國
立
交
通
大
學
資訊科學與工程研究所
碩
士
論
文
探 討 地 理 距 離 與 社 會 距 離 對 熟 識 網 絡 演 化 的 影 響
Explore the Simultaneous Effects of Geographic Distance and
Social Distance on the Evolution of Acquaintance Networks
研 究 生:賴鵬羽
指導教授:孫春在 教授
Explore the Simultaneous Effects of Geographic Distance and Social
Distance on the Evolution of Acquaintance Networks
研 究 生:賴鵬羽 Student:Peng-Yu Lai
指導教授:孫春在 Advisor:Chuen-Tsai Sun
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer Science June 2010
Hsinchu, Taiwan, Republic of China
探討地理距離與社會距離對熟識網絡演化的影響
學生:賴鵬羽 指導教授:孫春在 博士國立交通大學資訊科學與工程研究所
中文摘要
我們如何認識我們的朋友?從日常生活的經驗來看,我們的朋友不外乎是因 為擁有共同的生活環境或是社交圈有所重疊而產生交集。因此,當人們在選擇互 動對象時,應該同時考量地理距離與社會距離接近程度的影響。 本研究利用以下四條規則來進行熟識網絡的動態演化,包括:(1)友誼會受到 雙方互動次數及最近兩次互動的時間間距的影響;(2)個體離開後會有新的個體 加入;(3)個體會認識新的朋友;(4)個體會和他的朋友互動來維護友誼。我們並且 在網絡演化達到穩定狀態後,觀察網絡的拓樸性質。 研究結果發現不管是地理距離或是社會距離都能使熟識網絡演化成具有高 群聚度與低分隔度的小世界網絡。此外,社會距離對於群聚現象的影響力高於地 理距離,從這項結果可以幫助理解現今的社交網站為何會如此地流行。然而,社 交互動媒體只是提供更多維護友誼與結交朋友的方式,在時間、精力等交友資源 有限的情況下,大部分的人能夠保持連繫的朋友數都會相似。 關鍵字:地理距離、社會距離、小世界性質、社會網絡分析
Explore the Simultaneous Effects of Geographic Distance and Social Distance on the Evolution of Acquaintance Networks
Student:Peng-Yu Lai Advisor:Dr. Chuen-Tsai Sun
Institute of Computer Science and Engineering
National Chiao Tung University
ABSTRACT
How do we make acquaintances? From the experiences of our daily life, we almost have intersections with our acquaintances if we share the same living environment or the social networks are overlapped. Therefore, the effects of the geographic distance and the social distance must be taken into account when people choose their interactive objects.
In this study, we use the following four rules to implement the dynamic evolution of acquaintance networks, including: (a) friendships are affected by the times of interaction and the time interval of the last two interactions; (b) a new individual will join the network after the old one leaves; (c) individuals make new acquaintances; (d) individuals interact with their acquaintances to maintain the friendships. Moreover, we observe the topologies of networks when the evolution reaches the stationary state.
In the result, we find both the geographic distance and the social distance make the acquaintance networks evolved into small-world networks, which are characterized by higher clustering coefficient and lower degree of separation. Besides, the social distance has a greater influence on the cluster phenomenon than geographic
distance. From this result, we can realize why social networking sites are so popular nowadays. However, the social networking sites only supply more ways to maintain friendships and make acquaintances. The number of acquaintances most individuals keep in touch with is similar because of the limited resources, like time, energy, etc.
Keywords:geographic distance、social distance、small-world property、social network analysis
致 謝
俗話說:「凡走過必留下痕跡。」在寫著這篇致謝文的同時,代表我即將結 束碩士生涯,邁入人生的另一段旅程。回顧這些年讀碩班的生活,如人飲水冷暖 自知,在研究遇到瓶頸的時候,不管再多、再大的困難,也是咬著牙堅持下去。 如今,終於讓我順利走過這一切,完成了屬於自己的論文。 在這段旅程中,需要感謝的人太多了。首先感謝指導教授孫春在老師的精闢 指導,幫助我找到許多有價值的觀點來檢視我的研究,也讓我學習到如何去做好 研究。感謝口試委員曾憲雄老師、項潔老師、陳穎平老師的諄諄教誨,讓我的論 文能更臻完美。感謝崇源學長的熱心指導,不管是在系統設計或是結果分析上, 都給予我莫大的幫助。除此之外,也要感謝實驗室的學長及學弟們的陪伴,讓我 在這一年衝刺的階段,不會感到孤獨。博班的學長:宇軒、聖文、王豪、宜睿、 基成、勝毅、昱翔還有立先,或多或少在論文及實驗上幫助過我,在此由衷地感 謝你們,沒有你們也不會有今天的我,特別是聖文、勝毅及立先,在做研究之餘, 也能跟我一起吃飯及分享生活,讓我這一年的日子更加多采多姿。碩班的學弟: 謹譽、全榮、柏志、泰源、壯為、嘉宏、璽文,大夥為了畢業,一起努力及互相 打氣的日子,也是支持我走下去的原動力。還有誌宏、偉存、承宏、浩琮、景照, 跟你們一起打籃球,讓我能有更強健的體魄來面對挑戰,祝福你們在未來的一年 也能順利完成自己的研究。 最後,當然還要感謝支持我的家人及朋友,在生活及心靈上給我極大的支持 及安慰,才能讓我堅持到底,把論文完成,謹將這份喜悅與你們一同分享。 2010.07.06 于新竹目 錄
