國
立
交
通
大
學
運 輸 科 技 與 管 理 學 系 碩 士 班
碩 士 論 文
以基因演算法產生工件序列來最小化
自動導引車(AGV)之週期時間
Minimizing the AGV Cycle Time by the Job
Sequence Generated by a Generic Algorithm
研 究 生:游展宗
指導教授:黃寬丞 博士
以基因演算法產生工件序列來最小化
自動導引車(AGV)之週期時間
Minimizing the AGV Cycle Time by the Job Sequence
Generated by a Generic Algorithm
研 究 生:游展宗 Student:Zohn-Zong Yu
指導教授:黃寬丞 Advisor:Kuan-Cheng Huang
國立交通大學
運輸科技與管理學系
碩士論文
A ThesisSubmitted to Institute of Transportation Technology and Management College of Management
National Chiao Tung University In partial Fulfillment of the Requirements
for the Degree of Master
In
Transportation Technology and Management June 2008
Hsinchu, Taiwan, Republic of China
以基因演算法產生工件序列來最小化自動導引車
(AGV)之週期時間
研究生:游展宗 指導教授:黃寬丞 博士 國立交通大學 運輸科技與管理學系 碩士班摘要
自動導引車(Automated Guided Vehicle, AGV)是當今彈性製造系統(Flexible Manufacturing System, FMS)和自動化倉儲系統中很重要的作業設施。在生產的 流程中,有效加工時間佔的比例通常不大,相對花費在運送、等待的時間則佔 有相當大的比例,甚至某些研究結果指出工件搬運成本佔總加工成本可能高達 20%到 50%。
因此,本研究針對生產系統中常見的單迴圈(single loop) AGV 系統,在 AGV
車輛數為 1 台,加工機台為 2 台的條件下,以 ES (early start)為派遣法則
(dispatching policy),發展出一以最小化生產週期,也就是最大化其有效產出 (throughput),為目標的數學模式。實務上,最小工件集合(Minimal Job Set, MJS)
的數目均大於50,通常以最佳解(optimal solution)的精確求解方法(exact-solution
method)較不可行,因而本模式以基因演算法(Genetic Algorithm, GA)來產生工件 序列(job sequence),以處理問 MJS 數目在 100 以內的實際狀況。
演算法設計的主要目標,除了求解品質外,求解效率亦需兼顧在一設定時 間,以供決策者迅速做出必要的決定。此外,並將在運輸領域應用相當普遍(如 動態車輛調度、航機排班等問題)的時空網路(time-space network),與生產設施
的搬運問題相結合,發展出一混合整數規劃 (Mixed Integer Programming,
MIP),藉由 Lingo 8.0 以找出小型問題的最佳解及放鬆整數限制後的目標值下 限,來驗證所提出的基因演算法是否有效。數值測試的結果發現求解品質誤差
範圍均在1%內,而求解時間則在 1 分鐘內。在未來研究可以本研究為基礎,延
伸問題的規模,即處理更多AGV 及機台數量之問題。
Minimizing the AGV Cycle Time by the Job
Sequence Generated by a Generic Algorithm
Student:Zohn-Zong Yu Advisor:Dr. Kuan-Cheng Huang
Department of Transportation Technology and Management
National Chiao Tung University
Abstract
AGV (Automated Guided Vehicle) plays an important role for today’s manufacturing and warehousing systems. In a manufacturing process, the time actually spent on the machines is sometimes not very long; on the other hand, a significant portion of the whole process time is consumed for transporting and waiting. Therefore, this study considers a common single-loop AGV system and develops a mathematical model aiming to minimize the production cycle time (i.e., to maximize the production throughput), given the predetermined ES (Early Start) AGV dispatching policy.
Due to the complexity of the decisions, it is impossible to find the optimal solution for the problems with large size. Thus, this study designs a genetic algorithm to determine the sequence for the jobs in an MJS (Minimal Job Set) so as to reduce the AGV cycle time. This study also develops a mixed integer programming (MIP) model, which can find the optimal solution of small-size problems. In addition, its linear program (LP) relaxation is found to be a very tight lower bound. In order to verify the effectiveness of the developed solution algorithm, a series of test problems are designed for a system with two machines and one AGV.
Based on the result of the numerical experiment, it is found the solution generated by the heuristic algorithm is very close to the optimal solution, normally within 1% in terms of the objective function value. Besides, the solution quality is not sensitive to the problem size, and the computation time is acceptable for the realistic operation in the field.
誌謝
本論文得以順利完成,首先要感謝恩師黃寬丞老師,在老師細心指導、 鼓勵啟發之下,令我在論文研究過程中獲益良多。同時,感謝卓訓榮老師 及韓復華老師在論文提案及口試時,給予本論文諸多寶貴的意見與指導, 讓本論文更加完整。 感謝實驗室夥伴成員泰億、穎萱、宇彤、欣誼、格禎,在兩年的求學 過程,給予指導與幫忙,實驗室學弟妹們,兆哲、智翔、景堯、郁英、丞 博,給我許多的支持及鼓勵。感謝同學協政、盈君、永祥、珮瑜、岡翰、 槍胖、學弟禎翔,帶來精神上的歡樂氣氛,抒解緊張的壓力。感謝所有幫 助過我的人,我永遠不會忘記你們。 最後,我要將此論文獻給我的父母,謝謝你們這些年來不辭辛勞的付 出,所有榮耀都是屬於你們。 于風城交大 2008/6目錄
中文 摘要... iii 英文摘要...iv 誌謝...v 目錄...vi 圖目錄... viii 表目錄...ix 第一章 緒論...1 1.1 研究背景及動機...1 1.2 研究範圍與目的...1 1.3 研究流程...1 第二章 文獻探討...3 2.1 排程概述...3 2.1.1 排程的目的...4 2.1.2 排程問題之表示與分類...4 2.2 無人搬運車系統介紹...6 2.3 無人搬運車系統研究議題...7 2.3.1 設計議題...7 2.3.1.1 軌道設計問題...8 2.3.1.2 車輛數目問題... 11 2.3.2 作業議題... 11 2.4 單迴圈無人搬運車系統問題...12 2.4.1 AGV符號說明與作業流程 ...12 2.4.2 問題定義...15 2.5 基因演算法概述...17 2.5.1 基因演算法之源起...17 2.5.2 基因演算法之流程...17 2.5.3 基因演算法之特色...20 第三章 模式構建與基因演算法之執行流程...22 3.1 混合整數規劃模式...22 3.3 基因演算法之執行流程...24 第四章 數值測試與驗證結果...28 4.1 測試範例之數值資料...28 4.2 演算法之結果...29 4.3 參數之敏感度分析...324.3.1 突變率分析...33
