國
立
交
通
大
學
土木工程學系
碩
士
論
文
模糊評價方法應用於國家基礎建設投資改善項目
選擇之決策支援系統
Decision support system for prioritizing national infrastructure
investment based on fuzzy evaluation method
研 究 生:張曉德
指導教授:曾仁杰 博士
王世旭 博士
模糊評價方法應用於國家基礎建設投資改善項目選擇之
決策支援系統
Decision support system for prioritizing national infrastructure
investment based on fuzzy evaluation method
研 究 生:張曉德
Student:Hsiao-Te Chang
指導教授:曾仁杰
Advisor:Ren-Jye Dzeng
指導教授:王世旭
Advisor:Shyh-Shiuh Wang
國 立 交 通 大 學
土木工程學系
碩士論文
Submitted to Department of Civil Engineering College of Engineering
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
In
Civil Engineering July 2013
Hsinchu, Taiwan, Republic of China
i
模糊評價方法應用於國家基礎建設投資改善項目選擇之決策支援系統
研究生:張曉德 指導教授:曾仁杰 博士 王世旭 博士 國立交通大學土木工程學系 摘要 過去研究已證實模糊評價方法可用於評估國家基礎建設發展狀態。透過模糊評價方 法,政策決策者可更準確判斷各項指標之領先及落後程度,並運用判別矩陣瞭解各項指 標之相對狀態,以研擬國家基礎建設可能需提升之重點項目。惟模糊評價方法之計算過 程較為繁複,且模式使用涉及群集化分析、模糊理論等分析技術,可能造成一般政策決 策或審議人員使用上之困難,影響模糊評價方法之實用性。本研究根據模糊評價方法之 計算程序,以 Visual Basic 程式語言為開發工具,並結合 SPSS、MATLAB 及 Microsoft Excel 等統計軟體,建置具有自動匯入統計資料、自動運算、建立模糊評價判別矩陣、 建立學習地圖及建立國家基礎競爭力相對程度雷達圖之決策支援系統,提供政府單位及 研究人員使用。研究結果顯示,本系統未限制指標之數量、分佈狀態及類型,因此在分 析 IMD 國際調查報告上,運用本系統進行分析,可大幅縮短運算時間及提升計算結果 之準確性。 關鍵詞:國際調查報告、國家基礎建設、模糊評價方法、決策支援系統ii
Decision support system for prioritizing national infrastructure investment
based on fuzzy evaluation method
Student:Hsiao-Te Chang Advisor:Ren-Jye Dzeng Advisor:Shyh-Shiuh Wang Department of Civil Engineering
National Chiao Tung University
Abstract
Reseaches have indicated that fuzzy evaluation method can be used to
evaluate the developing state of the National Infrastructure. The policymakers
can define the leading and behind levels correctly through fuzzy evalution,
understand the relative state of the various indications by using the
discrimination matrix, and to study the important items of National
Infrastructure which may be promoted. However, the fuzzy evaluation method is
difficult to use for policymakers because there are some complicated
calculations such as cluster analysis and fuzzy functions. Based on the fuzzy
evaluation method, the present model calculates the data, creates the
discrimination matrix, creates the learning map and the competitive radar graph
automatically by creating a support system using Visual Basic programming,
and combining the SPSS, MATLAB and Microsoft Excel. Based on the
proposed model, the automated analysis can reduce the calculation by a wide
range, and improve the decision quality that may be useful to the policymakers.
iii
致謝
兩年的時間一下子就過了,在這段時間內經歷了許多事情,回想起來感觸頗深!首 先要先感謝我的指導老師 曾仁杰教授,第一次與老師見面是在交通大學入學口試的時 候,口試委員們的表情嚴肅,讓我在口試的時候感到非常緊張,唯獨老師還是帶著笑容 來參與這場口試,且與老師交談之中較無壓迫感,而得以舒緩緊張情緒,也非常謝謝老 師願意收我當學生,讓我得以順利進入研究生生涯的第一步。在老師這兩年細心與耐心 的指導下,學生在研究的邏輯思考以及解決問題技巧上的能力提升了不少,獲益匪淺, 在此誠摯向老師致謝。 同時,在曾老師的介紹下,讓我有這機會可以認識我的另一位指導老師 王世旭教 授,在研究論文中,由於程度上的落差以及規劃進度的落後,我時常感到非常大的壓力, 多虧王老師不厭其煩細心與耐心的指導,讓我能夠繼續堅持下去,王老師除了指導學生 論文外,也在人生價值觀上提供了不少建議,讓我得以從各方面作思考,並以樂觀的態 度來舒緩壓力,在未來的人生道路上,一定會謹記老師的教導,在此也誠摯感謝老師。 此外還要感謝口試委員潘南飛教授,在百忙之中抽空審閱學生論文,並提供許多寶 貴建議,使本論文更加完整。 另外還要謝謝趙得榮教授,謝謝趙老師抽空指點、並提供許多解決方法供學生參考, 才使學生獲得更多方向來完成論文,學生在此向趙老師說聲感謝。 而南山人壽周榮輝處長的指點以及介紹蘇百裕先生給我認識,對於一位未曾謀面的 晚輩,蘇前輩卻盡力指導,並提供晚輩許多程式方面的資訊,使得晚輩得以在論文上順 利進展,在此向您兩位致誠摯的謝意。 程式方面還要謝謝李嘉晃教授,感謝您介紹兩位資工所的阿杵學長以及維桓學長給 我認識,由於他們的幫助,讓我解決程式上的許多疑難雜症,真的非常謝謝李老師及兩 位學長的幫忙。還要謝謝丁君廷同學,抽空指點我程式方面的問題,且在資訊上讓我學 到不少知識,謝謝你。 當然還要感謝奕中、政凱、翊涵、筱涵等學長姊時常關心學弟並給予許多寶貴的建 議,以及同屆的暉凱、小郁、阿倉等許多好友也都時常互相打氣及鼓勵,也謝謝學弟妹 們的陪伴。 最後要感謝我的家人,感謝父母及小妹無時無刻的關心、並給予最大的支持,謝謝 爺爺奶奶包容曉德很少回去與你們聊天,謝謝叔叔嬸嬸的關心與照顧,感謝你們一直支 持與鼓勵我,謝謝。iv
目錄
摘要……….……….……….……….………….……….…………..…i Abstract...………...ii 致謝...………....iii 目錄………....iv 圖目錄………....v 表目錄 ... ix 第一章 緒論 ... 1 1.1 研究背景 ... 1 1.2 研究目的 ... 3 1.3 研究範圍及限制 ... 4 1.4 研究流程 ... 5 1.5 研究架構 ... 7 第二章 文獻回顧 ... 8 2.1 國家競爭力 ... 8 2.2 國家競爭力相關研究 ... 9 2.3 基礎建設與經濟發展 ... 12 2.4 相關國際調查報告 ... 13 2.4.1 IMD 國家競爭力年報 ... 14 2.4.2 IMD 國家競爭力年報評估對象與計算方式 ... 16 2.5 IMD 排名方式之缺點與 Wang 之模糊評價方法 ... 20 第三章選擇國家重要基礎建設項目之決策支援系統 ... 21 3.1 Wang 之模糊評價方法 ... 21 3.2 Wang 之模糊評價方法操作流程 ... 33 3.2.1 Wang 之模糊評價方法操作流程介紹 ... 33 3.2.2 Wang 之模糊評價方法操作流程缺點 ... 37 3.3 系統規劃 ... 42 3.4 系統實作 ... 48 3.4.1 系統規劃之實作 ... 48 3.4.2 系統自動化模組 ... 50 3.4.3 模糊程度轉換之改善 ... 53 3.4.4 系統自動化軟體應用 ... 56 3.4.5 補充說明 ... 58 第四章 系統案例使用示範 ... 60 4.1 系統使用操作案例 ... 60 4.2 系統操作案例分析結果與討論 ... 86 4.2.1 相對判別矩陣 ... 86v 4.2.2 國家基礎競爭力相對程度雷達圖 ... 89 4.2.3 學習地圖分析 ... 91 4.2.4 小結 ... 95 第五章 系統評估 ... 97 5.1 系統改善後之彈性評估 ... 97 5.2 系統改善後之準確性評估 ... 98 5.3 系統改善後之效率評估 ... 99 5.4 小結 ... 105 第六章 結論與建議 ... 107 6.1 結論 ... 107 6.2 建議 ... 108 參考文獻 ... 109 附錄一 系統讀取之 Excel 畫面 ... 111 附錄二 相對次數統計表 ... 115 附錄三 前 10 項劣勢程度指標之資料 ... 116 附錄四 TAIWAN 與 CANADA、SWEDEN、KOREA 之相對雷達圖 ... 118 附錄五 程式碼 ... 130
