後端於.NET Framework4.0 帄台開發,並使 用 Entity Framework 執行資料操作,避免 client 端程式與底層資料庫來源 直接連結,建立實體資料模型(EDM)對應真正的資料結構,隔開程式與資 料庫之間的聯繫,透過 LINQ(Language-Integrated Query)語法操作及存取 資料模型。 四、Tornado:商用搜尋引擎,作為本研究之爬蟲軟體,其支援多種開發語言 (VB.NET、C#、VB、C++),可處理多種資料來源格式,例如:電子檔、. 30.
(39) 網頁、壓縮檔、資料庫等等,本身並維護一詞庫加強中文資料處理能力, 縮短資料前處理階段時間,專注於知識本體建立及系統之智慧檢索環境。 五、Hyper-V、VMWare vSphere:提供雲端運算環境虛擬化基礎,本研究使用 兩種軟體虛擬化實現模式,Hyper-V 為一虛擬機監視器(Virtual Machine Monitor, VMM)頇運行於宿主作業系統上,為 Type2 之伺服器虛擬化技 術,負責對虛擬機提供硬體資源抽象化,為客系統提供運行環境。VMWare vSphere 則為虛擬化帄台(Hypervisor)負責虛擬機的託管和管理,為 Type1 之伺服器虛擬化技術,它直接運行在硬體之上,因此直接受底層體系架 構的規範。. 立. 政 治 大. 第二節雛型系統實作架構. ‧ 國. 學. 一、 虛擬化(Virtualization). ‧. 本研究使用雲端機櫃建置私有雲環境,其硬體結構如圖 15,單一伺服器內有. sit. y. Nat. 兩顆四核 CPU,每一核心可運行兩個執行緒(Thread),即每一台伺服器上可運行. io. al. er. 16 台虛擬機。虛擬化技術將各式各樣的資源抽象化,在虛擬環境中實現其在真實. n. 環境中的部分或全部功能。. Ch. engchi. i Un. 圖 15 雲端機櫃硬體配置圖 資料來源:本研究繪製. 31. v.
(40) 本研究在伺服器虛擬化之架構如圖 16,底層擁有大容量之網路硬碟,透過高 速網路交換器(Switch),四台伺服器及運行於伺服器上之虛擬機可存取此硬碟空間 並互相通訊,亦可與外部作通訊。伺服器主要針對三種硬體資源虛擬化:CPU、 記憶體、設備與 I/O。. 立. 政 治 大. ‧. ‧ 國. 學 圖 16 伺服器虛擬化示意圖. Nat. n. al. er. io. sit. y. 資料來源:本研究繪製. i Un. v. 本研究中 Type1 之伺服器其軟體配置如圖 17 中 Server2,Type2 之伺服器軟體. Ch. engchi. 配置如 Server1,Server1 上之虛擬機運行的作業系統(Operating System)為 Windows 2008 R2 Enterprise X86,採用 32 位元之作業系統是配合爬蟲軟體所需環境設定, Server2 上之虛擬機運行的作業系統為 Windows 2008 R2 Enterprise X64,兩台伺服 器上之虛擬機配置亦可互換或交互使用。. 32.
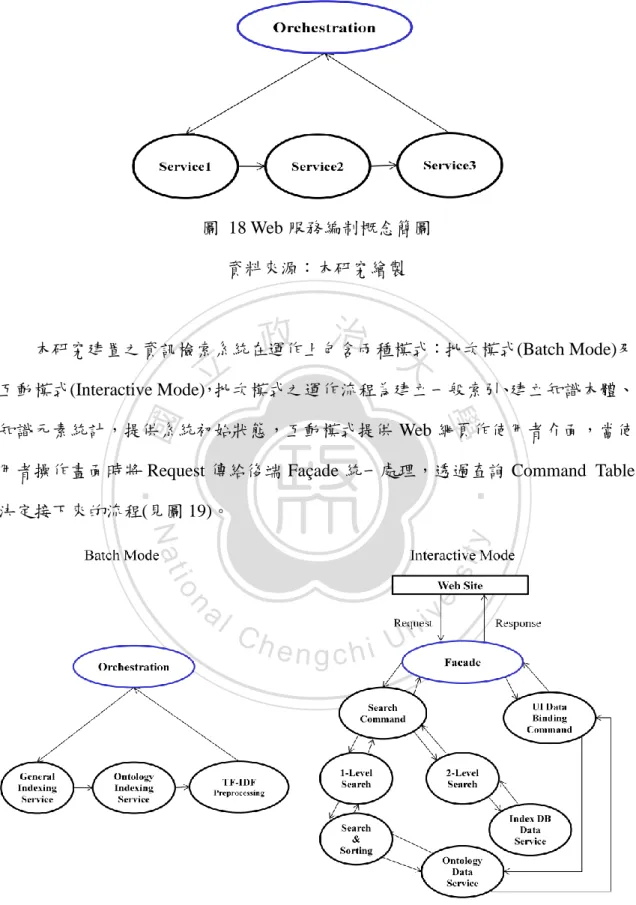
(41) 政 治 大 圖 17 伺服器虛擬化軟體配置示意圖 立 二、 服務導向架構(Service-Oriented Architecture, SOA). ‧. ‧ 國. 學. 資料來源:本研究繪製. sit. y. Nat. 當虛擬裝置被建立後,頇要透過某種方式被部署到資料中心(Data Center)才能. io. er. 被使用,服務導向架構催生了大量的由鬆散耦合的功能模組組成的業務,當這些. al. 業務被部署在資料中心時需要更加快捷、便利,本研究透過雲端運算環境之虛擬. n. iv n C hengchi U 化技術,在不同虛擬機上運行不同服務,發展適當的虛擬化環境並部署服務。服 務導向架構中常用 Web 服務編制(Web Services Orchestration)描述整合服務,如圖 18 所示概念,針對業務流程進行 Web 服務整合,需定義組成編制(Orchestration) 的服務,以及這些服務的執行順序,並頇定義呼叫哪些服務及呼叫服務的時機, 上述定義可視為一種簡單的流程,這種流程本身也是一個 Web 服務。. 33.
