Sharing knowledge in a supply chain using semantic web
應用語意網絡分享供應鏈中的知識
許展碩
國立暨南國際大學
資訊管理研究所
s1213520@ncnu.edu.tw
陳旻鈞
國立暨南國際大學
資訊管理研究所
u4360914@cc.ncu.edu.tw
黃俊哲
國立暨南國際大學
資訊管理研究所
chuang@im.ncnu.edu.tw
Abstract
Interoperability among multi-entities (companies) with heterogeneous knowledge sources becomes a research focus in the field of supply chain management (SCM). However, only few studies have addressed the problem of interoperability and knowledge sharing in supply chains. Current technologies, such as EDI, RosettaNet or the current Web, are useful for sharing data/information, rather than knowledge. This paper proposes a solution for knowledge sharing using the semantic web. The solution involves (i) a semi-structured knowledge model to represent knowledge in not only an explicit and sharable, but also a meaningful format, (ii) an agent-based annotation process to resolve issues associated with the heterogeneity of knowledge documents, and (iii) an articulation mechanism to improve the effectiveness of interoperability between two heterogeneous ontologies. Based on the proposed solution, entities in a supply chain represent, search, and share knowledge effectively.
Keywords: Supply chain (SC), knowledge sharing, interoperability, Semantic web, Semi-structured knowledge
摘要
整合異質性的知識資源已經成為供應鏈 管理中, 一個重要的研究領域. 然而只有少部 分的研究著墨在供應鏈的知識溝通及分享. 目前的技術,如EDI、RosettaNet及目前的web 技術, 主要提供資料或資訊分享的功能, 尚未 達 到 知 識 分 享 . 所 以 本 研 究 應 用 語 意 網 絡 (semantic web)的技術,提出一個知識分享的 解決方法. 這個方法包括以半結構的知識模 式呈現知識、具備代理機制的註解流程,以解 決 異 質 性 知 識 文 件 的 關 聯 議 題 以 及 應 用 articulation的機制,改善ontologies之間跨平台 的溝通效能. 關鍵字: 供應鏈, 知識分享, 跨平台溝通, 語 意網絡, 半結構化的智識1. Introduction
The semantic web is a web that includes documents, describing explicit relationships between thing and containing semantic information intended for automated processing by our machines [10]. It aims to create a web in which both humans and machines can understand the information [9] and to provide intelligent access to heterogeneous and distributed information, enabling agents to mediate between user needs and available information sources [9].
The semantic web has attracted much interest and has been applied in many areas [1] [15]. In a world of heterogeneous information, such as a supply chain, the semantic web enables a flexible and seamless integration of applications and data sources. The semantic web provides intelligent access, an understandable context, and inferred knowledge. Furthermore, it provides a well-defined structure, ontology, within which meta-knowledge can be applied [3]. The semantic web has great potential to share
knowledge in a scalable manner.
This paper proposes approaches to sharing knowledge with the semantic web and solving the problem of heterogeneous knowledge sources in a supply chain. All knowledge is modeled and represented using the semi-structured knowledge (SSK) model [7]. The representation using the SSK model (i) allows knowledge to be represented consistently and flexibly, and (ii) helps to share knowledge in a meaningful manner over the web. Given a SC benchmark ontology, the solution approach involves (i) an agent-based annotation process to overcome the heterogeneity of knowledge documents, and (ii) an articulation mechanism to improve the interoperability of knowledge, given two used ontologies. This paper is organized as follows. Section 2 presents the solution approaches. Section 3 proposes a platform on which to integrate the SSK model and the solution approaches. Section 4 presents the knowledge sharing process. Section 5 draws conclusions.