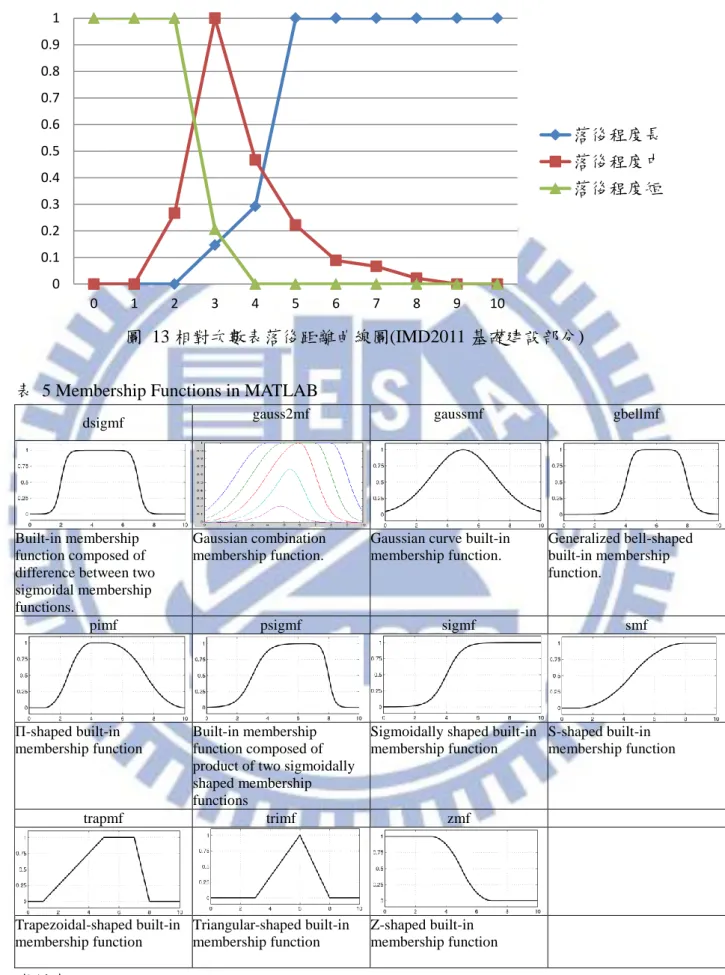
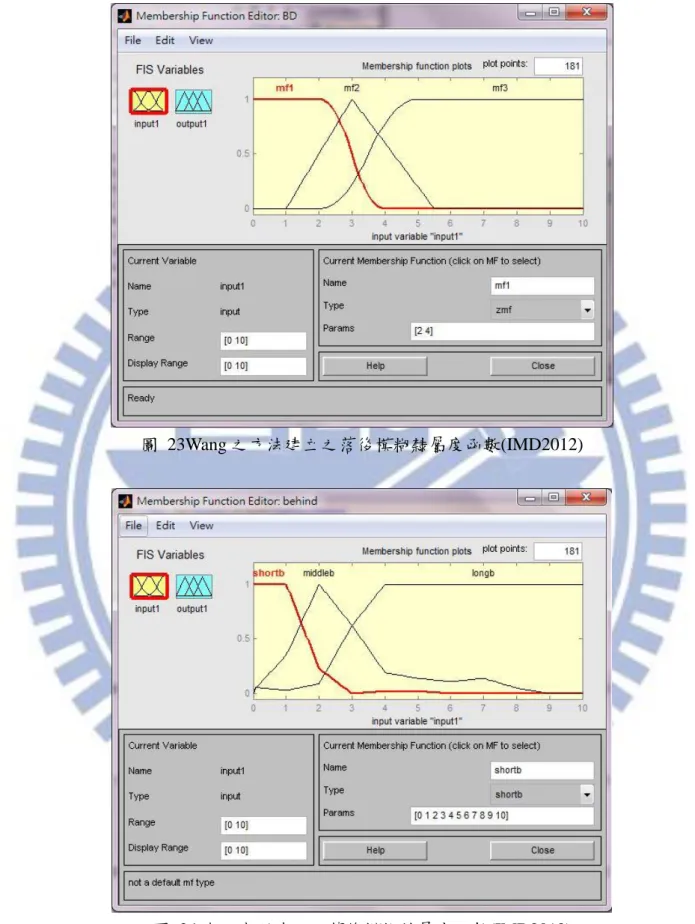
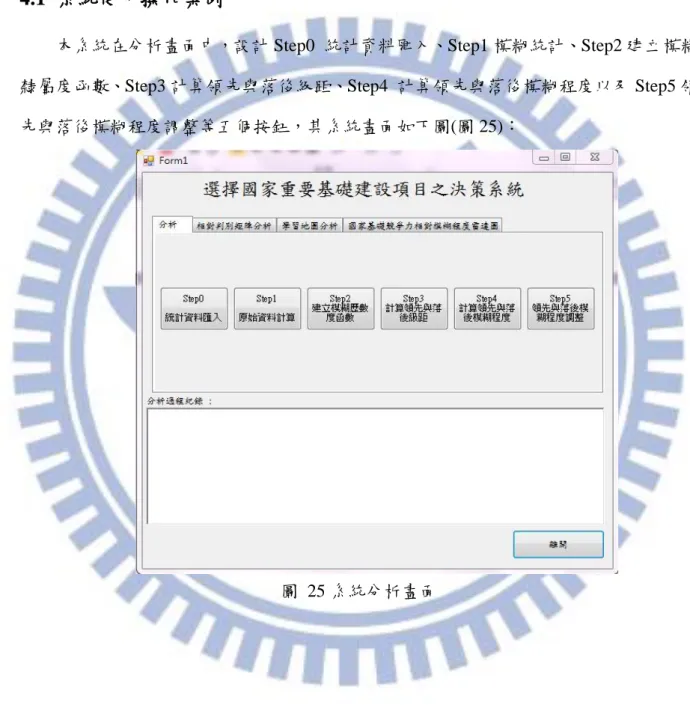
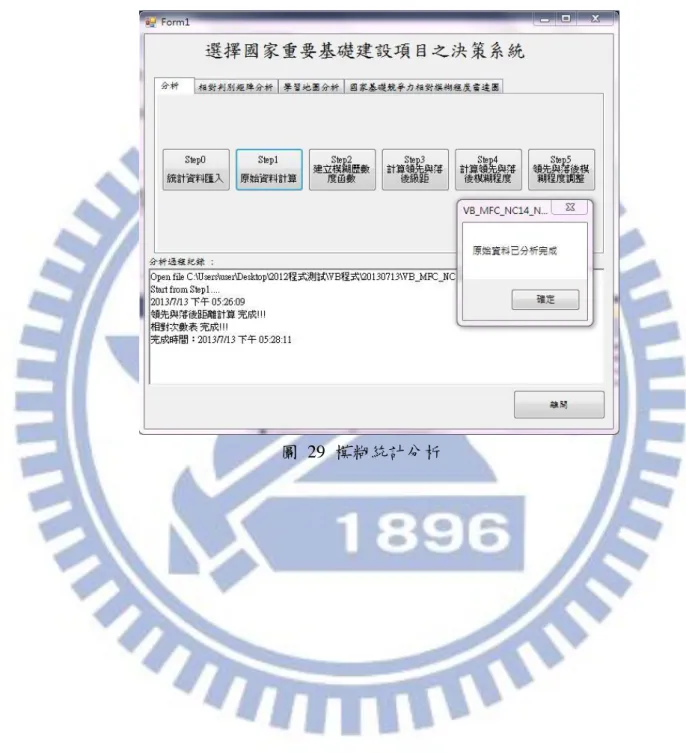
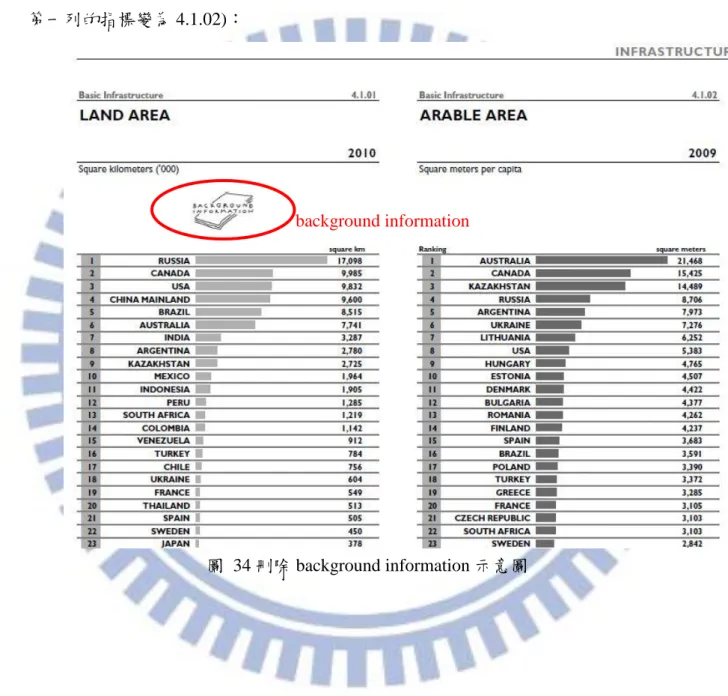
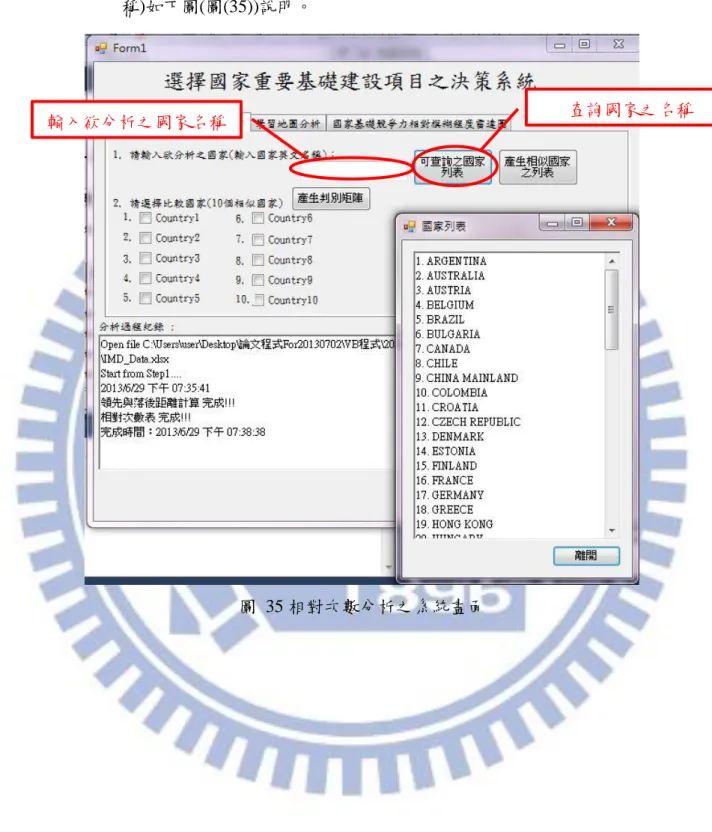
vi 圖目錄 圖 1 研究流程 ... 6 圖 2 鑽石模型之演進 ... 11 圖 3 IMD 國家競爭力指標架構圖 ... 16 圖 4 IMD 國家競爭力評估指標架構 ... 17 圖 5 群集特徵資料 ... 23 圖 6 不同群數之領先距離及落後距離 ... 23 圖 7 Membership Function 之組成 ... 25 圖 8 領先與落後距離判讀 ... 26 圖 9 相對領先及落後模糊程度判斷矩陣 ... 29 圖 10 台灣與新加坡之基本建設指標差異程度 ... 32 圖 11 Wang 之國家基礎建設競爭力決策之操作流程圖 ... 36 圖 12 相對次數表落後距離曲線圖(IMD2012 基礎建設部分) ... 37 圖 13 相對次數表落後距離曲線圖(IMD2011 基礎建設部分) ... 38 圖 14 不同群數之領先距離及落後距離 ... 39 圖 15 相對次數表落後距離曲線圖(IMD2012 基礎建設部分) ... 40 圖 16 Wang 之方法建立之落後模糊隸屬度函數(IMD2012 基礎建設部分) ... 40 圖 17 Wang 模糊評價方法操作時間 ... 41 圖 18 本研究系統規劃改善圖(上) ... 46 圖 19 本研究系統規劃改善圖(下) ... 47 圖 20 系統規劃及系統實作差異之流程圖 ... 49 圖 21 系統架構圖 ... 52 圖 22 相對次數表落後距離曲線圖(IMD2012) ... 54 圖 23 Wang 之方法建立之落後模糊隸屬度函數(IMD2012) ... 55 圖 24 本研究所建立之落後模糊隸屬度函數(IMD2012) ... 55 圖 25 系統分析畫面 ... 60 圖 26 Step0_統計資料匯入提示 ... 61 圖 27 IMD 2012 年度資料表範例 ... 61 圖 28 系統讀取之 Excel 格式(檔名:IMD_Data) ... 65 圖 29 模糊統計分析 ... 66 圖 30 建立模糊隸屬函數提示 ... 69 圖 31 領先長距離之函數輸入 ... 69 圖 32 落後模糊隸屬度函數規則 ... 70 圖 33 領先模糊隸屬度函數規則 ... 70 圖 34 刪除 background information 示意圖 ... 74 圖 35 相對次數分析之系統畫面 ... 76 圖 36 產生相似國家之列表 ... 77 圖 37 勾選欲比較國家 ... 78
vii 圖 38 TAIWAN 與 CANADA 之判別矩陣 ... 79 圖 39 學習地圖分析之系統畫面 ... 80 圖 40 國家基礎競爭力相對程度雷達圖系統畫面 ... 82 圖 41 TAIWAN 與 CANADA 標準差雷達圖 ... 84 圖 42 TAIWAN 與 CANADA 落後程度雷達圖 ... 84 圖 43 TAIWAN 與 CANADA 領先程度雷達圖 ... 85 圖 44 TAIWAN 和 CANADA 之相對判別矩陣 ... 87 圖 45 TAIWAN 和 SWEDEN 之相對判別矩陣 ... 87 圖 46 TAIWAN 和 KOREA 之相對判別矩陣 ... 88
圖 47 TAIWAN and CANADA 之 4.1 - Basic Infrastructure 標準差 ... 89
圖 48 TAIWAN and CANADA 之 4.1 - Basic Infrastructure 落後程度 ... 90
圖 49 TAIWAN and CANADA 之 4.1 - Basic Infrastructure 領先程度 ... 90
圖 50 本研究所建立之落後模糊隸屬度函數(IMD2012) ... 97 圖 51 相對次數表落後距離曲線圖(IMD2012) ... 98 圖 52 整理 IMD 國家競爭力資料時間 ... 99 圖 53 群集化分析 ... 100 圖 54 群內分佈狀態檢定時間 ... 100 圖 55 原始資料計算時間 ... 101 圖 56 模糊程度轉換時間 ... 102 圖 57 相對判別矩陣分析時間 ... 103 圖 58 學習地圖分析時間 ... 104 圖 59 國家基礎競爭力相對程度雷達圖分析時間 ... 104 圖 60 操作時間比較圖 ... 106 圖 61 國家工作表 ... 111 圖 62 標準化工作表 ... 112 圖 63 分群工作表 ... 112 圖 64 常態非常態工作表 ... 112 圖 65 分群群集工作表 ... 113 圖 66 計算工作表 ... 113 圖 67 相對次數工作表 ... 114
圖 68TAIWAN and CANADA 之標準差 ... 118
圖 69TAIWAN and CANADA 之落後程度 圖 70TAIWAN and CANADA 之領先程度 ... 118
圖 71TAIWAN and CANADA 之標準差 ... 119
圖 72TAIWAN and CANADA 之落後程度 圖 73TAIWAN and CANADA 之領先程度 ... 119
圖 74TAIWAN and CANADA 之標準差 ... 120 圖 75TAIWAN and CANADA 之落後程度
viii
圖 76TAIWAN and CANADA 之領先程度 ... 120 圖 77TAIWAN and CANADA 之標準差 ... 121 圖 78TAIWAN and CANADA 之落後程度
圖 79TAIWAN and CANADA 之領先程度 ... 121 圖 80TAIWAN and SWEDEN 之標準差 ... 122 圖 81TAIWAN and SWEDEN 之落後程度
圖 82TAIWAN and SWEDEN 之領先程度 ... 122 圖 83TAIWAN and SWEDEN 之標準差 ... 123 圖 84TAIWAN and SWEDEN 之落後程度
圖 85TAIWAN and SWEDEN 之領先程度 ... 123 圖 86TAIWAN and SWEDEN 之標準差 ... 124 圖 87TAIWAN and SWEDEN 之落後程度
圖 88 TAIWAN and SWEDEN 之領先程度 ... 124 圖 89TAIWAN and SWEDEN 之標準差 ... 125 圖 90 TAIWAN and SWEDEN 之落後程度
圖 91 TAIWAN and SWEDEN 之領先程度 ... 125 圖 92TAIWAN and KOREA 之標準差 ... 126 圖 93TAIWAN and KOREA 之落後程度
圖 94TAIWAN and KOREA 之領先程度 ... 126 圖 95 TAIWAN and KOREA 之標準差 ... 127 圖 96TAIWAN and KOREA 之落後程度
圖 97TAIWAN and KOREA 之領先程度 ... 127 圖 98 TAIWAN and KOREA 之標準差 ... 128 圖 99 TAIWAN and KOREA 之落後程度
圖 100 TAIWAN and KOREA 之領先程度 ... 128 圖 101 TAIWAN and SWEDEN 之標準差 ... 129 圖 102 TAIWAN and SWEDEN 之落後程度
ix 表目錄 表 1 WEF 與 IMD 國際調查報告之比較 ... 14 表 2 相對領先及落後模糊程度判斷矩陣區域之意義 ... 30 表 3 平均劣勢之數值意義 ... 31 表 4 劣勢指標學習地圖 ... 31
表 5 Membership Functions in MATLAB ... 38
表 6 Membership Functions in Matlab ... 54
表 7 4.1.01-LAND AREA ... 62 表 8 IMD_Data_original ... 63 表 9 4.1.01 分群結果 ... 64 表 10 4.1.01 分群群數判斷 ... 65 表 11 各指標之特徵資料 ... 67 表 12 相對次數表 ... 68 表 13 領先級距 ... 71 表 14 模糊程度(落後程度)... 72 表 15 領先與調整落後模糊統計(落後程度) ... 73 表 16 領先與調整落後模糊統計(去除 background information 之落後程度) ... 75 表 17 TAIWAN 4.1.12 之學習地圖 ... 81 表 18 TAIWAN 與 CANADA 相對模糊程度資料 ... 83 表 19 TAIWAN 平均劣勢程度排名 ... 86 表 20 顯著空間之指標 ... 88 表 21 4.1.04 之學習地圖 ... 91 表 22 4.2.09 之學習地圖 ... 92 表 23 4.2.12 之學習地圖 ... 93 表 24 4.5.10 之學習地圖 ... 94 表 25 前四項劣勢指標首要學習之對象國家 ... 95 表 26 Wang 操作時間與本研究操作時間比較 ... 105
