國
立
交
通
大
學
資訊科學與工程研究所
碩
碩
碩
碩
士
士
士
士
論
論
論
論
文
文
文
文
中 文 作 文 寫 作 輔 助 系 統
Chinese Essay Writing Auxiliary Systems
研 究 生:余思翰
指導教授:李嘉晃 教授
中
中
中
中文作文寫作輔助系統
Chinese Essay Writing Auxiliary Systems
研 究 生:余思翰 Student:Szu-Han Yu
指導教授:李嘉晃 Advisor:Chia-Hoang Li
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
中文作文寫作輔助系統
學生 : 余思翰 指導教授:李嘉晃 博士 國立交通大學資訊學院 資訊科學與工程研究所碩士班中文摘要
中文摘要
中文摘要
中文摘要
本文以數百篇指定題目的中學生文章為基底,實做出一個作文寫作輔助系 統。首先將作文語料庫的文章進行分解、重新整理,再利用處理過後產生的文字 片段拼湊出一篇新的、同為指定題目的作文。原型系統對語料庫文章的句子作切 割,並以接龍的方式來產生新的文章,接著對原型系統在架構及介面上加以改 良,改良後系統則是以關鍵詞串列作為新文章的內容架構,再提供填充字串讓使 用者完成一篇可閱讀的作文。兩個系統皆充分利用語料庫文章取材類似,句法偏 向簡短的特性,並且有機會產生一篇十分類似中學生所寫的作文,無論在題材、 或是句型方面都和語料庫中的文章十分相像。本文提出的系統仍在發展初段,仍 有改進空間,但已表達出一個作文寫作輔助系統可能的進行方式。
Chinese essay writing auxiliary systems
Student : Shin-Hung Lin Advisor:Prof. Chia-Hoang Lee
Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University
Abstract
In this paper, we propose and implement an auxiliary essay writing systems, which make use of hundreds of essays of some specific topic written by junior high school students. We decompose and reorganize the essay corpus into word segments, which will later be used to construct a new essay of the same topic. In the primitive system, each sentence in the corpus is partitioned into units. Users can select among these units to reforms a new essay by the way of solitaire. Then we continue to improve the system in framework and user interface. In the improved system, keyword lists are extracted from the corpus and stuffing strings are provided for the user to generate and modify a new human-readable essay. Both of two systems were made available by the features of similarity among essays in the corpus and the essays most constitute of shorter sentences. Each of the systems gets the chance to generate a
目錄
目錄
目錄
目錄
第一章 第一章第一章 第一章 、、、緒論、緒論緒論緒論 ...1 1.2 1.21.2 1.2 研究目的研究目的研究目的 ...1 研究目的 1.3 1.3 1.3 1.3 論文架構論文架構論文架構論文架構 ...2 第二章 第二章 第二章 第二章 、、、、相關研究相關研究相關研究相關研究 ...3 2.1 2.1 2.1 2.1 內容選擇內容選擇內容選擇內容選擇 ...3 2.2 2.2 2.2 2.2 斷詞與詞性標記斷詞與詞性標記斷詞與詞性標記斷詞與詞性標記 ...3 第三章 第三章 第三章 第三章 、、、、系統設計與實驗系統設計與實驗系統設計與實驗系統設計與實驗 ---- 接龍接龍接龍接龍 ...5 3.1 3.1 3.1 3.1 概念概念概念概念 ...5 3.2 3.2 3.2 3.2 前置作業前置作業前置作業前置作業 ...5 3.2.1 常用單元常用單元常用單元常用單元...5 3.2.2 句子分割句子分割句子分割句子分割...6 3.3 3.3 3.3 3.3 系統架構系統架構系統架構系統架構 ...8 3.3.1 初始單元集初始單元集初始單元集初始單元集 ...8 3.3.2 候選單元集候選單元集候選單元集候選單元集 ...9 3.3.3 候選單元串列集候選單元串列集候選單元串列集候選單元串列集 ...10 3.3.4 候選單元串列集排序候選單元串列集排序候選單元串列集排序候選單元串列集排序 ... 11 3.4 3.4 3.4 3.4 系統運行系統運行系統運行系統運行 ...13 3.5 3.5 3.5 3.5 實際操作與檢討實際操作與檢討實際操作與檢討實際操作與檢討 ...16 第四章 第四章 第四章 第四章 、、、、系統功能改良系統功能改良系統功能改良系統功能改良 ...18 4.1 4.1 4.1 4.1 概念概念概念概念 ...18 4.2 4.2 4.2 4.2 前置作業前置作業前置作業前置作業 ...18 4.2.1 關鍵詞關鍵詞關鍵詞關鍵詞...18 4.2.2 關鍵詞串列與填充字串關鍵詞串列與填充字串關鍵詞串列與填充字串關鍵詞串列與填充字串 ...20 4.3 4.3 4.3 4.3 系統架構系統架構系統架構系統架構 ...22 4.3.1 候選關鍵詞串列集候選關鍵詞串列集候選關鍵詞串列集候選關鍵詞串列集 ...22 4.3.2 候選填充字串集候選填充字串集候選填充字串集候選填充字串集 ...22 4.3.3 候選填充字串集排序候選填充字串集排序候選填充字串集排序候選填充字串集排序 ...24 4.4 4.4 4.4 4.4 系統運行系統運行系統運行系統運行 ...25 第五章 第五章 第五章 第五章 、、、、系統比較與討論系統比較與討論系統比較與討論系統比較與討論 ...28 5.1 5.1 5.1 5.1 系統改良成效系統改良成效系統改良成效系統改良成效 ...28 5.2 5.2 5.2 5.2 系統介面與操作系統介面與操作系統介面與操作系統介面與操作 ...29 第六章 第六章 第六章 第六章 、、、、未來工作與展望未來工作與展望未來工作與展望未來工作與展望 ...31 6.1 6.1 6.1 6.1 基礎功能改進基礎功能改進基礎功能改進基礎功能改進 ...316.2 6.2 6.2
圖
圖
圖
圖目錄
目錄
目錄
目錄
