國立交通大學
資訊工程學系
博士論文
動態知識擷取方法之研究
A Study of Knowledge Acquisition Methodologies
for Dynamic Knowledge
研 究 生: 林順傑
指導教授: 曾憲雄 博士
動態知識擷取方法之研究
A Study of Knowledge Acquisition Methodologies
for Dynamic Knowledge
研 究 生: 林順傑
Student: Shun-Chieh Lin
指導教授: 曾憲雄 博士
Advisor: Dr. Shian-Shyong Tseng
國 立 交 通 大 學
資 訊 工 程 學 系
博 士 論 文
A Dissertation
Submitted to Department of Computer Science College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy
in
Computer Science October 2006
Hsinchu, Taiwan, Republic of China
動態知識擷取方法之研究
學 生: 林順傑
指導教授: 曾憲雄 博士
國立交通大學 資訊學院
資訊工程系
摘要
知識擷取是在建立知識庫系統中的一個主要瓶頸。由於知識爆炸,知識可以 被 歸 納 成 靜 態 知 識 ( Static Substantive Knowledge ) 和 動 態 知 識 ( Dynamic Substantive Knowledge)兩大類。在過去 20 多年中,有很多的研究學者提出很多 知識擷取方法,從專家那邊萃取出靜態的知識,然而,這些方法在擷取知識的過 程中,因為缺乏足夠多的資訊,所以並沒有討論到如何發覺包括變種知識(Variant Knowledge)和演化性知識(Evolutional Knowledge)兩類的動態知識。因此, 如何蒐集到足夠多的資訊,並用來通知專家有新演化的物件產生,而且可以利用 並擴展舊有的知識庫,在知識擷取的領域中,也逐漸變成一個重要的議題。部分 現存的知識擷取系統,採取建構個人建構理論(Personal Construct Theory)上發 展出來的知識表格(Repertory Grid)技術來擷取在一個限定領域間,分辨並區分 開不同物件的靜態知識。EMCUD(Embedded Meaning Capturing and Uncertainty Deciding)是一種用來擷取隱含知識的技術。它在 1990 年被提出來協助專家萃 取知識的隱含意義並協助專家決定每一條隱含規則(embedded rule)的信賴程 度,用來擴展使用傳統知識表格方法產生的原始規則(original rule)。然而,們的想法是希望可以藉由觀察知識庫各個低信賴程度的隱含規則被推論的行 為,包括頻率以及趨勢變化並藉此用來學習可能的新演化物件,然後再引導專家 根據這些推論行為的趨勢來萃取便是這些物件的動態知識。在這篇博士論文中, 我們將提出一個包含推論記錄檔蒐集階段、知識學習階段以及知識精鍊階段等三 個階段新的知識擷取方法,Dynamic EMCUD,來協助專家察覺到新演化物件的 產生並萃取出這些物件的隱含規則。Dynamic EMCUD 在推論記錄檔蒐集階段可 以協助專家蒐集足夠的推論記錄。在隨著時間改變的環境中,在知識學習階段中 可以透過觀察頻繁的推論行為和演化行為的趨勢,讓專家察覺到新演化物件的產 生。最後,在知識精鍊的階段,Dynamic EMCUD 可以將一個小的多資料型態知 識表格和一個小的屬性序列表格(Attribute Ordering Table,AOT)個別整合到一 個主要的多資料型態知識表格和主要的屬性序列表格中,並用來調整弱隱含知識 來達到表格演化的能力。進一步來說,我們的方法可以很容易的延伸成包括多個 區域的知識庫系統和一個聯合的知識庫系統的聯合式的架構來協助整合從各個 搭載 Dynamic EMCUD 的區域知識庫系統所產生的演化物件的知識。並且協助專 家可以容以的利用足夠多的環境資訊來發覺更多其它新的物件知識。我們提出五 個演算法來幫助專家容易的萃取新物件的隱含規則。電腦蠕蟲和分散式阻斷服務 偵測以及警報分類模式建立兩個應用可以用來評估 Dynamic EMCUD 的效能,結 果顯示新的變種物件可以被快速發覺並可以快速的通知專家,並協助他們利用 Dynamic EMCUD 萃取出新演化物件的隱含規則。 關鍵詞: 知識擷取、知識表格、隱含知識擷取、入侵偵測、電腦蠕蟲、分散式阻 絕服務
A Study of Knowledge Acquisition Methodologies
for Dynamic Knowledge
Student: Shun-Chieh Lin Advisor: Dr. Shian-Shyong Tseng
Department of Computer Science College of Computer Science National Chiao Tung University
Abstract
. Knowledge acquisition is known to be a critical bottleneck of building knowledge based systems. Due to the explosion of knowledge, substantive knowledge can be classified into static substantive knowledge and dynamic substantive knowledge. Many knowledge acquisition methodologies have been proposed to systematically elicit rules of static substantive knowledge from domain experts in the past twenty years. However, none of these methods discusses the issue of discovering dynamic substantive knowledge including variant knowledge and evolutional knowledge due to the lack of sufficient information. Hence, how to collect sufficient information to help experts notice the occurrence of new evolved objects and to reuse and extend the original knowledge base becomes increasingly important in the knowledge acquisition field. Most of the existing systems employ the Repertory-Grid test originally developed by Personal Construct Theory in eliciting static substantive knowledge to identify different objects and distinguishing these objects in a selected domain. EMCUD (Embedded Meaning Capturing and Uncertainty Deciding), one of a
Repertory Grid based knowledge acquisition tools, has been proposed to elicit the embedded meanings of knowledge (embedded rules bearing on objects and object attributes) to classify objects and guide experts to decide the certainty degree of each embedded rule using an attribute ordering table (AOT), which records the relative importance of each attribute to each object, for extending the coverage of original rules. However, it still lacks the ability to discover the occurrence of new evolved objects due to insufficient information. Our idea is to monitor the frequent inference behaviors and the trend of weak embedded rules with lower certainty degree and learn the candidates of new evolved objects and then guide the experts to extract the dynamic knowledge of these objects according the trend of inference behaviors. In this dissertation, we will propose a new iteratively knowledge acquisition method,
Dynamic EMCUD which includes Log Collecting Stage, Knowledge Learning Stage,
and Knowledge Polishing Stage, to notify experts to extract the embedded rules of new evolved objects. The Dynamic EMCUD can collect sufficient inference log in Log Collection Stage and then notify experts the occurrence of evolved objects through observing the frequent inference behaviors and tracing the trend of evolutional behaviors over time in a changing environment in Knowledge Learning Stage. In the Knowledge Polishing Stage, the Dynamic EMCUD can integrate a small acquisition table increment and a small attribute ordering table (AOT) increment into the main acquisition table and the main AOT, respectively, for adapting the weak embedded rules to achieve the ability of grid evolution. Moreover, our method can be easily extended as a collaborative framework (including n local KBSs and a collaborative KBS) to integrate the new knowledge of new evolved objects generated from every local KBSs (each KBS deploy a Dynamic EMCUD) and help experts easily discover some other new evolved objects in the collaborative KBS with sufficient
of new objects. Two applications including in worms and distributed DoS detection, and alert classification model construction are used to evaluate the performance of
Dynamic EMCUD. The results show that the new variants can be discovered and
experts can be easily notified to quickly extract the knowledge of new objects according to the Dynamic EMCUD.