2. Approaches to knowledge sharing
using semantic web
2.1. Semi-structured Knowledge Model
In this section, the knowledge document is formulated using the semi-structured knowledge (SSK) model [7], based on the six dimensions of the Zachman Framework (Who, What, When, Where, Why, and How) [8], and the technique of knowledge representation - Resource Description Framework (RDF) – standardized by the semantic web. Semi-structured knowledge is generated as follows: K = K’O
U
KA whereK’O = IG U (KP U KT)
K’O: Organizational semi-structured knowledge
KA: Semi-structured knowledge after
annotation (called annotated knowledge)
IG: General information about problematic event
KP: Knowledge derived from knowledge workers
KT: The knowledge captured from the experts’ feedback
KP U KT: called feedback knowledge Annotated knowledge is comprised as follows:
KA: DB U DA U DR
DB: Basic description of annotated knowledge
DA: Descriptive information about annotation
DR: Description of relation among the documents, ontology, and generated knowledge.
KO: Organizational semi-structured knowledge such that KO = IG UISUKPUKT
IS: Information about the approach to solving the problematic event
2.2. Annotation
The annotation processes the unstructured formats of knowledge documents and allows supply chain entities to accessed them efficiently, such that these hetero-formatted or un-structured knowledge documents can be retrieved. The annotation includes three types of description - Basic description of annotated knowledge (DB), descriptive information about annotation (DA), and relationship description (DR) among the documents, ontology and generated knowledge. Ontology herein is based on the works of [3][14] and is revised to fit the supply chain domain [2]. z DB includes general statements about the
knowledge document and its source.
z DA is based on the 5W1H (What, Where, Who, When, Why, and How) to represent annotated knowledge using the SSK model. z DR presents two types of relationship - (i) the
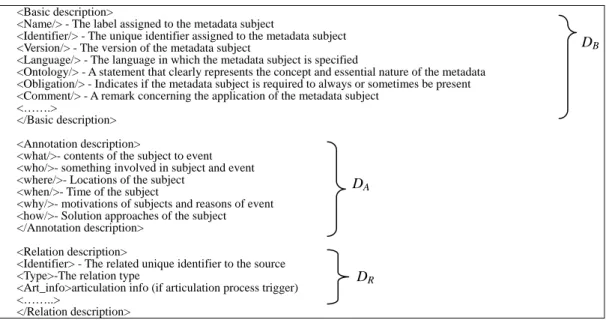
<Basic description>
<Name/> - The label assigned to the metadata subject
<Identifier/> - The unique identifier assigned to the metadata subject <Version/> - The version of the metadata subject
<Language/> - The language in which the metadata subject is specified
<Ontology/> - A statement that clearly represents the concept and essential nature of the metadata <Obligation/> - Indicates if the metadata subject is required to always or sometimes be present <Comment/> - A remark concerning the application of the metadata subject
<…….>
</Basic description> <Annotation description>
<what/>- contents of the subject to event <who/>- something involved in subject and event <where/>- Locations of the subject
<when/>- Time of the subject
<why/>- motivations of subjects and reasons of event <how/>- Solution approaches of the subject </Annotation description>
<Relation description>
<Identifier> - The related unique identifier to the source <Type>-The relation type
<Art_info>articulation info (if articulation process trigger) <……..>
</Relation description>
Fig. 1. Annotation using XML tags. relationship between the annotated knowledge
document and other heterogeneous /unstructured documents and (ii) the relationship between the benchmark ontology and heterogeneous ontology. The second relation description includes the information about how articulation is processed presented in section 2.3.
Although SSK is stored and presented in RDF and RDFS formats, to be easily understood, this paper illustrates the annotation format, using an XML tag, in Fig. 1.
2.3. Articulation
Articulation is a mechanism for supporting the interoperability of various supply chain sources, and solves the problems of the semantic interoperability. The articulation mechanism proposed in this section (i) efficiently resolves the heterogeneity of ontologies utilized by various business entities and (ii) appropriately intersects, unifies and differentiates heterogeneous ontologies with the benchmark ontology.