1
第一章 緒論
1.1 研究背景
在國家的發展當中,國家會經由決策之後提升其在國際之間的競爭力,然而部分國 家卻遲遲找不到正確的發展方向。因此,決策的選擇對於提升國家競爭力有著相當重要 的影響。 “國家競爭力”這個名詞被許多學者廣泛引用,最早由美國為了提升其產業競爭力, 而組成的總統諮詢委員會(President's Commission on Industrial Competitiveness)提出; 其用意為描述與競爭對手彼此之間的相對位置(陳曉卿 2011)。為了提升台灣在國際之間 的競爭力,必須與其他國家做比較,並找出與他國之間的差異,而當前最具有代表性的 國家競爭力評比為世界經濟論壇(The World Economic Forum,以下簡稱WEF)及瑞士洛桑 管理學院(International Institute for Management Development,以下簡稱IMD)所公布的競 爭力年報,除每年度出版國家競爭力報告(The World Competitiveness Yearbook,以下簡 稱WCY)外,自2007 年起WEF 亦出版旅行與觀光業競爭力報告(The Travel & Tourism Competitiveness Report),其中基礎建設皆為主要之評估面向,評估指標除傳統之基本建 設(如道路、鐵路之單位面積)外,亦包含科技建設(如固定電話線路數)、科學建設(如R&D 支出)、健康及環境建設(如污水處理廠數)及教育建設(如教育總支出)等因素,相關評估 結果可做為政府施政(Frenkel et al. 2003)或企業貿易及投資之參考(高希均、石滋宜 1996),如何由眾多評估指標中,挑選出落後其他經濟體系之基礎建設項目,則為有效 應用相關單位競爭力年報之關鍵,亦為擬定國家基礎建設發展策略之基礎。然而,WEF 與IMD 對於對國家競爭力的分析,採用相異之國家競爭力評估架構及指標來衡量,所 產生出之排名現象皆不相同(承立平 2011)。而基礎建設向來都是各國發展的重點項目, 在擬定國家基礎建設投資策略及計畫方面,需配合國家經濟、社會、文化及發展需求設 計,瑞士洛桑管理學院(IMD)將基礎建設定為四大指標之一,採用了59個國家的資料, 並選出五項優勢項目與五項弱勢項目來做評比。 然國家基礎建設涵蓋範圍廣泛,除一般傳統之道路、橋樑及港口等基礎建設項目外,2
亦包含科學、教育及健康等各種與國家發展相關之建設及設備,如何由眾多國家基礎建 設中,選擇國家應投資之重點項目,是極困難之決策(Mandele et al. 2006)。想要在有限 的資源當中來提升國家競爭力,勢必得對各項基礎建設做出適當的選擇。
實際上,對國家基礎建設的選擇通常不夠客觀,根據 Short and Kopp(2005) 回顧法 國、德國、英國、及荷蘭等國家之國家發展計畫,發現決策缺乏透明化及決策評估方法 不符合國家實際情況為普遍決策缺點。然造成以上問題的主要原因,係因目前擁有各種 國際相關統計資料,而在政策的決定上,往往需要在短時間內做出最適當的決定,在這 有效的期限內,決策者多半無法深入了解各國際相關統計資料的特性,因此在政策上面 加入了許多決策者主觀的判定,這些加入主觀判定的政策可能不符合國家發展的需求, 由於決策過程缺乏客觀之分析基礎,在政策制定上,將無法公開決策過程,造成非透明 化之決策。 過去有關國家重點基礎建設投資項目之研究,通常採用效益或成本分析(如 William and Donald 1987, Clark 1989)、會議或問卷調查(如 Gòmez-Limòn and Atance 2004,
Väntänen and Marttunen 2005)及政策回顧(如 Dixhoorn 1984, Glrigg 1985, Onera and Saritas 2005)等 3 種分析方式,效益或成本分析通常僅針對特定之基礎建設項目進行分 析,例如電信基礎建設、港口、下水道等,很少對於國家全部基礎建設進行分析,分析 結果無法瞭解不同類型基礎建設之相對重要性,較不適用於分析國家重點基礎建設項目; 問卷調查之研究,因研究結果受問卷項目、調查樣本及問卷時間之影響較大,因此分析 結果較易受到質疑;政策回顧方式,通常係全面分析國家基礎建設項目,然因每個國家 發展歷史及策略不同,決策者較難複製過去其他國家之發展策略,造成應用上之困難(王 世旭 2007)。 Wang(2013)認為參考國際調查報告、選擇國家劣勢指標之關鍵,在於判斷我國在這 項指標的表現與領先及落後國家之差異程度,因此一個國家需加強之指標,應符合與領 先國家差異大,且與落後國家差異小之條件。在過去研究提出之分析模式上,因各項指 標之分佈狀態不同(可能為常態分佈或非常態分佈),分析出來之排名無法完全代表 STD 之高低,在分析上較無 STD(標準差)的應用方式,且 STD 主要用於描述該國與多數國家
3
(平均值)表現之差異,而非本國與領先及落後國家之差異程度,因此影響選擇劣勢指標 之有效性。
從 Wang(2013)的研究中得知,為避免會議討論、問卷調查或政策回顧等研究之研究 缺點,本研究參考 Dzeng and Wang(2007)及 Wang, S. H. et al. (2013)之國家競爭力分析觀 點,將較客觀的公式化分析自動化,以比較出我國與其他國家在基礎建設上的差異,找 出與台灣發展相似的國家來做為學習對象。 Wang (2013)提出利用模糊評價方法評估國家各項基礎建設發展狀態之分析模型。透 過模糊評價方法,政策決策者可更準確判斷各項指標之領先及落後程度,並運用判別矩 陣瞭解各項指標之相對狀態,以研擬國家基礎建設可能需提升之重點項目。惟模糊評價 方法之計算過程較為繁複,且模式使用涉及群集化分析、模糊理論等分析技術,可能造 成一般政策決策或審議人員使用上之困難,影響模糊評價方法之實用性。
本研究根據 Wang (2013)之分析模型,以 Visual Basic 程式語言為開發工具,結合 SPSS、MATLAB 及 Microsoft Excel 等統計軟體,建置自動運算、建立模糊評價判別矩 陣及指標學習地圖之決策支援系統,提供政府單位及研究人員使用。本研究為使決策者 能更清楚了解國家在基礎建設方面需要提升的方向,採用瑞士洛桑管理學院(IMD)的資 料,並使用 Visual Basic 程式語言、SPSS 統計分析軟體、MATLAB 統計軟體、Microsoft Excel 資料表,來做群集化分析,考量群組之間的差異程度,再使用模糊評價分析,建 立模糊隸屬度函數以及模糊判別矩陣,以方便決策者在基礎建設方面能找出較適當的提 升方向。
1.2 研究目的
在 Wang(2013)的選擇國家競爭力劣勢指標之研究中,從 Dzeng and Wang(2007)到 Wang(2013),分析方法不斷的演進。從一開始以標準化國家統計資料做分群來挑選分析 國家之學習對象,到後來加入模糊評價方法,詳細的分析數據,並加入判別矩陣及學習 地圖,以圖形方式輔助決策者及後續研究人員來輕易了解並找出學習國家與劣勢指標。 在這些過程中,分析方法越來越複雜,使得數據在處理上將變得更加困難,且在得知數
4 據後還須個別繪製圖形,這些動作要讓決策者與研究人員使用顯得較困難。 本研究的目的在於建立可輔助決策之資訊系統,將 Wang(2013)之選擇國家競爭力指 標方法,以部分系統自動化方式,簡化其繁雜的計算,以提供決策者擬定國家重點發展 計畫與後續研究人員做參考。 本研究之主要目的如下: 1. 建立較精準的模糊程度轉換:在 Wang 的研究中,模糊程度轉換曲線是以手動 方式製作,本研究將採用輸入數據之方式來比對出較精確的模糊程度數據。 2. 建立國家基礎建設決策支援系統:在了解 IMD 國家競爭力年報以及 Wang(2013) 之選擇國家競爭力劣勢指標方法後,建立部分自動化系統,以簡化模糊評價分 析方法,提供決策者與後續研究人員做參考及使用。
1.3 研究範圍及限制
1. 研究範圍 本研究以瑞士洛桑管理學院(IMD)發表的國家競爭力年報(WCY)資料來作為分 析的依據,從 2012 年度的資料中找出指標學習地圖及建立國家基礎建設相對模 糊程度雷達圖。 2. 研究限制 (1) 由於本人在技術門檻及系統設計在時間上的限制,部分數據分析還是要手 動使用 SPSS 等統計軟體來做計算。 (2) 國家競爭力指標並非各國皆有資料,若某國家缺乏該項資料,該項指標之 群集數將以零來忽略計算。5
1.4 研究流程
本研究的流程如圖(1),其分為建立研究動機與目的、擬定研究流程與方法、文獻回 顧、建立決策支援系統、系統案例使用示範、系統評估以及結論與建議。茲說明各研究 流程如下: 1. 建立研究動機與目的:國家的發展將影響人民生活的水準,該如何提升國家競 爭力將是一大問題,國家基礎建設為國家之重要發展之一,找尋出適當的發展 方向將有效提升國家在國際之間的競爭力。 2. 擬訂研究流程與方法:在確定找出國家基礎建設正確發展方向以提升國家競爭 力之後,將擬訂本研究之流程與方法,以在限定的時間內能做出益於找出提升 國家基礎建設發展方向之方法。 3. 文獻回顧:蒐集的國內外相關文獻來對基礎建設之定義與國家競爭力資訊做了 解,並針對選擇國家競爭力劣勢指標理論作理解。 4. 建立決策支援系統:在理解國家競爭力劣勢指標理論後,建立決策支援系統, 並改善分析介面,以提供決策者及後續研究人員使用。 5. 系統案例使用示範:在建立出決策支援系統後,將對系統作案例示範,以方便 決策者及後續人員了解系統之操作。 6. 系統評估:將針對系統對於使用者的益處以及系統的效率做評估。 7. 結論與建議:將本研究做結論並提供後續研究之建議。 本研究在建立系統時,利用 SPSS 統計軟體做分群,並用 MATLAB 做模糊程度轉 換,最後交由 Visual Basic 2010 與 Microsoft Excel 分析並挑選出學習國家與指標,最後 再依照分析結果做比較與討論。6 建立研究動機與目的 文獻回顧 公共建設與投資 選擇國家競爭力劣勢指標 國家競爭力 建立決策支援系統 系統案例使用示範 系統評估 擬訂研究流程與方法 結論與建議 圖 1 研究流程
