A comparative analysis of web
image and textual queries
Hsiao-Tieh Pu
Graduate Institute of Library and Information Studies,
National Taiwan Normal University, Taipei, Taiwan
Abstract
Purpose – This study aims to examine the differences between web image and textual queries. Design/methodology/approach – A large number of web queries from image and textual search engines were analysed and compared based on their factual characteristics, query types, and search interests.
Findings – Useful results include the findings that web users tend to input short queries when searching for visual or textual information; that image requests have more zero hits and higher specificity, and contain more refined queries; that web image requests are more focused than textual requests on some popular search interests, and that the variety of textual queries is greater than that of image requests.
Originality/value – This study provides results that may enhance one’s understanding of web-searching behaviour and the inherent implications for the improvement of current web image retrieval systems.
Keywords Worldwide web, Visual databases, Query languages, Text retrieval, User studies Paper type Research paper
Introduction
There has been a substantial increase in the availability of image collections on the web. Several web search engines now attempt to index publicly accessible image files and offer image search capabilities (Tomaiuolo, 2002). For example, Google claims to have more than 11.8 billion indexed images (Google, 2004). Currently, such web image search engines provide keyword search options as in textual information retrieval, that is, by matching users’ typed-in keywords with the textual information attached to web images, including their filenames and available captions, HTML ALT tags, and the surrounding text appearing on the same web pages (Smith and Chang, 1997). Using text to search images may not prove successful in every case, however, especially when web images are not organized in controlled collections and adequate annotations are not available for searching. Searches that produce no hits are not uncommon. For example, in our analysis of a three-month log with over 2.4 million real image queries, almost 19 percent of the total queries resulted in no hits.
Undoubtedly, it is necessary to understand the differences between users’ queries for image and textual information before a more effective image retrieval system can be developed. Several studies on web textual queries have revealed that users tend to type in short queries, conduct short query sessions, and view few result pages (Jansen et al., 2000). The author’s previous study proposed a query categorization approach, automatically classifying web query terms into broad subject categories (Pu et al., 2002). The experimental data-sets contained over 5 million queries from three text-based search engines within different periods of time. The results were similar to
The Emerald Research Register for this journal is available at The current issue and full text archive of this journal is available at www.emeraldinsight.com/researchregister www.emeraldinsight.com/1468-4527.htm
Web image and
textual queries
457
Refereed article received 13 April 2005 Accepted for publication 14 June 2005
Online Information Review Vol. 29 No. 5, 2005 pp. 457-467
q Emerald Group Publishing Limited
1468-4527 DOI 10.1108/14684520510628864
those from other related studies, and showed that certain search behaviour persists across different users and languages. Meanwhile, through the successful integration of human and machine efforts, the frequency distributions of subject categories in response to changes in users’ search interests can be systematically observed in real time. However, these previous studies outlined above focused on textual searching behaviour: there has been less research undertaken on image-searching behaviour.
It is, therefore, important to analyse image queries from image search engines first, in order to understand how image requests differ from the above observations, and to examine the limitations or difficulties faced by web image search engines in dealing with a variety of image needs. Nevertheless, most image user studies have focused on understanding users’ image needs and search behaviour on a much smaller scale. Few studies have examined how people search for images on the web. Therefore, the purpose of this study was to examine the differences between image and textual queries in a large-scale retrieval environment, and to investigate any resulting implications for the development of effective web image retrieval techniques. The differences were compared in threefold: factual characteristics such as query length, query frequency, and the language used in queries; query types, such as the ratio of unique and refined searches; and popular search interests, such as the distribution of various broad subject categories.
Two data-sets were analysed in this study: one was a three-month data-set of 2,401,628 queries with 325,812 distinct query terms from VisionNEXT, which provides major image search services to the Chinese community; the other was a three-month data-set of 2,183,506 queries with 228,502 distinct query terms from Dreamer, which at one time provided web page search services in Taiwan. First, statistical analysis of over 4.6 million queries was conducted to compare the distribution of query length and query frequency. Second, top web image and textual queries were classified into various query types based on an analytic model modified by the uniqueness and refinement scheme developed by Enser and McGregor (1993). Third, top queries from the experimental data-sets were also classified into predefined broad subject categories to observe popular search interests apparent in image and textual queries. Although some material within the data-sets used in this study was slightly dated, the data-sets are nevertheless considered a useful and adequate source for the observation of major trends in web queries, particularly in relation to persistent search patterns and search interests.
