國 立 交 通 大 學
管理學院(資訊管理學程)碩士班
碩 士 論 文
結合貝氏網路與激勵理論之推薦機制
- 電影推薦系統設計
A Recommendation Mechanism Combined with
Bayesian Networks and Incentive Theory
- A Movie Recommend System Design
研 究 生:謝金育
指導教授:李永銘 博士
結 合 貝 氏 網 路 與 激 勵 理 論 之 推 薦 機 制
- 電 影 推 薦 系 統 設 計
A Recommendation Mechanism Combined with
Bayesian Networks and Incentive Theory
- A Movie Recommend System Design
研 究 生: 謝金育 Student:Chin-Yu Hsieh 指導教授: 李永銘 Advisor: Dr. Yung-Ming Li 國立交通大學 管理學院(資訊管理學程)碩士班 碩士論文 A Thesis
Submitted to Institute of Information Management College of Management
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of
Master of Science in Information Management June 2013
Hsinchu, Taiwan, the Republic of China
i
結合貝氏網路與激勵理論之推薦機制
- 電影推薦系統設計
研究生:謝金育 指導教授:李永銘 博士
國立交通大學管理學院(資訊管理學程) 碩士班
摘要
推薦系統被廣泛應用於網路上,用以幫助使用者快速找到適合或是感興趣的產品, 目前已發展出許多的推薦技術,例如內容導向式(Content-based Approach)、協同過濾式 (Collaborative Filtering Approach)、及混合式(Hybrid Approach)等推薦方法。雖然推薦技 術已日趨成熟,但其仍存在著一些問題,例如在使用者資訊不足的前提下,推薦系統無 法正確的提供推薦資訊。 本論文提出結合貝氏網路與激勵理論(Incentive theory)的推薦機制,在使用者資訊不 足的情況下仍然可以產生高度正確率的推薦。透過尋找出使用者輪廓檔(user profile)內資 訊之關聯規則,將其視為一個訊息源用以擴大使用者輪廓檔,從而避免使用輪廓檔資訊 不足的問題。而在新項目的評比方面,透過激勵理論(Incentive theory),在符合個人理性 (individual rationality)條件與誘因相容(incentive compatible)條件下鼓勵使用者對於新項 目分享。實驗證明,透過拓展使用者輪廓檔與鼓勵使用者評比是可以幫助系統在使用者 資訊不足的情況下提升系統的推薦準確率。ii
A Recommendation Mechanism Combined with
Bayesian Networks and Incentive Theory
- A Recommend System Design
Student:Chin-Yu Hsieh Advisor:Dr. Yung-Ming Li
Master Program of Institute of Information Management
College of Management
National Chiao Tung University
Abstract
The recommendation systems are widely used on the network to help users quickly find suitable or interested products. In this area, many recommendation techniques, such as Content-based Approach, Collaborative Filtering Approach, and Hybrid Approach, have been developed. Although the recommendation technology has become mature, there are still some problems. Recommendation systems cannot provide the correct information if we don’t have enough user information. The precision of the recommendation system will be increased dramatically, if a system gets more user potential information.
In this study, we attempts to propose a recommendation mechanism design combined with Bayesian networks and incentive theory. In lack of user profile information, our recommendation mechanism still has high precision. This mechanism approach uses Bayesian network to generate association rules from user profiles, a source of information used to expand the user profile, and avoid the problem of user profile shortage. In the new items problem, based on the theory of incentives, we propose a mechanism for encouraging data sharing. This encouraging mechanism satisfies individual rationality and incentive compatibility. Our experiments show that our proposed mechanism can significantly improve the performance of a recommender system under the short user profile situation.
iii
誌
謝
首先,我要感謝我的指導教授李永銘教授,感謝教授二年來對我的悉心指 導,讓我不僅在學術上獲益良多,而且在待人處世上亦得到更多的啟發。 感謝學位論文口試委員:尹邦嚴博士、林妙聰博士與陳炳文博士,他們的 指導與建議,讓本論文更臻完善。 感謝博士班學長無尾熊(賴政揚)與發哥(林聯發),感謝二位在我學習的過 程中給予我最大的協助與實質中肯的的建議。 感謝資訊經濟與科技應用實驗室(IEBI)一起學習的伙伴,文平、螢駿、彥 勳、良彥、曉珍、千琇與慧珊及交大資管所前後期的同學,能夠一起學習是難 忘的回憶,感謝他們在我研究所二年中對我的鼓勵與陪伴使我的求學生涯更多 采多姿。 最後我要感謝我的父母、姊姊、婉儀、麗華;好友欽文、易霖、玲億、明 輝與永淙的全力支持與鼓勵,使我在沒有後顧之憂的情形下,全力投入學業與 工作,並得以順利完成學業。
iv 目錄 中文摘要 ………I 英文摘要………II 誌謝………III 目錄 ………...………IV 表目錄………VI 圖目錄 ………VII 第一章、 緒論 ... 1 1.1 研究動機 ... 1 1.2 研究目的 ... 2 1.3 論文架構 ... 3 第二章、 文獻探討 ... 4 2.1 推薦系統 (RECOMMENDER SYSTEM) ... 4 2.1.1 內容為基礎的推薦系統(CONTENT-BASED): ... 7
2.1.2 協同過濾式 (COLLABORATIVE FILTERING APPROACH,CF)... 8
2.1.3 混合式 (HYBRID-BASED APPROACH) ... 12
2.2 關聯規則分析 (ASSOCIATION RULE ANALYSIS) ... 14
2.2.1 關聯規則 (ASSOCIATION RULES) ... 14
2.2.2 APRIORI 演算法 ... 17
2.3 貝氏網路模式 (BAYESIAN NETWORK MODEL) ... 19
2.3.1 貝氏定理 (BAYESIAN THEOREM) ... 19
2.3.2 貝氏網路 (BAYESIAN NETWORK ) ... 20
2.4 激勵理論(INCENTIVE THEORY) ... 23
2.4.1 代理問題架構 ... 24
2.4.2 委託代理理論基本模型 ... 27
2.4.3 激勵效果 ... 28
第三章、 研究架構與方法 ... 31
v
3.1.1 使用者輪廓(USER PROFILE)資訊拓展 ... 33
