結合網頁分類代理人之平行化階層式文件群聚法
曾守正 古惟中 國立高雄第一科技大學 國立高雄第一科技大學 資訊管理系 資訊管理系 [email protected] [email protected] 摘 要 面對網際網路上大量的網頁資訊,如何 有效組織這些網頁資訊已經成為很重要的課 題。本研究結合 WebACE 網頁分類代理人, 運用解群技術、平行處理架構,實現「以高 頻項目組合為基礎之階層式文件群聚法」 (FIHC, Frequent Itemset-based Hierarchical Clustering),希望能有效提升網頁文件群聚執 行效能,以及群聚品質。我們提出將 WebACE 網頁代理人所取得之分類網頁,利用「預先 分 類 資 料 之 解 群 方 法 」 (Pre-classified De-clustering Method, PCD) 切割成為均等的 工作單元,有效達成平行處理節點之間的負 載平衡。在我們的平行架構中,各運算節點 處理完成後,將運用 FIHC 演算法所產出之 群集主題樹 (Topic Tree),將各節點所回傳之 群集結果,利用 XML 檔案合併策略,將多 個相同標籤的群集結果進行合併動作。最 後,測試結果顯示在平行架構上採用 FIHC 演算法,在群聚品質與執行效能方面都有相 當大幅度的提升。 關鍵詞:FIHC 文件群聚、資料解群、平行處 理。 1. 簡介 1.1 研究動機與目的 網際網路上大量電子化的文件資訊,已 經產生資訊過載的現象。因此,自動化組織 文件資訊的需求將會愈來愈重要,Boley et al. [2] 的研究提出了WebACE (Web Agent for Document Categorization and Exploration) 網 頁代理人,可以針對使用者個人特性 (User Profile) 進行網頁分類的動作。但我們認為透 過分類操作的資料並不能完全表現出資料本 身的意涵,因此若可以將這些分類資料進行 更詳細的分群動作,依照文件的相似特徵進 行自動化文件群組的建立,則對於使用者而 言,將可以提供更詳盡的文件集展示內容。 因此,本研究針對網頁分類代理人結合 文件群聚演算法之加速議題及群集品質加以 探討,我們參考文件群聚研究領域常被提及 的相關演算法,得知傳統的文件群聚演算法 具有下列缺失: 1. 對於高維度特徵向量無法提供好的處 理效能, 2. 在處理過程還需要大量儲存空間配合, 3. 針對群集結果無法提供明確的群集描 述 (Cluster Description) 等。 對於上述傳統文件群聚演算法可能產生 的 問 題 , Fung et al.[7] 改 良 了 HFTC (Hierarchical Frequent Term-based Clustering) 文件群聚演算法 [1],發展出FIHC (Frequent Itemset-based Hierarchical Clustering) 文件群 聚演算法,該演算法經過驗證在執行效能以 及群聚品質都有很好的效果。除此之外, FIHC之群聚結果是以主題樹 (Topic Tree) 的方式呈現,並且在樹中的每一個群集都是 以高頻項目集 (Frequent Itemsets) 做為群集 描述,主題樹的階層關係與群集描述有利於 分散式環境下進行結果合併動作處理。 因此,為了加快文件群聚演算法執行速 度 , 減 少 使 用 者 等 待 時 間 , 我 們 希 望 由 WebACE 網頁代理人取得欲群聚的網頁文 件集,接著採用高群聚效果及高效能的FIHC 演算法,配合資料解群 (Data De-Clustering) 概念 [4] 的應用,實現在分散式架構上的快速處理作業,除了能利用分散式架構加快處 理速度以外,還能進一步提升文件群聚品 質,所以對於檢索系統使用者來說能獲得更 大的幫助。 本研究將以SETI@home研究專案裡,所 採用的切割工作單元 (Work Units) 概念為 基礎 [10],建構一個以平行處理架構為基礎 之文件群聚系統。而在分散式處理架構中, 為了達成參與運算節點間的負載平衡 (Load Balance),我們會辦法讓每一個節點之FIHC 處理程式所回傳之主題樹結構相近,使合併 後主題樹與原始單機執行主題樹的群集描述 相近,以達到分聚處理之目的。因此,本研 究在資料切割方面,以DocId分割方法 [9] 配 合PCD解群法,將整個文件集的資料平均分 散於切割出來的文件子群中,資料解群方法 使文件子群間彼此的相似性高,並且可用以 代表文件母群,讓切割出來的工作單元內容 相近,確實達到資料平均分配之目的。
最後,我們以WAP (WebACE Project) 測 試 文 件 資 料 集 [2][5] 為 文 件 群 聚 測 試 對 象,該文件資料集為多個文件群聚技術研究 所採用,所以我們認為此測試文件集在文件 群聚技術研究上有一定的公信度。我們透過 資料切割方法、FIHC演算法、合併策略運 用,與平行處理架構等技術之整合應用,經 過模擬處理流程,證實我們的方法確實可以 有效減少FIHC演算法處理時間,並且在某些 參數值條件下多節點執行的群集品質甚至比 單節點執行還要好。 1.2 研究貢獻 在過去文件群聚領域的研究中,主要是 以提升群聚品質及加快處理速度為目的。在 本論文中,我們的方法除了要達成相同目標 之外,在結果合併部份還提出了一些不同於 過去的新想法。綜合來說,整體的架構與方 法有以下特點: 1. 利用簡單的資料配置方法,達到以資料 解群方法切割工作單元的效果,這種資 料配置方法,簡稱為 PCD (Pre-Classified De-clustering) 解群法,我們將此解群方 法應用至文件群聚演算法,使文件群聚 演算法適用於平行處理架構,並且經過 實驗評估,本方法確實能有助於文件群 聚品質之提升。 2. 擴充網頁代理人功能,除了以分類方式 向使用者呈現網頁文件集內容之外,本 研究所提出的方法,可以加快文件集群 聚時間,並且是依照文件內容進行自動 化群組的動作,提供使用者更詳盡的網 頁文件集內容與呈現方式。 3. 在群集結果合併部份與傳統作法不同, 我們不是直接以群與群之間的相似度進 行合併,而是提出利用 FIHC 演算法產 出群集主題樹的特性作為合併的基礎, 省去結果合併過程中計算相似度的比對 動作,此種作法將可加快分散式群集合 併的動作。 2. 相關研究 2.1 文件群聚技術 文件群聚的目的是希望將所有內容相近 的文章集合在一起,然後給予各個群集一個 名稱或是摘要,便於使用者瀏覽或查詢。傳 統文件群聚演算法是以「階層式群聚法」 (Hierarchical Clustering) 與「分割式群聚法」 (Partitioned clustering) 為基礎,發展出如: 階層式聚合群聚 (Hierarchical Agglomerative Clustering, HAC) 、 K-means 分 群 法 、 Scatter/Gather文件群集瀏覽系統等。然而這 類群聚法在用於文件群聚時,卻無法針對高 維度特徵向量以及大量資料提供有效率的群 聚效果,而且在完成群聚操作後,無法提供 明確的群集描述 [1]。 為了解決上述需求,以改善標準文件群
