國 立 交 通 大 學
網路工程研究所
碩 士 論 文
藥物時程的服用時間彈性和劑量合併之機制
Timing Flexibility and Dose Grouping for Medicine Scheduling
研 究 生:王梅瑛
指導教授:邵家健 博士
藥物時程的服用時間彈性和劑量合併之機制
Timing Flexibility and Dose Grouping for Medicine Scheduling
研 究 生:王梅瑛 Student:Mei-Ying Wang
指導教授:邵家健 博士 Advisor:Dr. John Kar-Kin Zao
國 立 交 通 大 學
網 路 工 程 研 究 所
碩 士 論 文
A Thesis
Submitted to Institute of Network Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements for the Degree of Master in Computer Science
August 2009
Hsinchu, Taiwan, Republic of China
i
藥物時程的服用時間彈性和劑量合併之機制
學生:王梅瑛
指導
教授:邵家健 博士
國立交通大學網路工程研究所 碩士班
摘要
非住院病人的藥物服用是現今醫療保健過程中最容易出錯的一環。多數的服藥錯誤發生 在病人同時服用來自不同醫院、診所之處方用藥,和藥局購買的非處方用藥,卻沒有充 分了解與遵守用藥指示,尤其年長病人及慢性病患者特別容易發生這種錯誤。本論文中, 我們提出 Wedjat,一個在行動手機上使用的藥物提醒與監控工具 (Medication Reminder and Monitor, MRM)以及我們設計的藥物時程劑量分群的機制,目的是減少病人的服藥次 數,增加緊急的藥的服用機會,同時增加劑量服用時間的彈性,我們利用多維評估因素 決策方法來決定最佳的分群組合。Wedjat 有三個主要的特色: (1)遵守藥物指示與處方籤, 計劃適當的服藥時程,同時避開潛在的藥物-藥物/藥物-食物交互作用;(2)控制服藥劑量, 保持在適當的安全劑量範圍;(3)將時程接近的藥,合併在一起服用,減少繁複的提醒。 Wedjat 會維護使用者所有的用藥記錄,和家中主機的資料庫進行同步或上傳至遠端個人 健康記錄伺服器(Personal Health Record Server, PHR),做為往後醫療之用。ii
Timing Flexibility and Dose Grouping for Medicine
Scheduling
Student: Mei-Ying Wang
Advisor: Dr. John Kar-Kin Zao
Institute of Network Engineering
National Chiao Tung University
ABSTRACT
Out-patient medication administration has been the most error-prone process in contemporary health care. Most medication administration error was made when patients take various medicines from different sources at one time and with little or no directions, such as
prescriptions from different doctors, over-the counter medicines from several drug stores and nutritional supplements. Especially, Elderly or chronic ailment patients are likely to make these mistakes.
In this paper, we present Wedjat, a mobile phone based medication reminder and monitor to prevent these medication administration errors. We design a mechanism of dose grouping to decrease the number of in-take times and assign each in-take to a sufficiently long time slot and increase chances of taking emergency doses. Wedjat remind patient to take correct doses in right time and note down the in-take record for future medical care use. Three significant features of Wedjat are: (1) plan a proper intake schedule obey all intake medication directions and prescriptions and avoid all latent medicine-food/ medicine-medicine interactions; (2)
iii
control in-take dosage rate in safe range; (3) group in-take doses which in-take time are close to each others to prevent complicated remind. Wedjat maintains patient’s intake records and synchronize with local host database or upload to remote Personal Health Record Server.
iv
致 謝
首先感謝邵家健老師兩年來的指導,無論是在學術研究或做人處事方面,老師都給予我 莫大的幫助與啟發,真的很謝謝老師。 此外,我想感謝實驗室的各位同學,博政,嘉錡,星閔,勝焜,彥霖,兩年來,有他們 互相支持陪伴,讓我實驗室的生活變得更加愉快,在課業問題上遇到問題,他們也都會 非常不遺餘力的給與我協助與建議。實驗室的學弟妹們,子晉,家妤,志明,俊偉,鈞 凱,大家一起吃飯聊天,互相分享心情,讓實驗室的生活增添不少樂趣,也謝謝俊瑋和 子晉,常常幫我解決許多技術上的問題。 最後,我要謝謝所有可愛的親朋好友,還有我的爸爸媽媽,他們是默默支持我鼓勵我的 主要力量,沒有你們,我不可能完成這份論文。感謝我的男朋友,學增,雖然這一年他 不在我身邊,不過總是在我遇到挫折,沮喪難過的時候,給我加油打氣,幫我信心喊話, 謝謝你的支持。 要感謝的人太多了,真的謝謝所有鼓勵過我的你(妳)。v
目 錄
摘要 ... i ABSTRACT ... ii 致 謝 ... iv 目 錄 ... v 圖目錄 ... vii 表目錄 ... viii 第 1 章 綜論 ... 1 1.1 問題陳述 ... 1 1.2 研究方法 ... 2 1.3 論文大綱 ... 3 第 2 章 背景知識 ... 4 2.1 藥物排程規格書 ... 4 2.1.1 用藥參數 ... 4 2.1.2 特殊參數 ... 5 2.2 藥物排程演算法 ... 6 2.2.1 排程模組 ... 6 2.2.1.1 資源模組 ... 6 2.2.1.2 資源分配規則 ... 7 2.2.1.3 優先順序方案 ... 7 2.2.2 排程演算法 ... 8 2.2.2.1 一次一藥法 (One-Medicine-at-A-time, OMAT) ... 8 2.2.2.2 一次一劑量法 (One-Dose-at-A-time, ODAT) ... 9 2.3 多維評估因素決策方法 ... 11 2.3.1 決策矩陣的定義 ... 11 2.3.2 比重加權法 ... 12 2.3.3 修正後之層級分析法 ... 13 第 3 章 藥物時程之服用延伸一–服藥時間彈性 ... 14 3.1 原理 ... 14 3.2 操作機制 ... 14vi 3.2.1 修改之用藥排程規格書 ... 14 3.2.2 計算藥物時程之服用時間彈性 ... 15 3.2.2.1 無衝突藥物的服用時間彈性 ... 15 3.2.2.2 衝突藥物的服用時間彈性 ... 16 3.2.2.3 時間彈性之不確定性 ... 18 第 4 章 藥物時程之服用延伸二 – 劑量分群 ... 22 4.1 原理 ... 22 4.2 所有可能之分群組合 ... 22 4.2.1 劑量分組 ... 22 4.2.2 基本服用時間單元和所有可能之分群組合 ... 23 4.3 找出最佳分群組合 ... 26 4.3.1 決定評估因素和選擇 ... 26 4.3.2 階層化決策因子的比重 ... 27 4.3.3 效能之數值化 ... 39 4.3.4 選擇的評分 ... 40 第 5 章 實作議題 ... 46 5.1 實作原理 ... 46 5.2 操作方案 ... 47 5.3 系統設計 ... 47 5.4 使用者操作介面 ... 50 第 6 章 結語 ... 52 6.1 研究成果 ... 52 6.2 未來方向 ... 52 參考文獻 ... 53 附錄 ... 54
vii
圖目錄
圖 1: 典型的決策矩陣 ... 12 圖 2: 決策矩陣範例 ... 12 圖 3: 修正後之層級分析法決策矩陣範例 ... 13 圖 4: 單一藥物服用時間彈性範例 ... 16 圖 5: 藥物衝突關係之圖例 ... 17 圖 6: 多個藥物的時程時間彈性 ... 18 圖 7: 時間彈性的不確定性 ... 21 圖 8: 劑量分組圖例 ... 23 圖 9: 劑量基本服用時間單元 ... 24 圖 10: 所有可能之劑量分群組合 ... 25 圖 11: 分群之決策矩陣 ... 27 圖 12: 決策矩陣的效能數值 ... 40 圖 13: 調整後的矩陣效能數值 ... 40 圖 14: 實際藥物的彈性時程範例 ... 42 圖 15: 實際藥物的最佳分群組合 ... 43 圖 16: 實際藥物之滿足劑量數目限制的最佳組合 ... 44 圖 17: 錯過群組藥物之修正組合 ... 45 圖 18: Wedjat 輸入輸出資料流 ... 46 圖 19: Wedjat 功能模組 ... 48 圖 20: 藥物排程規格書相關類別 ... 49 圖 21: 藥物排程相關類別 ... 49 圖 22: Wedjat 使用者介面 ... 51viii
