行政院國家科學委員會專題研究計畫 成果報告
子計畫六:DVB-T 接收器通道解碼器之設計與實作(2/2)
計畫類別: 整合型計畫 計畫編號: NSC93-2220-E-110-007- 執行期間: 93 年 08 月 01 日至 94 年 07 月 31 日 執行單位: 國立中山大學資訊工程學系(所) 計畫主持人: 張雲南 計畫參與人員: 王植健、丁昱中、廖惟中 報告類型: 完整報告 報告附件: 出席國際會議研究心得報告及發表論文 處理方式: 本計畫可公開查詢中 華 民 國 94 年 10 月 31 日
行政院國家科學委員會專題研究計畫成果報告
DVB-T 接收器通道解碼器之設計與實作(2/2)
摘要
隨著多媒體壓縮及數位通訊技術的快速發展,傳統類比電視的系統也將逐漸 邁入歷史,取而代之的乃是嶄新的數位電視系統。在這波系統轉播的過程中,如 何快速掌握數位電視系統發展的相關技術例如數位視訊廣播接收器,則顯得非常 重要。本計畫即是針對數位視訊傳輸系統中關於通道編碼的協定,探討其解碼器 之設計與實作,以提出最佳化之電路架構。而在數位視訊傳播中所採用之錯誤更 正的通道編碼乃是採用連接及交錯碼的方式,因此在解碼器的設計裡包含了主要的四個模組:內部解交錯器(inner deinterleaver)、內部解碼器-腓特比解碼器(inner
decoder)、外部解交錯器(outer deinterleaver)和外部解碼器-禮德所羅門解碼器 (outer decoder)。本計畫在第一年期間已將各個模組的基本電路設計完成,而 第二年主要是將各個模組進一步的最佳化,尢其針對這四個模組都需要很大的資 料區塊儲存單元,如何有效地實現這些記憶單元成為整個設計的關鍵。因此本計 畫針對各個模組的資料存取特色提出基於單埠記憶體的儲存架構,可以有效降低 所需電路面積及避免使用移位暫存器所造成極大的動態功率消耗。此外,在腓特 比解碼器的設計中,針對協定所須解碼速度要求,可以減少原先一半的算術處理 單元。這四個模組已整合為一完整的通道解碼器,同時也完成矽智產設計所須的 驗證機制,並利用場效可程式化邏輯陣列中驗證其功能無誤。在晶片實作上從其 佈局繞線後所得的面積是所有文獻中最小的。 關鍵詞:腓特比解碼器、禮德-所羅門解碼器、通道解碼器、數位視訊地面廣播、 有限場域常數乘法器
ABSTRACT
With the rapid advancement of multimedia compression and digital communication techniques, the traditional analog television system is gradually replaced by novel digital televisn systems. During this transition era, how to grasp the key system development techqniues of the new digital television such as the design of terrestrial digital video broadcast (DVB-T) receiver has become a very important topic. The goal of this project is to address the design and implementation of the channel decoders based on the channel coding standard of the DVB-T protocol in order to propose an optimized architectural solution. The error control coding scheme adpoted in DVB-T system is based on the concatenated and interleaving codes. Therefore, the entire DVB-T channel decoder consists of four major modules including an inner Viterbi decoder, outer Reed-Solomon decoder and inner and outer de-interleaver modules. During the first year of this project, the preliminary architectures of all these modules have been proposed and implemented. They are further integrated and optimized in the second year of the project. Especailly all these four modules all require a significant amount of data storage space, how to efficiently realized these storage architectures has been the most important issue. In this project, based on the data access feature of the individual module behavior, the efficient data storage schemes have been proposed based on single-port RAM blocks which can lead to the reduction of silicon area and the dynamic power dissipation compared with the shift register based architecture. In addition, the number of arithmetic units used for Viterbi decoder can be reduced by half by folding technique to meet the decoding speed requirement. All the four modules have been integrated as a complete channel decoder, and the relevant verification schemes have also been
provided to justify as the silicon intellectural property. The proposed decoder has also been prototyped in the field-programmable chip. The layout of the decoders has shown that the required silicon area is the smallest one ever found in the literature.
Keywords: Viterbi decoder, Reed-Solomon decoder, channel decoder, DVB, deinterleaver
目錄
摘要...1
ABSTRACT...2
第一章
研究計畫之背景及目的 ...5
第二章
文獻探討 ...7
第三章
研究方法 ...17
第四章
研究成果 ...39
第五章
成果自評 ...44
參考文獻 ...45
第一章 研究計畫之背景及目的
隨著數位化科技不間斷地演進,人類生活的型態也隨著改變。譬如隨著 數位化影音編碼壓縮技巧的日益純熟,無論在影音品質的提昇或是數位內容 的儲存、交換與傳遞,都出現與以往大不相同的面貎。另一方面,隨著數位 通訊技術的改良,可以提供更佳的頻譜使用率,並克服以往因地形地物因素 造成接收不良或訊號忽強忽弱的現象,所以過去許多類比式的系統,無論是 對於衛星、地面或纜線的通訊都將逐漸汰換為數位式通訊系統,如行動通訊 從第一代的類比式通訊演進到目前的第三代多媒體服務數位系統。而數位影 音與通訊結合所產生的應用,近年來最受矚目的焦點之一乃是數位電視的推 動,在未來幾年,世界各先進國家將逐漸淘汰類比傳統的電視,進入嶄新的 數位電視的時代。如美國宣布將在 2006 年 5 月 31 日終止類比電視廣播並進 入全數位的時代,此已變成全球電視廣播業者的參考指標。而我國近幾年也 積極推動數位電視傳播系統,並於民國九十年六月決定採用歐洲電信標準協 會所制定的 DVB-T 視訊廣播標準,此一標準為 1997 年 2 月歐洲電信標準協 會認可歐洲數位地面電視廣播標準[1],所制訂的數位視訊廣播系統,其基本 接收器之架構圖如圖 1。由於傳播電視數位化乃是未來傳播方式之趨勢,因 此世界各國也都投入相當多資源於該項研究,如何在即將來臨的數位電視時 代掌握相關的電子技術,對於台灣的產業相當重要。 本計畫之主要目的在於設計應用於數位視訊地面廣播接收器(DVB-T)之 通道解碼器,並與其他子計畫進一步整合構成為一群體計畫,以實現一完整 之 DVB-T 接收器。詳細之 DVB-T 通道解碼的規格如[1]所示。關於通道解碼 器的設計一般可以採用 DSP 處理器或 ASIC 的方法,前者的優點是有彈性, 容易使用和可程式化,但其成本、速度、功率比較遜色。由於通道解碼器所包含之運算處理量很大,也有相當之規律性,因此適合利用 ASIC 之方式來實 現。因此本計畫將在符合 DVB 之系統標準規範下,從演算法、積體電路架構 以至於電路設計等各層面考量來實現最佳化之模組,及通道解碼器之矽智 產。本計畫在兩年期計劃的第一年,已經將個別模組的基本電路設計完成, 因此在第二年將進一步整合並最佳化各別模組,以達到減少晶片面積及功率 消耗之目的。其中尢其是各個模組都須要大量的記憶區塊來儲存解碼過程中 所產生的中間運算值,如何針對此一問題提出最佳化的架構,將是整個解碼 器效能的關鍵所在。 圖 1 DVB-T 架構
第二章 文獻探討
在 DVB-T 中所採用的通道編碼的方式是採用連接碼(concatenated codes)及資 料交錯的方式來提供錯誤更正的效果,因此完整通道解碼器是由以下的四個主要 模組連接而成:
一. 內部解交錯器 inner deinterleaver
二. 內部解碼器 inner decoder (viterbi decoder) 三. 外部解交錯器 outer deinterleaver
四. 外部解碼器 outer decoder (Reed-Solomon decoder)
圖二顯示了相關 DVB 在不同傳播媒介所採用不同的通道解碼規格。解碼器 所接收輸入資料的格式是 MPEGⅡ運輸封包(transport packet)。在一般情況下,它 只會有一組資料流輸入(input stream)。但也可以擴充為兩組輸入,其中一組輸入 可用來傳送比較重要而需要較好的保護的資料。相對而言,另一組則用來傳送較 次要的資料而可接受較低的保護。此計畫也支援這模式,分為 non- hierarchical mode 和 hierarchical mode。由於如圖二所示各個 DVB 相近規格,包含歐洲 DVB-C (Cable)有線 TV 標準,DVB-S (Satellite)衛星 TV 標準及 DVB-T (Terrestrial)無線 TV 標準,其解碼的差異度有限,因此本計畫所設計的解碼器將提供這幾種不同 規格的解碼功能。
以下針對上述通道解碼器的四個主要模組的相關設計方法,依序討論如下: 1 Inner deinterleaver 在 DVB-T 系統中的內部交錯器包含了兩個階層的交錯,第一層是位元交 錯,第二層是符號交錯。因此在解交錯的架構上將包含了一個符號解交錯器,再 加上一個位元解交錯器。 1.1符號解交錯器(Symbol deinterleaver) 符號交錯、解交錯為通道編解碼的一個主要部分,此一信號交錯是採區塊交錯 ( Block interleaving ), 將 每 一 個 OFDM ( Orthogonal Frequency Division Multiplexing)符號所產生之 1512 筆資料(2K 模式)或 6048 筆資料(8K 模式)以亂 數交錯的方式重新排列信號順序。在硬體的設計上因此有兩點須要特別處理的部 分,一是由於交錯順序在規格書上是由一排列函數 H(q)所定義,如將此資料重 排序的亂數位置存在一個表,顯然會浪費很大的記憶空間。而 H(q) 此一函數雖 然可以由一個基於移位暫存器架構之近似亂數產生器實現,但由於此一類似移位 暫存器的亂數產生器產生位置的總數為 2 的冪次方,為了符合區塊大小,因此亂 數產生器的結果得再進一步調整,但這也造成設計上的困難,可能無法達到即時 產生的功能必須加以克服。此外,多大的記憶區塊也是一個問題,因為對於奇偶 符號的排序方式各不相同,文獻[2]之解交錯器是採用兩塊 1512 或 6048 的記憶 體及兩個亂數位址產生器,此一方式雖然單純,但是所耗費的記憶體大小將是個 問題。 1.2位元解交錯器(Bit deinterleaver) 位元解交錯器是採用區塊交錯的方法,大小是 126 位元,位元交錯的資料排 列順序會依照調變的方式而不同。此一區塊資料交錯的排列方式是按照[1]所定 義的 He(w)函數。符號交錯器送出 126 個 v 位元的字元,yout = [ a0,a1... av-1 ],到 位元交錯器,每一個交錯器只收到一個位元,位元 a0送到編號 I0 的位元交錯器, 位元 av-1送到編號 I(v-1)的位元交錯器,對每一個位元交錯器輸入位元向量如下:
A (e) = (ae.0,ae.1,ae.2... ae.125) 其中 e = 0, 1, 2….. v-1
位元交錯器的輸出向量如下
B (e) = (be.0,be.1,be.2... be.125) 是被定義如下
be. He(w)= ae.w 其中 w = 0,1,2………125 其中 He(w)是個排列函數並且定義如下 I0:H0(w)=w I1:H1(w)=(w + 63) mod 126 I2:H1(w)=(w + 105) mod 126 I3:H1(w)=(w + 42) mod 126 I4:H1(w)=(w + 21) mod 126 I5:H1(w)=(w + 84) mod 126
位元交錯器的步驟在 2k mode 每一個 OFDM 符號會重複 12 次,在 8k mode 會重 複 48 次。
2 Inner decoder
信號經過內部解交錯後,則進行下一步內部解碼,也就是腓特比解碼。腓特 比的演算法乃是從 state 轉換圖中找出最接近的狀態轉換順序,可以針對迴 旋編碼(convolutional code)而得到最近似解的解碼方式。其計算上包含了 state metric 的累加與比較,以及回溯(traceback)找出 survivor 的路徑。而 就 DVB 所使用之 Viterbi 編碼而言,針對不同傳輸條件而衍生因應之不同的 傳送資料速率,乃採用一如圖三所示之基本母迴旋編碼器,具有 1/2 碼率 (code rate)與 7 個限制長度(constraint length),並加上 DVB 特定的穿刺 (puncturing)功能,以提供 2/3、3/4、5/6 與 7/8 四種不同碼率的迴旋碼。因此 要完成一多重碼率的迴旋碼解碼器,需使用解穿刺法再搭配原先碼率 1/2 的 Viterbi 解碼器,設計出一多重碼率 Viterbi 解碼器(Rate Compatible Viterbi
Decoder);並考慮如何有效率地在狀態數目為 64 的情況下,完成每個遞迴 (iteration)的 ACS(add-compare-select)運算,且適合超大型積體電路實現 的架構。其次需考慮存活路徑(survivor path)的尋找及解碼輸出,利用回溯 (trace-back)的設計方式得考量如何提高有效的回溯運算,並且存活路徑的記 憶體不能太大。尢其記憶體 RAM 的讀寫很耗費功率。 圖 3 DVB 的母迴旋編碼器 腓特比演算法搜尋狀態轉換圖中最可能路徑乃是先根據累加 branch metric 所得之 state metric 值來決定進入每一 state 之路徑,並將此一最可能之路徑以 decision bit 記錄下來,最後則由每一階段之 decision bit 來回溯找出整體的 survivor 路徑。因此,在硬體架構上如圖 4 包含了三個部份:branch metric unit(BMU)、 add compare select (ACS) unit 和 survivor memory unit(SMU)。其中以 ACS unit (ACSU)及 SMU 之設計最複雜,分別敘述如下。
VA 中的一個很重要的步驟就是計算 state metric,對於一個 rate-1/2 的 Viterbi
解碼器,計算的公式如下:
(
(
)
)
4 2 / 3 1 2 2 2 / 1 2 , min , min bm sm bm sm sm bm sm bm sm sm N j j j N j j j + + = + + = + + + 從這個公式可以看出 state metric(sm2j,sm2j+1)是從兩個加法的結果中,選擇 一個較小的數,一般稱這個動作為 add-compare-select(ACS)。一般說來目前有 兩 種 主 要 的 方 法 來 實 現 Viterbi 解 碼 器 的 ACS 模 組 : state-parallel[3] 和state-serial[4]。其中 state-serial 只用少數 ACS pair 來循序完成所有 states 的 ACS 運算,此一方法的優點是所需要的 ACS 硬體較少,然而其速度很慢。而 state-parallel 的方法中,若有 N 個 states,就需要 N 個 ACS units,每個 ACS unit 負責固定一個 state 的 ACS 運算。這種方法的好處是速度快,儲存 state metric 和 decision bit 的硬體較簡單;然而當 constraint 長度很大時,如 CDMA 及許多 TV broadcasting 的 應 用 如 HDTV ( High Definition TV )、 DVB ( Digital Video
Broadcasting),其架構需要很多的 ACS 運算元,耗費許多的硬體面積;更重要
的,因著 Viterbi 的演算特性需要許多整體訊號的聯結,因此繞線的複雜度會非 常的高。這是在設計 ACSU 中得注意的。
除了 ACSU 之外,SMU 的設計在 Viterbi 解碼器上更為重要,尢其是當 constraint 的長度很大時,survivor 路徑需要更長的距離收歛,也導致所需儲存
decision 結果的記憶體及相對應的操作增加。Register-Exchange(RE)和 Trace-Back
(TB)是目前最常使用的 SMU 的設計架構。其中 Trace-Back 的方式乃將某一特 定時間儲存所有組態其來源組態的訊息(i.e. decision bit) ,若要尋找出整體路徑 則須要做回溯(TraceBack)的動作。在 Viterbi 解碼動作一般定義了 L 及 D 分別 代表了 survivor path 及 decode path 的長度,當從任意組態回溯 L 個長度時會收 歛(converge)到一組態;而從此一組態再回溯的 D 個長度所得即為正確解碼輸 出。D 的大小則牽涉到 TB 的效率,也就是說,當 D 愈大代表得到一筆解碼結果 所需要的 TB 次數愈少;但是,另一方面則是代表了儲存 decision bit 所須要的 survivor path 記憶體愈大。
另一得到 survivor 路徑的方法是 RE,當每一階段從 ACSU 得到 decision 結 果時即動態的決定了 survivor 路徑;換句話說,RE 每一時間都更新整體的 survivor 路徑。RE 的優點在於操作上比較直接,而且解碼的 latency 最短,每當接受到一 新的輸入訊號就可得到一個解碼輸出;然而此一方法最主要的缺點在於需要大量 的暫存器和多工器,以及衍生而來繞線的問題;此外,每一時間各組暫存器都需
要有移位的操作帶來許多的電路交換的動作(switching activity),這都會導致所 消耗很大的功率。因此 TB 及 RE 各有其優缺點,一般而言在 constraint 長度小的 情況多半使用 RE,而當 constraint 長度大的情況則使用 TB。
R0
Branch Metric Decision Bit VITOUT BMU ACSU SMU
