英語文試題檢測與答題驗證系統設計與實作
78
0
0
全文
(2) 英語文試題檢測與答題驗證系統設計與實作 The Design and Implementation of a Marking and Validation System for the Computerized Base English Test. 研 究 生:張鈞凱. Student:Chun-Kai Chang. 指導教授:陳登吉. Advisor:Deng-Jyi Chen. 國立交通大學 理學院網路學習學程 碩士論文 A Thesis Submitted to Degree Program of E-Learning College of Science National Chiao Tung University in partial Fulfillment of the Requirements for the Degree of Master in Degree Program of E-Learning June 2005 Hsinchu, Taiwan, Republic of China. 中 華 民 國 九 十 四 年 六 月.
(3) 英語文試題檢測與答題驗證系統設計與實作 學生:張鈞凱. 指導教授:陳登吉 博士. 國立交通大學 理學院網路學習碩士在職專班. 摘要 在近年來全國不僅開始總動員學習英語,並且掀起了一股英語檢定風,造成 統計至九十三年底,共有三十二萬人次參加全民英語檢定熱潮。在如此繁重的試 務工作中,要如何讓檢定具有一定水準,讓試題的分級有一可靠的機制及參考標 準,讓批改答題的過程更有效率,這些都是我們所關心的,而且深深的影響到檢 定單位的公信力。 因此本論文嘗試去研究電腦化英語檢定測驗過程,如何讓試題列入適當的檢 定級數,又如何能讓電腦來協助閱卷老師,分擔閱卷批改過程的負荷,進而使得 評分閱卷老師的閱卷基礎較一致。進行試題檢測是因為要達到試題分級的目的, 因此我們提出利用詞彙表、字頻及詞彙數分析的方法,在命題委員命題完畢後, 能夠經過試題檢測客觀的分析,讓分級的過程中,有一個分級評量標準,使得試 題分級更具有公信力。在答題驗證部份,我們實作出拼字檢查、文法檢查及語義 檢查三大部份,輔助閱卷老師在批改過程中的各項檢查,以減少人工閱卷之時間 及錯誤。 關鍵字:自然語言處理、詞性標記、文法分析、詞彙表、字頻。. i.
(4) The Design and Implementation of a Marking and Validation System for the Computerized Base English Test. Student:Chun-Kai Chang. Advisor:Dr. Deng-Jyi Chen. Degree Program of E-Learning College of Science National Chiao Tung University. Abstract The English language skill training (teaching), learning, and assessment is a big industry around the world, especially in the territory of Asia countries. The traditional pen-paper based test delivery approach for English language skill assessment is still domination. However, the computer based test delivery approach has gradually received its attentions due to its advantages on using multimedia such as video, animation, voice, and color image to simulate the question presentation in the real world. Also, using computer and network to conduct a test delivery is less labor intensive and is relative efficiency for the test delivery management activities. In any test delivery approaches, test questions have to be designed and validated and answers from test takers must be graded. From test management point of views, each pen-paper based test sheet requires a qualified score marker to grade it. The grading process usually is very timeconsuming. Considering that there are million copies of test sheets needed to be graded, a lot of qualified score markers are demanded. And, usually, the grading criteria of each score marker may not be able to retain a consistent way after a long grading hour. In this thesis study, we attempt to design and implement 1) an English test question validation system and 2) a score marking system for English writing test under a computer based test delivery approach. Especially, the proposed English test question validation system is designed to help test question creators to verify if a created test question is met with the level of difficulty by analyzing several test item attributes associated with the question. Based on the report generated from the test question, test question creators can adjust the level of difficulty before the test question is submitted ii.
(5) to test question bank. The proposed scoring marking system for English writing test is designed to help score marker to give a more consistent and accurate grading result by analyzing the vocabulary, grammar, and possibly semantic errors found in the answer sheet. Each score marker can have a report analyzed by the proposed system for reference before a formal score is given. This will avoid problems mentioned above. We integrate several current tools (such as Aspell, Apple Pie parser, Worldnet, and so on) into our score marking system and test question validation system. The proposed system has been used to the NETPAW English test to demonstrate its applicability and feasibility.. Keyword: Natural Language Processing, Tag, Grammar Analysis, Word List, Word Frequency. iii.
(6) 誌謝 本論文承蒙指導教授陳登吉博士耐心指導與教誨,陳老師不僅在學術上給予 指導,在日常生活上也給我非常多的關照,也讓我兩年的研究生生涯過的相當的 積極充實,老師在做研究的方法和精神,深深的影響了學生,本論文亦在老師不 厭其煩的更正與修改下,得以順利完成,在此特對師恩致上無限的感激。 其次,感謝論文口試委員台大鄭恆雄教授、師大何榮桂教授、交大劉美君教 授及班主任莊祚敏教授,細心指正論文謬誤、不妥之處,並提供修正意見。 亦要感謝在生活上以及課業上給予我協助的同學,尤其是實驗室凃仲箎、李 嘉彪…等多位學長的經驗傳授,還有同窗兩年同學李玉珍、黃吉楠,以及學弟王 向榮、蔡東杰,在程式與技術上對我的指導與幫助。 研究所這兩年是我感到人生最忙碌也最充實的時光。最後,感謝養育我、栽 培我的父母,還有老婆在背後的支持與鼓勵,使我得以專心完成論文無後顧之 憂,也才能有今日的我,謝謝。. iv.
(7) 目次 摘要 ................................................................................................................................... i Abstract............................................................................................................................. ii 目次 ................................................................................................................................. iv 表目錄 ............................................................................................................................ vii 圖目錄 ........................................................................................................................... viii 一、緒論 .......................................................................................................................... 1 1.1 研究背景與動機 ............................................................................................... 1 1.2 研究目的與範圍 ............................................................................................... 2 1.3 研究方法與步驟 ............................................................................................... 2 1.4 章節概要 ........................................................................................................... 3 二、相關研究 .................................................................................................................. 4 2.1 英語詞彙資料庫─WordNet ............................................................................ 5 2.1.1 WordNet發展概況 ................................................................................. 6 2.1.2 WordNet的內容 ..................................................................................... 6 2.1.3 WordNet的設計 ..................................................................................... 7 2.1.4 WordNet的實例 ..................................................................................... 8 2.2 詞彙詞性標記 ................................................................................................... 9 2.3 Parser軟體─Apple Pie Parser ........................................................................ 11 2.4 GNU Aspell ..................................................................................................... 13 三、系統需求分析 ........................................................................................................ 16 3.1 系統概念 ......................................................................................................... 16 3.2 試題檢測需求分析 ......................................................................................... 19 3.2.1 輸入的檢測資料 .................................................................................. 19 3.2.2 檢測後的輸出資料 .............................................................................. 20 3.3 答題驗證需求分析 ......................................................................................... 22 3.3.1 拼字檢查 .............................................................................................. 22 3.3.2 文法檢查 .............................................................................................. 23 3.3.3 語義檢查 .............................................................................................. 23 四、系統設計與實作 .................................................................................................... 25 4.1 前處理 ............................................................................................................. 25 4.1.1 正規化(normalization) ......................................................................... 25. v.
(8) 4.1.2 斷句(sentence segmentation) ............................................................... 26 4.1.3 斷詞(tokenization)................................................................................ 26 4.2 試題檢測設計與實作 ..................................................................................... 27 4.2.1 詞彙表分析 .......................................................................................... 28 4.2.2 字頻分析 .............................................................................................. 31 4.2.3 詞彙數分析 .......................................................................................... 32 4.2.4 實作程式流程 ...................................................................................... 32 4.3 答題驗證設計與實作 ..................................................................................... 34 4.3.1 系統概念流程圖 .................................................................................. 34 4.3.2 使用態連結函式庫 .............................................................................. 36 4.3.3 系統程式架構 ...................................................................................... 37 4.3.4 Module程式說明.................................................................................. 44 五、系統展示與應用實例 ............................................................................................ 49 5.1 試題檢測系統 ................................................................................................. 49 5.1.1 範例一 .................................................................................................. 49 5.1.2 範例二 .................................................................................................. 52 5.2 答題驗證系統 ................................................................................................. 54 5.2.1 範例一 .................................................................................................. 54 5.2.2 範例二 .................................................................................................. 56 5.2.3 範例三 .................................................................................................. 57 5.2.4 範例四 .................................................................................................. 58 5.2.5 範例五 .................................................................................................. 59 5.2.6 本系統的限制 ...................................................................................... 62 六、總結 ........................................................................................................................ 64 6.1 總結 ................................................................................................................. 64 6.2 未來發展方向 ................................................................................................. 64 參考文獻 ........................................................................................................................ 66. vi.
(9) 表目錄 表 1 WORDNET中詞彙、同義詞集及詞義的數量......................................................... 7 表 2 具有多重意義的單字在TREE-BANK CORPUS 中分布的情形............................... 10 表 3 THE PENN TREEBANK 詞集分類一覽表................................................................ 12 表 4 ASPELL與其他拼字軟體比較表............................................................................ 14 表 5 原型詞彙表暨字頻資料庫結構一覽表................................................................ 28 表 6 衍生詞彙表資料庫結構一覽表............................................................................ 30 表 7 專有名詞資料庫結構一覽表................................................................................ 31 表 8 詞彙數資料庫結構一覽表.................................................................................... 32 表9. WORDNET_INDEX資料庫結構一覽表 .................................................................... 42. 表 10. WORDNET_DATA資料庫結構一覽表 ................................................................... 42. 表 11 WRODNET同義字資料庫查詢「HAPPY」同義字結果一覽表 .......................... 43 表 12 詞性輔助資料庫資料庫結構一覽表.................................................................. 44. vii.
