國立臺中教育大學資訊工程學系碩士論文
資料串流計算之記憶體排程器
In-Memory Scheduler for Data Stream
Processing
指導教授:賴冠州 教授
研究生:林郁鈞 撰
中華民國一零四年七月
I
謝誌
首先,最先感謝我的指導老師賴冠州教授,如果沒有老師循循善誘的 教導以及耐心的幫我修改論文,單憑我一個人是沒辦法將論文完成的,也 很感謝老師兩年來的諸多照顧,老師讓我能夠專注的在自己的研究領域之 中,不需要被諸多瑣碎雜事煩惱。接下來要感謝台中教育大學資訊工程學 系研究所的各位老師、同學以及學弟妹,研究所研讀了更多關於資訊工程 領域的課程讓我的論文能夠有一個明確的方向,同學們彼此之間相互討論、 請教、教導也讓我能度過重重難關,學弟妹貼心的問候與聊天,讓我在煩 悶的論文壓力中得到一絲放鬆,最後要感謝的就是我的家人,爸爸媽媽提 供我讀研究所的一切花費,讓我可以專心的撰寫論文,不需要為了生活費、 學雜費、住宿費等等問題去操心,哥哥們則是在我寫論文遇到瓶頸的時候, 提供意見來幫助我度過瓶頸,要感謝的人事物真的非常多,我想大聲地對 這兩年來幫助過我的每一個人說謝謝,沒有你們的幫助就沒有這篇論文, 我將完成這份論文的喜悅與所有幫助過我的人共享,感謝各位。II
摘要
近年來,物聯網(Internet of things)越來越熱門,許多不同的感測器被廣 泛的使用,因此持續回傳的資料量也越來越龐大,持續不斷需要處理的資 量流程稱為 data stream processing,如此龐大的資料量稱為巨量資料(Big Data)。
之前的研究通常使用批次處理軟體如 hadoop 來處理巨量資料,然而 hadoop 的 mapreduce 框架並無法有效率的處理 data stream processing,原因 在於 mapreduce 框架主要用來處理非結構化的資料,需要事先分析處理問 題的流程,找出資料中可以平行處理的地方,但是 data stream processing 需要立即處理,沒辦法進行事先分析,故如何有效率的處理 data stream processing 成為一個重要的新研究議題。
本篇論文選擇使用 Apache Spark 作為研究的主要程式,原本 Spark 分 配 task 的方式是隨機分配,可能導致將運算較複雜或者需要較多記憶體的 工作分配到運算速度較慢或記憶體容量較小的 worker 上面,使得運算時間 變長或者無法運算完畢,且因為是隨機分配,有可能會將 task 分配的太分 散,導致機器之間彼此的 communication time 過久和 CPU 閒置的問題。
因此,本研究開發了於 Spark 1.0.2 版本上使用的 profiling system 和提 出一個新的排程演算法,稱為 In-Memory Scheduler (IMS),In-Memory Scheduler 的演算法是基於 worker 的可用 CPU 數目、記憶體大小和 CPU 時脈進行排序,再利用排序好的序列來分配 task,藉此把 task 分配到效能
最佳的機器上優先執行,故本篇論文主要貢獻為修改 Spark 之排程機制,以
達縮短執行時間以及節省運算資源之目標。
III
Abstract
Recently, Internet of Things is emerging and a large amount of data is collected by different sensors. Due to the Internet of Things is emerging, the big data is generated. However, such a large data could not be analyzed efficiently by the traditional computing system.
In the meantime, cloud computing is a possible technology to process the big data. Cloud computing could adopt the virtualization technique to support the enough computing capability to handle the big data. So, we select cloud computing technology to handle big data.
Previous studies often apply batch processing approaches to handle these big data. However, batch processing could not meet the real-time and data stream processing requirements. So, stream processing for real time data is another important topic.
This study develops a profiling system in Spark 1.0.2 and proposes a new scheduling strategy that called In-Memory Scheduler (IMS) based on memory usage, available CPUs and CPU clock rate. IMS reschedules tasks based on memory usage, available CPUs and CPU clock rate. This proposed approach is evaluated in Apache Spark. Experimental results show the system performance improvement in the Spark stream processing system.
IV
目錄
謝誌 ... I 摘要 ... II Abstract ... III 目錄 ... IV 圖目錄 ... VI 表目錄 ... VIII 第一章 緒論 ... 1 1.1 背景 ... 1 1.2 動機 ... 3 1.3 議題 ... 4 1.4 目標 ... 5 1.5 論文架構 ... 6 第二章 相關研究 ... 8 2.1 雲端運算 ... 8 2.2 虛擬化技術 ... 12 2.3 即時串流處理 ... 15 2.4 Apache Hadoop ... 19 2.5 巨量資料 ... 21 2.6 聯邦雲 ... 24 第三章 研究方法與成果 ... 28 3.1 Profiling System ... 28 3.2 In Memory Scheduler 演算法 ... 35 第四章 實驗效能評估 ... 40 4.1 實驗環境 ... 40V 4.2 實驗結果 ... 51 第五章 結論及未來展望 ... 68 5.1 結論 ... 68 5.2 未來展望 ... 69 參考文獻 ... 71
VI
圖目錄
圖 2-1 Cloud Computing Stack... 10
圖 2-2 全虛擬化 ... 13
圖 2-3 半虛擬化 ... 13
圖 2-4 硬體輔助虛擬化 ... 14
圖 2-5 Spark 基礎架構圖 ... 18
圖 2-6 cluster mode 架構圖 ... 18
圖 2-7 Spark stream processing ... 19
圖 2-8 Overview of Map/Reduce and Hadoop ... 20
圖 2-9 5Vs of Big Data ... 23 圖 2-10 5V 特性之相對關係 ... 24 圖 2-11 聯邦雲 ... 25 圖 3-1 排程機制整體架構圖 ... 29 圖 3-2 Spark 階層圖 ... 31 圖 3-3 經修改過的 WordCount 之 dot 檔... 32 圖 3-4 經修改的 WordCount 之 DAG 圖 ... 33 圖 3-5 SparkKMeans RDD 之 DAG 圖 ... 33 圖 3-6 SparkPageRank RDD 之 DAG 圖... 34
圖 3-7 1.IMS Algorithm flow chart ... 37
圖 3-8 運用 IMS 演算法之整體系統流程圖 ... 37
VII
圖 3-10 Original Spark scheduling results ... 39
圖 4-1 軟體架構圖 ... 41 圖 4-2. 系統架構圖 ... 42 圖 4-3 VPN 架構 ... 43 圖 4-4 IBM BladeCenter HS22 和 HS23 上的虛擬機列表 ... 45 圖 4-5 HP ProLiant DL360 G6 上的虛擬機列表 ... 45 圖 4-6 512MB txt 檔執行 WordCount 之時間 ... 47 圖 4-7 1GB txt 檔執行 WordCount 之時間 ... 48 圖 4-8 executor 可用記憶體大小變更 ... 48 圖 4-9 IMS 演算法排程結果 ... 50 圖 4-10 原先 Spark 演算法排程結果 ... 50 圖 4-11 WordCount 執行 512MB 檔案所需核心數差異 ... 53 圖 4-12 WordCount 之效能改善幅度 ... 57 圖 4-13 K-means 執行 256MB 檔案所需核心數差異... 59 圖 4-14 K-means 之效能改善幅度 ... 62 圖 4-15 PageRank 執行 256MB 檔案所需核心數差異 ... 64 圖 4-16 PageRank 之效能改善幅度 ... 67
VIII
表目錄
表 3-1 繪製 DAG 圖之所需參數... 31