Keywords: Knowledge acquisition, Repertory grid, EMCUD, Intrusion detection, Computer worm, Distributed DoS
誌謝
盼呀盼的,終於取得夢寐以求的博士學位,對自己來說,算是完成小時候的 夢想。對於家人,也算是有個交代,尤其是陪在身邊一直默默支持鼓勵我的可愛 老婆 念怡,以及在去年才向這個世界報到的寶貝女兒 宸妤。猶記得七年前,從 未離開家鄉的我,帶著忐忑不安的心情,進入了交大校園就讀,在這浩瀚的學術 殿堂裡開始了我的求學生活,期間雖然經歷了許多的風風雨雨,但仍感謝妳的體 諒與包容,讓我可以無後顧之憂來完成這篇論文。對妳們無盡的感謝,絕非筆墨 可以形容。 回首這碩博士班七年多的求學過程中,從對新環境的適應、人際關係的培 養、資格考的歷練、領袖風範的訓練以及同儕間對於問題真理的激烈討論等,一 切均一步步扎扎實實的走過。而完成這篇博士論文,最應該感謝的便是從碩士班 期間,就一直旁邊諄諄教誨的恩師 曾憲雄教授,在浩瀚無涯的研究學海中,引 導我朝著正確的方向前進。他不僅奠定了我在研究領域上的基礎,訓練我獨立思 考解決問題以及批判突破的能力。更透過產學計畫的執行,培養我那些許的領導 與統御的能力。而在待人處事方面,他也以自身為典範,讓我們在不斷的磨練與 修正,讓我可以潛移默化的學習到面面俱到的解決問題的技巧。這些一切的收 穫,遠遠超過完成博士論文,取得博士學位所帶來的意義;溢於文字外的心情僅 能在此致上最深的感激。 此博士論文的完成,也非常感謝從論文研究計劃書口試、校內口試到校外 口試一路給予我許多論文修改建議的 孫春在教授與 胡毓志教授,讓我可以用 全新的觀點,重新檢視我的研究貢獻;在校內口試中,感謝 彭文志博士對論文 的研究方法分析的重要;以及在校外口試中給予我寶貴意見的高雄大學 蘇豐文 教授以及 洪宗貝教授、台南大學 黃國禎教授、與成功大學 朱治平教授,對 於論文方法與結果呈現,給於精闢的見解與指導,由於他們的協助,讓此論文最 後的成果能夠更加完整並增加整體論文的可讀性。 更不能忘記的,是一起奮鬥的知識工程實驗室的夥伴們,雖然每一年相處 的夥伴都不盡相同,但不變的是彼此的交誼與切磋,都是我能夠順利走到這裡的 助力,我也將帶著這裡的種種的回憶,往下一個人生旅程持續邁進。 僅將本篇論文的完成,獻給每一位給予我幫助及支持我的家人與朋友。Table of Contents
Abstract (In Chinese) ... I
Abstract (In English) ... III
Acknowledgement... VI
Table of Contents ...VII
List of Figures ... IX
List of Tables ...X
List of Algorithms ... XI
Chapter 1 Introduction... 1
Chapter 2 Related Work... 8
2.1 Knowledge Acquisition Systems...8
2.2 Repertory Grid Methodology and Relevant Systems ...9
2.3 Elicitation of Embedded Meanings ...12
2.4 Problems of Repertory Grid Knowledge Acquisition Methods ...17
Chapter 3 Dynamic Knowledge Acquisition Based Upon EMCUD ... 24
3.1 The Concept of Dynamic EMCUD ...24
3.2 Inference Log Collecting Based upon Meta Rule ...26
3.3 The NEO-Learning Module ...27
3.4 Grid Merging...32
3.5 Collaborative Framework of Dynamic EMCUD ...33
3.6 Implementation of Dynamic EMCUD...39
Chapter 4 Variant Knowledge Acquisition... 41
4.1 Idea ...41
4.2 Variant Objects Discovering Knowledge Acquisition (VODKA)...42
4.3 The Analysis of VODKA ...46
4.4 Experiments...48
Chapter 5 Evolutional Knowledge Acquisition ... 57
5.1 Trend Evolution Analysis...57
5.2 Capturing Evolutional Trend Using AST...58
5.3 Constructing the Dynamic AOT...60
5.4 Adjusting Certainty Factor of Collaborative Dynamic Knowledge ...64
5.5 Experiments...65
Chapter 6 Application in Worms and DDoS Detection... 74
6.1 The Background of Worms and DDoS Attack ...74
6.2 The Framework Worm Immune Service Expert System ...76
6.3 DDoS Intrusion Tolerance...79
6.4 Knowledge Base Maintenance ...91
6.5 Experiments...103
Chapter 7 Application in Alert Classification Model Construction ...109
7.1 Introduction...109
7.2 Decision Support System Architecture... 111
Chapter 8 Conclusion and Future Work ...126
Reference...129
Appendix A Introduction of DDoS...136
Appendix B The Example of Knowledge Class in DDoS Intrusion
Tolerance ...139
Appendix C The Examples for Rule Base Partitioning ...147
Appendix D Rule Class Construction Algorithms of Model Constructing
Phase ...151
Appendix E The Overview of The Related Tools ...160
Appendix F The Case Study of e-Learning Using VODKA ...162
List of Figures
Figure 3.2 The Flow of VODKA ...29
Figure 3.3 The Flow of TEA ...31
Figure 3.4 The Framework of Collaborative Knowledge Acquisition...34
Figure 4.1 The Time of Generating Rules Using Different Grid Size...48
Figure 5.1 Unfolding Step of Constructing AST ...59
Figure 5.2 Reconstructing Step of Constructing Dynamic AOT ...60
Figure 5.3 Worm Ontology Construction Flow...66
Figure 5.4 Example of Initial Nimda Concept Tree ...69
Figure 5.5 The Updated Nimda Ontology after Discovering Nimda.B...71
Figure 5.6 The Updated Nimda Ontology after Discovering Nimda.E...72
Figure 6.1 The Collaborative Framework for Worm Detection...77
Figure 6.2 The Experimental Environment for Detecting Computer Worms ...78
Figure 6.3 The Ontology of DDoS...80
Figure 6.4 Relationships Between of Knowledge Classes ...81
Figure 6.5 The Framework of KA Process ...85
Figure 6.6 An Example of Users’ Behavior ...89
Figure 6.7 The DDoS Intrusion Tolerance System Using Dynamic EMCUD ...91
Figure 6.9 An IDS Prototype System Based RP-MES...105
Figure 6.11 The Performance Comparison ...108
Figure 7.1 The Framework of Decision Support System ... 112
Figure 7.2 An Attack Tool Being Run Against Three Targets... 114
Figure 7.3 Meta-rules of Classification Rule Classes for On-line Monitoring ... 119
Figure 7.4 Decision Support System Prototype in Experiments...122
Figure 7.5 Alert Reduction Rate of Normal Behavior Classification Model...123
Figure 7.6 Observations of Percentages of Different Suspicious Flags ...124
Figure A.1 The General Topology of DDoS Attacks...137
Figure B.1 System State Diagram...139
Figure B.2 Role State Diagram ...140
Figure C.1 Part of The Network Ontology...148
Figure D.1 Three Types of Alert Behavior Classification Rule Classes ...151
Figure D.2 The Procedure of Normal Behavior Classification Rule Class Construction...154
List of Tables
Table 2.1 The Illustrative Example of a Repertory Grid with Ratings ...10
Table 2.2 An Example of Acquisition Table...14
Table 2.3 An Example of AOT ...15
Table 2.4 The Original Rule and Embedded Rules of Nimda3...15
Table 2.5 The Original Rule and Embedded Rules of Nimda1 and Nimda2 ...16
Table 2.6 The Acquisition Table of Four Computer Worms ...19
Table 2.7 The AOT Table of Four Computer Worms...20
Table 2.8 Partial Detection Rules Generated by EMCUD ...21
Table 2.9 The Mask Table of Ignored Attributes...22
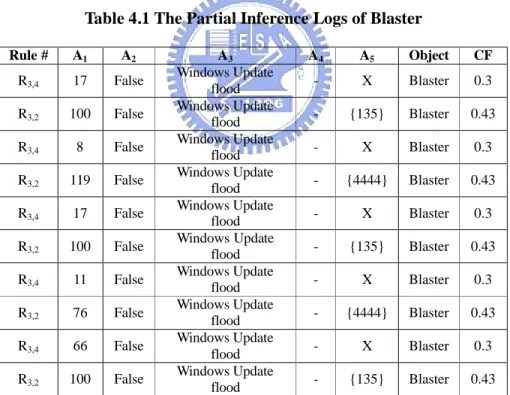
Table 4.1 The Partial Inference Logs of Blaster...44
Table 4.2 The Partial Inference Logs of Nimda ...49
Table 4.3 The New Variant Acquisition Table of Nimda.B...50
Table 4.4 The Partial Inference Logs of CodeRed ...51
Table 4.5 The New Variant Acquisition Table of CodeRed.II ...52
Table 4.6 The New Variant Acquisition Table of Blaster.B ...53
Table 4.7 The Adjusted Main Acquisition Table of Simple Computer Worms ....54
Table 4.8 AOT Table of Simple Computer Worms...54
Table 4.9 The Rules Generated from Table 4.7 and Table 4.8 ...55
Table 5.1 An Example of Original Nimda AT...69
Table 5.2 An Example of Original Nimda AOT ...69
Table 5.3 An Example of Nimda AST ...70
Table 5.4 An Example of Updated Nimda AT After Discovering Nimda.B...71
Table 5.5 An Example of Integrated Nimda AT ...71
Table 5.6 An Example of Updated Nimda AOT After Discovering Nimda.B...71
Table 5.7 An Example of Integrated Nimda AT After Discovering Nimda.E...72
Table 5.8 An Example of Updated Nimda AOT After Discovering Nimda.E...72
Table 6.1 The Ratio of Discovering New Evolved Worm ...104
Table 6.2 The Cluster Number with Different Similarity Threshold Settings and Number of Rules...107
Table 6.3 Accuracy Comparisons...107
Table 6.4 Comparison of Number of Clusters...108
Table A.1 The DDoS Attacks Developed from 1998 to 2002 ...136
Table C.1 Encodings of Expressions in RB...149
Table F.1 The Learning Sequence of Students...163
List of Algorithms
Algorithm 2.1 EMCUD Algorithm ...14
Algorithm 3.1 The Dynamic EMCUD Algorithm ...26
Algorithm 3.2 The Grid Merging Algorithm...32
Algorithm 4.1 VODKA Algorithm...43
Algorithm 6.1 The Characteristic Training Algorithm...88
Algorithm 6.2 Rule Base Partitioning Algorithm...100
Algorithm 6.3 Meta Apriori Algorithm ...102
Algorithm D.1 The Normal Behavior Classification Rule Class Construction Algorithm ...155
Algorithm D.2 The Suspicious/Intrusion Behavior Classification Rule Class Construction Algorithm...159
Chapter 1
Introduction