聚演算法可能遭遇的問題,Beil等人提出兩種 以高頻項目詞為群聚基礎的文件群聚演算 法 , 分 別 是 FTC (Frequent Term-based Clustering) 與 HFTC (Hierarchical Frequent Term-based Clustering) [1]。隨後Fung等人也 以 HFTC 演 算 法 為 基 礎 發 展 出 FIHC 方 法 [7],其文件群聚效果經過驗證後證實執行效 能都優於上述文件群聚演算法。 就分散式處理的適用性而言,傳統的文 件群聚演算法需要進行群與群的相似度比對 動作,因此要花費較多的運算資源。此外, 我們將FIHC文件群聚演算法與同樣是「以高 頻 項 目 詞 為 基 礎 之 文 件 群 聚 演 算 法 」 的 FTC、HFTC演算法相比較,發現FTC演算法 的非結構化群集結果,以及HFTC無法自訂群 集數量等特性 [1],並不適用於分散式處理結 果的合併操作。因此,我們希望採用FIHC演 算法,並修正配合WebACE網頁代理人以實 現平行處理架構上的快速文件群聚處理作 業。 2.2 FIHC 方法說明 FIHC 利用資料探勘關聯法則 Apriori 演 算法計算出文件集的頻繁特徵詞,這個概念 就如同購物籃分析 (Market Basket Analysis) 應用,將每份文件當成一個購物籃,而文件 集裡的特徵詞資料,則看成是購物籃中的項 目 。 該 演 算 法 裡 設 定 最 小 全 域 支 持 度 (Minimum Global Support, GS) 為門檻移除 倒置檔 (Inverted File) 中非高頻特徵詞的部 份。透過高頻特徵詞的應用,在 FIHC 文件 群聚過程中,可以有效降低特徵詞維度,使 它適用於大型與複雜的文件集運算。 此 外 , FIHC 是 以 群 集 為 主 (Cluster-Centered) 的群聚演算法,可以透過 群集支持度 (Cluster Support, CS) 門檻設 定,利用公式計算文件對於群集的歸屬程 度,最後FIHC是以主題樹的方式呈現群集結 果。運用主題樹作為群集結果呈現的好處 是,在主題樹裡的群集是以高頻特徵詞當作 群集描述,使用者可以很容易的由高頻項目 詞所構成的群集樹進行瀏覽。FIHC演算法包 含四個重要步驟,如圖 1所示。限於篇幅, 其詳細說明請讀者們參考 [7] 的說明。 tfij … tfi2 tfi1 Doci … … … … … tf2j … tf22 tf21 Doc2 tf1j … tf12 tf11 Doc1 Termj … Term2 Term1 tfij … tfi2 tfi1 Doci … … … … … tf2j … tf22 tf21 Doc2 tf1j … tf12 tf11 Doc1 Termj … Term2 Term1 圖 1:FIHC演算法流程 [7] 2.3 文件分配與解群技術 文件經過前置處理、求出關鍵詞,並計 算 其 出 現 頻 率 之 後 , 可 求 得 文 件 倒 置 檔 (Inverted File)。以倒置檔為主的分割方法主 要 有 兩 種 : 第 一 種 以 詞 識 別 符 號 (Term Identifier, TermId) 為分割依據,另一種則以 文件識別符號 (Document Identifier, DocId) 為分割依據 [9],DocId分割方法如圖 2所示。 本研究以解群 (De-Clustering) 的原理 [4],實現DocId分割方法:它會預先將資料切 割為內容相近的工作單元,接著分配給各個 運算節點,並在各節點的本地端中進行FIHC 演算法處理,產生群集主題樹後,回傳遠端 發出工作任務之節點。 圖 2:以文件為主的分割 [11] 2.4 WebACE 網頁代理人 WebACE是依照使用者過去所關注的網 頁文件資訊建立一個個人化瀏覽資訊。在 WebACE架裡使用二種群聚演算法,將使用 者瀏覽過的網頁資訊給予群聚處理,產生初 始群集。WebACE就可以利用這些群集來產
生新的查詢詞,並且搜尋相似的文件到這些 原始群集裡,達到文件分類的效果。限於篇 幅,詳細請讀者們參考 [8] 的說明。 2.5 SETI@home 專案 SETI@home主要的研究團隊是美國加 州柏克萊大學SETI小組負責,SETI全名為尋 找 外 星 智 慧 計 畫 (Search for Extraterrestrial Intelligence)。為了要加大運算能力,研究小 組發展出SETI@home系統架構 [10],如圖 3 所示,所接收到的電波會被分割成每筆大小 為 0.25 MByte的區塊 (亦稱為「工作單元」 (Work Unit),再將工作單元儲存到資料伺服 器 (Data Server) 中。資料伺服器利用科學資 料庫 (Science Database) 記錄工作單元的處 理情況,並利用使用者資料庫 (User Database) 管理全球參與運算的使用者。 圖 3:SETI@home資料伺服器架構 [10] 3. 系統架構與方法 在本章節我們先將要解決的問題詳細描 述,再提出本研究之系統架構、以及執行流 程,最後以範例說明完整處理過程。 3.1 問題描述 目前有許多文件群聚演算法被提出,但 面對龐大文件資料集,群聚演算法是否能快 速得到文件群聚結果,是個有待解決的問 題。對於系統加速問題,除了利用超級電腦 來執行,採用一般個人電腦所組成的集合也 可以達到提升系統效能的效果,本研究在前 面章節介紹,可以利用平行處理來分散演算 法之處理任務,減少系統執行的等待時間。 以下列出幾點是本研究在設計系統架構與方 法過程中需要考量到的議題: (1) 資料分配方面:由於本研究所採用的 群聚演算法為 FIHC 演算法,該演算法所產 生的群聚結果是以主題樹的方式呈現,如果 切割出來的工作單元與工作單元之間資料量 或內容差異過大,除了會造成工作負載不均 等,而且會讓主題樹節點差異過大,多個子 結果集合經過合併動作後,會與單機執行之 主題樹結構相似度降低。 (2) 處理時間方面:如果將文件群聚演算 法建置於單機系統上,而且要面對大量的文 件資料量,從文件前置處理,產生特徵向量, 到正式進行文件分群,勢必要花費相當多處 理時間,而且過長的等待時間也不符合使用 者需求,若能將處理過程中某部份運算分配 給其他電腦處理,那可大大降低處理時間。 (3) 在結果合併方面:若是採用一般群與 群之間相似度進行合併,在原始群集數量為 m,回收結果的群集量為n的情況下,群集比 對次數將會是m * n次,群集數量愈多就可能 造成比對次數也跟著增加。除了運用群與群 之間相似度比對的方法,Deb et al. [3] 將 RACHET (Recursive Agglomeration of Clustering Hierarchies by Encircling Tactic) 技 術應用在分散式階層文件群集合併策略方 面,在合併過程中,要先計算群與群之間的 歐幾里德距離 (Euclidean distance),建立群與 群之間的距離矩陣,所以在合併過程中勢必 要花費不少時間,因此我們認為結果合併問 題,是影響分散式文件群聚技術處理效能上 很重要的關鍵。 3.2 系統架構 本研究以平行處理架構為主如 圖 4所 示,圖中左半部屬於Server端部份,右半部屬 於Client端運算節點,我們規劃系統工作執行 可分為三個階段:
z Server 端切割文件集成為被下載的工 作單元:(a)主要是由 WebACE 代理人取 得經過簡單分類的網頁文件集、(b) 文 件前置處理,取出關鍵詞建立關鍵詞-文件矩陣,以 DocId 方法配合 PCD 方 法,將文件集切割為工作單元、(c) 選 擇未完的工作單元,將相關資料存放於 Server 端之資料伺服器 (Data Server, DS)。
z Server 端透過 Data Server 分派工作單 元:(c) Client 端取得 DS 所分派之工作 單元、(d)工作單元存放於 Client 的磁碟 進行 FIHC 文件群聚、(e) 利用 FIHC 文 件群聚演算法產出群集主題樹、(f) 每 一個節點將結果交由資料伺服器回傳 給 Server 端。 z Server 端接收回傳給果:(g) 將主題樹 合併,結果顯示至 Server 端之使用者。 圖 4:系統架構圖 在 此 , 我 們 假 設 表 1 範 例 文 件 集 為 WebACE代理人所取得之分類文件集,在以 下章節中我們將該文件集作為文件群聚目 標,該文件集主要分為cisi、cran、med這三 個類別,並且已經過前置處理,取出關鍵特 徵詞,最後以文件倒置檔的方式呈現。我們 利用該文件集展示:工作單元切割法、FIHC 處理結果,以及最後結果合併方法。 表 1:範例文件集 [7] Feature vector Doc.
Name flow, form, layer, patient, result, treatment
cisi.1 ( 0 1 0 0 0 0 ) cran.1 ( 1 1 1 0 0 0 ) cran.2 ( 2 0 1 0 0 0 ) cran.3 ( 2 1 2 0 3 0 ) cran.4 ( 2 0 3 0 0 0 ) cran.5 ( 1 0 2 0 0 0 ) med.1 ( 0 0 0 8 1 2 ) med.2 ( 0 1 0 4 3 1 ) med.3 ( 0 0 0 3 0 2 ) med.4 ( 0 0 0 6 3 3 ) med.5 ( 0 1 0 4 0 0 ) med.6 ( 0 0 0 9 1 1 ) 3.2.1 工作單元切割法 以下介紹我們所採用的工作單元切割方 法:PCD 資料解群法,以及範例執行結果。 3.2.1.1 預先分類資料之解群方法 (PCD) (1) 方法說明 對於經過網頁代理人 (Web Agent) 分類 之網頁資料 [2],本研究採用簡單的資料分配 方法達到切割工作單元的效果,提出解群後 的子群集文件是平均由每一個類別之文件集 取出的資料所組成,為了方便後續說明,我 們將這個方法稱之為「預先分類資料之解群 方 法 」 (Pre-classified De-clustering Method, PCD)。在此我們所面對的母群資料是已事先
經過分類,即母體文件集D = {D1, D2, …,
Dj},而且母體文件集是由多個類別C = {C1,
C2, …,Cn} 所組成,每一個類別的文件數量N
= {N1, N2, …, Nn},則每一個類別的文件組成
為Ci = {Di,1, Di,2, …,Di, N},其中i是文件集中 第i個類別,如果要切割出q個工作單元,則 每一個類別Ci要切割出q個均等的區塊P = {P i1, Pi2, …, Piq} , 類 別 裡 每 一 個 區 塊 符 合 { | , i iq j j i j N P D D R D q = ∈ ≅ },其中Ri是Ci未被 選擇為工作單元的文件子集,而每一個工作 單元分別是由各個類別中的區塊中的文件所 組成,而且每個區塊之文件數量要相近。 不過這個資料分配方法會因為每一個類 別裡的資料量不同,經過資料區塊分割後每 個區塊資料量也不一定相同,所以會有負載 不平衡的情況產生。例如:有一個擁有四個 類別資料集,這四個類別分別為 A{a1}、B{b1, b2, b3}、C{c1, c2, c3}、D{d1, d2, d3, d4, d5},將 這些資料依類別切割為二個工作單元,則每
個 類 別 會 被 切 割 為 二 個 區 塊 分 別 是 , Ap1{a1}、Bp1{b1, b2}、Bp2{b3}、Cp1{c1, c2}、 Cp2{c3}、Dp1{d1, d2, d3}、Dp2{d4, d5},在這種 情況下,類別裡的資料數量若無法被 2 整 除,就會造成第二個區塊比第一個區塊資料 量還少。同理,在類別 Ci裡的資料量 Ni無法 被工作單元 q 整除的情況下( ),最 後一個區塊的數量都是最少的。 mod 0 i N q≠ 如果是以一般Row Order的方式配置類 別區塊到各個工作單元裡,如圖 5(a) Raw Order所示,則WU1 = {Ap1, Bp1, Cp1, Dp1}、WU2 = {Bp2, Cp2, Dp2},也就是WU1 = {a1, b1, b2, c1, c2, d1, d2, d3}、WU2 = {b3, c3, d4, d5},會造成 工 作 單 元 資 料 量 有 差 異 , 所 以 我 們 利 用 Row-prime Order的方式配置資料 [6],以減 少資料負載差距過大的情況發生。如圖 5(b) Row-prime Order所示,則WU1 = {Ap1, Bp2, Cp1, Dp2}、WU2 = {Bp1, Cp2, Dp1},也就是WU1 = {a1, b3, c1, c2, d4, d5}、WU2 = {b1, b2, c3, d1, d2, d3}。 關於每個工作單元之資料量方面,PCD 解群法經過 Row-prime order 資料配置方法的 處理,除了第一個或最後一個工作單元的資 料數量可能比較少外,每個工作單元的資料 數量都是相等的,所以彼此間的差距並不大。
