以複式BCa估計法建構單一非對稱規格區間之C"pmk指標的信賴區間
51
0
0
全文
(2) 以複式 BCa 估計法建構單一 非對稱規格區間之C pmk 指標的信賴區間 ". Using Bootstrap Simulation to Construct BCa Confidence Interval for the Difference Between Two. C "pmk with Single Asymmetric Tolerance. 研究生:江旻育. Student:Min-Yu Jiang. 指導教授:唐麗英 博士. Advisor:Lee-Ing Tong. 洪瑞雲 博士. Ruey-Yun Horng 國 立 交 通 大 學. 工 業 工 程 與 管 理 學 系 碩士論文 A Thesis Submitted to Department of Industrial Engineering and Management College of Management National Chiao Tung University In Partial Fulfillment of the Requirements For the Degree of Master of Science In Industrial Engineering June 2003 Hsin-Chu, Taiwan, Republic of China. 中華民國九十三年六月.
(3) 以複式 BCa 估計法建構 ". 單一非對稱規格區間之 C pmk 指標的信賴區間 學生:江旻育. 指導教授:唐麗英 博士 洪瑞雲 博士. 國立交通大學工業工程與管理學系碩士班. 摘要 在高科技產業時代,產品品質是提昇產品競爭力的一個很重要的因素。許多 企業應用統計手法為其產品製程的品質把關,其中最常用到的工具就是製程能力 分析。由於實務上某些產業的製造過程常可見到非對稱之規格區間,例如,加工 模具零件的接合時,要求零件孔徑的大小為 2.0 +−00..15 03 mm,當產品的目標值偏向不 同方向的規格界限時會造成嚴重程度不同的損失,因而導致目標值的設定與規格 中心不同。所以,近年來學者在傳統指標中考慮了這個要素而發展出非對稱規格 之製程能力指標 C "pk 、 C "pm 和 C "pmk 等,而 C "pmk 指標更能反映出製程的真實績效。 由於 C "pmk 之估計式的機率分配過於複雜,目前中外學者也僅能推導出近似的機率 分配,相關的假說檢定與信賴區間的研究至今尚未發展出來,導致 C "pmk 指標無法 廣泛地被業界使用。因此,本研究之主要目的是針對 C "pmk 指標,以模擬重複多次 抽樣效果來降低抽樣成本以及對製程偏離常態假設時較不敏感的複式模擬法 (Bootstrap Simulation)來推導單一指標的信賴下限與兩個不同製程間指標差異值 的信賴區間,以評估製程的穩定性與推估兩個供應商或兩個製程之能力的優劣。 本研究最後並建立一個完整的應用流程可供業界人員方便使用,正確了解與判斷 製程的實際狀況。. 【關鍵詞】非對稱之規格、製程能力指標、複式模擬法、信賴下限、信賴區間。. i.
(4) Using Bootstrap Simulation to Construct BCa Confidence Interval for the Difference Between Two C "pmk with Single Asymmetric Tolerance Student:Min-Yu Jiang. Advisor:Lee-Ing Tong Ruey-Yun Horng. Department of Industrial Engineering and Management National Chiao Tung University. Abstract Process capability indices (PCIs) are widely utilized to determine whether a manufacturing process is capable of producing items within a specific tolerance. Among all the used PCIs, Cp and Cpk are two commonly used but they can not accurately measure the potential process capability when the process mean deviates from the center of the specifications or target value. Consequently, an advanced PCI, Cpmk" is proposed in recent year. As to asymmetric tolerance, Cpmk" is assumed to be more superior index than Cpm" and Cpk". However, the exact probability distribution of Cpmk" is too complicated to be derived so the related hypotheses testing and confidence interval cannot be developed. The reason makes the application of Cpmk" limited. Hence, the objective of this study is using the bootstrap simulation to construct a lower confidence limit for Cpmk" and a confidence interval for the difference between two Cpmk" value with Single Asymmetric Tolerance. The lower limit can be utilized as the information for improving process. The confidence interval can be effectively employed to determine which one of the two production processes or manufacturers has a better process performance. Then a detail procedure is written that engineers without statistic background could be able to adopt it well in practice. 【Key Words】Asymmetric tolerance, Process capability indices, Bootstrap simulation, Confidence interval.. ii.
(5) 誌 謝 本論文得以順利完成,首先要感謝指導教授唐麗英博士兩年來悉心的教誨及 論文寫作上的教導,在學業上和生活上皆授與相當多的知識與關心。同時也要感 謝洪瑞雲、李榮貴、黎正中老師在論文口試期間惠予的寶貴的意見與指正,使本 文更加完善,謹此衷心致謝。 碩士兩年的生活雖然短暫,但是卻是回憶最多的地方,在這裡我交了許多的 朋友,也有許多人在背後默默的支持,在此,我要感謝我的女友靜怡,給我鼓勵 及加油,並陪我度過種種難關;除此之外,特別感謝昌奇學長與珮芳學姊為學弟 的研究上提供許多寶貴的意見,帶領學弟跨入研究的門檻。以及阿嘉、老許、兩 光、卡拉蛙、聖慧、瑜芳、佩嵐、靜宜、阿嬌這幾位同窗好友,這兩年彼此相互 扶持,一起經歷過許多歡樂的時光,謝謝你們。這裡也特別要感謝其它研究室的 同學,祝祥、小艾、剛蛋、小古、博裕、建鴻、鹹蛋、長吉等,謝謝你們在這段 期間的鼎力相助,使得本文能順利完成;另外,還要感謝交大工管壘球隊的學長 與學弟們,讓我能擁有許多大家一起打球的珍貴回憶。 還有我的幾位大學的好友們,勝龍、哲愿、永全、俊彥、維菁、孟容、穎聖、 偉超等,謝謝你們一直以來的幫助與關心,祝福你們在自己的工作崗位上都能事 事順心。 最後要感謝我的父母和兩個妹妹,能讓我在這兩年研究所的生涯中專心致力 於研究,也不斷地為我加油打氣,讓我無後顧之憂,謝謝你們! 謹致於 交通大學工業工程與管理研究所. iii.
(6) 目 錄 中文摘要…………………..………………………..………………………..…….…I 英文摘要……………..…..………………………..………………………..…….….II 誌謝……………..…..………………………..………………………..…………….III 目錄……………………………………………………………………………….…IV 圖目錄…………………………………………………………………………….…VI 表目錄………...………………………………………………………………….….VI 第一章 緒論 1.1 研究背景與動機………………………………..…………………..……….….1 1.2 研究目的…………………………………………..…………….…….…….….5 1.3 研究範圍……………………………………………..………….……….….….5 第二章 文獻探討 2.1 製程能力指標介紹……………………………………..………..……….….…6 2.2 新型非對稱規格區間製程能力指標介紹………………..…………...…….…8 2.3 複式模擬法之介紹…………………………………………..…………...……11 2.4 其他相關文獻探討……………………………………………..……..….……15 第二章 以 BCa 區間估計法建構單一非對稱規格區間之 C "pmk 指標的信賴下 限及兩個製程能力指標 C "pmk 差異之信賴區間 3.1 運用複式模擬法建構 C "pmk 指標信賴下限的流程………………...…....……16 3.1.1 運用複式模擬法建構 C "pmk 指標信賴下限的有效性分析.…....………..18 3.1.2 運用複式模擬法建構 C "pmk 指標信賴下限的敏感度分析….……….….19 3.2 運用複式模擬法建構兩個 C "pmk 指標差異之信賴區間的流程..…………….27 3.2.1 運用複式模擬法建構 C "pmk 指標差異之信賴區間的有效性分析….…..28 iv.
(7) 3.2.2 運用複式模擬法建構 C "pmk 指標信賴區間的敏感度分析…….……..…29 3.3 製程能力指標 C "pmk 應用流程之建構………………………….………..……37 3.3.1 使用製程能力指標 C "pmk 來評估單一製程的穩定與優劣之流程……....37 3.3.2 使用製程能力指標 C "pmk 來比較兩個製程之能力的優劣之流程………38 第四章 實例說明…………………………………………………………………..39 第五章 結論……………………………………………………………………..…41 參考文獻………………………………………………………………………….….42. v.
(8) 圖 目 錄 圖 3-1 績效值在變動樣本數時之表現折線圖……………………………………..23 圖 3-2 績效值在變動平均值時之表現折線圖……………………………………..24 圖 3-3 績效值在變動標準差時之表現折線圖……………………………………..25. 圖 3-4 以複式模擬法建構單一製程能力指標 C "pmk 信賴下限之流程圖…………..26. 圖 3-5 三種衡量指標在變動樣本數時之表現折線圖……………………………..33 圖 3-6 三種衡量指標在變動平均值時之表現折線圖……………………………..34 圖 3-7 三種衡量指標在變動標準差時之表現折線圖……………………………..35 圖 3-8 以複式模擬法建構兩個製程能力指標 C "pmk 差異的信賴區間之流程圖…..36. 表 目 錄 表 3-1 非對稱規格區間之製程能力指標 C "pmk 95﹪信賴下限的模擬結果……..…19. 表 3-2 兩個製程能力指標 C "pmk 差異值 95﹪信賴區間的模擬結果…………….…30. 表 4.1、改善活動前:樣本 1………………………………………………………..39 表 4.2、改善活動後:樣本 2………………………………………………………..39. vi.
(9) 第一章 緒論 1.1 研究背景與動機 高科技產業時代為了滿足顧客的需求及提升產品的競爭力,必須儘速找到影 響產品品質的重要因素。在生產高品質產品的過程中,除了要有精密的生產設 備、良好的產品設計與穩定的產品製造過程之外,供應商的原料品質亦是一項重 要因素,目前許多企業都有品管部門來稽核供應商的供貨品質以保證其產品的品 質,因此製程與供應商的品質管制在產品的製造過程中是非常重要的。統計製程 管制(Statistical Process Control, SPC)的兩個重要工具即為管制圖與製程能力分 析,其目的是將製程中蒐集到的產品特性資料,利用統計方法使製程達到管制狀 態(in-control),然後再評估品質績效,進而提出改善製程的方法。 製程能力是指在製造過程中去除非隨機性因素的影響後,製程所呈現的實際 能力,而製程能力可用製程能力指標(Process Capability Index, PCI)將製程的真 實績效與規格之間的關係量化,以利評比。製程能力分析是指製程處於常態的管 制狀況下,透過製程能力指標來分析及判斷製程能力的優劣。因此,廠商對內可 以透過製程能力指標來了解產品本身的製程是否穩定;對外,製程能力指標可以 作為買賣雙方交易產品時的評估標準,採購人員亦可以利用上游物料供應商所提 供產品的製程能力指標來判斷哪一家供應商所提供的品質較優良。 Juran[14]最早提出 Cp 製程能力指標的觀念,隨後為 Kane[15]提出 Cpk 指標。. Cp 和 Cpk 指標是目前產業界最常使用的製程能力指標,其中 Cp 是一個關於製程標. 1.
