國立高雄大學資訊管理學系(碩士班)
碩士論文
社會網絡權重路徑隱匿之探討
Study of Weighted Path Anonymization on Social Networks
研究生:蔡政哲 撰
指導教授:王學亮 博士
I
社會網絡權重路徑隱匿之探討
國立高雄大學資訊管理學系 指導教授:王學亮 博士 研究生:蔡政哲摘要
近年來社會網絡蓬勃發展,各式各樣的網路社群服務紛紛崛起,提供許多便 利與好處,如:資訊的分享、訊息的快速傳播、更客製化的商業模式等等,但在 享受社會網絡所帶來的便利的同時,很可能遭受惡意者侵犯個人之隱私,如:個 人身份、病歷資料、宗教與政治性向、地理位置等資料之暴露,進而成為惡意者 危害之對象。因此如何於資料公開之前,進行有效的防範措施以防止隱私之侵犯, 已成為現下重要的研究課題之一。本研究擬針對社會網絡圖形資料上權重路徑之 隱私保護,進行探討並提出有效率之隱匿方法,以期保護社會網絡中敏感之路徑 隱私。在本研究中,首先提出 k-隱匿之路徑隱私(k-anonymous path privacy)之概念及問 題定義,其後再探討與提出三種處理此問題之貪婪式演算法,並實驗加以比較利 弊,希望本研究所提出之概念與處理方法,能夠協助抒解社會網絡上敏感路徑之 隱私侵犯之問題。
論文目錄
第一章 緒論... 1 1.1 研究背景與動機... 2 1.2 研究目的... 4 第二章 圖形隱匿之文獻探討... 5 2.1 社會網絡圖形節點資訊之隱匿... 6 2.2 社會網絡圖形關係(連結)與結構之隱匿... 7 2.3 社會網絡圖形關係權重之隱匿... 8 第三章 問題定義... 9 3.1 路徑隱私之隱匿... 10 3.2 路徑隱私之 k 隱匿 ... 11 第四章 貪婪式演算法... 134.1 K-Single Paths Anonymization Algorithm (KSP)... 15
4.2 K-Multiple Paths Anonymization Algorithm (KMPN) ... 17
4.3 K-Multiple Paths Anonymization Algorithm (KMPA) ... 19
第五章 實驗結果與分析... 21
5.1 實驗結果與評估方法... 22
5.2 研究限制與阻礙... 26
III
圖目錄
圖 1.1 社會網絡圖例 ... 4
圖 2.1 結構攻擊範例 ... 7
圖 3.1 k-anonymous weight privacy 之範例 ... 10
圖 3.2 隱匿前之原始網絡圖形... 11 圖 3.3 隱匿後之網絡圖形... 12 圖 4.1 KSP 隱匿前之範例 ... 16 圖 4.2 KSP 隱匿後之範例 ... 16 圖 4.3 KMPN 隱匿過後之範例 ... 18 圖 4.4 KMPA 隱匿前之範例 ... 20 圖 4.5 KMPA 隱匿過後之範例 ... 20 圖 5.1 擾動邊的比率(KSP+KMPN) ... 22 圖 5.2 執行時間(KSP+KMPN) ... 23 圖 5.3 執行時間(KMPN+KMPA) ... 23 圖 5.4 擾動邊的比率(KMPN + KMPA) ... 24 圖 5.5 修改長度之比率(KMPN+ KMPA) ... 24 圖 5.6 KMPN 與 KMPA 於不同 k 時之 KL-Divergence ... 25
第一章 緒論
科技的發展迅速,人與人之間的社會網絡互動也由生活進入了生活科技之中, 社會網絡成為近年來發展迅速的科技之一。個人可以透過社會網絡一起分享資料、 尋找朋友、了解他人背景…等等,然而在我們享受這些方便的科技與應用時,不 知不覺地也將自己暴露在危險之中。當我們漫遊在社會網絡時,許多公布的資料 也不經意地將自己的隱密資訊透漏給有心人士得取,若不對這些公佈的資料做適 當的處理,可能會造成人身、財務、名譽或其他損失產生。本研究將會提出相關 的問題並探討其解決方案。 本章節首先介紹研究之背景與動機,說明社會網絡中敏感資料保護的需求性 及重要性,其後介紹研究的目的。之後的章節會進一步詳細描述所欲處理之問題 的定義與說明,與解決問題所使用的研究方法和步驟,並將闡述實驗結果,比較 各種方法之優缺點,描述未來可發展之研究與限制。2 1.1 研究背景與動機 社會網絡近年來發展頻繁,應用範圍也相當廣泛,如:Facebook、Twitter 或其他的社群網站等,使用者可以透過社會網絡發布的訊息,進行資訊的交換、 交流,而每個人都期盼著透過這些資訊的共享與應用所帶來的龐大價值。資訊與 資源的共享確實帶來龐大的應用價值,除了可以使資源共享之外,也可用於研究 方面,如:社會心理學等,但其中也隱藏著不想被他人知道的敏感資訊,社會網 絡中,每個人都代表著一個點,點內包含了許多資訊:性別、習慣、興趣、性向… 等等,而人與人的關係則形成了邊,代表著兩個人之間的關係,邊也包含了許多 的資料,關係的緊密度,聯絡的次數…等等。當資訊被公布在社會網絡之中,我 們無法避免有心人士,透過發布的資訊來得知個人的隱私資料,所以必須做過適 當的資訊隱匿,再將資料公布,使傷害減至最低。 過去為了保護使用者的個人隱私,將資料做過簡單的處理再發布,刪除個人 姓名、遮蓋身分證字號或是限制存取等等,以保護使用者的個人隱私權,然而有 心人士獲取隱密資訊的方式有很多種,透過社會網絡得到使用者其他的相關訊息, 將之拼湊,很容易就取得使用者的個人隱私資料,這些簡單的隱匿方式無法讓使 用者安全的於社會網絡上活動。過去對不同形式的社會網絡資料隱匿方式大致分 為三類:關聯性資料(Relational Data)、交易資料(Transaction Data)與圖形資料 (Graph Data),有心人士想擷取隱匿資料的方法也有所不同,因此,也延伸出 不同的防範隱密資料的方式。 