(42) 圖 18 Web 服務編制概念簡圖 資料來源:本研究繪製. 政 治 大. 本研究建置之資訊檢索系統在運作上包含兩種模式:批次模式(Batch Mode)及. 立. 互動模式(Interactive Mode),批次模式之運作流程為建立一般索引、建立知識本體、. ‧ 國. 學. 知識元素統計,提供系統初始狀態,互動模式提供 Web 網頁作使用者介面,當使. ‧. 用者操作畫面時將 Request 傳給後端 Façade 統一處理,透過查詢 Command Table 決定接下來的流程(見圖 19)。. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 19 本研究系統服務流程簡圖 資料來源:本研究繪製. 34.
(43) 圖 19 所列之流程服務可概分為三大類:General Indexing Service、Ontology Indexing Service 及 Query Service,General Indexing Service 內含爬蟲功能部署到圖 17 所示雲端運算環境中 Server1 上之兩台虛擬機,Ontology Indexing Service 及 Query Service 則分別部署到 Server2 上之一台虛擬機。 Ontology Indexing Service 可再拆分為 Document and General Index Retrieval、 Ontology Relation Processing、Relation Weight Processing 三個更小的服務,分別負 責從一般索引模組文件庫取資料、建立知識本體索引關聯及計算關聯及詞彙權重 工作,如圖 20 所示。其中在關聯及詞彙權重計算的服務,本研究採用 Strategy Pattern,. 政 治 大. 定義一整組演算法,將每一個演算法封裝起來,可互換使用,更可以在不影響外. 立. 界的情況下個別抽換所引用的演算法,如圖 21 所示,亦即本研究採用 TF-IDF 及. ‧ 國. 學. TC 方式實作 ConcreteStrategyA,未來可採用不同演算法實作 ConcreteStrategyB、 ConcreteStrategyC 等等加入,隨需求改變而更換權重計算規則,抽換非常方便增加. ‧. io. sit. y. Nat. n. al. er. 系統彈性。. Ch. engchi. i Un. v. 圖 20 本研究知識本體索引服務流程簡圖 資料來源:本研究繪製. 35.
(44) +Strategy. Relation Weight Processing +ProcessingInterface() : void. 1. Strategy. *. +AlgorithmInterface() : void. ConcreteStrategyA. ConcreteStrategyB. ConcreteStrategyC. +AlgorithmInterface() : void. +AlgorithmInterface() : void. +AlgorithmInterface() : void. 圖 21 Strategy Pattern 類別圖 資料來源:本研究繪製. 政 治 大. 三、 三層式系統架構. 立. 展示層 (Presentation Layer). Data Binding View Components Data Binding. View Models. n. er. io. al. sit. Nat. Web Services. y. ‧. View Models Control. 商業邏輯層 (Business Logic Layer) Task. 學. ‧ 國. Model - View - ViewModel. iv Commands n CFacade hengchi U. Business Objects BOManager. Business Objects. Builder. 資料存取層 (Data Access Layer). LINQ or DataSet. SQL Server. ADO.Net Data Provider. 圖 22 系統三層架構圖 資料來源:本研究繪製. 36.