(10) 圖目錄 圖 1:三層關係的名詞語義網路圖例 ........................................................................... 8 圖 2:WORDNET 查詢 HAPPY 結果顯示畫面 ................................................................. 9 圖 3:APPLE PIE PARSER 解析樹 ................................................................................... 13 圖 4 :ASPELL 與其他拼字檢查程式核心測試比較圖................................................ 15 圖 5: ASPELL 在 UNIX 上執行畫面.............................................................................. 15 圖 6:同等級試題適性值的驗證與兩段式的動態調整流程圖 ................................. 16 圖 7:即時試卷的全部試題的 ICC 與 IIC 圖比較...................................................... 17 圖 8:試卷訊息曲線圖(TIC) ........................................................................................ 17 圖 9:系統概念示意圖 ................................................................................................. 18 圖 10:試題檢測系統概念示意圖 ............................................................................... 19 圖 11:試題檢測後輸出資料圖 ................................................................................... 22 圖 12:前處理系統概念示意圖 ................................................................................... 25 圖 13:網路英檢擬模試題畫面 ................................................................................... 26 圖 14:試題檢測系統流程概念示意圖 ....................................................................... 27 圖 15:試題檢測系統內資料庫關連示意圖 ............................................................... 31 圖 16:試題檢測系統程式流程圖 ............................................................................... 33 圖 17:試題檢測系統程式輸出畫面 ........................................................................... 34 圖 18:答題驗證系統概念流程圖 ............................................................................... 35 圖 19:答題驗證系統程式架構圖 ............................................................................... 37 圖 20:APPLE PIE PARSER’S PARSER 建立出解析樹 ..................................................... 40 圖 21:語義檢查 MOUDLE 程式流程圖 ....................................................................... 44 圖 22:形容詞與名詞單複數不一致 MODULE 程式流程圖 ....................................... 45 圖 23:主詞與動詞單複數不一致 MODULE 程式流程圖 ........................................... 47 viii.
(11) 圖 24:試題檢測範例一輸入畫面 ............................................................................... 49 圖 25:試題檢測範例一輸出畫面之一 ....................................................................... 50 圖 26:試題檢測範例一輸出畫面之二 ....................................................................... 51 圖 27:試題檢測範例一輸出畫面之三 ....................................................................... 52 圖 28:試題檢測範例二輸出畫面 ............................................................................... 53 圖 29:答題驗證系統輸入畫面 ................................................................................... 54 圖 30:答題驗證系統範例一輸出畫面 ....................................................................... 55 圖 31:答題驗證系統範例二輸出畫面 ....................................................................... 56 圖 32:答題驗證系統範例三輸出畫面 ....................................................................... 57 圖 33:答題驗證系統範例四輸出畫面 ....................................................................... 58 圖 34:答題驗證系統人工閱卷輸出畫面之一 ........................................................... 59 圖 35:答題驗證系統人工閱卷輸出畫面之二 ........................................................... 60 圖 36:答題驗證系統人工閱卷輸出畫面之三 ........................................................... 61 圖 37:答題驗證系統人工閱卷輸出畫面之四 ........................................................... 62. ix.
(12) 一、緒論 1.1 研究背景與動機 2002 年初,台灣加入世界貿易組織(World Trade Organization),成為該組織 的正式成員之一,促成國內企業與外國企業更頻繁之貿易關係與接觸,而英語為 國際通用之主要語言,它不論在通訊、溝通與資訊傳遞等各領域,都有著強勢的 影響力,故其重要性更為提高。據估計目前世界上約有 7.5 億至 10 億的人口使用 英語,而其中有 3 億人口的母語是英語。在全球化的競爭壓力之下,政府以及學 術界的領導人一再提出台灣必須提昇國民英語能力的呼籲。因此各級教育單位不 斷推出提昇國民的英語能力的方案。 身為我國最高行政單位的行政院,目前已提出「挑戰 2008 年:國家發展重 點計畫」,認為人的投資是所有建設和發展的基礎與目標,所以第一項就是「E 世代人才培育計畫」,其目標是:培育具有創意活力及國際對話能力的新世代, 也就是能夠嫻熟應用「資訊與英語」的新世代。面對未來的挑戰,首先就要強調 國民適應全球化與國際化的能力,同時也要營造一個國際化的環境和全民學習的 條件。使用外語(特別是英語)和網路通訊能力的培養乃成為這項計畫的重點,尤 其是英語,已經成為與世界接軌的主要工具,政府在六年內應該將英語的地位提 升為準官方語言,積極推動擴大英語應用的範圍,讓英語成為生活中的一部份。 「E 世代人才培育計畫」中更明確提出營造英語生活環境、平衡城鄉英語教 育資源、大專院校教學國際化、提高公務人員英語能力、推動英語與國際文化學 習…等五項具體的政策,而在推動英語與國際文化學習項目中,辦理「推廣全民 外語學習」方案,持續推動全民社區英語學習各方案;推行「全民英語能力檢定 測驗」、「全民網路英語能力檢定」。[17] 就因如此,全國不僅開始總動員學習英語,並且掀起了一股英語檢定風,造 成統計至九十三年底,共有三十二萬人次參加全民英語檢定熱潮[27]。光今年(九 十四年)一月及六月舉行的二次全民英語能力分級檢定初級檢定的報考者,居然高 達二十五萬人報考[31],其熱烈的情形已經不輸給學力測驗。在如此繁重的試務 工作中,要如何讓檢定具有一定水準,讓試題的分級有一可靠的機制及參考標 準,讓批改答題的過程更有效率,這些都是我們所關心的,而且深深的影響到檢 定單位的公信力。 在電腦與網路發達的二十一世紀,由於資訊科技與網際網路的快速發展,電 腦已改變人類生活的方式,對於教育與測驗環境亦有很大的改變,測驗的e化漸 成為現今之趨勢。就因如此,本研究想藉由電腦化為人類帶來便利當中,去研究 電腦化英語檢定測驗過程,如何讓試題列入適當的檢定級數,又如何能讓電腦來 協助閱卷老師,分擔閱卷批改過程的負荷,進而使得評分閱卷老師的閱卷基礎較 一致。. 1.
(13) 1.2 研究目的與範圍 本研究期望能達到以下的目的: 1. 訂定一個試題檢測標準,讓試題分級更具公信力。 2. 因應檢測結果分級制,試題檢測應依既定試題庫級數分級。 3. 改善人工試題檢測時,較無法達到統一標準的缺點。 4. 利用電腦先進行答題驗證,以減少人工閱卷之時間及錯誤。 5.簡答答題的數量龐大時,改善以人工方式審題,費時費力的缺點。. 此研究範圍主要是在網路英檢上,而應用到全民網路英檢上做為系統驗證。 網路英檢的測驗模式是在電腦上進行施測,而且平時可以 24 小時上網免費 學習及自我檢定,就因為可以在電腦上施測及學習,所以能夠大量的使用多媒體 素材,如:文字、圖片、動畫、聲音甚至影片,而多媒體素材每個部份的分析, 皆有其專業領域的技術,因此本論文研究範圍僅就文字式的試題及簡答答題部份 進行檢測及驗證。. 1.3 研究方法與步驟 首先我們會先了解試題檢測及答題驗證過程當中的各種需求,接著了解可能 的解決方法,之後針對我們提出的方法做需求分析,進而實作系統。詳細的步驟 條列如下: 1. 了解目前試題檢測的需求現況。 2. 探討試題檢測的方法。 3. 收集並且整理試題檢測過程當中之資料,並建立資料庫。 4. 設計出試題檢測的過程。 5. 分析答題驗證的需求。 6. 了解答題驗證的分析種類。 7. 設計答題驗證的分析方法。. 2.
(14) 8. 實作試題檢測及答題驗證系統。. 1.4 章節概要 第一章,我們提出撰寫本篇論文的動機與目的,以及研究方法與步驟。 第二章,介紹與本系統相關研究的內容。 第三章,介紹本系統的流程概念,進而提出試題測檢部份的需求分析,再探討答 題驗證部份的需求分析。 第四章,提出系統的設計概念,並且詳細介紹如何設計,進而實作出系統的方 法。 第五章,以實際範例示範試題檢測與答題驗證系統的結果,並且說明結果畫面中 各項數據的意義。 第六章,作一個總結,並對未來的發展擔出一些建議。. 3.