圖 圖 圖 圖 1 以最大長度分割法分割過的段落以最大長度分割法分割過的段落 ...8 以最大長度分割法分割過的段落以最大長度分割法分割過的段落 圖 圖 圖 圖 2 初始單元集的一部分初始單元集的一部分 ...8 初始單元集的一部分初始單元集的一部分 圖 圖 圖 圖 3 依據單元依據單元[每當依據單元依據單元每當每當每當 下課下課下課下課 時時時時]所產生的候選單元串列集所產生的候選單元串列集所產生的候選單元串列集所產生的候選單元串列集 ... 11 圖 圖 圖 圖 4 接龍系統的程式起始畫面接龍系統的程式起始畫面 ...14 接龍系統的程式起始畫面接龍系統的程式起始畫面 圖 圖 圖 圖 5 按下按下 S按下按下 TART鍵後便會顯示初始單元集鍵後便會顯示初始單元集...15 鍵後便會顯示初始單元集鍵後便會顯示初始單元集 圖 圖 圖 圖 6 選好初始單元選好初始單元,選好初始單元選好初始單元,按下,,按下按下 A按下 DD TO TEXT後的畫面後的畫面後的畫面後的畫面 ...16 圖 圖 圖 圖 7 不通順的文章片段不通順的文章片段 ...17 不通順的文章片段不通順的文章片段 圖 圖 圖 圖 8""""同學同學同學同學""""及及及""""喜歡及 喜歡""""對應的喜歡喜歡 對應的對應的對應的候選填充字串集候選填充字串集候選填充字串集候選填充字串集 ...24 圖 圖 圖 圖 9填充字串的各項參數填充字串的各項參數填充字串的各項參數填充字串的各項參數...25 圖 圖 圖 圖 10 第一個步驟第一個步驟第一個步驟第一個步驟 ---- 候選關鍵詞串列選擇候選關鍵詞串列選擇候選關鍵詞串列選擇候選關鍵詞串列選擇 ...26 圖 圖 圖 圖 11 第二個步驟第二個步驟第二個步驟第二個步驟 ---- 預設合成文章顯示預設合成文章顯示預設合成文章顯示預設合成文章顯示...26 圖 圖 圖 圖 12"下課下課下課下課"及及及及"通常通常通常通常"的候選填充字串的候選填充字串的候選填充字串的候選填充字串 ...27 圖 圖 圖 圖 13 程式主視窗介面操作程式主視窗介面操作。程式主視窗介面操作程式主視窗介面操作。。 ...29 。 圖 圖 圖 圖 14 關鍵詞串列選擇視窗介面操作關鍵詞串列選擇視窗介面操作 ...30 關鍵詞串列選擇視窗介面操作關鍵詞串列選擇視窗介面操作表格
表格
表格
表格目錄
目錄
目錄
目錄
表格 表格 表格 表格 1 部分關鍵詞列表部分關鍵詞列表 ...19 部分關鍵詞列表部分關鍵詞列表第一章
第一章
第一章
第一章、
、
、緒論
、
緒論
緒論
緒論
1
11
1.1
.1
.1
.1
研究動機
研究動機
研究動機
研究動機
自動文本產生在自然語言處理中是一個奧妙且有趣的範疇,在開始下筆寫 一篇作文之前必先費心構思整篇文章的主旨、論點、架構等文章內容的骨幹,在 寫作之時,則必須注意用字遣詞是否優美恰當,並加入各種修辭方法如譬喻、排 比、轉化等來加強讀者對文章的感受。寫作的學問是如此精深,致使各類寫作教 學書籍應需求而生。然而,對於一些容易發揮的中學生作文題目,學生寫出來的 文章立意取材皆十分相似,差別僅在於修辭的手法和文章的結構佈局。在一些實 驗後發現,不同文章中,主題相同的兩個句子,彼此接合後極有機會變成一句語 意語法皆通順,且在其他篇文章皆未曾出現過的新句子。因此本文便藉機探討以 文章接龍與改良後的合成方式來實做一個作文輔助系統,及其實用性及後續研 究。1
11
1.2
.2
.2
.2
研究目的
研究目的
研究目的
研究目的
如前文所述,寫作是一門深奧的藝術,一篇文章從內容構思、語句修飾到 最終的細節整理往往耗費不少時間。尤其取材必須兼顧靈活和不背離題目,若非 箇中老手勢必要花上許多工夫。因此,本文期盼藉著以"下課十分鐘"為題共 689 篇由中學生所撰寫的文章所構成的語料庫為基底,用語料庫文字片段擷取的方法 來做出一個半自動的作文寫作輔助系統,目的在輔助使用者能在短時間內產生一 篇通順的文章,當作自己寫作的範本,縮短作文寫作所需的時間。1.3
1.3
1.3
1.3
論文架構
論文架構
論文架構
論文架構
第一章為前言,敘述本文的研究動機與目的,提到本文系統之所以可行的 原因及基本概念。第二章為相關研究,說明自動文本產生的概念及實行的方法, 包括內容選擇(content selection)及斷詞系統。第三章將說明原型系統-接龍系統 所需的前置作業、基本架構以及系統運行的方式,並在最後一節探討系統在使用 上的缺點,改良後的系統-合成系統各項細目則在第四章一一說明。在第五章我 們將會檢討系統改良後的成效以及介紹程式的使用者介面。第六章我們探討系統 的可能的後續工作。第二章
第二章
第二章
第二章、
、
、相關研究
、
相關研究
相關研究
相關研究
本章節敘述相關研究及構想,包括自動文本產生議題探討。2
22
2.1
.1
.1
.1
內容選擇
內容選擇
內容選擇
內容選擇
內容選擇(content selection)是概念-文本產生中一個重要的部份,一個內容選 擇元件(content selection component)決定一個自然語言產生系統在文本產生時 該包含哪些內容,這類系統通常都會利用大型的資料庫,其中包含系統輸出所可 能涵蓋的內容。內容選擇最重要的一點是選出內容的共存性(coherence),讓產生 出來的文本能連成一氣["to produce a text that hangs together", McKeown, 1985]。 內容選擇可視為一種分類的工作[Duboue and McKeown ,(2003)],可利用一個文 本集合以及其對應固定某個領域的資料庫(表格型態)來學習資料庫中哪些項目 (entry)該成為輸出文本的內容。Regina Barzilay 和 Mirella Lapata(2003)為一 個足球賽事報告產生系統提出一個集合式的內容選擇模型(collective content selection),他們考慮資料庫中所有項目的子集合,並計算每個子集合的語意關聯 性,以分數最佳的子集合當作選擇的內容。 本文系統所使用的語料庫為數百篇同一題目的中學生作文。由於題目相 同,加上中學生的寫作能力差距不會太大,使得改良後系統的內容選擇工作較為 輕鬆,我們萃取出語料庫文章的關鍵詞串列成為輸出文章的內容骨幹。2
22
2.
..
.2
22
2
斷詞
斷詞
斷詞
斷詞與詞性標記
與詞性標記
與詞性標記
與詞性標記
英文中最小的語意單位為詞(word),詞由字母(letter)所組成,在一個句子 中,每個詞之間以空白隔開;而在中文句子中通常不存在任何空白,所有中文字(Chinese character 相當於英文 letter)彼此相鄰,故須先進行斷詞工作,將句子分 割為一串詞(相當於英文 word),之後便可如同英文一般進行詞性標記的工作。斷 詞與詞性標記是自然語言處理中基礎且重要的一部份,機器翻譯、資訊擷取、摘 要製作及自動作文評分系統等研究都需利用斷詞及詞性標記處理後的結果來進 行下一步動作,故斷詞的結果的正確率對研究成果有直接影響。本系統使用中央 研究院資訊科學研究所詞庫小組中文斷詞系統 1.0 版作為斷詞的工具,其正確率 在 95%-96%間[http://ckipsvr.iis.sinica.edu.tw/apply.htm]。
第三章
第三章
第三章
第三章、
、
、
、系統設計與實驗
系統設計與實驗
系統設計與實驗
系統設計與實驗
-
-
-
-
接龍
接龍
接龍
接龍
3.1
3.1
3.1
3.1
概念
概念
概念
概念
文字接龍是指從目前已經有的字串中猜測決定下一個該出現的字(詞),如果 每次只決定一個字(詞),則字串長度每次增加一,如此接龍進行的速度將十分緩 慢。每次決定的字(詞)數愈多,接龍的速度愈快。為了保持每次接龍語意上的完 整,本文定義"常用單元",即是在寫作時經常重複使用的文字片段,像是「最 快 樂 的 時間」、「活動 一下 筋骨」等常用用語。每次接龍決定一至多個常用單元 不僅可讓接龍速度加快,也較符合視覺上的感受。3.2
3.2
3.2
3.2
前置作業
前置作業
前置作業
前置作業
接龍系統所採用的作文語料庫為 689 篇中學生作文,作文的題目為"下課十 分鐘",每一篇皆經過人工批改,依文章的內容分為 1 ~ 6 級分,各級分的篇數依 序為 45、128、210、208、91、7 篇,經觀察後發現 1、2 級分的文章離題情況嚴 重,錯字繁多且較多不通順之語句,3、4 級分的文章語句雖較通順但內容較不 豐富,故本系統僅採用 5 級分以上的文章作為資料庫,累計共 98 篇。所有文章 皆經過斷詞處理及詞性標記,我們以 ES 表示經過斷詞及詞性標記處理過後的作 文語料庫。3.