表 3-2 Configuration of Virtual Machines ... 38
表 4-1 網路頻寬測量結果 ... 43
表 4-2 伺服器硬體規格 ... 44
表 4-3 虛擬機之規模大小 ... 46
表 4-4 Configuration of Virtual Machines in Site1... 49
表 4-5 Configuration of Virtual Machines in Site2... 49
表 4-6 512MB 文字檔切割成 5、10 和 15 個 partitions 的執行時間 ... 52 表 4-7 512MB 文字檔切割成 20 和 25 個 partitions 的執行時間 ... 52 表 4-8 1GB 文字檔切割成 10、20 和 30 個 partitions 的執行時間... 54 表 4-9 1GB 文字檔切割成 40 和 50 個 partitions 的執行時間... 54 表 4-10 2GB 文字檔切割成 20、30 和 40 個 partitions 的執行時間 ... 55 表 4-11 2GB 文字檔切割成 50 和 60 個 partitions 的執行時間 ... 55 表 4-12 256MB 檔案切割成 3、6 和 9 個 partitions 的執行時間 ... 58 表 4-13 256MB 檔案切割成 12 和 15 個 partitions 的執行時間 ... 58 表 4-14 512MB 檔案切割成 12、15 和 18 個 partitions 的執行時間 ... 59 表 4-15 512MB 檔案切割成 21 和 24 個 partitions 的執行時間 ... 60 表 4-16 1GB 檔案切割成 15、18 和 21 個 partitions 的執行時間... 60 表 4-17 1GB 檔案切割成 24 和 27 個 partitions 的執行時間... 61 表 4-18 256MB 檔案切割成 5、10 和 15 個 partitions 的執行時間 ... 63
IX 表 4-19 256MB 檔案切割成 20 和 25 個 partitions 的執行時間 ... 63 表 4-20 512MB 檔案切割成 10、20 和 30 個 partitions 的執行時間 ... 65 表 4-21 512MB 檔案切割成 40 和 50 個 partitions 的執行時間 ... 65 表 4-22 1GB 檔案切割成 20、30 和 40 個 partitions 的執行時間... 66 表 4-23 1GB 檔案切割成 50 和 60 個 partitions 的執行時間... 66
1
第一章 緒論
1.1
背景
近年來,物聯網(Internet of Things)的日漸興起,物聯網[30]是指將能 夠獨立給予 IP 位址的所有裝置,透過網際網路、傳統電信網等媒介,全部 連接起來,實現智能化識別與管理,許多不同且大量的感測器被廣泛的使 用,回傳的資料量也越來越龐大,這些龐大的資料量被稱為巨量資料(Big Data) [6][26],除了物聯網,包括氣象學、天文學、生物學、網際網路檔案 處理、社群網路、電子商務等等眾多領域也都應用到巨量資料的分析。由 於巨量資料的分析需求,若是企業或者一般使用者想要分析這些巨量資料 就必須要付出高額的成本來購買高效能機器才能分析出有意義的結果,且 資料量是源源不斷的生成且回傳,依靠傳統的小規模電腦叢集已經無法進 行分析和處理,因此符合擁有強大運算能力和降低使用者運算成本的雲端 運算(cloud computing)[27]成為處理巨量資料的合適技術,雲端運算透過虛 擬化技術提供足夠的運算資源來處理巨量資料,且因為是使用才付費的原 則,企業可以節省購買大量高效能機器的成本。 雲端運算主要的概念是將共享的軟體和硬體資源整合起來並且設置 在某處,再由使用者經由網路提供給電腦或其他裝置進行存取,部分如 Amazon、Google、Microsoft、Salesforce、GoGrid、AT&T 等公司提供雲端 服務給客戶使用,再依據使用者的需求來付費取得所需之運算資源,稱之 為用多少、付多少(pay as you go) 的方式。2 定義出服務模式主要分為三種,分別為軟體即服務(SaaS)、平台即服務 (PaaS)、基礎設施即服務(IaaS)。 雲端運算將運算資源當成服務提供給使用者,使用者依據自己所需之 服務進行付費並取得同等價值之運算資源,雲端運算具備下列八項特徵 [27]:1.用多少、付多少的自助服務、2.可隨時隨地利用任何擁有網路的裝 置進行存取、3.多人共同分享資源池、4.能夠快速重新部署、5.有監控與量 測的服務、6.使用虛擬化技術達到快速部署資源或取得服務、7.減少使用 者終端的處理負荷、8.降低了使用者對於 IT 專業的依賴性。 使用雲端運算不需要透過第三方認證來取得服務,只要使用者有需求 就可以透過網路來獲得運算資源,且運算資源不再是一個人所擁有,而是 採用大家共享資源的方式來提供服務給許多不同的使用者,雲端運算透過 虛擬化技術讓固定的運算資源可以擁有更高的使用率,使用者透過網路就 可以獲得大量運算資源,不再需要花費高額資金去購買高效能的機器。 在傳統的運算資源使用方式下,企業需要準備大量的運算機器來應付 短時間可能突然暴增的需求量,但是其實大多數的時間並不需要使用到這 麼多的運算機器,造成企業花了高額資金購買大量機器,卻無法有效率的 運用機器。 但是,透過雲端運算就能解決企業這樣的問題,雲端運算能滿足不同 變化的需求,如遇到需求量暴增的尖峰時期,可透過增加付費來獲得更多 運算資源,相反的,如遇到需求較少的時期,可以減少運算資源,藉此節 省企業消費金額,所以雲端運算擁有高度的彈性,可隨著使用者的需求變 化來做調整,更加符合現代社會使用者或企業的需求。
3
1.2
動機
除了上述的雲端運算技術之外,之前的研究對於這些巨量資料都是使 用批次處理像是 hadoop。但是,現在的資料不但越來越龐大且是會持續不 斷的產生,批次處理已經無法全面性的滿足現在使用者的需求,而且越來 越多的應用程式要求要在很短暫的時間內完成計算並回傳數值,故即時的 資料處理因應這個潮流應運而生,而且現在的資料量就像水流一樣不停的 傳送過來,因此串流處理也是成為新興研究的主題之一,同時滿足快速計 算完畢和處理持續不斷的資料量兩種條件的即時串流處理儼然成為一個 新的研究主題。 本篇研究論文的動機來自目前串流資料(stream processing)[6]處理的 使用十分普遍且需要即時性的處理,故即時串流處理的效率顯得越來越重 要,且因資料量越來越龐大,使用個人電腦或小規模的叢集系統已無法分 析出有意義的結果,所以需使用雲端運算來得到足夠的運算能力,故本篇 論文使用雲端運算環境以及提出一個改良即時串流資料處理系統排程機 制的演算法,藉此提升 real time data stream processing 的效率,本研究是使 用 Apache Spark[3]來進行開發以及效能評估,原先 Spark 分配 task 的方式 是隨機選取已經註冊的 worker,如果該台 worker 有可執行 task 的 CPU 就 將 task 分配下去,這樣的排程方式會出現一些風險,例如可能會造成將運 算較複雜或者需要較多記憶體計算的 task 分配到運算速度較慢或記憶體容 量較小的 worker 上面,使得運算時間變長或無法運算完畢,除此之外,因 為是隨機分配的排程演算法,所以每台 worker 的 CPU 使用並不會達到最 有效率的狀態,會產生 CPU 閒置的問題。 為了避免處理巨量資料造成機器之間過多的 communication time 和降4
低完成相同工作所需機器數目以及克服即時串流資料處理的效能瓶頸,故 本篇論文提出了一個新的排程演算法名為 In-Memory Scheduler (IMS), In-Memory Scheduler 的演算法是基於虛擬機所擁有的核心數、記憶體多寡 和核心數時脈來進行排程,先將 worker 按照其所擁有核心數、記憶體和核 心數時脈依序排列下來,接下來將此排列好的序列來分配 Task,使得效能 較優的虛擬機可以優先執行工作。因為 Spark 使用 Resilient Distributed Dataset(RDD)當成 input 進行運算,當資料從外部讀入記憶體中就會變成 RDD,Spark 的所有運算的 RDD 都是在記憶體中進行轉換,並不會有存回 硬碟或讀取硬碟的動作,要等到整個應用程式執行完畢後才會將 RDD 由 記憶體中轉移到硬碟中進行儲存,故改良 Spark 原先的排程機制必須 in memory 進行排程才符合 Spark 原先的設定,所以本篇論文以 in memory 的 排程為主要的目標。
1.3
議題
由於巨量資料的來臨以及即時串流處理的要求,如何快速且有效率的 進行即時串流資料處理成為了一個非常重要的議題,由於是即時處理,排 程機制的演算法不能太過於複雜,否則花費太多計算時間才得到排程結果, 已經違反了即時處理的要求。 故原先的 Spark 使用最簡單的隨機分配排程機制,若機器負荷不了計 算量崩潰,可用很快的速度重新隨機選取別台機器將工作再分配過去,用 極快的處理速度來面對問題,但是由於是隨機且不重複的去散佈 task,使 得 task 都分配在不同的機器上,若 task 與 task 之有相依性的話,則網路通5