(15) 二、相關研究 在此研究的背景當中,須使用到大量的詞彙資料庫、標記化語料庫(Tagged Corpus),還須要有語義、語法及拼字各方面的技術來支援,而目前國外對這些部 份的研究,均有相當的成果,因此研究當中就利用其相關技術,來讓系統運作更 完整。 1. 語義技術部份: 因為WordNet為國際間詞彙知識庫通用的架構,其是為了結合詞彙編篡資訊和 高速運算的所產生更多效益而提出的計畫。在多語環境(如WWW 全球資訊 網)中,WordNet提供了兼顧概念通性及語言通性的知識表達架構;更因詞彙 網路涵蓋了絕大多數富含資訊(information-rich)的語言;正可以擔任不同語 言間知識資訊轉換的座標。[18] 有 WordNet 之父之稱的心理學大師米勒(George A. Miller),給了大家的啟 發後,此刻許多研究者都在努力建立各種語言的 WordNets:Spanish WordNet、Chinese WordNet…等,WordNet 儼然已經成為語言研究者的必修 課;因為 WordNet 可以透過語意關係,連接到其他相關字,社會大眾也多了 一個比一般辭典更方便的工具。 而在台灣有許多有名的研究都開始使用WordNet,其中最具代表的是「中央研 究院中英雙語知識本體詞網」 (簡稱「研究院知識詞網」,Sinica BOW)目 前開放的雛型是由中研院與國家數位典藏計畫中的「語言座標」計畫所建構 完成。使用到的資料國外的有IEEE批准執行的SUMO(Suggested Upper Merged Ontology)知識本體(teknowledge.com 管理)及普林斯頓(Princeton University) 的WordNet。因為「語言座標」採用了「詞彙網路」(WordNet)的架構,為國 際間詞彙知識庫通用的架構。找到了英文對譯詞後,可藉EuroWordNet等網路 上開放的資料庫,對應到 20 幾種語言。[19] 就因為以上多項的原因,再加上 WordNet 的研究人員一直把 WordNet 視作一 個試驗,而不是一個產品。因此當 WordNet 中的詞語足夠多的時候,他們就 把 WordNet 向學術界免費公開,所以其程式碼及原始資料庫資料取得容易, 只要不盜用普林斯頓大學的商標來宣傳 WordNet 的任何派生產品。就基於這 些原因,所以本系統利用 WordNet 來做為我們語義分析的核心。 2. 語法技術部份: 語法的部份可以利用到自然語言處理(Natural Language Processing)技術中,已 經研究多年的解析(Parser)方法。而解析軟體在國外非常多,常見的有 Minipar、CG Parser、CASS Partial Parser、CHILL、ISSCO Tools、IMS Stuttgart、Apple Pie Parser、Link Grammar Parser…等。其中有些程式碼不易取 得,如 CASS Partial Parser 網站上只有提供 Parser 服務,沒有其他任何的介 紹。有些使用程式語言與本研究規畫使用的 C 語言不同,如 CHILL、ISSCO 4.
(16) Tools 這些則用 Prolog 語言,Prolog 語言是電腦人工智慧程式語言之一。若用 語言來選擇,其中有 Minipar、Apple Pie Parser(APP)、Link Grammar Parser 是 使用 C 語言,而 Link Grammar Parser 是用句法解析(syntactic parser)的方式去 解析,對於輸出結果是圖像的表達,對於後續處理較為不易。 最後可以選擇的有Apple Pie Parser (APP) 及Minipar,而有文章[9] 提到 APP 分 析 15 字以上的句子正確率可達 83%,而Minipar正確率可達 88.54%,均是不 錯的解析軟體。而其中APP支援Unix工作站,加上程式原始碼及資料庫方便取 得,且詞性分類採The Penn Treebank系統,分類適中易懂,所以本系統採用此 軟體做為解析之工具。 3. 拼字技術部份: 此處所提到的拼字指的像是 module ,將其英文字母拼錯而成 moudle 這樣的 拼字。而要像這樣檢查拼字,大家最熟悉的就是 Microsoft Word,如果在使用 Word 時有拼字錯誤,則其會在錯誤單字下標出紅色的波折線,像是上述的錯 字就會被顯示成「moudle」。這樣的拼字檢查技術,在國外中被使用的非常 普遍,基本上只要文字編輯的軟體,就有拼字檢查的功能,像是上述 Microsoft Word,還有 ConjuGNU、koffice、OpenOffice…等這些都是,但是其 要為研究上利用,則不如 Ispell、Aspell 純粹的拼字檢查工具軟體來的方便及 容易。 而 Aspell 主要是為超越 Ispell 而做出來的,因此其功能性及方便性都比 Ispell 來的好,加上又有做出程式庫,更方便被其他程式使用。同樣地,他的程式 取得也是非常的容易,支援 Unix 工作站,因此本系統採用 Aspell 來為我們做 拼字檢查的工作。 接下的章節中,就來介紹這些技術的相關研究,讓大家更為清楚其背景、理 論及用途。. 2.1 英語詞彙資料庫─WordNet WordNet 是普林斯頓大學(Princeton University)認知科學實驗室(Cognitive Science Laboratory)所發展出來的。該專案被稱為「英語詞彙資料庫」(a lexical database for the English language),主要是由George A. Miller教授所領導, WordNet是這樣一個系統,通過將同義詞的集合集中到稱為同義詞集(synonym sets)或同義集(synsets)的組合中來描述和分類單詞和概念。我不能過分吹捧這一重 要的長期項目,該項目代表了如此有前景的產業。因為它的開放性意味著實際上 任何開發人員都可以使用它,所以它十分重要。WordNet 有“不受限制的"許可 證。它很像 BSD 許可證,因為唯一真正的限制是不可以盜用普林斯頓大學的商 標來宣傳 WordNet 的任何派生產品。[5]. 5.
(17) 2.1.1 WordNet 發展概況 關於WordNet的不成熟的想法可以追溯到 20 多年前,而這一想法開始逐漸具 體化和清晰化則是 1985 年後才開始的。從 1985 年開始,WordNet作為一個知識 工程全面展開。不過,當時的WordNet和經過 20 年後今天的WordNet還是很不一 樣的。[24] 這一工程最初的前提之一是“可分離性假設"(Separability hypothesis),即語 言的詞彙成分可以被離析出來並專門針對它加以研究。詞彙編纂學的歷史明確地 告訴我們,在詞語水準上可以得到有用的研究成果。詞庫(詞典,lexicon)當然不 是完全獨立於其他語言成分的,但它的確是可以從其他成分中分離出來的。例 如,儘管語音和語法知識在一個人的早年生活中就成型了,但詞彙量卻可以隨著 智力活動的不斷積累而增加。這表明語言的不同成分涉及不同的認知過程。 另一個前提是“模式假設"(patterning hypothesis):一個人不可能掌握他運用 一種語言所需的所有詞彙,除非他能夠利用詞義中存在的系統的模式和詞義之間 的關係。這種系統化的心智模式至少從柏拉圖時代就成為一種進行推測的學問, 現代語言學研究開始在自然語言的語義結構中識別這樣的模式。但許多遵循這類 路線的出色的研究工作在這一問題上碰到了困難。一個作者可能提出一種語義理 論,並以 20 到 50 個英語單詞為例來展示他的理論,而留下另外 10 萬個單詞讓讀 者去做練習。 第三個前提就是所謂的“廣泛性假設"(comprehensiveness hypothesis):計算 語言學如果希望能像人那樣處理自然語言,就需要像人那樣儲存盡可能多的詞彙 知識。 建立包含詞語意義描述的大規模詞庫的方式之一是基於語義成分分析的詞彙 語義學(componential lexical semantics)的方法(也可譯為義素分析法)。這種方式把 一個詞的意義分析為更小的概念原子的組合。不過,定義一套概念原子卻非易 事。事實上,WordNet 主帥 George.A.Miller 在 1976 年他與 Philip N. Johnson-Laird 合作的《Language and Perception》一書中還躊躇滿志地探索義素分析的語義描寫 方法,但直到 1985 年,仍然沒有能夠出籠一個完整的定義清晰的清單,在上面 列舉出所有的概念原子。但發展到今天已經有非常大的進展,尤其是 WordNet 的 研究人員一直把 WordNet 視作一個試驗,而不是一個產品。因此當 WordNet 中的 詞語足夠多的時候,他們就把 WordNet 向學術界免費公開,讓世界上許多國家依 照 WordNet 的概念,開始做該國語言的語料庫,讓更多世人受惠。. 2.1.2 WordNet 的內容 WordNet 的描述物件包含 compound(複合詞)、phrasal verb(短語動詞)、 collocation(搭配詞)、idiomatic phrase(成語)、word(單詞),其中 word 是最基本的 單位。. 6.
(18) WordNet 並不把詞語分解成更小的有意義的單位(這是義素分析法 /componential analyses 的方法);WordNet 也不包含比詞更大的組織單位(如腳本、 框架之類的單位);由於 WordNet 把 4 個開放詞類區分為不同檔加以處理,因而 WordNet 中也不包含詞語的句法資訊內容;WordNet 包含緊湊短語,如 bad person,這樣的語言成分不能被作為單個詞來加以解釋。 人們經常區分詞語知識和世界知識。前者體現在詞典中,後者體現在百科全 書中。事實上二者的界限是模糊的。比如hit(“打")某人是一種帶有敵意的行 為,這是百科知識;而hit跟strike(“擊")多多少少同義,並且hit可以帶一個直接 賓語論元,這是詞語知識。但hit的直接賓語應該是固體(而不是像gas這樣的氣 體),這是詞語知識還是百科知識就界限模糊了。不過毫無疑問,要理解語言,這 兩部分知識是缺一不可的。Kay(1989)指出我們的大腦詞庫應該包含這兩部分知 識。但是百科知識太多難以駕馭,WordNet不試圖包括百科知識。不過,在 WordNet中,對於一些不常見的專業概念,比如不常見的植物和動物,詞語知識 和百科知識是融合在一起的。[7]. 2.1.3 WordNet 的設計 一般的詞典都是按照單詞拼寫的正字法原則進行組織的。但如果為了獲得詞 語意義資訊的目的,通過詞語語義屬性來組織詞典就更值得去做了。線上詞典跟 傳統的紙張詞典不同,允許使用者從不同的途徑去訪問詞典資訊。 第一個以意義作為組織原則的詞典是羅傑斯同義詞詞林(Roget's Thesaurus)。 傳統的詞典是通過提供給用戶關於詞語的資訊來幫助用戶理解那些他們不熟悉的 詞的概念意義。WordNet 既非傳統詞典,也非同義詞詞林。它混合了這兩種類型 的詞典。 WordNet跟同義詞詞林相似的地方是:它也是以同義詞集合(synset)作為基本 建構單位進行組織的。大家在腦子裏如果有一個已知的概念,就可以在同義詞集 合中中找到一個適合的詞去表達這個概念。下表表 5是目前WordNet的規模。 表 1 WordNet中詞彙、同義詞集及詞義的數量[5] POS Noun Verb Adjective Adverb Totals. Unique Strings 114,648 11,306 21,436 4,669 152,059. Synsets 79,689 13,508 18,563 3,664 115,424. Total Word-Sense Pairs 141,690 24,632 31,015 5,808 203,145. 但 WordNet 不僅僅是用同義詞集合的方式羅列概念。同義詞集合之間是以一 定數量的關係類型相關聯的。這些關係包括上下位關係、整體部分關係、繼承關 係等。. 7.