7
1.5 研究架構
本研究架構分為六章,概述如下: 第一章 緒論 本章說明研究本研究之研究動機、研究目的、研究範圍及限制、研究流程、研究架構。 第二章 文獻回顧 根據本研究目的,針對研究需要之相關條件進行分析與定義,包括國家基礎建設定義、 國家競爭力年報選擇、國家競爭力之判別矩陣及其它研究者挑選指標之方法,模糊理論介 紹等。 第三章 選擇國家重要基礎建設項目之決策系統 本章將說明 Wang(2013)之模糊評價方法及其操作流程,並針對 Wang(2013)之操作 方法做改善,以建立自動化系統之國家基礎建設決策支援系統,最後介紹系統實作。 第四章 系統案例使用示範 將採用 IMD2012 年度資料,並依國家競爭力指標評價之決策支援系統做分析,來 實際操作系統。 第五章 系統評估 將評估國家基礎建設決策支援系統之功效,以及其與傳統比較上的優點。 第六章 結論與建議 提出本研究之結論,並對後續研究之學者提出建議。8
第二章 文獻回顧
本研究主題在於分析國家競爭力報告,並找出適當方向來提升國家競爭力之基礎建 設,首先需要了解何為國家競爭力與其定義及其他相關研究,回顧國家基礎建設相關文 獻,並了解基礎建設與經濟發展和相關之國際調查報告,以作為後續研究之參照。2.1 國家競爭力
「國家競爭力」目前已是學術界、企業界和國家政府之間最熱門的話題(Cho 1998) 之一。從 1980 年代開始出現這個詞彙之後,國家競爭力已成為各國政府不得不去面對 的問題,在做決策上也開始參考競爭力相關資料,使國家透過政策與發展策略,從國際 社會中獲取最大資本利益(朱景鵬 2009)。 國家競爭力研究之著名學者-波特教授(Michael E.Porter)寫過三本有關「競爭優勢」 的書,前兩本的焦點是企業,而第三本則是國家,這樣的變化,來自於波特教授發現國 家環境對企業競爭成功有關鍵性的影響(國家競爭優勢(上))。就國家觀點而言,根據波 特教授所建立的「國家鑽石理論」,可發現國家競爭力市政府、產業與企業等層次競爭 力的綜合表現(劉漢榆、江怡玲 2006);而 Cho(1998)在其國家競爭力的評估模型中,所 考量的影響因子有自然、人為以及外來機會三項。由此可知,從國家競爭力當中可以顯 示出一國的經濟基礎、自然稟賦、對國外資金的吸引力與人才和科技技術的能力與水準, 其主要是在創造並維持國家的大環境,以加速企業創造附加價值的能力,並增進人民的 繁榮(行政院經建會 2007)。 在世界經濟論壇(WEF)中,將國家競爭力定義為「一個國家能快速而持續地改善國 民的生活水準,以獲得高經濟成長之能力,使一個國家能夠達到持續高經濟成長率的能 力」。 而在瑞士洛桑管理學院(IMD)中,各方面對於 IMD 在國家競爭力方面的定義有不同 的解讀方式。朱鎮明、朱景鵬對於 IMD 的競爭力解讀為:「國家與企業如何管理整體能 力以獲利或是增加國家財富」(朱鎮明、朱景鵬(2006)-政府效能對國家競爭力影響評析)。 江啟臣、黃富娟(2006)於「全球化下城市競爭力指標之探討」中指出,IMD 的國家競爭9 力為:「一國在其經濟與社會結構中,透過操控原有稟賦與附加價值的程序、對內吸引 力與對外開拓力,以及國際化形塑國內型經濟,來增加附加價值,進而增加國家財富的 能力」(江啟臣、黃富娟 2006)。
2.2 國家競爭力相關研究
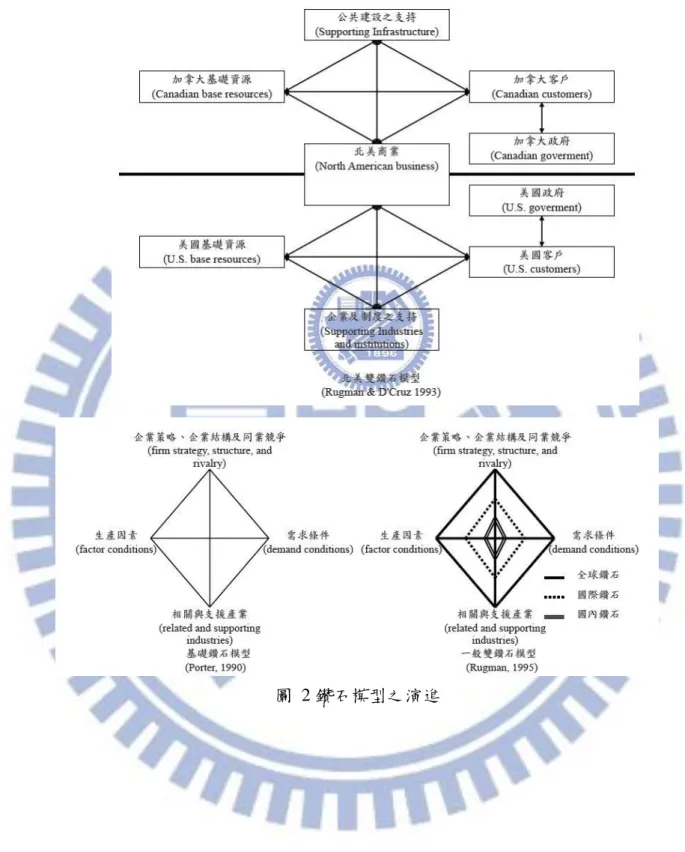
在國家競爭力相關研究中,著名學者Porter(1990)在書中提到:因為一國經濟乃由不 同產業所構成,產業不同,所需之條件或環境也會有差異。為此,我們可以知道,一國 條件或環境未必適合所有產業。而國家之所以會成功,係因產業或部分產業之成功所造 成,因此Porter分析當時財富情況相似之10 個貿易國家,並透過鑽石模型來表示此類國 家成功之原因。Porter認為,鑽石模型由四大類型組成: (1)生產因素:由國內幾種特殊產業提供。每個國家都有不同的要素優勢,應善用其占優 勢之生產條件來做發展。 (2)需求條件:包含規模、成長率及國內科技業需求與產量。此因素產生之優勢,將受經 濟尺度(如作業成本)及新技術影響。 (3)相關與支援產業:可用於壓制競爭對手,其來源包括提供產業未來發展需要之新技 術。 (4)企業策略、企業結構及同業競爭:主要為產業內之企業的組織與管理形態,以及市場 競爭的情形;特定產業可因此種因素獲得競爭優勢。而鑽石模型之執行流程(Keith & Lance 1997):(1)首先決定國家之重要產業群集 (Porter 僅將重要產業設定為工業);(2)決定主要貿易國家;(3)決定國家競爭力指 標;(4)導入鑽石模型分析模式。 Porter 之鑽石模式係依據分析丹麥、德國、義大利、日本、、瑞典、瑞士、英 國、美國(以上為先進國家)、南韓、新加坡(以上為新興工業國家)10 大工業國家,建 立之國家競爭力分析模式;然後續相關實證研究證明,Porter 鑽石模型(Home-Diamond) 並不適和小型及貧窮國家之競爭力分析。因此,後續有學者根據Porter 模型為基礎, 建立一般雙鑽石模型(Generalizability of theDouble-Diamond)及雙鑽石模型
10
(Double-Diamond) (鑽石模型演進如圖2)。
Porter 最先使用鑽石模型分析加拿大及紐西蘭之國家競爭力(Crocombe, Enright & Porter, 1991),分析加拿大之國家競爭力,並無適當考慮跨國活動影響(Rugman,1991); 分析紐西蘭之國家競爭力,未解釋其進出口成功因素及資源基礎產業(Cartwright,1993)。 Porter 當時未考慮跨國企業對競爭力影響之原因,係其認為國外直接投資(Foreign Direct Investment, FDI),不應列為國家競爭優勢項目,回流國內之FDI 對國家競爭優勢不一定 有利。Dunning(1992)分析跨國企業活動力之實證研究發現,全球75%之貿易量,皆由跨 國企業提供,建議應於Porter 鑽石模型中,加入跨國企業為第七個構面。Cartwright (1993) 認為基本鑽石模型應增加5 個off-shore 變數,用於判斷由其他國家所獲得之效益, Rugman & D'Cniz,(1993)亦有相似研究建議(王世旭 2007)。
11
12
2.3 基礎建設與經濟發展
在政府基礎建設投資與經濟成長方面,Aschauer (1989a, 1989b)發現政府公共建設投 資(固定資本形成毛額)佔國家 GDP(gross domestic product)比例,顯著影響民間投資之金 額;此外 Aschauer (1989b)以美國進行實證研究發現,政府公共建設投資具有刺激民間 投資之效果,且公共建設投資與民間投資具互補效果。
雖然 Aschauer (1989b)研究已證實公共基礎建設投資與經濟成長具有統計之正向關 係,但其尚未實證公共建設投資與經濟成長之因果關係(Afonso and St. Aubyn 2008)。 Arslanalp et al.(2011)研究指出,國家資本存量對 GDP 之影響,遠超過政府基礎投資比例。 Sutherland et al. (2009)以國家資本存量建立國家經濟成長之分析模型,可用於評估各項 基礎建設項目之發展狀態(良好或不足)。 經由上述之文獻回顧結果可知,過去研究對於國家基礎建設投資之相關研究,多著 重於政府公共基礎建設投資及國家資本存量(capital stock)之總額分析,較少探討各項基 礎建設項目應如何進行分配,因此若能參考國際調查報告,瞭解國家相對缺乏之基礎建 設項目,應有助於擬定國家基礎建設之發展及投資方向。 而在地區經濟成長的差異與整合上,經濟整合概念主要為處理國家或區域間發展不 均衡之問題(Herrerias and Ordoñez 2012),收斂俱樂部 (convergence clubs)則為評估國家 或地區經濟成長差異之主要工具。收斂俱樂部除可用於評估國家或地區之相似或差異性 外,亦可作為研究人員決定研究假設之之參考。目前許多研究已證實,許多國家或地區 皆具有收斂俱樂部之現象:China (Maasoumi and Wang, 2008), Greece (Fotopolos, 2006), the European Union (Pittau and Zelli, 2006) and Brazil (Andrade et al., 2004)。
傳統上進行收斂俱樂部分析時,不論係利用橫斷面資料(cross-section)或縱橫資 料(panel data),皆會採用 Barro- regressions (β convergence)作為分析指標(Herrerias and Ordoñez 2012),惟 Quah (1996)認為β convergence 等參數化方法具有假設嚴格、分析過 程複雜等缺點,因此提出分佈動態模型(distribution dynamics method)之分析方法,其透 過反覆比對收入、成本及產出比例之分佈圖形 (雙峰分佈或單峰分佈),以判斷影響國家 或地區收入之主要因素(Johnson 2005)。
13