3.
3.
3.2
22
2.
..
.1
11
1
常用單元
常用單元
常用單元
常用單元
本系統定義在作文語料庫中出現頻率大於等於 2 的文字片段為常用單元。 我們定義在經過斷詞處理後的文章中連續 n 個詞的序列為以詞為底的 n-gram(在
本文中皆簡稱為 n-gram),其長度為 n;我們用 Gram(S,n)表示句子 S 中所有 n-gram 所成的集合; Gram(S,m,n) = i m n=
U
...Gram S i
( , )
表示不同長度 n-gram 的集合。 以下列句子為例: 原 原句句::好好不不容容易易的的熬熬過過了了這這四四十十五五分分鐘鐘。。 S S::好好不不容容易易 的的 熬熬過過 了了 這這 四四十十五五 分分鐘鐘 。。 G Grraamm((SS,,22))::{{ 好好不不容容易易 的的,, 的的 熬熬過過,, 熬熬過過 了了,, 了了 這這,, 這 這 四四十十五五,, 四四十十五五 分分鐘鐘 }} G Grraamm((SS,,33))::{{ 好好不不容容易易 的的 熬熬過過,, 的的 熬熬過過 了了,, 熬熬過過 了了 這這,, 這 這 四四十十五五 分分鐘鐘 }} G Grraamm((SS,,22,,33))==GGrraamm((SS,,22)) ∪∪ GGrraamm((SS,,33)) 將作文語料庫中每一篇文章中的每一個句子(以逗號、句號、分號及驚嘆號 為準)的 n-gram set 聯集起來並紀錄頻率,形成一個作文語料庫的 total n-gramset,記為 Gram(ES,m,n) =
( , , )
S ESGram S m n
∈U
由於作文資料庫總字數並不多,無法確實反應每個 n-gram 的使用情形,故 本系統將中研院平衡語料庫 3.1 版納入參考,Gram(ES,m,n)中每個 n-gram 的總頻 率為其分別在作文語料庫及平衡語料庫中出現的頻率的總和,我們以 freq(g)表示 n-gram g 的頻率。最後,保留 Gram(ES,m,n)中頻率大於 1 的 n-gram 成為常用單 元集並記為 Gram_Dict。校][最 快樂][的 一段 時間],分割法並不唯一。長度愈長的單元所包含的語意 愈完整,我們希望將句子切割成較少的單元(每個單元會較長),因此,本系統 採用最長長度分割法來完成語料庫的句子分割。 最大長度分割法演算法如下: 1 2 3 { ( , 2, min{ , 6}) _ _ _ { , ( ) max _len( )} unit in _ _ with max frequence
} 1 n u h u t h t h t S w w w w Do
FU Gram S n Gram Dict
Max Len U U U FU length U FU m Max Len U S u m u u u u u = = ∩ = ∈ = = = L 遞迴處理 及 直到 及 小於
S表示一個經過斷詞處理的句子,max_len(G)為n-gram set G中所有長度最
長的n-gram的集合,max_freq(G)則代表G中頻率最高的n-gram,以S = "這 就 是 我 下課 十 分鐘 所得 到 歷險記"為例,將 S 切割成 Gram(S,2,6)後,長度最 長且存在於 Gram_Dict 的單元為[下課 十 分鐘],以此對 S 作分割後可得u = "h 這 就是 我",m = [下課 十 分鐘],u u = "所得 到 歷險記",將視為另一個新t 的句子處理,此時 S = m ,因此u u 與h u 皆為長度為零的空字串,遞迴處理結束。t 對作文語料庫中每一篇文章所有句子做分割後可得到分割好的作文語料庫 PES,一篇分割好的文章可表示成 1 2 n
pes
=
u u
L
u
,我們用unit(i,j)表示第i篇分 割好文章中的第j個單元。圖1為一篇語料庫作文的第一段經過分割後的樣子。圖 1 以最大長度分割法分割過的段落
3.3
3.3
3.3
3.3
系統架構
系統架構
系統架構
系統架構
接龍系統架構可分為初始單元集的生成和接龍所必須的候選單元集的產 生,以及最後供使用者選擇的候選單元串列集。3.3.1
3.3.1
3.3.1
3.3.1
初始單元集
初始單元集
初始單元集
初始單元集
接龍系統是由一個最初的單元開始,不斷往後接直到文章完成為止。我們 知道一篇作文的各段落有其規範的寫法(如常見的起、承、轉、合),若將作文 語料庫中後段的單元當作起始單元,產生的文章結構較不完整、自然。所以,我 們將分割好的作文語料庫中每一篇第一句話的第一個單元蒐集起來成為初始單 元集,記為Ini_Units。初始單元集將提供使用者作文接龍的第一個單元,圖二顯 示初始單元集中的第一到九項。
3.3.2
3.3.2
3.3.2
3.3.2
候選單元集
候選單元集
候選單元集
候選單元集
接龍的概念是參考已存在的文字片段來決定下一個要接在其後的詞(在本 系統中為單元),故系統必須提供一個機制根據前文決定一組可能適合當作接續 的單元組,我們稱這組單元為候選單元集。給定一個作文單元u,一個直覺的方 法是在切割好的作文語料庫中找出所有最後一個詞跟u的最後一個詞相同的單 元,將這些單元的下一個單元蒐集起來成為候選單元集,但中文的文法不像英文 等語文那樣嚴謹,我們可以利用中文模稜兩可的特性放寬接龍的條件,如此可避 免接出來的文章可能只是語料庫中的某篇作文而已,因此我們不限制最後一個詞 要跟u的最後一個詞相同,只要一個單元包含的詞和u包含的詞交集非空,便把 該單元的下一個單元視為候選單元。定義單元u及其對應的候選單元集為
{
}
( ) u ( , ) (pre_unit( ))u ( ) 0, ,Candidate u = c =unit i j Words c ∩Words u > for all i j
Words(u)為單元 u 所包含的詞,pre_unit(unit(i,j))= unit(i,j-1)。也就是在分割
好的作文語料庫中搜尋所有其Words集合和Words(u)交集個數大於0的單元,將 這些單元的下一個單元蒐集起來便是 Candidate(u)。假設 u = [每當 下課 時], Words(u) = {每當,下課,時},作文語料庫中所有與Words(u)交集大於等於1的單 元及其下一個單元包括: u unniitt((11,,00))uunniitt((11,,11)) ==[[每每當當 下下課課 時時]][[就就是是]] u unniitt((4477,,2211))uunniitt((4477,,2222)) ==[[此此 時時 的的]][[心心 都都]] u unniitt((2266,,55))uunniitt((2266,,66)) ==[[下下課課 時時]][[大大家家 都都]] u unniitt((2244,,1133))uunniitt((2244,,1144)) ==[[下下課課 時時]][[每每 個個 人人 都都]] u unniitt((77,,00))uunniitt((77,,11)) ==[[下下課課 時時]][[同同學學 紛紛紛紛]] … ……… … ………