4.3.2 母體大小分析...35
第五章 結論與建議...36
5.1 結論...36
圖目錄
圖 1- 1 研究流程圖 ...2 圖 2- 1 傳統式搬運系統示意圖 ...8 圖 2- 2 單迴圈搬運系統示意圖 ...9 圖 2- 3 區域式搬運系統示意圖 ...10 圖 2- 4 M台機台迴圈式AGV系統 ...14圖 2- 5 Gantt Chart for a Two Machine Loop Under the ES Policy...15
圖 2- 6 單點互換交配法 ...19
圖 2- 7 雙點互換交配法 ...19
圖 2- 8 均勻互換交配法 ...20
圖 3- 1 時空網路示意圖 ...22
圖 3- 2 演化流程圖 ...26
圖 4- 1 Size of MJS vs. Elapsed Time ...29
圖 4- 2 Size of MJS vs. Error...31
圖 4- 3 交配後的CT分佈圖 ...32
圖 4- 4 Mutation Rate vs. Error ...33
圖 4- 5 Size of MJS vs. Elapsed Time ...34
表目錄
表 2- 1 各搬運系統特色之比較 ...10 表 2- 2 各搬運系統優缺點之比較 ...10 表 4- 1 GA、IP與LP之求解時間表 ...29 表 4- 2 工件之加工時間 ...30 表 4- 3 GA、IP與LP之求解結果 ...30 表 4- 4 各種MJS大小的誤差值...32 表 4- 5 工件序列(Size of MJS=20)...30 表 4- 6 工件序列(Size of MJS=40)...30 表 4- 7 工件序列(Size of MJS=20)...31 表 4- 8 工件序列(Size of MJS=40)...31 表 4- 9 突變率對誤差值的影響 ...33 表 4- 10 突變率對求解時間的影響 ...34 表 4- 11 母體大小對誤差值及求解時間的影響 ...35第一章 緒論
1.1 研究背景及動機
在市場競爭愈形激烈的環境裡,企業皆致力於成本的降低、生產力的提高的方 法;而在諸多方法中,如何有效運用自動化生產設施便成為一門重要的課題。在 自動化生產系統上,是否能有效地把所需物料搬運至適當的地點存放或加工,對 於系統之績效有很大的影響。通常在生產的流程中,物料佔有效加工時間的比例甚小,相對花費在運送、等待的時間則佔有相當大的比例。所以Tompkin & White
(1984)曾清楚地指出,在製造成本中,工件搬運成本佔總加工成本的 20%到 50%。
而Han & McGinnis (1989)則指出工件完工所需的總時間,只有 5%花在製造上,其
它時間都浪費在工作的傳送或是存放於暫存區中。有鑒於此,如果能選擇一個適 當的工件搬運系統及適當的作業方式,將有助於降低在製品的存貨成本,並有效 率地提升企業的生產效率與整體競爭力。
然而搬運系統的成效良好與否,與軌道設計(flow-patch design)、車輛數(fleet size)多寡、車輛派送(vehicle dispatching)及工件排程(job scheduling)等問題有關,而 本研究利用基因演算法,快速尋找較佳的工件序列(job sequence),以最小化產品生 產週期(cycle time)。
1.2 研究範圍與目的
在生產系統中,物料的搬運本研究考量以無人搬運車(Automated Guild Vehicle, AGV)取代傳統的人力搬運,而由於在雙方向式軌道鋪設的模式會造成擁塞 (congestion)或碰撞(collision),而增加問題的複雜度;在此本研究內容僅針對單迴 圈單方向式軌道鋪設的模式;工件藉由AGV傳送至機台間加工,而所需的AGV數 量依迴圈內的總負載量來決定,在本研究中假設其為已知參數;車輛派送策略採 提早出發(early start)方式。 本研究的目的在以單迴圈式的無人搬運車系統中,以基因演算法,快速求解工 件序列;以使最小工件集合(Minimal Job Set, MJS)的生產週期最小或最大化其有效 產出(throughput)。
1.3 研究流程
本研究採用基因演算法做為求解方法,找出較佳的工件順序,其研究架構如 圖1-1 所示
圖 1- 1 研究流程圖 蒐集資料 界定研究範圍與主題 相關文獻回顧 模式構建 驗證模式與參數微調 結論與建議
第二章 文獻探討
本章在介紹一般排程研究的相關基礎概念及研究文獻,並逐漸探討本研究 中,導入AGV於生產系統之主題。第一節介紹排程問題的基本概念,第二節介紹 無人搬運車,第三節說明無人搬運車系統常見的研究議題,第四節描述單迴圈無 人搬運車系統,第五節介紹基因演算法。2.1 排程概述
排程問題的研究開始於本世紀初,從第一篇排程的學術論文發表於1950年代 初期,至今,排程問題在學術領域上的應用已相當廣泛和成熟。有關排程(scheduling) 的敘述與介紹整理如下: Grave在1981年曾定義排程為「在一段時間內,配置可用的資源來處理一群工 作,以達成所設定的目標」。1988年Steveson對排程所作的描述為「排程乃是某特 定作業的時間設定,而這所指特定作業乃包括設備及人力活動的使用」。Conway et al. (1967)指出當一群工件(jobs)之執行順序需要被決定時,就出現了所謂的排程問 題(scheduling problem),而排程的結果則是建議那一工件在那一資源上被執行。 Baker (1974)指出排程問題是決定所有工件,其每一個作業在機器上的開始時間及 加工的順序,所以排程問題實際上是包含資源限制與順序執行限制最佳化的問 題。Parunak (1991)指出一個排程決定了何時(when)及何地(where)做什麼事(what)。 Pinedo (1995)在其著作中亦提到排程是指在一段時間內,分配有限資源來處理一群 工件,以達到一個或多個的最佳目標。 吳 鴻 輝 和 李 榮 貴(1997) 指 出 , 在 製 造 環 境 裡 , 生 產 排 程 問 題 (production scheduling)是在探討工廠現場如何分配有限之資源(例如機器、作業員、搬運車等) 給一群工作(以工單方式呈現),以滿足組織之需求(如交期、製造時間或資源使用 率等)。每一工作必須依據其製程或途程之要求或規定來執行,這些要求包含一系 列有前後次序性之作業及每一作業所需要之特定機器及資源。這類排程問題屬於 現場之生產排程問題亦被稱為現場排程(shop scheduling)、短期排程(short-term scheduling)、廠區排程(shop floor scheduling)或日程計畫(daily scheduling)等。另外,在陳建良(1995)排程概述中,曾從六個特性探討排程問題,分別是領域、 評估標準、不定性、製程複雜性、易處理性和需求來源。因此指出:「由於排程 問題過於複雜,因此學術界乃著手研究簡單且定義明確的問題以求最佳解,而將 動態及隨機的排程環境視為進一步的推廣。」而其主要的目的是在面臨排程問題 時,有較明確的方向,來尋求排程問題的解答或相關資料。
2.1.1 排程的目的
當排程問題出現時,為了處理、解決問題,許多研究便開始產生。張保隆等 人(1997)描述排程乃是一種資源分配已完成特定作業的決策,其開始於產能的規劃 (包括設施與設備之規劃與選擇)及集體生產規劃的結果(包括設備的使用、人力之 需求、存貨與外包的利用),再經由集體生產規劃的分解已發展出生產的整個排程, 最後將整個生產排程依產能決策轉換成短期的人力、物料與機器設備的指派與分 配。亦指在符合時間的限制下,妥善運用所有資源,將訂單或生產計劃轉換成生 產活動的過程,以期使企業獲利最大。因此,主要目的不外乎有四個目的: 1. 使整個處理或製程的時間保持最短。 2. 使存貨的水準能夠保持低的水平。 3. 提高人員與機器的使用率。 4. 提昇顧客的服務水準以減少顧客等候時間。 基於此四個目的,因此一個好的排程必須要簡潔清楚、易於了解、易於實行 且具有彈性。2.1.2 排程問題之表示與分類