(10) 準差( σ )的函數,用來衡量製程產出範圍(六倍標準差)與規格寬度之間的關 係;Cpk 則是一個關於製程分配參數(即製程平均值 µ 與製程標準差 σ )的函數,. Cpk 比 Cp 多考慮了製程平均值 µ 偏離規格中心所造成的影響。然而 Cpk 與 Cp 兩個 製程能力指標均未考量製程平均值 µ 與目標值(target value)間差異大小對製程 的影響,因此,Chan et al.[6]提出新的製程能力指標 Cpm,此指標加入了田口損失 函數的概念,考量到製程平均值與目標值間差異大小之關係,使得 Cpm 能反映出 製程的期望損失,但是如果製程平均值與目標值相同,則 Cpm 指標會與 Cp 指標相 同,因此 Cpm 指標仍無法考慮到若目標值偏離規格中心,即非對稱規格中心對製 程能力的影響。針對這個缺點,Pearn et al.[19]提出 Cpmk 指標,此指標綜合了 Cpk 指標能考量製程平均值偏離規格中心的影響與 Cpm 指標能反映製程平均值與目標 值間差異大小之關係的優點能同時反應製程良率及製程之期望損失。 由於實務上某些產業的製造過程常可見到非對稱之規格區間,例如,加工模 具零件的接合時,要求零件孔徑的大小為 2.0 +−00..15 03 mm,當產品的目標值偏向不同 方向的規格界限時會造成嚴重程度不同的損失,因而導致目標值的設定與規格中 心不同。C p 、C pk 、C pm 與 C pmk 指標雖然也考慮了目標值不等於規格中心的狀況, 但是在製程平均值偏離目標值程度的處理上,仍會有高估或低估製程能力的現 象,容易對真實製程能力造成嚴重的誤判。目前針對非對稱規格區間之製程能力 指標已有相當多的研究,Pearn 與 Chen[18]提出 C "pk 指標來取代 C pk 指標,他們指 出當有兩個製程 E 與 F,其標準差相同( σ E = σ F ),製程平均值 µ E < T 與. 2.
(11) µ F > T , T 為目標值時,且 T − µ E = µ F − T ,假設 ( µ F − T ) Du = (T − µ E ) Dl 成 立,雖然 C "pk 與 Cpk 的指標值會相同,可是當製程平均值逐漸偏離目標值時, C "pk 值遞減的速度比 Cpk 值來的快,這證明 C "pk 比 Cpk 敏感度高,其中又指出在對稱規 格界限(T=m)的情況下,C "pk 指標即為 Cpk 指標,此也證明了 C "pk 指標的通用性。 Pearn 與 Lin[2]延續 Pearn 與 Chen[18]的研究發展出 C "pm 與 C "pmk 指標,證明 C "pmk 承 續 C pmk 的優點,並在非對稱規格的情況下能反映製程潛在的真實績效,即使是對 稱規格界限( T = m )的製程, C "pmk 指標會與 C pmk 指標相同,也說明了 C "pmk 指標 的通用性。 在計算任何製程能力指標時,業界常因成本的考量常常無法以全檢的方式來 蒐集製程資料及計算指標中之參數值,因而常用抽樣方法由樣本資訊來推估製程 的參數值,再代入製程能力指標中而得其估計值。但是,有抽樣就會有抽樣誤差, 當抽樣誤差越大,利用樣本來推估母體的參數值就越不準確,因此,為了要反映 出抽樣時所產生的誤差大小,必須以信賴區間的方式來估計真實之製程能力指標 值。因為製程能力指標之機率分配太複雜,以及當製程偏離常態假設時,要建構 製程能力指標之信賴下限或信賴區間非常困難,且必須在大樣本條件下才成立, 為了解決這個問題,Franklin et al.[13]利用能模擬重複多次抽樣效果來降低抽樣成 本以及對製程偏離常態假設時較不敏感的複式模擬法(Bootstrap Method)[9],分 別建構出 Cp、Cpk 與 Cpm 三個指標的 95﹪信賴下限及 90﹪的信賴區間。陳昭伶[1] 以複式模擬之修正偏度百分位數法(Biased-Corrected Percentile Bootstrap, BCPB). 3.
(12) 建構兩個製程能力指標 C pmk 差異之信賴區間。許慧先[3]利用複式模擬之修正偏 度百分位數法建構出 C pmk 指標之信賴下限,以及比較兩個製程能力指標 C pmk 差 異值的信賴區間,用來判斷不同供應商產品品質之優劣。謝旻憲[4]利用複式模擬 之修正偏度百分位數法建構單一非對稱規格區間之 C "pmk 指標的信賴下限。王怜雅 [5]以複式模擬之修正百分位數法建構非對稱規格區間下兩個 C "pmk 值差異之信賴 區間,來評估兩個製程或兩個供應商間製程能力之優劣。 複式區間估計法發展至今,其中之 BCa 區間估計法證明有較佳的效果,故 本研究採用複式模擬法之 BCa 區間估計法,在常態假設條件下,建構非對稱規 格區間之 C "pmk 指標信賴下限及兩個製程能力指標 C "pmk 差異之信賴區間,使業界 可以利用 C "pmk 之複式信賴區間,不論製程有對稱規格或非對稱規格界限,都能正 確地估計製程的真實績效。. 4.
(13) 1.2 研究目的 本研究共有以下三個目的: 1、 應用複式模擬法中之 BCa 區間估計法推導出關於一組樣本之 C "pmk 指標之 95 ﹪信賴下限。業界可以根據本研究所建構之 C "pmk 信賴下限結果,訂立某製程 是否需要改進,或評估製程的穩定與優劣。 2、 應用複式模擬法建構一個關於兩個 C "pmk 指標差距的信賴區間,然後利用此信 區間來取代傳統之假設檢定方式,用來推估兩個供應商或兩個製程之能力的 優劣。 3、 對業界提出一個完整的 C "pmk 複式信賴區間應用流程,並將此流程寫成電腦程 式,讓沒統計背景的工程人員也能快速得到正確的製程能力評比結果,更有 效提升企業的製程能力及競爭力。. 1.3 研究範圍 本研究的範圍僅限當製程屬於常態分配的狀況,在製程能力指標的選擇上, 僅採用 C "pmk 指標。. 5.
(14) 第二章 文獻探討 2.1 製程能力指標介紹 製程能力指標主要是以量化的方式展現製程的真實績效與規格之間的關 係,Juran[14]最早在日本提出 Cp 製程能力指標的觀念,用來比較產品規格寬度與 產品變異寬度的比率。之後 Kane[15]又提出 Cpk 指標,比 Cp 多考慮了製程平均值 µ 偏離規格中心對製程能力造成的影響。由於 Cp 及 Cpk 這兩個最早發明的指標計算 方便且容易瞭解,目前已成為企業界最常用來分析製程能力的工具,Cp 及 Cpk 定 義如下所示:. Cp =. USL − LSL 6σ. (1). USL − µ µ − LSL C pk = min , 3σ 3σ. (2). 其中 USL 為產品之規格上限,LSL 為產品之規格下限,σ為製程標準差,μ為 製程平均數。 Chan et al.[6]另提出製程能力指標 Cpm,Cpm 指標考量製程平均值與目標值是否 偏離的影響,其公式如下: C pm =. USL − LSL 6 σ 2 + (µ − T ). (3). 2. 其中 USL 為產品製程規格上限,LSL 為產品製程規格下限,m 為規格中心,T 為 製程的目標值。Cpm 指標的分母部份代表田口損失函數的期望值,其定義如下:. σ 2 + (µ − T )2 = E ( X − T )2. (4). 6.
(15) 當製程平均值趨近目標值時,Cpm 指標會越大,而當兩個值相同時,Cpm 指標有最 大值,代表製程能力優良;當製程平均值遠離目標值時,期望損失就越大,Cpm 指標值就會越小,表示製程能力越差。 Pearn et al.[19]提出第三代製程能力指標 Cpmk,此指標可以同時考慮製程平均 值與上下規格界限及目標值之間的關係,其公式如下: C pmk =. min{USL − µ , µ − LSL} 3 σ 2 + (µ − T ). (5). 2. 從指標可知,Cpmk 結合了 Cpm 之分母與 Cpk 的分子,因此能綜合了 Cpm 與 Cpk 的優點, 可同時反應製程良率及製程之期望損失。 因為考量成本和時間的問題,無法對產品做全檢的動作來獲得製程母體的平 均值和標準差,因此在實際應用製程能力指標時,只能對產品進行抽樣以獲得樣 本平均值 x 和樣本標準差 S,用以估計製程母體參數 µ 及 σ 。假設品質特性呈常. 態分配,製程能力指標 Cp、Cpk、Cpm、Cpmk 的估計式分別如下所示:. USL − LSL Cˆ p = 6S. (6). USL − x x − LSL , Cˆ pk = min 3S 3S. (7). Cˆ pm =. USL − LSL 6 S 2 + (x − T ). (8). 2. min{USL - x , x - LSL} Cˆ pmk = 2 3 S 2 + (x T ). (9). 7.