(a) Row Order
Work Unit A B C D WU1 Ap1 Bp1 Cp1 Dp1 WU2 Bp2 Cp2 Dp2 (b) Row-prime Order Work Unit A B C D WU1 Ap1 Bp2 Cp1 Dp2 WU2 Bp1 Cp2 Dp1 圖 5:資料配置方式比較 [6] 根據上述PCD解群法的說明,我們可以 利用圖 6演算法圖示加以說明其切割工作單 元的過程,若由網頁代理人取得之原始資料 分為四類Class 1~4,欲將原始資料集切割為 工 作 單 元 Work Unit 1~3 , 透 過 簡 單 的 Row-prime order配置方法,即可得到切割結 果。另外,我們可以利用圖 7的函式來展式 處理方法:輸入參數為文件陣列D[n]、欲切 割之工作單元數量q,該演算法中以D[i][j]代 表在文件集裡第i項類別的文件j,文件集共有 c 個 類 別 , 每 個 類 別 切 割 出 p 個 區 塊 , 以 Row-prime order將資料平均配置q個工作單 元中。 (2) 範例說明 我們以表 1作為範例文件集,展示PCD 演算法處理過程,此範例文件集主要分為 cisi、cran、med這三個類別,每一個類別所 包含的文件集如表 2所示,如果將這個文件 集切割為二個工作單元,首先,每個類別要 切割出二個文件數量相近的區塊,類別cisi 僅有一份文件,所以只有區塊cisip1,類別cran
可以切割出二個區塊cranp1、cranp2,類別med
可以切割出二個區塊medp1、medp2,如表 3所
示。
接下來,我們利用Row-prime order資料配 置方法進行區塊分配的動作,如表 4所示,
第一個工作單元WU1 由文件{cisi.1, cran.4,
cran.5, med.1, med.2, med.3}組成,第二個工
作 單 元 WU2 由 文 件 {cran.1, cran.2, cran.3,
med.4, med.5, med.6}組成。
Work Unit WU1 WU2 WU3 Class1 P11 P12 P13 Class2 P23 P22 P21 Class3 P31 P32 P33 Class4 P43 P42 P41 D11,D12,………,D1j D21,D22,………,D2k D31,D32,………,D3l D41,D42,………,D4m P11 P12 P13 P11 P23 P31 P43
Class 1 Class 2 Class 3 Class 4
P21 P22 P23 P31 P32 P33 P41 P42 P43
P12 P22 P32 P42 P13 P21 P33 P41
Work Unit 1 Work Unit 2 Work Unit 3
De-clustering
(Row-prime order)
圖 6:預先分類文件之解群演算法圖示
/*Input:D[n] –An array of documents.
We use D[i][j] to denote the document j of class i in collections.
q – Number of Work Unit.
Output:The work units in array Work_Unit[q]. */ Function PCD (D[n] , q){
Int i , j , q , c , m , x , temp; Int k = 1 , r = 1; Int Num_Of_Doc[c] ; String Work_Unit[q];
x = q;
for i = 1 to c {
m = Roundup(Num_Of_Doc[i]/q);
for p = r to x{ for j = k to m{
add D[i][j] to Work_Unit[p]; }
k = m + 1; // The partition (start) m = m + m; // The partition (end)
}
temp = r; // For Row-prime order r = x; x = temp; } return Work_Unit[q]; } 圖 7:PCD 演算法 表 2:預先分類文件集範例
類別名稱 文件集 cisi cisi.1
cran cran.1 , cran.2 , cran.3 , cran.4 , cran.5 med med.1 , med.2 , med.3 , med.4 , med.5 , med.6
表 3:類別區塊切割
類別 名稱
Partition 1 Partition 2
cisi cisip1{cisi.1}
cran cranp1{cran.1, cran.2, cran.3} cranp2{cran.4, cran.5}
med medp1{med.1, med.2, med.3} medp2 {med.4, med.5, med.6}
表 4:Row-prime order 資料配置方法
Work Unit cisi cran med
WU1 cisip1 cranp2 medp1
WU2 cranp1 medp2 3.2.2 FIHC 文件集經過解群成為多個工作單元,可 以將工作單元分配給平行處理節點,本研究 規劃在每一個運算節點上建置FIHC處理程 式 [5],當運算節點取得由部份倒置檔所組成 的工作單元後,以這些工作單元作為FIHC處 理程式的輸入資料,經過運算最後得到群集 主題樹。 主題樹最上層根節點屬於樹的Level 0 部 份,群集描述標籤為 “null”,所有沒有群集 歸屬的文件都是屬於此群集C(null),根節點 以 下 的 各 層 級 Level k 的 群 集 描 述 標 籤 是 k-itemset,k >= 1。假設,我們利用網路上的 Peer 1 與Peer 2 兩個節點處理之前由PCD解 群法所切割完成的工作單元,在GS = 0.3、 CS = 0.7、群集數量為 2 的條件下,文件群聚 結果如圖 8所示,我們所應用的切割工作單 元方法,經過群聚處理所得到 2 棵主題樹, 最後一個步驟則要進行樹合併的動作。 