陰 陰影影部部份份蒐蒐集集起起來來便便是是CCaannddiiddaattee((uu))。。
3.3.3
3.3.3
3.3.3
3.3.3
候選單元串列集
候選單元串列集
候選單元串列集
候選單元串列集
如果直接使用候選單元集,那麼每接一次字串長度會增加1單元的長度(2 到6 個詞),經實際操作後發現,要完成一篇文章,使用者選擇的次數將十分頻 繁。要減少使用者挑選候選串列集次數的方法便是增加每個候選單元的長度,我 們定義長度為n的候選單元串列集由候選單元集延伸而成,一個長度n的候選單 元串列為連續n個在原文中相鄰的單元,記為
( , )
{
( , )
( ,
1)
( ,
2)
( ,
1) |
( , )
( )
}
Candidate u n
unit i j unit i j
unit i j
unit i j
n
unit i j
Candidate u
=
+
+
+
−
∈
L
n為1的候選單元串列集就是候選單元集。候選單元串列集的長度關係到接 龍速度的快慢。根據對切割好的作文語料庫的觀察,一個句子約略由三個單元組 成,因此我們將候選單元串列集長度設為3,這樣接龍便會以大概一次接一句話 的速度進行。同樣以u = [每當 下課 時]為例: C Caannddiiddaattee((uu,,33))=={{ u unniitt((11,,11))uunniitt((11,,22))uunniitt((11,,33)) ==[[就就是是]][[我我 最最 期期待待 的的]][[時時候候]] u unniitt((4477,,2222))uunniitt((4477,,2233))uunniitt((4477,,2244))==[[心心 都都]][[有有如如]][[平平原原 上上]] u unniitt((2266,,66))uunniitt((2266,,77))uunniitt((2266,,88)) ==[[大大家家 都都]][[打打成成一一片片]][[、、]]
} } 圖3顯示依據單元[每當 下課 時]所產生的候選單元串列集排序過後的前9項, 下一節將提到排序的方法。 圖 3 依據單元[每當 下課 時]所產生的候選單元串列集
3.3.4
3.3.4
3.3.4
3.3.4
候選單元串列集排序
候選單元串列集排序
候選單元串列集排序
候選單元串列集排序
不是每個候選單元串列都可以和已存在的單元串列完美結合,不良的接龍 狀況包括:語句不通順或無意義以及和已存在的單元串列產生語意上的矛盾。而 候選單元串列集往往包含數十個選項,使用者必須一一查看哪些選項適合接在已 存在的單元串列之後,十分費時及傷神。若能對候選單元串列集事先作排序,將 接龍效果較好的候選單元串列排在較前面,讓使用者只需觀看前幾項便可挑出適 合的選項,將可提高系統的實用性與便利性。排序的方法有許多種,一個直覺的 想法是:一個候選單元串列和已存在單元串列的契合度可由此候選單元串列在原 文中的前文和已存在單元串列的相似度來略為判斷,簡單的實做方法就是計算已 存在單元串列最後一個單元和候選單元在原文中前一個單元的交集。假設目前已 存在的單元串列為Cur_Unit_List:
u u u
1 2 3L
u
n, 而 Candi_Unit_List =cu cu
1 2L
cu
m ∈ Candidate(u ,m) n 為候選單元串 列集中的一個串列,定義1
( _ _ ) (pre_unit( )) ( ) _ _
n
S Candi Unit List Words cu Words u
for a given Cur Unit List
= ∩ 為候選單元串列Candi_Unit_List相對於已存在的單元串列Cur_Unit_List的 語意關聯分數,也就是在蒐集Candidate(un)的過程中,用以挑選符合條件的單元 的公式所得到的值。依據語意關聯分數對候選單元串列集作排序,如此一來便可 減輕使用者挑選的負擔。 假設Cur_Unit_List = [每當 下課 時](un = [每當 下課 時]), Candi_Unit_List = [大家 都][打成一片][、] S S(([[大大家家 都都]][[打打成成一一片片]][[、、]])) = =SS((uunniitt((2266,,66))uunniitt((2266,,77))uunniitt((2266,,88)))) = =||WWoorrddss((pprree__uunniitt((uunniitt((2266,,66))))))∩∩WWoorrddss((uunn))|| = =||WWoorrddss(([[下下課課 時時]]))WWoorrddss(([[每每當當 下下課課 時時]]))|| = =22 而Candidate(u ,3)n 內各選項依照S分數排序後順序為: [ [就就是是]][[我我 最最 期期待待 的的]][[時時候候]] [ [同同學學 紛紛紛紛]][[離離開開]][[自自己己 的的 座座位位]] [ [大大家家 都都]][[打打成成一一片片]][[、、]] [ [每每 個個 人人 都都]][[好好像像 從從]][[鬼鬼門門關關]] [ [心心 都都]][[有有如如]][[平平原原 上上]]
3.4
3.4
3.4
3.4
系統運行
系統運行
系統運行
系統運行
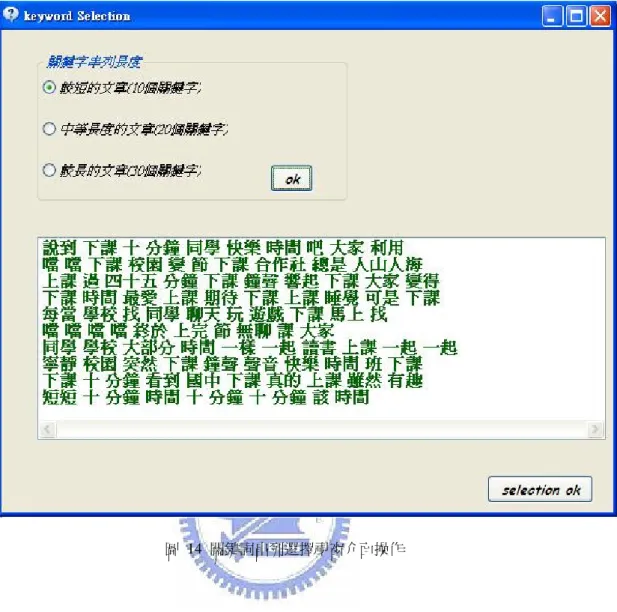
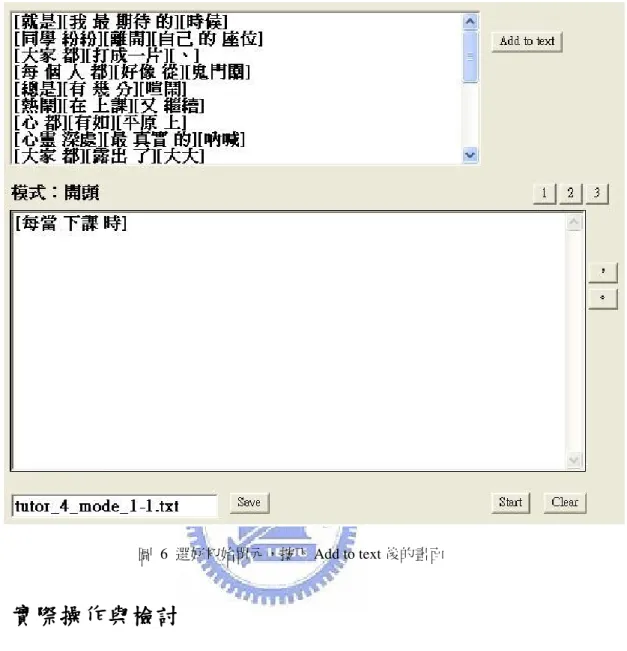
作文接龍一開始讓使用者從 Ini_Units挑選一個初始單元作為接龍的起始, 設為 Cur_Unit_List。接來下便依據Cur_Unit_List 最後一個單元產生一組候選單 元串列集供使用者挑選,將使用者選定的候選單元串列附加到 Cur_Unit_List 之 後,不斷重覆此過程直到接龍文章完成(由使用者自行判斷是否完成)。圖表4、5、 6大致說明系統運作流程:系統一開始的畫面如圖4所示,接龍模式分為開頭、 中段和結尾,分別經由標示為 1、2、3 的按鍵來切換;標示為","及"。"的按鍵 則是讓使用者在文章中加入逗號或句號;Save 按鍵可將接龍的文章存成以按鍵 左邊文字方塊內所顯示的文字檔;Start 鍵開始一篇新的接龍,而 Clear 鍵則清除 所有顯示,按下 Start 鍵後左側文字方塊便會顯示初始單元集(如圖 5 所示),點 選其中一項,再按下 Add to Text 鍵後,所選之單元串列便會加入在下方的文字 方塊內,同時重新顯示下組候選單元串列(依據所選之串列,如圖 6 所示),使用 者藉由循環來完成接龍文章。圖 6 選好初始單元,按下 Add to text 後的畫面