(19) 不同句法詞類中的語義關係類型也不同,比如儘管名詞都動詞都是分層級組 織詞語之間的語義關係,但在名詞中,上下位關係是 hyponymy 關係,而動詞中 是 troponymy 關係;動詞中的 entailment(繼承)關係有些類似名詞中的 meronymy(整體部分)關係。名詞的 meronymy 關係下面還分出三種類型的子關係 (見“WordNet 中的名詞"部分)。 我們現在用一個如圖 1 所示的名詞語義網路圖例來跟大家略為解說。 1. 下位關係(hyponymy):像物質(substance)再細分分類下去,也就是其下位關係 有生物物質(organic substance),而生物物質中再細分下去就有肌內(flesh)及骨頭 (bone)都算生物物質。 2. 反義關係(antonymy) :像兄弟(borther)及姊妹(sister)之間就是反義關係。 3. 部份和整體關係(meronymy) :像人的身體(body)就是屬於人(person)的一部份, 而手臂(arm)和腿(leg)就屬於身體的一部份。. 下位關係. 反義關係. 部份-整體關係. 圖 1:三層關係的名詞語義網路圖例[6]. 2.1.4 WordNet 的實例 圖 2是利用目前WordNet最新 2.0 版查詢「happy」的結果,其中第一行文字「The adj happy has 6 senses」告訴我們happy是一個形容詞(adj),而有 6 個詞義,其 6 個 詞義分別列出 6 個項目做各別說明。在單項說明中同時出現的單字,代表其彼此. 8.
(20) 之間是同義字的關係,例如項次 2. 中的「happy」及「pleased」是屬同義字的關 係。另外單項說明中括弧部份的內容,則是對該詞義做更詳細的說明。 而本論文中是利用 WordNet 來做同義字的分析資料,所以我們就只取出各項 次出現的同義字來利用,像此例就取出 pleased、felicitous、euphoric、well-chosen 四個字,來當做 happy 的同義字使用。. 圖 2:WordNet 查詢 happy 結果顯示畫面. 2.2 詞彙詞性標記 通常語料庫的資料(每個單字)如果做了詞性標記,那麼它就可以運用在語言 學的分析或者是研究句子文法的結構,例如名詞加名詞的組合,形容詞加動詞的 組合等等。 詞性標記(Tagging),就是一次看一個句子的每一個字,然後給每一個字一個 標記,也就是該單字的詞性。例如:John sometimes goes to school. 會被標記詞性 如下:John:NNP(單數專有名詞)、sometimes:RB(副詞)、goes:VBZ(動詞第三 人稱單數)、to:TO(介系詞 to)、school:NN(單數名詞)。 另外,有的英文單字是具有多重意義的單字,在使用時使用者不了解這個單 字的用法,以致於他們在使用時,會自己搞不清這個單字,在句子真正所代表的 意思。例如:“Good"這個單字,在下列兩種情形下有不同的詞性標記:. 9.
(21) 1. He-PP is-VBZ my-PP$ good-JJ friend-NN . –SENT 2. Christians-NNS believe-VVP the-DT good-NN will-MD go-VV to-TO heavenNNwhen-WRB they-PP die-VVP .-SENT 第一句的good 標記為JJ(形容詞),第二句的good 標記為NN(名詞)。在此雖是 同一個good,但卻有不同的詞性標記。表 2 是TreeBank 的corpus 中 同一個字有幾 種詞性的分布情形: 表 2 具有多重意義的單字在Tree-Bank corpus 中分布的情形。[8] Degree of ambiguity Total frequency (39,440) 35,340 單一詞性 ( 1 tag ) 4,100 多詞性 ( 2-7 tags ) 2 tags 3,760 3 tags 264 4 tags 61 5 tags 12 6 tags 2 7 tags 1 (still) [註 1]10.4 percent of the lexicon is ambiguous as to part-of-speech (types) [註 2]40 percent of the words in the Brown corpus are ambiguous (tokens). 從表 2 還是可以看到有許多單字是具有多重意義的。而詞性標記解決這類問 題有二種做法,Rule-based approach、Stochastic approach。 1. Rule-based approach: a. 依靠文法規則。像名詞片語就可以由一個限定詞性加上一個或一個以上的 形容詞: NP -> DT(JJ*)NN 例如: The pretty woman. b. 藉由形態分析(Morphological Analysis)的幫助,去消除語意不清的問題。 例如 X-ing 這類的單字,如果前面接動詞,那就把 X-ing 標記成動詞。 c. Supervised method:完成一個已經事先經過詞性標記的語料庫( pretaggedcorpus),讓學習者可以從語料庫中抓出他們想要的句子。優點是他 們可以找到同一文集中相似的句子,缺點是這種資料庫不能完全符合每一 個人的需求,總是會不夠用,要一直加進新的句子。 d. 額外的規則。這類的規則非常多,例如像"German" 這個單字,頭一個字 母是大寫就意謂著它可能是專有名詞。 ",",":","!", "." , 這些. 10.
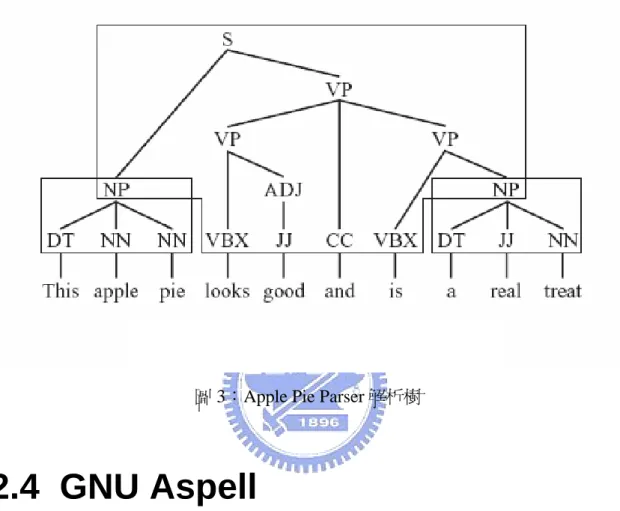
(22) 符號要和單字分開," ' "可能是所有格,要和前後單字連在一起然後 再做詞性標記。 2. Stochastic approach: 通常會一起使用下列的幾種方法: a. simple approach:對於語意模糊不清的字,我們就依照它出現的機率,給它 一個特定的詞性。 b. N-gram approach:要標記這個字的詞性,是由它的前 N 個字出現的機率所 決定。 c. Viterbi algorithm:用來找出標記一整句或一連串單字序列(word sequence)詞 性的演算法。. 2.3 Parser 軟體─Apple Pie Parser 語料庫的句法標注是語料庫語言學研究的前沿課題,它的處理目標是對語料 文本進行句法分析和標注,形成樹庫(treebank)語料。在這方面,英語語料庫 的研究已經做了許多工作,兩個比較大的研究專案是:英國 Lancaster 大學 UCREL 的Lancaster Treebank[1][2]和美國 Pennsayvania 大學的 Penn Treebank[3]。 前者的標記集較大,通過組織成不同的層次描述了詳細的短語句法資訊。而後者 的標記集則較為簡節,其最大的特點是增加了四個表明不同空元素(Null Elements)的標記。而兩者樹庫規模都達到了二百萬詞以上。在這些工作中提出 的骨架(skeleton)分析方法、機器自動分析和人工校對相結合的處理思路,為後 續的相關研究積累了豐富的經驗。[25][26] The Penn Treebank [4] 是美國賓夕法尼亞州立大學電腦與資訊科學系的LINC 實驗室 ( LINC Laboratory of the Computer and Information Science Department at the University of Pennsylvania ) 所建立的一個附有詞性標記的英文語料庫,它將詞性 分成 48 類的詞集( Tag set ),列出在表 3 The Penn Treebank 詞性集分類一覽表: 解析軟體在國外非常多,常見的有 Minipar、CG Parser、CASS Partial Parser、CHILL、ISSCO Tools、IMS Stuttgart、Apple Pie Parser、Link Grammar Parser 等。而其中 APP 支援 Unix 工作站,加上程式原始碼及資料庫方便取得, 且詞性分類採 The Penn Treebank 系統,分類適中易懂,所以本系統採用此軟體做 為解析之工具。 APP是一個bottom-up probabilistic chart方法的解析程式,它是用best-first search演算法來計算得到parse tree中最佳得分。採用和Penn Treebank同樣tagset的 方式,利用two non-terminals的技術來解析英文文法。[11][12]. 11.