As more image data is being put on the web, this study provides results that enhance our understanding of web image searching behaviour, which should benefit future related research. Additionally, according to Global Internet Statistics (2004), the Chinese community has the world’s second-largest online population (13.7 percent, representing over 100 million users), and the number of web pages in Chinese ranks fourth in the world (a combination of simplified and traditional Chinese codes) after English, German, and French (Alltheweb, 2003). With the increasing importance of Chinese users and content, research into the accompanying web-use characteristics will prove a valuable resource for online information service providers. Such analysis will also be valuable for studying cultural differences between Western and Chinese users, an area that has not been studied previously, to the author’s knowledge.
OIR
29,5
Related studies
Image organisation and retrieval
There are two major research areas related to image retrieval, namely, keyword-based and content-based image retrieval. Many existing image retrieval systems are keyword-based and utilise text-based classification schemes, for example, ICONCLASS (www.iconclass.nl/) and controlled vocabularies such as Getty’s Art and Architecture Thesaurus (www.getty.edu/research/conducting_research/vocabularies/aat/) for image description tasks (Jespersen and Jespersen, 2004). Basically, these subject analysis tools attempt to standardise the language used to describe and search for images. Rasmussen (1997) provided a review of the literature pertaining to text-based approaches to image retrieval. Such approaches suffer from the high cost and inconsistency of manual indexing, and automatic indexing cannot be successful without appropriate text accompanying the images. The main alternative to text-based searching of images is referred to as content-based image retrieval (CBIR), which takes into account visual attributes like colour, texture, and shape (Rui et al., 1999). But users search for high-level concepts more often than the above low-level features (Eakins, 2002), and this is commonly referred to as the semantic problem.
Image user studies
Image needs and search behaviour have been major concerns in the image retrieval field. Most of the research has focused on specific collections or specific groups of users. For example, Markey (1988), Hastings (1995) and Chen (2001) explored the use of images by art historians; Ornager (1997) and Markkula and Sormunen (2000) examined the use of newspaper image archives, and Keister (1994) analysed medical image queries. A number of studies have used query analysis to research users’ image needs and seeking behaviour. Various features of queries have been identified. Enser and McGregor (1993) employed the properties of uniqueness (unique/non-unique) and the concept of refinement (refined/non-refined) to map users’ requests. Enser (1995) presented another conceptual framework, dividing image retrieval into four models of query and search modes, based on linguistic and visual attributes. Fidel (1997) assumed that retrieval tasks may affect search behaviour and described a continuum of use between a data pole and an object pole; that is, each pole involves the retrieval of images for information and as objects. Jorgensen (1998) suggested 12 classes of image attributes derived from an analysis of users’ free-text image descriptions. The study showed that people mainly describe images using object, people, colour, and story classes. Hollink et al.’s (2004) study suggested that users prefer general descriptions to specific or abstract descriptions, and the frequently used categories were objects, events and relations between objects in the image. The above related image user studies have mostly been conducted using either written queries or else on a much smaller scale than the current study, and little empirical research has examined users’ queries in a digital environment. Web image retrieval and search behaviour
A number of search engines now make some provision for image searching. For example, Google, FAST, AltaVista, and Lycos offer similar keyword-based image search options. Since web images are mostly embedded in web documents and can be identified by MIME type or the file extension, these image search engines can simply extend their crawling process to include web images. The difficulty they encounter
Web image and
textual queries
resides mainly in deciding on the features for indexing, since web images usually lack appropriate accompanying texts. To improve the relevance of searching, the engines may take advantage of various techniques, such as the use of weighting mechanisms for indexing and the provision of relevance feedback based on users’ responses to displayed images. There are also systems that integrate web image-specific search services and directories, such as Columbia University’s webSEEK, which provides for both searching and browsing of 650,000 web images (Smith and Chang, 1997). As queries are the primary means by which users express their information needs to an information retrieval system, query analysis using search engine logs has become an emerging research area (Jansen and Pooch, 2001). Previous studies focused on textual queries, and show that web users mostly input short queries, view few search results, and request diverse content (Silverstein et al., 1999; Jansen et al., 2000). Few studies have examined users’ image searching behaviour on the web. Goodrum and Spink (2001) analysed 33,149 image queries executed on EXCITE. The results indicated that users input very few terms per query, and that most query terms occurred only once. At the time of the study, however, EXCITE was mainly used for searching textual information and did not provide an image search option.
