行政院國家科學委員會專題研究計畫 期中進度報告
兆級晶片系統前瞻技術研究--總計畫(2/3)
期中進度報告(精簡版)
計 畫 類 別 : 整合型 計 畫 編 號 : NSC 95-2221-E-002-362- 執 行 期 間 : 95 年 08 月 01 日至 96 年 07 月 31 日 執 行 單 位 : 國立臺灣大學電子工程學研究所 計 畫 主 持 人 : 陳良基 共 同 主 持 人 : 楊佳玲、簡韶逸、吳安宇、張耀文、黃鐘揚 處 理 方 式 : 期中報告不提供公開查詢中 華 民 國 96 年 06 月 11 日
行政院國家科學委員會專題研究計畫 期中進度報告
總計畫(2/3)
計畫類別: 整合型計畫 計畫編號: NSC 94-2215-E-002-039 執行期間: 95 年 08 月 01 日 至 96 年 07 月 31 日 執行單位: 國立臺灣大學電子工程學研究所 計畫主持人 : 陳良基 共同主持人 : 簡韶逸,楊佳玲,黃鐘揚,張耀文,吳安宇 計畫參與人 : 連崇志、王欽彥、江哲維、李權祐、林昱呈、林書彥 張育瑋、洪緯軒、陳依蓉、陳東傑、黃群翔、葉護熹 報告類型: 精簡報告 處理方式: 本計畫可公開查詢中 華 民 國
96 年 5 月 31 日
行政院國家科學委員會國家型研究計畫期中報告 總計畫 :兆級晶片系統前瞻技術研究(2/3) 計畫 編號:94-2215-E-002-039 執行期限:95年8月1日至96年7月31日 總計畫 主持人:陳良基教授 台灣大學電子工程研究所
一 、 總 計 畫 簡 介
本三年期(8/2005—7/2008)整合型技 術發展研究計畫係針對未來兆級晶片系 統 (Trillion-Transistor Scaled System-on-Chip, TS-SoC)研究領域之相 關核心技術進行研究,並以多媒體應用 作為系統整合平台的發展目標。本計畫 之系統整合架構圖如圖一所示,本計畫 研究兆級電晶體電路之系統層次設計問 題(含節能記憶體及容錯架構),再配合 上電路及多媒體平台的發展以及晶片內 傳輸系統的設計,共同建立一套完整性 的 TS-SoC 系統架構之設計經驗。本計 畫另一方面研發前瞻性的 EDA 相關軟 硬體工具之技術(含系統驗證設計工具 與實體設計工具等),藉以簡化並縮短兆 級電晶體電路及系統架構設計的研發時 程。兆級電晶體電路及系統所研發之架 構,皆會透過 CIC 完成晶片實現與測 試,以實際驗證各新穎性的兆級電晶體 電路及系統架構之可行性與實用性,同 時將設計經驗轉換成設計法則,以協助 並推動EDA 相關軟硬體工具的實現。此 整合型技術發展研究計畫,從學術研究 的創新性角度來衡量,預估每年至少有 十五篇以上的會議與期刊論文;而從科 技應用的實用性角度來評估,所發展出 來 的 新 穎 性 系 統 、SoC/VLSI 架 構 與 EDA 相關軟硬體工具等,對於國內日漸 蓬勃的積體電路設計和系統製造產業, 均有相當程度的貢獻。更重要的,是使 得台灣能夠引領世界級(World Class)積 體電路設計的潮流,在世界積體電路設 計界中佔有一席之地。 圖一 總計畫之系統整合架構圖二 、 各 子 計 畫 本 年 度 成 果
1. 子計畫一:平台式晶片系統之
節能記憶體架構
1.1 研究摘要 隨著製成技術的進步,漏電在單晶 片系統上造成之能源消耗的問題也越來 越重要。在處理器中,快取記憶體所需 之資源佔相當大部份,因此,有許多減 少快取記憶體漏電之機制被提出。然 而,這些機制都會引起無法預期之效能 衰退,因此並不適用於需要絕對遵守時 間限制之硬性即時系統(hard real-time system)應用程式。在本計畫中,我們利 用現有之快取記憶體漏電減少之電路設 計,提出第一個適用於硬性即時系統之 控制漏電機制。此考量時間限制之快取 記憶體漏電控制機制,利用每個工作 (task)之多餘時間(slack time)來決定是否 要將每個工作相對應之快取記憶體區塊 放入低漏電模式,並且保證每個工作可 在其時間限制內完成。實驗數據顯示, 我們所提出之漏電控制機制,與不管時 間限制之漏電控制機制相比,可達到幾 乎相同之漏電減少量。1.2 研究方法