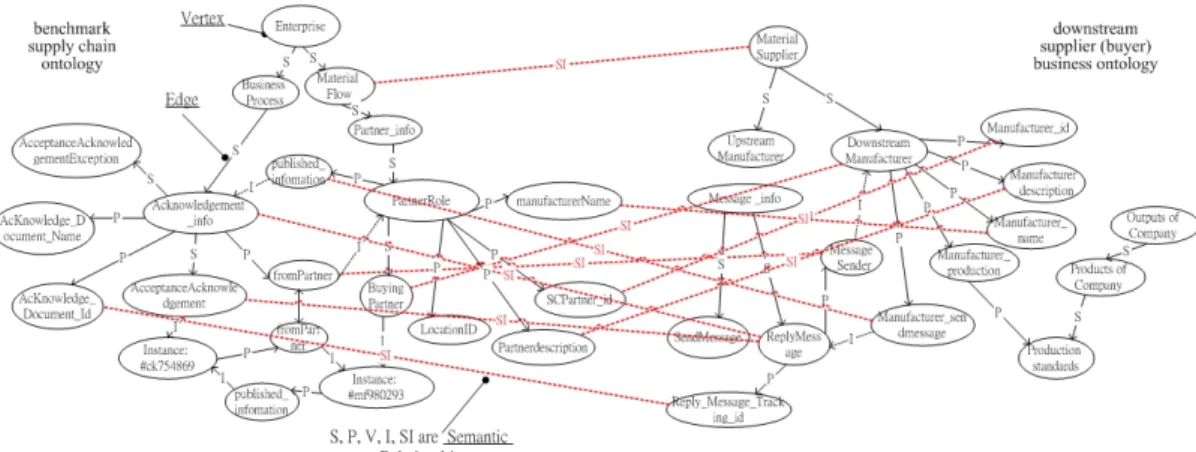
2.3.1. Graphic Conceptual Model and Semantic Relationship
The conceptual model proposed herein is
based on the work of [6], where an ontology O = (G, R) is represented using a directed labeled graph G, and numerous articulation rules (R). The graph of ontology G = (V, E) consists of a finite set of nodes V and a finite set of edges E (Fig. 2). The label of a node is a non-null string. The label of ontology is typically a noun-phrase that represents a concept [11]. Fig. 2 plots the illustrative graphical conceptual model with articulation rules (dotted lines). In the graphic conceptual model, the semantic relationships ‘SubclassOf’, ‘PropertyOf’, ‘InstanceOf’, and ‘S’emantic ‘I’mplication [11] are represented by edges, labeled ‘S’, ‘P’, ‘I’, ‘V’ and ‘SI’, respectively.
2.4.2. Semi-automatic Articulation Generator Fig. 3 depicts the structure of the articulation mechanism [13] and the interaction among the three parts - ontologies, the articulation generator, and the knowledge- sharing platform. This mechanism recognizes the need for heterogeneous ontologies; generates articulation rules, supports semantic interoperation, and aids the knowledge-sharing platform to query desired information.
A semi-automatic method [13] is
DB
DA
Fig. 2. Graphical conceptual model and articulation rules. proposed , which uses an automatic articulation
generator to determine whether the match between the concepts of the two ontologies is satisfactory. The articulation generator is a modular agent, which applies the hybrid heuristic method and linguistic matcher algorithm [2][12] to generate the scores of semantic similarity between the concepts of two ontologies. A human expert, knowledgeable about the semantics of concepts in both ontologies, validates the matches generated by the articulation generator using a graphic user interface tool.
Fig. 3. Components of articulation mechanisms. In summary, a heterogeneous knowledge document is generated according to a heterogeneous ontology. The annotating agent
annotates this heterogeneous document using articulation rules.
The experts’ feedback on, and updates of, the articulation are stored. The feedback is supported by the mechanism to enable further articulation, on which other users impose this heterogeneous ontology. This learning process improves the quality of the articulations. Since the conceptual model is simple and the articulation architecture is modular, great scalability can be achieved with few problems.