3.5
3.5
3.5
3.5
實際操作與檢討
實際操作與檢討
實際操作與檢討
實際操作與檢討
唯有實際操作才能真實地判斷出一個系統的好壞,並找出系統在背景理論 和使用界面上的優缺點,接龍系統為作文輔助寫作系統一個初步的實現,因此仍 有許多需要改進的地方。在不斷反覆操作系統之後,可以歸納出數個必須改進的 地方。首先,系統缺乏主題導向功能,在系統顯示出下一組候選單元串列集之前 使用者完全無法預知接龍文章接下來究竟會往何處發展,不能事先瞭解作文內容佳的選項往前移,但仍有可能唯一能使前後文通暢的選項還是排在較後面,如果 限制串列集的元素個數可能會讓接龍無法順利進行,這導致使用者必須逐一仔細 觀看每個選項並仔細比對檢查前後文,如此一來,要將文章完成必須花上不少時 間,作文輔助系統的目的便是要讓使用者輕鬆的完成一篇文章,因此,這部份也 必須做調整。此外,另一個需要調整的是:候選單元串列集內的所有選項皆無法 與前文配合,就像走進死胡同一般,這種情況一旦發生,使用者只能選擇重新開 始,並不是每次都能接出一篇自然的文章。圖7為一段不通順的接龍片段,文章 前半還算流暢,但後半便不知所云,即是所有選項皆無法與前文搭配的後果。 圖 7 不通順的文章片段
第四章
第四章
第四章
第四章、
、
、系統
、
系統
系統功能
系統
功能
功能改
功能
改
改良
改
良
良
良
第三章說明了作文寫作輔助系統-接龍系統的概念、實作以及操作檢驗, 在本章中,我們將針對3.5節提到的缺點進行改良。在相關研究中指出,文章的 生成通常需要兩個階段,內容選擇以及連結所選的內容,此一概念亦可套用在作 文寫作輔助系統上,設計出適合本系統內容選擇和連結的演算法,系統也將改以 合成的方式進行。4
44
4.
..
.1
11
1
概念
概念
概念
概念
自動文本產生系統中通常分為兩個部份,第一部份是挑選文本的材料,也 就是文章的主要內容概念,目的是產生文章的骨幹;第二部份則是句子完成,是 指將概念延伸成為完整的句子,就像是為骨幹填上血肉。改良系統將作文語料庫 中所包含的關鍵詞視為一篇作文的主要概念,定義了關鍵詞後,對於任何關鍵詞 串列中的兩個相鄰關鍵詞,便可在整個作文語料庫中搜尋可填入其中的字串達到 文章合成的功能。我們先對作文語料庫中的關鍵詞作定義,接著將語料庫中的每 篇文章分離成關鍵詞串列和填充字串兩部份,成為系統可利用的格式。4.2
4.2
4.2
4.2
前置作業
前置作業
前置作業
前置作業
本系統同樣需利用經過斷詞處理和詞性標記的作文語料庫,並將3、4集分 的文章加入,共506篇。庫和作文語料庫的字數比例懸殊,因此不能單憑在這兩個語料庫中出現的頻率來 判定一個詞是否為關鍵詞,像是"同學"在平衡語料庫中的頻率1640,高於作文語 料庫中的頻率948,但幾乎每篇作文都會寫到"同學",而平衡語料庫中僅有一小 部份比例的文章提到"同學",因此"同學"應該視為關鍵詞。但若將頻率除以語料 庫總字數,則會由於兩個語料庫懸殊的字數比例而導致幾乎每個詞都是關鍵詞。 若以詞性來看,許多作文語料庫包含的名詞如:學校、操場、老師、教室、廁所; 形容詞如:水洩不通、快樂、大排長龍等,均與題目密切相關,可當作關鍵詞, 而部分功能詞如:雖然、就 出現的頻率也相對較高,同樣可視為關鍵詞,但一 些名詞如:音樂、噪音僅在一兩篇文章中出現;大部分功能詞如:的、地、在等 並不適合當作關鍵詞,因此,光是以詞性來判斷是否為關鍵詞似乎也並不準確。 我們發現把作文語料庫和平衡語料庫中的所有詞彙分別蒐集起來並將其依照出 現的頻率排序,觀察一個詞彙分別在兩個語料庫中的排名,較能準確顯示該詞彙 在兩個語料庫中的使用傾向,因此我們利用這項特徵來挑出所有的關鍵詞,在經 過一些觀察後,我們將邊界值設為100是可行的,只要在平衡語料庫中的排名減 去在作文語料庫的排名差距大於100便可視為關鍵詞。但如果一個詞在兩個語料 庫中出現的頻率都不高時,由於平衡語料庫的詞彙數數倍於作文語料庫,其在兩 者中的排名差距必定懸殊,造成低頻詞都會成為關鍵詞,這並不合理,因此我們 僅取前300個詞為關鍵詞。表格1為部份關鍵詞顯示。 表格 1 萃取出來的關鍵詞組的部份顯示 關鍵詞 關鍵詞關鍵詞 關鍵詞 詞性詞性詞性詞性 排名排名排名排名 (平衡語料庫平衡語料庫平衡語料庫平衡語料庫) 排名 排名排名 排名 (作文語料庫作文語料庫) 作文語料庫作文語料庫 下課 VH 6359 2 , COMMACATEGORY 695 4 分鐘 Nf 978 8 十 Neu 334 9 時間 Na 132 17 學生 Na 123 19
上課 VA 1347 25 同學 Na 351 26 老師 Na 194 27 教室 Nc 1479 28 大家 Nh 150 33 玩 VC 680 36 些 Nf 273 39 。 PERIODCATEGORY 94818 40 合作社 Nc 3031 41 就是 Cbb 630 48 有的 Neqa 570 49 校園 Nc 711 52 去 VCL 288 54 噹 D 18776 57
4.2.2
4.2.2
4.2.2
4.2.2
關鍵詞串列
關鍵詞串列
關鍵詞串列與填充字串
關鍵詞串列
與填充字串
與填充字串
與填充字串
定義關鍵詞之後,便可對作文語料庫中的每一篇文章作關鍵詞與填充字串 作分離的動作。作法是先標記一篇文章中的關鍵詞,然後將這些關鍵詞萃取出來 形成一個關鍵詞串列;而兩個關鍵詞之間的其他詞則標記成這兩個關鍵詞所對應 的填充字串。關鍵詞串列代表一篇文章的骨幹,每篇語料庫文章可對應到一個關 鍵詞串列,但一串關鍵詞串列卻可能對應到多篇文章;而兩個關鍵詞所對應的填 充字串則代表這兩個關鍵詞如何可銜接成一個可閱讀的句子。對所有作文語料庫 的文章完成分離後,便可找出任意兩個關鍵詞間的所有填充字串。我們用 Keyword_list(i)表示從分離好的作文語料庫中第 i 篇文章萃取出來的關鍵詞串列;
