義 守 大 學
資訊工程學系
碩士論文
基於 OpenStack 有效提升 Hadoop
擴充性的研究與發展
The Investigation and Development of an
OpenStack Based Scalable Hadoop
System
指導教授: 柯松源 博士
研 究 生: 陳 奕 銘
基於 OpenStack 有效提升 Hadoop
擴充性的研究與發展
The Investigation and Development of an
OpenStack Based Scalable Hadoop System
研究生:陳奕銘 Student:Yi-Ming Chen 指導教授:柯松源 Advisor:Dr. Sung-Yuan Ko 義守大學 資訊工程研究所 碩士論文 A Thesis Submitted to
Department of Information Engineering I-Shou University
In Partial Fulfillment of the Requirements For the Master Degree
in
Information Engineering
January, 2015
I
基於 OpenStack 有效提升 Hadoop
擴充性的研究與發展
研究生:陳奕銘 指導教授:柯松源 博士義守大學
資訊工程研究所
雲端運算是近年來的一個新焦點、新方向,許多傳統的服務都慢 慢開始雲端化,而雲端化的方式大多數都是透過虛擬化來達成,而虛 擬化的工具、平台種類也很多,如:VMware 的 vSphere、Microsoft 的 Azure、Amazon 的 AWS 以及開放原始碼的 OpenStack 等。本研究的目的是在將本實驗室以前所開發的 BT-ECG[1][2]進行 虛擬化,BT-ECG 是一套基於 Hadoop 叢集的系統,我們把以前在實 體機器上執行的 Hadoop 叢集移植到虛擬機器上執行,虛擬化 Hadoop 主機叢集後,可以快速的透過增加更多的節點,來達到性能的提升。 本研究將使用開放原始碼的 OpenStack 打造一個私有雲。 關鍵詞:雲端運算、虛擬化、Hadoop、vSphere、Amazon、OpenStack
II
The Investigation and Development of an
OpenStack Based Scalable Hadoop System
Student:Yi-Ming Chen Advisor:Dr. Sung-Yuan Ko
Department of Information Engineering
I-Shou University
Cloud computing is a new trend in recent years. Many traditional services are beginning to migrate to cloud system. The most important characteristics of the cloud system is the virtualization. There are many virtualization platforms, such as: the vSphere of VMware, the Azure of Microsoft, the AWS of Amazon, and the opensource OpenStack.
The purpose of this research is to migrate the BT-ECG [1] [2] to the virtual machine. BT-ECG is a Hadoop cluster-based systems. Previously it was implemented on physical machines. Through virtualization, the performance can be improved by rapid deployment of more virtual machines.
In this research we will create a private cloud system by using the open source OpenStack.
Key Words: Cloud Computing, Virtualization, Hadoop, vSphere, Amazon, OpenStack
III 終於走到今天,即將邁入人生的第二階段,結束學生這個身份, 現在回想起來,我的求學過程,多采多姿,嘗盡酸甜苦辣,也因此我 從沒想過會念到碩士班,這兩年來過著非常充實的生活,很感謝我的 指導教授-柯松源博士,他這兩年給予我各種建議與方向,使我涉及更 多以往不曾踏入的領域,且在我怠惰懶散之時給予激勵,在我疑惑時 協助解答,使我能撐過這些時間,再來要感謝我身邊的這一群好朋友, 實驗室的夥伴,博鈞、明宗、衢宏、旻緯、鎧毅、建文、肇鈞等人, 在求學過程鼓勵激勵我,在我有困難的時候協助我給予我意見,感謝。 最後再次感謝柯松源、廖冠雄、楊吳泉三位教授,百忙之中抽空 幫我安排口試,因為有他們,我如今才能順利取得這張碩士畢業證書, 感謝所有給予我建議、幫助的人,謝謝。
IV 摘 要... I Abstract ... II 致謝... III 目 錄... IV 圖 目 錄... VII 表 目 錄... IX 略語表... X 第 1 章 前言... 1 1.1 研究動機 ... 1 1.2 論文架構 ... 2 第 2 章 背景知識... 3 2.1 雲端運算 ... 3 2.1.1 簡介 ... 3 2.1.2 雲端特徵 ... 3 2.1.3 服務模式 ... 4 2.2 Hadoop ... 5 2.2.1 HDFS ... 5 2.2.2 MapReduce ... 7 2.3 Hbase ... 8 2.4 Tomcat ... 10 2.5 BT-ECG ... 10 2.5.1 BT-ECG 概觀 ... 11 2.5.2 BT-ECG 雲端叢集架構 ... 12 2.6 VMware vSphere ... 12 2.6.1 vSphere 架構 ... 13
V 2.6.2 vSphere 軟體和功能 ... 14 2.6.3 VMware vSphere 附加元件 ... 15 2.7 OpenStack ... 15 2.7.1 OpenStack 系統核心與架構 ... 16 2.7.2 OpenStack 標準架構 ... 17 2.8 虛擬化 ... 18 2.8.1 x86 虛擬化 ... 19 2.8.2 全虛擬化 ... 20 2.8.3 半虛擬化 ... 20 2.8.4 CPU 硬體輔助虛擬化 ... 20 2.9 虛擬化軟體 ... 21 2.9.1 QEMU 介紹 ... 21 2.9.1 KVM 介紹 ... 22 2.9.2 OpenStack 的虛擬化支援 ... 22 第 3 章 研究環境與方法... 23 3.1 伺服器環境 ... 23 3.2 實驗方法 ... 23 3.3 實驗架構 ... 24 3.3.1 子系統架構 ... 24 3.3.2 網路架構 ... 26 3.3.3 創建 VM,子系統驗證流程 ... 28 3.3.4 佈署 VM 流程 ... 29 3.3.5 網路分配流程 ... 30 3.3.6 存儲建立流程 ... 31 3.3.1 建立動態增加 Hadoop 節點映像檔... 32 第 4 章 研究成果... 33 4.1 OpenStack Server 端 ... 33
VI 4.2 OpenStack Web 端 ... 34 4.3 BT-ECG ... 40 4.4 自動增加 Hadoop 節點 ... 41 第 5 章 結論與未來展望... 43 參考文獻... 44 附錄一... 47