在關聯性資料中,容易遭受到的連結性的攻擊,如醫院的病例資料經過簡單 的刪除姓名資料作為保護,就公開發布於社會網絡中,購物商場也在另一邊發布 了顧客的購買資料,卻沒有將姓名刪除,而攻擊者透過購物商場的資料中,其他 透露出的訊息進行比對(性別、年齡、住址…等等),很容易就得知這位消費者 曾經得過得什麼樣的病症,進而侵犯了他人的隱私。[1, 13, 14] 而在交易資料中,America Online(AOL)於 2006 年 8 月為了研究需求,公 布了大量的使用者「搜尋檢索」之資料提供協助,資料內容包含了六十五萬個使 用者在三個月的時間內搜尋的兩千萬筆檢所資料,公布之前,AOL 也將使用者 的姓名以隨機的代號所取代,但攻擊者可以透過使用者的習性與下關鍵字的模式, 找到代碼 4417749 的使用者的相關資訊[2]。即使查詢的語句並不包含使用者的 個人名稱、地址等資訊,但透過使用者特定的使用查詢習慣與模式,攻擊者還是 可以有效地找到使用者的個人隱私資料。 圖形資料中分為有權重與無權重之圖形,在無權重的圖形,攻擊者有可能透 過非結構性攻擊來獲取使用者資訊,每個點上的標籤(label),甚至利用點與點 之間的關係(link),攻擊者有可能利用圖形內的資訊來找尋使用者的隱私。即使 在每個點或是邊上沒有其他的資訊,圖形資料也可能會遭受到結構性的隱私侵犯 [5, 17],如同關聯性資料可以透過連結其他資訊與交易資料可以透過固定的模式
來取得隱密資料,圖形資料可以透過先前得知使用者周遭的關係結構來得知使用 者的資訊,目前已知的結構型態有四種:degree-attack、subgraph attack、
1-neighborhood attack 和 hub-fingerprint-attack[5, 7, 16]。
以下有基本三種敏感的資訊在圖形資料中是容易被攻擊且需要被保護隱私
的:點的資訊(node information)、連結的資訊(link information)和連結的權重
(edge weight)[3, 8, 9]。點的資訊,如:使用 e-mail 寄送郵件時,每個寄件者都 有個人的資訊:生日、年齡、聯絡方式、地址…等等,甚至是重要的交易資訊也 會流露其中。[6, 10-12]。連結的資訊代表著個體們之間的關係,可以用來表達資 金的交流、友誼、衝突、性關係或疾病傳染[9],這些關係是十分敏感的資訊, 當使用者不留意、不加以設定保護,很容易被其他非朋友關係的使用者所查詢、 得知。在應用上,連結的權重可以用來表達友好的程度、信任度、行為…等等。 若考量路徑(資訊或市場傳播),連結的權重則代表傳遞資訊的成本[4]。為了要 保護點的資訊,許多在關聯資料與交易資料中使用的一般化(generalization-based) 與抑制化(suppression-based)的方法被應用於此。保護連結的資訊,有一些研 究提出不同的隱私模型來應對不同類型的結構性攻擊,如:k-degree、 k-automorphism、k-isomorphism[4, 8, 9]。 權重圖形的部分,近期的研究以擾動的方式(perturbation-based)來隱匿連 結的權重並保持線性的特性,如 Gaussian randomization perturbation 和 greedy perturbation 的方法擾動圖上所有連結的權重,用以隱匿連結上容易暴露的資訊, 這部分會在第二章更加詳細的介紹。過去的研究,雖然保護了每筆權重的資料, 但卻無法隱藏其他敏感的隱藏資訊:最短路徑。因此,本研究將針對保護權重路 徑上的隱私來做思考與探討,進而提出一個新的方法用以隱匿敏感路徑,讓攻擊 者無法輕易地針對敏感路徑資訊做出攻擊。
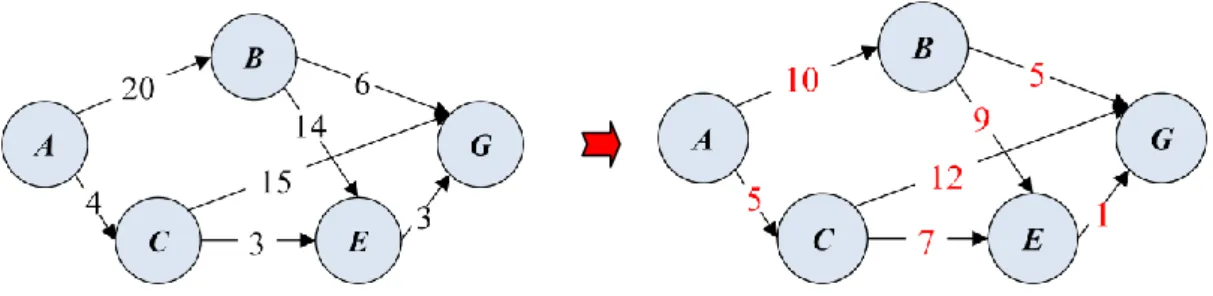
4 1.2 研究目的 社會網絡或商業網絡上權重圖形的路徑長度,對惡意攻擊者或商業競爭者可 能是具隱私或敏感性的資料。如圖 1.1 所示,若將路徑權重視為上游廠商(A 節 點)經過各中盤商到達下游廠商(H 節點)所需要的交易價格,則一旦圖形公布, 其他的競爭廠商會立即知道廠商之間最低成本的交易「路線」為何,因而洩漏了 彼此合作之商業機密。這不只是對上游廠商,甚至對中盤商之間的價格競爭皆會 受到影響,如圖中所示,(A 節點)與(B 節點)之交易價格為 4、(A 節點)與 (C 節點)之交易價格為 20,兩者相距頗大,(B 節點)與(C 節點)可能因此 圖形的公發布而進行價格的惡性競爭。同時,若 A 節點與 H 節點之間的最短路 徑{(A, B), (B, G), (G, H)}權重亦為其他廠商所知,則亦可能造成所有廠商之惡性 競爭。 因此在本研究中,我們擬探討如何考量隱匿兩節點間之最短路徑之問題,使 的公布之社會網絡圖形中,顯示出 k 條最短路徑,使的攻擊者無法輕易辨識原始 之最短路徑。攻擊者只能在 1/k 的機率中找到所隱匿之原始最短路徑。 圖 1.1 社會網絡圖例
第二章 圖形隱匿之文獻探討
在此章節中,會詳細描述過去文獻針對不同問題,提出各種不同類型的隱私 權保護方法,首先討論社會網絡圖形節點資訊之隱私問題與解決方法,其後描述 方法不足之處,進而衍伸社會網絡圖形關係與結構之隱私問題。而各種不同的關 係與結構,也發展出不同的解決方法,本研究將探討這些研究所遭遇的各種問題 與解決方法,找到其他尚未解決之問題,並在之後的章節探討如何抒解這些問 題。6
2.1 社會網絡圖形節點資訊之隱匿
