行政院國家科學委員會專題研究計畫 成果報告
應用於地理資訊系統之使用多視角影像重建三維建物模型
研究成果報告(精簡版)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 99-2221-E-004-011- 執 行 期 間 : 99 年 08 月 01 日至 100 年 09 月 30 日 執 行 單 位 : 國立政治大學資訊科學系 計 畫 主 持 人 : 何瑁鎧 共 同 主 持 人 : 唐政元 計畫參與人員: 碩士班研究生-兼任助理人員:王瑞鴻 碩士班研究生-兼任助理人員:李紹暐 博士班研究生-兼任助理人員:詹凱軒 報 告 附 件 : 出席國際會議研究心得報告及發表論文 公 開 資 訊 : 本計畫涉及專利或其他智慧財產權,1 年後可公開查詢中 華 民 國 100 年 12 月 07 日
中 文 摘 要 : 近年來由於資訊技術迅速成長,網路普及與頻寬提升,資訊 科技的應用進入前所未有的新領域,直接或間接的推動傳統 的地理資訊系統(GIS: Geographic Information System)由 二維往三維發展,而數位地球(digital earth)與數碼城市 (cyber city)等相關概念與研究應運而生,如何有效、精確 且迅速的建構數碼城市等研究日趨重要。 建構數碼城市,除了要建立環境中所有建築物的三維立體模 型外,同時還需考慮與地理資訊系統的結合,才能在日後方 便的對城市作分析、規劃與導覽等研究。在此前提下,我們 擬定了本計畫,希望能提供一個有效、精確且迅速的方式來 建立三維建物模型,並能與地理資訊系統結合以呈現之。 計畫內容主要就三維之建物模型建構進行研究,我們期望利 用低成本的數位相機,拍攝與蒐集多視角建物影像,進行建 物模型重建。主要的研究方法大抵可分為下列步驟:首先我 們利用 Harris filter 與 Difference of Gaussian 等方法 自動偵測各影像中稀疏對應點;其次我們利用稀疏對應點結 合三維幾何關係進行擴展,產生大量密集對應點;再者,我 們將利用極線轉換關係濾除與改善錯誤的對應後,再利用 bundle adjustment 將投影誤差最小化,並經過多次遞回處 理,進行相機重新校正與三維點雲最佳化;最後利用前述結 果的點雲資料重建建物模型,其中我們採用三維補綴面投影 之觀念,以 3D 幾何和關係來改善對應點的相似度計算。 我們透過模擬拍攝大量多視角影像進行實驗,利用上述方法 重建三維建物模型。我們未來也預計將所建立之模型與虛擬 實境導覽結合,進一步以虛擬實境技術呈現校園導覽。目前 在實驗實作上已有初步的成果,期望藉由此研究結果,未來 能與各研究領域進行整合,以期對地理資訊系統、都市計 畫、防災妨害與虛擬實境導覽等方面有皆所貢獻。
中文關鍵詞: Bundle Adjustment、Structure from Motion、Epipolar Transfer、Trifocal Tensor、三維模型重建、多視角影像、 地理資訊系統
英 文 摘 要 : The concepts and researches of Digital Earth as well as Cyber City come with the tide of fashion. Hence, the researches on efficiently and accurately
construct a Cyber City gradually becomes one of the major issues. In constructing a Cyber City, one has to consider not only the reconstruction of all the building models in the environments but also the integration with geographic information system (GIS)
in order to facilitate future planning, analysis, and navigation in the Cyber City. Under these concepts, we provide an efficient, accurate, and rapid
mechanism in three-dimensional building model reconstruction for GIS.
In this project, we produce/collect a large set of multi-view images about the buildings using low-cost digital cameras for reconstruction of
three-dimensional building models.. Using these images as inputs, we reconstruct the 3D models of these
buildings through the following steps. In the first step, we detect automatically a sparse set of
corresponding points using the Harris filter and Difference of Gaussian filter. In the second step, we can use the sparse corresponding points and
properties of 3D geometries to generate a quasi-dense set of corresponding points. And then we can apply the epipolar transfer to remove incorrect
corresponding points. After that, we can reduce the projection error by applying standard bundle
adjustment algorithm repeatedly and get the improved camera parameters and 3D point cloud. Finally, the three-dimensional build models can be reconstructed from the good corresponding points. Refer to the similarity measurement, the 3D patch projection is used to improve the results of correspondence. We take a large set of virtual multi-view images as the experimental data and apply our mechanism to reconstruct the 3D models. We integrate our results with geographic information system to generate a realistic campus model. One may hope to conduct a virtual reality system using our model for campus navigation.