VII 圖 1 HDFS 讀寫流程 ... 6 圖 2 MapReduce 執行流程 ... 8 圖 3 HDFS 運作模式 ... 10 圖 4 BT-ECG 手機端軟體與心電訊號擷取器 ... 11 圖 5 BT-ECG 資料流向 ... 11 圖 6 BT-ECG 叢集架構 ... 12 圖 7 vSphere 層級架構 ... 13 圖 8 OpenStack 核心架構 ... 17 圖 9 OpenStack 標準架構範例 ... 18 圖 10 x86 CPU 虛擬化特權階級 ... 19 圖 11 CPU 硬體輔助虛擬化特權階級 ... 21 圖 12 KVM 虛擬化的結構 ... 22 圖 13 多節點架構圖 ... 24 圖 14 單節點架構 ... 25 圖 15 多節點網路架構 ... 26 圖 16 單節點網路架構 ... 27 圖 17 創建 VM,子系統驗證流程 ... 28 圖 18 虛擬機創建流程 ... 29 圖 19 網路分配流程 ... 30 圖 20 存儲工作流程 ... 31
圖 21 OpenStack Nova 與 Cinder 服務狀態 ... 33
VIII 圖 23 Horizon 概觀 ... 35 圖 24 Horizon 執行實例列表 ... 36 圖 25 Horizon 創建虛擬機 ... 36 圖 26 Horizon 操縱虛擬機 ... 37 圖 27 Horizon 映像檔列表 ... 37 圖 28 Horizon 儲存空間列表 ... 38 圖 29 Horizon 存取權與安全性 ... 38 圖 30 Horizon 虛擬硬體樣板 ... 39 圖 31 Horizon 系統資訊 ... 39 圖 32 BT-ECG 即時心電圖顯示 ... 40 圖 33 BT-ECG 心電圖歷史紀錄 ... 40 圖 34 已做好的 Node 映像檔 ... 41 圖 35 原先 Task Tracker 列表 ... 41 圖 36 原先 Data Node 列表 ... 41 圖 37 創建 H-slave3 節點 ... 42 圖 38 上架完成 Task Tracker 列表 ... 42 圖 39 上架完成 Data Node 列表 ... 42
IX
表 1 雲端服務模式表 ... 4 表 2 伺服器環境 ... 23
X
AWS Amazon Web Services
HDFS Hadoop Distributed File System IaaS Infrastructure as a Service
KVM Kernel Based Virtual Machine LUN Logical Unit Number
LV Logical Volume OS Operating System PaaS Platform as a Service
RPC Remote Procedure Call Protocol SaaS Software as a Service
VMM Virtual Machine Monitor VM Virtual Machine
1 近年來,因為行動裝置的快速發展,導致數據量呈現爆炸性的規 模快速增長。隨著數據的增長,企業中的 IT 部門也試圖尋找新的方 法來有效的處裡、分析、存儲這些巨量數據,因此也造就了 Hadoop 的興起,它為使用者帶來簡單有效率的存儲和運算巨量資料的能力。 我們實驗室以前是將 Hadoop 安裝在實體的伺服器上運行[1][2], Hadoop 雖是個不錯的運算工具,但因為叢集的關係,需要準備多台 實體主機。為了節省掉硬體的成本,我們將實體主機虛擬化,虛擬化 可使 Hadoop 的佈建更有彈性。在原先使用實體主機的架構中,叢節 點的數目不易擴充,而在虛擬化之後,我們使用較高階的伺服器,在 此伺服器上可以經由配置 VM 來快速的增加叢節點的數量,並經由附 載平衡來提高 CPU 的使用率,如此不但可以降低硬體成本,也可以 提升系統性能。 VMware vSphere 是一套提供雲端基礎架構的虛擬化平台,它提 供了許多虛擬化功能,將各種硬體資源虛擬化,讓使用者能夠方便的 分配管理其硬體資源,並提供良好的資料備援功能,但它需要較高的 授權費用。基於節省成本的需求,我們使用了開放原始碼的解決方案 OpenStack,它的功能類似 Amazon 的 AWS,基於 OpenStack 可以實 現各種虛擬化的功能,並透過 Web 的方式來管理,使用上很方便。 在本研究中我們將使用 OpenStack 來搭建一個心電圖管理平台, 藉由虛擬化節點容易擴充的特性來提高 Hadoop 叢集的運算能力。
2 我們依照下列的步驟來達到我們的目標: 尋求適當虛擬化平台 建置虛擬化平台 OpenStack 熟悉虛擬化平台 OpenStack 建置虛擬化主機 建置 Hadoop 叢集 製作自動化增加 Hadoop 節點映像檔 應用 Hadoop 叢集(BT-ECG) 本文以“基於 Android 與雲端平台嵌入式心電圖監控系統的研發 [1]”與“雲端心電圖大量資料的分析與顯示 [2]”兩篇論文為基礎,將結 果移植到 OpenStack 平台上,將原本的實體機器虛擬化,提升硬體的 利用度。 本論文分為五章。第一章敘述本文的研究動機;第二章介紹雲端、 Hadoop、Tomcat、虛擬化、VMware vSphere、OpenStack 等背景知識; 第三章說明本專案的研究環境與方法;第四章介紹整體成果;第五章 結論;附錄介紹安裝 OpenStack 流程。
3 接下來介紹雲端的基礎結構、Hadoop 的功能、BT-ECG、VMware vSphere、OpenStack、虛擬化及虛擬化軟體。 雲端運算,是一種基於網際網路的運算模式,通過共享的軟硬體 資源與資訊,依據需求提供軟硬體資源給使用者 [3]。 雲端運算依賴資源的共享來達成大規模的經濟效益,服務提供者 整合大量資源並且提供租用服務給用戶使用,用戶可以方便的根據需 求隨時租賃資源,來應付顛峰時段所需要的大量資源,當不需要時可 立即退租,而退租後的資源將釋放出來,繼續供應其他用戶來進行申 請。 根據美國國家技術標準局定義 [4],雲端運算服務應該具備下面 幾項特徵: On-demand self-service(隨需求自行取用) 使用者可以依據使用需求,自行調整雲端服務的使用量。 Broad network access(隨時可透過網路使用)
使用者可以隨時透過網際網路,進行雲端服務的操作。 Resource polling(多人共享資源池)
4 體與虛擬資源的分配與指派。 Rapid elasticity(快速且彈性的佈署) 使用者可以依據需求很快速地調整資源的大小,對使用者而言有 取之不盡用之不竭的資源量,且隨時可以進行租賃。 Measured service (可以監控計算服務的使用量) 可以監控掌管計費、資源使用量、處理效能等,提供足以報告給 供應商與使用者的透明化服務使用資訊 根據美國國家技術標準局的定義,雲端服務有以下三種服務模式: 表 1 雲端服務模式表 SaaS(Software as a Service) 軟體即服務 PaaS (Platform as a Service) 平台即服務 IaaS (Infrastructure as a Service) 架構即服務 一、 架構即服務(IaaS) 透過虛擬化等技術,將硬體資源如:存儲裝置、網路裝置、伺服器 等資源組織成資源池,提供給使用者,讓使用者能掌握作業系統、儲 存空間、已佈署服務甚至網路元件等等。 二、 平台即服務(PaaS) 使用者可透過供應商提供的程式開發工具將自身應用建構於雲 端架構上,能掌握運作應用程式的環境(擁有主機部分權限),但沒有 作業系統、硬體、網路等架構權限。
5
三、 軟體既服務(SaaS)
透過網路提供軟體給使用者,使用者只要透過瀏覽器就能直接使 用軟體功能,使用者就只能操作軟體,不具備更高權限操縱其他功能。
Hadoop 是 Apache 軟體基金會提出的分散式運算平台。所用的程 式語言是 JAVA 語言,Hadoop 以分散式檔案系統(HDFS)和 MapReduce 為核心,提供分散式基礎架構。它是一個具有容錯、高效率與巨量的 儲存環境,是能夠支援到 Petabytes (1015)等級以上的磁碟空間 [5] [6]。