(23) 表 3 The Penn Treebank 詞性集分類一覽表. 所謂two non-terminals的技術指的是S (sentence) 及NP(noun phrase)兩個元素, 因為S及NP兩個元素在Penn Treebank語料庫裡佔了非常大的比率,所以分析出此 兩元素的組合規則,就可以解析出絕大多數的英文句子[10]。以下就以一個例子 加以說明。 下圖 3 中是英文句子「This apple pie looks good and is a real treat.」的parser tree,其利用三條規則將其解析完畢: Rule-1:NP -> DT NN NN。 Rule-2:NP -> DT JJ NN。 Rule-3:S -> NP VBX JJ CC VBX NP(其中第一個 NP 即 Rule-1 的 NP,第二個 NP 即 Rule-2 的 NP),做出:structure “(S <1> (VP (VP <2> (ADJ <3> )) <4> (VP <5> <6>)))”;。. 12.
(24) 最後,將 Rule-1 及 Rule-2 套入 Rule-3 的 structure 中,就得到最後的 parser 結 果:(S (NP (NPL (DT This) (NN apple)) (NN pie)) (VP (VP (VBZ looks) (ADJP (JJ good))) (CC and) (VP (VBZ is) (NPL (DT a) (JJ real) (NN treat)))) (. -PERIOD-)). 圖 3:Apple Pie Parser 解析樹. 2.4 GNU Aspell 對大部份的使用者都非常有用的應用程式,無疑是自動拼字檢查器 (automatic spell checkers)。 GNU (GNU’s Not UNIX) [15] Aspell 就是這樣的一 個程式。 直到 Aspell 工程開始之前,只有一個拼字檢查程式是自由軟體: International Ispell 。自然地, Ispell 結果在大部份的 Unix 機器上變得更加廣佈, 而且也成為 GNU 系統的標準拼字檢查器。不幸的是,由 Ispell 所作出的知識建 議,明顯地比那些由私權拼字檢查器所作出的還要糟糕。為了這個原因, Kevin Atkinson 在 1998 年開始致力於 Aspell 。 在下一年, Kevin 付出了許多他的時間給 Aspell,更加密集的開發。在此過 程中,許多觀念都被測試、整理,甚至有時候被捨棄。例如:他尋求創造一個稱 為 Pspell 的原生介面(generic interface),給目前存在系統內的所有拼字檢查器 使用。不幸的是,這個原生介面反而把整個系統弄的更複雜,因此他就放棄了。. 13.
(25) 他付出了很大努力的其他事情還有,根據 Ispell 所提供的字彙列表,製作出 更好的字彙列表(word list)。他很仔細地將英文列表分為英國、美國和加拿大 的拼法(spelling)。那項工作的結果也被個別地加以公開。 在 2002 年 8 月發行 GNU Aspell 0.5 之後, Aspell 開始成為 GNU 工程的一部 份,現在正努力尋求的是,希望在 GNU/Linux 散佈軟體上替換掉 Ispell 。 GNU Aspell 不只可以極佳的使用者介面,而作為拼字檢查程式被使用,它也 允許被其他程式作為程式庫而被連結。不管是作為一個程式使用或作為程式庫連 接, GNU Aspell 都可察覺多進程的使用(multi-process aware)。一個使用者的 個人字典,可以為該個使用者的所有 Aspell 進程所取得,而且任何改變,都會自 動地在所有的 GNU Aspell 進程間互相增殖(propagated)。儘管如此,任何一個 使用者,都可以對字典做出改進的結果,因為 GNU Aspell 會從使用者修正的錯 誤中學習,並且讓每個使用者可以擁有數個個人字典。 同時 GNU Aspell 所作出的建議,也比那些由 Ispell 或 Netscape 4.0 或 Microsoft Word 97 所作出的更好。 Kevin 為了將這更好的情形,定量地表示而開 發了一個測試環境,這測試環境與它所作出的結果都可以在 GNU Aspell 網頁 [14] 上取得。 表 4 Aspell與其他拼字軟體比較表[14] Aspell. Ispell Netscape 4.0 Microsoft Word 97. ○. ○. 88-98. 54. 55-70?. Personal part of Suggestions. ○. ○. ○. Alternate Dictionaries. ○. ○. ?. ?. International Support. ○. ○. ?. ?. Open Source Suggestion Intelligence. 14. 71.
(26) 圖 4 :Aspell與其他拼字檢查程式核心測試比較圖[14] 圖 5 為Aspell的輸出畫面. 文章輸入. 建議修改. 圖 5: Aspell 在 Unix 上執行畫面. 15.
(27) 三、系統需求分析 3.1 系統概念 本研究系統設計概念與流程主要是配合本實驗室研發之「二階段式試題適性 值調整」方式,以使試題更能真實反應受測者之英語能力,其概念如圖 6所示。 首先,分析試題並確定試題的評量目標,以多媒體試題開發設計單,確立試題所 欲評量的能力層次與學習內容。試題開發設計單設計多媒體試題。透過本實驗室 之試題檢測系統及命題專家檢核後,依其審定之適性值置入題庫。第二階段為施 測,以本實驗室之IRT分析器分析測驗結果以調整或修正試題,並將所得之反應 組型以現代測驗理論分析試題難度、鑑別度、猜測度等試題屬性,依據分析結果 重新調整或組合試題以建立適性化題庫。由於進行施測後,立即可以獲得試題特 徵曲線(ICC)與試題訊息曲線(IIC)(如圖 7)及試卷訊息曲線圖(TIC)(如圖 8)等各項 參考數據,可隨時進行適性值之分析與調整題庫。因此任何一次施測皆可視為下 一次測驗之預試,如此經試題檢測系統及專家審題後至入題庫,再經IRT分析器 分析測驗結果與調整題庫,即為本實驗室所稱「二階段式試題適性值調整」之方 式. 試題. 命題委員. 字表,字頻 文法句構 分析及驗 驗證調整寫 證系統 入相關適性 值. 以IRT分析 器進行第二 次適性值動. CAT施測. 預 試. 試題 DB. 以IRT分析 器進行第一 次適性值動 態調整. 態調整. 圖 6:同等級試題適性值的驗證與兩段式的動態調整流程圖. 16.
(28) 圖 7:即時試卷的全部試題的 ICC 與 IIC 圖比較. 圖 8:試卷訊息曲線圖(TIC). 17.
(29) 命題委員在進行試題命題時,可從 1.廣告 2.通告(含指示說明)3.會話(含 閒聊、訪問、小組討論、電話會話)4.新聞播報(含敘述性故事、笑話)5.學術 性演講(含演說、宣教)6.戲劇台詞(含影片對白)7.歌曲(含詩歌、童謠)… 等方向獲得命題教材來源,而產生一個新的試題,至於題型可能是選擇題、填充 題或問答題…等型式,但新的試題要如何歸至試題庫當中,放到適合的試題等 級,這就是要靠「試題檢測系統」,做出一個判斷的建議值給命題委員,讓委員 能夠迅速正確的將試題分級。. 命題 委員. 新試題. 試題檢 測系統. 試 人工 閱卷. 題. 適性值 分析. 庫 本研究將 製作的系統. 答題驗 證系統. 受測者 施測. 測驗 試卷. 選題 系統. 選題 規則. 圖 9:系統概念示意圖. 經分級後在試題庫中之試題,可以依每次不同等級及特性的測驗,訂定出良 好的選題規則,再經由選題系統進行選題,挑出一份適合等級難易度的測驗試 卷。此份測驗試卷就做為該場次測驗的依據,受測者則對測驗試卷進行施測,最 後做答時間結束後,受測者所答題的部份,會經由「答題驗證系統」利用電腦對 龐大的答題資料做初步的批改,系統批改出來的建議資料,會連同受測者的答題 部份,一同給閱卷老師進行人工閱卷,閱卷老師可以挔據答題驗證系統的建議或 是自己的判斷進行給分,最後評定出受測者正確的得分。得到所有受測者的得 分,可以再做試題的適性值分析,可能再重新調整試題的等級或難易度,讓試題 可以調整到更適合的等級。. 18.
(30) 整個系統流程的概念如圖 9所示,而本研究將專注於圖中「試題檢測系統」 及「答題驗證系統」兩大部份進行研究,並於下節開始分別詳述之。. 3.2 試題檢測需求分析 命題委員出一題新試題時,對於此新試題的題型、題目呈現、試題種類,就 已經先行規範好,待試題檢測系統針對詞彙表、字頻、詞彙數進行計算,填入其 屬性值後,將新試題納入試題庫內待測。. 試題檢測系統 命題 委員. 上傳時命題 老師填寫. 系統產生. 題型. 詞彙數. 題目 呈現. 詞彙表. 新試題. 試題 種類. 字頻. 圖 10:試題檢測系統概念示意圖. 3.2.1 輸入的檢測資料 在輸入檢測系統時,對於試題已有的資料包含: 1.題型: 選擇、填充、問答、題組。 2.題目呈現方式: 文字、聲音、圖片、動畫、影片。 3.試題種類: 聽力、閱讀、口語、寫作能力測驗。 19. 試 題 庫.