中文摘要... i ABSTRACT... ii 致 謝... iv 目 錄... v 表 目 錄... viii 圖 目 錄... ix 第一章 緒論... 1 1.1 研究動機... 1 1.2 研究背景... 4 1.3 研究目標及重要性... 7 1.4 研究問題... 8 第二章 文獻探討... 9 2.1 社會網絡的相關研究... 9 2.1.1 規則網絡模型... 10 2.1.2 隨機網絡模型... 11 2.1.3 小世界網絡模型... 11 2.1.4 無尺度網絡... 14 2.2 熟識網絡的動態演化... 16 2.3 地理距離相關文獻... 20 2.3.1 地理距離的重要性... 20 2.3.2 地理距離對社會網絡的影響... 21 第三章 研究方法... 23 3.1 模型描述... 233.2 設定初始網絡... 25 3.2.1 個體的屬性設定... 25 3.2.2 初始友誼的設定... 25 3.3 綜合性距離函數... 26 3.4 各項演化規則... 28 3.4.1 三條交友規則... 28 3.4.2 友誼衰退函數... 31 3.5 模型的操作... 33 3.5.1 輸入的參數... 33 3.5.2 資料的蒐集... 34 3.5.3 實驗步驟... 36 3.6 預期結果... 36 3.7 實驗設計... 38 3.8 驗證方法... 40 第四章 實驗分析... 41 4.1 參數的敏感度分析... 41 4.1.1 不同的初始網絡類型... 42 4.1.2 不同的初始交友數... 47 4.1.3 地理距離的影響程度不同時對熟識網絡的影響... 50 4.1.4 不同的互動行為取向... 54 4.2 模型驗證... 59 4.2.1 驗證方法... 59 4.2.2 真實的社會網絡資料... 60 4.2.3 模擬結果... 61 4.3 熟識網絡的抽樣調查... 64
第五章 結論... 66
5.1 結論... 66
5.2 未來展望... 67
表
目 錄
表 2-1 各種類型的社會網絡 ... 16 表 3-1 模型的實驗參數列表 ... 34 表 4-1 各種理論網絡的特性(群聚度、分隔度) ... 42 表 4-2 不同初始網絡在演化後的拓樸數據 ... 43 表 4-3 朋友的互動次數統計表 ... 57 表 4-4 不同設定下的平均友誼值統計表 ... 58 表 4-5 婦女網絡拓樸資料統計 ... 61 表 4-6 婦女網絡模擬實驗的平均交友數與平均交友數平方 ... 61 表 4-7 婦女網絡模擬實驗的群聚度與分隔度 ... 62圖
目 錄
圖 1-1 Facebook 的朋友推薦功能 ... 2 圖 1-2 社會網絡中的群聚現象示意圖 ... 5 圖 1-3 Bandura 的「三元交互決定論」 ... 6 圖 2-1 Watts 與 Strogatz 提出的小世界模型 ... 12 圖 2-2 平等式小世界網絡 ... 12 圖 2-3 貴族式小世界網絡 ... 12 圖 2-4 平等式小世界網絡的度分佈曲線 ... 13 圖 2-5 貴族式小世界網絡的度分佈曲線 ... 14 圖 2-6 冪次律分佈曲線 ... 15 圖 2-7 Davidsen et al.(2002)的認識朋友規則示意圖 ... 18 圖 3-1 本研究的模型架構圖 ... 23 圖 3-2 離開及加入網絡流程圖 ... 30 圖 3-3 認識新朋友流程圖 ... 30 圖 3-4 維護友誼規則流程圖 ... 30 圖 3-5 友誼衰退函數的衰退率曲線 ... 32 圖 3-6 友誼衰退函數執行流程 ... 33 圖 3-7 演化穩定下的網絡拓樸數據取值方式 ... 35 圖 3-8 實驗流程圖 ... 36 圖 4-1 不同初始網絡演化前後的平均朋友數 ... 44 圖 4-2 不同初始網絡演化前後的群聚度 ... 44 圖 4-3 不同初始網絡演化前後的分隔度 ... 45 圖 4-4 不同初始網絡演化前的交友數分佈情形 ... 46 圖 4-5 不同初始網絡演化後的交友數分佈情形 ... 46圖 4-6 不同初始分支度在演化前的各項網絡拓樸 ... 49 圖 4-7 不同初始分支度在演化後的網絡拓樸 ... 49 圖 4-8 地理距離影響程度不同時的平均交友數 ... 52 圖 4-9 地理距離影響程度不同時的群聚度 ... 52 圖 4-10 地理距離影響程度不同時的分隔度 ... 53 圖 4-11 交新朋友頻率變化時的平均交友數曲線 ... 55 圖 4-12 不同交友頻率的群聚度變化曲線 ... 56 圖 4-13 不同交友頻率的分隔度變化曲線 ... 57 圖 4-14 南部婦女網絡 ... 60 圖 4-15 婦女網絡與模擬結果的交友數分佈 ... 63 圖 4-16 前人的熟識網絡模型抽樣調查結果 ... 64 圖 4-17 本研究的熟識網絡模型抽樣調查結果 ... 65
第一章
緒論
你跟你的朋友是怎麼認識的呢?是因為分配到同一個班級而認識?還是因為 一起參加某一個同事的生日 party 而認識?抑或是先認識了某個朋友之後,透過 這個朋友的介紹才認識另一個朋友呢?...1.1 研究動機
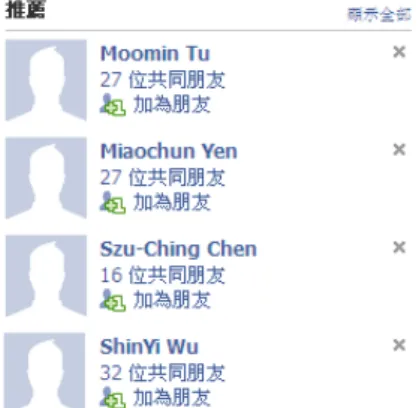
在我們日常生活的經驗中,我們常常會有這樣的感覺:如果當初沒有進到某 家公司、考上某間學校、加入某間實驗室的話,我們不會認識某些人;要是沒有 認識誰,也就不會認識某某人。經由上面的例子,我們了解人與人之間的相識受 到了周遭環境因素的影響。 幾年前,電視上的某個綜藝節目,其中有一個「超級任務」單元是幫觀眾找 尋失聯已久的朋友或親人,而節目的特派員會根據觀眾所提供的線索去尋人,但 是在線索不足的情況之下,特派員往往只能依據地緣關係或是透過以前認識的同 學或同事來幫忙找出這個人。特派員尋人的方式凸顯了環境因素對於人際關係形 成的重要性。Milgram(1967)在他著名的「六度分隔」實驗結果中也指出,要能 成功地將信件寄給收件者,必須經過認識收件者的人手上,而這些人不外乎是收 件者住所的鄰居或是和他的職業有關的人。因此,我們將影響人際關係的環境因 素大致上區分為兩類—「地理距離」與「社會距離」。 有句話說:「近水樓台先得月。」說明了距離對於人際關係的影響。當我們 剛進入一個班級或是搬進去某個社區,我們往往會先認識自己附近的人,比方說 座位前後左右的同學或是隔壁的住戶等等,一段時間過後,當我們已經認識了某些朋友之後,透過這些朋友的引介,我們可能會再認識這些人的朋友來拓展人際 關係,而這些居中引介的人,就是我們跟新朋友之間的「共同朋友」。兩個人的 共同朋友越多,代表兩人之間的關係越密切,則他們之間認識的可能性就越高 (Jin et al., 2001; Davidsen et al., 2002; Ebel et al., 2003)。以現在流 行的社交互動網站 facebook 為例,它上面有一項推薦可能認識的朋友的功能, 同時會顯示使用者跟被推薦的朋友之間的共同朋友數,如圖 1-1 所示,共同朋友 的數目越多,被推薦的機會就越高。
圖 1-1 Facebook 的朋友推薦功能
除此之外,拜科技進步之賜以及地圖資訊的完備,地理資訊系統(Geographic Information System, GIS)目前被廣泛地應用於諸如定位、最佳路徑搜尋、地形 狀況的了解等方面,透過地理資訊系統,我們也可以了解兩個個體之間距離的遠 近,並將其運用在人際間的互動。舉例來說 Google 於 2005 年推出一項手機應用 服務,叫作「Google Dodgeball」。Dodgeball 是一家提供簡訊服務的公司,最 值得一提的是它可以透過地理資訊系統找出當下在使用者附近有哪些朋友,使用 者只須發一封簡訊給 Dodgeball,它就會幫使用者找出清單中有哪些朋友正在附 近,並發簡訊通知他們,這樣一來,使用者不需一一打電話就能找朋友出來見面, 進行更密切地互動。