我們在本計畫中提出一考量時間限 制 之 快 取 記 憶 體 漏 電 減 少 機 制 (Timing-aware Leakage Control Scheme, TALC) 。 TALC 機 制 乃 針 對 有 n 個 periodic real time task 之 hard real-time 系 統 所 設 計 , 每 個 task 都 有 自 己 的 deadline , 且 用 EDF(Earliest Deadline First)排程演算法。圖二為 TALC 所使用 之基礎cache 架構,每個 cache line 可用 drowsy cache 或 state-destructive cache 兩
種不同的低漏電模式,而cache line 選用
低漏電模式是經由leakage mode bits 來 選擇。
我們所提出之TALC 機制,會根據
每個task 所有之 slack time 來決定 cache line 應運作在何種模式下,並保證因使 用低漏電模式所造成之效能損耗不會多 於task 之 slack time,因而保證可以完全
符合每個task 之時間限制。圖三為設計
概念。Drowsy window size 為將 cache line 放入 drowsy mode 之時間間隔,當 drowsy window size 愈大,所造成之效能
損耗也愈多,我們根據 slack time 的多
寡,來決定drowsy window size 的大小, 以將slack time 分配給 drowsy cache 運作 時所帶來的 timing overhead,並達到減 少漏電量並保持時間限制。TALC 演算 法分為 off-line 和 on-line 兩個主要步 驟,詳細方法在子計畫報告有詳細解說。 1.3 研究成果 圖四顯示我們所提出來的TALC 演 算法跟基本的 drowsy 機制比較分別在 1%、5%、10%、和 15%的 slack 下比較。 當 slack 為 1%時,TALC 演算法可減少 78.4%之快取記憶體漏電量,與基本之 Drowsy+Simple 機制相比,雖然減少的 漏電量較少,但 TALC 可使所有的 task 都 在 deadline 之 前 完 成 , 而 Drowsy+Simple 卻會使部份 task 錯過 deadline。因為 TALC 演算法本身可動態 調整drowsy window size 的關係,其減
之快取記憶體漏電量會隨 slack 愈大而
愈多。當slack 為 20%時,TALC 甚至可
以減少比Drowsy+Simple 更多之快取記
憶體漏電量。
Tag array Data array
Leakage mode Deco d e r Deco d e r D e coder D e coder tag index address = Leakage mode voltage controller voltage controller hit lock_ctrl
圖二 Baseline cache architecture of the proposed scheme. Slack time Period With Leakage Control Without Leakage Control
Full speed execution Wakeup overhead
Drowsy window
圖三 Illustration of using wake-up overehads to consume task slack time
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 1% 5% 10% 15% 20% Static slack L eakage s avi ng s
Drowsy+Simple, small TALC, small Drowsy+Simple, medium TALC, medium
圖四 Evaluation of leakage reduction.