訊的延遲將導致執行時間變長,故本篇論文想提升資源的使用率和降低機 器之間彼此透過網路的通訊時間,提出了名為 In-Memory Scheduler (IMS) 的演算法,希望能達成提升資源的使用率和降低機器之間的網路通訊時間, 使得整體執行時間縮短。 為了要達成這個目標,本篇研究修改 Spark 原始碼,包括原先每台 executor 只能統一設定相同數值的可用記憶體,導致擁有較多記憶體的機 器只能配合較小記憶體的機器,使用較少的記憶體來進行運算,而 Spark 本身最大的賣點就是 in memory 的計算,讓處理速度大幅提升,故本篇論 文修改 Spark 的原始程式碼,使得每台 executor 都可以使用到整台虛擬機 所擁有的記憶體。除此之外,也將原先的隨機分配 task 的排程演算法變更 為本篇論文提出的 IMS 演算法,按照可用核心數、記憶體大小和核心數時 脈來分配 task 要去的機器,此外,本篇研究開發適用於 spark 1.0.2 版本的 profiling system,方法為在 spark 執行過程中抓取參數,儲存成檔案並繪製 應用程式的 RDD DAG 圖,藉此讓使用者了解應用程式的內部運行結構, 有助於添加更多條件來設計即時串流處理排程演算法,例如了解 RDD 之 間的相依性或 Task 之間的記憶體使用量、I/O 存取量,透過關鍵路徑等等 演算法來排程出最好的 Task 執行順序後,再傳回由 IMS 排序好的優先執 行順序,希望藉由此流程大幅提升 Spark 的效能。
1.4
目標
使用雲端運算環境時,網路是一個很重要的媒介,不論是虛擬化技術 的使用、物聯網的應用、監控程式運行等等服務皆透過網路來進行,故網6
路延遲對於即時串流資訊處理是一個很重要的影響因素。每個應用程式的 運算結構中,task 與 task 之間有些會有相依性,若 task 是屬於需要高通訊 量的 task,一旦網路延遲變大,整體的執行時間就會出現大幅度的增加, 且若執行時間越來越久,租借機器來運算的成本也就會越來越高,所以要 如何降低網路延遲對執行時間的影響就是一個很重要的研究。 本篇研究提出的 IMS 演算法在不超過機器的最大負荷量的前提下,透 過將大部分的工作優先分配給計算能力較佳且能執行較多 task 的機器,不 但能讓 task 之間減少透過網路進行通訊,藉此降低執行時間,而且因為將 每台機器的 CPU 使用個數提升,相同的應用程式比起原先 Spark 的分配機 制能使用較少機器就能執行完畢且執行效率還更快,不但提升了即時串流 處理系統的整體效能,而且若是以租借機器來運算的使用者來說,可以租 借較少的機器來執行相同數量的 Task,降低了使用者租用機器的費用。
1.5
論文架構
本論文主要分為五個章節:第一章節說明本篇論文研究的背景、動機、 議題以及目標,在本章節說明研究的整體概述以及為何要提出新演算法來 達成所希望之效果。第二章節分為六個部分,分別是介紹雲端運算之相關 資訊、虛擬化技術的使用、即時串流處理、Apache Hadoop、巨量資料以 及聯邦雲這六類的相關文獻探討。 第三章節為研究方法與成果,本論文設計出應用於 Spark 1.0.2 的 profiling system,藉由優先讓 Spark 執行應用程式一遍後,取得相關參數以 檔案形式儲存起來並繪製出應用程式的 RDD DAG 圖,讓使用者了解每個7
不同應用程式的架構為何,搭配 profiling 出來的結果和 Task 的排程優化, 提升 Spark 的運算效能,以及提出一個名為 In-Memory Scheduler (IMS)的 新演算法,提升虛擬機的使用效率、減少執行時間以及降低使用者花費在 租用機器上的成本。第四章節為實驗效能評估,描述實驗的環境和實驗結 果的分析以及與原先 Spark 排程機制的比較。第五章節為本論文的結論以 及未來展望,最後則為參考文獻。
8
第二章 相關研究
2.1
雲端運算
雲端運算的架構在 Rafael Moreno-Vozmediano et al.[17]的文章中有介 紹將資料中心再加上雲端作業系統就形成了雲端架構的環境,也提出在聯 邦雲上關於虛擬化技術的使用,分析如何最佳化以及分配與重新分配運算 資源的策略。San Murugesan [13]的研究提出了雲端環境會遭遇到的問題, 例如如何管理雲端應用程序中的安全資訊、供應商該如何提高他們的服務 可靠度以獲得使用者的信任、如何將雲端運算和巨量資料,用於分析與行 動應用之間的關係產生各種新的應用等等。 雲端運算[18][27]擁有四種不同的部署模型,根據美國國家標準和技術 研究院(NIST)[14]的雲端運算定義中分為公用雲(Public Cloud)、私有雲 (Private Cloud)、社群雲(Community Cloud)、混合雲(Hybrid Cloud),以下 分別介紹四種不同的部署模式: 1. 公用雲:公用雲服務是透過網路和第三方服務供應商,開放服務供客戶 來使用,可分為免費提供服務或是向客戶收取比較低廉的價格來提供服 務,公用雲的使用者資料並不代表可以讓任何人檢視,而是由公用雲服 務供應商對使用者採取存取控制機制。 公用雲的好處是降低機房管理和硬體維護等成本、享有任何時間隨 付即用的便利和服務選擇性多樣化。缺點則是個人機密資料的資訊安全 問題和須承擔服務中斷的風險。目前比較知名的公用雲服務提供商有 Amazon EC2 和 Windows Azure 等。
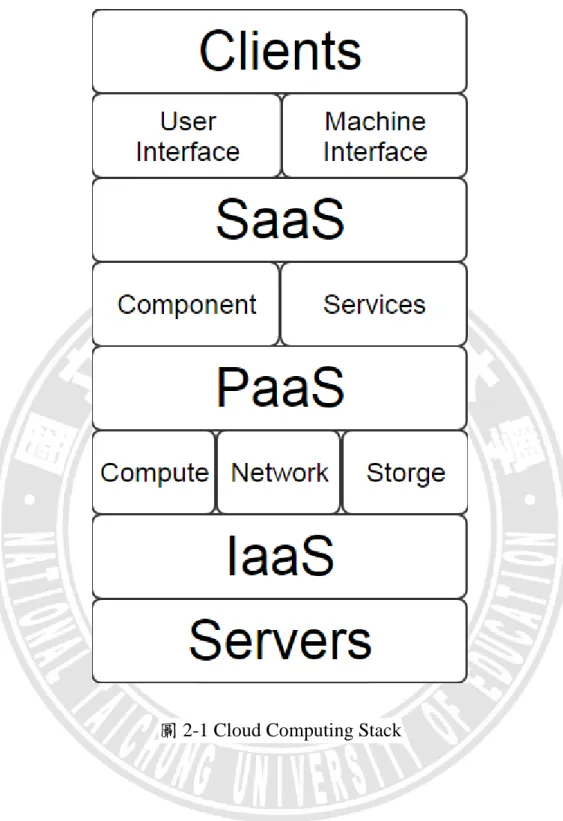
9 2. 私有雲:公用雲和私有雲的差別在於私有雲所提供的服務中,所有的資 料和程式都是由建構私有雲的組織內部所管理,而且不會有法規限制、 資訊安全疑慮以及網路頻寬的影響。 私有雲的優點為可以自行對伺服器軟硬體客製化和可從底層自行設計 防火牆或機密資料保護機制。缺點為維護成本比公用雲來的高。 3. 社群雲:社群雲是由於許多擁有相仿利益的組織因為其特殊需求而建立, 社群雲的實體資源由社群當中的組織進行管理或交由第三方管理,社群 雲多為企業所採用。 4. 混合雲:由各種不同種類的雲混合而成,包含公用雲、 私有雲或社群 雲,同時擁有公用雲和私有雲的優點,混合雲的用戶將非關鍵的資訊在 公用雲上面進行處理,而機密資訊則儲存在私有雲中,兼顧方便性及資 訊安全性,混合雲的服務收費機制則由目前提供服務的雲種類來計算。 雲端運算根據建置架構[40]分為三類,分別為應用程式、平台和基礎 設施來提供不同型態的服務,三種不同型態的服務如圖 2-1 所示,分別為 軟體即服務(SaaS)Software as a Service、平台即服務(PaaS) Platform as a Service 和基礎設施即服務(IaaS) Infrastructure as a Service[29],以下介紹這 三種不同的服務型態:
10
圖 2-1 Cloud Computing Stack
1. 軟體即服務(SaaS):軟體服務提供商會以租借的方式提供軟體給客戶, 而不須客戶購買,常見的方式是提供一組帳號密碼給客戶進行軟體租借。 軟體即服務是安裝於集中式的網際網路伺服器上並且確保在網際網路 或者區域網路中可以正常執行,軟體即服務是目前雲端運算中最流行的 類型,亦被稱為軟體需求。
11
優點在於高靈活性、卓越的服務、高度的可擴展性以及較低的維護 成本,目前市面上較知名的軟體即服務有 Google Apps 和 Saleforce.com。 採用 P2P 技術的 Skype、youtube、Facebook、Twitter 等網路應用程式 皆屬於不同類型的 SaaS 服務。
2. 平台即服務(PaaS):PaaS 是指提供了一個資訊開發人員的平台,資訊開 發人員可使用 PaaS 服務商提供的介面或 API 進行程式碼的撰寫,知名 的 SalesForce.com 的 Force.com 就是 PaaS。PaaS 提供了在相同的叢集 開發環境中服務、測試、部署和維護應用程式的主機。 優點在於用戶只需要專心在平台上撰寫程式碼,不必擔心底層的硬 體如何執行。目前基本上有四種類型的 PaaS,社交應用平台、計算平 台、網路應用平台以及業務應用平台。Facebook 就是一種社交應用平 台,其中第三方可以在上面撰寫應用程式提供給其他用戶使用。 3. 基礎設施即服務(IaaS):IaaS 是指將底層的基礎設施外包給使用者當 成一種服務來使用,知名的基礎設施服務提供商有 google、IBM、 Amazon.com 等等,IaaS 主要提供的服務項目是主機託管和發展環境, 客戶根據自己的需求向 IaaS 服務提供商購買基礎設施的服務,客戶於 使用期間付費,而非將基礎設施購買下來,IaaS 的商業模式是屬於使用 才付費的模式,用戶只需要支付他們使用的服務所需的費用,透過虛擬 化技術提供接近無限的計算資源給客戶,使承載的硬體效益變高,以前 需要企業級的 IT 基礎設施和資源是要支付相當龐大的費用來建構,有 了 IaaS 以後可以只需要花較低的租借成本就能享有企業級的 IT 基礎設 施和資源,這也就是 IaaS 最大的優勢所在。
12
2.2
虛擬化技術
虛擬化[33][39]技術是指一種資源管理的技術,是將電腦的各種實際運 算資源,譬如硬碟、中央處理器、記憶體、網路、伺服器等等資源予以抽 象化並轉換後提供給使用者,打破了以前覺得實體結構間不可分割的觀 念。 優點在於可以更加完善的使用原先各種實體運算資源,這些實體運算 資源透過虛擬化技術產生的虛擬部分是不受現有資源的架設方式、地區或 物理組態所限制。 由於透過虛擬化技術的運算資源將不受架設地點或者架設方式的影 響,因此十分適合應用在雲端運算的當中,其中目前雲端運算常用的虛擬 化 技 術 又 分 為 全 虛 擬 化 (Full-Virtualization)[38] 、 半 虛 擬 化 (Para-Virtualization)[38]、作業系統層虛擬化(OS- Virtualization) 、硬體輔助 虛擬化 (Hardware Assisted Virtualization),以下將對全虛擬、半虛擬、作業 系統層虛擬化以及硬體輔助虛擬化進行說明。 1. 全虛擬化:是比較常見的作法,全部的客戶作業系統都不會看到實際硬 體的資源為何,只能藉由 Supervisor 提供的虛擬硬體來進行運算,如圖 2-2 所示。優點為不需要修改作業系統核心,故能在大部分的作業系統 上運行。缺點則是因為透過二進位轉譯會消耗較多的硬體資源。 2. 半虛擬化:有鑒於一般的虛擬機工作皆是使用完全仿真的方式進行虛擬 化,導致效能上的低落,因此,XEN 在設計上,就希望各個操作系統 能將 XEN 的技術包含進去,如此一來在使用的時候,就可以有局部仿 真的方式產生,讓操作系統能夠直接使用到實際硬體的中央處理器、記13 憶體、硬碟等等資源,而不再需要透過 XEN 做仿真的操作,如圖 2-3 所示。優點為對於硬體資源的消耗較少,缺點為因為必須要修改作業系 統核心,因此能在半虛擬化平台上運作的作業系統種類較少。 圖 2-2 全虛擬化 圖 2-3 半虛擬化