湯璟聖(2003)根據不同的生產型態,在現場排程上亦將面臨到不同的問題。因 此從三項分類來探討,第一是依工件到達及作業特性的分類;第二是依機器數目 及路徑型態的分類;第三是α/β/γ三分法來描述。本論文將針對此三項分類進行相 關的探討,分別敘述如下: 1. 依工件到達及作業特性分類 工件的到達可為同時或間斷,其相對應到的作業特性分別為固定且已知的工 件資料與推測的資料。加上該工件的到達若呈某一機率分配,皆影響著其作業特 性,因此分類如下(黃維曄, 1994;周書賢, 2001): (1)靜態(Static)模式: 在排程中,工件數目及作業內容均為固定且為已知。即所有工件須同時 到達且同時完成作業內容的排程,且所有的工作中心在那段時間都是可以加 工處理的。 (2)動態(Dynamic)模式: 動態排程問題即是加工時間內,不斷有新的工件加入,這些工件的處理 時間不是已知的就是已推測出來的,但大多的研究已經將焦點放在於後者。 (3)確定性(Deterministic)模式: 工件在各機台上之加工時間為固定。 (4)隨機性(Stochastic)模式:工件在各機台上之加工時間不固定,且可能依循某種機率分配。 2. 依機器數目及路徑型態分類 一般而言,以工單處理性質來瞭解機器數目與路徑型態之所需,也因此從製 程的機器數目及工單流經機器的路徑型態來分類: (1)單一機器(single-machine)排程: 只有一部機器,且每一工單皆由此機器處理完成。這是所有可能加工環 境中最簡單的一種,是所有多機加工環境的特例。 (2)平行機器(parallel-machine)排程: 平行機台的生產方式,已被廣泛的應用在各工業中,這是因為產業中的 產能不斷的增加更新,使新舊機器共存於一個生產系統中,尤其是在頩頸工 作站中,往往都是採用平行機器加工來提高產能並使生產線更加平衡;因此 若能發展一有效的演算法應用在完全相同平行機台上,而此演算法能在較短 的時間內求得高品質的近似解,則為所有學者努力研究的首要目標。 (3)流線型工廠(flow-shop)排程: 流線排程是一種多階段作業的加工環境,所有工單的加工順序皆相同; 若所有工單在任一部機器上的加工順序亦相同,則稱之為排列流線流程 (permutation flow shop);若某些工單可跳過某些作業,則稱為開放式流程(open flow shop),其類似零工型工廠排程問題,但相異點在於所有工單經過機器 之順序是不固定的。其特點在於排程必須同時考慮每一工單經過處理機器之 順序及每一機器上工單處理順序;若每一階段機器不只一部,則稱為彈性流 線流程(flexible flow shop)。
(4)零工型工廠(job-shop)排程:
零工式工廠排程亦是多階段作業的加工環境,每一工單有自己的加工順 序;若每階段有多部相同機器,則稱為Job Shop with Duplicate Machine。零工 式工廠排程問題是最複雜、最實際、最常被討論的問題。 3. α/β/γ三分法:在α/β/γ三分法中,α定義加工環境,而加工環境用來表示機器數 目、機器型態以及工單流經機器的情形;β定義加工特性與限制;γ定義為欲最小 化的目標函數,即是排程績效評估標準。 在本研究中,工件在機台的加工時間為固定,即屬於確定性模式;在事先給 定一工件序列後,藉由AGV搬運至機台加工,為一排列流線型工廠排程。排程的 目標即為AGV在生產系統中的週期時間。AGV在搬運的過程中,除了裝卸時間、 負載及未負載的旅行時間,尚可能需於機台前等待正在加工之工件完工的等待時 間。此外,AGV每次負載的數量為一單位的工件,即單載量AGVS(automatic guided vehicle system),由於工件乃是藉由AGVS搬運,因此,以下即針對AGVS作出一詳 細的介紹。
2.2 無人搬運車系統介紹
無人搬運車系統是針對彈性製造系統的物料搬運而發展出來的。所謂的無人 搬運車系統,簡稱AGVS。根據美國儲運協會無人搬運車(MHI)對無人搬運車所下 的定義為:是一種使用電磁式,光學式或其它的自動導引控制,此種車輛可按照指 揮中心所下的指示,自行導引或依原先規劃好的路線前進,停止或轉彎,定位或 裝卸貨物。也就是說,車輛將可由程式的控制,來作自動的路徑選擇與定位的自 動搬運車輛。 無人搬運車系統廣泛應用在小到中量的製造作業中,包括彈性製造系統、倉 儲系統等。AGV 由於能於指定位置自動裝卸物料,可大幅減低人工搬運所造成的 可能疏失,增加系統的可靠度;此外,其亦具有高度彈性,易與系統中其它設備 密切配合運用,進而增加系統的效率;諸多優點使其成為近年來自動化工廠普遍 採用的物料搬運設備。而AGV 具有以下幾點優點(吳兆祥, 1990): 1. 無人搬運車系統可將物流搬運系統電腦化,可以與生產管理連線,使得: (1) 物流搬運效率最佳化。 (2) 減少或消除過多的人力操作。 (3) 能夜間無人化作業,達到24小時全天工作的目地。 (4) 不需依賴熟練技工,物料搬運依然可達到一定水準。 (5) 去除人為疏失所導致的產品損失。 2. 對長距離輕、中量的工件而言,專用的傳統輸送設備投資太大,且極佔空間, 造成工作人員工作的不便,無人搬運車系統有可能以較低的資本來完成以上 的工作。 3. 產品若為少量多樣化生產,無人搬運車的行走路徑易於變更,監控系統也較為 彈性。 4. 一旦機具或作業站增加,無人搬運車較其他系統容易擴充,隨時調整至最佳 的物流搬運流程,有助於最佳採購,庫存控制和作業調度,並且在惡劣的工 作區,工作效率不但不減,仍能保持穩定。 5. 無人化作業,將更能確保工業安全。 6. 減少物品搬運時的損壞,以減少製造成本。配合生產排程,使排程的正確性 提高,並減少排程耗用的工時。 7. 減少管理上的困擾(工研院工業經濟研究中心, 1998):(1) 增加管理效率:可經由電腦做及時監管現場狀況,並記錄及統計各品種之 產量。 (2) 減少人員疏失所造成的損失: a.開推高機常撞壞牆角或設備。 b.人員送錯目的或送錯產品種類。 (3) 自動暫存區之狀態:自動記億暫存區中,各位置之存貨有無與品種之狀 態。 (4) 可人車共道:人車共道,相對地增加人員活動空間。 (5) 獲得更清爽的工作場所:無輸送機的阻隔及堆高機的廢氣味,使員工獲得 更清爽的工作環境。 (6) 提昇公司形象:搬運自動化將可確保物料供應的準確性,提昇公司自動化 生產形象,以獲得客戶信賴,爭取更多的業務機會。 另外Vis(2006)指出,考量系統應用的環境及特殊情況,一個AGV系統可 以有各種不同的主要目標,分別述敘如下: 1. 最大化系統的有效產出(throughput),即每一時間單位AGV所能處理的工作量。 2. 最小化所有工件的完工時間。 3. 3.最小化AGVs的旅行時間(travel time),包含未負載或負載的車(empty or loaded vehicles)。 4. 平衡AGVs的工作量(workload)。
5. 最小化移動的總成本(total cost of movement) 6. 最小化工件的延遲時間(tardiness)。
7. 最小化工件裝載的等待時間(waiting time of loads)。
2.3 無人搬運車系統研究議題
回顧 AGVS 的學術研究,主要可分為兩種研究議題,設計議題(design issue)
與作業議題(operational issue)。每一議題都有一些相對的決策,以因應不同的目的。
為了更有效地操作AGV 系統的運作,Ganesharajah et. al (1998)指出在設計 AGV 系
統時需同時考慮這些議題的相關性:
2.3.1 設計議題
一個好的搬運系統,主要目的是將產品或在製品能夠以最短的時間運送到正 確的位置。因此在設計搬運系統的首要目標,就是讓搬運車能夠在搬運時所行走 的距離最小化。一般常見的設計議題可分為兩類,分別為:軌道設計問題(flow-path design problem)與車輛數目問題(fleet size problem)。
2.3.1.1 軌道設計問題
此問題主要探討車輛在不同軌道佈置上運作時,所呈現的優缺點和特性。而 針對軌道設計問題以其軌道佈設的不同而有其對應的議題,在此探討常用的三種 軌道佈置,傳統網路式(conventional)、單迴圈(single loop)及區域式(tandem system) 軌道設計(Le-Anh & De Koster , 2006)。
1. 傳統網路式搬運系統 傳統網路式(conventional)搬運系統是由系統中的工作站間有搬運需求的路徑 相連而成的網路,此網路可能包含交叉點及捷徑,搬運車行進的方向可以是單向 或是雙向的, Maxwell & Muckstade (1982)所提出的一種傳統式搬運系統如圖 2.1,在區塊佈置(block layout)之下搬運路徑設置為單向行進的網路(network);其範 圍能夠涵蓋所有區塊工作區的邊緣。以混整數規劃能夠求解此類的問題,將搬運 路徑分段,及決定行進方向,其目標式為最小化搬運車搬運總距離,若以此種模 型應用至實際問題時,規劃模型會變的很龐大,因此Goetz & Egbelu (1990)只考慮 兩個主要部門間的搬運,Sinriech & Tanchoco (1991)只考慮路徑交會處,並使用分 支界限法求解,以簡化問題求解模型。而此種搬運系統下,雙向行進的模型常不 容易控制,便以單向雙軌的設置方式取而代之,而如此一來便需要花費更多的空 間及成本。 圖 2- 1 傳統式搬運系統示意圖 資料來源:(張婷珺, 2006) 2. 單迴圈搬運系統 路徑設計的問題必須克服在軌道交會處車輛碰撞的情形,而單向的單迴圈 (single loop)之設計便可以避免此情形發生,在此設計型態中,搬運車只能沿迴圈 單向移動,且沒有捷徑或替代路徑,如圖2.2 所示。Tanchoco & Sinriech (1992)為 針對最佳化單迴圈設計之研究,先找出能夠最小化車輛搬運時間的路徑迴圈,且 必須經過所有工作站,再決定各工作站之裝卸點, Sinriech(1990)利用0-1 整數規
劃求解之,但因求解過程複雜,Tanchoco & Sinriech (1992)提出一個三階段的解法 求解此類型問題,而Sinriech & Tanchoco (1993)則使用啟發式解法找出正確的單迴 圈,並修改上述三階段解法的第三階段。
圖 2- 2 單迴圈搬運系統示意圖 資料來源:(張婷珺, 2006)