As we know, knowledge based system is an intelligent computer program that uses knowledge and inference procedures to solve problems that are difficult enough to require significant human expertise for their solutions, such as disease diagnosis, investment prediction, and computer science. A well-known fundamental problem to the development of knowledge based systems is the acquisition of the expert knowledge (the formation of real-world knowledge to some computerized knowledge representation) that makes these systems work. As a matter of fact, knowledge acquisition is known to be the critical bottleneck in building knowledge based systems [25].
The knowledge can be divided into two groups: substantive knowledge and strategic knowledge. Substantive knowledge is used to draw conclusions from the evidence it has, that is, to interpret input data and identify the current state, and strategic knowledge is used to decide what to do next according to the state. In [30], Gruber gave a good example to explain both kinds of knowledge: A military pilot follows the strategy of taking evasive action when in danger of being fired on. The pilot must use substantive knowledge to access the situation “Am I in danger of being attacked?” and strategic knowledge to respond “Climb to 30000 feet.” In general, substantive knowledge is used to identify relevant states of the world and strategic
knowledge is used to evaluate the utility of possible actions when a state is given. [30]
Substantive knowledge is represented explicitly in knowledge base, and is acquired directly from experts, manually or with some help from automated tools. For instance, in a computer worm detection application, the knowledge engineer consults the literature and interviews domain experts to acquire the knowledge of well-known worms (objects) using pre-defined attributes. This kind of substantive knowledge is treated as static because the environment is assumed stable in any time. In other words, the static knowledge remains the same when the environment is changed as time goes on. However, the environment of the cyber world is changing rapidly. New worms will be evolved from old worms or be developed to threaten the Internet and may cause the failure of worm detection knowledge based system. This kind of substantive knowledge is treated as dynamic knowledge which means that the knowledge will be updated or derived from well-known knowledge due to the adaptation of the changing environment with the times.
Many knowledge acquisition methodologies and related tools, e.g., NeoETS [10],
AQUINAS [11], KITTEN [64], EMCUD [34], KADS [81], KAMET [14], have been
proposed to improve the quality of the elicited static substantive knowledge (rules in knowledge base) in the past twenty years. Most of the existing systems employ the Repertory-Grid test originally developed by George Kelly’s Personal Construct Theory [39] in eliciting substantive knowledge, which could be used as an efficient knowledge acquisition technique in identifying different objects and distinguishing these objects in a domain.
With time goes on, some substantive knowledge might be modified or evolved from the original knowledge to adapt in a dynamic environment due to the adoption of new conditions. Some other substantive knowledge could be incrementally created to classify new objects due to the explosion of the knowledge. The dynamic knowledge includes variant knowledge and evolutional knowledge. The variant knowledge is usually derived from original objects, which means that the knowledge is changed as time goes on in the stable environment. The evolutional knowledge is changed over time due to the changing environment. For example, in a computer worm application, a famous worm, Nimda is the first worm to modify existing web sites to start offering infected files for download by using Unicode exploit to infect IIS web server. As the time goes by, Nimda.B, a variant of Nimda family, is developed to infect victim hosts through different attached file in e-mail. Although many knowledge acquisition methods have been proposed to rapidly build the knowledge base, the acquisition of dynamic knowledge has been hardly discussed. To acquire dynamic knowledge, the experts are required to be aware of the occurrence of new objects in knowledge acquisition systems. However, it is still difficult for experts to be aware of the new object without any additional related information.
EMCUD (Embedded Meaning Capturing and Uncertainty Deciding) was
proposed to elicit the embedded meanings of knowledge (embedded rules bearing on
m objects and k object attributes) to classify m objects (O1, O2, … , Om) based upon
repertory grids principles, which represents the information that domain experts take for granted but are implicit to the people who are not familiar with the application domain, and guide experts to decide the certainty degree of each embedded rule for extending the coverage of generated original rules. To simplify our discussion, assume
some objects in O1 class, which are classified by original rules of O1, belong to the
original object class (OO1) of O1. The other objects in O1 class, which are classified
by embedded rules of O1, belong to the extended object class (EO1) of O1. However,
some embedded rules may be with marginally acceptable certainty factor (CF) values due to the weak suggestions of domain experts. Due to the ability of embedded rules, some objects can not be classified by the original rule but might be able to be classified by the other embedded rules with different certainty degree. Hence, these objects might be evolved with the times and could be classified by the embedded rules of O1 with weak CF values. This kind of objects is singled out to be a variant object
class (VO1) of O1 because the similar characteristics of these objects (the related
ambiguous attributes or minor attributes) might become more and more important and need to be classified into a specific variant object class in EO1 after refining the
ambiguous attributes or adding some new attributes to improve the classification ability. The variant of an original object in this dissertation stands for a subset of the original object class having some different characteristics.
Although EMCUD extends the ability of knowledge acquisition systems to elicit substantive knowledge with the embedded rules, it is still limited to discover the dynamic knowledge of original objects due to the lack of the sufficient information. Owing to the different background and dynamic knowledge which can be changed as times goes by, the domain knowledge constructed at a time may become obsolete in the near future. Moreover, some evolutional knowledge needs to be evolved for adopting in a dynamic environment. It may result in the difficulty of observing the occurrence of new knowledge for human experts. Hence, how to collect sufficient relevant information to help experts notice the occurrence of dynamic knowledge and
reuse the original rule base becomes one important issue. Since the relative importance of each attribute to each object could be represented using attribute ordering table, some minor attributes can be relaxed or ignored to capture the embedded meanings with acceptable CF. In other words, these kinds of attributes can be ignored to be not used to classify the object with lower CF value. With the changing environment, new knowledge derived from old objects might be classified by embedded rules with the ignored attribute-value and marginally acceptable CF, and can not be distinguished from original objects.