14 3. 作業系統層虛擬化:在原先的作業系統上面模擬出一個行程,全部包含 中央處理器、記憶體、輸入輸出裝置等資源都共用原生的作業系統,優 點在於完全不會有虛擬硬體的負荷,跟原先的機器的效能執行起來並無 太大的差異,但是要使用這種虛擬化技術的限制就比較嚴格,原先的作 業系統和後來虛擬化出來的行程必須使用同一個核心,所以如果是在 Linux 下就只能模擬 Linux,在 Windows 下就只能模仿 Windows。
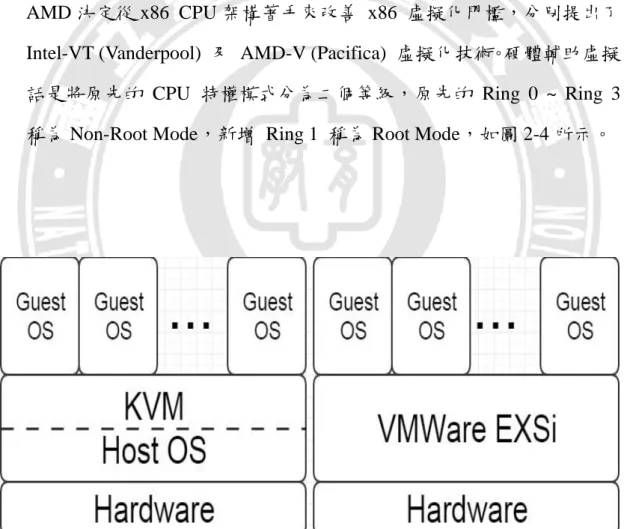
4. 硬體輔助虛擬化:軟體架構虛擬化技術各有其優缺點,因此 Intel 和 AMD 決定從 x86 CPU 架構著手來改善 x86 虛擬化門檻,分別提出了 Intel-VT (Vanderpool) 及 AMD-V (Pacifica) 虛擬化技術。硬體輔助虛擬 話是將原先的 CPU 特權模式分為二個等級,原先的 Ring 0 ~ Ring 3 稱為 Non-Root Mode,新增 Ring 1 稱為 Root Mode,如圖 2-4 所示。
15
2.3
即時串流處理
之前的研究通常使用批次處理的方法來處理巨量資料。然而,隨著資 料量不斷的增長,在個人電腦上使用批次處理已無法提供有效的分析和運 算結果,而且現今的許多應用不僅僅是批次資料而是持續不斷的 data stream processing,因此雲端運算和即時串流處理兩者結合成為符合時代走 向的新興技術,雲端運算透過 2.2 章節介紹的虛擬化技術提供足夠的運算 資源來處理巨量資料,而使用者需要在短時間內就運算完畢就要靠著即時 處理(real time processing)來完成。Wilhelm Kleiminger[34]的文章介紹關於 Hadoop 各個不同模組的介紹, Hadoop 的軟體資料庫是一個 framework,它允許橫跨叢集電腦的巨量資料 分佈式處理,是使用簡單的編程模型來處理巨量資料,也描述了改變原本 的 MapReduce 框架來處理即時運算和提出負載平衡的策略。Xiaomin Zhu et al.[36]的研究提出藉由 rolling-horizon(RH)的最佳化,在即時處理環境且 task 之間彼此沒有相依性的一個 energy-aware 排程方法稱為 Energy-Aware Rolling-Horizon(EARH),研究中亦有提出能做 RH 最佳化的排成架構以及 藉由 VM 的建立、遷移、或移除等等策略動態調整雲的規模,盡可能的符 合即時需求跟節省能源。Mitra Manidipa[12]的文章提出即時資料處理的挑 戰以及介紹分佈式訊息傳遞架構像是 Apache Kafka 和即時訊息處理平台 像是 Storm 來解決即時資料處理的挑戰。
Alok Gautam Kumbhare et al.[1]提出了一個使用於串流處理環境的演 算 法 名 為 Predictive Look-Ahead Scheduling algorithm for Continuous dataflows on Clouds(PLAStiCC),此演算法的預設環境為在有限制資源花費 的情況下,利用簡短的工作量以及效能的預測去主動管理資源 mapping for
16
continuous dataflow 來達成 QoS 的目標。Luca Foschini et al.[11]的研究論文 提出一個動態雲的架構稱為 Dynamic Cloud Infrastructure(DCI),在雲端環 境下用來解決動態以及自動化配置與部署服務,且 DCI 不需要事先知道關 於 service runtime behavior 的資訊,還能提出一個 data stream processing 的 管理模型。
Radu Tudoran et al.[16]的文章提出兩種有效率的策略用於雲端平台的 串流處理且用 ATLAS 應用程式來評估其效能,第一種策略是 overlap computation and communication 在串流處理的資料流中,第二種策略是藉 由複製資料到雲端環境,並且使用複製的資料進行運算,實驗結果顯示挑 選 到 合 適 的 雲 端 環 境 執 行 策 略 能 夠 改 善 應 用 程 式 的 效 能 表 現 。 Scott Schneider et al.[21]的研究論文提出三項貢獻,第一項提出在有存在狀態以 及使用者定義的 operators 下支援自動化發覺安全的資料平行化機會的語 言和編譯器,第二項為當有一個已知的核心數和主機的分散式叢集系統在 使用時,會使用 Runtime 來維持安全性,第三項為設計 streaming fission optimizations 的方法時,利用基本的技術的互相比較,以便維持安全性。 Tang Yuzhe et al.[24]的文章提出了結合多核心處理優點的 auto-pipelining solution 的設計,可以改善 streaming applications 的 throughput,他們使用 micro-benchmarks、synthetic workloads 以及 real-world applications 來評估 他們的設計,並且證明在不需要更改應用程式的程式碼情況下,就能最佳 化 stream processing applications 的 throughput,故本篇論文參考其使用多核 心系統來 pipeline data stream processing 的概念套用到多台虛擬機上來 pipeline data stream processing , 藉 此 提 升 即 時 串 流 處 理 的 效 能 以 及 throughput。
17
paradigm,與 SIMD(single instruction, multiple data)相關,在有限制的條件 下能夠更容易的進行平行處理,資料會不斷的傳入應用程式中就像水流不 斷的往前流動一樣,現今常用的應用是搭配即時處理,本篇論文使用 Apache Spark 來進行即時串流處理[23],Spark 為一種輕量化且快速的即時 串流處理系統,其特點在於執行速度比 Hadoop 更快、便於使用、擁有一 般性,可和多種軟體相互配合、可執行於各種不同的環境如 Hadoop、Mesos、 standalone 或 in the cloud。Spark 快速進行運算的原因在於 in memory computing,除了開始讀檔以及運算完畢將結果寫回硬碟會有 I/O 的干擾, 其餘的運算情形皆將資料放置於記憶體中變成 RDD 進行存取和轉換,故 I/O 干擾的情形並不嚴重,RDD 為 Spark 的核心概念,全名為 Resilient Distributed Datasets(RDDs),是一種容錯且平行處理的數據結構,RDD 中 必定包含(1)一組 RDD 的 partitions;(2)對父 RDD 的一組相依性;(3)一個 函數,表示父 RDD 上執行何種計算;(4)原本的數據,描述 partitions mode 和 data 存放的位置。Spark 為 stream processing 的系統,執行架構是 Task 固定不動,會變動的是不斷流入不同的資料流,是指 RDD 會不斷的傳送 到各個 Task 去進行轉換,為 data flow 的概念,故相依性是建構在 RDD 上 面,所以不會有因為 Task 的 dependency 而導致執行發生錯誤的情形發生。
圖 2-5 為 Spark 基礎架構圖,Spark 主要分為三個部分,Data Storage、 API 以及 Management Framework,本篇論文使用 HDFS 當作 Data Storage, 程式則使用 Scala 語言進行開發。
本篇論文使用 cluster 模式來進行實驗,其架構如圖 2-6 所示,Driver Program 擁有執行應用程式時產生的 SparkContext,跟 Cluster Manager 進 行溝通去分配要執行的 Task,再透過 Cluster Manager 將 Executor 啟動於 Worker Node 上,最後在 Executor 上面開啟 Task 後接收 RDD 帶來的資料
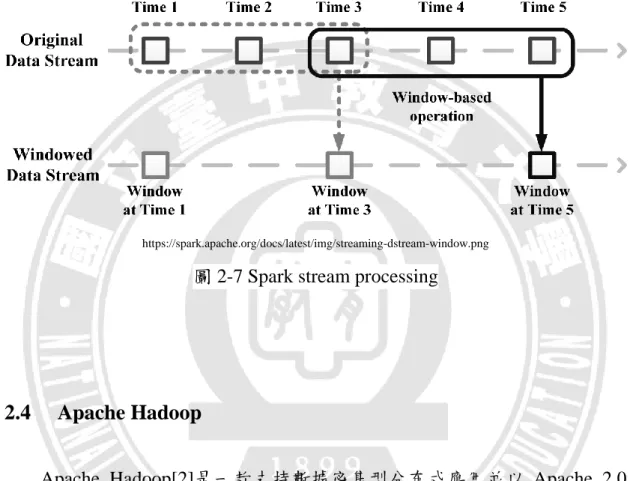
18 並進行運算,executor 彼此之間會進行資料交換。 http://cdn.infoq.com/statics_s1_20150630-0121_1/resource/articles/apache-spark-introduction/en/resources/2.png 圖 2-5 Spark 基礎架構圖 https://spark.apache.org/docs/1.2.0/img/cluster-overview.png 圖 2-6 cluster mode 架構圖 即時串流處理舉 Spark 為例,巨量資料傳入後,首先會被切成好幾個 Batches,接著將每個 Batches 以一個 Windows 為單位滑行,Windows 的大 小可由使用者自行定義,經由滑行過後產生的一部份資料即為即時處理系
19
統一次處理的資料量,最後再經由 Spark Engine 分析後得到計算結果, Spark stream processing 如圖 2-7 所示。
https://spark.apache.org/docs/latest/img/streaming-dstream-window.png
圖 2-7 Spark stream processing
2.4