然而,隨著時空背景的不同,地理距離與社會距離對組織中個體間的互動有 著不同的影響力。舉例來說,當我們進入研究所就讀,由於地理空間的距離較接 近,使我們容易認識同一間實驗室的人,彼此的互動也較多。而當我們畢業離開 之後,即使實驗室的成員各奔東西,但因彼此間的人脈關係密切,社會距離較接 近,所以仍會繼續交流互動,甚至還能認識曾經待過同一間實驗室的學長姐。此 外,不同性質的組織或社群,地理距離與社會距離對人際之間互動的影響力也不 盡相同。例如:某大企業各個子公司的主管或是某個宗親會、協會的成員。組織 中的成員雖然分散在各地,但是彼此之間由於有密切的人脈關係,所以會持續互 動。而同個社區的住戶或是辦公大樓中同一樓層的員工,因為地理距離接近,彼 此認識及互動的機會較多。因此,我們想了解當地理距離與社會距離的影響力不 同時,整個組織中人際關係的形成及演化將有何改變,並觀察趨於穩定後的人際 關係結構上是否有所差異。 最後,從科技發展的角度來檢視我們所要探討的問題。在從前通訊及交通都 不發達的時候,人們進行互動的對象大多是以住家或者工作地點為中心的人,因 此,地理距離的遠近主宰了社會距離的大小。隨著網際網路與社群網站如 MSN、 facebook、twitter 等出現之後,打破了這樣的觀念,社會距離相近的人未必地 理距離也會接近,就算是遠在地球兩端的人,也能透過社交媒體保持密切的互動, 社會距離與地理距離不再有密切的關聯。近年來,GIS、GPS 技術的成熟,加上 交通工具的發達,改變了人們對傳統地理距離的認知,人們所到之處都可以變成 發生互動的中心,因此人跟人之間的地理距離會隨著移動而有所改變,連帶影響 朋友之間的互動與認識新朋友的機率,甚至改變了社會距離的遠近。我們期望透 過本研究可以在這兩項因素對熟識網絡的影響有進一步的了解。
1.2 研究背景
人與人之間因為彼此的互動、交流,產生了許多複雜的關係,若將人視為個 體單元,人與人之間的關係視為連結,則人際關係便形成了網絡。而熟識網絡 (acquaintance network)所描述的是網絡中連結的兩個體,彼此互相認識的關係。 若是甲乙兩者之間只有甲認識乙,而乙卻不認識甲,則這樣的關係就不屬於熟識 網絡,好比說每個學生都認識學校的校長,但是校長卻不一定認識每一個在學的 學生,當校長不認識某個學生時,他們的關係便不是熟識網絡。此外,熟識網絡 連結的雙方在未來仍會繼續交流,而不是只見過一次面,就不再來往了。舉例來 說,一夜情跟網路拍賣買家與賣家的關係就不屬於熟識網絡。在現實社會中,熟 識網絡並非只侷限在朋友的關係,也可以是學長學弟,董事會成員,上司及下屬 等關係,甚至連兩個人之間是仇人,也都在熟識網絡討論的範疇中。總而言之, 熟識網絡中連結的兩個體,不僅要互相認識,彼此之間也要有多次的來往。 熟識網絡中互相認識的兩個體,連結關係並不會一直存在,而是隨著個體之 間的互動情形不停變化著。當個體間的互動越頻繁,彼此的關係會越密切,反之, 當個體間不再互動、交流時,兩人的關係也會隨著消失,因此整個熟識網絡的結 構是不停地變動著。在現實生活中有許多網絡型態,諸如:交通網絡、網際網絡 等,也和熟識網絡一樣不斷變化著,這樣的網絡被統稱為「複雜網絡」。複雜網 絡的拓樸特性一直是學者們致力研究的目標,近年來,最著名的研究便是 Watts 和 Strogatz 在 1998 年提出的小世界模型。 在小世界模型中,一個穩定的網絡普遍存在著兩種特徵-「高群聚度」與「低 分隔度」。其中,「高群聚度」表達了當 A、C 兩個個體同時與某一個個體 B 都有 連結時,則 A 有很高的機會與 C 連結,如圖 1-2 所示。在熟識網絡中很容易發現這樣的情形存在:當兩個陌生人之間有共同認識的人存在時,容易透過中介人的 引介而相互結識,形成三角閉合(triadic closure);此外,「低分隔度」說明了 網絡中任兩個個體之間的平均最短路徑長較小,意即我們可以透過較少的人來接 觸網絡中的其他個體,而這個特性與 Milgram 的「六度分隔」理論相呼應。近幾 年來,Watts 的模型為小世界現象的研究揭開了序幕,成為社會模擬研究的基礎 (Huang & Tsai, 2009)。然而,這樣的模型只著重於網絡全域拓樸特性的分析, 而忽略了網絡底層個體進行互動對整個網絡的影響。若我們想要研究一個非靜態 的網絡,必須將焦點放在個體間的行為及其動態變化的過程。 圖 1-2 社會網絡中的群聚現象示意圖 除了高群聚度及低分隔度外,真實世界中的許多複雜網絡系統也具有「個體 分支度呈冪次律(power-law)分佈」的特徵。這個特徵描述了在網絡中少數的個 體擁有大量的連結,而其他大部分的個體連結數很少的現象。最早提出模型來模 擬這個特徵的是 Barabasi 與 Albert(1999),自此之後,複雜網絡動態機制的研 究便開始蓬勃發展。在他們的模型中,節點與連結持續地被加入網絡,使得整個 網絡不斷成長且具有偏好連結(preferential attachment)的趨勢,也就是說新 加入的節點或連結傾向於連接到擁有較多連結的節點,在真實世界中,性關係網 絡(Liljeros et al., 2001)或是科學家合作網絡(Newman, 2001)都具有這樣的
特徵。 然而,某些網絡類型因為個體資源有限,連帶限制了每個個體的連結數。例 如:在電力輸送網中,一個變電所不會無限制地連接發電廠,或者在飛航網絡中, 一個機場只能容納有限的飛機數量等。而在熟識網絡中,也普遍存在這樣的情形。 由於人們的時間、精力有限,並不會一直結交朋友,因此必須有所取捨。一些互 動往來較少的朋友,彼此的關係會越來越淡,到最後形同陌路而不再有交集,故 熟識網絡中大部分個體的朋友數都會差不多(Amaral et al., 2000)。 為了能深入了解熟識網絡中個體間的互動對網絡的影響,過去有一些研究 (Jin et al., 2001; Davidsen et al., 2002; Ebel et al., 2003; Huang & Tsai, 2009)根據交友經驗提出數條互動規則來進行實驗,而實驗的結果都能符合真實 社會中的小世界現象。其中,Davidsen et al.(2002)的模型主要探討個體間的 交友行為,包括離開網絡及認識新朋友;而 Huang & Tsai(2009)的研究則強調個 體本身具有不同的交友資源及記憶能力,對交友行為的影響。若以 Bandura (1986) 的三元交互決定論架構(圖 1-3)來檢視本研究與這兩個研究的關係,前述
Davidsen et al.(2002)的研究屬於架構中的「行為」部分,而 Huang & Tsai(2009) 的研究則偏重於「個體」的部分,因此,本研究所探討的地理距離及社會距離兩 項因素正好可以補足架構中「環境」的部分。
圖 1-3 Bandura 的「三元交互決定論」
1.3 研究目標及重要性
對於社會網絡的研究,我們可以透過問卷或抽樣調查來蒐集資料進行分析。 然而,這樣的方式可能會面臨實驗數據有誤差的情況,例如:填問卷的人沒有據 實填寫而無法當成有效資料或是在抽樣調查時不管樣本空間多大都必定存在誤 差。隨著電腦運算能力的提升,許多研究便改以電腦模擬的方式來進行實驗,和 調查研究形成互相補充、參照和驗證的關係。因此,我們將提出一套以電腦模擬社會網絡(Computer Simulated Social Network, CSSN)為基礎的熟識網絡模擬模型,並輔以一些規則,在考量地理和社 會兩項距離因素的情形下,建構及演化熟識網絡。另外,由於朋友之間的友誼會 隨著時間漸漸衰退,所以我們會設定一個友誼衰退函數,使整個模型的模擬能更 貼近真實世界的交友情形。如果能將這個模型完成,將會使我們在探討環境因素 影響力不同的熟識網絡時有所依據,也可以觀察穩定後網絡拓樸的一些特徵是否 產生變化。除此之外,在模擬之初,我們會利用一些理論網絡,如:規則網絡、 隨機網絡等來進行實驗,並調控模型輸入的參數,進行敏感度分析。最後我們會 蒐集真實世界中的熟識網絡資料,來驗證我們的模型。 我們期望本論文能對社會及傳播研究者在了解與朋友關係相關的社會現象 提供一個參考,例如:八卦、謠言的散播、社會次文化的形成等,或是對公衛專 家在研究流病傳染的路徑及制定預防策略時有所幫助。除此之外,在網路遊戲的 虛擬世界中,遊戲玩家(player)若參加同一個公會,則同公會玩家之間的關係就 如同本研究所探討的社會距離,而在同一地圖一起遊戲的玩家,可能會因為彼此 之間的競爭或者合作而產生互動,這樣的情形在概念上也與地理距離是相近的, 因此,若我們想要探討虛擬世界中玩家的熟識網絡,也可以在本研究的基礎上繼
