國 立 交 通 大 學
電信工程學系碩士論文
中文大詞彙語音辨認之
語言模型改進
Improvement on Language Modeling for
Large-vocabulary Mandarin Speech Recognition
研 究 生:周建邦
指導教授:陳信宏 博士
中文大詞彙語音辨認之語言模型改進
Improvement on Language Modeling for
Large-vocabulary Mandarin Speech Recognition
研 究 生:周建邦 Student: Chien-Pang Chou
指導教授:陳信宏 博士 Advisor: Dr. Sin-Horng Chen
國立交通大學
電信工程學系
碩士論文
A Thesis
Department of Communication Engineering
College of Electrical Engineering and Computer Science
National Chiao Tung University
In Partial Fulfillment of Requirements
For the Degree of
Master of Science
In Electrical Engineering
中文摘要
本研究之目的為探討中文大詞彙語音辨認之語言模型改進。傳統大詞彙語音 辨認大多使用統計式語言模型,藉此計算數萬詞條之雙連文或三連文機率模型, 然而,此方法仍有其缺失,因其無法對於不包含在辭典中之詞彙進行辨識,其中 包含數量複合詞、專有名詞、不常出現之詞綴構詞等等,基此,本研究針對混合 詞及半詞(subword)之統計式語言模型進行探討,期望藉此增進辭典之涵蓋率, 降低無法進行辨識之詞條數目。 本研究分為三大主軸,首先,對於文字資料庫進行前處理,針對不適當內容 (英文、文章標題等)進行刪減、對於錯誤文字予以更正、斷詞、文字正規化等; 其次,建構混合詞及半詞統計式語言模型,探討字典收錄詞條之策略、將辭典未 收納之詞彙拆解為半詞之方法、以及混合模型之建立,最後,採用兩階段 (two-stage)辨認架構,針對辨認方法及實驗結果進行說明,並進一步分析與比較 架構式模型和傳統方法模型之語音辨認結果之優劣,針對本研究考量之三種構詞 (人名、詞綴及數量複合詞)的辨識效益進行深入分析。 為了驗證提出方法之效能,本研究採用 TCC300 麥克風語料為語音實驗語 料,語言模型則由台灣光華雜誌(Taiwan Paramora)及中文檢索標竿(NTCIR3.0)文 字語料庫求得,實驗結果顯示,相較於傳統採用之統計式語言模型,本研究所提 出的混合模型對於大詞彙語音辨認系統效能有所改善,整體詞辨認率(word accuracy)由 60.86%提升至 62.85%,經過深入分析發現,使用所提出之兩階段辨 認方法對於人名、詞綴及數量複合詞確實有所幫助,此三類辨認正確之數量增加 驗證了提出方法的有效性。Improvement on Language Modeling for
Large-vocabulary Mandarin Speech Recognition
Student: Chien-Pang Chou Advisor:Dr. Xin-Hong Chen
Department of Communication Engineering
National Chiao Tung University
Abstract
The purpose of this research is the improvement of language modeling for large-vocabulary Mandarin speech recongnition. Traditionally, large-vocabulary speech recognition is almost to employ statistical language model. By calculating million of bigram(or trigram) probability model is also having the drawback. Because we can not recognition the OOV(out-of-vocabulary) words(including determiner-measure compoundi word, name entity, and affix word). Because these reasons, we probe into the statistic language model which mixs word and subword. By this way, we not only hope that increasing the coverage of lexicon, but also decreaing the number of words which we can’t recognition correctly.
This thesis divides three parts. First, we explore the applicability of the corpus to be used to build the language model, and to observe the contents of corpus whether fit to build the language model or not. We delete the misfit contents and correct the wrong words. We hope to promote the whole recognition rate. Second, we want to train the statistic language model which mixs word and subword, and probe into the tactics that collect the entiry of recognition lexicon to building
誌謝辭
首先誠摯的感謝指導教授陳信宏教授、王逸如教授,兩位老師悉心的教導使 我體會到語音領域的深奧,兩位老師教導的方式不同,一個對於研究的態度是大 處著眼,另一個的態度則是小處著手,讓我學習到研究的重心在於理論的實現, 在研究的過程中,好好的享受過程、了解探討過程、分析結果,觀看結果是否合 理,並且驗證想法。老師對做學問的嚴謹更是我學習的典範。 這兩年多的研究所生活,幸好有大家的陪伴才得以順利度過,平常研究累了 就會聽到大家言不及義的打屁交談,加入戰局更得精神百倍,不會忘記大家的加 油聲,一起在實驗室相處的時光,因為有大家的加入,使得我在交大生活可以多 采多姿。 感謝希群學長對我的研究給予建言及想法,當我在進退兩難時,給予協助; 感謝阿德學長在我心情低落時,給予幾句關心及開導;感謝智合學長總是主動前 來詢問我的進度狀況,以給予幫助;感謝 barking 學長讓我見識何謂程式上的強 者;感謝 QQ、小宋、普烏同學,有你們的陪伴,我才能順利的度過研究所生活。 另外要特別感謝陪伴我六年多的黃小謬,也是我最、最..最可愛的女朋友, 當我因研究受挫折時都一直給我安慰、鼓勵,要我不要氣餒,使我能再接再厲而 不被挫折打敗,謝謝您一直陪伴著我,不管多遠都會到新竹看我,真的很感動, 幸好生命終有你的陪伴,可以陪著我度過研究所時期,以後我們還要繼續加油, 再一起手牽手走下去。 最後感謝我的雙親,給予學業上的信任與自由,以及支持我繼續努力,而得 到這多彩多姿的交大研究生活,有你們的支持,使我能不顧一切的往前衝,我也 才能努力到現在,謝謝您們!目錄
中文摘要 ... I ABSTRACT ... II 誌謝辭 ... III 目錄... IV 圖目錄 ... VI 表目錄 ... VII 第一章 緒論 ... 1 1.1 研究動機 ... 1 1.2 研究方向 ... 2 1.3 章節概要 ... 4 第二章 語音辨認基本系統的建立 ... 5 2.1 ACOUSTIC MODEL 的建立 ... 5 2.1.1 語音資料庫 ... 5 2.2.2 參數設定 ... 5 2.2 LANGUAGE MODEL 的建立 ... 6 2.2.1 文字資料庫 ... 7 2.2.2 文字前處理 ... 9 2.2.3 辨認辭典建立 ... 12 2.2.4 OOV 處理 ... 13 2.2.5 N-gram training ... 13 2.2.6 傳統 language model 之探討 ... 16 第三章 混合式語言模型 ... 17 3.1 三類詞拆解方法…………. ... 18 3.1.1 人名拆解方法 ... 19 3.1.2 詞綴拆解方法 ... 20 3.1.3 數量複合詞拆解方法 ... 21 3.2 挑選辨認辭典的SUBWORD半詞 ... 22 3.3 建立含WORD及SUBWORD的混合式辨認辭典 ... 23 3.4OOV 處理 ... 26 3.5N-GRAM TRAINING ... 263.6SMOOTHING (CUT OFF VALUE) ... 26