3. Knowledge sharing platform
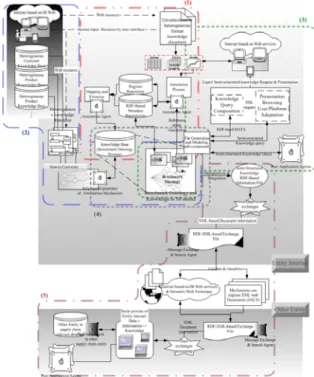
The knowledge-sharing platform (KSP) is proposed in Fig. 4. The proposed platform comprises (1) an agent-based annotation component; (2) an articulation component; (3) an interface component to present the SSK model; (4) a knowledge-based component to store the benchmark ontology, and (5) a transfer component to transfer knowledge through the semantic web. The components are detailed as follows.
3.1. Agent-based Annotation Component The aim of this annotation component is (i) to construct the conception schema that corresponds to the original heterogeneous documents; (ii) to extract (parse) knowledge contents and (iii) to correlate the identified elements in the SSK document with the concepts
Fig. 4. Proposed platform for sharing knowledge.
associated with the benchmark ontology. 3.2. Articulation Component
This component uses the approach presented in Section 2.3. The novelty of the articulation component is to provide a scalable and simple framework to develop articulation. This component performs a semi-automated compromise between the automatic activation by the articulation generator, and the domain experts’ manual determination of the adoption of articulation rules.
3.3. Interface Component
The component has three sub-components which are illustrated as follows.
1) R&P interface sub-component
The R&P sub-component requests and presents semi-structured knowledge. Interacting with the M&G sub-component, the R&P interface sub-component utilizes hypermedia front-ends (user interface) that guide a (human) user in (i) seeking and browsing the subject of the problematic event and its solution (S, IS); (ii)
illustrating problematic knowledge events (E, IG) associated with the elements in the benchmark ontology, and (iii) presenting the elements in response to queries, such as concepts and instances in the benchmark ontology [5]. Using this sub-component, knowledge workers also provide the subject of the problematic event and its solution (S, IS) and feedback knowledge (KP
U KT).
2) M&G sub-component
This sub-component is used to model and generate SSK. The ontologies are represented using conceptual graphic for domain experts to articulate. However, in the interface component, knowledge must be represented using the SSK model to understand easily and present the query to knowledge workers and experts. This sub-component primarily model and generate SSK using the knowledge elements from the KQO sub-component.
3) KQO sub-component
This sub-component queries (i) knowledge documents in the SSK model stored in the knowledge base; (ii) annotated knowledge in the SSK model stored in the meta-data repository, and (iii) knowledge elements using in the benchmark ontology, providing them to the M&G sub-component.
3.4. Knowledge Base Component
This component’s main purpose to store elements using in the benchmark ontology, articulation rules and knowledge documents in the SSK model, where (i) concepts and relationships between concepts are stored in RDFS format, and (ii) instances of these concepts with corresponding values of properties are stored in RDF format. These elements are represented and stored in RDF format, so the
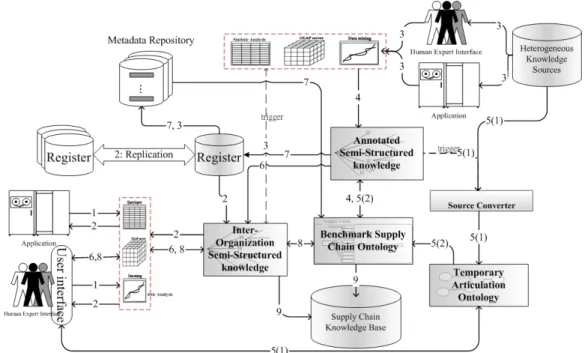
Fig. 5. Summary of sharing process. component also stores the element URI’s, which
can uniquely identify these ontology elements. Based on the characteristics of the RDF triple model [17], database management techniques have been widely applied in RDF-related research [16][18]. The details are not included in this paper, but can be found in [2].
3.5. Transferring Component
In this component, the ‘message exchange and search’ agent presented in Fig. 4 is involved in (i) seeking the desired knowledge files in every supply chain entity’s metadata repository, register and knowledge base, and (ii) transferring these desired knowledge files to knowledge workers via the semantic web or simply through the general web. The application or peer agents in each supply chain entity automatically respond to the messages associated with knowledge exchange.