英文關鍵詞: Bundle Adjustment, Structure from Motion, Epipolar Transfer, Trifocal Tensor, 3D Model Reconstruction, Multi-View Images, GIS
一、 研究背景與目的
由於資訊技術迅速發展,網際網路頻寬與電腦效能快速提升,傳統的地理資訊系統 (Global Information System, GIS)逐漸由原本的二維資訊往三維資訊發展,例如以 Google 近年推出的 Google Earth 開放平台最為典型。而數位地球(Digital Earth)、數碼城市(Cyber City)等相關概 念的研究也相繼而出。隨之三維地理資訊訊系統(3D GIS)近幾年來成為熱門的研究議題之一, 其中視覺化展示之相關研究也成為關注的焦點。 若三維地理資訊系統資料的建置完成,其應用的層面相當廣泛,例如都市管理[2]方面,三維 地理資訊系統可模擬都市景觀,提供政府更有效地進行都市規劃與建設;防災妨害上,三維 地理資訊可模擬災害造成的損失,並提早進行防治;此外還可以結合虛擬實境[13]技術,透 過電腦進行古蹟、校園導覽等。而三維地理資訊中,最重要的不外乎是建物模型,在 Google Earth 開放平台上,我們已經可以將建構完成的建物模型與地理資訊作結合,但其中建物模型 大多是利用 Google 提供之 SketchUp 模型繪圖軟體,由人工繪製而成。若利用此方式建構世 界上大量的建物模型,必定要耗費相當可觀的人力與時間。 在三維建物模型建構策略上,近年來世界各國之研究,除了上述完全以人工的方式建構之外, 可分為全自動與半自動兩種。然而若透過雷射掃瞄儀等主動式資料往往由於儀器成本相當高, 取得較不容易,而且還需要結合數位相機,才可進行材質敷貼(texture mapping),使模型更接 近真實建築物。而建物模型的精確度與擬真度也是相當重要的因素,為了提高精確度與擬真 度,反而大幅提高成本。目前數位相機普及,若我們可以直接以數位相機資訊,建構建物模 型,並利用有效的演算法則,提高模型精確度,就可以大幅降低三維地理資訊系統建置成本, 提高其經濟效益。 我們針對上述提出的問題,計畫採用低成本的數位相機取得建築物影像資訊進行研究,希望 此研究成果對於三維地理資訊系統中,建物模型建置有所貢獻。 本研究目的主要有: 1. 利用數位相機拍攝、蒐集多視角建築物影像資訊,並以適當的系統架構與演算法,分析影 像以取得高精確度的三維資訊。 2. 透過上述取得之高精確度三維資訊,進行建物模型建構。 3. 蒐集與追蹤目前三維地理資訊系統的相關研究與應用,與研究結果進行整合。 二、 文獻探討 誠如 Danahy, J.(1999)指出,三維視覺化虛擬實境逐漸改變都市規劃與設計的作法,不同於傳 統利用抽象地圖、文字說明、解釋、分析與辯證設計理念的方式,反而讓規劃者可以迅速得 到規劃後整個都市改變的結果。三維模型可以更容易讓人理解,快速確定具體的內容和方向, 使得長期都市規劃政策透過視覺體驗的模擬當作輔助,更有效率討論和明確辯證。 行政院農委會水土保持局曾經指出,三維景觀模式建立與模擬,可以使傳統二維平面資訊轉 換為三維資訊物件模型,以利使用者、決策者對於現場情況掌握、任務規劃、決策分析、判 斷更加真實快速,並趕上世界先進國家三維資訊系統之潮流趨勢。在電腦科技及資料獲取方
式之進步影響下,不同於以往二維(平面)方式,三維空間在簡易應用層面上,可讓使用者透 過查詢、超鏈結(Hyper-Link)方式獲得上述資訊,極適用於導覽及查詢為主的領域,可針對潛 勢災區水土保持及防災資料以 3D 形式進行導覽及查詢時之建置參考。除了 3D 空間物件表現 外,專家們結合各種屬性形成其他維度建成多維度系統,使觀察者可由不同角度對屬性有視 覺感應(可視化),在 internet 上以 VR、CAD 及 GIS 的方式整合查詢、展示及分析的功能,以 達到資訊傳播及提醒功能,可見得多維度系統之建立,是種真正的資料運用革命,尤其是對 我們世界之理解化(reasoning)、顯現化(representation)和結構化(structuring)尤然,更能發揮空 間資料的呈現與效用。
Martinec D. and Pajdla T.(2007)描述到以多視角影像重建模型,首先必須評估相機旋轉方位 (rotations)與移動量(translations)。作者採用線性最小二乘法自動評估旋轉方位,以線性二階錐 (Second Order Cone Programming)來評估移動量,以提高對應點精確度。Mellor, J.P.(2003)[10] 呈現一種方法,使用相機結合衛星定位系統、慣性感測器(inertial sensors)與自動測斜儀 (incli-nometer),拍攝數以千計之影像,偵測建築物表面高密度點雲資訊。同時利用雜訊重新 進行校正評估,補償影像明亮度之差異,並進行影像敷貼,建構出建築物模型。Kamberov, G. et al (2006)提出處理任意角度拍攝、未經相機校正之影像,為了解決如此決複雜又不一致問 題,建構三維幾何模型。 Furukawa, Y. et al(2007)[4][5]提出一種新的演算法,利用多視角影像產生密集小矩形補綴面 (patch),而這些密集補綴面覆蓋於物體表面上,並可見於影像中。其處理程序包含三個階段: 對應(matching)、擴展(expansion)與過濾處理(filtering),為了可以達到區域光度(photometric)的 一致性,與全域可見度一致性,因此在對應的過程中,找出稀疏分散於影像的對應點,並於擴 展過程中在有限區域範圍內擴增密集對應。作者將傳統對應的問題,結合三維幾何關係的處理, 使對應點的偵測更合理化,相對地準確度也會提高。然而,若尋找稀疏對應點的分佈不夠分散, 在擴展的步驟上則會造成部分區域沒有對應點可以擴展,而產生密集對應點分佈不均勻,且模 型建構產生空洞的問題。 三、 研究方法 本 計 畫 主 要 的 技 術 包 含 多 視 角 影 像 自 動 建 構 密 集 對 應 點 、 及 利 用 光 束 調 整 法 (Bundle Adjustment)最佳化相機參數與三維模型重建。透過這些技術,將可以獲取不錯的建物模型。 3.1 多視角幾何 要能夠整合多張影像的資訊,最重要的技術之一就是:多張影像彼此之影像對應(Image Correspondence)關係[1][3][6]。把多張影像物體投影到二維影像,根據影像與影像彼此之間, 找出相對投影幾何關係[8][9]。一旦找到彼此之幾何關係,就能夠整合多張影像的資訊。此小 節我們先介紹幾種較常用的多張影像之間的幾何關係: 3.1.1 極線幾何與基礎矩陣 在二張影像之間的內部投影幾何關係稱之為『極線幾何 Epipolar Geometry』[7],與影像中之 物體的形狀、顏色無關,主要的影響是來自於相機的內部參數及外部參數。『基礎矩陣
