行政院國家科學委員會專題研究計畫成果報告
計畫編號:NSC96-2416-H-110-023
關於 KMV 信用風險評估模型的三個重要議題之研究
The three important topics in
Moody’
s
KMV
c
r
e
di
t
r
i
s
k
mode
l
一、中英文摘要 中文摘要 在Moody’s KMV模型中,其令違約點的定義為短債加上二分之一長債。 由於地區、國情、企業規模與公司不同的財務結構以及產業類型的差異,此違 約點的定義是否具一般性則需加以驗證,否則將導致錯估企業的違約機率以及 風險的程度,因此本研究以Moody’s KMV模型為基礎,輔以門檻迴歸法與分 量迴歸法之比較,對違約點的定義做新的詮釋,找出是否存在結構性轉折,並 檢驗在利用門檻迴歸與分量迴歸的模型之下,新的違約點定義是否相較於原始 Moody’sKMV模型定義更有鑑別能力。 本研究以門檻迴歸與分量迴歸模型分別對十七個代理變數進行門檻點與分 量點檢定;以門檻迴歸模型而言,發現應收帳款周轉率、流動比率、短債/公司 規模(1)1、短債/公司規模(2)2、公司規模(1)、公司規模(2)、利息保障倍數、財 務槓桿、短期負債、負債比率等十個代理變數,對台灣上市上櫃企業違約點之 影響均存在著結構轉折現象,但是以分量迴歸分析而言,可以確定除了長債與 短債這兩個變數外,其它十五個財務變數對於企業資產市值的影響都不顯著。 另外,藉由門檻迴歸模型與分量迴歸模型實證結果所定義的修正後違約點,估 算『修正後』Moody’sKMV違約機率,利用 ROC 曲線與 CAP 曲線,來檢驗修 正後的Moody’s KMV違約機率的預測能力之準確性與效率性,發現以門檻回 歸模型與分量回歸模型修正之違約點所估算的違約機率其預測能力之準確性與 效率性均優於傳統Moody’s KMV模型,而且又以門檻迴歸模型優於分量迴歸 模型。 關鍵字:KMV、違約機率、違約點、門檻迴歸模型、分量迴歸模型 1 在本研究中所定義的公司規模(1):ln(營業收入淨額) 2 在本研究中所定義的公司規模(2):ln(營業收入淨額+營業外收入)
Abstract
In the Moody’sKMV model, the default point is defined as short-term liabilities plus one-half long-term liabilities. But the regionalism, national condition, business scale, financial structure and industrial type may not be the same in different countries. Therefore, it should be verified whether the generality of this definition of default point still exists, otherwise this will result in error of measuring default probability and risk. Hence, we would base on Moody’s KMV model, and take use of threshold regression and quantile regression to modify the definition of default of point and compare with each other. In other words, we try to renew the definition of default point, and find out whether that it existed structural change in this model or not. Besides, we want to estimate whether the new definition of default point were better and more persuasive than the original Moody’s KMV model under threshold regression and quantile regression.
In the research, we take seventeen variables to test the points of threshold and quantile respectively in threshold regression model and quantile regression model. As far as threshold regression model is concerned, we explore that receivable turnover, current ratio, short-term liability/ scales (1)1, short-term liability/ scales (2), firm size(1), firm size(2), interest coverage ratio, financial leverage, short-term liability, debt ratio, all these ten variables exist threshold effect significantly to the default point of listed companies in Taiwan. However, taking the quantile regression as an example, there are only two variables, such are long-term liability and short-liability, significantly affect the assets value of company, but the other fifteen financial variables are insignificantly. Furthermore, by the modified definition of default point with threshold regression model and quantile regression model, we calculate the verified default probabilities. Finally, we employ ROC curve and CAP curve to examine the accuracy and the efficiency of predictability. We explore that if we considered receivable turnover, current ratio, short-term liability/ scales (1), short-term liability/ scales (2), firm size(1), firm size(2), interest coverage ratio, financial leverage, short-term liability under threshold regression model; and besides if we take account of 0.85 quantile2 under quantile regression model , we have better accuracy and the efficiency than original Moody’sKMV model. Moreover, we also find the threshold regression model is superior to the quantile regression model.
Keywords: KMV, default probability, default point, threshold regression model,
quantile regression model
1
The business sales(1) is defined as taking nature log of sales.