在 Hadoop 中 MapReduce 提 供 分 散 式 運 算 的 模 型 、 Hadoop Distributed File System(HDFS)提供大量儲存空間,兩者的結合形成一 個大型的分散式運算平台。
Hadoop Distributed File System 簡稱 HDFS,它的設計理念是在超 大 型 的 分 散 式 儲 存 環 境 裡 , 建 立 一 個 獨 立 的 目 錄 系 統 (Single Namespace)。HDFS 資料存取特性採用 Write-once-read-many 存取模 式,當檔案創立或寫入後將不再允許修改,而是以附加的方式,建置 在原本檔案後面,而 HDFS 的檔案分割通常是以 64MB 為一個區塊 [7]。 HDFS 叢集內會有兩種節點分別為 NameNode 與 DataNode。 NameNode 負責管理檔案系統中的命名空間(name space),且維護檔案 系統的樹狀結構,掌管所有檔案和目錄,因此 NameNode 會知道所有
6
檔案區塊存在哪個 DataNode 上。DataNode 是檔案系統儲存資料的地 方,當 NameNode 或客戶端發送請求時,進行儲存或擷取區塊,並定 時回報 NameNode,目前區塊上的儲存訊息。
HDFS 的特色是每個檔案區塊都會擁有三個備份,且分別存放在 三台不同的 DataNode 上,通過 Heart beats 來檢測 DataNode 的健康 狀況,如發現 DataNode 有異常就會採取資料備份。因此每次啟動 Hadoop 時,HDFS 都會進入安全模式,此時不允許進行刪除或修改任 何檔案,主要是為了檢查各 DataNode 上的區塊有效性。 下面介紹 HDFS 的讀取與寫入流程: 圖 1 HDFS 讀寫流程 一、 檔案寫入 Client 向 NameNode 提出檔案寫入的請求。 NameNode 依據檔案大小與檔案區塊的設定狀況,回傳給 Client
7
他所管理的 DataNode 資訊。
Client 將檔案切分為多個 Block,依據 DataNode 的位置資訊,依 序將檔案寫入各 DataNode 中。 二、 檔案讀取 Client 向 NameNode 提出讀取檔案的請求。 NameNode 傳回檔案儲存的 DataNode 資訊。 Client 讀取檔案資訊。 三、 檔案區塊(block)複製 當 NameNode 偵測到部分檔案 Block 不符合預設最小份數或部分 DataNode 異常將會開始進行複製。 通知 DataNode 進行複製缺少的 Block。 DataNode 之間直接開始互相複製。 它是 Google 提出的一種軟體架構,適用於大規模資料(大於 1TB) 的平行運算,其「Map(映射)、Reduce(化簡)」兩種概念主要的想法都 是源自於函數式程式語言。若要實現 MapReduce 程式可以經由 C++、 Java 或其他成式語言來編寫。 MapReduce 其框架是由一個單獨執行在主節點上的 JobTracker 和執行在各叢集從節點上的 TaskTracker 共同組成的。主節點負責排 程所有工作,將這些工作分配到不同節點上。主節點監控他們的執行 狀況,並重新執行之前失敗的工作;叢節點僅負責由主節點指派的工
8 作。當一個 Job 被傳送時,JobTracker 接收到傳送作業和設定訊息之 後,會把設定資訊等,分配給叢結點,同時排程工作並監控 TaskTracker 的執行 [8]。 MapReduce 程式設計模型原理:利用輸入的 key/value 集合來產生 一個 key/value 集合。 一、 使用者自訂一個 map 函數進行接收 key/value,產生一個中 間的 key/value 集合。(將相同 key 值的 value 集合在一起傳遞 到 reduce 函數)
二、 使用者自訂一個 reduce 函數進行接收 key 相關的 value 集合。 Reduce 函數合併這些 value 值,形成較小的 value 集合。
圖 2 MapReduce 執行流程
Hbase 分散式資料庫和 Hadoop 同樣使用 Java 語言開發,以 HDFS 檔案系統為儲存基礎,將表格拆成很多份,經由不同的伺服器負責該 部分的儲存,藉此提高效能,提供類似 Google 的 Bigtable 分散式資 料庫功能。
9
Hbase 不是一般常見的 MySQL、SQLite 等關聯式資料庫系統, 它擁有類似表格的資料結構,其表格只有一個主要的索引 row key, Hbase 依賴 row key 來自動排序,並提供 Java 函式庫與 REST 等資料 存取介面,可以透過 get row( )或 scan( )等函數存取資料。
Habse 資料庫在寫入資料的時候,會先寫入節點主機的動態記憶 體中,並有 Write-Ahead Log 以防意外發生時可以復原,每隔一段時 間將資料寫入 HDFS 檔案系統中,因此 Hbase 資料庫可以提供高速的 寫入。資料讀取也是先從節點主機的動態記憶體中讀取,若找不到資 料才去 HDFS 檔案系統上找,以提升讀取速率。 因此 Hbase 具備分散式、高可用性、高效能且易擴充等特性,相 當適用於數量龐大的伺服器群集上執行,用來儲存 Petabytes 等級的 大量資料,且 Hbase 搭配著 MapReduce 功能,更利於資料快速運算 [9]。
在系統架構上,HMaster 負責與 HRegionServer 溝通,Client 先經 由 Zookeeper 對 Hmaster 進行訪問,進而取得 HRegionServer 的位置, 然後對 HRegionServer 進行訪問;當 HRegionServer 故障時,將會調 用其他 HRegionServer 處理客戶請求。
當 Client 要寫入資料時 HLog 會優先紀錄接著才寫入 MemStore 中暫存,而 MemStore 會一段時間就將資料寫入 StoreFile 中,這裡會 經由 HDFS Client 將資料 HFile 寫入 hadoop 的 DataNode 中,並複製 三個備份出來。
10
圖 3 HDFS 運作模式
Tomcat 是 Apache 軟體基金會的 Jakarta 項目中的核心之一,是 一個免費的開放原始碼的 Web Server,其實現對 Servlet 和 Java Server Page(JSP)支援。在本專案進行虛擬化的 Server 中,透過它對外提供一 個 Web 介面,並作為一個中間人,負責溝通終端設備(例:手機、平板) 與雲端的 Hadoop [10]。 BT-ECG [1] [2]是一套能夠擷取心電訊號的系統並且能夠紀錄使 用者心跳紀錄。心跳擷取裝置透過藍芽,將接收到的心電訊號訊號傳 遞到手機上即時顯示,使用者能夠將心電圖資料上傳到雲端伺服器並 且可以透過 Web 瀏覽器去察看即時的心電圖狀態也可以查詢歷史紀 錄,這一套心電圖軟體能夠用於個人的心臟健康管理,也可輔助醫療 人員即早發現病患心臟的異常現象。
11 圖 4 BT-ECG 手機端軟體 與 心電訊號擷取器 經由使用者配戴心電擷取裝置,透過藍芽跟身邊的 Android 裝置 進行連接,我們能透過 Android 裝置查看即時狀況並記錄,藉由網路 將訊號傳送至雲端伺服器,藉由此方式記錄心電訊號,日後或是遠端 使用者,可直接連接上雲端伺服器查看心電狀況。 圖 5 BT-ECG 資料流向
12
在雲端架構中,採用 Tmocat 做為 Web 的端口,讓使用者可以透 過 Web 查看歷史資料或是即時心電訊號。BT-ECG 系統是以 Hadoop 為基底,並利用它叢集運算的能力,對心電訊號進行分析,並藉由 Hbase 將資料做儲存。
圖 6 BT-ECG 叢集架構
