利用標籤社會網絡之影響力最大化達到目標式廣告行銷 - 政大學術集成
51
0
0
全文
(2) 利用標籤社會網絡之影響力最大化達到目標式廣告行銷. Influence Maximization in Labeled Social Network for Target Advertising. 研 究 生:李法賢 指導教授:沈錳坤. Advisor:Man-Kwan Shan 政 治 大. Nat. er. io. sit. y. ‧. 國立政治大學 資訊科學系 碩士論文. 學. ‧ 國. 立. Student:Fa-Hsien Li. A Thesis iv n submitted to C Department of Computer Science hengchi U National Chengchi University in partial fulfillment of the Requirements for the degree of Master in Computer Science. n. al. 中華民國九十九年十月 October 2010 i.
(3) 利用標籤社會網絡之影響力最大化達到目標式廣告行銷. 摘要 病毒式行銷(viral marketing)透過人際之間的互動,藉由消費者對消費者的推薦,達到廣 告效益。而廣告商要如何進行病毒式行銷?廣告商必須在有限資源下從人群中找出具有 影響力的人,將產品或是概念推薦給更多的消費者,以說服消費者會採納他們的意見。. 政 治 大. 利用社會網絡(Social network),我們可以簡單地將消費者之間的關係用節點跟邊呈. 立. 現,而 Influence Maximization 就是在社會網絡上選擇最具有影響力的 k 個消費者,而這. ‧ 國. 學. k 個消費者能影響最多的消費者。. 然而,廣告相當重視目標消費群,廣告目的就是希望能夠影響目標消費群,使目標. ‧. 消費群購買產品。因此,我們針對標籤社會網絡(Labeled social network)提出 Labeled. Nat. n. al. er. io. 社會網絡中影響到最多符合標籤條件的節點。. sit. y. influence maximization 的問題,不同過往的研究,我們加入了標籤的條件,希望在標籤. i Un. v. 針對標籤社會網絡,我們除了修改四個解決 Influence maximization problem 的方法,. Ch. engchi. Greedy、NewGreedy、CELFGreedy 和 DegreeDiscount,以找出影響最多符合類別條件的 節點的趨近解。我們也提出了兩個新的方法 ProximityDiscount 和 MaximumCoverage 來 解決 Labeled influence maximization problem。我們在 Offline 時,先計算節點與節點之間 的 Proximity,當行銷人員 Online 擬定行效策略時,系統利用 Proximity,Onlin 找出趨近 解。 實驗所採用的資料是 Internet Movie Database 的社會網絡。根據實驗結果顯示,在 兼 顧 效 率 與 效 果 的 情 況 下 , 適 合 用 ProximityDiscount 來 解 決 Labeled influence maximization problem。. ii.
(4) Influence Maximization in Labeled Social Networkx for Target Advertising. Abstract Influence maximization problem is to find a small subset of nodes (seed nodes) in a social network that could maximize the spread of influence. But when marketers advertise for some. 政 治 大. products, they have a set of target audience. However, influence maximization doesn’t take. 立. target audience into account.. ‧ 國. 學. This thesis addresses a new problem called labeled influence maximization problem, which. ‧. is to find a subset of nodes in a labeled social network that could influence target audience and maximizes the profit of influence. In labeled social network, every node has a label, and. y. Nat. er. io. sit. every label has profit which can be set by marketers.. We propose six algorithms to solve labeled influence maximization problem. To. n. al. Ch. i Un. v. accommodate the objective of labeled influence maximization, four algorithms, called. engchi. LabeledGreedy, LabeledNewGreedy, LabeledCELFGreedy, and LabeledDegreeDiscount, are modified from previous studies on original influence maximization. Moreover, we propose two new algorithms, called ProximityDiscount and MaximumCoverage, which offline compute the proximities of any two nodes in the labeled social network. When marketers make strategies online, the system will return the approximate solution by using proximities. Experiments were performed on the labeled social network constructed from Internet Movie Database, the result shows that ProximityDiscount may provide good efficiency and effectiveness.. iii.
(5) 致謝 很高興能從 DMLAB 畢業,這兩年說長不長,說短不短,卻讓我經歷了人生很重大的轉 折。在這非常感謝沈錳坤老師這兩年的指導,不僅讓我在學業上能夠接軌,也讓我學習 到許多待人處事的道理,最後在趕論文的階段,老師犧牲自己睡眠時間與我們一同奮戰, 令我感謝萬分。. 政 治 大 使我的論文不至難產;感謝與我素昧平生的國獻的大方相助。UFO、伯丞、詳閔、容瑜、 立 在我研究所的生涯中,要感謝所有的學長姐、同學和學弟。感謝 Cake 的大力相挺,. ‧ 國. 師益友。. 學. 戴張、斯越、世宏、家奇、林宏哲、郭紘維、柯柯柯、瀟灑哥和天線更是我這兩年的良. ‧. 謝謝你們的出現,你們使我的研究生生涯更具色彩,UFO 是我結伴打電動的好學長。. sit. y. Nat. 詳閔則是我訴苦的好對象。容瑜的認真一直是 DMLAB 第一。與戴張、斯越和世宏聊天. io. er. 讓我保持年輕,希望你們能順利畢業。家奇的爛漫瓊瑤故事每次講每次都讓我哈哈大笑。. al. iv n C h e恩師。天線跟我一起做的事情太多了,我就不在這 讓人又恨又愛。瀟灑哥是我的 JAVA ngchi U n. 宏哲的身材依舊可愛。郭紘維的客氣讓我覺得這世界上還是有好孩子的。柯柯柯的天真. 邊一一贅述。 此外,我要感謝我的家人,老爸老媽老哥和饅頭,我能無憂無慮的念書都是因為你 們是我的靠山。還有我的女朋友陳亦瑋,總在我人生低潮的時候拉我一把,謝謝妳,沒 有你,就沒有現在的李法賢。 還有一群我的大學同學,生虎、小飛、大祐、坊坊、阿丹、安芷嫻、林思吟、黃婉 婷、小咕、鋒鋒,和你們一起玩樂是我研究所唯一的消遣,謝謝你們的陪伴。也要謝謝 柏堯、志傑、建成的加入,讓實驗室變得更加熱鬧。 最後,謝這麼多人當然不能忘記謝天,老天,感謝你。 iv.
(6) 李法賢 謹誌于 政治大學資訊科學所 2010.10.19. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. v. i Un. v.
(7) 目錄 摘要 ........................................................................................................................ i 目錄 ...................................................................................................................... iii 圖目錄 .................................................................................................................. iv. 政 治 大. 表目錄 .................................................................................................................. vi. 立. 第一章 前言 ......................................................................................................... 1. ‧ 國. 學. 第二章 相關研究 ................................................................................................. 4. ‧. 2.1 Influence Maximization ............................................................................ 4. Nat. sit. y. 2.2 Independent Cascade Model ..................................................................... 6. er. io. 2.3 Weighted Cascade Model ......................................................................... 8. n. a. v. l C 第三章 研究方法 ................................................................................................. 9 ni. hengchi U. 3.1 問題定義.................................................................................................. 9 3.2 LabeledGreedy Algorithm ...................................................................... 10 3.2 LabeledCELFGreedy Algorithm............................................................. 13 3.3 LabeledNewGreedy Algorithm ............................................................... 14 3.4 LabeledDegreeDiscount .......................................................................... 16 3.5 ProximityDiscount .................................................................................. 18 3.5.1 Proximity for Independent Cascade Model ........................... 18 3.5.2 Computing Proximity ............................................................ 19 vi.
(8) 3.5.3 ProximityDiscount Algorithm................................................ 21 3.6 MaximumCoverage ................................................................................. 24 3.7 Proximity Threshold and Maximum Coverage Threshold ..................... 25 第四章 實驗結果與評估 ................................................................................... 27 4.1 實驗設計 ................................................................................................ 27 4.2 實驗結果 ................................................................................................ 28. 政 治 大. 第五章 結論與未來研究方向 ........................................................................... 36. 立. ‧ 國. 學. 5.1 結論 ........................................................................................................ 36 5.2 未來研究方向 ........................................................................................ 37. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. vii. i Un. v.
(9) 圖目錄. 圖 2.1:影響力在 Independent Cascade Model 擴散的過程.......................... 6 圖 3.1:Labeled influence maximization 之範例 .......................................... 10 圖 3.2:KTT's greedy algorithm .................................................................... 11 圖 3.3:CELFGreedy algorithm ..................................................................... 13. 治 政 大 圖 3.4:NewGreedy algorithm ....................................................................... 15 立 ‧ 國. 學. 圖 3.5:LabeledDegreeDiscount algorithm ................................................... 17 圖 3.6:前 k 條最短簡單路徑和前 k 條最短路徑之範例。 ....................... 20. ‧. sit. y. Nat. 圖 3.8:ProximityDiscount 的資料結構 ....................................................... 23. er. io. 圖 3.7:ProximityDiscount algorithm ............................................................ 23. n. a. v. l C algorithm ....................................................... 圖 3.9:Maximum k coverage 24 ni. hengchi U. 圖 3.10:MaximumCoverage algorithm ........................................................ 25 圖 4.1:實驗一( ={Drama},. )之效果。 .......................... 29. 圖 4.2:實驗一( ={Comedy},. )之效果。 ....................... 30. 圖 4.3:實驗二( ={Comedy, Biography}, )之效果 ........................................................................... 30 圖 4.4:實驗二( ={Comedy, Thriller},. viii.
(10) )之效果 ............................................................................... 31 圖 4.5:實驗二(目標標籤為所有的標籤,且所有的目標標籤之利潤皆為 1)之效果。 .................................................................................................. 32 圖 4.6:實驗三( ={Comedy, Drama},. ). 之效果。 ...................................................................................................... 33. 政 治 大. 圖 4.7:實驗三( ={Comedy, Thriller, Drama},. 立. )之效果。 ............................................ 33. ‧ 國. 學. 圖 4.7:LabeledDegreeDiscount、ProximityDiscount、MaximumCoverage. ‧. 和 LabeledNewGreedy 之執行時間比較。 ............................................... 35. n. er. io. sit. y. Nat. al. Ch. engchi. ix. i Un. v.