(16) 2.2 新型非對稱規格區間製程能力指標介紹 實務上許多產業的製造過程中經常出現非對稱之規格區間,可是當產品的目 標值偏向不同的規格界限時往往會造成嚴重程度不同的損失,因而導致目標值的 設定與規格中心的不同。傳統的製程能力指標雖然也考慮了目標值不等於規格中 心( T ≠ m )的狀況,但是在製程平均值偏離目標值程度的處理上,傳統製程能 力指標會嚴重的誤判真實之製程能力。為了在非對稱規格區間下能正確地反映出 製程的能力,Kane[15]提出的 C *pk 指標,Franklin 和 Wasserman[13]與 Kushler 和 ' Hurley[17]提出 C pk 指標,分別如下所示:. C *pk =. ' C pk =. d* − µ -T. (10). 3σ d − µ −T. (11). 3σ. 其中 d * = min ( Du , Dl },Du = USL − T,Dl = T − LSL , d =. USL − LSL 。 2. 但此二指標在面臨非對稱規格區間的問題時, C *pk 指標保守低估實際製程的 ' ' 卻又高估實際製程能力。C *pk 及 C pk 都無法正確地反映出製程的潛在績 能力,C pk. 效,因此,Pearn 與 Chen[18]針對非對稱規格之製程,修正 C pk 對指標中製程中心 與目標值的關係而推導出 C "pk , C "pk 指標如下: C. " pk. d * − A* = 3σ. (12). d* ( µ -T ) d* ( T - µ ) 其中 A* = max , 。 D D u l . Pearn 與 Chen[18]認為非對稱規格區間的製程能力指標值,會受到製程平均. 8.
(17) 值偏離目標值的方向與程度上不同的影響,他們指出當製程平均值偏離目標值 時,與製程平均值較近的規格界限之 C "pk 值的遞減速度比與製程平均值較遠的規 格界限之 C "pk 值的遞減速度來的快。因此他們建議在 C "pk 指標中,以差距比例的 關係代替原來差距( µ − T )的關係。假設當製程平均值靠近規格上限時, A* =. d* ( µ -T Du. ). ;當製程平均值靠近規格上限時, A* =. d* ( µ -T Dl. ). 。在對稱規. 格界限(T=m)時, d * = Du = Dl = d , A* = µ − m ,將 d * 及 A* 代入 C "pk 指標 公式時, C "pk 會變回原來的 C pk ,此證明了 C "pk 指標的通用性。同時,他們也定義 C "pk 的估計式,其公式如下:. d * − Aˆ * Cˆ "pk = 3S d* ( X -T ) d* (T - X , 其中 Aˆ * = max Du Dl . (13). ) , X = Σ . n i =1. Σ n ( X i − X ) Xi , S = i =1 。 n n −1 . Pearn 與 Lin[2]將發展 C "pk 指標的構想應用在 C pm 與 C pmk 指標上,修正指標中 的製程平均值與目標值的關係,又推導出 C "pm 與 C "pmk 指標,其公式分別如下: C "pm = C. '' pmk. d* 3. (14). σ 2 + A2 d * − A*. = 3. (15). σ 2 + A2. d ( µ -T ) d (T-µ ) * , 其中 A = max , d = min ( Du , Dl D D u l . },. d* ( µ -T ) d* ( T - µ ) = max , A 。 D D u l *. 很明顯地,從 C "pm 與 C "pmk 指標可以看出,如果製程是對稱規格 (T = m ) ,則. 9.
(18) A = A* = µ − T ,將之代入 C "pmk 指標, C "pmk 會變回原來的 C pmk 指標。並且當製. 程平均值落在目標值上( µ = T ),不論製程為對稱或非對稱規格區間,都能保 證可以獲得一個最大的 C "pmk 指標值。此外,亦可以很容易地證明當製程平均值落 於規格界限時( µ = LSL 或 µ = USL ) , C "pmk 指標值為 0;換句話說,當製程平 ,則 C "pmk > 0 。事實上,非對稱規格 均值介於上下規格界限內( LSL < µ < USL ) 區間之 C "pmk 製程能力指標,亦會受到製程平均值偏離目標值的方向與程度的影 響,當製程標準差 σ 固定時,製程平均值偏離目標值而接近較近的規格界限,其 指標值減少的速度快於較遠的規格界限的指標值。所以,在非對稱規格區間的製 程中,其所對應的損失函數對於目標值也是非對稱的。損失函數與非對稱損失函 數分別如下所示: T − x T − LSL x − T L( x ) = USL − T 1, . , LSL < x ≤ T, , LSL < x ≤ T, otherwise。. (16). 非對稱損失函數. 10.
(19) Pearn 與 Lin[2]認為當有兩個製程 E 與 F,其製程的標準差( σ E = σ F ) 、目 標 值 ( T ) 與 規 格 界 限 都 相 同 時 , 製 程 平 均 值 µE < T 與 µF > T , 且 T − µ E = µ F − T ,在 ( µ F − T ) Du = (T − µ E ) Dl 的條件下,製程 E 與 F 的製程能. 力指標相同。他們為了證明 C "pmk 的確優於其他指標,同時比較 C "pmk 、C pmk 、S pmk 、 C pa ( 1,1 ) 、 C pa ( 1,3 ) 與 C pa ( 0,4 ) 在製程 E 與 F 中的指標值。結果顯示只有製程 E. 與製程 F 的 C "pmk 指標值會相等,而製程 E 的 C pmk 與 S pmk 均大於製程 F 的相同指 標值,製程 F 的 C pa ( 1,1 )、 C pa ( 1,3 ) 與 C pa ( 0,4 ) 則大於製程 E 的相同指標值。證 明 C "pmk 指標在非對稱規格區間的通用性。 C "pmk 的估計式如下: '' C pmk =. d * − A* 3. (16). S 2 + A2. d ( X -T ) d (T- X 其中 Aˆ = max , D Dl u . ) ,d . d* ( X -T ) d* (T - X , Aˆ * = max Du Dl . *. = min ( Du , Dl. },. ) 。 . 2.3 複式模擬法之介紹 業界在蒐集資料時,常常因成本的考量無法以全檢的方式來蒐集製程資料以 計算未知的參數值,因此會使用抽樣方法由樣本資訊來推估製程的參數值,但 是,抽樣就會產生有抽樣誤差,當抽樣誤差越大,利用樣本估計值來推估母體的 參數就越不準確,因此,在成本與時間的考量下往往不知如何做取捨。而複式模 擬法[8]是近年來所發展的一種資料模擬及分析的技巧,隨著電腦的運算能力與速 11.
(20) 度增強,複式模擬法已廣泛地應用於生化、心理、經濟等領域上。 Efron[9]在 1979 年提出複式模擬法,此模擬法為一種利用樣本做重複抽樣的 方法。以複式模擬法來進行統計推論並未改變統計的基本觀念,而是以較少的樣 本來表達群體的分配,因此複式模擬法可以說是一種應用統計理論,以資料 (data-based)為主的模擬方法。其作法為從群體中先抽出一組樣本大小為 n 的原 始樣本 X,在這原始樣本 X 中以抽樣後放回的方式再抽出一組相同樣本大小為 n 的新樣本 X 1* ,稱為一組複式樣本(Bootstrap Samples),以這 n 個新樣本 X 1* 來計 ,如此重複 N 次後 (Efron[11]建議重複至少 1000 次(n=1000) 算所需之特徵值 S ( X 1* ) 所得之誤差會較小) ,將所得到的特徵值 S( X 1* ) 、S( X 2* )…S( X N* )由小到 大排列,即可得到一複式分配(Bootstrap Distribution) ,藉由複式分配替代原來群 體的分配,即可針對我們有興趣的參數執行相關的統計檢定或構建信賴區間。使 用複式模擬法的優點有二,分別為: 1. 利用一次抽樣的樣本數來模擬多次抽樣的效果,且藉由電腦來進行模擬的動 作,不但方便且節省了許多處理時間。複式抽樣方法之效果雖然無法如實際 抽樣多次的效果,但可藉由提高模擬次數來提高近似的程度。 2. 由於複式模擬法僅利用少數的樣本,因此抽樣時所需的成本較一般的重複抽 樣來的低。 在以複式模擬法建構信賴區間方面,Efron 提出四種衡量信賴區間的方式 [11]。Efron[9]在 1979 年發表以標準複式區間(Standard Bootstrap, SB)和百分位數. 12.
(21) 複式區間(Percentile Bootstrap, PB)來衡量信賴區間; Efron[12]在 1981 年發表以 修正偏度百分位數複式區間(Biased-Corrected Percentile Bootstrap, BCPB)來衡量 信賴區間;之後,Efron[8]在 1987 年又發表了與比前幾種區間估計法更佳的加速 修 正 偏 度 百 分 位 數 複 式 區 間 估 計 法 ( Biased-Corrected Accelerated Percentile Bootstrap, BCa)來衡量信賴區間。這些區間估計法分別敘述如下: 1.標準複式區間(Standard Bootstrap, SB): 假設我們選取的群體特徵值為θ,由樣本中以取後放回的方式重複抽樣得到 N. N 次之複式估計值 θˆ * (i ) ,可計算 N 組複式樣本平均值為 θˆ * = ∑θˆ * (i ) / N ,樣本 i =1. [. ]. 2 N 標準差為 Sˆθ* = ∑ θˆ * (i ) − θˆ * /( N − 1) ,則對此特徵值θ之(1-2α)100%的 i =1 . SB 信賴區間為 θˆ * ± zα S c* 。 2.百分位數複式區間(Percentile Bootstrap, PB): 將取後放回重複抽樣的 N 組複式估計值 θˆ * (i ) 由小到大排序後,取其第α百 分 位 數 與 第 (1−α. ) 百分位數,由這兩個百分位數點可求得特徵值θ之. ( 1 − 2α ) 100%的 PB 信賴區間為 [θˆ * (PL N ),θˆ * (PU N )],其中 PL 等於α,PU 等於 1α,N 為複式模擬之次數,θˆ * (PL N ) 為將 θˆ * (i ) 排序後第 PLN 個 θˆ * (i ) 值,θˆ * (PU N ) 為將 θˆ * (i ) 排序後第 PUN 個 θˆ * (i ) 值。 3.修正偏度百分位數複式區間(Biased-Corrected Percentile Bootstrap, BCPB): 將取後放回重複抽樣的 N 組複式估計值 θˆ * (i ) 由小到大排序後,可求得. (. ). p 0 = Pr θˆ * ≤ θˆ ,其中 θˆ 由複式抽樣法從母體抽出的原始樣本資料所計算的特徵 13.