D Register Path Metric De-puncture R1 DPT 3 3 3 Controller CLK RST DPT 1 1 1 VALID 2 2 1 6 20 64 64 8 1 R0
Branch Metric Decision Bit VITOUT BMU ACSU SMU
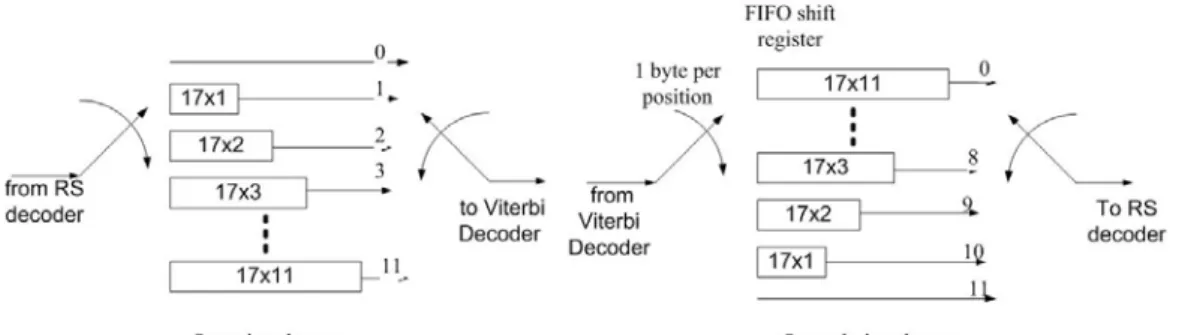
D Register Path Metric De-puncture R1 DPT 33 33 33 Controller CLK RST DPT 11 11 11 VALID 22 22 11 66 2020 64 64 64 64 88 11 圖 4 Viterbi 解碼器的架構 3. Outer deinterleaver Outer deinterleaver 使用迴旋交錯的方式,所以又稱迴旋交錯器,迴旋交錯 器是由 12 個分支組成的,分支的輸入端有一個開關周期的循環連接輸入的位元 組資料流,每一個分支都可以用深度 M x j (j=0,1,…,11) First-In,First-Out (FIFO) 移位暫存器來實現,其中 M=17,且每一個移位暫存器 8 位元寬。並且輸入和輸 出的開關必須同步。對於外部交錯器而言,一個使用 FIFO 移位暫存器設計的外 部交錯器是被提出在分支 0,架構如圖 5,使用 FIFO 移位暫存器設計的外部交 錯器,雖然設計方便簡單,但整個的面積會因為暫存器的關係,使得面積無法有 效的降低,並且此種設計由於開關交換的次數頻繁所以消耗功率也會很大。若使 用記憶體代替移位暫存器則可以減少大量的面積所以提出一個以記憶體為主的 外部解交錯器的設計。使用記憶體來設計會遇到計算位址的問題,對暫存器來 說,只需要將資料向前移位即可,但對記憶體來說則是將不同的資料存在不同的 位址上,並且依序讀出,如果對於 12 個不同分支用 12 個不同的記憶體來實作,
就會有 12 個位址產生器,和控制單元,所以如果能將 12 個記憶體合併為一個單 一的記憶體,則只需要一個位址產生器。一個以 6 個記憶體為架構的設計在[5], 其架構如圖 6。
圖 5 外部交錯器 FIFO 移位暫存器架構
圖 6 外部解交錯器記憶體架構 4. Outer incoder & decoder
禮德-所羅門(Reed-Solomon)codes 最早於 1960 年由 Reed 跟 Solomon 提出, 屬於線性方塊編碼(block codes)的一種,除了可以更正隨機錯誤之外,更可以 有效的更正叢集式錯誤(burst error),因此成為相當普遍的一種 Forward error correction 編碼方式。故此,Reed-Solomon (RS)codes 被廣泛的應用在通訊、 數位影音設備例如 CD、HDTV、xDSL 等等。也常與一般之 Convolutional code 結合成為連接碼(Concatenated code)應用在無線通訊之產品,如本計畫所探討
之 DVB-T 之應用。也因著如此廣泛之用途,無論如何解碼 Reed-Solomon codes 之演算法推導,或是設計適當高效率之解碼器架構,一直吸引相關產學界之注視。
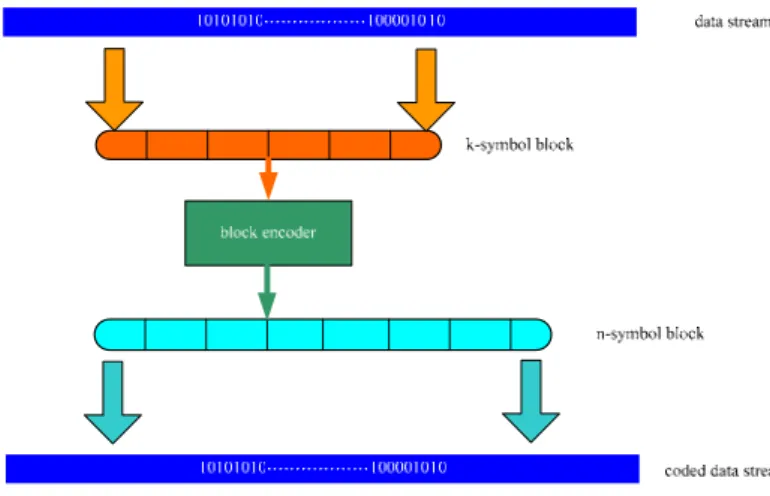
圖 7 區塊編碼
Reed-Solomon code 是區塊碼的一種,所謂的區塊碼是將資料分成一各固定 大小的區塊,並對這個區塊作保護編碼的動作,如圖 7 所示。Reed-Solomon code 一般以區塊碼( n,k,t)的格式代表:k 是每個 block 的 information symbol 數, n 是經過編碼後每個 block 的 symbol 數,symbol 可以表示一個到數個位元。 n-k=2t 代表每個 block 所加上的 parity symbol 數目,而 t=(n-k)/2 則是一個 (n,k,t) RS code 所能更正的最大 symbol 數量,考慮 erasure 的情況則能成功 的更正最多 2t=n-k 個 erasures。在 error 跟 erasure 同時存在的狀況下,則更
正錯誤能力可以n−k≥2v+ f 表示,其中 v 是 error 的數目,f 是 erasure 的數
目。如本計畫所探討之 DVB-T 之通道編碼器之使用,在 DVB 系統中所使用的是(204, 188, 8)Reed-Solomon code,symbol 之大小為一個 byte,可以有效的更正 8 個 symbol 錯誤
RS code 的編碼原理乃建構在 Galois field GF( m
2 ),因此原始資料跟編碼 後的資料乃以 polynomial 的方式來表示,polynomial 的項次代表每個 block 的
symbol 個數,而 polynomial 的係數為 GF( m
2 ) 上之元素,對應到傳輸資料的 Symbol,而 polynomial 的 x 變數的冪次方數(power)則表示編碼跟解碼的先後順
序。傳輸的資料以 2 1 0 1 2 1 ( ) k k m x =m +m x+m x ⋅⋅⋅m− x − 表示,經由 generator polynomial =
∏
n=−k − i i x x g 1 ( ) ) ( α 編碼產生資料 ) ( mod ] ) ( [ ) ( ) (x m x x m x x g x c = n−k + n−k ,其中α 為 GF( m 2 )之 primitive element。傳 送端之資料在傳送過程可能因為 channel noise 的原因而被修改,因而接收端接收 到的 polynomial R(x),可以表示成 c(x)跟 error polynomial E(x)的總合,也就是:0 1 2 2 1 1 ) ( ) ( ) ( R x R x R x R x E x c x R n n n n + + + + = + = − − − − L DVB-T 通道解碼的最後一個步驟即是禮德-所羅門解碼,其解碼之演算法可 分成主要四個步驟,如圖 8 所示包含了 (一) 錯誤症狀(syndrome)的計算,也就 是從 R(x)找出對於 generator polynomial 的根之反應(二) 找出錯誤多項式(error locator polynomial) (三) 找出錯誤多項式的根以確認信號的錯誤位置 (四) 計算 錯誤的值(error values)以更正信號。其中,尢以如何找出錯誤多項式最為關鍵。 Berlekamp 提出遞迴的方式找尋此一方程式,並且在 1969 年由 Massey 以 Linear feedback shift register(LFSR) 方式來解釋與實現,後來被稱為
Berlekamp-Massey(BM)演算法[6]。1975 年 Sugiyama 發現 error locator polynomial 也可以利用 Euclid’s greatest common divisor(GCD)最大公因數求解之演算法來得 到[7]。直到如今基於 Berlekamp-Massey(BM)演算法及 Euclid’s 演算法仍是最 主要找尋方程式的演算法。至於尋找多項式根的方法一般都採用 Chien 的搜尋法 來求得。而最後的錯誤大小則,由 Forney 演算法推導。這個過程必須計算 key equation,可以用 Berlekamp 演算法計算後或過程中來計算;而 Euclid 演算法也 可以藉由在 iterative process 中間維持某些額外資訊來計算。
圖 8 Reed-Solomon 解碼流程圖
大部分的 RS 解碼器之實作都採用基於 Euclidean 或是 BM 之演算法,一般 說來,Euclidean algorithm 的好處是具有計算規律性,故易於 VLSI 實作,但 是求解 error locator polynomial 則須要所有的 Syndrome 結果。至於 BM 演算 法則其所須之計算量一般來說會比 Euclid's 的方法少,只要克服演算法之條件 控制,應可以得到比 Euclid's 較小之硬體需求。故 Sarwate 跟 Shanbhag 提出 了經過 reformulate 的 BM 演算法,具有高度的規律性,可以媲美 Euclid's 演 算法的 data rates,以及更低的 gate 跟 control complexity。Arun 跟 Liu 也 提出了先利用 unfolding,再從 unfolding 過後的演算法中做進一步之簡化以得 到更快的 syndrome 跟 error 的計算。此外,也有些 Reed-Solomon code 解碼演 算法可以不直接計算 syndrome,利用 Inverse Fourier Transform 將原有的數 列轉換到 time domain,這些演算法比較罕見,複雜度比使用 syndrome 的演算 法來得高,目前也看不出其真正在實作上之優點。
第三章 研究方法
在上述關於 DVB-T 通道解碼器各個模組設計的介紹中可以得知,每個模組都須 用到相當數量的資料儲存單元,如何有效地設計這些儲存架構,對於解碼器的設 計相當重要。因此本計畫針對通道解碼器的設計將首重將所有的資料儲存以單埠 記憶體的架構來實現,各個模組在符合 DVB-T 系統標準規範下,從演算法、積體 電路架構以至於電路設計等各層面考量來實現 ASIC 最佳化之模組,朝單晶片之 方式來完成整個系統。至於不同模組之設計方法如下所述: 1.Inner deinterleaver 在 DVB-T 系統中的內部解交錯器主要包含了一個符號解交錯器及一個位元 解交錯器。本計畫所採取之設計方法如下所述: 1.1符號解交錯器(Symbol deinterleaver) 符號解交錯為 DVB 接收器中通道解碼的一個主要部分,負責將傳送端所打 散的資料順序還原。符號解交錯器是採用區塊解交錯的方法,區塊大小(Nmax) 也就是一個符號大小包含了 1512 (2k mode) 或 6048 (8k mode) 筆資料。進入解 交錯符號的資料按輸入順序可以定義為一序列 Yin = ( yin0,yin1, yin2,... yinNmax-1),解 交 錯 後 的 資 料 之 輸 出 順 序 序 列 可 以 表 示 為 向 量 Yout= ( yout0, yout1, yout2,...