收斂俱樂部之分析方法中,針對横斷面資料(Cross-sectional data)之分析,通常具由 嚴格之假設條件(例如變異數同質性);針對時間序列(time series)或縱橫資料(panel data) 之分析,通常需要較長時間之統計資料,惟產業環境變化極快,許多因技術發展、產業 環境及全球化趨勢產生之新指標(例如 Green technologies),可能不會有足夠之歷史資料 (例如 IMD 1989~2012 年,每年度皆有採用之基礎建設指標僅 16 個),因此針對横斷面 數據特性,建立不受資料分佈狀態限制(distribution free)之分析方法,應有助於增加收斂 俱樂部可分析之範圍。此外,過去研究收斂俱樂部多以總體經濟指標(例如 total factor productivity 或 GDP)進行分析,若能參考國際調查報告,分析國家或地區目前相對缺乏 之基礎建設項目(或其他相對劣勢項目),應可對時間序列或縱橫資料之分析結果進行更 多之討論及解釋,亦有助於決策者擬定國家政策方向。
2.4 相關國際調查報告
在國際上有許多不同的競爭力評估體系,其中以世界經濟論壇(World Economic Forum; WEF)的全球競爭力報告(Global Competitiveness Report)和瑞士洛桑管理學院 (International Institute for Management Development; IMD)的世界競爭力年報(World Competitiveness Yearbook; WCY)較具影響力。不論是從 WEF 角度,亦或是 IMD 的角度去看「國家競爭力」,都說明 WEF 及 IMD 對於國家競爭力的判斷都各有一套詳細的評估,因為這樣,WEF 與 IMD 可以說在國家 競爭力評估指標中深具影響力。在這兩個較具影響力的組織中, 可以得知,WEF 較重 視瞭解國家經濟成長因素為何,因此,為區別出不同經濟發展階段所面臨的問題,WEF 將經濟體區分為三階段,分別為:生產要素導向(factor-driven)、效率導向(efficiency-driven) 和創新導向(innovation-driven)。IMD 方面則較為重視國家向企業提供在環境上較具競爭 力的能力。因此,其在競爭力之指標上分成四大項:經濟表現(economic performance)、 政府效率(government efficiency)、企業效率(business efficiency)與基礎建設(infrastructure), 各大項向下皆有五個中項指標,共計 20 個中項指標,每個中項指標皆占 5%權重,總計 331 個細項指標,其比較如下表 1。
14 表 1 WEF 與 IMD 國際調查報告之比較 機構 世界經濟論壇(WEF) 瑞士洛桑國際管理學院(IMD) 競爭力之定 義 一國達到永續經濟成長及高國民平均所得 目標的總體能力。 一國經由經營其資產加工過程、吸引 力、積極性、全球化及親和性,並將此 種關係整合為經濟與社會模式,來創造 附加價值,以增加國家財富的能力。 評比結構 主觀調查指標達30%,量化指標占70%。 主觀調查指標占1/3,量化指標占2/3。 指標數與權 重 指標總數110 個,要項的權重設定較嚴 謹,依各國經濟發展階段不同給予不同之 權重計算國家分數,中指標比重不同。 選取的指標總數(331 個)較多(IMD, 2008),每個中指標所佔的比重皆固定為 5%。 指標體系 二大指標,十二項支柱指標(含企業BCI 指標)。 四大分類指標,分別為企業效能、政府 效能、基礎建設、經濟表現;各類之下 設定五項中指標。 評比弱勢項 目之方法 1.GCI 總排名前10 的國家 (1) 優勢項目:小指標排名≦ 10 名 (2) 弱勢項目:小指標排名 > 10 名 2.GCI 總排名11-50 名的國家 (1) 和自己國家之總排名(X)作比較 (2) 優勢項目:小指標排名≦ X (3) 弱勢項目:小指標排名 > X 3.GCI 總排名50 名以後的國家 (1) 優勢項目:小指標排名≦ 50 名 (2) 弱勢項目:小指標排名 > 50 名 1. 每一大指標(共有四大指標)下都選 出五項優勢項目與五項弱勢項目。 2. 選出方法: 各國小指標的數值,經過標準 化計算後,會有一個得分;就 每一類大指標下的所有小指標群,根據 其標準化過後之分數,選出較佳的前 5 名為優勢項目,最差的 5 名為弱勢項目。 資料來源:1996-1997 年、2008-2009 年之全球競爭力報告及世界競爭力年報 提升國家競爭力-國際競爭力評比架構之運用 本研究種點著重於基礎建設對於國家競爭力的提升,因此採用 IMD 作為研究上的 選擇。
2.4.1 IMD 國家競爭力年報
IMD 從 1989 年起就開始出版 WCY 年報,分析的國家、地區個數也逐年增加,目 前共計發表 24 本 IMD 全球競爭力年報(1989~2012),大致都包括 OECD 國家以及新興 工業化國家,其評估模式係「藉由專業的經濟觀點,透過實際數值及法令規章,評估一 國用來創造並維持一個可提升企業利潤及人民福利的環境之能力」IMD 分析全球競爭力 之首要目標(陳宛瑩-台灣之國家競爭力的定位與相關分析 2008),希望瞭解全球關鍵經濟15 體過去一個年度之績效表現。 IMD 將影響國家競爭力的變數歸納為四大類,本研究將其稱為四大指標,以 2012 年之 WCY 年報為例,其主要架構有: 一、經濟表現(Economic Performance) 此項指標係針對各個國家或地區內的總體經濟進行評估。主要分為五個面向探討, 分別為:(一)國內經濟(Domestic Economy)、(二)國際貿易(International Trade)、(三)國際 投資(International Investment)、(四)就業(Employment)、(五)價格(Prices),以及其細項指 標。
二、政府效能(Government Efficiency)
此項指標係指政府政策有利於競爭力的程度。主要分為五個面向探討,分別為:(一) 政府財政(Public Finance)、(二)財務政策(Fiscal Policy)、(三)制度架構(Institutional Framework)、(四)商業法規(Business Legislation)、(五)社會結構(Societal Framework),以 及其細項指標。
三、企業效率(Business Efficiency)
此項指標係指企業經營表現在創新、營利、責任方式的程度。主要分為五個面向探 討,分別為:(一)生產效率(Productivity and Efficiency)、(二)勞動市場(Labor Market)、(三) 財政(Finance)、(四)管理措施(Management Practices)、(五)態度與觀念(Attitudes and Values),以及其細項指標。
四、基礎建設(Infrastructure)
此項指標係指基本建設、技術、科學及人力資源在企業中被需求的程度。主要分為 五個面向探討,分別為:(一)基本建設(Basic Infrastructure)、(二)技術建設 (Technological Infrastructure) 、 ( 三 ) 科學建設 (Scientific Infrastructure)、(四)健康及環境(Health and Environment)、(五)教育(Education),以及其細項指標。
在各子項因素中的評估指標數目不同,每個子項因素包含各自獨立的指標,且每個 子項因素在最後計算競爭力排名時,其每項次指標的權重皆佔 5%的權重(合計權重共 為 100%)。
16 IMD國家競爭力年報 政府效率 經濟表現 企業效率 基礎建設 1. 國 內 經 濟 2. 國 際 貿 易 3. 國 際 投 資 4. 就 業 5. 價 格 1. 政 府 財 政 2. 財 務 政 策 3. 制 度 架 構 4. 商 業 法 規 5. 社 會 結 構 1. 生 產 效 率 2. 勞 動 市 場 3. 財 政 4. 管 理 措 施 5. 態 度 與 觀 念 1. 基 本 建 設 2. 技 術 建 設 3. 科 學 建 設 4. 健 康 與 環 境 5. 教 育 細項指標 細項指標 細項指標 細項指標 圖 3IMD 國家競爭力指標架構圖
2.4.2 IMD 國家競爭力年報評估對象與計算方式
IMD 國家競爭力評估之對象主要可分為兩類國家,第一類國家為經濟合作暨發 展組織(Organization for Economic Co-operation and Development,OECD)之會員國;第二 類國家為新興工業化國家及新經濟市場。IMD 選擇對全球貿易影響力高且可提供國際性 統計資料之國家或地區,但每年度 IMD 會因國際環境之變化,選擇不同之評估國家或 地區。IMD 國家競爭力計算包含(1)指標標準化、(2)合計複合指標、(3)合計子項因素、(4) 合計因素、(5)計算總體國家競爭力等5 個步驟。其計算流程及步驟如圖4 所示。
17 Step 1 指標標準化 Step 2 合計複合指標 Step 3 合計子項因素 Step 4 合計因素 Step 5 計算總體競爭力 統一競爭力各項指標尺度。 部分指標係由2項資料組成, 根據資料權重合計STD。 合計各項子項因素包含指標 之STD,定量指標權重約為 1,定性指標權重約為0.55 。 合計因素包含5個子項因素 STD,每個子項因素權重 5%。 合計4個因素之STD,每個 因素權重為25%。 圖 4 IMD 國家競爭力評估指標架構 STEP1 指標標準化
因各項指標尺度不一致,故 IMD 使用 SDM (Standard Deviation Method)模式數值轉 換各項指標原始數值為標準差(STD, standardized values)。 計算各國各指標之標準差: S = √∑(X−X̅)2 N ………(1) S:該項指標之標準差。 X:該國該項指標之數值。 X̅:該項指標之各國總平均。 N:該年度 IMD 之調查國家數量。 計算各國標準差: STD = X−X̅ S ………(2) S:該項指標之標準差。 X:該國該項指標之數值。 X̅:該項指標之各國總平均。 首先,IMD 針對每個指標,利用式(1),計算全部評估國家或地區之標準差,再代