In this dissertation, we will propose new knowledge acquisition methods which collect useful information to monitor the inference behaviors of weak embedded rules and to trace information over time in order to efficiently update the time-related knowledge in a dynamic environment. A Dynamic EMCUD which is an iterative process to assist experts in being aware of the occurrence of dynamic knowledge according to the analyzing results of inference behaviors is proposed. Each iteration consists of three Stages: Log Collecting Stage, Knowledge Learning Stage, and Knowledge Polishing Phase. A collaborative knowledge acquisition framework (including local KBSs and a collaborative KBS) based upon Dynamic EMCUD will be proposed to monitor the frequent inference behaviors of weak embedded rules and to trace the evolved behaviors of objects with the times from multiple KBSs for assisting experts in efficiently obtaining the dynamic knowledge. Each local KBS deploys
Dynamic EMCUD module to monitor the frequent inference behaviors of weak
embedded rules to iteratively construct an acquisition table increment. The AOT increment could be constructed using entropy or time series analysis technique to analyze the importance of each attribute to each object with the times to facilitate the
acquisition and adaptation of dynamic knowledge without too many interactions with experts in a changing environment.
Variant Objects Discovering Knowledge Acquisition (VODKA) will be proposed
to learn the new variant object in classification KB according to the occurrence frequency of these objects. The goal of the VODKA is to facilitate the acquisition of new inference rules for a classification KBS which identifies an object from its attribute-values in a small acquisition table increment. The new rules should be able to cope with these new objects which are similar to those previous known original rules in the KBS (they are object variants). Consequently, we enrich the knowledge base constructed by the VODKA and hence ease the effort of constructing the domain knowledge in a dynamic environment.
Because the static EMCUD may not be adaptive to the variant knowledge, a
Trend Evolution Acquisition (TEA) for constructing dynamic knowledge will be
thirdly proposed to adapt knowledge with time by recording each interested attribute’s information in each time point and update the evolutional knowledge base if necessary in a period of time. Consequently, a knowledge base can become more robust, flexible, and perform more learning from experiences during inference. The
VODKA generates a small acquisition table increment of new objects, and the TEA
generates an AOT increment. Finally, we use a Grid Merging approach to integrate the acquisition table increment and AOT increment into the original main acquisition table and the main AOT respectively for generating corresponding embedded rules of new objects.
However, some new evolved objects might be invisible or insignificant under each local KBS with Dynamic EMCUD, the profile of each KBS and the infrequent logs are analyzed in the collaborative KBS to collaboratively assist experts in discovering new objects. The infrequent inference logs can be analyzed by Dynamic
EMCUD and corresponding profiles to discover the interesting knowledge of new
objects which is unseen in each KBS. In order to acquire a meaningful CF value of each new discovered embedded rule of evolved objects, the CF value of each new embedded rule of evolved objects could be adjusted in the collaborative KBS based upon three cases in the CF adjusting function.
Based upon the collaborative framework, the dynamic knowledge could be elicited from the main acquisition table, which results in the ability of knowledge evolution. We illustrate two applications in worm and DDoS intrusion detection, and alert model construction to evaluate the utility of Dynamic EMCUD. We setup an experimental environment consisting of a firewall to filter computer worm traffic from Internet (normal traffic) and an attacking traffic generator to randomly generate various worms to infect a victim according the constructing models. The results show the Dynamic EMCUD is useful for assisting experts easily to be aware of the new variant worms and the corresponding knowledge can be quickly extracted.
Chapter 2
Related Work
Several knowledge acquisition methodologies and related systems are introduced in this chapter. Then Repertory Grid, one of the popular indirect knowledge acquisition techniques, and the elicitation of embedded meaning and some problems of traditional knowledge acquisition methodologies are discussed.
2.1 Knowledge Acquisition Systems
Since the knowledge in many domains, the experience of domain experts, is continuously growing, many knowledge acquisition methodologies have been proposed to help knowledge engineers acquire the useful knowledge and then to transfer these knowledge into knowledge base or other computerized representation forms. In general, there are three approaches for knowledge acquisition [21][34][48]:
(1) Interviewing experts by experienced knowledge engineers: interviewing experts is usually time-consuming if the communication between domain experts and knowledge engineers is insufficient.
(2) Machine learning: learning the knowledge by collecting many useful cases and instances with/ without the involvement of domain experts [57]. However, the quality of the results usually relies on the selected training cases.
using knowledge acquisition systems with/ without the help of knowledge engineers. These tools could reduce the effort of communication between knowledge engineers and domain experts and could reduce the risk and difficulty of selecting the suitable training cases.
The interviewing approach could be used to acquire dynamic knowledge by manually rebuilding the knowledge base. However, the experts may not be aware of the occurrence of dynamic knowledge. Since the machine learning is used to learn the knowledge from useful cases, the discovered knowledge is limited to classify the new evolutional knowledge. This is caused by the lack of insufficient context information. In the past decades, many knowledge acquisition systems, e.g., NeoETS [10],
AQUINAS [11], KITTEN [64], EMCUD [34], KADS [81], MCRDR [38], KAMET [14], MedFrame/CADIAG-IV [7][41][44] have been developed to build prototypes and to
iteratively elicit the knowledge from domain experts. However, all of these systems can not efficiently acquire dynamic knowledge due to the lack of sufficient information and the experts may not be aware of the occurrence of evolutional knowledge.
2.2 Repertory Grid Methodology and Relevant Systems
Repertory Grid, based on Kelly’s Personal Construct Theory [39] which reports how people make sense of the world, could be used as an efficient knowledge acquisition technique in identifying different objects and distinguishing these objects in a domain. It is the basis of several computer assisted knowledge acquisition tools, such as ETS [8][9], AQUINAS [11] and KSSO [26].
A single repertory grid represented as a matrix whose columns have element objects (labels) and whose rows have construct attributes (labels) can classify a class of objects, or individuals. The value assigned to an element-construct pair need not be Boolean. Grid values have numeric ratings, probabilities, and other characteristics, where each value reflects the degree of a construct to an element. Then, the expert is asked to fill the grid with 5-scale ratings, where “1” represents the most relevant attribute to the object; “2” represents that the attribute may be relevant to the object; “3” represents “unknown” or “no relevance”; “4” represents that the object may have the opposite characteristic; “5” represents the most relevant opposite characteristic to the object. The whole concept of Repertory Grid technique can be described as following steps:
(1) Elicit all of the element objects, e.g., E1, E2, E3, E4, E5 from the expert.
(2) Elicit the construct attributes (and their opposites), e.g., C1, C2, C3, C4 (C1’, C2’,
C3’, C4’), from the expert. Each time three elements are chosen to ask for a
construct to distinguish one element from the other two.
(3) Rate all of the [element, construct] entries of the grid with value range from 1 to 5. An illustrative example is given in Table 2.1.
Table 2.1 The Illustrative Example of a Repertory Grid with Ratings
Element Construct E1 E2 E3 E4 E5 C1 5 1 5 1 1 C1’ C2 4 4 4 1 4 C2’ C3 1 4 5 1 4 C3’ C4 1 4 4 5 5 C4’
As Repertory Grid technique has been widely used by researchers, some extensions have been made to enrich its representative ability for covering more
knowledge, the value assigned to an element-construct pair may be Boolean, numeric ratings, probabilities, etc. For example, Dixit and Pindyck [23], and Hwang [33] extended the Repertory Grid technique to the fuzzy table, in which constructs were fuzzy attributes that could be rated by means of fuzzy linguistic terms from a finite set. Castro-Schez et al. [15] developed a technique using a fuzzy repertory grid for acquiring the finite set of attributes or variables that the expert used in characterizing and discriminating a set of elements.