vSphere 是由 VMware 公司所提出的虛擬化解決方案,其中 ESXi 為其核心元件,ESXi 是一款作業系統它可以獨立安裝在實體主機上, 與 Virtual box、VMware Workstation 有所不同,不需要依附在作業系 統上。安裝好後,可以透過 Client 端連接上 ESXi 伺服器,在 ESXi 可 以開設立多台 VM(虛擬機),可以建立 Windows Server、Linux 等各式 伺服器,其功能性不輸給實體主機,透過控制端可方便的管理 [11]。
13 vSphere 是由許多虛擬化軟體組成的套件,其中包括 ESXi、vCenter Server 及 Client 等多項軟體組成。 vSphere 的層級架構可以分為三大層,端口層、管理層、虛擬 化層。 圖 7 vSphere 層級架構 一、 虛擬化層 虛擬化層包含著應用程式和基礎架構兩項服務。 基礎架構可以虛擬化、整合和分配硬體等功能: 運算服務:可以從不同的伺服器調用虛擬化的資源,強化運 算能力 存儲服務:可以在虛擬環境中有效的利用和管理
14 網路服務:提供虛擬環境中更容易地增強網路架構 應用程式可以確保應用的可靠性、安全性和可擴充性的功能: High Availability Fault Tolerance 二、 管理層 vCenter Server 是管理與配置虛擬化環境的中間人 三、 端口層
使用者可以透過 GUI 客戶端(vSphere Client 或 vSphere Web Client) 訪問 vSphere 資料中心,此外也可以透過 Comand Line 和 SDK 進行 管理訪問。 ESXi ESXi 是創建和運行虛擬機的系統平台,它將 CPU、RAM、硬碟 等資源虛擬化。透過它能夠運行虛擬機,安裝作業系統等功能。 vCenter Server 是一種 Windows 服務,安裝後會自動運行,是 ESXi 主機的中心 管理員,可控管多台 ESXi,將多台 ESXi 的資源加入池中進行管理, 還具備監控、管理物理與虛擬基礎架構的功能。
VMware vSphere Client
15
VMware vSphere Web Client
透過各種 Web 瀏覽器操作 vCenter Server 的 Web 軟體 vSphere vMotion
可以將運行中的虛擬主機從一台實體主機轉移到另一台實體主 機,同時可以不中斷主機、維持主機服務運作的完整性。
vSphere Storage vMotion
可以在儲存陣列間轉移虛擬機磁碟檔案,且不需要中斷服務,以 不中斷作業的方式將虛擬機磁碟檔案轉移到其他類別的儲存裝置中。 vSphere High Availability
可以提高虛擬機的可靠度,如果實體主機出現異常,受影響的虛 擬機將在其他有足夠空間的主機,重新上線服務。
vSphere Fault Tolerance
通過副本的方式保護虛擬機,提升可用性。虛擬機設置此功能後, 系統會自動創建原始或主虛擬機的副本。在主虛擬機上完成所有操作 也會鏡像於副本虛擬機,如果主虛擬機無法使用,則副本虛擬主機將 立即上線替補主虛擬主機。
OpenStack 是由 Rackspace 和 NASA 共同於 2010 年所發起的開 放原始碼專案,是基於 Python 語言所撰寫的開放原始碼軟體,其功 能就如同 Amazon AWS 一樣,通過運算、網通、儲存等模組組合而 成,將各種運算資源透過虛擬化,讓使用者可以透過虛擬機的方式彈
16 性擴充各種資源,是一套 IaaS 軟體,從成立至今每年仍然在不斷進 步,致力於整合兼容市場上各大虛擬化平台軟體 [12] [13]。 在本專案中基於開放原始碼,將使用 OpenStack 來虛擬化 Hadoop 主機叢集,增加資源的使用率。 Keystone(Identity service) OpenStack 的核心元件,主要提供 Nova、Glance、Cinder、Horizon 等認證服務。 Glance(Image Service) 管理虛擬磁碟映像的元件,主要提供映像建立、快照、儲存等功 能,在整個 OpenStack 中是重要的角色。 NOVA(Compute service) 提供虛擬機的主要元件,將計算、網路、存儲等資源虛擬化的重 要元件 [14]。
Cinder(Block Storage service)
提供區塊儲存的管理,能依據需求劃分不同大小的區塊,並指派 給不同的虛擬機。
Horizon(Dashboard)
以 OpenStack API 介面下去開發的,讓使用者透過 Web 的方式進 行 OpenStack 的使用與操作。
17 圖 8 OpenStack 核心架構 建 構 一 台 虛 擬 機 是 需 要 依 賴 多 種 元 件 組 成 , 下 面 是 一 張 OpenStack 官方典型的標準架構 [15]。 OpenStack 是一套具有高度變形與擴充能力的系統架構,開發者 可以依據不同的硬體需求,將不同的服務配置在不同的主機上,甚至 是配置在單一台主機上,運行 OpenStack。 依據圖 9 OpenStack 標準架構範例圖 9 可以發現,建構一台 VM 需要 Cinder、Nova、Glance、Neutron 來組成,其中 Neutron 在本實驗 中,採用 Nova-network 進行替代,會在下面進行說明。
18 圖 9 OpenStack 標準架構範例 虛擬化源自 60 年代 IBM 的 Mainframe 大型主機,是一項歷史悠 久的技術,藉由「分區」的技術來分配硬體資源 [16]。 虛擬化技術是將原本應該安裝在物理伺服器上的 OS,轉換成為 虛擬機器,讓一台物理伺服器上能運行多種不同作業系統,確保這些 OS 正常運作,與一般物理主機上的 OS 具有相同的功能。 藉由虛擬化物理伺服器,可以有效的將多台伺服器進行合併,除 了可以有效的利用硬體資源外,更能降低物理主機運行的電費、場地 費等費用。
19
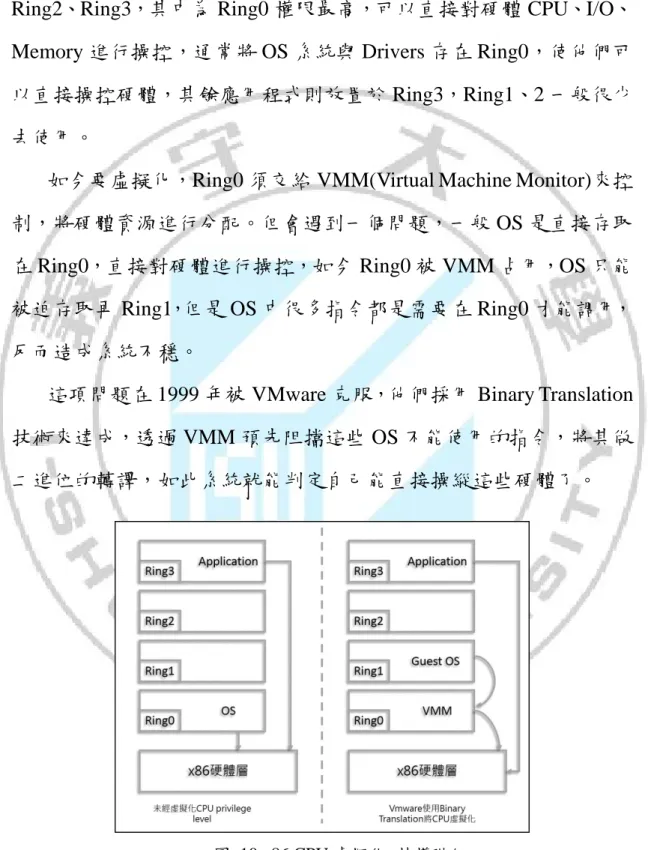
x86 CPU 的運作分為四個 privilege level(特權階級),Ring0、Ring1、 Ring2、Ring3,其中為 Ring0 權限最高,可以直接對硬體 CPU、I/O、 Memory 進行操控,通常將 OS 系統與 Drivers 存在 Ring0,使他們可 以直接操控硬體,其餘應用程式則放置於 Ring3,Ring1、2 一般很少 去使用。
如今要虛擬化,Ring0 須交給 VMM(Virtual Machine Monitor)來控 制,將硬體資源進行分配。但會遇到一個問題,一般 OS 是直接存取 在 Ring0,直接對硬體進行操控,如今 Ring0 被 VMM 占用,OS 只能 被迫存取再 Ring1,但是 OS 中很多指令都是需要在 Ring0 才能調用, 反而造成系統不穩。
這項問題在 1999 年被 VMware 克服,他們採用 Binary Translation 技術來達成,透過 VMM 預先阻擋這些 OS 不能使用的指令,將其做 二進位的轉譯,如此系統就能判定自己能直接操縱這些硬體了。
20
全虛擬化(Full Virtualization)是由 VMware 率先達成,透過 Binary Translation(二進位編譯)解決原先 x86 CPU 虛擬化後 OS 在 Ring1 上 無法完整調用指令的問題,將透過此方法把無法調用的指令轉為較低 階的語言,讓 Hypervisor 執行,使 Guest OS 擁有這些硬體。這種方 式優點在於 OS 不須做任何修改,直接安裝後系統就會認定自己能調 用各種硬體,算是支援度最佳的方案。
半虛擬化(Para Virtualization)是採用修改作業 Guest OS 的核心, 透過植入 Hypercall 讓原本不能虛擬化的指令經過 Hypercall interfaces 直接對硬體提出請求,使 Guest OS 可以保持在 Ring0,無須調降至 Ring1,而此種方法最大優點是 CPU 與 I/O 耗損很低,理論上效能能 夠超越全虛擬化,但受限於修改 OS 核心,因此只有少數 Linux 版本 可支援,OS 相容性並不高,而 Windows 無法修改 OS 核心,所以無 法採用半虛擬化的方式。