Methodology
This study used two logs, one from VisionNEXT and the other from Dreamer. VisionNEXT was the first and provides the largest image backend search service for several portals in Asia, including Sina in China and PCHome in Taiwan. Its collection includes over 10 million thumbnail images, collated from crawling the web, and over 100,000 images manually indexed using broad subject categories and assigned keywords. As shown in Figure 1, the search engine allows users to search by term, and
Figure 1.
Sample image search of “Mikado” (an endangered species of bird)
OIR
29,5
then returns nine thumbnail images per retrieved page for users to view and select. Each thumbnail was retrieved automatically by crawling the web and contained the URL of the image, the URL of the site where it resided, and other related information about the image. Simultaneously, the engine implements a pornography query filter, which is designed to filter out queries with sexual content, although not all customers utilise this function. Details about the company and its services can be found on its web site (www.VisionNEXT.com/). Interested readers may test its image retrieval functions by connecting to Sina Photo Search (http://pic.sina.com.cn/) or Want2 Photo Search (www.want2.com.tw/). Though the web sites are in Chinese, the query can be in either English or Chinese.
The second data-set was collected from Dreamer, at one time a Taiwan web search engine. It served general web users by providing a web directory and page search options like those of Yahoo! or AltaVista.
Table I displays the VisionNEXT log, collected during a three-month period from July to September 2002 (V-Image), and the Dreamer log, collected over a three-month period in early 1998 (D-Text). The two logs contained distinct query terms and their corresponding aggregated frequencies. In this paper, a query denotes a query term exactly as entered by a user, and may be either a single word or multiple words in English, or a sequence of characters in Chinese. Both logs comprised both Chinese and English queries, with nearly 10 percent (240,000 queries) of V-Image and 20 percent (430,000 queries) of D-Text being in English. In order to validate the hypothesis, the author analysed the query distribution in each month, and found that there was little variance. In other words, certain search patterns persist, irrespective of language or timeliness.
First, the factual characteristics of image queries were analysed and compared with analyses of search engine logs from previous research, including textual query studies on AltaVista (Silverstein et al., 1999), Excite (Jansen et al., 2000), and Dreamer (Pu et al., 2002), and an image query study of Excite (Goodrum and Spink, 2001). The main areas of comparison were query length and query frequency. Second, the top 1,000 web image and textual queries were categorized by query type, based on an analytic model modified by the uniqueness and refinement scheme developed by Enser and McGregor (1993). This is a favoured scheme because of the ease with which it can be used for identifying query types in the web searching environment, and the practicality of its application for examination of the differences between image and textual queries. In the author’s previous study on auto-categorization of web query terms (Pu et al., 2002), it was observed that an adequate number of high-frequency query terms accommodated most of the popular search interests. Therefore, the top 1,000 queries were manually classified into broad subject categories in order to observe the
Data-set Source Type of service
No. of distinct
query terms Total frequencies
V-Image VisionNEXT image queries (3 months from July to Sept. 2002)
Web image directory & search
325,812 2,401,628
D-Text Dreamer textual queries (3 months in early 1998)
Web site directory & page search
228,502 2,183,506
Table I. Experimental data-sets from image and textual search engines
Web image and
textual queries
distribution of popular search interests in image and textual queries. Because of the diversity of image and textual information needs, two different classification schemes were adopted for the categorization process. The scheme used to categorize image queries was developed by VisionNEXT and includes 13 broad subject categories, alphabetically listed, for animals and plants, animation and comics, arts, computing and communications, entertainment, geography and travel, nature, people-related, science and technology, shopping, society and culture, sports, and transportation. The scheme used to categorize textual queries was developed in the author’s previous work and includes 13 broad subject categories: arts and humanities, business and finance, computing and networks, games, education, entertainment, healthcare, news and media, recreation and chat, shopping, politics and society, reference, and travel.