Apache Hadoop
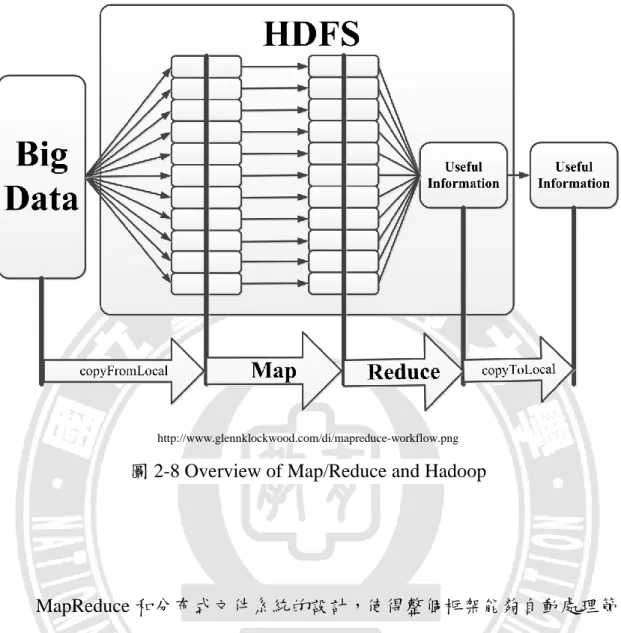
Apache Hadoop[2]是一款支持數據密集型分布式應用並以 Apache 2.0 許可協議發布的自由軟體框架,Hadoop 支援在大型的叢集電腦系統上運行 的應用程序。Hadoop 是根據 Google 公司發表的 MapReduce[31]和 Google 檔案系統的論文自行實作而成,MapReduce 框架的處理巨量資料之流程如 圖 2-8 所示。 Hadoop 的框架具有透明化特性,提供了可靠性和數據移動性,它實現了名 為 MapReduce 的編程範式,應用程序被分割成許多小部分,而每個部分都 能在叢集中的任意節點上執行或重新執行。Hadoop 還提供了分布式文件系 統,用來儲存所有計算節點的數據。
20
http://www.glennklockwood.com/di/mapreduce-workflow.png
圖 2-8 Overview of Map/Reduce and Hadoop
MapReduce 和分布式文件系統的設計,使得整個框架能夠自動處理節 點故障。Apache Hadoop 平台包括 Hadoop 內部核心、MapReduce、Hadoop 分布式文件系統(HDFS)以及 Apache Hive 和 Apache HBase 等等。本篇 論文使用的 Apache Spark 使用 Hadoop 分布式文件系統(HDFS)來進行資 料儲存,並且進行即時串流處理,透過分布式文件系統(HDFS)串聯每台機 器的儲存空間,有足夠的儲存空間來儲放巨量資料以便執行即時串流處 理。
21
2.5
巨量資料
巨量資料(Big Data)[6] [26]又被稱為大數據、海量資料、大資料等名稱, 定義是指資料量規模巨大到在合理的時間內,無法透過人工達到擷取、處 理、管理並分析整理出人類所能理解之資訊。最早是由 Gartner 公司的分 析師 Doug Laney 在 2001 年發表的「3D Data Management: Controlling Data Volume, Velocity, and Variety.」一文[37]中說出了資料處理的三個關鍵 挑戰–– 資料量、速度、多樣性,並在 2012 年 Doug Laney 給予巨量資料 一個全新的定義:「巨量資料是大量、高速、及類型多變的資訊資產,它 需要全新的處理方式,去促成更強的決策能力、洞察力與最佳化處理。」 Wu Xindong et.al[35]的研究定義了巨量資料和如何使用資料探勘演算 法來分析巨量資料,藉以分析出有意義的結果回應給使用者,Quan Jing et.al[15]的文章使用 BigDataBench 軟體來評估三種巨量資料系統,藉以評 斷各種不同系統的優缺點和適用之處,Jia Zhen et.al[8]的研究使用 45 種特 性來將巨量資料的 workloads 分類,根據不同的分類有不同的排程方式。
目前將巨量資料依據特性歸類為「3V」或「4V」或「5V」,本篇論文 以 5V 的觀點對巨量資料做介紹,5V 分別是資料量 Volume、資料傳輸速 度 Velocity、資料類型 Variety、真實性 Veracity 以及價值 Value,如圖 2-9 所示,以下針對巨量資料的 5V 特性進行介紹:
1、 資料量 Volume:以前人們使用電腦手動的畫出表格並且記錄下數據;
然而,現在的數據透過網路、機器、人與人之間的社群網路互動而 產生。日常生活中運用到的許多方面例如:電話來電、電話簡訊、 Line Message、網路搜尋、線上購物…都會一直不斷的生成資料,累
22
積而成龐大的數據量 ,因此資料量變的很容易就達到 TB(Tera Bytes,兆位元組),甚至有可能達到 PB(Peta Bytes,千兆位元組) 或 EB(Exabytes,百萬兆位元組)的等級。 2、 資料傳輸速度 Velocity:是指資料輸入輸出的速度,資料的傳輸是 連續不斷且非常迅速,輸出的數量每天都會越來越多。企業或政府 機構要處理不斷膨脹的資料量,回應、反應這些龐大資料量的速度 將成為最大的挑戰,因為很多資料的結果必須要即時得知才能發揮 最大的價值,故也有人稱 Velocity 為時效性。 3、 資料類型 Variety:巨量資料的來源種類包羅萬象,非常的多樣化, 如果必須將資料進行分類的話,最基礎的分類方式就是分為兩種: 結構化以及非結構化。以前的非結構化資料主要是文字,隨著網際 網路的蓬勃發展,非結構化資料增加了電子郵件、網頁、社交網路、 視訊、音樂、圖片等等,這些非結構化的資料更新速度非常快,導 致資料量大增,造成儲存、資料探勘、分析上的困難。 4、 真實性 Veracity:巨量資料分析出來的內容並非完全都是正確,必 須經由過濾資料將有偏差、偽造、異常的部分去除,防止這些異常 資料損害到資料系統的完整跟正確性,進而影響決策。 5、 價值 Value:巨量資料需經過分析後,才可取得重要價值。
23 http://gt3codeofhonor.blogspot.tw/2015/06/5vs-estrutura-do-bigdata-usar-o-big.html 圖 2-9 5Vs of Big Data 總資料量相等的情形下,與個別分析獨立的小型資料集相較之下,巨 量資料能夠將各個小型資料集合併後進行分析[35]且可以得到許多額外資 訊以及資料關聯性,可以應用於犯罪行為的預防、觀察商業走勢、避免傳 染病擴散、分析消費者消費習慣選擇等許多不同方面,巨量資料的 5V 特 性之間關聯性如圖 2-10 所示。
24 圖 2-10 5V 特性之相對關係
2.6
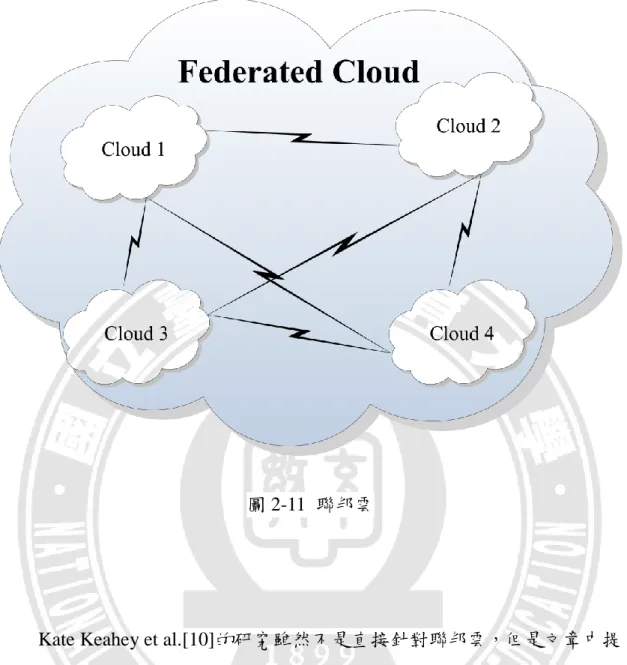
聯邦雲
由於單一雲系統能提供的運算能力已漸漸無法滿足使用者的需求,因 此衍生出一個新的觀念稱為聯邦雲,其概念架構如圖 2-11 所示。由於聯邦 雲的需求以及研究日益增加,故本篇論文也使用聯邦雲的架構來進行實驗, Sheheryar Malik et al.[22]的文章將有相依性高的 Task 分群進行平行處理, 將可大幅減少跨雲的機器彼此之間的網路傳輸量,本篇論文參考這樣的概 念來設計排程機制,以不造成機器負荷過重的前提之下,將工作集中分配 給運算能力較強且能執行較多工作的機器,降低跨雲機器彼此之間的網路 傳 輸 量 , 藉 以 降 低 執 行 時 間 , 以 達 到 更 好 的 效 能 表 現 。 Jose Luis Lucas-Simarro et al.[9]的文章提出了一個新穎的 cloud broker architecture 適 用於多雲環境,文 章內解釋了許多不 同的排程機制 ,並 且評估 High Performance Computing(HPC)和雲端環境中 Web 服務的效能表現,最後透 過實驗證明了他們所提出來的 cloud broker architecture 有更好的效能。25
圖 2-11 聯邦雲
Kate Keahey et al.[10]的研究雖然不是直接針對聯邦雲,但是文章中提 及的 outsourcing 的概念就能套用到聯邦雲解決資源不足的方法上,當資源 不足時,Provider 將增加新的 outsourcing 計算資源到雲端環境中。Rafael Moreno-Vozmediano et al.[17]的研究提出了雲端環境作業系統的概念以及 框架,雲端環境中的作業系統負責控管實體和虛擬資源,且針對其中每個 元件加以解釋,其中與聯邦雲相關聯的概念是 Federation Manager,其功能 是 使 用 Cloud Drivers 和 其 他 的 雲 端 運 算 系 統 連 結 起 來 , 藉 以 達 成 outsourcing 的目標且串接成為聯邦雲,文章中稱此概念為雲端運算聯邦 化。
26
Rodrigo N. Calheiros et al.[19]的文章提到 InterCloud 包含提供資源以 滿足 QoS 條件的雲端資料中心以及提出一個多個雲端系統相互合作的架 構,並且透過實驗證實多個雲端系統相互合作來執行變化量大的應用程式 有較佳的效能,也能更有效率的配置雲端系統上的資源。Gabriel Mateescua et al.[7] 的 研 究 分 析 了 owner-centric HPC 、 Grid computing 和 Cloud computing 並且討論每一種架構的優缺點,他們提出了一個混合性的架構 稱 為 Elastic Cluster , 說 明 Elastic Cluster 的 架 構 以 及 展 示 它 在 HPC workflows 上有更佳的效能表現,最後提出了一個分散式資訊系統結合了 分散式雜湊表以及關聯性資料庫的特點。Toosi, A.N. et al.[25]的研究提出 聯邦雲的環境下該如何配置資源才能達到較好的商業價值,文章中考慮了 使用模式以及基礎設施成本使獲利或使用率達到最高,內容提到的多目標 方法很有建設性,但是缺少考慮聯邦雲中的資源彼此之間的網路延遲,倘 若網路延遲太高,將導致等待傳送的時間遠大於計算時間,故本篇論文將 此種缺失進行改進,減少機器之間彼此的網路溝通量,藉此減少因為網路 延遲太高而可能導致的等待傳輸時間大於計算時間之現象。 聯邦雲的主要架構是擁有許多各個單一雲和物理實體機器,其各自的 網路設定也都可以不同,透過特殊的網路架設方式,使得每個不同的單一 雲彼此之間也能夠相互溝通,本篇論文參考聯邦雲的概念,在兩組不同的 實體機器上面架設叢集系統,並且架設 VPN,使得兩個不同叢集系統上面 的機器也能夠相互溝通,藉此模擬真實的聯邦雲透過網際網路交換資訊的 狀態。 現今的研究有提到目前的雲端運算環境還是屬於各自獨立架設的結構, 不過經過更長時間的發展之後,雲端運算服務供應商將會相互提供服務並 且增加自我提供服務之規模,目前雲端運算服務日趨商業化,並且能夠提