點代表著社會網絡中的一個個體,可能為人或是一個團體組織,在社會網絡 社群發達的現在,點上都有著容易辨識的資料,如:名稱、聯絡方式、偏好…等 等,不管是收送 e-mail、於 Facebook 使用相關應用程式、Twitter 的微網誌發布 等,皆會將資料傳送給任何使用相關服務的客戶。當自己的資料流露於這些社會 網絡之中,就如同寄送自己的個人檔案一般,讓他人一覽無遺。過去的研究,常 使用簡單隱匿之方式來隱藏資料,也就是將點上容易辨識身分的資訊,如:姓名、 身分證字號等,以其他的代號作為替代的指標,如:名字替換成 a、b、c…等代 碼。但是,當攻擊者有特殊的背景知識,如:目標的交友資料之圖形,攻擊者可 以透過目標交友的結構,於圖形中找到相同結構的目標點,進而侵犯隱私,光是 透過遮掩容易辨識身分之資料是無法防範攻擊者透過關係結構上的攻擊[7]。
2.2 社會網絡圖形關係(連結)與結構之隱匿 連結代表著社會網絡中每一個個體之間的連結,可以用來代表聯絡、合作的 關聯,也可以為交易的關係,2.1 節中提到簡單的隱匿,提供將點上可辨識的資 料遮掩住的方式,達到點上資訊的隱藏,但點與點之間的關係並無因此隱藏,除 此之外,若攻擊者得到了圖形結構的背景知識,即使遮掩了重要資料,攻擊者還 是可以透過結構猜測出所要攻擊的目標或是關係在圖形中的位置。 當攻擊者擁有目標點度數(degree)的背景知識,即可立刻於在圖形中找出 相同度數之點,並確認此即是目標。k-degree確保了點存在於圖形中無法透過點 的度數得知即將攻擊的目標為何[7],圖G中,V為G中所有點以度數做降冪排列 之序列向量,若向量V中不同的每一種度數都至少出現k次,即稱圖G為k-degree anonymous,舉例而言,若釋出的圖形G*中,若V={6,6,6,4,4,3,3},則G稱為2-degree anonymous,如此便無法透過度數立刻找到攻擊的目標。 除了透過度數攻擊找到目標,也有其他的結構資訊提供攻擊者做出選擇。當 攻擊者有了包含目標之子圖的背景知識,便可以從釋出的圖形中,找到相同結構 的子圖,並確認目標點為何者。另一種隱匿方法k-automorphism network在[17]中 被提出,k-automorphism的做法透過增加連結,使的在發布的圖形G*之中擁有k 個一模一樣的子圖,即使攻擊者知道任何子圖的背景知識,也無法辨識目標的位 置為何處。如圖2.1中攻擊者清楚知道(a)的結構,卻也無法精準得知V2為哪一 個節點。 但即使圖形已經過k-automorphism之隱匿,也有可能無法阻擋攻擊者獲取點 與點間「是否有連接」之資訊。當攻擊者想要找出兩個點之間是否有連結,且他 也擁有兩個目標點之結構,則只需在圖形之中找出將兩個結構相近或交疊之處, 即可輕易得知兩點間是否有關係[3],圖2.1中(a)、(b)為攻擊者知道目標兩點 之背景知識,但起初攻擊者並不清楚兩點是否有相連結,由隱匿後發布之圖形中 尋找結構可以發現,即使有多組點可以使攻擊者無法判別V2及V4為何者,但我 們可以得知,V2與V4之間確實有關聯。 k-isomorphism的方法,解決了個這個問題,k-isomorphism於[3]中定義,若 圖形G是k-secure則圖形G中至少要有k-1個其他分離的子圖,以圖2.1為例,若圖 形要為k-secure,則(a)、(b)各別都要存在於k個不同分離的子圖之中。 圖 2.1 結構攻擊範例
8 2.3 社會網絡圖形關係權重之隱匿 在過去保護社會網絡隱私的研究中,有許多新穎的模型與方法來隱藏圖形的 敏感資訊,大部分都是針對無權重的圖形隱私,發布的圖形都會針對點的資訊或 是一群點之間的關係連結做隱匿。但若考慮到權重圖形,一旦邊上附加了權重的 意義,會有更多的敏感資訊會透過圖形透露出來,使的攻擊者更容易下手,得到 使用者不想發布的資訊。權重可以用來分析網絡內的社群型態、商業交易網絡、 病毒式或目標式行銷和傳播、網絡連結的資訊散布等等[4]。在應用方面,邊的 權重也可以用來代表人與人之間的友誼、信賴度或是交易金額…等。 這些權重(路徑長度),不僅僅是透露簡單的關係訊息,甚至會造成嚴重的影 響與變化。例如企業之間的社會網絡,每一個節點都可以代表一間企業,企業與 企業之間的連結,可以代表之間的合作關係,而連結上的權重,則可以代表企業 之間的交易現金流量。若這些資料不做出適當的處理,直接為了研究、抑或是其 他用途所使用而公開於世,除了可以得各個企業之間的關係緊密度外,甚至透過 現金交易流量,推測企業之間的策略為何,有心人士可進一步的對其造成傷害與 破壞。 在下一個章節,將會介紹過去關係權重隱匿所遭遇之問題,並描述解決之道, 其後探討本研究所面臨的問題,並提出方法—k-anonymous path privacy,來協助 解決問題。
第三章 問題定義
在上一章節社會網絡圖形關係權重隱匿之研究中,成功保護圖形之中權重的 隱私,並維持最短路徑不變,以利發布後的資料還是能提供參考價值。但最短路 徑也是一項敏感的資訊,如何保護社會網絡圖形關係之權重資訊,本章 3.1 節將 會詳細描述過去所解決的問題並詳細定義何謂權重路徑之隱匿。3.2 節將介紹本 研究遭遇之問題定義,並提出新的概念與方法,用以解決本研究所遭遇之問題。10
3.1 路徑隱私之隱匿
邊上的權重(長度)是十分重要的資訊,為了保護這些敏感的資訊(敏感的
邊),近期的研究專注於保護兩點之間最短路徑之特性[4, 9]與權重隱私之 k-隱匿
(k-anonymous weight privacy)[8]。企業間的交易也是一種社會網絡圖形,權重 可能代表著交易金額,而交易金額是十分敏感的資訊,如何保護交易金額資料不 容易洩漏,且發布的圖形又可以提供企業間參考或研究使用,成為一項重要的課 題。Gaussian randomization perturbation 與 greedy perturbation 採取不新增、刪除 點與邊的方式並盡可能小幅度的更動所有邊的權重來保有兩點間原本之最短路 徑,如此便可達成目的。在[4]的研究中,提出一個線性規劃抽象模型使的經過 權重的修改後還能保有每條邊上權重之線性性質(包含最短路徑)。企業與各下 游同業間的交易量差距若十分龐大時,很容易成為下游商品價格惡性競爭之循環, 所以這也是一項敏感的資料,為此,必須將目標企業與其他下游企業之間的交易 量做一定程度的隱私保護。為了消除邊上權重的可辨識度,k-anonymous weight