youtNmax-1),符號內之資料交錯前後之排列順序方式按照 DVB 標準定義如下: youtq= yinH(q) 當 OFDM 的符號是偶數 youtH(q)= yinq當 OFDM 的符號是奇數 H(q)為一排列函數定義。按著以上的定義,在電路的運作上,可以針對偶數 符號按輸入資料順序寫入記憶體位置 0、1、2 …、Nmax −1,從記憶體讀出時則 按位置 H(0) 、H(1) 、 H(2) … 、H(Nmax −1) 的順序取出資料以達到解交錯的
目的;奇數符號的解交錯順序剛好相反,是以 H(q)順序寫入,以循序方式讀出。 由於奇偶的解交錯順序不同,因此某些符號解交錯器的架構設計乃使用兩個記憶 體,每個記憶體大小可以容納整個符號大小,一個負責儲存偶數符號資料,另一 個儲存奇數符號資料,各由一個 H(q)產生器來控制。然而,由於奇偶符號乃是 交替輸入,處理偶數符號的輸入可與處理先前奇數符號的輸出同時一併考量,此 時都是採用循序的位置;同樣的在處理奇數符號的輸入與偶數符號的輸出都按 H(q)的順序讀寫。既然讀寫位置一樣,就可以利用同樣的記憶體來處理奇偶符 號,而不須要使用到兩塊不同記憶體。 由以上的說明可知解交錯須要 H(q)產生器電路計算位址。若以查表方式儲 存 H(q)的方式設計電路,須要一個至少Nmax大小的記憶體。若按標準規格書提 供的方塊圖設計,只需很少的電路,但其缺點在於不一定每個週期都能產生 H(q) 值,如果當週期有資料輸入,得將資料先儲存在緩衝暫存器,此一緩衝暫存器的 數目會隨著 H(q)無法產生的週期數增加。 在本計畫針對附號解交錯的設計主要採用單埠記憶體來設計解交錯器,以降低其所須電路面積。 而由於單埠記憶體讀寫不能同時運作於同一塊記憶體上,因此須要使用多塊記憶體來達成解交錯 器運作時資料讀寫的需求。因此,本設計提出將解交錯記憶體分割成四個區塊來錯開讀寫衝突, 圖 9 所示。其中第一塊(2)與第二塊(3)記憶體大小為2048×W位元,第三 塊(4)與第四塊(5)記憶體大小為1024×W位元,其中 W 代表符號內每筆資料的位 元寛度。如果將符號資料按其輸入順序編號,則第一塊記憶體(2)負責存取小於2L 且偶數編號之資料,其中 L 在 2k 與 8k 模式下分別等於 2048 及 8192,第二塊(3) 負責存取小於2L且奇數編號之資料,第三塊(4)負責存取大於等於 2 L且偶數編號 之資料,第四塊(5)負責存取大於等於2L且奇數編號之資料。如此分四塊記憶體 的優點在於可以讓資料的讀寫發生在同一區塊的機率降到非常低。每次解交錯器 接受一筆新的輸入資料,同時也產生一筆輸出資料,因此每一週期資料須讀寫一 次。以循序讀寫來說明,由於連續兩個數必為一個奇數、一個偶數的特性,四塊
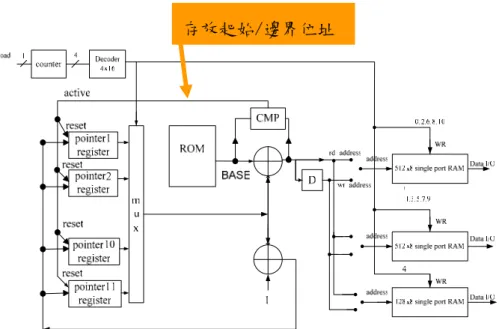
記憶體奇偶的分類,可以讓其中一塊負責讀取時,另一就負責寫入,不會導致衝 突。而以 H(q) 讀寫時,由於連續兩個 H(q)位址,在大部分的情況,一個會小於 2 L,另一個會大於 2 L,在此情況圖一的架構上單埠記憶體的讀寫不會有衝突。此 外,若有時連續兩個 H(q)都小於L2,若此兩個位址剛好為奇偶,則記憶體讀寫也 不會有衝突;但若不是,則可能會有讀寫同一區塊的問題發生。此時,寫入的資 料必須先儲存緩衝暫存器(10),以待稍後寫入。整個解交錯器在每一週期的運作 可以歸納為以下步驟: 1. 先設定讀寫資料之指標qR =0,qW =−1; 2. 判斷目前處理的輸入屬於偶數或奇數符號,來決定此周期讀出與寫入位址的 產生方式: 偶數符號:讀出位址RA =qR ,由Q1位址產生器(6) 產生。 寫入位址WA1=q ,由W Q2位址產生器(7) 產生。 寫入位址WA2=qW +1 ,由Q2位址產生器(7) 產生。 奇數符號:讀出位址RA =H(qR) ,由H1(Q)位址產生器(8) 產生。 寫入位址WA1=H(qw) ,由H2(Q)位址產生器(9)產生 寫入位址WA2=H(qw +1) ,由H2(Q)位址產生器(9)產生 3. 判斷每一個位址(RA, WA1, WA2) 所對應的記憶體:
由2.得知讀出位址至多一個,寫入位址至多兩個,將這些位址(Addr)由下列的 演算法判斷每一個位址所對應處理的記憶體區塊。
if (Addr<2L and Addr為偶數) block(Addr)=1;屬於第一塊記憶體(2);
if (Addr<2L and Addr為奇數) block(Addr)=2;屬於第二塊記憶體(3);
if (Addr≥ and Addr為偶數) block(Addr)=3;屬於第三塊記憶體(4); 2L
if (Addr≥ and Addr為奇數) block(Addr)=4;屬於第四塊記憶體(5); 2L
4.判斷有無發生記憶體讀寫衝突,來決定此周期實際執行的記憶體讀寫動作。 依讀出位址 RA 從第 block(RA)塊記憶體讀取資料;
1 + = R R q q ; 資料儲存於緩衝暫存器(10); if(讀出位址 RA 與寫入位址 WA1 不屬於同一塊記憶體) { 從緩衝暫存器取出資料依寫入位址 WA1 寫入記憶體; 1 + = W W q q ;
if(讀出位址 WA2 與位址 RA 及 WA1 皆屬於不同區塊記憶體) if(暫存器中還有未寫入的資料){ 從緩衝暫存器取出資料依寫入位址 WA2 寫入記憶體; 1 + = W W q q ; } } 5.判別目前符號是否處理完畢,以決定是否更換奇偶符號設定。 if (qR >bound)qR =0; (bound 在 2k 模式下為 2048,在 8k 模式下為 8192) if (qW >bound)qW =0; 回到步驟 2。 以2k模式下操作為例,假設從偶數符號開始: 周期 1: RA=qR =0,讀出第一塊記憶體(2)中的奇數符號中第0筆資料。 周期 2: RA=qR =1,讀出第二塊記憶體(3)中的奇數符號中第1 筆資料。 0 = =qW RW ,寫入第一塊記憶體(2)中的偶數符號中第0筆資料 周期 3: RA=qR =2,讀出第一塊記憶體(2)中的奇數符號中第2 筆資料。 1 = =qW RW ,寫入第二塊記憶體(3)中的偶數符號中第1筆資料。 循序時,讀寫皆可交錯於不同區塊記憶體 假設整個符號之1512筆資料處理完,則換成以H(q)的順序讀取記憶體中1512筆偶 數符號和寫入1512筆奇數符號。
周期 1: RA=H(qR =0)=0,讀出第一塊記憶體(2)中的偶數符號中第0筆資料。 周期 2: RA=H(qR =1)=1024,讀出第三塊記憶體(4)中的偶數符號中第1024 筆資料。 0 ) 0 ( 1=H qw = = WA ,寫入第一塊記憶體(2)中的奇數符號中第0筆資 料。 周期 3: RA=H(qR =2)=16,讀出第一塊記憶體(2)中的偶數符號中第16筆資 料。 1024 ) 1 ( 1=H qw = = WA ,寫入第三塊記憶體(4)中的奇數符號中第1024 筆資料。 以上3個周期,讀取與寫入記憶體都可交錯,假如到了第十八筆資料: 周期 18:RA= H(qR =17)=140,讀出第一塊記憶體(2)中的偶數符號中第140筆 資料。 WA1=H(qw =16)=66,屬於第一塊記憶體(2),與讀出位址屬於同一 塊記憶體,寫入暫停,不執行寫入。 周期 19:RA=H(qR =18)=1136,讀出第三塊記憶體(4)中的偶數符號中第1136 筆資料。 66 ) 16 ( 1=H qw = = WA ,寫入第一塊記憶體(2)中的奇數符號中第66筆 資料。 周期 20:RA=H(qR =19)=514,讀出第一塊記憶體(2)中的偶數符號中第514筆 資料。 140 ) 17 ( 1=H qw = = WA ,屬於第一塊記憶體(2),與讀出位址屬於同一 塊記憶體,寫入暫停,不執行寫入。 假如到了第二十三筆資料 .