27 供服務的種類也日益增加,若未來雲端運算服務供應商想要彼此聯合,勢 必要經過一番整合。每個雲端運算服務供應商都有各自不同的所在地和異 質性的硬體設備,如果要彼此整合起來,勢必是需要依靠著中介軟體來相 互溝通,用於整合使用的中介軟體在設計方面就要考量跨雲環境的控制以 及運算資源的配置。 除此之外,要整合雲端運算服務提供商將需要考量服務提供商彼此之 間的溝通以及運算資源的架構,整合雲端運算服務提供商的目的在於聯合 起來的雲端環境能有更好的互通性,在雲端運算的概念中,雲端運算服務 供應商彼此之間工作或服務的轉移難易度,稱之為互通性。異質的雲端環 境要能有更好的互通性,其中一個方法就是使用開放標準,讓不同的雲端 服務供應商彼此之間的溝通能更加順暢,當不同的雲端服務供應商的互通 性越來越好,那麼能提供給客戶的服務能力也就越來越強大,故造就了聯 邦雲的興起。當聯邦雲建立之後,若單一雲端運算服務供應商無法滿足客 戶的需求時,即可透過良好的互通性向其他的雲端服務供應商租借資源以 滿足客戶的需求。
28
第三章 研究方法與成果
此章節介紹現有 Spark 的排程機制的優缺點和改良缺點後所提出的新
排程演算法 IMS 以及實作於 spark 1.0.2 版本上的 Profiling System,透過 Profiling System 所分析出來的應用程式運作參數,在即時串流處理的環境 中搭配上不同的排程演算法如關鍵路徑演算法、bin-packing 演算法、0/1 Knapsack 演算法來進行 Task 的排程,再將排程好的 Task 傳到由 IMS 演算 法排序出來的機器執行順序,藉此提升 Spark 的效能。
3.1
Profiling System
Profiling System 是一種用於分析應用程式之行為與工作特性之工具, 為了瞭解各種不同的應用程式在使用 Spark 執行過程中的結構,本篇論文 在 Spark 中自行開發 Profiling System 來記錄下各種不同應用程式內部的執 行結構並且繪製出 RDD 的 DAG 圖,透過 Profiling System 所得到的參數 如 RDD 之間的相依性、Task 之間的 I/O 傳輸量或記憶體使用量等等,搭 配如關鍵路徑演算法、bin-packing 演算法、0/1 Knapsack 演算法等等排程 演算法來排程出較佳的 Task 執行順序,再創建出最適合該應用程式的 virtual cluster,最後使用此 virtual cluster 來執行由 IMS 演算法排程出來擁 有較好運算能力的機器序列,不但能縮短執行時間,還能提升 throughput。
在 2013 年已有能在 spark 平台上繪製出 RDD DAG 圖的程式,名為 Spark Replay Debugger[4],但是限定安裝在 Spark 0.8.0 之前的版本,若安 裝 0.8.0 版本之後的 spark 將無法順利執行,故本篇論文為了要在 spark1.0.2 版本上獲得應用程式內部結構,參考 Spark Replay Debugger 的程式架構後, 自行在 Spark1.0.2 版本上面實作完成,透過收集 Spark 內部的參數後,傳
29
到 GraphViz 繪製成 DAG 圖,Graph Visualization Software(GraphViz)[28] 是一個由 AT&T 實驗室開發的 open source 工具包,使用於繪製 dot 語言指 令碼描述的圖形,其授權為 Eclipse Public License。GraphViz 由 dot 語言的 圖形描述語言以及產生或處理 dot 檔案的工具組成,架構包含 dot、neato、 twopi、circo、fdp、dotty、lefty。
30
本篇論文自行開發的 Profiling System 使用時機是在第一次啟動 Spark 執行應用程式的時候先記錄下如:RDD 的相依性、Stage 的分層以及 Partition 的大小等等資訊,第一次執行結束後將這些資訊部分轉化為 DAG 圖,並產生 png 和 dot 檔,將其儲存在 Spark 資料夾中,藉此讓使用者了 解應用程式的內部運行結構,有助於提供條件來進行即時串流處理的排程 工作,例如取得 RDD 之間的相依性或 Task 之間的記憶體使用量、I/O 存 取量,再透過關鍵路徑演算法、bin-packing 演算法或 0/1 Knapsack 演算法 等等排程演算法來排程出較佳的 Task 執行順序,再藉此 Task 順序創建出 一個最適合應用程式執行的 Virtual Cluster,最後傳到由 IMS 演算法排程出 來擁有較好運算能力且較低 communication time 的序列去執行,就能夠大 幅度提升 Spark 的效能。因為即時串流處理是很長久且持續不斷的,所以 優先執行一次 Profiling System 來了解應用程式內部結構,使得排程機制有 更多參數進行排程優化是不影響 stream processing 的。整體的提升效能的 排程機制將分為三部分,如圖 3-1 所示,本篇論文實作第一部分 Profiling System 和第三部分 In-Memory Scheduler 排程演算法,第二部分則為目前 Spark 預設的創建機制。
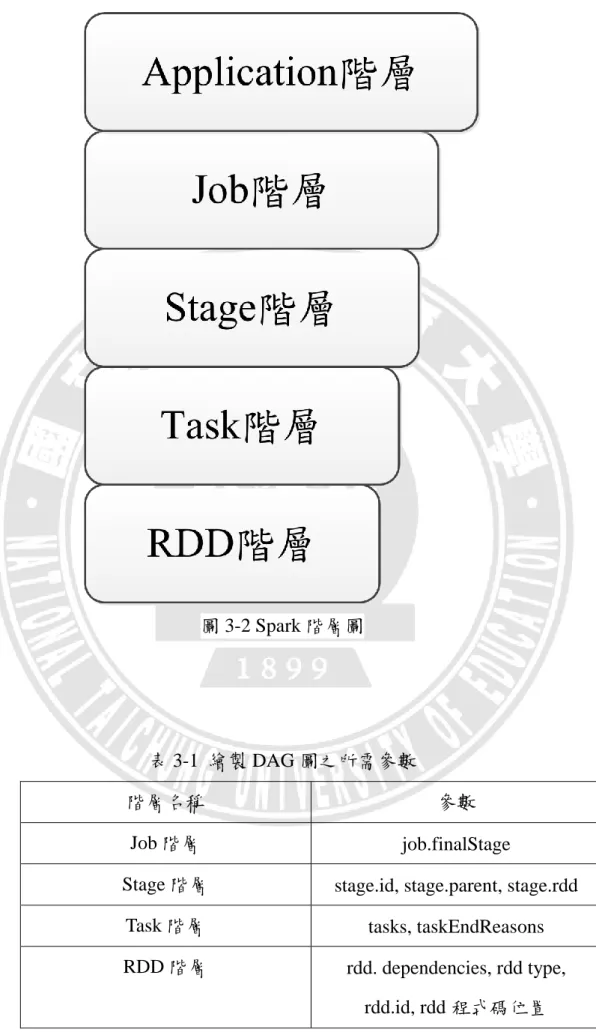
為了繪製出 RDD 的 DAG 圖,本篇論文擷取 Spark 內部各個不同階層 的部分參數,Spark 的階層關係如圖 3-2 所示,最上方為 Application 階層, 依序往下為 Job、Stage、Task、RDD 階層,例如:在 Job 階層抓取 finalStage、 在 Stage 階層抓取 stage id 和 stage parent、在 Task 階層抓取 tasks、在 RDD 階層抓取各個 rdd 的 id 和 rdd 的 dependencies…等如表 3-1 所示,藉由這些 參數來繪製各種不同應用程式的 RDD DAG 圖。
31
圖 3-2 Spark 階層圖
表 3-1 繪製 DAG 圖之所需參數
階層名稱 參數
Job 階層 job.finalStage
Stage 階層 stage.id, stage.parent, stage.rdd Task 階層 tasks, taskEndReasons RDD 階層 rdd. dependencies, rdd type,
32
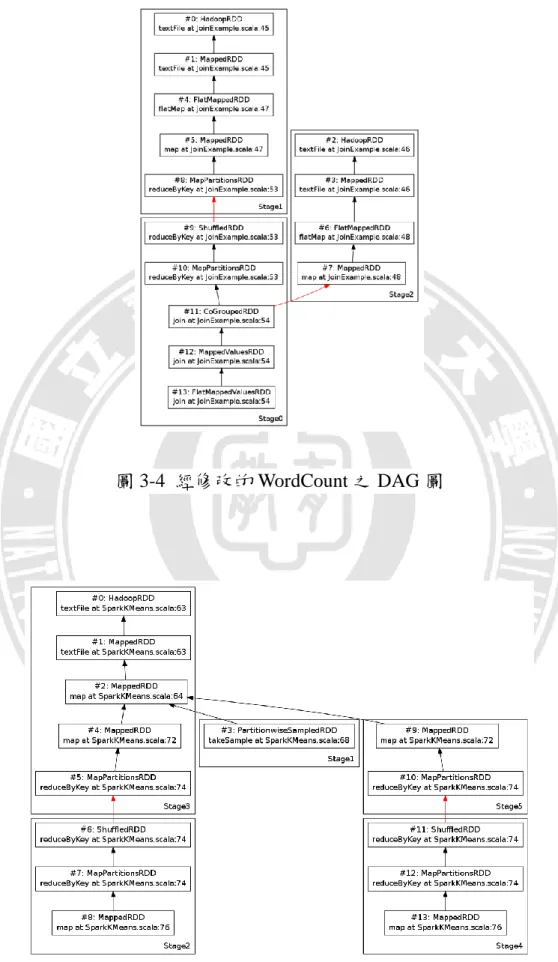
本篇論文執行三種不同應用程式來進行效能評估,分別為 WordCount、 K-means 以及 PageRank,故繪製出此三種應用程式的 RDD DAG 圖。RDD DAG 圖的繪製由 dot 檔的內容所描述,其描述內容畫面如圖 3-3 所示。圖 3-4 為經過修改的 WordCount,經由執行 profiling system 後所繪製出來的 DAG 圖,運算結構為輸入 2 個文字檔,計算字數後再將結果 join 起來, 紅色線代表 shuffle dependency,其餘依賴關係用黑色線表示,大框框表示 為 stage 且右下角顯示 stage 的 id,小框框則表示為 RDD,#號後為 rdd 的 id 以及 rdd 的類型,下方文字為 rdd 轉換指令以及所執行應用程式的程式 碼行數。圖 3-5 為 SparkKMeans 的 RDD DAG 圖,圖 3-6 為 SparkPageRank 的 RDD DAG 圖,經由這些 RDD DAG 圖可了解各種不同應用程式之運算 結果,可提供資訊協助資訊開發人員進行排程優化。
33
圖 3-4 經修改的 WordCount 之 DAG 圖
34
35
3.2
In Memory Scheduler 演算法
原先 Spark 的排程演算法是隨機分配且不會重複分配連續兩個 task 到 相同 worker,若 worker 上有可執行 task 的 CPU 就會分配 task 去執行,原 先的排程方式會導致 task 分散到四處的機器上去執行,造成機器之間的 communication time 過久,導致整體執行時間拉長,且若是租借機器來運 算的使用者,會導致每台機器的使用效益不高,租借的成本提升,故為了 解決上述的問題,本篇論文提出一個新的排程演算法稱為 In Memory Scheduler(IMS)演算法。
In-Memory Scheduler 的演算法是基於虛擬機所擁有的可用 CPU 數目、 記憶體大小以及 CPU 時脈進行 Task 排程,目標為將大部分的工作集中在 效能較佳的機器上執行,並且降低 Task 彼此之間的 communication time 以及節省運算成本,最終可達成有效分配運算資源以及縮短執行時間的效 益,IMS 演算法設計的並不複雜,原因在於即時串流處理需要在極短的時 間內進行排程,若演算法設計過於複雜,將會導致過多時間在執行排程演 算法,進而使執行時間變得更久,故因為在執行演算法不能過久的限制下, 本篇論文設計出一個短時間就能排程完畢且能提升即時串流處理效能的 排程演算法。
傳入 Spark 的資料將會被切成每個大小相同的 partitions,一個 partitions 相當為一個 Task,故每個 Task 的大小都相同,若第一個 Task 所需求的記 憶體大於可用機器的最大記憶體,就表示全部 Task 的需求都大於可用機器 的最大記憶體,根本無法執行這個程式,故在一開始啟動 spark 就會發現 沒有足夠資源可供執行而將此應用程式關閉。
36 Algorithm:In-Memory Scheduler Input:list
Output:executor index
1、 Put SparkContext into SortedlistBackend to find the executor with specific factors and sort the executors based on Total available CPUs, Memory and CPU Clock Rate.