表目錄
表格 1: 藥物排程規格書 ... 5 表格 2: 衝突參數 ... 6 表格 3: OMAT 虛擬碼 ... 9 表格 4: ODAT 虛擬碼 ... 10 表格 5: 修改後的藥物排程規格書 ... 15 表格 6: 所有可能的評估因子 ... 27表格 7: 相對比重的尺規 (Ma and Zheng, 1991, Satty,1980) ... 28
表格 8: 分類藥物之相對重要性尺規 ... 34
表格 9: 分類劑量因子之相對重要性尺規 ... 35
1
第 1 章 綜論
1.1 問題陳述
根據一項指標性的醫療錯誤研究顯示[1],用藥錯誤 (medication errors, ME)和藥物1
衝突反 應 (adverse drug reactions, ADR)是最常見的醫療錯誤。儘管藥物誤用可能發生在醫療過程 中的個個環節,像是藥品的採購,處方籤的開立,藥師配藥、給藥,病人服用藥物等等, 然而,最容易發生錯誤的是服藥階段。 多數的服藥錯誤發生在病人服用來自不同醫院、診所之處方用藥,和藥局購買的非處方 用藥,卻沒有充分了解與遵守用藥指示,尤其年長病人及慢性病患者特別容易發生這樣 的錯誤。常見的服藥錯誤有: (1) 忙碌的生活方式下不規律的服藥,導致劑量過量或不足; (2) 服藥的種類繁多,導致無法遵守複雜的服藥時程;(3)未經調和的多張處方籤,造成 藥物之間的交互作用;(4)缺乏適當服藥的知識;(5)有服藥上的疑問時,缺乏向醫藥人 員的諮詢;(6)缺乏監控、追蹤服藥的機制。近來,遠距醫療和遠距監控技術,已經被認 為是有效益提升非住院病人醫療照護品質的方法[2,3,4,5]。我們提出一套在手機上使用 的藥物提醒工具,並且根據已發展的排程演算法和排程規格做改進,本論文將針對藥物 時程的劑量時間彈性與劑量分群提出一個改善機制,希望能有效減少病人的服藥次數, 增加緊急的藥的服用機會,同時增加劑量服用時間的彈性。 1 本論文中的藥物泛指處方用藥、非處方用藥以及營養保健補給品
2
1.2 研究方法
在本論文中,我們將提出一套藥物時程劑量分群的機制以及 Wedjat 的設計與實作。 劑量分群的機制利用多維評估因素決定方法,並根據藥物的重要性,階層化評估因素之 間的相對比重,來找到滿足多維考量下的最佳的劑量分群組合,在病人錯過分群劑量時, 也能依照多維評估找到修改後的分群組合。 Wedjat 有下列三個主要的功能: 1) 發出服藥提醒:Wedjat 會在病人需服藥的前 15 分鐘,發出用藥提醒,它會反覆提醒 直到病人確認服藥或取消。我們用一個已發展的排程演算法 [2.2.2.1 小節] 來計算服 藥的時程,然後我們根據這個時程,做一些延伸改進,主要的目的是增進使用者服 藥的彈性與方便性,我們將在第三章和第四章說明我們設計的改進方法。Wedjat 應 用程式需安裝在行動裝置上,服藥提醒的功能將與行動裝置內建的應用程式行事曆 (Calendar) 結合。 2) 提供藥物辨別及服用的資訊:Wedjat 有一個內建的資料庫,紀錄藥物的重要資訊 (包 括藥品的照片,用藥指示,和注意事項等等),以及和病人相關的診所、醫院的資訊。 部分的資訊會在服藥提醒通知中出現,完整的資訊皆可從 Wedjat 提供的介面進行查 詢。 3) 維護使用者的用藥紀錄:Wedjat 會紀錄病人所有的用藥情況,包含什麼時間吃了什 麼藥,那些藥錯過沒有服用。 這些紀錄可以與家中主機上的資料庫進行同步,或者 上傳至遠端個人健康紀錄系統。3
1.3 論文大綱
接下來的文章將分成六個章節:第二章說明基本的知識背景,包括排程的用藥規格,排 程演算法 (OMAT & ODAT),與多維決策決定法 (MCDM)。第三章說明我們對服藥時程 所做的延伸,包括我們計算彈性時程的方法,以及改善劑量彈性時間的 OMAT 排程。 第四章說明我們如何將劑量的時程合併之方法。第五章介紹我們實作的方法,包括系統 的設計與操作原理與介面的設計等。最後一章說明我們的貢獻以及未來可行的研究方 向。
4
第 2 章 背景知識
2.1 藥物排程規格書
藥物排程規格書 (Medication Scheduling Specification, MSS [6] ) 包含用藥指示的資訊 (medicine direction),明確說明用藥的規則與限制,是一個機器可讀的格式,也是排程演 算法的輸入資料的格式。MSS 主要包含兩個部分,用藥參數 (Dosage Parameters, DP) 和 特殊參數 (Special Instructions, SI)。
2.1.1 用藥參數
DP 包含了藥物本身的資訊和服用規則的參數,如表格 1 所示。包括藥物的名稱 M,藥 物的最小單位劑量 G,療程長度以及劑量大小和服用時間間隔等限制。最小單位劑量 G 通常以 tablet/ capsule 等為單位,其它與劑量有關的參數皆以 G 為單位來表示,ex, k G 代表 k (tablet/capsule/..),而本文中所提及的時間參數,皆以一小時為單位。 服用的劑量範圍[dmin, dmax],也就是每次服用的劑量必須介於最小劑量和最大劑量 之間。服用時間間隔為[smin, smax],也就是任兩個連續劑量要保持在最小時間間隔 和最大時間間隔之間。以 Advil [7]為例,用藥指示說 “take 1 gel caplet every 4 to 6 hours. If pain or fever does not respond to 1 caplet, 2 caplets may be used.”,所以相對應的時間間 隔參數為 [4, 6],劑量範圍參數為[1, 2]。
在某一長度的時間內,可服用的最小與最大劑量限制為 (L, P)和 (B, R)。舉例來說, “The smallest effective dose should be used and do not exceed 6 gel caplets in 24 hours unless directed by a doctor.",對應到 MSS 裡的參數,最低劑量限制 (L, P)的值為 (0, 24),最高劑量限制 (B, R)的值為 (6, 24)。
絕對時間間隔參數[Smin, Smax]和絕對劑量範圍參數[Dmin, Dmax]提供較寬鬆的 時間和劑量限制。一般而言,[smin, smax]包含於[Smin, Smax],[dmin, dmax]
5
包含於[Dmin, Dmax]。舉例來說,Fosamax [7]的用藥指示內容提到“The usual dose of Fosamax is 10 milligram once a day or 70 milligram once a week."相對應的一般時間間隔 參數為[24, 24],一般劑量範圍為[1, 1],絕對時間間隔參數為[24, 168],絕對 劑量範圍為[1, 7]。排程時可利用絕對參數限制得到較大的彈性。
2.1.2 特殊參數
MSS 第二部分的參數是特殊參數 (Special Instructions, SI)。SI 參數說明該藥物 M 與其他 藥物或食物之間的交互作用關係。Interferer <List>描述 M 與所有其他有衝突關 係的藥物(食物)N 的服用關係,舉例來說,“The smallest effective dose should be used and do not exceed 6 gel caplets in 24 hours unless directed by a doctor.",意指這兩類藥物在服 用時至少要間隔兩小時以上,假設 M 為 Warfarin,則對應到 Interferer 的參數的結果,N 為 Crestor ,minfrinterferer 和 mintointerferer 的值皆為 2。一般來說,這兩 組參數的值不一定相等。
SI 的另一部分是 DosageParameters <List>,用來反映當 M 被其他藥物影響時,所 對應的用藥參數的改變,例如劑量的減小或服用頻次的改變。
Dosage Parameters
M Name of the medication G Granularity
[Tmin, Tmax] Minimum and maximum duration over which the medication is administered
[dmin, dmax] Nominal minimum and maximum dose size [smin, smax] Nominal minimum and maximum separations
between (consecutive) doses
[Dmin, Dmax] Absolute minimum and maximum dose size [Smin, Smax] Absolute minimum and maximum separations (B, R) Maximum intake over a specified time interval
given by budget B and replenishment delay R (L, P) Minimum intake over a specified time interval
given by lower bound L and interval length P
Special Instructions
Interferer <List> Interacting medications interferes N with M DosageParameters
<List>
Required changes of DosageParameters when some interferer affects M
6
Interferer
N Name of interferer medication
minfrinterferer Minimum separation from interferer N to medicine M