主題樹是群集結果概念上的呈現方式, 實際上FIHC處理程式是以XML檔案作為群 集結果輸出格式,所以平行處理架構上的參 與 運 算 節 點 所 回 傳 的 結 果 實 際 上 是 一 個 XML檔案,如 圖 9所示,圖中根元素標籤 (Tag) “root” 對應到主題樹中C(null) 節點, root是沒有群集歸屬之文件的儲存點,在根元 素底下包含了一些子元素,子元素標籤是 “cluster”,而子元素的屬性值 “label” 就是群 集名稱,主題樹階層的概念可以藉由XML文 件表達出來,所以我們可以利用FIHC處理程 式輸出的XML檔案做為主題樹合併的基礎。 cisi.1 cran.4 cran.5 flow med.1 med.2 med.3 patient cran.1 cran.2 cran.3 flow med.4 med.5 med.6 patient null 合併 null + 圖 8:產出之主題樹 -<root num_clusters="2" label="null" num_children="2" num_docs="2"> <documents num_docs="0" /> -<cluster label="Apple" num_children="0" num_docs="1">
- <documents num_docs="1"> <document>Doc.2</document> </documents>
</cluster>
-<cluster label="IBM" num_children="0" num_docs="1"> - <documents num_docs="1"> <document>Doc.4</document> </documents> </cluster> </root> 圖 9:FIHC 輸出結果範例 3.2.3 結果合併策略 (1) 方法說明 若是以 FIHC 演算法所產生的主題樹為 合併基礎,合併動作是把在主題樹中同一階 層而且是同一個主題名稱的內容進行合併, 而不需要將每一個群集進行一對一的比對動 作,如此不用處理過於繁雜的比對動作,達 到節省系統執行資源的目的。 FIHC 演算法所產生之主題樹的樹高是 依照群聚標籤詞的個數決定,例如根節點 Level 0,所有沒有群集歸屬的文件都是屬於 Level 0 的群集,而在 Level 1 的標籤是一個 字詞組成,在 Level 2 是二個詞所組成,Level k 是由 k 個詞所組成,我們可以利用這樣的 特性將同一層級裡相同標籤名稱的群集直接 進行合併。因此,主題樹進行合併時可能會 有三種情況,如下所示: Condition 1:負責結果合併的運算節點 不存在「合併後主題樹」,則新加入的主題樹
直接成為合併後主題樹。 Condition 2:兩棵主題樹的節點,位於 相同層級而且擁有相同主題標籤,兩節點所 代表的群集可以直接進行合併。 Condition 3:兩棵主題樹的節點,位於 相同層級但其中有某些節點之標籤不在合併 後主題樹裡,則以新增的方式將節點加入合 併後主題樹。 圖 10為主題樹合併範例,假設目前已存在合 併後主題樹(a),希望加入的回收後主題樹 (b),圖中灰色圓形圖是要增加之主題樹與原 始合併後主題樹不同的樹節點,實施合併動 作時,從Level 0 至Level 3 由上往下掃描,配 合先前所提到的三種情況進行節點合併,經 過結果合併步驟後,合併後主題樹如圖 11所 示。 z Level 0:兩樹之 Node(Null)都是未規類文 件群集,屬於 Condition 1 故直接合併。 z Level 1:Node(A)、Node(B)屬於 Condition
1 故直接合併,主題樹(b)之 Node(D)屬於 Condition 2 故以新增的方式將節點加入 合併後主題樹。
z Level 2:Node(A,B)、Node(A,D) 屬於 Condition 1 故直接合併,主題樹(b)之 Node(B,D) 、Node(D,G)、 Node(D,H)屬 於 Condition 2 故以新增的方式將節點加 入合併後主題樹。 z Level 3:主題樹(b)之 Node(A,B,I) 屬於 Condition 2 故以新增的方式將節點加入 合併後主題樹。 圖 10:主題樹合併 圖 11:合併後主題樹 圖 12:利用 OPENXML 函數取出節點元素 以上說明是概念上主題樹合併方法,我 們若以FIHC處理程式實際產出之XML檔案 作 為 合 併 基 礎 , 可 以 使 用 Microsoft SQL Server 2005 的 SQL Query Analyzer 執 行 OPENXML函數 [13],剖析XML文件,取出 根元素、子元素以及所屬的文件名稱,將 XML文件的資料以關聯表的形式存入資料 庫 , 以 利 後 續 合 併 處 理 相 關 動 作 。 利 用 OPENXML函數擷取節點元性之處理範例如 圖 12所示。 (2) 範例說明 在此,我們以概念上的主題樹來說明合 併結果,如圖 13所示,在本範例中單機執行 結果與平行處理架構執行結果相同,不過經 過我們的實證評估,多機執行結果與單機執 行結果並不一定完全相同,雖然群集結果不 同,但在某些參數值設定下,以多機執行之 群集品質是較單機群集品質好,關於群集品 質評估,我們在下一章節會加以說明。
cisi.1 cran.4 cran.5 flow med.1 med.2 med.3 patient cran.1 cran.2 cran.3 flow med.4 med.5 med.6 patient cisi.1 cran.1 cran.2 cran.3 cran.4 cran.5 flow med.1 med.2 med.3 med.4 med.5 med.6 patient 合併結果
(a) Peer 1 Topic Tree (b) Peer 2 Topic Tree (c) Result Work Unit 1 Work Unit 2
null 合併 null null