2 、 Store the sorted list in descending order by Total available CPUs, Maximum Usable Memory and Highest CPU Clock Rate.
3、 Get executor index in shuffle offers by sorted list 4、 Submit tasks to the specific executor by executor index 5、If (submit all tasks to executors)
Exit Else
Repeat above steps
第 一 步 先 將 執 行 應 用 程 式 產 生 的 SparkContext 傳 入 自 己 撰 寫 的 sortedlistBackend,此程式是使用 thread 形式來執行,在裡面擷取每台 executor 中所擁有的可用 CPU 數目、記憶體大小以及 CPU 時脈。第二步 依據可用 CPU 數目最多、記憶體大小最大、CPU 時脈數最高三種條件依 序排列 executor 存成一個 list。第三步擷取原先 Spark 的排程序列出來和已 經排序好的 list 比對 executor index。第四步使用已經排序後的機器順序分 配 task 到 executor 上面。第五步若所有的 task 都分配完畢就離開 IMS 演算 法,若還沒分配完畢就跳回第一步驟繼續往下執行,圖 3-7 為 IMS 演算法 之執行流程圖。
37
圖 3-7 1.IMS Algorithm flow chart
38
舉例說明 IMS 演算法的排程機制,假設目前擁有如表 3-2 所示的 1 台 master 加上 4 台 worker 虛擬叢集,有一個 16 個 task 的工作需要執行,使 用兩種排程演算法之排程去分配 16 個 task,各自排程結果如圖 3-9 和圖 3-10 所示,原本 Spark 的排程機制是隨機分配,可能導致將需較多記憶體 或執行較久之工作分配到記憶體較小或執行速率較慢的機器上面,且分配 Task 較分散,會造成機器之間擁有較長的 communication time 和每台機器 上有 CPU 閒置的問題,IMS 演算法依照可用 CPU 個數、記憶體大小和 CPU 時脈來給予優先權,讓可執行較多工作和擁有較多記憶體且運算速度較快 的機器優先取得工作,因表 3-2 顯示 Worker 4 可執行較多工作和擁有較多 記憶體,故會先將 Task 分配到 Worker 4 上面去執行,等到 worker 4 都排 滿 Task 後,再接著依照擁有 CPU 數目和記憶體大小分配 Task 給 worker3, 依此類推下去分配 Task,圖 3-8 表示 IMS 演算法於 Spark 系統中整體的執 行流程,包含從開始啟動到 task 產生再到分配給 executor 上後結束的整體 流程。
表 3-2 Configuration of Virtual Machines
Size Memory VCPU Disk
Master m1.medium 4GB 2 cores 40GB
Worker1 m1.medium 4GB 2 cores 40GB
Worker2 m1.medium 4GB 2 cores 40GB
Worker3 m1.large 8GB 4 cores 80GB
39
Core1 Core2 Core3 Core4 Core5 Core6 Core7 Core8 Worker1 Task15 Task16
Worker2 Task13 Task14
Worker3 Task9 Task10 Task11 Task12
Worker4 Task1 Task2 Task3 Task4 Task5 Task6 Task7 Task8 圖 3-9 IMS scheduling results
Core1 Core2 Core3 Core4 Core5 Core6 Core7 Core8 Worker1 Task1 Task6
Worker2 Task4 Task7
Worker3 Task2 Task5 Task9 Task11
Worker4 Task3 Task8 Task10 Task12 Task13 Task14 Task15 Task16 圖 3-10 Original Spark scheduling results
40
第四章 實驗效能評估
4.1
實驗環境
本篇論文使用 WordCount、K-means、PageRank 等三種應用程式來評 估所提出的 IMS 演算法的效能,且由於是使用 Spark 來進行執行,故所有 的資料處理都是 in memory,並不會有大量讀寫 disk 的狀況,故 I/O 的影 響在本篇論文的實驗環境下並不明顯。若記憶體不足以進行 Task 的運算, 就會直接移除掉該應用程式,故 Spark 將 disk 純粹作為儲存使用,並不會 將 disk 暫時充當記憶體容量來輔助計算。WordCount 是一個計算文字檔案 中有多少個字的應用程式,我們修改 WordCount 這個應用程式加入 join 的 指令,使得其內部的結構具有相依性。K-means[20]是一種分類資料點是否 聚集在一起的方式,基本精神就是物以類聚的概念去執行,給予一組資料, 將之分類為 k 類(k 值由使用者設定),主要目標在於將大量的資料點中找出 具有代表性的資料點,這些資料點可被稱為群中心(cluster centers)、代表點 (prototypes)、code words 等,然後再根據這些群中心去進行後續的處理, 包括資料壓縮或資料分類。PageRank[5]指的是網頁排名,又被稱為網頁級 別、Google 左側排名等,是一種由搜尋引擎根據網頁之間相互的超連結計 算的技術,其計算方式是計算各網頁的被連結數,因為超連結可被認為是 對被連結網站的信任投票,因此得票數越高的網站可以被推測其內容越重 要, 值 得 被排 序 在 前面 。PageRank 的運算公式被定義為 一個網站的 PageRank 值,來自於加總所有連結到該網站的網站之 PageRank 值除以本 身的導出連結數。 圖 4-1 為雲端系統之軟體架構圖,我們使用 Ubuntu 12.04 為 Operating System,使用 Openstack 來創建虛擬機,並於虛擬機安裝 hadoop 2.2.0 以及
41
Spark 1.0.2,Profiling System 在應用程式的下方跟著執行,當三種不同的 應用程式執行於虛擬機上就會記錄下其內部運作結構,執行結束後就產生 RDD 之 DAG 圖,並且儲存於 Spark 的資料夾當中。
42
圖 4-2 為實驗系統架構圖,使用者透過網際網路連接到 NTCU 的雲端 環境,然後在四台實體機上面虛擬化出八台虛擬機,然後組成兩組不同的 virtual cluster,最後透過 VPN 將兩組不同虛擬區域網路的 site 聯合成一個 類似聯邦雲概念,VPN 的架構如圖 4-3 所示,透過 VPN 將兩種不同設定 的虛擬區域網路連結成能彼此互相溝通的雲端運算環境。
43
圖 4-3 VPN 架構
為了瞭解在透過 VPN 串聯起來的叢集系統的網路頻寬,我們使用 iperf 軟體進行網路頻寬的測量,iperf 是一種常用於量測 TCP/UDP throughput 的工具,它屬於 client/server 的架構,可以在兩個端點間做單向或雙向的網 路頻寬測量,網路頻寬的測試結果如表 4-1 所示,可以看出如果 VM 開在 相同的 PM 上面使用的是內部機器的傳輸速度,可達 11.8 Gbits/sec,但是 如果 VM 開在相同叢集系統但是不同的 PM 上面就會透過虛擬區域網路連 線速度會稍微略降到 834 Mbits/sec,若 VM 開在不同叢集系統上面,均須 透過 VPN 來有辦法相互溝通,網路速度就會是真正透過網際網路的傳輸 速度,降到 165 Mbits/sec 左右的速度,故可得知使用虛擬區域網路傳輸速 度比真正透過網際網路連線的 VPN 傳輸速度要快上 10 倍左右。 表 4-1 網路頻寬測量結果 虛擬內網 透過 VPN 單一 PM 11.8 Gbits/sec 165 Mbits/sec 跨越 PM 834 Mbits/sec 168 Mbits/sec
44
因為 NTCU 的雲端環境有三種不同規格的實體伺服器,硬體規格如表 4-2 所示,我們想了解實體機器對 IMS 演算法和原本 Spark 演算法的效能 改善效果如何,故我們在每一種規格的實體伺服器上上面創建 2 台 medium 型態的虛擬機,圖 4-4 和圖 4-5 分別表示 site1 和 site2 的 openstack 創建在 相同實體機上虛擬機,各種型態的虛擬機規格如表 4-3 所示,總共有 6 台 workers,為何要選用 medium 的大小是因為 Spark 是 in memory 來做計算 的,且將 hadoop 和 spark 編譯在一起的時候,也需要足夠的記憶體才能編 譯,經過我們的測試發現要成功編譯必須要 medium 型態以上的資源才足 夠,故我們做實體機的異質性實驗就創建 medium 型態的虛擬機來進行實 驗。
表 4-2 伺服器硬體規格
Hardware Information Software Version
Model CPU RAM OS Hypervisor OpenStack IBM BladeCenter HS23 Intel Xeon E5-2640 2.5GHz*8 24GB Ubuntu 12.04 KVM 1.0 Grizzly IBM BladeCenter HS22 Intel Xeon E5620 2.4GHz*16 30GB HP ProLiant DL360 G6 Intel Xeon E5520 2.26GHz*16 30GB
45
圖 4-4 IBM BladeCenter HS22 和 HS23 上的虛擬機列表