虛擬化的發展越來越蓬勃,因此 Intel 與 AMD 將從 CPU 本身架 構著手,去修改原先的特權階級 Ring0、1、2、3,重新畫分歸類為 Not-Root mode,並再新增一個 Not-Root mode 階級(Ring-1),因此 OS 能夠維 持在 Ring0 等級,讓 VMM 可設置在 Root mode 層級如圖 11。
21
圖 11 CPU 硬體輔助虛擬化 特權階級
由 Fabrice Bellard 所開發虛擬化的自由軟體,它具有兩種模式, User mode 與 System mode 兩種模式。
現在較常使用的是 System mode,在這種模式下,QEMU 能夠模 擬一台電腦,並包含 CPU 及其他周邊裝置。在它的作用下能夠讓一 台主機上虛擬多部不同的電腦。
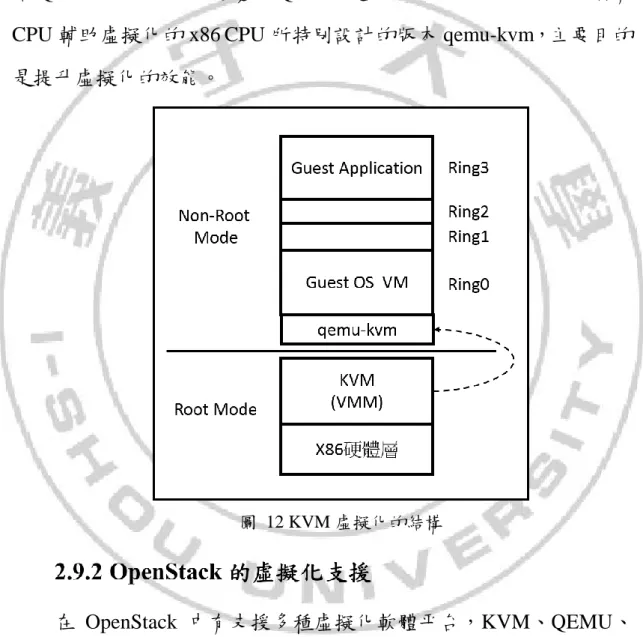
22
是開放原始碼的虛擬化軟體,全名為 Kernel-Based Virtual Machine。 KVM 需在具有 CPU 硬體輔助虛擬化(例: Intel、AMD-V)的 x86 CPU 上運行,它本身只負責 VMM 的工作,其它模擬硬體裝置的行為將交 給 QEMU 去運行。在這邊的 QEMU 是由 Fabrice Bellard 公司針對有 CPU 輔助虛擬化的 x86 CPU 所特別設計的版本 qemu-kvm,主要目的 是提升虛擬化的效能。
圖 12 KVM 虛擬化的結構
在 OpenStack 中有支援多種虛擬化軟體平台,KVM、QEMU、 LXC、UML、Xen、Hyper-V、vSphere、Bare Metal 等,但它以 KVM 與 QEMU 為主要虛擬化軟體,若搭建的伺服器主機 CPU 具有 CPU 硬體輔助虛擬化功能,將透過 KVM 進行虛擬化,此種方次效能會更 優於 QEMU,在本次實驗也將採用 KVM 進行虛擬化 [17]。
23 本實驗所採用的是一台高性能伺服器硬體如下: 表 2 伺服器環境 CPU I7-2600 @3.4GHz 記憶體 16 Gb 硬碟 1 TB 網路卡 2 張 作業系統 Ubuntu 本實驗主要目的是讓 Hadoop 在虛擬化的主機叢集上執行。將透 過 OpenStack 的功能快速展開虛擬機的架設並測試該平台。 我們將依下列順序進行: 1. 安裝實驗環境 Ubuntu14.04 Server 2. 設定 Ubuntu 工作環境 3. 建置 OpenStack 4. 建置 Debian Image
5. 於 OpenStack 上執行 Debian Image 6. 安裝 Hadoop 環境
7. 製作動態增加節點 Hadoop 映像檔 8. 運行 BT-ECG 環境
24 OpenStack 本身是一套很龐大的系統,其中由多數子系統組成, 而這些子系統又可以根據環境不同,選擇不同的配置,一般而言 Keystone、Glance、Nova、Nova-compute、Nova-network、Horizon 這 六大子系統是它的核心,根據前面介紹我們可以衍生出多種架構如: 圖 13 多節點架構圖 圖 13,這是一種標準的多節點架構,將核心元件與運算資源隔離 開來,Controller(管理節點)就能使用硬體規格較低的主機進行管理這 些核心元件,Compute(計算節點)就能將硬體支援專心供應虛擬機使 用。
25 圖 14 單節點架構 圖 14,這是僅有一台主機時使用的架構,同時也是本實驗所採 用的架構,將各大子系統集中於一台主機中,基於 OpenStack 靈活的 設計,使用者能夠依據自我硬體的狀況衍生出各式各樣的架構,因此 在建置前的規劃顯得相當重要。
26
在本小節會介紹網路的拓樸,下面有多節點與單節點的網路架構, 並加以說明[16]。
圖 15 多節點網路架構
各節點間透過 eth0 網卡進行管理階層的通訊,PC1 的 eth1 網卡 將與 PC2 的 eth1 網卡進行溝通藉由 nova-network 進行發送 Private IP, VM 虛擬機則經過 br100 將取得 Private IP 使 VM 虛擬機可以相互溝 通,若在 VM 上架設伺服器,故需使 VM 虛擬機可以從外部 SSH 或 連線則需要透過 Floating IP 賦予一組對外的 IP,藉此開通外到內的 網路。
27 圖 16 單節點網路架構 圖 16,主要是依賴 eth0 網卡來與外界溝通,而 eth1 不需要去做 任何設置,在這邊它只是作為一個端口使用,將 br100 橋接上 eth1, br100 扮演著重要的腳色就是連接各台虛擬機,並對它們發送 Private IP,藉此虛擬機就能相互溝通,若虛擬機要能夠從外部網路連進來, 那就需要從 Floating Pool 中賦予一組 IP 給指定虛擬機,使它具有外 到內的功能。
28
這邊以使用 Horizon 創建一台虛擬機為例,逐步介紹各子系統 間的驗證流程。
圖 17 創建 VM,子系統驗證流程
I. 使用者經由 Horizon (Dashboard)進行登入,Keystone (Identify) API 進行驗證。
II. 讀取 Glance (Image) API,查詢可使用映像檔列表。 III. Nova-compute 就接續開始進行虛擬機的創建。
經由圖 17 可知所有的程序都需要透過 Keystone 的驗證,通過驗 證後才能經由 API 達成互動。
29
將以下說明創建虛擬機時各 API 間的工作流程。
圖 18 虛擬機創建流程
I. 經由 Horizon 啟動創建虛擬機後,透過 nova-api 建立虛擬機,nova-api 會去解析各項參數並向 Keystone 進行驗證,進而呼叫 compute-api 建立虛擬機 VM,nova-compute 依據虛擬機參數信息(CPU、 記憶體、硬碟、網路等),存取並建立虛擬機的紀錄於資料庫中。 II. compute-api 經由 RPC (Remote Procedure Call Protoco)的方式將欲
建立虛擬機的基礎資訊封裝成信息,發送至中介軟體指定的信息 佇列「Scheduler」。
III. nova-scheduler 因為訂閱了信息佇列「Scheduler」,待接收到信息 後,根據目前叢集、計算節點資源等,選擇出恰當的實體主機部 屬。Nova-scheduler 虛擬機的基礎資訊與實體主機資訊再次封裝
30
發送至中介軟體指定的信息佇列「compute.實體主機」。
IV. 實體主機上 nova-compute 訂閱了信息佇列「compute.實體主機」, 接收到信息後,依據虛擬機的基礎資訊開始創建虛擬機。
V. Nova-compute 呼叫 network-api 進行網路 IP 的配置。
VI. Nova-network 會依據私有網路資源池,藉由 DHCP 進行 IP 分配。 VII. Nova-compute 透過呼叫 vloum-api 將儲存劃分出來,最後呼叫虛
化 Hypervisor 技術,完成部屬虛擬機。
在創建一台虛擬機的過程中,第一步為虛擬化各種硬體資源,第 二步將分配網路資源,本實驗中採用 nova-network,下方會介紹網路 的分配流程。
31
I. 於虛擬機創建的初期,虛擬網卡會配置 MAC address。 II. 從 IP POOL 中分配內部網路 IP address
III. 將 MAC address 與 IP address 信息發送至 DHCP Server 的設定裡 IV. 此後當啟動虛擬機啟動時,MAC address 與 IP address 就會自動綁 定生效。
虛擬機創建完成後,依據需求去創建存儲的硬碟空間,將以下介 紹新增硬碟空間與掛載的流程。
32
I. nova-api 呼叫 nova-compute 佈署 VM 虛擬機 II. nova-compute 呼叫 volume-api 進行創建儲存