續延伸。
1.4 研究問題
本研究主要探討下列三項研究問題: 1. 當熟識網絡的演化趨於穩定後,觀察網絡拓樸性質在兩項環境因素影響力改 變時的敏感度。例如:當整個網絡受到「社會距離」的環境因素影響較大時, 由於個體認識或是互動的對象都傾向於選擇自己的朋友或是朋友的朋友,是 否較易形成小團體(clique)的現象,使得群聚度會比同時考量兩個因素時還 來得高? 2. 將理論網絡(規則網絡、隨機網絡、小世界網絡)代入模型中進行演化,並觀 察網絡穩定後,在拓樸性質上是否具有相同的趨勢。假設實驗的結果一致, 我們會好奇各種理論網絡演化之後的拓樸性質(如:群聚度、分隔度)是不是都 會傾向於小世界網絡? 3. 初始網絡的總人數以及個體的交友數多寡是否對網絡的拓樸特性造成影響? 在一個人數眾多的團體中,網絡群聚的現象與人數較少的團體是否存在顯著 差異,而穩定後的平均交友數是否有所不同?此外,一開始交朋友數較多的個 體是否有辦法維持原本的友誼,且不斷地交新朋友呢?第二章
文獻探討
2.1 社會網絡的相關研究
自從 Milgram(1967)提出六度分隔理論以來,學界對於社會網絡中人際之間 互動所形成的現象便一直很有興趣。然而,一些社會網絡的研究方法卻有其缺點 存在,例如:在 Milgram(1967)的六度分隔實驗中,採用信件傳遞的方式來探究 人與人之間的相識鍊。在所有傳遞出去的途徑中,最後只有百分之十八能成功傳 到指定的收件人手中,屏除實驗參與者對收件人不認識的原因,有部分原因可能 是接到信件的人不願再將信件傳遞下去(Liben-Nowell et al., 2005)。然而, 隨著電腦運算能力大幅地增進,運用電腦來進行模擬的方法解決了這樣的問題。 Watts 與 Strogatz(1998)的模型提出了小世界網絡具有高群聚度與低分隔度的 特徵,而這些特徵普遍存在於社會網絡中,也符合真實社會的原貌,因此,他們 的模型成為了近年來社會網絡研究的濫觴。 在社會網絡研究中,群聚度與分隔度是兩項重要的拓樸性質,群聚度通常以 群聚係數來量測,而分隔度以網絡整體的平均最短路徑長度作為量測標準。在一 個網絡中,若某一個個體的所有相鄰點能形成完全圖(clique),則它的群聚係數 等於 1;反之,若所有相鄰點之間不存在任何連結,則該點的群聚係數會等於 0。 因此,我們可以將群聚係數理解為「某個體相鄰點間實際存在的連結數」與「相 鄰點形成完全圖所需的連結數」之間的比值,將所有個體的群聚係數加總後再取 平均,即為網絡的群聚度。詳細的計算公式如下: 2 1 2 ( 1) ( 1 N i i i i i i i E E C C k k N k k = 〈 〉 = 〈 〉 = −∑
− ) i (1) 其中,N 為個體總數, 代表網絡中與個體ki i相鄰的個體數,而在這 個個體之ki間所形成的連結數為Ei。以比較淺顯的方式來解讀,群聚度就是用來檢視網絡 平均每個個體的朋友中,有多少對也具有朋友關係。 至於平均最短路徑長度L的計算方式如下所示: , , 1 2 , ( 1) ( 1) u v u v u v u v u v L d d d N N N N ≠ ≠ = 〈 〉 = = − −
∑
∑
(2) 1 2 其中, 代表個體 跟個體 之間的最短路徑長度。一個網絡的分隔度越小, 表示兩個個體之間若不存在連結,則他們只須透過越少的個體就可以連到對方, 在這樣的情況下,網絡的群聚現象會較明顯,因此,群聚度與分隔度兩項拓樸性 質的變化通常是呈相反的趨勢。 , u v d u v 為了理解群聚度與分隔度值的大小,通常會與隨機網絡(random network) 模型比較平均最短路徑長度,而與規則網絡(regular Network)模型來比較群聚 度的大小。不管是群聚度或分隔度,必須在個體數及個體的平均連結數相同的情 況下才能進行比較。 2.1.1 規則網絡模型 若網絡中的每個個體均與它附近的個體相連,且連結數相同,則這樣的網絡 稱為規則網絡。若個體固定與鄰近的兩個個體相連,則這樣的規則網絡會形成一 個環狀的圖形(ring),而當個體與附近四個個體相連時,會形成一個二維的晶格 網絡(grid graph)(Huang & Tsai, 2009)。由於規則網絡中的個體通常與其附近的個體建立連結,因此,規則網絡具有 高群聚度的特性。然而,規則網絡的分隔度也相當高,與一般社會網絡強調的小 世界特徵並不相符,故在社會網絡的研究中,會與規則網絡來比較群聚度來判斷 網絡的群聚現象。 2.1.2 隨機網絡模型 由於網絡中個體之間連結的產生方式是透過隨機的機率來決定,因而稱作隨 機網絡。隨機網絡模型是由 Erdös & Rényi(1960)所提出,在他們的模型中,網 絡圖形具有pN N( −1) /2條連結,其中,N 為節點數,p為任兩個體間存在連結 的機率。根據他們的實驗分析,網絡的分隔度會隨著網絡的個體數大小呈對數性 地增長,因此,不管多大的網絡都存在最短路徑,與小世界的特徵吻合。至於網 絡的群聚度會隨著網絡的節點數增加而下降,意即網絡規模越大,群聚度越小, 與一般的社會網絡並不相似,此外,隨機產生的連結也無法反映區域性的群聚現 象,因此,隨機網絡不具有小世界網絡的群聚度特徵。當我們在研究社會網絡時, 會和相同規模的隨機網絡比較分隔度。 2.1.3 小世界網絡模型 由於規則網絡與隨機網絡無法同時兼具高群聚度與低分隔度兩種特徵,因此 無法有效地模擬真實的社會網絡。Watts 與 Strogatz 在 1998 年將規則網絡加上 隨機的捷徑(shortcut),提出了小世界網絡模型(Small-World Network Model)。 他們以機率β 來決定在一個規則網絡中,每個節點連出去的所有節點,有多少節 點會斷開並且重新連結。若β 等於 0,表示沒有任何節點被重新連結,因此仍是 一個規則網絡,而若β 等於 1,網絡中每個節點原本的連結都會斷開,再隨機連 結到其他節點,形成一隨機網絡。當β 介於 0 跟 1 之間,網絡除了保有原本規則
網絡高群聚度的特性之外,也因為部分的連結被隨機地重新分配,所以具有隨機 網絡低分隔度的性質。 圖 2-1 Watts 與 Strogatz 提出的小世界模型 小世界模型依照網絡中節點連結數目的差異,又可以分成「平等式」及「貴 族式」兩種,如圖 2-2 及圖 2-3 所示。 圖 2-2 平等式小世界網絡 圖 2-3 貴族式小世界網絡
在新增連結不必付出額外成本的情況下,網絡容易演化成「貴族式」的小世 界網絡。例如:網際網絡、或是科學家合作網絡。而當新增連結需要考量成本或 有其限度時,阻礙了富者愈富,貴族就會逐漸「平民化」,成為每個節點的連結 數都差不多的「平民式」網絡。在真實世界中,熟識網絡與交通運輸網絡就是平 民式的。 若以網絡中個體的連結數當作橫軸,累積的個體數當作縱軸繪成分佈曲線, 則平民式的小世界網絡會因為大部分個體的連結數都差不多,形成常態分佈曲線, 如圖 2-4 所示;而貴族式的小世界網絡則因為富者愈富的情況,導致圖形呈冪次 律(Power-Law)分佈,如圖 2-5。 圖 2-4 平等式小世界網絡的度分佈曲線
圖 2-5 貴族式小世界網絡的度分佈曲線
2.1.4 無尺度網絡
1999 年,Barabasi 與 Albert 採用偏好連結(preferential attachment)的 機制,使網絡拓樸能夠動態地成長。所謂的偏好連結就是當有新的節點加入網絡 時,會傾向連到具有較多連結的節點,且連過去的機率與節點的連結數成正比。 在這樣的網絡中,大部分的節點的連結數都很少,卻有少部分的節點擁有大量的 連結,這種現象就好比 80-20 法則中富者越富的情形,而這樣的網絡稱為無尺度 網絡(Scale-Free Network)。