3.7 混合式LANGUAGE MODEL之探討 ... 27
4.2.2 改變語言模型分數 ... 41 第五章 實驗結果與分析 ... 45 5.1 辨識語料分析 ... 45 5.2PERPLEXITY複雜度比較 ... 45 5.3WORD LATTICE上可涵蓋的三類長詞之比較 ... 46 5.4WORD LATTICE構詞結果分析 ... 49 5.5 理想上最佳辨認效能 ... 50 5.6 辨識效能比較 ... 52 5.6.1 辨識結果之細部剖析 ... 53 第六章 結論與未來展望 ... 58 6.1 結論... 58 6.2 未來展望 ... 58 參考文獻 ... 60 附錄一 ... 62 附錄二 ... 67
圖目錄
圖 1 -1:傳統式辨識流程 ... 2
圖 1-2:階層式 WORD-SUBWORD BASED ASR 系統架構 ... 2
圖 2-1 文字語料庫處理流程 ... 7 圖 2-2 文字資料庫 COVERAGE 曲線圖 ... 8 圖 2-3 文字前處理流程圖 ... 9 圖 2-4:傳統語言模型建立流程圖 ... 14 圖 3-1 文字資料庫處理流程 ... 17 圖 3-2 混合式辭典挑選方法...18 圖 3-3 數量複合詞 SUBWORD 斷詞辭典 ... 21 圖 3-4 WORD/SUBWORD 混合式辭典建立流程圖 ... 23 圖 3-5 WORD/SUBWORD 混合式語言模型建立 ... 26 圖 4-1 數量複合詞構詞模型 ... 29 圖 4-2 數字串 FSM ... 32 圖 4-3 定量複合詞 FSM ... 33 圖 4-4、計算輸入語句於 FSM 裡所造成的狀態轉移次數。 ... 34 圖 4-5、適用於定量複合詞的兩層式 FST MODEL 架構 ... 35 圖 4-6 新產生的節點和弧 ... 36 圖 4-7 弧上的 WORD PENALITY ... 38 圖 4-8 正確構詞 ... 39 圖 4-9 錯誤構詞 ... 40 圖 4-10 弧上語言模型新分數 ... 42
表目錄
表 2-1:參數抽取設定檔 ... 5 表 2-2:文字資料庫 WORD 及 CHARACTER 統計表 ... 7 表 2-3 文字資料庫分析 ... 8 表 2-4 文字正規化範例 ... 12 表 2-5 同音義異詞範例 ... 12 表 2-6 傳統方式辭典統計表 ... 13 表 3-1 各區間內的 COVERAGE RATE ... 19 表 3-2 各區間各類長詞分佈 ... 19 表 3-3 人名的拆解 ... 20 表 3-4 詞綴的拆解 ... 21 表 3-5 數量複合詞的拆解 ... 22 表 3-6 各類詞剩餘 SUBWORD 詞條數量 ... 23 表 3-7 混合式辭典建立各步驟之相對應詞條數與總數量 ... 25 表 3-8 WORD/SUBWORD 混合式語言模型辭典 ... 25 表 4-1 數詞半詞集合與各集合對應 STATE ID ... 31 表 4-2 定詞量詞分類與其對應 STATE ID ... 31 表 4-3 各類內部機率使用機率型態 ... 44 表 5-1 TCC300 辨認語料各類分佈 ... 45 表 5-2 PERPLEXITY 比較 ... 46 表 5-3 傳統語言模型 WORD LATTICE 上涵蓋率 ... 47表 5-4 WORD/SUBWORD 混合式語言模型 WORD LATTICE 三類詞涵蓋率 ... 47 表 5-5 各類第二級 SUBWORD 構詞組成數量 ... 48 表 5-6 三類在兩個語言模型構詞數量 ... 48 表 5-7 名字 SUBWORD 對語料中未出現人名的涵蓋情況 ... 49 表 5-8 構詞結果分析 ... 50 表 5-9 WORD LATTICE 上的最佳路徑比較 ... 51 表 5-10 字元(CHARACTER)辨認效能比較 ... 52 表 5-11 詞(WORD)辨認效能比較 ... 52 表 5-12 辨識結果中各類所佔總數量 ... 53 表 5-13 人名辨認情況 ... 54 表 5-14 詞綴辨認情況 ... 55 表 5-15 數量複合詞辨認情況 ... 55 表 5-16 數量複合詞中各類錯誤型態 ... 56
第一章 緒論
1.1 研究動機
近年來,語音辨識之相關研究大多自語音訊號層面著手,透過研究聲音之特性, 藉此提昇辨識率。然而,語音和語言密不可分,若語音辨識能回歸於基本之語言,針 對語言進行研究,對於辨識效果之提升將會有所助益。 在傳統大詞彙語音辨認中,語言模型所用之辨認辭典,大多是將語料中的詞依據 詞頻排序,進而取其排序前六萬者納入辭典,然而,語料中並非每個詞均會被辨認辭 典所收錄,進行語音辨認時,倘若出現辨認辭典未收錄之詞時,該詞將無法被辨認, 造成辨認上的錯誤,而此些不在辨認辭典中的詞稱為「Out-of-Vocabulary」,簡稱 OOV words,所佔比例稱「OOV rate」。 OOV rate 大小將會影響辨識效能,數値越大代表著越多詞將無法被辨識,而此現 象大多出現於拼音複雜或詞變化多的語言,如:德語、土耳其語、阿拉伯語、芬蘭語… 等皆有此現象,其中,阿拉伯語之語音辨識研究為突破 ASR 系統無法完全收錄詞彙對 於辨識效能之限制,運用 morphological analysis 建構語音辨認系統(R. Sarikaya et al, 2007),試圖藉此解決拼音複雜的阿拉伯語辨認辭典詞彙收錄不足的問題。自此反觀中文語音,中文語詞變化多元,特別是數量複合詞、專有名詞(本研究針 對人名)、不常出現之詞綴構詞…等,此些類別之詞可任意組合且變化無限,故中文語 音辨識亦存在著辨認辭典無法完整收錄詞彙而阻滯辨識效能成長的困境。基此,為突 破辭典詞彙收錄有限之限制,本研究試圖提出一個階層式 word-subword based ASR 系 統,針對混合詞及半詞(subword)之統計式語言模型進行探討,整體系統架構包含三個
1.2 研究方向
傳統基本語音辨識系統主要包含五大層面,包括:語音特徵參數的求取、聲學模 型(Acoustic Model, AM)的訓練、語言模型(Language Model, LM) 的訓練、辭典選取以 及辨識比對,如下圖 1-1 所示:
圖 1 -1:傳統式辨識流程
如先前所述,為改善傳統辨認辭典無法完整收錄詞彙的問題,本研究提出階層式
word-subword1 based ASR 系統架構,以此作為研究之思考脈絡與架構,如下圖 1-2 所
示:
圖 1-2:階層式 word-subword based ASR 系統架構
1
由上圖可知,階層式 ASR 架構由左至右可分為三大模組。首先,第一級模組為 word/subword based 辨認模組,本研究將針對如何建立 word/subword 混合式語言模型 (第一級語言模型)進行探討,而如何於此模組中選取所需的 word 和 subword 作為辨認 辭典,乃為本研究重要課題之一。
其次,第二級模組為 lattice extension 構詞模組,研究者將第一級模組之辨認辭典 未收納的詞彙進ㄧ步拆解為數個 subword 半詞串,而第二級模組於 word lattice 上將運 用此些 subword 短詞串進行構詞。然而,本研究所立基之實驗室目前除數量複合詞外, 其餘尚未建立構詞模型,無法立即精確地偵測出需要構詞的 subword 半詞串,基於此 限制,本研究運用查表法進行構詞,對於如何建立完整構詞模型,本研究尚無深入探 討。
最後,第三級模組為 lattice rescoring 模組,該模組針對第二級模組構詞產生之 extended word lattice 的路徑重新給予語言模型分數,藉此產生第二級語言模型,基此, 本研究將探討分數分配之相關議題,針對辨認方法及實驗結果進行說明,並進一步分 析與比較階層式和傳統式語音辨認結果之優劣。
1.3 章節概要
基於本研究所欲探討之相關議題,本文之章節架構與內容於下概述: 第一章 緒論:介紹研究動機、研究方向及章節概要。
第二章 語音辨認基本系統的建立:回顧傳統聲學模型和語言模型的建立方式,包括: 文字前處理、辨認辭典的建立、OOV 處理、smoothing 方法及 perplexity 計算, 並運用 HTK toolkit 以訓練傳統語言模型,以此作為和階層式語言模型辨識效 能之比較基礎。 第三章 混合式語言模型:將語料之人名、詞綴和數量複合詞(DM)以 subword 短詞方 式進行拆解,並探討辭典收錄之範圍,並運用 HTK 工具以訓練 word/subword 混合式語言模型。 第四章 第二級語言模型:將第一級辨認產生的 word lattice 透過構詞形成第二級 extended word lattice,再針對其路徑給予分數配置,進而產生第二級語言模型。 第五章 實驗解果與分析:檢視有意義長詞之辨識效能、實驗相關分析,並與傳統語
音辨認效能進行比較。
第二章 語音辨認基本系統的建立