privacy 於[8]如此定義:邊(i j)為 k 隱匿若且為若於(i)存在至少權重為 wi,tl
的 k 條邊,l= 1, ..., c 且 c k,滿足|| wi,j - wi,tl || ≦, l=1,..., c,為一個預設的正
數來控制隱私的程度,而(i)為一個集合,代表所有連接點 i 出發的邊,
k-anonymous weight privacy 保證 i 出發的邊中,至少有 k 條邊之間差距≦,即 可達成將差異龐大的交易資料,適當地隱藏,如圖 3.1,從每一個企業出發的現 金成本之間的差距皆不超過 5,且企業間的現金成本已經與原始圖形不同,而企 業 A 與 G 之間的最短路徑仍然是 A→C→E→G。 這些方法保護了每個關係上權重的隱私,也保留了最短路徑的特性,然而, 最短路徑也是一個重要的敏感資訊,例:交易流量。各個企業之間的交易情報與 資訊暴露在公開場合中,透過上述研究之方法雖然將交易流量皆以混淆,但卻無 法防止他人知道最短現金流量之路徑。以圖 2.2 為例,A 與 G 企業之間為上下游 之關係,A 企業透過中間的通路商間接與 G 合作,透過先前的研究擾動交易流 量後,我們還是可以得知 A 與 G 之間極有可能透過 C 與 E 達成合作關係,使的 A 企業的策略情報無意間洩漏給他人得知。如何防範最短路徑之隱私,不使有心 人是惡意侵犯,為本研究欲解決之問題。
3.2 路徑隱私之 k 隱匿 個體間的關係在不同的社會網絡圖中,有各式各樣不同的形式,所面臨的問 題也有所不同,前述的研究都以保持最短路徑為原則,來隱藏原本圖形上的權重 或各權重間差值之利害關係,但考量到最短路徑也是一種極為敏感的隱私資料, 如交友關係、組織之間的金錢流向…等等,透過上述研究無法防範攻擊者得取最 短路徑之資料,所以本研究中提供另一種不同形式的隱私保護:k-anonymous path privacy,用以保護兩點之間的最短路徑,不易被攻擊者所察覺,但也保持原來的 最短路徑不變之特性。在實際用途上,企業間的合作關係也是一種社會網絡,路 徑上的權重代表企業間的現金流量,保護企業間的交易隱私是十分重要的,假使 某些惡意人士透過企業間之現金流量,來猜想企業之決策,需使的惡意攻擊者無 法 從 擾 動 過 後 之 圖 形 中 , 輕 易 地 得 知 企 業 間 的 合 作 關 係 , 我 們 可 以 透 過
k-anonymous path privacy 的方法,達到保護企業決策之目的。
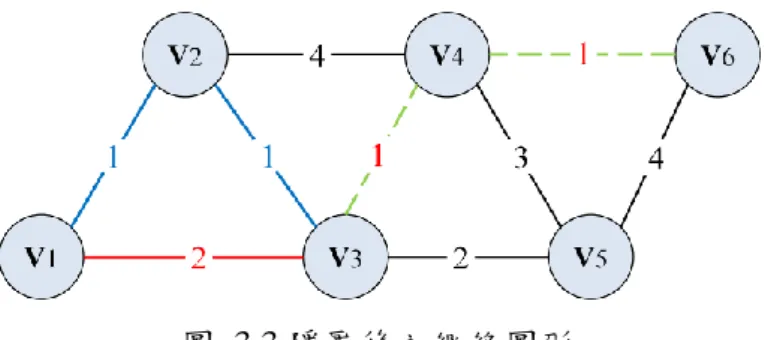
此方法最直覺的想法,就是另外做出(k-1)對一樣長度之最短路徑,使攻 擊者對此敏感資訊的辨識度,降低至 1/k,如此一來,敏感的路徑資訊就無法輕 易的被察覺,進而保護隱私。圖 3.2 為含有六個點之無向權重圖形,假設 v1與 v6之間的最短路徑(v1, v3, v4, v6)是十分敏感,且需要被保護、隱匿的,可利用 一種的方法,即是擾動其他路徑的權重使的此兩點之間至少擁有 k 條最短路徑。 假設此範例之隱私層級需求為 k = 2,圖 3.3 中挑選下一條 v1與 v6之間的路徑(v1, v2, v3, v4, v6),將此路徑之中 v2與 v3之間的權重修改為 1 之後,v1與 v6之間的最 短路徑就變成 2 條,如圖 3.3。因此,給予一個圖形 G,多組起始點與終點 H, 與隱私的層級 k,k-anonymous path privacy 的目標為盡可能的更動其他路徑之權 重使的存在於 H 之內的每一對配對點的最短路徑至少要有 k 條。如此一來,攻 擊者能猜到每一對配對點的原始最短路徑之機會將成為 1/k,即達成隱匿最短路 徑之需求。
12
第四章 貪婪式演算法
針對每次考量一條路徑,且不可重複修改邊之權重的 Greedy-based 隱匿方式, 我們提出下列之做法。給定一個起始點與終點配對的集合 H,H 之內每一對的最 短路徑間,邊是有可能會重疊的。邊的種類大致分為三種,根據他們是否為最短
路徑上的邊來決定他們的種類[9]。若邊 ei,j不屬於任何 H 之中任一對的最短路徑
上的邊,則稱 ei,j為 non-visited(NV)edge,若邊 ei,j屬於 H 之中每一對的最短路
徑上的邊,則稱為 all-visited(AV)edge,若邊 ei,j屬於 H 之中至少一對的最短路
徑上的邊,不與 AV edge 相同,則稱為 partially-visited(PV)edge。舉例而言, 圖 3.1 中,v1與 v6的最短路徑為 p1,6 = {(v1, v3), (v3, v4), (v4, v6)}且次短路徑為 p’1,6 =
{(v1, v2), (v2, v3) , (v3, v4) , (v4, v6)}。由上定義可知,邊 e3,4和 e4,6都是 all-visited edges,
邊 e1,2、e1,3與 e2,3為 partially-visited edges,其他的邊都為 non-visited edges。可以
輕易觀察到,即使更改 AV 之權重也不會使的最短路徑更動,但會影響最短路徑 之長度,而有條件且適度的更動 NV 之權重亦不會更動最短路徑,更動 PV 之權 重則不會影響某些其他配對的最短路徑,這些特性不論在隱匿單一或是多個最短 路徑都是十分的有利與方便的。
對於給定的一對起始點與終點,k-anonymous path privacy 的目標為盡可能 的更動其他路徑之權重使的配對點的最短路徑可以達成 k 條。我們提出一種 greedy-based 的方法並修改第一最短路徑之後的 k-1 名次短路徑之邊的權重,使 這些次短路徑都與最短路徑成為一樣的長度。以只修改 non-visited edges 為例, 首先要找到次短路徑,並以比例分配的方式,找出合適的邊扣除權重。例如圖 3.1,v1與 v6之次短路徑為 p1,6 = {(v1, v2), (v2, v3), (v3, v4), (v4, v6)},則次短路徑之