圖 2-6 冪次律分佈曲線
如圖 2-6 所示,無尺度的連結數分佈情形也會呈現冪次律的分佈。Barabasi 與 Albert 的模型成功地產生了網際網絡的連結現象,除此之外,他們的模型也 為之後的社會網絡動態演化的研究開啟了序頁。
2.2 熟識網絡的動態演化
在真實世界中,許多社會網絡都具有無尺度的現象,例如:性關係網絡 (Liljeros et al., 2001)、科學家合作網絡(Newman, 2001)、電影演員合作網 絡(Amaral et al., 2000)等等,如表 2-1 所示。在這些網絡中,個體與個體之 間的連結往往都只是一次性(one-time cost)的關係,一旦連結建立了,便會永 遠存在。然而,某些網絡卻不具有無尺度分佈的現象,如:董事會成員網絡(Davis et al., 2003; Conyon & Muldoon, 2006)。在董事會成員網絡,連結表示兩個 個體在同一個董事會的關係,而要成為董事會的成員,必須要經過不斷地努力及 工作才能成為領導階層,而成員間的關係也是要持續經營才能維持下去,因此, 每個董事會成員所能維持的關係有其上限,不可能一直擴張,造成網絡的連結數 分佈沒有無尺度的情形(Newman et al., 2002)。 表 2-1 各種類型的社會網絡 網絡類型 節 點 連結的關係 性關係網絡 人 發生性接觸 科學家合作網絡 科學家 共同完成一篇論文 好萊塢電影網絡 電影演員 合演同一部電影 董事會網絡 公司的領導階層 在同一個董事會 熟識網絡描述人與人之間相識的關係,自然是一種社會網絡,不過熟識網絡 與董事會網絡一樣,必須經過相識的雙方持續地互動,連結關係才不會斷掉。如 同許多動態演化的網絡模型,熟識網絡也需要一套規則來進行演化。至於人際之 間互動的規則如何訂定,我們將針對過去相關的熟識網絡研究及其模型來討論及
比較。 Jin et al.(2001)提出一套熟識網絡的演化模型,並觀察網絡結構的變化。 在他們的模型中,主要有三條規則: (1)當不相識的兩人相遇時,便會建立友誼,而相遇的機率與兩人之間共同朋友 數目有關係,若兩人有越多的共同朋友越有機會認識。 (2)友誼並非只有存不存在的差別,也不是建立友誼之後就不會消失。當兩人有 一段時間沒有見面,友誼便會隨著時間慢慢地衰退,而且時間越長,友誼衰 退得越快。 (3)一個人結交的朋友數有上限,一旦超過上限值就幾乎不可能再交新的朋友。 藉由這些規則,他們的模型成功模擬出許多真實社會網絡的特徵,包括高群 聚度及低分隔度,尤其是網絡的群聚度,透過共同朋友的介紹來認識,會比網際 網絡中採用偏好連結的方式來添加連結還要高得多,因此,網絡的結構呈現群聚 的現象而分散成許多的群落(community)。此外,由於每個人結交的朋友數量有 限制以及友誼會受到時間衰退的影響,個體的連結不會無限制地增加,所以網絡 的交友數分佈呈常態分佈。 Jin et al.(2001)的模型認為增加新個體對網絡結構的變化影響不大,所以 個體不會離開或加入網絡。然而,在真實社會中,我們認識的人會因為某些因素 離開網絡,也會有新的人加入網絡。在 Davidsen et al.(2002)提出的模型中, 便將這個部分納入考慮。他們的模型主要有兩條規則: (1)一個被隨機選到的人,會從他的朋友中任意挑出兩個人並介紹它們認識,如 果他們本來不認識,就會新增一條連結。要是這個人沒有兩個以上的朋友,則他 就把自己介紹給其他人,如圖 2-7 所示。 (2)網絡中存在一定的機率會讓一個被挑中的個體離開網絡,並加入一個新個體,
同時此個體會隨機認識一個人。
圖 2-7 Davidsen et al.(2002)的認識朋友規則示意圖
Jin et al.(2001)的模型與 Davidsen et al.(2002)的模型都考量了個體在 認識新朋友時會受到共同朋友的影響,和本研究所探討的社會距離概念上很接近。 在 Davidsen et al.(2002)的兩條規則基礎上,Huang & Tsai(2009)認為熟識網 絡的朋友在認識之後還要不斷進行互動來更新友誼,以確保友誼長存,因此加入 了第三條交友規則。在一個時間單位,網絡中會有固定比例的朋友連結被挑出來 進行更新友誼,而在更新友誼時,會受到個體本身的交友資源以及對友誼的念舊 度所影響,若是雙方的友誼在更新後,淡化到一定程度以下,則雙方的連結便會 移除。
雖然 Huang & Tsai(2009)的模型中所訂定的交友規則已經很貼近真實社會 的交友經驗,也將友誼當作連結上的權重值(weight)來決定連結是否繼續存在於 網絡,然而,朋友之間友誼的深淺對互動行為的影響並沒有被考慮,例如:交情 越好的朋友,越常進行互動。因此,本研究除了探討地理距離的因素對熟識網絡
的影響外,也將友誼的因素納入考量,即為另一個重要的環境因素-「社會距 離」。
在介紹完幾個與熟識網絡研究相關的模型之後,本研究將以這些模型的規則 作為本模型的雛形,並加以改良,包括將地理距離與社會距離的因素加入互動對 象的選擇策略中,及考量時間對友誼的影響。
2.3 地理距離相關文獻
本研究主要探討環境因素對於熟識網絡中個體互動的影響,並專注在地理距 離與社會距離兩項環境因素。在這一節,我們討論過去一些研究中,將網絡與地 理因素結合的部分。 2.3.1 地理距離的重要性 在真實世界中,某些網絡類型中的個體單元具有固定的位置,例如:鐵路交 通、飛機航站網絡、電力輸送網等。在這樣的網絡中,建立大範圍或長距離連結 的花費會比短程的連結高出許多,使得個體單元會傾向於和鄰近的個體單元建立 連結,因此,地理距離的遠近決定了建立連結所需的花費,進而影響整個網絡的 演化。 Xulvi-Brunet et al.(2007)提出一套模型來研究地理距離的限制對動態網 絡的影響,在他們的模型中有兩個主要觀點。首先,每個節點對於網絡中其他節 點的認知有一定的距離限制,在這個距離外的節點,便無法得知,換句話說,節 點只能和範圍內的鄰居建立連結。然而,每個節點的距離限制並不相等,若節點 的連結數越多,代表它在網絡中的地位越重要,所以能影響的範圍就會越大。這 樣的概念也能解釋為何我們的熟識網絡研究除了地理距離的因素外,仍考量了社 會距離的影響。當一個人認識的人越多,便有較多機會透過他的朋友來認識異質 區域的人。 此外,他們認為新增節點的位置並非隨機分配,而必須考慮網絡中現有節點 的位置。在日常生活中,電力配送站不會隨便設在一個人煙稀少且距離其他配送 站太遠的地方以節省輸送成本,而在一條小路中,不可能同時開兩家一樣的加油站。因此,新節點的位置距離現有節點不能太近或太遠。實驗結果顯示,電力輸 送網絡與飛航網絡最主要的差別在於建立長距離連結時所需的花費不同,導致網 絡的拓樸結構會有些許差異,但兩者的群聚現象明顯都與節點的地理位置相關。 Billen et al.(2009)的研究也認為許多網絡存在空間相依性(spatial dependence),意即兩節點建立連結的機率與彼此在空間中的距離有關。他們藉 由觀察相鄰矩陣的特徵值波譜(eigenvalue spectra)來了解網絡拓樸結構的變 化情形,並將隨機網絡、無尺度網絡及小世界網絡等理論網絡代入模型中一一進 行模擬。實驗結果顯示,當網絡的空間相依性增加時,會造成波譜的改變,使網 絡中的三角形個數及群聚度上揚。 總結來說,若網絡中的個體單元有固定位置,且連結的建立有成本上的考量 時,地理空間的距離就是影響網絡拓樸的重要因素。在熟識網絡中,朋友之間必 須持續地保持互動才能維持友誼的連結,也可以視為一種花費,而地理距離的遠 近是否會影響互動的花費,造成網絡的拓樸改變,便是我們接下來要探討的目 標。 2.3.2 地理距離對社會網絡的影響 空間分析與社會網絡分析都是觀察個體單元間的互動關係,概念上似乎可以 將兩者整合起來,但為了保護隱私權,調查資料會刻意排除受訪者的地理位置。 為了解決這樣的問題,Baybeck & Huckfeldt(2002)利用 GPS 與 GIS 技術來定位 受訪者的地理坐標,所以能得到任何一對朋友之間的地理距離。近年來,社會學 家認為地理空間對於現代社會人際互動愈來愈沒意義,我們可能會住在一個地方, 再到其他地方工作,而在假日又到另一個地方上教堂,所以我們所結交的朋友是 分散在許多地方,這種形式的關係稱為空間分散網絡(spatially dispersed