4. Sharing Process
Based on the aforementioned solution approaches and KS platform, the sharing process is described and exemplified by considering the transportation shipment problem occurring in a
distributor.
Fig. 5 summarizes the knowledge sharing process. Knowledge workers and application agents seek knowledge for resolving problematic events. The knowledge-sharing platform supports the retrieval of desired semi-structured knowledge. The steps are detailed as follows.
Step 1: Knowledge workers illustrate a
problematic event (E, IG) using the SSK model offered by the interface component. Peer agents can also acquire knowledge using this interface. The interface component sends the requirements, which are filled in by the peer agents, to request and search for desired knowledge elements, and aids knowledge workers to illustrate problematic events with these elements.
Step 2: If (i) desired elements of particular
semi-structured knowledge are presented in the benchmark ontology, or (ii) desired knowledge documents in the SSK model are presented in the knowledge base, or (iii) a useful knowledge document link is presented in the register and the knowledge has been annotated and stored in the metadata repository, then these elements and
these documents are sent directly to users and agents. Otherwise, the conversation process in step 3 is initiated.
Step 3: During this process, the search agent,
employed in the semantic web technique [4], constructs an inter-organizational communication bridge and delivers heterogeneous knowledge documents to the knowledge workers according to their requirements. Knowledge workers, experts and agents in other organizations then provide their solution-related knowledge. If the subject of the problematic event and its solution (S, IS) is in an unstructured format such as html, Word®-based text file, or another heterogeneous semi-structured type, such as an XML file, then go to step 4, the annotation process.
Step 4: In this annotation process, the annotation
agent annotates unstructured/ heterogeneous knowledge documents and generates KA using the SSK model in form of ‘annotated knowledge documents’. If the original knowledge documents are obtained from hetero-partners, which have their own ontology and compose knowledge in their own specific format, then go to step 5, the articulation process.
Step 5(1): In this step, the heterogeneous
ontology of hetero-partner is represented using a graphical conceptual model. Then, the articulation generator uses the heuristic methods to identify articulation rules. Temporary articulation ontology is constructed using ontology algebra. It is presented and browsed by experts to validate the articulation rules by the interface component.
Step 5(2): Using these articulation rules,
knowledge documents from heterogeneous sources are annotated as annotated knowledge in
the SSK model (KA). After the articulation ends, the articulation rules are stored in the knowledge base.
Step 6: The document that includes annotated
knowledge, KA, is simply browsed via the R&P interface subcomponent only, or it further adds other semi-structured knowledge.
Step 7: In this step, the annotated knowledge
documents are stored in the meta-data repository, and the index and links between the locations of knowledge sources are registered. Each entity in the supply chain has a register. They all upgrade and replicate information on links synchronously; therefore, the annotation component always maintains consistent content. After that, annotated data (meta-data) about annotated knowledge documents are extracted and mapped onto the benchmark ontology.
Step 8: The M&G sub-component presents the
subject of the problematic event and its solution (S, IS) in the SSK model to experts and knowledge workers to resolve the problematic event. All knowledge workers are allowed to give feedback (KP U KT) on solution-related knowledge.
Step 9: Store the SSK documents and the
updated benchmark ontology in the knowledge base.
This well-defined process not only supports knowledge sharing activities, but also allows the system to know which component should be communicated with and what message will be received or sent. An illustrative example in details is discussed in [2].
5. Conclusions
This paper proposes the solutions for knowledge sharing in a supply chain, specifically solving the problem of knowledge
interoperability. The semi-structured knowledge model has been presented to formulate knowledge not only to be explicit and sharable, but also meaningful. The annotation process has been presented to annotate heterogeneous and un-structured knowledge documents as KA. KA was stored in the meta-data repository. The articulation mechanism has been presented to resolve semantic heterogeneity between two ontologies. The semi-structured knowledge-sharing platform has been presented and based on the semantic web. The platform allows the entities in the supply chain to represent, generate, search for and share knowledge effectively. The knowledge sharing process clarified these solution activities.