+ PCD 圖 13:範例群集結果比較 4. 實驗結果與討論 4.1 測試資料集 本研究採用的測試文件集為WAP測試文 件資料集,該文件資料集是WebACE研究專 案 [2] 所產出的分類文件資料,運用此資料 集也符合我們在之前章節所提出的PCD解群 概念,PCD可以結合網頁代理人之分類功 能,將資料進行工作單元切割。 WAP 所包含的文件總數是 1560 份,將 全部文件分為 20 類,每個類別的文件數量分 別為 5~341 份不等。 4.2 實驗介紹 本 研 究 所 提 出 之 系 統 架 構 是 為 了 將 WebACE代理人所產出之分類網頁資料,利 用PCD解群分配法將文件群聚的資料與任務 平均分散至平行處理架構裡的各工作站中, 以加快FIHC文件群聚演算法之處理速度,並 且依照網頁文件內容進行更詳細之文件群聚 動作,提升群聚品質。我們將模擬單一主機 執行,以及多個運算節點同時執行的條件 下,FIHC處理程式所花費的文件群聚時間, 如此可以瞭解平行處理加速效果。此外,我 們亦探討多節點運算之群集品質,以及工作 單元切割方法對於群集結果的影響。對於上 述各項評估衡量準則,我們可以觀察FIHC平 行處理架構之執行效率 (Efficiency) 與群聚 準確性 (Accuracy),而整體實驗評估項目及 內容,如圖 14所示。最後,我們對於各項數 據提出一些評估與比較。 圖 14:實驗評估項目 4.3 數據分析及效能評估 4.3.1 多節點執行群聚準確性評估 (1) 以解群方法切割工作單元之群聚準確性 評估 本研究以F-measure評估法 [7][12] 作為 文件群聚結果準確性評量之依據,我們比較 平 行 處 理 架 構 上 與 單 機 執 行 之 FIHC 演 算 法,在各項參數值設定條件下的文件群聚準 確 性 , 將 每 個 節 點 所 回 傳 之 群 集 結 果 的 F-measure值予以平均計算,再與單一節點執 行結果進行比較。 首先,我們以GS值做為檢測對象,GS 參數值主要是會影響在群聚過程裡高頻項目 集合的產生,以及群集解體 (Clusters Disjoint) 公式計算 [7]。在此我們將CS設為 0.65,然 後以GS為變數,將GS值設定為 0.15 至 0.4, NC設為 10,在此條件下,測試不同的GS值 在平行處理架構上執行FIHC演算法與單機 執行FIHC演算法對於群集正確性之影響,如 圖 15所示,各種GS值在平行處理架構執行 FIHC演算法的情況下,大多數得到的群集準 確性是比單機執行還好。 接著,我們以同樣的計算方法,測試不 同的CS值在平行處理架構上執行FIHC演算 法與單機執行FIHC演算法對於群集正確性 之影響,將GS設為 0.25,NC設為 10,在此 條件下測試多種CS值 0.3 至 0.7,測試結果如 圖 16所示,我們發現單機執行與在平行處理 架構執行,群集準確性差別不大。 最後,我們比較不同的群集數量,對於 平行處理架構執行與單機執行的影響,不同 的群集數量參數設定主要是會影響到FIHC 演算法最後主題樹裁切 (Tree Pruning) 步驟
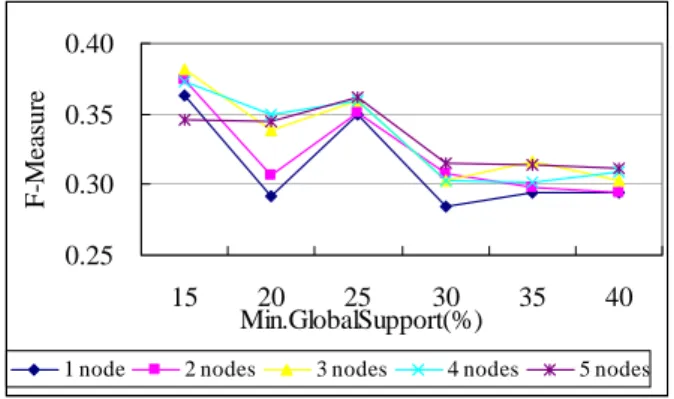
[7]。我們將GS設為 0.25,CS設為 0.35,在此 條件下,以較少的群集數量作為輸入參數, 在平行處理架構執行之群聚正確性比單機執 行要好,如圖 17所示。 0.25 0.30 0.35 0.40 15 20 25 30 35 40 Min.GlobalSupport(%) F-M ea su re
1 node 2 nodes 3 nodes 4 nodes 5 nodes
圖 15:F-measure for various GS value by
PCD 0.25 0.30 0.35 0.40 30 40 50 60 70 Min.ClusterSupport(%) F-M ea su re
1 node 2 nodes 3 nodes 4 nodes 5 nodes
圖 16:F-measure for various CS value by
PCD 0.25 0.30 0.35 0.40 4 6 8 10 Num. of Clusters F-M ea sur e
1 node 2 nodes 3 nodes 4 nodes 5 nodes
圖 17:F-measure for various NC value by
PCD (2) 以偏斜方法切割工作單元之群聚準確性 評估 我們將測試資料集以偏斜方法切割工作 單元,測試在多機執行的情況下所獲得之 F-measure 值,測試過程所使用的參數條件, 與前述評估解群方法之群聚準確性所設定的 條件相同,我們使用各種 GS 值、CS 值、NC 值作為評估準則。我們可以發現以偏斜方法 將資料切割為多個工作單元的執行結果,所 計算而得的 F-measure 值是優於單一主機執 行結果,甚至還優於利用解群方法切割工作 單元的結果,主要是因為我們所採用的偏斜 切割方法是在已資料分類的情況下進行,是 一種較極端的偏斜資料配置方法,主要是用 來與均勻的解群方法進行比較,所以在工作 單元內的資料本身相似度就比較高,於是經 過分散式群聚演算後得到這樣的結果。 但是偏斜資料所組成的工作單元,其每 個工作單元所產生的群聚主題樹之間相似度 很低,合併群集與原始群集之主題樹組成結 構差異很大。在此,我們以 WAP 測試文件集 裡的 15 份 Art 類別文件與 33 份 Cable 類別文 件為例,說明文件在群集中配置的結果,在 GS=0.25、CS=0.35、NC=6 的條件下執行二 個工作單元,並且將群集結果合併,把合併 群集與原始群集進行比較,我們可以得知合 併群集相似於原始群集的比例僅有 14% (由 於篇幅限制,在此將不列出詳細文件在群集 中配置之結果)。 因此,若考量合併群集與單機執行的原 始群集結果之間相似度問題,偏斜資料分配 方法是不適合的,關於本研究驗證主題樹結 構相似度的方法,在下一章節合併後群集描 述評估會加以說明。 4.3.2 合併後群集描述評估 我們先將這些主題樹之群集描述進行聯 集合併的動作,然後將合併後之群集描述集 合與單一主機執行之群集描述集合進行比 較,確認樹狀結構的相似程度,以下我們進 行兩項評估動作: z 多機與單一主機執行之群集結果比較。 z 解群方法與偏斜配置方法各別取得的主 題樹進行合併動作,同樣以 Level 1 之群 集描述作為評估依據,比較這兩種資料分 配方法對於群集結果的影響。 (1) 多機執行與單一主機執行比較
實證過程中我們發現,在平行處理架構 上之FIHC文件群集結果雖然不一定與單一 主機執行時相同,但群集品質確有可能會更 佳,以表 5為例,在GS=0.25、CS=0.35、NC=6 的條件下,利用多節點執行二個工作單元, 比在單一主機執行未切割工作單元之文件集 多了 3 個群集描述,而且二種群集結果的文 件配置也可能不同。 在此,與4.3.1節相同,我們利用WAP測 試文件集裡的 15 份Art類別文件與 33 份Cable 類別文件,加以說明文件在群集中配置的結 果,此範例顯示,在相同群集描述標籤的條 件下,比較每一個群集內文件配置的情況, 得知合併群集相似於原始群集的比例約 54% (由於篇幅限制,在此將不列出詳細文件在群 集中配置之結果),明顯優於偏斜切割工作單 元的結果。 表 5:群集描述詞比較 1 node 2 nodes