這 這((NNeepp)) 短短短短短短短短短短短短短短短短((VVHH)) 的的((DDEE)) 十十十十十十十十((NNeeuu)) 分分分分分分分分鐘鐘鐘鐘鐘鐘鐘鐘((NNff)) ,,對對((PP)) 每每((NNeess)) 個個((NNff)) 人 人((NNaa)) 來來((DD)) 說說((VVEE)) 或或多多或或少少((DD)) 都都((DD)) 有有((VV__22)) 一一定定((AA)) 用用處處((NNaa))。。不不同同 ( (VVHH)) 的的((DDEE)) 人人((NNaa)) 對對((PP)) 時時時時時時時時間間間間間間間間((NNaa)) 快快慢慢((NNaa)) 有有((VV__22)) 不不同同((VVHH)) 感感受受 ( (NNaa)) ,,在在((PP)) 這這((NNeepp)) 十十十十十十十十((NNeeuu)) 分分分分分分分分鐘鐘鐘鐘鐘鐘鐘鐘((NNff)) 充充實實((VVHHCC)) 自自己己((NNhh)) 的的((DDEE)) ;;在在 ( (PP)) 這這((NNeepp)) 十十十十十十十十((NNeeuu)) 分分分分分分分分鐘鐘鐘鐘鐘鐘鐘鐘((NNff)) 得得過過且且過過((VVHH)) 的的((DDEE)) ,,你你((NNhh)) 問問((VVEE)) 我我 ( (NNhh)) 該該該該該該該該((DD)) 做做((VVCC)) 什什麼麼((NNeepp)) —— 時時時時時時時時間間間間間間間間((NNaa)) 是是((SSHHII)) 自自己己((NNhh)) 的的((DDEE)) ,,好好好好好好好好 好 好 好 好 好 好 好 好((VVHH)) 把把把把把把把把握握握握握握握握((VVCC)) 吧吧吧吧吧吧吧吧((TT)) !! 將關鍵詞和期間的填充字串分離後可得到關鍵詞串列: S S00 短短短短短短短短短短短短短短短短((VVHH)) SS11 十十十十十十十十((NNeeuu)) SS22 分分分分分分分分鐘鐘鐘鐘鐘鐘鐘鐘((NNff)) SS33 時時時時時時時時間間間間間間間間((NNaa)) SS44 十十十十十十十十((NNeeuu)) S S55 分分分分分分分分鐘鐘鐘鐘鐘鐘鐘鐘((NNff)) SS66 十十十十十十十十((NNeeuu)) SS77 分分分分分分分分鐘鐘鐘鐘鐘鐘鐘鐘((NNff)) SS88 該該該該該該該該((DD)) SS99 時時時時時時時時間間間間間間間間((NNaa)) SS1100 好好好好好好好好 好 好 好 好 好 好 好 好((VVHH)) SS1111 把把把把把把把把握握握握握握握握((VVCC)) SS1122 吧吧吧吧吧吧吧吧((TT)) SS1133 以及期間所對應的填充字串,null string為空填充字串: S S00::這這((NNeepp)) S S11::的的((DDEE)) S S2:2:nnuullllssttrriinngg S S33::,,對對((PP)) 每每((NNeess)) 個個((NNff)) 人人((NNaa)) 來來((DD)) 說說((VVEE)) 或或多多或或少少((DD)) 都都((DD)) 有有((VV__22)) 一一 定 定((AA)) 用用處處((NNaa)) 。。不不同同((VVHH)) 的的((DDEE)) 人人((NNaa)) 對對((PP)) S S44::快快慢慢((NNaa)) 有有((VV__22)) 不不同同((VVHH)) 感感受受((NNaa)) ,,在在((PP)) 這這((NNeepp)) S S5:5:nnuullllssttrriinngg S S66::充充實實((VVHHCC)) 自自己己((NNhh)) 的的((DDEE)) ;;在在((PP)) 這這((NNeepp)) S S7:7:nnuullllssttrriinngg S S88::得得過過且且過過((VVHH)) 的的((DDEE)) ,,你你((NNhh)) 問問((VVEE)) 我我((NNhh)) S S99::做做((VVCC)) 什什麼麼((NNeepp)) —— S S1100::是是((SSHHII)) 自自己己((NNhh)) 的的((DDEE)) ,, S S111:1:nnuullllssttrriinngg S S1122::nnuullllssttrriinngg S S1133::nnuullllssttrriinngg
處理過後的作文語料庫,每篇作文詞數平均為298.6,標準差為62;平均關 鍵詞數為74.6,標準差為17.9;平均關鍵詞密度為0.25,標準差為0.04,可看出 詞數和關鍵詞數約成比。
4.3
4.3
4.3
4.3
系統架構
系統架構
系統架構
系統架構
4.3.1
4.3.1
4.3.1
4.3.1 候選關鍵詞串列
候選關鍵詞串列
候選關鍵詞串列集
候選關鍵詞串列
集
集
集
如前文所述,一個關鍵詞串列可視為一篇文章的骨幹,由於每篇文章的關 鍵詞密度相差不大,因此一篇文章愈長,其所萃取出的關鍵詞串列也愈長,所以 我們可藉由關鍵詞串列的長短來控制合成文章的長度(總字數)。改良系統提供三 種關鍵詞串列長度:較短(10 個關鍵詞)、中等(20 個關鍵詞)、較長(30 個關鍵 詞)供使用者選擇。候選關鍵詞串列的產生的方式是:從已經分離好的作文語料 庫中隨機挑選數個關鍵詞串列,並擷取每個串列的前n個詞。我們將選出來的關 鍵詞串列記為 Sel_list,其中第 i 個關鍵詞記為 Sel_list(i),直接從語料庫作文萃 取關鍵詞串列的好處是可以確保一個關鍵詞和其左右鄰近其他關鍵詞在語意上 的關聯性,這避開了兩個關鍵詞因關聯性不高而無法連結成一個句子的窘境。
4.3
4.3
4.3
4.3.2
.2
.2
.2
候選填充字串
候選填充字串
候選填充字串集
候選填充字串
集
集
集
有了關鍵詞串列,便可為這個串列填入填充字串,改良系統提供的方法是:
( _ , , 1) { _ ( )[ , 1] _ ( , ) _ ( ) & & _ ( , 1) _ ( 1) 1 length( _ ( )) }
SCandi Sel list i i S string k j j
Keyword list k j Sel list i Keyword list k j Sel list i
j Keyword list k for all k