二、報告內容 1. 計畫緣由及目的 Moody’s KMV 信用風險模型係利用企業權益市值與其波動度求算企業資 產市值等資訊,然後再假定若企業資產市值低於某一違約點時即為違約,據此 求得企業之違約距離和違約機率,且因為該模型經濟意涵的簡單易懂與估計之 精確性,而使得Moody’s KMV信用風險模型廣受產業與學術界之關注,其模 型是以 Black and Scholes (1973) 的選擇權評價模型與 Merton (1974)公司債權評 價模型為基礎,所發展出的一套信用風險評估模型,該模型不僅利用企業的財 務報表的資料,也考慮了企業的權益市場價值,此模型的主要優點在於可以利 用股票市場的即時資訊所反映的企業價值來計算破產機率或違約機率,因而不 需要等待信用評等機構每隔一段期間才發佈一次的信用評等即可立即評估企業 信用風險。 然而,由於違約事件的發生與該公司所座落的地區、國情也有一定的關連, 加上經過長期的景氣循環,目前的產業結構或時空環境與Moody’s KMV信用 風險評估模型甫提出的當時時已存在著顯著差異,因此原始的 Moody’s KMV 信用風險模型中對於企業違約點的定義是否會因為台灣上市上櫃企業特質的不 同而異?若企業特質會影響企業信用風險,又問,企業信用風險是否會隨著企 業特質的良窳而存在著不同的影響效果,亦即企業特質的良窳對企業信用風險 之影響是否存在著結構轉變現象?又若該影響效果存在著結構轉變現象時,我 們該如何修正模型中違約點的定義以評估或衡量台灣上市上櫃企業的信用風 險?最重要的是,修正後的Moody’s KMV信用風險模型的預測能力與效率性 是否較原始Moody’sKMV更佳?這些連鎖問題相當值得我們更深入地探究。 若以計量實證中的迴歸模型觀點,非線性或結構轉折主要可由不同時間點 因素,或模型中解釋變數其值高低所造成,目前計量實證上處理此類問題的方 法上,以 Hansen (1999)所提出的門檻迴歸模型最受肯定;另外,Koenker (1979) 所提出的分量迴歸模型,其核心意涵則是迴歸模型中被解釋變數在不同分配位 置時,解釋變數對被解釋變數之影響可能存在著不同的效果,不同於傳統迴歸 模型,分量迴歸並非以樣本均數值觀點估算模型係數值,而是依模型中殘差值 正負給予不同權重,藉此區分樣本所對應的分配位置,估算各種不同分配位置 情況下模型的係數值。綜上所述,Hansen (1999)所提的門檻迴歸模型(threshold regression model)可歸屬於因為解釋變數高低不同水準所形成的門檻效果,而 Koenker (1978)所提出的分量迴歸模型(quantile regression model)則類同於因 為被解釋變數值高低不同水準所形成的門檻效果。因為本文所有問題皆發自於 Moody’s KMV 信用風險模型中違約點之定義可能因為企業體質之良窳而存在 門檻效果,然此可能存在的門檻效果究竟係因解釋變數(公司特質)高低不同 引起?抑或肇因於被解釋變數(違約點)之分配特性?為了進一步釐清此相關 問題,所以本研究將分別採用 Hansen (1999)與 Koenker (1979) 所提出的門檻迴 歸模型及分量迴歸模型設定門檻點前後不同的違約點定義,據此修正原始 KMV 模型將違約點定義為單純線性的缺陷,以求能更適切且精確地估算台灣上市上 櫃企業的信用風險。 綜上所述,本計劃主要研究目的如下:
(1) Moody’s KMV 模型中違約點的定義能否適用於台灣的上市上櫃企業信用 風險之評估? (2) 利用門檻迴歸模型與分量迴歸模型兩種不同的計量方法,探究 Moody’s KMV 信用風險模型中違約點的定義所可能存在的門檻效果,究竟係因解釋 變數(公司特質)高低不同引起?抑或肇因於被解釋變數(違約點)之分 配特性?若存在著門檻效果時其違約點的定義,是否仍為短期負債加上二 分之一長期負債呢? (3) 以公司經營能力、財務流動性、公司規模、公司償債能力、負債程度做為 門檻變數推估出的新違約點定義,重新估算台灣公司企業的違約機率,是 否能夠比傳統 KMV 模型更具有財務預警的能力? 為了有系統地探究上述問題,本研究計畫除了上述的緒論背景之外,主要 架構分別有:第二部份為回顧與整理過去相關之文獻;第三部份則是詳細說明 本研究所使用的研究方法與實證模型;第四部份則以本研究計畫所採用之研究 方法進行有系統的實證與分析,最後則將本研究計畫之成果做成具體的結論與 建議。接續地將針對相關文獻進行系統性的回顧。 2. 文獻回顧及探討 早期信用風險模型的建立大多運用計量統計方法,像是 Z-Score Model (Altman, 1968)、Qualitative Model、Probit Model、Logistic Model、線性區別模 型 (the discriminate model) 以及類神經網路分析(neural network analysis)等方法 均被廣泛地運用在信用風險管理議題上,因為這些模型係以企業歷史資料做為 模型投入變數以預測企業未來違約的可能性,所以又被稱為 look backward 分析 法,雖立意甚佳,但因為這些模型缺乏嚴謹的理論架構支持,且模型的市場資 訊內涵較為薄弱,加上企業的過去表現無法完全代表企業未來違約與否,因此 可能較難以提供確切的預測能力,可將這些早期的信用風險模型歸類為歷史模 型 (actual model )。對此問題,信用風險評估模型的發展在 1990 年代後,逐漸 分成為兩大類,一為結構式模型 (structure form model),另一類為縮減式模型 (reduced form model),兩者基本的差異在於模型所投入的變數不同。此外,這 些模型大多立基於市場資訊用以預測標的對象未來的違約可能性,故其模型建 構的分析手法被學者稱為 look forward 分析法。
就結構式模型而言,其基本理論係以 Black and Sholes (1973)的選擇權定價 理論為宗,並由 Merton (1974)予以公式化,而之後的一系列模型演進大致上係 放寬或修正 Merton (1974)的原始模型。此類模型的最大特色是其投入變數必須 利用被評價企業資產價值及其波動性與資本結構相關的參數,較具有直覺性經 濟意義,違約風險則決定於企業資產市值與負債價值之間的關係。而現實環境 上,大中多無法直接取得企業的資產市值、資產市值波動性等模型相關的參數
資訊,故應用上通常有較高的難度1。 縮減式模型則主要採用市場價格資訊做為模型投入變數,利用市場價格、 信用利差或信用評等轉換等資訊,將隱含在這些資訊的違約機率加以模型化。 此方法忽略公司特性,且信用等級通常來不及反應公開資訊,但在實際運算上, 具有數學運算上的容易性。與結構式模型最大的差異在於無須對破產或違約加 以定義(如公司資產價值低於負債總額或是現金流量不足以涵蓋利息支出),而 直接將違約假設為不可預期的隨機事件,服從某一外生設定的違約過程(default process)。縮減式模型中較具代表性的主要分為四類:違約基礎法 (default-based approach)、信用評等轉移法 (rating-transition approach)、信用價差法 (spread approach) 、 市 場 基 礎 法 之 風 險 中 立 評 價 模 型 (market-based risk neutral approach ),其中,結構式模型係採用企業個別資訊,並利用非線性估計法求算 出受評企業資產市值、波動性與資本結構相關的參數,然後代入模型中估算受 評企業之違約機率,較具有直覺性之經濟意義,但投入模型的變數難以直接觀 察而產生量化執行上的困難是其缺點。而縮減式模型則採用市場價格、信用利 差或信用評等轉換等資訊,將隱含在這些資訊的違約機率加以模型化,並使得 具有數學運算上的容易性,但信用等級資訊公開的即時性不足,且此類模型多 相同評等的公司被視為違約情形相同而忽略公司個別特性,致使企業信用狀況 無法即時且正確地被反映,是其缺點。相關的代表性文獻如:信用價差法(Jarrow and Tumbull, 1995)、信用評等轉移法(Jarrow et al., 1997、Das and Tufano, 1996、 Lando, 1998、Arvanitis, Gregory and Laurent, 1999 等)、信用價差法(Duffie and Singleton, 1997、Madan and Unal, 2000 等),以及市場基礎法之風險中立評價模 式(Bierman, Hass, 1975、Yawitz, 1977、Johnhart, 1979、Fons, 1987 與 Su-Lien Lu and Chau-Jung Kuo, 2005 等)。
上述部分模型的核心或基礎已被延伸發展成實務上常見的模型,例如: Moody’sKMV、Credit Grades、Credit Metrics、CreditRisk+
、Credit Portfolio View 等。其中,Moody’sKMV為美國舊金山 KMV 顧問公司於 1993 年運用 Black and Scholes (1973)的選擇權訂價理論與 Merton (1974)的公司債評價模型所發展出 「預期違約頻率」(epected dfault fequency;EDF),採用股票市值衡量風險、預 期違約頻率、違約點、違約距離等因子,做為信用風險指標加以轉換為違約機 率。而 Credit Grades 係於 997 年由摩根大通(J.P Morgan Chase & Co.)所發展, 透過較為完整的信用風險資訊的整合,更能反映信用風險狀況。模型之理論基 礎在於違約時點是由公司資產價值和公司資本結構之隨機過程所決定,當公司 資產價值低於負債總額,違約事件即發生。
Credit Metrics 又稱為信用計量法(CreditMetrics™),係由摩根大通公司於