(22) 值,接著可計算 z 0 = Φ −1 ( p 0 ) ,z0 為 p0 的常態累積反函數,PB 信賴區間中的 PL 和 PU 修正為 PL = Φ (2 z 0 − zα ) 及 PU = Φ (2 z 0 + zα ) ,則(1-2α)100%的 BCPB 信. [. ]. 賴區間可求得為 θˆ * (PL N ),θˆ * (PU N ) ,其中 N 為複式模擬之次數, θˆ * (PL N ) 為將. θˆ * (i) 排序後第 PLN 個 θˆ * (i) 值,θˆ * (PU N ) 為將 θˆ * (i) 排序後第 PUN 個 θˆ * (i) 值。 4.加速修正偏度百分位數複式區間(Biased-Corrected Accelerated Percentile Bootstrap, BCa): 將取後放回重複抽樣的 N 組複式估計值 θˆ * (i ) 由小到大排序後,可求得. (. ). p 0 = Pr θˆ * ≤ θˆ ,其中 θˆ 由複式抽樣法從母體抽出的原始樣本資料所計算的特徵. 值,接著可計算 z 0 = Φ −1 ( p 0 ) ,z0 為 p0 的常態累積反函數,則 PB 信賴區間中的 . . z +z. . z +z. . α 0 1−α 0 及 PU = Φ z 0 + ,其中 PL 和 PU 修正為 PL = Φ z 0 + ( ) ( 1 a z z 1 a z z1−α ) − + − + α 0 0 . ∑ (θˆ N. α=. i =1. (. *. − θˆi*. ). 3. ). 2 6∑ θˆ* − θˆi* i =1 N. 3 2. [. ]. ,而(1-2α)100%的 BCa 信賴區間為 θˆ * (PL N ),θˆ * (PU N ) ,. 其中 N 為複式模擬之次數,θˆ * (PL N ) 為將 θˆ * (i ) 排序後第 PLN 個 θˆ * (i ) 值,θˆ * (PU N ) 為將 θˆ * (i ) 排序後第 PUN 個 θˆ * (i ) 值。 BCa 複式信賴區間估計法樣本數的增加,其估計誤差以 1. n 的速率向零趨. 近,而 SB、PB 及 BCPB 信賴區間估計法的估計誤差修正速率均為 1 n ,因此複 式區間估計法發展至現階段,一般建議使用 BCa 區間估計法較佳。. 14.
(23) 2.4 其他相關文獻探討 1. Franklin et al.[13] 利用複式模擬之修正偏度百分位數法,分別建構出 C p 、 C pk 與 C pmk 個三個指標的 95﹪信賴下限及 90﹪的信賴區間。 2. 許慧先[3]利用複式模擬之修正偏度百分位數法建構出 C pmk 指標之 95%信賴 下限,以及比較兩個製程能力指標 C pmk 差異值的 95%信賴區間,用來判斷不 同供應商之間產品品質之優劣。 3. 謝旻憲[4]利用複式模擬之修正百分位數法建構單一非對稱規格區間之 C "pmk 指標的信賴下限,利用此信賴下限判斷真實製程能力的範圍並衡量製程能力 的好壞。 4. 王怜雅[5]以複式模擬之修正百分位數法建構非對稱規格區間下兩個 C "pmk 值 差異之信賴區間,來評估兩個製程或兩個供應商間製程能力之優劣。 總合以上的探討,本研究希望藉由 C "pmk 製程能力指標的優點以複式模擬法之 BCa 區間估計法來建構單一非對稱規格區間之 C "pmk 指標的信賴下限及兩個 C "pmk 指標差異之信賴區間,同時應用於製程為對稱的規格界限上,亦能正確地估計製 程的真實績效。. 15.
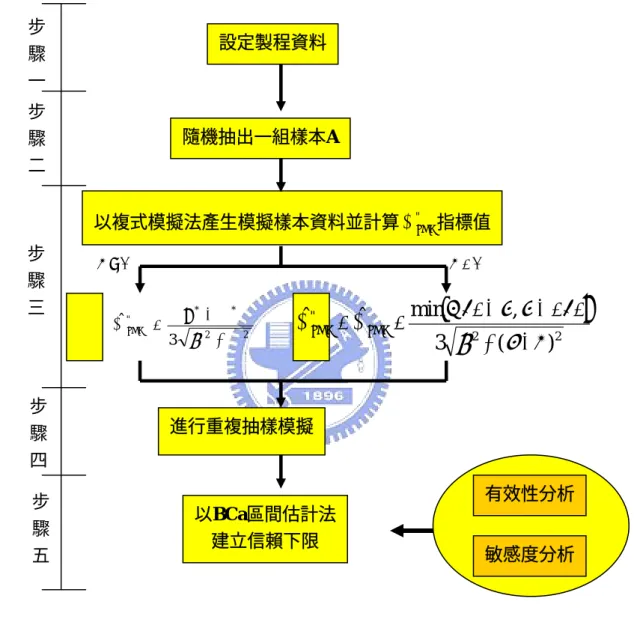
(24) 第三章 以 BCa 區間估計法建構單一非對稱規格區間之 C "pmk 指標的信賴下限 及兩個製程能力指標 C "pmk 差異之信賴區間 本研究主要是以複式模擬法之 BCa 區間估計法建構單一非對稱規格區間之 C "pmk 指標的信賴下限及兩個 C "pmk 指標差異之信賴區間。以下 3.1 節將介紹複式模. 擬法建構 C "pmk 指標信賴下限的流程,3.2 節將介紹複式模擬法建構兩個 C "pmk 指標 差異之信賴區間的流程。. 3.1 運用複式模擬法建構 C "pmk 指標信賴下限的流程 本節將說明如何使用複式模擬法之 BCa 區間估計法建構非對稱規格區間之 C "pmk 指標的信賴下限,建構流程如下:. 步驟一:模擬產生非對稱規格區間之製程資料。 以統計分析軟體〈Statistical Analysis System, SAS 〉產生一組常態分配的 製程資料,且規格屬非對稱規格區間,例如:製程平均值 µ 訂為 51,製 程標準差 σ 訂為 3,規格上限 USL 訂為 61,規格下限 LSL 訂為 40,目 標值 T 訂為 49,規格中心 m 訂為 50.5 為非對稱規格區間。 步驟二、以隨機方式抽出一組樣本。 由步驟一產生的製程資料中,隨機抽取一組樣本,樣本數為 30,簡稱 樣本 A 。 步驟三:以複式模擬法模擬資料並計算 C "pmk 指標值。. 16.
(25) 從 A 樣本中,以抽出後放回的抽樣方式,抽出一組樣本數同樣為 30 的 資料,簡稱為樣本 A1 ,由樣本 A1 計算平均值 X 1 樣本標準差 S1 ,從這些 資料可得到樣本 A1 的 Cˆ "pmk 。 步驟四:重複進行步驟三 N 次。 為了建構一個良好的信賴下限,通常將重複次數設定為 N = 1000 次,也 就是重複進行步驟三 1000 次並算得 1000 個 Cˆ "pmk 。將此 1000 個 Cˆ "pmk 值 由小到大排列,形成一個複式分配。 步驟五:以 BCa 區間估計法建立信賴下限。 * 值比,找出 先 算 出 原 始 樣 本 A1 的 Cˆ "pmk , 然 後 與 1000 個 Cˆ "pmk. (. ˆ" p 0 = Pr Cˆ "* pmk ≤ C pmk. ) 的機率,並將之轉換為 z ,就可以找到信賴下限 0. ∑ (Cˆ. 1000. *. − Cˆ i*. ). 3. z 0 + zα ,其中 α = i =1 , 的機率百分比 PL = Φ z 0 + 3 1 − a ( z 0 + zα ) 1000 22 6 ∑ Cˆ * − Cˆ i* i =1 . (. ). 將此百分比乘以 1000 即可得到信賴下限在 1000 個值中的位置,此位置 所對應的 Cˆ * 值就是在 (1 − 2α ) 100%的信心水準下, C "pmk 指標之信賴下 限。本研究由以上一連串的執行步驟模擬出來的結果可得到信賴下限 C "pmk (Pl , B ) = 1.016178 。. 17.
(26) 3.1.1 運用複式模擬法建構 C "pmk 指標信賴下限的有效性分析 本研究以蒙地卡羅模擬來驗證 BCa 區間估計法建構 C "pmk 指標信賴下限之有 效性,其分析步驟如下: (1). 將 3.1 節中之步驟三至步驟五的動作重複執行 1000 次,可以得到 1000 組 C "pmk 指標的信賴下限。. (2). 計算製程 A 實際非對稱規格製程能力指標 C "pmk 值。由第二章公式 (15) 可得知 C "pmk 值為 1.15171。. (3). 實際 C "pmk 指標值與模擬出 1000 組的 C "pmk 指標之信賴下限做比較,發 現 1000 組中有 925 個值小於 1.15171,即表示實際製程指標值大於複 式模擬法所建構的指標信賴下限的機率約為 92.5﹪。本研究方法在此 製造條件下建構的指標信賴下限涵蓋真實指標的機率稱為績效,故績 效約為 0.925。. 接著比較績效指標與所訂之信賴水準,如果績效值達到此信賴水準時,即可 判定此模擬結果具有很高的可信度。當績效指標符合一樣本數 n = 1000、P = 0.95 之 二 項 分 配 的 隨 機 變 數 , 其 涵 蓋 真 實 績 效 95 ﹪ 比 例 的 信 賴 區 間 為 0.95 ± 1.96 (0.95)(0.05) / 1000 = 0.95 ± 0.0135 = (0.9365, 0.9635) ,表示我們有 95﹪. 的信心認為真實績效的信賴區間應落於 0.9365 至 0.9635 之間。因此模擬的績效 若高於 0.9365,即表示所得到的 BCa 複式信賴下限效果很好,而研究結果發現在 常態下績效約為 92.5﹪,雖略低於 0.9365,但已經非常接近,證明本研究以複式. 18.