18
入式(2),計算標準值(STD)。標準值可解釋為該國特定指標距離全部國家平均值之標準 差倍數,在一般情況下,指標之標準值越高代表越好(如空運品質、能源基礎建設),有 些指標正好相反(如行動電話成本、二氧化碳排放量),越低標準值越具競爭力。WCY 依 據標準值計算結果,依據指標定義進行排名。在競爭力數值之計算模式方面,IMD 採 用標準差計算模式(Standard Deviation Method, SDM), 以解決競爭力調查指標單位不 同之問題。 STEP2 合計複合指標 因 IMD 採用計算國家競爭力排名之指標中,部分指標係由 2 項資料組成,如教育 評估指標(educational assessment)是由數學(Mathematics)及科學(Sciences)兩項資料組成, 因此 IMD 對給予資料不同之權重。複合指標計算公式如式(3): Cij = ∑w1SIj+ ∑ w2SIj………(3) Cij:第 i 項指標第 j 個國家複合指標之標準值 w:代表該項數據資料之權重 Sij:第 i 項資料第 j 個國家之標準值 STEP3 合計子項因素 IMD 共包含 20 個子項因素(sub-factor),每個子項因素內含不同數量之競爭力指標, 且競爭力指標又可分為統計資料與調查資料 2 類,加總時之權重並不一致,子項因素計 算公式如式(4):
ykj = ( ∑iϵHSij+ ∑iϵHCij)+21 ( ∑iϵHSij+ ∑iϵHCij)………(4) ykj:第 K 個子項因素第 j 個國家之標準值 H:代表該項指標屬於統計資料 S:代表該項指標屬於問卷調查 Sij:代表單一指標 Cij:代表複合指標 統計資料指標(佔總指標數之 2/3)在計算總排名時的權重約為 1,調查資料指標(佔總 指標數之 1/3)權重約為 0.5,當遺漏特定國家或地區之某項指標資料情況時,IMD 將以 0 作為標準值。
19 STEP4 合計因素 IMD 每項因素具有 5 個子項因素,每個子項因素在加總計算競爭力排名時,皆具 有相同的權重(每個子項因素權重為 5%),因素計算公式如式(5): ZEj = ∑kϵEykj……….(5) ZEj:第 E 個因素第 j 個國家之因素標準值 IMD 固定各個子項因素之權重,不考慮子項因素所包含之指標數量,係因為 IMD 相信此種方式可確保評估結果之一致性,此外統計資料有時會發生錯誤或遺漏情況,固 定各子項因素之權重,防止因為資料不對稱(disproportionate)造成之問題,影響評估結果 之信度。 STEP5 計算總體國家競爭力 第五個步驟為計算總體國家競爭力,總體國家競爭力包含 4 個競爭力因素,每個因 素權重皆為 25%(即 5 個子項因素權重之總和),加權合計各項因素之標準差,即可獲得 總體國家競爭力。總體國家競爭力計算公式如式(6): fj = ∑ ZEj………..(6) fj:第 j 個國家之總體國家競爭力 ZEj:第 E 個因素第 j 個國家之因素標準值 計算國家或地區之總體競爭力得分後,IMD 轉換所有國家之競爭力得分至 0~100 分之間。利用比例方式計算各國家競爭力的得分以及排名。在排名結果的呈現上,WCY 提供不同觀點之排名比較方式,包括依據人口規模排名(人口超過 2000 萬或小於 2000 萬)、人均 GDP 排名(平均每人 GDP 超過或小於$10,000)及依地理區域(中歐及東非、亞 洲太平洋地區、美洲)等方式。
20
2.5 IMD 排名方式之缺點與 Wang 之模糊評價方法
根據2.4節中提到之IMD國家競爭力年報排名計算方式,可以知道IMD在計算排名時 未考慮到的資料型態分佈之情形。依Porter國家競爭力評估架構,瑞士洛桑管理學院 (IMD),自1989 年起每年發表國家競爭力年報(WCY),且自1996 年後,IMD 依競爭力 指標排名,挑選一個國家10 項排名最低的指標為劣勢指標;10 項排名最高的指標為優 勢指標,然此種方式容易忽略排名略高然競爭力得分更低之指標,造成IMD 建議之劣 勢指標可能無法提升最大程度之國家競爭力,且目前國家競爭力年報僅公佈指標之數值 及排名,並未清楚呈現所有評估指標之優劣勢狀態,使用者很難由統計資料中,瞭解那 些指標可能未來成為優勢指標或劣勢指標,進而決定適當策略(王世旭 2007)。 故為克服IMD 優劣勢指標選擇之問題,Wang(2013)逐步改良競爭力排名分析方法, 從分群技術之改良,以取特徵值方式來善用分群後之結果,到加入模糊化程度,以客觀 且一致性之方式,進而來輔助決策者制定國家基礎建設發展之方向,Wang(2013)之模糊 評價方法將於第三章作說明。
21
第三章選擇國家重要基礎建設項目之決策支援系統
本研究根據 Wang (2013)建立之模糊評價方法,以 Visual Basic 程式語言為開發工具, 結合 SPSS、MATLAB 及 Microsoft Excel 等統計軟體,改善 Wang(2013)中較為複雜之手 動操作部分,來建立選擇國家重要基礎建設項目之決策支援系統。 在 Wang(2013)的模糊評價方法操作中,採用 IMD 競爭力報告後,由於資料數量較 多,需要花費許多時間去整理其中的資訊,且在數據輸入時,也容易發生輸入錯誤或者 解讀數據誤判等情形,這些原因都將影響決策者正確決策之方向。本章將先介紹 Wang(2013)之模糊評價方法,接著說明 Wang(2013)之模糊評價方法操作流程與系統規劃, 最後將介紹本研究之系統實作。
3.1 Wang 之模糊評價方法
在國家基礎建設劣勢指標方面,有許多分析方法。本研究將參考 Wang(2013)之模糊 評價方法,以下將對 Wang(2013)之模糊評價方法逐步做介紹,Part I 為 Wang 在 2010 年 之前的方法,Part II 和 Part III 為 Wang 在 2013 年新增的方法,也是本研究系統化之重 點。 Part I:建立領先及落後模糊隸數度函數 此部分為 Wang 99 年度之主要成果。首先採用群集化分析技術,將國家分為群間差異最 大,且群內差異最小之數個群集,再考量群集內及群集間之差異程度,配合模糊理論分 析技術,建立競爭力差異之隸屬度函數,作為單一國家領先與落後程度之判斷基礎,再 利用重心法解模糊化,決定各項指標領先及落後之模糊程度。領先及落運算程序說明如 下。 Step1 指標標準化 因 IMD 採用之競爭力指標之尺度不同,進行群集分析前先進行指標尺度標準化, Wang 依據 IMD 之標準化程序(數值轉換為標準差)模式,轉換所有競爭力指標。22
Step2 群集化分析
目前常用之群集分析方法可分為階層式群集分析(hierarchical Clustering)及 K-means 群集分析(K-means Clustering)2 類,階層式群集分析優點在於使用簡單,適用於當研究 者不瞭解分析樣本之可能分群數時使用,缺點為分析方法及過程並不嚴謹,可能會造成 樣本歸納至不適當之群集中,提昇組內變異量;K-means 群集分析優點在於樣本分類結 果較佳,可有效降低階層式群集組內變異量較大之問題,缺點在於分析時研究者需先自 行設定群數。因此在實際研究上,許多研究先以階層式群集評估可能之分群數,再利用 K-means 群集調整樣本所處之群集,降低組間變異量。Wang 參考其他學者之作法,先 以階層式群集分析預估分群群數,再利用 K-means 群集分析進行樣本所處群集之調整。 除了群集採用之分析技術外,決定觀察值之分群群數,亦為群集分析使用上之關鍵問題, 因此學者曾提出 RMSSTD (Root- Mean- Square Standard Deviation)、R2
(determination coefficient)、SPRSQ (Semi-partial R- Square)等判斷適當群數之評量指標。RMSSTD 代表 各群集之標準差總和,RMSSTD 越低代表群體內差異越小相似性高;R2代表 1 減去群 集後與未群集前變異量之比值,當分群群數等於樣本數時 R2為 1,當分群群數僅為 1 時 R2為 0,R2高則代表各群集內之變異小相似性高,通常用於推論群集間之相異性;SPRSQ 代表群集結合前後之變異增加量與未群集前變異量之比值,亦等於群數變動時之 R2增 減量,SPRSQ 越小代表合併群集不會造成變異量之增加,應進行合併。本研究採用 RMSSTD、R2、SPR 等 3 項指標,決定群集群數。 Step3 群內分佈狀態檢定 群內分佈狀態檢定之目的,係為選擇領先群集及落後群集之參考國家。根據 Pallant(2005)建議,當資料型態為偏態分佈時,中位數更能代表多數資料之狀況,因此 本研究依 Pallant (2005)建議之 95%顯著水準,對基礎建設各項指標進行常態性檢定,若 樣本數大於 51,採用 Kolmogorov- Smirnov 檢定;若樣本數小於 50,則採用 Shapiro- Wilk 檢定,判斷各項基礎建設指標是否為常態分佈。
23
Step4 計算領先及落後距離
根據群集結果,各群皆具有最高國家(Cn(max))、中間國家(Cn(med))及最低國家(Cn(min))
等 3 項特徵資料(如圖 5),最高國家(Cn(max))代表群集內數值最高之國家;中間國家(Cn(med)) 有兩種可能,若群內資料屬常態分佈,則中間國家代表群集之平均值、若群內資料非屬 常態分佈,則中間國家代表群集之中位數;最低國家(Cn(min))代表群集內數值最低之國 家。 Highest country (Cn(max)) Lowest country (Cn(min)) Middle country (Cn(med)) 圖 5 群集特徵資料
分群結果可能為偶數群(Even Cluster)或奇數群(Odd Cluster)2 種,Wang 分別定義不同群 數之領先距離及落後距離如圖 6。其中群數越大表示較為落後,群數越低則代表越為領 先。
Cn(max)