近年來語音辨認之相關研究最常採用的聲學模型為隱藏式馬可夫模型(Hidden Markov Model, HMM),透過該機率模型,描述發音過程之狀態(State)轉移現象與輸出 結果,該方法之辨識效能佳,故本系統亦採用此模型,並加入語言模型,期望藉由語 言模型之改進來幫助提升語音辨識率。
2.1 Acoustic model 的建立
對於聲學模型(Acoustic Model, AM)之建立透過以下兩小節來介紹,如下:
2.1.1 語音資料庫
目前語料採用的是PTSND第一年40小時。我們將所有可用語料的十分之九歸於訓 練語料,十分之ㄧ歸於測試語料。其中訓練語料的時間大約有8.5個小時。
2.2.2 參數設定
在進行訓練或辨識之前,我們均會先將輸入的語音均進行前處理,即求取其語音 參數。我們求取的語音參數是梅爾倒頻譜參數(Mel-Frequency Cepstral Coefficients; MFCC),利用語音在頻譜上具有短時間穩定的特性,並且MFCC有考慮到補償人耳 的聽覺效應。 而語音參數求取時所使用之系統參數如下所示: 表 2-1:參數抽取設定檔 取樣頻率 16 kHz 音框長度 30ms 音框平移 10ms Filter bank 個數 24 個梅爾刻度三角濾波器
為了能求得切割位置,我們先以Read speech(TCC300)所訓練之HMM模型來切 割我們欲建立初始模型的訓練語料,初始訓練語料目前只選取單純的資料使用,也就 是語料內容裡沒有背景聲(有背景聲下的語音辨識目前不是我們研究的方向),同時 只能有國語411音節(Syllable)與Particle這兩種資料,資料的數量為665個sub-turn、 字數35,388字,時間約2.05個小時。
因為Read speech不會去訓練Particle這類在Spontaneous speech常出現的聲音模型,因此 在進行切割(Forced Alignment),Particle則使用相近411音節替代。 在求得411與Particle的切割資訊(Boundary Information)之後,我們會進行已知 位置的初始模型訓練。訓練出的聲母和Particle採用3個狀態,韻母用5個狀態之HMM 模式,Mixture個數均為16。 本研究採用 left-to-right HMM,儘管口腔聲道會隨時間而變,但語音訊號具備短 時間的穩定特性,故假設同一音框(Frame)之口腔狀態是相同的。另外,本研究採
用混和高斯模型(Gaussian Mixture Model),代表音框語音參數與各狀態相似程度之狀
態觀測機率(State Observation Probability)。
本研究之訓練模型、估計參數時採用的方法則利用Baum-Welch參數估計法,從已 知狀態序列,根據轉移規則,推測出每個音框所屬的最佳口腔狀態,並重複估測聲學 模型至穩定為止;至於辨識工作的進行則是使用Viterbi search,讓每個音框均對所有 模型進行估計,並找出最佳結果。另外,採用的訓練軟體為英國劍橋大學開發的HMM Tool Kit (HTK)【3】。
2.2 Language model 的建立
對於語言模型(Language Model, LM)之建立,傳統方法上會在決定辨認辭典前, 將文字資料庫經過文字前處理之流程,之後可由統計方式得到辨認辭典及不收錄在辭 典內的 OOVwords,在將此些 OOV words 經過拆解來解決 OOV 問題,經過這些步驟 後之語料會對語言模型之效能有所助益,最後,利用處理過後的語料進行語言模型的 訓練,訓練流程如下圖(圖 2-1)所示並且用以下數小節分開敘述之:圖 2-1 文字語料庫處理流程
2.2.1 文字資料庫
辨識系統之語言模型,通常需要透過大量的文字資料來進行訓練,利用大量的文 字資料訓練出一個涵蓋範圍廣泛、適用於各個領域的語言模型,基於此種模型的普遍 性,稱為「General LM」。因此,一個好的語言模型,其所需要的條件,必須擁有大量 的文字資料庫,而本研究使用下述兩個文字資料庫來建立語言模型: (1)光華雜誌:內容為光華雜誌的文章,蒐集範圍為 1976 年到 2000 年之間。 (2) NTCIR:內容由各個不同學科領域之文章所構成,為建立資訊檢索系統的標竿 測試集。 研究者針對訓練語言模型所使用之光華雜誌與 NTCIR 兩語料庫進行詞、字元數 量統計,結果於表 2-2 中呈現,如下: 表 2-2:文字資料庫 word 及 character 統計表 語料庫 詞數(Word) 字數(Character) 詞條數 光華雜誌、NTCIR 112,966,482 210,480,091 518,539 文章的平均詞長= 1.8632 由下圖(圖 2-2)可知,收納於語料庫的詞依據詞頻排序後,累加至次序到達辨 認辭典限制值(六萬)時,語料庫詞條數涵蓋率到達 96.67%,其 OOV rate 約為 3.33%, 換言之,將有 3.33%的詞數無法收錄於辭典中,而本研究將針對無法收錄者進行拆詞, 以 subword 短詞形式呈現之,以解決 OOV 對於語音辨識造成錯誤結果之問題。圖 2-2 文字資料庫 coverage 曲線圖 研究者針對光華雜誌與 NTCIR 兩大資料庫之可拆解為 subword 短詞者進行統計, 統計結果如下(表 2-3): 表 2-3 文字資料庫分析 文章內容分析如下 總詞條數 各類所佔 比例(%) 總詞數 各類所佔 比例(%) NTCIR、光華雜誌 518,539 112,966,482 文章細分如下 人名 102,408 19.75% 1,588,822 1.40% 詞綴 18,364 3.54% 3,500,370 3.10% 數量複合詞 265,869 51.27% 4,894,156 4.33% ㄧ般詞2 131,898 25.44% 102,983,134 91.17% 2 ㄧ般詞:意指不需進行 subword 短詞拆解者
2.2.2 文字前處理
在進行訓練語言模型之前,須先將語料庫的文章進行前處理,將文章中會影響辨 認效能的內容移除或修改,再經由斷詞、正規化和消除 OOV 後,將此些經過處理後 的文章,用以訓練 word-based 之語言模型。文字前處理流程如圖 3-1 所示,以下方塊 內容將在 2.2.2.1 至 2.2.2.4 各小節分開敘述之。 圖 2-3 文字前處理流程圖2.2.2.1 文章斷詞
在此建立語言模型是經由統計的方式建立,語言模型是在統計詞和詞之間的連接 機率關係,所以得把語料庫的文章斷詞成為以詞為單位的資料,來統計詞和詞之間的 機率,而語言模型的好壞也會和斷詞時所決定詞的邊界有關,這個部分可參考相關論 文【5】。斷詞之斷詞辭典所收錄的詞愈多,文章斷詞之後的結果,較不會有搶詞的現 象出現,也就是斷詞辭典的大小,會影響到斷詞結果的正確率。斷詞辭典無法收錄所 有的詞,這些未收錄的詞中,有些詞是有規則的,可以利用構詞規則產生,把輸入文 句中符合構詞規則的詞成為斷詞的候選詞,再經由斷詞規則進行斷詞,其中這些有規 則詞且和數量有關為「定量複合詞」、「數詞定詞」、「數量定詞」、「時間詞」、「地方詞」、 「位置詞」等,這些我們稱為「數量複合詞」。在進行斷詞時,再加上構詞單元,能讓(1)人名:主要來源有 (1.1)聯考榜單。 (1.2)文字資料庫(光華雜誌、NTCIR)經由現有的六萬詞辭典斷詞後,把連續的一字 詞串,用半自動的方式,以姓氏為首的挑出連續兩個一字詞及連續三個一字 詞。再以人工判別是否為人名。 (2)詞綴:分成前詞綴、後詞綴,主要來源包括 (2.1)中研院所提供的詞綴範例。 (2.2)文字資料庫(光華雜誌、NTCIR)經由現有的六萬詞辭典斷詞後,以半自動的方 式取得,方法如下。 (a)以詞綴為首,分別挑出包含詞綴且詞頻高的二字詞及三字詞,以人工的方式 去辨別是否為前(後)詞綴。 (b)詞頻少的二字詞及三字詞,不代表大部分都是前(後)詞綴,前(後)詞綴是三字 詞可能性比二字詞高,所以現階段只針對三字詞處理。為了再縮小範圍,把 挑出來的三字詞再給予詞類(POS)限制,由於詞綴的詞類大部分是名詞,所 以挑出詞類(P 為名詞(Na、Nb、Nc、Nd)的三字詞,在以人工的方式辨別三 字詞是否為前(後)詞綴。 (3)股票名:經由股票網站收集股票公司名。 (4)定量複合詞(DM):文字資料庫(光華雜誌、NTCIR)經由現有的六萬詞辭典斷詞後, 挑出詞類(POS)為 DM 的詞,由於構詞規則不夠嚴緊,定量複合 詞(DM)有少數的錯誤,但大部分的定量複合詞(DM)都是正確 的,所以這部分錯誤暫不討論。 (5)縣市鄉鎮:經由地圖資訊取得。 (6)學校及科系名:經由聯考榜單取得。 (7)核心詞:核心詞是由中研院八萬八千詞去除其他種類的詞後所剩的詞。
2.2.2.2 標點符號處理
中文所使用的標點符號(PM)共有十六種,可區分為標號與點號兩大類,其中標號常用的有書名號、破折號、省略號、括號、引號等九種,而點號則有逗號、頓號、句 號、冒號、分號、問號、驚嘆號共七種,這兩大類中又以點號跟說話時的停頓有較大 的關聯性【6】,所以在文章中標點符號上的處理,利用點號中的四種點號(句號、分 號、驚嘆號、問號)把文章分段,由於在聲學模型中並未有考慮到標點符號的模型,所 以把文章中所有的標點符號先予以移除。