Fundamental Matrix』便是用來描述二張影像之間的極線幾何關係。在未校正相機之下,當我 們只在影像上測量,直接將取得的資訊進行運算的話,基礎矩陣便是一個重要的方法,因為 它包含了所有兩張不同影像相關聯的幾何資訊。我們可以利用基礎矩陣來表示極線限制的關 係。
3.1.2 利用粒子群最佳化演算法估測基礎矩陣
粒子群最佳化演算法(Particle Swarm Optimization ,PSO)是基於粒子個體和群體不斷演化計算 的方法,目的是將群體中每個粒子個體透過不斷移動搜尋,直到達到停止條件為止。為了更 容易解釋粒子群最佳化演算法,我們以二維 line fitting 問題來做說明, x、y 兩個軸分別都是 對應點編號1, 2, 3, …, n,其中 n 為對應點數,而 z 軸為任兩組對應點直線解與所有對應點評 估出來之殘餘誤差(residual),因此三維曲面則為所有的解。為了讓殘餘誤差最低,其中最佳 解則是曲面中最低點,並限制 x 軸的值不能等於 y 軸的值,才能解直線方程式。圖中幾個候 選解我們稱之為「粒子」,每個粒子包含兩個變數:位置 posij與速度 velij。其方程式如(3-1) 所示,其中 pbij為第 j 個粒子過去最佳位置,gbi為所有粒子中過去最佳位置之第 i 維數值, 透過這兩個式子不斷更新粒子位置,期望能找到最佳解。而式子中 w、c1與 c2 為加速因子, r1 與 r2 為 0~1 之亂數值,Δt 為每一回合迭代時間,因此其值為 1。
t
ij t i t ij t ij t ij tij w vel c r pb pos c r gb pos
vel 1 1 1 2 2
,pos pos velijt t
t ij t ij 1 1 (3-1) 當我們要透過粒子群最佳化演算法來解基礎矩陣,Hartley[7]的書中曾提過八點演算法,即表 示有八組對應點座標時,即可以計算出一組基礎矩陣,但我們主要問題在於估測出來的基礎 矩陣要是好的。因此,我們可以直接將 line fitting 問題從維度 i=1, 2(兩個點可以解方程式), 改為維度 i=1, 2, …, 8(八組對應點可以解基礎矩陣),透過粒子群最佳化演算法不斷更新, 以求得最佳解。 3.1.3 利用三焦張量輔助評估多視角幾何 上一節所討論為兩張影像的幾何關係,由於我們的研究是在多視角影像的情況下進行,也稱 為未校正的序列影像。這些影像我們是不知道拍攝相機內外部參數的,就好比不知道各台相 機拍攝的相對位置以及使用幾倍焦距進行拍攝的。在我們的計畫使用到從運動恢復結構 (structure from motion)的方法,而這個方法即是在進行校正的動作,將所有二維影像旋轉矩陣、 位移矩陣及相對位置計算出來,並且是在同一座標系統下求得三維座標。從運動恢復結構是 從單一影像開始計算,先找出所有影像最多特徵點的其中一張,逐步加入其他影像進行特徵 點對應以及過濾。過濾時使用到重投影(reprojection)的方法,此計畫最後評估方法也是使用重 投影計算誤差以判斷是否改善。從運動恢復結構此方法也包裝在 Bundler[14]這項工具中,許 多研究在多視角影像的環境下為了搜尋出所有影像特徵點對應關係都會使用到 Bundler。而且 在電腦視覺擁有豐富資歷的 Yasutaka Furukawa[4]也推薦它是一個自動產生相機參數很好的 軟體。 關於多視角影像的研究可以使用 Bundler 計算多張影像在同一個座標系統下的相機參數,但 在此之前必頇有每兩張影像之間特徵點的對應關係。所以對應點的對應狀況一定會影響相機 參數計算的結果。Bundler 雖然被許多研究廣為使用,但仍有對應點錯誤的情況。Bundler 對 應點的比對必頇依賴基礎矩陣的準確性,所以它在過濾對應點的方法也是以兩張影像為基礎,
而我們的計畫加入三焦張量(Trifocal Tensor) [7]數學模型以三張影像幾何關係改善對應點的 準確度。 本計畫主要目的是在多視角影像的環境下過濾對應點並取得該影像的相機參數。所以會先輸 入多張未校正的影像,接著計算每一張影像的特徵點與特徵點之間的對應關係,隨後加入基 礎矩陣的幾何關係過濾掉部分對應點,最後以從運動中恢復結構的方法計算相機參數,而我 們的流程而是使基礎矩陣過濾後的對應點加入三焦張量重覆過濾,使任三張影像都滿足三焦 張量的幾何關係,使對應點的對應關係能夠更精確。由於在取得多視角影像特徵點以及對應 點使用到 Bundler,接下來章節中首先驗證 Bundler 可用性,以及將三焦張量用於過濾對應點, 最後擴展到多張影像進行實驗以達到最終目的。 3.2 從多視角幾影像重建三維點雲 在進行三維物體重建前,我們必須先找出影像間的幾何對應關係,過程中我們會先自動產生 稀疏對應點,進一步再擴展為密集對應點而產生物體三維座標點資訊。 3.2.1 多視角幾何萃取精確影像對應 此節將介紹如何從多視角影像中萃取精確影像對應,在萃取影像特徵點的部份,我們使用海 利斯角隅偵測及高斯差分方法在多視角影像中萃取出特徵點;對應點配對的部份,我們透過 極線幾何的特性縮小對應點配對的範圍,並以我們提出的漸進式走訪法發掘潛在的候選點, 我們以補綴面基礎的區塊比對方法,加上我們提出的相互支持概念與動態高斯濾波法,在多 視角影像中萃取精確影像對應;三維點重建的部份,我們使用直接線性轉換將萃取出的對應 點轉換為三維點。 補綴面為基礎比對方法在投影補綴面三維點至多視角影像時,若兩台像機的影像投影面與補 綴面三維點的距離差異過大,則會造成投影點過於集中或是過於分散兩種情況,如圖 1,當 投影點過於集中時,投影點所涵蓋的像素區塊量變少而且重複性高,當投影點過於分散雖然 投影點所涵蓋的像素區塊量不變,但是會因為縮放的比例造成像素資訊程度性的失真,當出 現此兩種情況時,相似度的測量容易發生誤判的情況,其中投影點過於集中造成的影響尤其 嚴重,資訊量過少的情況並不容易處理,因此我們提出相互支持概念,將參照影像與投影影 像的角色互換,將投影點過於集中的情況皆轉為投影點過於分散的情況。 圖 1:投影點集中與分散示意圖、相互支持概念示意圖。 透過上述相互支持概念的處理,補綴面為基礎比對方法在投影補綴面三維點至多視角影像時 只會產生投影點分散的情況,接著我們提出動態高斯濾波法改善因為縮放的比例造成像素資 訊程度性的失真的問題,將投影點的角點與其對角相鄰點的二分之一距離向外延伸,可以得 到動態高斯濾波網格的 4 個角點,如圖 2 動態高斯濾波法示意圖左圖所示,對動態高斯濾波