2. 子計畫三:兆級晶片系統中超
高畫質動態影像處理核心低功
率平行架構設計
2.1 研究摘要 本計畫進行兆級晶片系統中,動態影 像編解碼器之前瞻架構設計研究。由於晶 片中可以整合的電晶體數快速成長,晶片可以提供越來越強大的運算能力,另一方 面,可攜式設備卻要求這樣強大的運算引 擎必須在功率消耗上更有效率。本研究兩 大主軸:第一,未來大畫面動態影像的需 求將更為普及,高度平行化架構與系統是 一個趨勢。支援超高畫質與複雜運算的最 佳化平行架構及其設計法則的提出,將是 這個主軸的目的。第二個研究主軸則是進 一步在高度平行架構之下,研究關於功率 導向的設計,進行低功率與功率感知相關 研 究 。 本 計 畫 以 Motion JPEG2000 與 H.264/AVC 為主要研究平台,進行以上所 述之高平行且功率導向的架構設計與系 統化研究。 2.2 研究方法與成果 在本年度的研究中,我們主要進一 步研究Motion JPEG 2000 的最佳化架構 設計與開發功率感知式H.264/AVC 編碼 器。 • 擁有可延展性嵌入式區塊編碼架構的 JPEG 2000 編解碼器[1] 對於不同應用與產品規格,一個功 能固定的硬體架構常需要大幅度的修 改,我們的研究針對JPEG 2000 最複雜 的 EBCOT 模組,研究發展可以彈性應 變的 scalable 架構,研究的方法是透過 深入的運算特性分析,了解一個架構在 不同運算需求之下,硬體使用率的情 形,由架構中萃取出基本的Bit-plane 運 算單位,以此作為可以延展的基礎,讓 硬體可以更有效率地用來運算資料,減 少運算單元不足或是閒置的情形,如此 的 彈 性 架 構 可 以 快 速 達 成 最 佳 的 Cost/Performance ratio。 • 功率感知 H.264/AVC 編碼器[2] 低功率已經是一個設計的必要條 件,除了低功率之外,新的功率感知觀 念也愈來愈普及。H.264/AVC 中移動估 計模組是運算量最大,也最有演算法發 揮空間的部分,當功率消耗非常關鍵 時,可以調整移動估計的方法,減少部 分運算,反應在犧牲部分視訊品質,以 換 取 較 少 的 功 率 消 耗 。 其 他 像 是 H.264/AVC 中有相當多的模式與參數, 不同的模式與參數有其特殊的應用考 量,複雜度亦有所不同,這些可變的選 擇 形 成 一 個 Power-Rate-Distortion 或 Complexity-Rate-Distortion 的最佳化問 題。 2.3 結果與討論 Motion JPEG 2000 方面的研究提出 一個以Bit-Plane 編碼引擎為基礎的具可 延展性的嵌入式區塊編碼架構,如圖五 所示。當某些bit-plane 因為量化或原先 有效數值就不大,使得整個bit-plane 不 需要運算時,Bit-Plane 引擎可以彈性調 整給不同的 code-block 來運用,達到硬 體使用率的最佳化。表一是晶片實作的 規格,圖六是這個測試晶片的照片。 H.264/AVC方面已完成功率感知的 編碼器設計,架構如圖七所示。其中的 設計特色包括有低功率的Integer ME與 Fractional ME設計,以及基於不同參 數,工作模式,與ME演算法所設計出的 可重組化架構,提供功率可調的機制。 所 設 計 出 的 晶 片( 圖 八 ) 成 功 展 現 出 2.8mW到 67.2mW的可調範圍(表),可以 因應不同使用情形下,使用者可以選擇 不同功率模式,或是搭配自動的功率選 擇軟體控制。 ImageDWT Bit-plane Coder Bit-plane Coder Bit-plane Coder Bit-plane Coder EBC I/ F Bi t-st re am s I/ F Tile Memory Packed Bit-planes 圖五、Motion JPEG 2000 以位元平面 (Bit-Plane) 為基礎的系統架構圖 表一 JPEG 2000 編解碼器晶片規格 Technology TSMC 0.18μm 1P6M CMOS Tapeout CIC T18-95C Die Size 3.52 x 3.52 mm2
Core Size 2.47 x 2.47 mm2
Logic Gate Count 302,785 gate
On Chip SRAM 9.5 KB
Max Clock Rate 60 MHz
Power Consumption 180.3 mW 圖六 Motion JPEG 2000 編解碼器晶片 Sy st e m Bu s I n te rf ace System_Controller (SYS_CTL)
FSM Coding ParameterRegister File (RF)