2.2.2.3 斷詞後的資料庫—英文串取代
由於我們的辨認目標為中文詞,聲學模型中並沒有去訓練這類英文詞的聲音模 型,所以文章中的英文詞我們以一個類別看待它,把它歸類成「LONGFW」這個類別, 在進行辨認的過程中,並不把這個類別收錄至辭典內,而將這個類別視為 unknown words(即 OOV)。2.2.2.4 文字正規化
文字正規化可分為兩大部分,首先,由於文章的內容,有些是阿拉伯數字、詞和 符號都必須由寫法轉為語音讀法;另ㄧ方面,文章內有些詞只是寫法不同,但在讀音 上及語義上是相同的,需把這類的詞合併成同一個詞。這些步驟稱為文字正規化。第一部份:寫法轉讀法
在文章之中,有些阿拉伯數字、詞或符號必須由寫法轉為語音讀法,這個過程稱 為文字正規化,舉例來說「90%」應該讀為「百分之九十」。經由蒐集整理的結果, 我們發現到大部分由構詞規則構出的詞,也就是定量複合詞(DM)、數量定詞(Neqa)、 數詞定詞(Neu)、時間詞(Nd)、地方詞(Nc)、位置詞(Ncd)等六類的數量複合詞,如果含 有阿拉數字及特殊符號,都需要被正規化為讀法,文字正規化轉換範例如下表(表 2-4):表 2-4 文字正規化範例 未正規化之詞 已正規化之詞 90.2 九十點二 90% 百分之九十 90.20% 百分之九十點二零 一零零號 一百號 TEL 電話號碼
第二部份:合併同音義異詞
某些詞和詞之間在發音上和語義上是相同,只是寫法上有所不同,而這類的詞會 在辨認上造成混淆,所以把這類的詞統一合併成一個詞(如表 2-5)。經過這個步驟可將 文章詞更集中,促使 OOV 量減少。 表 2-5 同音義異詞範例 同音義異詞 佰、仟 百、千 部份 部分 佈告欄 布告欄 憤憤不平 忿忿不平 洩露國家機密 洩漏國家機密2.2.3 辨認辭典建立
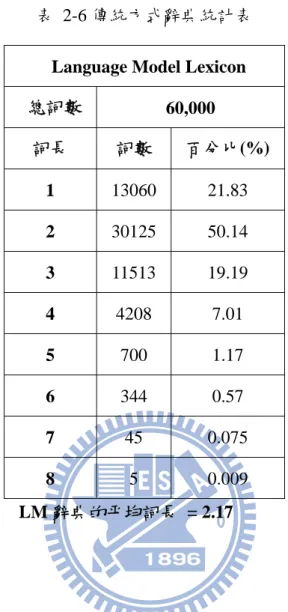
本研究所指的傳統語言模型辭典,其收錄方式為將語料庫中的詞統計按詞頻排 序,進而加上所有中文的一字詞,以此累積至六萬詞,分佈如表 2-6:表 2-6 傳統方式辭典統計表
Language Model Lexicon
總詞數 60,000 詞長 詞數 百分比(%) 1 13060 21.83 2 30125 50.14 3 11513 19.19 4 4208 7.01 5 700 1.17 6 344 0.57 7 45 0.075 8 5 0.009 LM 辭典的平均詞長 = 2.17
2.2.4 OOV 處理
針對未收錄於六萬詞辭典之 OOV word【7】進行拆解,將辭典未收錄之長詞,轉 變成辭典可辨識之短詞,換言之,將 OOV word 拆解為可由辭典內的詞所構成。2.2.5 N-gram training
由下圖(圖 2-4)可知,經過先前所述之文字前處理、OOV 處理動作後,語料庫內 的文章將可利用 HTK tools 進行 bi-gram 語言模型的訓練、辨認,過程中將設定 cut-off 值,因而產生大量 bi-gram,進而轉成 word network 形式,藉由 bi-gram 將詞與詞相互 串聯,形成 word network。圖 2-4:傳統語言模型建立流程圖
2.2.5.1 機率的 Smoothing
在訓練 bi-gram 機率時,倘若分子的 Count( )‧ 值為 0 時,即 bi-gram 機率等於零, 因於 training data 中未出現者,並非代表 testing data 不會出現,故於此情況下,機率 的給定是不合理的,而當詞接詞之 count 值很小時,所計算出的 n-gram 機率也是不準
確。因此,須對計算出的機率予以 smoothing 動作【4】,使所有的 n-gram 機率均能被
良好的估計。
Good-Turing discounting for n-gram 是常見的 smoothing 方法,它可表示如下:
1 1 1 1 2 1 1 1 1 1 1 1 ( | , , ) ( , , ) ( | , , ) ( , , ) 0 ( , , ) min ( , , ) max ( , , ) ( , , ) i i n i i n i i i n i i n i i n i a i n i i n i i n i P w w w a w w P w w w Count w w Count w w d Count w w Count w w Count w w Count K K K K K K K K 1 1 1 ( , , ) max (wi n , ,wi ) Count wi n wi K K (2.2)
其中,a w( i n 1,,wi1)為 back-off 係數,當計算出次數為 0 時,則利用(n-1)-gram,乘 上 back-off 係數,來表示出現次數為 0 的機率,並分配給它一個適當的機率值。 1 1 ( i n , , i ) a w w 的選定,還會經過 normalization,令其滿足 1 1 ( i | i n , , i ) 1 w V P w w w w
(2.3) 若是 Count 的值很小,造成機率預測不準確時,解決方式則為當詞串次數小於 max 次 時,會乘上一個根據 Good-Turning discounting 所計算出來的值d (Discount aCoefficient Factor),減低其機率,並將扣除的機率分給未出現的 n-gram 機率使用。
2.2.5.2 Perplexity 計算
利用建立好的 LM,將可以算出語言模型的 Perplexity (PPL),而語言模型的好壞, 可透過 perplexity 進行測量,perplexity 定義如下: ˆ 2 1 2 , 2 1 ˆ log ( , ... ) H m PP H P w w w m (2.4) 上式意指一個句子之內容乃由 m 個詞所組成,對於每個新詞提供的平均資訊量, entropy(鏑值,以 H 表示),經過 ergodic 的假設與適當地化簡,最後以上式來對 H 做近 似。然而,計算 log probability 是以 10 為基底,因此數學式修改如下: ˆ 10 1 2 , 10 1 ˆ log ( , ... ) H m PP H P w w w m (2.5) 其中 1 2, 1 1 ( , ..., ) ( | ) m m i i i P w w w P w w
;2.2.6 傳統 language model 之探討
傳統式語言模型通常會受限於辨認辭典大小之限制,對於沒有收錄之六萬辨認辭 典的詞將會被拆解成辭典內的短詞,而其拆解方式並無一定地規則,故此,拆解後的 詞在辨認結果中無法以有意義之長詞呈現,進而影響整體詞的辨識效能,因此傳統式 辭典對於語料庫之涵蓋率(cover rate)高低會影響到語言模型之辨識效能,尤其是 中文詞種變化繁多的語言更為明顯。第三章 混合式語言模型
如先前第二章所述,中文語詞變化複雜,辭典無法完全收錄之,因而使得語音辨 識效能成長有限,為突破此困境,本研究採取 word(詞)和 subword(半詞)並存之 混合式語言模型,詞的部份是針對高詞頻的詞為保留長詞的形式針,而半詞的部份對 人名、詞綴和數量複合詞三類進行規則性轉化,將之為拆解為 subword 半詞串,並在 混合式辭典收錄高詞頻的詞及半詞,進而訓練混合式語言模型,再由辨認結果得到之 subword 半詞透過第二級構詞模組,將第一級拆解之半詞組合回原先有意義之長詞, 讓詞辨識效能較傳統方式有所提升。 在進行混合式語言模型訓練之前,文字資料庫的處理過程如圖 3-1 所示,其中, 文字前處理及 OOV 處理與訓練傳統式語言模型相同,而相異之處在於文字前處理之 後增加了「三類詞拆解成半詞」及辨認辭典為「混合式」辨認辭典,以此建立第一級 之混合型語言模型。 圖 3-1 文字資料庫處理流程 進行語音辨認時,ㄧ個語言模型需相對搭配一個適當的辭典。如下圖(圖 3-2)所 示,本研究混合式辭典有別於傳統式辭典,除一般常見詞外,亦於辨認辭典中加入 subword 半詞,故 subword 集合的大小將相對地影響著辨認辭典內收錄ㄧ般常見詞之可高至某ㄧ程度時,即決定第一級辨認所需之辨認辭典。 圖 3-2 混合式辭典挑選方法 然而,由於人名、詞綴和數量複合詞此三類在語料庫中變化多元且複雜,儘管辭 典中無法完全收錄這三類詞,但此三類詞之組成結構上有各有其規則性,可依據其結 構,將此些類別之詞個別拆解為 subword 半詞串,再將此些小單位 subword 半詞集合 依詞頻高低,有比例性地收錄至辨認辭典中,促使第ㄧ級辨認後,word lattice 上相鄰 節點可產生出 subword 半詞串,進而供給第二級構詞使用。
3.1 三類詞拆解方法
本研究針對人名、詞綴和數量複合詞三類進行拆解,拆解過程中,為避免辨認辭 典收錄過多的 subword 短詞,反而犧牲原先未經拆解即可收錄之高詞頻一般詞空間, 故將詞頻高之詞保留其長詞形式,不將之拆解為 subword 半詞串。研究者於詞頻排序 後,依據範圍內之詞的 coverage rate,如表 3-1 所示,發現次序 45,000 之後,coverage rate 增加的速度趨緩,故此,將長詞的 threshold 設定為 45,000,次序於該值之內者則 不進行拆解,以完整的長詞出現(如表 3-2 所示),而次序在此值之外者,則進一步拆為 subword 半詞串。表 3-1 各區間內的 coverage rate 次序 次序之內的 coverage rate