mintointerferer Minimum separation from medicine M to interferer N 表格 2: 衝突參數
2.2 藥物排程演算法
目前有兩個已發展的藥物排程演算法,One-Medicine-at-A-Time (OMAT) 和 One-Dose-at-A-time (ODAT) [8],它們是根據即時系統排程理論[9]所設計出來的演算法, 這一章將會介紹這兩個演算法它們所運用的模型,以及它們的主要概念和用途。2.2.1 排程模組
2.2.1.1 資源模組OMAT 和 ODAT 運用即時系統排程理論的資源模組 (Resource Model) 的概念。它在排 程時分配給每一藥物一個虛擬處理器 (virtual processor PM) 和一個虛擬資源 (virtual resource RM) 來處理排程時的相互時間關係。PM 負責處理同一藥物的每劑服用時間的 間隔關係 (intra-dose separations),RM 負責處理有交互作用的藥物(或食物)之間的服用時 間間隔關係 (inter-dose separations)。當我們在計算服藥時程時,我們將每一藥物 (medicine) 視為一個任務 (task) ,每一劑 (dose) 的服用視為一個在 PM 上執行的工作 (job),一連串的工作組合成一個任務。一個工作的起始點 (start time) 代表使用者必須 服藥的時間點 (in-take time)。一個藥物的時程就是一個時間表,每一個時間代表每一劑 藥物必須被服用的時間點。
7
2.2.1.2 資源分配規則
排程演算法利用 PM 來處理連續劑量之間的正確時間間隔。它將每一劑藥物視為一個在 PM 上執行的非搶占式工作 (non-preemptable job1),每一個工作的執行時間 (execution time)為最小時間間隔 smin,也就是每一個工作會占用 PM 最小時間間隔長度的時間, PM 同一時間只能執行一個工作。另外,它將最大時間間隔長度視為兩個連續工作之間 的相對期限時間 (relative-deadline),以確保連續劑量的服用時間不超出最大時間間隔。 為了避免藥物-藥物的衝突或藥物-食物的衝突,排程演算法利用 RM 來處理衝突藥物(食 物)之間的服用時間間隔關係。任一個藥物被排程時,會占用所有與它有衝突關係的藥 物的虛擬資源 RM,從該工作開始的時間點往前占用 minfrinterferer 時間,往後占 用 mintointerferer 時間。換句話說,它利用占用別人的資源來擋住與它有衝突關 係的藥物,也就是任何一個工作只有在 PM 和 RM 沒有被占用時,才能開始執行。 2.2.1.3 優先順序方案
OMAT 和 ODAT 根據藥物的優先順序 (priority) 來做為排程的順序。它利用幾種優先順 序的決定方法,分配給每種藥物優先順序,演算法在執行時會從最高優先順序的藥物排 到最低優先順序的藥物。優先順序決定方法有下列五種:
1) MVF (most-victimized-first):它根據最糟情況的阻斷時間 (worst case blocking time) 來決定優先順序,也就是在最糟情況下,RM 可能被占用的時間長度,時間長度 越長,優先順序越高。 2) MIF (most-interactions-first):它根據衝突藥物的數量來決定優先順序,也就是衝 突藥物越多的藥物,優先順序越高。 3) SSDF (shortest-separation-difference-first):它根據時間間隔的差距長度來決定優先 順序,也就是最小時間間隔跟最大時間間隔的差,相差越短的,優先順序越高。 1 一個非搶占式工作是一種從執行的開始到結束都不容許被中斷的工作
8
4) RM (rate-monotonic):它根據藥物服用的週期來決定優先順序,週期越短的,優 先順序越高。
5) EDF (earliest deadline first):這是一種動態決定優先順序的方法,它會根據現有工 作的期限時間來決定不同劑量的優先順序,期限時間越早的,優先順序越高。
2.2.2 排程演算法
這一小節介紹 OMAT 與 ODAT 的演算法概念,表格 3 和表格 4 分別為 OMAT 和 ODAT 的虛擬碼,它們使用一個布林植 feasibleSchedule 來表示排程器是否排出一個合理 的服藥時程,當 feasibleSchedule 的值為真時,MIS 陣列的內容即為正確排程的結 果,也就是所有藥的服藥時程。 2.2.2.1 一次一藥法 (One-Medicine-at-A-time, OMAT) OMAT 排程演算法會根據藥物的優先順序,一次排一種藥,依次排完所有藥的服藥時程。 在排程時,OMAT 會排出每種藥在療程期裡的所有劑量 (dose) 的服用時程。它利用 Resource Model 來確保所有劑量之間的安全時間間隔。OMAT 排程法會指定給每種藥一 個固定的優先順序,所以 EDF 優先順序決定法在 OMAT 裡不適用。
OMAT 試著排出所有藥的時程,而且在遵守用藥規則和限制上,表現的比 ODAT 更好, 但是 OMAT 適合傾向準時服藥的使用者,因為當使用者延遲或遺忘吃藥時,整個時程 就必須重排。
Basic OMAT 在排程時會盡可能排出緊密的時程,讓每劑 (dose) 的服用時程越接近越好, 這也導致排程失敗的機率較高,因為當有藥物衝突時,較高優先順序的藥可能把時間都 占滿,以致低優先順序的藥很難成功排程。為解決此問題所發展出的另一版本的 OMAT, 稱為 advanced OMAT,它在排程時會將每劑的服用時程盡可能的安排在靠近期限時間 (respective deadline),也就是它會盡可能排出時間鬆散的時程,大幅提高了排程成功的 機率。
9
2.2.2.2 一次一劑量法 (One-Dose-at-A-time, ODAT)
ODAT 排程演算法每次只排出下一劑的服用時程,它會根據 EDF 動態優先順序決定法 來決定下一個最急迫的藥物來排程。當使用者服完這個劑量後,ODAT 會再決定下一劑 的服用時程,所以我們無法預先知道往後的時程。ODAT 在遵守藥物的規則和限制上表 現的較差,但是 ODAT 在處理使用者即時的服藥行為,表現的比 OMAT 好,所以 ODAT 適合傾向於延遲吃藥的使用者。 INPUT: ListMedicationScheduleSpec MSS[number_medicines] PrioritySchemes PS OUTPUT: Boolean feasibleSchedule
List MedicineIntakeSchedule MIS[number_medicines] PROCEDURE:
FOR every MSS[i]{
CREATE JobModel, ResourceModel CREATE integer latestStartTime } ASSIGN priority to every MSS[i]
based on PrioritySchemes PS SET feasibleSchedule to TRUE
FOR every MSS[i] according to descending priority{ SET latestStartTime of MSS[i] to 0
SET ResourceModel.feasible of MSS[i] to TRUE WHILE ResourceModel.feasible of MSS[i] is TRUE {
FOR i from JobModel.release_time to
JobModel.deadline of MSS[i] { IF ResourceModel.processor[i]==0 and ResourceModel.resource[i]==0 {
SET Tavail to I THEN BREAK }} IF Tavail is found
IF Tavail>=MSS[i].TheraphyDuration THEN BREAK APPEND Tavail to ResourseModel.Schedule
SET latestStartTime of MSS[i] to Tavail
SET JobModel.release_time to (Tavail+ nsmin) SET JobModel.deadline to
(JobModel.release_time + asmax) FOR k from Tavail to (Tavail + nsmin)
SET ResourceModel.process[k] of MSS[i] to 1 FOR every interferer MSS[i].IP[j]{
FOR k from { (Tavail – MSS[i].IP[j].minFrInterferer) to (Tavail + MSS[i].IP[j].minToInterferer) SET ResourceModel.resource[k] of MSS[MSS[i].IP[j].med_id] to 1 }} ELSE
SET ResourceModel.feasible of MSS[i] to FALSE SET feasibleSchedule to FALSE }
IF feasibleSchedule is TRUE {
SET MIS[i] to ResourceModel.Schedule of MSS[i]} RETURN feasibleSchedule and MIS[]
END PROCEDURE
10 INPUT:
List MedicationScheduleSpec MSS[number_medicines] PrioritySchemes PS
OUTPUT:
Boolean feasibleSchedule
List MedicineIntakeSchedule MIS[number_medicines] PROCEDURE:
FOR every MSS[i]
CREATE JobModel, ResourceModel
SET numberMedicines to the length of MSS[] array CREATE integer array