Module-Wise Gated Clock CTL System Clock Coarse Prediction CTL (MBPipeline_Stage1_CTL) FSM Information RFMB Coding Fine Prediction CTL (MBP_S2_CTL) Block Engine CTL (MBP_S3_CTL) FSM RF In-Module Gated Clock CTL Latch Latch Pipeline Registers Pipeline Registers Pipeline Registers IME Engine Latch Latch Latch FME Engine Intra-Predictor (IP) Entropy Coder (EC) Reconstruction Engine (Rec) Deblocking Filter (DB) SWLMs LMs LMs
Encoding data/control path Clock control path
1st Stage 2nd Stage 3rd Stage
MB Pipeline
Clock signal
圖七 Flexible H.264/AVC 編碼器系統 表二 Power-Aware H.264/AVC 晶片規格
Technology TSMC 0.18μm 1P6M CMOS
Pad/Core Voltage 3.3V (Core) / 1.8V (I/O)
Core Area 3.47 x 3.70 mm2
Logic Gates 452.8 K (2-input NAND gate)
SRAM 16.95 KBytes
Search Range H[-32,+31] V[-16,+15]
Power Consumption 33.5-67.2 mW for SDTV, 1 ref
@ 54MHz, 1.8V
(Measured Results) 40.3 mW for CIF, 2 ref @
27MHz, 1.8V
9.8-15.9 mW for CIF, 1 ref @ 13.5MHz, 1.3V
8.7 mW for QCIF, 2 ref @ 6.25MHz, 1.3V
2.8-4.3 mW for QCIF, 1 ref @ 3.125MHz, 1.3V SW SRAMs SW SRAMs SRAMs SR A M s IME FME Controllers EC & DB IP & Rec 圖八 Power-Aware H.264/AVC 編碼器晶片照片
3. 子計畫四:適用於兆級晶片系
統之低功率繪圖處理單元
3.1 計畫摘要 本計畫以開發適用於兆級晶片系統 之低功率繪圖處理單元技術為研究的重 點,本研究將以低功率、高彈性、以及 高畫質為主要研究方向,在演算法層次 以及電路架構層次同步進行。在第一年 的計畫之中,我們進行了浮點運算單元 及頂點運算器架構設計之研究。在第二 年中,基於第一年的成果,我們實作在 GPU 中的重要元件—頂點運算器,並將 一些適合視訊編碼的加速指令加入;另 一方面,我們也對於三維運算中的後端 運算,也就是著色的部分做記憶體的分 析,並提出了一個可見度測試引擎的架 構而能進一步減少記憶體頻寬。 3.2 研究方法與成果 我們在本年度中實作下線的晶片如 圖九所示,晶片規格如表三所示,在 50MHz 的工作頻率下,此晶片可以達到 12.5 Mverteice/sec,且僅需 8.6mW 的功 耗,此外,此頂點處理器也可以處理視 訊編碼之中運動偵測的運算,可達到每 秒30 張 CIF 畫面的處理能力。此處理器 的功率方面的表現如圖十所示,在圖十(a)中可以看到,在使用全部的技巧之 後,和單純VLIW SIMD 的頂點處理器 相比,可以節省 86%的功率消耗到達 8.6mW ; 在 圖 十 (b) 中 , 我 們 以 (Mvertices/s)/mW 作為指標來比較幾個 已提出的論文,可以看出,和ISSCC2006 的論文比較,我們的效能可以達到 1.82 倍 。 我 們 的 此 項 成 果 , 也 被 VLSI Symposium 2007 所接受 [3]。 此外,在本年度中,我們也提出了一個 可見度揀選(visibility testing)的演算法 及其硬體架構設計。可見度揀選已有很 多演算法,常常看到的都是由軟體演算 法的角度去解可見度的問題,其中有不 少是對於特定的一些場景,如走道、大 遮蔽物,去做特殊的演算法。我們整理 有考慮到硬體運作及非限定模型這類論 文,有以下一些特性:在應用(applicaiton) 部份,發展很多對三維空間中物體排序 的 演 算 法 , 如 二 元 空 間 切 割 樹 排 序 (binary space partition tree sorting)、潛在 可見集合(potentially visibility set)等方 法;而在架構或硬體部分,大致上可以 分為兩派:階層深度緩衝區(hierarchical z buffer) 及 階 層 遮 蔽 圖 像 (hierarchical occlusion map),經常是假設在應用軟體 利用一些物體排序演算法作排序,硬體 部份是屬輔助加速(accelerate)的角色, 利用把深度或遮蔽情形的緩衝區做成階 層的形式,使後面顯示對於一些三角形 可以快速的判斷可見度進而達到節省頻 寬的目的。雖然相關研究已不少,但關 於硬體實現的部分研究相較之下少之又 少。