20,000
89.16 %
40,000
94.50 %
45,000
95.20 %
45,000+15,000
395.48 %
60,000
96.67 %
表 3-2 各區間各類長詞分佈 詞彙分類 前四萬五千詞 四萬五千詞 至六萬詞 六萬詞之後 人名_詞條總數 1,440 1,102 99,866 人名_總數量 856,418 120,929 611,475 詞綴_詞條總數 3,511 1,720 13,133 詞綴_總數量 2,946,539 189,465 364,366 數量複合詞_詞條總數 3,706 1,759 260,404 數量複合詞_總數量 3,690,546 196,423 1,007,187 一般詞_詞條總數 36,343 10,419 85,136 一般詞_總數量 100,021,253 1,158,397 1,803,4843.1.1 人名拆解方法
本研究之實驗室所收集的中文人名共有 414,280 條,而研究者針對文章中出現的 中文人名詞條之詞進行拆解方法有兩種,於下詳述: (1) 第一種:姓氏 + 名字 倘若將名字全收錄於辭典中,詞條數將會過多,約有 50,438 種,故研究者將常出 現的名字以二字名字之 subword 形式收集於辭典中,人名收集於字典中,而此對於辨 認用途比較小,通常只出現在人名部份,受收錄詞條數量所限制。 (2) 第二種:姓氏 + 名字的第一字 + 名字的第二字之多寡。 另一方面,在人名中,假使以名字為單位,可分成兩種情況(詳見下表 3-3),分別 為將保留名字全名,以及名字拆成連續一字詞此兩方式。 表 3-3 人名的拆解 人名 拆解結果 孔慶華 孔 慶華 方士豪 方 士豪 王文政 王 文政 王文珊 王 文 珊 林松源 林 松 源 蔣友華 蔣 友 華
3.1.2 詞綴拆解方法
本研究所收集之中文前後詞綴共 20,246 條,研究者針對文章中出現之中文詞綴 詞條之詞進行拆解,而拆解方式有兩種(如表 3-4 所示): (1) 前詞綴:前綴詞 + 後接詞 (2) 後詞綴:前接詞 + 後綴詞 將詞綴拆解成以上兩種情形,而前接詞、後接詞若收錄在辨認辭典內,因為前後 接詞具有一般詞的特性,出現頻率也比較高,則對於辨認上較有幫助,所以這裡將次 序不在 45,000 threshold 值內的詞綴,均拆成前綴詞加上後接詞或前接詞加上後綴詞兩 種,再收錄這些拆解過後產生的前接詞和後接詞 subword 短詞,而前後綴詞因我們會 收錄全部一字詞,故這部份不考慮收錄的多寡。表 3-4 詞綴的拆解 詞綴 拆解結果 下眼皮 下 眼皮 大工程 大 工程 大西瓜 大 西瓜 人事局 人事 局 上海人 上海 人 工作室 工作 室
3.1.3 數量複合詞拆解方法
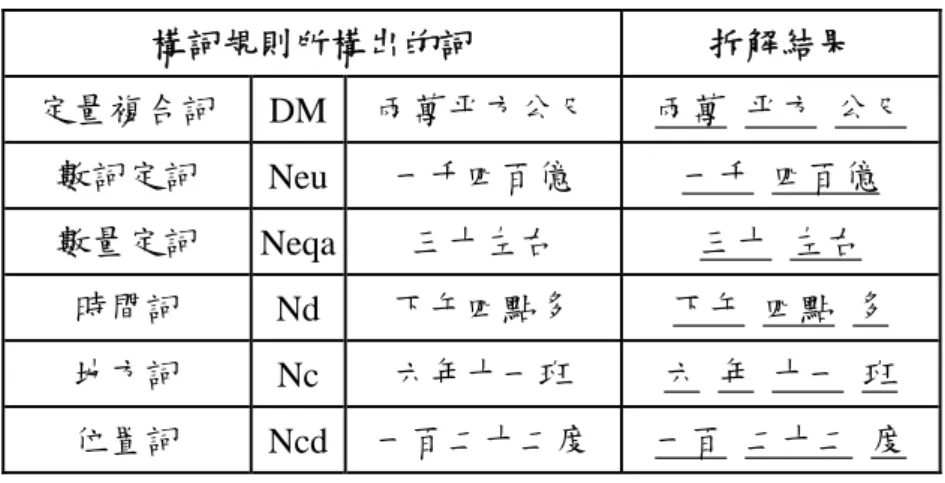
本研究之數量複合辭之拆解方法,乃先建立一專門將數量複合詞斷成小單元 subword 短詞之斷詞辭典(如圖 3-3 所示),辭典包含所有數字的變化、所有量詞(見附 錄一),進而運用所產生的數量複合詞 subword 斷詞辭典,將數量複合詞切割為 subword 小單元。 圖 3-3 數量複合詞 Subword 斷詞辭典表 3-5 數量複合詞的拆解 構詞規則所構出的詞 拆解結果 定量複合詞 DM 兩萬平方公尺 兩萬 平方 公尺 數詞定詞 Neu 一千四百億 一千 四百億 數量定詞 Neqa 三十左右 三十 左右 時間詞 Nd 下午四點多 下午 四點 多 地方詞 Nc 六年十一班 六 年 十一 班 位置詞 Ncd 一百二十二度 一百 二十二 度
3.2 挑選辨認辭典的 subword 半詞
本研究將人名、詞綴和數量複合詞此三類有句法規則的詞拆解為 subword 短詞, 因而產生此三類之 subword 集合。於此些 subword 集合中,有部份 subword 和詞頻排 序 45,000 之內的詞重複,本研究之處理方法為將之視為已經收錄於辭典者,並針對未 收錄至辭典的 subword 來斟酌收錄的 subword 詞條數量。 其中,詞綴、數量複合詞兩類之 subword 數量不多且重複性高,於語料庫出現之 頻率較高,故本研究將此兩類之 subword 短詞全數收入辭典;然而,人名拆解後的名 字由於通常只出現在人名,較不具有一般詞性質,故對名字類之 subword 收錄數量予 以限制。換言之,收錄優先次序以詞綴、數量複合詞兩類為主,人名類則為最後考量。 如先前所述,去除詞頻排序 45,000 內本已存在的 subword 短詞後,其剩餘之詞乃 為本研究考慮收錄之 subword 短詞,由表 3-6 可發現,姓氏、前後接詞、數量複合詞 和全部一字詞此些集合之詞條數不多,故將之全數收錄至辭典中,在刪除各類彼此重 複之 subword 後,共已收錄 11,932 詞;另ㄧ方面,辭典剩餘空間由人名之名字 subword 填補之,直至到達辭典 60,000 詞之容量上限為止,填補入辭典的名字 subword 數量為 3,068 詞,而其餘沒有以二字名字 subword 收錄的詞則拆成連續一字詞,而ㄧ字詞部分 已全數收錄至辭典中。表 3-6 各類詞剩餘 subword 詞條數量 分類 全部 subword 考慮收錄的 subword 短詞數 人名_姓氏 363 19 人名_名字 50,438 48,917 綴詞_前接詞 7,125 1,320 綴詞_後接詞 1,789 205 綴詞_前綴詞 136 0 綴詞_後綴詞 161 0 數量複合詞 1,729 873 全部一字詞 13,110 9,789
3.3 建立含 word 及 subword 的混合式辨認辭典
如先前所述,本研究跳脫傳統式辭典收錄方法,不再純粹單以詞頻大小來收錄 word 長詞,而是多運用某些辭典空間來收錄 subword 半詞,進而組成 word 和 subword 並存的混合式語言模型相對應之辭典。在下面圖 3-4 中,研究者試圖呈現本研究所採 用之混合式辭典的建立流程,而該圖由左至右可分為三大步驟,每步驟之上半部方塊 圖代表語料庫內容與狀態,下半部長條圖代表語料庫相對應的 wordlist,以細虛線代 表次序在 45,000 詞的分界線,以粗虛線代表次序在 60,000 詞之分界線,如下:綜觀上圖(圖 3-4),混合式辭典建立之三大步驟依序於下說明之。首先,步驟(一) 之語料庫狀態為未進行人名、詞綴和數量複合詞之拆解,此三類保留其長詞型態存在 於語料中,此時的語料庫經過錯誤文章的刪除、斷詞、標點符號處理和文字正規化之 文字前處理動作;而其所對應之 word list 分為五種,包含:人名、詞綴、數量複合詞、 一字詞和一般詞,經由詞頻排序後,對於次序在 45,000 內之詞不進行拆解,以完整的 詞保存之,而次序於 45,000 以上之人名、詞綴和數量複合詞三類長詞則進ㄧ步拆解為 subword 短詞,接續邁入步驟(二)。
接下來,進ㄧ步檢視步驟(二)之 word list,研究者除將拆解後的 subword 短詞納入 辭典外,並於辭典中補上未曾在次序 45,000 內出現的一字詞,進而運用辭典內次序 45,000(細虛線)到次序 60,000(粗虛線)之間的容量空間來收錄各類 subword 集合。如同 4.2 章所述,subword 集合收錄方法之優先次序以詞綴、數量複合詞兩類為主,人名類 為輔;其中,儘管人名類拆解為姓氏 subword 與名字 subword,詞綴類拆解為前後綴 詞 subword 及前後接詞 subword,但由於姓氏 subword 與前後綴詞 subword 均為本辭 典已完整收納之一字詞,故僅考慮收錄名字 subword 以及前後接詞 subword。在收納 完 subword 集合後,則大抵決定本研究之辨認辭典,然而,超出辭典容量限制(60,000 詞)之ㄧ般詞,即為步驟三所欲處理之 OOV。基此,就步驟(二)之語料庫狀態來說,其 同時存在保留長詞型態與拆解後之 subword 短詞形式的人名、詞綴和數量複合詞,而 ㄧ般詞則原始之長詞狀態呈現之。 最後,於步驟(三),為處理 OOV 問題,將對於未收納於辭典內的一般詞進行拆解, 而本研究解決 OOV 之策略為運用辭典內的六萬詞形成斷詞字典,將之切割為辭典內 所收納之詞,故所有中文詞將均轉變為混合式辨認辭典內所涵蓋之詞。然而,本研究 乃針對中文語音辨認進行研究,文字前處理之英文串(類別 LONGFW)未進行處理,因 而於語音辨識時,類別 LONGFW 仍被視為 OOV。