(11) 表目錄. 表 4.1:Dataset 裡面不同 Label 的演員之數量 ...................................... 27. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. x. i Un. v.
(12) 第一章 前言 隨著網際網路的發展,虛擬社群網站層出不窮,像是 facebook、Plurk、Flickr、無名部 落格、奇摩知識家、批踢踢實業坊…等等,越來越多人參與網路社群,人們互動的模式. 政 治 大 然而,社群網站可以以社群網絡(Social network)表示。社會網絡由節點與邊所組成, 立. 隨著這些社群網站的興起而有所改變。. ‧ 國. 學. 節點可以代表人,而兩節點之間有邊,則代表這兩個人之間有關係。舉 facebook 社群網 站為例,facebook 上的使用者表示成社會網絡裡的節點,每一個使用者都是一個節點,. ‧. 而兩個節點之間有邊則可代表使用者互相加對方為好友,邊在此定義下表示友誼關係。. sit. y. Nat. 在社會網絡中,節點和邊隨著定義不同而有所改變,繼續以 facebook 為例,節點仍. io. er. 代表人,而我們可以定義兩個節點之間的邊代表這兩人參加了同一俱樂部或是擁有共同. al. v. n. 的喜好,例如都加入腳踏車的俱樂部或是都喜歡騎腳踏車。隨著我們的定義不同,Social. i n C U hengchi network 所代表的意義也有所不同。. 有許多跟社會網絡的結構和特性有關的研究,例如 Pattern mining[24],Community detection[4]、Link prediction[17]、Label prediction[3]等等研究。Pattern mining 是從社會 網絡中找出經常出現的 subgraph。而 Community detection 主要是從社會網絡中找出 Communities, Community 裡的節點有較多的邊相連,而不同 Communities 的節點較沒 有邊相連。Link prediction 是預測兩個不相連的節點是否在未來會有邊相連;Label prediction 則是透過鄰居的標籤來預測未知節點的標籤。 社會網絡的興起,改變了廣告行銷的形式,從以往傳統的電視廣告、報紙平面廣告 轉 變 成 其 他 行 銷 手 法 , 像 是 病 毒 式 行 銷 (viral marketing) 和 口 語 傳 播 1.
(13) (word-of-mouth)[2][15][6][10][18][21]。 病毒式行銷利用已消費的使用者當作活廣告,透過口語傳播推薦給他們的朋友,說 服尚未購買商品的消費者。病毒式行銷可以視為一種散播資訊和接收資訊的過程。然而, 隨著網路的興起,推薦或是傳播消息的管道不再單單局限於面對面的傳播,社會網絡提 供了傳遞消息的管道。 許多資訊和創意在社會網絡上散播,廣告也不例外。行銷人員可以分析社會網絡的 結構,挑選使用者進行病毒式行銷。例如:免費給予部落客商品,供他們使用,他們再. 政 治 大. 將商品資訊放在部落格上,散播消息給觀看部落的消費者,說服他們購買商品。. 立. 然而,行銷人員要如何找到具有影響力的人?某人具有影響力代表他能夠影響其他. ‧ 國. 學. 人去接受資訊或是改變觀念,例如:部落客可以影響觀看他們部落格的人去購買某件商 品。行銷人員要如何使得廣告得到最好的效益?要如何在有限的預算內,找到有影響力. ‧. 的人,使其影響到最多的人?這樣的問題在社會網絡的學術研究中稱做 Influence. y. Nat. sit. maximization problem。. n. al. er. io. 現有許多研究提出解決 Influence maximization problem[3][12][16][22]的方法。然而,. i Un. v. Influence maximization problem 並沒有考慮到目標對象的不同,具有不同的重要性。因. Ch. engchi. 此我們針對標籤社會網絡提出 Labeled influence maximization problem。在標籤社會網 絡中,節點都有標籤,而每個標籤都有權重值,代表標籤的重要性。我們要從標籤社會 網絡中找出影響最多符合目標類別條件的人的 k 個人,這樣的問題我們稱作 Labeled influence maximization problem。 由於行銷人員在擬定行銷策略時,會測試不同的目標標籤的組合,企圖從中找出最 符合效益的組合。而我們可以視這些組合為行銷人員所下的查詢,而系統會針對不同的 查尋回傳不同的結果。 我們透過觀察、分析社會網絡的結構,找出具有影響力的人,使他們成為訊息的散 播者,將資訊傳遞給其他人。 2.
(14) 這 篇 論 文 主 要 的 貢 獻 在 於 我 們 針 對 標 籤 社 會 網 絡 提 出 Labeled influence maximization problem,使得問題更貼近真實情況。我們共提出了六個新的方法來解決 Labeled influence maximization problem。其中 LabeledGreedy、LabeledNewGreedy、 LabeledCELFGreedy 和 LabeledDegreeDiscount 是我們修改之前研究的解法而得的方法, 我們也提出了兩個新的方法,分別為 ProximityDiscount 和 MaximumCoverage。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 3. i Un. v.
(15) 第二章 相關研究. 2.1 Influence Maximization Influence Maximization Problem 是社會網絡(Social Network)領域裡熱門的研究題目,主. 政 治 大. 要探討在社會網絡中,我們要如何挑選 k 個人,透過這 k 個人傳遞影響力,使得最多的. 立. 人被影響(像是被說服購買一個產品或是接受一個新的概念)。. ‧ 國. 學. 最早研究 Influence Maximization 的是 Domingos 和 Richardson[6],他們利用機率的. ‧. 方式將 Influence Maximization 視為 Algorithmic Problem,而 Kemp、Kleinberg 和 Tardos[12] 則是最早把 Influence Maximization 視為最佳化的問題,並且利用 Greedy algorithm 來解. y. Nat. er. io. sit. 決 Influence maximization problem。若要找出 k 個種子節點(Seed nodes),則 Greedy algorithm 會執行 k 回合,每回合選出影響力最大的節點。. n. al. Ch. i Un. v. 接著,許多的論文也都專注於解決 Influence maximization problem,例如 Leskovec et. engchi. al.[16] 提出了“Cost-Effective Lazy-Forward(CELF)”的方式,利用 Greedy algorithm 在選 擇種子節點時,每回合選出的種子節點的影響力會隨著回合增加而遞減的特性來減省運 算量。實驗顯示 CELF 可以提升 Greedy algorithm 700 倍的效率,且效果與 Greedy algorithm 相同。 而 W. Chen et al.[3]也提出改善 Greedy algorithm 效率的 NewGreedy,以及一個 Degree discount heuristic,叫做 DegreeDiscountIC,來提升解決 Influence Maximization Problem 的效率。NewGreedy 的精神在於先決定邊是否會傳遞影響力,在模擬影響力擴散之前把 沒有傳遞影響力的邊拿掉,因此模擬時的社會網絡會較原本社會網絡來得小,如此亦可. 4.
(16) 節省運算量。 而 DegreeDiscount 則是利用經驗法則,優先選擇 Degree 較高的節點當作種子節點, 但與一般 Degree Heuristic 方法不同之處在於,每回合選完種子節點後,會重新計算種 子節點第一層鄰居的影響力期望值,而鄰居的影響力會受到種子節點的影響而打折扣。 另外,經實驗證明,DegreeDiscount 的效果較一般的 Degree Heuristic 和 Centrality-Based Heuristic 來得好,且相較於 Greedy Algorithm,DegreeDiscount 的效率快上百萬倍[3]。 然而,我們的研究與前述的研究最大的不同在於我們針對標籤社會網絡(Labeled. 政 治 大. social network)以及 Labeled influence maximization problem,在以往的研究,探討的社 會網絡並沒有標籤之分。. 立. ‧ 國. 學. 標籤社會網絡上的節點都具有標籤,而不同的標籤又有不同的權重值,舉例而言, facebook 的使用者有多種類別的人,有國中生、高中生、大學生…等等,而 Labeled. ‧. influence maximization problem 在探討如何選出 k 個種子節點,而這 k 個種子節點可以影. Nat. sit. y. 響最多某種標籤的人,例如影響最多大學生,為了方便閱讀,之後稱欲影響的標籤為目. n. al. er. io. 標標籤(Target label),而目標標籤節點(Target label node)即是我們想要影響的人。. i Un. v. 在標籤社會網絡中,每個標籤具有不同的權重值,代表受重視的程度不同,舉例而. Ch. engchi. 言,若蘋果想要在 facebook 推銷 iPhone 4,那目標標籤節點可能為大學生,因此大學生 的權重值較高, 假設影響一個大學生 等同於影響十個高中生 ,則 Label influence maximization problem 不僅多了標籤的考量,而標籤上的權重值也會影響最後的利潤 (Profit)。 我 們 針 對 標 籤 社 會 網 絡 提 出 了 兩 個 方 法 , 分 別 為 MaximumCoverage 和 ProximityDiscount,並且修改先前研究 Influence maximization 的四個解法,使其適用在 Label influence maximization problem。. 5.