The categorization tasks, including classifying web queries using the uniqueness/refinement scheme and predefined broad subject categories, were mostly carried out by three graduate students with substantial experience in internet surfing, sufficient knowledge of image indexing and retrieval, and adequate training in subject indexing techniques. During the categorization process of this study, three principles were applied. First, human analysts were used to judge the subject domain(s) of a query based on possible search purposes. Second, because a popular query usually represents one topic, it was assigned only one category. Third, each query was categorized by at least two analysts, and another analyst not previously engaged in the categorization process made the final decision if inconsistency occurred. Although the human analysts may have suffered from subjectivity, inconsistency, and lack of domain knowledge, they were only involved in classifying top query terms into appropriate categories. More importantly, the purpose of categorization was mainly to observe various trends of image and textual queries, so the distortion caused by a few invalid human categorizations would not, in fact, seriously affect the accuracy of the results.
Results Query length
The average image query length in V-Image was 3.08 characters in Chinese (Table II). This is slightly shorter than the average textual query length in D-Text, where the mean was 3.18. According to general statistics on the Chinese language (Chien and Pu, 1996), the average word length is 1.5-1.6 characters; hence, 3.08 or 3.18 characters can be treated both as a word bi-gram or word pair. Research on AltaVista and Excite textual query logs identified a mean of approximately 2.35 terms per query in English, which is similar to a term pair. In other words, users mostly input one keyword with one single concept, regardless of the language used in the queries. In addition, the average length of an English query was 1.10 words in D-Text and 1.40 in V-Image, and so is much shorter than that shown by the results reported in the above studies. The reason for this is that these queries mostly consisted of proper nouns such as “IBM,” “Microsoft,” and so on. It was suggested that queries in English by Chinese users
Language in queries V-Image D-Text
Chinese query 3.08 3.18
English query 1.40 1.10
Table II.
Average query length in image and textual queries
OIR
29,5
might not be as complex as those of English users. At the same time, the 3.74 words found in the Excite image query study were much longer than the results obtained in the above studies, mostly owing to the fact that at least one term in each query was used as an image request term in that study. Based on these studies, it appears that web users type in short queries not only when searching for textual information, but also when searching for visual information. In addition, it is noted that a zero-hit image query tended to be much longer (4.12 characters in Chinese) than the average length of non-zero-hit queries (2.83 characters in Chinese), which indicates a higher level of specificity and the limitations of current web image search engines.
Query frequency
Table III lists the frequency distribution of distinct query terms. Nearly 15 percent of the image queries occurred more than three times, while less than 12 percent of the textual queries did so. Meanwhile, the top 1,000 image queries comprised over 56 percent of the total frequencies, compared with only 35 percent of the textual queries. Moreover, the top 5 percent of the image queries comprised over 80 percent of the total frequency, and the top 25 queries in the data-set had fully 14.61 percent of the total frequency, despite representing only 0.00027 percent of the distinct queries. Based on the above analysis, it appears that there is a strong trend in these image requests corresponding to Pareto’s 80/20 law; that is, 20 percent of queries accounts for almost 80 percent of the total frequencies. In other words, these web image queries focused on popular queries or certain subject domains. It is concluded that image needs are subsets of web requests; hence, the variety of content in textual queries may be greater in terms of query frequency than that in image queries. However, it needs to be noted that these image queries contained more terms that occurred once than did in the textual queries (9 percent vs 5.48 percent). The major reason for the higher rate was zero-hit searches, which accounted for 82.65 percent of the total queries that occurred once.
Query types
In Enser and McGregor’s study (1993), uniqueness was a key attribute of image queries, with requests being for unique images (that is, a specific person, place or event of which there is only one), or non-unique images (that is, a certain type of person, item or place). They also noted that users further refined their queries based on time, location, action, event or technical specification attributes. Based on the above scheme, the top 1,000 queries of V-Image and D-Text were mapped into four categories along two dimensions: unique (for example, “London Bridge”), or non-unique (for example, “dinosaurs”), and refined (specified, based on time, location, activity, and so forth) or non-refined. An example of a query in the unique refined category is “French Emperor Louis XIV”; and one in the non-unique refined category is “carnivore dinosaur.”