Moreover, several models have been proposed for handling uncertainties in expert systems through generating more meaningful rules from the Repertory Grid oriented approaches. EMYCIN certainty factor model was first used to decide on the degree of the belief of a rule for uncertain reasoning [67]. Embedded Meaning
Capturing and Uncertainty Deciding (EMCUD) knowledge acquisition system was
proposed to extract rules with embedded meaning from repertory girds by defining the impacts of the constructs to each element [34] and was successive applied in a medical diagnostic system for acute exanthema [35]. WebGrid, Calgary’s web-based knowledge modeling and inference tool, is based on Repertory Grid elicitation and analysis [65].
However, none of these methodologies discusses the issue of discovering dynamic knowledge. Therefore, a new collaborative knowledge acquisition system based upon EMCUD is hence proposed in this dissertation to help domain experts be aware of the occurrence of dynamic knowledge and to create additional attributes for extracting dynamic knowledge through the observations of the interested inference results and the time based analysis.
2.3 Elicitation of Embedded Meanings
The embedded meanings referred to here represent the information that domain experts take for granted but are implicit to the people who are not familiar with the application domain. For example, a physician may describe the typical feature of Measles to be 3 to 4 days of fever, cough, desquamation, and brick-red maculopapular, but usually he/she does not mean only when all of these features happen, then the patient has Measles. It is possible that patient does not have a cough or desquamation while Measles can still be implied only with less certainty. Embedded meanings are likely to be ignored during the process of knowledge acquisition, especially in some application domains such as medical diagnosis. This is the reason why experts can usually make a conclusion even when the required information is not complete while most of expert systems may fail to have a conclusion if the premise part are only partially matched.
The lack of embedded meaning will probably make an expert system fail to infer some cases being trivial to experts. The initial knowledge and the embedded meanings will make the same conclusion with different certainties; therefore, their relationships may be used to guide experts to decide the degree of certainties for embedded meanings. SEEK [59] and SEEK2 [28] have been proposed to obtain embedded meanings by some efficient refinement processes. However, the major problem with SEEK and SEEK2 is the case database being assumed to be available because it is difficult to collect sufficient cases in some applications.
Moreover, it would be also time-consuming and boring for experts to offer a conclusion for each case in the database before starting the refinement procedure.
Thus, EMCUD is proposed to elicit the embedded meanings of knowledge from the existing hierarchical repertory grids given by experts [34]. Additionally, it will also guide experts to decide the certainty degree of each rule with embedded meaning for extending the coverage of generated original rules. EMCUD can be used to elite part of dynamic knowledge since the embedded meaning included. However, it is still weak to acquire more dynamic knowledge due to insufficient context information.
To capture the embedded meanings of the resulting grids, the Attribute Ordering Table (AOT), which is used to record the relative importance of each attribute to each object, is employed. The values in each AOT entry, a pair of attribute and object, may be labeled “X”, “D” or an integer number. “X” means no relationship existing between the attribute and the object. “D” means that the attribute dominates the object, i.e., if the attribute is not equal to the entry value, it is impossible for the object to be implied. Integer numbers are used to represent for the relative important degree of the attribute to the object instead of dominating the corresponding object. If the attribute does not equal the attribute-value, it is still for the object to be implied. The larger integer number implies the attribute being more important to the object.
Using AOT, the original rules generate some rules with embedded meaning, and the Certainty Factor (CF) of each rule, which is between -1 and 1, could be determined to indicate the degree of supporting the inference result. The higher CF is, the more reliable result is. The EMCUD algorithm is listed as Algorithm 2.1.
Algorithm 2.1 EMCUD Algorithm Input: The hierarchical grids.
Output: The guiding rules with embedded meaning.
Step1: Build the corresponding AOT with each grid of the hierarchical multiple grids.
Step2: Generate the possible rules with embedded meaning.
Step3: Select the accepted rules with embedded meaning through the interaction with experts.
Step4: Generate automatically the CF of each rule with embedded meaning.
All rules generated by EMCUD could be categorized into two classes: original and embedded rules with acceptable CF value, and discarded rules with unacceptable CF value, according to the confidence degree of domain experts. To decide the CF value of each embedded rule, we have to first decide on the upper and the lower bounds of CF values of accepted embedded rules. CF values of each rule can be automatically determined by a fuzzy mapping function. Thus, the useful embedded rules with corresponding CF values could be used to cover more uncertainty cases.
It is called the Acquisition Table instead of repertory grid to distinguish it from the grids derived by applying other methods. An example of acquisition table for Nimda, a worldwide popular computer worm, is shown in Table 2.2, and the other example of AOT is shown in Table 2.3.
Table 2.2 An Example of Acquisition Table
Object
Attribute Nimda1 Nimda2 Nimda3
Mail_Attachment Readme.exe puta!!.scr null
Upload_Medium Admin.dll Admin.dll cool.dll
Table 2.3 An Example of AOT
Object
Attribute Nimda1 Nimda2 Nimda3
Mail_Attachment 2 1 X
Upload_Medium 3 4 3
Executed_File_Name 3 4 D
The original and embedded rules generated according to Nimda3 in the third column of the Table 2.2 are shown as Table 2.4.
Table 2.4 The Original Rule and Embedded Rules of Nimda3
Conditions Conclusion
Rule #
Mail_Attachment Upload_Medium Executed_File_Name Object CF
RNimda3, 0 null cool.dll httpodbc.dll Nimda3 0.8
RNimda3, 1 - cool.dll httpodbc.dll Nimda 0.6
R Nimda3, 2 - ¬ (cool.dll) httpodbc.dll CodeRed 0.4
The original rule of Nimda3 is numbered as RNimda3, 0 “IF (Mail_Attachment =
null) AND (Upload_Medium = cool.dll) AND (Executed_File_Name = httpodbc.dll) THEN Nimda3” with the CF = 0.8.
Since the ordering value between Mail_Attachment and Nimda3 is “X”, Mail_Attachment in the premise of original rule should be eliminated, and Upload_Medium can be negated as R Nimda3, 2 when its ordering value is nether “D”
nor “X”; however, Executed_File_Name should always exist in every embedded rule because it dominates Nimda3. After that, a Certainty Sequence (CS) value is used to represent the degree of certainty for an embedded rule, which is calculated by negating some predicates of its original rule by following formula (2.1),
i k i
CS(R )=SUM(AOT[Att , Obj ]) (2.1)
where Attk belongs to the attribute set of Ri, and Obji is the object of Ri. So, from
Finally, after all the CS values are calculated, rules would be sorted according to the CS values and interacted with experts by acquiring upper-bound (UB) and lower-bound (LB). The CF value can now be generated by the following formula (2.2),
(
)
i i a a a i CS(R ) CF(R )=UB(R )- UB(R )-LB(R ) MAX(CS) × (2.2)where MAX(CSi) is the maximum CS value in all embedded rules generated from the
original Ra with the same object. So, CF value of R Nimda3, 2 is 0.4 after the calculation,
and part of results followed the example above are shown as Table 2.5.
Table 2.5 The Original Rule and Embedded Rules of Nimda1 and Nimda2
Conditions Conclusion
Rule #
Mail_Attachment Upload_Medium Executed_File_Name Object CF
RNimda1, 0 Readme.exe Admin.dll Riched20.dll Nimda1 0.8
RNimda1, 1 ¬Readme.exe Admin.dll Riched20.dll Nimda1 0.7
RNimda2, 0 puta!!.scr Admin.dll Riched20.dll Nimda2 0.8
RNimda2, 1 ¬puta!!.scr Admin.dll Riched20.dll Nimda2 0.6
Since embedded rules with weak acceptable CF values usually mean domain experts may lack the strong confidence, objects matching weak embedded rules derived from original objects may be the candidates of new variants. For example, the object satisfying the conditions of the embedded rules with CF = 0.5 means the expert might suggest that it would be marginally classified into the object class and the negated attributes of the embedded rule might be not clearly defined. Therefore, the fired frequencies of this kind of weak embedded rules should be used to discover the occurrence of new variant objects.