networks)。因此,Baybeck 與 Huckfeldt 想了解空間分散網絡對於訊息的擴散 有何影響。研究結果顯示地理空間對朋友的互動來往有一定的限制,但對於朋友 的互相知道並沒有影響。 隨著網際網絡的發達,改變了人們的互動方式,人們可以藉由電子郵件、部 落格等來經營自己的人際關係。在這樣的情況下,人際關係的構成是否就跳脫了 地理空間的限制呢?答案是否定的。Liben-Nowell et al.(2005)針對一個叫 LiveJournal 的線上社群網站進行研究,他們透過觀察使用者的好友清單來確認 朋友關係,並將使用者基本資料中的所在地代入定位系統來計算地理距離。研究 結果顯示,當 A 跟 B 兩個人的地理距離越遠時,成為朋友的機率越小。此外,網 站使用者的好友清單中,平均只有三分之一的朋友與使用者身處不同的所在地, 顯示地理距離仍是影響人際互動的重要因素,但不是唯一的因素,少部分距離遙 遠的人會受到非地理因素的影響而成為朋友。我們認為這樣的因素和人際關係的 牽引有關,因此,本研究將以地理距離與社會距離這兩項因素來進行熟識網絡的 探討。
第三章
研究方法
3.1 模型描述
在本節當中,將介紹本研究的模型架構以及相關的設定,如圖 3-1 所示。 圖 3-1 本研究的模型架構圖 首先,在執行初期,我們會產生一個初始的網絡,並將時間單位T設定為 0。初 始網絡中除了節點之外,也存在著若干連結,節點代表個體,而連結則象徵兩個體之間具有朋友關係。連結上除了雙方的友誼值之外,還記錄彼此的互動次數及 最後一次進行互動的時間。每一對朋友的初始互動次數均設為 1,最後一次的互 動時間設為 0。在設定完個體的屬性及連結的初始友誼後,便開始進行熟識網絡 的動態模擬。 在每一回合的模擬中必須包含兩個步驟:執行友誼衰退函數及挑選一個體來 參與互動。由於友誼會隨著時間而漸漸變淡,因此,每個回合會挑選一條連結來 執行友誼衰退函數並更新連結上的友誼值,若更新後的友誼值低於斷交的門檻, 則連結便會被移除。接下來,系統會根據「平均交友資源分配值」隨機挑出一個 個體來進行互動。「平均交友資源分配值」是利用個體的交友資源除以個體當下 的朋友數所得的數值,當「平均交友資源分配值」越大時,個體越有機會參加互 動。而在每一次的互動中,共有三條交友規則可選擇,分別是:離開及加入網絡、 認識新朋友以及和朋友維護友誼。然而,個體的資源有限,所以個體只能執行三 條交友規則的其中一條,我們以 及 兩個參數來決定挑選出來的個體要進行 哪一條交友規則。系統會隨機產生一個介於 0 到 1 之間的實數 1 p p2 p,若p小於 , 則該回合個體會離開網絡再加入新的個體。若 1 p p大於p1,則p會再跟 比大小 來決定個體在該回合要認識新朋友或是和朋友維護友誼。若 2 p p小於 ,個體會 認識新朋友,否則,個體選擇和朋友維護友誼。 2 p 每一回合的模擬結束後,時間單位T會自動加 1,然後再繼續進行下一回合 的模擬。基本上,網絡的模擬可以不斷的進行下去,但是當網絡的演化趨於穩定 時,我們便停止模擬並開始蒐集資料,至於蒐集哪些資料及穩定狀態的判斷會在 之後的小節加以說明。
3.2 設定初始網絡
3.2.1 個體的屬性設定 在本模型中,網絡的每一個節點都代表一個個體,而每個個體都具有各自的 屬性。以下針對個體的屬性逐一介紹: (1)ID:個體的編號。網絡中的個體都具有一個獨一無二的編號,用來區分個體。 (2) re :個體的交友資源。個體的交友資源多寡,將影響個體參與互動的頻 率,同時也限制了朋友的數量。 source (3)q:個體對於友誼的念舊度,也可以看成個體對友誼的記憶力。若個體念舊度 越高,對舊友誼越重視,當執行維護友誼規則時,更新後的友誼值受到舊友 誼的影響較大。 (4)θ:個體的友誼斷交門檻值。當個體與他的朋友之間的友誼小於此門檻值時, 他們之間的朋友關係就會斷掉。 (5) ( , )x y :個體在平面上的坐標位置。每個個體會隨機分配一組坐標位置,且位 置不會重複。 3.2.2 初始友誼的設定 每一條連結上的權重值代表每一對朋友之間的友誼,而友誼與個體的交友資 源以及交友個數有關。以下是初始友誼 fu v, 的設定方式: , 1 ( 2 u u v u v res res f k k = × + v) (3) 其中, 與 分別代表個體 u 的交友資源及目前的朋友數。由於個體的交友資 源有限,當他結交的朋友越多時,每個朋友能分配到的資源越少,使得友誼容易 變淡。而友誼必須靠雙方的付出來維繫,因此將兩人的交友資源除以交友數所得 u res ku的值取平均,作為兩個體剛認識時的初始友誼。
3.3 綜合性距離函數
為了了解地理距離與社會距離兩項環境因素對熟識網絡中個體挑選互動對 象的影響,我們提出一個綜合性距離函數,除了能同時考量兩個體間的地理距離 及社會距離外,也能根據重視程度的不同來調整變數: ( , ) ( , ) (1 ) ( , ) ED u v = ×w GD u v + − ×w SD u v (4) 其中, 為兩個體 、 v 的綜合性距離函數值, 及 則分別 為 u、v 之間的地理距離與社會距離,而 表示組織中的個體在選擇互動對象時, 對地理距離因素的重視程度。當 等於 1 時,表示個體只會選擇地理距離與自己 較接近的個體進行互動;當 等於 0 時,個體完全不考慮地理距離因素,只挑選 和自己社會距離較接近的個體互動,因此 是介於 0 跟 1 之間的實數。若個體在 選擇互動對象時,同時考量地理距離與社會距離,且不偏重於某一因素,則 的 值設定為 0.5。 ( , ) ED u v u GD u v( , ) SD u v( , ) w w w w w 雖然公式(4)看起來是一個線性整合的關係式,然而地理距離與社會距離若 分開來看,可以形成兩套獨立的複雜系統,因此這樣的表示法只是將兩個複雜的 因素綜合來看。除此之外,計算出來的綜合性距離函數值與得到的網絡拓樸數據 之間也無法透過證明或其他方式來進行預測,故仍需進行模擬才能知道結果。 至於地理距離的部分,則是計算兩個體在平面上的直線距離,亦稱歐幾里得 距離(Euclidean Distance),公式如下:2 ( , ) ( u v) ( u v) GD u v = x −x + y −y 2 (5) 其中,xu和 為個體 u 在平面上的坐標位置。若兩個體在平面上的位置越接近, 則地理距離越小。而社會距離部分,則是以兩個體間關係的密切程度做為衡量的 標準。在現實生活中,我們雖然認識了很多人,但在這些人當中,有些人跟我們 是好朋友,常常互動;有些人只是點頭之交,發生互動的機會不多,因此關係有 深有淺,而這種關係的深淺被視為兩人之間的友誼。為了方便實驗,我們將友誼 量化為介於 0 到 1 之間的實數,以 u y , u v f 表示,fu v, 值越大,表示兩個體的友誼越深 厚,互動機會越高。 此外,若是兩個體之間有越多的共同朋友,代表兩個體的關係越密切,不管 彼此認不認識,都可能因為這些共同朋友的邀約,增加了許多互動機會。因此, 在關係的密切程度上,除了考量兩個體的友誼之外,也會考慮兩個人之間共同朋 友的影響。在本模型中,我們會找出兩個體之間路徑長為 1 或 2 的所有路徑,並 分別計算各個路徑的權重值。若路徑長度等於 1,則權重值即為連結上的友誼值; 若路徑長度為 2,則將路徑上兩條連結的友誼值相乘,作為該條路徑的權重值, 最後將所有路徑的權重值加總,以weightu v, 表示。weightu v, , u v 值越大,兩個體的關 係越緊密,社會距離也越小。因此,我們將weight 值取倒數,來計算兩個體的 社會距離: , 1 ( , ) u v SD u v weight = (6) 當計算完地理距離 GD 與社會距離SD時,將這兩項數值分別進行正規化,