1典型的理論文獻包括 Black and Cox (1976)、Bernnan and Schwartz (1977, 1978, 1980)、Geske (1977)、Ingersoll (1976, 1977a, 1977b)、Leland (1994)、Leland and Tofe (1996)、Longstaff and Schwartz (1995)、Zhou (1997)等。
1997 年所開發出以風險值(VaR)為核心的動態量化風險管理系統。信用計量法 基於債務人的信用評級、未來特定期間(通常為 1 年)評級發生變化的概率、違 約貸款的回收率及債券市場上的信用風險價差計算出的市場價值及其波動性, 進而評估個別或投資組合的信用風險值。該方法係以市價評價法來進行風險評 估,並採用投資組合法進行信用風險的分析,債務人評等的調升或調降皆會造 成信用投資組合的市價變動。CreditRisk+ 則是 1996 年,由瑞士信貸第一波士頓 銀行(Credit Suisse First Boston, CSFB)所提出,以違約機率及波動性計算投資組 合中信用暴險的預期違約損失分配,可應用於放款、衍生性金融商品等信用風 險的衡量。在信用風險加成模型中,投資組合內個別放款違約機率小,且違約 無相關性,故以「卜瓦松分配」(Poisson distribution)來求算 1 年中發生 n 次違 約事件的機率,且建構各種違約數目發生的機率分配圖。
至於 Credit Portfolio View 又稱為信用投資組合觀點法,係於 1997 年由麥 肯錫公司所發展,將總體經濟狀況納入考慮,以過去總體經濟變數的歷史資料 為基礎,來預測違約機率。再利用此計算出的違約機率與外部評等機構所提供 的違約機率來求算出轉移調整比率,而將移轉矩陣轉換成以目前經濟狀況為條 件的評等轉移矩陣,以衡量投資組合的信用風險,反映投資組合受目前的經濟 狀況影響所產生的真實風險。 上述信用風險評估模型中,又以Moody’s KMV信用風險模型最被廣泛採 用,其主要理論架構便在於將企業權益市值視為一種以企業資產市值為標的, 且履約價格為企業短期負債加二分之一長期負債的買權,其中的短期負債加二 分之一長期負債又稱為違約點(default point)。因此 Moody’sKMV信用風險模型 認為,當企業資產市值在未來某特定期間內若低於違約點時,企業即發生所謂 的違約,所以Moody’s KMV信用風險模型的違約機率,即代表企業資產價值 低於違約點的機率,而根據Moody’s KMV內部之說法,此一違約點的定義係 源自於模型最適化過程與預測的精確性所得出之結果。
Patel and Vlamis (2006)利用 Moody’sKMV信用風險模型針對英國 112 家房 地產企業進行違約機率的研究,結果發現Moody’sKMV信用風險模型對這 112 家房地產企業的違約與否具有良好的預警能力。Naoya and Nobuya (2005)以 Moody’sKMV信用風險模型分別估算 TOYOTA、NISSAN、HONDA 的違約機 率,結果發現Moody’s KMV信用風險模型所估算出來的違約機率具有參考指 標。Kealhofer (2001)分別以 Moody’sKMV信用風險模型、Moody’s對企業的信 用評等以及資產報酬率(return on asset, ROA)做為違約指標,藉以判斷北美企業 的違約可能性,結果發現Moody’s KMV信用風險模型對於預測企業違約的可 能性,具有較信用評等以及 ROA 為佳的區別能力。顯見 Moody’sKMV信用風 險模型應用於國外企業違約預測的可靠性。
加上二分之一長期負債來定義企業是否發生違約,但本研究認為,企業的經營 能力、財務流動性、公司規模、償債能力、負債程度等五大構面才是影響企業 違約機率之要素(因),相對的,企業的短期負債加二分之一長期負債應該只是 企業違約與否的最後徵兆(果)。因此,若是以模型最適化方法來設定違約點定 義的思維,實為倒因為果,本研究認為,應該先釐清影響企業違約機率之因素 為何,並以這些影響因素之特性來建構違約點的定義公式,再以此定義代入模 型所估算出來的違約機率才能確切地反映台灣上市上櫃企業經營特性。 雖然違約點定義式須考慮是否存在著結構轉折現象的問題,但本研究也認 為,影響企業違約與否的並非如同Moody’s KMV信用風險模型違約點所設定 只包含企業的短期與長期負債!本研究認為,經營能力比較卓越的公司,通常 財務流動性良好,公司規模也越趨龐大,資金也比較雄厚,償債能力也越高, 所以較能抵抗市場風險,因此相對應的違約可能性會比較小;反之,經營能力 比較差的公司,通常財務流動性不佳,公司規模也較小,資金也比較缺乏,償 債能力也比較薄弱,發生違約的可能性也比較高。陳肇榮 (1983)之研究認為企 業失敗的第一階段會發生公司因流動性不足造成資金週轉困難,形成以軋票調 度資金狀況。劉思言 (2000)探討東南亞金融風暴期間危機公司與正常公司的營 運資金管理是否有顯著之差異,實證結果顯示流動負債佔總資產比率、負債比 率、流動比率、速動比率、淨流動性比率、修正後的流動比率、應收帳款週轉 率、現金流量類變數均是區別正常公司與危機公司的重要指標。林素菁 (2002) 實證結果顯示,當上市企業的速動比率愈小、固定比率愈大或銷貨品質愈低時, 該企業的危機發生率會提高。簡郁蓉 (2007)探討台灣金融機構違約風險之影響 因素,發現金融機構的流動性與其違約風險兩者之間呈現負向顯著關係。吳蕙 真 (2007)以台灣集團企業為研究對象,發現在 2003 至 2005 年間,台灣集團企 業在危機發生前二年現的金流量比率愈高時,愈不容易發生財務危機。 Ohlson (1980) 利用 Logistic 分析建立財務危機預測模型,結果發現公司規 模、資本結構、負債比率、資產報酬率及流動性對企業發生財務危機具有顯著 的預測能力。陳侑宣 (2004)以商業銀行為研究對象,發現商業銀行的規模對商 業銀行的違約機率與未預期損失率,皆有顯著的影響效果。易丹輝、吳建民 (2004)以及張榮、陳銀忠與周勇 (2006)皆以台灣上市企業為研究對象發現,當 上市企業的規模越大時其相對應的違約距離(default distance)也越大,違約機率 愈小。蔡苑霖 (2006)以 D/E ratio 做為企業資本結構的代理變數,並以台灣上市 企業為研究對象發現,上市企業的違約風險會與其資本結構呈正向相關,故可 知企業規模或資本結構將會影響到企業未來之違約風險之高低。 另外,企業的償債之能力也可能會直接影響公司的違約風險,假若公司沒 有能力清償其負債的話,可能就會面臨破產、倒閉等等風險。Beaver (1996)以 財務變數為危機指標,79 家危機公司組成樣本,利用財報上之資料,判斷發生 財務危機的公司,其研究結果發現現金流量/負債總額,負債總額/資產總額等
等比率具有預測能力。Blum (1974)以現金流量理論及流動性、獲利性與變異性 指標建立企業失敗預測模式,其研究發現現金流入量/負債總額、淨值/負債總 額等比率具有預測能力,且在危機發生前一年的正確區別率高達 94%。 綜上所述,本研究分別依據企業經營能力、企業財務流動性、企業規模、 企業償債能力等六大構面,歸納出影響違約機率之因素分別如下: 經營能力:應收帳款週轉率、總資產週轉率、存貨週轉率 流動能力:流動比率、速動比率、短債/公司規模(1)、短債/公司規模(2) 企業規模:公司規模(1)、公司規模(2)、公司規模(3) 償債能力:現金流量比率、利息保障倍數、財務槓桿(負債對淨值比率) 負債程度:負債比率、短期負債、負債總額、長期負債 3. 研究方法與步驟 (1) 基本理念 若僅將上述六大構面因素納入違約點定義式中,並以此估算出違約點公式 裡面短期負債與長期負債的係數值,最終模型所估算出的違約機率尚不足以反 映台灣上市上櫃企業的違約風險。本研究認為,企業的經營能力優劣、流動能 力高低、企業規模的大小、償債能力的良窳,以及負債程度的高低,對企業違 約點定義式的影響也可能存在著差異,易言之,上述六大構面的高低水準不同, 對模型違約點定義式的影響,是否可能存在著結構轉折現象呢?又若存在著結 構轉折現象,是僅只於這六大構面高低不同水準的影響?抑或是因為違約點不 同的分配位置所致呢?為了探究此一可能存在的結構轉折問題,本研究將分別 採用 Hansen (1996, 1999, 2000)所提出的門檻迴歸模型法,以及 Koenker and Basset (1978)所提出的分量迴歸模型法做進一步地驗證。
(2) Moody’sKMV信用風險模型說明
KMV 公司所發展之違約風險衡量模式(即Credit Monitor Model),主要是利 用Black and Sholes (1973)的選擇權評價理論(the option price theory)與Merton (1974)的公司債評價模式為基礎,利用企業的權益市值、權益報酬率的標準差、 負債價值以及無風險利率,推算出企業資產市值以及資產市值的波動性,進而求 出預期違約機率。,其詳細的計算步驟如下 步驟一、計算公司資產的市場價值及波動性 利用選擇權的角度來看,將公司的權益視為以公司資產為標的的買權,假設 債權人持有公司的資產,股東有權利於到期時從債權人手裡買回公司資產。所以 選擇權的賣方為債權人,買方為股東,履約價為公司負債的帳面價值,到期日為 負債的到期期間。所以,當資產價值在到期日無法達到負債帳面價值的水準時, 權益(買權)持有者將不會執行其權利,此時股東將放棄經營,公司將屬於債權人 所有。反之,當若公司資產價值大於負債帳面價值,則股東會執行該選擇權,將