(31) 3.2.2 檢測後的輸出資料 因為命題委員的生活與成長背景不同,所以對於每個試題的難易程度,在認 知上大致不會完全相同,因此在此系統中提供三種較為客觀的資料,供命題委員 最後判定出試題適當的級數。 1.詞彙表: 有學習過英文經驗的人,在參加任何測驗時,都不難體會到試題詞彙的難易 度,會直接影響到該次測驗難易度。 所以教育部讓國中小學習英文時,就會公佈「國中小學英語最基本一千字 詞」,這個字彙表的制定是參考民國八十三年教育部發布之「國民中學課程 標準」參考字彙表及多國學校的詞彙表,最後再依我國中小學階段學生之生 活經驗,及其學習英語之目標,與外語學習環境等因素加以篩選調整完成。 同樣的在負責我國學生最重要考試的大學入學考試中心,對於英文科的詞彙 甚為重視,早已針對詞彙部份進行多年的相關研究,計有黃自來等(民 82) 的《高中英文 5000 基本單詞》收錄於《大學入學考試中心英文試題與中學英 語文教材之相關性參考題庫命題制度建立及命題人才培訓研究報告》、張武 昌等(民 87)《高中常用字彙表》收錄於《八十四年度基礎科目英文考科試 題研發工作計畫研究報告》、黃春騰等(民 89)《字彙表》收錄於《英文閱 讀能力檢定考試規劃研究期末報告》等研究成果。近年來新字不斷擴增,還 有其他多項因素考量,鄭恆雄等(民 91)乃參考上述研究成果、國高中教科 書、美國小學教科書及世界各國的研究等完成《大考中心高中英文參考詞彙 表編修研究計畫報告》。 使用詞彙表的好處: (1) 考試範圍明確。 (2)對於詞彙難易度有統一的參考標準。 (3)更科學地維持測驗歷次施測難易度平行, 2.字頻: 從詞彙研究的角度來看,詞彙統計研究已有很長的歷史了。古印度語言學家 在研究婆羅門教的經典《吠陀經》時,就進行過單詞數目的統計。1898 年德 國學者 F.W.Kaeding 編制了世界上第一部頻率詞典《德語頻率詞典》。1944 年,英國數學家 G.U.Yule 發表了《文學詞語的統計研究》,大規模地使用概 率和統計方法來研究語言。1949 年,法國學者 R.Michea 提出建立“統計詞彙 學"。1965 年,德國學者 R.D.Keil 把詞頻統計與現代統計學結合起來,提出 了“詞彙計量學(lexicometric)"。. 20.
(32) 字頻就是一個字的使用頻率,也就是一個單字使用次數與所統計的材料的總 字數的比例,一般用百分比表示,這樣可以比較直接地看出一個單字覆蓋 面。 例如我們說一篇 2000 字的文章,其中“beauty"用了 78 次,那麼“beauty" 的頻率就是:78/(2000×100)=3.9%。3.9%的概念就是說在一百個字中,就 有 3.9 個是單字“beauty",可見“beauty"的使用頻率是相對高的。摸清楚 一個字的使用頻率,意義非常重要,編制教材,編寫字詞典,電腦資訊處理 等,都要參照有關單字的使用頻率分析,依此作為依據。比如像小學的語文 教材的編寫,首先就要選擇使用頻率高的字,如果遇到低頻字、罕用字,就 要注意回避。 而在此處我們是使用字頻,是對單一個英文單字進行統計,而非使用「詞 頻」,因為詞頻則須要先做切詞的工作,而切詞的工作困難度較高。 3.詞彙數: 張郇慧(1996:135)的研究顯示,以英語為母語的人士,所寫的私人信函的 英文詞彙平均長度為 6.03[13]。因此如果一個試題句子的詞彙數愈多,則代表 此試題的難度亦有可能愈高,同樣的一位英文的初學者,其能閱讀句子的詞 彙數是比較少的。所以我們藉由統計試題每句的詞彙數,來提供給命題委員 參考,如果詞彙數多則有可能句子較難,如果詞彙數少則有可能句子較容 易。 其檢測完成後輸出資料如圖 11所示,圖中標號Ⅰ的區域,就是詞彙表分析後 的輸出資料;圖中標號Ⅱ的區域,就是字頻分析後的輸出資料;圖中標號Ⅲ的區 域,就是詞彙數分析後的輸出資料。此三種分析資料輸出後,命題委員就依此分 析資料判定出試題適當的級數。. 21.
(33) Ⅰ. Ⅱ. Ⅲ. 圖 11:試題檢測後輸出資料圖. 3.3 答題驗證需求分析 受測者在簡答題作答完畢後,其答題的部份在閱卷老師批改過程中,是須要 經過「拼字檢查」、「文法檢查」、「語義檢查」三大步驟:. 3.3.1 拼字檢查 受測者在答題中常有許多拼字上的錯誤,例如:They do not have morden machines but they can still do it well. 其中誤拼成 morden 的字,有可能是 modern。 這都是一些有可能犯的拼字錯誤。 受測者對於想使用的單字,可能一時想不起來,而無法確定這個單字的正確 拼法,甚至是一時的筆誤,又沒做最後的檢查,以至於造成拼字上的錯誤。 因此我們利用 2.4 節所提到的 GNU Aspell 來幫忙完成此一工作,一個句子 輸入 Aspell 後,其可以幫我們檢查出錯誤的拼字,並且列出此錯誤拼字有可能對 的拼法。在此部份我們是純做拼字錯誤的檢查,至於字意使用不當或是用錯字, 在此部份不做檢查,而列入下一節的文法檢查來完成。例如:I have much apples. 此句有文法使用上的錯誤,但完全沒有拼字錯誤,所以拼字檢查無法檢查出。. 22.
(34) 3.3.2 文法檢查 曾任暨南國際大學校長李家同在「專門替中國人寫的英文基本文法」一書中 提到: 我們發現我們中國人寫英文句子時,會犯獨特的錯誤,比方說,我們常 將兩個動詞連在一起用,我們也會將動詞用成名詞,我們對過去式和現 在式毫無觀念。更加不要說現在完成式了。而天生講英文的人是不可能 犯這種錯的。[22] 進而提出他認為中國人應該注意英文文法最基本規則: 規則(1):兩個動詞是不能聯在一起用的。 規則(2):如一定要同時用兩個動詞,後者的前面必須加“to"或者將後者加 入“ing"。 規則(3):主詞如果是第三人稱,現在式及單數,動詞必須加 s.。 規則(4):絕大多數的否定的句子,不能直接加“not"。 規則(5):在不定詞“to"的後面,必須用原形動詞。 規則(6):英文中有所謂的助動詞。 規則(7):英文問句要有助動詞。 規則(8):特殊動詞隨主詞的變化。 諸如此類的英文文法真是非常多,也是在此答題系統最重要的一環。 而我們在此利用 2.3 節所提到的 Apple Pie Parser 程式,為我們解析出句子的句構 及標記詞性,再利用程式去檢查其句構上種種的文法問題,進而達到文法檢查的 目的。. 3.3.3 語義檢查 在答題驗證過程的最後一步就是語義檢查,命題委員在命題時,對於該題的 答案一定會有些標準答案或是答題的方向,而我們也必須針對這些部份進行檢 查,檢查受測者在答題裡是否有符合標準的部份,有符合該題也才能給分,沒有 符合當然該題不能算對。就像考作文一樣,如果洋洋灑灑的寫了一大篇的文章, 可是文不對題,那老師一定不會給你分數的。 我們對於語義檢查的部份,就必須先由命題委員對於該試題的答題標準,先 給數個答案的關鍵字,來做為語義檢查部份的標準答案,就像是選擇題出完題 後,就會有一個標準答案是「C」一樣。再來利用 2.1 節提到的英語詞彙資料庫 23.
(35) ─WordNet,針對關鍵字在資料庫中找尋出相對的同義字。最後,我們就將這些 關鍵字與關鍵字的同義字來比對答題的內容,如果有用到這些字,表示有達到答 題標準,就給予通過語義檢查;如果沒有,則表示沒有達到答題標準,不能通過 語義檢查。. 24.
(36) 四、系統設計與實作 4.1 前處理 現在的電腦速度快,命題老師在試題的出題上,已經不再單單是以前的純文 字,一定會為了試題的生動與活潑,加入大量的圖片、聲音、影片,成為多媒體 試題,而此系統只單單做文字上的檢測,所以原始的試題需經由以下三道前處理 的步驟,以簡化系統後續流程的工作。[30]. 前處理 原始 試題. 正規化. 斷句. 斷詞. 前處理 試題. 圖 12:前處理系統概念示意圖. 4.1.1 正規化(normalization) 我們從系統得到試題或是答題,或許可能含有各式各樣的多媒體內容,我們 須要從混合了文件標題、主題文字、圖片與影音檔案的網頁內,將主體文字的部 份擷取出來,並以純文字方式儲存這些試題或是答題的文字內容。 而在目前現有的網路英檢試題中,都是在此系統概念提出前,就已經命題完 畢,許多試題中的文字部份,都是以圖片格式製作而成(如圖 13)。所以在此次研. 25.
(37) 究中,無法輕易的將其轉換成純文字格式,我們是利用人工將圖片、影音檔案 中,利用人工的方式,將其文字的部份取出來使用。. 圖 13:網路英檢擬模試題畫面. 4.1.2 斷句(sentence segmentation) 每個英文句子的結尾,皆是以句點或是問號來做為結束,就以此為斷句的依 據,但須要排除一些例外的情形,例如:”Mr.”,使用到縮寫,則此時的句點並不 能代表句子結束,必須要特別處理。 我們利用一小段副程式來做此部份工作,程式流程中主要是以句點及問號來 做為斷句的依據。而在程式中如果遇到句點時,會去找尋程式中建立的縮寫資 料,如果是縮寫就視為單字,直到有句點時又不是縮寫,則達到斷句條件,進行 斷句工作。而目前縮寫資料只有生活中較常用到的縮寫,例如:Dr.、Miss.、 Nov.、a.m.。. 4.1.3 斷詞(tokenization) 斷詞的工作在英文句子處理中算是相當容易。由於英文的詞與詞之間是以空 白(space)作為間隔,例外僅發生於兩個狀況,第一是大部份的文件格式中,標點 符號會緊接在詞之後,無空白間隔;其次是縮寫詞的情形,常見的如 “I" 與 “am" 縮寫成 “I’m",“is" 與 “not" 縮寫成 “isn’t"。因此斷詞的工作是 26.