non-visited edges 即是 e1,2與 e2,3。而最短路徑的 non-visited edges 即是 e1,3,他的
長度為 2。因此 e1,2與 e2,3之總和必須要減少至 2 就可使兩條路徑擁有相同的長 度,次短路徑也成為了最短路徑。持續重複此流程,直到完成 k-1 名最短路徑為 止,圖形便會形成 k 條最短路徑。 在演算法中會使用到下列變數: vi:節點 i; ei,j:節點 vi與 vj之間的邊;
wi,j:ei,j的權重;
SPi,j:節點 vi與 vj之間的最短路徑;
di,j:最短路徑 SPi,j之長度;
NVL:所有最短路徑上之 non-visited edges 清單;
AVLh:在第 h 對起點與終點之 all-visited edges 清單;
PVLh:在第 h 對起點與終點之 partially-visited edges 清單;
14
MEW:可修改之路徑的總長度;
NSP:下一條次短路徑(Next Shortest path);
SPL:最短路徑清單(Shortest Path List);
給定一個圖形 G,多對起始點與終點(vi, vj)的集合 H 和隱私層級 K,以不
能修改最短路徑的邊為原則,目標為不新增或刪除任何點與邊盡可能的更動其他 路徑之權重使的配對點的最短路徑可以達成 k 條。以下介紹三類—分別以 non-visited 與以 all-visited edges 兩種修改方式為基準之演算法,本研究將會相互 比較此兩種類型之優缺點。
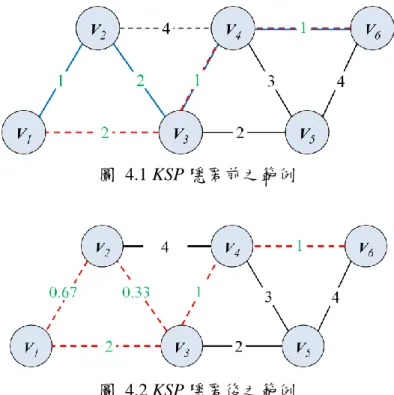
4.1 K-Single Paths Anonymization Algorithm (KSP) 輸入: (1)圖形 G, (2)想要隱匿最短路徑之起始點 i 與終點 j, (3)K,隱私層級,釋出圖形中擁有 K 條最短路徑, 輸出:隱匿後之圖形 G*, 1. 找出最短路徑 SPi,j與它的長度 di,j; 2. For(m=2 to K){ 3. 找出第 m 條 NSP 路徑 NSPi,j與長度 Ndi,j; 4. 計算 NSPi,j之中 NVW 之值; 5. For (NSPi,j上的每一條邊){ 6. If (邊在 NVL 之中){ 7. ME := ME + 此邊; 8. MEW := MEW +邊長; 9. } 10. } 11. If ( ME = ){ 12. continue; //放棄此路徑,找下一條次短路徑 13. } 14. For(ME 內的每一條邊){ 15. ;//依照比例分配扣除 16. 更新圖形 G* 17. };//所有邊都做完 18. };//完成 K-1 個最短路徑 輸出 G*; 圖 4.1,設定起點為 v1,終點為 v6,隱匿層級 k = 2,首先找出最短路徑:p1,6 = {(v1, v3), (v3, v4), (v4, v6)},接下來尋找其次短路徑,為:p’1,6 = {(v1, v2), (v2, v3), (v3, v4), (v4, v6)}。由於 e1,2與 e2,3為 non-visited edges,所以選擇此兩邊各別修改為: e1,2 = 0.67,e1,3 = 0.33。如圖 4.2。
16
圖 4.1 KSP 隱匿前之範例
4.2 K-Multiple Paths Anonymization Algorithm (KMPN)
在此演算中,本研究以為了不更動到最短路徑為原則之考量,將 non-visited edges 做為修改的目標,每挑選下一條次短路徑時,只蒐集 non-visited edges 並以 比例分配的方式對其做修改,達成 k-anonymous path privacy 之目的。
輸入: (1)圖形 G,
(2)想要隱匿最短路徑之起始點與終點之集合 H, (3)K,隱私層級,釋出圖形中擁有 K 條最短路徑, 輸出:隱匿後之圖形 G*,
1. 初始化 SPL = ; //shortest path list 2. while (H ){ 3. 找 H 下一對最短路徑 SPi,j與長度 di,j; 4. SPL := SPi,j ; //將最短路徑存入清單 5. For (m=2 to K){ 6. ME := ; 7. MEW = 0; 8. 找出第 m 條 NSP 路徑 NSPi,j與長度 ; 9. If( 與 di,j相等){ 10. SPL := SPL+NSPi,j; //存入最短路徑清單之中 11. continue; 12. }Else{ 13. If ( (NVW- ( Ndi,j -di,j)) < 0){ 14. m-1;// 相差權重數次短路徑無法完全吸收 15. continue; //放棄此路徑,找下一條次短路徑 16. }else{ 17. For (NSPi,j上的每一條邊){ 18. If (邊在 NVL 之中){ 19. ME := ME +此邊; 20. MEW := MEW +邊長; 21. } 22. } 23. If ( ME = ){ 24. continue; //放棄此路徑,找下一條次短路徑 25. } 26. For(ME 內的每一條邊){