周期 23:RA=H(qR =22)=1089,讀出第四塊記憶體(5)中的偶數符號中第1089 筆資料。 514 ) 19 ( 1=H qw = = WA ,寫入第一塊記憶體(2)中的奇數符號中第514 筆資料。 1288 ) 20 ( 2=H qw = = WA ,寫入第三塊記憶體(4)中的奇數符號中第 1288筆資料。 在周期 23時,可同時寫入兩筆資料,緩衝暫存器(10)儲存著寫入位址為H(21) 和H(22)的資料。在影像廣播接受器的應用下,所須的緩衝暫存器至多只須31筆。 圖 9 Symbol deintereleaver 功能架構圖 由上述之步驟可知,解交錯的架構必須包含一個每週期產生一個 H(q)函數 值的電路提供資料讀出位址,由H1(Q)位址產生器產生,及每週期產生連續二個 H(q)、H(q+1)函數值的電路提供資料寫入位址,由H2(Q)位址產生器產生。按照 標準[1]所定,H(q)的計算乃是基於一個循環移位暫存器架構之亂數產生器,此 一亂數產生器可能會產生大於Nmax的數值,則其數值將被拿掉。為了能確保每 MEMORY controller generator Data_in Data_out load valid clk 6 6 reset 13 13 2048 2048 1024 1024 Buffer generator generator generator 13 13 13 13 In_addr1 In_addr2 out_addr In_1 In_2 (1) (2) (4) (5) (3) (7) (6) (9) (8) (10) ) ( 1 Q H ) ( 2 Q H 2 Q 1 Q
一週期都能產生正確的 H(q)值,在設計上因此提出H1(Q)位址產生器的設計如 圖 10 所顯示之架構,其中主要乃是利用展開的方式,將標準所定如圖 10 所示之 展開,以產生二個 ' R 值,將正確值當做輸出。同樣的,H2(Q)位址產生器則是 展開循環移位暫存器更多次,以達到如圖 11 所示,產生四個 ' R 值,再從中選出 適當的两個值處理為兩個連續 H(q)輸出。 文獻中目前有的記載乃採用雙區塊的記憶體分別對單偶符號解交錯,因此, 本計畫的架構大幅地降低 symbol deinterleaver 所須的記憶體面積大小,也由於 symbol deinterleaver 記憶體佔了通道解碼器面積很高的比重,連帶讓通道解碼器 的面積大幅縮小。 ' 1 + i R ' i R 圖 10 H1(Q)位址產生器
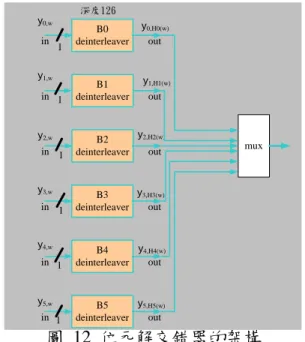
' i R ' 1 + i R ' 2 + i R ' 3 + i R ) (q H H(q+1) 圖 11 H2(Q)位址產生器 1.2位元解交錯器(Bit deinterleaver) 如前所述位元交錯的方式乃是採用區塊交錯的方法,由 v 條 126 位元通道所 組成,區塊大小為 126×v 位元(v 的值與調變的方式有關,最大值為 6),每次 接收 v 位元,依序分給 v 條通道,每條通道接收 126 位元的值後,依據不同的對 應函式輸出。因此位元交錯位元交錯器在 2k mode 時,每接收一個 OFDM 符號將 會重複執行 12 個循環,8k mode 時則執行 48 循環。關於位元解交錯器的設計, 可以很單純的由記憶體及適當的位址產生器構成,同樣的,在此一計畫也將採用 基於 single port 記憶體的設計方法來實現。由於位元交錯器乃以 126 個 bit 為 一組,共計六組,若採用記憶體實現,則每一組至少須 126 × 1 bits 的記憶體。 但因記憶體一個 word 最少需 4 bits,所以共需 128 × 4 bits 大小的記憶體, 且由於每一周期資料進入必須有讀與寫的動作,但由於 single port 記憶體不能
於一個周期中同時進行讀寫工作,因此,解決的方法為藉由位元 packing 的方式 來降低讀寫的頻率,也就是一個週期進行寫入記憶體兩筆資料動作,下一個週期 則讀出兩筆資料,依此使 single port 記憶體設計得以實現,也提高了記憶體使 用率,共需 64 × 4 bits 大小的記憶體。然而一開始先將六組 126 bits data 依 序寫入到記憶體位置,之後一個週期每個記憶體進行讀取後,下一個週期再對每 個記憶體相同位置進行寫入動作,當初藉由位元 packing 的方式來降低讀寫的頻 率,一次讀寫兩筆資料,故排列函數有所改變了,如下列改變
輸入向量: B (e) = (be.0,be.1,be.2... be.62) 其中 e = 0, 1, 2….. V-1
輸出向量: A (e) = (ae.0,ae.1,ae.2... ae.62) 其中 e = 0, 1, 2….. V-1
輸出入向量對應 be. He(w)= ae.w 其中 w = 0,1,2….. 62 I0:H0(w)=w I1:H1(w)=(w + 31) mod 63 I2:H1(w)=(w + 52) mod 63 I3:H1(w)=(w + 21) mod 63 I4:H1(w)=(w + 10) mod 63 I5:H1(w)=(w + 42) mod 63 第 一 次 六 組 的 所 要 讀 取 的 資 料 起 始 位 址 依 序 如 下 ( I0,I1,I2,I3,I4,I5)=(0,31,52,21,10,42) ,然而對此位址進行讀取後,再對 此位址進行寫入資料的動作,然而當 126 bit 資料讀取完畢,且將更新的 126 bits 資 料 寫 入 到 記 憶 體 後 , 讀 取 的 資 料 起 始 位 址 依 序 如 下 ( I0,I1,I2,I3,I4,I5)=(0,62,41,42,20,21) ,其由上一次所計算的起始位址再 加上排列函數而得,如 I1 的起始位址為(31+31) mod 63 = 62,I2 的起始位址 為(52+52) mod 63 = 41,I3 的起始位址為(21+21) mod 63 = 42,I4 的起始位 址為(10+10) mod 63 = 20,I6 的起始位址為(42+42) mod 63 = 21,之後依序
如上述函式計算即可得每次記憶體所要讀取的起始位址,這樣就可以用 single port 來實現,且可以降低記憶讀寫的頻率。
圖 12 位元解交錯器的架構 2. Inner decoder
針對於 constraint 長度很大的 Viterbi 解碼器之設計,其關鍵問題包含 ACSU 如何在 state 數目很多的情況下有效率地完成每個 iteration 的 ACS 運算,以及更 重要的 survivor 路徑的尋找及解碼輸出。很明顯的 RE(Register Exchange)的設 計方式不適合於大 constraint 長度的應用,然而 TB(Traceback)的設計則需要考 量到如何提高有效的回溯運算,並且 Survivor Path 的記憶體不能太大,尢其記憶 體 RAM 的讀寫很耗費功率及時間。此外,這兩部分(ACSU 及 SMU)如何聯繫 溝通也非常重要,也影響到如何得到最佳化 Viterbi 解碼器設計。針對 DVB-T 的 Viterbi 解碼器之設計,由於所需的狀態數為 64,且其解碼速度需求頗高,因此, 本計畫乃先採用所謂的 state-parallel 方式來設計 ACSU,也就是每個階段各個狀 態的計算都由一專門的 ACS 計算單元來處理。此一單元從兩個 state metric 的加 法結果,選擇一個較小的數,並產生 decision bit。但由於 ACS 需累加 branch metric,則所使用的加法器必定終會溢位(overflow) ,這邊我們使用 [8]的模組正 規化 (Modulo Normalization) 方法來解決溢位問題。我們所設計的 ACSUcore 架
y0,w in in in in in y1,w y2,w y3,w y4,w B0 deinterleaver y0,H0(w) out B1 deinterleaver out B2 deinterleaver out B3 deinterleaver out B4 deinterleaver out y1,H1(w) y2,H2(w) y3,H3(w) y4,H4(w) mux 1 1 1 1 1 深度126 in y5,w B5 deinterleaver out y5,H5(w) 1
構如圖 13 所示,可使用一個減法器產生 decision bit
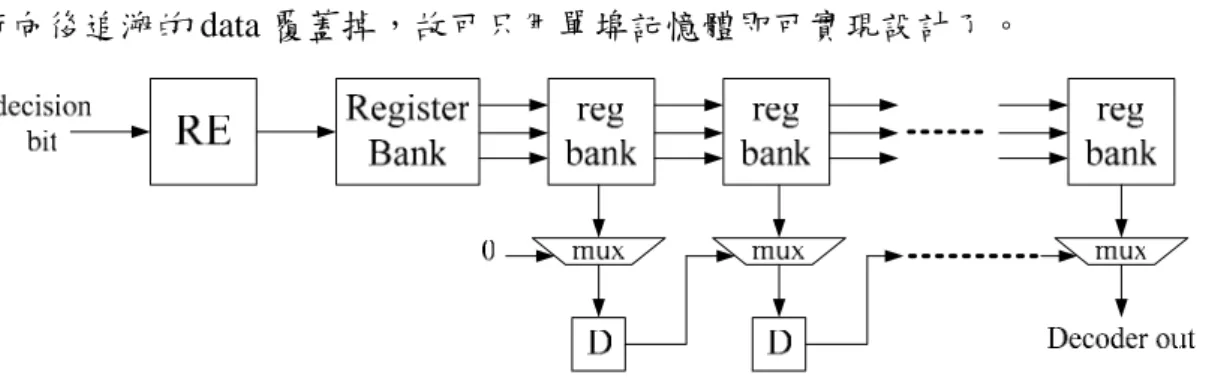
而關於 SMU 之設計,如前所述,RE 和 TB 各有其優缺點,因此本計畫提出 一個類似混合式(hybrid)的架構,一方面是做局部的 RE,另一方面則是做整 體的 TB。也就是當 ACSU 產生每個 iteration 的 decision bits,會先以一 K-級 RE 模組找出長度 K 之最佳路徑,而此路徑會儲存在 survivor path 記憶體做為以後整 體 TB 尋找長度 L 之 Survivor 路徑之用。與一般純粹的 TB 方式相較,後者所存 的結果是 iteration 間 state 到 state 轉換的最小路徑,其路徑長度為 1;而混合架 構則是預先已找出路徑長度 K 的最小路徑,雖然找出整體最小路徑仍須藉由 TB 的方式,但可預期其搜尋的速度一定比較快,因為混合向後追溯式 SMU 方塊是 以路徑長度 K 長度向後追溯搜尋長度 L 之 Survivor 路徑,進而可減少 TB 次數來 達到減少功率消耗。圖 14 是原始的混合向後追溯式 SMU 方塊圖 [9],[10],使用 了多個暫存器組 (Register Bank),暫存器的特性是只要輸入訊號改變就會消耗功 率,且跟 RE 相比,暫存器的使用量並沒有減少,僅是減少了多工器的數量,在 K 值使用範圍愈來愈大的應用當中 (例如 HDTV spc. K=7),暫存器至少需要 2K-1×(5K)=2240 個,這將會需要大量的繞線面積以及功率消耗。因此在圖 15 中 SMU 中的移位暫存器以記憶體元件取代,在混合式的架構中也有使用到 RE,但 原始的 RE 所需要的級數約為 5~6 倍的 K,5~6 倍的 K 為長度 L 之 Survivor 路 徑的長度,在架構中的 RE 級數只需要 1 倍左右的 K 就夠了,因需先以一 K-級 RE 模組找出長度 K 之最佳路徑,這是真正達到低功率的關鍵。在傳統的 TB 設 圖 13 ACSU 架構圖