(38) 將標點符號與其所鄰接的詞分離,並將縮詞拆開。例如句子 “The stock didn’t rise $5." 經斷詞後成為 “The stock did n’t rise $5 ."。名詞的所有格與阿拉伯 數字並不在我們處理斷詞的考慮範圍內。譬如“Kevin’s" 與 “1500",皆是當 成一個詞處理。 對於斷詞這個部份,我們是利用Apple Pie Parser程式中,有一個斷詞的副程 式來幫我們處理。例如上段提到的例句” The stock didn't rise $5. ”,其就會完成 斷句而成「(S (NPL (DT The) (NN stock)) (VP (VBD did) (RB n't) (VP (VB rise) (NPL ($ $) (CD 5)))) (. -PERIOD-))」. 4.2 試題檢測設計與實作 測驗試題. 前處理. 網路英檢參考 詞彙表. 詞彙表分析. 詞彙表級數 網路英檢試題 統計資料庫. 試 題. 字頻、詞彙數 分析. 字頻、詞彙數 級數. 庫. 圖 14:試題檢測系統流程概念示意圖. 試題檢測系統設計後其流程概念圖如圖 14 所示,命題委員命題好的測驗試 題,經過上一節提到的前處理步驟,得到單純的文字模式進行系統檢測。首先依 據「網路英檢參考詞彙表」進行詞彙表分析,分析出詞彙表級數,再依據「網路 英檢試題統計資料庫」分別對字頻及詞彙數進行分析,分析出字頻及詞彙數的級 數,提供給命題委員做為判斷試題級數的參考數據。. 27.
(39) 4.2.1 詞彙表分析 依據「網路英檢參考詞彙表」,將字彙分為入門級、基礎級、初級、中級、 中高級,「網路英檢參考詞彙表」主要參考兩份詞彙表資料,第一份是大學入學 考試中心委託由台灣大學外文系鄭恆雄教授領導的高中英文參考詞彙表編修研究 計畫小組,從八十九年九月起至九十一年六月止,以二年時間,編製出的「大學 入學考試中心高中英文參考詞彙表」[20];另一份是國立高雄師範大學英語系莊 永山教授研發的「網路英檢入門級 500 字參考字彙表」及「網路英檢基礎級 1000 字參考字彙表」[28]。 我們參考其詞彙表分級方式,將詞彙由 Level 1~6 共分為六級: Level 1:依據入門級參考詞彙共 500 字,主要參考「網路英檢入門級 500 字 參考詞彙表」。 Level 2:依據基礎級參考詞彙共 1000 字,主要參考「高中英文參考詞彙 表」之第一級,及「網路英檢基礎級 1000 字參考詞彙表」。 Level 3:依據初級參考詞彙共 2000 字,主要參考「高中英文參考詞彙表」 之第二級。 Level 4:依據中級參考詞彙共 4000 字,主要參考「高中英文參考詞彙表」 之第三、四級。 Level 5:依據中高級參考詞彙共 6500 字,主要參考「高中英文參考詞彙 表」之第五、六級。 Level 6:超出上述 Level 1~5 所列詞彙。 1.原型詞彙表: 因為高中英文參考詞彙表有 25 項之編輯原則,其中有 9 項原則說明許多詞彙 為何不列入詞彙表之原則,所以我們將以上Level 1~5 所列入詞彙稱之為「原 型詞彙表」,建立一個資料庫來處理相關資料,其資料庫欄位格式如下表 5 所示: 表 5 原型詞彙表暨字頻資料庫結構一覽表 欄位. 型態. 校對. 說明 記錄詞彙表序號. wid. int(11). word. varchar(32). level. int(11). 記錄原型詞彙表單字的 Level. freqlv1. int(11). 記錄原型詞彙表字頻使用情形. utf8_general_ci. 28. 存放原型詞彙表單字.
(40) 2.衍生詞彙表: 高中英文參考詞彙表共 25 項之編輯原則中,其中有 10 項原則說明許多詞彙為 何不列入詞彙表[21]: (1) 由於英文形容詞大部分均可接詞尾-ly 變成副詞,故凡是含有詞尾-ly 之副 詞均不列入。(除非意義不同,如 roughly 及 scarcely。) (2) 由於英文形容詞有許多可接詞尾-ness 變成名詞,故凡是含有詞尾-ness 之 名詞均不列入。 (3) 由於英文形容詞有許多可接詞頭 in-、im-、ir-、il-、un-等變成否定形容 詞,故此種形容詞均不列入。(除非含此種否定詞頭之詞彙比不含此種否定 詞頭之詞彙更常用,如 independence、infinite 及 innumerable 等。) (4) 由於英文接 non-(非)詞頭的形容詞或名詞數量甚多而且大多屬低頻詞彙, 如 nonpoisonous (adj.)及 nonparticipant (n.), 同時其意義均可自其詞頭之意義 「非」引伸出來,故除了 nonsense (n.) 及 nonviolent (adj.)兩個常用詞彙之 外,其他均不列入。 (5) 由於英文動詞有許多可接詞頭 re-表示重複動作,故凡是含有表示重複動作 詞頭 re-之動詞均不列入。(但是 review 由於和 view again 意義不盡相同, 故列入。) (6) 由於英文動詞有許多可接詞尾-ment 構成名詞,故凡是以-ment 構成名詞之 動詞均把-ment 放在動詞後之括號內,表示該動詞可以接-ment 構成名詞, 其詞類則標為 v./(n.)。(如果接-ment 之後,原來的動詞拼法改變,則整個 含-ment 的詞彙重列一遍,如 argue (argument。)但是如接-ment 後意義不 同,則列為不同詞彙,如 commit 及 commitment。 (7) 英文有許多動詞可接詞尾-ing 或-ed 變成形容詞,因為相當規律,故均不列 入。(除非意義不同,如 promising (有前途的)及 learned (有學問的)。) (8) 英文有許多名詞可接詞尾-less 變成形容詞,如 fearless 及 homeless,因為 相當規律,故均不列入。 (9) 英文反身代名詞由於詞尾均為-self 或 selves,如 yourself 及 ourselves,相 當規則,故不列入。所有格代名詞如 your、her、our 及 their 可以接 -s 成 為 yours、hers、ours 及 theirs,故把這些代名詞列為 your(s)、her(s)、our(s) 及 their(s),不分開列舉。至於 my,其相對應之代名詞為 mine,拼法甚不 相同,故分開列舉。而 his 之相對應代名詞同為 his,故只列為 his。 (10) 複合詞(compounds)因為大多數可從其組成詞彙瞭解其意義,故儘量不列 入。但是有些複合詞難以從其組成詞彙瞭解其意義者,則列入本表,如 greenhouse、homework、household、housework 等。ought to 及 used to 因 為當作助動詞使用,故各列為一個詞彙。 29.
(41) 而這些不列入詞彙表之詞彙,也有被使用到的機會,故在系統中依據參考詞 彙表的原型詞彙表,做出一個具有以上所列 10 個不列入原則,及相關詞類變 化的衍生詞彙表,讓具有相同級數及詞類變化的詞彙,能夠相對應到適當的 原型詞彙。 表 6 衍生詞彙表資料庫結構一覽表 欄位. 型態. 校對. 說明. word. varchar(50). utf8_general_ci. 存放衍生詞彙表單字. original. varchar(50). utf8_general_ci. 衍生詞彙表所對映到原型詞彙表的 單字. 在衍生資料庫查詢過程中,其處理的原則是: (1) 在高中英文參考詞彙表中有的詞彙,則以此詞彙級數為主。例如: commitment 其動詞是 commit,兩者皆在原型詞彙表中,故算其各自的 Level,所以 commitment 是 Level 5,commit 則是 Level 4。 (2) 衍生詞彙則與其原型詞彙同等級,例如:abandonment 是 abandon 加上 ment 衍生而來,在原型詞彙中沒有,所以其就與 abandon 同算是 Level 4。 (3) 複合詞主要是兩個詞彙組合而成,而其級數則是以當中最高詞彙級數為 主。例如:bookmark 是由 Level 1 的 book 及 Level 2 的 mark 所組合而 成,其級數則是以最高級數 mark 的 Level 2 為主。. 3.專有名詞詞彙表: 高中英文參考詞彙表之編輯原則中,對於專有名詞的處理原則如下: 專有名詞因為數量太多,難以取捨,而且大致不影響文章之理解,故均不列 入。(除了五個專有名詞:English,因為本參考詞彙表的詞彙屬於這個語言, 故列入;Mandarin 因為是國語,故列入;Confucius (孔夫子),因為是中國之 至聖先師,世界聞名,故列入;Christmas/Xmas,因為已經是普世皆知的節 日,又因為 Xmas 常誤拼為 X’mas,故列入;Bible 因為是西方文化之基礎, 故列入。) 然而專有名詞的出現也是常有的事,例如:Paris、Itay,如果依照先前詞彙表 Level 的分級,因為沒有列入原型詞彙表 Level 1~5,所以會被列入 Level 6, 可是其詞彙的難度又沒有到達實際 Level 6 的難度,所以我們建立一個專有名 詞詞彙表,特別將這些專有名詞標記出來,以免讓命題委員誤判試題級數。 其資料庫欄位如表 7,其只有存放專有名詞的單字,如果有查詢到則代表其是 專有名詞。 30.