Table IV shows the percentages of the four categories in terms of image and textual queries, and so provides a practical way to examine their differences. It is interesting
Query occurs
Data-set Once (%) Twice (%) 3 times (%) . 3 times (%)
V-Image 9.00 3.74 2.10 85.17
D-Text 5.48 3.74 2.64 88.14
Table III. Distribution of query frequency in image and textual queries
Web image and
textual queries
that most of the popular image queries (75.85 percent) were unique searches, compared with 34.22 percent of the popular textual queries, which may indicate a higher level of specificity compared with textual queries. On the other hand, most of the popular textual queries were non-unique searches (64.5 percent), compared with 17.91 percent of the popular image queries, which seems to explain the problem of the large number of results frequently retrieved via popular textual queries. The unique image queries included many personal name searches, particularly in the entertainment domain (for example, “Britney Spears”), while non-unique textual queries focused on general concepts, such as “music”, “game”, “software”, and so on. Further, refined queries occurred more than five times more often in popular image queries than in popular textual queries. It was found that the percentage of refined queries was very low in popular textual queries. Further investigation of the unique and refined query types may provide insight into the characteristics of image searching.
Search interests
As well as comparing the factual characteristics and query types of web image and textual queries, the study also looked into users’ search interests as revealed by the queries. The study categorized the top 1,000 image and textual queries using two different classification schemes as described in the previous section. Although the categorization process was unavoidably subjective, a rough picture of the popular image and textual search interests emerged.
Since the image search engine studied implements a filter for sexual content, such requests were mostly filtered out, even when there seemed to be a need for such information. To facilitate comparison, the adult-related category in the set of textual subject categories was, therefore, removed. Table V lists results of the subject
Data-set Non-unique (%) Non-unique refined (%) Unique (%) Unique refined (%)
V-Image 17.91 3.72 75.85 2.52
D-Text 64.50 0.85 34.22 0.43
Table IV.
Image and textual query types within the experimental data-sets
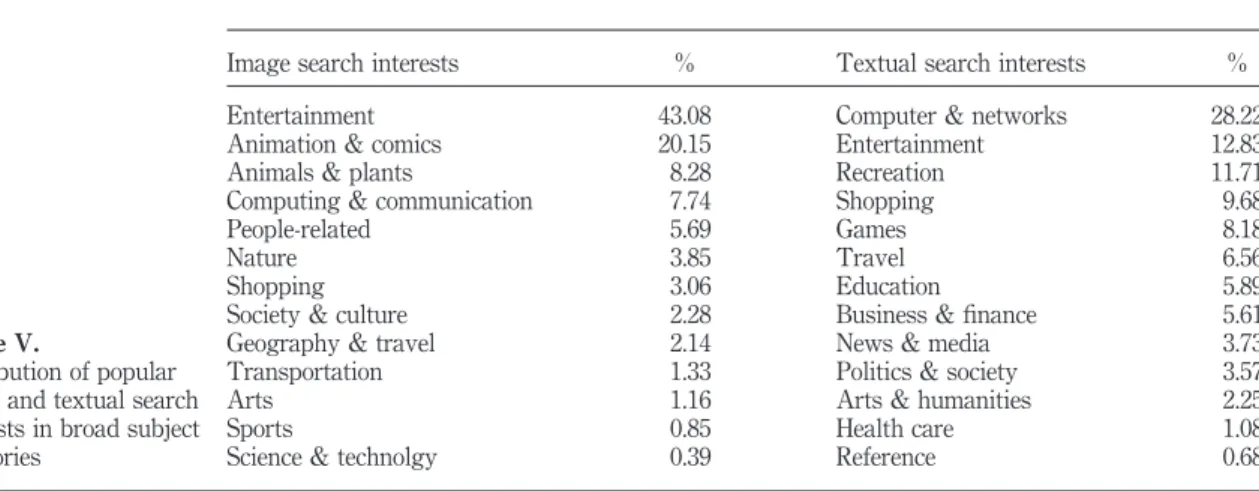
Image search interests % Textual search interests %
Entertainment 43.08 Computer & networks 28.22 Animation & comics 20.15 Entertainment 12.83 Animals & plants 8.28 Recreation 11.71 Computing & communication 7.74 Shopping 9.68
People-related 5.69 Games 8.18
Nature 3.85 Travel 6.56
Shopping 3.06 Education 5.89
Society & culture 2.28 Business & finance 5.61 Geography & travel 2.14 News & media 3.73 Transportation 1.33 Politics & society 3.57
Arts 1.16 Arts & humanities 2.25
Sports 0.85 Health care 1.08
Science & technolgy 0.39 Reference 0.68 Table V.