亦有研究探討單迴圈的其他設計型態,Chen et al.(1999)以混整數規劃模型 來設計雙軌單迴圈(single loop dual rail, SLDR)之搬運系統,系統為兩個平行軌 道組成之單一迴圈,其模型中之目標函數能夠將搬運車錯誤率納入考量,文中與 單軌單迴圈(Single-loop single-rail, SLSR)及單軌網路(single-rail network, SRN) 兩種軌道設計作比較,發現單軌單迴圈型態在設計上最為簡易,但缺乏搬運彈性, 且一旦出現錯誤,整個系統便全面停擺。而單軌網路式型態雖能提供搬運的替代 路徑以避免整個系統停擺之情形,但控制機制過於繁雜;雙軌單迴圈系統則兼具 設計簡單、控制容易且能透過轉盤裝置增加搬運的彈性的優點,是相較之下較佳 的設計型態。Asef-Vaziri et al.(2000)提出一個Tanchoco and Sinriech(1992)的 替代數學規劃方式,其只需較少的二元變數(binary variable),且能考慮較大的 可行解空間,能夠同時求解單向單迴圈設計及裝卸點位置的問題。 3. 區域式設計系統 除單迴圈以外,另一種簡化系統控制的路徑設計為區域式設計(tandem configuration design),在已決定設施佈置及各裝卸點之下,將搬運系統分為多個獨 立的區域,且每個區域搬運路徑自成一個迴圈,由一部搬運車負責運送,若要進 行 跨 區 域 的 搬 運 時 , 則 需 透 過 轉 運 站 如 圖2.5 所示,此設計型態為Bozer & Sirinivasan (1989)提出的,同時也提出一個衡量產出績效之分析模型;而這兩位作 者也在1992年提出一個區域式系統的啟發式集合分割(set partitioning)法,目標在使 系統中的搬運車工作負荷能夠平均分佈,並與傳統的設計型態作一比較,而結果 顯示出當系統所需的搬運車越多時,區域式設計是較佳的方案Bozer & Sirinivasan (1992)。
Choi et al. (1994)建立模擬模型來比較單迴圈與區域式設計,結果單迴圈設計 有較短的搬運時間與閒置時間,而區域式設計則能完成較多的搬運;而在Bischak &
Stevens ( 1995)的研究中指出,區域式系統會有較高的期望搬運時間,因其在跨區 域搬運時需要額外耗費轉運的時間。
圖 2- 3 區域式搬運系統示意圖 資料來源:(張婷珺, 2006)
對於上述提到的三種路徑設計系統,張婷珺(2006)引用Le-Anh & De Koster (2006)所整理各種系統的特色於表2-1中,以及於表2-2比較各種設計系統之優缺點。 表 2- 1 各搬運系統特色之比較 特點 傳統式 單迴圈 區域式 互相獨立的區域數量 只有一個能連 通整個系統的 區域 只有一個能連通 整個系統的區域 分成數個區域, 以轉運緩衝區來 連通各個區域 每區的搬運車數量 多台 多台 一台 以雙向行進 困難 困難 易達成 交通控制 困難 困難 簡易 搬運車排程或派工 複雜 簡單 簡單 壅塞的機率 高 低 不會發生壅塞 轉運空間的需求 不需要 不需要 需要 資料來源:(張婷珺, 2006) 表 2- 2 各搬運系統優缺點之比較 路徑設計系統 優點 缺點 傳統式 搬運上較有彈性 有替代的搬運路徑可供選擇 搬運路徑較短 對系統出錯不敏感 控制上較複雜 容易發生壅塞的情形 擴充(expansion)困難 單迴圈 控制簡易 相較於傳統式,減低了壅 搬運上較無彈性 對系統出錯較敏感
塞、阻塞的問題 有可能發生阻塞的情形 需要較高的搬運產能 搬運距離長 擴充不易 區域式 不會發生壅塞或阻塞的情形 易於控制 擴充容易 雙向行進使搬運更有效率 需要額外的轉運緩衝區 每區限制只有一台搬運車 對系統出錯敏感 轉運時需耗費額外的時間 資料來源:(張婷珺, 2006)
2.3.1.2 車輛數目問題
此問題的研究是為了滿足生產需求所需要的車輛數目,它是在軌道設計已決 定的條件下,所需考量的問題。車輛數目問題可在總車輛旅行時間已知的條件下 求得;而總車輛旅行時間包括負載、裝卸時間及未負載的旅行時間。對於車輛數 目問題的求解,可利用分析性模式(analytical model) 及模擬(simulation)方法求之。Maxwell & Kucktadat (1982)指出利用作業研究中運輸問題之數學模式,以空車 運行時間最短為目標,以求得車輛需求數目最小的模式,並指出搬運車數目會受 到軌道佈置、車輛速度、裝卸時間及車輛阻塞時間等因素影響。Lin(1990)根據 Maxwell & Kucktadat (1982)所提出的運輸問題模式提出另一個解題演算法,將之轉 化成以最小化成流量問題。
Newton(1985)以連續模式(continuous model)運行模擬並計算所需的車輛數 目。作者使用兩種不同的派車法則來進行模擬;第一種派車法則,是以無人搬運 車尋找距離最短的工作站進行搬運(vehicle looks for work,VLFW),另一種派車 法則,是以無人搬運車根據工作站呼叫的順序進行搬運(first in work,FIW),綜 合此兩種派車法則的模式,可求出無人搬運車平均作業時間的上、下界的值,進 而計算出所需車輛數目。Rajotia et al. (1998)提出一種在彈性製造系統環境下,決 定最佳系統無人搬運車數量的方法。利用混合整數規劃,目標為最小化未負載旅 行時間,來求算無人搬運車需求數量;考慮的因素包括無人搬運車負載旅行時 間、未負載旅行時間、等待時間及塞車時間。最後以模擬的方式來驗證所求出的 車輛數目的正確性。
2.3.2 作業議題
在 決 定 軌 道 佈 設 的 種 類 及 得 知 所 需 使 用 的AGV 數 量 之 後 , 作 業 問 題 (operational issue)隨之衍生而來;由於本研究的研究對象為單迴圈之AGVS,因此 僅針對單迴圈AGVS的作業議題,探討相關的文獻。緩衝是用來儲存WIP(work in process),它是影響排程優劣的因素之一,Kise et al. (1991)指出,AGVS中以1台AGV,服務2台機台,且機台中無任何緩衝,生產n
個工件,以O(n3)的演算法可找出最佳的工件序列以最小化其完工時間。Agnetis et al.
(1996 )以相同的生產條件但機台(包含輸入站及輸出站)具有轉換裝置(swapping devices),此裝置可使AGV在卸下待加工之工件後,可承載已加工完成的工件。在 其研究中,決策上要求將相同的工件併裝在一起,稱之為Lot;此時Lot中的工件數 量可稱為Lot size。其研究發現當Lot size大於某一critical value時,此類排程的問題 可於多項式時間內求解之。Hall et al., (2001)以單一迴圈的軌道佈設中,考量 AGV1~4台,機台2~10台,探討常用派車策略有三種:分別為Early start、Latest start 及No wait,其在數值測試中,派車策略採No wait,針對MJS大小為n,n<=100時, 以一GA求解工件序列來最小化工件的週期時間與拉氏鬆弛法所求得的解之間,誤 差約在5%左右。 對於機台為具有一無限容量或無任何容量的緩衝裝置,可以演算法在合理時 間內求解之;然而,若機台為具有一有限容量的緩衝裝置,則其為一NP-complete 問題(Papadimitriou, 1980)。綜合上述,本研究的將研究問題定義為:在單一迴圈的 流線型工廠,機台數量2台,且機台具有一容量限製的緩衝裝置(輸入緩衝及輸出緩 衝)。而以AGV服務生產系統的數量假設為1台,且其派車的方式為early start。在 假設的加工條件下,本研究欲藉由基因演算法,以最小化工件完工時間為目標, 進而找出較佳(最佳)的工件序列及對應的週期時間。
2.4 單迴圈無人搬運車系統問題
本論文研究主題在軌道佈設方面,係以於單方向單迴圈為研究標的,本節將 介紹單迴圈軌道佈設中的相關設施規劃及作業流程,並以數學模式來定義單迴圈 無人搬運車系統問題。2.4.1 AGV 符號說明與作業流程
軌道佈設為單迴圈的AGVS,如圖 2-5,其作業流程及模式建構,本研究引用 (Hall et al., 2001)所使用符號及相關參數,其說明如下: 1.與軌道佈設相關之符號: I :輸入站(工件由此進入系統)。 O :輸出站(工件由此離開系統)。 2.與機台相關之符號: m :AGVS 內的機台數量。 M1,…,Mm:迴圈式AGVS 內的機台配置編號。 3.與分區(zone)相關之符號: 分區是指將軌道分成數個單位區段,在每個單位區段中,僅能容納一台AGV,此單位區段即為分區。 l1:第1 台機台與輸入站間的分區數。 li:第i 台機台與第 i-1 台機台間的分區數。 lm+1:第m 台機台與輸出站間的分區數。 lm+2:輸出站與輸入站間的分區數。 l:迴圈中,所有分區數量總和,
∑
+ = = 2 1 m i i l l 。 4.與 AGV 相關之符號: v:系統中的 AGV 數量 5.與工件相關之參數: P1,…,Pk :工件的種類。 r1,…,rk :最小工件集合中,各工件比例。 n:最小工件集合中,所有工作數的總合,n = r1+· · ·+rk。 σ(j):在工件序列 σ 中排序為第 j 個的工件。 6.與時間相關之符號: pi,q:工件i 在機台 Mq的加工時間。 (如以m=2 為例,則可加以簡化為 ai:工件i 在機台 M1的加工時間,bi:工件i 在機台M2的加工時間。) δ:AGV 通過任一分區的旅行時間。 ε:裝載或卸載工件所需的時間。 x:AGV 從I 裝載工件,運送至 M1,卸下工件至M1加工所花的時間。 y:AGV 從M1裝載工件,運送至M2,卸下工件至M2加工所花的時間。 z:AGV 從M2裝載工件,運送至O,卸下工件至 O 所花的時間。 γ:AGV 在系統中的總活動時間,γ= lδ+2(m + 1)ε。圖 2- 4 M 台機台迴圈式 AGV 系統 資料來源:(Hall et al., 2001) 不同工件序列,將造成AGV 在機台前的等待時間長短不一,本研究目的即在 尋找一最佳的工件序列,以使AGV 週期時間最小化,即最大化有效產出。決策變 數描述如下: σ :代表一個工件序列。 σ(j):工件序列σ 中的第 j 個工件。 Tσ(i)σ(i+1):在I 揀起工件序列σ 中的第 i 工件與第 i+1 個工件的間隔時間。 Tσ :在第σ 工件序列中,生產最小工件集合的週期時間。 Tσ= Tσ(1)σ(2)+Tσ(2)σ(3)+· · ·+Tσ(n)σ(1)。 Wqi :AGV 在機台Mq等待卸載工件i 的時間。