3.1.1.1 輪廓檔項目分類 ... 33 3.1.1.2 建構貝氏網路結構 ... 34 3.1.1.3 產生條件機率表 ... 37 3.1.2 鼓勵使用者對於新項目(影片)進行評比 ... 42 3.1.2.1 IR 條件 (INDIVIDUAL RATIONALITY個人理性) ... 46 3.1.2.2 IC 條件 (INCENTIVE COMPATIBLE誘因相容) ... 46 第四章、 實驗設計與結果 ... 47 4.1 測試資料來源與實驗環境 ... 47 4.2 關聯規則相關工具 ... 49 4.3 貝氏網路相關工具 ... 50 4.4 推薦系統相關工具 ... 51
4.5 使用者輪廓(USER PROFILE)資訊拓展實驗 ... 53
4.5.1 使用者輪廓拓展 ... 53 4.5.2 推薦系統效益驗證 ... 55 4.6 鼓勵使用者評比實驗 ... 59 4.6.1 激勵程度計算 ... 59 4.6.2 鼓勵使用者評比驗證 ... 63 第五章、 結論與未來方向 ... 65 5.1 研究結論 ... 65 5.2 管理意涵 ... 66 5.3 未來研究方向 ... 67 參考文獻-中文部份 ... 68 參考文獻-英文部份 ... 68
vi 表目錄 表 1SUPPORT 值和 CONFIDENCE 值的意義 ... 16 表 2 高頻項目組 ... 16 表 3 K-ITEMSET... 18 表 4 項目分類交易紀錄檔 ... 34 表 5MOVIELENS 交易資料集 ... 48 表 6 軟硬體開發環境與平台 ... 49 表 7 門檻值與指標數值表 ... 56 表 8 三種輪廓檔指標數值表 ... 57
vii 圖目錄 圖 1 研究步驟示意圖 ... 3 圖 2 推薦系統架構圖[5] ... 6 圖 3 協同式推薦系統架構[17] ... 10 圖 4 循序式組合 ... 12 圖 5 線性式組合 ... 13 圖 6APRIORI 演算法之虛擬碼 ... 18 圖 7APRIORI 演算法之副函式虛擬碼 ... 18 圖 8DAG ... 20 圖 9 下雨與感冒的貝式網路模型 ... 21 圖 10 含有機率表之貝氏網路 ... 23 圖 11 研究架構 ... 32 圖 12 使用者輪廓檔 ... 33 圖 13 貝氏網路架構法則長度 1 ... 35 圖 14 鏈狀結構 ... 35 圖 15 收斂結構 ... 36 圖 16 網路結構(完整圖形) ... 36 圖 17 氏網路架構圖及機率表 ... 38 圖 18 貝式網路機率狀況示意圖 ... 39 圖 19 使用者輪廓拓展 ... 40 圖 20 使用者輪廓拓展使用事後推論 ... 41 圖 21 使用者I的預期支付 ... 44 圖 22 鼓勵分享示意圖 ... 45 圖 23WEKA 開發工具 ... 50 圖 24MSBNX 操作畫面 ... 51 圖 25TASTE系統結構 ... 52 圖 26 資訊拓展實驗架構 ... 53 圖 27WEKA 關聯規則參數設定 ... 54 圖 28 使用者輪廓拓展 ... 54 圖 29 貝氏網路關聯 ... 55 圖 30 門檻值與指標數值圖 ... 56 圖 31 三種輪廓檔指標數值圖 ... 58 圖 32 鼓勵評比實驗架構 ... 59 圖 33 使用者 1-10 預期效用 ... 60 圖 34 使用者 11-20 預期效用 ... 62
viii
圖 35 使用者 21-30 預期效用 ... 62 圖 36 使用者回評 ... 64 圖 37 使用者回評比例 ... 64
1
第一章、 緒論
1.1 研究動機
由於市場白熱化的競爭,越來越多的企業利用網路來從事服務或商品行 銷,除了商品本身品質的提升外,服務的品質更是成為關注的焦點,如何留住 既有的客戶以及尋找潛在的客戶,更是成為當前主要的議題。網際網路逐漸成 為現代人取得資訊的重要管道之一,且無時無刻都有新的資訊產生。網路上充 斥著大量的資訊與資料,資訊超載(Information Overload)的問題日趨嚴重,而 推薦系統可從大量的資訊裡篩選出使用者有興趣的項目,進而推薦給使用者。 常見的推薦系統主要有內容導向式推薦(Content-Based Filtering)、協同式推薦 (Collaborative-Filtering)以及混合式推薦 (Hybrid Recommendation Method),而 協同式推薦技術相關研究近來更是成為推薦系統發展的主流。 協同式推薦的方法通常是利用使用者的輪廓(User Profile),收集使用者的 所有資訊(例如使用者曾經瀏覽過的網站,網站屬性) ,記錄著使用者個人的 背景與相關興趣等等,再經由不同的推薦機制,推薦合適的產品給使用者。不 同的推薦機制皆有各自的優缺點,大多是利用使用者的喜好來做為推薦的依 據。當使用者的輪廓(User Profile)和/或適用的資料集具有高訊息密度時,推薦 系統所推薦給使用者的產品通常是正確而且是有效率的。但是當使用者輪廓或 適 用 的 資 料 集 資 訊 不 完 整 時 這 些 推 薦 機 制 卻 都 有 著 相 同 的 冷 啟 始 問 題 (Cold-Start problem),亦即系統中存在著「新使用者」與「新推薦項目」。 冷啟始問題於電影的推薦中更是一個需要被關注的議題,因「新使用者」 與「新推薦項目」情況的產生在電影推薦系統上是屢見不鮮的。當新的影片被 存入系統時,由於新的影片沒有被使用者評分過,所以系統無法進行有效的推 薦。而新進使用者在一開始進入系統時,由於系統並不知道新進使用者的喜 好,所以無法正確推薦影片給使用者。 一般而言,改善新進使用者於推薦系統正確率不高的方法是採取隨機推薦 的方式,即先隨機挑選幾部影片讓使用者試看,使用者在看過系統所挑選的影 片過後可以給予評分,得以讓系統瞭解使用者的影片種類的喜好,再根據評分2 結果推薦影片給使用者。或是利用分類法則將產品分類定找出使用者有興趣相 類似的產品進行推薦[1] [2]。或是使用資料探勘中關聯規則(Association rules) 的技術更進一步來擴大使用者輪廓資訊[3]。雖然關聯規則可以找出於使用者輪 廓資訊內產品間潛在的關係,但其仍會因為信賴度門檻定義選擇的問題而使得 某些規則遺失使得推薦正確率降低。 而改善新推薦項目的問題,大多是採用問卷方式來調查使用者的興趣,再 根據問卷收集結果依照最新加入或最熱門...等方式做推薦,來吸引使用者。 不過此種方是牽涉到問卷設計與問卷發放與回收的機制,由推薦的時效性方面 來看似乎是緩不濟急。
1.2 研究目的
根據上述研究動機,本論文預期達成的目的可歸納為下列二項: (1) 提供更正確的使用者輪廓(User Profile)資訊擴大方式,避免因為關聯規則 信賴度門檻定義選擇的問題而使得某些規則遺失使得推薦正確率降低。 (2) 鼓勵使用者對於新項目(影片)進行評比,避免因為一個新的物件或產品, 因大多數的人都不願意第一個去嘗試,進而使得新產品被推薦的機會不 高。使用者與推薦系統產生良性互動,透過正確率移轉價值方式結合使用 者利益與推薦系統利益,此方式可增加使用者轉換成本進而產生鎖定效果 (Lock-in Effect)。3
1.3 論文架構
本文共分為五個章節,第二章為文獻探討,說明目前推薦系統的類型與相 關文獻的討論;第三章為研究架構與方法,說明本論文所提出的方法;第四章 分析實驗數據之結果;第五章結論,總結本論文所提出的論點與未來研究方向。 圖 1研究步驟示意圖 相關 文獻收集與探討 推薦系統 文獻收集與探討 關聯規則 文獻收集與探討 貝氏網路 文獻收集與探討 使用者輪廓 資訊拓展 關聯規則 與 貝氏網路架構 激勵理論 代理問題 個人理性 誘因相容 實證研究 與 說明 產生資料 建構貝氏網路 鼓勵使用者評比 績效比較與說明4
第二章、 文獻探討
本章將介紹一些與本論文有關聯的前人研究。在第一節裡,先探討各種推 薦系統常用的方法,包含以內容為基礎的推薦系統、協同式推薦系統與混合式 推薦系統等等;第二節中,將探討對於資料探勘領域裡關聯規則(Association Rules)的研究,包含其演算法步驟之說明;第三節為說明貝氏網路理論,包含 貝氏機率與貝氏圖型模式;第四節則是介紹激勵理論中代理人機制,包含個人 理性條件(Individual Rationality,IR)與誘因相容條件(Incentive Compatible, IC)等機制之說明。2.1 推薦系統 (Recommender System)
推薦系統 (Recommender System) 是一種資訊過濾 (Information Filtering, IF) 機制,主要是為了減少使用者在搜尋資訊過程中所附加的額外成本,其可 依據使用者的喜好、興趣、行為或需求,推薦出使用者潛在需求的資訊、服務 或產品[4] 。在資訊過濾系統中,會將資料庫中每筆資料或所新增資料與使用 者輪廓資訊加以比對,藉此過濾出與使用者相關的內容,並加以整合、分類、 註解或索引,方便去判斷彼此的相關性如圖 2 [5]所示。 隨著網路科技的進步,有太多資訊充斥在我們生活中,要如何將這些有用 或無用的資訊過濾出來,是網路智慧領域上的重要問題。依據推薦資訊的方式 推薦系統區分為二類[6]:
(1) 非 個 人 化 推 薦 系 統 (Non-Personalized Recommender System) : 此類推薦只將熱門產品或資訊全部呈現給使用者,因此每位使用者將 會看到相同的產品或資訊。