(45) 圖 22 為 本 研 究 之 系 統 三 層 架 構 圖 , 前 端 展 示 層 使 用 MVVM(Model -View-ViewModel)開發方式,Model 是資料,View 是介面,ViewModel 負責控制 介面與資料,是利用 DataBinding 的機制所產生出的設計模式。商業邏輯層又可再 切分為 Task 及 Business Objects 兩層,Task 負責封裝商業法則,執行運算、判斷, 進行資料處理,透過 Façade 作為單一介面負責收到 Request 後查詢 Command Table, 根據 Command 內容操作 Business Objects,Business Objects 負責儲存各種資料,提 供 Task 資料來源,展示層與商業邏輯層透過 Web Service 的方式作呼叫。資料存取 層負責資料庫之存取,不包含任何的商業邏輯,使用 Entity Framework 執行資料操. 政 治 大. 作並透過 LINQ 語法操作及存取資料模型。. 立. 第三節雛型系統實作流程. 知識本體的建構分為下面兩階段進行:. ‧. ‧ 國. 學. 一、 建立知識本體. sit. y. Nat. 第一階段:定義知識本體中的 Class,並將 Class 組成一個層次化的結構。在. io. er. 此階段中,依據半導體產業相關概念定義 Class 即 Entity,並描述 Entity 之間的關. al. iv n C h e n g三個資料表主要分別記錄 EntityType、ModelRelation、RelationType Entity 名稱、 chi U n. 聯,產生概念模型。本研究使用關聯式資料庫之資料表描述概念模型(如附錄一),. Entity 之間的關聯、關聯名稱。 第二階段:將各 Class 對應之實例(Instance)填入。在此階段中,根據每一 Entity 定義將相對應的詞彙加入,此階段建立之詞庫將作為本體索引及知識元素統計之 基礎。本研究亦使用關聯式資料庫之資料表記載(如附錄一),TermList、Relation、 RelationType 三個資料表主要分別記錄詞彙名稱及所屬 Entity、Term 之間的關聯、 關聯名稱。. 37.
(46) 二、 設定資料來源與資料處理 在此階段中,使用 Tornado 商業軟體作為爬蟲,依據設定之資料來源網址將大 量新聞、產業報告等抓回來並建立一般索引庫,Tornado 提供控制台畫面輸入欲建 立一般索引庫之網址,畫面如圖 23 所示,並可設定搜尋層數及最大連線數,本研 究資料來源包含半導體產業或科技產業之研究中心、產業報告網站、研究單位、 新聞網頁、廠商網站等等,詳細清單請參照附錄二。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. i Un. v. 圖 23 Tornado 軟體控制台畫面. Ch. engchi. 資料來源:Tornado. 資料前置處理階段,使用 Tornado 進行斷詞及建立一般索引,一般索引庫記錄 每份文件所對應之詞彙及詞彙出現之頻率,一般文件庫則儲存所有抓回來之文件, 並有記錄文件標題、作者、內文之欄位,上述步驟除了蒐集原始資料也建立一般 索引,此階段將所需資料來源蒐集的前置作業完成,下一階段將進行本體索引建 立的步驟。. 38.
(47) 三、 建立本體索引 前一階段完成之原始資料蒐集包含設定網址內的所有內容,為過濾掉較無相 關性之內容並建立本體索引,此階段撰寫一批次程式根據知識本體的詞彙清單從 一般文件庫抓取相關的文件,並建立索引,本研究使用關聯式資料庫之資料表儲 存上述內容(如附錄一),資料表分別為 TermList 紀錄詞彙清單,批次程式如圖 24 所示根據此清單於每日固定時間,將 LastSearchTime 欄位記錄時間後新產生的文 件從一般文件庫抓回本體文件庫,RawDocs 儲存實際文件內容,DocIndex 則記錄 詞彙與文件之對應關係。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 24 批次程式 Log 檔 資料來源:本研究整理 四、 統計知識元素 在此階段中,計算詞彙本身在每份文件的重要程度及兩兩詞彙間之關聯度大 小,前者使用 TF-IDF 方式,後者採用 TC 計算,本研究對前者的實作方式作了一 些微調,公式轉換如下:. 39.