18 27. ;//依照比例扣除 28. 更新圖形 G* 29. }; 30. SPL := SPL+NSPi,j; //存入最短路徑清單之中 31. };//end of If/Else 32. }; //end of If/Else 33. };//完成 K-1 個最短路徑 34. }; // end of while (H ) 35. 輸出 G*; 如圖 4.1,承上一小節之演算法,使的 H = {(v1, v6), (v2, v6)},隱匿層級 k = 2, 首先找出第一對—(v1, v6)之最短路徑:p1,6 = {(v1, v3), (v3, v4), (v4, v6)},並與前一 小節相同,將 e1,2、e1,3兩邊各別修改為:0.67、0.33。其後,針對第二對—(v2, v6) 尋找最短路徑:p2,6 = {(v2, v3), (v3, v4), (v4, v6)}與次短路徑 p’2,6 = {(v2, v4), (v4, v6)}。 且 e2,4為 non-visited edges,所以選擇此邊修改為:e1,2 = 1.33,如圖 4.3。 圖 4.3 KMPN 隱匿過後之範例
4.3 K-Multiple Paths Anonymization Algorithm (KMPA) 第二種演算法裡,與前者提到之方法不同之處,在於增加了容許修改其他對 起點與終點之 all-visited edges,以可負擔修改長度之邊的數量增加為前提,所提 出的想法。 輸入: (1)圖形 G, (2)想要隱匿最短路徑之起始點與終點之集合 H, (3)K,隱私層級,釋出圖形中擁有 K 條最短路徑, 輸出:隱匿後之圖形 G*,
36. 初始化 SPL = ; //shortest path list 37. while (H ){ 38. 找 H 下一對最短路徑 SPi,j與長度 di,j; 39. SPL := SPi,j ; //將最短路徑存入清單 40. For (m=2 to K){ 41. ME = ; 42. MEW = 0; 43. 找出第 m 條 NSP 路徑 NSPi,j與長度 ; 44. If( 與 di,j相等){ 45. SPL := SPL+NSPi,j; //存入最短路徑清單之中 46. continue; 47. }Else{ 48. If ( (NVW- ( Ndi,j -di,j)) < 0){ 49. m-1;// 相差權重數次短路徑無法完全吸收 50. continue; //放棄此路徑,找下一條次短路徑 51. }else{ 52. For (NSPi,j上的每一條邊){ 53. If (邊在 NVL 之中){ 54. ME := ME + 此邊; 55. MEW := MEW +邊長;
56. }else If (邊在其他 AVLh之中&&不在任一 PVLh內 ){
57. ME := ME + 此邊; 58. MEW := MEW +邊長; 59. }
60. }
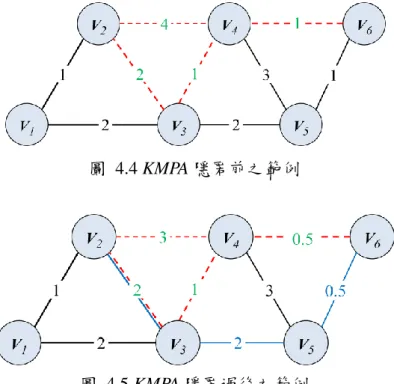
20 62. continue; //放棄此路徑,找下一條次短路徑 63. } 64. For(ME 內的每一條邊){ 65. ;//依照比例扣除 66. 更新圖形 G* 67. }; 68. 更新 AVLh、PVLh與 NVL; 69. SPL := SPL+NSPi,j; //存入最短路徑清單之中 70. };//end of If/Else 71. }; //end of If/Else 72. };//完成 K-1 個最短路徑 73. }; // end of while (H ) 74. 輸出 G*; 如圖 4.4,使的 H = {(v2, v6), (v2, v5)},隱匿層級 k = 2,首先找出第一對—(v2, v6)之最短路徑:p2,6 = {(v2, v3), (v3, v4), (v4, v6)},接下來尋找其次短路徑,為:p’1,6
= {(v2, v4), (v4, v6)}。e2,4為 non-visited edges,e4,6也為第一對之 all-visited edge,
依照演算法只能選擇其他對的 all-visited edge 來修改,所以路徑只將 e2,4修改為:
e2,4 = 3。其後,針對第二對—(v2, v5)尋找最短路徑:p2,5 = {(v2, v3), (v3, v5)}與次短
路徑 p’2,5 = {(v2, v4), (v4, v6), (v6, v5)}。除 e6,5為 non-visited edges,e4,6也為 pair:
{(v2, v6)}之 all-visited edge,所以選擇此邊修改為:e1,2 = 1.33,如圖 4.5 所示。
圖 4.4 KMPA 隱匿前之範例
第五章 實驗結果與分析
於上一章節中,本研究提供了兩種不同達成 k-anonymous path privacy 之方 法,為了檢測演算法之正確性與其效能,於本章節中,我們提供了一組人造資料 並展現兩種方法的實驗結果。在章節前篇,本研究將比較此兩種方法之間實驗結 果的優劣,並分析 non-visited edges 與 all-visited edges 這兩種類型方法之間有何 不同之處,其後描述實驗上的困難與限制。
22
5.1 實驗結果與評估方法
為了評估兩種不同演算法的特性,我們將實驗分為兩個階段,第一階段採用 於[15]蒐集之現實世界的資料集,EIES(Electronic Information Exchange System) 在時間為 2 的時候之交友資料當作初期試驗對象,用以比較 KSP 與 KMPN。此 資料內容為多名研究者參與先前計算機研討會中其他研究之間所形成的社會網 絡,研究者們所形成的關係大致上可分為四個層級數值:1(與對方不熟稔)至 4(與對方熟悉、來往頻繁)。此資料包含了 48 名研究者,他們之間共有 830 個關係存在,且為無方向之圖形。第二階段採用人工製作之圖形做為實驗對象, 此圖形包含了 65 個節點與 1021 條邊,結點之間的邊隨機給予 1 至 100 的長度, 資料都是隨機形成的,本研究採用同樣組別的起始點與終點,比較 KMPN 與 KMPA 之間的差異。