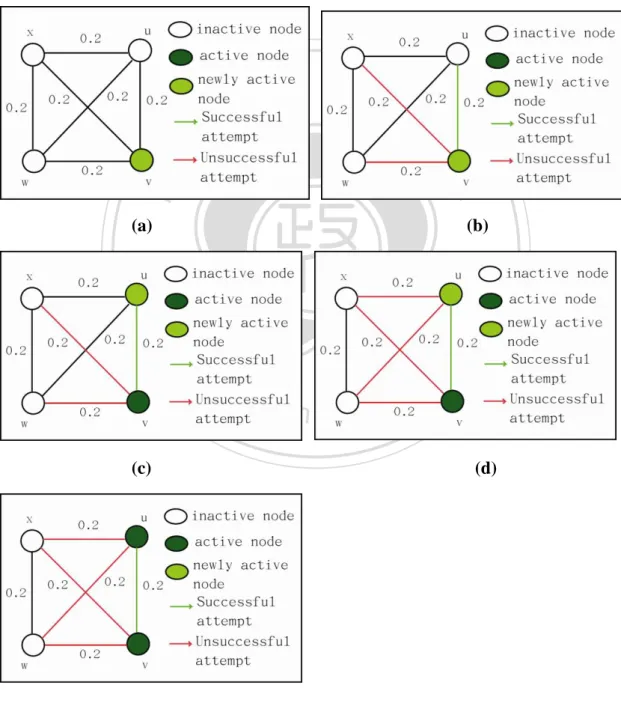
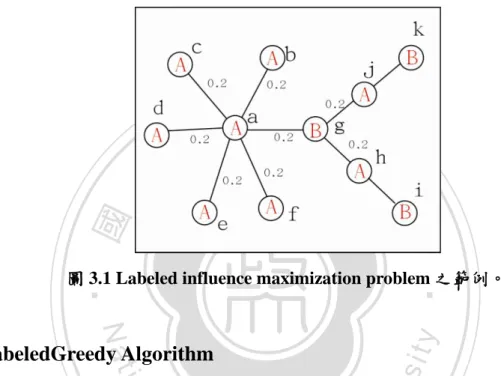
(17) 2.2 Independent Cascade Model Independent cascade model 是由 Goldenberg,Libai 和 Muller[10][11]所提出,而此模 型可以模擬社會網絡中影響力的擴散。Independent cascade model 裡假設:在社會網絡 中的每點不是處於 Active 狀態,就是處於 Inactive 狀態。當點 A 是 Inactive 時,表示 A 並沒有被影響(例如:採納某種意見);而當 A 為 Active 時,則表示 A 受到別人影響。. 立. 政 治 大. ‧ 國. 學. (a). (b). ‧. n. er. io. sit. y. Nat. al. Ch. engchi. (c). i Un. v. (d). (e) 圖 2.1 Independent cascade model 的影響力擴散過程。 6.
(18) 普遍的研究[3][12][16][22]皆假設節點只能由 Inactive 狀態轉變成 Active 狀態,而不 能從 Active 變為 Inactive。 用 Independent cascade model 模擬影響力的擴散,一開始,只有種子節點的狀態為 Active,其餘的節點都屬於 Inactive。而影響力擴散的過程為一階段一階段進行,當節點 v 在第 t 階段變為 Active 時,它會被給予一次機會,企圖影響與節點 v 相鄰且狀態為 Inactive 的節點 w,使其變為 Active,而節點 v 成功的機率為. ,此機率是此模型的一. 個參數,是獨立機率,表示節點 v 影響節點 w 的機率跟其他節點影響 w 的機率並無關聯。. 政 治 大. 如果節點 v 成功影響節點 w,則 w 會在 t+1 階段變為 Active,但若節點 v 無法影響. 立. 節點 w,則在接下來的階段,節點 v 都不會再去嘗試影響節點 w。. ‧ 國. 學. 此過程一直持續,直到沒有節點還會由 Inactive 轉變為 Active 為止。Figure 1.即是 Independent cascade model 在模擬影響力擴散的過程。. ‧. 圖中社會網絡有四個節點,編號分別為節點 u、v、w 和 x,而任兩個節點有邊代表. Nat. n. al. er. io. 重值代表影響的機率,此例子中影響成功的機率為 0.2。. sit. y. 兩個節點有關係。例如:x 和 u、v 和 w 有節點,代表 x 與此三個節點有關係。邊上的權. i Un. v. 圖 2.1(a)、圖 2.1(b)、圖 2.1(c)、圖 2.1(d)和圖 2.1(e)呈現 Independent Cascade Model. Ch. engchi. 的過程。(a)先讓節點 v 為 Active,此時稱 v 為種子節點。(b)在第一階段,v 會嘗試去影 響它的鄰居 u、w 和 x,而影響成功的機率即是邊上的權重 0.2。而 v 成功影響 u,u 因 此轉變成 Active 狀態,然而 x 與 w 不受影響,仍為 Inactive 狀態。(c)節點 v 只有一次影 響它鄰居的機會,因此 v 在接下來的階段不會再去影響它的鄰居。而此時換 u 去影響它 的鄰居 x 和 w。(d)節點 u 沒有成功影響 x 和 w,因此 x 和 w 仍是 Inactive。(e)沒有新的 點為 Active,則停止程序。 最後為 Active 的點只有 v 和 u,代表此次模擬只影響了兩個 節點。 既然我們可以利用 Independent cascade model 模擬社會網絡裡影響力的傳遞、擴散, 則我們可以試著找某些點(在限制之內的點數)當作種子節點,由它們將影響力擴散至它 7.
(19) 們的鄰居,再由它們的鄰居將影響力擴散至它們的鄰居的鄰居…一直擴散下去,直到無 法傳遞下去無止,而我們要如何選擇種子節點?此即是 Influence maximization 問題 [1,9]。. 2.3 Weighted Cascade Model Weighted cascade model 與 Independent cascade model 的模擬過程一樣,唯一差別在 於給定邊上影響機率值的方式,在 Independent cascade model 中,邊上的影響機率值是. 政 治 大. 一開始就給定的值,可以為 0.1、0.01 或是隨機一個機率值。而在 Weighted cascade model 中,每條邊. 可視為. 和. 立兩條有向的邊。而. ‧ 國. 的影響力機率值則為. 。. ‧. io. sit. y. Nat. n. al. er. 反地,. 回合有. 學. Degree,若點 u 在第 i 回合被影響,則點 u 在第. 上的影響力機率值為. Ch. engchi. 8. i Un. v. ,. 為v的. 的機率影響節點 v,相.
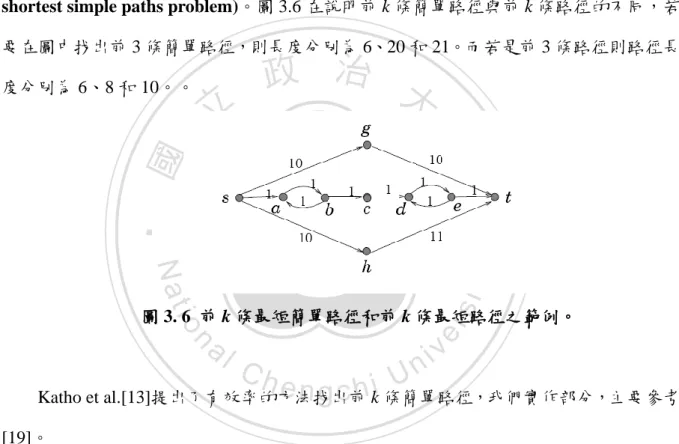
(20) 第三章 研究方法. 3.1 問題定義 給定(1)標籤社會網絡 ,(2) 預算 B 和(3) 目標標籤集合. 政 治 大. ,. 。其中,. ,V 是所有節點的集合,E 是所有邊的集合,. 立,. 之集合。針對每個節點. 為所有標籤. ;節點 u 的權重值為. 。B 是一個整. ‧ 國. 學. 數,代表種子節點的數量。而目標標籤則是我們的目標消費群的標籤。. 中. 且. ,. ,使得. ‧. 目的是在 G 中選出種子節點集合 , 。. Nat. y. 最大,其. er. io. sit. 此問題與先前 Influence maximization 的不同之處在於,目前的問題考慮到節點屬於 不同的標籤,且不同標籤具有不同的權重,使得問題更貼近現實情況。現實社會中,廣. n. al. Ch. i Un. v. 告商打廣告時,都有目標消費群,而目標消費群很可能共同擁有某種特徵,例如:年齡. engchi. 層在四十歲左右或者是熱愛騎腳踏車…等等,在之前的研究,雖然找得到影響最多節點 的種子節點,但這些種子節點卻不一定影響到最多某種標籤的節點。 以圖 3.1 為例,圓裡面的 A 和 B 是節點的標籤,而 a, b, c…,k 則是節點的編號,邊 上的權重是影響機率值(0.2),若我們的目標標籤為 B 且預算為 1。則在先前的研究 (Influence maximization problem)是不考慮節點的標籤,單純考慮節點影響的個數,不管 用 Degree centrality 或是 Greedy algorithm,我們都會選擇點 a 作為起始點。 若是在 Labeled influence maximization problem 問題定義之下,我們不單單考慮節點 的數量,也會考慮節點的標籤。一般解決此問題的想法,是去掉標籤為 A 的節點,只留. 9.
(21) 標籤為 B 的節點,再從中選出一個種子節點。但此方法有兩個缺點:第一,標籤社會網 絡可能會不連通,導致節點與節點之間不能互相影響。第二可能去掉最佳的種子節點(種 子節點可能是類別為 A 的節點)。事實上,選擇節點 g 作為種子節點,最有可能影響最 多標籤為 B 的節點。. 立. 政 治 大. ‧ 國. 學 ‧. 圖 3.1 Labeled influence maximization problem 之範例。. y. Nat. er. io. sit. 3.2 LabeledGreedy Algorithm. 最佳化 Influence maximization 是一個 NP-hard 的問題[12],現有的研究[3][12][16][22]. n. al. Ch. i Un. v. 皆提出了 Approximation algorithm,找出趨近解,目前多數的解法為 Greedy algorithm,. engchi. [12]是最早以 Greedy algorithm 來解決 Influence maximization problem 的研究,因此我們 以作者的名字縮寫當作方法的名稱,稱作 KKT’s greedy algorithm 每回合選出能使影響 力增加最多的節點作為種子節點。 KKT’s greedy algorithm 進行回合制的挑選,每一回合選出那一回合影響力最大的節 點 v。一開始,. ,接著每一回合選一個種子節點加入,在第 t 回合時,選擇 , 可以使. marginal gain 最大化[7]。 (1) (1)裡,. 是利用 Independent cascade model 去模擬 的影響力,計算社會. 10.