(48) TF = IDF =. 該詞彙於文件中出現的次數. 文件中知識本體詞彙出現的次數 文件長度. 所有文件數 關鍵字出現的文件數. Weight = TF. IDF. 針對 TF 微調主要是加入更多知識本體的概念,分子部分除了原本公式定義詞 彙於文件中出現的次數外,還加入文件中知識本體詞彙出現的次數,但後者權重 較低,經由多次調整得到前者佔 75%、後者佔 25%比例之檢索結果較佳,因此微 調 TF 分子部分。分母部分則使用文件長度取代原本公式之文件中所有詞彙出現的. 政 治 大 件內所有詞彙出現次數,僅能計算出知識本體詞彙出現次數,為避免知識本體詞 立. 次數,此微調原因在於本研究並未實作斷詞部分,從 Tornado 取回資料無法判別文. ‧ 國. 學. 彙建立不完全影響整體計算結果,故將分母部分作此微調,上述微調仍然是根據. TF-IDF 原始精神。TC 則為計算兩詞彙同時出現的次數,當新文件被抓回本體文件. er. io. sit. y. Nat. 五、 實作檢索介面. ‧. 庫時,同時也頇重新計算 TF-IDF 及 TC 的值。. al. 此階段實作使用者介面部分,如圖 25 所示,主要可分為四個區塊,左邊第一. n. iv n C hengchi U 個區塊包括使用者登入介面及樹狀選單,樹狀選單分為個人及總體兩種,個人樹 狀選單需待使用者登入後才能使用,總體樹狀選單則將知識本體的架構及詞彙以. 階層式的形式展示出來,樹狀選單提供使用者勾選有興趣的詞彙作為搜尋關鍵字。 本研究利用 EntityType 資料表將樹狀選單之架構動態產生,TermList 資料表將各節 點下之詞彙動態加入,當 Relation 資料表中記錄兩詞彙之關聯時,亦會在詞彙展開 時顯示出來,PersonalTree 資料表則記錄個人化樹狀選單應顯示之詞彙(如附錄 一)。 第二區塊為右方統計列表,此區塊於檢索過程不同時機可分為三種內容,第 一,於使用者開始檢索前秀出 My Favorite 及 Top10,分別代表此使用者點擊率最. 40.
(49) 高之詞彙清單及所有使用者點擊率最高之詞彙清單,本研究將此使用者操作記錄 存在 Favorite 資料表(如附錄一)。第二種為使用者按下搜尋鍵後,出現使用者興趣 檔統計分類及 Ontology 統計分類,前者代表這一組搜尋結果與個人化樹狀選單關 聯度較高之詞彙清單,後者代表與整個知識本體關聯度較高之詞彙清單。第三種 於使用者選取一筆搜尋結果後,將列出 Ontology 統計清單,為此篇文章對應到 Ontology 之詞彙清單。. 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. n. al. i n C U 圖 25 h 使用者操作介面首頁 engchi. v. 資料來源:本研究整理. 第三區塊則為介面中間之搜尋框及排序選擇,直接於搜尋框輸入關鍵字或是 由前兩區塊之樹狀選單及統計列表勾選關鍵字,都可將有興趣的關鍵字加入搜尋 條件,按下搜尋鍵即可得到檢索結果,並可於此區塊右方選擇依關聯度或日期排 序。. 41.
(50) 第四區塊為中間搜尋結果區塊,列出搜尋結果筆數及搜尋時間,並有分頁切 換按鈕,每一篇搜尋結果則列出標題、日期及一部分文件內容,文件內容對應到 使用者輸入之關鍵則以紅色顯示。 當使用者同時輸入多個關鍵字時,本研究假設此多個關鍵字間為 AND 關係, 計算步驟如下: 一、使用者輸入 n 個關鍵字,將 n 個關鍵字個別之 TF-IDF 值加總 二、根據半導體產業知識本體,找出 p 個與關鍵字相關聯的詞彙,此兩兩詞 彙間之關聯度為 q,計算每個關聯之兩詞彙 TC 即為此關聯權重值 q. 政 治 大. 三、將步驟二共 p 個權重值 q 個別乘以關聯詞彙本身之 TF-IDF 值後加總. 立. 四、將步驟一與步驟三之兩組加總值再相加,即為衡量文章符合使用者輸入. ‧ 國. ‧. 第四節雛型系統操作情境. 學. 關鍵字及半導體產業知識本體程度之數值. sit. y. Nat. 系統首頁如圖 25 所示,預設顯示關鍵字為台積電之搜尋結果,此時為未登入. io. er. 狀態,使用者欲取得完整智慧檢索環境功能頇於左上角輸入帳號密碼登入系統,. al. iv n C hengchi U 狀選單的子集合,右方則有使用者個人歷史記錄中較常作為搜尋關鍵字之詞彙, n. 登入後如圖 26 所示,個人樹狀選單下包含使用者設定較常使用之詞彙,為總體樹. 及全體較常作為搜尋關鍵字之詞彙列表。使用者進入此畫面後即可開始資訊檢索 動作,圖 27 中使用者於樹狀選單勾選「英特爾」 、於右方 Favorite 欄位勾選「併購」 及「聯電」 、Top 10 欄位勾選「光阻」 ,最後於搜尋框手動輸入「新竹」 ,並按下搜 尋鍵,由於樹狀選單中記錄「英特爾」有同義字為「Intel」,因此兩個詞彙皆會被 加入搜尋框。. 42.