The future works include (i) Semantic logic inference engine for peer application agents, (ii) Effective heuristic methods for generating articulation.
References
[1] B. Berendt, A. Hotho, and G. Stumme, “Towards semantic web mining,” Proc. Of
the 1st International Semantic Web Conference (ISWC2002), Sardinia, Italia, pp.
264-278, 2002.
[2] M. C. Chen, “Knowledge sharing in supply chain with semantic web,” Dissertation, Department of Information Management, National Chi-Nan University, Taiwan, 2003. [3] D. Fensel, I. Horrocks, H. F. Van, S. Decker,
M. Erdmann, and M. Klein, “OIL in a nutshell,” In Knowledge Acquisition, Modeling, and Management, Proc. of the European Knowledge Acquisition Conference (EKAW-2000), R. Dieng et al.
(Eds.), Lecture Notes in Artificial Intelligence, LNAI, Springer-Verlag, 2000.
[4] T. Finin and A. Joshi, “Special section on semantic web and data management: agents, trust, and information access on the semantic web,” ACM SIGMOD Record, vol. 31, no. 4, 2002.
[5] F. Frasincar, G. J. Houben, R. Vdovjak, and P. Barna, “RAL: An algebra for querying RDF,” The 3rd International Conference On
Web Information Systems Engineering
(WISE 2002), Tok Wang Ling, Umeshwar
Dayal, Elisa Bertino, Wee Keong Ng, Angela Goh (Eds.), IEEE Computer Society, Singapore, pp. 173-181, 2002.
[6] M. Gyssens, J. Paredaens, and G. D. Van, “A graphoriented object database model,” in
Proc. PODS, pp. 417–424, 1990.
[7] C. C. Huang and C. M. Kuo, “Transformation and searching of semi-structured knowledge in organizations,” To appear in Journal of
Knowledge Management, 2003.
[8] W. H. Inmon, J. A. Zachman, and J. G. Geiger, Data Stores, Data Warehousing, and
the Zachman Framework: Managing Enterprise Kknowledge. McGraw-Hill
Companies, Inc. NY, US, 1997.
[9] O. Lassila, F. van Harmelen, I. Horrocks, J. Hendler, D. L. McGuinness, “The semantic Web and its languages,” Intelligent Systems,
IEEE [see also IEEE Expert], vol. 15 iss. 6,
pp. 67-73, 2000.
[10] W. Li, “Intelligent information agent with ontology on the semantic Web,” Intelligent
Control and Automation, 2002. Proceedings of the 4th World Congress on , vol. 2, pp.
1501-1504, 2002.
[11] P. Mitra, M. Kersten, and G. Wiederhold, “A graphoriented model for articulation of ontology interdependencies,” Advances in
Database Technology-EDBT 2000, Lecture Notes in Computer Science, 1777, pp.
86–100, 2000.
[12] P. Mitra, and G. Wiederhold, “Resolving terminological heterogeneity in ontologies,”
Proc. of Workshop on Ontologies and Semantic Interoperability at the 15th European Conference on Artificial Intelligence (ECAI), Lyon, France, 2002.
[13] P. Mitra, G. Wiederhold, and S. Decker, “A scalable framework for interoperation of Information sources,” in Proc. of the 1st
Semantic Web Working Symposium,
Stanford. Retrieved from http://www.semanticweb.org/SWWS/, 2001.
[14] D. E. O'Leary, “Impediments in the use of explicit ontologies for KBS development,”
International Journal of Human-Computer Studies, vol. 46, no. 2-3, pp. 327-337, 1997.
[15] J. Peer, “Bringing together semantic web and web services,” Proc. of the 1st
International Semantic Web Conference (ISWC2002), Sardinia, Italia, 279-291, 2002.
[16] URL Persistent_RDF_Databases: http://www.w3.org/1999/07/13-persistant-R
DF-DB.html
[17] URL RDF: http://www.w3.org/TR/rdf/ [18] URL RDFDB: http://guha.com/rdfdb/