(22) 網絡中少節點受到集合 的影響,由 Inactive 變為 Active。 而當選完 k 個 Seed nodes 後,KKT’s greedy algorithm 會停止,圖 3.2 即是 KKT’s greedy algorithm 的 Pseudo code。 KKT’s Greedy Algorithm (G, k) 1: initialize and 2: for to k do 3: for each vertex 4: 5: for to R do 6: 7: end for 8: 9: end for 10:. 政 治 大. 學 ‧. ‧ 國. 立. end for output S. sit. y. Nat. 11: 12:. do. n. al. er. io. 圖 3.2 KKT’s greedy algorithm 的 pseduo code。. 其中. Ch. 是將 Set. i Un. v. i e n g當作 c hIndependent cascade model 中的種子節點,. 計算其所能影響的數量。而影響的擴散與機率有關,因此模擬時,讓程式跑 10000 遍後 再取平均值作為加入節點 後能多影響的數量。 然而,KKT’s Greedy algorithm 所選出的 k 個點是否能夠有好的效果?KKT’s greedy algorithm 所得的效果跟最佳化的結果差多少?然而,要探討此問題時,必須先了解 這個函數,此函數具有 Submodular[5]特性:邊際效益遞減的特性。 定義 3.1:具有 Submodular 特性的函數會符合下列式子 (2) 其中集合. 。而對於社會網絡上每一個節點 v,(2)都成立。 11.
(23) 而用 KKT’s greedy algorithm 去找 k 個起始點時,每一回合多影響的點的數量會有 Submodular 特性。隨著 k 變大,每一回合能影響的數量會變小,並且符合(2)。 [20] 中 證 明 了 若 方 法 擁 有 Submodularity 特 性 , 則 此 方 法 可 以 達 到 63% Approximation 。 換 句 話 說 , 若 S* 是 會 造 成 影 響 力 最 佳 化 的 k 個 點 的 集 合 , 則 ,其中 是用 KKT’s Greedy algorithm 選出的 k 個種 子節點,而且. 。. 政 治 大 ,其中 n 與 m 是社會網絡上的節點和邊的個數,R. 雖然 KKT’s greedy algorithm 可以保證一定的效果, 但效率並不佳,找 k 個點所耗 的 Time complexity 為. 立. ‧ 國. 甚至是幾天。. 學. 為模擬的次數,當社會網絡的節點數大時,所需的運算時間將會非常久,動輒好幾小時,. ‧. 上述的 Greedy algorithm 並不適用於 Labeled influence maximization problem,因此. sit. y. Nat. 我們修改了 Greedy algorithm,稱作 LabeledGreedy,而 LabeledGreedy 能解決 Labeled. io. al. er. influence maximization problem。. v. n. LabeledGreedy 在評斷種子節點集合 的影響力時,我們是利用 Independent cascade model 去模擬 的影響力。. Ch. i Un. engchi且. 被 影響. ,代表選 S 可以得. 到多少利潤。 要選 k 個點作為起始點,則我們每一回合選擇那回合裡影響力邊際效益最大的節點。 在 t 回合時,選擇此回合可以增加最多影響力的節點. ,如此在 t 回時可得到最大的邊. 際效益,LabeledGreedy 就是在保證每一回合都可以達到最大的邊際效益。 (3) 在(3)中,函數. 具有 submodular 特性,隨著 t 變大,每一回合影響的點越來越. 少。 既然函數. 是 submodular function,則代表用 LabeledGreedy 來解決 Labeled 12.
(24) influence maximization problem,至少可以達到 63%的 approximation。. 3.2 LabeledCELFGreedy Algorithm CELFGreedy(G,k) 1: initialize ; 2: for each vertex do 3: = 4: end for 5: for i to k do 6: for every vertex 7: 8: while true do 9:. 立. ‧ 國. if. 政 治 大. then. 學. 10: 11: 12:. do. break else. ‧ sit. n. er. io. al. y. Nat. 13: 14: 15: end if else 16: end while 17: end for 18: end for 19: return S. Ch. engchi. i Un. v. 圖 3.3 CELFGreedy algorithm. 在[16]中,作者利用了 KKT’s greedy algorithm 中. 的 Submodularity 特性來減. 少運算量,此方法稱作 Cost-Effective Lazy Forward selection(CELF)。假設 ,對所有的 假設. , 為種子節點所成的集合。. ,. , 根 據 定 義 3.1 ,. 。當種子節點之集合變大時,增加節點 v 所增加的影響力會遞減,符合 ,。 13.
(25) 在 KKT’s greedy algorithm 中,每一回合要找出影響力增加最多的節點時,必須檢 查所有的節點,然而,作者所提出的方法 CELF,在加入一個新的種子節點至 S 後,為 了加速,每個節點 v 的. 不一定要重算,CELF 利用 Submodularity 減少重算的機會。. 首先,將所有的 設為無限大,並將所有的 放入 Priority queue(根據 由大到小排 序)中,接著從 Priority queue 裡取出 ,若 是無限大,則根據目前的種子節點之集合 計 算 ,並再將其放入 Priority queue 中。由於 Submodularity 的特性, 會隨著種子節點 之集合 變大而遞減。因此,在第 k 回合時,依序 Poll 出 Queue 中的 ,. ,根據目. 政 治 大. 前的種子節點之集合 重新計算 ,並且放入 Priority queue 中, 經過重算後通常不會. 立. 太小,仍會在 Priority queue 的前端,若某一個 經過運算後被放到 Priority queue 後,. ‧ 國. 學. 又再次被 Poll 出來,則代表此節點 v 為我們這回合所要選的種子節點,如此一來,不一 定每個節點 v 都要去計算 。. ‧. 由於 CELFGreedy 並不能解決 Labeled influence maximization problem,因此我們修. Nat. , 如 此 即 可 解 決 Labeled influence maximization. n. al. er. io. problem。. 修改成. sit. y. 改其演算法,將圖 3.3 中第 13 行的. Ch. engchi. i Un. v. 3.3 LabeledNewGreedy Algorithm 除了 Lazy forward selection,[3]的作者提出了 NewGreedy,以改進 KKT’s Greedy algorithm 模擬時的效率。改進的方法起因於 Independent cascade model 的假設:每一條 邊. 在模擬時,u 只有一次影響 v 的機會,在第 i 回合,若 u 變成 Active node,則在第. i+1 回合,u 會試圖影響 v,不管 u 在此回合有沒有成功影響 v,u 不會再試圖影響 v。 既然每條邊在每次模擬的時候只會使用一次,我們便可以在一開始就選擇邊是否會 使用到(根據邊上的機率而定),若邊 則代表在此模擬中. 有選到,則代表. 會傳遞影響力,若. 沒有選到,. 不會傳遞影響力(v 不會被 u 影響,且 u 不會被 v 影響),則把它從 14.
(26) 社會網絡 G 中拿掉,得到新的社會網絡 G’。我們定義. 代表在 G’中,種子節點 S. 可以影響的點之集合。在 G’中,與種子節點 S 有連通的點都是會被 S 所影響的點。 我們用線性時間掃描 G’(用 DFS 或是 BFS),舉例而言,若是用 DFS,則在 DFS tree 中每一個節點 v 能夠影響的數量等於 DFS tree 中的節點數。如此,我們便可得到 ,對於所有的. 。接著,對於節點. 話,會有多少個節點 被影響,當. 和. ,我們計算選擇 v 作為種子節點的. , 會等於. ;當. ,. 。. 因此,我們隨機產生 G’共 R 次,每次都利用線性掃描計算 ,再選出 平均值最大 O(m),因此整個演算法的時間複 政 和治 需要 大. 的節點 v 作為種子節點。我們計算. 立. ,NewGreedy 較原來的 KKT’s Greedy algorithm 整整快了 n 倍。. 學. ‧ 國. ‧. NewGreedyIC (G, k) 1: initialize and. io. sit. y. Nat. 2: for to k do 3: set for all 4: for to R do 5: compute G’ by removing each edge from G with probability 6: compute 7: compute | | for all 8: for each vertex do 9: if then 10: | | 11: end if 12: end for 13: end for 14: set 15:. n. al. er. 雜度為. 16: 17:. Ch. engchi. i Un. v. end for output S 圖 3.4 NewGreedy algorithm 15.
(27) 同樣地,NewGreedy 並不適用於 Labeled influence maximization problem,因為在計 算. 時沒有考慮到 Label 的因素,所以我們將原來的 NewGreedy 改成. LabeledNewGreedy,主要修改圖 3.4 中第 7 行和第 10 行|. 的計算方式,改成針對. 數量時,不再是計算以節點 v 為 root 的 DFS tree(or BFS tree). Target label。在計算. 裡點連通的個數,而是要計算以節點 v 為 root 的 DFS tree 裡的目標標籤節點之 profit, 即. 政 治 大 且. 立. 代表 v 可以在 G’中影響標籤為. 的 profit,而在第 i 回,我們選 profit 最大. ‧. ‧ 國. 學. 的節點 當作我們的種子節點。. 3.4 LabeledDegreeDiscount. y. Nat. sit. [3]提出了 DegreeDiscount heuristic,此經驗法則假設影響力不易擴散,因此只看節. n. al. er. io. 點與第一層鄰居的關係,優先選取 Degree 高的節點。節點 v 的 Degree 越高,代表 v 的. i Un. v. 影響力期望值越大。若要挑選 k 個種子節點,則 DegreeDiscount 會進行 k 回合,每回合. Ch. engchi. 選一個種子節點。每回合選完一個種子節點 w 後,DegreeDiscount 會重新計算 w 鄰居 v 的影響力期望值,而 v 的影響力期望值會因為選了 w 而打折扣,DegreeDiscount 就是依 照(4)來重新計算節點的影響力期望值。 (4). 且. 代表節點 v 的影響力期望值, 量,而. 、. 且. ,. 則是節點 v 鄰居的數. , 為種子節點之集合,. 則是同時是節點 v 的. 鄰居中種子節點的數量。而(4)所想表達的是節點 v 不被種子節點影響且可以影響尚未被 選為種子節點的節點的期望值。 針對 Labeled influence maximization problem,因此我們修改 DegreeDiscount,使其 16.