所有的實驗均在 Intel Core 2 Duo P8700 CPU, 2.53 GHz 且 4GB 記憶體之機器 上執行。作業系統為 Microsoft Windows 7,實驗方式皆以 Java 程式碼實作完成。
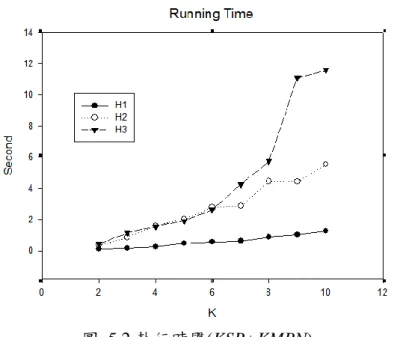
第一階段,我們隨機挑選五對起始點與終點後,將實驗結果帄均。除了執行 時間,我們也計算了擾動邊的比率,此比率為:(被擾動的邊數量/所有最短路 徑上之邊的數量)。可以由圖 5.1 得知 KSP 與 KMPN 之擾動邊的比率即使隨著 k 的增加,仍然是十分穩定的停留在 30%至 40%,對於單一對起始點與終點的配 對做隱匿時(H1),帄均擾動的比率約為 40%,在多對配對隱匿時(H2、H3), 帄均為 39%與 36%。 圖 5.1 擾動邊的比率(KSP+KMPN) 執行時間部分,當 k 的數量增加時,H1 的上升趨勢較為緩慢,由於可以修 改的次短路徑較容易尋找,時間的增加量並不龐大。但當配對數量增加時,由於
KMPN 無法修改非 non-visited edge 之邊,時間量在不斷的尋找可修改的次短路 徑上大幅的增加了。
圖 5.2 執行時間(KSP+KMPN)
第二階段我們將增加修改 all-visited edges 與第一階段描述之方法來做比較。 圖 5.3 為執行此兩種演算法所花費的時間,KMPA 所花費的時間較 KMPN 來的少, 推測原因為由於 KMPA 提供了 all-visited edges 修改的方法,使的找可修改的次 短路徑之選擇也較多,由於 KMPN 只能修改 non-visited edges,所以當大多數的 邊皆被經過時,將會花費大量的時間尋找可修改之次短路徑。 圖 5.3 執行時間(KMPN+KMPA) 圖 5.4 為所有最短路徑被擾動邊的比率,我們可以觀察到,只透過 KMPN 之 方法修改的比率較 KMPA 方法少,這與本研究預期的結果相符。演算法挑選下一 條次短路徑後,由於可以修改的邊的容許度變高,使 all-visited edges 也加入修改, 所以每一條次短路徑邊的修改比率將會比只修改 non-visited edges 要來的多。
24 圖 5.4 擾動邊的比率(KMPN + KMPA) 圖 5.5 為修改長度所占最短路徑經過的邊之長度的比率,此比率為:(修改 的長度/所有最短路徑經過之邊的長度總和),由圖可知兩種方法的修改長度比 率皆在 40%以下,也隨著 k 的增長有著逐漸上升的趨勢。不論是 KMPN 抑或是 KMPA,兩者之間的修改比率相異性並不大,推測應是最短路徑與次短路徑間的 長度差距不遠,即使 KMPN 有可能因為尋找 non-visited edges 而使的次短路徑長 度增加,但增加的幅度有限,使兩種方法之間的差距並不明顯。 圖 5.5 修改長度之比率(KMPN+ KMPA) 為了評估兩種演算法之結果圖形的資訊損失(information loss),我們採用
Kullback and Leibler (KL) divergence 計算修改過後的圖形與修改之前圖形的
差異。KL divergence 是用來衡量擁有相同隨機變數 x 下的機率分配 f 與 g 之相 異性,通常分配 f 代表真實的分布數據,分配 g 代表一個理論、模型或是近似 f 的另一項分配。 本研究中,我們將分配 f 視為修改前之權重於路徑上的比率分配,而分配 g 視為修改後的分配結果,透過 KL divergence 來比較修改前與修改過後的差異性 之大小,當兩者之間沒有差異,則 KL divergence 之值為 0,若差異愈大,KL
divergence 之值也愈大。本研究所使用的 KL divergence 公式如下: 以 4.1 小節只修改 non-visited edges 為例,由於次短路徑 p’1,6 = {(v1, v2), (v2, v3), (v3, v4), (v4, v6)}將 e1,2與 e2,3修改為 0.67 與 0.33,計算此條路徑修改前與修改後的 差異,如下式:
以 4.3 小節加入 all-visited edges 修改考量為例,由於 e4,6屬於 all-visited edges,
因此計算方式必須考量經過修改後之最短路徑長度,第一對起始點與終點之最短 路徑長度已被修正為 3.5,如下式: 0.069228 圖 5.6 為於人造資料中只修改 NV 與一同修改 NV 和 AV 之 KL Divergence 之比較 圖。可以由此觀察到,當 k 值愈大時,資訊損失也會逐漸提升。但 KMPA 的資訊 損失較 KMPN 少,推測由於 KMPN 只能修改 NV,必須不斷尋找可修改之次短路 徑,次短路徑愈長使權重修改量上升,進而與原始路徑之權重分配相差較遠。 圖 5.6 KMPN 與 KMPA 於不同 k 時之 KL-Divergence
26 5.2 研究限制與阻礙 在社會網絡中,人與人的關係是十分緊密的,如此,任一組起始點與終點, 當 k 愈大時,其路徑上有 all-visited edges 的機會便十分稀少,由於人與人之間十 分的接近,所以有許多的次短路徑提供選擇,所有路徑皆通過同一條邊的機率自 然也十分稀少,實驗中必須使用人工製作之圖形使的路徑通過同一條邊,提高 all-visited edges 的數量。 其次,由於演算法為貪婪式,必須一條條的確認次短路徑是否可以修改,使 的當 k 的數量增加時,如上一小節的實驗結果,執行時間也大部份的占用於尋找 次短路徑上,如何更有效的尋找可以修改的次短路徑,是本研究未來需考量的重 點之一。
第六章 結論與未來研究方向