網格的 4 個角點做雙線性內插,可以得到動態高斯濾波網格的格點,如圖 2 動態高斯濾波法 示意圖右圖所示,將格點連線即可得到高斯濾波網格,分別將投影點周遭像素中心位於動態 高斯濾波網格內的像素,計算像素中心位置與投影點位置的水平與垂直位移量,將水平與垂 直位移量分別代入高斯函數得到高斯係數,對投影點周遭做動態的高斯濾波,投影點的影像 資訊即為所有周遭像素中心位於動態高斯濾波網格內的像素之像素資訊,乘上相對高斯係數 的總和。 圖 2:動態高斯濾波法示意圖。 3.2.2 多視角影像自動建構密集對應點 首先我們延續 Furukawa, Y. et al(2009)[4]提出利用多視角影像重建模型的方法,其觀念主要是 將以往處理影像對應時,比對的影像區塊(block)結合三維空間觀念(如圖 3 所示),其中 I1、 I2、I3…分別代表不同視角拍攝之影像,空間中綠色區塊為物體表面之 3D patch,影像平面上 皆可以看見此 patch 投影區域。傳統上若要比對對應點時,此影像上的 patch 皆是以固定大小 之影像區塊來計算其相似度,但由於 3D patch 經過不同視角投影後,此區塊將會造成變形, 以固定大小之影像區塊來做處理則不太合理。因此必須加入三維關係處理,以提高對應點處 理之精確度。 圖 3:利用 3D patch 比對相似度。 四、 結果與討論 4.1.1 粒子群最佳化演算法於估測基礎矩陣實驗結果 首先我們呈現兩個視角幾何,利用粒子群最佳化演算法評估基礎矩陣的實驗結果。第一組資 料是由 3DMAX 模擬場景,由兩台相機拍攝多視角影像,由於場景是我們模擬配置,因此可 以取得 ground truth 資料,第二組資料是由 Christoph[15]提供多視角影像和光達點雲資料,也 可以由投影矩陣計算出多視角相片中的 ground truth 資料幫助計算誤差,我們將透過三種方法 比較實驗結果,分別是 PSO、LMedS_PSO、LMedS,最後做討論與分析。 我們用 3DMAX 建模並且假設兩台相機拍攝兩張相片,相片解析度為 800x600,籃子大小為 80x60,共有 100 個,初始找尋對應點時採用 SIFT 演算法,共可以找到 2494 組對應點,而 用來驗證的 ground truth 資料,則有 1306 組對應點。另外,光達資料是一種雷射成像系統, 可以將三維模型中的座標記錄下來,相機對物體拍攝相片後,只要透過投影矩陣,即可計算 出三維物體在相片上的座標,我們可以透過這個步驟獲得 ground truth 資料,如圖 4。
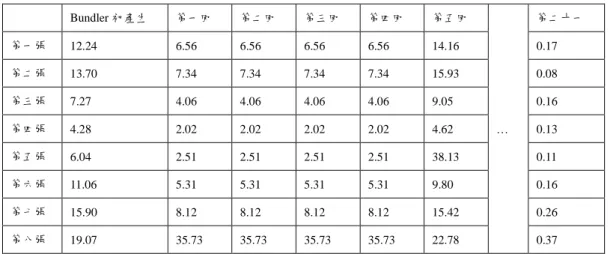
圖 4:由左至右分別為 3DMAX 實驗相片,LiDAR 第一組與第二組實驗相片。 我們採用較接近的疊代次數來比較實驗結果,PSO 實驗採用 10 組隨機取樣的粒子個體經過 疊代計算 117 次,共進行 1170 次疊代,而 LMedS_PSO 方法先計算成功取樣機率為 80%,正 確資料為 50%的一組結果,套用隨機取樣公式需要 412 次,接著隨機取樣 9 組粒子個體後, 結合 LMedS 的一組結果,之後 10 組再進行疊代 76 次,共需要 1172 疊代次數,而 LMedS 的方法直接將成功取樣機率設為 99%,正確資料為 50%,需要疊代 1177 次。 完成上述的步驟後,我們稱為進行一組實驗,在本研究中,將使用 1000 組資料的平均誤 差當作實驗結果,如表 1、2。 表 1:3DMAX 場景估測基礎矩陣結果 方法 1000 組平均誤差 1000 組標準差 1000 組需要時間 PSO 0.077 像素 0.0547 像素 5 小時 LMedS_PSO 0.086 像素 0.0548 像素 18 小時 LMedS 0.097 像素 0.0548 像素 41 小時 表 2:3DMAX 場景估測基礎矩陣標準差分佈 方法 小於平均標準差 小於 0~1 倍 小於 1~2 倍 PSO 678 個 667 個 11 個 LMedS_PSO 632 個 629 個 3 個 LMedS 581 個 577 個 4 個 從表 1、2 中我們可以發現,PSO 的平均誤差和花費的時間皆是最少的,而小於平均標準差 的數量也是最多,而其兩兩組資料也都是類似的結果。從圖表中我們看出,PSO 的方法在接 近的疊代次數中,時間成本和平均誤差值皆是表現最好的。 從三組實驗結果看出來,三種方法用接近的疊代計算次數比較,使用 PSO 的方法比過去使用 強健式方法 LMedS 快上不少,平均誤差值也較小,而我們另外結合兩種方法的 LMedS_PSO 則是在時間成本、平均誤差值皆介於中間,這是可以預期的,第一組 3DMAX 資料因為是我 們用電腦模擬,包括相機的參數皆有的情況下,算出來的誤差值較小,而第二組 LIDAR 資 料因為在找對應點時遇到記憶體不足的問題,調整後已經造成些誤差,再來利用投影矩陣投 影回相片上時,需要做正規化,這部份也產生了誤差,因此整體比較下來,誤差比 3DMAX 資料大,但是就 LIDAR 資料來說,我們提出的方法是有效率且誤差值較小的,有了這些資 訊後,適合未來繼續進行相關研究。 4.1.2 利用三焦張量輔助評估多視角幾何實驗結果 將三焦張量的幾何關係在三張影像進行實驗,從實驗結果可以發現三焦張量確實可以將 Bundler 對應點的準確性提升。也因此我們將三焦張量的幾何特性擴增到多張影像上,刪除不 符合的對應點,使任三張影像皆具有此關係。下表 7 為實驗刪除對應點平均誤差的變化情形。