負債償還後,繼續經營公司。 由於權益所擁有的選擇權特性,我們可以利用權益市值透過BSM選擇權訂價 公式反推求得隱含的公司資產市值與波動性。
1
2 f r E A V V N d BeN d (1) 其中 VE:公司權益市值 VA:公司資產價值 B:公司負債帳面價值 rf:無風險利率 τ:距到期日的期間 N(d1)、N(d2)為常態分配的累積機率函數
2
1 ln VA/B rf A / 2 d (2) 其中的d2 d1 ,而 則表示企業資產市值的波動性。透過求解下列的非A 線性聯立方程式,可同時求得隱含於權益市值中的資產市值及其波動性:
2
1 2 , rT E A A E A E V V N d Be N d V N d V (3) 步驟二、計算違約距離與違約機率 在決定公司在某特定期間的違約機率前,除了計算出資產市值及其波動性 外,必須計算出違約間距。
2
ln A/ t A/ 2 A V B t DD t (4) 由於違約事件發生在公司資產價值低於負債總額(違約點)時,通常將負債 總額視為公司之違約點,而違約距離係指公司資產市值與違約點相距多少標準 差。如果經由資產波動性來衡量及標準化,即可導出公司的違約距離,數字愈 大則代表資產的價值距離違約點愈遠,故公司違約的機率越小。
2
ln A / t A/ 2 t A V B t P N t (5) (3) 求解方法-Broyden 非線性估計法 大部分文獻多採用傳統的牛頓法來求解第 3 式中的聯立方程式,雖然牛頓 法有方法簡單易懂、收斂速度快的優點,但因為在每次疊代運算時都需先行計 算出 Jacobian 矩陣與其逆矩陣,除非有效能強大之電腦設備,否則將導致電腦 耗費相當時日才能完善處理此類大量的資料,因此,為了符合現實設備之效能 並追求大量資料處理時的效率性,本研究將採用 Broyden Method 求算企業資產 市值與其波動度資訊。Broyden Method 是由 Broyden, C.G. (1965)年在”A Class of Methods for solving NonlinearSimultaneousEquations.”Math.Comput.中公開提出,其基本原 理如下: 令 B0為一近似F
X0 的矩陣
1 1 k k k k x x B F x (6) 為了導出Bk1,且 '
1 1 k k B F X ,在求解方便性之下,令X ,Xk X*Xk1, 由於函數 F 在 X*這點可以微分,所以我們給定一ε>0及一 δ>0滿足下列式子: * x x (7)
* * * * F( )-F(x x )-F' x x x x x (8)
* * * * F( )-F( )-F' xx x x x x x (9) 如果 * x x 很小,則上式可改寫為:
* * * F x F x F' x xx (10) 若B* F'
x ,令 * s x x與令
*
yF x F x 時,則我們使 B*滿足下式:
* * * *
F x F x B xx B s y (11) 如果n1, * B 可以唯一決定,但若 n≧2,可能會有許多的 B*滿足上式,若 * B還須滿足: , 0 n T zR z s s z 且B z* Bz (12) 則 * B 可被唯一決定,故在使用此法時,只須設定一B 的矩陣作為初值,在每次0 疊代過程中,B會逐漸逼近Jacobian矩陣
* T T y Bs s B B s s (13) 雖然上述方法可解決計算一階導數矩陣時不具效率的問題,但此法仍需在 每次疊代時計算 B 的逆矩陣。為此,作者引入 Sherman-morrison 法,主要應用 了下列兩項引理: 引理一: 令v
,
w
R
n,則det
IvwT
1 w vT 且det
IvwT
1 w vT (14) 引理二: 令u
,
v
R
n,A 為一非零值矩陣,則
1
T T A uv A IA uv (15)
1
det IA uv T 0 (16) 由引理一可知:
1
1 det T 1 T IA uv A u v (17) 如果0,則可導出:
1 1 1 1 1 1 1 ( ) T T T A uv A A uv A A u v (18) 令Hk
Bk 1,Hk1
Bk1 1,並利用引理一與引理二可作下列推導:
1 1 T k k k k k k T k k y B s s H B s s (19) 令引理二的 A, u, v 分別為 k k k k k T k k y B s A B v s u s s , , (20) 由引理二及(22)式可知若 1 1 T k k k k T k k y B s B s s 且
0 T k k k k T k k H y s s s s ,則 1
( ) T k k k k k k k T k k k H y s s H H H H y s 如此,便可在每次疊代過程中,使 H 逐漸逼近於Jacobian矩陣的逆矩陣,如此 即可避免計算大量的逆矩陣數值時耗費相當時日的問題。 (4) 違約點的估計-門檻迴歸模型法 在經由 Broyden 非線性估計法同時估算出每家企業每年的資產市值與其波 動度參數之後,根據Moody’s KMV信用風險模型對將企業資產市值低於企業 短期負債加二分之一長期負債時定義為違約,本研究接續將以 1998 年至 2007 年台灣曾經發生違約的上市上櫃企業,以 Broyden 非線性估計法估算這些違約 企業的資產市值與波動度,並以該資產市值做為違約企業在違約當時的違約點 的代理變數(被解釋變數),然後以該時點違約企業的短期負債、長期負債,以 及本研究前述的影響企業違約的六大構面因素(解釋變數),分別以門檻迴歸模 型法及分量迴歸模型法,估算短期負債、長期負債以及影響企業違約的六大構 面因素對違約企業資產市值影響的係數值,做為本研究針對Moody’s KMV原 始違約點設定修正後的違約點定義。 門檻迴歸模型考慮到了自變數與應變數可能存在著非線性的關係,用途上 有較客觀的研究方式,採用樣本資料中的門檻變數(threshold variable)決定不同 的分區點,進而估計出合適的門檻值。為避免非線性估計之不易,Hansen (1999) 於一非動態縱橫資料上提出門檻模型之設定及其估計與檢定之方法,建議以兩 階段線性最小平方法來估計門檻值,先分別逐一設定門檻值,藉由最小平方法, 個別求得殘差平方和(sum of squared errors,SSE),透過最小之 SSE,反推求取 門檻估計值,最後,將此門檻估計值分區求算各區間之迴歸係數,並進行結果 分析。 假若已知門檻變數為何,我們認為在不同變數區間的樣本觀察值會有結構 性的差異,可表示如下:
' ' 1 2 it i it it it it it y u x I q x I q e (21) 其中,I(.)是指標函數,亦可表示如下: ' 1 ' 2 , , i it it it it i it it it u x e q y u x e q (22) 較簡要的寫法可寫成:
' it i it it y u x e (23) 其中xit
又可因指標函數之不同而區分成
it
it
it it it x I q x x I q ,模型係 數值亦因此而可表達為
' ' ' 1, 2 ,也就是樣本觀察值可依門檻變數qit大於 或小於門檻值γ分為二個區間,而這兩個區間的迴歸結構會有顯著差異。 我們將變數以平減平均值的方法,消除掉個別效果 * i u ,並令y*it yit yi, 且令 *
it it i x x x 與 * it it i e e e ,因此調整後的方程式可表達為:
* ' * * it it it y x e (24) 在給定任一γ值下,的估計值可利用 OLS 求得,我們以矩陣表示如下:
'
1
' * * * * ˆ X X X Y (25) 將(29)式代入(28)式之後,模型殘差可表達為ˆ*
* *
ˆ e Y X ,而方差 值為
* ' * 1 ˆ ˆ S e e ,為求得最適門檻值,最簡單也最直覺的方法就是使均 方差極小,若以最小平方法求得的門檻估計值可以表達如下式
1 ˆ arg min S (26) 而殘差變異數為
2 *' * 1 1 1 ˆ ˆ ˆˆ 1 e e 1 S n T n T (27) 為了測試樣本資料是否存在顯著的門檻效果,我們建立虛無假說如下: 0 1 2 H: (28) 若在各種值之下虛無假說皆成立,表示樣本資料不在在結構轉折現象。 但要注意的是,此檢定的分配是非標準分配,這通常稱為「Davies Problem」(詳 見 Davies, 1977,1987、Andrews and Ploberger, 1994 與 Hansen, 1996), Hansen (1996)建議可利用拔靴法來求得此概似檢定的近似分配。檢定值如下:
0 1 1 2 ˆ ˆ S S F (29) 而臨界值則需經由拔靴法求得一階近似分配來找到近似值。若檢定值大於臨界值,則拒絕虛無假設,ˆ有顯著門檻效果。 確定門檻效果存在後,Chen (1993)與 Hansen (1997)則指出要進一步檢定估 計值ˆ與實際值0是否相符。同樣的,此近似分配也是高度非標準。Hansen (1997) 認為建立γ信賴區間的最佳方式就是利用 γ的最大概似統計量建構非拒絕域, 虛無假說如下: 0 0 H: (30) 概似檢定值如下:
1 1 1 2 ˆ ˆ S S LR (31) Hansen 也提出了一個簡單的公式,找出臨界值,公式如下:
2 log 1
1
c (32) 若檢定值LR1
c ,則接受此虛無假設。 門檻值的原理在於將資料客觀的劃分 2 個或 2 個以上的區塊,呈現資料本 身的原貌,但是為了避免區塊中的觀察值個數發生過少的情形,因此可將資依 門檻變數中所有的值由小至大排序後 ,分別排除最小部分與最大部份的 η%(η>0),以最後剩餘的 N 個可能值來測試。本研究以 1997 至 2007 年期間違 約公司違約當年資產市值分別依公司規模由小到大依序排列,採用 Hansen (1999)的建議,以排序後資料的各百分位數(1%,1.2%,1.4%,…,1.8%,2%, 2.2%,…….,99%)相對應值來估算,並於各百分點求算其迴歸平方差值。因此 我們可以將門檻值定義為
ˆ arg min RS (33) 亦即門檻值為使均方差值最小時之門檻變數值。接著依門檻值將樣本劃分為不 同區間,運用最小平方法分別估計各區間之迴歸係數值。 11 12 21 22 ˆ ˆ , ˆ ˆ , ti it it it it it ti it it it it SD LD e q DP SD LD e q α α (34) 為了檢定是否存在門檻效果,首先建立虛無與對立假說0 11 21 12 22 1 11 21 12 22 ˆ ˆ ˆ, ˆ ˆ ˆ ˆ, ˆ H H : : (35) 檢定值為 0 1
1 2 ˆ ˆ RS RS F ,其中的 ˆ2 1 ˆˆ' 1
ˆ e e RS n n ,RS 表示由全部0 樣本中以拔靴法抽樣所計算出之均方差值,而RS1
則表示給定各種門檻值情 況下求算出之均方差值。 由於會有干擾項的存在,使得傳統檢定統計量的分配呈現為非標準分配,依 Hansen (1996)建議利用拔靴法來求得此概似檢定的近似分配,而拔靴法反覆抽 樣後的P-value可表示為: 1 ˆ P-valueP F( ( )F( ) ) (36) 其中為在樣本觀測值中Fˆ() F1() 的條件期望值。因此以拔靴法反覆 抽樣後得出的P-value是由模擬大量獨立檢定統計量而計算出來的,當P-value 小於臨界值 (critical value),則表示有足夠的證據可以拒絕無門檻效果的虛無假 設。我們即可依此估計之門檻迴歸做為新違約點之定義,代回先前所介紹之模 型,重新估算違約機率。 (5) 違約點的估計-分量迴歸模型法 雖然門檻迴歸模型將迴歸的自變數依不同的門檻值來將原始的研究樣本切 分成不同的子樣本,再依據這些不同的子樣本分別做模型的估計,但此方法因 為解釋變數高低(或大小)不同的水準對被解釋變數很有可能產生不同的影響 效果,其方法雖立意甚佳,但也因為如此,相對地此種模型的估計結果也極有 可能因為不同的門檻值設定或求解結果的不同而有所差異,同時,此種模型將 樣本再切分成不同子樣本的方法除了因為門檻值設定的不同而犯了樣本選擇偏 誤之外,它亦可能遺漏掉其它未納入估計的子樣本,從而對所欲探討的議題將 造成的不小的潛在影響,因此,本研究將再輔以分量迴歸模型來分析,以補門 檻迴歸模型之不足。 假設y 代表不同企業的違約點,i x 代表影響此違約點的變數,例如企業的i 短期負債與長期負債等,代表第i i家企業其資產價值位於全體樣本企業資產 價值分配的分量位置, i u代表在給定不同分量點之下模型的誤差項。如此,本 研究的分量迴歸模型可設定如下:' i i i y xu (37)
' Quant y xi i inf y F y x: i xi (38)
Quant ui xi 0 (39) 其中第(41)式中的 表示在給定分量點()之下所求得之迴歸係數值,而第 (42)式Quant
y xi i 表示給定分量點()之下的條件分量迴歸估計式,亦即代表 i y 在第個分量水準之下的特性可用 ' i x 來描述, F y xi
則是給定在 x的情況 下之條件分配,與最小平方法相同的是,分量迴歸亦假設了在給定了自變數 i x 之下模型的殘差均為零。但分量迴歸與最小平方法最大的差異在於::分量迴歸 模型並非以殘差平方值總和最小來估算模型的係數值,而是以模型正負殘差的 加權平均總和最小的方式,以線性規畫方法估算其模型係數值,如下:
'
1 min n i i i y x
(40)
1 ifif 00 u u u u u (41) 若第(45)式中的誤差項( i u)為正,代表第i家企業的資產價值位於被解釋變 數(第i家企業違約時的資產市值)條件分量值之上,反之,若誤差項( i u)為負, 代表第i家企業的資產價值位於被解釋變數(第i家企業違約時的資產市值)條件 分量值之下。其意涵為利用介於 0 和 1 之間的分量點,做為所給定的不同分量 點()做為分量迴歸模型中正、負誤差項的權數,來區分被解釋變數分配中的位 置,在本研究中即代表不同企業的不同違約點。 4. 實證結果與討論 (1) 資料來源與變數定義 本研究以西元 1998 年 1 月 1 日起至 2007 年 12 月 31 日止的排除金融業後 所有台灣上市上櫃公司為研究對象,資料來源則以台灣經濟新報資料庫(Taiwan Economics Journal,以下簡稱 TEJ 資料庫)。以跳票擠兌、倒閉破產、繼續經營 疑慮、重整、紓困求援、接管、全額下市、財務吃緊停工以及淨值為負等九種 狀況作為違約的定義。 在本研究所採用的樣本期間內,違約與正常的上市上櫃企業分別有 159 家 以及 1392 家。若以產業來區分,所有樣本公司共分佈於 27 個產業中,其中以 建材營造業的違約家數最多,共計有 19 家;其次是電子零組件業的 16 家、食 品工業以及光電業的 13 家公司。佔總樣本比例最高的是食品工業的 37.14%; 其次則為玻璃陶瓷業的 30%以及建材營造業的 26.03%。 若以時間序列面顯示, 2005 年發生違約家數共計 29 家(18.24%)佔最多,其次為 2001 年的 28 家(17.61%)以及 2004 年的 23 家(14.47%)。而 2007 年、1998 年以及 1999 年發生違約的家數則僅分別有 2 家(1.26%)、3 家(1.89%)以及 9 家 (5.66%)。至於為何 2005 年違約企業家數最多,本研究認為這可能歸因於整體 國際經濟情勢走軟加上原油價格開始飆高,造成台灣產業經營之困境所致。 所使用各變數資料之定義做一詳述如下: 權益波動度( ):S 依研究公司當年之日股價資料計算其變異數,並予以年化而得之,在此年化依 一般文獻常採用之 252 天營業日做為年化基礎。 無風險利率(rf): 本研究以研究當年底公佈之台灣五大行庫一年期存款利率,台灣五大行庫為台 灣銀行、合作金庫、第一銀行、華南銀行和彰化銀行。 預期資產成長率( ):A 在 Merton (1976)文中認為預期資產成長率應以公司長期成長率為主,因此 本研究以 Broyden 法求解公司市場價值,分別計算各公司各年資產成長率後再 加以算數平均,以此數據做為公司長期成長率。一般平均報酬率以有幾何平均 與算數平均兩種較廣為使用的方法,而由於算數平均具有在計量統計上存有不 偏之特性,因此本文捨棄幾何平均而以算數平均數代之。 短期負債: 依 TEJ 資料庫中各公司年底流動負債總額做為短期負債金額,其中包含短 期借款、應付商業本票、應付帳款及票據、應付費用、預收款項 、其他應付款 1、應付所得稅、一年內到期長期負債、其他流動負債2。 長期負債: 取自 TEJ 資料庫中各公司年底長期負債,其中含公司債、銀行長期借款、 應付租賃款、分期付款之設備款、應付機器進口關稅、股東往來、央行及同業 融資等。 應收帳款周轉率: 是公司給予其交易對手的一種融資方式,讓交易對手可以先取得貨物,付 1 應付銷項稅額、應付股利、應付所得稅、應付員工紅利、應付設備款、應付董監事酬勞。 2 其他流動負債包含代收款、暫收款等….