使 GD 值及SD值均為介於 0 到 1 的實數,再代入綜合性距離函數中計算ED值, 而ED值亦介於 0 到 1 之間。若兩個體間的ED值越小,彼此互動的機會越大。
3.4 各項演化規則
3.4.1 三條交友規則本模型採用的三條交友規則以 Davidsen et al.(2002)及 Huang & Tsai(2009) 所提出的交友規則為基礎,並稍作改良以符合本研究所要探討的問題。以下分別 介紹三條規則及其運作方式: (一)規則一、離開及加入網絡: 在熟識網絡中,當個體離開網絡時,該個體原先在網絡中的所有連結全部移 除,並加入一個新的個體來取代他原本在平面上的位置,因此,個體數保持 固定,而這樣的設定也符合現實的情況。舉例來說,當一個班級有學生轉學 離開或是一個公司機構因員工離職而出現職缺時,通常都會補進相同數目的 人進來,因此網絡中的個體數保持不變。此外,Jin et al.(2001)指出,和 網絡中連結的變化相比,個體數目的變化速度要慢得多,對網絡的結構不會 產生立即性的影響,故本模型在網絡演化過程中不考慮個體總數的變化。而 當新個體加入網絡之後,並不認識其他個體,此時新個體會依據綜合性距離 函數值的大小,按比例隨機挑選一個體建立連結,象徵新個體一進入網絡, 馬上就認識一個個體,而雙方由於剛認識,所以互動次數設為 1,互動時間 則設為該次互動的時間單位T。規則一的執行流程請見圖 3-2。 (二)規則二、認識新個體: 個體會從網絡中不認識的個體挑選一個來認識,而挑選的方式仍然依照該個
體與其他不認識個體之間的綜合性距離函數值ED大小來決定,若ED值越 小,彼此越有機會認識。在一個地理距離影響力較大的組織中,個體傾向於 和自己位置較相近的個體結識,因此,在這樣的組織中,若社會距離相同, 則地理距離越小,所得到的ED值越小;反之,在一個社會距離影響力較大 的組織中,個體傾向於認識社會距離較小的個體,此時地理距離越小,ED 值未必會越小。兩個體認識後,會產生一條新連結,而連結的設定方式與規 則一相同。規則二的執行流程請見圖 3-3。 (三)規則三、與舊識維護友誼: 個體會從所有已經認識的個體中,根據綜合性距離函數值ED的大小,挑選 一個體來維護友誼,ED值越小,被挑中的機會越大。在挑選完之後,兩個 體開始維護友誼,而維護後的新友誼將採用 Huang & Tsai(2009)所提出的 友誼更新公式來計算,公式如下: , , 1 (1 ) 2 new old u v u v u v u v res res f q f q k k ⎛ ⎞ = × + − ×⎜ + × ⎝ ⎠⎟ (7) old, u v f 與 new, u v f 分別代表個體 u 、 維護友誼前後的友誼值,v q為個體對於友誼 的念舊度,q越大代表個體對舊友誼越重視,而resu及ku則表示個體 u 的 交友資源及交友個數。兩個體維護友誼後,友誼值 new, u v f 會增加或減少,若是 減少到一個極限,則兩個體之間的關係形同陌路,雙方的連結就會斷掉,因 此,我們會設定友誼斷交的門檻值θ,當更新後的友誼值 new, u v f 小於θ時,便 將兩個體之間的連結移除。規則三的流程圖請見圖 3-4。
圖 3-2 離開及加入網絡流程圖 圖 3-3 認識新朋友流程圖
3.4.2 友誼衰退函數 在本模型中,除了三條交友規則之外,我們還考量了友誼會隨著時間衰退的 情形。當兩個體認識之後,若是沒有持續保持互動,友誼會隨著時間漸漸衰退, 且時間拉得越長,友誼衰退越多。不過,若是兩個體之間互動的次數夠多,使得 雙方的友誼很深厚,即使隔了一段時間沒有互動,友誼也不會率退得太快。因此, 我們在友誼衰退函數中,主要考慮了兩個因素:「上一次互動後經過的時間」及 「互動的次數」。以下式子為本模型所提出的友誼衰退函數: , , 1 _ ( , ) 1 max( ,1) u v u v update count u v f f t N = × Δ (8) 其中,fu v, 表示兩個體 u、v 之間的友誼, tΔ 為 、v 上一次互動後經過的時間差, 為 、 互動的次數, 為網絡中的個體總數。為了展現時間 的變化對友誼的影響,我們採用參數T來標記每次互動發生時的時間單位,當我 們要計算時間差 u _ ( , updat ount u v t ) e c u v N Δ 時,只需將該回合的時間單位T減去兩個體上一次互動的時 間Tlast_time u , )( v 即可。在互動次數相同的情況下,若Δ 越大,指數運算的結果越大,t 友誼會衰退的越多。而在本模型的設計中,一個時間單位只有一個個體能夠與他 人進行互動,為了確保網絡中的所有個體至少獲得一次的互動機會,因此,當 tΔ 小於 時,友誼並不會衰退,我們將時間間距 視為每一次互動完之後的友誼 保鮮期,一旦過了保鮮期而沒有再次互動,友誼就會開始衰退。而兩個體間互動 的次數越多,友誼衰退的速度越慢,故我們將 取倒數,當 固 定時,updat 越大,友誼的衰退率越小。友誼衰退函數的效果,如圖 3-5 所示。 N N updat _count u v)( , ) e Δt _ e count(u v,
友誼衰退函數是針對具有朋友關係的兩個體所設計,因此,若兩個體間不認 識,則友誼衰退函數便不會有作用。在每一次的時間單位中,系統會根據目前網 絡中所有連結的友誼值大小,隨機挑選一對朋友來執行友誼衰退函數,友誼值越 小,越有機會被挑中。經過友誼衰退函數的作用後,兩個體之間的友誼值可能不 變,也可能會變小,當友誼變得比友誼斷交門檻值θ還要小時,則兩個體之間的 連結便會被移除,不再具有朋友關係。最後,我們將友誼衰退函數的執行流程表 示出來,請參考圖 3-6。 0.0 0.2 0.4 0.6 0.8 1.0 1 1001 2001 3001 4001 5001 6001 7001 8001 9001 10001 Time Step T 消退率 update count = 1 update count = 2 update count = 3 update count = 4 update count = 5 update count = 6 update count = 7 update count = 8 圖 3-5 友誼衰退函數的衰退率曲線
圖 3-6 友誼衰退函數執行流程
3.5 模型的操作
在了解完本模型的架構及功能後,本節將繼續針對實驗的進行方式、所用到 的參數以及數據資料的蒐集詳加描述。 3.5.1 輸入的參數 首先,本小節將所有實驗進行中使用到的參數一一介紹,包含參數名稱及其 意義,如表 3-1 所示。表 3-1 模型的實驗參數列表 參數名稱 參數意義 參數值 N 網絡中的個體總數 正整數 round 模擬實驗執行的次數 正整數 M 初始網絡中的連結總數 正整數 NetType 初始網絡所使用的理論網絡類型 1-規則網絡、2-小世界 網絡、3-隨機網絡 w 地理距離因素的影響力 0~1 1 p 個體離開網絡的頻率 0~1 2 p 個體交新朋友的頻率 0~1 res 個體的交友資源數量 0~1 q 個體對友誼的念舊度 0~1 theta 個體的友誼斷交門檻值 0~1 在表 3-1 中,參數 有幾個選項可供選擇,包括:規則網絡、小世界 網絡、隨機網絡等等。而利用這些理論網絡當作初始網絡來進行模擬,主要是因 為現實世界中的熟識網絡可能以不同的網絡型態呈現。例如探討班級或辦公室等 具有固定疆界的熟識網絡演化動態時,可以採用規則網絡作為初始網絡。除此之 外,我們也可以比較不同的網絡類型演化後得到的結果,是否會產生差異。 NetType 3.5.2 資料的蒐集 為了幫助我們了解網絡整體的演化情形,本實驗在模擬的過程中會蒐集下列 網絡拓樸資料: (1)平均分支度< >k :用來了解網絡中平均一個個體會結交多少朋友。 (2)平均分支度平方 2 :將所有個體的分支度平方之後加總取平均值,目的是 k < > 用來觀察網絡中所有個體交友數的集中情形。若每個個體的交友數越集中在 平均分支度,則 2 的值會越接近 k < > < > 的平方。 k