表 7:LIDAR 場景估測基礎矩陣標準差分佈 Bundler 初產生 第一回 第二回 第三回 第四回 第五回 … 第二十一 第一張 12.24 6.56 6.56 6.56 6.56 14.16 0.17 第二張 13.70 7.34 7.34 7.34 7.34 15.93 0.08 第三張 7.27 4.06 4.06 4.06 4.06 9.05 0.16 第四張 4.28 2.02 2.02 2.02 2.02 4.62 0.13 第五張 6.04 2.51 2.51 2.51 2.51 38.13 0.11 第六張 11.06 5.31 5.31 5.31 5.31 9.80 0.16 第七張 15.90 8.12 8.12 8.12 8.12 15.42 0.26 第八張 19.07 35.73 35.73 35.73 35.73 22.78 0.37 實驗結果可以看出整體誤差情況是比較低的,在我們這組實驗中第二十一回的結果比預想種 降低的幅度還要更大,每一張影像平均誤差都在 1 個 pixel 以下。從這邊我們也可以很清楚的 了解對應點的組合狀況會很嚴重影響投影矩陣的產生結果。另外,也同時了解到三焦張量的 幾何特性確實能夠使影像間對應點準確率大大的提升。 4.1.3 多視角幾何萃取精確三維點雲實驗結果 在利用多視角幾何萃取精確影像對應部分,我們提出相互支持概念與動態高斯濾波法,改善 以補綴面為基礎比對方法於多視角影像中的影像縮放問題,我們將透過實驗證實相互支持概 念與動態高斯濾波法的實質成效。 我們在架設好的 3ds Max 實驗場景中擺設貼上花紋圖樣的正方體物件,並在正方體物件的表 面取 9 個已知 3 維點,以實驗場景中的 1 號相機所拍攝的影像作為參照影像(Reference Image), 如圖 5 以 1 號像機拍攝參照影像圖所示,已知 3 維點投影在參照影像上的分佈,接著實做補 綴面基礎的比對方法,在三維空間中建立三維補綴面,並依序將三維補綴面上的 49 個 3 維點 投影在實驗場景中 109 部相機所拍攝的多視角影像,重新排列出像素區塊取出關鍵影像資訊 後,使用正規化相關匹配法進行相似度量測,並與單純在投影點周遭框一個 7x7 方形像素區 塊的區塊比對方法、以及補綴面基礎的比對方法加入我們提出的相互支持概念與動態高斯濾 波法,三者進行比較。 圖 5:以 1 號像機拍攝參照影圖與相似度實驗結果折線圖。 相似度實驗結果折線圖所示,分別呈現 9 個已知三維點的實驗結果,橫軸代表相機的編號, 縱軸代表用正規化相關匹配法所測得的相似度大小,相似度值為-1 至 1,相似度越趨近於 1 代表相似程度越高,折線的部份 Block 代表的是區塊比對方法,Patch 代表的是補綴面基礎的 比對方法,SM+DG 代表的是補綴面基礎的比對方法加上我們提出的相互支持概念與動態高
斯濾波法。 從實驗結果可以得知補綴面基礎的比對方法相較於區塊比對方法,較不容易受到多視角影像 拍攝視角變化的影響,可以有效改善區塊比對方法的影像旋轉問題,因此在相似度判斷的正 確性比較高,另外補綴面基礎比對方法特有的影像縮放問題,經過我們提出的相互支持概念 與動態高斯濾波法處理之後,在相似度判斷的正確性上有顯著的提升。 因此我們進一步們將在多視角影像的環境下,進行萃取精確影像對應與三維點重建的實驗, 如圖 6 三維點重建實驗場景介紹圖所示,我們在 3ds Max 實驗場景中,分別對於暴龍 (Tyrannosaurus Rex)及翼龍(Pteranodon)兩組模型進行實驗,其中暴龍的實際尺寸為長度 14 公 尺、寬度 4 公尺、高度 6.5 公尺,暴龍的實際尺寸為長度 336 公尺、寬度 130 公尺、高度 48 公尺,在暴龍的實驗場景中,我們架設了 30 部相機,在翼龍的實驗場景中,我們架設了 25 部相機,並透過相機取得一系列多視角影像,照片的像素比例皆為 1600 x 1200,多視角影像 的拍攝以可以將模型完全入鏡為原則,相機的擺設方式並無一定規律。 圖 6:三維點重建實驗場景介紹圖。 在萃取影像特徵點的部份,我們使用海利斯角隅偵測及高斯差分方法在多視角影像中萃取出 特徵點,,對應點配對的部份,我們透過極線幾何的幾何特性縮小對應點配對的範圍,並以 直接線性轉換計算出對應候選點的三維點座標。實驗中比對區塊大小為 7 x 7 的像素區塊,我 們以補綴面基礎的區塊比對方法,加上我們提出的相互支持轉換、動態高斯濾波法與綜合性 相似度評估函數,對三維點進行相似度量測,並使用 K-Means 分群演算法與線性內插法發掘 潛在的三維點,在多視角影像中萃取精確影像對應與三維點重建。 圖 7:暴龍與翼龍點雲影像圖。 實驗結果如圖 7 暴龍與翼龍點雲影像圖所示,點雲影像圖是我們使用 3ds Max 軟體,將於三 維空間之點雲資訊攝影後的結果,經過三維點重建後的點雲資訊,每一個三維點除了有三維 座標之外,還有綜合性相似度評估函數所計算出來的分數,其值的範圍為-1 至 1,我們以 0.4 做為門檻值(threshold),過濾掉分數低於門檻值的三維點,可以透過調整門檻值將不理想的三 維點去除,門檻值愈高三維點中離群資訊的數量就愈少,但通過門檻值的三維點數量也會愈 少,反之,門檻值愈低過門檻值的三維點數量就愈多,但三維點中離群資訊的數量也愈多, 以 0.4 做為門檻值過濾之後,暴龍有 28005 個三維點,翼龍有 28664 個三維點。 從實驗結果的觀察中發現,我們以相互支持轉換、動態高斯濾波法與綜合性相似度評估函數,