款額稍後再收取,而應收帳款比率就是衡量當企業有發生淨賒銷的情況,必須 經過多少次的收帳循環才能回收現金,所以應收帳款周轉率愈高,表示企業回 收資金的狀況良好,對若應收帳款周轉率的比例偏低,則代表此筆應收帳款未 來變成呆帳的機會就變高,使得營運活動的淨現金流量減少,造成公司有可能 會面臨資金不足而引起財務危機的風險。 存貨周轉率: 存貨是公司還未銷售出去的貨品,我們可以藉由觀察存貨周轉率的指標來 判斷公司的經營能力,若存貨周轉率愈高,則代表公司的產銷控管能力良好, 公司沒有存貨積存的問題,公司營運資金運作良好,短期償債能力提高,公司 發生違約風險的機率就降低。 總資產周轉率: 用以衡量公司使用資產來創造收益的程度,若此比率為高,代表公司的資 產運作能力較佳,但若此率率偏低,代表公司的內部運作有危機,無法將資產 有效地進行配置以創造出收益,一但公司有此問題發生,就很有可能引發財務 危機,無法藉由資產創造收益的能力償付所有借貸款,也較難取得額外資金。 流動比率: 表示每元流動負債有多少元流動資產來保障。流動比率愈高表示短期償債 能力越強,愈不容易出現週轉不靈的問題,計算方式為:流動資產/流動負債。 速動比率: 表示速動資產與流動負債的比率,速動資產表示比流動資產更容易變現的 資產,即將存貨與預付費用剔除,因為存貨可能賣不出去,所以不一定能變現。 預付費用雖然是資產,但通常無法取回變現。因此其較流動比率更能代表短期 償債能力。 短債 / 公司規模: 但解讀流動比率與速動比率必須謹慎,因為過高的比率可能意味著公司有 太多閒置現金或客戶拖欠了大筆帳款;相對的,較低的比率並不意味著公司有 無法償還短期債務的風險,可能是因為公司所在行業並沒有太多應收帳款,或 其經營不需要太多庫存,或客戶支付的速度較慢。但是可以確定的是短期負債 的發行確會影響公司的流動性,過多的短債可能會令公司短期償債能力降低, 甚至可能引至週轉不靈的結果。因此本研究以短期負債佔整個公司規模的比 率,亦可做為流動性的替代變數之一。計算方式有二,分別為:短期負債/ln(營 業收入淨額)以及短期負債/ln(營業收入淨額+營業外收入)。 公司規模:
在一般的文獻中,往往將公司規模的代理變數設定為公司資產總額取 ln 的 數值。在本研究裡,除了資產總額之外,還考慮到公司的營業收入淨額、營業 收入與營業外收入總額作為公司規模的替代變數。 現金流量比率: 是用來衡量營業活動所產生的淨現金流量與流動負債之比例,可顯示企業 償還即將到期債務的能力,亦即衡量企業短期償債能力的動態指標,現金流量 越高,則表示企業短期償債能力越佳,反之則企業短期償債能力越差。 利息保障倍數: 為稅 前 息 前 淨 利 /利 息 費 用 , 代 表 可用來償付當期利息費用的稅前息前 淨利的大小,及對當期利息費用的保障程度。 用 以 衡 量 企 業 由 稅 前 息 前 淨 利 支 付 利 息 費 用 的 能 力 , 倍 數 越 高 , 表 示 債 權 人 受 保 障 程 度 越 高 , 亦 即 債 務 人 支 付 利 息 的 能 力 越 高 。 財務槓桿: 為負債對股東權益比,就股東的立場而言,希望有較高的負債,這樣表示 利用較高的財務槓桿,如果經營得當可收舉債營運效果,增強其獲利能力,此 外,股東亦可以較少的投資控制整個企業。但若公司舉債程度越高,獲利不如 預期,將可能使企業面臨倒閉的風險,而使違約機率增加。 負債總額: 除長期負債與短期負債外,尚包含遞延貸項、應計退休金負債、遞延所得 稅、土地增值稅準備、各項損失準備、什項負債、其他負債及準備等科目。 負債比率: 取自 TEJ 資料庫中各公司年底負債比率,其計算方式為公司總負債除以總 資產,而總負債除了上述短期負債與長期負債外,尚包含、遞延貸項、應計退 休金負債、遞延所得稅、土地增值稅準備、各項損失準備、什項負債、其他負 債及準備。 (2) 違約點定義的修正:門檻迴歸的實證分析 本研究分別以企業經營能力、財務流動性、企業規模、償債能力、負債程 度等構面指標做為門檻變數,然後以違約企業資產市值為被解釋變數、門檻變 數做為被解釋變數,依據 Hansen (1999, 2000)以迴歸的 MSE 最小的方法,分別 找出這六大構面變數各自的門檻點,然後再將所有發生違約的企業其資產市 值、短期負債、長期負債,分別依照這五大構面共計十七個門檻變數由小而大 排序,然後再分別依據這些門檻變數的門檻點,分別將樣本區分成門檻前以及
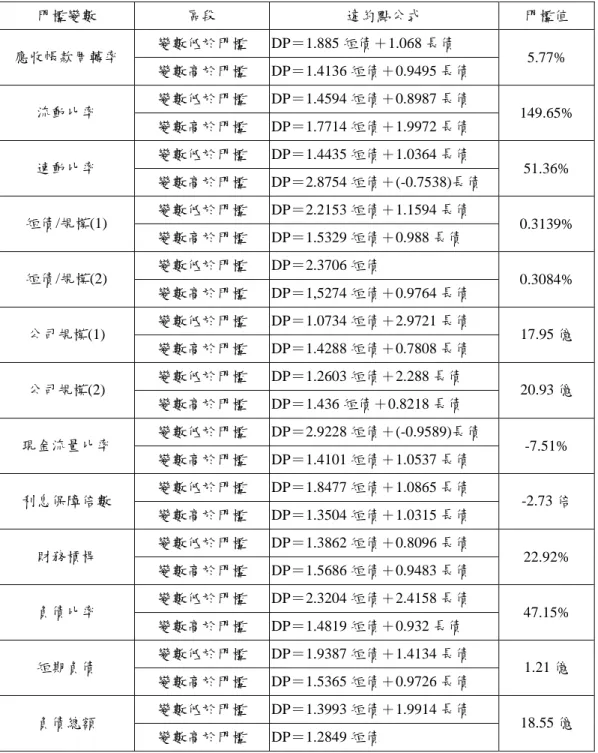
門檻後兩大子樣本,依然利用違約企業的資產市值為被解釋變數,企業短期負 債與長期負債為解釋變數,以最小平方法估計這兩大子樣本樣本各自的短期負 債以及長期負債係數值,做為「新的違約點定義」。其門檻迴歸模型可簡單表達 如下: 1 11 12 1 2 21 22 2 i i i i i i i SD LD DP SD LD (42) 其中,DP 表示第i i家違約企業的於違約當日的資產市值;SD 與i LD 則分i 別表示第i家違約企業的於違約當日的短期負債與長期負債。與1 為迴歸模2 型的截距項,在Moody’sKMV信用風險模型中違約點的定義, 1 。2 0 11 與 表達為違約點定義式中「短期負債」的係數值,在 Moody’21 sKMV信用風 險模型中, 11 ,若以門檻效果的觀點來說21 1 除了不見得與11 相等,21 也可能不等於 1。而 與12 表達為違約點定義式中「長期負債」的係數值,22 在Moody’s KMV信用風險模型, 12 22 ,同樣地,若以門檻效果的觀0.5 點來說 除了不見得與12 相等,也可能不等於 0.5。22 由實證結果發現,只有應收帳款週轉率、流動比率、短債占規模(1)比率、 短債占規模(2)比率、企業規模(1)、企業規模(2)、利息保障倍數、財務槓桿、負 債比率,以及短期負債共計十個變數存在著顯著的門檻效果。接著再以各個變 數的門檻值將資料切分成門檻前與門檻後兩個子樣本,然後再分別以最小平方 法對這兩個子樣本進行迴歸,估計企業短期負債與長期負債對企業違約點的影 響係數值,結果如表 1。
表 1:門檻迴歸修正後的違約點定義 門檻變數 區段 違約點公式 門檻值 變數低於門檻 DP=1.885 短債+1.068 長債 應收帳款周轉率 變數高於門檻 DP=1.4136 短債+0.9495 長債 5.77% 變數低於門檻 DP=1.4594 短債+0.8987 長債 流動比率 變數高於門檻 DP=1.7714 短債+1.9972 長債 149.65% 變數低於門檻 DP=1.4435 短債+1.0364 長債 速動比率 變數高於門檻 DP=2.8754 短債+(-0.7538)長債 51.36% 變數低於門檻 DP=2.2153 短債+1.1594 長債 短債/規模(1) 變數高於門檻 DP=1.5329 短債+0.988 長債 0.3139% 變數低於門檻 DP=2.3706 短債 短債/規模(2) 變數高於門檻 DP=1,5274 短債+0.9764 長債 0.3084% 變數低於門檻 DP=1.0734 短債+2.9721 長債 公司規模(1) 變數高於門檻 DP=1.4288 短債+0.7808 長債 17.95 億 變數低於門檻 DP=1.2603 短債+2.288 長債 公司規模(2) 變數高於門檻 DP=1.436 短債+0.8218 長債 20.93 億 變數低於門檻 DP=2.9228 短債+(-0.9589)長債 現金流量比率 變數高於門檻 DP=1.4101 短債+1.0537 長債 -7.51% 變數低於門檻 DP=1.8477 短債+1.0865 長債 利息保障倍數 變數高於門檻 DP=1.3504 短債+1.0315 長債 -2.73 倍 變數低於門檻 DP=1.3862 短債+0.8096 長債 財務槓桿 變數高於門檻 DP=1.5686 短債+0.9483 長債 22.92% 變數低於門檻 DP=2.3204 短債+2.4158 長債 負債比率 變數高於門檻 DP=1.4819 短債+0.932 長債 47.15% 變數低於門檻 DP=1.9387 短債+1.4134 長債 短期負債 變數高於門檻 DP=1.5365 短債+0.9726 長債 1.21 億 變數低於門檻 DP=1.3993 短債+1.9914 長債 負債總額 變數高於門檻 DP=1.2849 短債 18.55 億 資料來源:本研究整理 有了新的違約點定義後,便可依樣本中所有上市上櫃公司之經營能力、財 務流動性、公司規模、償債能力、負債程度的財務變數分為大於以及小於門檻 值的兩個群體,並套用不同的違約點定義,可得出修正後的違約機率。 (3) 違約點定義的修正:分量迴歸的實證估計
不同於迴歸模型 (least square method) 的迴歸估計是以條件平均值的觀念 為出發點,Koenker and Baset (1978)所提出的分量迴歸模型能將離群值和群體
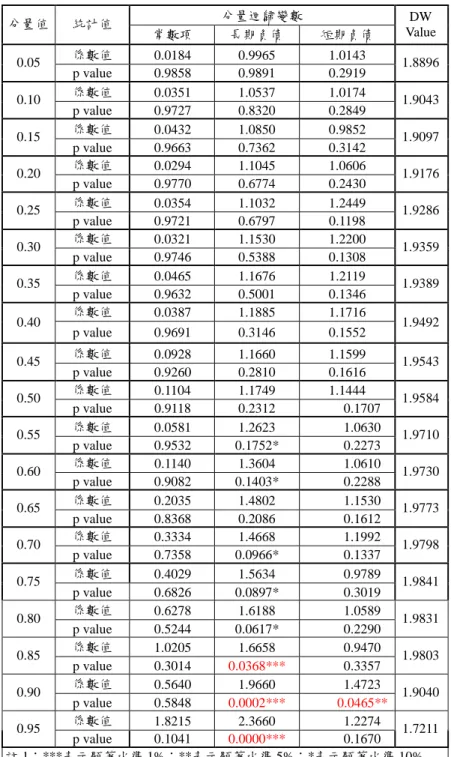
平均概念同時考量的計量方法,因為分量迴歸係在給定不同的分量點之下,來 估計在因變數不同的分配位置下,自變數對因變數的影響係數,且由多數財務 金融相關的實證文獻中的敘述統計中亦可發現,金融資產之報酬多屬非對稱分 配,若以最小平方迴歸法將致所欲估計之參數產生偏誤,加上風險管理側重下 方風險(down-side risk)更勝於整體的平均風險,有鑑於此,本研究在此節採用 Koenker and Baset (1987)所提出的分量迴歸模型來估計違約點,以彌補門檻迴 歸模型所可能產生的樣本選擇偏誤,並嘗試由被解釋變數不同分量位置之不同 來探究台灣上市上櫃企業違約點設定之適切性。 本研究根據分量迴歸模型所估計之實證結果,發現僅有當企業資產市值較 高時,違約點的定義會存在著結構轉折現象。所謂企業資產市值較高,係指企 業的資產市值高於新台幣 11.5 億以上稱之。此門檻值對所有上市上櫃企業而言 係屬偏低,其原因可能是違約企業在違約當時的股價已經快速地下跌以反映違 約事件,而使所對應的企業資產市值也呈偏低的現象。但因為負債總額係包含 了企業的短期負債、長期負債以及其它負債等資訊,因此有必要再針對企業負 債總額中的短期負債以及長期負債,對企業的資產市值再次地進行分量迴歸估 計,其結果如表 2 所示。