ReleaseTimeCurrentJobs[numberMedicines] SET ScheduleComplete to 0
SET feasibleSchedule to TRUE
WHILE (feasibleSchedule is TRUE) and
(scheduleComplete < numberMedicines){ FIND MSS[i] with earliest time in
ReleaseTimeCurrentJobs[] and highest priority FOR k from JobModel.release_time
to JobModel.deadline of MSS[i]{ IF ResourceModel.processor[k]==0
and ResourceModel.resource[k]==0{ SET Tavail to k THEN BREAK }}
IF Tavail is found
IF Tavail >= MSS[i].TheraphyDuration {
INCREMENT scheduleComplete THEN BREAK } APPEND Tavail to ResourseModel.Schedule APPEND ResourceModel.Schedule to MIS[i] SET JobModel.release_time to (Tavail+nsmin) SET JobModel.deadline to
(JobModel.release_time + asmax)
SET ReleaseTimeCurrentJobs[i] to(Tavail+nsmin) FOR k from Tavail to (Tavail + nsmin)
SET ResourceModel.process[k] of MSS[i] to 1 FOR every interferer MSS[i].IP[j] {
FOR k from (Tavail – MSS[i].IP[j].minFrInterferer) to (Tavail + MSS[i].IP[j].minToInterferer) { SET ResourceModel.resource[k] of MSS[MSS[i].IP[j].med_id] to 1 }} ELSE
SET feasibleSchedule to FALSE } RETURN feasibleSchedule and MIS[]
END PROCEDURE
11
2.3 多維評估因素決策方法
多維評估因素決策方法 (Multi-Criteria Decision Making Methods, MCDM [10]) 是一種幫 助決策者在考慮多方面且互相矛盾的評估下,做出較佳決策的方法。它的目標在於用一 種透明化的方式,突顯這些互相矛盾的評估,找出一個較佳的妥協方案。
2.3.1 決策矩陣的定義
多維度決策問題可以用一個簡單的數學矩陣表示。如圖 1 所示,一個決策矩陣 (Decision Matrix) 是一個 (m × n) 的矩陣,橫軸代表所有的評估因素 (或稱為目標),縱軸代表所 有可能的選擇。aij的數值代表在 Cj這個維度的評估下,Ai這個決定的效能表現好壞 (i = 1…m, j = 1…n)。假設決策者已經決定所有評估因素之間的相對重要性,也就是相對的 比重 (relative weight),Wj即代表 Cj所占的比重。 多維度決策矩陣的定義如下: A = { Ai, for i = 1, 2, 3, …, n} C = {Cj, for j = 1, 2, 3, …, m} A 和 C 皆是一個有限的集合 (finite set),A 包含所有可能選擇的決定,C 包含所有決策 者考量的因素,也就是期望的目標。多維度決策方法會考量所有相關的評估因素,找出 一個最佳的選擇 A*。12 Alts. C1 (W1) C2 (W2) … … Cn (Wn) A1 a11 a12 … a1n A2 a21 a22 … a2n . … . … Am am1 am2 … amn 圖 1: 典型的決策矩陣
2.3.2 比重加權法
比重加權法 ( Weighted Product Model Method, WPM) 利用相對數值比較來算出兩種選 擇 (Ak和 AL) 在多維度考量下的優劣。它的計算方式如下列公式: R AK⁄AL aK⁄aL W 1 比重加權法計算兩種選擇在每一評估因素的分數的比值,然後根據每一評估因素所占的 比重,做指數次方,再將每一維度所算出來的值相乘。結果大於 1 的話,表示 Ak這個 選擇比 AL好,反之如果數值小於 1,表示 AL比 Ak好。在 m 種選擇之下要找出最佳選 擇,最多需要比較 C(m, 2) 種組合,也就是任兩種可能的組合。 舉例來說,如果有一個多維度決策矩陣的數值如圖 2 所示: Alts. C1 (0.20) C2 (0.15) C3 (0.35) C4 (0.30) A1 25 20 10 30 A2 10 30 20 30 A3 30 10 30 20 圖 2: 決策矩陣範例
13 利用 WPM 的方法計算,A1和 A2的比較值為:
R(A1/ A2) = (25/ 10)0.20 × (20/ 30)0.15 × (10/ 20)0.35 × (30/ 30)0.30 = 0.8867 < 1
所以在這種計算方法下,A2比 A1好。
2.3.3 修正後之層級分析法
修正後之層級分析法 (Revised Analytic Hierarchy Process, R_AHP) 利用相對重要性的概 念,來比較不同選擇之間的優劣。它會將原本的多維決策矩陣的數值,轉換成相對的比 較值。舉例來說,假設原本的矩陣為圖 2,在 R_AHP 方法中,會將這個矩陣轉換成相 對重要性比較值的矩陣,轉換後的結果如圖 3 所示: Alts. C1 (0.20) C2 (0.15) C3 (0.35) C4 (0.30) A1 25/30 20/30 10/30 30/30 A2 10/30 30/30 20/30 30/30 A3 30/30 10/30 30/30 20/30 圖 3: 修正後之層級分析法決策矩陣範例 它將每個維度的數值,除以該維度裡的數值的最大值,然後再依照下列公式,計算每種 選擇的分數,分數最高的是此方法中的最佳選擇。 AR_AHP max w 2 所以 A1的分數為: A1, R_AHP-score = (25/ 30)×0.20 + (20/ 30)×0.15 + (10/ 30)×0.35 + (30/ 30)×0.30 = 0.683 同樣的方式,我們可以計算 A2和 A3的分數: A2, R_AHP-score = 0.749 A3, R_AHP-score = 0.8 所以這三種選擇的好壞順序為: A3 > A2 > A1
14
第 3 章 藥物時程之服用延伸一–服藥時間
彈性
3.1 原理
我們利用 OMAT 演算法 [2.2.2.1] 的排程結果做服藥時間的延伸。我們計算 OMAT 裡每 一劑服用時間的可容忍彈性時間範圍,依據此彈性時間範圍,我們可將時程接近的劑量 合併。由於劑量合併時考量許多因子,所以我們採用多維決策決定法,來找出最佳的合 併組合,下一節將詳細闡述我們設計的方法。3.2 操作機制
3.2.1 修改之用藥排程規格書
我們把原本的 MSS 做小幅度的修改,修改後的 MSS 可分成三個部分。第一部分是與處 方籤內容有關的參數 (Prescription Parameters),包含處方籤內有的資訊,像是藥物的名 稱、劑量、療程等等;第二部分是劑量參數 (Dosage Parameters),與原本的 MSS 類似, 不同的地方是我們精簡了某些參數,我們將原本的一般服用時間間隔 [nsmin, nsmax] 精 簡為服藥的週期 period,由於一般處方用藥會有一定的給藥頻次,例如,一天三次,我 們可以從這個服藥頻次轉換成服藥的週期,對於一些非處方用藥規則中的一般服藥時間 間隔,我們則可以取這個範圍內的某個值為服藥週期,例如,nsmin 和 nsmax 的中間值。 第三部分是藥物的衝突參數 (Interaction Parameters, IP),每一個衝突藥物會用一組衝突 參數來表示。我們精簡 Special Instruction 裡面的 change Dosage Parameters 並將裡面的 衝突參數獨立出來,我們將動態改變 MSS 的資料處理方法視為實作上的考量,所以暫 時省略 change Dosage Parameters。15
Prescription Parameters (PP)
Medicine Identifier M
Medicine Dose g
Medicine Form Capsule/Tablet/… Medicine Amount n
Therapy Duration T Dosage Parameters (DP)
Nominal Frequency Separations period Max. In-take Amount B over
Interval R
(B, R)
Min. Intake Amount L over Interval P
(L, P)
Absolute Min. & Max. Dose [Dmin, Dmax] Absolute Min. & Max.
Separations [asmin, asmax]
Interaction Parameters (IP) <List>
Interferer Identifier N
Min. Separation from M to N minToInterferer Min. Separation from N to M minFrInterferer
表格 5: 修改後的藥物排程規格書
3.2.2 計算藥物時程之服用時間彈性
3.2.2.1 無衝突藥物的服用時間彈性
沒有衝突的藥物排程中,每種藥物的時程是獨立的、不互相影響的,所以我們可以就單 一藥物 OMAT 排程的結果來計算每劑的可服用彈性時間範圍 (flexibility)。
假設藥物 A 總共需服用 n 劑 (A1….An),每劑的時程點依序為 t(A1)…t(An)。根據藥物服
用規則限制,任何連續劑量間,須滿足時間間隔限制,也就是任一劑量 Ai須與前後劑
量 (Ai-1與 Ai+1) 保持在適當的時間間隔範圍 [asmin, asmax],我們定義 Ai的可服