而在AGVS 中,有關 AGV 之作業流程描述如下:在穩態狀況(steady state),
假如工件(i-q)正在 Mq中加工(q=1,…,m,i>=m+1)。不考慮可能的等待時間, AGV 包含以下的活動(括號內為處理時間): 1. 揀起工件Ji在輸入站I(ε)。 2. 移動至M1(l1*δ),裝載工件 Ji於M1(ε)。 3. 卸載完成的工件J(i-1) 於M1(ε)。 4. 移動至M2(l2*δ)。
5. 裝載工件J(i-1)於M2(ε),卸載完成的工件J(i-2)於M2(ε) 。
6. 直到 AGV 卸載完成的工件J(i-m)於Mm(ε),
7. 移動至輸出站(l(m+1)*δ),卸載完成的工件 J(i-m)於輸出站O(ε),
8. 回到輸入站I(l(m+2)*δ)重新揀起另一個新的工件。
AGV 可以在系統內持續的運作,當它到達輸入站 I 時,立即給予一個工件而
沒有任何的停等時間,此種AGV 派送方式,即為本研究採用的 early start rule;而
在機台前時,由於每一機台皆具有一輸入緩衝(input buffer)及輸出緩衝(output buffer),緩衝的容量皆為單一工件,因而產生機台可能未完成加工作業而存在等待 時間。
2.4.2 問題定義
有關在本研究中的主要假設,考慮採用單迴圈AGVS,AGV數量已事先得知, AGV派送策略採ES(early start),若以2台機台為例,其甘特圖如圖2-6。圖 2- 5 Gantt Chart for a Two Machine Loop Under the ES Policy 資料來源:(Hall et al., 2001)
以α/β/γ 排程分類來定義上述之問題,則可表示為:AGV1,lp2|k≧2,es| Ct,
其中各符號表示意義如下: α:加工環境的條件
AGV1, lp2:以 1 台 AGV 服務的 AGVS,其軌道佈設為單迴圈,機台數量 2 台。
β:加工特性與限制的條件。
k=1:所有工件皆相同,即加工時間相等。 k=2:工件可能有不同的類型。
es:an Early Start policy in used for AGV dispatching。 γ:排程目標最小化。
Ct =C :在穩態條件下,生產最小工件集合時的最佳週期時間。 t*
AGV 在作業過程中,不管工作序列的決策為何,AGV 在系統中的總活動時間 為γ,其中含裝、卸工件及承載工件、未承載工件的旅行時間之總和,其為一定值, 即γ = lδ+6ε。MJS 的生產週期最小化即為排程的目標函數,可根據(Hall et al., 2001) 的數學關係式(如下)及其演算法計算此生產週期:
{
}
∑
= − + − = n i i i i σ a w b T 1 () 1 2 ) 1 ( , , max σ σ γ (1) 其中, max{
0, σ max{
σ 1, σ(),γ}
}
2 ) 1 ( ) ( 2 i i i i i b a w b w = − + − − (2) ) 1 ( ) 1 ( σ σ a a n+ = (3) n w w0 2 2 = (4) 證明: 1 1 ( 2) ( 3) 6 1 2 1 2 i i i i i i Tσ + σ + =lδ + ε+w+ +w = +γ w+ +w (5) 其中, 1i 1 max 0,{
( 1)- - 6 - 2i-1}
i w+ aσ lδ ε w + = (6){
1}
2 max 0, ( ) 6 1 i i i w = bσ − −lδ ε−w+ (7){
σ −γ}
={
σ −γ − σ −γ}
= + − + + + ) ( 1 2 ) 1 ( ) ( 1 1 1 1 2 max , max0, , i i i i i i i w w b a w b w (8){
γ}
γ max σ 1, σ(), 2 ) 1 ( 1 1 2 i i i i i w a w b w + + = + − − + (9) (1)為完成n個工件所需的生產週期。(2) AGV在M2等待卸載工件i的時間,公式 中產生了遞迴,即需得知前一工件在M2的等待時間,才可得知下一工件在M2的等 待時間。(3)為工件在M1 的加工時間,經過一週期後,第一個工件與第n+1個工件 的加工時間仍相同。(4)為AGV於M2欲卸下工件n+j時的等待時間,與第j個工件的等待時間相同。(5)表示AGV於I揀起Jδ(i+2)及Jδ(i+3)的間隔時間,其R.H.S為γ及AGV
分別在M1、M2等待卸載工件i及i+1的時間加總;AGV於M1、M2的等待時間分別為
(6)、(7),(6)+(7)即為(8),在式子(8)等號兩邊各加γ,即可得到(9),亦等於(5),將 所有工件的間隔時間加總,即可得到(1)。
2.5 基因演算法概述
2.5.1 基因演算法之源起
在達爾文(Charles Darwing)的進化論中提到『適者生存,不適者淘汰』(Survive of the first)的進化理論,解釋了自然界的基本現象,物種在不斷變遷或惡劣的環境 中為了生存及適應環境,而不斷進化,產生生存力及適應力更強的下一代。 生物在繁殖的過程中染色體(Chromosome)會進行交配及突變來改變基因的組 成,使得子代和親代及子代之間產生差異性。生物就是利用這種繁殖的機制,造 成無數的變異發生,使得每一個個體有著不同的特性,而在自然環境的考驗及彼 此之間的競爭下,將不適生存者淘汰,而生存者繼續藉由繁殖不僅將優良的基因 延續,還有可能使下一代擁有更好的基因。如此,一代比一代進步。這種自然界 奇妙力量的展現,顯示了它的無限可能與無窮潛力。 基因演算法(Genetic Algorithms,簡稱GA,有人稱之遺傳演算法或者基因遺傳 演算法)可以追溯到1950年代,生物學者和電腦學家合作,嘗試在電腦上模擬出基 因的運作。緊接著在1960年代初期,密西根大學的約翰.賀藍(John Holland)和他 的同事們將電腦化的遺傳學-染色體、基因、配對基因、適配函數等-應用到其 到許多領域。 1967年,一位賀藍的學生貝格力(J.D. Bagley)在其畢業論文中首度創用了「基 因演算法」這個名詞,來描述這種最適化的技術。然而,許多學者質疑,因為基 因演算法相當倚賴隨機選擇,而這些選擇是任意且不可預測的。開啟遺傳演算法 大門的賀藍博士(Dr. John Holland),於1975年在密西根大學發表了闡述自然與人工 系統的適應問題著作(Holland, 1975),該書總結了賀藍博士二十年來對於學習、演 化與創造的研究心得,此文奠定了遺傳演算法的發展基礎與思考架構。2.5.2 基因演算法之流程
在基因演算法中我們稱每一個體稱為染色體,每一染色體的基因的值是由亂 數產生,而每一世代的染色體所成的集合稱做群體(Population)。在每一世代中的 每一個染色體互相競爭,較適合生存環境的有較高的適存值(Fitness value),而有 較高的適存值的染色體可以複製出較多的子代,然後從其中選擇配對來交配 (Crossover)產生下一代,以期可以產生適存度更高的下一代。再者,為了避免錯過 某些有用的資訊,乃加入突變(Mutation)的處裡,以產生出有用的資訊,不過一般 而言,突變率(Mutation Rate)通常是很低的。 如此一代一代的演化下去,將產生適存值較高的染色體,而該染色體即是我 們需要的解。基因演算法的限制為在搜尋解答時不保證找到真正的最佳解,而是 找出近似解,但此近似最佳解是經過廣大解答空間演化到某種程度的可能最適解。對於若干無法預知最佳解的狀況下,基因演算法可以快速求得某種程度之滿 意解。因此適合非線性等多變數複雜問題之求解。
基因演算法的基本運算為選擇、交配和突變等機制,而這些機制之操作狀態 通常是根據隨機值而改變的,因此即使在環境參數完全固定不變下,每一次運算 求解所得之答案可能並不相同。演化流程中,相關的機制或參數茲說明如下: 1. 染色體編碼與解碼(encoding and decoding):在基因演算法中需將問題及結果 表