(3)群聚度< >C :藉此來了解網絡中個體的聚集程度,至於群聚度的定義及算法 請見第二章。 (4)分隔度< >L :可以用來了解網絡中個體要認識其他個體時所需的平均路徑長 度,詳細的定義及算法請見第二章。 為了提高實驗的效率,本實驗以 (個體數)回合當作資料蒐集的間距,並 觀察這些網絡拓樸數據的變化。當網絡拓樸數據的變化不在劇烈且收斂在某個數 值附近時,我們認為網絡的演化已經達到了穩定的狀態,此時我們會將一段穩定 狀態下的數值取平均值,當作穩定狀態的數據,如圖 3-7 所示。 N 圖 3-7 演化穩定下的網絡拓樸數據取值方式 除了以上四項網絡拓樸數據之外,若我們想更進一步了解網絡中個體的交友 數分佈情形,在本實驗的模擬過程中也會每 回合做一次統計。由於每一次統 計得到的個體數分佈不一,不足以代表一段長時間演化下的結果,因此,我們採 用 Bruce(2001)提出的方法來解決這個問題: N
1 1 ( ) ( ) M i i p k p M = =
∑
k (9) 其中, 為交友數 的個體在網絡全部個體中所占的比例,而 代表第i次 統計時的分佈情形,最後將 ( ) p k k p ki( ) M 次的統計加總後取平均便得到p k( )。 3.5.3 實驗步驟 圖 3-8 實驗流程圖3.6 預期結果
在本模型中,主要以< >k 、<k2 > 、 C< > 、< >L 四項整體的拓樸數據作 為觀察網絡演化的指標,因此,在本節中,我們將探討模型的各項規則以及輸入 參數的數值對這些拓樸數據的影響,才能讓我們對接下來的實驗該如何設計有一 些概念。 首先,我們針對本模型在每一回合的模擬中都會用到的友誼衰退函數以及三 條交友規則來進行討論。在這些演化的規則中,友誼衰退函數以及維護友誼規則 中的友誼更新公式都會作用在網絡已經存在的連結,而連結在經過作用後所得到 的新友誼若是低於友誼斷交門檻值,則該連結便會被移除,因此這兩項規則會導 設定參數 執行模擬實驗 蒐集統計資料 分析數據致< >k 及<k2 >下降,進而讓群聚度< > 下降及分隔度C < >L 上升。而在離開 及加入規則中,當個體離開網絡時會將其所有的連結移除,所以對四項拓樸性質 也會產生相同的影響,甚至有可能讓網絡直徑1 變成無限大。 至於在認識新朋友規則中,個體結交新朋友會建立新的連結,使網絡的連結 總數增加,因此在這條規則的作用下, k< > 和 2 k < > 會增加。而當連結數增加 時,任兩個體之間的最短路徑長度可能會變小,則整個網絡的分隔度< >L 就會 下降且群聚度 上升。整體來說,除了認識新朋友規則會使網絡的連結增加 之外,其他三條模擬規則都會減少網絡的連結,在這樣連結互有增減的情況下, 我們較難預測網絡最後會變得如何,因此增加了系統的複雜性。 C < > 然而,熟識網絡不可能無限制地增加連結,畢竟人們的時間、精力及記憶能 力有限。若我們想探討這些因素對熟識網絡演化結果的影響,我們可以改變res、 q、th 等變數的設定來進行實驗。當 越大,代表個體有越多的交友資源來 結交朋友,因此,我們預期 會增加。變數 eta res k < > q越大,個體越重視舊友誼,朋 友關係越不易斷裂,故q跟 的關係成正相關。而 th 決定朋友之間對友誼 淡化的容忍度,若 th 越大,友誼關係存在的門檻就越高,一旦個體多結交了 一些朋友,就越容易使某些連結斷掉,導致平均分支度 k < > eta k eta < > 下降,所以 跟 兩者之間會是負相關。 theta k < > 接下來,我們繼續針對 、 、w p1 p2這三項參數對拓樸數據的影響進行討論。 本研究想要了解當地理距離與社會距離這兩項環境因素的影響力不同時,網絡的 拓樸是否會有差異,因此本模型以參數 來調控兩項環境因素的影響力大小。在 所統計的四項拓樸數據中,我們預期 w k < > 及 2 k < > 受到 的影響將不明顯。承w 1網絡直徑:網絡圖形中,任意兩個節點之間所存在的最大路徑長度,稱為該網絡的網絡直徑。若 一個網絡不是連通圖,則其網絡直徑為無限大;反之,若網絡是完全圖,則網絡直徑等於 1。
上一段所言,交友數的多寡和個體的交友資源比較有關係,反而與環境因素的變 化較不相關。我們認為環境因素會影響個體在選擇互動對象時,是傾向找地理距 離和自己比較近的人,還是去找跟自己關係比較好的人。因此,當 越接近 0 或 1,表示越偏重於某項因素,則網絡中的群聚現象應該會越明顯,我們預期 與 w C < > < >L 2 k < 會受到影響。 在本模型中, 和 這兩項參數是用來決定模擬時,個體執行三條交友規 則的頻率,若 越大,個體越容易離開網絡,而 越大,個體越容易結交新的 朋友。然而,在一個熟識網絡中,成員的離開及加入不可能太頻繁,否則模擬便 會變得不合理。因此, 通常會設定一個極小的值,大概介於 0 到 0.01 之間。 我們認為如此小的值對網絡的拓樸數據影響較不顯著。相對而言, 值的設定 便很重要,因為它將決定網絡中連結總數的變化。若 越大,連結會變得越多, 及 就會上升,使得 1 p p2 1 p 1 p > 2 p 2 p 2 p k < > < > 增加、C < >L 降低;反之,若 越小,個體 越傾向和朋友維護友誼,連結非但不會增加,還有可能減少,故四項拓樸數據的 變化會相反。 2 p
3.7 實驗設計
在上一小節中,我們介紹完各項規則對網絡拓樸的影響,以及預測了各個參 數改變的效果。接著我們便要在這一節說明將進行哪些實驗來驗證我們的猜測。 我們依照參數的不同,分成以下幾個部分: 一、網絡的個體數N 真實世界中,存在著許多組織、團體,每個組織的成員數不盡相同,有大到 幾百人、幾千人組成的龐大組織,也有十幾個人所形成的小集團。若是我們要對不同人數的熟識網絡一一進行實驗,恐怕會耗費太多時間而沒有效率。因此,我 們會以幾個差距較顯著的個體數來進行實驗,如 10 的正整數次方或是 50 的倍數。 若實驗的結果差異不大,或是數據變化的趨勢相同,則我們的模型便能適用於不 同大小的熟識網絡。 二、初始網絡的連結數M 在我們的模型中,初始網絡一開始便存在連結,因此,在設定參數值時,網 絡的連結總數也是我們比較的重點之一。我們認為初始網絡的連結越多,網絡演 化到穩定狀態所需要的時間越長。此外,若初始網絡的連結總數定得太多,則在 模擬的前期會因為個體交友資源的限制,使得連結不斷被移除,所以M 的設定 必須適當。我們預計在其他參數固定的情況下,採用三到五組不同的連結總數來 進行實驗,而這幾個值會形成公差為 4 的等差數列。 三、不同類型的初始網絡NetType 在相同的參數設定下,我們會使用不同的理論網絡作為初始網絡來進行模擬, 包括規則網絡、隨機網絡、小世界網絡。不同的網絡類型除了能反映不同的探討 目標外,也能測試模型的可靠性。在這個部分,我們預計採用以上三組參數來進 行實驗。 四、地理因素的影響力w 本研究最大的目標就是找出當環境因素的影響力改變時,個體的互動是否會 產生變化,因此,不同的 值設定所產生的結果是我們觀察的重點。我們預計以 五組不同的 值來進行模擬,分別是 0,0.25,0.5,0.75 及 1。 w w 五、新舊朋友的偏好度p2 在本模型中,留在網絡中的個體若要進行互動,可以有兩種選擇:結交新朋
友或是找朋友互動。我們以參數 來控制兩條規則被執行的機率,若 越大, 代表網絡中的個體越熱衷於交新朋友;反之,則個體越常找朋友維護友誼。我們 認為 的改變會造成熟識網絡結構上的變化,如平均分支度 2 p p2 2 p < > ,也可能會使k 網絡的平均友誼值不同。因此,我們將以五組不同的 值進行實驗,分別為 0, 0.25,0.5,0.75,1。 2 p 六、其他參數 剩下的幾個參數包括:交友資源 re 、念舊度s q、友誼斷交門檻 th 及個體 離開網絡的機率 。由於本模型的部分設定參考了前人的模型,而這幾個參數 在他們的研究中已經做過詳細的分析,因此這些參數我們將沿用前人的設定來進 行實驗,並比較結果。 eta 1 p