Distribution of popular image and textual search interests in broad subject categories
OIR
29,5
categorization of image and textual queries, showing the broad subject category in descending order of total appearance in the test set. The analysis shows that the entertainment category was important for both image and textual queries. However, certain categories, such as animals and plants, and nature in image queries, were not very important in textual requests. Comparing the two distributions, image queries seemed to be much more skewed toward certain subject interests than textual queries. For example, the top three categories constituted 71.51 percent of the image requests compared with 52.76 percent for textual requests, which corresponds to the results of the analysis of query frequency described in the previous section. In other words, web image requests were more focused on some popular search interests than were textual requests. It may also be concluded that the variety of textual queries was greater than that of image requests.
Discussion and conclusion Implications for image retrieval
There has been an explosive increase in the availability of image collections on the web. Searching digital images on a networked environment is growing rapidly. Although the design and technology of image databases have been studied extensively, high-precision and robust solutions remain hampered by limits to knowledge about user issues associated with image retrieval. Current image retrieval systems provide keyword search options as in textual information retrieval. However, using text to search images may not prove successful in every case, and query failure is not unusual. Despite substantial efforts made in many image retrieval studies, the author considers that there is still the paramount challenge of bridging the gap between research on image user studies and retrieval technologies. Undoubtedly, it is necessary to investigate the characteristics of image queries before a more effective image retrieval system can be developed.
This study examined the differences between web image and textual queries. Overall, web users tend to input short queries when searching for either textual or visual information. In such a situation, term suggestion and relevance feedback techniques could be applied to provide more hints and interactions that would assist users to search more effectively. Further, image queries are clearly as diverse as textual queries. There are, however, strong trends in the use of popular search queries for web images in terms of their rank/frequency ratio. In dealing with popular search topics, it is suggested that human manipulation, such as categorization or summarization, would be helpful for users browsing or searching serendipitously. As for the query types, image queries show more unique searches, while textual queries exhibit more non-unique searches. This indicates a higher level of specificity for image queries and explains the problem of the large number of results frequently retrieved via popular textual queries. The automatic annotation technique is useful for increasing the number of appropriate texts for web images, and helps to achieve a better matching of users’ queries. Finally, based on observation of the distribution of search interests, image and textual queries revealed some similar popular search interests, such as entertainment and people-oriented categories; and some different interest categories including animals and plants, and nature in image queries, and business and finance in textual queries. It is therefore suggested that search result representation should consider providing both textual and image information at the same time to fulfill
Web image and
textual queries
different types of requests. To sum up, clearly current text-retrieval technology is not capable of fulfilling such complex image requests. Effective image searching can only be achieved through a good integration of human effort and advanced image retrieval techniques.
Limitations and future research
Through a comparative analysis of textual and image queries, this paper investigates the implications for the design of more effective web image searching techniques. There are, however, some limitations that need to be considered. First, a more comprehensive understanding of users’ search behaviour could be obtained if additional data-sets were collected. Query logs render sparse data on users’ information requests. Resources such as users’ query sessions and click streams can provide much contextual information and reveal more about how users search, browse, and access information on the web. Furthermore, the process of analysing the factual characteristics of over 4 million queries was done automatically, and the top 1,000 queries were manually categorized, based on their potential search purposes. Though the categorization process was unavoidably subjective, a rough picture of the popular image and textual search interests emerged. But knowing what the top queries are is not sufficient for providing a complete picture of search interests, and a division of subjects into 13 categories is rather a broad way of describing all aspects of users’ search interests. A more thorough analysis is necessary for image retrieval applications. Finally, for future research, zero-hit queries are good sources for an analysis of the probable causes of problems in image searching. The complexity and variety of image queries in terms of their refined types could be further investigated. References
Alltheweb (2003), “Language distribution of 2.3 billion web pages in July 2003”, available at: http://ucdata.berkeley.edu:7101/language-distribution-of-the-web-table.htm
Chen, H. (2001), “An analysis of image queries in the field of art history”, Journal of the American Society for Information Science and Technology, Vol. 52 No. 3, pp. 260-73.