carolyn, compani, elit, galaxi, gateway, worldwid
carolyn, compani, elit, galaxi, gateway, worldwid,
claud, hideo, strategist
無論如何,在本範例中雖然原始群集與 合併群集並不完全一樣,不過我們可由圖 17 比較該參數條件下之群集F-measure值,發現 切 割 為 二 個 工 作 單 元 的 群 集 結 果 之 F-measure值是優於單機執行的群集結果。所 以我們可以歸納出下列觀察現象: z 群集數量及標籤變多 透過工作單元的切割,降低每次群聚處 理的資料量,如此一來文件不會因為整個原 始文件集裡某些文件所產出的高頻項目組影 響,而失去了文件本身應該有的意義。而利 用部份文件集作為群聚對象的好處是,除了 能加快處理速度,還可以產出更切合某些文 件的群集描述標籤。因此,在本研究裡,在 子結果合併動作後,所產出之合併群集會有 更多的群集標籤。 並且就整體群聚水準來說,這種部份群 集結果不同的現象,是我們可以接受的,不 過在未來的研究中我們仍希望可以達到分散 式處理的目的,就是合併群集與原始群集完 全相同的目標。 z 標籤數量控制 但是我們發現切割工作單元的方法,在 結果合併後可能會產出太多群集描述標籤, 雖然這樣可以用更詳細的方法來組織群集, 不過這也有可能會造成群集數量過多的現 象,而我們採用的解群切割方法,剛好可以 讓合併後主題樹不會過於寬闊,組成結構近 似於原始主題樹。因此,本研究所使用的方 法,會有折衷的效果,既可以達到精確組織 文件群集的目的,又不會讓合併群集數量過 多。總之,把合併群集與原始群集進行比較, 解群切割方法達到的效果就是,合併群集的 標籤與文件配置部份與原始結果相同,部份 獨立出來文件群集用更合適的標籤來建構這 些新的群集。 圖 18:群集描述集合關係圖 所以關於單機執行與多節點執行FIHC 演算法之群集結果,兩者之間的群集關係可 以由圖 18群集描述集合關係圖來說明,單一 主 機 執 行 之 群 集 描 述 集 合 , 我 們 以 OriginalResult代表,多節點執行回傳之群集 描述集合我們以SubResult代表,兩種群集集 合的關係如下: z a:利用多節點執行之群集描述集合,與 單 一 主 機 執 行 之 原 始 群 集 描 述 集 合 比 較,所缺少的群集描述。 z b、c、d:兩個 SubResult 之群集描述合併 後,與單一主機執行之原始群集描述集合 比較,相同的群集描述。 z e、f、g:利用多節點執行之群集描述集 合,與單一主機執行之原始群集描述集合 比較,額外多出來的群集描述。 (2) 解群方法與偏斜配置方法比較 我們可以從實驗結果得知,在相同參數 條件下,均勻的解群方法與偏斜方法所產生 之合併群集對於原始群集的相似比例,很明
顯的解群切割方法是優於偏斜的切割方法, 並且透過主題樹結果呈現,我們發現若合併 群集之群集描述與原始群集之群集描述相同 的部份愈多,合併群集的文件配置的情況與 原始群集相同的機會愈高,所以在本研究 裡,我們可以利用群集描述來估算合併群集 與原始群集相似度。 一般常用的正確率估算方法有二種,一 種是正確率 (Precision)、另一種是查全率 (Recall),如圖 19所示,在此,Precision值愈 高代表合併群集與原始群集描述相同的數量 愈多,Recall值愈高代表合併群集與原始群集 主題樹結構愈相近,計算公式如下所示: A precision A B = + , A recall A C = + 圖 19:評估合併群集與原將群集相似度之方 法 在此,我們分別以直方圖代表Precision 測試,折線圖代表Recall測試,兩種工作單元 切割方法比較,如圖 20所示,採用解群方法 之群集描述Precision都有達到 60%以上,而 採 用 偏 斜 方 法 切 割 工 作 單 元 群 集 描 述 Precison最高僅到達 40%。另外,以解群方法 切 割 工 作 單 元 之 群 集 描 述 Recall 可 以 高 達 95%以上,而採用偏斜方法切割工作單元之 群集描述查全率皆在 85%以下,所以無論是 Precision或Recall,在合併後主題樹群集描述 與原始群集結果之間比較,以解群方法切割 工作單元都是優於偏斜的資料切割方法。因 此,我們可以瞭解以解群方法切割工作單元 可以有效達到與原始群集結果相近的目的。 4.3.3 執行效能評估 我們將FIHC演算法建置於硬體環境,並 設 定 演 算 法 參 數 為 GS=0.05 、 CS=0.25 、 NC=5,分別以單機執行與平行處理架構 2~5 個節點同時執行,測試結果如圖 21所示,將 工作單元切割為 2~5 個,以 2~5 個運算節點 同時執行的方式執行FIHC演算法。就執行效 率而言,多運算節點架構之FIHC演算法是優 於單機執行之FIHC演算法,就整體來說,平 行處理架構之FIHC演算法,隨著工作單元數 量增加,參與運算的節點增加,執行效率明 顯提升。 0% 20% 40% 60% 80% 100% 2 3 4 5 Num. of Partitipants P ercen ta g e
Precision(Evenly) Precision(Skew) Recall(Evenly) Recall(Skew)
圖 20:解群方法與偏斜分配方法之比較 0 50 100 150 200 250 300 1 2 3 4 5 Num. of Participants Tim e ( se c. ) 圖 21:以平行處理架構執行 FIHC 效能比較 5. 結論與建議 本研究結合 WebACE 網頁代理人所產生 之預先分類文件資料,我們提出將解群方法 應用至 FIHC 文件群聚演算法,藉由 PCD 解 群法的應用實現切割工作單元的概念,使文 件群聚技術適用於平行處理架構。並且在分 散式運算環境中,子結果群集合併動作是影 響整體處理效能的關鍵,所以本研究提出以 群集描述為基礎的結果合併策略。最後我們 將本研究所提出之系統架構與方法予以模擬 測試,由實證評估結果得知,本研究所提出 之系統架構與方法,在執行效率方面,多運 算節點架構之 FIHC 演算法明顯優於單機作 業,而在各種常用的參數值設定下,多運算 節點群聚結果比單機執行 F-measure 值高,