III. scheduler 會根據設定的方法,選擇適當的儲存節點,將指令發送 給 nova-volume。 IV. nova-volume 接收到創建的指令,開始建立邏輯磁區 LV,並發布 LUN V. nova-compute 接收到 nova-volume 創建完成的信息後,呼叫虛擬化 層驅動,將 LUN 掛載給配置的虛擬機。
本實驗將使用 Hadoop 內建的 hadoop-daemon.sh,透過這個 Shell 可以執行 Hadoop 的單點啟動,基於快速簡單,我們採用最直接的做 法,將這個 Shell 寫入開機啟動中,讓虛擬機發動的同時就自動下達 這串指令,自動上線。
Hadoop-daemon.sh start tasktracker Hadoop-daemon.sh start datanode
本實驗即透過這兩串指令寫入 rc.local 檔內,使 Debian 虛擬機起 動的同時就能自動上架,無須再做其他設定檔更動,但這種方法有致 命缺點,即是若 Hadoop 重新啟動過後,因為 slave 文件檔未進行修 改,因此新加的節點並不會跟著起動,需透過預先設定好的 Shell 指 令或從 hadoop/bin 裡手動再啟動。
33 我們將 Server 端成功的配置在 OpenStack 環境,可以在遠端直接 透過 Web 訪問到我們所架設的 Server,並且可以進行虛擬機的創建, 同時內部網路與外部網路都可以正常運作,還可以針對虛擬機額外掛 增儲存空間。 OpenStack 基礎功能架設完成後,我們上傳了一個已經安裝完成 的 Debian 映像檔,在上方建立一個 Master、兩個 Slave 的 Hadoop 叢 集,並且安裝 Tomcat,將 BT-ECG 運行起來,再透過手機端與藍芽心 電訊號擷取裝置連接,從 Web 查看訊息,確認系統都已經確實架設 完畢。
透過指令 nova-manage service list 與 cinder-manage service list 可 以查詢到 Nova 與 Cinder 下各個 API 是否有正常啟動、最後刷新時間 等狀態。
34
登入 OpenStack 的 Horizon 後,可以優先看到左側選單如圖 22, 有三大項,運算、管理員、身分,以下列舉幾個重要的分頁介紹。
35
在這邊優先介紹專案內的頁面,透過概觀頁面能夠查看當線帳號 內的使用狀況,如 CPU、記憶體、IP 數量等訊息。
36 執行實例的分頁圖 24 能夠查看當前發動的虛擬機,並查看相關 狀態如:IP 位置、樣板、是否開機、啟動時間等,還能透過右上方按鈕 直接啟動虛擬機。 圖 24 Horizon 執行實例列表 在發動執行實例圖 25,能夠指派虛擬機的名稱,啟動虛擬機的樣 板、數量,最後設定啟動的來源,即可創建一台虛擬機。 圖 25 Horizon 創建虛擬機
37 虛擬機創建完成後,能夠在 Web 端透過 novnc 的方式直接在 網頁上操作虛擬機如圖 26。 圖 26 Horizon 操縱虛擬機 映像檔頁面圖 27,能夠查看當前權限能使用的映像檔,也可以 透過右上方按鈕來新增映像檔。 圖 27 Horizon 映像檔列表
38 儲存空間圖 28,能查看擁有的儲存空間、容量、掛載狀態、位 置,可以依據需求新增或刪除儲存空間。 圖 28 Horizon 儲存空間列表 存取權與安全性圖 29,能夠設置安全性群組管理 VM 對外的埠 口,並掛載 Floating IP 給虛擬機使用。 圖 29 Horizon 存取權與安全性
39 在管理者系統頁面中,可以管理虛擬硬體樣板,可以根據需求調 整 CPU、記憶體、硬碟空間、Swap 等,創建好的樣板在創建虛擬機 時就會出現。 在系統資訊圖 31 中,可以查看各個服務的連接狀態,在運算伺 服器的分頁則顯示類似圖 21 的狀態表。 圖 31 Horizon 系統資訊 圖 30 Horizon 虛擬硬體樣板
40
透過 OpenStack 建立 Debian 虛擬機後,在 Master 主機上安裝 Hadoop、HBase、Tomcat,叢結點則安裝 Hadoop、Hbase,環境設置 完後啟動 Hadoop,並運行 BT-ECG Store,成功運行後我們可以透過 Web 去察看量測者的即時心電圖 圖 32,也可以去翻閱歷史資料圖 33,當調閱出不正常的心電訊號時,系統會自動標示出來,且異常會 自動發送 mail 至指定信箱。
圖 32 BT-ECG 即時心電圖顯示
41 當 Hadoop 已經運行後,若要增加節點,僅須透過 node 映像檔啟 動全新的虛擬機即可 輕鬆自動上架。 圖 34 已做好的 Node 映像檔 圖 35 原先 Task Tracker 列表 圖 36 原先 Data Node 列表
42
圖 37 創建 H-slave3 節點
圖 38 上架完成 Task Tracker 列表
43 本次實驗中,透過 OpenStack 成功建立出一套雲端的虛擬化平台, 我們使用這套平台在上方建置的 Hadoop 的主機叢集,並且在上方移 植 BT-ECG。 在移植的過程中發現 Openstack 有許多優點,這些功能對未來擴 充或是管理伺服器都帶來更多的便利性,例如: 透過瀏覽器就能直接操縱虛擬機,如此一來就能跨平台操作,不會 被環境受限。 創建虛擬機時,可依據樣板創建多台虛擬機,切自動修改 Hostname。 現階段增加 Hadoop 節點的方法對於 OpenStack 的環境而言,是 最簡單也是最快速的方法,但要手動啟動虛擬機才能自動上架,理想 情況是能讓 Master 主機去與 OpenStack 平台進行溝通,透過特定信 息觸發自動去啟動虛擬機。 最後在本次的研究中,也發現許多廠商開始重視叢集運算, VMware 發起專案 Serengeti 可快速建立、擴充 Hadoop 叢集,而 OpenStack 中也建立一個新的子系統 Sahara,它們的目標都是要達到 可以讓使用者依據自己需求去做設置然後自動化的建立擴充 Hadoop 叢集。OpenStack 成立時雖並不長,但它的成長速度相當驚人,每年 會進行一次大改版,因此是一個值得深入研究探討並加以應用的雲端 平台。
44
[1] 王綱民, “基於 Android 與雲端平台嵌入式心電圖監控系統的 研發,” 於
碩士論文, 高雄市, 2011.
[2] 高誜亨, “雲端心電圖大量資料的分析與顯示,” 於
碩士論文,
高雄市.[3] “Cloud computing,” 4 Feb 2013. [線上]. Available: http://en.wikipedia.org/wiki/Cloud_computing.
[4] M. a. Grance, “Effectively and Securely Using the Cloud Computing Paradigm,” 2009.
[5] 陸嘉恒, Hadoop 實戰技術手冊, 台北市: 佳魁資訊股份有限公 司, 2012.
[6] “Apache Hadoop,” 4 Feb 2013. [線上]. Available: http://en.wikipedia.org/wiki/Apache_Hadoop.
[7] “HDFS Architecture Guide,” 4 Aug 2012. [線上]. Available: http://hadoop.apache.org/docs/r1.2.1/hdfs_design.html.
[8] T. White, Hadoop 技術手冊(第三版), 台北市: 碁峰資訊股份有 限公司, 2013.
[9] “HBase Architecture 101 - Storage,” 12 Oct 2013. [線上]. Available: http://www.larsgeorge.com/2009/10/hbase-architecture-101-storage.html.
[10] “Apache Tomcat,” 23 Aug 2014. [線上]. Available: http://zh.wikipedia.org/wiki/Apache_Tomcat.