(28) 適用於 Labeled influence maximization problem,稱作 LabeledDegreeDiscount。 LabeledDegreeDiscountIC(G, k) 1: initialize 2: for each vertex v do 3: compute its degree 4: 5: initialize 6: end for 7: for do 8: select 9:. if u is target label node do. ‧ 國. 學. else do end if else. ‧. 10: 11: 12: 13: 14: 15:. 政 治 大 for each neighbor do 立 v of u and. n. al. er. io. sit. y. Nat. 16: end for 17: end for 18: output S. i Un. v. 圖 3.5 LabeledDegreeDiscount algorithm. Ch. engchi. 我們稍加修改(4),使其加入 Label 條件設定,可以得到(5)和(6),即可以算出節點 v 的利潤期望值。 , if. (5). , if 假設集合. 且. ,. 且. (6) 且. 為節點 v 的鄰居中被選為種子節點且為目標標籤節點的個數,. ,. 為節點 v 的鄰居中被選為種子節點的個數,而. ={u|. , 且. 且. }為 v. 的 Degree(與 DegreeDiscount 計算 Degree 的方式不同),p 為影響的機率。(5)可視為 v 不 17.
(29) 被種子節點影響的機率,且 v 可以影響目標標籤節點的利潤期望值。公式(5)和公式(6) 的差別在於節點 v 本身是否為目標標籤節點。 要用 LabeledDegreeDiscount 選出 k 個種子節點,則必須跑 k 回合,每回合選出影響 力 期 望 值 最 高 的 節 點 , 而 節 點 的 期 望 值 的 算 法 就 根 據 (5) 和 (6) 來 算 , 圖 3.5 是 LabeledDegreeDiscount 的演算法。. 3.5 ProximityDiscount. 政 治 大. 由於我們可以事先得到社會網絡的資料,因此我們不必等到行銷人員需要查詢時才. 立. 開始找種子節點,我們可以事先處理(preprocessing),找出最具影響力的 k 個人,待使用. ‧ 國. 學. 者查詢時回傳答案。. 然而,此種方是只適用於社會網絡。若是在標籤社會網絡中,目標標籤及目標標. ‧. 籤的權重值並不是固定的值,因此 Labeled influence maiximization 的結果隨著標籤的不. Nat. sit. y. 同而有所改變,因此,我們無法事先所有的答案都算好。所以我們提出了. n. al. er. io. proximityDiscount 來解決 Labeled influence maximization problem。. i Un. v. 由於行銷人員在擬定行銷策略時,會測試不同的目標標籤的組合,以企圖找出最符. Ch. engchi. 合效益的目標標籤之集合。而我們不大可能將這些組合事先運算好,待行銷人員查詢時 回傳。因此 ProximityDiscount 分成 Offline 和 Online 處理兩個部分。Offline 時,事先算 出標籤社會網絡中任兩點之間的 Proximity(鄰近性),當 Online 有查詢時,再透過 Proximity 算出 k 個種子節點。 有 許 多 方 法 [8][9][14][23] 都 可 以 拿 來 計 算 節 點 之 間 的 Proximity 。 但 我 們 計 算 Proximity 的方法概念上與[14]的 Cycle Free Effective Conductance(CFEC)相似。 CFEC 透過在社會網絡上 Random walk,得出從節點 v 走到節點 u 之間的機率值, 此即 Proximity,而 Proximity 可以視為影響力擴散的機率值。 而 CFEC 與其他方法[8][9][23]最大的不同在於,CFEC 在 Random walk 時,不會重 18.
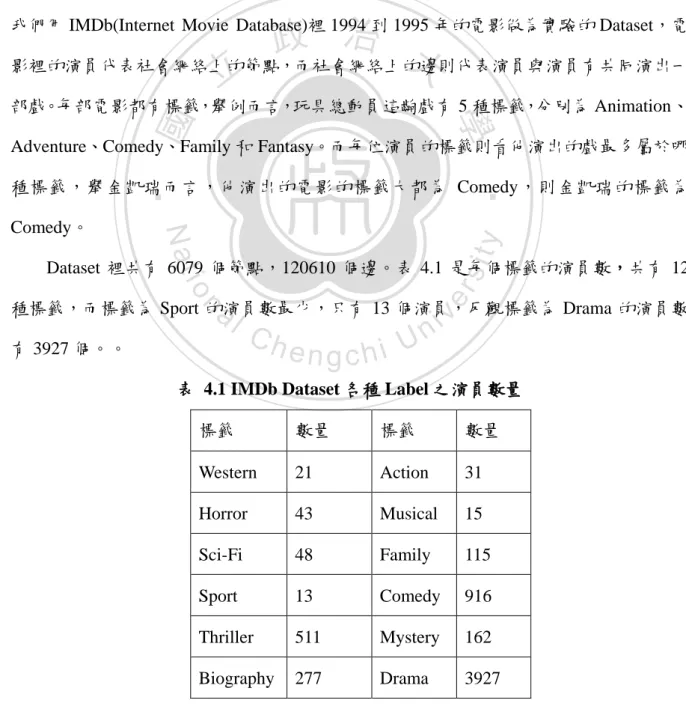
(30) 覆經過同一個節點兩次,因此路徑(Path)不會有迴圈(Cycle)發生,所經過的路徑都是簡 單 路 徑 (Simple path) , 此 條 件 也 與 Independent cascade model 較 為 符 合 , 因 為 在 Independent cascade model 中模擬時,並沒有考慮節點被成功影響兩次以上的情況。 3.5.1 Proximity for Independent Cascade Model 在 Independent cascade model 中,Random walk 每走一步的機率就是邊上的權重值, 點 s 走到點 t 的機率. ,. 是節點 s 與節點 t 的邊之權重值,而且節點與節點之. 間的影響力具有 symmetric 的特性, – …–. ,則從. 。因此,若是一條 path P =. –. 政 治 大. 為起始點依照 P 的順序 Random walk 的機率為:. 立. Prob(P) =. ‧. 令. ‧ 國. 重複的機率。. 學. 因此若是要計算 s-t proximity,則相當於計算節點 s 隨機走到 t,且經過的節點不會. 代表從 s 開始走 Random walk,經過的點不會重複,走到 t 的機率,. n. al. er. io. sit. y. Nat. 則. i Un. v. 在 Undirected graph 中,Random walks 具有可逆性(Reversibility property)[14],因此 。 而. Ch. engchi. 則是將所有 s-t 簡單路徑的機率加總。假設 是 s-t 簡單路徑所成的集. 合,因此我們可以得到. 3.5.2 Computing Proximity 雖然我們可利用(7)算出 s 到 t 的 proximity,但在這之前,我們得先找出所有的簡單 路徑,當社會網絡很大時,找出所有的簡單路徑所需的計算量非常大,而且有些簡單路 徑透過(6)計算後,得到的值非常的小,若我們將找到的簡單路徑依機率值大小排序,則. 19.
(31) 第 100 條最短路徑的機率值可能是最短路徑的百萬分之 1[2],如此小的機率值並不會對 整體有顯著影響。因此,我們利用 Approximation 的方式來算 我們只用機率值較高的前 k 條 s-t 簡單路徑, 徑的機率值小於第 1 條路徑的機率值的. ,來計算. 。 。當第 k 條路. 時,我們停止繼續找第 k+1 條路徑。. 而我們將找前 k 條機率值高的簡單路徑轉換成找前 k 條最短簡單路徑(Find k shortest simple paths problem)。圖 3.6 在說明前 k 條簡單路徑與前 k 條路徑的不同,若 要在圖中找出前 3 條簡單路徑,則長度分別為 6、20 和 21。而若是前 3 條路徑則路徑長 度分別為 6、8 和 10。。. 立. 政 治 大. ‧. ‧ 國. 學 sit. y. Nat. n. al. er. io. 圖 3. 6 前 k 條最短簡單路徑和前 k 條最短路徑之範例。. Ch. engchi. i Un. v. Katho et al.[13]提出了有效率的方法找出前 k 條簡單路徑,我們實作部分,主要參考 [19]。 由於 Independent cascade model 中邊的權重值是固定的獨立機率,影響力擴散的機 率由路徑上的邊之權重值相乘而得。然而,影響力的機率每乘上一個權重值,其實相當 於在標籤社會網絡上多走一步,因此我們只需算路徑的長度即可知道路徑的機率值,因 此我們先將標籤社會網絡的邊的權重值轉成長度,再透過找 s-t 前 k 條最短簡單路徑, 即可得出 s-t proximity。 首先我們將標籤社會網絡上邊的權重(我們假定. 20. )利用(8)轉成長度。.
(32) (8) 標籤社會網絡上的邊有長度後,我們可透過(9)定義路徑的機率值。 (9) R 是一些 s-t 簡單路徑所成的集合。如此,最短路徑則具有最高的機率值,第二短 路徑則有第二高的機率值,R 中第 k 短路徑的機率值會大於最短路徑的機率值乘上. 。. 我們將邊上的權重值轉成長度之後,要找任兩點之間的前 k 條機率值最大的路徑可. 政 治 大. 以視為找前 k 條最短簡單路徑,因此我們可以利用演算法找出任兩點的前 k 條最短簡單 路徑。. ‧ 國. 。. 學. 因此,. 立. 由於計算任兩個 Nodes 之間的 Proximity 所需的計算量很大,因此我們是用 Hadoop. ‧. 來執行。. sit. y. Nat. 藉著算點與點之間的 proximity,我們可以知道每一個節點影響其它節點的機率。而. io. er. 當節點 v 跟其他節點的 proximity 很高,代表節點 v 很有機會影響其他節點。. al. n. iv n C h e n g c h i UProximityDiscount,來解決 Labeled 利用 3.5.1 節的 Proximity,我們提出了新的方法. 3.5.3 ProximityDiscount Algorithm. influence maximization problem,ProximityDiscount 的概念跟 LabeledDegreeDiscount 相似, 但 ProximityDiscount 考慮的較 LabeledDegreeDiscount 精確。 LabeledDegreeDiscount 利用. 來計算節. 點 v 利潤的期望值。然而這個方法有兩個缺點:第一,LabeledDegreeDiscount 只考慮了 第一層的鄰居,並沒有考慮到第二層、第三層甚至第 n 層的鄰居;第二, LabeledDegreeDiscount 在計算節點 v 的期望值時,只扣掉了鄰居為種子節點的利潤,並 沒有考慮到種子節點也可能會影響節點 v 的鄰居。然而,ProximityDiscount 改進了這兩 個缺點。 21.