示成可以運算的形式,即染色體編碼與解碼。例如將設計變數以" 0110.... "之 二進制字串表示,例如9 的十進制值為" 9 ",二進制值為" 1001 "。 2. 適應值(fitness):每個生物對於大自然環境都有不同的適應性,適者生存不適者 淘汰。適應函數就如同大自然環境,用來衡量每個染色體對於該問題所對應的分 數,此分數稱為適應值(fitness)。演化的過程,即在尋找最大或最小的適應值。 3. 適應值函數(fitness function):產生適應值的函數,適應值函數是染色體的演化 環境。將染色體解碼後,代入適應函數即可求得其適應值,再依照適應值大小, 來評估染色體所代表解答的好壞。適應函數即代表最佳化問題的目標函數。 4. 選擇(selection):基因演算法的選擇機制是模擬自然界適者生存的現象,適應值 越高的染色體,存活機率較高,反之則存活機率較低。適應值較高的染色體所擁 有的後代可能較多,如果某個染色體的適應值明顯高於其他染色體,就有機會藉 由世代交替,逐漸成為此母體內的主體。常見的選擇方式有:輪盤法(roulette wheel selection)、競爭法(tournament selection)。 (1) 輪盤法:母體中每個染色體的適應值在輪盤上都有相對應的面積,相對面積越 大者被選中的機會越高。此方法只能直接尋找較大值,且適應值不得小於零。 若要搜尋最小值,則必須以一個常數減去原來的適應值作為新的適應值。其優 點是容易使用,而且能區分出適應值之間的差異,缺點是當母體中有一個染色 體的表現特別突出時,尤其是演化初期,則在最佳解尚未出現時可能就會支配 全部母體,落入局部最佳解的問題。輪盤法選擇的程序如下: a. 首先計算出母體中每個染色體的適應函數值fi。 b. 分別計算出母體中每個染色體的機率,即Pi = fi/
∑
fi 。 c. 再計算出母體中每個染色體的累積機率,CP 。 i d. 隨機選取一介於0~1的數值Ri,當Ri-CP >0時,即還取該條染色體。 i e. 重覆以上步驟,直到所選取的個數與初始母體的個體數相同。 (2) 競爭法:採用競爭式選擇法(Tournament Selection),適應函數值愈高的個體愈容易被選中,其程序如下: a. 首先計算出母體中每個染色體的適應函數值fi。 b. 將fi降羃排序,依序取fi作為下一個母體,選取的個數與初始母體的個體數 相同。 5. 交配(crossover):交配的過程是隨機的選擇交配槽中的兩個母代個體,彼此交 換位元資訊進而產生兩個新的個體,藉由累積前代的優秀位元資訊,以期望能繁 殖出更優秀的個體。但是並非所有被選中的母代個體都要進行交配,而是由預先 設定的交配機率(probability of crossover)來決定交配是否進行。最基本的交配法是 單點式交配法(single-point crossover),其程序為先在交配槽中隨選取兩個個體作為 母代,然後在字串的N 個基因中隨機的選取一點做為交換點(crossover point)將位 於交換點右側的母代基因交換,產生兩個新的個體,如此即完成單點交配。除此 之外,也介紹兩點式交配法及均勻式交配法(連立川等人,2006)。 (1)單點交配(One-Point Crossover):隨機挑選一個交配點,將交配點之後的 基因進行互換,如圖2-7,其中「|」為交換點)。 圖 2- 6 單點互換交配法 (2)兩點交配(Two-Point Crossover):每對染色體中隨機挑選兩個交配點,並 於兩個交配點之間進行基因互換,如圖2-8,其中「|」為交換點)。 圖 2- 7 雙點互換交配法 (3)均勻交配(Uniform Crossover):兩個子個體各位元的來源取決於一隨機亂 數的旗標值狀態,若旗標值為1,則子個體一繼承父、子個體二繼承母, 若旗標值為0 則子個體一繼承母、子個體二繼承父,可參考圖5。採用 超過一個切點,其考量是避免在單點交配時,切點之前的基因總是與之 父個體 111|1111 母個體 000|0000 子個體1 111|0000 子個體2 000|1111 父個體 1|1111|1 母個體 0|0000|0 子個體1 1|0000|1 子個體2 0|1111|0
後的基因分開的現象。一般研究認為,採用兩點交配即可獲得良好的效果。因為 交配機制只是產生新答案,更多的切點並不保證答案變得更好,必須搭配選擇機 制,才能讓較好的個體保留下來,如圖2-9。 圖 2- 8 均勻互換交配法 6.突變:為模仿生物基因的隨機突變而來。例如突變率0.1%,則表示基因總數中有 0.1%的基因要進行突變。基因總數為母體大小、染色體個數。例如,0.1 %代表1000 個基因中才反轉一個基因,由0變1或由1變0突變的機率一般而言很小。突變運算 可以幫助GA 脫離局部最佳解(local optimal)。以隨機方式抽取染色體中的若干編碼 進行改變(由0變1或由1變0),便可產生突變(mutation)。 7. 結束規則:為了讓GA 演化順利進行,需預先設定結束規則,使GA 依該條件 終止演化循環。文獻上常見的停止規則有四種: (1) 當染色體適應值已滿足預先設定的目標值。 (2) 當達到預先設定之最大代數,例如200 代。 (3) 母體內各染色體的同質性已達到預先設定的水準。例如,母體內最好和最差的 染色體,其適應值的差異已達到預定的範圍。 (4) 達到最大的失敗次數,即無法進一步找到更佳解的演化代數,例如100 個世代 不再進步則停止。 江吉雄(2001)指出,演化的過程為一個迴圈,因此必須設定停止執行的判斷, 用以表示演化結束。停止的時機通常可以參考兩個項目,一個是時間成本,一個 是收斂程度。時間成本直接受演化代數影響,若希望演算在可預期的時間內結束, 可以將演化代數設為固定值。收斂程度則較為彈性,當某一代的母體,其染色體 的適應值趨近一致的時候,則停止演化。兩者並沒有絕對的好壞,可根據需要而 選用,亦可同時採用,即演化進行到某個代數之前,停止條件參考的是收斂程度, 而最多進行到該代數為止,使得演化能在可預期的時間中結束。
2.5.3 基因演算法之
特色 整體來看,基因遺傳法的搜尋方式有點類似隨機搜尋,但卻不完全是隨機搜 尋,因為基因遺傳法有其自成系統的基因運算元,以及適者生存的再生法則,茲 列出其不同於一般演算法的特色如下(黃少廷,1998): 1. 直接使用以字元組成的字串(string)搜尋,亦即是以可行解的編碼字串來進行 父個體 1111111 母個體 0000000 旗標狀態 0110100 子個體1 0110100 子個體2 1001011搜尋,而非可行解本身。 2. 以一個母體多點來進行搜尋,而非以單獨一點。 3. 直接由目標函數的資訊進行搜尋,而不用輔知識。 4. 以適合度的觀念來決定搜尋點的優劣。 5. 進行搜尋的過程並非經由固定的路徑,而是經由計算出的機率配合隨機性的 產生。 6. 使用一些隨機的操作,這些操作包含選取、交換以及突變,然而這些操作並 非僅是盲目的動作,而是在隨機進行的過程中包含了他們所要傳達的資訊。
第三章 模式構建與基因演算法之執行流程
由於本研究核心問題在以基因演算法來決定一工件序列,以最小化工件的週
期時間。在此本研究先提出一混合整數規劃模式(Mixed integer programming,
MIP),可用於求解小型問題的最佳解,並以其整數限制的放鬆來產生一下限值, 之後以基因演算法求解問題的近似解,就有求解品質與效率的比較基礎。MIP 所 使用的解題工具-Lingo 8.0,而 GA 程式的撰寫則是使用 Matlab 7.0。本章的架構 為3.1 節介紹模式構建,3.2 為基因演算法的流程。
3.1 混合整數規劃模式
式(1)到式(4)的問題,事實上也可以運輸領域中常見的時空網路(time-space network)來表示,本研究已經初步先發展出一混合整數規劃模型。延續前述兩台機 台M1、M2為例子,AGV 從輸入站 I 開始負載工件,再運送至各個加工機台(M1、 M2)加工,最後送至輸出站 O 所對應的時間。如圖 3-1。橫軸代表時間,縱軸代表 空間,即機台(含 I、O)的位置,相關符號意義,說明如下: 圖 3- 1 時空網路示意圖 qis:代表工件序列中,第i 個工件為工件種類 s 之二元變數(binary variable)。 (i=1,…,n,s=1,…,k)Ui:AGV 裝載著 i+2 工件從 I 出發,之後 AGV 又回到 I 所需的時間,也就
是相鄰兩工件在I 出發的時間,i=1,…,n。 M2 M1 I O z y W2i x Time Ui W1i+1 Location
W1i+1:AGV 在 M1等待工件i 完工的時間。 W2i:AGV 在 M2等待工件i 完工的時間。 x:AGV 從 I 裝載工件,運送至 M1,卸下工件至M1加工所花的時間。 y:AGV 從 M1裝載工件,運送至M2,卸下工件至M2加工所花的時間。 z:AGV 從 M2裝載工件,運送至O,卸下工件至 O 所花的時間。 Objection function: i i Min
∑
U (10) Subject to: s 1 s i q =∑
∀i=1 L, ,n (11) s i s i q =r∑
∀s =1 L, ,k (12) 1 1 2 i i i U =W + +W + γ ∀i =1 L, ,n (13) 1 1 1 1 2 i s s i i s W + a q γ W − + ≥∑
− − ∀i=1 L, ,n (14) 1 2 1 i s s i i i W ≥∑
b q − −γ W + ∀i =1 L, ,n (15) s i q ∈binary ∀i=1 L, ,n and ∀s=1 L, ,k (16) 1 0 i W ≥ ∀i=1 L, ,n (17) 2 0 i W ≥ ∀i =1 L, ,n (18) 目標式(10)表示為:將所有工件完工時間最小化,即為本研究所構建的模式之 主要目的。(11)規範在工件序列中,第 i 個工件須為 k 種工件中的其中任一種,以 qis二元變數代表之。(12)相同的工件種類數加總即為 MJS 中的工件比例。(13)則表示完工時間為工件AGV 在機台 1 等待工件 i+1 完工的時間加上 AGV 在機台 2
等待工件 i 完工的時間及一固定常數值。而(14)及(15)分別代表 AGV 在 M1及 M2
的等待時間。(16)~(18)則就決策變數加以規範。