(2) 個 人 化 推 薦 系 統(Personalized Recommender System):
根據使用者的興趣和購買行為,向使用者推薦感興趣的訊息或商品。 隨著電子商務規模的擴大,商品類型快速增長,使用者需要花費大量的時 間才能找到自己想買的商品。。為瞭解決這些問題,個性化推薦系統應運 而生。
5
屬 性 導 向 推 薦 系 統 (Attribute-Based Recommender System) : 依據使用者對產品特定屬性的喜好,提供符合該項屬性的資訊或 產品。 項 目 相 關 導 向 推 薦 系 統 (Item-to-Item Correlation Recommender System) : 利用歷史紀錄比對出同時購買的項目,即找出項目的關聯規則, 再利用此規則進行項目之間相互推薦。
使用者相關導向推薦系統 (People-to-People Correlation Recommender System):
針對使用者找出具有相類似喜好的其他使用者,再依據同好對產 品或資訊的評價找出適合的項目推薦給使用者。
推薦機制的技術大致上可以分成以下三種:以內容為基礎的推薦系統 (Content-Based) [7][8]、協同式推薦系統(Collaborative Filtering)[9]、混合式推薦 系統(Hybrid)[7][10],以下分別說明。
6
7
2.1.1 內容為基礎的推薦系統(Content-Based):
使用者面對選擇之時,會依據印象中接近或是類似程度較高的產品。所選 擇的產品都會包含個人喜好的特徵。內容式推薦系統,又稱為以特徵為基礎過 濾(Feature-Based Filtering)。其依據的準則是對物品內容分析,而不是其他使用 者的評價。其概念主要源自於「資訊擷取(Information Retrieval, IR) 」中的方法,主要 著重於項目 (Item) 的分析,藉由分析項目的屬性特徵,再與使用者的輪廓資 料做比對,藉此推薦出使用者可能會有興趣的項目。這種技術一般都稱之為內 容式資訊過濾技術推薦(Content-Based Recommender)。對於此種推薦方式而 言,了解使用者的喜好性趣是相當重要的問題。收集使用者的喜好可分為以下 兩種方式: 隱性(Implicit)資料收集: 系統針對使用者行為進行記錄,此種紀錄可能是在使用者不知情的情 況下,或是知情但是是在不與使用者有互動,或鮮少互動的過程中進行。 其目的為方便推測使用者背後的行為。不過也因與使用者的互動極少,可 能造成系統推測的錯誤率提高。 顯性(Explicit)資料收集: 在使用者使用系統的過程中(可能為「使用前」或「使用中」或「使 用後」),系統會透過詢問使用者的方式收集使用者對系統的評價或感受。 此種方法是得到使用者偏好最直接的方法,但是也因此有可能會引發使用 者的負面情緒反應。 使用者與系統互動程度的多寡是顯性與隱性最大的差別,交流程度越高, 所得到的喜好資訊將可能為使用者真實的偏好,但此種方式對使用者造比較大 的負擔。一個可以完全反應出使用者偏好,又可降低使用者負擔的資訊取得方 式,將是設計推薦系統需考量因素之一。而內容為基礎的推薦系統,有以下缺 點: 特殊化問題(Over-specialization Problem): 舉例來說,於線上書店推薦系統中,當系統知道使用者特別喜歡看勵
8
志小說的時候,系統只會推薦勵志小說給使用者閱讀,這種方法,比較會 導致使用者只想專注的看某一些類型的小說,一個好的推薦系統事要避免 這種情形的發生。
有限分析問題(Limited Analysis Problem):
物件會以許多形式上的出現,如音樂、雜誌、電腦、視訊、廣告... 等等,目前現階段僅對於處理文字技術方面比較成熟。
新使用者問題(New User Problem):
新加入的使用者,在系統上沒有任何使用記錄時或是使用程度不足 時,會導致無法很正確且即時的做出有效的推薦。
2.1.2 協同過濾式 (Collaborative Filtering Approach, CF)
協同過濾主要是利用全體的觀點來產生推薦項目給特定的個人使用,主要 是的重點在於建立大量使用者的輪廓(User Profile),除了紀錄每一個使用者所 設定的主題之外,還記錄使用者個人的背景與相關興趣等等,之後針對使用者 所查詢的主題,透過用戶模型(User Modeling)技術形成社群 (Community) ,亦 即在某些特定行為或偏好上有相類似特性成員的集合,並透過這些鄰近者所組 成的鄰近群組之意見或建議,來產生使用者有興趣的推薦資訊給特定的使用者 做為參考[11]如圖 3 [17]所示。而依據所採用的演算法又將協同過濾概分為二 種主要的類別[12]: (1) 以記憶為基之協同過濾 (Memory-Based CF): 依據使用者的歷史記錄,與資料庫中每一筆紀錄比較其相似度以找出 與使用者喜好相類似的鄰近族群,再依族群的喜好進行推薦。其中最常使 用的方法為最接近鄰居法 (Nearest Neighbors) 。以記憶為基之協同過濾又 可以細分為以下二項 以使用者為基礎(User-based)的協同過濾: 用相似統計的方式取得具有相同愛好或特徵的使用者,所以稱 之為以使用者為基礎(User-based)的協同過濾或基於鄰居的協同過 濾(Neighbor-based Collaborative Filtering)。其方法步驟如下:
9 I. 使用者資訊收集: 收集可以代表使用者喜好的資訊並給與評分。其評分方式有 二種。一般的網站的使用評分的方式稱為「主動評分」。另外一 種稱為「被動評分」,根據使用者的行為模式由系統代替使用者 進行評價,不需要使用者直接打分或輸入評價資料,例如電子商 務網站記錄使用者購買的商品記錄。
II. 最近鄰搜索(Nearest neighbor search, NNS)
其出發點為與使用者興趣喜好相似的另一使用者,換句話說 即為計算兩個使用者的相似度。例如:找出 10 個和 A 有相類似 喜好的使用者,將其對 B 的評分作為 A 對 B 的評分預測。一般 即會根據資料之不同採用不同的演算法,目前較多使用的相似度 演算法有 Person Correlation Coefficient、Cosine-based Similarity 與 Adjusted Cosine Similarity。
III. 產生推薦結果 有了最近鄰居集合,即可對使用者的喜好進行預測,進而產 生推薦結果。依據推薦目的之不同採取不同形式推薦,一般而 言,常見推薦方式有 Top-N 推薦和關聯規則推薦。Top-N 推薦 為針對單獨使用者產生,對每個使用者有不同的結果,關聯推薦 是對最近鄰居使用者的記錄進行關聯規則 (association rules)探 勘。 以項目為基礎(Item-based)的協同過濾 隨著使用者數量增加,以使用者為基礎的協同推薦的演算法其 計算時間會跟著變長,進而造成效能降低。Sarwar 於 2001 年提出基 於 項 目 的 協 同 過 濾 推 薦 演 算 法 (Item-based Collaborative Filtering Algorithms)。「可以引起使用者興趣的項目,必定和之前高評分的項 目相類似」,此為其演算法的基本假設。使用者之間的相似度改採用 項目間的相似度來代替。其方法步驟如下:
I. 收集使用者資訊:
10 II. 針對項目的最近鄰搜索: 首先計算已經評價過的項目和即將要預測的目標項目的相 似度,透過加權(即相似度)各已評價項目的分數,得到待目標項 目的預測值。例如:對 A 和 B 進行相似度計算,首先要找出 同時對 A 和 B 評過分數的組合,再對找出的組合進行相似度 計算,一般常用的演算法與以使用者為基礎(User-based)的協 同過濾採用的方式相同。 III. 產生推薦結果 此方式不需考慮使用者間的差異,所以精確度較差。但其優 點為不需要使用者的歷史資訊,或對使用者進行識別。因此可以 採用離線方式完成相似性計算(大量),進而降低線上計算。尤其 是在使用者數量多於項目數量的情形下可以顯著提高推薦效率。 (2) 以模式為基之協同過濾 (Model-Based CF) : 將使用者歷史記錄,經由統計或機器學習方式來建構出使用者偏好模 型,進而利用此偏好模型來產生推薦。目前常見的方法包括, 潛在語意 索引(Latent Semantic Indexing, LSI) 、關聯式規則(Association Rules) 、貝 式網路 (Bayesian Network) 或迴歸分析 (Regression Analysis) 等等。
11
協同式推薦系統,雖然可以避免以內容為基礎式的推薦可能會發生的問 題,如特殊化、分析物件內容有限等,但還是有其他缺點:
新使用者問題(New User Problem):
新加入的使用者,於系統內無任何使用記錄時或是使用程度不高時, 將無法正確且即時的做出有效推薦。此問題亦發生於內容為基礎的推薦系 統中。 稀疏化問題(Sparsity Problem): 推薦系統通常都會對於數量相當龐大的產品或物件來作為評價與推 薦,但是使用者所接觸到的物件大部分都只佔非常小的比例。當產品的數 量大於使用者,或兩者的比例十分懸殊時,系統在尋找到適合的推薦者來 進行推薦的命中率或推薦成功率就會降低。
新物件問題(New Item Problem):