With the changing environment, the adaptation of the acquired rules should be required to cope with the dynamic knowledge. However, experts may not be aware of the occurrence of the candidates of new variants and may have insufficient evidence to construct the dynamic knowledge of the variants using conventional repertory grid approaches. Although EMCUD could be used to generate more useful embedded rules for covering more similar cases, it still lacks the ability of grid evolution for coping with new dynamic knowledge; e.g., EMCUD should manually regenerate the original and embedded rules again by the interaction with domain experts after collecting sufficient information about these knowledge. Therefore, enhancing the adaptation ability of embedded rules becomes increasingly important to achieve the ability of grid evolution in classification KBS.
In this dissertation, the embedded rules from EMCUD are categorized into three classes: the original rules with strong CF, the embedded rules with marginally acceptable CF, and the discarded rules with low CF. Hence, a new knowledge acquisition methodology is proposed to discover the occurrence of new variant objects using the fired frequency of embedded rules with marginally acceptable CF.
2.4 Problems of Repertory Grid Knowledge Acquisition Methods
With the changing environment, the adaptation of the acquired rules should be required to cope with the new variants. However, experts may not be aware of the occurrence of the candidates of new variants and may have insufficient evidence to construct the knowledge of the variants using conventional Repertory Grid approaches. Although EMCUD could be used to generate more useful embedded rules for covering more similar objects in extended object class, it still lacks the ability ofgrid evolution for singling these new variants out; e.g., EMCUD should manually regenerate the original and embedded rules to classify these variant objects by the interaction with domain experts after collecting sufficient information about these variants. Therefore, enhancing the adaptation ability of embedded rules becomes increasingly important to achieve the ability of grid evolution in classification KBS.
In this dissertation, the embedded rules from EMCUD are categorized into three classes: the original rules with strong CF, the embedded rules with marginally acceptable CF, and the discarded rules with low CF. Hence, a new knowledge acquisition methodology is proposed to discover the occurrence of new variant objects using the fired frequency of embedded rules with marginally acceptable CF. A simple computer worm detection prototype in Example 2.1 is used to illustrate the inability for discovering variants using EMCUD.
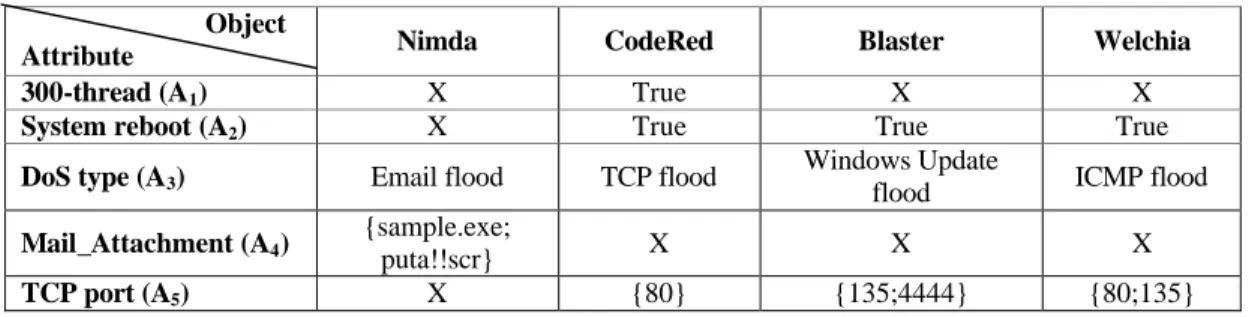
Example 2.1 The Example of Classifying Four Computer Worms
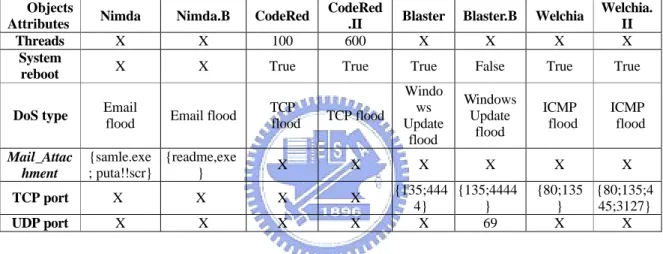
In recent years, computer worm is dramatically increasing to threaten the reliability of Internet. Table 2.6 shows the acquisition table of four computer worms [40[51][50][80] including Nimda, CodeRed, Blaster, and Welchia using five attributes including 300-thread, System reboot, DoS type, Mail_Attachment, and TCP port. The 300-thread means 300 threads with Boolean are simultaneously executed by one program. The system reboot Boolean attribute will be set to True if the system has been automatically rebooted. The attacking methodologies of worms could be classified into one kind of DoS type with String attribute [50]. The email attached file attribute with Set data type is also a useful attribute to classify these worms. Most of worms could communicate each other using different TCP port with Set data type.
Table 2.6 The Acquisition Table of Four Computer Worms
Object
Attribute Nimda CodeRed Blaster Welchia
300-thread (A1) X True X X
System reboot (A2) X True True True
DoS type (A3) Email flood TCP flood
Windows Update
flood ICMP flood
Mail_Attachment (A4)
{sample.exe;
puta!!scr} X X X
TCP port (A5) X {80} {135;4444} {80;135}
An example of constructing an AOT table from the acquisition table shown in Table 2.6 is given as follows:
EMCUD: If DoS type is not equal to Email flood, is it possible for Nimda to be implied?
EXPERT: No.
The answer means the DoS type dominate Nimda, and hence AOT [Nimda,DoS type] = ”D”.
EMCUD: If Email attached file is not equal to any element of {sample.exe, puta!!scr}, is it possible for Nimda to be implied?
EXPERT: YES.
The answer means that Email attached file does not dominate Nimda. The questions for 300-thread and Nimda will not be asked, since the entry [Nimda, 100-thread] is labeled “X”. Therefore, the entry AOT [Nimda, 300-thread] is labeled “X”, too. This is the same as the entries AOT [Nimda, System reboot] and AOT [Nimda, TCP port]. The entry AOT [Nimda, Mail_Attachment] is set to be 1, since the Email attached file is the only attribute that does not dominate Nimda. If there are more than one attributes do not dominate the object, e.g. the System reboot, the DoS
type, and the TCP port do not dominate Blaster, the following questions will be asked by EMCUD.
(1) Is System reboot more important than DoS type? (2) Is System reboot less important than DoS type? (3) Is System reboot as important as DoS type?
The expert indicates that System reboot is as important as DoS type to Blaster. Moreover, the expert also indicates that System reboot is more important than TCP port to Blaster; and hence the entries AOT [Blaster, System reboot] = AOT [Blaster, DoS type] = 2 and AOT [Blaster, TCP port] = 1. After each entry value of AOT is determined, shown in Table 2.4, the embedded meaning implied by the AOT could be extracted.
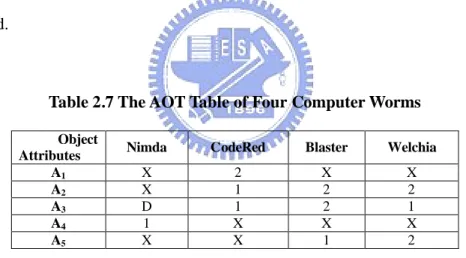
Table 2.7 The AOT Table of Four Computer Worms
Object
Attributes Nimda CodeRed Blaster Welchia
A1 X 2 X X
A2 X 1 2 2
A3 D 1 2 1
A4 1 X X X
A5 X X 1 2
Now we use the first column of Table 2.6 to show the information implied by an AOT. The column expresses the following meanings:
(1) A3 dominates Nimda: If A3 is not equal to Email flood, it is impossible for Nimda
to be implied.