(27) 模擬法建構非對稱規格區間之 C pmk 指標信賴下限的方法其有效性。 ". 3.1.2 運用複式模擬法建構 C "pmk 指標信賴下限的敏感度分析 本研究以蒙地卡羅模擬的方式進行 C "pmk 指標信賴下限的敏感度分析,藉由改 變製程參數值(製程平均值 µ 與標準差 σ )和抽樣樣本數,分析步驟如下: (1)改變製程平均值 µ 與標準差 σ 及抽樣樣本數。 (2)以不同參數組合來重複進行 3.1 節步驟一至步驟五 1000 次,得到不 同的績效值。 (3)評估績效值,找出 BCa 法建構 C "pmk 信賴下限的適當參數範圍。 本小節將製程參數設定為 USL=61、LSL=40、T=49,針對( µ , σ )=(49, 2)、 (49, 3) 、 (49, 4) 、 (51, 2) 、 (51, 3) 、 (51, 4) 、 (53, 2) 、 (53, 3) 、 (53, 4) 、 (54, 2)、 (54, 3)及(54, 4) ,樣本數在 20、30 及 50 的情況下,依照 3.1 節中之步驟進行 1000 次的模擬分析。其不同參數組合下的模擬結果,如表 3.1 所示。 表 3-1 非對稱規格區間之製程能力指標 C "pmk 95﹪信賴下限的模擬結果 平均值. 49. 49. 49. 標準差. 樣本數. 績效. 2. 20 30 50. 0.884 0.923 0.930. 3. 20 30 50. 0.897 0.911 0.925. 4. 20 30 50. 0.906 0.910 0.923. 19.
(28) 51. 51. 51. 53. 53. 53. 54. 54. 54. 20 30 50. 2. 0.913 0.928 0.940. 0.894 0.910. 20 30 50. 0.937. 4. 20 30 50. 0.911 0.928 0.933. 2. 20 30 50. 0.889 0.925 0.932. 3. 20 30 50. 0.925 0.936. 3. 20 30 50. 4. 20 30 50. 2. 3. 20 30 50. 4. 20 30 50. 0.972. 0.931 0.925 0.960. 0.921 0.924 0.953. 0.925 0.951 0.981. 0.921 0.941 0.969. 針對不同參數組合(製程平均值、製程標準差與抽樣樣本數),其分析結果 如下: (1)固定製程平均值與製程標準差,樣本數變動的績效分析 當固定製程平均值為 49、51、53、54,標準差為 2、3、4,變動樣本數為 20、. 20.
(29) 30、50 時,所有績效值的折線圖如圖 3-1 (a)至 3-1 (l)所示。 由圖 3-1 (a)至 3-1 (l)可知,除了 (µ, σ ) = (53, 3) 時,績效值會有不規則的跳動, 其他不同參數組合之績效值會隨著樣本數增加而遞增。當樣本數為 20 時,12 個 參數組合中,沒有任何一組落於真實的績效 95﹪信賴區間;當樣本為 30 時,12 個參數組合中,有 2 組落於真實的績效 95﹪信賴區間;當樣本為 50 時,12 個參 數組合中,有 7 組落於該區間中;並且當樣本數大於 30 以上時,有 6 組非常接 近真實的績效 95﹪信賴區間。顯示樣本數的增加能提高模擬的正確性。當樣本 數大於或等於 30 時,績效值均在 0.910 以上,因此,我們建議在使用本研究流程 時,樣本數至少 30 以上。 (2)固定製程標準差與樣本數,製程平均值變動的績效分析 當固定製程標準差為 2、3、4,樣本數為 20、30、50,變動製程平均值為 49、 51、53、54 時,績效值的折線圖如圖 3-2 (a)至 3-2 (i)所示。 由圖 3-2 (a)至 3-2 (i)可知,除了 (σ , n) = (3, 20) 時,績效值會有不規則的跳動 外,其他不同參數組合之績效值均會隨著平均值增加而遞增。 (3)固定製程平均值與樣本數,製程標準差變動的績效分析 當固定製程平均值為 49、51、53、54,樣本數為 20、30、50,變動製程標準 差為 2、3、4 時,績效值的折線圖如圖 3-3 (a)至 3-3 (l)所示。 由圖 3-3 (a)至 3-3 (l)可知,除了 (µ, n) = (49, 20) 時,績效值均會隨著標準差增 加而略升; (µ, n) = (51, 30) 、 (53, 20) 時,績效值會有不規則的跳動外,其他不同. 21.
(30) 參數組合之績效值均會隨著標準差變大而遞減。 綜而言之,由 BCa 信賴下限的有效性分析可知,樣本數大於 30 的狀態下, 有 9 組落於真實績效值等於 0.95 的 95﹪信賴區間,有 6 組非常接近此信賴區間 績效值並且都在 0.910 以上,這表示本研究所提供的 BCa 信賴下限建構流程具有 非常高的可信度。因此本研究建議在建構單一製程能力指標 C "pmk 信賴下限時,樣 本數最好大於或等於 30 會有比較好的效果。 上述之單一製程能力指標 C "pmk 信賴下限的建構流程如圖 3-4 所示。. 22.
(31) 績 0.950 效 0.900 值 0.850. 績 0.950 效 0.900 值 0.850 20. 30. 50. 20. 樣本數. 30. 50. 樣本數. (a )(µ, σ ) = (49, 2). (b)(µ, σ ) = (49, 3) 績 0.945 0.93 效 0.915 0.9 值 0.885. 績 0.940 效 0.920 0.900 值 0.880 20. 30. 20. 50. 30. 50. 樣本數. 樣本數. ( c )(µ , σ ) = (49, 4 ). (d )(µ, σ ) = (51, 2). 績 0.95 效 0.9 值 0.85. 績 0.950 效 0.900 值 0.850 20. 30. 50. 20. 樣本數. 30. 50. 樣本數. ( f )(µ, σ ) = (51, 4). ( e ) (µ , σ ) = (51, 3 ) 績 1.000 效 0.950 值 0.900. 績 1.000 效 0.950 值 0.900 20. 30. 50. 20. 樣本數. 30. 50. 樣本數. ( g )(µ, σ ) = (53, 2). (h)(µ, σ ) = (53, 3) 績 1 效 0.95 0.9 值 0.85. 績 1 效 0.95 值 0.9 20. 30. 20. 50. 30. 50. 樣本數. 樣本數. (i )(µ, σ ) = (53, 4). ( j )(µ, σ ) = (54, 2). 績 1 效 0.95 0.9 值 0.85. 績 1 效 0.95 0.9 值 0.85 20. 30. 50. 20. 樣本數. 30 樣本數. (k )(µ, σ ) = (54, 3). (l )(µ, σ ) = (54, 4). 圖 3-1 績效值在變動樣本數時之表現折線圖. 23. 50.
(32) 0.960 績 0.940 效 0.920 值 0.900. 績 0.950 效 0.900 值 0.850 49. 51. 53. 54. 49. 平均值. 51. 53. 54. 平均值. (a )(σ , n) = (2, 20). (b)(σ , n) = (2, 30) 0.945 績 0.93 效 0.915 0.9 值 0.885 0.87. 績 0.970 效 值 0.920 49. 51. 53. 54. 49. 平均值. 51. 53. 54. 平均值. (c)(σ , n) = (2, 50). (d )(σ , n) = (3, 20) 1.000 績 效 0.950 值 0.900. 0.96 績 0.94 效 0.92 值 0.9 0.88 49. 51. 53. 49. 54. 51. 53. 54. 平均值. 平均值. (e)(σ , n) = (3, 30). ( f )(σ , n) = (3, 50). 0.940 績 0.920 效 0.900 值 0.880 0.860. 0.940 績 0.920 效 0.900 值 0.880 49. 51. 53. 49. 54. 51. ( g )(σ , n) = (4, 20). (h)(σ , n) = (4, 30). 0.96 績 0.94 效 0.92 值 0.9 49. 51. 53. 53. 平均值. 平均值. 54. 平均值. (i )(σ , n) = (4, 50). 圖 3-2 績效值在變動平均值時之表現折線圖. 24. 54.
(33) 績 0.940 效 0.920 值 0.900. 績 0.920 效 0.900 0.880 值 0.860 2. 3. 2. 4. (a )(µ, n) = (49, 20). (b)(µ, n) = (49, 30) 績 0.915 0.9 效 0.885 0.87 值. 0.940 0.930 0.920 0.910 2. 3. 4. 2. 標準差. 績 效 值 3. 0.950 0.940 0.930 0.920. 4. 2. 標準差. 4. ( f )(µ, n) = (51, 50) 績 效 值. 0.940 0.930 0.920 0.910 3. 3 標準差. (e)(µ, n) = (51, 30). 2. 4. (d )(µ, n) = (51, 20). 績 0.940 效 0.920 值 0.900 2. 3 標準差. (c)(µ, n ) = (49, 50). 績 效 值. 4. 標準差. 標準差. 績 效 值. 3. 0.940 0.930 0.920 0.910. 4. 2. 標準差. 3. 4. 標準差. ( g )(µ, n) = (53, 20). (h)(µ, n ) = (53, 30). 績 0.98 效 0.96 值 0.94. 績 0.93 效 0.92 值 0.91 2. 3. 4. 2. 標準差. 3. 4. 標準差. (i )(µ, n ) = (53, 50). ( j )(µ, n) = (54, 20) 績 1 效 0.95 值 0.9. 績 0.96 效 0.94 值 0.92 2. 3. 4. 2. 標準差. 3 標準差. (k )(µ, n) = (54, 30). (l )(µ, n) = (54, 50). 圖 3-3 績效值在變動標準差時之表現折線圖. 25. 4.
(34) 步 驟 一. 設定製程資料. 步 驟 二. 隨機抽出一組樣本A. 以複式模擬法產生模擬樣本資料並計算 C "pmk 指標值 步 驟 三. 步 驟 四 步 驟 五. 圖 3-4. T ≠M. Cˆ "pmk =. T =M d * − A* 3 σ. 2. + A2. min{USL − µ , µ − LSL} Cˆ "pmk = Cˆ pmk = 3 σ 2 + (µ − T ) 2. 進行重複抽樣模擬. 有效性分析 以BCa區間估計法 建立信賴下限. 敏感度分析. 以複式模擬法建構單一製程能力指標 C "pmk 信賴下限之流程圖. 26.