因為一個新的物件或產品,因大多數的人都不願意第一個去嘗試,進 而新產品被推薦的機會不高。 協同過濾是目前使用最成功的推薦系統技術,而其最著名的應用是一個稱 為「Tapestry」的郵件篩選分類系統,由 Goldberg 於 1992 年提出[19] ,此系 統被視為最早應用協同推薦系統的設計。Palo Alto 研究中心發展這項實驗性郵 件系統的原因,主要是由於研究中心工作人員每天需接收大量的電子郵件但卻 無從篩選分類進而造成工作效率降低。 另一著名的系統為 1994 年所發展的 GroupLens[23],此系統主要是應用於 新聞內容的篩選上,透過此統來幫助讀者過濾其感興趣的新聞內容。系統建立 的前提為讀者以前感興趣的東西在未來也會有興趣閱讀。讀者看過內容後給予 一個評比分數,系統將記錄其分數作為系統未來推薦參考之用。 在 GroupLens 後還有相近的 MovieLens(電影推薦)、Ringo(音樂推薦)與 Jster(笑話推薦)等等,經技術不斷的進步,網路越加發達,使用者參與的程度 越來越高,使得推薦系統也發展得越來越嚴密。
12
2.1.3 混合式 (Hybrid-Based Approach)
混合式推薦系統(Hybrid Approach)即是結合了內容式推薦與協同式推薦的 兩種方法所形成的推薦系統。以內容為基礎的推薦與協同過濾正好可以互補其 缺點,取其各自的優點,所以有學者提出結合以內容為基礎與協同過濾這兩種 方法[13]。現今技術中主要的兩種混合形式:循序組合(Sequential Combination) 如圖 4,線性組合 (Linear Combination) 如圖 5。 循序組合:這一個類型的推薦系統主要分成兩步驟 步驟 1. 內容式過濾法先找出有相同喜好相似的使用者。 步驟 2. 再透過協同式過濾法進行預測。 圖 4循序式組合 內容為基礎 推薦系統 協同過濾為 基礎推薦系 統 使用者 歷史紀錄13 線性組合: 其概念非常直觀與單純,就是將協同式和內容式推薦系統計算出來所 得到的數值,或是將內容為基礎和協同式推薦系統所計算的數值分別加權 相加。 圖 5線性式組合 內容為基礎 推薦系統 協同過濾為 基礎推薦系 混合模式 使用者行為紀錄 使用者評價紀錄
14
2.2 關聯規則分析 (Association Rule Analysis)
關聯式規則(Association Rules, AR),又稱關聯規則,是資料探勘領域中相 當重要的研究課題,主要是從大量數據中探勘出有價值的資料項目之間相關 性。關聯規則被用來解決的問題如:「若一個消費者購買了 A 產品,那麼他有 多大機會將會購買 B 產品?」以及「若一個消費者購買了產品 A 和 B,那麼其 還將購買其他哪些產品?」,其他相關研究如,DAN 資料的分析、紋理特徵 (Texture Features)的分析等等,因為此項研究的結果與企業決策的制定有相當 程度的互動。 關聯規則主要在於處理分析大量且雜亂無章的資料,並將資料分析減少成 為易於觀察、理解與解釋的靜態資料。關聯規則最早由 Agrawal et al. (1993) 所 提出,並隨後於 1994 年提出 Apriori 演算法運用在關聯規則的推導。後續許 多關聯規則相關的研究亦基於此演算法,如 F-P 演算法、以布林運算為基礎的 演算法、 Pincer-Search 演算法等等,皆是著名的關聯規則探勘的演算法。以下 即針對關聯規則的基本定義及 Apriori 演算法分別詳細說明之。
2.2.1
關聯規則 (Association Rules) 關聯規則的定義為:在交易資料庫中有多筆的銷售交易記錄,每一筆交易 紀錄可能含有一項或多項商品以形成該次交易紀錄。 令 I ={I1, I2, … , Im}是所有相異項目(Items)所成的集合。假設資料庫 D 有 n 個交易紀錄,T ={T1, T 2, … , T n},而每筆交易記錄 Tp , 都是由一部份的項目 所組成之集合,即 TpI, 其中 p = 1, 2, …, n 。 某一集合 X, 若 X I , 則稱 X 為項目集(itemset),若此 X 包含 k 個項 目,則稱 X 為 k-項目集(k-itemset)。 簡言之,商品項目組所成的集合所代表的就是某些特定商品組合,如:{麵 包,牛奶}、{啤酒,尿布,汽水}。若在項目集合中 X 與 Y 之間有一關聯規 則存在, 其表示為 X Y,X、Y I 且 X Y=,其中 I 是交易資料庫中所 有項的集合,如: XY ,說明成「購買 X 產品的前提下,同時也會購買 Y」。 然而,所找出來的關係不一定是強烈相關的,所以需要一些指標來判斷這15 些關係是否具有可信度。而在關聯式演算法中最常使用的兩個衡量指標,信賴 度 (Confidence) 與支持度 (Support)。 支持度 (Support) 代表某項目集在所有交易中出現的頻率,其計算公式為 如下:
總交易 產品 和 交易中同時包含X Y Y X P 假設:交易資料庫中有 100 筆交易,若其有 50 筆交易被發現同時含有 {啤酒,尿布,汽水},則{啤酒,尿布,汽水}項目集的支持度即為 50/100=50%。 在規則探勘的過程中會發掘出各種組合的項目集,支持度太低的項目集不具代 表性,因此需設定一個最低門檻值(Threshold)做為過濾的依據,稱之為最小支 持度 (Minimum Support) 。所找出的項目集的支持度若超過最小支持度則稱為 一個頻繁項目集 (Frequent Itemset) 。若支持度越高,就表示此項目集同時出 現的機率就越高。 信賴度 (Confidence) 其利用了條件機率的概念來定義關聯規則可信賴的 程度。也就是 X 出現的條件下,Y 也會跟著出現的條件機率。數值越高,規 則的可靠度也就越高。信賴度的計算方式如下:
產品的交易 包含 和 交易中同時包含 X Y X |X Y P 假設:交易資料庫中有 100 筆交易,若其有 50 筆交易被發現同時含有 {啤酒,尿布,汽水},而有 60 筆交易含有{啤酒}, 則關聯規則「啤酒=>汽 水, 尿布」的信賴度即為 50/60=83.3%。若信賴度太低則表示該關聯規則沒有 代表性,因此需設定一個最低門檻值(Threshold)做為過濾的依據,稱之為最小 信賴度 (Minimum Confidence) 。若信賴度越高,就表示這條法則成立的機率 就越高。經由關聯規則計算結果所代表之意義,如表 1所示:16 表 1 Support 值和 Confidence 值的意義 低 Confidence 高 Confidence 高 Support 發生頻率高,但關聯規則 不正確。 發生頻率高,且關聯規則正確。 低 Support 發生頻率低,且關聯規則 不正確。 發生頻率不高,但關聯規則正確 率很高。 由支持度與與信賴度的公式不難發現,X→Y 之支持度等同於 Y→X 之支 持度支,即說明支持度是具有反身性的(Reflexive)。但信賴度並不具有反身 性,即 X→Y 的信賴度和 Y→X 的信賴度是不同的。由於信賴度沒有反身性, 如果信賴度門檻值定義不佳,可能就會失去其中一組規則。以表 2為例,假設 表中是四組超過最小支持度的頻繁項目集。假設最小信賴度為 100%, A→B 因符合門檻值而被採用,而 B→A 則因不符門檻值而被刪除。但若 A 產品和 C 產品互為替代品,則對顧客而言,於購買 B 產品的前提下,A 產品和 C 產 品都是會考慮選擇的產品。但因為 A 產品與 C 產品交替選擇的關係進而造成 B→A 因不符最小信賴度而被刪除。 表 2高頻項目組 L3 頻繁項目集 AEB CDB ABD CBF
17
2.2.2
Apriori 演算法在關聯規則探勘技術的研究中,由 Agrawal etal. (1994) 所發表的 Apriori 演算法最廣為人知,此一演算法已成為關聯規則中最具代表性的演算法之一。 此演算法的核心概念就是藉由不斷地掃瞄資料庫的交易記錄,並計算出各種可 能的項目組合 (候選項目集) 的支持度,最後只留下支持度達到門檻值的頻繁 項目集。Apriori 演算法運作步驟如下[14]:
(1) 計算每一個 items 的 support,找出大於或等於 minsupport 的 itemses,稱 為 seed set(large itemsets)
(2) 利用(1)所找出的 large itemsets 產生出下一階段可能成為 large itemsets 的 itemsets,稱為 candidate itemses。
(3) 計算 candidate itemses 的 support
(4) 找出(3)中大於或等於 minsupport 的 itemses,成為新的 seed set (5) 重複(1) ~ (4),直到找不到新的 seed set 為止
圖 6與圖 7為 Apriori 演算法之虛擬碼,演算法中的表示符號說明如下: 資料庫欄位為<TID, item>,欄位 item 的中順序皆按字典順序(lesicographic)排 列。itemset 中 item 個數為 size,k-itemset 表示此 itemset 中有 k 個 item。Lk為
large itemsets 的集合,Ck為 Candidate itemset 的集合,其中 k 為 item 的個數(如
表 3)。 Apriori 演算法是目前資料探勘領域中最常使用之驗算法其優點與缺點如 下所述: 優點: 簡單易懂、實現複雜度低 缺點 在找高頻項目集合時,會產生大量的候選項目集合(Candicate Itemset) 必須經常掃瞄整個資料庫,造成執行效率不佳 .