+ = + = + = + = L 舉例來說,假如Sel_list為: 同 同 同 同 同 同 同 同學學學學學學學學((NNaa)) 喜喜喜喜喜喜喜喜歡歡歡歡歡歡歡歡((VVKK)) 短短短短短短短短短短短短短短短短((VVHH)) 下下下下下下下下課課課課課課課課((VVHH)) 時時時時時時時時間間間間間間間間((NNaa)) 吧吧吧吧吧吧吧吧((TT)) 節節節節節節節節((NNff)) 課課課課課課課課((NNaa)) 十十十十十十十十 ( (NNeeuu)) 分分分分分分分分鐘鐘鐘鐘鐘鐘鐘鐘((NNff)) 可填入第0個詞"同學"和第1個詞"喜歡"之間的填充字串集為 S SCCaannddii((SSeell__lliisstt,,00,,11)) == {{ S S__ssttrriinngg((33))[[1122,,1133]] == ""便便 帶帶 著著 所所"" S S__ssttrriinngg((9944))[[1199,,2200]] == ""都都 很很"" S S__ssttrriinngg((229977))[[22,,33]] == ""都都 非非常常"" S S__ssttrriinngg((229977))[[8877,,8888]] == ""都都"" S S__ssttrriinngg((447700))[[1122,,1133]] == ""所所 期期待待 的的 。。 我我"" … ……… … … } } 圖 8 為可填在"同學"、"喜歡"兩個關鍵詞之間的候選填充字串集的一部份,圖中 為排序過後的結果,no words表示兩個關鍵詞間可不用再填入任何文字。
圖 8 "同學"及"喜歡"對應的候選填充字串集
4.3.3
4.3.3
4.3.3
4.3.3
候選填充字串集
候選填充字串集
候選填充字串集排序
候選填充字串集
排序
排序
排序
如同候選單元串列集,我們也對候選填充字串集作排序的動作以減輕使用 者的負擔。考慮Sel_list(k)和Sel_list(k+1)及其所對應,屬於SCandi(i,i+1)的一個 填充字串S_string(i)[j,j+1],在直覺上我們認為關鍵詞串列Keyword_list(i)的第j+2 個關鍵詞若與 Sel_list(k+2)相同,則此填充字串在語意上與現有串列搭配度應該 與兩者不相同時來的好。因此定義語意關聯分數 0 _ ( 2) _ ( , 2) ( _ ( )[ , 1]) 1 _ ( 2) _ ( , 2) _ ( )[ , 1] ( _ , , 1)
if Sel list k Keyword list i j NS S string i j j
if Sel list k Keyword list i j S string i j j SCandi Sel list k k
+ ≠ + + = + = + + ∈ + 此外,一個填充字串在原文中的位置也會對將其加入合成文章後,合成文 章的整體流暢度有所影響,舉例來說,在考慮Sel_list中的第1、2個關鍵詞時, 單就位置而言,假設作文語料庫中文章的關鍵詞密度相差不大,S_string(i )[2,3]1 可能會優於S_string(i )[15,16]2 ,這是因為S_string(i )[2,3]1 通常會比較符合文章首
1
( _
( )[ ,
1])
1
if i
j
i
j
PS S
string k
j j
if i
j
≠
−
+
=
=
其中S_string(k)[j,j+1] ∈ SCandi(i,i+1),如此的算法至少可避免接近文章末段的 文句出現在合成文章的一開始。而Total_score( S_string(k)[j,j+1] ) = NS + PS,我 們依據Total_score對SCandi(i,i+1)裡的候選填充字串排序。圖9為填充字串"都 非 常" (相對於關鍵詞"同學"、 "喜歡"所產生之候選填充字串集)的各項參數資料, next keyword 代表在原文中的下一個關鍵詞(在圖例中,"喜歡"的下個關鍵詞為" 下課");es id 為所屬文章編號,position 代表在關鍵詞串列中的位置,如"喜歡" 是串列中第 87 個關鍵詞;score 為依照 4.3.3 節所述排序方法所得到的分數; between words表示該填充字串。 圖 9 填充字串的各項參數 使用關鍵詞串列做文章合成,文章會在最後一個關鍵詞結束,此時有可能 出現語意不完整的情況,看起來就像是文章的最後一句話被最後一個關鍵詞截斷 (關鍵詞只是一種表達概念的方法),為了解決這個問題,我們附加"。"到使用者 所選出的關鍵詞串列最後,讓"。"成為所有串列的最後一個關鍵詞,這樣一來, 我們就可以在原本串列的最後一個關鍵詞和新加入的"。"之間也填入填充字串, 語意截斷的問題可以因此獲得改善。
4.4
4.4
4.4
4.4
系統運行
系統運行
系統運行
系統運行
作文合成分成兩個步驟,第一個步驟為關鍵詞串列的選擇,本系統預設每次顯示10 個關鍵詞串列供使用者選擇,使用者可按更新鍵更新系統顯示的候選 關鍵詞串列集。第二個步驟是預設合成文章顯示以及合成文章的修改。關鍵詞串 列一旦選定便可決定兩兩相鄰關鍵詞間的所有的候選填充字串集,這些填充字串 集經過排序後,由系統各自從排名前五項的填充字串中隨機挑選一項出來合成系 統的預設文章。當然,系統預設文章可能不是整篇都很通順,因此,本系統提供 機制,讓使用者可找出相鄰兩個關鍵詞間所對應的其他填充字串集,以便讓使用 者修改預設文章,系統介面將在 5.2 節詳述。圖 10 為第一個步驟的選擇視窗, 反白的部份為挑選的關鍵詞串列;依據此關鍵詞串列產生的預設合成文章則如圖 11所示;而圖12則顯示圖11中可填於"下課"及"通常"間的其他候選填充字串, 由於系統預設所選的填充字串未必適當,故系統提供可讓使用者做替換的其他選 項。 圖 10 第一個步驟 - 候選關鍵詞串列選擇 圖 11 第二個步驟 - 預設合成文章顯示
第五章
第五章
第五章
第五章、
、
、
、系統比較
系統比較
系統比較
系統比較與
與
與
與討論
討論
討論
討論
本章將對作文寫作輔助系統的原型系統以及進一步改良後的合成系統進行 比較與分析,觀察改良後的系統是否確實改善原本系統的缺點,並且保留優點。5.1
5.1
5.1
5.1
系統改良成效
系統改良成效
系統改良成效
系統改良成效
候選關鍵詞串列存在的目的就是要讓使用者大致瞭解合成文章將會包含哪 些概念,這個機制讓系統缺乏主題導向的問題確實獲得相當程度的解決,雖然目 前所提供的方法稍微缺乏彈性,但至少使用者不會對文章的走向一無所知。另 外,候選填充字串集的元素個數也較候選單元串列集來得少,加上預設合成文章 的機制,使用者只需修改文章較不通順的地方,不必再逐一檢查所有的填充字 串。而填充字串集元素個數較少的原因很顯然是因為同時被左右兩邊的關鍵詞限 制住,相對的候選單元串列僅受前一單元最後一個詞制約,在雙重制約的情況下 使得填充字串集雖然較小但與前後文的契合度卻更加可靠。系統經過改良後,使 用者走入死胡同的情況也有改善,這似乎也可歸功於填充字串雙重制約的特性, 但候選填充字串集所有選項都不合適的狀況還是存在。在系統的原始構想中,我 們盡量不讓使用者自行輸入任何東西,而以提供選項的方式讓使用者作選擇,這 是考量到一旦讓使用者輸入就必須同時提供一個機制判斷輸入是否適當並且與 前後文契 合,但由於作文語料庫內的文章數不足,因此不論是單元串列集或是 填充字串集都無法完全避開所有選項皆不適合的困境,因此在合成系統中,我們5.2