混合式辭典建立過程中,三個階段語料庫所相對應之詞條數與詞總數變化如下表 (表 3-7)所示: 表 3-7 混合式辭典建立各步驟之相對應詞條數與總數量 分類/單位 步驟(一) 步驟(二) 步驟(三) 詞條數/條 518,539 165,071 55,471 詞總數/個 112,966,482 119,652,666 128,092,663 由表 3-7 可發現,第三步驟之詞條數為 55,471,與研究原先設定之辭典容量的 60,000 條有所差距,其乃因本研究所設計的混合式辭典全數收錄ㄧ字詞,然而,原始 語料資料庫中並無涵蓋所有中文一字詞,因而形成詞條總數之落差,由此可知,混合 式辭典中仍有 4,529 條的集合空間尚未完整運用。 相較於傳統式語言模型之辭典,本研究所採用的辭典僅收錄詞頻次序於 45,000 以內之常見長詞,進而運用剩餘的詞條空間來收錄三類長詞經拆解後產生的 subword 短詞,如下表(3-8)所示: 表 3-8 word/subword 混合式語言模型辭典
Language Model Lexicon
總詞數 60866 詞長 詞數 百分比(%) 1 13060 21.83 2 32313 53.80 3 9950 16.58 4 3798 6.33 5 551 0.92
3.4 OOV 處理
解決 OOV words 方式和訓練傳統語言模型時相同,針對未收錄於六萬詞辭典之 OOV word【7】進行拆解,將 OOV word 拆解為可由辭典內的詞所構成。
3.5 N-gram training
訓練 word/subword 語言模型過程與建立傳統式語言模型相似,兩者之差異,如先 前所述,於長詞拆解為 subword 短詞部份,不再僅針對 OOV words,而是將人名、詞 綴和數量複合詞三類均拆解成 subword 短詞,Word/subword 混合式語言模型建立過程 如下圖所示(圖 3-5):
圖 3-5 Word/subword 混合式語言模型建立
3.6 Smoothing (cut off value)
本研究之 smoothing 採用較常見之 katz smoothing,數學式如下
1 1 1 1 2 1 1 1 1 1 1 1 ( | , , ) ( , , ) ( | , , ) ( , , ) 0 ( , , ) min ( , , ) max ( , , ) ( , , ) i i n i i n i i i n i i n i i n i a i n i i n i i n i P w w w a w w P w w w Count w w Count w w d Count w w Count w w Count w w Count K K K K K K K K 1 1 1 ( , , ) max (wi n , ,wi ) Count wi n wi K K
訓練語言模型則需較多的資料量,相對下使用 back off 之資料比率則較少,其語言模 型之模糊度較低,辨識率較高,故就語音辨認而言,選擇適當的 cut off 值顯得相當重 要。
3.7 混合式 language model 之探討
本研究中混合式語言模型是為階層式架構的第一級語言模型,藉由人名、詞綴及 數量複合詞有規則地拆解成較短的半詞,使得此些有規則但未被收錄至辭典中的長 詞,可在第一級辨認結果中能以半詞(subword)的型態被辨識出來,然而再透過第二 級之構詞模組,將這些連續地半詞串進行構詞,使其恢復為原來的長詞型態,並經過 rescoring 模組產生第二級語言模型,透過此兩階段架構使語言模型增進長詞之辨識效 能。第四章 第二級語言模型
從第一級 word/subword 混合式語言模型延伸至第二級語言模型,主要是藉由第一 級 word lattice 進行構詞擴充至第二級 extended word lattice,將 subword 短詞串構詞轉 變為意義長詞,在構詞的過程中,extended word lattice 上會產生新的節點和弧,並給 予新的路徑分數,而研究者將於本小節針對新產生之節點數和路徑選擇加以討論。
本研究採用 two-stage 方法來提升長詞之辨識率,而第二級主要可分為兩部分: (1)word lattice 構詞:在 word lattice 上,將可構回長詞之 subword 串均構成長詞, 目前人名和詞綴先以查表方式查詢 word lattice 上哪些 subword 可構回人名或詞綴此兩 類長詞,而數量複合詞則運用 Finite State Machine (FSM)架構將此些 subword 構回數量 複合詞。
(2)語言模型分數分配:在 extended word lattice 上將會產生新的節點(Node)、連接節 點與節點間的弧(Arc),而在 Arc 上必須給予此些新的路徑聲學模型分數和語言模型分 數。
4.1 Word lattice 構詞
在第一級 word lattice 上,透過構詞模組來將 word lattice 擴展成第二級 extended word lattice,換言之,將第一級 word lattice 上符合長詞的 subword 短詞組合構回有意 義之長詞,本研究中 word lattice 有進行構詞的詞類包括:數量複合詞、人名、詞綴以 及 OOV,分別以下敘述之:
4.1.1 人名、詞綴及 OOV 構詞構詞
目前此部份尚未建立長詞構詞模型,暫時以查表法(search table)來替代之,將實驗 室收集之人名、詞綴和第ㄧ級文字資料庫處理時產生的 OOV words 視為表(table),進 而可在 word lattice 把相鄰節點(均為詞)組合成長詞來表上搜尋(search)比對,如有符合 表中之長詞者即將此長詞構出(即 word lattice 上產生新節點)。
4.1.2 數量複合詞構詞
數量複合詞的構詞本論文採用 FSM (Finite State Machine, 有限狀態機)的架構來 產生,透過每個狀態(state)轉移時串接成詞來觀察是否符合構詞規則,凡是符合規則的 詞則將路徑所經過的狀態依序串接產生構詞後的數量複合詞。在此之前,必須建立數 量複合詞的 FSM 架構,其中,欲建立此架構則考慮三個部份:首先,決定數量複合 詞的半詞集合,以及該集合與狀態之間的關連;其次,建立一個以 state transition 為主 體的 FSM 架構;最後,訓練 FSM 架構下的 state transition probability。
經過以上三個部份來組成如下圖(圖 5-1)之架構: S 1 2 15 E 3 23 NUM 一百 兩百 ‧ ‧ 十萬 十一萬 ‧ ‧ M 個 打 ‧ ‧ Zero 零 NUM2 一十 一十一 ‧ ‧ DIG 一 二 ‧ ‧ Word A Word B P(2|1) P(E|2) P(15|1) P(1|1) P(3|3) P(E|3) P(E|1) P(1|S) P(2|23) P(2|3) P(23|15) P(3|S) P(3|15) 圖 4-1 數量複合詞構詞模型
在圖 4-1 中,該構詞模型乃以 Finite State Matchine(FSM)架構組成之,此架構中依 據斷詞器構詞時所需之構詞集合來設定狀態(State),再透過構詞規則使得狀態之間有 規則地彼此相連,其中,S 代表構詞時長詞之開始狀態,而 E 代表構詞時長詞結束之
構詞規則中擷取出來的。
在 FSM 架構中須存在狀態轉移機率,透過這些機率來描述在數量複合詞該類別 中可組合成各數量複合詞之情況,且這些半詞串接的總轉移機率將在第二級 extended word lattice 時被使用當做數量複合詞之內部機率(intra probability)來進行語言模型的 分數配置。
4.1.2.1 定義定量複合詞半詞集合及該集合與狀態的對應關係
如第三章所述,數量複合詞半詞集合乃收集全部數字變化型態及構詞規則中之所 有量詞集合,在此將該集合分成兩大類:一類是純粹與數字有關,另一類則是數字以 外的定詞、量詞、修飾詞等。 數字集合 針對數字串組合方式,以結構分析方式將數字組合分類,分類原則如下: a. 兼顧構詞能力、平均詞長、詞義完整度 譬如『一百萬』可以拆成(1)『一』『百』『萬』 (2)『一百』『萬』 (3) 『一』『百萬』及(4)『一百萬』此四種。 其中,以構詞能力而言,優先順序為(1) > (2) (3)>(4),而以平均詞長而言,順 序為 (4)>(2) (3)>(1),另外,以詞義完整度排序則為(4)>(2)>(3)>1。 最後在整體考量下,以收錄(4)形式之半詞為佳。 b. 同質性高者歸為一個集合 譬如『一百萬』與『兩百萬』同結構、同性質,且有同樣的語法角色,則將 『一百萬』~『九百萬』歸為一個集合。 另外如『一十一』與『一十九』有同樣用法,則歸到同一個集合。而『一十 一』與『十一』有不同用法,則將兩種組合分開到不同集合中。 以此原則將數字集合做分類,總共得到 28 類集合,分別給予集合與 state 對應如 下表(表 4-1)所示:表 4-1 數詞半詞集合與各集合對應 state ID 集合 State ID 集合 State ID 一~九 501 一千億~九千億 515 十~十九 502 一兆~九兆 516 一十一~九十九 503 十兆~十九兆 517 一百~九百 504 一十一兆~九十九兆 518 一千~九千 505 一百兆~九百兆 519 一萬~九萬 506 一千兆~九千兆 520 十~十九萬 507 一二~八九 一二十~八九十 521 一十一萬~九十九萬 508 零 522 一百萬~九百萬 509 百 523 一千萬~九千萬 510 千 524 一億~九億 511 萬 525 十一億~十九億 512 億 526 一十一億~九十九億 513 兆 527 一百億~九百億 514 兩 528 其中在上表(表 4-1)中,『一十一』~『一十九』沒有獨立成一個集合,原因是其 角色在長結構的數詞串中與『二十』~『九十九』有相同角色(譬如『一百一十五』與 『一百七十五』的例子)。 定詞、量詞、修飾詞集合 以目前斷詞系統所採用的定詞、量詞集合和分類做集合類別與狀態做對應。共 22 大類,86 個集合(86 個狀態),分布如下表(表 4-2)所示: 表 4-2 定詞量詞分類與其對應 state ID 定詞量詞類別 State ID 定詞量詞類別 State ID 標準量詞 92-97 動量詞 90 暫時量詞 91 特殊數量定詞 3-5 數詞定詞 特指定詞