在一些手持裝置上並沒有提供許多 的記憶體存放一些額外的模型資料,也 可能沒有很好的軟體演算法實驗平台, 所以如果能在硬體上能做相對的設計, 發展適合硬體的演算法,如此便可以有 效地做著色的動作,也可以降低花費在 遮蔽部分的運算及頻寬。 3.3 計畫成果自評 在今年度的計畫之中,我們將第一 年所設計之可程式化的浮點數頂點著色 處理器實現出來,其特色為低功率以及 能夠支援加速移動估計的指令以間接加 速視訊編碼的功能,這兩項特色在目前 的文獻中並未能發現類似的作品,此項 作品在今年度已獲國際重量級的會議 VLSI Symposium 2007,我們也將會把我 們的成果發表於國際期刊之中。此外, 我們在今年中也對可見度測試的方向進 行探討,也提出了其對應之演算法及硬 體架構,預計此種方法在應用軟體的搭 配之下,將可以大量的減少記憶體頻寬 及運算量,達到降低功率損耗的目標。 在明年度的計畫之中,我們預計將 把此可見度測試的引擎實現,並將會把 重心放到像素著色處理器以及其他著色 (rendering)的相關研究方向上。 IM CMA GPREG TMPREG Processor Core 圖九、所提出之頂點運算器之晶片照。 表三、頂點著色器之晶片實作規格。
Process Technology Chip Size Supply Voltage Clock Frequency Performance Power Consumption On-chip Memory TSMC 0.18μm CMOS 1P6M 2.7mm x 3.3 mm 1.8V 50MHz Graphics: 12.5Mvertices/s
Video: CIF 30fps SR{H[-24,24) V[-16,16)} with FS algorithm and PDE
(*)8.6 mw CMA : 4KB IM : 768B TMPREG : 0.5KB Features OpenGL ES 2.0 Support Shader Model 3.0
Video encoding IME capability
(*)ShaderProgram : Specular Light with 20 instructions
59.9 28.1 17.2 8.6 VLIW SIMD CMA AMT ERAT 53% Power (mw) ISSCC04 [9] ISSCC05 [5] ISSCC06 [15] 0.144 0.67 0.8 1.45 This Work Mvertice/s mW x4.62 x1.2 x1.82
(*)ShaderProgram: Specular Light with 20 instructions (**)Total early reject case will perform transformationonly
71% 86% VLIW SIMD CMA AMT VLIW SIMD CMA VLIW SIMD (a) (b) 圖十、和其他已提出處理器之比較。
4. 子計畫五:兆級晶片系統中晶
片內通訊電路及系統設計
4.1. 計畫摘要 本計畫負責兆級電晶體電路及系統 的晶片內通訊設計。隨著製程科技的演 進,晶片內所能容納的電晶體數目急遽 增加,而其尺寸也相對減小。當晶片內 IP之間需要互相傳遞訊號時,其間的傳 輸通道會因此而日益惡化。如何提供晶 片內IP 間可靠的晶片內IP間訊號傳遞 技術以及如何降低訊號傳輸間的連線複 雜 度 將 是 未 來 兆 級 電 晶 體 晶 片 系 統 (TS-SoC)設計中最急需克服的重要設 計議題之一。在本計畫中,將研究如何 利用晶片內通訊之技術解決上述問題。 4.2 研究成果 本年度本子計畫提出兩項重點突 破:(1)在圖映(Mapping)部分提出之二 項 式 收 斂 圖 映 法 (binomial mapping algorithm, BMAP)並達到硬體成本最佳 化,本技術已發表於NOCS2007 [4]。其 演算法如圖十一所示,以實際之影像應 用:VOPD 和MPEG-4 模擬,其效果在 頻寬上可節省45%,硬體成本之節省從 51%提升至85%,如圖十二所示。(2) 提 出 動 態 調 整 通 道 之 流 量 控 制 技 術 (dynamic channel flow control) ,如圖 十三所示。和傳統的虛擬通道流量控制 (virtual channel flow control)相比,使用 較少之緩衝器,即可降低至少52%的延 遲時間,如圖十四所示。圖十一 二項式收斂圖映演算法
圖十三 動態調整通道之流量控制技術 圖十四 通道的利用率之模擬結果
5. 子計畫六:兆級晶片系統實體
整合之研究