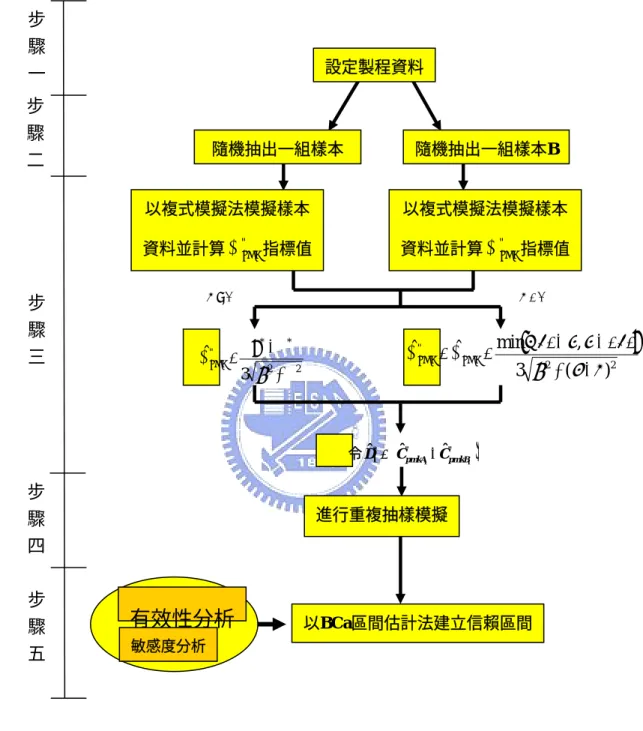
(35) 3.2 運用複式模擬法建構兩個 C "pmk 指標差異之信賴區間的流程 本節將說明如何使用複式模擬法之 BCa 區間估計法建構兩個非對稱規格之 製程能力指標 C "pmk 差異的信賴區間,其建構流程如下: 步驟一:設定非對稱規格區間之製程資料。 以統計分析軟體〈Statistical Analysis System,SAS 〉產生兩組常態分配的 製程資料 A 與 B ,且規格屬非對稱規格區間例如,製程 A 平均為 310, 製程標準差為 12,製程 B 平均為 305,製程標準差為 7,假設製程規格 上限為 352,規格下限為 273,目標值為 310,規格中心為 313 之非對稱 規格區間。 步驟二、以隨機方式各抽出一組樣本。 由步驟一產生製程 A 與 B 的資料,分別隨機抽取出一組原始樣本,樣 本數皆為 30,簡稱樣本 A 與樣本 B 。 步驟三:以複式模擬法模擬樣本資料並計算兩個指標之差異值。 從 A 樣本中,以抽出後放回的抽樣方式,抽出一組樣本數同樣為 n 的資 料,簡稱為樣本 A1 ,由樣本 A1 計算平均值 X 1 樣本與標準差 S1 ,從這些 資料可計算出樣本 A1 的 Cˆ "pmk 值,以 Cˆ "pmkA 1 表示。用同樣的方法抽取樣本 B1 , 及 計 算 Cˆ "pmkB 1 值 , 然 後 令 兩 個 指 標 的 差 異 值 為. (. ). Dˆ 1* = Cˆ "pmkA1 − Cˆ "pmkB 1 。. 步驟四:重複步驟三 N 次。. 27.
(36) 重複進行步驟三 N = 1000 次並算得 1000 個 Dˆ 1* ,將 1000 個 Dˆ 1* 值由小到 大排列,形成一個複式分配。 步驟五:以 BCa 區間估計法建構 C "pmk1 − C "pmk 2 信賴區間。. [. ]. 以 BCa 區間估計法找到 Dˆ * 分配的信賴區間 Dˆ * (PL N ), Dˆ * (PU N ) 。先以 BCa 區間估計法算出原始樣本 A1 與樣本 B1 的 Dˆ 1* 值,然後與這 1000 個 Dˆ *. (. ). 值比較,找出 p 0 = Pr Dˆ * ≤ Dˆ 1* 的機率,並將之轉換為 z 0 ,就可找到信 z 0 + zα 及 賴 上 、 下 限 的 機 率 百 分 比 PL = Φ z 0 + 1 − a ( z 0 + zα ) . ∑ (Dˆ. 1000. *. − Dˆ i*. ). 3. z 0 + z1−α i =1 其中 a = PU = Φ z 0 + ,由百分比乘以 3 ( ) 1 a z z − + 1000 0 1−α 2 2 6 ∑ Dˆ * − Dˆ i* i =1 . (. ). 1000 即可得到信賴上、下限在 1000 個值中的位置,位置所對應的 Dˆ * 值 就是在 (1 − 2α ) 100%信心水準下, Cˆ "pmk 指標差異之的信賴區間。. 3.2.1 運用複式模擬法建構 C "pmk 指標差異之信賴區間的有效性分析 本研究以蒙地卡羅模擬來驗證 BCa 區間估計法建構 C "pmk 指標信賴區間之有 效性,其分析步驟如下: (1) 將 3.2 節中之步驟三至步驟五的動作重複執行 1000 次,可以得到 1000 組 C "pmk 指標差異值的信賴區間。 (2) 計算製程 A 與製程 B 實際非對稱規格製程能力指標 C "pmk 差異值。. D=. min{USL - T , T - LSL} - µ A - T 3 {σ A2 + (µ A - T )2 }. _. min{USL - T , T - LSL} - µ B - T. 28. 3 {σ B2 + (µ B - T )2 }. = 0.083204.
(37) (3) 實際 C "pmk 指標差異值與模擬出 1000 組的 C "pmk 指標差異值之信賴區間做. 比較,發現 1000 組中有 935 個涵蓋 D 值,即表示實際製程指標 C "pmk 差 異值落於 BCa 信賴區間的機率約為 93.5﹪。本研究方法在此製造條件下 建構之信賴區間涵蓋真實指標的機率稱為績效,故績效約為 0.935。 接著比較績效指標與所訂之信賴水準,如果績效值達到此信賴水準時,即可 判定此模擬結果具有很高的可信度。當績效指標符合一樣本數 n = 1000、P = 0.95 之 二 項 分 配 的 隨 機 變 數 , 其 涵 蓋 真 實 績 效 95 ﹪ 比 例 的 信 賴 區 間 為. (0.9365, 0.9635),表示我們有 95﹪的信心認為真實績效的信賴區間應落於 0.9365 至 0.9635 之間。因此模擬的績效若高於 0.9365,即表示所得到的 BCa 複式信賴區 間效果很好,而我們在常態下績效約為 0.935,非常接近 0.9365,證明本研究以 複式模擬法建構非對稱規格區間之 C "pmk 指標信賴區間的方法其有效性。. 3.2.2 運用複式模擬法建構 C "pmk 指標信賴區間的敏感度分析 本研究以蒙地卡羅模擬的方式進行 C "pmk 指標差異值之信賴信賴區間的敏感 度分析,藉由改變製程參數值(製程平均值 µ 與標準差 σ )和抽樣樣本數,分析 步驟如下: (1)改變製程平均值 µ 與標準差 σ 及抽樣樣本數。 (2)以不同參數組合來重複進行 3.2 節步驟一至步驟五 1000 次,得到不 同的績效值。 (3)評估績效值,找出 BCa 法建構 C "pmk 信賴區間的適當參數範圍。. 29.
(38) 本小節將製程參數設定為 USL=353、LSL=273、T=310,針對( µ A , σ A )=(310, (300, 7)、 (295, 5),樣本數在 10) 、 (310, 12)、 (310, 14), ( µ B , σ B )=(305, 9)、 20、30 及 50 的情況下,依照 3.2 節中之步驟進行 1000 次的模擬分析。其不同參 數組合下的模擬結果,如表 3.2 所示。 表 3-2 兩個製程能力指標 C "pmk 差異值 95﹪信賴區間的模擬結果 平均值 A 平均值 B 標準差 A 標準差 B 樣本數. 10. 310. 305. 12. 14. 10. 315. 300. 12. 14. 10. 320. 295. 12. 績效值 區間長度 區間變異. 9. 20 30 50. 0.862 0.933 0.962. 1.091 0.8092 0.4943. 0.0495 0.0264 0.0146. 7. 20 30 50. 0.902 0.935 0.944. 1.0524 0.9173 0.6032. 0.0413 0.0347 0.0294. 5. 20 30 50. 0.893 0.923 0.942. 1.1785 0.7924 0.5497. 0.0510 0.0225 0.0159. 9. 20 30 50. 0.931 0.940 0.978. 0.7978 0.6183 0.5616. 0.0338 0.0285 0.0064. 7. 20 30 50. 0.901 0.920 0.966. 1.1589 0.8043 0.6453. 0.0628 0.0454 0.0167. 5. 20 30 50. 0.928 0.926 0.940. 1.2542 1.1285 0.6595. 0.0389 0.0294 0.0116. 9. 20 30 50. 0.894 0.921 0.926. 1.0546 0.5622 0.4452. 0.0344 0.0177 0.0086. 7. 20 30 50. 0.951 0.973 0.966. 0.9532 0.8846 0.4269. 0.0464 0.0267 0.0153. 30.
(39) 14. 20 30 50. 5. 0.925 0.933 0.946. 1.0653 0.8753 0.5127. 0.0488 0.0307 0.0131. 針對不同參數組合(製程平均值、製程標準差與抽樣樣本數) ,其分析結果如下:. (1)固定製程平均值與製程標準差,樣本數變動的績效分析 當固定製程平均值為 (µ A , µ B ) = (310, 305)、 (315, 300) 及 (320, 295),標準差為. (σ. A. , σ B ) = (10, 9) 、 (12, 7) 及 (14, 5) ,變動樣本數為 20、30、50 時,三種衡量指標. (績效值、區間長度之平均值與區間長度之變異數)的折線圖如圖 3-5 (a)至 3-5 (i) 所示。 由圖 3-5 (a)至 3-5 (i)可知,績效值會隨著樣本數增加而略升,區間長度之平 均值與變異數會隨著樣本數增加而遞減。當樣本數為 20 時,9 個參數組合中, 只有 1 組落於真實的績效指標 95﹪信賴區間;當樣本為 30 時,9 個參數組合中, 有 1 組落於真實的績效 95﹪信賴區間;當樣本為 50 時,9 個參數組合中,有 5 組落於該區間中;並且當樣本數大於 30 以上時,有 6 組非常接近真實的績效 95 ﹪信賴區間。顯示樣本數的增加能提高模擬的正確性。當樣本數大於或等於 30 時,績效值均在 0.920 以上,因此,我們建議在使用本研究流程時,樣本數至少 30 以上。 (2)固定製程標準差與樣本數,製程平均值變動的績效分析 當固定製程標準差為 (σ A , σ B ) = (10, 9) 、 (12, 7) 及 (14, 5) ,樣本數為 20、30、 50,變動製程平均值為 (µ A , µ B ) = (310, 305)、 (315, 300) 及 (320, 295) 時,三種衡量 31.