Cn(min) Cn(med) Cn-1(min) Cn-1(med) Cn-1(max)
short middle long Cluster n Cluster n-1 long middle short leading distances (LD) (LDL) (LDs) (LDM) behind distances (BD) (BDs) (BDM) (BDL) Cn(max)
Cn(min) Cn(med) Cn-2(min) Cn-2(med)Cn-2(max) short middle long Cluster n Cluster n-2 long middle short leading distances (LD) (LDL) (LDs) (LDM) behind distances (BD) (BDs) (BDM) (BDL) Cluster n-1 Cn-1(max) Cn-1(min)
(a)Odd Cluster (b)Even Cluster 圖 6 不同群數之領先距離及落後距離 1. 落後距離(behind distances):代表與領先國家之差異程度,距離越小越佳,可分為長、 中、短 3 種距離: 長距離(BDL):(Cn-1(med))-(Cn(med)),係為後群集與前群集中間國家之差異狀態,代表在一 般條件下,某國達到前群集中間國家水準應提升之距離,因此若某國落後距離高於 BDL, 則代表該國與領先國家差異極大,因此落後程度高。 中距離(BDM):(Cn-1(med))-(Cn-1(max)),係為後群集之最高國家與前群集中間國家之差異狀 態,代表在最佳條件下,某國達到前群集中間國家水準應提升之距離,因此若某國落後 距離少於 BDL然高於 BDM,則代表該國屬於後群集中競爭力較佳之國家,因此落後程
24 度中等。 短距離(BDS):(Cn-1(max))-(Cn-1(med)),係為前群集之最低國家與中間國家之差異程度,代 表某國由前群集之最低國家,變為群集內中間國家之距離,因此若某國落後距離少於 BDS,則該國仍屬於前群集,因此落後程度低。 2. 領先距離(leading distances):代表與落後國家之差異程度,距離越大越佳,亦分為長 (long)、中(middle)、短(short)3 種距離: 長距離(LDL):(Cn-1(med))-(Cn(med)),係為前群集與後群集中間國家之差異,代表某國由前 群中間國家變為與後群集中間國家之距離,因此若某國領先距離高於 LDL,則顯示該國 遠離後群集,屬於前群集國家,領先程度高。 中距離(LDM):(Cn-1(min))-(Cn(med)),係為前群集中間國家與後群集之最高國家之差異狀態, 代表在最差條件下,某國由前群國家變為後群中間國家之距離,因此若某國落後距離少 於 ADL然高於 ADM,則顯示該國仍屬於前群集,因此領先程度中等。 短距離(LDS):(Cn(max))-(Cn(med)),係為後群集中最高國家與中間國家之差異程度,代表某 國由群集內之最高國家,變為群集內之中間國家距離,因此若某國領先距離少於 LDS, 則該國極可能屬於後群集,因此領先程度低。 Step5 模糊統計
根據 STEP 4 之定義,Wang 分別計算 WCY 基礎建設 113 項指標之長、中及短距離, 再根據式(7),統計長、中及短距離之各組相對次數。Wang 設定之模糊統計分組(class), 係假設領先及落後距離之統計結果符合常態分佈,因此 3 STD 之涵蓋機率可幾乎包含全 部之統計結果(涵蓋機率為 99.7%),因此採用 3 STD 為分組界限值(fuzzy threshold),並 切割為 10 組,每組相距 0.3 STD。 μ(μ0) = lim n→∞ A∗ n … … … . . … … . … (7) μ(μ0):各組之相對次數 A*: 各組之出現次數 n: 最高出現次數
25
Step6 建立領先及落後之模糊隸屬函數
建立模糊隸屬函數之方式可分為 Intuition, Inference, Rank ordering, Angular fuzzy sets, Neural networks, Genetic algorithms, and Inductive reasoning 等 7 種,其中 Inductive reasoning 適用於可詳細定義輸入及輸出資料關聯性之情況(Sivanandam et al. 2007),因此 Wang 採用 Inductive reasoning 方式,決定模糊隸屬函數。模糊隸屬函數由 Core, Support and Boundary 三部分組成(如圖 7),且隸屬度之函數值(Membership value)介於 0~1。
μ(x) Core Support Boundary Boundary 1 圖 7 Membership Function 之組成 Part II:選擇基礎建設競爭力相似國家 傳統上以指標實際數值(或標準差)判斷兩個國家競爭力表現之差異時,實際數值無 法完全代表兩國之績效等級,亦即雖然指標數值不同,惟實際上兩國績效表現其實為相 似(等級相同,亦即領先落後程度相似),因此若僅以實際數值(或標準差)進行差異之判 斷,決策者很可能會誤以為相較於學習對象,我國之競爭力為劣勢,進而持續加強指標 之投資,影響重點投資方向之有效性。Wang 為克服上述問題,提出以模糊得分判斷國 家競爭力差異性,此種作法主要優點,在於決策者係根據指標相對狀態(領先落後程度) 判斷差異性,而非僅以指標之數值進行判斷。Wang 定義之國家基礎建設競爭力相似度, 代表被分析國家與其他國家在領先及落後得分之差異,兩國之差異越小,則代表兩國競 爭力組成越相似。茲說明選擇基礎建設競爭力相似國家之運算程序如下。
26 Step7 計算領先與落後距離 Wang 定義之領先及落後距離,代表對象國家與領先群集及落後群集之中間國家之 差異值,與 step4 之定義相同,中間國家可能有兩種數值,若群集檢定結果屬常態分佈, 採用平均值作為中間國家;若群內資料非屬常態分佈,則以中位數(median)代表中間國 家。本研究領先及落後距離之計算公式如式(8)及式(9)。
behind class =OCSTD-FCaverage or median0.3 ……(8) leading class =OCSTD-LCaverage or median
0.3 ……(9) OCSTD:目標國家之 STD FC average or median:第 1 群集平均值或標準差 LC average or median:最後群集平均值或標準差 假設某項指標最適群數分為 4 群(如圖 8),案例國家距離 Cluster 1 之平均值(或中位數) 中間國家之距離則稱為落後距離,案例國家距離 Cluster 4 中間國家之距離則稱為領先距 離。 C3(med) C1(med)
Cluster 4 Cluster 2 Cluster 1
object behind distances leading distances Cluster 3 圖 8 領先與落後距離判讀 Step8 計算領先及落後模糊度
根據 step6 及 step7 之結果,Wang 設定輸入及輸出資料為(x, y),其中 x 為落後距離 (或領先)距離和 y 為落後(或領先)之模糊程度(輸出),且 x 及 y 之隸屬函數圖形相同。根 據上述定義,Wang 建立模糊判斷規則如下:
Rule1: IF x is short, THEN y is short Rule2: IF x is middle, THEN y is middle Rule3: IF x is long, THEN y is long
27
在參考 Wang(1994)之解模糊化程序,決定領先及落後程度(如式(10)): 𝜇𝑜𝑖𝑖 = 𝜇𝐼𝑖 (𝑥) … … … . … (10)
式(4)中,oi表示輸出區域之規則 i,和 Ii
表示輸入區域規則 i。
解模糊化之方式,可分為 Max-membership principle、Centroid method、Weighted average method、Mean–max membership、Centre of sums、Centre of largest area, and First of maxima or last of maxima 等 7 種方式,Wang 選擇最常採用之 Centroid method 解模糊化。重心法 之計算公式如下(Wang 1994): 𝑦 =∑ 𝜇𝑂𝑖𝑦̅𝑖 𝑖 𝑀 𝑖=1 ∑𝑀𝑖=1𝜇𝑂𝑖𝑖 … … … (11) 式(11)中,y 代表領先(或)落後之模糊度, 𝑦̅𝑖 表示區域中心值,Oi (一個模糊區域的中心 點,在所有的點中它是最小的,代表一個區域中隸屬函數的隸屬度等於 1 的絕對值定義) 和 M 在模糊隸屬函數的數量基礎上,根據上述程序,即可計算一個國家在各項指標之 領先(leading fuzzy degree, LEFD)及落後模糊度(lagging fuzzy degree, LAFD)。
Wang 根據 step 7~8 依序計算出各國於各項指標之領先及落後模糊程度,惟領先模糊度 及落後模糊度代表之意義不同,領先模糊度大,代表該國與落後國家之差異越大,亦即 越具優勢;落後模糊度越大,則代表該國與領先國家之差異越大,亦即較為劣勢,因此 為使模糊程度之方向性一致,Wang 以式(12)對落後模糊度進行轉換。
調整後之落後模糊度(adjusted lagging fuzzy degree, ALAFD)=LAFDmax–LAFDij…(12)
式(12)中,LFADmax代表可能之最大落後模糊度(8.7),LFADij代表第 i 國在第 j 項指標之