改善補綴面基礎的區塊比對方法,進行相似度量測,並使用 K-Means 分群演算法與線性內插 法發掘潛在的三維點,在對應點與三維點精確度的提升上皆有很好的成效,在暴龍與翼龍的 實驗中,我們所獲得的點雲資訊,存在大量精確的三維點,而且僅有少數的離群資訊,其中 模型較細緻的部份,像是暴龍的爪子、牙齒,以及翼龍的尖嘴、頭冠及後腳,這些部位的三 維點皆可精確的被找到,雖然我們藉由綜合性相似度評估函數所計算出來的分數,設定門檻 值降低離群資訊的數量,但仍然會有少數離群資訊的存在,這些分數高的離群資訊會出現的 原因,是由於多視角影像中的實體物件具有光滑的表面或是局部性紋路不明顯所致,另外, 若多視角影像的反光問題過於嚴重,或者反光的照片數量過多,也有可能會造成此現象。 五、 結論 所以我們使用連續多角度拍攝,從拍攝的多視角影像,希望能以幾何特性來自動重建物體模 型。實驗中,我們成功的將粒子群最佳化演算法應用在估測基礎矩陣上,先藉由兩個基礎實 驗,讓我們更了解演算法特性後,轉換至估測基礎矩陣的問題,並跟過去強健式估測方法做 比較,不論計算時間成本或是平均誤差值的結果,都是粒子群最佳化演算法最為理想,除了 粒子群最佳化演算法外,我們結合最小平方中值法的特性,建立最小平方中值表格,取中位 數當作我們評估值,也確實適合用於估測基礎矩陣。使用粒子群最佳化演算法解題,可以避 免過去幾種強健式估測方法內部需要大量的計算時間,根據實驗數據統計,我們僅需強健式 估測方法(本計畫用 LMedS 當作比較方法)的 1/8 時間,即可完成接近的取樣次數,在此情況 下,實驗粒子群最佳化演算法的標準差小於平均值的比例較高。 此外,從我們實驗的結果可以觀察出三焦張量的確可以過濾出不正確的對應點,我們在刪除 的過程中先以權重最高的對應點進行刪除,再重覆計算三焦張量以過濾對應點,整體提升對 應點刪除的準確性,在第二十一回合也使整體誤差平均降到 1 個 pixel 以下,得到一個很好的 結果。在這幾組數據中都一再指出三焦張量的幾何特性的確可以過濾掉較差的對應點關係使 整體對應點準確率提升。 本計畫中我們探討了如何在多視角影像萃取精確影像對應的議題,們基於多視角影像之間的 幾何關係,對於多視角萃取影像對應與三維點重建皆提出了新的方法,成功的改善了對應點 與三維點的精確度。我們分析了區塊比對方法、補綴面為基礎比對方法,發現在多視角影像 的環境下,區塊比對方法與補綴面為基礎比對方法,容易受到多視角影像間拍攝視角旋轉與 拍攝距離差異的影響,產生區塊比對旋轉問題、區塊比對縮放問題、補綴面為基礎比對縮放 等問題,這些問題會造成比對區塊內的像素群組不相同及其相對位置不一致,以至於相似度 測量上的不準確,因此,我們建立實驗環境、取得相機參數,並在多視角萃取影像對應與三 維點重建過程中,使用我們提出的相互支持轉換、動態高斯濾波法與綜合性相似度評估函數, 改善補綴面為基礎比對方法,並使用 K-Means 分群演算法與線性內插法發掘潛在的對應點與 三維點,在多視角影像中萃取精確影像對應與三維點重建。 在多視角影像的環境下,補綴面基礎的區塊比對方法加上相互支持轉換、動態高斯濾波法與 綜合性相似度評估函數後,可以有效的改善補綴面為基礎比對縮放問題,提高相似度測量值 的辨識力與可信度,使用 K-Means 分群演算法及線性內插法,可以有效的發掘潛在的對應點 與三維點,讓所求出的三維點更加貼近三維空間真實物體表面,我們所提出的方法在對應點 與三維點精確度的提升上皆有很好的成效。
未來,如何在多視角影像的環境下萃取精確影像對應與三維點重建,是個值得研究的議題, 對應點與三維點的精確度,將會影響未來三維立體模型重建,或者其他相關應用的成效,雖 然我們所提出的方法經由實驗結果證實,可以在多視角影像的環境下,提升萃取影像對應與 三維點重建的精確度,但本研究所提出的方法或許仍然有其他可以改進的空間,我們將未來 可以將影像的色彩資訊,加入綜合性相似度評估函數的相似度量測之中,藉由光度一致性、 色彩一致性與幾何強健性的綜合性評估,提升相似度測量值的辨識力與可信度。 參考文獻
[1] Brown, M. Z., Burschka, D., (2003), “Advances in Computational Stereo”, IEEE Trans. Pattern Analysis and Machine Intelligence, Vol. 25, No. 8, pp. 993-1008.
[2] Danahy, J. (1999), “Visualization Data Needs in Urban Environmental Planning and Design”, in Proceedings of the Photogrammetric Week, Karlsrnhe, pp. 351-365.
[3] Dubuisson, M. P., Jain, A. K., (1994), “A Modified Hausdorff Distance for Object Matching”, Proc. of IAPR Int. Conf. on Pattern Recognition, Vol. 1 pp. 566-568.
[4] Furukawa, Y. and Ponce J.(2007), "Accurate, Dense, and Robust Multi-View Stereopsis", in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp.1-8. [5] Furukawa, Y. and Ponce, J. (2008), “Accurate Camera Calibration from Multi-View Stereo
and Bundle Adjustment”, in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp.1-8.
[6] Georgescu, B., Meer, P. (2004), “Point Matching under Large Image Deformations and Illumination Changes”, IEEE Trans. Pattern Analysis and Machine Intelligence, Vol. 26, No. 6, pp. 674-688.
[7] Hartley, R. and Zisserman, A. (2003), Multiple View Geometry in Computer Vision, 2nd Ed., Cambridge University Press.
[8] Lhuillier, M. and Quanm L. (2003), “Image-Based Rendering by Joint View Triangulation”, IEEE Transcations on Circuits and Systems for Video Technology, Vol.13, No.11, pp. 1051-1063.