群體量詞 90 個體量詞 90 準量詞 90 指示定詞 11 程度數量定詞 9 前程度副詞 8 部分數量定詞 10 全體數量定詞 6 修飾詞 14-16, 18-26, 31-37, 地址班級 27-28, 30 時間 51-82 其他 29
4.1.2.2 以構詞規則建構 FSM 架構
依據上一小節 4.1.2.1 所決定出的狀態集合及其所對應的半詞集合,將目前實驗室 斷詞系統所使用的構詞規則,轉換成以狀態表示法所形成的規則,以此來建構 FSM 系 統所需之狀態轉移路徑。在建構定量複合詞 FSM 時,為了減少 search space 大小,進而採用 subnet 概念實 現,將數字部分與數字以外的部分各自建立一個 FSM 結構,再將兩個 FSM 結構結合 起來以建構數量複合詞整體的 FSM 架構,此類架構以下圖(圖 4-2 和圖 4-3)來表示。
圖 4-3 定量複合詞 FSM 圖 4-2 中,數字串範圍為一到九九九九,各狀態代表意義如下:狀態 522 代表「零」、 狀態 501 代表「一至九」、狀態 502 代表「十至十九」、狀態 503 代表「一十一至九十 九」、狀態 504 代表「一百至九百」、狀態 505 代表「一千至九千」,此架構為數字串之 FSM 結構,在整體數量複合詞架構下視為「狀態 199」。 圖 4-3 中,為數字部分(狀態 199)和非數字部份搭配在一起的結構,其各自狀態連 結起來代表意義如下: I. 數字(199)+幾(1)+長度單位(92) II. 數字(199)+多(4)+量詞(90) III. 不到(41)+數字(199)+量詞(90) 由上述可觀察到此作法雖然降低 search space 的大小,但此舉會造成許多路徑共 用同一個數字 state(狀態 199)的情形,並且必須多考慮 inter state transition probability 和 intra number state transition probability。然而此法的好處是,往後可以針對數字部分 獨立處理,包含分出獨立類別、單獨建立各種型態的數字 FSM 結構。另外,將來也 可以考慮將數字部分的 intra state transition probability 做正規化動作,讓某一結構的數 字組合享有共同的機率。
態轉移時所產生的狀態轉移次數,以此些次數來計算狀態轉移機率。 在此以 4.1.2.2 所述之 FSM 架構為例,針對以下輸入語句做訓練過程的介紹。 步驟一. 將輸入詞串轉換成狀態序列 將訓練語料庫中數量複合詞串轉換成狀態序列,並作為 FSM 的輸入資訊。 以下為幾個輸入詞串轉換為 state sequence 的例子。 語句輸入 => 轉換後的狀態序列對應 1. 一千兩百多個 => 505 504 4 90 2. 不到五百三十個 => 41 504 503 90 3. 一百五十幾公尺 => 504 503 1 92' 步驟二. 計算狀態轉移次數 基於前述兩層式 FSM 架構,計算不同輸入序列所造成的狀態轉移次數。當輸入 詞串遇到數字狀態時,則進入階層式數字 FSM 中,同樣計算所走路徑次數。 下圖(圖 4-4)為將上述輸入詞串作為 FSM 訓練過程中計算狀態轉移次數的範例。 圖 4-4、計算輸入語句於 FSM 裡所造成的狀態轉移次數。
步驟三. 計算狀態轉移機率
依據不同路徑下的各狀態所記錄的下一狀態出現個數和次數,依轉移機率總和等 於 1 的方式計算各狀態轉移機率。
由於不同路徑有不同的狀態轉移方式,即使是相同狀態,在不同路徑下也會有不 同的狀態轉移機率,只有在相同路徑下的分支路徑才會共用狀態轉移機率,而這些轉 移機率將會使用在第二級 extended word lattice 中數量複合詞之內部機率的分數配置。
步驟四. 建立定量複合詞的 baseline FST Model
基本的定量複合詞 FST Model 的建立,可以先將整個訓練語料中所含的 FT word 視為一個類別(FT class),並在這個類別下定義兩層 FST,包含第一層 FST 的 Inter Word Model 和第二層 FST 的 Intra FT Word Model,架構如下圖所示。
<b> 4 90 <e> 41 199 90 199 1 92 2 1 1 1 501 <b> <e> 522 502 504 503 501 2 2 2 505 1 503 522 501 504 522 503 501 1 1 圖 4-5、適用於定量複合詞的兩層式 FST Model 架構
在 intra FT word model 中,建立 FST for FT word(定量複合詞 FSM 結構)及 FST for number(數字串 FSM 結構)兩層 FST,針對第一層 FT word 的狀態轉移,以訓練語料統 計出各狀態間的狀態轉移次數,並針對每一個狀態利用轉移機率和等於 1 來計算其狀 態轉移機率。對於 FT word 的數字串狀態部分(狀態 199),則再將數字狀態獨立建出一 個純粹由數字半詞所建構的 FST,以同樣方式來計算所有數字組合所造成的狀態轉移 機率。
4.2 語言模型分數配置
本研究對於 extended word lattice 新產生路經給予分數的方法有二種:
第一種方法為 word penality 影響:從未構詞前 subword 短詞串的分數直接相加給構詞 後的弧,此時 word penality(數值不更變)之存在會使得原半詞串路徑將被壓抑,而選擇 構詞後路徑,進而影響 extended word lattice 上最佳路徑,產生第二級辨認結果。 第二種方法為改變語言模型分數:將構詞的人名、詞綴和數量複合詞均以類別取代, 進而透過 inter probability(外部機率)和 intra probability(內部機率)來分別計算一般詞和 類別間的機率以及某類別內出現長詞之機率,藉此兩機率來給予新的語言模型分數。
圖 4-6 新產生的節點和弧
在圖 4-6 中,arc1-arc2 和 n1 為 extended word lattice 新產生之弧(arc)和節點(node), arc3 至 arc5、S1 和 S2 則為尚未構詞前第一級語言模型 word lattice 上的弧和節點,S1
和 S2 均為 subword 短詞,可進行構詞得到長詞 n1。
4.2.1 Word penality 影響
本研究不改變語言模型分數,而是將第一級 word/subword 語言模型中短詞串的分 數直接相加,以此給予構出長詞弧上分數,進而藉由 word penality 參數 p 和 s 來影響 最佳路徑,換言之,在 word penality 數值不變之下,會使得 subword 半詞串的原路徑 會被壓抑,轉而比較相信構詞後之路徑。
Word penality 係數 p 和 s
傳統上訓練語言模型時,產生 word lattice 時將會從統計的 bi-gram 機率來給予這 些路徑分數,而當進行辨認時,在路徑上利用 word penality p 和 s(即第二級和第一級 設定值相同)此兩個參數來影響弧上原始之聲學模型和語言模型的分數,重新尋找構詞 後辨認語料之最符合、最接近的路徑,以求得到最高辨識效能。 微調前(弧上): 受 p 和 s 影響後(弧上): 聲學模型分數:A 聲學模型分數:A + p 語言模型分數:L 語言模型分數:L‧s 受 word penality 影響之原理 每經過一個弧,弧上的分數將會被 p 和 s 所影響,在某路徑上節點數越多時,其 通過之弧數量也越多,分數變動將會越大,因此,在加入 p 和 s 後,倘若 p 為負值時, 兩條原始分數相同的路徑,會因為該路徑上節點數越多導致分數會越來越低。基此, 於最佳路徑時,將會選擇節點數較少路徑者。然而,我們在 word penality 沒有變動下, 使得最佳路經相對地信任構詞後的新路徑進而選擇該構詞之路徑,則將第一級時拆解 成 subword 短詞串透過第二級構詞後恢復為原有之有意義長詞。
圖 4-7 弧上的 word penality