18 表 3 k-itemset K- itemset 項目集含有 K 個 Item
Lk Large k-itemsets 集合(皆大於 minsupport)
1) itemset , 2)support count Ck Candidate k-itemsets 集合
1) itemset , 2)support count
1) L1 = {large 1-itensets};
2) for (k = 2; Lk-1≠ 0; k++) do begin
3) Ck = apriori-gen(Lk-1); //New candidates
4) forall transactions t D do begin
5) Ct = subset(Ck , t) //Candidates contaied t
6) forall candidates c Ct do 7) c.count ++; 8) end 9) Lk = {c Ck | c.count ≧ minsup } 10) end 11) Answer = Uk Lk 圖 6 Apriori 演算法之虛擬碼 圖 7Apriori 演算法之副函式虛擬碼 1) insert into Ck
2) select p.item1, p.item2,… ,p.itemk-1,q.itemk-1 3) from Lk-1p,Lk-1q
4) where p.item-1 = q.item-1, p.item-k-2 = q.item-k-2, p.item-k-1 < q.item-k-1; 5) forall itemsets c_Ck do
6) forall (k-1)-subsets s of c do 7) if ( s Lk-1 ) then 8) delete c from Ck
19
2.3 貝氏網路模式 (Bayesian Network Model)
貝氏信任網路 (Bayesian Belief Network,BBN)是結合貝氏機率理論與圖形 模式所發展出來的知識表示方式,藉由節點、連結與條件機率表三部分[15]。 貝氏網路是一個有向的非循環圖,每個節點代表一個隨機變數,每條連結線指 出兩個變數之間的交互關係[16]。簡言之,這個有向圖是這些變數之聯合機率 分佈的分解表示法。以下將分別針對貝氏定理及貝氏網路做一較為詳細之說 明。
2.3.1 貝氏定理 (Bayesian Theorem)
假設 C1 ,C2 ,…… ,Cn 為樣本空間 ( Sample Space) S 的分割,且有一事件 ( Event ) A,在此前提下有兩定理存在:定理 1:總機率法則 (Law of Total Probability)
i i i P A C C P A P | 定理 2:貝氏定理 (Bayes’ Rule)
i i i j j j C A P C P A P C A P C P A C P | | | 其中 P(Ci): 事前機率 (Prior Probability)P(A| Ci):樣本機率 (Sample Probability)
P(Cj | A):事後機率 (Posterior Probability)
從公式可知,貝氏定理可結合事前機率 (Prior Probability) 與樣本機率 (Sample Probability) 來推算事後機率(Posterior Probability) 。較一般利用統計方 法來說,貝氏定理更有效的運用有限的樣本資訊與經驗值,使得分析資料時不 需太多樣本資訊即可得到理想的統計數值,進而做更有完整與有效率的推論。
20
2.3.2 貝氏網路
( Bayesian Network
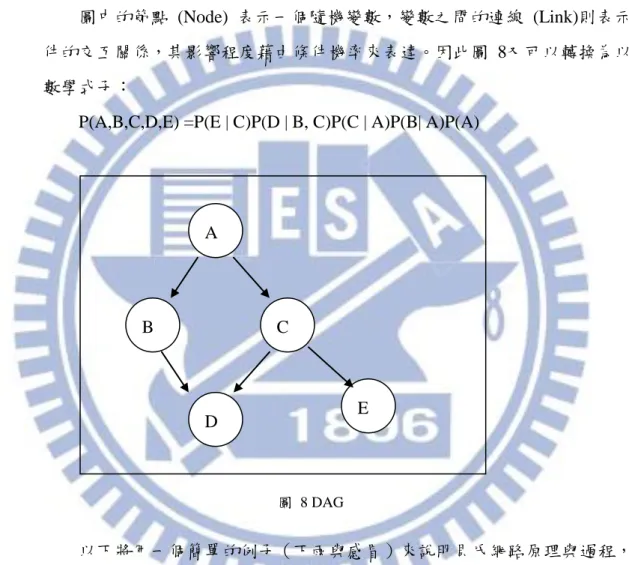
)在圖形模式上,貝氏網路是一個有向的非循環圖 (Directed Acyclic Graphs, DAG),每個節點代表一個隨機變數,每條連結線指出兩個變數之間的交互關 係。換句話說,這個有向圖是這些變數之聯合機率分佈的分解表示法。圖 8就 是 DAG 的一個簡單例子。 圖中的節點 (Node) 表示一個隨機變數,變數之間的連線 (Link)則表示事 件的交互關係,其影響程度藉由條件機率來表達。因此圖 8又可以轉換為以下 數學式子:
P(A,B,C,D,E) =P(E | C)P(D | B, C)P(C | A)P(B| A)P(A)
圖 8 DAG 以下將用一個簡單的例子(下雨與感冒)來說明貝氏網路原理與過程,此 例將說明貝氏網路中的因果關係並非是決定性的,而是推論性,而節點之間的 推測關係是透過條件機率表來呈現。 假設有 A、B 二位民眾出門沒帶雨具,而下雨將可能會導致感冒。根據天 氣預報下雨的機率為 60%。令淋雨導致感冒的機率為 70%,而未下雨但得到感 冒的機率為 10%,其表示方式如下 R 表示下雨事件,
A
, B
表示 A,B 得到感冒的變數。
R
Y
0
.
6
,
P
R
N
0
.
4
P
。 A B D C E21
A
|
R
Y
0
.
7
,
P
B
|
R
Y
0
.
7
P
淋雨導致感冒的機率。
A
|
R
N
0
.
1
,
P
B
|
R
N
0
.
1
P
未下雨但得到感冒。 圖 9為下雨與感冒的貝式網路模型。透過此模型可以推導出在 A 已經得到 感冒的情形下 B 得到感冒的機會。 圖 9下雨與感冒的貝式網路模型 計算在沒有任何資訊的提供下 A 和 B 發生感冒的機率
|
0
.
7
0
.
6
0
.
4
2
)
(
A
P
A
Y
R
Y
P
R
Y
P
感冒,
下雨
|
N
N
0
.
1
0
.
4
0
.
04
)
(
A
P
A
Y
R
P
R
P
感冒,
沒下雨
|
Y
Y
0
.
1
0
.
4
0
.
09
)
(
A
P
A
N
R
P
R
P
沒感冒,
下雨
|
N
N
0
.
9
0
.
4
0.36
)
(
A
P
A
Y
R
P
R
P
沒感冒,
沒下雨
0.46
04
.
0
42
.
0
)
(
A
感冒
P
P
(
A
沒感冒
)
0
.
09
0
.
36
0.45
B 的行況同 A 所以機率為R(下雨事件)
A(感冒與否)
B(感冒與否)
22
0.46
04
.
0
42
.
0
)
(
B
感冒
P
P
(
B
沒感冒
)
0
.
09
0
.
36
0.45
A 已發生感冒前提下,推導其他節點(R 和 B)的機率值
Y R P 與P
RN
表示觀察到 A 已發生感冒時,發生下雨機率的變化。
0
.
91
46
.
0
6
.
0
7
.
0
Y
|
|
Y
Y
A
P
R
Y
A
P
Y
A
R
P
Y
R
P
0
.
0
9
46
.
0
4
.
0
1
.
0
N
|
|
N
Y
A
P
R
Y
A
P
Y
A
R
P
N
R
P
若觀察到 A 已發生感冒,下雨的機率則有可能提升。 當下雨機率改變時,推導 B 發生感冒機率的變化
|
0
.
7
0
.
91
0
.
637
)
(
B
P
B
Y
R
Y
P
R
Y
P
感冒,
下雨
|
N
N
0
.
1
0
.
0
9
0
.
009
)
(
B
P
B
Y
R
P
R
P
感冒,
沒下雨
0.646
009
.
0
637
.