用彈性時間範圍為 I(Ai),時程點的左半段區間稱為可提早的時間範圍 (allowable
16 Ai在滿足與前一劑量 Ai-1的時間限制下,彈性時間的區間範圍如下: I A t A +asmin, t A +asmax 3 Ai在滿足與下一劑量 Ai+1的時間限制下,彈性時間的區間範圍如下: I A t A -asmax, t A -asmin 4 所以 Ai在滿足兩者的限制下,可服用的時間範圍為(3)與(4)的交集: I A I A I A 5 舉例來說,假設藥物 A 的服用頻次為每八小時一次,時間間隔限制為 [6, 10],OMAT 的排程結果如圖 4 所示,我們可以看到,A2在滿足與 A1的間隔限制下,可服用的範圍 為 [6, 10] (藍綠色區間),A2在滿足與 A3的間隔限制下,可服用的區間為 [6, 10] (橘黃 色區間),所以由公式(5)我們可以推出 A2的可服用時間範圍為 I(A2) = [6, 10],這段時間 範圍可分成,可提早的時間範圍 [6, 8] (圖 4 的(1)),可延遲的時間範圍 [8, 10] (圖 4 的 (2))。我們可以用同樣的方式計算每一劑的可服用時間範圍。 3.2.2.2 衝突藥物的服用時間彈性 當藥物之間有交互作用時,可服用時間範圍的計算方式與前一小節的方法相似,唯一不 同的是要考量衝突藥物之間的間隔限制。我們可以利用 Resource Model 來計算有衝突之 劑量的彈性時程。此時要考量的限制因素有兩點: 1) 同一藥物的連續劑量之間的間隔限制 2) 衝突藥物之間的間隔限制 2 4 6 8 10 12 14 16 18 20 22 24 0 A1 A2 A3 A4 asmin asmax asmax asmin 圖 4: 單一藥物服用時間彈性範例 (1) (2)
滿足 條限 情況 的連 間。 因此 舉例 示, 的衝 假設 器 PM 12, 2 I1(C2 I3(C2 Iinter( I(C2) 同樣 足第一條限制 限制下的可服 況來計算。計 連續時間長度 此,任何一個 I I 例來說,假設 Crestor 的時 衝突間隔限制 設圖 6 為 Cr M 和虛擬資 24…),War 2) = 2) = (C2) = [ ) = 樣的方法,我 制下的可服 服用時間範 計算方式為從 度,我們稱 個有衝突劑 I M A I N A 設使用者同 時間間隔限 制皆為兩小 restor 和 W 資源 RM,P( rfarin 的服用 = [0+10 = [24-1 11, 13] = I1(C2) 我們可以算 服用彈性時間 範圍,可利用 從該劑量的 稱這段區間為 劑量 Mi的可 I M A I tA N +m 同時服用 Cre 限制為 [10, 小時。 圖 5: Warfarin 的排 (W)和 R(W 用時程為 ( , 0+14] = 4, 24-10] ∩ I3 (C2) 算出每劑的可 17 間範圍可利 用藥物 M 的 的時程點往前 為 Iinter (Mi) 可服用時間範 I M A I minToInter estor 和 Wa 14],Warf 藥物衝突關 排程結果,P W)為 Warfar (4, 9, 15…) [10, 14] = [10, 14] ∩ Iinter (C2) 可服用時間 利用前述方法 的虛擬資源 前和往後計 ,即為 Mi劑 範圍的計算 M I N A r N , tA N arfarin 兩種 farin 的時間 關係之圖例 P(C)和 R(C rin 的 PM 和 。以 C2為例 ) = [ 間範圍。 法來計算 ( (Virtual R 計算 Virtual 劑量在滿足 算方式如下 M 6 … I N +minFr 種藥,它們之 間間隔限制為 例 C)分別代表 和 RM,Cres 例,可服用 [11, 13] (公式(5))。 Resource, []) Resource 沒 足條件 2 下的 : N A rInter N 之間的關係 為 [4, 6], 表 Crestor 的 stor 的服用時 用區間 I(C2) 滿足第二 ) 被占用的 沒有被占用 的可服用區 係如圖 5 所 它們之間 的虛擬處理 時程為 (0, )為: 的 用 區 所 ,
18 3.2.2.3 時間彈性之不確定性 前述的可服用彈性時間範圍存在不確定性。當某一劑量在它的彈性時間範圍內,在原本 排定的時間點之前或之後服藥 (提早或延遲吃藥),會影響它的前後劑量的可容許彈性時 間範圍,同時也會影響與它有衝突的藥物的可服用時間範圍,也就是說這樣的彈性時間 範圍會依照使用者實際服藥的時間動態改變。為了能夠根據劑量的服用時間彈性範圍預 先做時程上的安排,我們分析彈性時間範圍的特性,避開動態改變的時間段,取其固定 的時間段。 每一劑量的可服用時間範圍會被前後劑量的時程點所限制,同時也被前後衝突劑量的時 程點所限制,這樣的時間範圍存在幾個特性: 1) 任何劑量的時程點一定包含在它的彈性時間範圍內。 2) 當某劑量在有效的彈性時間範圍內的任何一時間點服用,其前後劑量的時程永遠是 合法的、有效的時程點。 3) 當某劑量在可提早的時間範圍服用時,不會縮小前後劑量的可提早時間範圍,會影 響前後劑量的可延遲時間段 (可能會縮小原本的可延遲時間)。同理,當劑量延遲服 W3 W2 W1 C2 C1 P(C) 2 4 6 8 10 12 14 16 18 20 22 24 2 4 6 8 10 12 14 16 18 20 22 24 0 R(C) P(W) R(C) 圖 6: 多個藥物的時程時間彈性 0 C3
19 用時,會影響前後劑量的可提早時間。 4) 當劑量延遲服用時,會影響下一個衝突劑量的可提早時間範圍,當劑量提早服用時, 會影響前一個衝突劑量的可延後時間範圍。 第一點是非常直觀的特性,OMAT 排出來的時程即為滿足所有服用限制的時程,而可服 用的時間範圍,也是滿足所有限制的彈性時間,所以每一劑量的時程點一定包含在該劑 量的可服用時間範圍內。 第二個特性的原因是因為任何劑量的彈性時間範圍都被前後的時程點所限制 (公式 (3), (4)),所以不管在彈性時間範圍內怎麼移動,前後劑量的時程點是合法的。我們可以推 論,任一劑量在有效範圍內的提早或延遲服用,不會影響所有其他劑量的時程 (但是會 影響前後劑量的彈性時間範圍)。 第三個特性,我們討論當某一劑量在其可服用時間範圍內移動,對其前後劑量的影響。 由於藥物的劑量間,須滿足最大最小間隔限制,也就是說,同一藥物的任何連續劑量間, 須保持在最小與最大距離之間。當某一劑量 Ai提早服用,代表它遠離下一劑量 Ai+1的 時間,同時接近前一個劑量 Ai-1的時間,所以下一劑量 Ai+1可遠離它的距離縮小了
(Ii(Ai+1)的可延遲時間),可以接近它的距離增加了 (Ii(Ai+1)的可提早時間)。Ai的前一劑
量 Ai-1可接近它的距離縮小了 (Ii(Ai-1)的可延遲時間),可以遠離它的距離增加了 (Ii(Ai-1)
的可提早時間),反之亦然。對交集後的可服用區間的影響,I(Ai+1)的可延遲時間可能縮 小或不變,可提早時間可能增加或不變;I(Ai-1)的可延遲時間可能縮小或不變,可提早 時間可能增加或不變。舉例來說,假設藥物 A 的服用頻次為 8 小時一次,時間間隔範圍 為 [6, 10],時程與每一劑量的可服用時間範圍如圖 7 (a),當 A3從 16 提早到 15 服用, I3(A2)與 I3(A4)都減少一個單位的可延遲時間,交集後的結果 I(A2)與 I(A3)也減少一個單 位的可延遲時間,可提早時間皆不變,如圖 7 (b)。當 A3從 16 延遲到 17 服用,則 I3(A2) 與 I3 (A4)都減少一個單位的可提早時間,交集後的結果 I(A2)與 I(A4)一樣也減少一個單位 的可提早時間,但是可延後時間皆不變。當我們反向看這樣的關係,假設原本的時程為 圖 7 (b),A3從原定的時間點 15 延後到 16 服用,I3(A2)的可提早時間段縮小 (從[5, 8]
20 變成[6, 8]),但是交集後 I(A2)的可提早時間段沒有改變 [6, 8],I(A2)的可延遲時間段增 加 ( [8, 9] -> [8, 10]),I(A4)的可提早時間段也沒有改變,I(A4)的可延後時間段也增長 1 單位。類似的現象也會發生在 A 的時程從圖 7 (c)變成圖 7 (a)的時候。 總而言之,當某一劑量延後服用時,它的前後劑量的可提早時間可能會縮小或不變,它 的可延後時間可能會延長或不變。所以,當劑量延後服用時,其前後劑量原有的可延後 時間段仍有效 (不會因此縮小原有的可延後時間),同理,當劑量提前服用時,其前後劑 量原有的可提早時間段仍有效 (不會因此縮小原有的可提早時間)。 第四個特性,由於衝突劑量之間須滿足衝突間隔限制,也就是衝突劑量之間至少須遠離 衝突間隔時間單位,當劑量延遲服用時,代表它更接近下一個衝突劑量,所以下一個衝 突劑量可以提前的時間就縮小了,但不影響下一劑量的可延後時間。同理,當某劑量提 早服用時,則它的前一個衝突劑量的可延後時間就縮小了,不影響前一劑量的可提早時 間。所以,衝突劑量之間亦滿足單向時間範圍不變的特性。所以我們可以利用單向的彈 性時間範圍 (每個劑量的可延遲時間或每個劑量的可提早時間) 預先做時程上的處理。
21 2 4 6 8 10 12 14 16 18 20 22 24 0 A1 A2 A3 A4 2 4 6 8 10 12 14 15 18 20 22 24 0 A1 A2 A3 A4 2 4 6 8 10 12 14 17 18 20 22 24 0 A1 A2 A3 A4 圖 7: 時間彈性的不確定性 (a) (b) (c)
22
第 4 章 藥物時程之服用延伸二 – 劑量分
群
4.1 原理
我們取劑量的可延遲時間,做為每個劑量的可服用時間,可將時間段相交疊的劑量分在 同一群 (group),合併服用。下面章節中所用提到的可服用時間皆為前述的可延遲時間 段。我們先將時程內的所有劑量依照其相互交集關係分成一到多個組別 (cluster),然後 計算每個類別內之劑量的所有可能的分群組合,再依照多維決策決定法,決定一個最佳 的分群組合,每個類別所計算出來的最佳分群組合起來便是整個時程的最佳分群方式。 節介紹我們將所有劑量分到一至多個類別的方式,4.2 節會介紹我們如何計算每個類別 內之所有可能的分群組合,4.3 節會介紹我們如何利用多維決策決定法(MCDM)來決定 最佳的分群組合。4.2 所有可能之分群組合
4.2.1 劑量分組