計裡,需要 4L (Survivor path Length) 長度的記憶體才有辦法達到每個時脈能有 1 bit 的解碼輸出,在這裡的架構中,僅使用 L 長度的記憶體就能夠做到。進而我 們探討使用單埠記憶體,因內部解碼器-腓特比解碼器(inner decoder)其可能在 做儲存 decision bits 與執行 TB 時可能會對同一個記憶體進行讀/寫,但是這樣就 需要 Dual Port 的記憶體,然而 Dual Port 記憶體其面積又比單埠記憶體大,所以 進而需控制記憶體的讀/寫讓記憶體在同一時間只能進行讀取或寫入,然而在此 架構採用先以一 6-級 RE 模組找出長度 6 之最佳路徑,然而則此 Decision Bits 共 有 64 (64 states) * 6 = 384 bits 需儲存,而此架構 SMU 其採用 3 個 memory bank 其為 ( 32 x 32 大小) ,同一時間對三個記憶體進行寫入,所以一次可寫入 96 bits ,故將 384 bits 儲存須花費 4 個 cycle 且佔用每個 memory bank 4 個儲存空間, 在將此 6 級寫入到記憶體後進行向後追溯,一次可以向後追溯 6 級,所以七次可 向後追溯 42 級,然後將最後一次追溯的 6 級當成 output,然而 3 個 memory bank 為儲存空間有 32 個其共可儲存 48 級的路徑長,故當進行寫入時不會將等會要進 行向後追溯的 data 覆蓋掉,故可只用單埠記憶體即可實現設計了。
3. Outer deinterleaver
針對外部解交錯器,在 DVB-T 所使用的一個迴旋解交錯器。迴旋交錯器是由 12 個分支組成的,分支的輸入端有一個開關周期的循環連接輸入的位元組資料流, 每一個分支都可以用深度 M x j (j=0,1,…,11) 的 FIFO (First-In First-Out ) 移位暫存器來實現,其中 M=17,且每一個移位暫存器 1 位元組。並且輸入和輸 出的開關必須同步。若是直接按此一迴旋解交錯器的資料流圖來實作,需要十二 組不同長度的移位暫存器,此一方式,無論就面積或功率的消秏都不適當。[5] 使 用六組區塊記憶體如圖 16 所示將兩組路徑的移位暫存器整合,但是這會造成許 多的記憶體被浪費掉。為了避免使用移位暫存器,及降低記憶體區塊的個數,圖 17 為解交錯器的架構圖,其中包含了位址產生器的硬體架構。由於必須支援 12 個不同深度的暫存器,且由於多個移位暫存器路徑整合在同樣的記憶體內,因此 在記憶體的管理,必須配合 12 個指標暫存器指向 12 個路徑的記憶體位置,以及 一個機制來區分這些移位暫存器路徑在記憶體的區塊位置。所以使用到一顆 ROM 去儲存每個移位暫存器的基底起始位置。指標暫存器永遠指向相對應之分 支移位暫存器路徑下一筆資料可以存放之住址。累加器在調整指標位址,當資料 進入一筆,累加器就加一,下一筆資料就可以存放在加 1 後的位址,但是在經過 了一段長度後,一旦此一路徑存滿,指標暫存器就得指向從頭住址開始放置資 料。比較器用來比較記憶體所代表的分支暫存器儲存資料是否填滿,若是超過所 圖 15. Memory based 混合向後追溯式
配置的長度,比較器就會提出警告,表示記憶體已滿,並且通知位址產生器要從 頭開始儲存了。圖 17 中的比較器可以分享給十二個分支指標暫存器,達到節省 資源的好處。然後我們也可以以一個記憶體去實現,這樣只需要一個位址產生器 即可在硬體上的複雜度最低,但是如何能製造位址產生器能符合規格的需要,則 必須使用移位暫存器方法改成記憶體相對應位址,使其輸出依然是正確的,但是 沒有使用單一記憶體而使用三個,是由於記憶體只支援二的次冪深度,雖然 outer deintrleaver 只需要 1122 x 8 bits,但是必須用二的次冪的記憶體區塊,故將奇數 路徑分成在不同的區塊,主要是因為在做 outer interleavin 時,其為有 12 個分支, 然而其分支為每 12 個 iteration 輪流一次,且依序做交錯的運作,故在設計 outer deinterleaving 當其目前為寫入奇數路徑記憶體時,此時我們可以對偶數路徑記憶 體做讀取 data 的動作,然而在下一個 cycle 則為對偶數區塊做寫入動作時,然而 此時我們可對奇數路徑區塊記憶體做讀取 data 的動作,依此方式對記憶體區塊 做讀取/寫入動作,我們可以避免掉同時間對同一個記憶體區塊做讀取/寫入動 作,故此架構只需要用 single port 的記憶體區塊即可。 圖 16 文獻中外部解交錯器記憶體架構示意圖
圖 17 外部解交錯器架構 4. Outer decoder
禮德-所羅門解碼器的架構如前所述,包含了四個主要的模組。圖 18 中,顯 示計算 Syndrome 之模組架構方塊圖,輸入之 Symbol 循序地進入,緊接著分別
進入計算各個 SyndromeS 之電路,而各個j Syndrome 之計算乃以 Horner’s rule
之方式求得,當計算S 時將輸入之 Symbol 乘上j
j
α 後暫存於暫存器內,再加上下
一個 Symbol,如此遞迴處理,如圖 19 所示。其次,關於第二部分模組的設計, 通常是使用 Euclid algorithm 或是 Berlekamp-Massey algorithm 我們選擇使用 modified decomposed inversionless Berlekamp-Massey algorithm [11],[12]去實現, 如圖 20 所示,並且在計算 error locator polynomial 和 key equation 用同一個硬體。 這是因為這個架構和這個方法有最小的面積並且也能夠達到我們速度上的需 要。Euclid algorithm 雖然 error polynomial 和 key equation 可以同時間算出,並 且所需的週期數少,但是實現的面積卻比 modified decomposed inversionless Berlekamp-Massey algorithm 來的大。
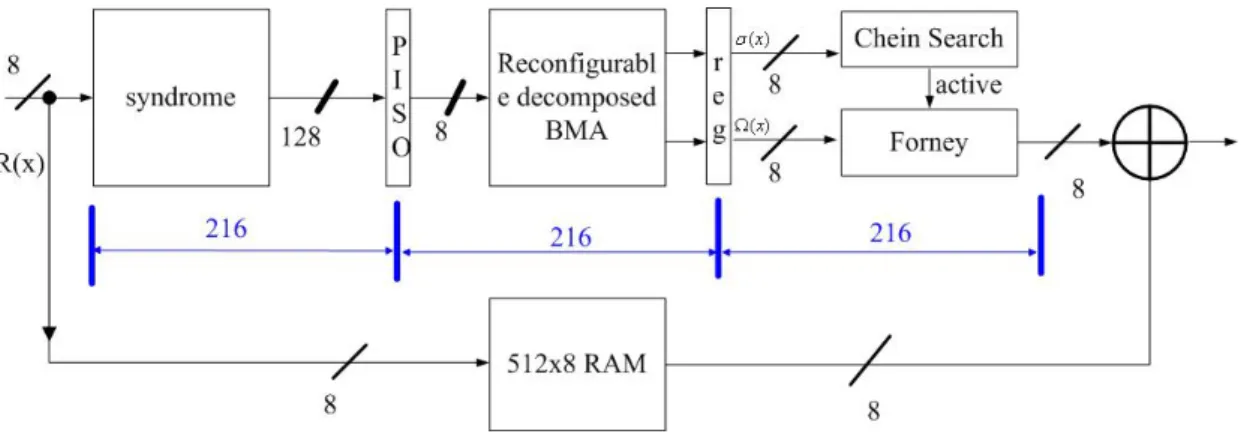
圖 18. Reed-Solomon 解碼器的功能區塊圖
圖 19. Syndrome 計算之架構
圖 20 Decomposed inversionless Berlekamp-Massey 之架構
定整個禮德-所羅門解碼器的關鍵路徑(critical path),並且也影響面積的大小,以 整個禮德-所羅門解碼器的設計來看,從第一個主要部分計算錯誤症狀,到第四 部份計算錯誤值都會用到有限場乘法器。在第一部分,第三部分,第四部份使用 的是變數-常數有限場乘法器,其中常數是α1 ~α16, 減少此一乘法器的面積對 於整體禮德-所羅門解碼器的設計有極大的影響。 在 DVB-T 中,使用了有限場域 GF(28 ),包含 256 個元素,每一個符號是用 8 個位元(bit)來表示,令 p(x) = x8 + x4 + x3 + x2 + x8 + 1 是 GF(28)的基本多項式 (primitive polynomial)並且α是多項式的基本元素。對任何元素,可以定義成 a(x)
= 7 0 j j j= a x
∑
並且也可以表達成列向量的型式 a = [a7, a6,…, a0]。兩個元素 a(x)和 b(x)相乘可以定義成 c(x) = a(x)‧b(x) mod p(x)。a(x)‧b(x)的計算在標準基底(standard basis)下,可以分為兩種,一是最高位元優先(MSB first),另一個是最低位元優先 (LSB first) ,分別可以表示成 最大位元優先 2 7 0 1 1 7 ( ) ( ) ( ) mod ( )
( ) [ ( ) mod ( )] [ ( ) mod ( )] [ ( ) mod ( )]
c x a x b x p x b a x b a x x p x b a x x p x b a x x p x = = + + + ⋅⋅⋅ + 最小位元優先 7 6 1 0 ( ) ( ) ( ) mod ( )
( ((0 ( ) ) mod ( ) ( ) ) mod ( ) ( ) ) mod ( ) ( )
c x a x b x p x a x b x p x a x b x p x a x b x p x a x b = = ⋅⋅⋅ + + + ⋅⋅⋅ + + ( ) j a x b 的部分在硬體來看是 AND 的運算,而其他”+”的部分則是 XOR 的運算, 而乘上 x 的運算則是將括弧裡的數往左移一位,而最高位元的數字必須依照 p(x) 的規則將最大位元的值回授給其他的位元,這個運算就是 mode p(x)。假設跨弧 的數為 k(x),則 ( )k x x⋅ mod ( )p x 如下 7 6 5 4 3 2 6 5 4 3 7 2 7 1 7 0 7 ( ) mod ( ) ( ) ( ) ( ) k x x⋅ p x =k x +k x +k x + k +k x + k +k x + k +k x +k x+k 基本上實作有限場乘法器有序列和平行的做法,但序列的做法必須額外的加入暫 存器和控制電路,再實作上來說並不實際。比較一般的方法是採用平行的計算,
有一種方法是使用半心臟收縮的架構(semisystolic)[13],這種架構可以用在最大 位元優先,也可以用在最小位元優先,此種架構就好像一級一級的運算,若從最 小位元優先來看,首先運算a x b 在來將此值傳送給下一級作( ) 0 a x b x( ) 1⋅ mod ( )p x 此值算完後同樣傳給下一級作b a x2( ( )⋅x x) mod ( )p x 同理依序下去直到最後一 級。另一種做法則是將 ( )b x x⋅ mod ( )p x 以矩陣的方式展開 [14],然後在乘上 a(x) 的列向量,以上兩種談的都是變數-變數的有限場域乘法器,但是變數-常數有限 乘法器卻是其整個解碼器主要使用的計算元,所以最佳化變數-常數有限場乘法 器有其必要。 在[12]中的乘法器,就常數乘法器來講並不需要 AND,只需根據 G 矩陣和 a(x)向量相乘,即可得知相乘後的結果,能夠如此做的原因是因為已經是先知道 b(x)的值了,舉例如下,在乘以常數α5的運算中,c7,c6 和 c3中的 a7 + a6項可 以共用,而 c4,c3中的 a5 + a4項可以共用,同理 c2和 c0的 a7 + a3項可以共用,