(40) 指標的折線圖如圖 3-6 (a)至 3-6 (i)所示。 由圖 3-6 (a)至 3-6 (i)可知,三種衡量指標並沒有明顯隨著平均值差距的增 加,產生顯著的變動趨勢。 (3)固定製程平均值與樣本數,製程標準差變動的績效分析 當固定製程平均值為 (µ A , µ B ) = (310, 305)、 (315, 300) 及 (320, 295),樣本數為 20、30、50,變動製程標準差為 (µ A , µ B ) = (310, 305) 、 (315, 300) 及 (320, 295) 時, 績效值的折線圖如圖 3-7 (a)至 3-7 (i)所示。 由圖 3-7 (a)至 3-7 (i)可知,區間長度之平均值會隨著標準差間之比例 ( σ A σ B )增加而略升;績效值與區間長度之變異數沒有明顯地隨著標準差間之 比例增加而有顯著變化。 綜而言之,由 BCa 信賴區間的有效性分析可知,樣本數大於 30 的狀態下, 有 6 組落於真實績效值等於 0.95 的 95﹪信賴區間,有 6 組非常接近此信賴區間 績效值並且都在 0.920 以上,這表示本研究所提供的 BCa 信賴區間建構流程具有 非常高的可信度。由 BCa 信賴區間的敏感度分析可知,樣本數增加能提高模擬 的績效值與結果的正確性,因此本研究建議在建構兩個製程能力指標 C "pmk 差異之 信賴區間時,樣本數最好大於或等於 30 會有比較好的效果。 上述之兩個製程能力指標 C "pmk 差異的信賴區間之建構流程如圖 3-8 所示。. 32.
(41) 績效值. 區間長度. 區間變異. 績效值. 2.000 1.000 0.000. 區間長度. 區間變異. 2.000 1.000 0.000 20. 30. 50. 20. 樣本數. 30. 50. 樣本數. (a) (µ A , µ B ) = (310, 305) , (σ A , σ B ) = (10, 9) (b) (µ A , µ B ) = (310, 305) , (σ A , σ B ) = (12, 7) 績效值. 區間長度. 區間變異. 績效值. 2.000 1.000 0.000. 區間長度. 區間變異. 2 1 0. 20. 30. 20. 50. 30. (c) (µ A , µ B ) = (310, 305) , (σ A , σ B ) = (14, 5) 績效值. 區間長度. 50. 樣本數. 樣本數. (d) (µ A , µ B ) = (315, 300), (σ A , σ B ) = (10, 9). 區間變異. 績效值. 2 1 0. 區間長度. 區間變異. 2.000 1.000 0.000 20. 30. 50. 20. 樣本數. 30. 50. 樣本數. (e) (µ A , µ B ) = (315, 300) , (σ A , σ B ) = (12, 7) (f) (µ A , µ B ) = (315, 300) , (σ A , σ B ) = (14, 5) 績效值. 區間長度. 區間變異. 績效值. 1.500 1.000 0.500 0.000. 區間長度. 區間變異. 1.500 1.000 0.500 0.000 20. 30. 50. 20. 樣本數. 30. 50. 樣本數. (g) (µ A , µ B ) = (320, 295) , (σ A , σ B ) = (10, 9) (h) (µ A , µ B ) = (320, 295) , (σ A , σ B ) = (12, 7) 績效值. 區間長度. 區間變異. 1.5 1 0.5 0 20. 30. 50. 樣本數. (i) (µ A , µ B ) = (320, 295) , (σ A , σ B ) = (14, 5). 圖 3-5 三種衡量指標在變動樣本數時之表現折線圖 33.
(42) 績效值. 區間長度. 績效值. 區間變異. 區間長度. 區間變異. 1.000 0.500 0.000. 2.000 1.000 0.000 (310, 305). (315, 300). (320, 295). (310, 305). 樣本數(μA,μB). (a) (σ A , σ B ) = (10, 9) ,n=20 績效值. (315, 300). (320, 295). 樣本數(μA,μB). 區間長度. (b) (σ A , σ B ) = (10, 9) ,n=30 績效值. 區間長度. (310, 305). (315, 300). 區間變異. 區間變異. 2. 2.000 1.000 0.000. 1 0 (310, 305). (315, 300). (320, 295). 樣本數(μA,μB). 樣本數(μA,μB). (c) (σ A , σ B ) = (10, 9) ,n=50 績效值. (320, 295). 區間長度. (d) (σ A , σ B ) = (12, 7) ,n=20. 區間變異. 績效值. 2 1 0. 區間長度. 區間變異. 2.000 1.000 0.000. (310, 305). (310, 305). (315, 300) (320, 295) 樣本數(μA,μB). (e) (σ A , σ B ) = (12, 7) ,n=30 績效值. 區間長度. 區間變異. 績效值 2.000. 1.0000. 1.000. 0.0000. 0.000. (315, 300). (310, 305). (320, 295). (g) (σ A , σ B ) = (14, 5) ,n=20 區間長度. 區間長度. (315, 300). (315, 300). (320, 295). (h) (σ A , σ B ) = (14, 5) ,n=30. 區間變異. 1 0.5 0 (310, 305). 區間變異. 樣本數(μA,μB). 樣本數(μA,μB). 績效值. (320, 295). (f) (σ A , σ B ) = (12, 7) ,n=50. 2.0000. (310, 305). (315, 300) 樣本數(μA,μB). (320, 295). 樣本數(μA,μB). (i) (σ A , σ B ) = (14, 5) ,n=50. 圖 3-6 三種衡量指標在變動平均值時之表現折線圖. 34.
(43) 績效值. 區間長度. 區間變異. 績效值. 1.500 1.000 0.500 0.000. 區間長度. 區間變異. 1.0000 0.5000 0.0000 (10, 9). (12, 7). (10, 9). (14, 5). 標準差( σA,σB). 區間長度. (14, 5). 標準差(σA,σB). (a) (µ A , µ B ) = (310, 305) ,n=20 績效值. (12, 7). (b) (µ A , µ B ) = (310, 305) ,n=30. 區間變異. 績效值. 區間長度. (10, 9). (12, 7). 區間變異. 2. 2.000 1.000 0.000. 1 0 (10, 9). (12, 7). (14, 5). 標準差(σA,σB). 標準差(σA,σB). (c) (µ A , µ B ) = (310, 305) ,n=50 績效值. 區間長度. (14, 5). (d) (µ A , µ B ) = (315, 300) ,n=20 績效值. 區間變異. 2.0000 1.0000 0.0000. 區間長度. 區間變異. 2.0000 1.0000 0.0000. (10, 9). (12, 7). (10, 9). (14, 5). (e) (µ A , µ B ) = (315, 300) ,n=30 績效值. 區間長度. (12, 7). (14, 5). 標準差(σA,σB). 標準差(σA,σB). (f) (µ A , µ B ) = (315, 300) ,n=50. 區間變異. 績效值. 2.0000 1.0000 0.0000. 區間長度. 區間變異. 2.0000 1.0000 0.0000. (10, 9). (12, 7). (10, 9). (14, 5). (g) (µ A , µ B ) = (320, 295) ,n=20 區間長度. (10, 9). (12, 7). (14, 5). 標準差(σA,σB). 標準差(σA,σB). 績效值. (12, 7). (h) (µ A , µ B ) = (320, 295) ,n=30. 區間變異. 2 1 0 (14, 5). 標準差(σA,σB). (i) (µ A , µ B ) = (320, 295) ,n=50. 圖 3-7 三種衡量指標在變動標準差時之表現折線圖. 35.
(44) 步 驟 一. 設定製程資料. 步 驟 二. 步 驟 三. 隨機抽出一組樣本. 隨機抽出一組樣本B. 以複式模擬法模擬樣本. 以複式模擬法模擬樣本. 資料並計算 C "pmk 指標值. 資料並計算 C "pmk 指標值. T ≠M. T =M. min{USL− µ, µ − LSL} Cˆ "pmk = Cˆ pmk = 3 σ 2 + (µ − T ) 2. d* − A* Cˆ "pmk = 3 σ 2 + A2. (. ˆ * = Cˆ " − Cˆ " 令D pmkA1 pmkB1 1. 步 驟 四 步 驟 五. 圖 3-8. ). 進行重複抽樣模擬. 有效性分析. 以BCa區間估計法建立信賴區間. 敏感度分析. 以複式模擬法建構兩個製程能力指標 C "pmk 差異的信賴區間之流程圖. 36.
(45) 3.3 製程能力指標 C "pmk 應用流程之建構 目前實務上最常被使用的製程能力指標為 C pk ,然而它往往不能反應平均值 偏離目標值與非對稱規格製程的清況,甚至誤判製程能力。根據之前學者的文獻 探討中發現製程能力指標 C "pmk 能改善這樣的缺點,本研究以複式模擬法建構出 C "pmk 指標之信賴下限與兩個指標差異值之信賴區間,以彌補 C "pmk 相關的假說檢. 定與信賴區間未被發展出之實務應用上的限制。. 3.3.1 使用製程能力指標 C "pmk 來評估單一製程的穩定與優劣之流程 本小節將說明如何利用 3.1 節所構建的方法來評估製程(供應商)的穩定與 優劣,其應用流程說明如下: 步驟一、蒐集樣本資料,建議樣本數超過 30 筆。 步驟二、將樣本資料及製程的規格上下限、目標值、模擬重複次數及α值輸 入撰寫程式之欄位中。 步驟三、由步驟二的執行結果產生製程能力指標 C "pmk 之 100(1-α)%信賴 下限。 步驟四、利用以下之原則來判別製程(供應商)之優劣。 1.. 當信賴下限大於某特定值時,則製程(供應商)製程能力佳。. 2.. 當信賴下限所小於某特定值時,則製程(供應商)製程能力不 佳,應及時改善。. 37.