Chien, L.-F. and Pu, H.-T. (1996), “Important issues of Chinese information retrieval”, Computational Linguistics and Chinese Language Processing, Vol. 1 No. 1, pp. 205-21. Eakins, J. (2002), “Towards intelligent image retrieval”, Pattern Recognition, Vol. 35 No. 1,
pp. 3-14.
Enser, P.G.B. (1995), “Progress in documentation: pictorial information retrieval”, Journal of Documentation, Vol. 51 No. 2, pp. 126-70.
Enser, P.G.B. and McGregor, C. (1993), “Analysis of visual information retrieval queries”, British Library Research and Development Report, No. 6104, Computer Laboratory, University of Cambridge, Cambridge.
Fidel, R. (1997), “The image retrieval task: implications for the design and evaluation of image databases”, The New Review of Hypermedia and Multimedia, Vol. 3, pp. 181-99. Global Internet Statistics (2004), available at: http://global-reach.biz/globstats/index.php3 Goodrum, A. and Spink, A. (2001), “Image searching on the Excite web search engine”,
Information Processing and Management, Vol. 37 No. 2, pp. 295-312. Google (2004), “Image search”, available at: http://image.google.com/
OIR
29,5
Hastings, S. (1995), “Query categories in a study of intellectual access to digitized art images”, Proceedings of the ASIS 58th Annual Meeting, Chicago, IL, Vol. 32, pp. 3-8.
Hollink, L., Schreiber, G., Wielinga, B. and Worring, M. (2004), “Classification of user image descriptions”, International Journal of Human-Computer Studies, Vol. 61 No. 5, pp. 601-26. Jansen, B.J. and Pooch, U. (2001), “A review of web-searching studies and a framework for future research”, Journal of the American Society for Information Science, Vol. 52 No. 3, pp. 235-46. Jansen, B.J., Spink, A. and Saracevic, T. (2000), “Real life, real users, and real needs: a study and analysis of user queries on the web”, Information Processing and Management, Vol. 36 No. 2, pp. 207-27.
Jespersen, H.P. and Jespersen, K.J. (2004), “The problem of subject access to visual materials”, Journal of Educational Media and Library Sciences, Vol. 42 No. 1, pp. 37-48.
Jorgensen, C. (1998), “Attributes of images in describing tasks”, Information Processing & Management, Vol. 34 Nos 2/3, pp. 161-74.
Keister, L. (1994), “User types and queries: impact on image access systems”, Proceedings of the ASIS 57th Annual Meeting, Alexandria, VA, Vol. 31, pp. 7-22.
Markey, K. (1988), “Access to iconographical research collections”, Library Trends, Vol. 37 No. 2, pp. 154-74.
Markkula, M. and Sormunen, E. (2000), “End-user searching challenges indexing practices in the digital newspaper photo archive”, Information Retrieval, Vol. 1 No. 4, pp. 259-85. Ornager, S. (1997), “Image retrieval: theoretical and empirical user studies on accessing
information in images”, Proceedings of the ASIS 60th Annual Meeting, Washington, DC, Vol. 34, pp. 202-11.
Pu, H.-T., Chuang, S.-L. and Yang, C. (2002), “Subject categorization of query terms for exploring web users’ search interests”, Journal of the American Society for Information Science & Technology, Vol. 53 No. 8, pp. 617-30.
Rasmussen, E. (1997), “Indexing images”, Annual Review of Information Science and Technology, Vol. 32, pp. 169-96.
Rui, Y., Huang, T.S. and Chang, S.F. (1999), “Image retrieval: current techniques, promising directions and open issues”, Journal of Visual Communication and Image Representation, Vol. 10 No. 4, pp. 1-23.
Silverstein, C., Henzinger, M., Marais, H. and Moricz, M. (1999), “Analysis of a very large web search engine query log”, SIGIR Forum, Vol. 33 No. 1, pp. 6-12.
Smith, J. and Chang, S. (1997), “An image and video search engine for the World Wide Web”, in Sethi, I. and Jain, R. (Eds), Storage and Retrieval for Image and Video Databases V: Proceedings of SPIE, Newport Beach, CA, Vol. 3022, pp. 84-95.
Tomaiuolo, N.G. (2002), “When image is everything”, Searcher, Vol. 10 No. 1, available at: www. infotoday.com/searcher/jan02/tomaiuolo.htm