也就是多機執行之群集品質較單機執行為 佳,若進一步瞭解 FIHC 參數設定對於多節 點執行 F-measure 值的影響,不同的「最小 全域支持度 (Minimum Global Support)」以及 「群集數量」這兩種參數設定對於多節點執 行影響較大。除了上述 F-measure 值與執行 效 能 的 測 試 , 本 研 究 再 將 屬 於 平 均 分 配 (Evenly) 的解群法與偏斜 (Skew) 分配方法 進行比較,以資訊檢索領域常用的評估準則 Precision、Recall 加以測試,我們可以驗證解 群方法確實可以加強合併群集與單機執行的 原始群集結果之間的相似度。 利用分散處理的目的,就是把一個工作 分配到多個主機執行,讓多機執行的結果取 代原始結果,不過在實驗過程中,我們發現 分散式架構之 FIHC 演算法所產出的群集結 果與單一主機執行的合併群集結果,群集內 文件配置情況並不一定完全相同,就我們在 論文中所提出的理論來說,我們可以大膽假 設,若文件資料量愈龐大,每個工作單元的 特徵會更接近母體,兩種群集結果應該會愈 相近,不過值得注意的是,本研究所提出之 方法是一個創新的嘗試,關於群集結果差異 的部份,我們認為這是在未來可以深入研 究,還有許多值得改進的地方。 參考文獻
[1] Beil, F., Ester, M., and Xu, X., “Frequent Term-Based Text Clustering,” Proceedings of
the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, 2002, pp. 436 – 442.
[2] Boley, D., Gini, M., Gross, R., Han, E.
H.(Sam), Hastings, K., Karypis, G., Kumar, V., Mobasher, B., Moore, J., “Document Categorization and Query Generation on the World Wide Web Using WebACE,” Journal of
Artificial Intelligence Review, Vol. 13, No. 5-6,
1999, pp. 365-391.
[3] Deb, D., Fuad, M. M., and Angryk R. A.,
“Distributed Hierarchical Document Clustering”, IASTED Conference on Advances
in Computer Science and Technology, Puerto
Vallarta, Mexico, January 23-25, 2006, pp.328-333.
[4] Fang, M. T., Lee, R. C. T., and Chang, C. C., “The Idea of De-Clustering and its
Applications”, Proceedings of 12th
International Conference on Very Large Data Bases-VLDB’86, (Kyoto, Japan). Aug. 1986,
pp.181-188.
[5] FIHC Toolkit.
http://www.cs.sfu.ca/~ddm/dmsoft/Clustering/ fihc_index.html.
[6] Frank S.C. Tseng and Pey-Yin Chen, “Parallel Association Rule Mining by Data De-Clustering to Support Grid Computing,”
The 9th Pacific Asia Conference on Information Systems: PACIS 2005, Bangkok,
Thailand, July 7-10, 2005, pp. 1071-1084.
[7] Fung, B. C. M., Wang, K., and Ester, M.,
“Hierarchical Document Clustering Using Frequent Itemsets,” Proceedings of the SIAM
International Conference on Data Mining (SDM ’03), 2003, pp. 59-70.
[8] Han E.-H., Boly D., Gini M., Gross R.,
Hastings K., Karypis, “WebACE: A Web Agent for Document Cateorization and Exploration,” Proceedings of Agents 98, 1998.
[9] Jeong, B. S., and Omiecinski, E., “Inverted file partitioning schemes in multiple disk systems,” IEEE Transactions On Parallel And
Distributed Systems, Vol. 6, No. 2, February
1995, pp.142-153.
[10] Korpela, E., Werthimer, D., Anderson, D., Cobb, J., and Leboisky, M., “SETI@home-Massively Distributed Computing for SETI,” IEEE Computational
Science and Engineering, Vol. 3, No. 1,
Jan-Feb, 2001, pp.78-83.
[11] Macfarlane, A., “Distributed Inverted Files And Performance : A Study Of Parallelism And Data Distribution Method In IR,” Department of Information Science, City University, London, A thesis for the degree of Doctor of Philosophy, August 2000.
[12] Steinbach, M., Karypis, G., and Kumar, V., “A Comparison of Document Clustering Techniques,” KDD Workshop on Text Mining, (Boston, MA, USA). August 20-23, 2000.
[13] 曾守正、周韻寰,「資料庫系統進階實務」