0
)
(
B
感冒
P
由上述例子可知貝氏網路以整體性觀點來調整整個網路,換句話說當機率 值調整時,貝氏網路上所有相關節點可根據其條件機率而同時調整,此特性使 得在推論過程,若中有新資訊進來便能立即反應出整體事件可能發生的機率。 如上述例子中,當以知 A 已發生感冒,則下雨的機率由 0.6 提升為 0.91,相同 情況下 B 發生感冒的機率也因下雨機率的增加而提升至 0.646。 圖 10為含有機率表之貝氏網路架構圖,假定圖中節點是我們想了解問題 變數,以本論文來說就是過去被評價過的項目,而圖中的機率表,則是表示父 節點於各種狀態下,子節點被評價的機率。23 圖 10含有機率表之貝氏網路
2.4 激勵理論(Incentive theory)
在經濟發展的過程中,分工與交易的出現帶來了激勵問題。激勵理論是用 於處理需要、動機、目標和行為四者間關係的理論。30 年代經濟學家開始關心 被傳統經濟理論所忽視的企業內部管理效率問題,認識到激勵的重要性,並開 始對激勵問題進行研究。與管理學通過對人的多種需求研究激勵不同,經濟學 對激勵的研究是以經濟人為出發點,以利潤最大化或效用最大化為目的。 進入 70 年代以後,激勵問題成為其中非常重要的研究課題。而委託代理理論 (Principal-agent Theory)亦是激勵理論的主要內容之一,其主要研究為委託代理 關係。指一個或多個行為主體依據明示或隱含的契約,指定另一些行為主體為 其服務,並授予一定的決策權利,並根據後者提供服務數量和質量對其支付相 應的報酬。授權者就是委託人,被授權者就是代理人。如何設計一套激勵機制 來激勵代理人努力工作即為委託代理理論的核心工作。本論文即透過此激勵模 式來激勵使用者進行新產品的推薦與評比。以下分別簡述代理問題架構和幾項 委託代理理論基本模型。24
2.4.1 代理問題架構
代理問題即為一種機制設計(mechanism design)[17]與選擇的問題。此類問 題當中將有一個「委託人」(principal)和一個或多個「代理人」(agents);委託 人的支付函數式(Payoff)為共同的知識,代理人的支付函數只有代理人自己知 道,委託人和其他代理人皆不知道。舉例來說,在一級密封價格拍賣(The first-price sealed auction)中,賣方不知道買方對拍賣品的評價;而在雙方叫價 拍賣中,拍賣人(auctioneer)亦不知道買方的評價,也不知道賣方的商品成本; 以企業訂價的角度來看,在企業(壟斷型)對商品的訂價中,企業亦不知道消費 者願意付出的最高價格。 委託人或許可以直接要求代理人說明自己的類型,但代理人可能不會說 實話,除非委託人能提供給代理人足夠的「激勵」 (Incentive),而激勵可以為 貨幣或非貨幣的型態。因提供激勵是有成本的,因此委託人將面臨成本與收益 的問題。 委託人設計機制目的是最大化自己的期望效用函數。其將會面臨二個條件 (約束)。[17][C3] 個人理性條件(individual rationality,IR): 如果一個理性的代理人有任何興趣接受委託人設計的機制,則其代理 人在此機制下所獲得的期望效用必須「不小於」其在「不接受」這個機制 時 所 得到的最大期望效用。 此條件 又稱為 「參與 約束」 (participation constraint)。另外在「不接受」這個機制時所得到的最大期望效用稱為保 留效用(reservation utility)。 誘因相容條件(incentive compatible,IC): 此條件又稱為激勵相容條件,在委託人不知道代理人類型的前提下, 於此機制內代理人必須有其積極性來選擇委託人希望他選擇的行動。顯 然,只有當代理人選擇委託人所希望的行動時得到的期望效用「不小於」 他選擇其他行動時得到的效用時,代理人才有積極性選擇委託人所希望的 行動。 滿足「個人理性條件」的機制又稱為「可行機制」(feasible mechanism);25 滿足「誘因相容條件」的機制又稱為「可實施機制」(implementagle),如果一 個機制滿足「個人理性條件」與「誘因相容條件」時,可稱此機制是「可行的 可實施機制」。委託人的問題是選擇一個「可行的可實施機制」以最大化其預 期效用(「可行的可實施機制」可能有很多個)。 以下將透過上述原則以工資設計機制為例說明代理問題。假設有兩名參賽 者,委託人與代理人,委託人付工資E雇用代理人進行工作。代理人可能會以 不同努力的程度來進行工作,以m
mH,mL
表示代理人努力程度有兩種可 能,m 與H m 分別是高、低努力。L 表示代理人工作的成果,是代理人幫委託 人賺到的利潤。 委託人的報酬函數是利潤減去工資 E,代理人的報酬是由工資與努力 工 作 程 度 決 定 , 寫 成 u
E,m
。 試 想 利 潤 有 N 種 可 能 金 額 , 寫 成
N
1, 2,..., ,其中12 ...N。工作努力程度與 m 與利潤大小之間 有 隨 機 關 係 , 努 力 程 度 mi 的 代 理 人 賺 取 不 同 金 額 利 潤 的 機 率 是
i i iN
i p p p p 1, 2,..., ,其中iH,L表示努力程度高、低,而p 則表示in mi努力 代理人賺到n利潤的機率,n1,2,...,N。 用一個例子來說明以上架構,
0,200,600
表示代理人創造的利潤可能 是 0 或 200 或 600,而pH
0.1,0.2,0.6
與pL
0.5,0.4,0.3
分別說明m 和H mL 代理人賺到不同利潤的機率。由上述資料可算出m 與H m 代理人幫委託人賺到L 的預期利潤分別是 400 與 260。平均來說,m 會賺到較高的預期利潤,但是H mL 也有 0.3 的機率會賺到 600 的高利潤。 「資訊不對稱」是代理問題的重點,也就是代理人努力程度是m 或是H mL 委託人無法觀察到。所以委託人無法根據代理人實際付出的努力來付工資,而 只好由利潤來決定工資的大小。m (努力) 代理人也可能得到低利潤,H m (不L 努力) 代理人也可能賺到高利潤。 我們藉由分析代理人的最適決策。面對E
工資函數,代理人必定會以追 求u
E,m
極大化為目標來決定以下二項選擇: 是否接受工作。26 (若接受)選擇何種程度的努力來工作。 所以委託人設計E
時必需將代理人對E
的最適反應考慮在內。我們 將委託人的契約設計(contract design)問題,分為下二步驟解決: 先假設委託人的目標是希望代理人選擇mˆ 努力程度,則最佳工資契約 ) ( * E 應該滿足下二條件: 個人理性條件(individual rationality,IR): 拒絕工作的代理人將獲得保留效用水準 u ,而在E*()工資函數 下,代理人接受契約並用mˆ 的努力程度工作得到的效用水準。最佳工 資契約必需使得u
E*
,mˆ
u。如果此條件不滿足,理性的代理人 將會選擇拒絕工作。
誘因相容條件(incentive compatible,IC): 以m~表示其他任意努力程度,m~mˆ。在E*()之下,代理人用m~ 的努力程度工作會得到u
E*
,m~
效用,工人用mˆ 的努力程度工作會 得到u
E*
,mˆ
。最佳工資契約必需使得u
E*
,mˆ
u
E*
,m~