Wittrock(1985)指出在實務上,MJS 大小 n 大多大於 50 個工件以上,而本研究
所探討的問題大小則為 n≦100。上述混合整數規劃模式究竟可以在合理時間內處
3.3 基因演算法之執行流程
本研究利用基因演算法來求迅速搜尋理想的工件序列,以有效提升求解過程 中的效率。在此,一個基因(gene) 代表一個工件,一條染色體代表一工件序列, 也對應到一個搜尋空間的解,和其目標值-AGV 週期時間。茲將演算法的流程分 別說明如下,其流程圖如圖3-3: 一、染色體的編碼(encoding):本研究採用Bean (1994)所提出 Random keys 代表各工作生產順序的指標,以下
的舉例將過程說明如下:假設有有三種工件,即A、B、C,每日生產目標為 100、 200、200,則最小工件集合 MJS={A, B, B, C, C}。而 rA:rB:rC=1:2:2,而工件 數n=rA+rB+rC,即為5 個工件。隨機產生 5 個介於 0~1 的數值,如 (0.46, 0.91, 0.33, 0.75, 0.51),此即所謂 random keys,其代表一染色體。將染色體中的所有基因做升 羃排序後,即為(0.33, 0.46, 0.51, 0.75, 0.91),依序對應其之原始所在位置做為其所 代表的工件序列,如0.33 原始所在位置為 3,0.46 原始所在位置為 1,0.51 原始所 在位置為5,0.75 原始所在位置為 4,0.75 原始所在位置為 2,則此一染色體所代 表的工件序列為31542。 (0.46, 0.91, 0.33, 0.75, 0.51)≡3→1→5→4→2 二、設定初始母體(initial population): 在進行基因演算法運算之前,必須先隨機地產生 s 條染色體,在本研究中即為 s 個工件序列,這 s 條染色體稱為初始母體。而後,在每代運算過程中,在選擇(如 後述)步驟時,亦選出s 條染色體做為下一代的母體。 三、交配(crossover): 交配運算是提供進化的主要運算,交配率則是設定交配發生的機率。本研究 先選取母體中所有不同兩條染色體的組合,之後就所選取的每對染色體組合都進 行交配,即交配率100%,並產生兩個子代染色體。交配後所產生的母體染色體個 數增為(sC2*2+s)。在交配過程執行中,若產生相同的工件序列,則另予以刪除之, 以增加程式的運算效率。就選取兩個不同的染色體而言,則其子代(offspring)可經 由Bean (1994)所提出的方法來得之,交配規劃利用以下之範例來描述: (1) 所選取之兩條染色體: Parents1:(0.46, 0.91, 0.33, 0.75, 0.51)≡3→1→5→4→2 Parents2:(0.84, 0.32, 0.64, 0.14, 0.48)≡4→2→5→3→1 (2)單點交配(single-point crossover):
隨機挑選一個交配點,將交配點之後的基因進行互換。設假交配點為第二個 基因之後,則交配後新的染色體如下: Children1:(0.84, 0.32, 0.33, 0.75, 0.51)≡2→3→5→4→1 Children2:(0.46, 0.91, 0.64, 0.14, 0.48)≡4→1→5→3→2 四、突變(mutation): 雖然突變帶可能帶來的優良基因,但是也可能造成部分優良基因無法繼續延 續,因此通常突變率不會設定太高。本研究中,突變率假設以P%來代表之,而突 變執行的方式係針對上述完成交配後的染色體來執行,以下例的描述加以說明: (1)隨機選取一基因的截斷點,假設為第二個基因。 (0.84, 0.32, 0.33, 0.75, 0.51) ≡2→3→5→4→1 (2)將截斷點之後的基因,重新隨機產生一新的random keys,如(0.95, 0.23, 0.60), 則突變後的染色體如下: (0.84, 0.32, 0.95, 0.23, 0.60)≡4→2→5→1→3 執行完突變步驟之後,母體染色體的數目會增加,但因為有隨機性,確切的 數目不會固定,但其期望值為(sC2*2+s)*(1+P%)。 五、解碼(decoding): 將產生的順序,參考原始之MJS:{A, B, B, C, C},將順序轉換為所對應的工 件序列,如以下之範例。 順序 4 2 5 1 3 工件序列 C B C A B 六、求解其適應函數值(fitness value): 隨著問題的不同所得的目標函數亦有所不同,目標函數可以用來評估母體中 染色體的優劣,但當目標函數是愈小愈佳時,通常利用適應度函數來修正使其為 極大化,修正方式是將目標函數取倒數。f (x) = 1/ x, f (x)是適應度函數(fitness
function), x是目標函數值(objective function value)。本研究利用式(1)求得每一工件 序列的CT,而其適應函數值:fitness value=1/CT。 七、選擇(selection): 一般而言,選擇的方式有輪盤法與競爭法,經過二者績效(求解品質)的比較之 後,本研究採用競爭法,即將由母體中的染色體做降羃排序後,選取前s個染色體 做為下一代母代。 八、停止規則(termination criteria):
本研究以當搜尋到指定的代數作為停止條件,而在此指定代數經過多次測試 後,設為一固定值。 圖 3- 2 演化流程圖 在執行上述基因演算法的過程中,需對相關的參數加以調整與控制。然而, 參數控制與調校的方式並無絕對的好或壞,因此截至目前為止並沒有一套完善的 選擇過程 (Selection process) 設定初始母體
(Set initial population) 交配過程 (Crossover process) 染色體編碼 (Encoding) 是否達到搜尋終止條件 (Termination criteria) No Output 適應函數 (Fitness function) Yes 突變過程 (Mutation process) 母體取代 (Next population) 染色體解碼 (Decoding)
機制,可以確保能讓我們找到最適的參數設定值。必需依靠付出許多實驗訓練的 代價來找尋理想的參數(Srinivas, 1994)。 事實上截至目前為止,並沒有一套完整的理論,可以用來證明遺傳演算法一 定可以找到整體之最佳解,但許多實證研究及應用,驗證了遺傳演算法的搜尋效 能。因此遺傳演算法仍廣泛的被應用於在無法預知最佳解的狀況,或搜尋空間極 大、搜尋成本極高的狀況下,以系統化的方法在合理的時間內求得滿意解。
第四章 數值測試與驗證結果
為 了 驗 證 本 研 究 利 用 基 因 演 算 法 所 求 得 的 工 件 序 列 是 否 適 當 , 藉 由 Lingo8.0 執行 MIP 作為 GA 求解效能優劣之比較,同時也對重要的 GA 參數結果, 進行比較其敏感度分析。在4.1 節中,介紹數值測試的資料,包含問題的設定。4.2 節中,提供部分基因演算法所求得的解及其品質的比較,4.3 則是進行演算法所求 得的解的敏感度分析。4.1 測試範例之數值資料
本研究所研究的議題,以排程的表示方法為:AGV1,lp2|k≧2,es| Ct,即AGV1
台,加工機台 2 台。假設工件種類為 20 種,另外,工件數(n)設假介於 20~100, 即各工件種類分別有 1~5 個。工件在各機台的加工時間為已知條件,加工時間分 別為a1,…,a20,b1,…,b20,可藉由均勻分佈的方式隨機來產生20 種工件在 2 機台之加工時間,數值分別介於30(min)~300(min)。另外,就每個問題規模隨機產 生20 測試問題,而每個測試問題則以 GA 求解 10 次(simulation runs)。 而在本研究的所使用的基因演算法,其相關參數亦需設定,其假設方式說明 如下: 1. 母體大小(population size): 母體大小即指染色體數目,每一條染色體就代表一組可行解,母體染色體數 目即代表在可行解區域內所搜尋的解數。母體設的愈大,每一代執行所需的時間 就越長,計算成本就越高,但是平行搜尋的廣度也較高,因此較不易落入局部最 佳解。反之,若母體設的較小,則每一代訓練所需的時間也較短,但其訓練的品 質可能也會因為搜尋廣大較低,而較易落入局部最佳解,可能使求解品質變得較 差。所以必需依欲解決問題的特性和複雜度,選擇一個適當的母體大小,才可以 使得基因演算法能夠兼顧「效率」和「效用」,在此,本研究以經驗的法則,參 考工作之數目n,將初始母體大小定為 n/4。 2. 交配率(crossover rate): 交配運算是提供進化的主要運算,交配率則是設定交配發生的機率,如果交 配率設的越高交配可以發生的較頻繁,代表其可以獲得較好的求解品質。在此, 交配率設定為100%,選取的每對染色體均進行交配。 3. 突變率(mutation rate): 由於一般突變率發生機會極小,因此本研究設假為3%。
4.2 演算法之結果
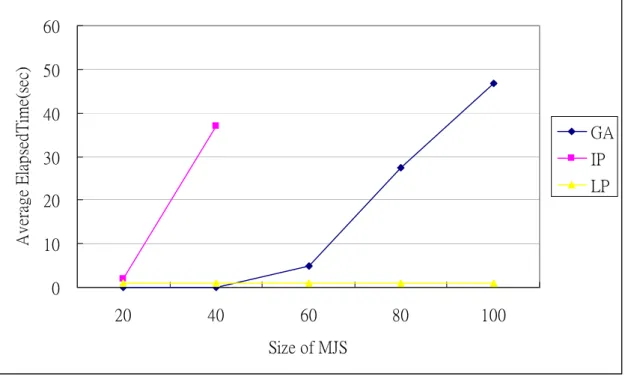
1.求解時間:若以(10)~(18)之 MIP,可求得最佳之工件序列,但問題規模變大, 則無法在合理時間內求得。透過刪除二元整數變數的限制(16),此即為一實數線性 規劃(linear LP),可藉由 Lingo8.0 迅速求得 LP 之解,此為混合整數規劃的下限(lower bound, LB)。當 n≦40 時,以 Lingo8.0 執行 MIP 模式、LP 及 GA,其求解時間均
在2 分鐘之內;而當 n>40 時,MIP 的求解時間在 24 小時內,無法求出結果,但