45
[11] “虛擬化概述及 VMware VSphere 介紹,” 8 May 2013. [線上]. Available: http://bobolee.blog.51cto.com/6854994/1195475.
[12] 陳伯龍、程志鵬、張傑, 用 OpenStack 建立如 Amazon 的雲端 環境, 台北市: 佳魁資訊, 2014.
[13] “OpenStack,” [線上]. Available: http://www.openstack.org/. [14] “OpenStack Nova Architecture,” 11 Apr 2011. [線上]. Available:
http://ken.pepple.info/openstack/2011/04/22/openstack-nova-architecture/.
[15] “OpenStack Installation Guide for Ubuntu 14.04,” 15 Oct 2014. [線上]. Available:
http://docs.openstack.org/juno/install-guide/install/apt/content/ch_overview.html.
[16] 熊信彰, VMware vSphere5 虛擬化全面啟動, 台北市: 碁峰資訊 股份有限公司, 2012.
[17] “OpenStack Configuration Reference -juno,” 23 Jan 2015. [線 上]. Available:
http://docs.openstack.org/juno/config-reference/content/section_compute-hypervisors.html.
[18] “云计算战争:OpenStack vs VMware,” 3 Apr 2014. [線上]. Available: http://www.openstack.cn/p1206.html.
[19] “Pets vs. Cattle,” 26 Feb 2014. [線上]. Available: https://blog.engineyard.com/2014/pets-vs-cattle.
[20] “VMware 發表自家的 OpenStack 版本,” 26 Aug 2014. [線上]. Available: http://www.ithome.com.tw/news/90434.
46
[21] “OpenStack 集群的網路設置,” 6 Jul 2014. [線上]. Available: http://blog.chetui.org/openstack-network-config.html. [22] “OpenStack: 虚拟机创建的 50 个步骤和 100 个知识点(1),” 21 Aug 2014. [線上]. Available: http://www.cnblogs.com/popsuper1982/p/3927390.html. [23] 楊文誌, 雲端運算技術指南, 台北市: 松崗資產管理股份有限公 司, 2010. [24] “VMware vSphere® 為雲端基礎架構的建立提供領導世界的虛 擬化平台,” [線上]. Available: http://www.vmware.com/tw/products/vsphere/.
[25] “Big Data 價值實踐四大心法,” Nov 2013. [線上]. Available: http://www.etusolution.com/index.php/tw/etu-news/newsletter-tw/222-etu-newsletter-2013nov.
[26] “Project Serengeti,” [線上]. Available: http://www.projectserengeti.org/.
[27] “vSphere Big Data Extensions,” [線上]. Available: http://www.vmware.com/tw/products/vsphere/features/big-data.html.
[28] VMware vSphere Hypervisor(ESXi), http://blog.faq-book.com/?page_id=6276, VMware.
[29] “VMware vSphere Documentation,” [線上]. Available:
https://www.vmware.com/support/pubs/vsphere-esxi-vcenter-server-pubs.html.
47
環境配置
vim /etc/hostname controller vim /etc/hosts 140.127.194.aaa controller vim /etc/network/interfaces auto eth0iface eth0 inet static
address 140.127.194.aaa netmask 255.255.255.0 gateway 140.127.194.253
dns-nameservers 192.83.191.8 192.83.191.9 auot eth1
iface eth1 inet manual auto br100
iface br100 inet static
address 140.127.194.bbb pre-up ifconfig eth1
48
bridge-ports eth1 0.0.0.0 bridge_ports eth1
bridge_stp off
安裝 openstack 資料庫
apt-get install ubuntu-cloud-keyring
echo "deb http://ubuntu-cloud.archive.canonical.com/ubuntu" \ "trusty-updates/juno main" > /etc/apt/sources.list.d/cloudarchive-juno.list
更新系統資料
apt-get update && apt-get dist-upgrade
安裝 database
apt-get install mariadb-server python-mysqldb vim /etc/mysql/my.cnf
[mysqld]
#修改 bind-address bind-address = 0.0.0.0 #最末端新增下列
49
default-storage-engine = innodb innodb_file_per_table
collation-server = utf8_general_ci init-connect = 'SET NAMES utf8' character-set-server = utf8
service mysql restart
安裝 Messaging server
apt-get install rabbitmq-server
# rabbitmqctl change_password guest 07927743 Changing password for user "guest" ...
...done.
安裝 Identity service
配置環境
mysql -u root -p
CREATE DATABASE keystone;
GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'localhost' IDENTIFIED BY '07927743';
GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'%' IDENTIFIED BY '07927743';
50
生產一個隨機密鑰給 Administration token 使用 openssl rand -hex 10
1006a51f77aa5f342b10
安裝與設定
apt-get install keystone python-keystoneclient vim /etc/keystone/keystone.conf [DEFAULT] #這裡要修改成剛剛產生的隨機密鑰 admin_token = 1006a51f77aa5f342b10 [database] #修改資料庫的來源跟密碼 connection = mysql://keystone:07927743@controller/keystone [token] #新增 UUID 的來源和 SQL 的驅動 provider = keystone.token.providers.uuid.Provider driver = keystone.token.persistence.backends.sql.Token 同步資料庫
51
完成安裝
service keystone restart 刪除 ubuntu 預設的 SQLite
rm -f /var/lib/keystone/keystone.db
設置每小時刪除一次無效 token 避免累計過大增加 server 負擔 (crontab -l -u keystone 2>&1 | grep -q token_flush) || echo '@hourly /usr/bin/keystone-manage token_flush >/var/log/keystone/keystone-tokenflush.log 2>&1' >> /var/spool/cron/crontabs/keystone
Identity service 建置
配置環境
設置 Administration token 與 Endpoint
export OS_SERVICE_TOKEN=1006a51f77aa5f342b10
export OS_SERVICE_ENDPOINT=http://controller:35357/v2.0
新增 tenants users 和 roles
新增 admin tenant
52
新增 admin user
keystone user-create --name admin --pass 07927743 --email [email protected]
新增 admin role
keystone role-create --name admin
將 admin tenant 和 user 添加到 admin role
keystone user-role-add --user admin --tenant admin --role admin *不會顯示任何信息
新增 service tenant
53
新增 Identity service entity
keystone service-create --name keystone --type identity --description "OpenStack Identity"
新增 Identity service API endpoints
keystone endpoint-create --service-id $(keystone service-list | awk '/ identity / {print $2}') --publicurl http://controller:5000/v2.0 --internalurl http://controller:5000/v2.0 adminurl http://controller:35357/v2.0 --region --regionOne
驗證操作
取消臨時設置的 OS_SERVICE_TOKEN 與 OS_SERVICE_ENDPOINT
54
unset OS_SERVICE_TOKEN OS_SERVICE_ENDPOINT 使用 admin 取得 authentication token
keystone tenant-name admin username admin --os-password 07927743 --os-auth-url http://controller:35357/v2.0 token-get
使用 admin 查看 tenan 列表
keystone tenant-name admin username admin --os-password 07927743 \
--os-auth-url http://controller:35357/v2.0 tenant-list
使用 admin 查看 user 列表
keystone tenant-name admin username admin --os-password 07927743 --os-auth-url http://controller:35357/v2.0 user-list
55
使用 admin 查看 role 列表
keystone tenant-name admin username admin --os-password 07927743 --os-auth-url http://controller:35357/v2.0 role-list
新增環境憑證腳本
vim admin-openrc.sh export OS_TENANT_NAME=admin export OS_USERNAME=admin export OS_PASSWORD=07927743 export OS_AUTH_URL=http://controller:35357/v2.0 source admin-openrc.sh安裝 Image Service
配置環境
mysql -u root -pCREATE DATABASE glance;
GRANT ALL PRIVILEGES ON glance.* TO 'glance'@'localhost' IDENTIFIED BY '07927743';
56
GRANT ALL PRIVILEGES ON glance.* TO 'glance'@'%' IDENTIFIED BY '07927743';
設置 admin 的環境憑證 source admin-openrc.sh 新增 glance user
keystone user-create --name glance --pass 07927743
將 glance user 添加到 admin role
keystone user-role-add --user glance --tenant service --role admin *不會顯示任何信息
新增 glance service entity
keystone service-create --name glance --type image --description "OpenStack Image Service"
57
新增 Image Service API endpoints
keystone endpoint-create --service-id $(keystone service-list | awk '/ image / {print $2}') --publicurl http://controller:9292 --internalurl http://controller:9292 --adminurl http://controller:9292 --region regionOne