, 才能確定代理人會選擇mˆ 的努力程度。滿足此條件後,對代理人最好 的是選擇mˆ 的努力程度工作,這正好和委託人的目標一致,因此稱為 誘因相容條件。 一套有效用的激勵機制必須符合誘因相容與個人理性條件。誘因相容就是 機制設計者同時思考個人追求與社會追求,使得追求個人利益的行為,正好與 社會實現集體價值最大化的目標相吻合。而個人理性條件是指代理人接受合同 下的期望收益(效用)要大於其他市場機會下能獲得的最大期望收益。27
2.4.2 委託代理理論基本模型
委 託 代 理 理 論 是 建 立 於 非 對 稱 訊 息 賽 局 的 基 礎 上 , 而 非 對 稱 訊 息 (asymmetric information)指的是部份參與人擁有但另一部分參與人不擁有的 訊息。從非對稱發生的時間看,可分別稱為事前非對稱和事後非對稱。事前非 對稱訊息賽局的模型稱為逆向選擇模型 (adverse selection),事後非對稱訊息 的模型稱為道德風險模型(moral hazard)。前者是委託人與代理人的資訊不對 稱所造成;後者原因為簽訂契約雙方一些行動的不可觀察性或無法驗證性而行 成。委託代理理論的任務是研究在利益衝突和訊息不對稱的環境下,委託人如 何設計最好契約來激勵代理人來達成委託人想要達成的目標。以下簡述幾個較 為著名的委託代理理論模型。 代理模型 最早研究委託代理模型的是 Radner,1981 和 Rubbinstein,1979。其 透過重複賽局模型證明,若委託人和代理人有長期的合作關係時,代理人 無法用偷懶的;方式提高自身的福利且由於在長期契約的保護下向代理人 提供了“個人保險” (self-insurance),委託人可以免除代理人的風險。即 使合同不具法律上的可執行性,出於聲譽的考慮,合同雙方都會各盡義務。 效應模型 棘輪效應(ratchet effects)指的是委託人以代理人過去的成績作為標 準,因為過去的成績包含著有用的訊息。過去的成績與代理人的主觀努力 有關,代理人越努力,好成績可能性越大,代理人給自己的“標準”也越高。 當代理人意識到努力帶來的結果是“標準”的提高,其努力的積極性將會降 低。這種標準成績上升的傾向稱為“棘輪效應”。在長期的過程中,棘輪效 應會抵銷激勵機制。 風險模型 於委託代理人模型中,主要討論的是代理人道德風險的問題。是實28 上,委託人也同樣存在道德風險。其衡量的方式存在很大的主觀意識。代 理人可能無法觀察到委託人觀察到的東西。在這種情況下,就存在委託人 的道德風險問題。根據契約,當觀察到的產出高時,委託人應該支付給代 理人高的報酬,但委託人可以謊報產出不高,進而逃避責任,而把本應支 付給代理人的收入佔為己有。相同的如果代理人預設委託人可能耍賴,其 將不會積極努力工作。 監督模型 存在委託代理關係就無法避免監督問題。事實上,在非對稱訊息的情 況下,委託人對代理人訊息的了解程度可以由委託人自己選擇。比如說, 通過僱傭監工或花更多的時間和精力,委託人可以在一定程度上更多的了 解代理人的訊息。從而加強對代理人的激勵和監督。但訊息的獲取又是有 成本的,於是,委託人面臨著選擇最優監督力度的問題。 由於委託代理關係於實際社會中是存在的,因此委託代理理論被用於解決 各種問題。例如老闆與僱員、股東與經營者,選民與官員,醫生與病人,都是 委託代理關係。因此,經由激勵機制的影響,設計最佳的激勵機制,將會越來 越廣泛的被應用於生活各方面。
2.4.3 激勵效果
從效果的角度而言,一般將激勵的效果分為二項,顯性激勵和隱性激勵兩 種。以下將分別說明何謂顯性激勵與隱性激勵及優缺點。 顯性激勵(explicit incentive mechanism)
委託人為了激勵代理人選擇委託人所冀望的行動,會依據可以觀察的 結果進行獎勵或懲罰代理人。此類型的激勵機制稱為「顯性激勵機制」。
換句話說,顯性激勵是指代理人預期可獲得收入的總和,其包含物質 或精神的收入,物質收入例如工資、獎金或其他實物收入,精神方面的補 償例如職位的提升與獲得榮譽的肯定等等。在實施顯性激勵的過程中,委
29 託人將處於被動狀態,其只能以自身的行為方式或結果改變自己所處的狀 態。隨代理人目的不同,不同的顯性激勵方式效果也會不同,如榮譽的肯 定,對某些人極具補償效果而對另外一些人則不然。 優點 其特點是代理人可以感覺到或預期可得到此項激勵。此種激勵機 制是經由代理人所盡力去爭取但結果卻不由代理人決定,透過此方誘 導代理人選擇委託人所冀望行動的一種激勵方式。 缺點 顯性激勵機制的缺陷在於它並不能使代理人自願發揮自己的全 部內在潛力,從而不能使顯性激勵完全發揮其作用。
隱性激勵(Implicit incentive mechanism)
隱性激勵,主要是針對公開的顯性收入(物質或精神)之外,採用非公 開的隱蔽收入進行激勵的一種方式。例如公關費用(非公開沒有既定標準 的各種津補貼)。無“薪” 隱性的激勵,則更能體現出委託人領導能力。 優點 隱性激勵具有降低激勵成本(由於隱性激勵收入沒有統一的標 準,因此激勵的標準可以靈活調整)、增加代理人的收入、激勵效用 能夠持且兼具標準與獎勵名單不公開,能夠降低代理人們心理不平衡 因素。 缺點 價值導向不明確: 一般而言,激勵的重要作用之一,是通過樹立標竿、獎勵績 優,而隱性激勵在某些程度上會使得組織能夠傳遞的訊息幅度有 限,甚至連被激勵者本人都不清楚具體的激勵標準。 激勵效果的不確定性: 由於“隱性”的包袱,成績優異代理人能夠得到激勵,卻不能
30 公開其榮譽,換句話說代理人能夠清楚自身的獎勵情況,卻不清 楚獎勵的標準及與其他代理人的對比,進而使得努力的方向變得 模糊。此類型隱性激勵效果模糊,無法有效激勵成績優異者,亦 不能有效激發成績落後者。 激勵公平性: 一般而言,「公平、公開與公正」為激勵機制的基本要求,而 隱性激勵在某些程度上需避免「公平、公開與公正」原則。一旦公 平原則受到質疑,其對組織和諧的破壞性更勝於顯性激勵。
31
第三章、 研究架構與方法
3.1 研究架構
本論文之研究架構如圖 11所示,其中包含了兩個主要部分,分別為使用 者輪廓(User Profile)資訊拓展與鼓勵新項目評比: 使用者輪廓(User Profile)資訊拓展: 利用貝氏網路事後推論特性更正確找出使用者輪廓中各個有興趣項目 種類的潛在關聯性,避免因為關聯規則信賴度門檻定義選擇的問題而使得某 些規則遺失使得推薦正確率降低。 例如 以下二條規則 冒險片(Adventure)-> 奇幻片(Fantasy) 奇幻片(Fantasy)-> 冒險片(Adventure) 假設 冒險片(Adventure)-> 奇幻片(Fantasy) 規則成立 但 奇幻片(Fantasy)-> 冒險片(Adventure) 因不符合門檻值而被過濾掉, 其被過濾掉的原因為,科幻片(Sci-Fi)與 冒險片(Adventure) 互為替代 品,導致出現的次數降低進而使得以下二項規則都會被過濾掉。 奇幻片(Fantasy)-> 冒險片(Adventure) 奇幻片(Fantasy)-> 科幻片(Sci-Fi) 鼓勵使用者對於新項目(影片)進行評比: 透過激勵理論的代理人機制設計滿足個人理性條件與誘因相容條件的 激勵模型來最大化其自身(使用者與推薦系統)的期望效用函數,讓使用者願 意去嘗試新的物件或產品。 以下將針對研究架構中的兩個核心之細部功能詳細說明之。32 圖 11研究架構
推薦系統
拓展個人
使用者輪廓檔
貝氏網路
與
關聯規則
提高正確率
全體
使用者輪廓檔
鼓勵
新項目評比
33 3.1.1
使用者輪廓(User Profile)資訊拓展