(33) 與 LabeledDegreeDiscount 相同,ProximityDiscount 每選一個種子節點 w 後,要更新 且. 的利潤期望值,更新的方法如(14):. (14) 首先,我們先計算節點 v 不被種子節點 S 影響的機率,而這個機率為. 政 治 大 接著計算節點 v 的利潤期望值,若節點 v 與節點 u 的 proximity 不為 0,則代表節 立. proximity( , ))。. 越大,則代表節點 v 的期望值越大,節. ‧ 國. 學. 點 v 有機會影響節點 u,若. 點 v 就越有影響力。但在計算節點 v 影響節點 u 的機率值之前,我們必須先計算種子節. y. sit. io. al. n. 而. 是計算節點 v 不被種子節點 S 影響的機率,. er. 公式(14)中,. Nat. 扣。. ‧. 點 S 影響節點 u 的機率,因為節點 u 有可能已經被 S 影響,所以節點 v 的影響力要打折. Ch. 節點影響卻被節點 v 影響的機率。. engchi U. v ni. 是計算點. 不被種子. 公式(14)不僅考慮第一層的影響力,我們計算節點 v 的影響力時,對於任一節點 u 只要有 proximity(v,u)不為 0,我們都視為是節點 v 有機會影響節點 u。此外,在計算節 點 v 的利潤期望值時,我們亦考慮了種子節點對於節點 v 所影響的節點的影響。 在實作方面,每個節點 v 都有 n 個 Linked list 串連節點 , 視標籤社會網絡中有幾種標籤而定,每一個 Linked list 此,當我們要計算點 v 能夠影響多少標籤為 list. 裡面的元素即可。. 22. 儲存標籤為. ,n 的節點。因. 的機率值時,我們只需要累加 Linked.
(34) 圖 3.7 ProximityDiscount 的資料結構. ‧. ‧ 國. 立. 政 治 大. 學. ProximityDiscount (G, k) initialize for do if do for every vertex v do. v’s total profit;. y. n. al. end for for every vertex. end for end if else choose the highest end for. Ch. sit. io. s = new added seed node in the i-1 loop for every vertex ,. er. else. Nat. end for. n engchi U. iv ;. do. 且. ,. do. , add v to S. 圖 3.8 ProximityDiscount algorithm. 圖 3.7 是實作時用的資料結構,假設有 , , 23. , ,n 個節點,我們建立一個.
(35) 長度為 n 個 Array,存放節點 ,. ,不被種子節點影響的機率值 NP( ),. 以及兩個 Linked list A 和 B。圖中,NP( )、NP( )、NP( )…NP(. )為節點不被種子. 節點影響的機率。A 後面所連接的是標籤為 A 的節點,B 連接的是標籤為 B 的節點。 假設第一回合選完的種子節點為. 且目標標籤為 A,則必須針對節點. , ,. , 重 新 計 算 點 u 的 期 望 值 ( 利 用 (14)) 。 我 們 先 更 新 所 有 的 節 點. , ,. 不被種子節點影響的機率,接著在針對每個點. , ,. 利用(14)去. 計算期望值,而計算期望值時,只須累加 A 後面所串連的節點的利潤即可,最後選出期. 政 治 大. 望值最大的點當作這回合的種子節點。. 立. ‧ 國. 學. 3.6 MaximumCoverage. 計算完 Proximity 後,我們可以得到任一個任兩點之間的 proximity。我們可以視每. ‧. 一個節點 v 為明星,把. sit. y. , 是社會網絡中的節點,而 F 是由 V 的子集 ,. n. al. 是由節點 的粉絲所成的集合。. er. io. 合所形成的集合,. Nat. 給定一個集合. 的節點 u 視為節點 v 的粉絲。. i Un. v. 原本要解決的 Labeled influence maximization problem 可以轉變成 Maximum k. Ch. engchi. coverage problem。Maximum k coverage problem 是要找到由一個集合 且最大化. ,亦即 能包含最多節點. ,. ,. 。簡單地說,就是找出 k 個明星,而. 這 k 個明星能夠影響最多的粉絲。 Maximum k coverage problem 是 NP-hard 的問題,因此,我們使用 Greedy algorithm 來解決此問題, 圖 3.9 是 Maximum k coverage 的演算法,主要精神在於每一回合挑出 聯集後能增加最多的元素的集合。而用在 MaximumCoverage 上則是每回合挑出粉絲聯 集後利潤增加最多的明星。圖 3.10 即是 MaximumCoverage 的演算法,在實作部分,每 個明星都有一個長度為社會網絡中的節點數的位元,用來表示擁有的粉絲為誰,若明星 有粉絲 ,則第 i 個位元為 1,反之則為 0。因此,我們要比對聯集後的粉絲數量,我們 24.
(36) 只需將兩個明星的位元作 or 的運算,有多少個位元為 1 則代表兩個明星加起來有多少 粉絲。 Maximum k Coverage 1: 2: for i = 1 to k do 3:. select. 4: 5: end for 6: output. 政 治 大. 圖 3.9Maximum k coverage problem 之 Greedy algorithm。. 立. ‧. ‧ 國. 學. MaximumCoverage (G, k) initialize for do for each vertex. Nat. sit. n. al. er. io. end for output S;. y. end for. Ch. engchi. i Un. v. 圖 3.10 MaximumCoverage algorithm. 3.7. Proximity Threshold and Maximum Coverage Threshold 透過前處理,我們事先計算點與點之間的 Proximity。但有些 Proximity 值相當低,. 因為可能兩個節點 u 和 v 距離太遠,當在算明星有哪些粉絲時,我們可以忽略掉 Proximity 值小的粉絲,因此可以定義出 Proximity threshold ,當 Proximity(u,v)值大於 時,我們 視粉絲 v 為明星 u 的粉絲。 透過調整 的大小,我們可以決定怎樣的粉絲才稱得上是粉絲,也就是我們去定義 有多少機率被明星影響的人才是粉絲。若 很小,明星可能有很多的粉絲,但明星可以 25.
(37) 影響到這些粉絲的機率卻不高。若 很大,則我們可能只視明星第一層的鄰居為粉絲, 只考慮第一層的影響力。 對於 ProximityDiscount 而言,只要是 Proximity 不為 0,ProximityDiscount 都納入考 量,但實際在影響的時候,過小的機率是可以被忽略的,忽略掉一些過小的 Proximity, 不僅能減少執行運算量,也有可能提升效果。減少運算量的原因為每回合選完一個種子 節 w 後,我們都會針對與種子節點 proximity 不為 0 的節點 v,重新計算節點 v 的期望值。 若. 的數量變少,則相對要重新計算期望值的點就會因此變少。. 政 治 大. 至於為何有可能提升效果,原因在於有些 proximity 值雖小,但積少成多,造成長. 立. 尾效應,如此在選種子節點時就會有誤選的情況發生,造成效果不如預期。. ‧ 國. 學. 至於 MaximumCoverage 方面,我們亦可以透過 Proximity threshold 刪掉一些影響機 率非常低的點,留下有機會影響的點。另外,當我們在選擇種子節點時,回合與回合之. ‧. 間所增加的粉絲數要達到 Maximum coverage threshold 以上,也就是說,. Nat. sit. y. maximum coverage threshold。因為我們是用 Greedy 的方式去解 Maximum k coverage. n. al. er. io. problem,每回合增加的粉絲數也會具有 Submodularity,因此當. i Un. maximum. v. coverage threshold,代表再增加新的明星也無法增加 Maximum coverage threshold 數量的. Ch. engchi. 粉絲,倒不如重新再選,選擇粉絲群較大的明星。. 另外,也要考慮到 Proximity threshold 和 Maximum coverage threshold 之間的關係。 若 Proximity threshold 值很高的時候,則 Maximum coverage threshold 就不能太大,因為 Proximity threshold 高代表對於粉絲的認定較為嚴格,粉絲的數量自然就會少,當每位明 星擁有的粉絲數較少,種子節點之集合增加一個明星能增加的粉絲數理所當然地會少於 Proximity threshold 低的時候,而此時若 Maximum coverage threshold 太大,則在選擇種 子節點時,會一直重複挑粉絲群最大的明星,而這些明星存在同一 Component 中,如此 影響力就會只侷限在某一個 Component 中。. 26.
(38) 第四章 實驗. 4.1 實驗設計. 政 治 大 影裡的演員代表社會網絡上的節點,而社會網絡上的邊則代表演員與演員有共同演出一 立. 我們用 IMDb(Internet Movie Database)裡 1994 到 1995 年的電影做為實驗的 Dataset,電. ‧ 國. 學. 部戲。每部電影都有標籤,舉例而言,玩具總動員這齣戲有 5 種標籤,分別為 Animation、 Adventure、Comedy、Family 和 Fantasy。而每位演員的標籤則看他演出的戲最多屬於哪. sit. y. Nat. Comedy。. ‧. 種標籤,舉金凱瑞而言,他演出的電影的標籤大都為 Comedy,則金凱瑞的標籤為. io. al. er. Dataset 裡共有 6079 個節點,120610 個邊。表 4.1 是每個標籤的演員數,共有 12. v. n. 種標籤,而標籤為 Sport 的演員數最少,只有 13 個演員,反觀標籤為 Drama 的演員數 有 3927 個。。. Ch. engchi. i Un. 表 4.1 IMDb Dataset 各種 Label 之演員數量 標籤. 數量. 標籤. 數量. Western. 21. Action. 31. Horror. 43. Musical. 15. Sci-Fi. 48. Family. 115. Sport. 13. Comedy. 916. Thriller. 511. Mystery. 162. Biography. 277. Drama. 3927. 27.