(42) 表 7 專有名詞資料庫結構一覽表 欄位 word. 型態 varchar(64). 校對 utf8_general_ci. 說明 存放專有名詞的單字. 而「原型詞彙表」、「衍生詞彙表」及「專有名詞詞彙表」之間的關連性如 錯誤! 找不到參照來源。所示。任何一個詞彙要查詢詞彙表時,是先查詢衍生詞 彙表資料庫,找到原型詞彙後,才再對映到原型詞彙表中,查詢出詞彙的級數。 而專有名詞資料庫在查詢時就較為簡單,直接去查詢資料庫,如果資料庫有列 到,則就算題專有名詞。. 原型詞彙表 及字頻資料庫. 衍生詞彙表 資料庫 待驗證 試題. 專有名詞資料庫. 輸出 查詢 結果. 試題詞彙數資料庫 圖 15:試題檢測系統內資料庫關連示意圖. 4.2.2 字頻分析 依據現有的網路英檢試題資料庫,先將其試題的資料,依照上一節詞彙表查 詢方式,進行字頻統計,做為往後字頻分析的參考數據。只要有對映到原型詞彙 表資料庫中的詞彙,則該詞彙的字頻統計數字加一,也就是在表 5原型詞彙表資 料庫中「freqlv1」欄位名稱中的數字加一。例如:某一個試題是「How are you ?」,就分別在「how」、「are」、「you」三個單字的字頻數加一。 如果只是單純統計字頻的數字,就只能看到這個單字在網路英檢試題資料庫 被使用的次數,例如:this 這個字的字頻是 339,這樣的一個數字,似乎看不出什. 31.
(43) 麼端倪,339 到底是多還是少呢?因此我們還做出一個字頻統計的比例分析,是 以字頻去除以所有原型詞彙表字頻的總合,並以千分一的單位來顯示。. 4.2.3 詞彙數分析 經過前處理完畢的試題,就會分出一個一個純粹的單字,利用資料庫來統計 每個不同詞彙數試題出現句子的次數,如下表 8資料庫欄位資料,例如:Hunting and fishing are my hobbies.,此句經分析後,得到詞彙數是 6 個字的句子,所以其 在資 料庫中的wordnum是 6,因此可以在sentnum中查到資料庫中曾經有多少句。 表 8 詞彙數資料庫結構一覽表 欄位. 型態. 校對. 說明. wordnum. int(10). 一個句子的詞彙數. sentnum. int(10). 記錄句子詞彙數的數量. 4.2.4 實作程式流程 了解以上對於詞彙表分析、字頻分析及詞彙數分析的設計與實作概念後,現 在針對試題檢測如圖 16所示的整個系統程式流程,做個詳細的說明。 首先,待檢測試題經過前處理後,一整個句子的試題,就會被切出一個個的 詞彙,而去計算這個句子中的詞彙數共有幾個,就可以去詞彙數資料庫中,去查 詢出這樣詞彙數的句子,在資料庫當中出現過幾句,查出結果後,就直接將此結 果輸出,就完成詞彙數分析的部份。 同樣的在經過前處理得到的這些詞彙,接著會將這些詞彙送入衍生詞彙資料 庫查詢,查詢出該詞彙的所對映到的原型詞彙,例如:books 是名詞的複數,就 會查出原型詞彙是 book;swam 是過去式或過去分詞,就會查出原型詞彙是 swim。 從衍生詞彙中對映出原型詞彙後,下一步就可以送至原型詞彙表及字頻資料 進行查詢動作,其後就可以查詢出此原型詞彙的詞彙表級數與字頻,而完成詞彙 表分析及字頻分析。. 32.
(44) 測驗試題. 前處理. 查詢衍生詞彙 資料庫. 計算詞彙數. 查詢原型詞彙表 及字頻資料庫. 查詢詞彙數 資料庫. 是否為專有名詞. YES. 列為專有名詞. NO. 輸出結果 圖 16:試題檢測系統程式流程圖. 如果經過上述過程,在原型詞彙表中查詢不到的詞彙,那就有兩種情形:一 種是專有名詞;另一種是沒有列入詞彙表中,而算是 Level 6 的詞彙級數。所以 我們接著將這些原型詞彙表中查詢不到的詞彙,可以先判斷其字首若為大寫,則 可列為專有名詞,送到專有名詞資料庫中查詢,如果有查詢到,則列為專有名 詞;如果沒有查詢到,則列為 Level 6 的詞彙級數。 最後試題檢測系統程式執行完成後,其輸出畫面如圖 17所示,其畫面中各部 份內容的意義,將會於第五章系統展示中詳細說明。. 33.
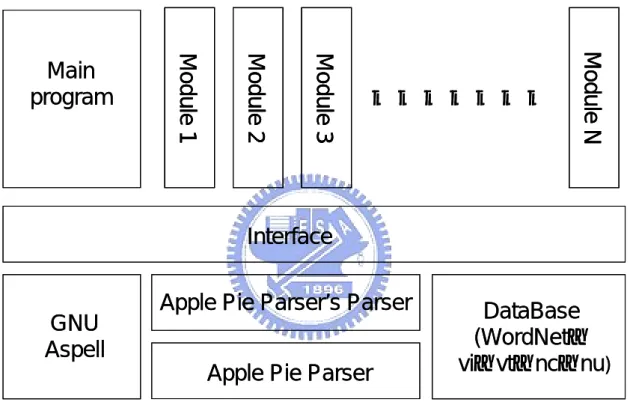
(45) 圖 17:試題檢測系統程式輸出畫面. 4.3 答題驗證設計與實作 4.3.1 系統概念流程圖 受測者在簡答題作答完畢後,其答題的部份,須進入答題驗證系統,開始進 行閱卷,其流程圖如圖 18說明如下: 1. 前處理: 首先,須經過前處理,主要是要處理斷句及斷詞的部份,處理完成為單一句 子後,再做接下來各項的檢驗程序。 2. 拼字檢查: 進行拼字檢查過程中,沒有發現任何一個拼字錯誤視為合格,否則只要有一 個錯誤出現,均視為不合格。檢查只要是不合格者,則直接送至評分系統, 結束此句接下來的驗證工作。如果檢查合格者送至下一步驟進行標記詞性。. 34.
(46) 受測者答題. 前處理 YES. 標記詞性. 拼字檢查 NO. 文法檢查. Error. 評分 系統. Warning. 語義檢查. 人工 閱卷. 圖 18:答題驗證系統概念流程圖. 3. 標記詞性: 標記詞性就是一次看一個句子的每一個字,然後給每一個字一個標記,也就 是該單字的詞性。而標記詞性完畢的句子即可送至文法檢查。 4. 文法檢查: 進行文法檢查的結果有分為「error」及「warning」。結果出現 error 時,表示 句構上有嚴重錯誤,若送至下一步文法規則檢查會有問題,應立即停止檢查 步驟,將結果送至評分系統進行評分;若為 warning 則表示此文法錯誤仍在錯 誤容許範圍內,可以繼續送至下一步文法規則檢查,或進行語義檢查。 5. 語義檢查: 語義檢查則是針對受測者答題部份檢查,是否有符合標準答案部份進行檢 查,檢查完畢的結果送至評分系統做最後的記分。. 35.
數據
![表 2 具有多重意義的單字在Tree-Bank corpus 中分布的情形。[8]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8705866.199642/21.892.162.735.333.735/表2具有多重意義的單字在TreeBankcorpus中分布的情形8.webp)

![表 4 Aspell與其他拼字軟體比較表[14]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8705866.199642/25.892.116.757.554.785/表4Aspell與其他拼字軟體比較表14.webp)
+7
![圖 4 :Aspell與其他拼字檢查程式核心測試比較圖[14] 圖 5 為Aspell的輸出畫面 文章輸入 建議修改文章輸入建議修改 圖 5: Aspell 在 Unix 上執行畫面](https://thumb-ap.123doks.com/thumbv2/9libinfo/8705866.199642/26.892.253.640.129.542/輸出畫面文章輸入建議修改文章輸入建議修改圖Aspell在上執行畫.webp)



Outline
相關文件
In this work, for a locally optimal solution to the NLSDP (2), we prove that under Robinson’s constraint qualification, the nonsingularity of Clarke’s Jacobian of the FB system
Otherwise, if a principle of conduct passes only the universal test but fails to pass this test, then it is an “imperfect duty.” For example, the principle “takes care of
• 測驗 (test),為評量形式的一種,是觀察或描述學 生特質的一種工具或系統化的方法。測驗一般指 的是紙筆測驗 (paper-and-pencil
For HSK: If a test taker is late and the listening test has not begun, test takers can enter the test room and take the test; if a test taker is late and the listening test has
In this thesis, we have proposed a new and simple feedforward sampling time offset (STO) estimation scheme for an OFDM-based IEEE 802.11a WLAN that uses an interpolator to recover
In accordance with the analysis of relevant experimental results carried in this research, it proves that the writing mechanism and its functions may improve the learning
YCT (Levels I-IV)Test: If a test taker is late and the listening test has not begun, test takers can enter the test room and take the test; if a test taker is late and the listening
This research is focused on the integration of test theory, item response theory (IRT), network technology, and database management into an online adaptive test system developed