於上圖 4-7 中,A1 到 A5、L1 到 L5 分別為 word lattice 上 arc1 至 arc5 的原始聲學 模型和原始語言模型分數,而長詞 n1 則是短詞 S1 和短詞 S2 構詞出來。 基此,新路經的分配如下: arc1: A1 = A3 + A4 L1 = L3 + L4 arc2: A2 = A5 L2 = L5 因而產生出兩條分數相同的路徑,研究者進而透過 word penality 係數的影響,藉此選 擇最佳路徑,而如先前所述,路徑經過越多節點(或弧)則會增加愈多 p 值,當 p 是負 值時,則多節點之路徑分數將越低。
研究者於下列舉兩個例子進行說明: 例子一
圖 4-8 正確構詞
在上圖 4-8 中,Path1 為第一級 word/subword 語言模型之最佳路徑,Path2 第二級 語言模型構詞後產生的新路徑,由於 Path2 的分數是由 Path1 相關節點間相加得來, 當 Path1 為第一級時最高分數的路徑時,此時將會有兩條最高分數的路徑,即 Path1 和 Path2,當兩條路徑分數相同時,因為 Path1 會經過 5 個節點和 6 個弧、Path2 經過 2 個節點和 3 個弧,故當加入 word penality 後,Path1 將會比 Path2 多增加三個 p 值, 且當 p 是負值時,Path2 的分數則會比 Path1 來得大,基此,辨認結果可透過 word penality 影響(但不變更其數值,保留與第一級相同之值),最後將會決定選擇 Path2 做為最佳路 徑。
例子二 圖 4-9 錯誤構詞 於此例子中,顯示出在第二級構詞時,將會有「過分構詞」的現象,當第一級 word/subword 語言模型辨認正確路徑時,經過構詞後,節點數變少了,使得原先因 word penality 分數落後的路徑 Path3 再度取得分數領先,形成過分構詞的詞出現所導致的錯 誤。 路徑分數變化如下:
由圖 4-9 可知,Path1 為第一級的最佳路徑,Path2 則為第一級因 word penality (p = -15 , s = 15)影響而落後給 Path1 的路徑(Path2 原始分數領先 Path1 原始分數),Path3 為第二級構詞後的最佳路徑。在第一級 word/subword 混合式語言模型中,那時並不存 在 Path3,因為 Path3 是 Path2 的節點經過第二級構詞後所產生的,而新路徑 Path3 上 的分數是由 Path2 的分數相加,因此,Path2 和 Path3 兩條路經在還未受 word penality 影響之前分數將會相同。
第一級時,未受 word penality 影響之前,Path2 分數大於 Path1 分數,而第一級辨 認時加入 word penality 後,因而使得 Path1 分數大於 Path2,故 Path1 為第一級辨認結 果。
第二級時,透過構詞產生了新路徑 Path3,Path3 分數和 Path2 分數相同(如先前所 述,未受 word penality 影響之前,此兩路徑分數相同),所以在第二級未加入 word penality 前,Path3 的分數會大於 Path1,但第二級辨認在使用 word peality(p 和 s 保持 和第一級相同數值狀況下)後,由於 Path1 和 Path3 均為 1 個節點和 2 個弧,Path3 分數 將會大於 Path1 分數,第二級辨認結果則變成 Path3。
4.2.2 改變語言模型分數
研究者於上一小節探討保持第一級和第二級 word lattice 在條件相同情況下,透過 word penality 之影響,使得原路徑被壓抑,進而選擇構詞後的新路徑。於本小節中, 研究者將改變第二級語言模型分數,即第二級 extended word lattice 上路徑分數不再直 接由第一級未構詞前之半詞串路徑相加而來,而是對構詞的人名、詞綴和數量複合詞 視為三種類別,再由語料裡去統計類別和詞之間的機率(外部機率, inter-probability), 以及類別內出現某長詞的機率(內部機率, intra probability),藉此兩機率對第二級之
本論文則利用以下數學式來重新計算第二級語言模型分數:
n n-1 n n-1 n n n n-1 n n-1 n n-1 n n-1 n n-1 n n-1 n n-1 P(W |W ) = P(C |C ) P(W |C ) , for C , C FT, MD, PN, other P(W |W ) , for C other and C otherP(C |C ) , for C FT, MD or PN and C FT, MD or PN P(C |C ) = P(W |C ) 其中 n n-1 n n-1 n n-1 L j j-1 n n j=1 n n n n n
, for C other and C FT, MD or PN P(C |W ) , for C FT, MD or PN and C other
P(SW |SW , C ) , for C FT P(W |C ) = P(W |C ) , forC MD or PN
1 , for otherwise 圖 4-10 弧上語言模型新分數 n1:新產生的節點(Node),屬於某個 class,arc1:新產生的弧(Arc) 先將構詞出的長詞依分類視為某個類別(class),有人名(PN)、詞綴(MD)及數量複 合詞(FT)等三種 class,其中再將詞綴分類細緻化,將前後詞綴依綴詞分成前詞綴 142 個類別和後詞綴 159 個類別,最後統計計算某類別中出現某長詞 n1 的機率。Pr (arc1) = Pr(class|W1) Pr (n1|class) 給予新路徑弧上的分數 Pr(class|W1) 是 inter-word probability描述詞和類別之間的機率 Pr (n1|class) 是 intra-word probability描述類別中出現某長詞的機率
此處以下兩點來描述內外部(inter and intra)機率之求法
A. 外部機率(Inter-word probability) Pr(class|W1) 的求法:
將第二級構詞所產生的詞中,把人名、詞綴和數量複合詞視為三大類別{PN, MD, FT},再將三個大類別各自細分成多個小類別,計算一般詞和這些類別之間連接的機 率。目前由於類別細分需要較長時間,目前實驗室在分類上尚未完整,究此,暫以簡 單之類別進行分類 (以詞綴為例),最後可觀察到類別細緻化後之實驗結果對本研究所 提出路徑分數給予之方式有正面幫助,使辨認效果更佳。 在詞綴類別細分上,以「綴詞」來區分類別,將前後詞綴中具相同綴詞的詞放置同 ㄧ類別,如此下來有 301 個詞綴類別及人名和數量複合詞兩個大類別共有 303 個類別, 進而使用這些類別來計算分數配置時所需的外部機率,計算過程如下: 機率計算步驟如下: 步驟 1:將語料中不在辨認辭典中人名、詞綴和數量複合詞分別以上述類別存在。 說明:目前由於人名和數量複合詞分類尚未建立,這裡僅針對詞綴加以分類,分類 方法如前面所述,再將訓練語料中且不在辭典內的三類詞以這些類別替代。 步驟 2:對以類別替代後之訓練語料進行統計來求取詞和類別之間的 bi-gram 機率。
B. 內部機率(Intra-word probability) Pr (n1|class) 的求法:
於此部分,機率採人名、詞綴和數量複合詞各自的類別分開獨立計算機率模型
a. 人名(PN):
將語料內不在辨認辭典中的人名,依據其於文章中的出現次數列出,將這些人名 「以 word 的形式」來計算某人名出現在此類別之機率,倘若辨認語料(TCC300 測 試語料)中人名出現此些人名之外,則藉由 smoothing 方式來給予一個較低之分數, 使其在辨認時亦可能辨認正確,在此 smoothing 方式採 Good-Turing smoothing。
測試語料)中詞綴出現此些詞綴之外,則藉由 smoothing 方式來給予一個較低之分 數,使其在辨認時亦可能辨認正確,在此 smoothing 方式採 Good-Turing smoothing。
c. 數量複合詞(FT):
(1) 半詞二連文機率模型:將語料內不在辨認辭典中的數量複合詞,依據其於文章 中的出現次數列出,將此些數量複合詞「以半詞(subword)的形式」來統計這些 半詞互相連接的次數,進而計算數量複合詞半詞之間串接機率。
(2) Finite State Machine(FSM)機率模型:將語料內不在辨認辭典中的數量複合 詞,依據其於文章中的出現次數列出,將此些數量複合詞「以狀態(state)的形 式」呈現,統計訓練語料中這些狀態的轉移次數,再利用此些次數來計算在 FSM 架構內狀態間轉移的機率,此部分詳細計算方式為章節 4.1.2.3 所述。 此時各類內部機率所使用機率形態如下表 4-3 所示: 表 4-3 各類內部機率使用機率型態 人名 詞綴 數量複合詞
機率型態 word uni-gram word uni-gram 1. subword bi-gram
2. FSM transition probability
經由 A 和 B 兩方面分別可求得「詞和類別」之外部連接機率和類別內某詞出現之 內部機率,藉由此內外部機率的關係來描述 extended word lattice 上新產生之節點與前 一個節點之間連接機率,以此來決定新產生弧上之分數。