我們將時程裡的所有劑量依照其可服用時間相互重疊的關係,分成一到多個組別。組別 裡的任兩個劑量,不是有直接的交集,就是有間接的交集。所謂的直接交集,是指這兩 個劑量的可服用時間有重疊;間接交集,是指這兩個劑量的可服用時間段沒有時間上的 重疊,但是中間可能存在一到多個直接交集的關係,例如劑量 Ai與劑量 Cj沒有直接交 集,但是 Ai與 Mk有直接交集,Mk與 Cj也有直接交集,則 Ai與 Cj為間接交集關係。 假設有 n 個劑量 (d1, d2,….,dn),分成 m 個組別 (S1, S2,….,Sm) 每一劑量皆滿足以下特性:23 1) 每一個劑量皆屬於某一組別,且只屬於某一組別。 2) 每一劑量與該組別裡的其他任何劑量,一定存在直接或間接的交集關係,且至少與 一個劑量有直接交集關係。 舉例來說,假設有三種藥 A,B,C,總共有 8 個劑量,服用時程及可服用時間如圖 8 所示, 這八個劑量依彼此的交集關係分成下列三個組別: S1 = {d1, d2} S2 = {d3, d4, d5, d6} S3 = {d7, d8}
4.2.2 基本服用時間單元和所有可能之分群組合
我們將劑量依照相互重疊的關係分到不同組別後,由於類別之間的劑量沒有任何時間交 集關係,也就是彼此互相獨立,所以我們可以依照組別來做分群決定。在分群時,我們 將服用時間段相重疊的劑量合併一起服用,但是一個劑量可能同時與多個劑量重疊於不 同的時間段,這時候我們須考慮所有可能的分群方式 (group)。這一小節便討論如何找 出每個類別內的所有可能的分群方式。 每一劑量(di)的可服用時間段會根據它與其它劑量的交集被切成一到多份連續的時間段 A B C d1 d2 d3 d4 d5 d6 d7 d8 0 2 4 6 8 10 12 14 16 18 20 22 24 26 圖 8: 劑量分組圖例24 (di1,…,dik)。每一小份我們稱為 di的子時間段,以圖 8 的第二個組別 S2 = {d3, d4, d5, d6} 為 例,這四個劑量分別可以被切成不同大小的子時間段,如圖 9 所示。d3被分成兩個子時 間段,d4被分成一個子時間段,d5被分成兩個子時間段,d6被分成兩個子時間段。所有 可能的分群方式即為所有可能的子時間段的組合,也就是子時間段的個數相乘, 2×1×2×2 = 8,如圖 10 所示,每一橫列代表一個可能的組合方式,框起來的部分代表 時間段重疊,分在同一群 (group),每一種組合方式即為該類別內的所有劑量的服用時 間的組合,可能包含一到多個群,例如圖中的組合 1,包含了三個群,裡面共有四個劑 量的服用時間,第一個群裡有 dose 3 和 dose4 (6 點到 10 點服用),第二個群裡有 dose5 (10 點到 14 點服用),第三個群裡有 dose6 (14 點到 16 點服用)。 d61 d62 d51 d52 d31 d32 6 8 10 12 14 16 18 20 C B A d41 圖 9: 劑量基本服用時間單元
25 d31, d41 d51 d61 d31, d41 d51 d62 d31, d41 d52, d61 d31, d41 d52 d62 d32, d51 d41 d61 d32, d51 d41 d62 d52, d61 d32 d41 d32 d41 d52 d62 組合 1 組合 2 組合 3 組合 4 組合 5 組合 6 組合 7 組合 8 圖 10: 所有可能之劑量分群組合
26
4.3 找出最佳分群組合
我們利用多維決策決定法來選出每個組別內的最佳組合,每個組別的最佳組合結合起來 便是整個時程的最佳組合。將我們的決定問題對應到多維決定方法,大致可分為幾個步 驟,第一,先決定相對應的評估因素與選擇,第二,決定每個評估因素所占的比重,第 三,量化每個選擇對應到每個評估因素的數值,第四,利用多維決策方法來評分,我們 這裡選擇的是具代表性的線性方法,Revised AHP method 來評分,評分後得到最高分數 的即是最佳選擇。下面將詳細介紹每個步驟的細節。4.3.1 決定評估因素和選擇
我們的選擇即是每個組別內之劑量的所有可能組合。相對應的評估因素就是我們在選擇 時所考量的因子。我們分群的目標是希望讓重要的藥有較大的服用機會,同時希望能減 少服藥次數,也希望能讓服藥的時間有較大的彈性。我們針對這些目標訂定我們考量的 因子。這些因子主要可分為兩類,一類是與分群 (group) 有關的因子,另一類是與劑量 (dose) 有關的因子。如表格 6 所示,第一行是與劑量有關的因子,包括這個劑量的重要 性,劑量的可服用時間,劑量的服用時間被切成幾個子時間段。第二行是與劑量的子時 間段有關的因子,包括子時間段的長度,該時間段與其他子時間段的順序關係;該子時 間段的結尾離最後可以吃的時間 (deadline) 有多遠;錯過該子時間段的服藥時間後,後 面還剩幾個子時間段 (還剩幾次機會可以服藥)。第三行是與分群有關的因子,包括每一 群裡包含幾種藥,這個 group 的可服用時間長度,最後一個是與分群組合 (combination of groups) 有關的因子,每一個組合內總共有幾群。27 劑量因子 劑量時間段因子 群組因子 可服用時間長度 時間段長度 群組服用時間長度 藥物重要性 剩餘時間段個數 劑量個數 時間段個數 距離期限的時間 群組個數 表格 6: 所有可能的評估因子 但是並非所有相關的因子都是我們在做多維決策決定時的評估因素,只有與目標相關的 因子會被考慮,我們選擇的有效因子有三個,一個是與分群有關的,組合內的群組數目, 另外兩個是與劑量的子時間段有關的因子,子時間段長度,以及剩餘的子時間段個數。 舉例來說,圖 8 的第一類別 S1 = {d1, d2}的所有可能選擇有兩個 (d11, d21), (d12, d21), d11 的時間是[0, 4],d12 的時間是[4, 6],d21 的時間是[0, 4],評估因素則有五個,一個 是組合內的群組數目,每一劑量分別有兩種與劑量相關之考量因子,因此決策矩陣的大 小會隨選擇的多寡以及劑量個數而改變。S1 的決策矩陣如圖 11 所示。 分群組合 群組個數 (w1) 時間段長 (d1j) (w2) 剩餘次數 (d1j) (w3) 時間段長 (d2j) (w4) 剩餘次數 (d2j) (w5) (d11, d21) (d12, d21) 圖 11: 分群之決策矩陣
4.3.2 階層化決策因子的比重
4.3.2.1 階層化比較法 我們利用階層化 (Hierarchy) 的概念,來比較決策因子的相對重要性。每一層內的決策 因子比較是利用成對比較法 (pairwise comparison)。它的概念是將兩兩評估因素相比, 由決策者決定每一對評估因素的相對重要性,最後將它套用至數學的特徵方程式 [Saaty, 1980],算出每個評估因素的比重。我們利用一個刻度尺(scale)來量化成對比較的重要性 比率 (wi/ wj)。這樣的刻度尺是一對一的對應關係 (one-to-one-mapping),它將語言形態 的重要性選擇對應到數值化的重要性比率,這樣的集合通常是離散的有限項集合。我們28
使用 [Ma and Zheng, 1991]所提出來的刻度尺,如表格 7 所示。
每一層的所有評估因素的比較值可以用一個矩陣 A 表示,矩陣 A 的每一個元 aij代表第
i 個 criteria 與第 j 個 criteria 的重要性比值 (wi/wj)。很明顯的 aij = 1/aji,所以 A 是一個倒
值矩陣 (reciprocal matrix)。所以可以推導成下列的方程式[Saaty, 1980]: a w w n w 7 for i = 1, 2, …, n 或者表示成特徵方程式: A W n W 8 n 為 criteria 的個數,對應到特徵值為 n 的特徵向量 W 即為每個評估因素的比重值。 相對比重 定義 說明 1/1 相等重要 兩比較因子的貢獻程度相等重 要 9/7 稍微重要 稍微傾向於重視某一因子 9/5 頗重要 強烈傾向於重視某一因子 9/3 極重要 非常強烈傾向於重視某一因子 9/1 絕對重要 絕對傾向於重視某一因子 9/8, 9/6, 9/4, 9/2 相鄰尺度間的中間值 折衷選擇值 上列的倒數值 當比較角色顛倒時,會得到倒 數數值
表格 7: 相對比重的尺規 (Ma and Zheng, 1991, Satty,1980)
在階層化的比較中,我們將所有的決策因子分為三個階層,第一層,群組因子與劑量因 子的比較,第二層,劑量與劑量之間的比較,第三層,劑量因子之間的比較。以 S1為
例,第一層比較所有與分群有關的因子與所有與劑量有關的因子之間的相對重要性;第 二層比較 dose 1 與 dose2 之間的相對重要性;第三層針對每個劑量比較劑量內的兩個因 子之間的相對重要性,dose 1 的子時間段長與 dose 1 的剩餘次數的相對重要性,dose 2 的子時間段長與 dose 2 的剩餘次數的相對重要性。為了滿足關係的一致性,第三層的劑 量因子比重和會滿足第二層的劑量間相對比重關係,第二層的劑量比重和會滿足第一層 的比重相對關係。階層化比重值計算的程序可分為幾個步驟:
29 步驟 1)
第一層的比較,比較群組因素 (Group Criteria) 與劑量因素 (Dose Criteria)的相對重要性, 它的比重比較矩陣 AG/D如下所示,aij = wi / wj。 步驟 2) 利用特徵方程式 AW = n W 計算出當 n 為 2 時所對應的特徵向量。w1是群組因素的比 重與 w2劑量因素的比重。 步驟 3) 正規化步驟 2 求出來的特徵向量 W,將向量裡每一元的值除以向量裡所有元的值的和。 w1 w2 W normalize w w + w w w + w WN = wG wD a11 a12 a21 a22 w1 w2 = 2 w1 w2 AG/D W = n W G D a11 a12 a21 a22 AG/D = G D
30 步驟 4) 第二層的比較,比較兩兩劑量之間的相對重要性,它的比較矩陣 A 如下圖所示。 步驟 5) 利用特徵方程式 AW = n W 計算特徵值為 n (dose 的個數)相對應的特徵向量。 w1 w2 . . wn = n AD/D W = n W AD/D w1 w2 . . wn d1 d2 . . dn a11 a12 . . . a1n a21 a22 . AD/D = d1 d2 . . . dn an1 an2 . . . ann . .