[9] Lowe, D.G. (2004), “Distinctive Image Features from Scale-Invariant Keypoints”, International Journal of Computer Vision, Vol.60, pp.91-110.
[10] Mellor, J.P. (2003), "Geometry and Texture from Thousands of Images", International Journal of Computer Vision 51, pp. 5-35.
[11] Snavely, N., Seitz, S. M., and Szeliski, R. (2006), “Photo Tourism: Exploring Photo Collections in 3D”, ACM Transactions on Graphics, Vol. 25, No. 3, pp. 137-154.
[12] Snavely, N., Seitz, S. M., and Szeliskix R. (2008), “Modeling the World from Internet Photo Collections”, International Journal of Computer Vision, Vol. 80, No. 2, pp. 189-210.
[13] Volz, S., and Klinec, D. (1999), “Nexus: the Development of a Platform for Location Aware Application”, in Proceedings of the third Turkish-German Joint Geodetic Days, Vol. 2, Istanbul, pp. 599-608.
[14] http://phototour.cs.washington.edu/bundler/
1
參加「ICMT 2011 年第二屆多媒體技術國際研討會」心得報告
一、 2011 年多媒體技術國際研討會 1. 會議簡介
「多媒體技術國際研討會」(ICMT: International Conference on Multimedia Technology)為近年來在多媒體領域新崛起之重要國際性研討會。今年之研討 會為第 2 屆,由 IEEE 與杭州電子科技大學、寧波大學、南京信息工程大學及 University of Louisville 共同主辦,與會學者專家來自世界各地,會中發表的都 是最新的學術研究成果。
本屆會議於 2011 年 7 月 26 日至 7 月 28 日在中國浙江杭州舉行,會議涵蓋之 主題包含四大主軸,分別為 Multimedia Tools and Systems、Image Processing Technology、Network Applications、Multimedia Entertainment Service。期中 Multimedia Tools and Systems 主軸包含 Multimedia Coding and Transmission、 Multimedia Storage, Retrieval、Digital Libraries Authentication、Multimedia Data Mining 、 Multimedia Authentication 、 Digital Watermarking 、 Content-based Multimedia Retrieval 、 Multimedia Performance and Management 、 Video Segmentation and Tracking 與 Video Indexing and Editing,Image Processing Technology 主軸包含 Image Filtering and Enhancement、Restoration、Wavelets and multi-Resolution Processing 、 Stereoscopic and 3-D Processing 、 Motion Detection and Estimation、Computer Vision、Biomedical Imaging、Remote Sensing Imaging 、 Geophysical and Seismic Imaging 、 Optical Imaging 、 Color Reproduction、Image Representation and Rendering 與 Image Quality Assessment, Network Applications 主軸包含 Multimedia Broadcasting Systems on the Web、 Multimedia Communication Systems 、 Multimedia Networking 、 Distributed Multimedia Systems 、 Multimedia Transport/Routing Protocols 、 Distributed Multimedia Systems、Digital Video Broadcasting 與 Video Streaming,Multimedia Entertainment Service 主軸包含 Multimedia Technologies and Games、Graphics and Virtual Worlds、Virtual Reality、Mobile Multimedia、Video-on-Demand、 Human-Computer Interfaces 、 Video Conference 與 Virtual / Real Video Communication。
大會安排了七場專題演講,第一場由 Aly A. Farag 教授(Electrical and Computer Engineering, University of Louisville, USA) 主 講 , 講 題 為 Advances on Topological Registration Approaches with Applications;第二場由 Edwin Hancock 教授(Department of Computer Science, University of York, UK)主講,講題為 Facial Shape, Texture and Reflectance from a Single View;第三場由 Jie Yang 教 授 ( 中 國 上 海 交 通 大 學 影 上 處 理 與 圖 形 識 別 研 究 所 ) 主 講 , 講 題 為 3D
2
visualization and its Applications;第四場由 Demetri Terzopoulos 教授(Computer Science Department, University of California, USA)主講,講題為 Computer Vision in Virtual Reality;第五場由 Gerald Schaefer 博士(Department of Computer Science, Loughborough University, UK)主講,講題為 Navigating Large Image Databases;第六場由 Vijay K. Arora 教授(Division of Engineering and Physics, Wilkes University, USA) 主 講 , 講 題 為 Quantum Nanophysics and Nanoengineering of Low-Dimensional Devices and Circuits;第七場由 Alexander P. Yefremov 教 授 (Peoples’ Friendship University of Russia) 主 講 , 講 題 為 Relativistic Danger for Spacecraft from Fast Satellites of the Solar-System Planets。可惜議程安排與專業報告衝突,無法一一前往聆聽,至為可惜。