5.1 計畫摘要 在此計畫中,我們提出了一個嶄新 的 MP-tree 表示法來處理擁有大區塊 (macro block)的混合尺寸設計。基於二 元樹的特性,MP-tree 可以有效地並且 有彈性地處理擁有許多不同限制的大區 塊擺置問題。對一給定的全域擺置結 果,我們所提出的大區塊擺置器將會最 佳化大區塊的位置、降低最佳化所造成 的大區塊位移、並保留晶片的中心區域 給 標 準 單 元(standard cell)的擺置與繞 線 。 由 在 ISPD’06 placement contest benchmark 上所進行的實驗,我們所提 出 的 大 區 塊 擺 置 器 與 Capo 10.2 、 NTUplace3、或 mPL6 的結合可以在穩 固性(robustness)與品質(quality)上大幅 度地勝過學術界頂尖的混合尺寸擺置 器。例如,此一結合的方法可以修正兩 組由 NTUplace3 所產生的非法擺置, 以及七組由 mPL6 所產生的非法擺置, 同時分別減少 7% 與 4% 的平均半周 長(HPWL)。 5.2 研究方法 混合尺寸擺置器 我們使用二階段的擺置流程,第一 階段是 macro placement,第二階段是 standard-cell placement 流程如圖十五所 示。 在 macro placement 中 我 們 使 用 packing-tree floorplan 的表示方式,如圖 十六所示,packing tree 是一個二進位元 樹 , 共 有 四 種 packing tree , 分 別 是 TL-packing 、 TR-packing 、 BL-packing 和 BR-packing 四種,利用 group macro 的方式做macro position 的最佳化。 圖十七是multi-packing tree(MP-tree) 的最佳化流程,在產生 MP-tree 後,主 要 是 利 用 simulated annealing 來調整 macro 的 位 罝 , 並 利 用 所 提 出 的 evaluation 方 法 來 決 定 是 否 接 受 annealing 的結果。 5.3 實驗結果 我 們 將 所 提 出 來 的 演 算 法 以 與 Capo 10.2、NTUplace3、或 mPL6 擺置 器 做 整 合 , 並 以 ISPD’06 placement contest benchmark 來做實驗結果如表四 所示,此一結合的方法可以修正兩組由 NTUplace3 所產生的非法擺置,以及七 組由 mPL6 所產生的非法擺置,同時分 別 減 少 7% 與 4% 的 平 均 半 周 長 (HPWL)。圖十五: Our mixed-size placement flow.
圖十六: A packing tree with its four types of packing.
圖十七 Our MP-tree macro placement flow.
表四 The resulting HPWL’s and CPU times for different placers without (“w/o”) and with MP-trees (“MPT”) (utilization rate = 90%). NR: No legal results can be obtained.
6. 子計畫七:兆級晶片系統模擬
與正規驗證之整合技術
6.1 計畫摘要 本子計劃今年持續去年的進度,繼 續在正規驗證引擎以及RTL 設計除錯之 輔助工具上進行研究,主要完成的項目 有二:(一) 針對複雜的電路結構所設計 強健的限制條件滿足產生器,以及 (二) 高階設計內涵自動萃取演算法以提高設 計驗證與除錯的效能。其中項目一我們 的限制條件滿足產生器之基本效能與現 今世上最快的產生器並駕齊驅,但是我 們再加上針對複雜電路所設計之專門演 算法,我們的產生器之效能能夠在快上 15 到 20 倍。至於項目二我們開發出一 套不限制於程式碼風格之高階設計內涵 自動萃取演算法,能夠自動的從RTL 電 路描述檔中萃取出各式各樣複雜的有線 狀態自動機以及計數器,這是連現今業 界最先進的電子電路設計自動化工具都 做不到的事,這些演算法將有助於本計 劃在第三年實現智慧型的電路驗證與除 錯工具。 6.2 研究成果 限制條件滿足產生器 我們提出了一個快速限制條件滿足 產生器,演算法在子計畫報告中有詳細 描述。表爆為跟跟目前以發表最快速的 Conjunctive Normal Form (CNF) [5][6]的 比較,在基本效能與現今世上最快的產生器並駕齊驅,但是我們所提出針對複 雜電路所設計之專門演算法,我們的產
生器之效能能夠在快上15 到 20 倍。
表 五 . Equivalence checking (EC)
experiments
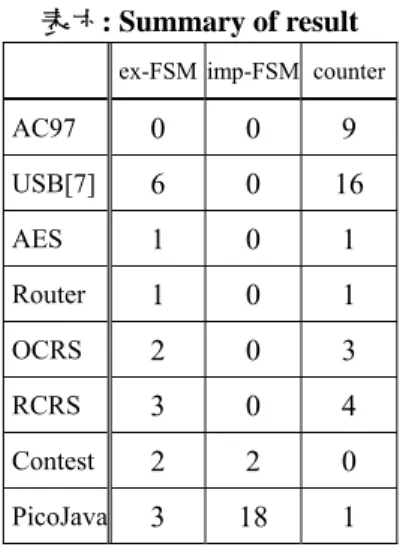