31 步驟 6) 正規化步驟 5 求出來的特徵向量 W,將向量裡每一元的值除以向量裡所有元的值的和。 步驟 7) 將正規化後的特徵向量乘上步驟 3 所算出來的劑量比重值 wD,乘完後的值才是劑量真 正的比重值。 wd1 wd2 . . wdn wD wd1 wd2. . . wdn = WD/D w1 w2 . . wn W normalize w w + … + w WN w w + … + w . w w + … + w = wd1 wd2. . . . wdn
32 步驟 8) 第三層的比較,比較劑量的子時間段長度與剩餘次數的相對重要性,每一個劑量都有一 個這樣的矩陣,n 個劑量就有 n 個矩陣。 步驟 9) 利用特徵方程式 AW = n W 計算特徵值為 2 時相對應的特徵向量。 步驟 10) 正規化步驟 9 所求出的特徵向量 W w1 w2 W normalize w w + w w w + w WN = wdi-duration wdi-time ADf/Df W = 2 W ADf/Df w1 w2 = 2 w1 w2 ADf/Df = a11 a12 a21 a22 di-duration di-time di-duration di-time
33 步驟 11) 將步驟 10 正規化後的向量乘上該劑量的比重 wdi (步驟 7 的結果)。 步驟 12) 重複(步驟 9, 10, 11) n 回合,n 為 dose 的個數。最後可得到每個評估因素的比重值,如 下所示。 運用上述的機制,可以階層化的比較相對重要關係,推導出所有的決策考量因子的比重 (weight of criteria)。有了這些資訊,便可建立我們的決策矩陣,然後利用 Revised AHP method 來為每個選擇評分,進而得到較佳的選擇。 wG wd1-duration wd1-time . wdn-duration wdn-time wdi-duration wdi-time = wdi-duration wdi-time wdi
34 4.3.2.2 藥物相對重要性分類 我們設計了一套機制來降低決策者在比較決策因子之相對重要性的複雜度。我們定義了 三類的藥物重要性,讓醫藥人員能夠很簡單將病人的藥物依照不同的緊急程度 (重要性) 分類。然後根據藥物的重要性,轉換成與劑量相關的評估因子相對比重。我們設計的分 類方式如下: Class 1) 重要藥物: 意指該藥物對病人的病情或健康控制有極大的影響,病人忘記服 藥 可能有嚴重的危險,像是控制高血壓、心臟病等藥物。 Class 2) 一般藥物:意指該藥物偶爾忘記服用不會有嚴重的危險。
Class 3) 非必要性藥物:意指該藥物是需要時服用的藥 (take when need),也就是 PRN (pro re nata) 用藥,像是退燒藥或頭痛藥等,當病人覺得不舒服 或出現某些症狀時才需服藥。 不同類別的藥物之間的相對重要性,如下表所示: 藥物重要性比較 相對重要性 相對比重 重要藥物 vs. 一般藥物 頗重要 9/5 一般藥物 vs. 非必要性藥物 頗重要 9/5 重要藥物 vs. 非必要性藥物 極重要 9/3 同一類藥物 相等重要 1/1 表格 8: 分類藥物之相對重要性尺規 我們可以利用這些分類,自動轉換成上一小節介紹的階層化比較的第二層,劑量之間的 重要性比較。關於第三層劑量內評估因素比較,我們針對不同重要性的藥有不同的考量。 重要藥物通常不太能容許病人忘記服藥,所以對於這類的藥物,我們希望能有較大的服 用機會,所以在分群時,我們會希望安排在剩餘子時間段 (remaining slots) 較多的時間 段內,時間的彈性為次要的考量。對於一般藥物,基本上有容許病人少次錯過藥的彈性, 所以我們會以時間彈性長度為主要考量,時間長度大,病人在服用時間上的彈性較大, 系統重排的機率較低,但是當病人錯過此次服藥後,後面可以再吃的機率較低。對於需
35 要時服用的藥物,我們將這兩個因子視為一樣重要。這些對應關係如下表所示: 藥物分類 時間段長 vs. 剩餘次數 相對比重 重藥劑量 稍微重要 7/9 一般劑量 稍微重要 9/7 非必要性劑量 相等重要 1/1 表格 9: 分類劑量因子之相對重要性尺規 下面我們介紹一個簡單的例子,幫助你了解整個轉換還有運算的過程,同時我們比較不 同重要性的運算結果。 假設有 A, B 兩種藥物,A 藥為第一類重要藥物,B 藥為第二類一般藥物,排程後 A1 , B1, 可服用時間分別是[0, 6]和[4, 8],如下圖。 按照階層化的比較方法,我們可以推導出決策矩陣中每個評估因素的比重。 步驟 1) 群組因素和劑量因素比較,我們假設群組因素與劑量因素 一樣重要,所以相對重要性矩陣為: G D 1/1 1/1 1/1 1/1 AG/D = G D A1 B1 0 6 4 8
36 步驟 2) 利用特徵方程式解 W 步驟 3) 正規化 W 步驟 4) 比較劑量之間的重要性,從藥物的分類自種轉換。 步驟 5, 6) 利用特徵方程式計算 W 然後正規化。 w1 w2 = 2 w1 w2 AD/D W = n W 1/1 9/5 5/9 1/1 0.8742 0.4856 W 0.6429 0.3571 WN A1 B1 1/1 9/5 5/9 1/1 AD/D= W normalize 0.7071 0.7071+ 0.7071 WN = 0.5 0.5 0.7071 0.7071 0.7071 0.7071+ 0.7071 w1 w2 = 2 w1 w2 AG/D W = n W 1/1 1/1 1/1 1/1 0.7071 0.7071 W A1 B1
37 步驟 7) 將步驟 6 算出來的 W,乘上劑量的比重值 (步驟三) 步驟 8-11) 比較劑量內因子的相對重要性,這裡有兩個劑量,所以重複兩個回合。 A1的評估因子比重: W normalize 0.6139 0.7894 × wd1 WN 0.4375 0.5625 0.1407 0.1808 0.3215 w1 w2 = 2 w1 w2 Alevel-3-A1 W = n W 1/1 7/9 9/7 1/1 0.6139 0.7894 W Alevel-3-A1 = 1/1 7/9 9/7 1/1 di-duration di-time di-duration di-time 0.5 = 0.3215 0.1786 0.6429 0.3571 WN Wlevel-2 wD wd1 wd2 =
38 B1的評估因子比重: W normalize 0.7894 0.6139 × wd2 WN 0.5625 0. 4375 0.1005 0.0781 0.1786 w1 w2 = 2 w1 w2 Alevel-3-B1 W = n W 1/1 9/7 7/9 1/1 0.7894 0.6139 W Alevel-3-B1 = 1/1 9/7 7/9 1/1 di-duration di-time di-duration di-time
39 步驟 12) 每個評估因子的比重值 (小數後兩位,四捨五入)
4.3.3 效能之數值化
由於我們的評估因素裡沒有抽象的因子,因此可以很具體的用數值來表示,唯一要注意 的是量化後的值,是否符合多維矩陣的意義。我們希望在每一行的元素裡,值越大的表 示相對應的選擇在這個評估因素底下表現較好,也就是我們希望它的數值與表現的好壞 成正比 (值越大的越好)。以 S1 為例,轉換出來的決策矩陣如圖 12。子時間段的長度是 越長越好,越長代表該劑量在子時間段內服用的時間彈性越大,子時間段的剩餘次數是 越多越好,代表劑量錯過這個子時間段後,還可以再服用的機會越高,群數是越少越好, 因為每一群代表一次的服藥,數量越少代表使用者須吃藥的次數越少,所以我們必須將 群數的值取倒數 N . G 。 另外,如果我們選擇的決策決定法為非線性方法,例如第二章所介紹的 WPM method, 則矩陣裡的每個元的值不能為零,否則它將導致該選擇的分數永遠為零,而看不到其他 評估因子對這個選擇的影響,這個情況的處理方法可以將該行的評估因素值加上一個特 定的常數值,來避免數值為零的情形。調整後的值如圖 13 所示,我們將有 0 值的行的 每一個元的值加常數值 1,然後將每一行的值除上該行的最大值。 wG wd1-duration wd1-time wd2-duration wd2-time = 0.50 0.14 0.18 0.10 0.0840 Alts. 群組個數 (w1) 時間段長 (d1j) (w2) 剩餘次數 (d1j) (w3) 時間段長 (d2j) (w4) 剩餘次數 (d2j) (w5) (d11, d21) 1 4 1 4 0 (d12, d21) 2 2 0 4 0 圖 12: 決策矩陣的效能數值 分群組合 群組個數 (w1) 時間段長 (d1j) (w2) 剩餘次數 (d1j) (w3) 時間段長 (d2j) (w4) 剩餘次數 (d2j) (w5) (d11, d21) 1/2 4/4 2/2 4/4 1/1 (d12, d21) 2/2 2/4 1/2 4/4 1/1 圖 13: 調整後的矩陣效能數值
4.3.4 選擇的評分
我們利用 2.3.3 節介紹修正後之層級分析法的方法,來為每種選擇評分,分數的高低代 表選擇的好壞。評分方式如下: A max w這裡的 A 指的是決策矩陣,aij是決策矩陣裡的每個相對應元的值。在 Revised AHP method
裡,它將原本矩陣裡每一行的數值,除上該行的最大值,消除不同維度下的量化單位的 影響。假設我們最後得到的決策矩陣如表格 10。 我們可以算出 Alternative 1 和 Alternative 2 的分數: A1, score = (1/2)×0.56 + (2/2)×0.12 + (2/2)×0.16 + (4/4)×0.09 + (1/1)×0.07= 0.72 A2, score = (2/2)×0.56 + (2/4)×0.12 + (1/2)×0.16 + (4/4)×0.09 + (1/1)×0.07= 0.86
41 分群組合 群組個數 (0.56) 時間段長 (d1j) (0.12) 剩餘次數 (d1j) (0.16) 時間段長 (d2j) (0.09) 剩餘次數 (d2j) (0.07) (d11, d21) 1/2 4/4 2/2 4/4 1/1 (d12, d21) 2/2 2/4 1/2 4/4 1/1 表格 10: 決策矩陣範例