46 我們輸入 512MB 和 1GB 的文字檔去執行修改過的 WordCount 應用程 式量測其執行時間,執行時間結果如圖 4-6 和圖 4-7 所示,由實驗結果顯 示,在虛擬機的型態都相同的情況底下,代表記憶體大小和可用核心數都 相同,我們提出的 IMS 演算法比起原本 Spark 的排程演算法並無較佳的效 能表現,原因在於三種實體伺服器的 CPU 時脈分別為 2.26GHz、2.4GHz 和 2.5GHz,CPU 時脈差距很小,無法對執行效能有明顯的改善,故接下 來我們往虛擬機異質性進行實驗,實驗結果將在 4.2 小節進行分析和討 論。 表 4-3 虛擬機之規模大小
Tiny Small Medium Large Xlarge
VCPUs 1 1 2 4 8
RAM 512MB 2GB 4GB 8GB 16GB
47
圖 4-6 512MB txt 檔執行 WordCount 之時間
本篇論文在各兩台實體機上分別架設了 2 組 site,分別為後面段落的 site1 和 site2。表 4-4 為 Site1 中的五台虛擬機的硬體配置,表 4-5 為 Site2 中的三台虛擬機的硬體配置,我們使用一台 master 和七台不同型態大小的 workers 串接起來成為一組 Virtual Cluster,再來進行虛擬機異質性實驗和 效能評估。原本 Spark 的設定是所有 worker 上面的 executor 都只能統一分 配可用記憶體,透過 spark.executor.memory 這個環境變數來進行設定,預 設值為 512MB,但是因為只能統一設定可用記憶體,造成擁有較大記憶體 的虛擬機需要遷就較小記憶體的虛擬機來配置可用記憶體,若設定太大的 可用記憶體,會導致記憶體不到設定值的機器無法分配到工作執行,故我 們去修改底層配置記憶體的程式碼,以及變更 spark.storage.memoryFraction 從預設的 0.6 改為 1,使得每個 worker 上的 executor 所擁有的可用記憶體 變大,如圖 4-8 所示。
48
圖 4-7 1GB txt 檔執行 WordCount 之時間
49
表 4-4 Configuration of Virtual Machines in Site1
Size Memory VCPU Disk
Master m1.medium 4GB RAM 2 VCPU 40GB Disk
Worker1 m1.large 8GB RAM 4 VCPU 80GB Disk
Worker2 m1.large 8GB RAM 4 VCPU 80GB Disk
Worker3 m1.large 8GB RAM 4 VCPU 80GB Disk
Worker4 m1.large 8GB RAM 4 VCPU 80GB Disk
表 4-5 Configuration of Virtual Machines in Site2
Size Memory VCPU Disk
Worker5 m1.medium 4GB RAM 2 VCPU 40GB Disk
Worker6 m1.medium 4GB RAM 2 VCPU 40GB Disk
Worker7 m1.xlarge 16GB RAM 8 VCPU 160GB Disk
圖 4-9 和圖 4-10 表示不同演算法的排程結果,假設目前有二十八個 task 的工作要執行,原本 Spark 的排程演算法是隨機分配 task 給 worker,只要 有可執行工作的 CPU 就分配 task 執行,然而 IMS 演算法會給予 worker 優 先權,由表 4-4 和表 4-5 顯示 worker7 擁有最大的記憶體和可用 CPU 個數, 所以會優先將 task 分配到 worker7 去執行,再依照表 4-4 和表 4-5 所示 worker1、worker2、worker3 和 worker4 比 worker5 和 worker6 擁有較大的 記憶體和可用 CPU 個數,所以當 worker7 的 CPU 都已經排滿 task 後,再 來分配工作給 worker1,依此類推的分配工作,IMS 演算法使得在不超過 機器負荷量的前提之下,盡可能讓每台機器都擁有最高的 CPU 使用率,可 以減少執行應用程式所需的機器數量,並且因工作分配的較集中,降低了 機器之間彼此的 communication time,進一步降低整體的執行時間。
50
Core1 Core2 Core3 Core4 Core5 Core6 Core7 Core8
Worker1 Task9 Task10 Task11 Task12
Worker2 Task13 Task14 Task15 Task16
Worker3 Task17 Task18 Task19 Task20
Worker4 Task21 Task22 Task23 Task24
Worker5 Task25 Task26
Worker6 Task27 Task28
Worker7 Task1 Task2 Task3 Task4 Task5 Task6 Task7 Task8
圖 4-9 IMS 演算法排程結果
Core1 Core2 Core3 Core4 Core5 Core6 Core7 Core8
Worker1 Task2 Task11 Task17 Task24
Worker2 Task6 Task8 Task18 Task23
Worker3 Task7 Task13 Task16 Task21
Worker4 Task3 Task14 Task19 Task20
Worker5 Task5 Task9
Worker6 Task4 Task12
Worker7 Task1 Task10 Task15 Task22 Task25 Task26 Task27 Task28
51
4.2 實驗結果
在虛擬機異質性的實驗中,我們使用一台 master(medium 型態)加上七 台 worker (1 台 xlarge、4 台 large、2 台 medium 共 7 台)組成虛擬叢集系統, 其規格如表 4-4 和表 4-5 所示,而效能評估使用三種不同的應用程式 WordCount、K-means 和 PageRank,測量其執行時間以及 throughput 的變 化,由實驗結果來分析 IMS 演算法與原先 Spark 排程演算法之效能改善。 第一個測試程式為 WordCount 程式,WordCount 是將輸入的文字檔中 的字數經過計算以後,輸出每個字出現過幾次的結果,WordCount 為 CPU-Intensive 型態的應用程式,我們將 WordCount 程式修改為兩個輸入檔 案計算完字數後,再進行 join,最後得到結果,其測試的參數分別為 2 個 512MB、1GB、2GB 文字檔,並經由不同數目的分割,分別執行五次後計 算執行時間。表 4-6 和表 4-7 為 512MB 文字檔切割成 5、10、15、20 和 25 個 partitions 後,使用原先 Spark 排程演算法和 IMS 演算法的執行時間, partitions 為 Spark 執行裡面最小的資料單元,由表 4-6 和表 4-7 可得知 IMS 演算法相較於原先的 Spark 演算法有較短的執行時間,且因 Spark 預設的 partitions 數為 2,每個 partition 最大可為 128MB,在總檔案大小不變且較 少 partitions 的情形底下,IMS 演算法有明顯的提升效能。由表 4-6 可觀察 出在 5 個 partitions 的情形下,使用 IMS 演算法的執行時間較短,圖 4-11 為兩種演算法輸入 512MB 檔案在不同 partitions 的情形下執行 WordCount 所用核心數,由圖 4-12 可知,IMS 演算法在 5 和 10 個 partitions 的情形下 執行 WordCount 能夠節省 2 個 cores,故證實 IMS 演算法不僅能提升即時 串流處理效能,還能節省運算資源。
52
表 4-6 512MB 文字檔切割成 5、10 和 15 個 partitions 的執行時間 512MB 文字
檔執行順序
5 partitions 10 partitions 15 partitions Original IMS Original IMS Original IMS 第 1 次 187.6 s 129.1 s 201.7 s 137.9 s 177.3 s 161.9 s 第 2 次 189.5 s 161.9 s 189.2 s 148.5 s 184.3 s 184.2 s 第 3 次 193.4 s 157.2 s 200.2 s 133.1 s 1861 s 182.8 s 第 4 次 198.1 s 159.0 s 183.9 s 129.2 s 180.2 s 179.2 s 第 5 次 189.3 s 161.6 s 182.2 s 134.0 s 179.5 s 182.5 s 表 4-7 512MB 文字檔切割成 20 和 25 個 partitions 的執行時間 512MB 文字 檔執行順序 20 partitions 25 partitions
Original IMS Original IMS
第 1 次 193.7 s 172.6 s 184.6 s 157.7 s 第 2 次 181.9 s 176.2 s 175.7 s 174.1 s 第 3 次 180.8 s 173.2 s 180.3 s 178.5 s 第 4 次 173.3 s 166.4 s 181.5 s 176.8 s 第 5 次 178.6 s 180.3 s 178.3 s 177.9 s
53
圖 4-11 WordCount 執行 512MB 檔案所需核心數差異
表 4-8 和表 4-9 為 1GB 文字檔切割成 10、20、30、40 和 50 個 partitions, 使用原先 Spark 排程演算法和 IMS 演算法的執行時間比較,partitions 皆設 定為執行五次。由表 4-8 和表 4-9 可得知使用 IMS 演算法的執行時間大部 分都比原本 Spark 排程演算法來的短,並且在 10 個 partitions 的情況下效 能改善最明顯,執行時間大約縮短百分之二十,整體平均下來 IMS 演算法 的執行時間大約縮短百分之五。