(51) 政 治 大. 學. ‧ 國. 立 圖 26 使用者個人化操作介面 資料來源:本研究整理. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. 圖 27 使用者檢索畫面 資料來源:本研究整理. 43. v.
(52) 搜尋結果為根據「Intel」、「英特爾」、「併購」、「聯電」、「光阻」及「台積電」 這六個關鍵字所查詢到之文章,預設以關聯度大小排序,共計此組關鍵字搜尋到 140 項結果,花費 2.1738281 秒,文章中對應到關鍵字的詞彙皆會以紅字顯示,當 搜尋結果超過 10 筆,則會以分頁方式呈現,右方兩個統計列表即將此組搜尋結果 進一步根據個人化樹狀選單及總體樹狀選單之詞彙作分類,以詞彙為單位列出包 含該詞彙之文件篇數,使用者點選詞彙後方數字即可看到此分類文章,例如點選 中芯可查看此分類下之九篇文章,此為查詢鑽回功能,如圖 28 所示。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 28 查詢鑽回功能畫面 資料來源:本研究整理. 若使用者並非想要先查看某一分類文章,而是參考右方列表後欲加入原先未 輸入之詞彙作為關鍵字,則可點選詞彙前之方框,勾選此詞彙加入搜尋框,並按 下搜尋鍵,則系統將以原先輸入關鍵字組加上新輸入關鍵字重新查詢,例如勾選 日本一詞則將產生一組新的搜尋結果為日本及原先搜尋結果之聯集,如圖 29 所示,. 44.
(53) 共 144 筆搜尋結果,此為查詢擴展功能,使用者亦可於右方列表點選單一詞彙展 開一新分頁作此詞彙之查詢。. 立. 政 治 大. ‧. ‧ 國. 學. Nat. y. 圖 29 查詢擴展功能畫面. n. er. io. al. sit. 資料來源:本研究整理. Ch. i Un. v. 當使用者欲點選某一篇文章查看詳細內容時有兩種方法,第一為點選文章標. engchi. 題連結到原始網頁,第二為點選 more 查看系統抓回來之純文字檔,例如使用者點 選關聯度最高之第一篇文章「面臨庫存壓力及新進業者威脅 2005 年晶圓代工誰將 勝出?-懂市場-新電子科技雜誌」 ,若點選標題列則導回資料來源網站,如圖 30 所 示,此方法可查看原始網頁之圖片,另一方法則點選 more 將連結到文件庫之純文 字檔案內容,如圖 31 所示,此方法之結果右方將有一列表顯示文章與知識本體對 應之詞彙,使用者可勾選詞彙加入搜尋框作為搜尋條件。. 45.
數據

+2

相關文件
二、本校於報名表中對於學生資料之蒐集,係為學生成績計算、資料整理及報 到作業等招生作業之必要程序,並作為後續資料統計及學生報到註冊作業
二、本校於報名表中對於學生資料之蒐集,係為學生成績計算、資料整理及報 到作業等招生作業之必要程序,並作為後續資料統計及學生報到註冊作業
利用 Microsoft Access 資料庫管理軟體,在 PC Windows 作業系 統環境下,將給與的紙本或電子檔(如 excel
利用 Microsoft Access 資料庫管理軟體,在 PC Windows 作業系統環境 下,將給與的紙本或電子檔(如 excel
在上 一節中給出了有單位元的交換環 R 上的模的定義以及它的一些性質。 當環 R 為 體時, 模就是向量空間, 至於向量空間中的部分基本概念與定理, 有些可以移植到模上來。 例如 子
本校為一科技大學,學生之來源大多屬技職體系之職業高中及專科學
就知識及相關理論的最新發展,體育教師可運用他們的專業知識,把新元素例如資訊素養、企 業家精神、人文素養,以及
利用 Microsoft Access 資料庫管理軟體,在 PC Windows 作業系 統環境下,將給與的紙本或電子檔(如 excel