LP 仍可迅速求得結果,而 GA 則在 2 分鐘內。如下圖 4-1 及表 4-1,其中 GA 表示
以Generic Algorithm 求解的時間,而 IP 表示以 Mix Integer program 求解的時間,
LP 表示實數線性規劃求解的時間。 0 10 20 30 40 50 60 20 40 60 80 100 Size of MJS A ver ag e E lap sed T im e( sec) GA IP LP
圖 4- 1 Size of MJS vs. Elapsed Time 表 4- 1 GA、IP 與 LP 之求解時間表 Size of MJS Method 20 40 60 80 100 Algorithm 0.0 0.0 5.0 27.3 46.7 IP 2.0 37.0 * * * LP 1.0 1.0 1.0 1.0 1.0 註1:求解時間單位為秒 註2:*表示求解時間超過 24hr
2.求解品質:當 n≦40 時,可以 MIP 求解之;求解過程中亦發現其解與 LP 目標值
相等;而n=60~100,IP 無法在合理時間求解之,則以 LP 之目標式值為其為下限
(LB),以表 4-2 為 20 組加工時間中的其中一組為例,表 4-3 為以此組加工時間以 GA、IP 及 LP 等方法之求解結果。工件在機台 1 及機台 2 之加工時間(process time,
PT)分別表示為 P1,j、P2,j。 表 4- 2 工件之加工時間 表 4- 3 GA、IP 與 LP 之求解結果 Size of MJS Method 20 40 60 80 100 GA 3652 7337 10981 14637 18279 IP 3639 7278 # # # LP 3639 7278 10917 14556 18195 註2:#表示無法在合理的時間內求解
以Lingo 8.0 所求解 MIP 模式中,Size of MJS=20(obj=3639)及 40(obj=7278)兩
種問題規模大小時,其所得到的工件序列分別如表4-4 及表 4-5 所示: 表 4- 4 工件序列(Size of MJS=20) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 工 件 序 列 n c d e l t m h o i a j k b f g p q r s 表 4- 5 工件序列(Size of MJS=40) 1 2 3 4 5 6 7 8 9 10 P1,j 158 228 285 219 223 59 92 146 106 260 P2,j 287 32 158 152 295 152 233 102 186 222 11 12 13 14 15 16 17 18 19 20 P1,j 82 267 155 159 202 241 229 67 174 287 P2,j 57 78 199 293 96 200 145 93 243 183 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 g a b c k d d f e t t k m h h i i e l n 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 工 件 序 列 a c j j f p b r g n p o q q m r s s l o Job type PT Job type PT
而以GA 所求 Size of MJS=20 及 40 兩種問題規模大小時,以 GA 其所得到的 工件序列分別為分別如表4-6 及表 4-7 所示: 表 4- 6 工件序列(Size of MJS=20) 表 4- 7 工件序列(Size of MJS=40) 有關誤差百分比,則就各測試問題即分別計算出此10 次中最小值及平均值, 再計算20 個測試問題之平均值,發現各個問題規模的平均誤差百分比在各種 MJS 大小下,均落在1%之內(誤差百分比 Error=100*(GA-LB)/LB),如圖 4-2 及表 4-4。 0.0% 0.2% 0.4% 0.6% 0.8% 1.0% 20 40 60 80 100 Size of MJS A ve ra g e Erro r( % ) min/10 runs avg/10 runs 圖 4- 2 Size of MJS vs. Error 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 工 件 序 列 b o l m h g r p c q k f s t n d a j i e 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 o e d s f s b n r J k g m q a q j n g t 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 工 件 序 列 o i f i h b r h p c d a m p l t e k c l
表 4- 8 各種 MJS 大小的誤差值 Size of MJS 20 40 60 80 100 Average Error(min) 0.17% 0.38% 0.36% 0.62% 0.55% Average Error(avg) 0.53% 0.57% 0.68% 0.90% 0.92% 此外,為呈現GA 的求解效能,以一 Size of MJS=100 的一組測試例題,將其 中一個simulation run 的過程做詳細的記錄。在 GA 執行演化的過程中,若將其母 體中的染色體之 CT 均加以紀錄之後,發現其從隨機產生的染色體到交配完成其 間,染色體的適應值分佈逐漸收斂一定值,即代表由隨機產生的染色體,透過演 算法的執行流程後,可求得出近似解。當初始母體大小為 25 時,此 25 條染色體 中誤差最小值為8.83%,最大值為 15.17%。在經過數個世代交配後,誤差值從第 1 代為3.58%、第 5 代為 1.21%至第 10 代的 0.92%。圖 4-3 表示為以 GA 求解上述測 試例題時,各代中染色體之CT 分佈圖。
0
100
200
300
400
500
600
700
18300
18700
19100
19500
19900
20300
Cycle time
出現 次數G=1
G=5
G=10
圖 4- 3 交配後的 CT 分佈圖4.3 參數之敏感度分析
針對GA 所使用的參數,本研究透過一系列的數值測試,以分析參數對求解 品質與求解效率的影響,然後設定相關參數的大小;在此分別探討突變率及母體大小兩種參數,對其進行敏感度分析。
4.3.1 突變率分析
1.求解品質方面: 透過突變率的改變,可以發現其對誤差值的影響;以MJS 大小 n 為 40,100 為例,當突變率到達3%時,誤差值似乎已收斂至定值,如圖 4-3 及表 4-4。 0.0% 0.2% 0.4% 0.6% 0.8% 1% 3% 5% Mutation RateA
vera
ge
E
rro
r(%
)
MJS(40) MJS(100)圖 4- 4 Mutation Rate vs. Error 表 4- 9 突變率對誤差值的影響 Mutation rate Size of MJS 1% 3% 5% 40 0.24% 0.23% 0.22% 100 0.55% 0.45% 0.45% 2.求解時間方面: 在比較求解效率方面,分析各種不同的突變率,在執行基因演算法所需花費 的時間,其結果發現影響不大,如圖4-4 及表 4-5。
45 46 49 0 10 20 30 40 50 1% 3% 5% Mutation Rate Ela p se d Tim e( se c) MJS(20) MJS(40) MJS(60) MJS(80) MJS(100)
圖 4- 5 Size of MJS vs. Elapsed Time 表 4- 10 突變率對求解時間的影響 Size of MJS 20 40 60 80 100 1% 0.02 1 4 25 45 3% 0.02 1 5 27 46 5% 0.09 1 6 30 49 註1:求解時間單位為秒
4.3.2 母體大小分析
綜合以上分析,本研究以MJS 大小為 n=100、突變率設定為 3%為例,再分別 比較母體大小為 10、18、25、32、40,分析執行所需花費的時間及誤差大小;結 果可發現當母體大小愈大時,其求解時間愈長,但求解品質則呈現愈佳的情況, 因此將母體大小設定為 25 時,即 n/4 時,既可可在合理的時間(一分鐘內)求得出 較佳的解,其求解品質亦在可接受的範圍內,如圖4-5 及表 4-6。 0 10 20 30 40 50 10 18 25 32 40 Population size A ver age E laps ed T im e( sec ) 0.0% 0.2% 0.4% 0.6% 0.8% 1.0% 1.2% 1.4% A v er ag e E rro r(% )Average Elapsed Time(sec) Average Error(%)
圖 4- 6 Population Size vs. Elapsed Time & Error 表 4- 11 母體大小對誤差值及求解時間的影響
Population size 10 18 25 32 40 Error 1.21% 0.79% 0.45% 0.24% 0.11% Elapsed time(sec) 2 8 14 23 44