因此共節省了 4 個 XOR。利用相同的 XOR 運算下可以節省不必要的 XOR。 其中圖 18 中的 PISO 是將 16 個 syndrome 的值轉成序列的輸出,此設計將 RS Decoder 分成 3 級管線化,每個符號 8 位元寬,第一筆進入到 RS 解碼器區塊 必須隨著管線移動到下一級,然而在第三級已經可以開始將資料輸出了,故管線 化所以記憶體 RAM 的深度要 204 的兩倍,然而若是單一塊記憶體且資料寬度為 8 位元寬,則其每個 cycle 都必須進行讀取跟寫入兩動作,若是這樣,則記憶體 須為 dual port 的記憶體,考量記憶體最佳化,所以我們將記憶體寬度設計為 16 位元,等於說然而一次寫入為寫入兩筆符號,一次讀取為讀取兩筆,這樣設計就 為假設原本兩個 cycle 要將兩筆 data 同時寫入與讀取,現在換成記憶體資料寬度 為 16 位元,則只要第一個 cycle 讀取 16 位元,第二個 cycle 寫入 16 位元,這樣 就可以避免同時對記憶體進入讀取與寫入了,進而達成 single port 的記憶體了。
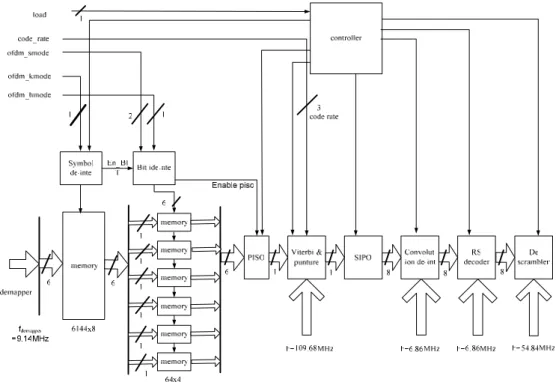
5. DVB-T 通道解碼器系統架構 整個 DVB-T 系統的架構如 圖 21 , 我 們 以 解 碼 端 來 說 明 , 資 料 先 經 過 內 部 解 交 錯 器 (Inner de-interleaver),以避免之後的 Viterbi 解碼器收到一連串錯誤的資料,內部交錯 器做兩種操作一是寫入位元區塊到矩陣記憶體,同時讀出其它位址的資料,而這 個的位址計算是定義在 DVB-T 規範中[1]。下一個運算是 depuncturing,0 位元會 插 入 在 特 殊 的 位 置 用 來 還 原 成 原 來 的 資 料 。 接 下 來 是 作 解 碼 器 (Viterbi decoder),其輸出然後被送到外部交錯器然後再送到 Reed-Solomon 解碼器。因為 OFDM 的 stream mode 最大為 6 bits,所以系統只需提供最大 6 bits 寬的記憶體, 並且支援 2K 和 8K mode 所以最多會用 6048 個記憶體,因為 odd symbol 和 even symbol 排列所需的位址值並不相同所以必須提供兩個記憶體區塊。Inner decoder 經由一個 parallel-in-serial-out 的介面接收從 inner deinterleaver 而來的資料,inner decoder 支援不同的 code rate。因為 inner deinterleaver 每一個 cycle 可能會丟出 一個 6 bits 的資料而 inner decoder 一次只能處理 1 bit 為了達到速度的要求,我 們給于 inner decoder 快 inner deinterleaver 6 倍的速度,也就是 54.84 MHz。因為 outer decoder 和 outer deinterleaver 是以 block 作處理,每個 block 為 8bits 但是 inner decoder 每次只會送出 1bit,所以必須透過一個 serial-in-parallel-out 的介面將資料 收集成為一個 block 後再送出給 outer deinterleaver。也因為如此所以 outer deinterleaver 和 outer decoder 只需要 6.86 MHz 的速度。
圖 21 DVB-T 通道解碼器系統架構圖
6 . DVB-T 通道解碼器矽智產之製作
為了提升此一計畫所設計之通道解碼器之價值,將按矽智產設計的條件,應用在 此一通道解碼器。關於此一通道解碼器的矽智產設計如下所述:
6.1 Provided design models
z Reference model in C: 我們提供了C Reference model,使用者可輕易的將它整合到自己的設計裡,此模 組與RTL Code皆支援多種模式,可模擬出正確的編、解碼輸出。當使用者拿到 我們的 IP 時,可先經由 Reference model 來模擬不同工作環境下的系統模式所達 到的解碼效能,來決定使用 RTL Code 時產生之效果。 z RTL model in Verilog:
提供 RTL synthesizable code 及相對應的 Testbench、Test patterns 和合成 Script files,可經由 script 來完成合成,符合 CIC 所提出的 coding guideline,可進行系 統模擬驗證。
6.2 Verification strategy
IP 的驗證策略如下,首先寫出符合 function 的 C code,然後用 Verilog 寫成 RTL code,與 C code 驗證功能是否相同。再來使用 FPGA 做功能驗證,和時序 的驗證,FPGA 驗證,將其解碼電路下載至 FPGA,已驗證後我們的通道解碼器 確實可供使用。且除了可以在 silicon 層次驗證我們的解碼電路外,也可以讓使 用者將解碼器直接整合在系統上作更完整之測試。證明正確無誤後,進一步作合 成,合成後的 netlist code 與 C model 做驗證比對,證明無誤。而要達到 100% 的 code coverage 需相當多的輸入資料,我們採用自動驗證方法如圖 22 所示。並使 用 nLint 來驗證整個 IP 的 coding style 並達到零錯誤的目標。
file RTL API netlist creat compare No error Modelsim (script) Verilog-XL (script) .exe 圖 22 驗證示意圖 z FPGA 驗證
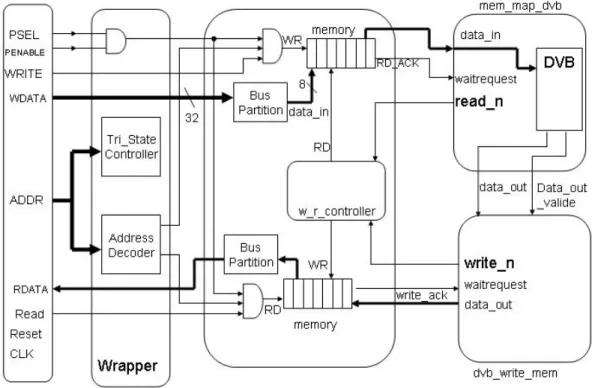
最後我們也將整個解碼器在 FPGA 上面實現,並將它架構在 Altera NIOS SOPC 系統所採用的 Avalon 匯流排進一步測試,如圖 23 所示,透過匯流排將測試資料 從 memory 傳送到解碼器。整個測試流程如下:
(2)經由 DMA 方式透過 avalon bus 去讀取記憶體內容,然後將此讀入之資料一一 對應到解碼器的輸入埠後,開始做解碼動作。
(3)經由硬體解碼後會有兩組資料輸出分別為 data_out 與 data_out_valid,將此兩 資料傳送給 dvb_write_mem,當接收到 data_out_valid 為 1 時表示為此資料為 valid,故我們再透過 Avalon bus 將此 data 寫入到記憶體內。
(4)由於考量使用者讀取資料速度不同,故先將其寫入到記憶體的空間,利用記 憶體來當作使用者的 buffer。
第四章 研究成果
DVB-T 通道解碼器的各個模組,己經實作、驗證且並在 FPGA 上面執行。 本計畫中的各個模組都採用了些獨特的設計。如下整理所述: z 實現 decoder、deinterleaver 過程所需耗費的空間,一般都以 Flip-Flop 方式、 或 dual port 記憶體實現,為了節省成本,針對不同區塊,特殊化其設計, 使得本 IP 能以 single port 記憶體的方式實現通道解碼器各個模組架構,並 妥善運用空間,將耗費的記憶體減到最小,大幅減少通道解碼器面積。 z 依製程所提供記憶體規格,最佳化設計以降低所需記憶體。 z 支援多種歐規數位視訊廣播標準,數位電視按傳輸方式可以分為地面 (terrestrial)、衛星(satellite)和有線(cable)三種,目前,DVB-S(satellite)和 DVB-C(cable)分別作為衛星和有線的傳輸標準已被世界各國採納,成為全 球化的標準,而 DVB-S 和 DVB-C 兩者本 IP 皆有支援。 z 利用少量暫存器,設計出一個嶄新符號解交錯器的硬體架構,使單一周期 讀寫不會衝突於同一塊記憶體,而能將所需要之暫存空間改為使用 single port 記憶體且容量只須約一個符號大小以降低成本,也相對應的設計出可在 單一週期同時產生一筆及兩筆交錯函數值的硬體架構,使得在某些情況可 同時寫入兩筆資料,使所需暫存器減少。達到最少的記憶體使用,比起文 獻中記載的兩區塊記憶體減少一半。 z 提供符合 DVB 通道解碼標準之簡單傳輸 API,方便使用者應用,也能於硬 體未實現之前,運用它做初步的驗證,可縮短整體設計所費時間。 z 具自動驗證的功能。只需執行指令及參數,就顯現出驗證結果,代替了原 本繁雜的驗證過程。體單元取代暫存器單元的方式來實現,使得解碼速度和降低功率消耗都有 更佳的表現。
z 由於 Reed-solomon decoder 演算法的複雜,所得到的 gate count、power 都相
當大,所以我們提供了低複雜度的 Reed-solomon 架構,僅需三個 FFMs, 可分享硬體,減少不必要的運算量,電路複雜度低,功率消耗低,critical path 只有 4.07ns。 z 在外部禮德-所羅門解碼器的設計上,本計劃採用了一個最佳化之常數有限 場域乘法器之架構。表 3 所列乃是針對所提之最佳化的有限場域常數乘法 器的結果比較,當乘上α 冪次方愈大時,透過共享的機制愈能降低所須的 邏輯閘。而表 4 針對所有乘法器所須的邏輯閘統計,可以發現大約可以降 低約 20%的數目 z 而在內部腓特比解碼器,本計畫在關鍵的 SMU 的設計上採用了一個混合回 溯的方式,並以記憶體的方式來實現路徑記憶體,其結果可由表所示。 z 在外部解交錯器中,迴旋解碼器的十二條路徑被整合成二個區塊記憶體。 此一方式可以避免移位暫存器使用上的問題。表 2 比較了幾個不同記憶體 使用方式,其一是直接分別將每個路徑的移位暫存器記憶體實作,其二是 文獻中六塊記憶體使用的方式,其三是本計畫採用的方式。由此表可知, 本計畫的方法可以達到最佳之記憶體使用。
SMU 架構 Hardware Requirement Decoding Latency
Register Exchange
Reg:8x2 Mux:4x32
32+2
Traceback Mem:(8x32)x4, Stack:(1x32)x2 32x4
Hybrid (Register bank) Reg:8x32+2x12 Mux:4x4 32+4 Hybrid (memory) Reg:8x5, Mux:4x5 Buffer:8x5, Mem:8x32 32+4 表 2 迴旋解交錯器不同架構比較表 記憶體實際需求 記憶體大小 記憶體使用率 direct 1122 1697 67 [5] 1122 1280 88 Proposed 1122 1152 97.4 表 3. 變數-常數有限場乘法器不同架構的比較表
常數乘法器 XOR gate count
係數 α1 α2 α3 α4 α5 α6 α7 α8 α9 α10 α11 α12 α13 α14 α15 α16 [14] 3 6 9 12 16 19 21 23 22 21 21 21 20 21 23 24 [13] 3 6 9 12 15 18 21 45 45 45 45 53 45 37 37 37 Proposed 3 5 8 10 12 15 17 18 17 17 17 16 16 16 19 18 表 4 變數-常數有限場乘法器不同架構的總數比較表 16 個變數-常數有限場乘法器的 XOR GATE 總合 [14] 282 [13] 473 Proposed 224 整個 DVB-T 通道解碼器的各個模組,都採用了記憶體為主的方式來實作,