(39) 針對 Labeled influence maximization problem,我們提出六種解決方法,分別為 LabeledGreedy 、 LabeledNewGreedy 、 CELFLabeledGreedy 、 LabeledDegreeDiscount 、 MaximumCoverage 和 ProximityDiscount。由於 LabeledGreedy 和 CELFLabeledGreedy 所 需的運算量太大,而根據[3]的實驗顯示,NewGreedy 的效果與 CELFGreedy 差不多,因 此 我 們 接 下 來 的 實 驗 只 會 比 較 LabeledNewGreedy 、 LabeledDegreeDiscount 、 MaximumCoverage 和 ProximityDiscount 的效果。 實 驗 時 , 若 標 記 方 法 名 稱 為 MaximumCoverage_threshold_0.05 則 代 表 方 法 為. 政 治 大. MaximumCoverage with proximity threshold 0.05。. 立. 實驗採用 Independent cascade model 模擬影響力的擴散,影響機率為 0.05。. 皆為 1 比較;(3)針對多個標籤,每個. ‧. io. sit. y. Nat. 4.2 實驗結果. 皆不一定比較。. er. 每個. ‧ 國. 學. 實驗部分,針對效果,有三種比較方式,(1)針對單一標籤比較;(2)針對多個標籤,. 實驗一:針對單一標籤的比較. n. al. Ch. i Un. v. 圖 4.1 分別比較 LabeledNewGreedy、ProximityDiscount、LabeledDegreeDiscount 和. engchi. MaximumCoverage with proximity threshold 0.05(簡稱 MaximumCoverage)四種方法的效 果;圖 4.1 中,目標標籤為 Drama,而影響一個標籤為 Drama 的演員的利潤為 1。Drama 的演員數是 Dataset 裡最多的,共有 3927 個演員。由圖可見,LabeledNewGreedy 的效 果是四個方法裡面最好的。ProximityDiscount 在第一個種子節點時,影響的利潤跟 LabeledNewGreedy 相 同 , 而 較 LabeledDegreeDiscount 多 出 大 約 100 , 也 多 出 MaximumCoverage 大約 70,這是 ProximityDiscount 領先 LabeledDegreeDiscount 與 MaximumCoverage 兩個方法幅度最大的時候。ProximityDiscount 只有在種子節點數量為 4 的時候會輸給 LabeledDegreeDiscount,其餘的情況都較 LabeledDegreeDiscount 來得好。. 28.
(40) 然而,隨著種子節點數量越來越多,ProximityDiscount 領先 MaximumCoverage 和 LabeledDegreeDiscount 的幅度則越來越小。此外,MaximumCoverage 的結果也普遍較 LabeledDegreeDiscount 來得好,雖然領先幅度不像 ProximityDiscount 一樣大,除了種子 節 點 為 3 時 , MaximumCoverage 輸 給 LabeledDegreeDiscount , 其 餘 皆 顯 示 MaximumCoverage 的效果較 LabeledDegreeDiscount 好。. 立. 政 治 大. ‧. ‧ 國. 學. n. Ch. engchi U. 圖 4.2 是目標標籤為 Comedy,且. er. io. sit. y. Nat. al. 圖 4.1 實驗一( ={Drama},. v ni. )之效果。. 的情況進行四種方法的比較,由. 圖可知,ProximityDiscount 在種子節點數量較小的時候會贏 LabeledDegreeDiscount、 MaximumCoverage 和 LabeledNewGreedy,但隨著種子節點數量越大,ProximityDiscount 領 先 的 幅 度 越 小 , 甚 至 被 MaximumCoverage 、 LabeledDegreeDiscount 和 LabeledNewGreedy 超過。MaximumCoverage 和 LabeledDegreeDiscount 在此實驗中,當 種子節點數量超過 5 時,效果較 ProximityDiscount 來得好。而 LabeledNewGreedy 雖然 在種子節點數量小的時候表現不佳,種子節點數量為 1 的時候輸給 ProximityDiscount 約 25 利潤,但隨著種子節點數量變多,LabeledNewGreedy 效果越來越好,在種子節點 數量大於 15 後,效果較其他三種方法來得好。 29.
(41) 立. 政 治 大 )之效果。. ‧. ‧ 國. 學. 圖 4.2 實驗一( ={Comedy},. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 4.3 實驗二( ={Comedy, Biography},. )之效果。. 實驗二:針對多個標籤,而目標標籤的利潤皆為 1 的比較 圖 4.3 目標標籤為 Comedy 和 Biography,而. 和. 皆為 1。實. 驗顯示,LabeledNewGreedy 的效果是最好的。而 ProximityDiscount 在此條件設定下,. 30.
(42) 只有在種子節點小於 5 的時候,效果較 MaximumCoverage 和 LabeledDegreeDiscount 來 得好。當種子節點數量增多後,MaximumCoverage 和 LabeledDegreeDiscount 的效果皆 會優於 ProximityDiscount。 圖 4.4 為目標標籤為 Thriller 和 Comedy,. 和. 皆為 1 的比較,. 與 圖 4.3 相 似 , ProximityDiscount 在 種 子 節 點 數 量 較 小 的 時 候 , 效 果 較 LabeledDegreeDiscount 和 MaximumCoverage 來 得 好 , 當 種 子 節 點 數 量 較 大 時 , MaximumCoverage 和 LabeledDegreeDiscount 的效果較 ProximityDiscount 來得好,而兩. 政 治 大. 者的效果持平。反觀 LabeledNewGreedy 在此種目標標籤和標籤權重值的設定之下,只. 立. 有在種子節點數量為 1 的時候領先 profit 約 10,其餘情況皆較其他三種來得差,最差的. ‧ 國. 學. 情況是在種子節點數量為 2 的時候,影響的利潤少於 ProximityDiscount 約 38,但隨著 種子節點數量變多,利潤的差距也越來越小。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. 圖 4.4 實驗二( ={Comedy, Thriller},. i Un. v. )之效果。. 圖 4.5 目標標籤為所有的標籤,且所有的標籤的利潤皆為 1,而在這樣的目標標籤 條 件 的 限 制 下 , 其 結 果 就 是 Influence maximization 的 結 果 。 由 實 驗 顯 示 , 31.
(43) LabeledNewGreedy 的 結 果 是 四 種 方 法 裡 面 最 好 的 , 其 次 是 ProximityDiscount 。 ProximityDiscount 在種子節點數量較小的時候,效果都明顯優於 MaximumCoverage 和 LabeledDegreeDiscount,並且與 LabeledNewGreedy 持平。當種子節點較多的時候, ProximityDiscount 的效果都較 LabeledDegreeDiscount 來得好或是持平。而當種子節點數 量大於 9 時,MaximumCoverage 的效果都較 LabeledDegreeDiscount 的效果來得好。. 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. al. v. n. 圖 4.5 實驗二(目標標籤為所有的標籤,且所有的目標標籤之利潤皆為 1)之效果。. Ch. engchi. i Un. 實驗三:比較多個目標標籤,且目標標籤的利潤皆不一定 圖 4.6 是目標標籤為 Comedy 和 Drama,而. ,. 的實. 驗結果。在此條件設定下,影響一個標籤為 Comedy 的演員相當於影響三個標籤為 Drama 的 演 員 。 由 圖 可 見 , LabeledNewGreedy 的 效 果 是 四 種 方 法 裡 面 最 好 的 , 其 次 是 ProximityDiscount 。 ProximityDiscount 在 種 子 節 點 數 量 小 於 4 時 , 效 果 與 LabeledNewGreedy 持 平 。 而 與 LabeledDegreeDiscount 比 較 , ProximityDiscount 贏 LabeledDegreeDiscount 的利潤最多達 90。此外,MaximumCoverage 在此次實驗中,不 管種子節點數量為多少,效果都較 LabeledDegreeDiscount 來得好。 32.
(44) 立. 政 治 大 )之效果。. ‧. ‧ 國. 學. 圖 4.6 實驗三( ={Comedy, Drama},. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 4.7 實驗三( ={Comedy, Thriller, Drama}, )之效果。. 圖 4.7 中目標標籤為 Thriller、Comedy 和 Drama,而 和. 、. 。在此目標標籤設定情況下,LabeledNewGreedy 是四種方法裡面效 33.
(45) 果最佳的方法,其次是 ProximityDiscount。ProximityDiscount 的效果在種子節點數量為 1 的時候,利潤多過 LabeledDegreeDiscount 和 MaximumCoverage 約 340,且在種子節點 數量小於 4 的時候,結果與 LabeledNewGreedy 相同。 由以上面實驗數據可知,ProximityDiscount 在種子節點數量較小的時候,像是種子 數量為 1 或 2 時,效果明顯優於 LabeledDegreeDiscount 和 MaximumCoverage,而當種 子節點數量變大時,贏的幅度會越來越小。由此可知,ProximityDiscount 在判斷影響力 最 大 的 節 點 時 , 較 MaximumCoverage 和 LabeledDegreeDiscount 來 得 好 。 反 觀. 政 治 大. MaximumCoverage,雖然在種子節點數量小時,效果會較 ProximityDiscount 來得差,但. 立. 在種子節點數量較大時,利潤所增加的幅度會較 ProximityDiscount 來得明顯。而. ‧ 國. 學. MaximumCoverage 與 LabeledDegreeDiscount 相比,MaximumCoverage 的效果不是優於 LabeledDegreeDiscount,不然就是與其持平。. ‧. 此外,LabeledNewGreedy 在目標標籤有 Comedy 時(如圖 4.2、圖 4.3 和圖 4.4),效. Nat. sit. y. 果較於其他三種方法來得差,我們推測社會網絡的節點結構在目標標籤為 Comedy 或目. n. al. er. io. 標 標 籤 為 Comedy 搭 配 節 點 數 量 較 其 少 的 標 籤 , 例 如. i Un. ={Comedy, Biography} 或. v. ={Comedy, Thriller},的情況下, LabeledNewGreedy 的方法較不適用,其原因可能標. Ch. engchi. 籤是 Comedy 的節點在標籤社會網絡上有特殊結構性。. 但 在 圖 4.5 、 圖 4.6 和 圖 4.7 , Comedy 搭 配 節 點 數 量 較 其 多 的 Drama , LabeledNewGreedy 的效果又較其他方法來得好。其原因可能是標籤為 Drama 的節點數 量較標籤為 Comedy 多出 3011 個節點,因此 LabeledNewGreedy 在影響 Comedy 的節點 時,其特殊結構性質所產生的利潤變小的效應被 Drama 帶來的利潤效應給蓋過去,因此 效果還是優於其他三種方法。 圖 4.8 是四種方法在執行目標標籤為 Comedy 且 Comedy 的利潤為 1 的資料時所需 的 時 間 , LabeledDegreeDiscount 需 要 0.1 秒 , ProximityDiscount 需 要 235 秒, MaximumCoverage 需要 20 秒,而 LabeledNewGreedy 則需要 30000 秒。 34.