28 Step9 計算國家差異程度 完成各國於各項指標之 LEFD 及 ALAFD 計算後,再以式(13)計算分析國家(本國) 與其他國家之 LEFD 及 ALAFD 累計變異量。 累計變異量(total variance)=√∑(𝑐𝑖− 𝑜𝑖)2………(13) 式(7)中,ci代表 c 國在第 i 項指標之 LEFD(或 ALAFD)模糊程度,oi代表分析國家 o 在 第 i 項指標之 LEFD(或 ALAFD)模糊程度。 Step10 選擇相似國家
Wang 以各國 LEFD 及 ALAFD 累計變異量為群集指標(群集分析之運算方式同 step2), 對全部國家進行分類,並累計變異量最小群集中,LEFD 及 ALAFD 累計變異量最小之 10 個國家為學習對象。 Part III:選擇相對劣勢指標 根據國家基礎建設組成之相似性分析結果,可定義出與我國高相似性、中相似性及 低相似性之國家,並作為選擇學習指標及學習目標之依據。茲說明選擇相對劣勢指標之 計算程序如下。 Step11 計算顯著差異之判斷界限 Wang 為更有效判斷相似國家與分析國家之差異性,以 95%之顯著水準為判斷界限, 亦即當分析國家在某項指標之 LEFD 及 ALAFD 時,優於或小於相似國家 2 倍標準差範 圍時,此項指標即為我國與學習國家具顯著差異之指標。相關計算公式如式(14)~(18)。 一個國家 LEFD(或 ALAFD)模糊程度之平均變異量(vcl) = 𝑣𝑐𝑡 𝑖 ………(14) 全部國家 LEFD(或 ALAFD)模糊程度平均變異量之平均值(ml) = ∑ 𝑣𝑐𝑙 𝑛 …………(15) 全部國家 LEFD(或 ALAFD)模糊程度平均變異量之標準差(sdl) = √ ∑(𝑣𝑐𝑙−𝑚𝑙)2 𝑛−1 …(16) LEFD(或 ALAFD)之顯著上限(ceiling) = 𝑚𝑐𝑙+ 2 × 𝑠𝑑𝑙………(17) LEFD(或 ALAFD)之顯著下限(floor) = −(𝑚𝑐𝑙+ 2 × 𝑠𝑑𝑙)………(18) 式(8)中,vct代表 c 國家 LEFD(或 ALAFD)之累計變異量,i 代表基礎建設競爭力之總指
29 標數;式(9)中,n 代表總國家數。 Step12 建立相對領先及落後模糊程度判斷矩陣 根據兩個國家之領先(落後國家)及落後(領先國家)模糊程度,以領先模糊程度為 X 軸,調整落後模糊程度為 Y 軸,繪製相對領先及落後模糊程度判斷矩陣(如圖 7(a)),其 中第 I 象限指標,代表相對學習國家,本國在該項指標之領先程度及調整後之落後程度 皆優於學習國家,亦即相較於學習國家,本國具有相對之優勢,因此定義為 S 空間;第 II 象限指標代表領先程度優於學習國家,然落後程度劣於對象國家,惟實際上此種情況 不可能發生,因此本研究稱第 II 象限為不發生空間;第 II 象限指標代表領先程度劣於 學習國家,然落後程度優於對象國家,惟實際上此種情況亦不可能發生,因此第 III 象 限亦為不發生空間;第 IV 象限指標,代表相對學習國家,本國在該項指標之領先程度 及調整後之落後程度皆劣於學習國家,亦即相對學習國家而言,本國具有相對之劣勢, 因此本研究定義為 W 空間。 Wang 分別於 S 空間及 W 空間標示 Step11 計算之顯著差異上下限(領先程度上下限 為 Xc、–Xc;落後程度上下限則為 Yc、–Yc),因此 S 空間及 W 空間亦可各分為 4 個區 域,其中第 I 象限包含 S1、S2、S3及 N 等區域、第 IV 象限包含 W1、W2、W3及 N 等區 域(如圖 9(b))。區域英文代表其屬於優劣勢指標,編號則代表優劣勢之程度(編號越大則 優劣勢程度越大),此外本研究為便於進行差異程度之計算,給予各區域指標劣勢程度, 數值越大則代表該空間指標之劣勢程度越高。各區域空間代表之意義如表 2。 III (−, +) 不發生空間 II (+, −) 不發生空間 I (+, +) 領先空間 (S) IV (−, −) 顯著空間 (W) 0 X Y S3 W3 0 X Y N N W1 W2 S1 S2 -yc yc xc -xc (a)區域意義 (b)區域空間定義 圖 9 相對領先及落後模糊程度判斷矩陣
30 表 2 相對領先及落後模糊程度判斷矩陣區域之意義 區域 劣勢 程度 界限值 說明 S1 4 (≧xc, ≦yc) 本國領先程度顯著大於學習國家,惟兩國落後程度相似。 S2 3 (≦xc, ≧yc) 兩國領先程度相似,惟本國落後程度顯著小於學習國家。 S3 1 (≧xc, ≧yc) 本國領先程度顯著大於學習國家,且本國落後程度顯著小於 學習國家。 N 2 (≦xc, ≦yc) (≧–xc, ≧– yc) 兩國領先及落後程度皆無顯著差異。 W1 5 (≧–xc, ≦– yc) 兩國領先程度相似,惟本國落後程度顯著大於學習國家。 W2 6 (≦–xc, ≧– yc) 本國領先程度顯著小於學習國家,惟兩國落後程度相似。 W3 7 (≦–xc, ≦– yc) 本國領先程度顯著小於學習國家,且落後程度顯著落後學習 國家。 S3區域指標代表本國領先程度顯著大於學習國家,且本國落後程度亦顯著小於學習 國家,亦即本國較接近領先國家,且亦顯著較優於落後國家,因此本國具有大幅度優勢 (劣勢程度:1);N 區域指標代表兩國領先及落後程度皆無顯著差異,亦即兩國表現相似 (劣勢程度:2);S2區域指標代表兩國領先程度相似,惟本國落後程度顯著小於學習國家, 亦即兩國雖然領先落後國家之程度相似,然本國表現較接近領先國家,因此本國具有中 幅度優勢(劣勢程度:3);S1區域指標代表本國領先程度顯著大於學習國家,惟兩國落後 程度相似,亦即兩國雖然落後領先國家之程度相似,然本國表現相對較佳(學習對象較 接近落後國家),因此本國具有小幅度優勢(劣勢程度:4)。 W1區域指標代表兩國領先程度相似,惟本國落後程度顯著大於學習國家,亦即兩 國雖然領先程度程度相似,然本國表現相對較差(學習對象較接近領先國家),因此本國 具有小幅度劣勢(劣勢程度:5);W2區域指標代表本國領先程度顯著小於學習國家,惟 兩國落後程度相似,亦即兩國雖然落後領先國家之程度相似,然本國表現較接近落後國 家,因此本國具有中幅度劣勢(劣勢程度:6);W3區域指標代表本國領先程度顯著小於 學習國家,且落後程度顯著落後學習國家,亦即本國表現較接近落後國家,且亦顯著較 接近落後國家,因此本國具大幅度劣勢(劣勢程度:7)。
31 Step13 分析相似國家與目標國家各項指標之差異程度 若僅以最相似之國家為學習對象,除可能忽略其他相對劣勢之指標外,亦無法完全 呈現本國競爭力之優勢及劣勢,因此 Wang 以最相似之 10 個國家為分析對象,分別繪 製 10 個相似國家之相對領先及落後模糊程度判斷矩陣,並決定各項指標之所屬區域及 劣勢程度,完成後再計算本國各項指標之平均劣勢程度,平均劣勢之數值意義如表 3。 表 3 平均劣勢之數值意義 平均 劣勢 程度 意義 投資策略 1 大幅度優勢 維持 2 表現相似 維持 3 中幅度優勢 維持 4 小幅度優勢 觀察 5 小幅度劣勢 加強 6 中幅度劣勢 加強 7 大幅度劣勢 加強 若平均劣勢程度<3,則表示本國在該項指標表現較具優勢,僅需維持即可;若平均 劣勢程度 3~5,則表示該項指標僅具小幅度優勢,因此需持續觀察;若平均劣勢程度≧5, 則表示該項指標為劣勢指標,需加強此類指標之投資。 Step14 建立劣勢指標學習地圖 根據 step11~13 之分析結果,可針對國家之劣勢指標建立學習地圖,其作法係先刪 除競爭力組成不相似之國家,提供本國決定學習國家及設定提升目標之參考(如表 4)。 表 4 劣勢指標學習地圖 Rank 國家 指標單 位 1 C1 5.00 2 C2 3 C3 4.72 4 C4 5 C5 6 C6 7 O 1.86
32 Step15 模式驗證-國家競爭力組成差異判斷 Wang(2013)比較傳統方法(以標準差或排名)與 Wang(2013)之模型分析,於國家競爭 力組成差異之判斷、學習對象及學習重點(劣勢指標)選擇結果之差異,以驗證模型之效 度。在下列以新加坡為例,說明透過領先及落後模糊程度計算模型,對於國家競爭力組 成差異判斷之效果。Wang(2013)先依標準差繪製新加坡及台灣基礎建設競爭力之雷達圖 (圖 10(a)),再以本研究建立之領先及落後模糊程度計算模型,分別繪製兩個國家之領先 模糊程度(圖 10(b))及落後模糊程度(圖 10(c))雷達圖。 (a)標準差 (b)領先模糊程度 (c)落後模糊程度 圖 10 台灣與新加坡之基本建設指標差異程度 圖 10(a)顯示,台灣在 4.1.04、4.1.06、4.1.11~4.1.19 等 10 項指標之標準差(亦可代表 其實際數值)低於新加坡,因此若僅以標準差作為判斷,會認為上述 10 項指標皆屬相對 落後指標,惟透過領先及落後模糊程度計算模型,台灣僅於 4.1.11 及 4.1.12 項指標領先 (落後國家)程度顯著小於新加坡,且亦僅有 4.1.11、4.1.12 及 4.1.19 等 3 項指標之落後(領 先國家)程度顯著小於新加坡,因此台灣較為劣勢之指標僅有 4.1.11、4.1.12 及 4.1.19 等 3 項,且其中 4.1.11 及 4.1.12 指標之劣勢程度最大。由上述分析可知,本模型可有效判 4.1.02 4.1.03 4.1.04 4.1.05 4.1.06 4.1.07 4.1.10 4.1.11 4.1.12 4.1.14 4.1.15 4.1.16 4.1.17 4.1.18 4.1.19 4.1.21 4.1.24 Taiwan Singapore 4.1.02 4.1.03 4.1.04 4.1.05 4.1.06 4.1.07 4.1.10 4.1.11 4.1.12 4.1.14 4.1.15 4.1.16 4.1.17 4.1.18 4.1.19 4.1.21 4.1.24 Taiwan Singapore 4.1.02 4.1.03 4.1.04 4.1.05 4.1.06 4.1.07 4.1.10 4.1.11 4.1.12 4.1.14 4.1.15 4.1.16 4.1.17 4.1.18 4.1.19 4.1.21 4.1.24 Taiwan Singapore