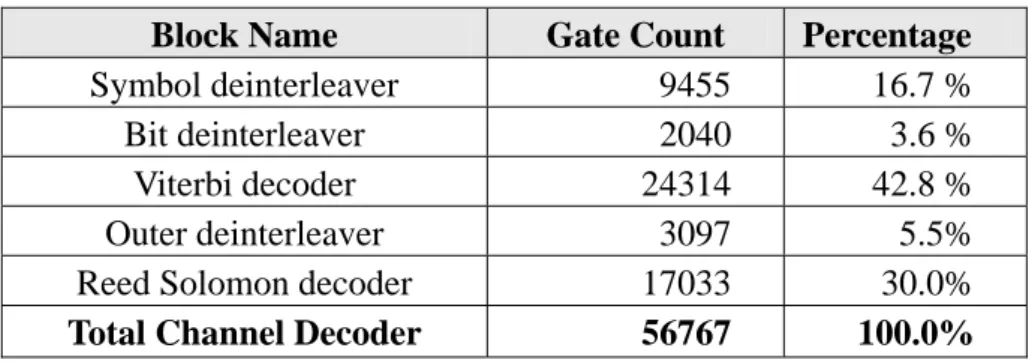
因此所須面積及功率都可以大大降低,各個模組所佔邏輯閘及記憶體的分佈如表 5 及表 6 所示。圖 24 乃是一完整 DVB-T 解碼器在 TSMC 0.35um 製程下的 layout,其面積約 15mm2。由於本計劃所提出之通道解碼器架構,除了將與其他 相關計畫整合以完成整體 DVB-T 接收器的設計,並產出一數位矽智產元件,以 供輸出及可重複使用性。圖 25 為完整通道解碼器之 IP 規格,其腳位定義在表 7。 表 5 各功能區塊所佔 Gate count 百分比
Block Name Gate Count Percentage
Symbol deinterleaver 9455 16.7 %
Bit deinterleaver 2040 3.6 %
Viterbi decoder 24314 42.8 %
Outer deinterleaver 3097 5.5%
Reed Solomon decoder 17033 30.0%
Total Channel Decoder 56767 100.0%
表 6 各功能區塊使用記憶體百分比
Block Name 使用記憶體 Percentage
Symbol deinterleaver 6144 bytes 73.3 %
Bit deinterleaver 192 bytes 2.3 %
Viterbi decoder 384 bytes 4.6 %
Outer deinterleaver 1152 bytes 13.7%
Reed Solomon decoder 512 bytes 6.1%
Total Channel Decoder 8384 bytes 100.0%
圖 24 . Layout of DVB-T 通道解碼器 Report Technology TSMC 0.35um 2P4M Chip Size 15.4 mm2 Core Size 9.3 mm2 Clock Rate 109.89MHz Gate Count 56767 Power Dissipation 53.9mW
data_in priority reset 8 6 data_invalid DVB-T ofdm_smode ofdm_hmode ofdm_kmode 1 1 1 2 1 1 code_rate 3 1 clk_108 2 data_ovalid data_out 圖 25 . DVB-T 通道解碼器 Interface 表 7. DVB-T Channel Decoder Interface I/O 腳位
Pin Name Bits I/O Description
clk_108 1 I System Clock=109.68MHz,以滿足 DVB-T 標準
data_in 6 I Data input
data_invalid 1 I When asserted ,data input is valid
priority 1 I In hierarchical mode 1: high 0: low priority
reset 1 I When asserted, Synchronous reset
ofdm_smode 2 I 0: QPSK, 1: 16-QAM, 2: 64-QAM
ofdm_hmode 1 I When asserted, hierarchical mode
ofdm_kmode 1 I When asserted: 8k mode,otherwise: 2k mode code_rate 3 I depuncture Code rate = 0: 1/2,1: 2/3,2: 3/4,
3: 5/6,4: 7/8,5~7: reserved
data_out 8 O Data out
第五章 成果自評
本計畫按預期不僅完成了內部解碼腓特解碼器、外部解碼器禮德-所羅門解 碼器及內解交錯器之設計與實作,而且也整合了各個模組為符合 DVB-T 功能規 範的通解解碼器。帶給參與研究學生許多的相關訓練,包括晶片設計、FPGA 之 使用、矽智產之設計及 DVB-T Channel Decoder 的演算法,而實質研究成果如下 z 專利: 用於數位影像廣播系統之符號解交錯器 中華民國專利發明第 I 241779 號z 論文: Y.-N. Chang, “Design of An Efficient Memory-based DVB-T Channel Decoder,” in Proc. of 2005 IEEE Int. Symposium on Circuits and Systems, pp. 5019-5022, Kobe, Japan, May, 2005.
本計畫所提的架構,包含有限場域常數乘法器的設計,內外交錯器的架構都 是在文獻裡未見過,這些架構及整體使用單埠記憶體的 DVB-T 通道解碼器的設 計也正準備發表相關的 Journal paper。下線的準備工作也大致完成,預計明年初 完成此一通道解碼器的下線。
參考文獻
[1]. “Digital Video Broadcasting (DVB); Framing structure, channel coding and modulation for digital terrestrial television,” ETSI EN 300 744 V1.4.1, Jan. 2001.
[2]. L. Horvath, I.B. Dhaou, H. Tenhunen and J. Isoaho, “A novel, high-speed reconfigurable demapper symbol deinterleaver architecture for DVB-T,” in Proc.
ISCAS, pp. 382 – 385, June 1999.
[3]. G. Fettweis and H. Meyr, “High-speed parallel Viterbi decoding: algorithm and VLSI-architecture,” IEEE Communications Mag., vol. 29-5, pp. 46 -55, May 1991.
[4]. Y. N. Chang, H. Suzuki, and K. K. Parhi, “A 2-Mb/s 256-state 10-mW rate-1/3 Viterbi decoder,” IEEE J. Solid-State Circuits, vol. 35, pp. 846-834, Jun. 2000.
[5]. J.B. Kim, Y.J. Lim, M.H. Lee, “A low complexity FEC Design for DAB,” in
Proc. ISCAS, vol. 4 , pp. 522 – 525, May 6-9, 2001.
[6]. J.L. MASSEY, “Shift-register synthesis and BCH decoding,” IEEE Trans.
Inform. Theory, vol. IT-15, pp. 122-127, Jan 1969.
[7]. Y. Sugiyama, M. Kasahara, S. Hirasawa, and T. Namekawa, “A method for solving key equation for decoding goppa codes,” Info. Control, vol. 27, pp. 87-99, 1975.
[8]. Shung, Bernard C, Paul H S, and etc., “VLSI architectures for metric normalization in the Viterbi algorithm,” IBM Corp, pp.1723-1728, 1990.
[9]. E. Boutillon, N. Demassieux, “High speed low power architecture for memory management in a Viterbi Decoder,” IEEE Int. Symp. On Circuits and
Systems, vol. 4, pp.284-287, 1996.
[10]. P. J. Black, T. H. Y. Meng, “Hybrid survivor path architectures for Viterbi decoders,” IEEE Int. Conf. on ICASSP, vol. 1, pp.433-436, 1993.
[11]. H.C. Chang, C.B. Shung, and C.Y. Lee, “A Reed-Solomon product-code (RS-PC) decoder chip for DVD application,” IEEE J. Solid-State Circuits. vol. 36, pp. 229-238, Feb. 2001.
[12]. I.S. Reed, M.T. Shih, T.K. Truong, “VLSI design of inverse-free Berlekamp-Massey algorithm,” IEE Proc., vol. 138, pp. 295-298, Sep. 1991. [13]. S.K. Jain, L. Song, K.K. Parhi, “Efficient semisystolic architectures for
finite-field arithmetic,” IEEE Trans. VLSI Syst., vol. 6, pp. 101-113, Mar. 1998. [14]. J.H. Jeng, J.M. KUO and T.K. Truong, “A high efficient multiplier for the
RS decoder,” IEEE Int. Symp. VLSI Technology, Systems, and Applications, pp. 116-118, June 8-10, 1999.
[15] M. Massel, “Digital television DVB-T COFDM and ATSC 8-VSB,” Digita