本研究中,致力於協助如何保護最短路徑之隱私,以用來解除社會網絡中, 隱私被侵犯之威脅。文中,我們提出了新的觀點:k-anonymous path privacy 與三 項貪婪式演算法,希望能以最少的修改量,達成路徑之 k 隱匿。除此,本研究加 以比較三個演算法之間的特性與成效,實驗證實透過貪婪式演算法達成不同條件 與環境之 k-anonymous path privacy 是可行的。
未來,將會針對 partially-visited edges 之修改方案進行更深一步的研究,並 考慮保護其他不同的隱私問題,如:最小生成樹或其他。
28
參考文獻
[1] L. Backstrom, D. P. Huttenlocher, J. M. Kleinberg, and X. Lan. Group formation in large social networks: membership, growth, and evolution. In KDD, pages 44–54, 2006.
[2] M. Barbaro and T. Z. Jr. A face is exposed for AOL searcher no. 4417749. New
York Times, Aug 2006.
[3] J. Cheng, A. Fu, and J. Liu, K-isomorphism: privacy preserving network publication against structural attacks, In SIGMOD conference, 459-470, 2010. [4] S. Das, O. Egecioglu, A.E. Abbadi, Anonymizing weighted social network
graphs, In ICDE, pages 904-907, 2010.
[5] M. Hay, G. Miklau, D. Jensen, D. F. Towsley, and P. Weis. Resisting structural re-identification in anonymized social networks. PVLDB, 1(1):102–114, 2008. [6] Y. He and J.F. Naughton, Anonymization of set-valued data via top-down, local
generalization, in VLDB 2009.
[7] K. Liu and E. Terzi. Towards identity anonymization on graphs. In SIGMOD
Conference, pages 93–106, 2008.
[8] L. Liu, J. Liu, J. Zhang, Privacy preservation of affinities in social networks, In ICIS, 2010.
[9] L. Liu, J. Wang, J. Liu, J. Zhang, Privacy preservation in social networks with sensitive edge weights, In SDM, pages 954-965, 2009.
[10] A. Meyerson and R. Williams. On the complexity of optimal k-anonymity. In Proc. of PODS, 2004.
[11] R. Motwani and S.U. Nabar, Anonymizing unstructured data, arXiv: 0810.5582v2, [cs.DB], 2008.
[12] H. Park and K. Shim. Approximate algorithms for k-anonymity. In Proceedings
of the 2007 ACM SIGMOD International Conference on Management of Data,
pages 67–78, 2007.
[13] P. Samarati and L. Sweeny. Generalizing data to provide anonymity when disclosing information. In Proc. of ACM Symposium on Principles of Database Systems, page 188, 1998.
[14] L. Sweeny. k-anonymity: a model for protecting privacy. International Journal on Uncertainty, Fuzziness and Knowledge-based Systems, 10(5):557–570, 2002. [15] S. Wasserman and K. Faust, Social network analysis: methods and applications,
Cambridge University Press, New York, 1994.
[16] B. Zhou and J. Pei. Preserving privacy in social networks against neighborhood attacks. In ICDE, pages 506–515, 2008.
[17] L. Zou, L. Chen, and M. T. Ozsu. K-automorphism: A general framework for privacy preserving network publication. In VLDB, 2009.