表 2:不同分量水準下企業長、短期負債對違約點影響係數 分量迴歸變數 分量值 統計值 常數項 長期負債 短期負債 DW Value 係數值 0.0184 0.9965 1.0143 0.05 p value 0.9858 0.9891 0.2919 1.8896 係數值 0.0351 1.0537 1.0174 0.10 p value 0.9727 0.8320 0.2849 1.9043 係數值 0.0432 1.0850 0.9852 0.15 p value 0.9663 0.7362 0.3142 1.9097 係數值 0.0294 1.1045 1.0606 0.20 p value 0.9770 0.6774 0.2430 1.9176 係數值 0.0354 1.1032 1.2449 0.25 p value 0.9721 0.6797 0.1198 1.9286 係數值 0.0321 1.1530 1.2200 0.30 p value 0.9746 0.5388 0.1308 1.9359 係數值 0.0465 1.1676 1.2119 0.35 p value 0.9632 0.5001 0.1346 1.9389 係數值 0.0387 1.1885 1.1716 0.40 p value 0.9691 0.3146 0.1552 1.9492 係數值 0.0928 1.1660 1.1599 0.45 p value 0.9260 0.2810 0.1616 1.9543 係數值 0.1104 1.1749 1.1444 0.50 p value 0.9118 0.2312 0.1707 1.9584 係數值 0.0581 1.2623 1.0630 0.55 p value 0.9532 0.1752* 0.2273 1.9710 係數值 0.1140 1.3604 1.0610 0.60 p value 0.9082 0.1403* 0.2288 1.9730 係數值 0.2035 1.4802 1.1530 0.65 p value 0.8368 0.2086 0.1612 1.9773 係數值 0.3334 1.4668 1.1992 0.70 p value 0.7358 0.0966* 0.1337 1.9798 係數值 0.4029 1.5634 0.9789 0.75 p value 0.6826 0.0897* 0.3019 1.9841 係數值 0.6278 1.6188 1.0589 0.80 p value 0.5244 0.0617* 0.2290 1.9831 係數值 1.0205 1.6658 0.9470 0.85 p value 0.3014 0.0368*** 0.3357 1.9803 係數值 0.5640 1.9660 1.4723 0.90 p value 0.5848 0.0002*** 0.0465** 1.9040 係數值 1.8215 2.3660 1.2274 0.95 p value 0.1041 0.0000*** 0.1670 1.7211 註 1:***表示顯著水準 1%;**表示顯著水準 5%;*表示顯著水準 10% 註 2:短期和長期負債虛無假設分別為:短期負債係數值 = 1,及長期負債 係數值= 0.5 資料來源:本研究整理 由表 2 可清楚發現,當企業資產市值較高(分量點高於 0.85)時企業短期 負債對違約點的影響係數值顯著異於原始Moody’s KMV信用風險模型中所設 定的係數值 1,顯見原始 Moody’sKMV信用風險模型中違約點的設定實有改善 之空間。為了確切定義出高低不同企業資產市值水準之下企業違約點之公式,
且因為分量迴歸核心意涵在於被解釋變數不同分配位置之下,解釋變數對被解 釋數的影響會有差異。 因此本研究將所有已違約的樣本企業依其資產市值由小而大排序,再插補 法找出排序第 85%所對應的企業資產市值,最後得到的門檻點是 11.5 億,然後 以此資產市值將違約企業樣本切分成高與低資產市值兩個子樣本,分別以傳統 迴歸模型方式分別對這兩個子樣本再進行係數值的估計,並以估計出來的結果 做為高低不同資產市值水準下,所對應的違約點定義,其結果如下的表 3。 表 3:高低不同資產市值之下,長、短期負債對違約點影響係數 短期負債 長期負債 係數 1.2248 1.4584 P-value 0.043** <0.0001*** R2 0.8519 低 資 產 市 值 調整後 R2 0.8497 短期負債 長期負債 係數 1.2919 0.7097 P-value 0.036** 0.1375 R2 0.8322 高 資 產 市 值 調整後 R2 0.8155 註 1:***表示顯著水準 1%;**表示顯著水準 5%;*表示顯著水準 10% 註 2:短期和長期負債虛無假設分別為:短期負債係數值 = 1,及長 期負債係數值= 0.5 資料來源:本研究整理 接下來分別將以上兩個區段的長短債係數作為新的違約點定義,套入違約點 修正後的Moody’s KMV信用風險模型求得所有企業(包含違約與無違約)的違約 機率,再與修正前的Moody’sKMV模型中違約點的定義(短期負債係數值=1,長 期負債係數值=0.5)與門檻迴歸模型所求得的違約機率 CAP 曲線(cumulative accuracy profiles;CAP)、ROC(receiver operating characteristic curve;ROC)進行 比較分析。
(4) 違約點修正後模型的預測能力與效率性
其中在進行 ROC 曲線的驗證時,我們必須先了解 ROC 的理論基礎,ROC 是利用型一誤差(type Ⅰ error)和型二誤差(type Ⅱ error)的關係來進行模型驗證 效力的判別,型一誤差是指實際上有發生違約的公司在模型估計出來的結果卻 被判別為正常公司,而型二誤差是指實際上為正常公司,但模型估計出來的結 果卻被判別為違約公司。 CAP 在檢驗模型精確率的應用上,則是利用正常戶和違約戶的比例繪製 CAP 關係圖,藉以區別模型的效力,我們將所有樣本公司經過模型配適後,會 得出一個違約機率,將此違約機率由大排到小,假定我們先選取前 5%的樣本 公司,並計算出在前 5%的樣本公司中,實際上有發生違約情況的公司家數佔 選取樣本的比例,接著再選取前 10%的樣本公司,進行相同的步驟,以此類推,
最後再將選取公司的百分比繪製為橫軸,將發生違約公司佔選取樣本公司比繪 製為縱軸,即可繪製出 CAP 曲線,並可計算 CAP 曲線下的面積。 表 4:門檻與分量迴歸修正後的模型與原始 Moody’sKMV之 ROC 比較 年份 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 平均 Moody’sKMV 0.4235 0.4302 0.4637 0.4297 0.4066 0.4404 0.4537 0.5656 0.5441 0.4672 0.4625 應收帳款周轉率 0.3444 0.7061 0.4513 0.4709 0.4097 0.5880 0.4875 0.6776 0.6932 0.8738 0.5703 流動比率 0.3370 0.6924 0.4751 0.4585 0.4088 0.4604 0.3728 0.6340 0.6554 0.5871 0.5082 短債/規模(1) 0.5679 0.6364 0.4610 0.4556 0.5393 0.5078 0.5521 0.6938 0.6349 0.8635 0.5912 短債/規模(2) 0.5759 0.6068 0.4653 0.4472 0.5480 0.4972 0.5523 0.6835 0.6465 0.8606 0.5883 公司規模(1) 0.3765 0.3710 0.4913 0.4821 0.4495 0.4349 0.4415 0.6152 0.5803 0.6301 0.4872 公司規模(2) 0.3691 0.3668 0.4828 0.4727 0.4925 0.4749 0.4242 0.6326 0.6733 0.6314 0.5020 利息保障倍數 0.3605 0.3636 0.4747 0.4734 0.4713 0.5410 0.4257 0.6958 0.7360 0.8619 0.5404 財務槓桿 0.5426 0.7907 0.5176 0.5257 0.4238 0.5043 0.4033 0.6573 0.7017 0.8452 0.5912 短期負債 0.5537 0.6734 0.4737 0.4601 0.4664 0.5435 0.5473 0.7033 0.6573 0.8751 0.5954 門檻 迴歸 模型 負債比率 0.2827 0.5677 0.4459 0.4827 0.2817 0.3935 0.3108 0.5902 0.6322 0.7027 0.4690 分量迴歸模型 0.3889 0.3816 0.4924 0.4388 0.4169 0.4436 0.3928 0.6132 0.6593 0.8768 0.5104 資料來源:本研究整理 由表 4 我們可以發現在 ROC 檢定之下,絕大多數變數修正後的模型的 Accuracy ratio 均大於傳統 Moody’sKMV模型;但是以負債比率為門檻變數修 正後之模型,在 ROC 檢定下,其結果並無證據顯示其預測能力與效率性能夠 優於傳統 Moody’s KMV 模型。