without circuit info with circuit info Time: secs QuteSAT zChaff [1] miniSat [2] QuteSAT -J NIMO -u NIMO C2670 0.16 0.24 0.19 0.04 0.02 0.01 C3540 8.36 7.20 6.49 0.38 0.58 0.01 C5315 2.39 2.62 2.48 0.27 0.61 0.02 C7552 3.71 7.55 22.5 0.39 1.38 0.05 S13207 1.31 1.67 1.04 1.01 0.28 0.06 S35932 25.4 29.24 21.5 0.67 66.8 0.16 S38417 36.2 85.59 30.9 3.14 8.62 0.45 S38584 29.8 48.46 33.9 20.8 67.9 0.78 B12 0.69 1.43 0.69 0.2 0.24 0.03 B14 2529 >3600 793.4 16.7 3380 0.48 B15 116 168.8 83.0 15.9 158.5 2.37 B17 737 >3600 665.5 54.4 >3600 14.4 B20 >3600 >3600 3185 76.6 >3600 2.17 a-rank 1.69 2.69 1.39 N/R N/R N/R 高階設計內涵自動萃取演算法 我們提出了一個自動化演算法可以在不 同coding styles 的 RTL codes 中自動萃取 FSM 和 counter,演算法在子計畫報告中 有詳細描述。表六是萃取後的結果,每 個 design 都有不同的 coding style,以 USB[7]為例,含有 533 行 codes,共有 33 “always” blocks,我們的演算法能成 中萃取其中所有的FSM 和 counter。
表六: Summary of result ex-FSM imp-FSM counter
AC97 0 0 9 USB[7] 6 0 16 AES 1 0 1 Router 1 0 1 OCRS 2 0 3 RCRS 3 0 4 Contest 2 2 0 PicoJava 3 18 1
7.總結
在這期的研究計畫中,在SoC 系統 中的靜\動態影像壓縮系統如 JPEG 2000 和 H.264,以及在繪圖系統中提出了高 效能和高效率及低耗能的系統架構,在 系統 cache 記憶體方面利用 off-line 和 on-line 的 workload 分析能有效的降低系 統記憶體的leakage power。在系統方塊 中的通訊電路中所提出之控制流量演算 法和通訊架構能有效的降低硬體成本和 提高系統方塊間的溝通效率。在系統模 擬與正規驗證之整合方面,所提出來的 高速限制條件滿足產生器和高階設計內 涵自動萃取演算法可以快速對TS-SoC 系統 作正規驗証,在實體整合方面,所提出的 placement 演算法,能有效減小平均繞線 長度,使的 TS-SoC 系統實現化更為可 行。參考文獻
[1]Y.-W. Chang, C.-C. Cheng, C.-C. Cheng, H.-C. Fang and L.-G. Chen, “Design and Implementation of JPEG 2000 Codec with Bit-Plane Scalable Architecture,” in Proc. of
IEEE Workshop on Signal Processing Systems (SiPS 2006), pp. 432~437, Oct. 2006.
[2]T.-C. Chen, Y.-H. Chen, C.-Y. Tsai, S.-F. Tsai and L.-G. Chen, “2.8 to 67.2mW Low-Power and Power-Aware H.264 Encoder for Mobile Applications,” to appear, in Proc. of IEEE
International Symposium on VLSI Circuits, June
[3]Y.-M. Tsao, C.-H. Chang, Y.-C. Lin, S.-Y. Chien, and L.-G. Chen, “An 8.6mW 12.5Mvertices/s 800MOPS 8.91mm2 stream processor core for
mobile graphics and video applications,” VLSI
Symposium 2007, June 2007.
[4] Wein-Tsung Shen, Chih-Hao Chao, Yu-Kuang Lien and An-Yeu (Andy) Wu “ A New Binomial Mapping and Optimization Algorithm for Reduced-Complexity Mesh-Based On-Chip Network, " First International Symposium on Networks-on-Chip, pp. 317-322, 2007.
[5] M.W. Moskewicz, C.F. Madigan, Y. Zhao, L. Zhang, and S. Malik, “Chaff: engineering an efficient SAT solver”, DAC 2001, pp. 530 – 535.
[6] N. Een and N. Sörensson, “MiniSat: A SAT solver with conflict clause minimization”, SAT ’05.