2. 發表論文
本次會議,攜同博士班研究生詹凱軒先生一同出席。大會安排我們於 7 月 27 日晚上發表論文,題目為「3D Model Reconstruction Refinement from Multiple Images」。
論文主要之貢獻在於對影像處理中之影像對應(image matching)方法之精進。 影像對應是影像處理中一個非常基本且重要的問題,良好的影像對應方法可 作為由多張影像建立三維物體模型以及多種影像處理問題的基石。大抵在 2004 年,David Lowe 曾經提出一個特別的演算法(SIFT: Scale Invariant Feature Transform)在影像對應上有不可忽視之貢獻,然而他的方法可能受雜訊影響而 導致精確度不良。我們的論文採用改良的方法,對抗雜訊較佳,能提高精確 度。實驗證明我們的方法的確提高了在雜訊干擾下的精確度。 與會學者對我們的研究成果相當有興趣,但由於會議安排不善,不同類別的 論文被安排在同一場次報告,同時論文集之安排也非常凌亂,台上報告論文, 台下在找相關資料卻屢屢無法找到(發表之論文眾多,只拿到與本人研究有關 之部分論文集,然台上報告者之論文並不在手邊之論文集內),因此對他人之 報告無法有最好的瞭解。 二、 綜合感想 急功近利,是時下社會中的通病,生活上如此、工作上如此、學術研究上也如此。 而此次研討會上所聽到歐美科技先進大國科研政策推動負責人或科研經費核准負 責人對科研的看法與態度,卻令我震驚不已,久久不能忘懷。記得以前我們常常用 愛迪生的故事(愛迪生在研究製作燈泡的過程中,嘗試過無數材料均不成功,旁人 笑他虛擲光陰一事無成,可是他說:「不會啊,我已經知道這些材料都不能用,這 就不會虛擲光陰了。」)來鼓勵(或安慰)自己。可是在實際研究上卻急功近利, 卻跳不出「虛擲光陰一事無成」的框框(陰影),豈不自相矛盾。
3 值得一提的是,我們今日的科技文化,大多數吸收自美國與日本,而忽略了歐洲與 蘇聯以及中國大陸。在歐洲的科技文化中,除了包含理工方面的科學外,並包含有 社會科學及其與理工方面學科的互動與關連。(不要忘了文藝復興與產業革命都起源 於歐洲) 。在台灣,我們僅注意到了前者,而對後者幾乎是完全忽略了。這究竟是 我們忽略精神文化,忽略了我們五千多年來的悠久歷史與社會,還是我們只是盲目 的從美國吸取表面的科技而導致的現象?金庸的天龍八部中,在少林寺藏經閣打掃 的老僧曾以「高深的武學,必須與深厚的佛學根基相輔相成,才能化去武學中暴戾 之氣而無後患」(文字或有出入,僅取其意),規勸學武之人。我們在學習歐美科 技(嚴格而言,該說是美國科技)之時,是否也犯下了急就章學武的禁忌,只學到 表面的科技而忽略了精神文化的層面呢?台灣目前重利輕義的奇特現象,似乎忽略 了社會層面的整體考量。我們不尊重生命、不尊重生活、不尊重社會、不尊重環境, 這些弊病在未來的日子中,終將點滴的蠶食我們所有的努力與成果。我們在努力建 設台灣成為科技島的時候,不可不察。 本人 90 年代(西元)初期曾於日本名古屋所舉辦之機器人運動控制研討會上發表論 文,會中遇見相當多的韓國學生,他們在會中並未發表論文,但學校補助他們全額 旅費來參加/觀摩,同時一個學校有相當多的補助名額。當時本人曾為文感慨韓國政 府/學校或私人機構對人才培育的投資,足以令我們借鏡。後來教育部編列預算,補 助在校博士班學生出國參加研討會(也許侷限於經費而在資格上有所限制,但已經在 培育年輕學者/子上,跨出了第一步)。現在我們常常為了防弊而因噎廢食,譬如研 擬出國參加研討會必須為 rank 1 會議的限制,其出發點應該是希望國內學者專家出 國參加最好的研討會,不要參加次級的會議。立意精闢,但可作為目的而非手段。 否則其他國家或單位群起而效法,今後我們自辦的研討會,參加的人就少了。(不一 定是我們辦的研討會不好,可能只是新辦的研討會知道/參加過的人不多,資料欠 缺,根本不被考慮列入排行榜中)。投資與回收,在研究中,本來就很難有定論的。 如果要看到回收的影子才肯投資,當初貝爾實驗室大概也沒辦法研究出電晶體 (transistor),今天我們大概也沒有電腦可以使用。研擬開會設限只是期中一例。因噎 廢食,做不得的。 同時,在研究中,我們注重國外發表的論文而輕視國內發表的論文,無論是期刊論 文或研討會論文,只要是國內發表的都被輕視,長期以來為人作嫁的結果,只是讓 美國(絕大部分是美國)的期刊與會議辦得越來越好,論文水準越來越高,自己的期 刊與會議水準越來越不受重視。這是不對的。1988 年我剛回國不久後參加一個國內 的研討會,會中與一位影像處理界的資深教授聊天,談起這個現象。該教授回應, 國內的期刊與會議論文在老師升等或學生畢業時,所算的點數比較少,所以無法與 國外的期刊或會議相比。當時我問到,計算點數是誰來決定,資深教授的回應是我 們自己決定。情況就明朗了,如果我們自己(其實要資深教授帶頭)能肯定自己(國內)
4 的期刊與會議,同時鼓勵同儕與學生們投稿時,將好的研究成果優先投在國內發 表,點數不會少算,這樣一來,自己的期刊或會議有一流的論文,國外自然不敢輕 視,自然而然能提升國內期刊與會議的水準。二十年前如果做了,今天國內的期刊 與會議論文水準一定可觀。這種事,今天不做明天就會後悔的,可是有多少人肯做 呢? 報告人:何瑁鎧 二0一一年七月三十日初稿 八月二十四日修正
國科會補助計畫衍生研發成果推廣資料表
日期:2011/11/29國科會補助計畫
計畫名稱: 應用於地理資訊系統之使用多視角影像重建三維建物模型 計畫主持人: 何瑁鎧 計畫編號: 99-2221-E-004-011- 學門領域: 影像處理無研發成果推廣資料
99 年度專題研究計畫研究成果彙整表
計畫主持人:何瑁鎧 計畫編號: 99-2221-E-004-011-計畫名稱:應用於地理資訊系統之使用多視角影像重建三維建物模型 量化 成果項目 實際已達成 數(被接受 或已發表) 預期總達成 數(含實際已 達成數) 本計畫實 際貢獻百 分比 單位 備 註 ( 質 化 說 明:如 數 個 計 畫 共 同 成 果、成 果 列 為 該 期 刊 之 封 面 故 事 ... 等) 期刊論文 0 0 100% 研究報告/技術報告 0 0 100% 研討會論文 2 2 100% 篇 論文著作 專書 0 0 100% 申請中件數 0 0 100% 專利 已獲得件數 0 0 100% 件 件數 0 0 100% 件 技術移轉 權利金 0 0 100% 千元 碩士生 3 3 100% 博士生 1 1 100% 博士後研究員 0 0 100% 國內 參與計畫人力 (本國籍) 專任助理 0 0 100% 人次 期刊論文 2 2 100% 研究報告/技術報告 0 0 100% 研討會論文 1 1 100% 篇 論文著作 專書 0 0 100% 章/本 申請中件數 0 0 100% 專利 已獲得件數 0 0 100% 件 件數 0 0 100% 件 技術移轉 權利金 0 0 100% 千元 碩士生 0 0 100% 博士生 0 0 100% 博士後研究員 0 0 100% 國外 參與計畫人力 (外國籍) 專任助理 0 0 100% 人次其他成果