(46) 雖然 ProximityDiscount 和 MaximumCoverage 的執行時間較 LabeledDegreeDiscount 久,但還在可接受的範圍之內。而兩者方法的效果雖然較 LabeledNewGreedy 來得差, 但 卻 也 優 於 LabeledDegreeDiscount 。 因 此 , 在 考 慮 效 果 與 效 率 的 情 況 下 , ProximityDiscount 和 MaximumCoverage 會是較好的選擇。. 3 *10 4 2.35 *10 2 2.03 *101. 1.25 *10. 立. 1. 政 治 大. ‧. ‧ 國. 學 sit. y. Nat. io. al. er. 圖 4.8 LabeledDegreeDiscount、ProximityDiscount、MaximumCoverage 和. v. n. LabeledNewGreedy 之執行時間比較。. Ch. engchi. 35. i Un.
(47) 第五章 結論與未來研究方向 5.1 結論 Influence maximization problem 是要在社會網絡中找出 k 個具有影響力的人,使得社會 網絡中有最多的人受到影響,然而,Influence maximization problem 並沒有考慮到不同. 政 治 大. 的 對 象 , 具有不 同 的重要 性 。因此 我 們針對 標 籤社會 網 絡 提出 Labeled influence. 立. maximization problem。. ‧ 國. 學. 在標籤社會網絡中,節點都有標籤,而每個標籤都有權重值,代表標籤的重要性。. ‧. 而 Labeled influence maximization problem 是指我們如何從標籤社會網絡中找出影響最多 符合目標標籤 (Target label)條件的人的 k 個人。. y. Nat. er. io. sit. 我們共提出了六個新的方法來解決 Labeled influence maximization problem。其中 LabeledGreedy、LabeledNewGreedy、LabeledCELFGreedy 和 LabeledDegreeDiscount 是修. n. al. Ch. i Un. v. 改原本研究 Influence maximization problem 的方法,此外,我們也提出了兩個新的方法. engchi. 來 解 決 Labeled influence maximization problem , 分 別 為 ProximityDiscount 以 及 MaximumCoverage, 根據實驗結果顯示,在兼顧效率與效果的情況下,ProximityDiscount 會是最好的選 擇 。 ProximityDiscount 在 種 子 節 點 數 量 較 小 的 情 況 下 , 效 果 明 顯 地 優 於 LabeledDegreeDiscount 和 MaximumCoverage , 而 當 種 子 節 點 數 量 變 大 時 , MaximumCoverage 的效果會較 LabeledDegreeDiscount 和 ProximityDiscount 來得好。因 此,我們可以依照行銷人員所需來決定方法,若行銷人員所需的 k 值較小,則可以用 ProximityDiscount 來求解,反之則用 MaximumCoverage。. 36.
(48) 5.2 未來研究方向 Proximity threshold 的設定會影響 MaximumCoverage 和 ProximityDiscount 的效果和 效率,Proximity threshold 設得越高,ProximityDiscount 和 MaximumCoverage 的執行效 率就越快,但效果卻不一定變好。因此,如何找到合適的 Proximity threshold 是值得研 究的目標。 此 外 , 目 前 針 對 Labeled influence maximization 所 提 出 的 方 法 , 包 括 LabeledNewGreedy、LabeledDegreeDiscount、MaximumCoverage 和 ProximityDiscount,. 政 治 大. 主要都是依據 Independent cascade mode 的特性而得,是否可以針對 Weighted cascade. 立. model 提出解決 Labeled influence maximization problem 的方法。. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 37. i Un. v.
(49) 參考文獻 [1] F. Bass, “A New Product Growth Model for Consumer Durables,” Management Science, Vol. 5, No. 5, 1969. [2] J. Brown and P. Reinegen, “Social Ties and Word-of-mouth Referral Behavior,” Journal of Consumer Research, Vol. 14, No. 3, 1987.. 政 治 大. [3] W. Chen, Y. Wang, and S. Yang, “Efficient Influence Maximization in Social Networks,”. 立. Proc. of ACM International Conference on Knowledge Discovery and Data Ming. ‧ 國. 學. SIGKDD, 2009.. ‧. [4] A. Chin and M. Chignell, “A Social Hypertext Model for Finding Community in Blogs,” Proc. of Conference on Hypertext and Hypermedia, 2006.. y. Nat. Float,” Management Science, Vol. 23, 1997. n. al. Ch. er. io. sit. [5] G. Cornuejols, M.Fisher and G. Nemhauser, “Location of Bank Accounts to Optimize. i Un. v. [6] P. Domings and M. Richardson, “Mining the Network Value of Consumers,” Proc. of. engchi. ACM International Conference on Knowledge Discovery and Data Mining SIGKDD, 2001. [7] P. G. Doyle and J. L. Sell, “Random Walks and Electrical Networks,” The Mathematical Association of America, 1985. [8] C. Faloutsos, K. S. McCurley, and A. Tomkins, “Fast Discovery of Connection Subgraphs,” Proc. of ACM International Conference on Knowledge Discovery and Data Mining SIGKDD, 2004. [9] B. Gallagher, H. Tong, T. Eliassi-Rad, and C. Faloutsos, “Using Ghost Edges for. 38.
(50) Classification in Sparsely Labeled Networks,” Proc. of ACM International Conference on Knowledge Discovery and Data Mining SIGKDD, 2008. [10] J. Goldenberg, B. Libai, and E. Muller, “Using Complex Systems Analysis to Advance Marketing Theory Development,” Academy of Marketing Science Review, Vol. 2001, No. 9, 2001. [11] J. Goldenberg, B. Libai, and E. Muller, “Talk of the Network: A Complex Systems Look at the Underlying Process of Word-of-Mouth,” Marketing Letters, Vol.12, No. 3 ,. 政 治 大. 2003.. 立. [12] D. Kempe, J. Kleinberg, and E. Tardos, “Maximizing the Spread of Influence through a. ‧ 國. 學. Social Network,” Proc. of ACM International Conference on Knowledge Discovery and Data Mining SIGKDD, 2003.. ‧. [13] N. Katoh, T. Ibaraki and H. Mine, “An Efficient Algorithm for k Shortest Simple Paths,”. y. Nat. sit. Networks, Vol.12 , pages.411-427,1982.. n. al. er. io. [14] Y. Koren, S. C. North, and C. Volinsky, “Measuring and Extracting Proximity in. i Un. v. Networks,” Proc. of ACM International Conference on Knowledge Discovery and Data Mining SIGKDD, 2006.. Ch. engchi. [15] J. Leskovec, L. A. Adamic, and B. A. Huberman, “The Dynamics of Viral Marketing,” ACM Transactions on the Web, Vol. 1, No. 1, 2007. [16] J. Leskovec, A. Krause, C. Guestrin, C. Faloutsos, J. VanBriesen, and N. Glance, “Cost-effective Outbreak Detection in Networks,” Proc. of ACM International Conference on Knowledge Discovery and Data Ming SIGKDD, 2007. [17] D. Liben-Nowell and J. Kleinberg, “The Link Prediction Problem for Social Network,” Proc. of International Conference on Information and Knowledge Management CIKM, 2003. 39.
(51) [18] V. Mahajan, E. Muller, and F. Bass, “New Product Diffusion Model in Marketing: A Review and Directions for Research,” Journal of Marketing, Vol.54, No.1m pages.1-26, 1990. [19] E. Q. V. Martins and M. M. B. Pascoal, “A New Implementation of Yen’s ranking loopless paths algorithm,” Quarterly Journal of the Belgian, French and Italian Operations Research Societies, 2002. [20] G. Nemhauser, L. Wolsey, and M. Fisher, “An Analysis of the Approximations for. 政 治 大. Maximizing Submodular Set Functions,” Mathematical Programming, Vol.14, No.1,. 立. 1978.. ‧ 國. 學. [21] M. Richardson and P. Domingos, “Mining Knowledge-Sharing Sites for Viral Marketing,” Proc. of International Conference on Knowledge Discovery and Data. ‧. Mining, 2002.. Nat. sit. y. [22] J. Scripps, P. N. Tan, and A. H. Esfahanian, “Exploring the Link Structure and. n. al. er. io. Community-based Node Roles in Networked Data,” Proc. of IEEE International Conference on Data Mining ICDM, 2007.. Ch. engchi. i Un. v. [23] H. Tong, C. Faloutsos, and J. Y. Pan, “Fast Random Walk with Restart and Its Applications,” Proc. of IEEE International Conference on Data Mining ICDM, 2006. [24] X. Yan and J. Han, “gSpan: Graph-Based Substructure Pattern Mining,” Proc. of the 2002 IEEE International Conference on Data Mining ICDM, 2002.. 40.
(52)
數據


+7




相關文件
3.8.1 學校能因應工作的進展和達到預期目標 的程度,適切地調整年度目標和推行策略,逐 步深化過去兩年關注事項的成果。.
透過自我的意志力 (Agency),再運用策略和方法 (pathway) 來達成目標。. 自我意志力
以課程為目標時,課程包含的是所欲達成的 一組目標,強調課程目標的重要性,所以也 著重於課程目標的選擇、組織、敘寫,並以
最佳解裡面如果沒有greedy choice的話, 則想辦法 把最佳解裡面的一些東西和greedy choice互換. 結 果發現這個新解跟greedy choice一樣好
結 果發現這個新解跟greedy choice一樣好(也是一個 最佳解) 或者發現這個新解更好(矛盾, 所以最佳解
結 果發現這個新解跟greedy choice一樣好 (也是一個 最佳解) 或者發現這個新解更好 (矛盾, 所以最佳解 裡面不可能沒有greedy
• 下面介紹三種使用greedy algorithm產生minimum cost spanning
Namespace 關鍵字, 它會將所定義的名稱 區域化, 只有在該區域時方能看到在該區 域中所定義的名稱, 因此其許可同樣的名