安裝與設定
apt-get install glance python-glanceclient vim /etc/glance/glance-api.conf
[DEFAULT]
58 default_store = file [database] #修改資料庫的來源跟密碼 connection = mysql://glance:07927743@controller/glance [keystone_authtoken] #設置 Identity service 許可 auth_uri = http://controller:5000/v2.0 identity_uri = http://controller:35357 admin_tenant_name = service admin_user = glance admin_password = 07927743 [paste_deploy] flavor = keystone [glance_store] #設置鏡像的存儲路徑 filesystem_store_datadir = /var/lib/glance/images/ vim /etc/glance/glance-registry.conf [database] 修改資料庫的來源跟密碼
59 connection = mysql://glance:07927743@controller/glance [keystone_authtoken] 設置 Identity service 許可 auth_uri = http://controller:5000/v2.0 identity_uri = http://controller:35357 admin_tenant_name = service admin_user = glance admin_password = 07927743 [paste_deploy] flavor = keystone 同步資料庫
su -s /bin/sh -c "glance-manage db_sync" glance
完成安裝
service glance-registry restart service glance-api restart 刪除 ubuntu 預設的 SQLite rm -f /var/lib/glance/glance.sqlite
驗證操作
60 mkdir /tmp/images cd /tmp/images 下載測試鏡像檔 wget http://cdn.download.cirros-cloud.net/0.3.3/cirros-0.3.3-x86_64-disk.img 上傳鏡像檔到 Image Service
glance image-create --name "x86_64" --file cirros-0.3.3-x86_64-disk.img --disk-format qcow2 --container-format bare --is-public True --progress
查看上傳的鏡像屬性 glance image-list
移除暫存資料夾 rm -r /tmp/images
61
安裝 Compute service
配置環境
mysql -u root -p
CREATE DATABASE nova;
GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'localhost' \ IDENTIFIED BY '07927743';
GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'%' \ IDENTIFIED BY '07927743';
新增 nova user
keystone user-create --name nova --pass 07927743
將 nova user 添加到 admin role
keystone user-role-add --user nova --tenant service --role admin 新增 nova service entity
keystone service-create --name nova --type compute --description "OpenStack Compute"
62
新增 Compute Service API endpoints keystone endpoint-create \
--service-id $(keystone service-list | awk '/ compute / {print $2}') \ --publicurl http://controller:8774/v2/%\(tenant_id\)s \
--internalurl http://controller:8774/v2/%\(tenant_id\)s \ --adminurl http://controller:8774/v2/%\(tenant_id\)s \ --region regionOne
安裝與設定 Controller Node
apt-get install nova-api nova-cert nova-conductor nova-consoleauth nova-novncproxy nova-scheduler python-novaclient nova-compute sysfsutils
63
vim /etc/nova/nova.conf [DEFAULT]
#設置 RabbitMQ message broker 許可 rpc_backend = rabbit rabbit_host = controller rabbit_password = 07927743 auth_strategy = keystone my_ip = 140.127.194.aaa vnc_enabled = True vncserver_listen = 0.0.0.0 vncserver_proxyclient_address = 140.127.194.aaa novncproxy_base_url = http://140.127.194.aaa:6080/vnc_auto.html [glance] #設置 Image Service 位置 host = controller [database] #修改資料庫的來源跟密碼 connection = mysql://nova:07927743@controller/nova
64 [keystone_authtoken] #設置 Identity service 許可 auth_uri = http://controller:5000/v2.0 identity_uri = http://controller:35357 admin_tenant_name = service admin_user = nova admin_password = 07927743
完成安裝 Compute Node
service nova-api restart service nova-cert restart
service nova-consoleauth restart service nova-scheduler restart service nova-conductor restart service nova-novncproxy restart service nova-compute restart 刪除 ubuntu 預設的 SQLite rm -f /var/lib/nova/nova.sqlite
65
驗證操作
查看各個 Compute Service 狀態 nova service-list 查看 Image Service 的鏡像列表 nova image-list安裝 Networking 元件
安裝與設定 Compute Node
apt-get install nova-network vim /etc/nova/nova.conf auth_strategy = keystone my_ip = 140.127.194.bbb vnc_enabled = True vncserver_listen = 0.0.0.0 vncserver_proxyclient_address = 140.127.194.ccc
66 novncproxy_base_url = http://140.127.194.aaa:6080/vnc_auto.html network_api_class = nova.network.api.API security_group_api = nova network_manager=nova.network.manager.FlatDHCPManager force_dhcp_release=True firewall_driver=nova.virt.libvirt.firewall.IptablesFirewallDriver flat_network_bridge=br100 fixed_range=10.10.0.0/22 flat_network_dhcp_start=10.10.0.10 network_size=1022 # Floating IPs #auto_assign_floating_ip=true #default_floating_pool=public public_interface=eth1
service nova-api restart
service nova-scheduler restart service nova-conductor restart service nova-network restart
67
service nova-api-metadata restart
新增 Network
nova network-create demo-net --bridge br100 --multi-host T \ --fixed-range-v4 10.10.0.0/24
nova-manage floating create ip_range 140.127.194.0/24 --pool=public
nova net-list
安裝 DashBoard
安裝與設定
apt-get install openstack-dashboard apache2 libapache2-mod-wsgi memcached python-memcache && dpkg --purge openstack-dashboard-ubuntu-theme
vim /etc/openstack-dashboard/local_settings.py OPENSTACK_HOST = "controller"
service apache2 restart service memcached restart
68
安裝 Block Storage service
配置環境
mysql -u root -p
CREATE DATABASE cinder;
GRANT ALL PRIVILEGES ON cinder.* TO 'cinder'@'localhost' \ IDENTIFIED BY '07927743';
GRANT ALL PRIVILEGES ON cinder.* TO 'cinder'@'%' \ IDENTIFIED BY '07927743';
keystone user-create --name cinder --pass 07927743
keystone user-role-add --user cinder --tenant service --role admin keystone service-create --name cinder --type volume --description "OpenStack Block Storage"
keystone service-create name cinderv2 type volumev2 --description "OpenStack Block Storage"
69
keystone endpoint-create --service-id $(keystone service-list | awk '/ volume / {print $2}') --publicurl http://controller:8776/v1/%\(tenant_id\)s --internalurl http://controller:8776/v1/%\(tenant_id\)s --adminurl http://controller:8776/v1/%\(tenant_id\)s --region regionOne
keystone endpoint-create --service-id $(keystone service-list | awk '/ volumev2 / {print $2}') --publicurl http://controller:8776/v2/%\(tenant_id\)s --internalurl http://controller:8776/v2/%\(tenant_id\)s --adminurl http://controller:8776/v2/%\(tenant_id\)s --region regionOne
70
安裝與設定 Controller Node
apt-get install api scheduler python-cinderclient cinder-volume python-mysqldb
vim /etc/cinder/cinder.conf [DEFAULT]
#設置 RabbitMQ message broker 許可 rpc_backend = rabbit rabbit_host = controller rabbit_password = 07927743 my_ip = 140.127.194.bbb glance_host = controller [database] #修改資料庫的來源跟密碼 connection = mysql://cinder:07927743@controller/cinder
71 [keystone_authtoken] #設置 Identity service 許可 auth_uri = http://controller:5000/v2.0 identity_uri = http://controller:35357 admin_tenant_name = service admin_user = cinder admin_password = 07927743 vim /etc/tgt/targets.conf iinclude /var/lib/cinder/volumes/ ls /dev/[sh]d* pvcreate /dev/sdb
vgcreate cinder-volumes /dev/sdb service cinder-scheduler restart service cinder-api restart
service cinder-volume restart service tgt restart