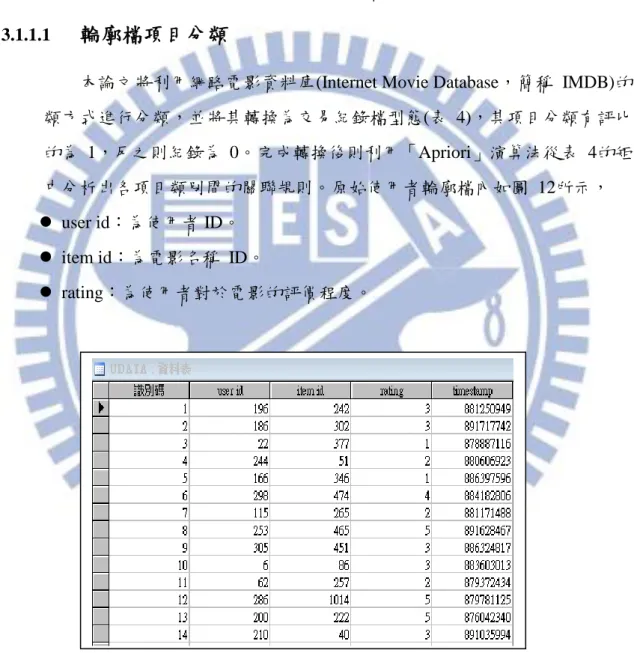
本論文期望利用全體使用者輪廓檔內項目類別間潛在的關係來拓展使用 者輪廓資訊不足的個別用戶。此資訊拓展可分為三部分,第一部分為將輪廓檔 內的項目進行分類以利第二部分關聯規則的探勘並建置貝氏網路結構。第三部 分則是貝氏網路機率表的產生與拓展使用者輪廓檔。以下對三部份進行說明。 3.1.1.1輪廓檔項目分類
本論文將利用網路電影資料庫(Internet Movie Database,簡稱 IMDB)的分 類方式進行分類,並將其轉換為交易紀錄檔型態(表 4),其項目分類有評比過 的為 1,反之則紀錄為 0。完成轉換後則利用「Apriori」演算法從表 4的矩陣 中分析出各項目類別間的關聯規則。原始使用者輪廓檔內如圖 12所示, user id:為使用者 ID。
item id:為電影名稱 ID。
rating:為使用者對於電影的評價程度。
34
表 4項目分類交易紀錄檔 使用者 ID
(Transaction ID)
Action Adventure Animation Comedy Crime …
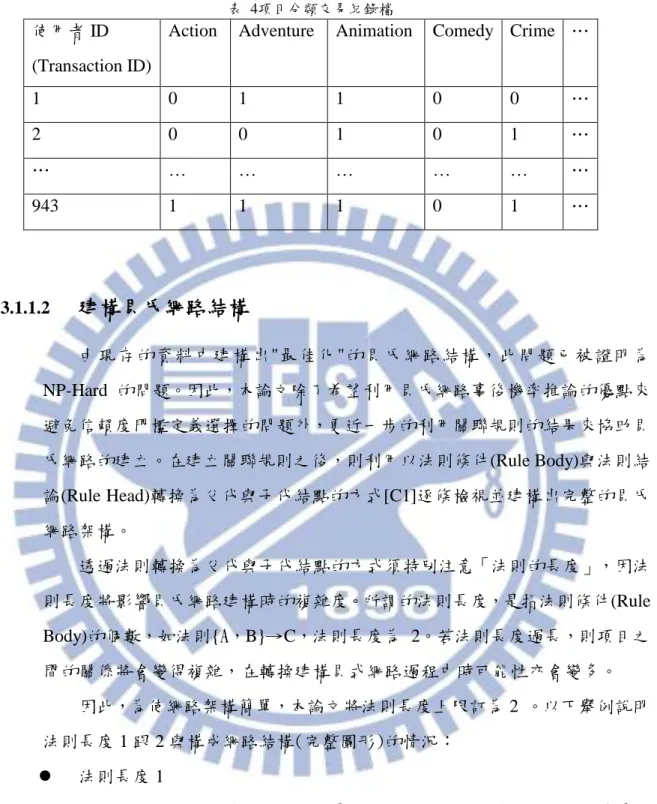
1 0 1 1 0 0 … 2 0 0 1 0 1 … … … … … 943 1 1 1 0 1 … 3.1.1.2
建構貝氏網路結構
由現存的資料中建構出"最佳化"的貝氏網路結構,此問題已被證明為 NP-Hard 的問題。因此,本論文除了希望利用貝氏網路事後機率推論的優點來 避免信賴度門檻定義選擇的問題外,更近一步的利用關聯規則的結果來協助貝 氏網路的建立。在建立關聯規則之後,則利用以法則條件(Rule Body)與法則結 論(Rule Head)轉換為父代與子代結點的方式[C1]逐條檢視並建構出完整的貝氏 網路架構。 透過法則轉換為父代與子代結點的方式須特別注意「法則的長度」,因法 則長度將影響貝氏網路建構時的複雜度。所謂的法則長度,是指法則條件(Rule Body)的個數,如法則{A,B}→C,法則長度為 2。若法則長度過長,則項目之 間的關係將會變得複雜,在轉換建構貝式網路過程中時可能性亦會變多。 因此,為使網路架構簡單,本論文將法則長度上限訂為 2 。以下舉例說明 法則長度 1 跟 2 與構成網路結構(完整圖形)的情況: 法則長度 1 法則長度為 1 時,法則條件屬性視為關聯中父代節點,法則決策屬性 則是視為關聯中的子代節點如圖 13所示。35 圖 13貝氏網路架構法則長度 1 法則長度 2 法則長度為 2 時,仍是以法則條件屬性視為關聯中父代節點,法則決 策屬性則是視為關聯中的子代節點方式建構。但其會有以下二種不同的結 構: 鏈狀結構: 若條件屬性中的兩屬性,也有法則存在時形成 此結構,如圖 14 圖 14鏈狀結構 {A,B}→D A→B {X,Y}→D X→Y A B D X Y A B C D E A→C B→C C→D E→D
36 收斂結構:若條件屬性中的兩屬性,沒有法則存在時形成此 結構,如圖 15 圖 15收斂結構 構成網路結構: 若任三個節點出現完整圖形時,如圖 16。會存在條件獨立的情形, 此時計算子節點與父節點之間的「條件熵(Conditional entropy)」值(或稱 為 unexplained information 值)的大小,並透過去除「條件熵」值較低的 關聯,以簡化貝氏網路。 圖 16網路結構(完整圖形) B→A B→C C→A A B C {A,B}→D {X,Y}→D A B D X Y
37 3.1.1.3
產生條件機率表
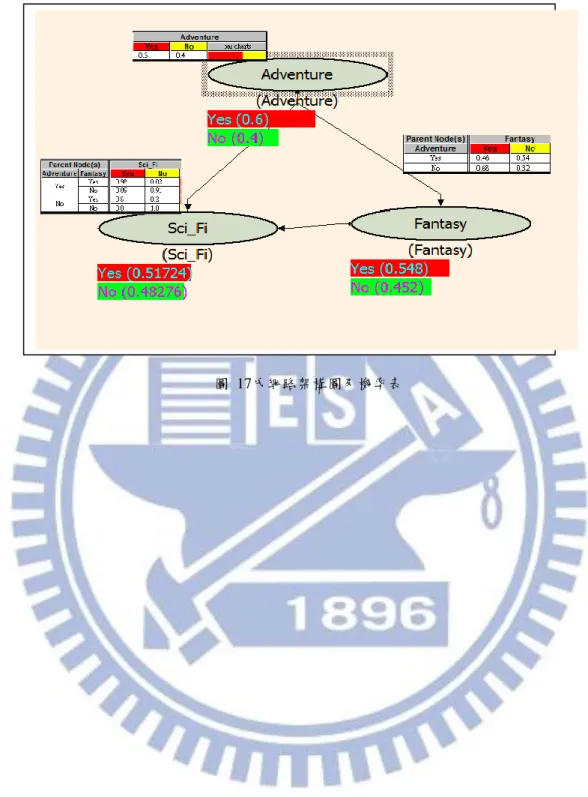
透過法則條件(Rule Body)與法則結論(Rule Head)轉換為父代與子代結點 的方式逐一檢視關聯規則並建構完成貝氏網路的架構後,接下來即可透過貝氏 網路聯合機率分配定理計算圖中每個節點的機率表,如圖 17所示。
n i iparents
x
x
p
x
p
1))
(
|
(
)
(
表示為在父節點發生的前提下,x 發生的機率 Parents(x): x 節點父節點之機率。 圖 18為貝氏網路架構與機率示意圖,以下說明圖中各節點所表示的意義。 圖中橢圓表示推薦系統中各項目(於本論文中為電影類別)間之關係。 灰色橢圓節點(Fantasy、Comedy、War)則表示為使用者輪廓檔中已評 比之項目。 節點數字部分表示在灰色橢圓節點發生的前提下,各節點的機率值。 虛線節點(Adventure、Action、Thriller)則表示其機率大於所設定的門 檻值(此處假設為 0.7),超過門檻值之節點將會添加至使用者輪廓資 訊不足的個別用戶中。 建構完成貝氏網路架構與機率計算後即可透過貝氏網路所推論之項目類 關係添加至使用者輪廓資訊不足的個別用戶中,其方式如圖 19、圖 20所示38
39 圖 18貝式網路機率狀況示意圖
Romance
Sci-Fi
Thriller
Action
War
Drama
Crime
Comedy
Adventure
Fantasy
已評比
evidence=1
已評比
evidence=1
已評比
evidence=1
0.588
0.745
0.724
0.847
0.614
0.478
0.679
40 圖 19使用者輪廓拓展 規則: Adventure(冒險片), ==> Fantasy(奇幻片) 資訊不足之輪廓檔(User 20) 0, Adventure(冒險片), 0,0,0, 0, 0,0, 0, 0, 0, 0, 0, 0,0, 0,War, 0 拓展輪廓檔(User 20)
0, Adventure(冒險片), Fantasy(奇幻片),0,0, 0, 0,0, 0, 0,0, 0, 0, 0, 0,War, 0 添 加 規 則 在 Adventure 已發生 的前提下,Fantasy 發生的機率超過門 檻值(0.7)
41
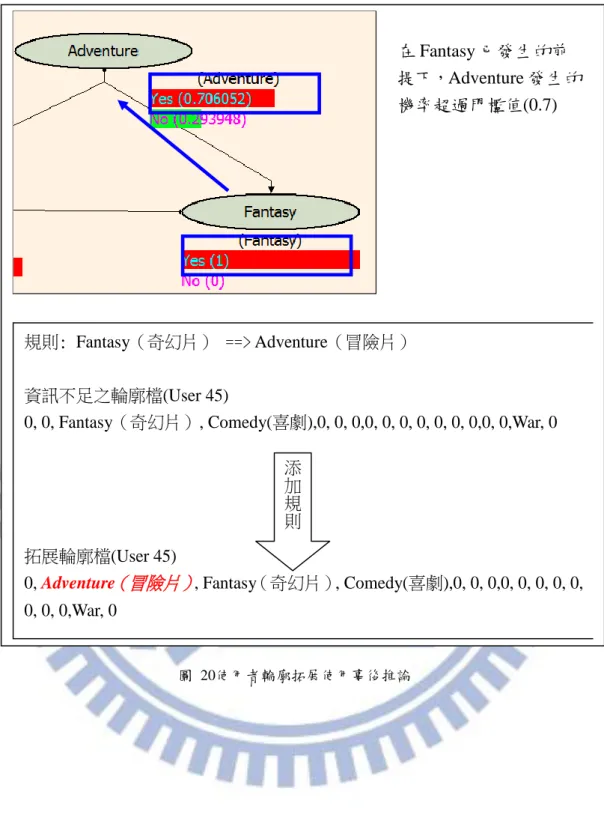
圖 20使用者輪廓拓展使用事後推論
規則: Fantasy(奇幻片) ==> Adventure(冒險片) 資訊不足之輪廓檔(User 45)
0, 0, Fantasy(奇幻片), Comedy(喜劇),0, 0, 0,0, 0, 0, 0, 0, 0, 0,0, 0,War, 0
拓展輪廓檔(User 45)
0, Adventure(冒險片), Fantasy(奇幻片), Comedy(喜劇),0, 0, 0,0, 0, 0,0, 0, 0, 0, 0,War, 0 添 加 規 則 在 Fantasy 已發生的前 提下,Adventure 發生的 機率超過門檻值(0.7)
42

![圖 2推薦系統架構圖[5]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8638012.192988/16.892.130.805.100.903/圖2推薦系統架構圖5.webp)
![圖 3協同式推薦系統架構[17]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8638012.192988/20.892.158.809.136.1033/圖3協同式推薦系統架構17.webp)