但若以整體的優越性而言,不論採用 Hansen (1992)抑或 Koenker and Basset (1978)所修正的違約點定義並計算台灣上市上櫃 企業的違約機率,其預測能力均顯著優於以原始Moody’s KMV信用風險模型 中所估計之違約機率。 但若僅考量違約點修正後的信用風險模型預測能力,尚無法證明經過修正 後違約點的『新』Moody’sKMV信用風險模型較『原始』的 Moody’sKMV信 用風險模型好。因此本研究再接續針對這兩個模型的效率性(CAP)加以比較, 其結果如下表 5 所示: 表 5:門檻與分量迴歸修正後的模型與原始 Moody’sKMV之 ROC 比較 資料來源:本研究整理 年份 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 平均 Moody’sKMV 0.3750 0.5750 0.4083 0.3231 0.4813 0.4517 0.4063 0.6303 0.7288 0.7000 0.5080 應收帳款周轉率 0.4000 0.6750 0.4717 0.4212 0.4563 0.6283 0.4875 0.7039 0.7231 0.8750 0.5842 流動比率 0.3750 0.7250 0.4767 0.4019 0.5000 0.5017 0.3875 0.6645 0.6673 0.7750 0.5475 短債/規模(1) 0.4750 0.6750 0.4933 0.4462 0.5625 0.5450 0.5500 0.7184 0.6769 0.8750 0.6017 短債/規模(2) 0.5000 0.6250 0.4933 0.4423 0.5688 0.5417 0.5750 0.7250 0.6769 0.8500 0.5998 公司規模(1) 0.3000 0.4750 0.4950 0.4500 0.5063 0.5150 0.4625 0.6776 0.6750 0.8000 0.5356 公司規模(2) 0.3750 0.6250 0.4967 0.4346 0.5250 0.5350 0.4750 0.6855 0.6846 0.8000 0.5636 利息保障倍數 0.4250 0.7250 0.5067 0.4115 0.5438 0.5850 0.5000 0.7382 0.7712 0.8500 0.6056 財務槓桿 0.4250 0.7750 0.5067 0.4519 0.4813 0.5583 0.4688 0.6816 0.6923 0.8500 0.5891 短期負債 0.4500 0.6750 0.5067 0.4385 0.5438 0.5683 0.5313 0.7197 0.6846 0.8750 0.5993 門檻 迴歸 模型 負債比率 0.3000 0.5750 0.4467 0.4731 0.3375 0.4350 0.3063 0.5776 0.6173 0.7000 0.4769 分量迴歸模型 0.3750 0.6250 0.4633 0.3885 0.4875 0.5150 0.4375 0.6592 0.6981 0.9000 0.5549
經上述實證結果,可以發現本研究以台灣上市上櫃公司為研究對象,在使 用以上九個變數做為門檻變數以及利用分量迴歸修正原始Moody’s KMV 模型 違約點定義之後,這兩種方法所估計之違約機率能夠對於違約預測能力以及效 率性(型二誤差)方面均有所改善。本研究推論此一結果可能由於台灣地區在 會計制度、法律規章的發展愈趨完善,財務報表之內容能夠清楚透明地表現出 公司實際狀況,且台灣證券市場在近幾年的發展也趨向於效率市場,故股價能 夠正確反應出公開資訊,這些發展對於利用財報資料以及市場價格對信用風險 做估算的Moody’sKMV模型之預測能力得以逐年提高。 最後,本研究想比較門檻迴歸模型以及分量迴歸模型,到底何種方法之預 測能力以及準確性較適合這些樣本期間?所以我們把門檻迴歸模型、分量迴歸 模型和傳統Moody’sKMV模型這十年的 ROC、CAP 分別加總平均來加以分析 比較,結果如下的表 6 所示: 表 6:原始與修正後模型之 ROC、CAP 比較表 Moody's KMV 模型 門檻迴歸模型 分量迴歸模型 平均 ROC 0.4625 0.5443 0.5104 平均 CAP 0.5078 0.5703 0.5549 資料來源:本研究整理 由表 6 我們可以發現門檻迴歸模型其 ROC 與 CAP 之精確比分別較分量迴 歸模型與 Moody’s KMV 模型之精確比為高,而分量迴歸模型也比 Moody’s KMV 模型之精確比還高,所以我們可以得到,在 1998 年至 2007 年共計十年 的台灣上市上櫃公司資料為樣本期間而言,門檻迴歸模型的信用風險預警能力 是比分量迴歸模型為佳的結論! (5) 違約點修正後違約機率統計推論 有別於過去相關文獻多只修改違約點定義並據以估算違約機率,並無對違約 機率之統計推論多所著墨,因此本研究將採用 Hansen and Schuermann (2006)所提 出的方法,求算本研究所估算出來違約機率的信賴水準,以此檢定樣本期間內違 約機率是否顯著異於零? 為了進行違約機率的統計推論工作,本研究採用每次自總樣本中抽取 1,000 筆,重覆抽取 10,000 次的拔靴法計算傳統 Moody’sKMV、門檻迴歸修正後的模 型,以及分量迴歸修正後的模型,其違約機率的平均值與標準差,並以此計算 95%的信賴區間,藉此做為違約機率統計推論之依據。 由研究結果發現,雖然自 1998 年至 2007 年期間內,每年的平均違約機均顯 著異於零,由此可見不論Moody’sKMV或本研究所修正後的模型,最終所算出 的違約機率雖然很小,但顯著異於零代表著這些上市上櫃企業的違約可能性是確 實存在的,亦凸顯出台灣上市上櫃企業信用風險管理議題之重要性。
5. 計畫結論與建議 (1) 計畫結論 本研究利用 1998 年至 2007 年共計十年的台灣上市上櫃公司資料為樣本期 間,使用所有符合 TEJ 定義之違約公司共計 159 家,並利用公司的經營能力、 財務流動性、公司規模、償債能力、負債程度等五大構面做為企業特質良窳的 代理變數,總計共十個門檻變數來修正Moody’s KMV模型,以計算台灣上市 上櫃共計 1551 家公司之違約機率,並與傳統 Moody’sKMV模型所得出之結果 做比較,得出以下結論: (i) 本研究經由門檻迴歸模型發現,應收帳款周轉率、流動比率、短債/公 司規模(1)、短債/公司規模(2)、公司規模(1)、公司規模(2)、利息保障倍 數、財務槓桿、短期負債、負債比率等門檻變數,對台灣上市上櫃企業 違約點之影響均存在著顯著的門檻效果,亦即違約點的定義並非是如同 Moody’s KMV模型所述之線性關係;綜合以上,傳統 Moody’s KMV 模型設定之違約點定義並不完全適用於台灣上市上櫃企業。 (ii) 若以分量迴歸模型而言,利用企業的長期負債與短期負債這兩個變數對 公司資產市值進行分量迴歸分析,可以發現長期負債與短期負債係數 值,和企業資產市值之間並非為全然的線性關係,且在百分之五信賴水 準下,分量值超過 0.85 後就有足夠證據顯示企業短期負債對企業違約 點之影響係數值不為 1,驗證了本研究最核心之論述,意即企業特質良 窳抑或資產市值之高低,將使得原始 Moody’sKMV信用風險模型中的 違約點定義公式產生結構性轉折現象。
(iii)本研究並利用 CAP 曲線與 ROC 曲線,來分別檢驗修正後 Moody’sKMV 違約機率的預測能力之準確性與效率性,發現不論門檻迴歸抑或分量迴 歸模型,修正後的違約點所估算的違約機率其預測能力的準確性與效率 性均優於傳統Moody’sKMV模型,可以確定本研究所提出的方法能獲 致較Moody’sKMV的原始違約點定義所估算的違約機率而言具有較精 確的預測能力。 (2) 建議事項 本研究分別利用門檻迴歸模型以及分量迴歸模型修正後的違約點,所計算出 之違約機率,不論在預測準確性(ROC)和預測效率性(CAP)而言,均優於原 始Moody’sKMV所估算之違約機率,且門檻迴歸模型又優於分量迴歸模型,由 此證據可充分證明:原始Moody’sKMV違約點的定義,無法確切反映台灣上市 上櫃企業經營特性!所以本研究認為,雖然分量迴歸模型仍不失為一個好的方 法,但若要估算台灣上市上櫃企業之違約機率,必須以企業經營特性為門檻變數 所建構之門檻迴歸模型,所估算的違約點與其違約機率,最能完整與貼切地詮釋 台灣上市上櫃企業的信用風險。