4.4
實際案例 我們以一個實際的藥物案例,來測試分群後的結果,我們選擇兩種互相有衝突劑量的藥 物,以及三種不同服藥頻次的藥物來做分群實驗。這些藥物的相關參數如表格 11。 藥物名稱 Rosuvastatin Magnesium Oxide Spironolacto ne Amlodipine Propranolol 頻次 一天一次 一天三次 一天一次 一天兩次 一天三次 服藥週期 24 8 24 12 8 最小時間間隔 12 4 12 6 4 最大時間間隔 36 16 36 18 16 衝突藥物 Magnesium Oxide (2, 2) Rosuvastatin (2, 2) 無 無 無 服用劑量限制 無 無 無 無 有 重要性分類 一般藥物 一般藥物 一般藥物 重要藥物 一般藥物 表格 11: 實際藥物案例的相關參數42 下面是這五種藥的排程結果,以及每個劑量的可服用時間段,我們可以將所有劑量依照 時間重疊關係分成兩個群組。 R M S M1 A1 P1 M2 A2 M3 0 2 4 6 8 10 12 14 16 18 20 22 24 R1 S1 P2 P3 A P 圖 14: 實際藥物的彈性時程範例
43 利用我們設計的分群方法,可以找到最佳的分群組合,如下圖: R M S M11 A11 P11 M21 A21 M31 0 2 4 6 8 10 12 14 16 18 20 22 24 R11 S11 P21 P31 A P M12 S12 S13 S14 S15 A12 A13 P12 P22 A22 P32 圖 15: 實際藥物的最佳分群組合
44 當使用者限制單次服藥數量時,我們仍可從現有的所有分群選擇中,找到符合限制的最 佳選擇,下面是當劑量數量小於 4 時的最佳選擇。 R M S M11 A11 P11 M21 A21 M31 0 2 4 6 8 10 12 14 16 18 20 22 24 R11 S11 P21 P31 A P M12 S12 S13 S14 S15 A12 A13 P12 P22 A22 P32 圖 16: 實際藥物之滿足劑量數目限制的最佳組合
45 當使用者錯過第一群的劑量時,我們仍可找到下一個最佳的分群組合,方法是從現有的 分群組合中,忽略有 S11和 P11的組合,忽略每個組合內的 R11,即可找到修改後的最佳 組合,如下圖。 R M S M11 A11 P11 M21 A21 M31 0 2 4 6 8 10 12 14 16 18 20 22 24 R11 S11 P21 P31 A P M12 S12 S13 S14 S15 A12 A13 P12 P22 A22 P32 圖 17: 錯過群組藥物之修正組合
46
第 5 章 實作議題
5.1 實作原理
Wedjat 在.Net Framework 上開發,執行的作業平台環境為 Windows Mobile 6.0,並與手 機內建的 Calendar 應用程式結合。
從圖 18 可以清楚看到 Wedjat 的資料流,Wedjat 輸入的資料是使用者的處方籤和使用者 的喜好設定,用藥指示則是預先儲存在手機上的資料庫裡。Wedjat 的排程結果將透過 Calendar API 寫入手機的 Calendar 裡,當使用者按下服藥的確認鍵後,Wedjat 將輸出使 用者的用藥紀錄,並定期上傳至遠端個人健康紀錄系統。
47
5.2 操作方案
Wedjat 將時程裡的每一群組的劑量,視為一鬧鈴觸發事件,輸出至行事曆。預設在服藥 時間的前 15 分鐘提醒使用者。當使用者確認服藥,Wedjat 會儲存使用者的服藥時間與 內容。當使用者延遲吃藥時,鬧鈴會持續提醒,直到服藥的時程無效,或使用者關掉鬧 鈴為止。當使用者錯過群組的服藥時間,排程器會動態的修改時程,並且更新行事曆的 內容。如果使用者持續一段時間都沒有服藥,導致低於有效劑量時,Wedjat 會發出警示 訊息,建議使用者聯絡醫生或諮詢藥師。5.3 系統設計
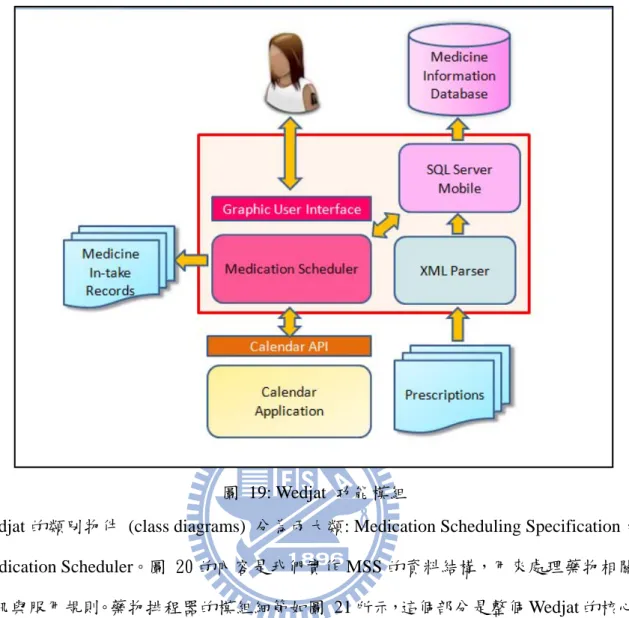
Wedjat 的功能模組如圖 19 所示。Wedjat 的核心是藥物排程器 (Medication Scheduler), 負責安排使用者的服藥時程,動態更新修改時程。Wedjat 前端的功能模組負責處理輸入 的資料,Wedjat 從遠端系統接收使用者的處方籤 (xml 檔案格式),然後經由 XML Parser 解析資料,再經由 SQL Server Mobile 將資料輸入至手機的資料庫,與資料庫內存的用 藥指示整合為 MSS,所以 SQL 裡存有排程所需的資訊 MSS 以及藥物相關的資訊、注意 事項等等。排程器排程時,會向 SQL Server Mobile 查詢藥物的 MSS 資訊。Wedjat 後端 的功能模組負責處理輸出的資料,排程器會將排程的結果,經由 Calendar API 寫入行事 曆,並監控使用者的服藥行為,做動態的反應。如果使用者按下服藥確認鍵,排程器會 輸出服藥紀錄。如果使用者錯過服藥,排程器會動態的修改時程,更新 Calendar 的內容, 或者對使用者發出相對應的警示訊息。
48
圖 19: Wedjat 功能模組
Wedjat 的類別物件 (class diagrams) 分為兩大類: Medication Scheduling Specification, Medication Scheduler。圖 20 的內容是我們實作 MSS 的資料結構,用來處理藥物相關的 資訊與服用規則。藥物排程器的模組細節如圖 21 所示,這個部分是整個 Wedjat 的核心, 負責運算所有藥物的時程。它為每種藥物產生一個 JobModel 和一個 ResourceModel 物件,這部分是實作 Resource Model 的概念,每一個 JobModel 物件裡會有每一種藥 目前要排程的工作 (job) 的資訊,也就是下一個需要被排程的劑量,deadline 的初始 值為 nsmin,之後的值為上一個工作的起始時間加上 asmax。 ResourceModel 物件 則是用來確保藥物的劑量間的時間間隔與衝突劑量間的時間間隔,它擁有兩個整數陣列 resource 和 processor,陣列裡的每一個元的初始值為 0,當某一工作被排程時,會占用 processor k 個時間單位,k 為該工作執行的時間,所以會從該工作的起始時間往後占用 k 的時間單位,這段時間的 processor 會被設為 1。當被排程的藥物有衝突藥物時,它會 占用衝突藥物的 resource,從該工作的起始時間往前占用 minFrInterferer,往後占用
49
minToInterferer,也就是將該時間段的 resource 設為 1。只有在 processor 和 resource 皆 為 0 時,工作才能被開始執行。MIS 是藥物排程器輸出的服藥時程,是一個 List 的資 料型態,每一個紀錄藥物的 ID,需服用的時間與劑量。
Medicine Priority 實作了第二章介紹的 5 種藥物優先順序的決定方式,EDF 只適用於 ODAT 演算法。
Class MSS{
int med_id; DosageParameters dp; List<InteractionParameters> ip; }
Class DosageParameters{ int T;
int nsmin, nsmax, asmin, asmax; inr dmin, dmax, Dmin, Dmax; int B, R, L, P;
}
Class InteractionParameters{
int med_id; int mintoInterferer; int minFrInterferer;
}
圖 20: 藥物排程規格書相關類別
Class MedicationScheduler{ int feasibleSchedule;
public bool OMAT(List<MSS> mss,
PrioritySchemes ps, ref List<MIS> mis); public bool ODAT(List<MSS> mss,
PrioritySchemes ps, ref List<MIS> mis); private void SetDoseSize(List<MSS> mss, ref List<MIS> mis);
private void SetProcessor(int latestStartTime, MSS mss, ref ResourceModel rm);
private void SetResource(int med_id, List<MIS> mis, List<MSS> mss, ref ResourceModel rm);
}
Class ResourceModel{
int[] resource = new int[T]; int[] processor = new int[T];
bool feasible = TRUE; List<int> schedule = NULL; int priority = 0;
}
Class JobModel{
int release_time = 0;
int execution_time = ns_min;
int deadline = release_time + execution_time; }
Class MIS{
int med_id; int time; int dose_size; }
Enum PrioritySchemes{RM, MVF, MIF, SSDF, EDF}; 圖 21: 藥物排程相關類別
50
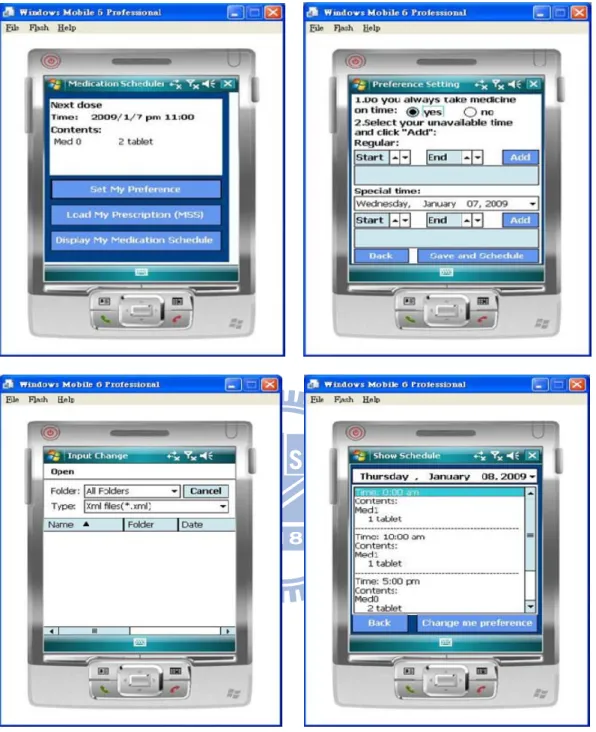
5.4 使用者操作介面
我們為 Wedjat 設計的使用者介面如圖 22 所示,第一頁有三個按鍵,讓使用者可以選擇 設定自己的喜好,裝載藥物處方籤檔案,顯示目前的排程結果。在 Preference Setting 的 頁面,使用者可以設定自己的服藥習慣,作息,以及某些不想被排程的特殊時段。使用 者設定完自己的喜好與裝載自己的處方籤後,可選擇啟動排程。排程後的結果會顯示在 Show Schedule 的頁面,同時也會寫入 Calendar Application 裡,使用者可以在這兩個地 方查詢自己的的服藥時程。51