(2) A4 does not dominate Nimda: If A4 is nether equal to sample.exe nor puta!!scr, it
In practice, the hierarchy rules could be generated while hierarchical grids are given. To simplify the discussion, Table 2.8 shows partial detection rules (simple rules) of a classification KBS based upon the Table 2.6 and Table 2.7 to classify these worms using five attributes in single grids. Ri,j represents the j-th highest rank of CF in object
i, and the highest rank is 0. The R1,0 is the original rule of Nimda to classify the
original Nimda objects and R1,1 is the embedded rule of Nimda to classify the
extended Nimda objects.
Table 2.8 Partial Detection Rules Generated by EMCUD
Conditions Conclusion CF
Rule
# A1 A2 A3 A4 A5 Object
R1,0 - - Email flood (sample.exe;puta!!scr) - Nimda 0.8 R1,1 - - Email flood ¬ (sample.exe;puta!!scr) - Nimda 0.4
R2,0 True True TCP flood - - CodeRed 0.8
R2,1 True False TCP flood - - CodeRed 0.6
R2,2 False True TCP flood - - CodeRed 0.4
R2,3 True False ¬ (TCP flood) - - CodeRed 0.4
R3,0 - True Windows update flood - {135;4444} Blaster 0.7 R3,1 - True Windows update flood - ¬{135;4444} Blaster 0.57 R3,2 - False Windows update flood - {135;4444} Blaster 0.43
R3,3 - True ¬ (Windows update
flood) - {135;4444} Blaster 0.43
R3,4 - False
Windows update
flood - ¬{135;4444} Blaster 0.3
R4,0 - True ICMP flood - {80;135} Welchia 0.8
R4,1 - True ¬ (ICMP flood) - {80;135} Welchia 0.67
R4,2 - True ICMP flood - ¬{80;135} Welchia 0.53
R4,3 - True ¬ (ICMP flood) - ¬{80;135} Welchia 0.4
The Mask Table of minor attributes shown in Table 2.9 indicates the minor attributes for all embedded rules [76]. Each row in Mask Table is a bit vector of attributes, where the ith bit is set to 1 representing the ith minor attribute is negated or ignored. For example, the M2,3 (0, 1, 1, 0, 0) means the 2nd and 3rd minor attributes in
Table 2.9 The Mask Table of Ignored Attributes Mask # A1 A2 A3 A4 A5 M1,0 0 0 0 0 0 M1,1 0 0 0 1 0 M2,0 0 0 0 0 0 M2,1 0 1 0 0 0 M2,2 1 0 0 0 0 M2,3 0 1 1 0 0 M3,0 0 0 0 0 0 M3,1 0 0 0 0 1 M3,2 0 1 0 0 0 M3,3 0 0 1 0 0 M3,4 0 1 0 0 1 M4,0 0 0 0 0 0 M4,1 0 1 0 0 0 M4,2 0 0 0 0 1 M4,3 0 1 0 0 1
In Internet, each worm can be represented as a set of attribute-value pairs. We can automatically collect such attribute-value pairs and feed them into our classification KBS to classify them in the suitable category. Since new worms might have been derived from old discovered worms, the difference between their attribute-values seems to be slight. As mentioned above, EMCUD could generate lots of embedded rules with different CF values for accommodating the knowledge of the changed worms due to the property of minor attributes; e.g., R1,1 “IF (DoS type =
Email flood) AND ¬ (Mail_Attachment = (sample.exe; puta!!scr)) THEN Nimda”, a
marginally acceptable embedded rule with CF = 0.4, may be fired by a new Nimda variant which is treated as a member of original Nimda class. If this rule has been fired frequently due to a specific email attached file attribute-value “readme.exe”(more evidence of the occurrence of the candidates of Nimda variants have been gathered), a new original rule “IF (DoS type = Email flood) AND
(Mail_Attachment = readme.exe) THEN Nimda.B” , a subset of extended Nimda
object class namely Nimda.B, with CF = 0.8 together with an embedded rule “IF
with CF = 0.5 could be generated to single the Nimda.B class out of the extended Nimda object class.
In summary, to acquire dynamic knowledge, the experts are required to be aware of the occurrence of new objects in the interviewing approach and knowledge acquisition systems. However, it is still difficult for experts to be aware of the new object without any additional related information. The machine learning approaches which can learn the useful model according to the selected training cases also lack the ability of discovering dynamic knowledge unless more context information can be included in the training process. Although many knowledge acquisition methodologies and related tools have been proposed to improve the quality of the elicited static knowledge by domain experts with/without knowledge engineers in the past twenty years, most of them are lack of the ability of discovering dynamic knowledge unless rebuilding the knowledge base in the dynamic environment. Therefore, a new knowledge acquisition method to acquire the dynamic knowledge is required.
Chapter 3
Dynamic Knowledge Acquisition Based Upon
EMCUD
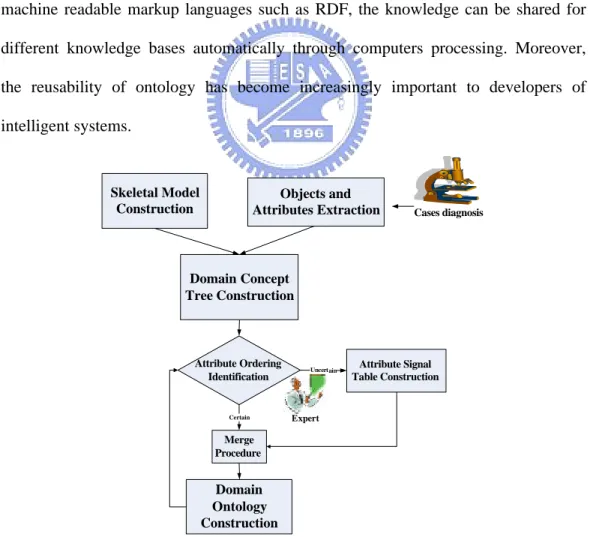
Although many researchers proposed new knowledge acquisition approaches to acquire different domain knowledge, few of them discuss the acquisition of dynamic knowledge due to the changing environment as time goes on. These traditional knowledge acquisition methodologies are weak to discover dynamic knowledge due to the lack of insufficient context information to notice experts the occurrence of dynamic knowledge. New objects might be discovered using incremental learning methods with enough new cases and the experts should be able to be aware of the occurrence of these objects to acquire the knowledge of them again. The knowledge acquisition systems should be capable of representing the dynamic knowledge. Therefore, we propose Dynamic EMCUD combining the advantages of interviewing, machine learning and knowledge acquisition systems to collect sufficient information for assisting experts to be aware of dynamic knowledge.
3.1 The Concept of Dynamic EMCUD
As we know, generating rules in EMCUD would be cost inefficient if the size of Acquisition Table (AT) and Attribute Ordering Table (AOT) are too large. After collecting sufficient information of new evolved objects, EMCUD has to manually
regenerate the original and embedded rules to classify these new objects with the large main AT. Therefore, the concept of Dynamic EMCUD shown in Figure 3.1 is proposed to help experts incrementally generate the dynamic knowledge based upon a
New Evolved Object learning (NEO-learning) module for enhancing the explanation
power of the original embedded knowledge base.
Figure 3.1 The Concept of Dynamic EMCUD
The dynamic knowledge base (embedded rule base) will be created according to the original main AT and AOT table using EMCUD. Then the inference behaviors (facts/attribute-value pairs) will be collected iteratively based upon the initially constructed knowledge base to discover the candidates of the variants during Log Collecting Stage. The NEO-learning module is proposed in Dynamic EMCUD, including Variant Object Discovering Knowledge Acquisition (VODKA) and Trend
Evolution Acquisition (TEA) to help domain experts construct a small AT increment
and an AOT increment, respectively, after confirming the occurrence of new variant objects in Knowledge Learning Stage. VODKA and TEA will be detailedly described in Chapter 4 and Chapter 5, respectively.