(46) 3.3.2 使用製程能力指標 C "pmk 來比較兩個製程之能力的優劣之流程 本小節將說明如何利用 3.2 節所構建的方法來判斷兩個製程或供應商之優 劣,其應用流程說明如下: 步驟一、蒐集兩筆樣本資料,樣本 A 與樣本 B,建議各樣本數超過 30 筆。 步驟二、將樣本資料及製程的規格上下限、目標值、模擬重複次數及α值輸 入撰寫程式之欄位中。 步驟三、由步驟二的執行結果產生一製程能力指標 C "pmk 差異值之 100(1-α) %信賴區間。 步驟四、判別兩個製程(供應商)之優劣。判定原則如下: 1.. 信賴區間所包含的兩個數皆為正時,表示製程(供應商)A 優於製 程(供應商)B。 (信賴區間未包含 0). 2.. 當信賴區間所包含的兩個數皆為負時,表示製程(供應商)B 優於 製程(供應商)A。 (信賴區間未包含 0). 3.. 當信賴區間所包含的兩個有正有負時,表示製程(供應商)A 與製 程(供應商)B 之製程能力沒有顯著差異。 (信賴區間包含 0). 38.
(47) 第四章 實例說明 本章引用 Cheng[7]發表之論文中的實例來說明如何運用本研究之評估流程。 汽車零件製造商在製程處於管制狀態下,從生產線上抽取 60 個零件來檢驗其製 造能力,量測單位為英吋(inch),規格上限為 2.3,規格下限為 1.4,目標值為 1.75。同時,定義製程能力指標 C "pmk 值大於 1 時,製程能力判定為良好;在改善 活動前、後分別抽取 60 個樣本為樣本 1 與樣本 2,樣本資料如表 4.1、表 4.2 所 示。. 表 4.1、改善活動前:樣本 1 2.05 1.85 1.75 1.65 1.65. 1.55 1.65 1.50 1.65 1.65. 1.65 1.65 2.05 1.95 1.75. 1.65 1.65 1.55 1.65 1.65. 1.65 1.65 1.70 1.65 1.75. 1.75 1.65 1.75 1.65 1.65. 1.65 1.75 1.65 1.75 2.00. 1.75 1.85 1.85 1.65 2.10. 1.65 1.60 1.75 1.75 1.65. 1.75 1.75 1.85 1.70 2.05. 1.85 1.75 1.75 1.85 1.75. 1.85 1.60 1.85 1.75 1.85. 1.75 1.75 1.75 1.75 1.75. 1.75 1.75 1.75 1.65 1.75. 1.65 1.65 1.65 1.75 1.85. 1.95 1.95 1.95 1.75 1.75. 表 4.2、改善活動後:樣本 2 1.65 1.65 1.65 1.65 1.65. 1.65 1.65 1.75 1.75 1.65. 1.75 1.65 1.65 1.65 1.75. 1.65 1.85 1.85 1.95 1.85. 1.75 1.65 1.65 1.75 1.75. 1.75 1.75 1.75 1.75 1.75. 1.65 1.85 1.65 1.75 1.65. 39. 1.65 1.65 1.65 1.85 1.75.
(48) 利用 3.1 與 3.2 節所構建的方法來判斷製程進行改善活動後,製程能力是否 有明顯的提升,其應用流程說明如下: 步驟一、收集改善活動前、後的樣本資料各 60 筆,如表 4.1、表 4.2。 步驟二、將樣本 1 的資料及製程目標值 1.75、規格上限 2.3、規格下限 1.4 及模擬重複次數輸入撰寫程式之欄位中。 步驟三、由樣本 1 所得之 C "pmk 指標 95﹪的信賴下限為 0.7638853。判定此時 的製程能力不佳。 步驟四、輸入樣本 2 的資料,並重複執行步驟二。 步驟五、由樣本 2 所得之 C "pmk 指標 95﹪的信賴下限為 1.155853。判定改善 活動後製程能力有顯著的提升。 步驟六、將兩筆樣本資料,製程目標值、規格上下限及模擬重複次數輸入撰 寫程式之欄位中。 步驟七、所得之 C "pmk 指標差異值的信賴區間為(-1.323151,-0.4195106) 。 根據判斷法則,因為信賴區間未包含 0,判定製程 2 的製程能力優 於製程 1,所以改善活動有顯著的績效,製程能力明顯提升。. 40.
(49) 第五章 結論 製程能力指標 C "pmk 能同時應用於對稱與非對稱規格的實際製程狀況,能同時 考慮製程平均值、製程變異與製程平均值偏移目標值的情況。本研究流程應用複 式模擬法之 BCa 區間估計法推估單一樣本之 C "pmk 指標值之信賴下限與兩個 C "pmk 指標差異值的信賴區間,經由有效性分析與敏感度分析後,皆有良好的績效成 果。為了增加本研究方法的實用價值,我們也撰寫了詳細的應用流程,希望能迅 速推廣到各個領域。 現將本研究的主要貢獻彙整如下四點: 1.. 本研究發展出一複式區間估計法來推估關於一組樣本之 C "pmk 指標之信賴下 限。業界可以根據本研究所建構之 C "pmk 信賴下限結果,訂立某製程是否需要 改進,或評估製程的穩定與優劣。. 2.. 本研究發展出一複式區間估計法來建構一個關於兩個 C "pmk 指標差距的信賴 區間,利用此信賴區間來取代傳統之假設檢定方式,用來推估兩個供應商或 兩個製程之能力的優劣。. 3.. 本研究對業界提出一個完整的 C "pmk 複式信賴區間應用流程,讓工程人員能快 速得到正確的製程能力評比結果,更有效提升企業的製程能力及競爭力。. 4.. 由於 C "pmk 證明比其他所有製程能力指標更具代表性,其應用價值應非常高, 但由於 C "pmk 之機率分配無法求得,故 Cˆ "pmk 及其相關信賴區間與假設檢定均 無法得到,因此藉由本研究的發展可確實增加 C "pmk 指標的實用性。. 41.
(50) 參考文獻 [1] 陳昭伶,“以複式模擬法構建兩個製程能力指標差異之信賴區間”交通大學 工業工程所碩士論文, 1998. [2] 林碧川,“非對稱規格區間之製程能力指標的統計性質”交通大學工業工程 所博士論文, 1999. [3] 許慧先,“以複式模擬法構建單一製程能力指標 C pmk 之信賴下限及兩個製程 能力指標 C pmk 差異之信賴區間”交通大學工業工程所碩士論文, 2000. [4] 謝旻憲,“以複式模擬法構建單一非對稱規格區間之 C "pmk 指標的信賴下限” 交通大學工業工程所碩士論文, 2001. [5] 王怜雅,“以複式模擬法構建非對稱規格區間下兩個製程能力指標 C "pmk 值差 之信賴區間”交通大學工業工程所碩士論文, 2001. [6] Chan, L. K., Cheng, S. W. and Spring, F. A.,“ A New Measure of Process Capability: Cpm,” Journal of Quality Technology, 30, pp. 162-175, 1988. [7] Cheng, S. W., “Practical Implementation of the Process Capability Indices,”. Journal of Quality Technology, 30, pp. 162-175, 1988. [8] Efron, B., “Better bootstrap confidence intervals,” J. Amer. Statist. Assoc. 82, pp. 171-200, 1987. [9] Efron, B. “ Bootstrap Methods: Another Looking at the Jackknife.” Ann. Statist. 7, 1-26. 1979. [10] Efron, B. and Ging, G., “ A Leisurely Look at the Bootstrap, the Bootstrap, the Jackknife and Cross-Validation,” American Statistician, 37, pp. 36-48, 1983. [11] Efron, B. and Tishirani, R. J., A Introduction to the Bootstrap, Chapman& Hall, 1993. [12] Efron, B. and Tibshirani, R. J., “Bootstrap Methods for Standard Errors, Confidence Interval, and Other Measures of Statistical Accuracy,” Statistical Science, 1, pp. 42.
(51) 54-77, 1986. [13] Franklin, L. A. and Wasserman, G. S.,“ Bootstrap Lower Confidence Limits for Capability Indices,” Journal of Quality Technology, 24(4), pp. 196-210, 1992. [14] Juran, J. M., Gryna, F. M. and Bingham, R. S., Quality Control Handbook, McGraw-Hill, New York, 1974. [15] Kane, V. E., “Process Capability Indices,” Journal of Quality Technology, 18(1), pp. 41-52, 1986. [16] Kotz, S. and Johnson, N.L., Process Capability Indices, Chapman & Hall, 1993. [17] Kushler, R. H. and Hurley, P., “ Confidence bounds for capability indices, ”. Journal of Quality Technology, 24, 188-195. [18] Pearn, W.L. and Chen, K.S.,“A new generalization of process capability index. Cpk,”Journal of Applied Statistics, 25,pp.79-88,1998. [19] Pearn, W. L., Kotz, S. and Johnson, N. L.,“ Distributional and Inferential Properties of Process Capability Indices,” Journal of Quality Technology, 24, pp. 216-233, 1992.. 43.
(52)
數據

相關文件
0 allow students sufficient time to gain confidence and the skills of studying in English, allow time for students to get through the language barrier, by going through
If the bootstrap distribution of a statistic shows a normal shape and small bias, we can get a confidence interval for the parameter by using the boot- strap standard error and
For the proposed algorithm, we establish a global convergence estimate in terms of the objective value, and moreover present a dual application to the standard SCLP, which leads to
Sunya, the Nothingness in Buddhism, is a being absolutely non-linguistic; so the difference between the two "satyas" is in fact the dif- ference between the linguistic and
To decide the correspondence between different sets of fea- ture points and to consider the binary relationships of point pairs at the same time, we construct a graph for each set
To convert a string containing floating-point digits to its floating-point value, use the static parseDouble method of the Double class..
The objective of this study is to establish a monthly water quality predicting model using a grammatical evolution (GE) programming system for Feitsui Reservoir in Northern
The objective of this study is to analyze the population and employment of Taichung metropolitan area by economic-based analysis to provide for government