5.2
5.2
5.2
系統
系統
系統
系統介面
介面
介面與操作
介面
與操作
與操作
與操作
在整個系統實現與改良的過程中,介面的設計是很重要的一部分,合成系 統的程式介面分成主視窗及關鍵詞串列選擇視窗,主視窗的控制元件說明如下: 圖 13 程式主視窗介面操作。在程式視窗上按下"create keyword list"後會跳出關鍵詞串列選擇視窗,選好
串列後會回到主視窗,此時視窗畫面如圖13 所顯示,在視窗最上方顯示關鍵詞 串列和填充字串標籤,最下方的文字方塊顯示預設合成文章,我們以不同顏色的 字體來顯示關鍵詞和填充字串,字串標籤一經點選文字顯示會從"……"變為 "****"同時中間的listbox會顯示該字串標籤所對應的填充字串集,文字方塊中對 應部份的字體也會變成與周遭不同的顏色,右方的 listbox 則是用來顯示被選填 充字串如位置分數、語意關聯分數的各項參數。
圖 14 關鍵詞串列選擇視窗介面操作
而關鍵詞串列選擇視窗如圖14所示,radio box內有短、中、長三個選項供
使用者選擇關鍵詞串列長度,按下 ok鍵便會在下方 listbox 中顯示10 組所選長
第六章
第六章
第六章
第六章、
、
、
、未來工作與展望
未來工作與展望
未來工作與展望
未來工作與展望
本系統經過實驗、檢討、修正後已具有雛型,但許多功能仍可再加強,並 且加入更多功能以使系統更活潑、實用。我們將系統的改進與加強分成兩部份討 論:現有基礎功能改進和附加功能的增加。6.1
6.1
6.1
6.1 基礎功能改進
基礎功能改進
基礎功能改進
基礎功能改進
關鍵詞串列修改 關鍵詞串列修改 關鍵詞串列修改 關鍵詞串列修改 目前關鍵詞串列的產生方式是隨機從分離好的作文語料庫中選取任一串列 並且擷取前n個詞,這樣產生出來的串列未必每一個關鍵詞都能讓使用者滿意。 可以讓使用者對已經選好的串列作修改,也就是對串列中的關鍵詞作替換、刪除 甚至加入其他關鍵詞等動作直到使用者對整個串列感到滿意為止。但這部份同時 必須考慮到串列經使用者變更後是否仍能從作文語料庫中找到相對應的填充 串,未經修改的串列至少有其對應的填充字串可利用,一經修改此部份便無法保 證。 以 以 以 以包含關鍵詞用語包含關鍵詞用語包含關鍵詞用語包含關鍵詞用語代替關鍵詞代替關鍵詞代替關鍵詞 代替關鍵詞 關鍵詞串列代表合成文章的骨幹,目的是讓使用者瞭解合成文章的主要內 容,而單憑關鍵詞串列有時各關鍵詞的關聯性並不是那麼明顯,如串列:上課、 久、有時候、打鐘、下課、十、分鐘……,其中上課、久、有時候三個詞的關聯 性並不明確,若改成關鍵用語串列:上課 太 久、有時候 會、下課 十 分鐘…… 概念會更清晰,更有助於使用者對文章內容的掌握。 文章長度控制 文章長度控制 文章長度控制 文章長度控制如前文所述,關鍵詞串列的長度愈長,合成文章的字數愈多,但實際操作 系統後發現,即使選擇中等或較長的串列,所產生的文章字數仍感不足,據觀察, 這是由於語料庫中作文關鍵詞密度大所致。有可能一句話中每個詞都是關鍵詞, 一個20 個關鍵詞的串列只是三、四句話的濃縮,即使替換填充字串字數也難以 超過200字,改變關鍵詞串列的萃取方式或許能改善此種狀況,像是在原文中兩 個相鄰的關鍵詞只取其中一個加入關鍵詞串列或是限定關鍵詞串列中任兩個關 鍵詞至少相隔幾個詞。
6.
6.
6.
6.2
22
2
附加功能增加
附加功能增加
附加功能增加
附加功能增加
替換用語和同義詞 替換用語和同義詞 替換用語和同義詞 替換用語和同義詞 我們知道同一句話有不同的表達方式;我們也常用不同的詞彙來表達同一 個概念,如"每當下課時"和"一到下課"在作文語料庫中便經常交替使用;"鈴聲" 和"鐘聲"是一樣的概念,一篇好的作文不該一直重複使用某個詞或是用語,提供 可替換用語和同義詞替換可使系統的彈性更大,使用者更能隨心所欲地創造出令 自己滿意的文章。 其他進階功能 其他進階功能 其他進階功能 其他進階功能 其他更進階的功能包括從平衡語料庫或是其他語料庫中尋找填充字串,這 必須考慮到合成文章離題的可能性,另外加強合成文章的修辭也是可嘗試的進階 功能,這部份或許可從較常使用的排比或譬喻法著手。此外,目前為止,合成的參考文獻
參考文獻
參考文獻
參考文獻
[1] Regina Barzilay & Mirella Lapata, Collective Content Selection for Concept-To-Text Generation, Proceedings of the conference on Human Language Technology and Empirical Methods.(2003)
[2] Besag, On the statistical analysis of dirty pictures.
Journal of the
Royal Statistical Society
, 48:259–302.(1986)[3]Boykov, O. Veksler, R. Zabih., Fast approximate energy minimization via graph cuts. In ICCV, 377–384.(1999).
[4] Kiyotaka Uchimoto & Satoshi Sekine & Hitoshi Isahara, Text Generation from Keywords.(2002)
[5] 中央研究院資訊科學研究所詞庫小組中文斷詞系統



![圖 8 "同學"及"喜歡"對應的候選填充字串集 4.3.34.3.34.3.3 4.3.3 候選填充字串集候選填充字串集 候選填充字串集排序候選填充字串集排序 排序 排序 如同候選單元串列集,我們也對候選填充字串集作排序的動作以減輕使用 者的負擔。考慮 Sel_list(k) 和 Sel_list(k+1) 及其所對應,屬於 SCandi(i,i+1) 的一個 填充字串 S_string(i)[j,j+1] ,在直覺上我們認為關鍵詞串列 Keyword_li](https://thumb-ap.123doks.com/thumbv2/9libinfo/8051303.162409/32.892.388.542.110.265/集候選填充字串集候選填充字串集排序候選填充字串集排序排序排序.webp)