The ignored attribute-value pair of the minor attribute will be treated as an item and a set of ignored attribute-value pairs will be treated as a transaction to discover the association between interesting attribute-value pairs. The AT increment, which can be generated by monitoring the frequency of the weak embedded rules using VODKA, is used to record the new evolved objects and the attributes which are updated or added to generate the dynamic knowledge. The AOT increment is used to help experts to generate the adaptive relative importance of each attribute to each object as time goes on by tracing the importance evolving trends of all attributes during a time interval in TEA. Through integrating the AT increment and the AOT increment into the main AT and the main AOT respectively using Grid Merging algorithm in Knowledge Polishing Stage, it can generate the rules of new evolved objects with the grid evolution ability using original EMCUD. The Dynamic EMCUD is shown as Algorithm 3.1.
Algorithm 3.1 The Dynamic EMCUD Algorithm Input: The original main AT, AOT and embedded rule base RB. Output: The rules with embedded meaning about variants.
Stage I: Collect all facts of the weak embedded rules as inference log of the RB. Stage II: Generate the new variants acquisition table AT’.
Step 1: Discover large itemsets L using the inference log.
Step 2: Generate AT’ using L and additional attributes provided by experts. Step 3: Update the AOT’ according to AT’.
Stage III: Use EMCUD to generate rules of new variants. Step 1: Generate rules according to AT’ and AOT’.
Step 2: Merge AT’ into original main acquisition table AT. Step 3: Merge AOT’ into original main AOT.
3.2 Inference Log Collecting Based upon Meta Rule
Without loss of generality, assume there are k attributes to classify m objects in the main acquisition table. Thus, the total number of the embedded rules used in
Dynamic EMCUD is limited. In order to assist domain experts in noticing and
analyzing the occurrence of the candidates of variant objects, the following four meta rules are used in Dynamic EMCUD to collect the frequent inference log (fact/ raw data) of weak embedded rules to help experts notice the occurrence of new objects.
MR1: IF Ri,j is fired THEN Increase Ci,j by one.
MR2: IF CF(Ri,j) ≤ THCF, THEN Log Ri,j.
MR3: IF Ci,j ≥ THcnt AND CF(Ri,j) ≤ THCF THEN Run VODKA Algorithm to
acquire the variants acquisition table increment AND Reset TimeOut.
MR4: IF TimeOut = THPeriod THEN Run VODKA Algorithm AND Reset TimeOut.
The meta rule MR1 is used to count the fired frequency of each embedded rule
(Ci,j). The meta rule MR2 means that all facts (attribute-value pairs) of the embedded
rules with marginally acceptable CF lower than strong CF bound threshold (THCF) are
logged as a record, (Ri,j, A1, A2, … .,Ak, CF(Ri,j)). The meta rule MR3 means that if
there exists one weak embedded rule with fired frequency exceeding the warning line threshold (THCNT), new variants may be discovered iteratively using VODKA. The
meta rule MR4 means that VODKA will be executed periodically to refresh the new
variants acquisition table. The TimeOut will be reset when MR3 or MR4 is triggered.
3.3 The NEO-Learning Module
As we know, the KBS is proposed to help experts solve the difficult problems in a specific domain based upon the pre-constructed static knowledge base. However, the new objects will be developed or discovered as times goes on and might result in the inefficiency of KBS. Based upon the embedded rules generated by EMCUD, some new evolved objects may be classified into well-known object class by the weak embedded rule with weak CF which is not strongly suggested by experts. Through monitoring the frequency of these weak embedded rules, the candidates of new
characteristics of these candidates of new objects could be extracted from these collected inference logs. The evidence of the new objects can be confirmed by experts and some attributes could be modified and added when the dynamic knowledge is needed to be singled out. Moreover, the relationships between these inference logs might be represented as the significance of each attribute to each new object. Hence, analyzing the evolving trends of all attribute should be useful in capturing the realistic significance of the attribute to the object.
The NEO-learning module can help experts analyze the interesting inference logs of weak embedded rules to learn the evidence of new evolved objects using the
VODKA to notice experts the occurrence of the new objects. Based upon the
confirmed new objects, the relationships of all attributes of each object are analyzed to set the significance of the attribute with the times using TEA to help experts decide the CF values of the embedded rules of new objects, which can be generated using
EMCUD according to the discovered objects stored in an AT increment and an AOT
increment. Finally, the AT increment and the AOT increment will be integrated with the main AT and the main AOT, respectively.
3.3.1 Frequent Events Analysis
EMCUD lacks the ability of grid evolution for singling the new evolved objects
out of well-known objects since experts may be unaware of the occurrence of the new evolved objects without sufficient information. Hence, we propose VODKA to monitor the frequent behaviors of interesting inference logs of the weak embedded rules with the lower CF values for helping experts notice the occurrence of the new objects.
Figure 3.2 The Flow of VODKA
The novelty of the VODKA shown in Figure 3.2 is to collect the inference logs of weak embedded rules from each KBS to learn the candidates of new evolved objects for experts to make a confirmation. The minor attribute-value pairs between inference logs of weak embedded rules are useful to help experts discover new knowledge and determine whether new object is evolved based upon fired frequency. For each object, if its inference logs of weak embedded rules are frequent, the frequent minor attribute-value pairs could be treated as candidates of new evolved objects. Furthermore, new attributes or attribute-values of the new object could be defined and used to generate a small AT increment. Hence, these candidates will be used to help experts single the new objects out of the extended object class using the new object acquisition module based upon the AT increment.
Therefore, if the new objects are confirmed by experts, the related ambiguous attributes (minor attributes), which might result in the marginally acceptable CF values of weak embedded rules, could be refined or new attributes could be added to improve the classification ability. If the initial data type of a minor attribute is too rough to describe the object, a superior data type is recommended and the values of the attribute in both original object and new evolved object should be modified.
type (Hwang and Tseng, 1990). If changing the data type still can not discriminate the new variants from original objects, acquiring new attributes from domain experts will be suggested in the new objects acquisition module. According to the complexity of relations between objects and attributes or even the relations between different tables, it is hard for experts to cooperate with each other in building every column and every row for each table. Finally, the result of new objects and corresponding attributes can be used to construct the AT increment.
3.3.2 Trend Evolution Analysis
Although the original idea of constructing AOT makes EMCUD more adaptive to elicit embedded meanings, the relative importance of all attributes to each object could be adjusted since the dynamic knowledge may change or evolve with the times. It means that some embedded rules, which are recommended by experts now, may become uncertain in the near future. Each object in the AOT is decomposed to record the relative importance of each attribute to the object with the times. Since the traditional Repertory Grid-based KA methods do not record the evolved trend of each new object and the EMCUD is difficult in deciding the ordering of all attributes of the object by experts, the TEA, which can discover the evolution of the relative importance of each attribute to each object with the times, is proposed to help experts monitor the significant importance changing of all attributes to each object in a time interval.
As shown in Figure 3.3, the object can be singled out of the old object according to the viewpoints of experts or the learning results of the frequency events analysis. Each attribute can be simply assigned as “0” or “1” in each time point for indicating
whether it is important to each object or not, where “0” represents the attribute is considered as the unimportant attribute to the object and “1” represents the attribute is important to the object. The domain expert can then decide which attributes are required to be traced with the times if some ordering values of the attributes are hard to be decided immediately.
Figure 3.3 The Flow of TEA
The “0” or “1” is called an attribute event et of each object in a time point t, and
the attribute event sequence of “0” and “1” is recorded in a table to capture the evolved behavior of each object. Hence, the AOT increment can be generated for evolving the relative importance of each attribute to each object (ordering values) according to the sequence of “0” and “1” events with the times using a time series analysis approach. Since the “1” means an attribute is important to an object, the consecutive “1” recorded in consecutive time points indicates that relative importance of the object should become higher. On the contrary, the consecutive “0” indicates that the relative importance of the object should be lower. Hence, a simplified time series analysis is proposed to capture the trend meaning and incrementally adjust the CF value of each rule. Let the initial value of each signal sequence be the original AOT value of the attribute to the object.